
url
stringlengths 34
116
| markdown
stringlengths 0
150k
⌀ | screenshotUrl
null | crawl
dict | metadata
dict | text
stringlengths 0
147k
|
|---|---|---|---|---|---|
https://python.langchain.com/docs/integrations/providers/cloudflare/ | ## Cloudflare
> [Cloudflare, Inc. (Wikipedia)](https://en.wikipedia.org/wiki/Cloudflare) is an American company that provides content delivery network services, cloud cybersecurity, DDoS mitigation, and ICANN-accredited domain registration services.
> [Cloudflare Workers AI](https://developers.cloudflare.com/workers-ai/) allows you to run machine learning models, on the `Cloudflare` network, from your code via REST API.
## Embedding models[](#embedding-models "Direct link to Embedding models")
See [installation instructions and usage example](https://python.langchain.com/docs/integrations/text_embedding/cloudflare_workersai/).
```
from langchain_community.embeddings.cloudflare_workersai import CloudflareWorkersAIEmbeddings
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:56.810Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/cloudflare/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/cloudflare/",
"description": "Cloudflare, Inc. (Wikipedia) is an American company that provides",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4597",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"cloudflare\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:56 GMT",
"etag": "W/\"c7ca5c92f1533beef436a9814f27560c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::qrh8j-1713753656316-b877b0179ab1"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/cloudflare/",
"property": "og:url"
},
{
"content": "Cloudflare | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Cloudflare, Inc. (Wikipedia) is an American company that provides",
"property": "og:description"
}
],
"title": "Cloudflare | 🦜️🔗 LangChain"
} | Cloudflare
Cloudflare, Inc. (Wikipedia) is an American company that provides content delivery network services, cloud cybersecurity, DDoS mitigation, and ICANN-accredited domain registration services.
Cloudflare Workers AI allows you to run machine learning models, on the Cloudflare network, from your code via REST API.
Embedding models
See installation instructions and usage example.
from langchain_community.embeddings.cloudflare_workersai import CloudflareWorkersAIEmbeddings |
https://python.langchain.com/docs/integrations/providers/clarifai/ | ## Clarifai
> [Clarifai](https://clarifai.com/) is one of first deep learning platforms having been founded in 2013. Clarifai provides an AI platform with the full AI lifecycle for data exploration, data labeling, model training, evaluation and inference around images, video, text and audio data. In the LangChain ecosystem, as far as we're aware, Clarifai is the only provider that supports LLMs, embeddings and a vector store in one production scale platform, making it an excellent choice to operationalize your LangChain implementations.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python SDK:
[Sign-up](https://clarifai.com/signup) for a Clarifai account, then get a personal access token to access the Clarifai API from your [security settings](https://clarifai.com/settings/security) and set it as an environment variable (`CLARIFAI_PAT`).
## Models[](#models "Direct link to Models")
Clarifai provides 1,000s of AI models for many different use cases. You can [explore them here](https://clarifai.com/explore) to find the one most suited for your use case. These models include those created by other providers such as OpenAI, Anthropic, Cohere, AI21, etc. as well as state of the art from open source such as Falcon, InstructorXL, etc. so that you build the best in AI into your products. You'll find these organized by the creator's user\_id and into projects we call applications denoted by their app\_id. Those IDs will be needed in additional to the model\_id and optionally the version\_id, so make note of all these IDs once you found the best model for your use case!
Also note that given there are many models for images, video, text and audio understanding, you can build some interested AI agents that utilize the variety of AI models as experts to understand those data types.
### LLMs[](#llms "Direct link to LLMs")
To find the selection of LLMs in the Clarifai platform you can select the text to text model type [here](https://clarifai.com/explore/models?filterData=%5B%7B%22field%22%3A%22model_type_id%22%2C%22value%22%3A%5B%22text-to-text%22%5D%7D%5D&page=1&perPage=24).
```
from langchain_community.llms import Clarifaillm = Clarifai(pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID)
```
For more details, the docs on the Clarifai LLM wrapper provide a [detailed walkthrough](https://python.langchain.com/docs/integrations/llms/clarifai/).
### Text Embedding Models[](#text-embedding-models "Direct link to Text Embedding Models")
To find the selection of text embeddings models in the Clarifai platform you can select the text to embedding model type [here](https://clarifai.com/explore/models?page=1&perPage=24&filterData=%5B%7B%22field%22%3A%22model_type_id%22%2C%22value%22%3A%5B%22text-embedder%22%5D%7D%5D).
There is a Clarifai Embedding model in LangChain, which you can access with:
```
from langchain_community.embeddings import ClarifaiEmbeddingsembeddings = ClarifaiEmbeddings(pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID)
```
For more details, the docs on the Clarifai Embeddings wrapper provide a [detailed walkthrough](https://python.langchain.com/docs/integrations/text_embedding/clarifai/).
## Vectorstore[](#vectorstore "Direct link to Vectorstore")
Clarifai's vector DB was launched in 2016 and has been optimized to support live search queries. With workflows in the Clarifai platform, you data is automatically indexed by am embedding model and optionally other models as well to index that information in the DB for search. You can query the DB not only via the vectors but also filter by metadata matches, other AI predicted concepts, and even do geo-coordinate search. Simply create an application, select the appropriate base workflow for your type of data, and upload it (through the API as [documented here](https://docs.clarifai.com/api-guide/data/create-get-update-delete) or the UIs at clarifai.com).
You can also add data directly from LangChain as well, and the auto-indexing will take place for you. You'll notice this is a little different than other vectorstores where you need to provide an embedding model in their constructor and have LangChain coordinate getting the embeddings from text and writing those to the index. Not only is it more convenient, but it's much more scalable to use Clarifai's distributed cloud to do all the index in the background.
```
from langchain_community.vectorstores import Clarifaiclarifai_vector_db = Clarifai.from_texts(user_id=USER_ID, app_id=APP_ID, texts=texts, pat=CLARIFAI_PAT, number_of_docs=NUMBER_OF_DOCS, metadatas = metadatas)
```
For more details, the docs on the Clarifai vector store provide a [detailed walkthrough](https://python.langchain.com/docs/integrations/vectorstores/clarifai/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:57.373Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/clarifai/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/clarifai/",
"description": "Clarifai is one of first deep learning platforms having been founded in 2013. Clarifai provides an AI platform with the full AI lifecycle for data exploration, data labeling, model training, evaluation and inference around images, video, text and audio data. In the LangChain ecosystem, as far as we're aware, Clarifai is the only provider that supports LLMs, embeddings and a vector store in one production scale platform, making it an excellent choice to operationalize your LangChain implementations.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3529",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"clarifai\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:56 GMT",
"etag": "W/\"1b389d177aa2dceda3fb1f239f9c5b43\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::g2tfq-1713753656586-913e96e68a3c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/clarifai/",
"property": "og:url"
},
{
"content": "Clarifai | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Clarifai is one of first deep learning platforms having been founded in 2013. Clarifai provides an AI platform with the full AI lifecycle for data exploration, data labeling, model training, evaluation and inference around images, video, text and audio data. In the LangChain ecosystem, as far as we're aware, Clarifai is the only provider that supports LLMs, embeddings and a vector store in one production scale platform, making it an excellent choice to operationalize your LangChain implementations.",
"property": "og:description"
}
],
"title": "Clarifai | 🦜️🔗 LangChain"
} | Clarifai
Clarifai is one of first deep learning platforms having been founded in 2013. Clarifai provides an AI platform with the full AI lifecycle for data exploration, data labeling, model training, evaluation and inference around images, video, text and audio data. In the LangChain ecosystem, as far as we're aware, Clarifai is the only provider that supports LLMs, embeddings and a vector store in one production scale platform, making it an excellent choice to operationalize your LangChain implementations.
Installation and Setup
Install the Python SDK:
Sign-up for a Clarifai account, then get a personal access token to access the Clarifai API from your security settings and set it as an environment variable (CLARIFAI_PAT).
Models
Clarifai provides 1,000s of AI models for many different use cases. You can explore them here to find the one most suited for your use case. These models include those created by other providers such as OpenAI, Anthropic, Cohere, AI21, etc. as well as state of the art from open source such as Falcon, InstructorXL, etc. so that you build the best in AI into your products. You'll find these organized by the creator's user_id and into projects we call applications denoted by their app_id. Those IDs will be needed in additional to the model_id and optionally the version_id, so make note of all these IDs once you found the best model for your use case!
Also note that given there are many models for images, video, text and audio understanding, you can build some interested AI agents that utilize the variety of AI models as experts to understand those data types.
LLMs
To find the selection of LLMs in the Clarifai platform you can select the text to text model type here.
from langchain_community.llms import Clarifai
llm = Clarifai(pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID)
For more details, the docs on the Clarifai LLM wrapper provide a detailed walkthrough.
Text Embedding Models
To find the selection of text embeddings models in the Clarifai platform you can select the text to embedding model type here.
There is a Clarifai Embedding model in LangChain, which you can access with:
from langchain_community.embeddings import ClarifaiEmbeddings
embeddings = ClarifaiEmbeddings(pat=CLARIFAI_PAT, user_id=USER_ID, app_id=APP_ID, model_id=MODEL_ID)
For more details, the docs on the Clarifai Embeddings wrapper provide a detailed walkthrough.
Vectorstore
Clarifai's vector DB was launched in 2016 and has been optimized to support live search queries. With workflows in the Clarifai platform, you data is automatically indexed by am embedding model and optionally other models as well to index that information in the DB for search. You can query the DB not only via the vectors but also filter by metadata matches, other AI predicted concepts, and even do geo-coordinate search. Simply create an application, select the appropriate base workflow for your type of data, and upload it (through the API as documented here or the UIs at clarifai.com).
You can also add data directly from LangChain as well, and the auto-indexing will take place for you. You'll notice this is a little different than other vectorstores where you need to provide an embedding model in their constructor and have LangChain coordinate getting the embeddings from text and writing those to the index. Not only is it more convenient, but it's much more scalable to use Clarifai's distributed cloud to do all the index in the background.
from langchain_community.vectorstores import Clarifai
clarifai_vector_db = Clarifai.from_texts(user_id=USER_ID, app_id=APP_ID, texts=texts, pat=CLARIFAI_PAT, number_of_docs=NUMBER_OF_DOCS, metadatas = metadatas)
For more details, the docs on the Clarifai vector store provide a detailed walkthrough. |
https://python.langchain.com/docs/integrations/providers/clickhouse/ | We need to install `clickhouse-connect` python package.
```
from langchain_community.vectorstores import Clickhouse, ClickhouseSettings
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:57.620Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/clickhouse/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/clickhouse/",
"description": "ClickHouse is the fast and resource efficient open-source database for real-time",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3529",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"clickhouse\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:56 GMT",
"etag": "W/\"20458bbb44151795501b9d8b4273dc06\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vxtcc-1713753656596-2309dcb9321e"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/clickhouse/",
"property": "og:url"
},
{
"content": "ClickHouse | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "ClickHouse is the fast and resource efficient open-source database for real-time",
"property": "og:description"
}
],
"title": "ClickHouse | 🦜️🔗 LangChain"
} | We need to install clickhouse-connect python package.
from langchain_community.vectorstores import Clickhouse, ClickhouseSettings |
https://python.langchain.com/docs/integrations/providers/aleph_alpha/ | ## Aleph Alpha
> [Aleph Alpha](https://docs.aleph-alpha.com/) was founded in 2019 with the mission to research and build the foundational technology for an era of strong AI. The team of international scientists, engineers, and innovators researches, develops, and deploys transformative AI like large language and multimodal models and runs the fastest European commercial AI cluster.
> [The Luminous series](https://docs.aleph-alpha.com/docs/introduction/luminous/) is a family of large language models.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install aleph-alpha-client
```
You have to create a new token. Please, see [instructions](https://docs.aleph-alpha.com/docs/account/#create-a-new-token).
```
from getpass import getpassALEPH_ALPHA_API_KEY = getpass()
```
## LLM[](#llm "Direct link to LLM")
See a [usage example](https://python.langchain.com/docs/integrations/llms/aleph_alpha/).
```
from langchain_community.llms import AlephAlpha
```
## Text Embedding Models[](#text-embedding-models "Direct link to Text Embedding Models")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/aleph_alpha/).
```
from langchain_community.embeddings import AlephAlphaSymmetricSemanticEmbedding, AlephAlphaAsymmetricSemanticEmbedding
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:57.474Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/aleph_alpha/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/aleph_alpha/",
"description": "Aleph Alpha was founded in 2019 with the mission to research and build the foundational technology for an era of strong AI. The team of international scientists, engineers, and innovators researches, develops, and deploys transformative AI like large language and multimodal models and runs the fastest European commercial AI cluster.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"aleph_alpha\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:56 GMT",
"etag": "W/\"4188e7fef486c70784f87c720703ae06\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nhxcp-1713753656479-0e6e596bcefd"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/aleph_alpha/",
"property": "og:url"
},
{
"content": "Aleph Alpha | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Aleph Alpha was founded in 2019 with the mission to research and build the foundational technology for an era of strong AI. The team of international scientists, engineers, and innovators researches, develops, and deploys transformative AI like large language and multimodal models and runs the fastest European commercial AI cluster.",
"property": "og:description"
}
],
"title": "Aleph Alpha | 🦜️🔗 LangChain"
} | Aleph Alpha
Aleph Alpha was founded in 2019 with the mission to research and build the foundational technology for an era of strong AI. The team of international scientists, engineers, and innovators researches, develops, and deploys transformative AI like large language and multimodal models and runs the fastest European commercial AI cluster.
The Luminous series is a family of large language models.
Installation and Setup
pip install aleph-alpha-client
You have to create a new token. Please, see instructions.
from getpass import getpass
ALEPH_ALPHA_API_KEY = getpass()
LLM
See a usage example.
from langchain_community.llms import AlephAlpha
Text Embedding Models
See a usage example.
from langchain_community.embeddings import AlephAlphaSymmetricSemanticEmbedding, AlephAlphaAsymmetricSemanticEmbedding
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/analyticdb/ | This page covers how to use the AnalyticDB ecosystem within LangChain.
You need to install the `sqlalchemy` python package.
```
from langchain_community.vectorstores import AnalyticDB
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:57.575Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/analyticdb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/analyticdb/",
"description": "AnalyticDB for PostgreSQL",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"analyticdb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:56 GMT",
"etag": "W/\"d91cbd0c3a191edce6350b0c5468570c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::6tcw2-1713753656632-9dbd8eb33d03"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/analyticdb/",
"property": "og:url"
},
{
"content": "AnalyticDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "AnalyticDB for PostgreSQL",
"property": "og:description"
}
],
"title": "AnalyticDB | 🦜️🔗 LangChain"
} | This page covers how to use the AnalyticDB ecosystem within LangChain.
You need to install the sqlalchemy python package.
from langchain_community.vectorstores import AnalyticDB |
https://python.langchain.com/docs/integrations/providers/annoy/ | ## Annoy
> [Annoy](https://github.com/spotify/annoy) (`Approximate Nearest Neighbors Oh Yeah`) is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mapped into memory so that many processes may share the same data.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
## Vectorstore[](#vectorstore "Direct link to Vectorstore")
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/annoy/).
```
from langchain_community.vectorstores import Annoy
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:57.711Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/annoy/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/annoy/",
"description": "Annoy (Approximate Nearest Neighbors Oh Yeah)",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"annoy\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:57 GMT",
"etag": "W/\"fb32a7edb4dcdb49f58c6a5f4b87ce1c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::7vff4-1713753657078-f367b9d0276f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/annoy/",
"property": "og:url"
},
{
"content": "Annoy | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Annoy (Approximate Nearest Neighbors Oh Yeah)",
"property": "og:description"
}
],
"title": "Annoy | 🦜️🔗 LangChain"
} | Annoy
Annoy (Approximate Nearest Neighbors Oh Yeah) is a C++ library with Python bindings to search for points in space that are close to a given query point. It also creates large read-only file-based data structures that are mapped into memory so that many processes may share the same data.
Installation and Setup
Vectorstore
See a usage example.
from langchain_community.vectorstores import Annoy
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/anyscale/ | `Anyscale` also provides [an example](https://docs.anyscale.com/endpoints/model-serving/examples/langchain-integration) how to setup `LangChain` with `Anyscale` for advanced chat agents.
```
from langchain_community.llms.anyscale import Anyscale
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:58.521Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/anyscale/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/anyscale/",
"description": "Anyscale is a platform to run, fine tune and scale LLMs via production-ready APIs.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3534",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"anyscale\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:58 GMT",
"etag": "W/\"097992ddb1d4a61a5f3aa0a3406c20e2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::8fs27-1713753658341-cc64ddb81b72"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/anyscale/",
"property": "og:url"
},
{
"content": "Anyscale | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Anyscale is a platform to run, fine tune and scale LLMs via production-ready APIs.",
"property": "og:description"
}
],
"title": "Anyscale | 🦜️🔗 LangChain"
} | Anyscale also provides an example how to setup LangChain with Anyscale for advanced chat agents.
from langchain_community.llms.anyscale import Anyscale |
https://python.langchain.com/docs/integrations/providers/cnosdb/ | ## CnosDB
> [CnosDB](https://github.com/cnosdb/cnosdb) is an open-source distributed time series database with high performance, high compression rate and high ease of use.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install cnos-connector
```
## Connecting to CnosDB[](#connecting-to-cnosdb "Direct link to Connecting to CnosDB")
You can connect to CnosDB using the `SQLDatabase.from_cnosdb()` method.
### Syntax[](#syntax "Direct link to Syntax")
```
def SQLDatabase.from_cnosdb(url: str = "127.0.0.1:8902", user: str = "root", password: str = "", tenant: str = "cnosdb", database: str = "public")
```
Args:
1. url (str): The HTTP connection host name and port number of the CnosDB service, excluding "http://" or "https://", with a default value of "127.0.0.1:8902".
2. user (str): The username used to connect to the CnosDB service, with a default value of "root".
3. password (str): The password of the user connecting to the CnosDB service, with a default value of "".
4. tenant (str): The name of the tenant used to connect to the CnosDB service, with a default value of "cnosdb".
5. database (str): The name of the database in the CnosDB tenant.
## Examples[](#examples "Direct link to Examples")
```
# Connecting to CnosDB with SQLDatabase Wrapperfrom langchain_community.utilities import SQLDatabasedb = SQLDatabase.from_cnosdb()
```
```
# Creating a OpenAI Chat LLM Wrapperfrom langchain_openai import ChatOpenAIllm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
```
### SQL Database Chain[](#sql-database-chain "Direct link to SQL Database Chain")
This example demonstrates the use of the SQL Chain for answering a question over a CnosDB.
```
from langchain_community.utilities import SQLDatabaseChaindb_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)db_chain.run( "What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?")
```
```
> Entering new chain...What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?SQLQuery:SELECT AVG(temperature) FROM air WHERE station = 'XiaoMaiDao' AND time >= '2022-10-19' AND time < '2022-10-20'SQLResult: [(68.0,)]Answer:The average temperature of air at station XiaoMaiDao between October 19, 2022 and October 20, 2022 is 68.0.> Finished chain.
```
### SQL Database Agent[](#sql-database-agent "Direct link to SQL Database Agent")
This example demonstrates the use of the SQL Database Agent for answering questions over a CnosDB.
```
from langchain.agents import create_sql_agentfrom langchain_community.agent_toolkits import SQLDatabaseToolkittoolkit = SQLDatabaseToolkit(db=db, llm=llm)agent = create_sql_agent(llm=llm, toolkit=toolkit, verbose=True)
```
```
agent.run( "What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?")
```
```
> Entering new chain...Action: sql_db_list_tablesAction Input: ""Observation: airThought:The "air" table seems relevant to the question. I should query the schema of the "air" table to see what columns are available.Action: sql_db_schemaAction Input: "air"Observation:CREATE TABLE air ( pressure FLOAT, station STRING, temperature FLOAT, time TIMESTAMP, visibility FLOAT)/*3 rows from air table:pressure station temperature time visibility75.0 XiaoMaiDao 67.0 2022-10-19T03:40:00 54.077.0 XiaoMaiDao 69.0 2022-10-19T04:40:00 56.076.0 XiaoMaiDao 68.0 2022-10-19T05:40:00 55.0*/Thought:The "temperature" column in the "air" table is relevant to the question. I can query the average temperature between the specified dates.Action: sql_db_queryAction Input: "SELECT AVG(temperature) FROM air WHERE station = 'XiaoMaiDao' AND time >= '2022-10-19' AND time <= '2022-10-20'"Observation: [(68.0,)]Thought:The average temperature of air at station XiaoMaiDao between October 19, 2022 and October 20, 2022 is 68.0.Final Answer: 68.0> Finished chain.
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:58.618Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/cnosdb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/cnosdb/",
"description": "CnosDB is an open-source distributed time series database with high performance, high compression rate and high ease of use.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3531",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"cnosdb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:58 GMT",
"etag": "W/\"684223da802195a249aada1863827611\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::qfv6k-1713753658367-2f2161e3ebae"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/cnosdb/",
"property": "og:url"
},
{
"content": "CnosDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "CnosDB is an open-source distributed time series database with high performance, high compression rate and high ease of use.",
"property": "og:description"
}
],
"title": "CnosDB | 🦜️🔗 LangChain"
} | CnosDB
CnosDB is an open-source distributed time series database with high performance, high compression rate and high ease of use.
Installation and Setup
pip install cnos-connector
Connecting to CnosDB
You can connect to CnosDB using the SQLDatabase.from_cnosdb() method.
Syntax
def SQLDatabase.from_cnosdb(url: str = "127.0.0.1:8902",
user: str = "root",
password: str = "",
tenant: str = "cnosdb",
database: str = "public")
Args:
url (str): The HTTP connection host name and port number of the CnosDB service, excluding "http://" or "https://", with a default value of "127.0.0.1:8902".
user (str): The username used to connect to the CnosDB service, with a default value of "root".
password (str): The password of the user connecting to the CnosDB service, with a default value of "".
tenant (str): The name of the tenant used to connect to the CnosDB service, with a default value of "cnosdb".
database (str): The name of the database in the CnosDB tenant.
Examples
# Connecting to CnosDB with SQLDatabase Wrapper
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_cnosdb()
# Creating a OpenAI Chat LLM Wrapper
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
SQL Database Chain
This example demonstrates the use of the SQL Chain for answering a question over a CnosDB.
from langchain_community.utilities import SQLDatabaseChain
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
db_chain.run(
"What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?"
)
> Entering new chain...
What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?
SQLQuery:SELECT AVG(temperature) FROM air WHERE station = 'XiaoMaiDao' AND time >= '2022-10-19' AND time < '2022-10-20'
SQLResult: [(68.0,)]
Answer:The average temperature of air at station XiaoMaiDao between October 19, 2022 and October 20, 2022 is 68.0.
> Finished chain.
SQL Database Agent
This example demonstrates the use of the SQL Database Agent for answering questions over a CnosDB.
from langchain.agents import create_sql_agent
from langchain_community.agent_toolkits import SQLDatabaseToolkit
toolkit = SQLDatabaseToolkit(db=db, llm=llm)
agent = create_sql_agent(llm=llm, toolkit=toolkit, verbose=True)
agent.run(
"What is the average temperature of air at station XiaoMaiDao between October 19, 2022 and Occtober 20, 2022?"
)
> Entering new chain...
Action: sql_db_list_tables
Action Input: ""
Observation: air
Thought:The "air" table seems relevant to the question. I should query the schema of the "air" table to see what columns are available.
Action: sql_db_schema
Action Input: "air"
Observation:
CREATE TABLE air (
pressure FLOAT,
station STRING,
temperature FLOAT,
time TIMESTAMP,
visibility FLOAT
)
/*
3 rows from air table:
pressure station temperature time visibility
75.0 XiaoMaiDao 67.0 2022-10-19T03:40:00 54.0
77.0 XiaoMaiDao 69.0 2022-10-19T04:40:00 56.0
76.0 XiaoMaiDao 68.0 2022-10-19T05:40:00 55.0
*/
Thought:The "temperature" column in the "air" table is relevant to the question. I can query the average temperature between the specified dates.
Action: sql_db_query
Action Input: "SELECT AVG(temperature) FROM air WHERE station = 'XiaoMaiDao' AND time >= '2022-10-19' AND time <= '2022-10-20'"
Observation: [(68.0,)]
Thought:The average temperature of air at station XiaoMaiDao between October 19, 2022 and October 20, 2022 is 68.0.
Final Answer: 68.0
> Finished chain.
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/cohere/ | ## Cohere
> [Cohere](https://cohere.ai/about) is a Canadian startup that provides natural language processing models that help companies improve human-machine interactions.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python SDK :
```
pip install langchain-cohere
```
Get a [Cohere api key](https://dashboard.cohere.ai/) and set it as an environment variable (`COHERE_API_KEY`)
## Cohere langchain integrations[](#cohere-langchain-integrations "Direct link to Cohere langchain integrations")
| API | description | Endpoint docs | Import | Example usage |
| --- | --- | --- | --- | --- |
| Chat | Build chat bots | [chat](https://docs.cohere.com/reference/chat) | `from langchain_cohere import ChatCohere` | [cohere.ipynb](https://python.langchain.com/docs/integrations/chat/cohere/) |
| LLM | Generate text | [generate](https://docs.cohere.com/reference/generate) | `from langchain_cohere.llms import Cohere` | [cohere.ipynb](https://python.langchain.com/docs/integrations/llms/cohere/) |
| RAG Retriever | Connect to external data sources | [chat + rag](https://docs.cohere.com/reference/chat) | `from langchain.retrievers import CohereRagRetriever` | [cohere.ipynb](https://python.langchain.com/docs/integrations/retrievers/cohere/) |
| Text Embedding | Embed strings to vectors | [embed](https://docs.cohere.com/reference/embed) | `from langchain_cohere import CohereEmbeddings` | [cohere.ipynb](https://python.langchain.com/docs/integrations/text_embedding/cohere/) |
| Rerank Retriever | Rank strings based on relevance | [rerank](https://docs.cohere.com/reference/rerank) | `from langchain.retrievers.document_compressors import CohereRerank` | [cohere.ipynb](https://python.langchain.com/docs/integrations/retrievers/cohere-reranker/) |
## Quick copy examples[](#quick-copy-examples "Direct link to Quick copy examples")
### Chat[](#chat "Direct link to Chat")
```
from langchain_cohere import ChatCoherefrom langchain_core.messages import HumanMessagechat = ChatCohere()messages = [HumanMessage(content="knock knock")]print(chat.invoke(messages))
```
Usage of the Cohere [chat model](https://python.langchain.com/docs/integrations/chat/cohere/)
### LLM[](#llm "Direct link to LLM")
```
from langchain_cohere.llms import Coherellm = Cohere()print(llm.invoke("Come up with a pet name"))
```
Usage of the Cohere (legacy) [LLM model](https://python.langchain.com/docs/integrations/llms/cohere/)
### ReAct Agent[](#react-agent "Direct link to ReAct Agent")
```
from langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_cohere import ChatCohere, create_cohere_react_agentfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.agents import AgentExecutorllm = ChatCohere()internet_search = TavilySearchResults(max_results=4)internet_search.name = "internet_search"internet_search.description = "Route a user query to the internet"prompt = ChatPromptTemplate.from_template("{input}")agent = create_cohere_react_agent( llm, [internet_search], prompt)agent_executor = AgentExecutor(agent=agent, tools=[internet_search], verbose=True)agent_executor.invoke({ "input": "In what year was the company that was founded as Sound of Music added to the S&P 500?",})
```
### RAG Retriever[](#rag-retriever "Direct link to RAG Retriever")
```
from langchain_cohere import ChatCoherefrom langchain.retrievers import CohereRagRetrieverfrom langchain_core.documents import Documentrag = CohereRagRetriever(llm=ChatCohere())print(rag.get_relevant_documents("What is cohere ai?"))
```
Usage of the Cohere [RAG Retriever](https://python.langchain.com/docs/integrations/retrievers/cohere/)
### Text Embedding[](#text-embedding "Direct link to Text Embedding")
```
from langchain_cohere import CohereEmbeddingsembeddings = CohereEmbeddings(model="embed-english-light-v3.0")print(embeddings.embed_documents(["This is a test document."]))
```
Usage of the Cohere [Text Embeddings model](https://python.langchain.com/docs/integrations/text_embedding/cohere/)
### Reranker[](#reranker "Direct link to Reranker")
Usage of the Cohere [Reranker](https://python.langchain.com/docs/integrations/retrievers/cohere-reranker/) | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:59.196Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/cohere/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/cohere/",
"description": "Cohere is a Canadian startup that provides natural language processing models",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6210",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"cohere\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:58 GMT",
"etag": "W/\"92b739695663c960bb841daa3330c13d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::54c7l-1713753658918-ce4d62a84c98"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/cohere/",
"property": "og:url"
},
{
"content": "Cohere | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Cohere is a Canadian startup that provides natural language processing models",
"property": "og:description"
}
],
"title": "Cohere | 🦜️🔗 LangChain"
} | Cohere
Cohere is a Canadian startup that provides natural language processing models that help companies improve human-machine interactions.
Installation and Setup
Install the Python SDK :
pip install langchain-cohere
Get a Cohere api key and set it as an environment variable (COHERE_API_KEY)
Cohere langchain integrations
APIdescriptionEndpoint docsImportExample usage
Chat Build chat bots chat from langchain_cohere import ChatCohere cohere.ipynb
LLM Generate text generate from langchain_cohere.llms import Cohere cohere.ipynb
RAG Retriever Connect to external data sources chat + rag from langchain.retrievers import CohereRagRetriever cohere.ipynb
Text Embedding Embed strings to vectors embed from langchain_cohere import CohereEmbeddings cohere.ipynb
Rerank Retriever Rank strings based on relevance rerank from langchain.retrievers.document_compressors import CohereRerank cohere.ipynb
Quick copy examples
Chat
from langchain_cohere import ChatCohere
from langchain_core.messages import HumanMessage
chat = ChatCohere()
messages = [HumanMessage(content="knock knock")]
print(chat.invoke(messages))
Usage of the Cohere chat model
LLM
from langchain_cohere.llms import Cohere
llm = Cohere()
print(llm.invoke("Come up with a pet name"))
Usage of the Cohere (legacy) LLM model
ReAct Agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_cohere import ChatCohere, create_cohere_react_agent
from langchain_core.prompts import ChatPromptTemplate
from langchain.agents import AgentExecutor
llm = ChatCohere()
internet_search = TavilySearchResults(max_results=4)
internet_search.name = "internet_search"
internet_search.description = "Route a user query to the internet"
prompt = ChatPromptTemplate.from_template("{input}")
agent = create_cohere_react_agent(
llm,
[internet_search],
prompt
)
agent_executor = AgentExecutor(agent=agent, tools=[internet_search], verbose=True)
agent_executor.invoke({
"input": "In what year was the company that was founded as Sound of Music added to the S&P 500?",
})
RAG Retriever
from langchain_cohere import ChatCohere
from langchain.retrievers import CohereRagRetriever
from langchain_core.documents import Document
rag = CohereRagRetriever(llm=ChatCohere())
print(rag.get_relevant_documents("What is cohere ai?"))
Usage of the Cohere RAG Retriever
Text Embedding
from langchain_cohere import CohereEmbeddings
embeddings = CohereEmbeddings(model="embed-english-light-v3.0")
print(embeddings.embed_documents(["This is a test document."]))
Usage of the Cohere Text Embeddings model
Reranker
Usage of the Cohere Reranker |
https://python.langchain.com/docs/integrations/providers/apache_doris/ | ## Apache Doris
> [Apache Doris](https://doris.apache.org/) is a modern data warehouse for real-time analytics. It delivers lightning-fast analytics on real-time data at scale.
> Usually `Apache Doris` is categorized into OLAP, and it has showed excellent performance in [ClickBench — a Benchmark For Analytical DBMS](https://benchmark.clickhouse.com/). Since it has a super-fast vectorized execution engine, it could also be used as a fast vectordb.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
## Vector Store[](#vector-store "Direct link to Vector Store")
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/apache_doris/).
```
from langchain_community.vectorstores import ApacheDoris
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:59.498Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/apache_doris/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/apache_doris/",
"description": "Apache Doris is a modern data warehouse for real-time analytics.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"apache_doris\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:59 GMT",
"etag": "W/\"211365757a133ccc6364ed40523d5b97\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::s8kb2-1713753658909-95a735767be7"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/apache_doris/",
"property": "og:url"
},
{
"content": "Apache Doris | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Apache Doris is a modern data warehouse for real-time analytics.",
"property": "og:description"
}
],
"title": "Apache Doris | 🦜️🔗 LangChain"
} | Apache Doris
Apache Doris is a modern data warehouse for real-time analytics. It delivers lightning-fast analytics on real-time data at scale.
Usually Apache Doris is categorized into OLAP, and it has showed excellent performance in ClickBench — a Benchmark For Analytical DBMS. Since it has a super-fast vectorized execution engine, it could also be used as a fast vectordb.
Installation and Setup
Vector Store
See a usage example.
from langchain_community.vectorstores import ApacheDoris
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/apify/ | This integration enables you run Actors on the `Apify` platform and load their results into LangChain to feed your vector indexes with documents and data from the web, e.g. to generate answers from websites with documentation, blogs, or knowledge bases.
You can use the `ApifyWrapper` to run Actors on the Apify platform.
```
from langchain_community.utilities import ApifyWrapper
```
You can also use our `ApifyDatasetLoader` to get data from Apify dataset. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:40:59.438Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/apify/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/apify/",
"description": "Apify is a cloud platform for web scraping and data extraction,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "8087",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"apify\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:58 GMT",
"etag": "W/\"421e15bfa6aa593856349aef749ae285\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::fgt7r-1713753658929-befc18a95475"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/apify/",
"property": "og:url"
},
{
"content": "Apify | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Apify is a cloud platform for web scraping and data extraction,",
"property": "og:description"
}
],
"title": "Apify | 🦜️🔗 LangChain"
} | This integration enables you run Actors on the Apify platform and load their results into LangChain to feed your vector indexes with documents and data from the web, e.g. to generate answers from websites with documentation, blogs, or knowledge bases.
You can use the ApifyWrapper to run Actors on the Apify platform.
from langchain_community.utilities import ApifyWrapper
You can also use our ApifyDatasetLoader to get data from Apify dataset. |
https://python.langchain.com/docs/integrations/providers/college_confidential/ | There isn't any special setup for it.
```
from langchain_community.document_loaders import CollegeConfidentialLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:00.153Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/college_confidential/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/college_confidential/",
"description": "College Confidential gives information on 3,800+ colleges and universities.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4600",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"college_confidential\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:59 GMT",
"etag": "W/\"6390ef70f3875ac635754a066009f72c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::m82k4-1713753659678-91b924a2f124"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/college_confidential/",
"property": "og:url"
},
{
"content": "College Confidential | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "College Confidential gives information on 3,800+ colleges and universities.",
"property": "og:description"
}
],
"title": "College Confidential | 🦜️🔗 LangChain"
} | There isn't any special setup for it.
from langchain_community.document_loaders import CollegeConfidentialLoader |
https://python.langchain.com/docs/integrations/providers/confident/ | ## Confident AI
> [Confident AI](https://confident-ai.com/) is a creator of the `DeepEval`.
>
> [DeepEval](https://github.com/confident-ai/deepeval) is a package for unit testing LLMs. Using `DeepEval`, everyone can build robust language models through faster iterations using both unit testing and integration testing. \`DeepEval provides support for each step in the iteration from synthetic data creation to testing.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
You need to get the [DeepEval API credentials](https://app.confident-ai.com/).
You need to install the `DeepEval` Python package:
## Callbacks[](#callbacks "Direct link to Callbacks")
See an [example](https://python.langchain.com/docs/integrations/callbacks/confident/).
```
from langchain.callbacks.confident_callback import DeepEvalCallbackHandler
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:00.327Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/confident/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/confident/",
"description": "Confident AI is a creator of the DeepEval.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4598",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"confident\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:59 GMT",
"etag": "W/\"5480c7ac7302b3aa9d8be8610650f8c5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::6jz7h-1713753659677-03e61d01cac3"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/confident/",
"property": "og:url"
},
{
"content": "Confident AI | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Confident AI is a creator of the DeepEval.",
"property": "og:description"
}
],
"title": "Confident AI | 🦜️🔗 LangChain"
} | Confident AI
Confident AI is a creator of the DeepEval.
DeepEval is a package for unit testing LLMs. Using DeepEval, everyone can build robust language models through faster iterations using both unit testing and integration testing. `DeepEval provides support for each step in the iteration from synthetic data creation to testing.
Installation and Setup
You need to get the DeepEval API credentials.
You need to install the DeepEval Python package:
Callbacks
See an example.
from langchain.callbacks.confident_callback import DeepEvalCallbackHandler
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/context/ | ## Context
> [Context](https://context.ai/) provides user analytics for LLM-powered products and features.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
We need to install the `context-python` Python package:
```
pip install context-python
```
## Callbacks[](#callbacks "Direct link to Callbacks")
See a [usage example](https://python.langchain.com/docs/integrations/callbacks/context/).
```
from langchain.callbacks import ContextCallbackHandler
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:00.217Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/context/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/context/",
"description": "Context provides user analytics for LLM-powered products and features.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3531",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"context\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:59 GMT",
"etag": "W/\"ca48ec5a8999407ba33c8895d980754c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tl469-1713753659655-9a55a721ef2f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/context/",
"property": "og:url"
},
{
"content": "Context | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Context provides user analytics for LLM-powered products and features.",
"property": "og:description"
}
],
"title": "Context | 🦜️🔗 LangChain"
} | Context
Context provides user analytics for LLM-powered products and features.
Installation and Setup
We need to install the context-python Python package:
pip install context-python
Callbacks
See a usage example.
from langchain.callbacks import ContextCallbackHandler
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/comet_tracking/ | ## Comet
> [Comet](https://www.comet.com/) machine learning platform integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring

In this guide we will demonstrate how to track your Langchain Experiments, Evaluation Metrics, and LLM Sessions with [Comet](https://www.comet.com/site/?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook).
[](https://colab.research.google.com/github/hwchase17/langchain/blob/master/docs/ecosystem/comet_tracking)
**Example Project:** [Comet with LangChain](https://www.comet.com/examples/comet-example-langchain/view/b5ZThK6OFdhKWVSP3fDfRtrNF/panels?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook)

### Install Comet and Dependencies[](#install-comet-and-dependencies "Direct link to Install Comet and Dependencies")
```
%pip install --upgrade --quiet comet_ml langchain langchain-openai google-search-results spacy textstat pandas!{sys.executable} -m spacy download en_core_web_sm
```
### Initialize Comet and Set your Credentials[](#initialize-comet-and-set-your-credentials "Direct link to Initialize Comet and Set your Credentials")
You can grab your [Comet API Key here](https://www.comet.com/signup?utm_source=langchain&utm_medium=referral&utm_campaign=comet_notebook) or click the link after initializing Comet
```
import comet_mlcomet_ml.init(project_name="comet-example-langchain")
```
### Set OpenAI and SerpAPI credentials[](#set-openai-and-serpapi-credentials "Direct link to Set OpenAI and SerpAPI credentials")
You will need an [OpenAI API Key](https://platform.openai.com/account/api-keys) and a [SerpAPI API Key](https://serpapi.com/dashboard) to run the following examples
```
import osos.environ["OPENAI_API_KEY"] = "..."# os.environ["OPENAI_ORGANIZATION"] = "..."os.environ["SERPAPI_API_KEY"] = "..."
```
### Scenario 1: Using just an LLM[](#scenario-1-using-just-an-llm "Direct link to Scenario 1: Using just an LLM")
```
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandlerfrom langchain_openai import OpenAIcomet_callback = CometCallbackHandler( project_name="comet-example-langchain", complexity_metrics=True, stream_logs=True, tags=["llm"], visualizations=["dep"],)callbacks = [StdOutCallbackHandler(), comet_callback]llm = OpenAI(temperature=0.9, callbacks=callbacks, verbose=True)llm_result = llm.generate(["Tell me a joke", "Tell me a poem", "Tell me a fact"] * 3)print("LLM result", llm_result)comet_callback.flush_tracker(llm, finish=True)
```
### Scenario 2: Using an LLM in a Chain[](#scenario-2-using-an-llm-in-a-chain "Direct link to Scenario 2: Using an LLM in a Chain")
```
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandlerfrom langchain.chains import LLMChainfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import OpenAIcomet_callback = CometCallbackHandler( complexity_metrics=True, project_name="comet-example-langchain", stream_logs=True, tags=["synopsis-chain"],)callbacks = [StdOutCallbackHandler(), comet_callback]llm = OpenAI(temperature=0.9, callbacks=callbacks)template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.Title: {title}Playwright: This is a synopsis for the above play:"""prompt_template = PromptTemplate(input_variables=["title"], template=template)synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=callbacks)test_prompts = [{"title": "Documentary about Bigfoot in Paris"}]print(synopsis_chain.apply(test_prompts))comet_callback.flush_tracker(synopsis_chain, finish=True)
```
### Scenario 3: Using An Agent with Tools[](#scenario-3-using-an-agent-with-tools "Direct link to Scenario 3: Using An Agent with Tools")
```
from langchain.agents import initialize_agent, load_toolsfrom langchain.callbacks import CometCallbackHandler, StdOutCallbackHandlerfrom langchain_openai import OpenAIcomet_callback = CometCallbackHandler( project_name="comet-example-langchain", complexity_metrics=True, stream_logs=True, tags=["agent"],)callbacks = [StdOutCallbackHandler(), comet_callback]llm = OpenAI(temperature=0.9, callbacks=callbacks)tools = load_tools(["serpapi", "llm-math"], llm=llm, callbacks=callbacks)agent = initialize_agent( tools, llm, agent="zero-shot-react-description", callbacks=callbacks, verbose=True,)agent.run( "Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")comet_callback.flush_tracker(agent, finish=True)
```
### Scenario 4: Using Custom Evaluation Metrics[](#scenario-4-using-custom-evaluation-metrics "Direct link to Scenario 4: Using Custom Evaluation Metrics")
The `CometCallbackManager` also allows you to define and use Custom Evaluation Metrics to assess generated outputs from your model. Let’s take a look at how this works.
In the snippet below, we will use the [ROUGE](https://huggingface.co/spaces/evaluate-metric/rouge) metric to evaluate the quality of a generated summary of an input prompt.
```
%pip install --upgrade --quiet rouge-score
```
```
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandlerfrom langchain.chains import LLMChainfrom langchain_core.prompts import PromptTemplatefrom langchain_openai import OpenAIfrom rouge_score import rouge_scorerclass Rouge: def __init__(self, reference): self.reference = reference self.scorer = rouge_scorer.RougeScorer(["rougeLsum"], use_stemmer=True) def compute_metric(self, generation, prompt_idx, gen_idx): prediction = generation.text results = self.scorer.score(target=self.reference, prediction=prediction) return { "rougeLsum_score": results["rougeLsum"].fmeasure, "reference": self.reference, }reference = """The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building.It was the first structure to reach a height of 300 metres.It is now taller than the Chrysler Building in New York City by 5.2 metres (17 ft)Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France ."""rouge_score = Rouge(reference=reference)template = """Given the following article, it is your job to write a summary.Article:{article}Summary: This is the summary for the above article:"""prompt_template = PromptTemplate(input_variables=["article"], template=template)comet_callback = CometCallbackHandler( project_name="comet-example-langchain", complexity_metrics=False, stream_logs=True, tags=["custom_metrics"], custom_metrics=rouge_score.compute_metric,)callbacks = [StdOutCallbackHandler(), comet_callback]llm = OpenAI(temperature=0.9)synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)test_prompts = [ { "article": """ The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building, and the tallest structure in Paris. Its base is square, measuring 125 metres (410 ft) on each side. During its construction, the Eiffel Tower surpassed the Washington Monument to become the tallest man-made structure in the world, a title it held for 41 years until the Chrysler Building in New York City was finished in 1930. It was the first structure to reach a height of 300 metres. Due to the addition of a broadcasting aerial at the top of the tower in 1957, it is now taller than the Chrysler Building by 5.2 metres (17 ft). Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France after the Millau Viaduct. """ }]print(synopsis_chain.apply(test_prompts, callbacks=callbacks))comet_callback.flush_tracker(synopsis_chain, finish=True)
```
### Callback Tracer[](#callback-tracer "Direct link to Callback Tracer")
There is another integration with Comet:
See an [example](https://python.langchain.com/docs/integrations/callbacks/comet_tracing/).
```
from langchain.callbacks.tracers.comet import CometTracer
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:00.451Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/comet_tracking/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/comet_tracking/",
"description": "Comet machine learning platform integrates",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4598",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"comet_tracking\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:40:59 GMT",
"etag": "W/\"c88cbd393454ed897389c597464447b6\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::swct2-1713753659859-6cabd849bf63"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/comet_tracking/",
"property": "og:url"
},
{
"content": "Comet | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Comet machine learning platform integrates",
"property": "og:description"
}
],
"title": "Comet | 🦜️🔗 LangChain"
} | Comet
Comet machine learning platform integrates with your existing infrastructure and tools so you can manage, visualize, and optimize models—from training runs to production monitoring
In this guide we will demonstrate how to track your Langchain Experiments, Evaluation Metrics, and LLM Sessions with Comet.
Example Project: Comet with LangChain
Install Comet and Dependencies
%pip install --upgrade --quiet comet_ml langchain langchain-openai google-search-results spacy textstat pandas
!{sys.executable} -m spacy download en_core_web_sm
Initialize Comet and Set your Credentials
You can grab your Comet API Key here or click the link after initializing Comet
import comet_ml
comet_ml.init(project_name="comet-example-langchain")
Set OpenAI and SerpAPI credentials
You will need an OpenAI API Key and a SerpAPI API Key to run the following examples
import os
os.environ["OPENAI_API_KEY"] = "..."
# os.environ["OPENAI_ORGANIZATION"] = "..."
os.environ["SERPAPI_API_KEY"] = "..."
Scenario 1: Using just an LLM
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler
from langchain_openai import OpenAI
comet_callback = CometCallbackHandler(
project_name="comet-example-langchain",
complexity_metrics=True,
stream_logs=True,
tags=["llm"],
visualizations=["dep"],
)
callbacks = [StdOutCallbackHandler(), comet_callback]
llm = OpenAI(temperature=0.9, callbacks=callbacks, verbose=True)
llm_result = llm.generate(["Tell me a joke", "Tell me a poem", "Tell me a fact"] * 3)
print("LLM result", llm_result)
comet_callback.flush_tracker(llm, finish=True)
Scenario 2: Using an LLM in a Chain
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
comet_callback = CometCallbackHandler(
complexity_metrics=True,
project_name="comet-example-langchain",
stream_logs=True,
tags=["synopsis-chain"],
)
callbacks = [StdOutCallbackHandler(), comet_callback]
llm = OpenAI(temperature=0.9, callbacks=callbacks)
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template, callbacks=callbacks)
test_prompts = [{"title": "Documentary about Bigfoot in Paris"}]
print(synopsis_chain.apply(test_prompts))
comet_callback.flush_tracker(synopsis_chain, finish=True)
Scenario 3: Using An Agent with Tools
from langchain.agents import initialize_agent, load_tools
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler
from langchain_openai import OpenAI
comet_callback = CometCallbackHandler(
project_name="comet-example-langchain",
complexity_metrics=True,
stream_logs=True,
tags=["agent"],
)
callbacks = [StdOutCallbackHandler(), comet_callback]
llm = OpenAI(temperature=0.9, callbacks=callbacks)
tools = load_tools(["serpapi", "llm-math"], llm=llm, callbacks=callbacks)
agent = initialize_agent(
tools,
llm,
agent="zero-shot-react-description",
callbacks=callbacks,
verbose=True,
)
agent.run(
"Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?"
)
comet_callback.flush_tracker(agent, finish=True)
Scenario 4: Using Custom Evaluation Metrics
The CometCallbackManager also allows you to define and use Custom Evaluation Metrics to assess generated outputs from your model. Let’s take a look at how this works.
In the snippet below, we will use the ROUGE metric to evaluate the quality of a generated summary of an input prompt.
%pip install --upgrade --quiet rouge-score
from langchain.callbacks import CometCallbackHandler, StdOutCallbackHandler
from langchain.chains import LLMChain
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from rouge_score import rouge_scorer
class Rouge:
def __init__(self, reference):
self.reference = reference
self.scorer = rouge_scorer.RougeScorer(["rougeLsum"], use_stemmer=True)
def compute_metric(self, generation, prompt_idx, gen_idx):
prediction = generation.text
results = self.scorer.score(target=self.reference, prediction=prediction)
return {
"rougeLsum_score": results["rougeLsum"].fmeasure,
"reference": self.reference,
}
reference = """
The tower is 324 metres (1,063 ft) tall, about the same height as an 81-storey building.
It was the first structure to reach a height of 300 metres.
It is now taller than the Chrysler Building in New York City by 5.2 metres (17 ft)
Excluding transmitters, the Eiffel Tower is the second tallest free-standing structure in France .
"""
rouge_score = Rouge(reference=reference)
template = """Given the following article, it is your job to write a summary.
Article:
{article}
Summary: This is the summary for the above article:"""
prompt_template = PromptTemplate(input_variables=["article"], template=template)
comet_callback = CometCallbackHandler(
project_name="comet-example-langchain",
complexity_metrics=False,
stream_logs=True,
tags=["custom_metrics"],
custom_metrics=rouge_score.compute_metric,
)
callbacks = [StdOutCallbackHandler(), comet_callback]
llm = OpenAI(temperature=0.9)
synopsis_chain = LLMChain(llm=llm, prompt=prompt_template)
test_prompts = [
{
"article": """
The tower is 324 metres (1,063 ft) tall, about the same height as
an 81-storey building, and the tallest structure in Paris. Its base is square,
measuring 125 metres (410 ft) on each side.
During its construction, the Eiffel Tower surpassed the
Washington Monument to become the tallest man-made structure in the world,
a title it held for 41 years until the Chrysler Building
in New York City was finished in 1930.
It was the first structure to reach a height of 300 metres.
Due to the addition of a broadcasting aerial at the top of the tower in 1957,
it is now taller than the Chrysler Building by 5.2 metres (17 ft).
Excluding transmitters, the Eiffel Tower is the second tallest
free-standing structure in France after the Millau Viaduct.
"""
}
]
print(synopsis_chain.apply(test_prompts, callbacks=callbacks))
comet_callback.flush_tracker(synopsis_chain, finish=True)
Callback Tracer
There is another integration with Comet:
See an example.
from langchain.callbacks.tracers.comet import CometTracer |
https://python.langchain.com/docs/integrations/providers/couchbase/ | [Couchbase](http://couchbase.com/) is an award-winning distributed NoSQL cloud database that delivers unmatched versatility, performance, scalability, and financial value for all of your cloud, mobile, AI, and edge computing applications.
We have to install the `couchbase`package.
```
from langchain_community.document_loaders.couchbase import CouchbaseLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:00.901Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/couchbase/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/couchbase/",
"description": "Couchbase is an award-winning distributed NoSQL cloud database",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3532",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"couchbase\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:00 GMT",
"etag": "W/\"e28ae362c3c219f78b63b31d31a8d8b8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::zmgp6-1713753660160-0243fa2d7b90"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/couchbase/",
"property": "og:url"
},
{
"content": "Couchbase | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Couchbase is an award-winning distributed NoSQL cloud database",
"property": "og:description"
}
],
"title": "Couchbase | 🦜️🔗 LangChain"
} | Couchbase is an award-winning distributed NoSQL cloud database that delivers unmatched versatility, performance, scalability, and financial value for all of your cloud, mobile, AI, and edge computing applications.
We have to install the couchbasepackage.
from langchain_community.document_loaders.couchbase import CouchbaseLoader |
https://python.langchain.com/docs/integrations/providers/confluence/ | ## Confluence
> [Confluence](https://www.atlassian.com/software/confluence) is a wiki collaboration platform that saves and organizes all of the project-related material. `Confluence` is a knowledge base that primarily handles content management activities.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install atlassian-python-api
```
We need to set up `username/api_key` or `Oauth2 login`. See [instructions](https://support.atlassian.com/atlassian-account/docs/manage-api-tokens-for-your-atlassian-account/).
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/confluence/).
```
from langchain_community.document_loaders import ConfluenceLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:01.655Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/confluence/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/confluence/",
"description": "Confluence is a wiki collaboration platform that saves and organizes all of the project-related material. Confluence is a knowledge base that primarily handles content management activities.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"confluence\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:01 GMT",
"etag": "W/\"bb5678a91dbb40376a7c7c4f9f0de22b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::p9qs5-1713753661117-0402a7a148eb"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/confluence/",
"property": "og:url"
},
{
"content": "Confluence | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Confluence is a wiki collaboration platform that saves and organizes all of the project-related material. Confluence is a knowledge base that primarily handles content management activities.",
"property": "og:description"
}
],
"title": "Confluence | 🦜️🔗 LangChain"
} | Confluence
Confluence is a wiki collaboration platform that saves and organizes all of the project-related material. Confluence is a knowledge base that primarily handles content management activities.
Installation and Setup
pip install atlassian-python-api
We need to set up username/api_key or Oauth2 login. See instructions.
Document Loader
See a usage example.
from langchain_community.document_loaders import ConfluenceLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/ctransformers/ | ## C Transformers
This page covers how to use the [C Transformers](https://github.com/marella/ctransformers) library within LangChain. It is broken into two parts: installation and setup, and then references to specific C Transformers wrappers.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python package with `pip install ctransformers`
* Download a supported [GGML model](https://huggingface.co/TheBloke) (see [Supported Models](https://github.com/marella/ctransformers#supported-models))
## Wrappers[](#wrappers "Direct link to Wrappers")
### LLM[](#llm "Direct link to LLM")
There exists a CTransformers LLM wrapper, which you can access with:
```
from langchain_community.llms import CTransformers
```
It provides a unified interface for all models:
```
llm = CTransformers(model='/path/to/ggml-gpt-2.bin', model_type='gpt2')print(llm('AI is going to'))
```
If you are getting `illegal instruction` error, try using `lib='avx'` or `lib='basic'`:
```
llm = CTransformers(model='/path/to/ggml-gpt-2.bin', model_type='gpt2', lib='avx')
```
It can be used with models hosted on the Hugging Face Hub:
```
llm = CTransformers(model='marella/gpt-2-ggml')
```
If a model repo has multiple model files (`.bin` files), specify a model file using:
```
llm = CTransformers(model='marella/gpt-2-ggml', model_file='ggml-model.bin')
```
Additional parameters can be passed using the `config` parameter:
```
config = {'max_new_tokens': 256, 'repetition_penalty': 1.1}llm = CTransformers(model='marella/gpt-2-ggml', config=config)
```
See [Documentation](https://github.com/marella/ctransformers#config) for a list of available parameters.
For a more detailed walkthrough of this, see [this notebook](https://python.langchain.com/docs/integrations/llms/ctransformers/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:01.779Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/ctransformers/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/ctransformers/",
"description": "This page covers how to use the C Transformers library within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "7921",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"ctransformers\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:01 GMT",
"etag": "W/\"7964000082fb06a877d87e26348f6f7b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::rhmjj-1713753661391-6f629b501947"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/ctransformers/",
"property": "og:url"
},
{
"content": "C Transformers | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the C Transformers library within LangChain.",
"property": "og:description"
}
],
"title": "C Transformers | 🦜️🔗 LangChain"
} | C Transformers
This page covers how to use the C Transformers library within LangChain. It is broken into two parts: installation and setup, and then references to specific C Transformers wrappers.
Installation and Setup
Install the Python package with pip install ctransformers
Download a supported GGML model (see Supported Models)
Wrappers
LLM
There exists a CTransformers LLM wrapper, which you can access with:
from langchain_community.llms import CTransformers
It provides a unified interface for all models:
llm = CTransformers(model='/path/to/ggml-gpt-2.bin', model_type='gpt2')
print(llm('AI is going to'))
If you are getting illegal instruction error, try using lib='avx' or lib='basic':
llm = CTransformers(model='/path/to/ggml-gpt-2.bin', model_type='gpt2', lib='avx')
It can be used with models hosted on the Hugging Face Hub:
llm = CTransformers(model='marella/gpt-2-ggml')
If a model repo has multiple model files (.bin files), specify a model file using:
llm = CTransformers(model='marella/gpt-2-ggml', model_file='ggml-model.bin')
Additional parameters can be passed using the config parameter:
config = {'max_new_tokens': 256, 'repetition_penalty': 1.1}
llm = CTransformers(model='marella/gpt-2-ggml', config=config)
See Documentation for a list of available parameters.
For a more detailed walkthrough of this, see this notebook. |
https://python.langchain.com/docs/integrations/providers/ctranslate2/ | [CTranslate2](https://opennmt.net/CTranslate2/quickstart.html) is a C++ and Python library for efficient inference with Transformer models.
The project implements a custom runtime that applies many performance optimization techniques such as weights quantization, layers fusion, batch reordering, etc., to accelerate and reduce the memory usage of Transformer models on CPU and GPU.
A full list of features and supported models is included in the [project’s repository](https://opennmt.net/CTranslate2/guides/transformers.html). To start, please check out the official [quickstart guide](https://opennmt.net/CTranslate2/quickstart.html).
```
from langchain_community.llms import CTranslate2
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:02.230Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/ctranslate2/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/ctranslate2/",
"description": "CTranslate2 is a C++ and Python library",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"ctranslate2\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:01 GMT",
"etag": "W/\"f590c250e55c8f10d6f9b8fd2afb5e63\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::dhf8l-1713753661779-9ddc6191078a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/ctranslate2/",
"property": "og:url"
},
{
"content": "CTranslate2 | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "CTranslate2 is a C++ and Python library",
"property": "og:description"
}
],
"title": "CTranslate2 | 🦜️🔗 LangChain"
} | CTranslate2 is a C++ and Python library for efficient inference with Transformer models.
The project implements a custom runtime that applies many performance optimization techniques such as weights quantization, layers fusion, batch reordering, etc., to accelerate and reduce the memory usage of Transformer models on CPU and GPU.
A full list of features and supported models is included in the project’s repository. To start, please check out the official quickstart guide.
from langchain_community.llms import CTranslate2 |
https://python.langchain.com/docs/integrations/providers/dashvector/ | This document demonstrates to leverage DashVector within the LangChain ecosystem. In particular, it shows how to install DashVector, and how to use it as a VectorStore plugin in LangChain. It is broken into two parts: installation and setup, and then references to specific DashVector wrappers.
A DashVector Collection is wrapped as a familiar VectorStore for native usage within LangChain, which allows it to be readily used for various scenarios, such as semantic search or example selection.
```
from langchain_community.vectorstores import DashVector
```
For a detailed walkthrough of the DashVector wrapper, please refer to [this notebook](https://python.langchain.com/docs/integrations/vectorstores/dashvector/) | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:02.363Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dashvector/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dashvector/",
"description": "DashVector is a fully-managed vectorDB service that supports high-dimension dense and sparse vectors, real-time insertion and filtered search. It is built to scale automatically and can adapt to different application requirements.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4599",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dashvector\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:01 GMT",
"etag": "W/\"0924d38a39d5d6394a90dce015bff15d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wv8xj-1713753661797-69a4925ab5e0"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dashvector/",
"property": "og:url"
},
{
"content": "DashVector | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DashVector is a fully-managed vectorDB service that supports high-dimension dense and sparse vectors, real-time insertion and filtered search. It is built to scale automatically and can adapt to different application requirements.",
"property": "og:description"
}
],
"title": "DashVector | 🦜️🔗 LangChain"
} | This document demonstrates to leverage DashVector within the LangChain ecosystem. In particular, it shows how to install DashVector, and how to use it as a VectorStore plugin in LangChain. It is broken into two parts: installation and setup, and then references to specific DashVector wrappers.
A DashVector Collection is wrapped as a familiar VectorStore for native usage within LangChain, which allows it to be readily used for various scenarios, such as semantic search or example selection.
from langchain_community.vectorstores import DashVector
For a detailed walkthrough of the DashVector wrapper, please refer to this notebook |
https://python.langchain.com/docs/integrations/providers/cube/ | We have to get the API key and the URL of the Cube instance. See [these instructions](https://cube.dev/docs/product/apis-integrations/rest-api#configuration-base-path).
```
from langchain_community.document_loaders import CubeSemanticLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:02.302Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/cube/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/cube/",
"description": "Cube is the Semantic Layer for building data apps. It helps",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"cube\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:01 GMT",
"etag": "W/\"0079d179924db3707f2cfbb28513b423\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::f6d56-1713753661788-a770ce2fec3c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/cube/",
"property": "og:url"
},
{
"content": "Cube | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Cube is the Semantic Layer for building data apps. It helps",
"property": "og:description"
}
],
"title": "Cube | 🦜️🔗 LangChain"
} | We have to get the API key and the URL of the Cube instance. See these instructions.
from langchain_community.document_loaders import CubeSemanticLoader |
https://python.langchain.com/docs/integrations/providers/datadog/ | ## Datadog Tracing
> [ddtrace](https://github.com/DataDog/dd-trace-py) is a Datadog application performance monitoring (APM) library which provides an integration to monitor your LangChain application.
Key features of the ddtrace integration for LangChain:
* Traces: Capture LangChain requests, parameters, prompt-completions, and help visualize LangChain operations.
* Metrics: Capture LangChain request latency, errors, and token/cost usage (for OpenAI LLMs and chat models).
* Logs: Store prompt completion data for each LangChain operation.
* Dashboard: Combine metrics, logs, and trace data into a single plane to monitor LangChain requests.
* Monitors: Provide alerts in response to spikes in LangChain request latency or error rate.
Note: The ddtrace LangChain integration currently provides tracing for LLMs, chat models, Text Embedding Models, Chains, and Vectorstores.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
1. Enable APM and StatsD in your Datadog Agent, along with a Datadog API key. For example, in Docker:
```
docker run -d --cgroupns host \ --pid host \ -v /var/run/docker.sock:/var/run/docker.sock:ro \ -v /proc/:/host/proc/:ro \ -v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro \ -e DD_API_KEY=<DATADOG_API_KEY> \ -p 127.0.0.1:8126:8126/tcp \ -p 127.0.0.1:8125:8125/udp \ -e DD_DOGSTATSD_NON_LOCAL_TRAFFIC=true \ -e DD_APM_ENABLED=true \ gcr.io/datadoghq/agent:latest
```
2. Install the Datadog APM Python library.
```
pip install ddtrace>=1.17
```
3. The LangChain integration can be enabled automatically when you prefix your LangChain Python application command with `ddtrace-run`:
```
DD_SERVICE="my-service" DD_ENV="staging" DD_API_KEY=<DATADOG_API_KEY> ddtrace-run python <your-app>.py
```
**Note**: If the Agent is using a non-default hostname or port, be sure to also set `DD_AGENT_HOST`, `DD_TRACE_AGENT_PORT`, or `DD_DOGSTATSD_PORT`.
Additionally, the LangChain integration can be enabled programmatically by adding `patch_all()` or `patch(langchain=True)` before the first import of `langchain` in your application.
Note that using `ddtrace-run` or `patch_all()` will also enable the `requests` and `aiohttp` integrations which trace HTTP requests to LLM providers, as well as the `openai` integration which traces requests to the OpenAI library.
```
from ddtrace import config, patch# Note: be sure to configure the integration before calling ``patch()``!# e.g. config.langchain["logs_enabled"] = Truepatch(langchain=True)# to trace synchronous HTTP requests# patch(langchain=True, requests=True)# to trace asynchronous HTTP requests (to the OpenAI library)# patch(langchain=True, aiohttp=True)# to include underlying OpenAI spans from the OpenAI integration# patch(langchain=True, openai=True)patch_all
```
See the [APM Python library documentation](https://ddtrace.readthedocs.io/en/stable/installation_quickstart.html) for more advanced usage.
## Configuration[](#configuration "Direct link to Configuration")
See the [APM Python library documentation](https://ddtrace.readthedocs.io/en/stable/integrations.html#langchain) for all the available configuration options.
### Log Prompt & Completion Sampling[](#log-prompt--completion-sampling "Direct link to Log Prompt & Completion Sampling")
To enable log prompt and completion sampling, set the `DD_LANGCHAIN_LOGS_ENABLED=1` environment variable. By default, 10% of traced requests will emit logs containing the prompts and completions.
To adjust the log sample rate, see the [APM library documentation](https://ddtrace.readthedocs.io/en/stable/integrations.html#langchain).
**Note**: Logs submission requires `DD_API_KEY` to be specified when running `ddtrace-run`.
## Troubleshooting[](#troubleshooting "Direct link to Troubleshooting")
Need help? Create an issue on [ddtrace](https://github.com/DataDog/dd-trace-py) or contact [Datadog support](https://docs.datadoghq.com/help/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:03.049Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/datadog/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/datadog/",
"description": "ddtrace is a Datadog application performance monitoring (APM) library which provides an integration to monitor your LangChain application.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"datadog\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:02 GMT",
"etag": "W/\"8f5613293c620712bdf1ba5d28571bbd\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::c5znt-1713753662616-2c3d2c37e515"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/datadog/",
"property": "og:url"
},
{
"content": "Datadog Tracing | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "ddtrace is a Datadog application performance monitoring (APM) library which provides an integration to monitor your LangChain application.",
"property": "og:description"
}
],
"title": "Datadog Tracing | 🦜️🔗 LangChain"
} | Datadog Tracing
ddtrace is a Datadog application performance monitoring (APM) library which provides an integration to monitor your LangChain application.
Key features of the ddtrace integration for LangChain:
Traces: Capture LangChain requests, parameters, prompt-completions, and help visualize LangChain operations.
Metrics: Capture LangChain request latency, errors, and token/cost usage (for OpenAI LLMs and chat models).
Logs: Store prompt completion data for each LangChain operation.
Dashboard: Combine metrics, logs, and trace data into a single plane to monitor LangChain requests.
Monitors: Provide alerts in response to spikes in LangChain request latency or error rate.
Note: The ddtrace LangChain integration currently provides tracing for LLMs, chat models, Text Embedding Models, Chains, and Vectorstores.
Installation and Setup
Enable APM and StatsD in your Datadog Agent, along with a Datadog API key. For example, in Docker:
docker run -d --cgroupns host \
--pid host \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-v /proc/:/host/proc/:ro \
-v /sys/fs/cgroup/:/host/sys/fs/cgroup:ro \
-e DD_API_KEY=<DATADOG_API_KEY> \
-p 127.0.0.1:8126:8126/tcp \
-p 127.0.0.1:8125:8125/udp \
-e DD_DOGSTATSD_NON_LOCAL_TRAFFIC=true \
-e DD_APM_ENABLED=true \
gcr.io/datadoghq/agent:latest
Install the Datadog APM Python library.
pip install ddtrace>=1.17
The LangChain integration can be enabled automatically when you prefix your LangChain Python application command with ddtrace-run:
DD_SERVICE="my-service" DD_ENV="staging" DD_API_KEY=<DATADOG_API_KEY> ddtrace-run python <your-app>.py
Note: If the Agent is using a non-default hostname or port, be sure to also set DD_AGENT_HOST, DD_TRACE_AGENT_PORT, or DD_DOGSTATSD_PORT.
Additionally, the LangChain integration can be enabled programmatically by adding patch_all() or patch(langchain=True) before the first import of langchain in your application.
Note that using ddtrace-run or patch_all() will also enable the requests and aiohttp integrations which trace HTTP requests to LLM providers, as well as the openai integration which traces requests to the OpenAI library.
from ddtrace import config, patch
# Note: be sure to configure the integration before calling ``patch()``!
# e.g. config.langchain["logs_enabled"] = True
patch(langchain=True)
# to trace synchronous HTTP requests
# patch(langchain=True, requests=True)
# to trace asynchronous HTTP requests (to the OpenAI library)
# patch(langchain=True, aiohttp=True)
# to include underlying OpenAI spans from the OpenAI integration
# patch(langchain=True, openai=True)patch_all
See the APM Python library documentation for more advanced usage.
Configuration
See the APM Python library documentation for all the available configuration options.
Log Prompt & Completion Sampling
To enable log prompt and completion sampling, set the DD_LANGCHAIN_LOGS_ENABLED=1 environment variable. By default, 10% of traced requests will emit logs containing the prompts and completions.
To adjust the log sample rate, see the APM library documentation.
Note: Logs submission requires DD_API_KEY to be specified when running ddtrace-run.
Troubleshooting
Need help? Create an issue on ddtrace or contact Datadog support. |
https://python.langchain.com/docs/integrations/providers/databricks/ | ## Databricks
The [Databricks](https://www.databricks.com/) Lakehouse Platform unifies data, analytics, and AI on one platform.
Databricks embraces the LangChain ecosystem in various ways:
1. Databricks connector for the SQLDatabase Chain: SQLDatabase.from\_databricks() provides an easy way to query your data on Databricks through LangChain
2. Databricks MLflow integrates with LangChain: Tracking and serving LangChain applications with fewer steps
3. Databricks as an LLM provider: Deploy your fine-tuned LLMs on Databricks via serving endpoints or cluster driver proxy apps, and query it as langchain.llms.Databricks
4. Databricks Dolly: Databricks open-sourced Dolly which allows for commercial use, and can be accessed through the Hugging Face Hub
## Databricks connector for the SQLDatabase Chain[](#databricks-connector-for-the-sqldatabase-chain "Direct link to Databricks connector for the SQLDatabase Chain")
You can connect to [Databricks runtimes](https://docs.databricks.com/runtime/index.html) and [Databricks SQL](https://www.databricks.com/product/databricks-sql) using the SQLDatabase wrapper of LangChain.
## Databricks MLflow integrates with LangChain[](#databricks-mlflow-integrates-with-langchain "Direct link to Databricks MLflow integrates with LangChain")
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. See the notebook [MLflow Callback Handler](https://python.langchain.com/docs/integrations/providers/mlflow_tracking/) for details about MLflow's integration with LangChain.
Databricks provides a fully managed and hosted version of MLflow integrated with enterprise security features, high availability, and other Databricks workspace features such as experiment and run management and notebook revision capture. MLflow on Databricks offers an integrated experience for tracking and securing machine learning model training runs and running machine learning projects. See [MLflow guide](https://docs.databricks.com/mlflow/index.html) for more details.
Databricks MLflow makes it more convenient to develop LangChain applications on Databricks. For MLflow tracking, you don't need to set the tracking uri. For MLflow Model Serving, you can save LangChain Chains in the MLflow langchain flavor, and then register and serve the Chain with a few clicks on Databricks, with credentials securely managed by MLflow Model Serving.
## Databricks External Models[](#databricks-external-models "Direct link to Databricks External Models")
[Databricks External Models](https://docs.databricks.com/generative-ai/external-models/index.html) is a service that is designed to streamline the usage and management of various large language model (LLM) providers, such as OpenAI and Anthropic, within an organization. It offers a high-level interface that simplifies the interaction with these services by providing a unified endpoint to handle specific LLM related requests. The following example creates an endpoint that serves OpenAI's GPT-4 model and generates a chat response from it:
```
from langchain_community.chat_models import ChatDatabricksfrom langchain_core.messages import HumanMessagefrom mlflow.deployments import get_deploy_clientclient = get_deploy_client("databricks")name = f"chat"client.create_endpoint( name=name, config={ "served_entities": [ { "name": "test", "external_model": { "name": "gpt-4", "provider": "openai", "task": "llm/v1/chat", "openai_config": { "openai_api_key": "{{secrets/<scope>/<key>}}", }, }, } ], },)chat = ChatDatabricks(endpoint=name, temperature=0.1)print(chat([HumanMessage(content="hello")]))# -> content='Hello! How can I assist you today?'
```
## Databricks Foundation Model APIs[](#databricks-foundation-model-apis "Direct link to Databricks Foundation Model APIs")
[Databricks Foundation Model APIs](https://docs.databricks.com/machine-learning/foundation-models/index.html) allow you to access and query state-of-the-art open source models from dedicated serving endpoints. With Foundation Model APIs, developers can quickly and easily build applications that leverage a high-quality generative AI model without maintaining their own model deployment. The following example uses the `databricks-bge-large-en` endpoint to generate embeddings from text:
```
from langchain_community.embeddings import DatabricksEmbeddingsembeddings = DatabricksEmbeddings(endpoint="databricks-bge-large-en")print(embeddings.embed_query("hello")[:3])# -> [0.051055908203125, 0.007221221923828125, 0.003879547119140625, ...]
```
## Databricks as an LLM provider[](#databricks-as-an-llm-provider "Direct link to Databricks as an LLM provider")
The notebook [Wrap Databricks endpoints as LLMs](https://python.langchain.com/docs/integrations/llms/databricks/#wrapping-a-serving-endpoint-custom-model) demonstrates how to serve a custom model that has been registered by MLflow as a Databricks endpoint. It supports two types of endpoints: the serving endpoint, which is recommended for both production and development, and the cluster driver proxy app, which is recommended for interactive development.
## Databricks Vector Search[](#databricks-vector-search "Direct link to Databricks Vector Search")
Databricks Vector Search is a serverless similarity search engine that allows you to store a vector representation of your data, including metadata, in a vector database. With Vector Search, you can create auto-updating vector search indexes from Delta tables managed by Unity Catalog and query them with a simple API to return the most similar vectors. See the notebook [Databricks Vector Search](https://python.langchain.com/docs/integrations/vectorstores/databricks_vector_search/) for instructions to use it with LangChain. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:02.898Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/databricks/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/databricks/",
"description": "The Databricks Lakehouse Platform unifies data, analytics, and AI on one platform.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"databricks\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:02 GMT",
"etag": "W/\"50639575805baceb57dfcd0e33ad100d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::nvx8d-1713753662451-e9940f530d0b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/databricks/",
"property": "og:url"
},
{
"content": "Databricks | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "The Databricks Lakehouse Platform unifies data, analytics, and AI on one platform.",
"property": "og:description"
}
],
"title": "Databricks | 🦜️🔗 LangChain"
} | Databricks
The Databricks Lakehouse Platform unifies data, analytics, and AI on one platform.
Databricks embraces the LangChain ecosystem in various ways:
Databricks connector for the SQLDatabase Chain: SQLDatabase.from_databricks() provides an easy way to query your data on Databricks through LangChain
Databricks MLflow integrates with LangChain: Tracking and serving LangChain applications with fewer steps
Databricks as an LLM provider: Deploy your fine-tuned LLMs on Databricks via serving endpoints or cluster driver proxy apps, and query it as langchain.llms.Databricks
Databricks Dolly: Databricks open-sourced Dolly which allows for commercial use, and can be accessed through the Hugging Face Hub
Databricks connector for the SQLDatabase Chain
You can connect to Databricks runtimes and Databricks SQL using the SQLDatabase wrapper of LangChain.
Databricks MLflow integrates with LangChain
MLflow is an open-source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. See the notebook MLflow Callback Handler for details about MLflow's integration with LangChain.
Databricks provides a fully managed and hosted version of MLflow integrated with enterprise security features, high availability, and other Databricks workspace features such as experiment and run management and notebook revision capture. MLflow on Databricks offers an integrated experience for tracking and securing machine learning model training runs and running machine learning projects. See MLflow guide for more details.
Databricks MLflow makes it more convenient to develop LangChain applications on Databricks. For MLflow tracking, you don't need to set the tracking uri. For MLflow Model Serving, you can save LangChain Chains in the MLflow langchain flavor, and then register and serve the Chain with a few clicks on Databricks, with credentials securely managed by MLflow Model Serving.
Databricks External Models
Databricks External Models is a service that is designed to streamline the usage and management of various large language model (LLM) providers, such as OpenAI and Anthropic, within an organization. It offers a high-level interface that simplifies the interaction with these services by providing a unified endpoint to handle specific LLM related requests. The following example creates an endpoint that serves OpenAI's GPT-4 model and generates a chat response from it:
from langchain_community.chat_models import ChatDatabricks
from langchain_core.messages import HumanMessage
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
name = f"chat"
client.create_endpoint(
name=name,
config={
"served_entities": [
{
"name": "test",
"external_model": {
"name": "gpt-4",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": "{{secrets/<scope>/<key>}}",
},
},
}
],
},
)
chat = ChatDatabricks(endpoint=name, temperature=0.1)
print(chat([HumanMessage(content="hello")]))
# -> content='Hello! How can I assist you today?'
Databricks Foundation Model APIs
Databricks Foundation Model APIs allow you to access and query state-of-the-art open source models from dedicated serving endpoints. With Foundation Model APIs, developers can quickly and easily build applications that leverage a high-quality generative AI model without maintaining their own model deployment. The following example uses the databricks-bge-large-en endpoint to generate embeddings from text:
from langchain_community.embeddings import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
print(embeddings.embed_query("hello")[:3])
# -> [0.051055908203125, 0.007221221923828125, 0.003879547119140625, ...]
Databricks as an LLM provider
The notebook Wrap Databricks endpoints as LLMs demonstrates how to serve a custom model that has been registered by MLflow as a Databricks endpoint. It supports two types of endpoints: the serving endpoint, which is recommended for both production and development, and the cluster driver proxy app, which is recommended for interactive development.
Databricks Vector Search
Databricks Vector Search is a serverless similarity search engine that allows you to store a vector representation of your data, including metadata, in a vector database. With Vector Search, you can create auto-updating vector search indexes from Delta tables managed by Unity Catalog and query them with a simple API to return the most similar vectors. See the notebook Databricks Vector Search for instructions to use it with LangChain. |
https://python.langchain.com/docs/integrations/providers/dataforseo/ | ## DataForSEO
> [DataForSeo](https://dataforseo.com/) provides comprehensive SEO and digital marketing data solutions via API.
This page provides instructions on how to use the DataForSEO search APIs within LangChain.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Get a [DataForSEO API Access login and password](https://app.dataforseo.com/register), and set them as environment variables (`DATAFORSEO_LOGIN` and `DATAFORSEO_PASSWORD` respectively).
```
import osos.environ["DATAFORSEO_LOGIN"] = "your_login"os.environ["DATAFORSEO_PASSWORD"] = "your_password"
```
## Utility[](#utility "Direct link to Utility")
The DataForSEO utility wraps the API. To import this utility, use:
```
from langchain_community.utilities.dataforseo_api_search import DataForSeoAPIWrapper
```
For a detailed walkthrough of this wrapper, see [this notebook](https://python.langchain.com/docs/integrations/tools/dataforseo/).
You can also load this wrapper as a Tool to use with an Agent:
```
from langchain.agents import load_toolstools = load_tools(["dataforseo-api-search"])
```
## Example usage[](#example-usage "Direct link to Example usage")
```
dataforseo = DataForSeoAPIWrapper(api_login="your_login", api_password="your_password")result = dataforseo.run("Bill Gates")print(result)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:03.162Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dataforseo/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dataforseo/",
"description": "DataForSeo provides comprehensive SEO and digital marketing data solutions via API.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3533",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dataforseo\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:02 GMT",
"etag": "W/\"cc6ed27911d9c438db0cdbd56644cf96\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::f6d56-1713753662622-91d73573a4de"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dataforseo/",
"property": "og:url"
},
{
"content": "DataForSEO | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DataForSeo provides comprehensive SEO and digital marketing data solutions via API.",
"property": "og:description"
}
],
"title": "DataForSEO | 🦜️🔗 LangChain"
} | DataForSEO
DataForSeo provides comprehensive SEO and digital marketing data solutions via API.
This page provides instructions on how to use the DataForSEO search APIs within LangChain.
Installation and Setup
Get a DataForSEO API Access login and password, and set them as environment variables (DATAFORSEO_LOGIN and DATAFORSEO_PASSWORD respectively).
import os
os.environ["DATAFORSEO_LOGIN"] = "your_login"
os.environ["DATAFORSEO_PASSWORD"] = "your_password"
Utility
The DataForSEO utility wraps the API. To import this utility, use:
from langchain_community.utilities.dataforseo_api_search import DataForSeoAPIWrapper
For a detailed walkthrough of this wrapper, see this notebook.
You can also load this wrapper as a Tool to use with an Agent:
from langchain.agents import load_tools
tools = load_tools(["dataforseo-api-search"])
Example usage
dataforseo = DataForSeoAPIWrapper(api_login="your_login", api_password="your_password")
result = dataforseo.run("Bill Gates")
print(result) |
https://python.langchain.com/docs/integrations/providers/arangodb/ | [ArangoDB](https://github.com/arangodb/arangodb) is a scalable graph database system to drive value from connected data, faster. Native graphs, an integrated search engine, and JSON support, via a single query language. ArangoDB runs on-prem, in the cloud – anywhere.
Connect your `ArangoDB` Database with a chat model to get insights on your data.
```
from arango import ArangoClientfrom langchain_community.graphs import ArangoGraphfrom langchain.chains import ArangoGraphQAChain
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:03.776Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/arangodb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/arangodb/",
"description": "ArangoDB is a scalable graph database system to",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4611",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"arangodb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:02 GMT",
"etag": "W/\"7e21d83c03ad2a52240cd5862d5988b4\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::k52mr-1713753662876-5fe2263b4bed"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/arangodb/",
"property": "og:url"
},
{
"content": "ArangoDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "ArangoDB is a scalable graph database system to",
"property": "og:description"
}
],
"title": "ArangoDB | 🦜️🔗 LangChain"
} | ArangoDB is a scalable graph database system to drive value from connected data, faster. Native graphs, an integrated search engine, and JSON support, via a single query language. ArangoDB runs on-prem, in the cloud – anywhere.
Connect your ArangoDB Database with a chat model to get insights on your data.
from arango import ArangoClient
from langchain_community.graphs import ArangoGraph
from langchain.chains import ArangoGraphQAChain |
https://python.langchain.com/docs/integrations/providers/datadog_logs/ | ```
pip install datadog_api_client
```
We must initialize the loader with the Datadog API key and APP key, and we need to set up the query to extract the desired logs. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:03.838Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/datadog_logs/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/datadog_logs/",
"description": "Datadog is a monitoring and analytics platform for cloud-scale applications.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4600",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"datadog_logs\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:03 GMT",
"etag": "W/\"77f10f4cebaa621a891d376d4d1d4db2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::xhgjf-1713753663168-496c435bf90a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/datadog_logs/",
"property": "og:url"
},
{
"content": "Datadog Logs | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Datadog is a monitoring and analytics platform for cloud-scale applications.",
"property": "og:description"
}
],
"title": "Datadog Logs | 🦜️🔗 LangChain"
} | pip install datadog_api_client
We must initialize the loader with the Datadog API key and APP key, and we need to set up the query to extract the desired logs. |
https://python.langchain.com/docs/integrations/providers/arthur_tracking/ | The following guide shows how to run a registered chat LLM with the Arthur callback handler to automatically log model inferences to Arthur.
```
def make_langchain_chat_llm(): return ChatOpenAI( streaming=True, temperature=0.1, callbacks=[ StreamingStdOutCallbackHandler(), ArthurCallbackHandler.from_credentials( arthur_model_id, arthur_url=arthur_url, arthur_login=arthur_login ), ], )
```
```
Please enter password for admin: ········
```
Running the chat LLM with this `run` function will save the chat history in an ongoing list so that the conversation can reference earlier messages and log each response to the Arthur platform. You can view the history of this model’s inferences on your [model dashboard page](https://app.arthur.ai/).
```
>>> input >>>>>>: What is a callback handler?A callback handler, also known as a callback function or callback method, is a piece of code that is executed in response to a specific event or condition. It is commonly used in programming languages that support event-driven or asynchronous programming paradigms.The purpose of a callback handler is to provide a way for developers to define custom behavior that should be executed when a certain event occurs. Instead of waiting for a result or blocking the execution, the program registers a callback function and continues with other tasks. When the event is triggered, the callback function is invoked, allowing the program to respond accordingly.Callback handlers are commonly used in various scenarios, such as handling user input, responding to network requests, processing asynchronous operations, and implementing event-driven architectures. They provide a flexible and modular way to handle events and decouple different components of a system.>>> input >>>>>>: What do I need to do to get the full benefits of thisTo get the full benefits of using a callback handler, you should consider the following:1. Understand the event or condition: Identify the specific event or condition that you want to respond to with a callback handler. This could be user input, network requests, or any other asynchronous operation.2. Define the callback function: Create a function that will be executed when the event or condition occurs. This function should contain the desired behavior or actions you want to take in response to the event.3. Register the callback function: Depending on the programming language or framework you are using, you may need to register or attach the callback function to the appropriate event or condition. This ensures that the callback function is invoked when the event occurs.4. Handle the callback: Implement the necessary logic within the callback function to handle the event or condition. This could involve updating the user interface, processing data, making further requests, or triggering other actions.5. Consider error handling: It's important to handle any potential errors or exceptions that may occur within the callback function. This ensures that your program can gracefully handle unexpected situations and prevent crashes or undesired behavior.6. Maintain code readability and modularity: As your codebase grows, it's crucial to keep your callback handlers organized and maintainable. Consider using design patterns or architectural principles to structure your code in a modular and scalable way.By following these steps, you can leverage the benefits of callback handlers, such as asynchronous and event-driven programming, improved responsiveness, and modular code design.>>> input >>>>>>: q
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:04.369Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/arthur_tracking/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/arthur_tracking/",
"description": "Arthur is a model monitoring and observability",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3539",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"arthur_tracking\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"a7117eacf9e09c192411b8e8b7f36227\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::ptbzf-1713753664298-8a23a2df899f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/arthur_tracking/",
"property": "og:url"
},
{
"content": "Arthur | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Arthur is a model monitoring and observability",
"property": "og:description"
}
],
"title": "Arthur | 🦜️🔗 LangChain"
} | The following guide shows how to run a registered chat LLM with the Arthur callback handler to automatically log model inferences to Arthur.
def make_langchain_chat_llm():
return ChatOpenAI(
streaming=True,
temperature=0.1,
callbacks=[
StreamingStdOutCallbackHandler(),
ArthurCallbackHandler.from_credentials(
arthur_model_id, arthur_url=arthur_url, arthur_login=arthur_login
),
],
)
Please enter password for admin: ········
Running the chat LLM with this run function will save the chat history in an ongoing list so that the conversation can reference earlier messages and log each response to the Arthur platform. You can view the history of this model’s inferences on your model dashboard page.
>>> input >>>
>>>: What is a callback handler?
A callback handler, also known as a callback function or callback method, is a piece of code that is executed in response to a specific event or condition. It is commonly used in programming languages that support event-driven or asynchronous programming paradigms.
The purpose of a callback handler is to provide a way for developers to define custom behavior that should be executed when a certain event occurs. Instead of waiting for a result or blocking the execution, the program registers a callback function and continues with other tasks. When the event is triggered, the callback function is invoked, allowing the program to respond accordingly.
Callback handlers are commonly used in various scenarios, such as handling user input, responding to network requests, processing asynchronous operations, and implementing event-driven architectures. They provide a flexible and modular way to handle events and decouple different components of a system.
>>> input >>>
>>>: What do I need to do to get the full benefits of this
To get the full benefits of using a callback handler, you should consider the following:
1. Understand the event or condition: Identify the specific event or condition that you want to respond to with a callback handler. This could be user input, network requests, or any other asynchronous operation.
2. Define the callback function: Create a function that will be executed when the event or condition occurs. This function should contain the desired behavior or actions you want to take in response to the event.
3. Register the callback function: Depending on the programming language or framework you are using, you may need to register or attach the callback function to the appropriate event or condition. This ensures that the callback function is invoked when the event occurs.
4. Handle the callback: Implement the necessary logic within the callback function to handle the event or condition. This could involve updating the user interface, processing data, making further requests, or triggering other actions.
5. Consider error handling: It's important to handle any potential errors or exceptions that may occur within the callback function. This ensures that your program can gracefully handle unexpected situations and prevent crashes or undesired behavior.
6. Maintain code readability and modularity: As your codebase grows, it's crucial to keep your callback handlers organized and maintainable. Consider using design patterns or architectural principles to structure your code in a modular and scalable way.
By following these steps, you can leverage the benefits of callback handlers, such as asynchronous and event-driven programming, improved responsiveness, and modular code design.
>>> input >>>
>>>: q |
https://python.langchain.com/docs/integrations/providers/argilla/ | ## Argilla
> [Argilla](https://argilla.io/) is an open-source data curation platform for LLMs. Using `Argilla`, everyone can build robust language models through faster data curation using both human and machine feedback. `Argilla` provides support for each step in the MLOps cycle, from data labeling to model monitoring.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Get your [API key](https://platform.openai.com/account/api-keys).
Install the Python package:
## Callbacks[](#callbacks "Direct link to Callbacks")
```
from langchain.callbacks import ArgillaCallbackHandler
```
See an [example](https://python.langchain.com/docs/integrations/callbacks/argilla/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:04.676Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/argilla/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/argilla/",
"description": "Argilla is an open-source data curation platform for LLMs.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"argilla\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"6433b95371bb1bfef96668fe88e1eaf4\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::tj78w-1713753664348-e71ed6cbd72a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/argilla/",
"property": "og:url"
},
{
"content": "Argilla | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Argilla is an open-source data curation platform for LLMs.",
"property": "og:description"
}
],
"title": "Argilla | 🦜️🔗 LangChain"
} | Argilla
Argilla is an open-source data curation platform for LLMs. Using Argilla, everyone can build robust language models through faster data curation using both human and machine feedback. Argilla provides support for each step in the MLOps cycle, from data labeling to model monitoring.
Installation and Setup
Get your API key.
Install the Python package:
Callbacks
from langchain.callbacks import ArgillaCallbackHandler
See an example. |
https://python.langchain.com/docs/integrations/providers/arcee/ | [Arcee](https://www.arcee.ai/about/about-us) enables the development and advancement of what we coin as SLMs—small, specialized, secure, and scalable language models. By offering a SLM Adaptation System and a seamless, secure integration, `Arcee` empowers enterprises to harness the full potential of domain-adapted language models, driving the transformative innovation in operations.
Get your `Arcee API` key.
```
from langchain_community.llms import Arcee
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:04.602Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/arcee/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/arcee/",
"description": "Arcee enables the development and advancement",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3540",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"arcee\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"a6b57ef8853d45b8510a44c8a77cbf41\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::wl5px-1713753664371-4cfd84e3edde"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/arcee/",
"property": "og:url"
},
{
"content": "Arcee | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Arcee enables the development and advancement",
"property": "og:description"
}
],
"title": "Arcee | 🦜️🔗 LangChain"
} | Arcee enables the development and advancement of what we coin as SLMs—small, specialized, secure, and scalable language models. By offering a SLM Adaptation System and a seamless, secure integration, Arcee empowers enterprises to harness the full potential of domain-adapted language models, driving the transformative innovation in operations.
Get your Arcee API key.
from langchain_community.llms import Arcee |
https://python.langchain.com/docs/integrations/providers/arcgis/ | [ArcGIS](https://www.esri.com/en-us/arcgis/about-arcgis/overview) is a family of client, server and online geographic information system software developed and maintained by [Esri](https://www.esri.com/).
`ArcGISLoader` uses the `arcgis` package. `arcgis` is a Python library for the vector and raster analysis, geocoding, map making, routing and directions. It administers, organizes and manages users, groups and information items in your GIS. It enables access to ready-to-use maps and curated geographic data from `Esri` and other authoritative sources, and works with your own data as well.
We have to install the `arcgis` package.
```
from langchain_community.document_loaders import ArcGISLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:04.530Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/arcgis/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/arcgis/",
"description": "ArcGIS is a family of client,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"arcgis\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"c3904a530e306b0de1d93590a20d2bdf\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::q7hbv-1713753664296-b25abd139f2b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/arcgis/",
"property": "og:url"
},
{
"content": "ArcGIS | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "ArcGIS is a family of client,",
"property": "og:description"
}
],
"title": "ArcGIS | 🦜️🔗 LangChain"
} | ArcGIS is a family of client, server and online geographic information system software developed and maintained by Esri.
ArcGISLoader uses the arcgis package. arcgis is a Python library for the vector and raster analysis, geocoding, map making, routing and directions. It administers, organizes and manages users, groups and information items in your GIS. It enables access to ready-to-use maps and curated geographic data from Esri and other authoritative sources, and works with your own data as well.
We have to install the arcgis package.
from langchain_community.document_loaders import ArcGISLoader |
https://python.langchain.com/docs/integrations/providers/arxiv/ | [arXiv](https://arxiv.org/) is an open-access archive for 2 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
First, you need to install `arxiv` python package.
Second, you need to install `PyMuPDF` python package which transforms PDF files downloaded from the `arxiv.org` site into the text format.
```
from langchain_community.document_loaders import ArxivLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:05.445Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/arxiv/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/arxiv/",
"description": "arXiv is an open-access archive for 2 million scholarly articles in the fields of physics,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4613",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"arxiv\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"b1ab40b107f5180565756cce418f63bf\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::rcjd5-1713753664825-2a91aaf1609f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/arxiv/",
"property": "og:url"
},
{
"content": "Arxiv | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "arXiv is an open-access archive for 2 million scholarly articles in the fields of physics,",
"property": "og:description"
}
],
"title": "Arxiv | 🦜️🔗 LangChain"
} | arXiv is an open-access archive for 2 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
First, you need to install arxiv python package.
Second, you need to install PyMuPDF python package which transforms PDF files downloaded from the arxiv.org site into the text format.
from langchain_community.document_loaders import ArxivLoader |
https://python.langchain.com/docs/integrations/providers/awadb/ | ## AwaDB
> [AwaDB](https://github.com/awa-ai/awadb) is an AI Native database for the search and storage of embedding vectors used by LLM Applications.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
## Vector store[](#vector-store "Direct link to Vector store")
```
from langchain_community.vectorstores import AwaDB
```
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/awadb/).
## Embedding models[](#embedding-models "Direct link to Embedding models")
```
from langchain_community.embeddings import AwaEmbeddings
```
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/awadb/).
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:05.560Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/awadb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/awadb/",
"description": "AwaDB is an AI Native database for the search and storage of embedding vectors used by LLM Applications.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"awadb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"40af25203d62d5bf211a7a7988a8c19d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::m4x6q-1713753664790-8a386547434a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/awadb/",
"property": "og:url"
},
{
"content": "AwaDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "AwaDB is an AI Native database for the search and storage of embedding vectors used by LLM Applications.",
"property": "og:description"
}
],
"title": "AwaDB | 🦜️🔗 LangChain"
} | AwaDB
AwaDB is an AI Native database for the search and storage of embedding vectors used by LLM Applications.
Installation and Setup
Vector store
from langchain_community.vectorstores import AwaDB
See a usage example.
Embedding models
from langchain_community.embeddings import AwaEmbeddings
See a usage example.
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/atlas/ | ## Atlas
> [Nomic Atlas](https://docs.nomic.ai/index.html) is a platform for interacting with both small and internet scale unstructured datasets.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python package with `pip install nomic`
* `Nomic` is also included in langchains poetry extras `poetry install -E all`
## VectorStore[](#vectorstore "Direct link to VectorStore")
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/atlas/).
```
from langchain_community.vectorstores import AtlasDB
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:05.700Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/atlas/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/atlas/",
"description": "Nomic Atlas is a platform for interacting with both",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6408",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"atlas\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:05 GMT",
"etag": "W/\"883767e5887a91c446bb99574145eeda\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::wf55v-1713753665004-85d8686fdd73"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/atlas/",
"property": "og:url"
},
{
"content": "Atlas | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Nomic Atlas is a platform for interacting with both",
"property": "og:description"
}
],
"title": "Atlas | 🦜️🔗 LangChain"
} | Atlas
Nomic Atlas is a platform for interacting with both small and internet scale unstructured datasets.
Installation and Setup
Install the Python package with pip install nomic
Nomic is also included in langchains poetry extras poetry install -E all
VectorStore
See a usage example.
from langchain_community.vectorstores import AtlasDB
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/azlyrics/ | There isn't any special setup for it.
```
from langchain_community.document_loaders import AZLyricsLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:05.924Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/azlyrics/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/azlyrics/",
"description": "AZLyrics is a large, legal, every day growing collection of lyrics.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3540",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"azlyrics\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:04 GMT",
"etag": "W/\"8e535829b0438d176dbf91c12b1f9434\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::qvg7r-1713753664988-e4569a7f6176"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/azlyrics/",
"property": "og:url"
},
{
"content": "AZLyrics | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "AZLyrics is a large, legal, every day growing collection of lyrics.",
"property": "og:description"
}
],
"title": "AZLyrics | 🦜️🔗 LangChain"
} | There isn't any special setup for it.
from langchain_community.document_loaders import AZLyricsLoader |
https://python.langchain.com/docs/integrations/providers/astradb/ | ## Astra DB
> [DataStax Astra DB](https://docs.datastax.com/en/astra/home/astra.html) is a serverless vector-capable database built on `Apache Cassandra®`and made conveniently available through an easy-to-use JSON API.
See a [tutorial provided by DataStax](https://docs.datastax.com/en/astra/astra-db-vector/tutorials/chatbot.html).
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Install the following Python package:
```
pip install "langchain-astradb>=0.1.0"
```
Get the [connection secrets](https://docs.datastax.com/en/astra/astra-db-vector/get-started/quickstart.html). Set up the following environment variables:
```
ASTRA_DB_APPLICATION_TOKEN="TOKEN"ASTRA_DB_API_ENDPOINT="API_ENDPOINT"
```
## Vector Store[](#vector-store "Direct link to Vector Store")
```
from langchain_astradb import AstraDBVectorStorevector_store = AstraDBVectorStore( embedding=my_embedding, collection_name="my_store", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/vectorstores/astradb/).
See the [example provided by DataStax](https://docs.datastax.com/en/astra/astra-db-vector/integrations/langchain.html).
## Chat message history[](#chat-message-history "Direct link to Chat message history")
```
from langchain_astradb import AstraDBChatMessageHistorymessage_history = AstraDBChatMessageHistory( session_id="test-session", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)
```
See the [usage example](https://python.langchain.com/docs/integrations/memory/astradb_chat_message_history/#example).
## LLM Cache[](#llm-cache "Direct link to LLM Cache")
```
from langchain.globals import set_llm_cachefrom langchain_astradb import AstraDBCacheset_llm_cache(AstraDBCache( api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,))
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/llms/llm_caching/#astra-db-caches) (scroll to the Astra DB section).
## Semantic LLM Cache[](#semantic-llm-cache "Direct link to Semantic LLM Cache")
```
from langchain.globals import set_llm_cachefrom langchain_astradb import AstraDBSemanticCacheset_llm_cache(AstraDBSemanticCache( embedding=my_embedding, api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,))
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/llms/llm_caching/#astra-db-caches) (scroll to the appropriate section).
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/memory/astradb_chat_message_history/).
## Document loader[](#document-loader "Direct link to Document loader")
```
from langchain_astradb import AstraDBLoaderloader = AstraDBLoader( collection_name="my_collection", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/document_loaders/astradb/).
## Self-querying retriever[](#self-querying-retriever "Direct link to Self-querying retriever")
```
from langchain_astradb import AstraDBVectorStorefrom langchain.retrievers.self_query.base import SelfQueryRetrievervector_store = AstraDBVectorStore( embedding=my_embedding, collection_name="my_store", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)retriever = SelfQueryRetriever.from_llm( my_llm, vector_store, document_content_description, metadata_field_info)
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/retrievers/self_query/astradb/).
## Store[](#store "Direct link to Store")
```
from langchain_astradb import AstraDBStorestore = AstraDBStore( collection_name="my_kv_store", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/stores/astradb/#astradbstore).
## Byte Store[](#byte-store "Direct link to Byte Store")
```
from langchain_astradb import AstraDBByteStorestore = AstraDBByteStore( collection_name="my_kv_store", api_endpoint=ASTRA_DB_API_ENDPOINT, token=ASTRA_DB_APPLICATION_TOKEN,)
```
Learn more in the [example notebook](https://python.langchain.com/docs/integrations/stores/astradb/#astradbbytestore). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:06.402Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/astradb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/astradb/",
"description": "DataStax Astra DB is a serverless",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4667",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"astradb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:05 GMT",
"etag": "W/\"7a43e598a237ddfb90a084112eaefbb3\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::zvqrn-1713753665451-66d7a098cf96"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/astradb/",
"property": "og:url"
},
{
"content": "Astra DB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DataStax Astra DB is a serverless",
"property": "og:description"
}
],
"title": "Astra DB | 🦜️🔗 LangChain"
} | Astra DB
DataStax Astra DB is a serverless vector-capable database built on Apache Cassandra®and made conveniently available through an easy-to-use JSON API.
See a tutorial provided by DataStax.
Installation and Setup
Install the following Python package:
pip install "langchain-astradb>=0.1.0"
Get the connection secrets. Set up the following environment variables:
ASTRA_DB_APPLICATION_TOKEN="TOKEN"
ASTRA_DB_API_ENDPOINT="API_ENDPOINT"
Vector Store
from langchain_astradb import AstraDBVectorStore
vector_store = AstraDBVectorStore(
embedding=my_embedding,
collection_name="my_store",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
Learn more in the example notebook.
See the example provided by DataStax.
Chat message history
from langchain_astradb import AstraDBChatMessageHistory
message_history = AstraDBChatMessageHistory(
session_id="test-session",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
See the usage example.
LLM Cache
from langchain.globals import set_llm_cache
from langchain_astradb import AstraDBCache
set_llm_cache(AstraDBCache(
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
))
Learn more in the example notebook (scroll to the Astra DB section).
Semantic LLM Cache
from langchain.globals import set_llm_cache
from langchain_astradb import AstraDBSemanticCache
set_llm_cache(AstraDBSemanticCache(
embedding=my_embedding,
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
))
Learn more in the example notebook (scroll to the appropriate section).
Learn more in the example notebook.
Document loader
from langchain_astradb import AstraDBLoader
loader = AstraDBLoader(
collection_name="my_collection",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
Learn more in the example notebook.
Self-querying retriever
from langchain_astradb import AstraDBVectorStore
from langchain.retrievers.self_query.base import SelfQueryRetriever
vector_store = AstraDBVectorStore(
embedding=my_embedding,
collection_name="my_store",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
retriever = SelfQueryRetriever.from_llm(
my_llm,
vector_store,
document_content_description,
metadata_field_info
)
Learn more in the example notebook.
Store
from langchain_astradb import AstraDBStore
store = AstraDBStore(
collection_name="my_kv_store",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
Learn more in the example notebook.
Byte Store
from langchain_astradb import AstraDBByteStore
store = AstraDBByteStore(
collection_name="my_kv_store",
api_endpoint=ASTRA_DB_API_ENDPOINT,
token=ASTRA_DB_APPLICATION_TOKEN,
)
Learn more in the example notebook. |
https://python.langchain.com/docs/integrations/providers/assemblyai/ | [AssemblyAI](https://www.assemblyai.com/) builds `Speech AI` models for tasks like speech-to-text, speaker diarization, speech summarization, and more. `AssemblyAI’s` Speech AI models include accurate speech-to-text for voice data (such as calls, virtual meetings, and podcasts), speaker detection, sentiment analysis, chapter detection, PII redaction.
Install the `assemblyai` package.
```
pip install -U assemblyai
```
The `AssemblyAIAudioTranscriptLoader` transcribes audio files with the `AssemblyAI API` and loads the transcribed text into documents. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:06.677Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/assemblyai/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/assemblyai/",
"description": "AssemblyAI builds Speech AI models for tasks like",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4614",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"assemblyai\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:05 GMT",
"etag": "W/\"40994891c9c23e2d954d949c7f031a90\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::rrvbb-1713753665757-2c5ce0350c72"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/assemblyai/",
"property": "og:url"
},
{
"content": "AssemblyAI | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "AssemblyAI builds Speech AI models for tasks like",
"property": "og:description"
}
],
"title": "AssemblyAI | 🦜️🔗 LangChain"
} | AssemblyAI builds Speech AI models for tasks like speech-to-text, speaker diarization, speech summarization, and more. AssemblyAI’s Speech AI models include accurate speech-to-text for voice data (such as calls, virtual meetings, and podcasts), speaker detection, sentiment analysis, chapter detection, PII redaction.
Install the assemblyai package.
pip install -U assemblyai
The AssemblyAIAudioTranscriptLoader transcribes audio files with the AssemblyAI API and loads the transcribed text into documents. |
https://python.langchain.com/docs/integrations/providers/bageldb/ | [BagelDB](https://www.bageldb.ai/) (`Open Vector Database for AI`), is like GitHub for AI data. It is a collaborative platform where users can create, share, and manage vector datasets. It can support private projects for independent developers, internal collaborations for enterprises, and public contributions for data DAOs.
```
from langchain_community.vectorstores import Bagel
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:06.724Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/bageldb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/bageldb/",
"description": "BagelDB (Open Vector Database for AI), is like GitHub for AI data.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"bageldb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:05 GMT",
"etag": "W/\"fa06ba2aded717918376c96fc2c8c2d9\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::5fbxs-1713753665713-282087e19ea3"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/bageldb/",
"property": "og:url"
},
{
"content": "BagelDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "BagelDB (Open Vector Database for AI), is like GitHub for AI data.",
"property": "og:description"
}
],
"title": "BagelDB | 🦜️🔗 LangChain"
} | BagelDB (Open Vector Database for AI), is like GitHub for AI data. It is a collaborative platform where users can create, share, and manage vector datasets. It can support private projects for independent developers, internal collaborations for enterprises, and public contributions for data DAOs.
from langchain_community.vectorstores import Bagel |
https://python.langchain.com/docs/integrations/providers/baidu/ | ## Baidu
> [Baidu Cloud](https://cloud.baidu.com/) is a cloud service provided by `Baidu, Inc.`, headquartered in Beijing. It offers a cloud storage service, client software, file management, resource sharing, and Third Party Integration.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Register and get the `Qianfan` `AK` and `SK` keys [here](https://cloud.baidu.com/product/wenxinworkshop).
## LLMs[](#llms "Direct link to LLMs")
### Baidu Qianfan[](#baidu-qianfan "Direct link to Baidu Qianfan")
See a [usage example](https://python.langchain.com/docs/integrations/llms/baidu_qianfan_endpoint/).
```
from langchain_community.llms import QianfanLLMEndpoint
```
## Chat models[](#chat-models "Direct link to Chat models")
### Qianfan Chat Endpoint[](#qianfan-chat-endpoint "Direct link to Qianfan Chat Endpoint")
See a [usage example](https://python.langchain.com/docs/integrations/chat/baidu_qianfan_endpoint/).
```
from langchain_community.chat_models import QianfanChatEndpoint
```
## Embedding models[](#embedding-models "Direct link to Embedding models")
### Baidu Qianfan[](#baidu-qianfan-1 "Direct link to Baidu Qianfan")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/baidu_qianfan_endpoint/).
```
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
```
## Vector stores[](#vector-stores "Direct link to Vector stores")
### Baidu Cloud ElasticSearch VectorSearch[](#baidu-cloud-elasticsearch-vectorsearch "Direct link to Baidu Cloud ElasticSearch VectorSearch")
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/baiducloud_vector_search/).
```
from langchain_community.vectorstores import BESVectorStore
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:07.214Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/baidu/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/baidu/",
"description": "Baidu Cloud is a cloud service provided by Baidu, Inc.,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3541",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"baidu\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:06 GMT",
"etag": "W/\"8a9dbd55acc6039947e109121e23c027\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::v5hc9-1713753666822-ed78dd53a21b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/baidu/",
"property": "og:url"
},
{
"content": "Baidu | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Baidu Cloud is a cloud service provided by Baidu, Inc.,",
"property": "og:description"
}
],
"title": "Baidu | 🦜️🔗 LangChain"
} | Baidu
Baidu Cloud is a cloud service provided by Baidu, Inc., headquartered in Beijing. It offers a cloud storage service, client software, file management, resource sharing, and Third Party Integration.
Installation and Setup
Register and get the Qianfan AK and SK keys here.
LLMs
Baidu Qianfan
See a usage example.
from langchain_community.llms import QianfanLLMEndpoint
Chat models
Qianfan Chat Endpoint
See a usage example.
from langchain_community.chat_models import QianfanChatEndpoint
Embedding models
Baidu Qianfan
See a usage example.
from langchain_community.embeddings import QianfanEmbeddingsEndpoint
Vector stores
Baidu Cloud ElasticSearch VectorSearch
See a usage example.
from langchain_community.vectorstores import BESVectorStore
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/bananadev/ | You'll need to set up a Github repo for your Banana app. You can get started in 5 minutes using [this guide](https://docs.banana.dev/banana-docs/).
Alternatively, for a ready-to-go LLM example, you can check out Banana's [CodeLlama-7B-Instruct-GPTQ](https://github.com/bananaml/demo-codellama-7b-instruct-gptq) GitHub repository. Just fork it and deploy it within Banana.
To use Banana apps within Langchain, you must include the `outputs` key in the returned json, and the value must be a string.
```
@app.handler("/")def handler(context: dict, request: Request) -> Response: """Handle a request to generate code from a prompt.""" model = context.get("model") tokenizer = context.get("tokenizer") max_new_tokens = request.json.get("max_new_tokens", 512) temperature = request.json.get("temperature", 0.7) prompt = request.json.get("prompt") prompt_template=f'''[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```: {prompt} [/INST] ''' input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda() output = model.generate(inputs=input_ids, temperature=temperature, max_new_tokens=max_new_tokens) result = tokenizer.decode(output[0]) return Response(json={"outputs": result}, status=200)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:07.493Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/bananadev/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/bananadev/",
"description": "Banana provided serverless GPU inference for AI models,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"bananadev\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:06 GMT",
"etag": "W/\"8774ea0905edc4bd62833dc26661a8fd\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::hwbpg-1713753666828-d69fe2ad0761"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/bananadev/",
"property": "og:url"
},
{
"content": "Banana | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Banana provided serverless GPU inference for AI models,",
"property": "og:description"
}
],
"title": "Banana | 🦜️🔗 LangChain"
} | You'll need to set up a Github repo for your Banana app. You can get started in 5 minutes using this guide.
Alternatively, for a ready-to-go LLM example, you can check out Banana's CodeLlama-7B-Instruct-GPTQ GitHub repository. Just fork it and deploy it within Banana.
To use Banana apps within Langchain, you must include the outputs key in the returned json, and the value must be a string.
@app.handler("/")
def handler(context: dict, request: Request) -> Response:
"""Handle a request to generate code from a prompt."""
model = context.get("model")
tokenizer = context.get("tokenizer")
max_new_tokens = request.json.get("max_new_tokens", 512)
temperature = request.json.get("temperature", 0.7)
prompt = request.json.get("prompt")
prompt_template=f'''[INST] Write code to solve the following coding problem that obeys the constraints and passes the example test cases. Please wrap your code answer using ```:
{prompt}
[/INST]
'''
input_ids = tokenizer(prompt_template, return_tensors='pt').input_ids.cuda()
output = model.generate(inputs=input_ids, temperature=temperature, max_new_tokens=max_new_tokens)
result = tokenizer.decode(output[0])
return Response(json={"outputs": result}, status=200) |
https://python.langchain.com/docs/integrations/providers/baseten/ | Export your API key to your as an environment variable called `BASETEN_API_KEY`.
```
export BASETEN_API_KEY="paste_your_api_key_here"
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:07.428Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/baseten/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/baseten/",
"description": "Baseten is a provider of all the infrastructure you need to deploy and serve",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3541",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"baseten\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:06 GMT",
"etag": "W/\"fe8fb58b13587c9c8922b8ad14b8cbb3\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::8fxw7-1713753666810-91ee60c912ff"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/baseten/",
"property": "og:url"
},
{
"content": "Baseten | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Baseten is a provider of all the infrastructure you need to deploy and serve",
"property": "og:description"
}
],
"title": "Baseten | 🦜️🔗 LangChain"
} | Export your API key to your as an environment variable called BASETEN_API_KEY.
export BASETEN_API_KEY="paste_your_api_key_here" |
https://python.langchain.com/docs/integrations/providers/baichuan/ | ## Baichuan
> [Baichuan Inc.](https://www.baichuan-ai.com/) is a Chinese startup in the era of AGI, dedicated to addressing fundamental human needs: Efficiency, Health, and Happiness.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Register and get an API key [here](https://platform.baichuan-ai.com/).
## LLMs[](#llms "Direct link to LLMs")
See a [usage example](https://python.langchain.com/docs/integrations/llms/baichuan/).
```
from langchain_community.llms import BaichuanLLM
```
## Chat models[](#chat-models "Direct link to Chat models")
See a [usage example](https://python.langchain.com/docs/integrations/chat/baichuan/).
```
from langchain_community.chat_models import ChatBaichuan
```
## Embedding models[](#embedding-models "Direct link to Embedding models")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/baichuan/).
```
from langchain_community.embeddings import BaichuanTextEmbeddings
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:07.298Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/baichuan/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/baichuan/",
"description": "Baichuan Inc. is a Chinese startup in the era of AGI,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4613",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"baichuan\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:06 GMT",
"etag": "W/\"76d6efb5752e577b8e768836c9c3a267\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::qfjn6-1713753666841-51d62e294d03"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/baichuan/",
"property": "og:url"
},
{
"content": "Baichuan | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Baichuan Inc. is a Chinese startup in the era of AGI,",
"property": "og:description"
}
],
"title": "Baichuan | 🦜️🔗 LangChain"
} | Baichuan
Baichuan Inc. is a Chinese startup in the era of AGI, dedicated to addressing fundamental human needs: Efficiency, Health, and Happiness.
Installation and Setup
Register and get an API key here.
LLMs
See a usage example.
from langchain_community.llms import BaichuanLLM
Chat models
See a usage example.
from langchain_community.chat_models import ChatBaichuan
Embedding models
See a usage example.
from langchain_community.embeddings import BaichuanTextEmbeddings
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/beautiful_soup/ | [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/) is a Python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML,\[3\] which is useful for web scraping. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:07.697Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/beautiful_soup/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/beautiful_soup/",
"description": "Beautiful Soup is a Python package for parsing",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"beautiful_soup\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:07 GMT",
"etag": "W/\"0038b9b331fe05a04eb8db97a9403184\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::qvdxl-1713753667459-0177ad7e28d3"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/beautiful_soup/",
"property": "og:url"
},
{
"content": "Beautiful Soup | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Beautiful Soup is a Python package for parsing",
"property": "og:description"
}
],
"title": "Beautiful Soup | 🦜️🔗 LangChain"
} | Beautiful Soup is a Python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML,[3] which is useful for web scraping. |
https://python.langchain.com/docs/integrations/providers/bilibili/ | ## BiliBili
> [Bilibili](https://www.bilibili.tv/) is one of the most beloved long-form video sites in China.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install bilibili-api-python
```
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/bilibili/).
```
from langchain_community.document_loaders import BiliBiliLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:08.369Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/bilibili/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/bilibili/",
"description": "Bilibili is one of the most beloved long-form video sites in China.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"bilibili\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:07 GMT",
"etag": "W/\"9239939182072936a7531d1a931e033f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::4gtsm-1713753667801-a625dbd88bb7"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/bilibili/",
"property": "og:url"
},
{
"content": "BiliBili | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Bilibili is one of the most beloved long-form video sites in China.",
"property": "og:description"
}
],
"title": "BiliBili | 🦜️🔗 LangChain"
} | BiliBili
Bilibili is one of the most beloved long-form video sites in China.
Installation and Setup
pip install bilibili-api-python
Document Loader
See a usage example.
from langchain_community.document_loaders import BiliBiliLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/bibtex/ | ## BibTeX
> [BibTeX](https://www.ctan.org/pkg/bibtex) is a file format and reference management system commonly used in conjunction with `LaTeX` typesetting. It serves as a way to organize and store bibliographic information for academic and research documents.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
We have to install the `bibtexparser` and `pymupdf` packages.
```
pip install bibtexparser pymupdf
```
## Document loader[](#document-loader "Direct link to Document loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/bibtex/).
```
from langchain_community.document_loaders import BibtexLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:08.469Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/bibtex/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/bibtex/",
"description": "BibTeX is a file format and reference management system commonly used in conjunction with LaTeX typesetting. It serves as a way to organize and store bibliographic information for academic and research documents.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"bibtex\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"cbc2ec2dad2337868e80ca0bbecdcf7b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::vbvhh-1713753668249-96e5bbca24e8"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/bibtex/",
"property": "og:url"
},
{
"content": "BibTeX | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "BibTeX is a file format and reference management system commonly used in conjunction with LaTeX typesetting. It serves as a way to organize and store bibliographic information for academic and research documents.",
"property": "og:description"
}
],
"title": "BibTeX | 🦜️🔗 LangChain"
} | BibTeX
BibTeX is a file format and reference management system commonly used in conjunction with LaTeX typesetting. It serves as a way to organize and store bibliographic information for academic and research documents.
Installation and Setup
We have to install the bibtexparser and pymupdf packages.
pip install bibtexparser pymupdf
Document loader
See a usage example.
from langchain_community.document_loaders import BibtexLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/beam/ | ## Beam
> [Beam](https://www.beam.cloud/) is a cloud computing platform that allows you to run your code on remote servers with GPUs.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* [Create an account](https://www.beam.cloud/)
* Install the Beam CLI with `curl https://raw.githubusercontent.com/slai-labs/get-beam/main/get-beam.sh -sSfL | sh`
* Register API keys with `beam configure`
* Set environment variables (`BEAM_CLIENT_ID`) and (`BEAM_CLIENT_SECRET`)
* Install the Beam SDK:
## LLMs[](#llms "Direct link to LLMs")
See a [usage example](https://python.langchain.com/docs/integrations/llms/beam/).
See another example in the [Beam documentation](https://docs.beam.cloud/examples/langchain).
```
from langchain_community.llms.beam import Beam
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:08.792Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/beam/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/beam/",
"description": "Beam is a cloud computing platform that allows you to run your code",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4613",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"beam\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"7134e6447f335c233311876bb011a6b5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::dkxrp-1713753668244-97e36a100a0b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/beam/",
"property": "og:url"
},
{
"content": "Beam | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Beam is a cloud computing platform that allows you to run your code",
"property": "og:description"
}
],
"title": "Beam | 🦜️🔗 LangChain"
} | Beam
Beam is a cloud computing platform that allows you to run your code on remote servers with GPUs.
Installation and Setup
Create an account
Install the Beam CLI with curl https://raw.githubusercontent.com/slai-labs/get-beam/main/get-beam.sh -sSfL | sh
Register API keys with beam configure
Set environment variables (BEAM_CLIENT_ID) and (BEAM_CLIENT_SECRET)
Install the Beam SDK:
LLMs
See a usage example.
See another example in the Beam documentation.
from langchain_community.llms.beam import Beam
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/blackboard/ | [Blackboard Learn](https://en.wikipedia.org/wiki/Blackboard_Learn) (previously the `Blackboard Learning Management System`) is a web-based virtual learning environment and learning management system developed by Blackboard Inc. The software features course management, customizable open architecture, and scalable design that allows integration with student information systems and authentication protocols. It may be installed on local servers, hosted by `Blackboard ASP Solutions`, or provided as Software as a Service hosted on Amazon Web Services. Its main purposes are stated to include the addition of online elements to courses traditionally delivered face-to-face and development of completely online courses with few or no face-to-face meetings.
There isn't any special setup for it.
```
from langchain_community.document_loaders import BlackboardLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:08.877Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/blackboard/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/blackboard/",
"description": "Blackboard Learn (previously the Blackboard Learning Management System)",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3542",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"blackboard\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"ab73e48287c28697275f34526c89f955\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::58b4d-1713753668441-4511408957d6"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/blackboard/",
"property": "og:url"
},
{
"content": "Blackboard | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Blackboard Learn (previously the Blackboard Learning Management System)",
"property": "og:description"
}
],
"title": "Blackboard | 🦜️🔗 LangChain"
} | Blackboard Learn (previously the Blackboard Learning Management System) is a web-based virtual learning environment and learning management system developed by Blackboard Inc. The software features course management, customizable open architecture, and scalable design that allows integration with student information systems and authentication protocols. It may be installed on local servers, hosted by Blackboard ASP Solutions, or provided as Software as a Service hosted on Amazon Web Services. Its main purposes are stated to include the addition of online elements to courses traditionally delivered face-to-face and development of completely online courses with few or no face-to-face meetings.
There isn't any special setup for it.
from langchain_community.document_loaders import BlackboardLoader |
https://python.langchain.com/docs/integrations/providers/bittensor/ | ## Bittensor
> [Neural Internet Bittensor](https://neuralinternet.ai/) network, an open source protocol that powers a decentralized, blockchain-based, machine learning network.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Get your API\_KEY from [Neural Internet](https://neuralinternet.ai/).
## LLMs[](#llms "Direct link to LLMs")
See a [usage example](https://python.langchain.com/docs/integrations/llms/bittensor/).
```
from langchain_community.llms import NIBittensorLLM
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:09.015Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/bittensor/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/bittensor/",
"description": "Neural Internet Bittensor network, an open source protocol",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"bittensor\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"82a54ed639eac581732f61b225afb7a5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::swct2-1713753668692-2c0dbebc5cd0"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/bittensor/",
"property": "og:url"
},
{
"content": "Bittensor | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Neural Internet Bittensor network, an open source protocol",
"property": "og:description"
}
],
"title": "Bittensor | 🦜️🔗 LangChain"
} | Bittensor
Neural Internet Bittensor network, an open source protocol that powers a decentralized, blockchain-based, machine learning network.
Installation and Setup
Get your API_KEY from Neural Internet.
LLMs
See a usage example.
from langchain_community.llms import NIBittensorLLM
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/breebs/ | [Breebs](https://www.breebs.com/) is an open collaborative knowledge platform. Anybody can create a `Breeb`, a knowledge capsule based on PDFs stored on a Google Drive folder. A `Breeb` can be used by any LLM/chatbot to improve its expertise, reduce hallucinations and give access to sources. Behind the scenes, `Breebs` implements several `Retrieval Augmented Generation (RAG)` models to seamlessly provide useful context at each iteration.
```
from langchain.retrievers import BreebsRetriever
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:09.229Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/breebs/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/breebs/",
"description": "Breebs is an open collaborative knowledge platform.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"breebs\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"98053850571d1d070c121b2bea2838fa\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::qzgk6-1713753668899-440195497c0c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/breebs/",
"property": "og:url"
},
{
"content": "Breebs (Open Knowledge) | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Breebs is an open collaborative knowledge platform.",
"property": "og:description"
}
],
"title": "Breebs (Open Knowledge) | 🦜️🔗 LangChain"
} | Breebs is an open collaborative knowledge platform. Anybody can create a Breeb, a knowledge capsule based on PDFs stored on a Google Drive folder. A Breeb can be used by any LLM/chatbot to improve its expertise, reduce hallucinations and give access to sources. Behind the scenes, Breebs implements several Retrieval Augmented Generation (RAG) models to seamlessly provide useful context at each iteration.
from langchain.retrievers import BreebsRetriever |
https://python.langchain.com/docs/integrations/providers/forefrontai/ | This page covers how to use the ForefrontAI ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific ForefrontAI wrappers.
```
from langchain_community.llms import ForefrontAI
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:09.205Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/forefrontai/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/forefrontai/",
"description": "This page covers how to use the ForefrontAI ecosystem within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3537",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"forefrontai\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:08 GMT",
"etag": "W/\"7ab1c27d30dcc30f9a0a0e8effedc2f6\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::bnwhw-1713753668925-74a6295730a1"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/forefrontai/",
"property": "og:url"
},
{
"content": "ForefrontAI | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the ForefrontAI ecosystem within LangChain.",
"property": "og:description"
}
],
"title": "ForefrontAI | 🦜️🔗 LangChain"
} | This page covers how to use the ForefrontAI ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific ForefrontAI wrappers.
from langchain_community.llms import ForefrontAI |
https://python.langchain.com/docs/integrations/providers/flyte/ | ## Flyte
> [Flyte](https://github.com/flyteorg/flyte) is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform.
The purpose of this notebook is to demonstrate the integration of a `FlyteCallback` into your Flyte task, enabling you to effectively monitor and track your LangChain experiments.
## Installation & Setup[](#installation--setup "Direct link to Installation & Setup")
* Install the Flytekit library by running the command `pip install flytekit`.
* Install the Flytekit-Envd plugin by running the command `pip install flytekitplugins-envd`.
* Install LangChain by running the command `pip install langchain`.
* Install [Docker](https://docs.docker.com/engine/install/) on your system.
## Flyte Tasks[](#flyte-tasks "Direct link to Flyte Tasks")
A Flyte [task](https://docs.flyte.org/en/latest/user_guide/basics/tasks.html) serves as the foundational building block of Flyte. To execute LangChain experiments, you need to write Flyte tasks that define the specific steps and operations involved.
NOTE: The [getting started guide](https://docs.flyte.org/projects/cookbook/en/latest/index.html) offers detailed, step-by-step instructions on installing Flyte locally and running your initial Flyte pipeline.
First, import the necessary dependencies to support your LangChain experiments.
```
import osfrom flytekit import ImageSpec, taskfrom langchain.agents import AgentType, initialize_agent, load_toolsfrom langchain.callbacks import FlyteCallbackHandlerfrom langchain.chains import LLMChainfrom langchain_openai import ChatOpenAIfrom langchain_core.prompts import PromptTemplatefrom langchain_core.messages import HumanMessage
```
Set up the necessary environment variables to utilize the OpenAI API and Serp API:
```
# Set OpenAI API keyos.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"# Set Serp API keyos.environ["SERPAPI_API_KEY"] = "<your_serp_api_key>"
```
Replace `<your_openai_api_key>` and `<your_serp_api_key>` with your respective API keys obtained from OpenAI and Serp API.
To guarantee reproducibility of your pipelines, Flyte tasks are containerized. Each Flyte task must be associated with an image, which can either be shared across the entire Flyte [workflow](https://docs.flyte.org/en/latest/user_guide/basics/workflows.html) or provided separately for each task.
To streamline the process of supplying the required dependencies for each Flyte task, you can initialize an [`ImageSpec`](https://docs.flyte.org/en/latest/user_guide/customizing_dependencies/imagespec.html) object. This approach automatically triggers a Docker build, alleviating the need for users to manually create a Docker image.
```
custom_image = ImageSpec( name="langchain-flyte", packages=[ "langchain", "openai", "spacy", "https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.5.0/en_core_web_sm-3.5.0.tar.gz", "textstat", "google-search-results", ], registry="<your-registry>",)
```
You have the flexibility to push the Docker image to a registry of your preference. [Docker Hub](https://hub.docker.com/) or [GitHub Container Registry (GHCR)](https://docs.github.com/en/packages/working-with-a-github-packages-registry/working-with-the-container-registry) is a convenient option to begin with.
Once you have selected a registry, you can proceed to create Flyte tasks that log the LangChain metrics to Flyte Deck.
The following examples demonstrate tasks related to OpenAI LLM, chains and agent with tools:
### LLM[](#llm "Direct link to LLM")
```
@task(disable_deck=False, container_image=custom_image)def langchain_llm() -> str: llm = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0.2, callbacks=[FlyteCallbackHandler()], ) return llm([HumanMessage(content="Tell me a joke")]).content
```
### Chain[](#chain "Direct link to Chain")
```
@task(disable_deck=False, container_image=custom_image)def langchain_chain() -> list[dict[str, str]]: template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.Title: {title}Playwright: This is a synopsis for the above play:""" llm = ChatOpenAI( model_name="gpt-3.5-turbo", temperature=0, callbacks=[FlyteCallbackHandler()], ) prompt_template = PromptTemplate(input_variables=["title"], template=template) synopsis_chain = LLMChain( llm=llm, prompt=prompt_template, callbacks=[FlyteCallbackHandler()] ) test_prompts = [ { "title": "documentary about good video games that push the boundary of game design" }, ] return synopsis_chain.apply(test_prompts)
```
### Agent[](#agent "Direct link to Agent")
```
@task(disable_deck=False, container_image=custom_image)def langchain_agent() -> str: llm = OpenAI( model_name="gpt-3.5-turbo", temperature=0, callbacks=[FlyteCallbackHandler()], ) tools = load_tools( ["serpapi", "llm-math"], llm=llm, callbacks=[FlyteCallbackHandler()] ) agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, callbacks=[FlyteCallbackHandler()], verbose=True, ) return agent.run( "Who is Leonardo DiCaprio's girlfriend? Could you calculate her current age and raise it to the power of 0.43?" )
```
These tasks serve as a starting point for running your LangChain experiments within Flyte.
## Execute the Flyte Tasks on Kubernetes[](#execute-the-flyte-tasks-on-kubernetes "Direct link to Execute the Flyte Tasks on Kubernetes")
To execute the Flyte tasks on the configured Flyte backend, use the following command:
```
pyflyte run --image <your-image> langchain_flyte.py langchain_llm
```
This command will initiate the execution of the `langchain_llm` task on the Flyte backend. You can trigger the remaining two tasks in a similar manner.
The metrics will be displayed on the Flyte UI as follows:
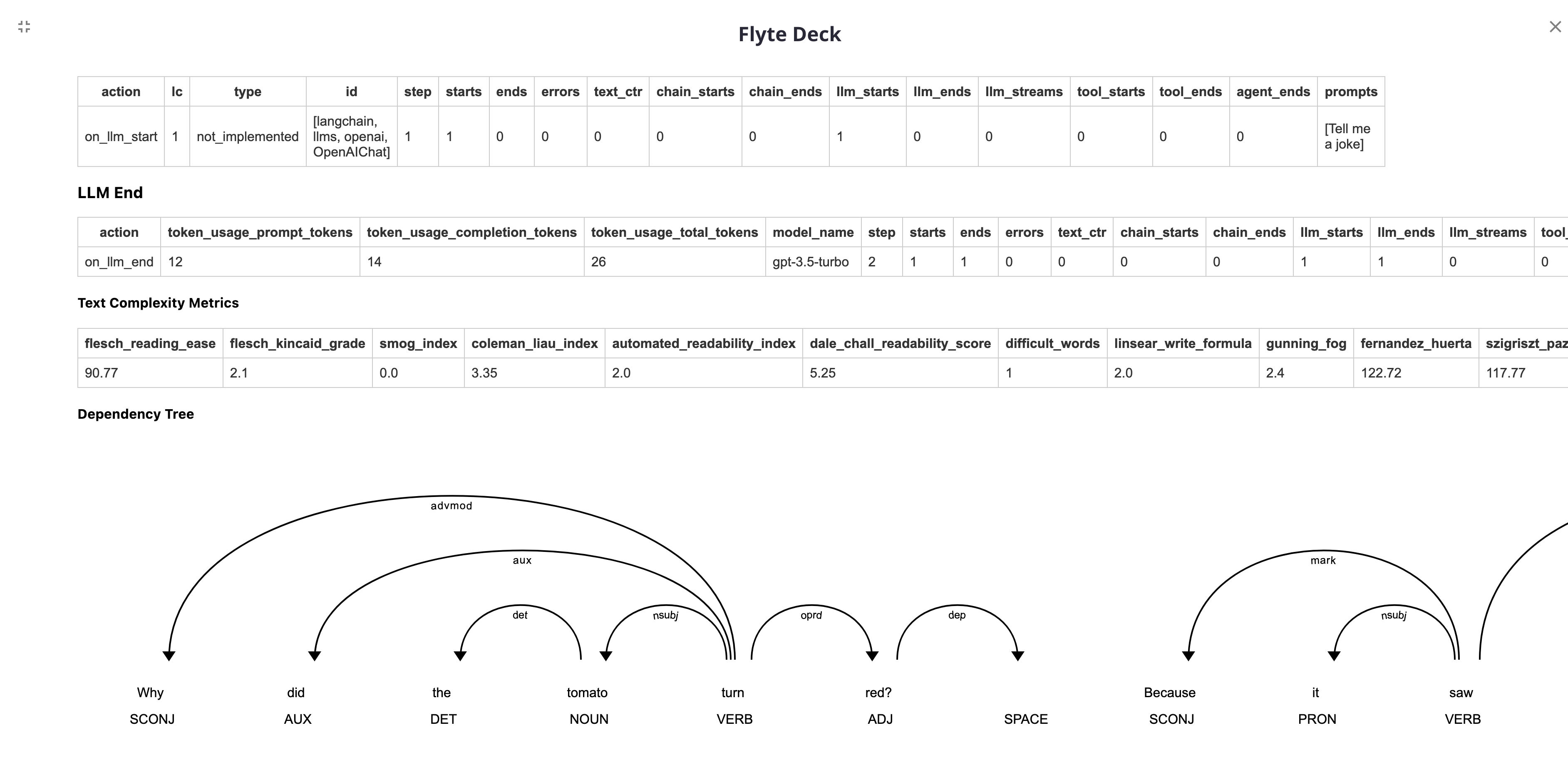 | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:09.558Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/flyte/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/flyte/",
"description": "Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"flyte\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:09 GMT",
"etag": "W/\"dbf68abda496e3314f40f8e19a463ca0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::gwsts-1713753668929-4ef3038f5256"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/flyte/",
"property": "og:url"
},
{
"content": "Flyte | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines.",
"property": "og:description"
}
],
"title": "Flyte | 🦜️🔗 LangChain"
} | Flyte
Flyte is an open-source orchestrator that facilitates building production-grade data and ML pipelines. It is built for scalability and reproducibility, leveraging Kubernetes as its underlying platform.
The purpose of this notebook is to demonstrate the integration of a FlyteCallback into your Flyte task, enabling you to effectively monitor and track your LangChain experiments.
Installation & Setup
Install the Flytekit library by running the command pip install flytekit.
Install the Flytekit-Envd plugin by running the command pip install flytekitplugins-envd.
Install LangChain by running the command pip install langchain.
Install Docker on your system.
Flyte Tasks
A Flyte task serves as the foundational building block of Flyte. To execute LangChain experiments, you need to write Flyte tasks that define the specific steps and operations involved.
NOTE: The getting started guide offers detailed, step-by-step instructions on installing Flyte locally and running your initial Flyte pipeline.
First, import the necessary dependencies to support your LangChain experiments.
import os
from flytekit import ImageSpec, task
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.callbacks import FlyteCallbackHandler
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.messages import HumanMessage
Set up the necessary environment variables to utilize the OpenAI API and Serp API:
# Set OpenAI API key
os.environ["OPENAI_API_KEY"] = "<your_openai_api_key>"
# Set Serp API key
os.environ["SERPAPI_API_KEY"] = "<your_serp_api_key>"
Replace <your_openai_api_key> and <your_serp_api_key> with your respective API keys obtained from OpenAI and Serp API.
To guarantee reproducibility of your pipelines, Flyte tasks are containerized. Each Flyte task must be associated with an image, which can either be shared across the entire Flyte workflow or provided separately for each task.
To streamline the process of supplying the required dependencies for each Flyte task, you can initialize an ImageSpec object. This approach automatically triggers a Docker build, alleviating the need for users to manually create a Docker image.
custom_image = ImageSpec(
name="langchain-flyte",
packages=[
"langchain",
"openai",
"spacy",
"https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.5.0/en_core_web_sm-3.5.0.tar.gz",
"textstat",
"google-search-results",
],
registry="<your-registry>",
)
You have the flexibility to push the Docker image to a registry of your preference. Docker Hub or GitHub Container Registry (GHCR) is a convenient option to begin with.
Once you have selected a registry, you can proceed to create Flyte tasks that log the LangChain metrics to Flyte Deck.
The following examples demonstrate tasks related to OpenAI LLM, chains and agent with tools:
LLM
@task(disable_deck=False, container_image=custom_image)
def langchain_llm() -> str:
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.2,
callbacks=[FlyteCallbackHandler()],
)
return llm([HumanMessage(content="Tell me a joke")]).content
Chain
@task(disable_deck=False, container_image=custom_image)
def langchain_chain() -> list[dict[str, str]]:
template = """You are a playwright. Given the title of play, it is your job to write a synopsis for that title.
Title: {title}
Playwright: This is a synopsis for the above play:"""
llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
callbacks=[FlyteCallbackHandler()],
)
prompt_template = PromptTemplate(input_variables=["title"], template=template)
synopsis_chain = LLMChain(
llm=llm, prompt=prompt_template, callbacks=[FlyteCallbackHandler()]
)
test_prompts = [
{
"title": "documentary about good video games that push the boundary of game design"
},
]
return synopsis_chain.apply(test_prompts)
Agent
@task(disable_deck=False, container_image=custom_image)
def langchain_agent() -> str:
llm = OpenAI(
model_name="gpt-3.5-turbo",
temperature=0,
callbacks=[FlyteCallbackHandler()],
)
tools = load_tools(
["serpapi", "llm-math"], llm=llm, callbacks=[FlyteCallbackHandler()]
)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
callbacks=[FlyteCallbackHandler()],
verbose=True,
)
return agent.run(
"Who is Leonardo DiCaprio's girlfriend? Could you calculate her current age and raise it to the power of 0.43?"
)
These tasks serve as a starting point for running your LangChain experiments within Flyte.
Execute the Flyte Tasks on Kubernetes
To execute the Flyte tasks on the configured Flyte backend, use the following command:
pyflyte run --image <your-image> langchain_flyte.py langchain_llm
This command will initiate the execution of the langchain_llm task on the Flyte backend. You can trigger the remaining two tasks in a similar manner.
The metrics will be displayed on the Flyte UI as follows: |
https://python.langchain.com/docs/integrations/providers/browserless/ | ## Browserless
> [Browserless](https://www.browserless.io/docs/start) is a service that allows you to run headless Chrome instances in the cloud. It’s a great way to run browser-based automation at scale without having to worry about managing your own infrastructure.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
We have to get the API key [here](https://www.browserless.io/pricing/).
## Document loader[](#document-loader "Direct link to Document loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/browserless/).
```
from langchain_community.document_loaders import BrowserlessLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:10.316Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/browserless/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/browserless/",
"description": "Browserless is a service that allows you to",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"browserless\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:09 GMT",
"etag": "W/\"e708e71c87f2f5858f6effa48977cfe1\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::qfjn6-1713753669225-3819d5cde3ba"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/browserless/",
"property": "og:url"
},
{
"content": "Browserless | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Browserless is a service that allows you to",
"property": "og:description"
}
],
"title": "Browserless | 🦜️🔗 LangChain"
} | Browserless
Browserless is a service that allows you to run headless Chrome instances in the cloud. It’s a great way to run browser-based automation at scale without having to worry about managing your own infrastructure.
Installation and Setup
We have to get the API key here.
Document loader
See a usage example.
from langchain_community.document_loaders import BrowserlessLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/geopandas/ | ## Geopandas
> [GeoPandas](https://geopandas.org/) is an open source project to make working with geospatial data in python easier. `GeoPandas` extends the datatypes used by `pandas` to allow spatial operations on geometric types. Geometric operations are performed by `shapely`.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
We have to install several python packages.
```
pip install -U sodapy pandas geopandas
```
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/geopandas/).
```
from langchain_community.document_loaders import OpenCityDataLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:10.536Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/geopandas/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/geopandas/",
"description": "GeoPandas is an open source project to make working",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3537",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"geopandas\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:09 GMT",
"etag": "W/\"192d64e05ea14b1e156e1a47b8861877\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::kfn55-1713753669320-58b4a5ea5901"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/geopandas/",
"property": "og:url"
},
{
"content": "Geopandas | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "GeoPandas is an open source project to make working",
"property": "og:description"
}
],
"title": "Geopandas | 🦜️🔗 LangChain"
} | Geopandas
GeoPandas is an open source project to make working with geospatial data in python easier. GeoPandas extends the datatypes used by pandas to allow spatial operations on geometric types. Geometric operations are performed by shapely.
Installation and Setup
We have to install several python packages.
pip install -U sodapy pandas geopandas
Document Loader
See a usage example.
from langchain_community.document_loaders import OpenCityDataLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/brave_search/ | ## Brave Search
> [Brave Search](https://en.wikipedia.org/wiki/Brave_Search) is a search engine developed by Brave Software.
>
> * `Brave Search` uses its own web index. As of May 2022, it covered over 10 billion pages and was used to serve 92% of search results without relying on any third-parties, with the remainder being retrieved server-side from the Bing API or (on an opt-in basis) client-side from Google. According to Brave, the index was kept "intentionally smaller than that of Google or Bing" in order to help avoid spam and other low-quality content, with the disadvantage that "Brave Search is not yet as good as Google in recovering long-tail queries."
> * `Brave Search Premium`: As of April 2023 Brave Search is an ad-free website, but it will eventually switch to a new model that will include ads and premium users will get an ad-free experience. User data including IP addresses won't be collected from its users by default. A premium account will be required for opt-in data-collection.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
To get access to the Brave Search API, you need to [create an account and get an API key](https://api.search.brave.com/app/dashboard).
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/brave_search/).
```
from langchain_community.document_loaders import BraveSearchLoader
```
## Tool[](#tool "Direct link to Tool")
See a [usage example](https://python.langchain.com/docs/integrations/tools/brave_search/).
```
from langchain.tools import BraveSearch
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:10.674Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/brave_search/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/brave_search/",
"description": "Brave Search is a search engine developed by Brave Software.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"brave_search\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:09 GMT",
"etag": "W/\"9c7d04986fbeaf289400dc9e4bbd243b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vp7cr-1713753669328-46cde8c60037"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/brave_search/",
"property": "og:url"
},
{
"content": "Brave Search | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Brave Search is a search engine developed by Brave Software.",
"property": "og:description"
}
],
"title": "Brave Search | 🦜️🔗 LangChain"
} | Brave Search
Brave Search is a search engine developed by Brave Software.
Brave Search uses its own web index. As of May 2022, it covered over 10 billion pages and was used to serve 92% of search results without relying on any third-parties, with the remainder being retrieved server-side from the Bing API or (on an opt-in basis) client-side from Google. According to Brave, the index was kept "intentionally smaller than that of Google or Bing" in order to help avoid spam and other low-quality content, with the disadvantage that "Brave Search is not yet as good as Google in recovering long-tail queries."
Brave Search Premium: As of April 2023 Brave Search is an ad-free website, but it will eventually switch to a new model that will include ads and premium users will get an ad-free experience. User data including IP addresses won't be collected from its users by default. A premium account will be required for opt-in data-collection.
Installation and Setup
To get access to the Brave Search API, you need to create an account and get an API key.
Document Loader
See a usage example.
from langchain_community.document_loaders import BraveSearchLoader
Tool
See a usage example.
from langchain.tools import BraveSearch
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/gitbook/ | ## GitBook
> [GitBook](https://docs.gitbook.com/) is a modern documentation platform where teams can document everything from products to internal knowledge bases and APIs.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
There isn't any special setup for it.
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/gitbook/).
```
from langchain_community.document_loaders import GitbookLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:10.793Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/gitbook/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/gitbook/",
"description": "GitBook is a modern documentation platform where teams can document everything from products to internal knowledge bases and APIs.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3538",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"gitbook\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:10 GMT",
"etag": "W/\"f7f16154c22b1823ee3642d8d08180f8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::68vtp-1713753669975-61b344a9945f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/gitbook/",
"property": "og:url"
},
{
"content": "GitBook | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "GitBook is a modern documentation platform where teams can document everything from products to internal knowledge bases and APIs.",
"property": "og:description"
}
],
"title": "GitBook | 🦜️🔗 LangChain"
} | GitBook
GitBook is a modern documentation platform where teams can document everything from products to internal knowledge bases and APIs.
Installation and Setup
There isn't any special setup for it.
Document Loader
See a usage example.
from langchain_community.document_loaders import GitbookLoader |
https://python.langchain.com/docs/integrations/providers/git/ | First, you need to install `GitPython` python package.
```
from langchain_community.document_loaders import GitLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:11.588Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/git/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/git/",
"description": "Git is a distributed version control system that tracks changes in any set of computer files, usually used for coordinating work among programmers collaboratively developing source code during software development.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3539",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"git\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:10 GMT",
"etag": "W/\"6825de4822840ffa900eb3aa1ee714ae\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::skngc-1713753670857-d7fa974830ce"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/git/",
"property": "og:url"
},
{
"content": "Git | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Git is a distributed version control system that tracks changes in any set of computer files, usually used for coordinating work among programmers collaboratively developing source code during software development.",
"property": "og:description"
}
],
"title": "Git | 🦜️🔗 LangChain"
} | First, you need to install GitPython python package.
from langchain_community.document_loaders import GitLoader |
https://python.langchain.com/docs/integrations/providers/github/ | [GitHub](https://github.com/) is a developer platform that allows developers to create, store, manage and share their code. It uses `Git` software, providing the distributed version control of Git plus access control, bug tracking, software feature requests, task management, continuous integration, and wikis for every project.
There are two document loaders available for GitHub.
```
from langchain_community.document_loaders import GitHubIssuesLoaderfrom langchain.document_loaders import GithubFileLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:11.524Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/github/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/github/",
"description": "GitHub is a developer platform that allows developers to create,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"github\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:10 GMT",
"etag": "W/\"c43433bcec0dec876637fd63cc67650f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::9tqlr-1713753670792-e2f72ccfb343"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/github/",
"property": "og:url"
},
{
"content": "GitHub | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "GitHub is a developer platform that allows developers to create,",
"property": "og:description"
}
],
"title": "GitHub | 🦜️🔗 LangChain"
} | GitHub is a developer platform that allows developers to create, store, manage and share their code. It uses Git software, providing the distributed version control of Git plus access control, bug tracking, software feature requests, task management, continuous integration, and wikis for every project.
There are two document loaders available for GitHub.
from langchain_community.document_loaders import GitHubIssuesLoader
from langchain.document_loaders import GithubFileLoader |
https://python.langchain.com/docs/integrations/providers/google_serper/ | This page covers how to use the [Serper](https://serper.dev/) Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search. It is broken into two parts: setup, and then references to the specific Google Serper wrapper.
## Setup[](#setup "Direct link to Setup")
* Go to [serper.dev](https://serper.dev/) to sign up for a free account
* Get the api key and set it as an environment variable (`SERPER_API_KEY`)
## Wrappers[](#wrappers "Direct link to Wrappers")
### Utility[](#utility "Direct link to Utility")
There exists a GoogleSerperAPIWrapper utility which wraps this API. To import this utility:
```
from langchain_community.utilities import GoogleSerperAPIWrapper
```
You can use it as part of a Self Ask chain:
```
from langchain_community.utilities import GoogleSerperAPIWrapperfrom langchain_openai import OpenAIfrom langchain.agents import initialize_agent, Toolfrom langchain.agents import AgentTypeimport osos.environ["SERPER_API_KEY"] = ""os.environ['OPENAI_API_KEY'] = ""llm = OpenAI(temperature=0)search = GoogleSerperAPIWrapper()tools = [ Tool( name="Intermediate Answer", func=search.run, description="useful for when you need to ask with search" )]self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
```
#### Output[](#output "Direct link to Output")
```
Entering new AgentExecutor chain... Yes.Follow up: Who is the reigning men's U.S. Open champion?Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.Follow up: Where is Carlos Alcaraz from?Intermediate answer: El Palmar, SpainSo the final answer is: El Palmar, Spain> Finished chain.'El Palmar, Spain'
```
For a more detailed walkthrough of this wrapper, see [this notebook](https://python.langchain.com/docs/integrations/tools/google_serper/).
### Tool[](#tool "Direct link to Tool")
You can also easily load this wrapper as a Tool (to use with an Agent). You can do this with:
```
from langchain.agents import load_toolstools = load_tools(["google-serper"])
```
For more information on tools, see [this page](https://python.langchain.com/docs/modules/tools/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:11.743Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/google_serper/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/google_serper/",
"description": "This page covers how to use the Serper Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3539",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"google_serper\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:11 GMT",
"etag": "W/\"64516ca5f8ef5103f50ead78ccc0362c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::nhxcp-1713753671371-cfd6f5494ce8"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/google_serper/",
"property": "og:url"
},
{
"content": "Serper - Google Search API | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the Serper Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search.",
"property": "og:description"
}
],
"title": "Serper - Google Search API | 🦜️🔗 LangChain"
} | This page covers how to use the Serper Google Search API within LangChain. Serper is a low-cost Google Search API that can be used to add answer box, knowledge graph, and organic results data from Google Search. It is broken into two parts: setup, and then references to the specific Google Serper wrapper.
Setup
Go to serper.dev to sign up for a free account
Get the api key and set it as an environment variable (SERPER_API_KEY)
Wrappers
Utility
There exists a GoogleSerperAPIWrapper utility which wraps this API. To import this utility:
from langchain_community.utilities import GoogleSerperAPIWrapper
You can use it as part of a Self Ask chain:
from langchain_community.utilities import GoogleSerperAPIWrapper
from langchain_openai import OpenAI
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
import os
os.environ["SERPER_API_KEY"] = ""
os.environ['OPENAI_API_KEY'] = ""
llm = OpenAI(temperature=0)
search = GoogleSerperAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search"
)
]
self_ask_with_search = initialize_agent(tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True)
self_ask_with_search.run("What is the hometown of the reigning men's U.S. Open champion?")
Output
Entering new AgentExecutor chain...
Yes.
Follow up: Who is the reigning men's U.S. Open champion?
Intermediate answer: Current champions Carlos Alcaraz, 2022 men's singles champion.
Follow up: Where is Carlos Alcaraz from?
Intermediate answer: El Palmar, Spain
So the final answer is: El Palmar, Spain
> Finished chain.
'El Palmar, Spain'
For a more detailed walkthrough of this wrapper, see this notebook.
Tool
You can also easily load this wrapper as a Tool (to use with an Agent). You can do this with:
from langchain.agents import load_tools
tools = load_tools(["google-serper"])
For more information on tools, see this page. |
https://python.langchain.com/docs/integrations/providers/gooseai/ | This page covers how to use the GooseAI ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific GooseAI wrappers.
```
import osos.environ["GOOSEAI_API_KEY"] = "YOUR_API_KEY"
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:11.898Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/gooseai/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/gooseai/",
"description": "This page covers how to use the GooseAI ecosystem within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3539",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"gooseai\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:11 GMT",
"etag": "W/\"23f0e428c11a16431afd01981082b984\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vks9p-1713753671527-2062d47a8a7b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/gooseai/",
"property": "og:url"
},
{
"content": "GooseAI | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the GooseAI ecosystem within LangChain.",
"property": "og:description"
}
],
"title": "GooseAI | 🦜️🔗 LangChain"
} | This page covers how to use the GooseAI ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific GooseAI wrappers.
import os
os.environ["GOOSEAI_API_KEY"] = "YOUR_API_KEY" |
https://python.langchain.com/docs/integrations/providers/golden/ | [Golden](https://golden.com/) provides a set of natural language APIs for querying and enrichment using the Golden Knowledge Graph e.g. queries such as: `Products from OpenAI`, `Generative ai companies with series a funding`, and `rappers who invest` can be used to retrieve structured data about relevant entities.
The `golden-query` langchain tool is a wrapper on top of the [Golden Query API](https://docs.golden.com/reference/query-api) which enables programmatic access to these results. See the [Golden Query API docs](https://docs.golden.com/reference/query-api) for more information.
There exists a GoldenQueryAPIWrapper utility which wraps this API. To import this utility:
```
from langchain_community.utilities.golden_query import GoldenQueryAPIWrapper
```
You can also easily load this wrapper as a Tool (to use with an Agent). You can do this with: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:12.242Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/golden/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/golden/",
"description": "Golden provides a set of natural language APIs for querying and enrichment using the Golden Knowledge Graph e.g. queries such as: Products from OpenAI, Generative ai companies with series a funding, and rappers who invest can be used to retrieve structured data about relevant entities.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4600",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"golden\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:11 GMT",
"etag": "W/\"976edbfac57521cac7d3d2d5c530d4ce\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::5wtns-1713753671542-f897a02e5781"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/golden/",
"property": "og:url"
},
{
"content": "Golden | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Golden provides a set of natural language APIs for querying and enrichment using the Golden Knowledge Graph e.g. queries such as: Products from OpenAI, Generative ai companies with series a funding, and rappers who invest can be used to retrieve structured data about relevant entities.",
"property": "og:description"
}
],
"title": "Golden | 🦜️🔗 LangChain"
} | Golden provides a set of natural language APIs for querying and enrichment using the Golden Knowledge Graph e.g. queries such as: Products from OpenAI, Generative ai companies with series a funding, and rappers who invest can be used to retrieve structured data about relevant entities.
The golden-query langchain tool is a wrapper on top of the Golden Query API which enables programmatic access to these results. See the Golden Query API docs for more information.
There exists a GoldenQueryAPIWrapper utility which wraps this API. To import this utility:
from langchain_community.utilities.golden_query import GoldenQueryAPIWrapper
You can also easily load this wrapper as a Tool (to use with an Agent). You can do this with: |
https://python.langchain.com/docs/integrations/providers/gpt4all/ | ## GPT4All
This page covers how to use the `GPT4All` wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python package with `pip install gpt4all`
* Download a [GPT4All model](https://gpt4all.io/index.html) and place it in your desired directory
In this example, We are using `mistral-7b-openorca.Q4_0.gguf`(Best overall fast chat model):
```
mkdir modelswget https://gpt4all.io/models/gguf/mistral-7b-openorca.Q4_0.gguf -O models/mistral-7b-openorca.Q4_0.gguf
```
## Usage[](#usage "Direct link to Usage")
### GPT4All[](#gpt4all-1 "Direct link to GPT4All")
To use the GPT4All wrapper, you need to provide the path to the pre-trained model file and the model's configuration.
```
from langchain_community.llms import GPT4All# Instantiate the model. Callbacks support token-wise streamingmodel = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)# Generate textresponse = model("Once upon a time, ")
```
You can also customize the generation parameters, such as n\_predict, temp, top\_p, top\_k, and others.
To stream the model's predictions, add in a CallbackManager.
```
from langchain_community.llms import GPT4Allfrom langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler# There are many CallbackHandlers supported, such as# from langchain.callbacks.streamlit import StreamlitCallbackHandlercallbacks = [StreamingStdOutCallbackHandler()]model = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)# Generate text. Tokens are streamed through the callback manager.model("Once upon a time, ", callbacks=callbacks)
```
## Model File[](#model-file "Direct link to Model File")
You can find links to model file downloads in the [https://gpt4all.io/](https://gpt4all.io/index.html).
For a more detailed walkthrough of this, see [this notebook](https://python.langchain.com/docs/integrations/llms/gpt4all/)
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:12.664Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/gpt4all/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/gpt4all/",
"description": "This page covers how to use the GPT4All wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"gpt4all\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:11 GMT",
"etag": "W/\"ac79222235f297ed55caf6d116cb4e4f\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::zhgv5-1713753671903-12dc40a20edf"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/gpt4all/",
"property": "og:url"
},
{
"content": "GPT4All | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the GPT4All wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.",
"property": "og:description"
}
],
"title": "GPT4All | 🦜️🔗 LangChain"
} | GPT4All
This page covers how to use the GPT4All wrapper within LangChain. The tutorial is divided into two parts: installation and setup, followed by usage with an example.
Installation and Setup
Install the Python package with pip install gpt4all
Download a GPT4All model and place it in your desired directory
In this example, We are using mistral-7b-openorca.Q4_0.gguf(Best overall fast chat model):
mkdir models
wget https://gpt4all.io/models/gguf/mistral-7b-openorca.Q4_0.gguf -O models/mistral-7b-openorca.Q4_0.gguf
Usage
GPT4All
To use the GPT4All wrapper, you need to provide the path to the pre-trained model file and the model's configuration.
from langchain_community.llms import GPT4All
# Instantiate the model. Callbacks support token-wise streaming
model = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)
# Generate text
response = model("Once upon a time, ")
You can also customize the generation parameters, such as n_predict, temp, top_p, top_k, and others.
To stream the model's predictions, add in a CallbackManager.
from langchain_community.llms import GPT4All
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# There are many CallbackHandlers supported, such as
# from langchain.callbacks.streamlit import StreamlitCallbackHandler
callbacks = [StreamingStdOutCallbackHandler()]
model = GPT4All(model="./models/mistral-7b-openorca.Q4_0.gguf", n_threads=8)
# Generate text. Tokens are streamed through the callback manager.
model("Once upon a time, ", callbacks=callbacks)
Model File
You can find links to model file downloads in the https://gpt4all.io/.
For a more detailed walkthrough of this, see this notebook
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/graphsignal/ | ## Graphsignal
This page covers how to use [Graphsignal](https://app.graphsignal.com/) to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
* Install the Python library with `pip install graphsignal`
* Create free Graphsignal account [here](https://graphsignal.com/)
* Get an API key and set it as an environment variable (`GRAPHSIGNAL_API_KEY`)
## Tracing and Monitoring[](#tracing-and-monitoring "Direct link to Tracing and Monitoring")
Graphsignal automatically instruments and starts tracing and monitoring chains. Traces and metrics are then available in your [Graphsignal dashboards](https://app.graphsignal.com/).
Initialize the tracer by providing a deployment name:
```
import graphsignalgraphsignal.configure(deployment='my-langchain-app-prod')
```
To additionally trace any function or code, you can use a decorator or a context manager:
```
@graphsignal.trace_functiondef handle_request(): chain.run("some initial text")
```
```
with graphsignal.start_trace('my-chain'): chain.run("some initial text")
```
Optionally, enable profiling to record function-level statistics for each trace.
```
with graphsignal.start_trace( 'my-chain', options=graphsignal.TraceOptions(enable_profiling=True)): chain.run("some initial text")
```
See the [Quick Start](https://graphsignal.com/docs/guides/quick-start/) guide for complete setup instructions. | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:12.913Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/graphsignal/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/graphsignal/",
"description": "This page covers how to use Graphsignal to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4601",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"graphsignal\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:12 GMT",
"etag": "W/\"4ee38152e7eace6ff7112d8fbc6579ac\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::dzpq5-1713753672691-8fa34691594c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/graphsignal/",
"property": "og:url"
},
{
"content": "Graphsignal | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use Graphsignal to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.",
"property": "og:description"
}
],
"title": "Graphsignal | 🦜️🔗 LangChain"
} | Graphsignal
This page covers how to use Graphsignal to trace and monitor LangChain. Graphsignal enables full visibility into your application. It provides latency breakdowns by chains and tools, exceptions with full context, data monitoring, compute/GPU utilization, OpenAI cost analytics, and more.
Installation and Setup
Install the Python library with pip install graphsignal
Create free Graphsignal account here
Get an API key and set it as an environment variable (GRAPHSIGNAL_API_KEY)
Tracing and Monitoring
Graphsignal automatically instruments and starts tracing and monitoring chains. Traces and metrics are then available in your Graphsignal dashboards.
Initialize the tracer by providing a deployment name:
import graphsignal
graphsignal.configure(deployment='my-langchain-app-prod')
To additionally trace any function or code, you can use a decorator or a context manager:
@graphsignal.trace_function
def handle_request():
chain.run("some initial text")
with graphsignal.start_trace('my-chain'):
chain.run("some initial text")
Optionally, enable profiling to record function-level statistics for each trace.
with graphsignal.start_trace(
'my-chain', options=graphsignal.TraceOptions(enable_profiling=True)):
chain.run("some initial text")
See the Quick Start guide for complete setup instructions. |
https://python.langchain.com/docs/integrations/providers/dataherald/ | This page covers how to use the `Dataherald API` within LangChain.
There exists a DataheraldAPIWrapper utility which wraps this API. To import this utility:
```
from langchain_community.utilities.dataherald import DataheraldAPIWrapperfrom langchain_community.tools.dataherald.tool import DataheraldTextToSQLfrom langchain_openai import ChatOpenAIfrom langchain import hubfrom langchain.agents import AgentExecutor, create_react_agent, load_toolsapi_wrapper = DataheraldAPIWrapper(db_connection_id="<db_connection_id>")tool = DataheraldTextToSQL(api_wrapper=api_wrapper)llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)prompt = hub.pull("hwchase17/react")agent = create_react_agent(llm, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)agent_executor.invoke({"input":"Return the sql for this question: How many employees are in the company?"})
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:13.014Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dataherald/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dataherald/",
"description": "Dataherald is a natural language-to-SQL.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3543",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dataherald\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:12 GMT",
"etag": "W/\"4c05dc443e2a7ba28c6852926726bb80\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::j722k-1713753672680-4ab676d8900b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dataherald/",
"property": "og:url"
},
{
"content": "Dataherald | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Dataherald is a natural language-to-SQL.",
"property": "og:description"
}
],
"title": "Dataherald | 🦜️🔗 LangChain"
} | This page covers how to use the Dataherald API within LangChain.
There exists a DataheraldAPIWrapper utility which wraps this API. To import this utility:
from langchain_community.utilities.dataherald import DataheraldAPIWrapper
from langchain_community.tools.dataherald.tool import DataheraldTextToSQL
from langchain_openai import ChatOpenAI
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent, load_tools
api_wrapper = DataheraldAPIWrapper(db_connection_id="<db_connection_id>")
tool = DataheraldTextToSQL(api_wrapper=api_wrapper)
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input":"Return the sql for this question: How many employees are in the company?"}) |
https://python.langchain.com/docs/integrations/providers/deepsparse/ | This page covers how to use the [DeepSparse](https://github.com/neuralmagic/deepsparse) inference runtime within LangChain. It is broken into two parts: installation and setup, and then examples of DeepSparse usage.
```
config = {'max_generated_tokens': 256}llm = DeepSparse(model='zoo:nlg/text_generation/codegen_mono-350m/pytorch/huggingface/bigpython_bigquery_thepile/base-none', config=config)
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:13.304Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/deepsparse/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/deepsparse/",
"description": "This page covers how to use the DeepSparse inference runtime within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3543",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"deepsparse\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:12 GMT",
"etag": "W/\"31bdcf89764ef7d045066301c5cd218d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::wl5px-1713753672771-e2eab5f65aaa"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/deepsparse/",
"property": "og:url"
},
{
"content": "DeepSparse | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the DeepSparse inference runtime within LangChain.",
"property": "og:description"
}
],
"title": "DeepSparse | 🦜️🔗 LangChain"
} | This page covers how to use the DeepSparse inference runtime within LangChain. It is broken into two parts: installation and setup, and then examples of DeepSparse usage.
config = {'max_generated_tokens': 256}
llm = DeepSparse(model='zoo:nlg/text_generation/codegen_mono-350m/pytorch/huggingface/bigpython_bigquery_thepile/base-none', config=config) |
https://python.langchain.com/docs/integrations/providers/gradient/ | There exists an Gradient LLM wrapper, which you can access with See a [usage example](https://python.langchain.com/docs/integrations/llms/gradient/).
```
from langchain_community.llms import GradientLLM
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:13.407Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/gradient/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/gradient/",
"description": "Gradient allows to fine tune and get completions on LLMs with a simple web API.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3540",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"gradient\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:12 GMT",
"etag": "W/\"7d5fe06235fe84293b7ebc55c95d2e7d\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::8rqbx-1713753672887-1dbda2800933"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/gradient/",
"property": "og:url"
},
{
"content": "Gradient | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Gradient allows to fine tune and get completions on LLMs with a simple web API.",
"property": "og:description"
}
],
"title": "Gradient | 🦜️🔗 LangChain"
} | There exists an Gradient LLM wrapper, which you can access with See a usage example.
from langchain_community.llms import GradientLLM |
https://python.langchain.com/docs/integrations/providers/deepinfra/ | This page covers how to use the `DeepInfra` ecosystem within `LangChain`. It is broken into two parts: installation and setup, and then references to specific DeepInfra wrappers.
DeepInfra provides a range of Open Source LLMs ready for deployment.
```
from langchain_community.llms import DeepInfra
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:14.001Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/deepinfra/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/deepinfra/",
"description": "DeepInfra allows us to run the",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3544",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"deepinfra\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:13 GMT",
"etag": "W/\"72316b13e51ed3ec1b59144082df5632\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tql9z-1713753673788-bd60003a14dc"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/deepinfra/",
"property": "og:url"
},
{
"content": "DeepInfra | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DeepInfra allows us to run the",
"property": "og:description"
}
],
"title": "DeepInfra | 🦜️🔗 LangChain"
} | This page covers how to use the DeepInfra ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific DeepInfra wrappers.
DeepInfra provides a range of Open Source LLMs ready for deployment.
from langchain_community.llms import DeepInfra |
https://python.langchain.com/docs/integrations/providers/grobid/ | GROBID is a machine learning library for extracting, parsing, and re-structuring raw documents.
It is designed and expected to be used to parse academic papers, where it works particularly well.
_Note_: if the articles supplied to Grobid are large documents (e.g. dissertations) exceeding a certain number of elements, they might not be processed.
This page covers how to use the Grobid to parse articles for LangChain.
Once grobid is installed and up and running (you can check by accessing it http://localhost:8070), you're ready to go.
```
from langchain_community.document_loaders.parsers import GrobidParserfrom langchain_community.document_loaders.generic import GenericLoader#Produce chunks from article paragraphsloader = GenericLoader.from_filesystem( "/Users/31treehaus/Desktop/Papers/", glob="*", suffixes=[".pdf"], parser= GrobidParser(segment_sentences=False))docs = loader.load()#Produce chunks from article sentencesloader = GenericLoader.from_filesystem( "/Users/31treehaus/Desktop/Papers/", glob="*", suffixes=[".pdf"], parser= GrobidParser(segment_sentences=True))docs = loader.load()
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:14.942Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/grobid/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/grobid/",
"description": "GROBID is a machine learning library for extracting, parsing, and re-structuring raw documents.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4255",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"grobid\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:14 GMT",
"etag": "W/\"c52fd99688c87c03a16937747c3fdd48\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::54c7l-1713753674875-67c20c36f78a"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/grobid/",
"property": "og:url"
},
{
"content": "Grobid | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "GROBID is a machine learning library for extracting, parsing, and re-structuring raw documents.",
"property": "og:description"
}
],
"title": "Grobid | 🦜️🔗 LangChain"
} | GROBID is a machine learning library for extracting, parsing, and re-structuring raw documents.
It is designed and expected to be used to parse academic papers, where it works particularly well.
Note: if the articles supplied to Grobid are large documents (e.g. dissertations) exceeding a certain number of elements, they might not be processed.
This page covers how to use the Grobid to parse articles for LangChain.
Once grobid is installed and up and running (you can check by accessing it http://localhost:8070), you're ready to go.
from langchain_community.document_loaders.parsers import GrobidParser
from langchain_community.document_loaders.generic import GenericLoader
#Produce chunks from article paragraphs
loader = GenericLoader.from_filesystem(
"/Users/31treehaus/Desktop/Papers/",
glob="*",
suffixes=[".pdf"],
parser= GrobidParser(segment_sentences=False)
)
docs = loader.load()
#Produce chunks from article sentences
loader = GenericLoader.from_filesystem(
"/Users/31treehaus/Desktop/Papers/",
glob="*",
suffixes=[".pdf"],
parser= GrobidParser(segment_sentences=True)
)
docs = loader.load() |
https://python.langchain.com/docs/integrations/providers/diffbot/ | [Diffbot](https://docs.diffbot.com/docs) is a service to read web pages. Unlike traditional web scraping tools, `Diffbot` doesn't require any rules to read the content on a page. It starts with computer vision, which classifies a page into one of 20 possible types. Content is then interpreted by a machine learning model trained to identify the key attributes on a page based on its type. The result is a website transformed into clean-structured data (like JSON or CSV), ready for your application.
```
from langchain_community.document_loaders import DiffbotLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:16.365Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/diffbot/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/diffbot/",
"description": "Diffbot is a service to read web pages. Unlike traditional web scraping tools,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4611",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"diffbot\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:16 GMT",
"etag": "W/\"0c4a6a15446570964c4a39c812ee5c48\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::swct2-1713753676035-c57ab6c5bb51"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/diffbot/",
"property": "og:url"
},
{
"content": "Diffbot | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Diffbot is a service to read web pages. Unlike traditional web scraping tools,",
"property": "og:description"
}
],
"title": "Diffbot | 🦜️🔗 LangChain"
} | Diffbot is a service to read web pages. Unlike traditional web scraping tools, Diffbot doesn't require any rules to read the content on a page. It starts with computer vision, which classifies a page into one of 20 possible types. Content is then interpreted by a machine learning model trained to identify the key attributes on a page based on its type. The result is a website transformed into clean-structured data (like JSON or CSV), ready for your application.
from langchain_community.document_loaders import DiffbotLoader |
https://python.langchain.com/docs/integrations/providers/groq/ | Welcome to Groq! 🚀 At Groq, we've developed the world's first Language Processing Unit™, or LPU. The Groq LPU has a deterministic, single core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.
Beyond the architecture, our software is designed to empower developers like you with the tools you need to create innovative, powerful AI applications. With Groq as your engine, you can:
Want more Groq? Check out our [website](https://groq.com/) for more resources and join our [Discord community](https://discord.gg/JvNsBDKeCG) to connect with our developers!
```
pip install langchain-groq
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:16.875Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/groq/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/groq/",
"description": "Welcome to Groq! 🚀 At Groq, we've developed the world's first Language Processing Unit™, or LPU. The Groq LPU has a deterministic, single core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3543",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"groq\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:16 GMT",
"etag": "W/\"af1cc2691e54d9338a2a2cc449da12b6\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::wl5px-1713753676819-309b5aaeac77"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/groq/",
"property": "og:url"
},
{
"content": "Groq | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Welcome to Groq! 🚀 At Groq, we've developed the world's first Language Processing Unit™, or LPU. The Groq LPU has a deterministic, single core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.",
"property": "og:description"
}
],
"title": "Groq | 🦜️🔗 LangChain"
} | Welcome to Groq! 🚀 At Groq, we've developed the world's first Language Processing Unit™, or LPU. The Groq LPU has a deterministic, single core streaming architecture that sets the standard for GenAI inference speed with predictable and repeatable performance for any given workload.
Beyond the architecture, our software is designed to empower developers like you with the tools you need to create innovative, powerful AI applications. With Groq as your engine, you can:
Want more Groq? Check out our website for more resources and join our Discord community to connect with our developers!
pip install langchain-groq |
https://python.langchain.com/docs/integrations/providers/discord/ | [Discord](https://discord.com/) is a VoIP and instant messaging social platform. Users have the ability to communicate with voice calls, video calls, text messaging, media and files in private chats or as part of communities called "servers". A server is a collection of persistent chat rooms and voice channels which can be accessed via invite links.
It might take 30 days for you to receive your data. You'll receive an email at the address which is registered with Discord. That email will have a download button using which you would be able to download your personal Discord data.
**NOTE:** The `DiscordChatLoader` is not the `ChatLoader` but a `DocumentLoader`. It is used to load the data from the `Discord` data dump. For the `ChatLoader` see Chat Loader section below.
```
from langchain_community.document_loaders import DiscordChatLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.086Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/discord/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/discord/",
"description": "Discord is a VoIP and instant messaging social platform. Users have the ability to communicate",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"discord\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:16 GMT",
"etag": "W/\"f19cb1389445418e7b3dad99eaeda118\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::qvdxl-1713753676833-14fd3f8fa45c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/discord/",
"property": "og:url"
},
{
"content": "Discord | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Discord is a VoIP and instant messaging social platform. Users have the ability to communicate",
"property": "og:description"
}
],
"title": "Discord | 🦜️🔗 LangChain"
} | Discord is a VoIP and instant messaging social platform. Users have the ability to communicate with voice calls, video calls, text messaging, media and files in private chats or as part of communities called "servers". A server is a collection of persistent chat rooms and voice channels which can be accessed via invite links.
It might take 30 days for you to receive your data. You'll receive an email at the address which is registered with Discord. That email will have a download button using which you would be able to download your personal Discord data.
NOTE: The DiscordChatLoader is not the ChatLoader but a DocumentLoader. It is used to load the data from the Discord data dump. For the ChatLoader see Chat Loader section below.
from langchain_community.document_loaders import DiscordChatLoader |
https://python.langchain.com/docs/integrations/providers/docarray/ | [DocArray](https://docarray.jina.ai/) is a library for nested, unstructured, multimodal data in transit, including text, image, audio, video, 3D mesh, etc. It allows deep-learning engineers to efficiently process, embed, search, recommend, store, and transfer multimodal data with a Pythonic API.
We need to install `docarray` python package.
LangChain provides an access to the `In-memory` and `HNSW` vector stores from the `DocArray` library.
```
from langchain_community.vectorstores DocArrayHnswSearch
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.176Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/docarray/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/docarray/",
"description": "DocArray is a library for nested, unstructured, multimodal data in transit,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"docarray\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:17 GMT",
"etag": "W/\"959bf959ac29db2b3ca14240144ffe1c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::8bcxv-1713753676946-2473b6a1649f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/docarray/",
"property": "og:url"
},
{
"content": "DocArray | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DocArray is a library for nested, unstructured, multimodal data in transit,",
"property": "og:description"
}
],
"title": "DocArray | 🦜️🔗 LangChain"
} | DocArray is a library for nested, unstructured, multimodal data in transit, including text, image, audio, video, 3D mesh, etc. It allows deep-learning engineers to efficiently process, embed, search, recommend, store, and transfer multimodal data with a Pythonic API.
We need to install docarray python package.
LangChain provides an access to the In-memory and HNSW vector stores from the DocArray library.
from langchain_community.vectorstores DocArrayHnswSearch |
https://python.langchain.com/docs/integrations/providers/gutenberg/ | There isn't any special setup for it.
```
from langchain_community.document_loaders import GutenbergLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.259Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/gutenberg/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/gutenberg/",
"description": "Project Gutenberg is an online library of free eBooks.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3543",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"gutenberg\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:16 GMT",
"etag": "W/\"342a8c0f15c850ba85920fb14b703ab0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::vp7cr-1713753676952-b325e413130f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/gutenberg/",
"property": "og:url"
},
{
"content": "Gutenberg | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Project Gutenberg is an online library of free eBooks.",
"property": "og:description"
}
],
"title": "Gutenberg | 🦜️🔗 LangChain"
} | There isn't any special setup for it.
from langchain_community.document_loaders import GutenbergLoader |
https://python.langchain.com/docs/integrations/providers/doctran/ | [Doctran](https://github.com/psychic-api/doctran) is a python package. It uses LLMs and open-source NLP libraries to transform raw text into clean, structured, information-dense documents that are optimized for vector space retrieval. You can think of `Doctran` as a black box where messy strings go in and nice, clean, labelled strings come out.
```
from langchain_community.document_loaders import DoctranQATransformer
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.296Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/doctran/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/doctran/",
"description": "Doctran is a python package. It uses LLMs and open-source",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3547",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"doctran\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:16 GMT",
"etag": "W/\"8036cfa1069d20550063935e38d95cf2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::5qmdt-1713753676970-92c1fb54806c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/doctran/",
"property": "og:url"
},
{
"content": "Doctran | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Doctran is a python package. It uses LLMs and open-source",
"property": "og:description"
}
],
"title": "Doctran | 🦜️🔗 LangChain"
} | Doctran is a python package. It uses LLMs and open-source NLP libraries to transform raw text into clean, structured, information-dense documents that are optimized for vector space retrieval. You can think of Doctran as a black box where messy strings go in and nice, clean, labelled strings come out.
from langchain_community.document_loaders import DoctranQATransformer |
https://python.langchain.com/docs/integrations/providers/hacker_news/ | ## Hacker News
> [Hacker News](https://en.wikipedia.org/wiki/Hacker_News) (sometimes abbreviated as `HN`) is a social news website focusing on computer science and entrepreneurship. It is run by the investment fund and startup incubator `Y Combinator`. In general, content that can be submitted is defined as "anything that gratifies one's intellectual curiosity."
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
There isn't any special setup for it.
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/hacker_news/).
```
from langchain_community.document_loaders import HNLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.597Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/hacker_news/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/hacker_news/",
"description": "Hacker News (sometimes abbreviated as HN) is a social news",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4604",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"hacker_news\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:17 GMT",
"etag": "W/\"7f2b8b8b08aef4c9e9516a489f0571e8\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wkrjw-1713753677106-477a8b9309fa"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/hacker_news/",
"property": "og:url"
},
{
"content": "Hacker News | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Hacker News (sometimes abbreviated as HN) is a social news",
"property": "og:description"
}
],
"title": "Hacker News | 🦜️🔗 LangChain"
} | Hacker News
Hacker News (sometimes abbreviated as HN) is a social news website focusing on computer science and entrepreneurship. It is run by the investment fund and startup incubator Y Combinator. In general, content that can be submitted is defined as "anything that gratifies one's intellectual curiosity."
Installation and Setup
There isn't any special setup for it.
Document Loader
See a usage example.
from langchain_community.document_loaders import HNLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/dingo/ | This page covers how to use the DingoDB ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific DingoDB wrappers.
There exists a wrapper around DingoDB indexes, allowing you to use it as a vectorstore, whether for semantic search or example selection.
```
from langchain_community.vectorstores import Dingo
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:17.900Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dingo/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dingo/",
"description": "This page covers how to use the DingoDB ecosystem within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4612",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dingo\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:17 GMT",
"etag": "W/\"90cf1c101e945e5f0867d6cc27e9bc90\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::dzpq5-1713753677191-bc8ffe0ef34c"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dingo/",
"property": "og:url"
},
{
"content": "DingoDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the DingoDB ecosystem within LangChain.",
"property": "og:description"
}
],
"title": "DingoDB | 🦜️🔗 LangChain"
} | This page covers how to use the DingoDB ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific DingoDB wrappers.
There exists a wrapper around DingoDB indexes, allowing you to use it as a vectorstore, whether for semantic search or example selection.
from langchain_community.vectorstores import Dingo |
https://python.langchain.com/docs/integrations/providers/helicone/ | Helicone is an [open-source](https://github.com/Helicone/helicone) observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
With your LangChain environment you can just add the following parameter.
Now head over to [helicone.ai](https://www.helicone.ai/signup) to create your account, and add your OpenAI API key within our dashboard to view your logs.
```
from langchain_openai import OpenAIimport openaiopenai.api_base = "https://oai.hconeai.com/v1"llm = OpenAI(temperature=0.9, headers={ "Helicone-Property-Session": "24", "Helicone-Property-Conversation": "support_issue_2", "Helicone-Property-App": "mobile", })text = "What is a helicone?"print(llm(text))
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:18.056Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/helicone/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/helicone/",
"description": "This page covers how to use the Helicone ecosystem within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4604",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"helicone\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:17 GMT",
"etag": "W/\"987b31969831ec4b5b56416d0f625417\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::hwbpg-1713753677500-2d630e579409"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/helicone/",
"property": "og:url"
},
{
"content": "Helicone | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the Helicone ecosystem within LangChain.",
"property": "og:description"
}
],
"title": "Helicone | 🦜️🔗 LangChain"
} | Helicone is an open-source observability platform that proxies your OpenAI traffic and provides you key insights into your spend, latency and usage.
With your LangChain environment you can just add the following parameter.
Now head over to helicone.ai to create your account, and add your OpenAI API key within our dashboard to view your logs.
from langchain_openai import OpenAI
import openai
openai.api_base = "https://oai.hconeai.com/v1"
llm = OpenAI(temperature=0.9, headers={
"Helicone-Property-Session": "24",
"Helicone-Property-Conversation": "support_issue_2",
"Helicone-Property-App": "mobile",
})
text = "What is a helicone?"
print(llm(text)) |
https://python.langchain.com/docs/integrations/providers/docugami/ | ## Docugami
> [Docugami](https://docugami.com/) converts business documents into a Document XML Knowledge Graph, generating forests of XML semantic trees representing entire documents. This is a rich representation that includes the semantic and structural characteristics of various chunks in the document as an XML tree.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install dgml-utilspip install docugami-langchain
```
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/docugami/).
```
from docugami_langchain.document_loaders import DocugamiLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:18.415Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/docugami/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/docugami/",
"description": "Docugami converts business documents into a Document XML Knowledge Graph, generating forests",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3548",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"docugami\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"42c2dd2b87d0e82828605cfdad925ba5\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::l2gfp-1713753677993-5c3645ce0fb8"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/docugami/",
"property": "og:url"
},
{
"content": "Docugami | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Docugami converts business documents into a Document XML Knowledge Graph, generating forests",
"property": "og:description"
}
],
"title": "Docugami | 🦜️🔗 LangChain"
} | Docugami
Docugami converts business documents into a Document XML Knowledge Graph, generating forests of XML semantic trees representing entire documents. This is a rich representation that includes the semantic and structural characteristics of various chunks in the document as an XML tree.
Installation and Setup
pip install dgml-utils
pip install docugami-langchain
Document Loader
See a usage example.
from docugami_langchain.document_loaders import DocugamiLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/hazy_research/ | This page covers how to use the Hazy Research ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific Hazy Research wrappers.
There exists an LLM wrapper around Hazy Research's `manifest` library. `manifest` is a python library which is itself a wrapper around many model providers, and adds in caching, history, and more.
```
from langchain_community.llms.manifest import ManifestWrapper
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:18.525Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/hazy_research/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/hazy_research/",
"description": "This page covers how to use the Hazy Research ecosystem within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3544",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"hazy_research\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"6942322e96b5694188dda931654a6d2c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::f5j7h-1713753678178-aabe87b6d867"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/hazy_research/",
"property": "og:url"
},
{
"content": "Hazy Research | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use the Hazy Research ecosystem within LangChain.",
"property": "og:description"
}
],
"title": "Hazy Research | 🦜️🔗 LangChain"
} | This page covers how to use the Hazy Research ecosystem within LangChain. It is broken into two parts: installation and setup, and then references to specific Hazy Research wrappers.
There exists an LLM wrapper around Hazy Research's manifest library. manifest is a python library which is itself a wrapper around many model providers, and adds in caching, history, and more.
from langchain_community.llms.manifest import ManifestWrapper |
https://python.langchain.com/docs/integrations/providers/docusaurus/ | ## Docusaurus
> [Docusaurus](https://docusaurus.io/) is a static-site generator which provides out-of-the-box documentation features.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
```
pip install -U beautifulsoup4 lxml
```
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/docusaurus/).
```
from langchain_community.document_loaders import DocusaurusLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:18.583Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/docusaurus/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/docusaurus/",
"description": "Docusaurus is a static-site generator which provides",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"docusaurus\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"5333483ee04ce160b39799c3567a6d43\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::dz74w-1713753678288-ab4bf398a4d7"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/docusaurus/",
"property": "og:url"
},
{
"content": "Docusaurus | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Docusaurus is a static-site generator which provides",
"property": "og:description"
}
],
"title": "Docusaurus | 🦜️🔗 LangChain"
} | Docusaurus
Docusaurus is a static-site generator which provides out-of-the-box documentation features.
Installation and Setup
pip install -U beautifulsoup4 lxml
Document Loader
See a usage example.
from langchain_community.document_loaders import DocusaurusLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/hologres/ | [Hologres](https://www.alibabacloud.com/help/en/hologres/latest/introduction) is a unified real-time data warehousing service developed by Alibaba Cloud. You can use Hologres to write, update, process, and analyze large amounts of data in real time. `Hologres` supports standard `SQL` syntax, is compatible with `PostgreSQL`, and supports most PostgreSQL functions. Hologres supports online analytical processing (OLAP) and ad hoc analysis for up to petabytes of data, and provides high-concurrency and low-latency online data services.
```
pip install hologres-vector
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:19.009Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/hologres/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/hologres/",
"description": "Hologres is a unified real-time data warehousing service developed by Alibaba Cloud. You can use Hologres to write, update, process, and analyze large amounts of data in real time.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"hologres\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"6bc6a2f30d40df1ee0e06af95a04c1ff\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::2wll9-1713753678522-9c98790ea689"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/hologres/",
"property": "og:url"
},
{
"content": "Hologres | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Hologres is a unified real-time data warehousing service developed by Alibaba Cloud. You can use Hologres to write, update, process, and analyze large amounts of data in real time.",
"property": "og:description"
}
],
"title": "Hologres | 🦜️🔗 LangChain"
} | Hologres is a unified real-time data warehousing service developed by Alibaba Cloud. You can use Hologres to write, update, process, and analyze large amounts of data in real time. Hologres supports standard SQL syntax, is compatible with PostgreSQL, and supports most PostgreSQL functions. Hologres supports online analytical processing (OLAP) and ad hoc analysis for up to petabytes of data, and provides high-concurrency and low-latency online data services.
pip install hologres-vector |
https://python.langchain.com/docs/integrations/providers/dropbox/ | ## Dropbox
> [Dropbox](https://en.wikipedia.org/wiki/Dropbox) is a file hosting service that brings everything-traditional files, cloud content, and web shortcuts together in one place.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
See the detailed [installation guide](https://python.langchain.com/docs/integrations/document_loaders/dropbox/#prerequisites).
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/dropbox/).
```
from langchain_community.document_loaders import DropboxLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:19.068Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dropbox/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dropbox/",
"description": "Dropbox is a file hosting service that brings everything-traditional",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3548",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dropbox\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"b4cc68b0b87fbe3c2b46ab4da7dc45dc\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::wl5px-1713753678625-169d83fdea14"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dropbox/",
"property": "og:url"
},
{
"content": "Dropbox | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Dropbox is a file hosting service that brings everything-traditional",
"property": "og:description"
}
],
"title": "Dropbox | 🦜️🔗 LangChain"
} | Dropbox
Dropbox is a file hosting service that brings everything-traditional files, cloud content, and web shortcuts together in one place.
Installation and Setup
See the detailed installation guide.
Document Loader
See a usage example.
from langchain_community.document_loaders import DropboxLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/html2text/ | The ASCII also happens to be a valid `Markdown` (a text-to-HTML format).
```
from langchain_community.document_loaders import Html2TextTransformer
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:19.163Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/html2text/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/html2text/",
"description": "html2text is a Python package that converts a page of HTML into clean, easy-to-read plain ASCII text.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4604",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"html2text\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"247bbeb2d309e1d016cd5908097dab6c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::qfjn6-1713753678702-2c9cda90b7af"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/html2text/",
"property": "og:url"
},
{
"content": "HTML to text | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "html2text is a Python package that converts a page of HTML into clean, easy-to-read plain ASCII text.",
"property": "og:description"
}
],
"title": "HTML to text | 🦜️🔗 LangChain"
} | The ASCII also happens to be a valid Markdown (a text-to-HTML format).
from langchain_community.document_loaders import Html2TextTransformer |
https://python.langchain.com/docs/integrations/providers/huawei/ | ## Huawei
> [Huawei Technologies Co., Ltd.](https://www.huawei.com/) is a Chinese multinational digital communications technology corporation.
>
> [Huawei Cloud](https://www.huaweicloud.com/intl/en-us/product/) provides a comprehensive suite of global cloud computing services.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
To access the `Huawei Cloud`, you need an access token.
You also have to install a python library:
```
pip install -U esdk-obs-python
```
## Document Loader[](#document-loader "Direct link to Document Loader")
### Huawei OBS Directory[](#huawei-obs-directory "Direct link to Huawei OBS Directory")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/huawei_obs_directory/).
```
from langchain_community.document_loaders import OBSDirectoryLoader
```
### Huawei OBS File[](#huawei-obs-file "Direct link to Huawei OBS File")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/huawei_obs_file/).
```
from langchain_community.document_loaders.obs_file import OBSFileLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:19.198Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/huawei/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/huawei/",
"description": "Huawei Technologies Co., Ltd. is a Chinese multinational",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4604",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"huawei\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:18 GMT",
"etag": "W/\"8d711171fa22bd742c816b9e7a68f225\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wcgrm-1713753678826-4ea54854c0f5"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/huawei/",
"property": "og:url"
},
{
"content": "Huawei | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Huawei Technologies Co., Ltd. is a Chinese multinational",
"property": "og:description"
}
],
"title": "Huawei | 🦜️🔗 LangChain"
} | Huawei
Huawei Technologies Co., Ltd. is a Chinese multinational digital communications technology corporation.
Huawei Cloud provides a comprehensive suite of global cloud computing services.
Installation and Setup
To access the Huawei Cloud, you need an access token.
You also have to install a python library:
pip install -U esdk-obs-python
Document Loader
Huawei OBS Directory
See a usage example.
from langchain_community.document_loaders import OBSDirectoryLoader
Huawei OBS File
See a usage example.
from langchain_community.document_loaders.obs_file import OBSFileLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/dspy/ | ## DSPy
[DSPy](https://github.com/stanfordnlp/dspy) is a fantastic framework for LLMs that introduces an automatic compiler that teaches LMs how to conduct the declarative steps in your program. Specifically, the DSPy compiler will internally trace your program and then craft high-quality prompts for large LMs (or train automatic finetunes for small LMs) to teach them the steps of your task.
Thanks to [Omar Khattab](https://twitter.com/lateinteraction) we have an integration! It works with any LCEL chains with some minor modifications.
This short tutorial demonstrates how this proof-of-concept feature works. _This will not give you the full power of DSPy or LangChain yet, but we will expand it if there’s high demand._
Note: this was slightly modified from the original example Omar wrote for DSPy. If you are interested in LangChain \\<\> DSPy but coming from the DSPy side, I’d recommend checking that out. You can find that [here](https://github.com/stanfordnlp/dspy/blob/main/examples/tweets/compiling_langchain.ipynb).
Let’s take a look at an example. In this example we will make a simple RAG pipeline. We will use DSPy to “compile” our program and learn an optimized prompt.
## Install dependencies[](#install-dependencies "Direct link to Install dependencies")
!pip install -U dspy-ai !pip install -U openai jinja2 !pip install -U langchain langchain-community langchain-openai langchain-core
## Setup[](#setup "Direct link to Setup")
We will be using OpenAI, so we should set an API key
```
import getpassimport osos.environ["OPENAI_API_KEY"] = getpass.getpass()
```
We can now set up our retriever. For our retriever we will use a ColBERT retriever through DSPy, though this will work with any retriever.
```
import dspycolbertv2 = dspy.ColBERTv2(url="http://20.102.90.50:2017/wiki17_abstracts")
```
```
from langchain.cache import SQLiteCachefrom langchain.globals import set_llm_cachefrom langchain_openai import OpenAIset_llm_cache(SQLiteCache(database_path="cache.db"))llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0)def retrieve(inputs): return [doc["text"] for doc in colbertv2(inputs["question"], k=5)]
```
```
[{'text': 'Cycling | Cycling, also called bicycling or biking, is the use of bicycles for transport, recreation, exercise or sport. Persons engaged in cycling are referred to as "cyclists", "bikers", or less commonly, as "bicyclists". Apart from two-wheeled bicycles, "cycling" also includes the riding of unicycles, tricycles, quadracycles, recumbent and similar human-powered vehicles (HPVs).', 'pid': 2201868, 'rank': 1, 'score': 27.078739166259766, 'prob': 0.3544841299722533, 'long_text': 'Cycling | Cycling, also called bicycling or biking, is the use of bicycles for transport, recreation, exercise or sport. Persons engaged in cycling are referred to as "cyclists", "bikers", or less commonly, as "bicyclists". Apart from two-wheeled bicycles, "cycling" also includes the riding of unicycles, tricycles, quadracycles, recumbent and similar human-powered vehicles (HPVs).'}, {'text': 'Cycling (ice hockey) | In ice hockey, cycling is an offensive strategy that moves the puck along the boards in the offensive zone to create a scoring chance by making defenders tired or moving them out of position.', 'pid': 312153, 'rank': 2, 'score': 26.109302520751953, 'prob': 0.13445464524590262, 'long_text': 'Cycling (ice hockey) | In ice hockey, cycling is an offensive strategy that moves the puck along the boards in the offensive zone to create a scoring chance by making defenders tired or moving them out of position.'}, {'text': 'Bicycle | A bicycle, also called a cycle or bike, is a human-powered, pedal-driven, single-track vehicle, having two wheels attached to a frame, one behind the other. A is called a cyclist, or bicyclist.', 'pid': 2197695, 'rank': 3, 'score': 25.849220275878906, 'prob': 0.10366294133944996, 'long_text': 'Bicycle | A bicycle, also called a cycle or bike, is a human-powered, pedal-driven, single-track vehicle, having two wheels attached to a frame, one behind the other. A is called a cyclist, or bicyclist.'}, {'text': 'USA Cycling | USA Cycling or USAC, based in Colorado Springs, Colorado, is the national governing body for bicycle racing in the United States. It covers the disciplines of road, track, mountain bike, cyclo-cross, and BMX across all ages and ability levels. In 2015, USAC had a membership of 61,631 individual members.', 'pid': 3821927, 'rank': 4, 'score': 25.61395263671875, 'prob': 0.08193096873942958, 'long_text': 'USA Cycling | USA Cycling or USAC, based in Colorado Springs, Colorado, is the national governing body for bicycle racing in the United States. It covers the disciplines of road, track, mountain bike, cyclo-cross, and BMX across all ages and ability levels. In 2015, USAC had a membership of 61,631 individual members.'}, {'text': 'Vehicular cycling | Vehicular cycling (also known as bicycle driving) is the practice of riding bicycles on roads in a manner that is in accordance with the principles for driving in traffic.', 'pid': 3058888, 'rank': 5, 'score': 25.35515785217285, 'prob': 0.06324918635213703, 'long_text': 'Vehicular cycling | Vehicular cycling (also known as bicycle driving) is the practice of riding bicycles on roads in a manner that is in accordance with the principles for driving in traffic.'}, {'text': 'Road cycling | Road cycling is the most widespread form of cycling. It includes recreational, racing, and utility cycling. Road cyclists are generally expected to obey the same rules and laws as other vehicle drivers or riders and may also be vehicular cyclists.', 'pid': 3392359, 'rank': 6, 'score': 25.274639129638672, 'prob': 0.058356079351563846, 'long_text': 'Road cycling | Road cycling is the most widespread form of cycling. It includes recreational, racing, and utility cycling. Road cyclists are generally expected to obey the same rules and laws as other vehicle drivers or riders and may also be vehicular cyclists.'}, {'text': 'Cycling South Africa | Cycling South Africa or Cycling SA is the national governing body of cycle racing in South Africa. Cycling SA is a member of the "Confédération Africaine de Cyclisme" and the "Union Cycliste Internationale" (UCI). It is affiliated to the South African Sports Confederation and Olympic Committee (SASCOC) as well as the Department of Sport and Recreation SA. Cycling South Africa regulates the five major disciplines within the sport, both amateur and professional, which include: road cycling, mountain biking, BMX biking, track cycling and para-cycling.', 'pid': 2508026, 'rank': 7, 'score': 25.24260711669922, 'prob': 0.05651643767006817, 'long_text': 'Cycling South Africa | Cycling South Africa or Cycling SA is the national governing body of cycle racing in South Africa. Cycling SA is a member of the "Confédération Africaine de Cyclisme" and the "Union Cycliste Internationale" (UCI). It is affiliated to the South African Sports Confederation and Olympic Committee (SASCOC) as well as the Department of Sport and Recreation SA. Cycling South Africa regulates the five major disciplines within the sport, both amateur and professional, which include: road cycling, mountain biking, BMX biking, track cycling and para-cycling.'}, {'text': 'Cycle sport | Cycle sport is competitive physical activity using bicycles. There are several categories of bicycle racing including road bicycle racing, time trialling, cyclo-cross, mountain bike racing, track cycling, BMX, and cycle speedway. Non-racing cycling sports include artistic cycling, cycle polo, freestyle BMX and mountain bike trials. The Union Cycliste Internationale (UCI) is the world governing body for cycling and international competitive cycling events. The International Human Powered Vehicle Association is the governing body for human-powered vehicles that imposes far fewer restrictions on their design than does the UCI. The UltraMarathon Cycling Association is the governing body for many ultra-distance cycling races.', 'pid': 3394121, 'rank': 8, 'score': 25.170495986938477, 'prob': 0.05258444735141742, 'long_text': 'Cycle sport | Cycle sport is competitive physical activity using bicycles. There are several categories of bicycle racing including road bicycle racing, time trialling, cyclo-cross, mountain bike racing, track cycling, BMX, and cycle speedway. Non-racing cycling sports include artistic cycling, cycle polo, freestyle BMX and mountain bike trials. The Union Cycliste Internationale (UCI) is the world governing body for cycling and international competitive cycling events. The International Human Powered Vehicle Association is the governing body for human-powered vehicles that imposes far fewer restrictions on their design than does the UCI. The UltraMarathon Cycling Association is the governing body for many ultra-distance cycling races.'}, {'text': "Cycling UK | Cycling UK is the brand name of the Cyclists' Touring Club or CTC. It is a charitable membership organisation supporting cyclists and promoting bicycle use. Cycling UK is registered at Companies House (as “Cyclists’ Touring Club”), and covered by company law; it is the largest such organisation in the UK. It works at a national and local level to lobby for cyclists' needs and wants, provides services to members, and organises local groups for local activism and those interested in recreational cycling. The original Cyclists' Touring Club began in the nineteenth century with a focus on amateur road cycling but these days has a much broader sphere of interest encompassing everyday transport, commuting and many forms of recreational cycling. Prior to April 2016, Cycling UK operated under the brand CTC, the national cycling charity. As of January 2007, the organisation's president was the newsreader Jon Snow.", 'pid': 1841483, 'rank': 9, 'score': 25.166988372802734, 'prob': 0.05240032450529368, 'long_text': "Cycling UK | Cycling UK is the brand name of the Cyclists' Touring Club or CTC. It is a charitable membership organisation supporting cyclists and promoting bicycle use. Cycling UK is registered at Companies House (as “Cyclists’ Touring Club”), and covered by company law; it is the largest such organisation in the UK. It works at a national and local level to lobby for cyclists' needs and wants, provides services to members, and organises local groups for local activism and those interested in recreational cycling. The original Cyclists' Touring Club began in the nineteenth century with a focus on amateur road cycling but these days has a much broader sphere of interest encompassing everyday transport, commuting and many forms of recreational cycling. Prior to April 2016, Cycling UK operated under the brand CTC, the national cycling charity. As of January 2007, the organisation's president was the newsreader Jon Snow."}, {'text': 'Cycling in the Netherlands | Cycling is a ubiquitous mode of transport in the Netherlands, with 36% of the people listing the bicycle as their most frequent mode of transport on a typical day as opposed to the car by 45% and public transport by 11%. Cycling has a modal share of 27% of all trips (urban and rural) nationwide. In cities this is even higher, such as Amsterdam which has 38%, though the smaller Dutch cities well exceed that: for instance Zwolle (pop. ~123,000) has 46% and the university town of Groningen (pop. ~198,000) has 31%. This high modal share for bicycle travel is enabled by excellent cycling infrastructure such as cycle paths, cycle tracks, protected intersections, ubiquitous bicycle parking and by making cycling routes shorter, quicker and more direct than car routes.', 'pid': 1196118, 'rank': 10, 'score': 24.954299926757812, 'prob': 0.0423608394724844, 'long_text': 'Cycling in the Netherlands | Cycling is a ubiquitous mode of transport in the Netherlands, with 36% of the people listing the bicycle as their most frequent mode of transport on a typical day as opposed to the car by 45% and public transport by 11%. Cycling has a modal share of 27% of all trips (urban and rural) nationwide. In cities this is even higher, such as Amsterdam which has 38%, though the smaller Dutch cities well exceed that: for instance Zwolle (pop. ~123,000) has 46% and the university town of Groningen (pop. ~198,000) has 31%. This high modal share for bicycle travel is enabled by excellent cycling infrastructure such as cycle paths, cycle tracks, protected intersections, ubiquitous bicycle parking and by making cycling routes shorter, quicker and more direct than car routes.'}]
```
## Normal LCEL[](#normal-lcel "Direct link to Normal LCEL")
First, let’s create a simple RAG pipeline with LCEL like we would normally.
For illustration, let’s tackle the following task.
**Task:** Build a RAG system for generating informative tweets.
* **Input:** A factual question, which may be fairly complex.
* **Output:** An engaging tweet that correctly answers the question from the retrieved info.
Let’s use LangChain’s expression language (LCEL) to illustrate this. Any prompt here will do, we will optimize the final prompt with DSPy.
Considering that, let’s just keep it to the barebones: **Given {context}, answer the question {question} as a tweet.**
```
# From LangChain, import standard modules for prompting.from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnablePassthrough# Just a simple prompt for this task. It's fine if it's complex too.prompt = PromptTemplate.from_template( "Given {context}, answer the question `{question}` as a tweet.")# This is how you'd normally build a chain with LCEL. This chain does retrieval then generation (RAG).vanilla_chain = ( RunnablePassthrough.assign(context=retrieve) | prompt | llm | StrOutputParser())
```
## LCEL \\<\> DSPy[](#lcel-dspy "Direct link to lcel-dspy")
In order to use LangChain with DSPy, you need to make two minor modifications
**LangChainPredict**
You need to change from doing `prompt | llm` to using `LangChainPredict(prompt, llm)` from `dspy`.
This is a wrapper which will bind your prompt and llm together so you can optimize them
**LangChainModule**
This is a wrapper which wraps your final LCEL chain so that DSPy can optimize the whole thing
```
# From DSPy, import the modules that know how to interact with LangChain LCEL.from dspy.predict.langchain import LangChainModule, LangChainPredict# This is how to wrap it so it behaves like a DSPy program.# Just Replace every pattern like `prompt | llm` with `LangChainPredict(prompt, llm)`.zeroshot_chain = ( RunnablePassthrough.assign(context=retrieve) | LangChainPredict(prompt, llm) | StrOutputParser())# Now we wrap it in LangChainModulezeroshot_chain = LangChainModule( zeroshot_chain) # then wrap the chain in a DSPy module.
```
## Trying the Module[](#trying-the-module "Direct link to Trying the Module")
After this, we can use it as both a LangChain runnable and a DSPy module!
```
question = "In what region was Eddy Mazzoleni born?"zeroshot_chain.invoke({"question": question})
```
```
' Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy'
```
Ah that sounds about right! (It’s technically not perfect: we asked for the region not the city. We can do better below.)
Inspecting questions and answers manually is very important to get a sense of your system. However, a good system designer always looks to iteratively benchmark their work to quantify progress!
To do this, we need two things: the metric we want to maximize and a (tiny) dataset of examples for our system.
Are there pre-defined metrics for good tweets? Should I label 100,000 tweets by hand? Probably not. We can easily do something reasonable, though, until you start getting data in production!
## Load Data[](#load-data "Direct link to Load Data")
In order to compile our chain, we need a dataset to work with. This dataset just needs to be raw inputs and outputs. For our purposes, we will use HotPotQA dataset
Note: Notice that our dataset doesn’t actually include any tweets! It only has questions and answers. That’s OK, our metric will take care of evaluating outputs in tweet form.
```
import dspyfrom dspy.datasets import HotPotQA# Load the dataset.dataset = HotPotQA( train_seed=1, train_size=200, eval_seed=2023, dev_size=200, test_size=0, keep_details=True,)# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.trainset = [x.without("id", "type").with_inputs("question") for x in dataset.train]devset = [x.without("id", "type").with_inputs("question") for x in dataset.dev]valset, devset = devset[:50], devset[50:]
```
```
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/datasets/table.py:1421: FutureWarning: promote has been superseded by mode='default'. table = cls._concat_blocks(blocks, axis=0)
```
## Define a metic[](#define-a-metic "Direct link to Define a metic")
We now need to define a metric. This will be used to determine which runs were successful and we can learn from. Here we will use DSPy’s metrics, though you can write your own.
```
# Define the signature for autoamtic assessments.class Assess(dspy.Signature): """Assess the quality of a tweet along the specified dimension.""" context = dspy.InputField(desc="ignore if N/A") assessed_text = dspy.InputField() assessment_question = dspy.InputField() assessment_answer = dspy.OutputField(desc="Yes or No")gpt4T = dspy.OpenAI(model="gpt-4-1106-preview", max_tokens=1000, model_type="chat")METRIC = Nonedef metric(gold, pred, trace=None): question, answer, tweet = gold.question, gold.answer, pred.output context = colbertv2(question, k=5) engaging = "Does the assessed text make for a self-contained, engaging tweet?" faithful = "Is the assessed text grounded in the context? Say no if it includes significant facts not in the context." correct = ( f"The text above is should answer `{question}`. The gold answer is `{answer}`." ) correct = f"{correct} Does the assessed text above contain the gold answer?" with dspy.context(lm=gpt4T): faithful = dspy.Predict(Assess)( context=context, assessed_text=tweet, assessment_question=faithful ) correct = dspy.Predict(Assess)( context="N/A", assessed_text=tweet, assessment_question=correct ) engaging = dspy.Predict(Assess)( context="N/A", assessed_text=tweet, assessment_question=engaging ) correct, engaging, faithful = [ m.assessment_answer.split()[0].lower() == "yes" for m in [correct, engaging, faithful] ] score = (correct + engaging + faithful) if correct and (len(tweet) <= 280) else 0 if METRIC is not None: if METRIC == "correct": return correct if METRIC == "engaging": return engaging if METRIC == "faithful": return faithful if trace is not None: return score >= 3 return score / 3.0
```
## Evaluate Baseline[](#evaluate-baseline "Direct link to Evaluate Baseline")
Okay, let’s evaluate the unoptimized “zero-shot” version of our chain, converted from our LangChain LCEL object.
```
from dspy.evaluate.evaluate import Evaluate
```
```
evaluate = Evaluate( metric=metric, devset=devset, num_threads=8, display_progress=True, display_table=5)evaluate(zeroshot_chain)
```
```
Average Metric: 62.99999999999998 / 150 (42.0): 100%|██| 150/150 [01:14<00:00, 2.02it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell)
```
```
Average Metric: 62.99999999999998 / 150 (42.0%)
```
| | question | answer | gold\_titles | output | tweet\_response | metric |
| --- | --- | --- | --- | --- | --- | --- |
| 0 | Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars? | Brian Virtue | {'Thirty Seconds to Mars', 'Levolution (album)'} | Brian Virtue, who has worked with bands like Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue... | Brian Virtue, who has worked with bands like Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue... | 1.0 |
| 1 | Are both the University of Chicago and Syracuse University public universities? | no | {'Syracuse University', 'University of Chicago'} | No, only Syracuse University is a public university. The University of Chicago is a private research university. #university #publicvsprivate | No, only Syracuse University is a public university. The University of Chicago is a private research university. #university #publicvsprivate | 0.3333333333333333 |
| 2 | In what region was Eddy Mazzoleni born? | Lombardy, northern Italy | {'Eddy Mazzoleni', 'Bergamo'} | Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy | Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy | 0.0 |
| 3 | Who edited the 1990 American romantic comedy film directed by Garry Marshall? | Raja Raymond Gosnell | {'Raja Gosnell', 'Pretty Woman'} | J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 American romantic comedy film directed by Garry Marshall. #PrettyWoman #GarryMarshall #JFLawton | J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 American romantic comedy film directed by Garry Marshall. #PrettyWoman #GarryMarshall #JFLawton | 0.0 |
| 4 | Burrs Country Park railway station is what stop on the railway line that runs between Heywood and Rawtenstall | seventh | {'Burrs Country Park railway station', 'East Lancashire Railway'} | Burrs Country Park railway station is the seventh stop on the East Lancashire Railway line that runs between Heywood and Rawtenstall. | Burrs Country Park railway station is the seventh stop on the East Lancashire Railway line that runs between Heywood and Rawtenstall. | 1.0 |
... 145 more rows not displayed ...
Okay, cool. Our zeroshot\_chain gets about 42.00% on the 150 questions from the devset.
The table above shows some examples. For instance:
* Question: Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars?
* Tweet: Brian Virtue, who has worked with bands like Jane’s Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars, showcasing… \[truncated\]
* Metric: 1.0 (A tweet that is correct, faithful, and engaging!\*)
footnote: \* At least according to our metric, which is just a DSPy program, so it too can be optimized if you’d like! Topic for another notebook, though.
## Optimize[](#optimize "Direct link to Optimize")
Now, let’s optimize performance
```
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
```
```
# Set up the optimizer. We'll use very minimal hyperparameters for this example.# Just do random search with ~3 attempts, and in each attempt, bootstrap <= 3 traces.optimizer = BootstrapFewShotWithRandomSearch( metric=metric, max_bootstrapped_demos=3, num_candidate_programs=3)# Now use the optimizer to *compile* the chain. This could take 5-10 minutes, unless it's cached.optimized_chain = optimizer.compile(zeroshot_chain, trainset=trainset, valset=valset)
```
```
Going to sample between 1 and 3 traces per predictor.Will attempt to train 3 candidate sets.Average Metric: 22.33333333333334 / 50 (44.7%)Score: 44.67 for set: [0]New best score: 44.67 for seed -3Scores so far: [44.67]Best score: 44.67Average Metric: 22.33333333333334 / 50 (44.7%)Score: 44.67 for set: [16]Scores so far: [44.67, 44.67]Best score: 44.67Bootstrapped 3 full traces after 9 examples in round 0.Average Metric: 24.666666666666668 / 50 (49.3%)Score: 49.33 for set: [16]New best score: 49.33 for seed -1Scores so far: [44.67, 44.67, 49.33]Best score: 49.33Average of max per entry across top 1 scores: 0.49333333333333335Average of max per entry across top 2 scores: 0.5533333333333335Average of max per entry across top 3 scores: 0.5533333333333335Average of max per entry across top 5 scores: 0.5533333333333335Average of max per entry across top 8 scores: 0.5533333333333335Average of max per entry across top 9999 scores: 0.5533333333333335Bootstrapped 2 full traces after 13 examples in round 0.Average Metric: 25.66666666666667 / 50 (51.3%)Score: 51.33 for set: [16]New best score: 51.33 for seed 0Scores so far: [44.67, 44.67, 49.33, 51.33]Best score: 51.33Average of max per entry across top 1 scores: 0.5133333333333334Average of max per entry across top 2 scores: 0.5666666666666668Average of max per entry across top 3 scores: 0.6000000000000001Average of max per entry across top 5 scores: 0.6000000000000001Average of max per entry across top 8 scores: 0.6000000000000001Average of max per entry across top 9999 scores: 0.6000000000000001Bootstrapped 1 full traces after 2 examples in round 0.Average Metric: 26.33333333333334 / 50 (52.7%)Score: 52.67 for set: [16]New best score: 52.67 for seed 1Scores so far: [44.67, 44.67, 49.33, 51.33, 52.67]Best score: 52.67Average of max per entry across top 1 scores: 0.5266666666666667Average of max per entry across top 2 scores: 0.56Average of max per entry across top 3 scores: 0.5666666666666668Average of max per entry across top 5 scores: 0.6000000000000001Average of max per entry across top 8 scores: 0.6000000000000001Average of max per entry across top 9999 scores: 0.6000000000000001Bootstrapped 1 full traces after 2 examples in round 0.Average Metric: 25.666666666666668 / 50 (51.3%)Score: 51.33 for set: [16]Scores so far: [44.67, 44.67, 49.33, 51.33, 52.67, 51.33]Best score: 52.67Average of max per entry across top 1 scores: 0.5266666666666667Average of max per entry across top 2 scores: 0.56Average of max per entry across top 3 scores: 0.6000000000000001Average of max per entry across top 5 scores: 0.6133333333333334Average of max per entry across top 8 scores: 0.6133333333333334Average of max per entry across top 9999 scores: 0.61333333333333346 candidate programs found.
```
```
Average Metric: 22.33333333333334 / 50 (44.7): 100%|█████| 50/50 [00:26<00:00, 1.87it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell)Average Metric: 22.33333333333334 / 50 (44.7): 100%|█████| 50/50 [00:00<00:00, 79.51it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell) 4%|██ | 8/200 [00:33<13:21, 4.18s/it]Average Metric: 24.666666666666668 / 50 (49.3): 100%|████| 50/50 [00:28<00:00, 1.77it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell) 6%|███ | 12/200 [00:31<08:16, 2.64s/it]Average Metric: 25.66666666666667 / 50 (51.3): 100%|█████| 50/50 [00:25<00:00, 1.92it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell) 0%|▎ | 1/200 [00:02<08:37, 2.60s/it]Average Metric: 26.33333333333334 / 50 (52.7): 100%|█████| 50/50 [00:23<00:00, 2.11it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell) 0%|▎ | 1/200 [00:02<07:11, 2.17s/it]Average Metric: 25.666666666666668 / 50 (51.3): 100%|████| 50/50 [00:21<00:00, 2.29it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell)
```
## Evaluating the optimized chain[](#evaluating-the-optimized-chain "Direct link to Evaluating the optimized chain")
Well, how good is this? Let’s do some proper evals!
```
evaluate(optimized_chain)
```
```
Average Metric: 74.66666666666666 / 150 (49.8): 100%|██| 150/150 [00:54<00:00, 2.74it/s]/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead. df = df.applymap(truncate_cell)
```
```
Average Metric: 74.66666666666666 / 150 (49.8%)
```
| | question | answer | gold\_titles | output | tweet\_response | metric |
| --- | --- | --- | --- | --- | --- | --- |
| 0 | Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars? | Brian Virtue | {'Thirty Seconds to Mars', 'Levolution (album)'} | Brian Virtue, known for his work with Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue #Producer... | Brian Virtue, known for his work with Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue #Producer... | 1.0 |
| 1 | Are both the University of Chicago and Syracuse University public universities? | no | {'Syracuse University', 'University of Chicago'} | No, only Northeastern Illinois University is a public state university. Syracuse University is a private research university. #University #PublicPrivate #HigherEd | No, only Northeastern Illinois University is a public state university. Syracuse University is a private research university. #University #PublicPrivate #HigherEd | 0.0 |
| 2 | In what region was Eddy Mazzoleni born? | Lombardy, northern Italy | {'Eddy Mazzoleni', 'Bergamo'} | Eddy Mazzoleni, the Italian professional road cyclist, was born in Bergamo, Italy. #EddyMazzoleni #Cycling #Italy | Eddy Mazzoleni, the Italian professional road cyclist, was born in Bergamo, Italy. #EddyMazzoleni #Cycling #Italy | 0.0 |
| 3 | Who edited the 1990 American romantic comedy film directed by Garry Marshall? | Raja Raymond Gosnell | {'Raja Gosnell', 'Pretty Woman'} | J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 romantic comedy directed by Garry Marshall. #PrettyWoman #GarryMarshall #RomanticComedy | J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 romantic comedy directed by Garry Marshall. #PrettyWoman #GarryMarshall #RomanticComedy | 0.0 |
| 4 | Burrs Country Park railway station is what stop on the railway line that runs between Heywood and Rawtenstall | seventh | {'Burrs Country Park railway station', 'East Lancashire Railway'} | Burrs Country Park railway station is the seventh stop on the East Lancashire Railway, which runs between Heywood and Rawtenstall. #EastLancashireRailway #BurrsCountryPark #RailwayStation | Burrs Country Park railway station is the seventh stop on the East Lancashire Railway, which runs between Heywood and Rawtenstall. #EastLancashireRailway #BurrsCountryPark #RailwayStation | 1.0 |
... 145 more rows not displayed ...
Alright! We’ve improved our chain from 42% to nearly 50%!
## Inspect the optimized chain[](#inspect-the-optimized-chain "Direct link to Inspect the optimized chain")
So what actually happened to improve this? We can take a look at this by looking at the optimized chain. We can do this in two ways
### Look at the prompt used[](#look-at-the-prompt-used "Direct link to Look at the prompt used")
We can look at what prompt was actually used. We can do this by looking at `dspy.settings`.
```
prompt_used, output = dspy.settings.langchain_history[-1]
```
```
Essential Instructions: Respond to the provided question based on the given context in the style of a tweet, ensuring the response is concise and within the character limit of a tweet (up to 280 characters).---Follow the following format.Context: ${context}Question: ${question}Tweet Response: ${tweet_response}---Context:[1] «Brutus (Funny Car) | Brutus is a pioneering funny car driven by Jim Liberman and prepared by crew chief Lew Arrington in the middle 1960s.»[2] «USS Brutus (AC-15) | USS "Brutus", formerly the steamer "Peter Jebsen", was a collier in the United States Navy. She was built in 1894 at South Shields-on-Tyne, England, by John Readhead & Sons and was acquired by the U.S. Navy early in 1898 from L. F. Chapman & Company. She was renamed "Brutus" and commissioned at the Mare Island Navy Yard on 27 May 1898, with Lieutenant Vincendon L. Cottman, commanding officer and Lieutenant Randolph H. Miner, executive officer.»[3] «Brutus Beefcake | Ed Leslie is an American semi-retired professional wrestler, best known for his work in the World Wrestling Federation (WWF) under the ring name Brutus "The Barber" Beefcake. He later worked for World Championship Wrestling (WCW) under a variety of names.»[4] «Brutus Hamilton | Brutus Kerr Hamilton (July 19, 1900 – December 28, 1970) was an American track and field athlete, coach and athletics administrator.»[5] «Big Brutus | Big Brutus is the nickname of the Bucyrus-Erie model 1850B electric shovel, which was the second largest of its type in operation in the 1960s and 1970s. Big Brutus is the centerpiece of a mining museum in West Mineral, Kansas where it was used in coal strip mining operations. The shovel was designed to dig from 20 to in relatively shallow coal seams.»Question: What is the nickname for this United States drag racer who drove Brutus?Tweet Response: Jim Liberman, also known as "Jungle Jim", drove the pioneering funny car Brutus in the 1960s. #Brutus #FunnyCar #DragRacing---Context:[1] «Philip Markoff | Philip Haynes Markoff (February 12, 1986 – August 15, 2010) was an American medical student who was charged with the armed robbery and murder of Julissa Brisman in a Boston, Massachusetts, hotel on April 14, 2009, and two other armed robberies.»[2] «Antonia Brenner | Antonia Brenner, better known as Mother Antonia (Spanish: Madre Antonia ), (December 1, 1926 – October 17, 2013) was an American Roman Catholic Religious Sister and activist who chose to reside and care for inmates at the notorious maximum-security La Mesa Prison in Tijuana, Mexico. As a result of her work, she founded a new religious institute called the Eudist Servants of the 11th Hour.»[3] «Luzira Maximum Security Prison | Luzira Maximum Security Prison is a maximum security prison for both men and women in Uganda. As at July 2016, it is the only maximum security prison in the country and houses Uganda's death row inmates.»[4] «Pleasant Valley State Prison | Pleasant Valley State Prison (PVSP) is a 640 acres minimum-to-maximum security state prison in Coalinga, Fresno County, California. The facility has housed convicted murderers Sirhan Sirhan, Erik Menendez, X-Raided, and Hans Reiser, among others.»[5] «Jon-Adrian Velazquez | Jon-Adrian Velazquez is an inmate in the maximum security Sing-Sing prison in New York who is serving a 25-year sentence after being convicted of the 1998 murder of a retired police officer. His case garnered considerable attention from the media ten years after his conviction, due to a visit and support from Martin Sheen and a long-term investigation by Dateline NBC producer Dan Slepian.»Question: Which maximum security jail housed the killer of Julissa brisman?Tweet Response:
```
### Look at the demos[](#look-at-the-demos "Direct link to Look at the demos")
The way this was optimized was that we collected examples (or “demos”) to put in the prompt. We can inspect the optmized\_chain to get a sense for what those are.
```
demos = [ eg for eg in optimized_chain.modules[0].demos if hasattr(eg, "augmented") and eg.augmented]
```
```
[Example({'augmented': True, 'question': 'What is the nickname for this United States drag racer who drove Brutus?', 'context': ['Brutus (Funny Car) | Brutus is a pioneering funny car driven by Jim Liberman and prepared by crew chief Lew Arrington in the middle 1960s.', 'USS Brutus (AC-15) | USS "Brutus", formerly the steamer "Peter Jebsen", was a collier in the United States Navy. She was built in 1894 at South Shields-on-Tyne, England, by John Readhead & Sons and was acquired by the U.S. Navy early in 1898 from L. F. Chapman & Company. She was renamed "Brutus" and commissioned at the Mare Island Navy Yard on 27 May 1898, with Lieutenant Vincendon L. Cottman, commanding officer and Lieutenant Randolph H. Miner, executive officer.', 'Brutus Beefcake | Ed Leslie is an American semi-retired professional wrestler, best known for his work in the World Wrestling Federation (WWF) under the ring name Brutus "The Barber" Beefcake. He later worked for World Championship Wrestling (WCW) under a variety of names.', 'Brutus Hamilton | Brutus Kerr Hamilton (July 19, 1900 – December 28, 1970) was an American track and field athlete, coach and athletics administrator.', 'Big Brutus | Big Brutus is the nickname of the Bucyrus-Erie model 1850B electric shovel, which was the second largest of its type in operation in the 1960s and 1970s. Big Brutus is the centerpiece of a mining museum in West Mineral, Kansas where it was used in coal strip mining operations. The shovel was designed to dig from 20 to in relatively shallow coal seams.'], 'tweet_response': ' Jim Liberman, also known as "Jungle Jim", drove the pioneering funny car Brutus in the 1960s. #Brutus #FunnyCar #DragRacing'}) (input_keys=None)]
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:19.711Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/dspy/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/dspy/",
"description": "DSPy is a fantastic framework for",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3549",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"dspy\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:19 GMT",
"etag": "W/\"170f5946f67c3806186e8c8f46cc03b4\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::cjjk8-1713753679028-63cd3794fa32"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/dspy/",
"property": "og:url"
},
{
"content": "DSPy | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DSPy is a fantastic framework for",
"property": "og:description"
}
],
"title": "DSPy | 🦜️🔗 LangChain"
} | DSPy
DSPy is a fantastic framework for LLMs that introduces an automatic compiler that teaches LMs how to conduct the declarative steps in your program. Specifically, the DSPy compiler will internally trace your program and then craft high-quality prompts for large LMs (or train automatic finetunes for small LMs) to teach them the steps of your task.
Thanks to Omar Khattab we have an integration! It works with any LCEL chains with some minor modifications.
This short tutorial demonstrates how this proof-of-concept feature works. This will not give you the full power of DSPy or LangChain yet, but we will expand it if there’s high demand.
Note: this was slightly modified from the original example Omar wrote for DSPy. If you are interested in LangChain \<> DSPy but coming from the DSPy side, I’d recommend checking that out. You can find that here.
Let’s take a look at an example. In this example we will make a simple RAG pipeline. We will use DSPy to “compile” our program and learn an optimized prompt.
Install dependencies
!pip install -U dspy-ai !pip install -U openai jinja2 !pip install -U langchain langchain-community langchain-openai langchain-core
Setup
We will be using OpenAI, so we should set an API key
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
We can now set up our retriever. For our retriever we will use a ColBERT retriever through DSPy, though this will work with any retriever.
import dspy
colbertv2 = dspy.ColBERTv2(url="http://20.102.90.50:2017/wiki17_abstracts")
from langchain.cache import SQLiteCache
from langchain.globals import set_llm_cache
from langchain_openai import OpenAI
set_llm_cache(SQLiteCache(database_path="cache.db"))
llm = OpenAI(model_name="gpt-3.5-turbo-instruct", temperature=0)
def retrieve(inputs):
return [doc["text"] for doc in colbertv2(inputs["question"], k=5)]
[{'text': 'Cycling | Cycling, also called bicycling or biking, is the use of bicycles for transport, recreation, exercise or sport. Persons engaged in cycling are referred to as "cyclists", "bikers", or less commonly, as "bicyclists". Apart from two-wheeled bicycles, "cycling" also includes the riding of unicycles, tricycles, quadracycles, recumbent and similar human-powered vehicles (HPVs).',
'pid': 2201868,
'rank': 1,
'score': 27.078739166259766,
'prob': 0.3544841299722533,
'long_text': 'Cycling | Cycling, also called bicycling or biking, is the use of bicycles for transport, recreation, exercise or sport. Persons engaged in cycling are referred to as "cyclists", "bikers", or less commonly, as "bicyclists". Apart from two-wheeled bicycles, "cycling" also includes the riding of unicycles, tricycles, quadracycles, recumbent and similar human-powered vehicles (HPVs).'},
{'text': 'Cycling (ice hockey) | In ice hockey, cycling is an offensive strategy that moves the puck along the boards in the offensive zone to create a scoring chance by making defenders tired or moving them out of position.',
'pid': 312153,
'rank': 2,
'score': 26.109302520751953,
'prob': 0.13445464524590262,
'long_text': 'Cycling (ice hockey) | In ice hockey, cycling is an offensive strategy that moves the puck along the boards in the offensive zone to create a scoring chance by making defenders tired or moving them out of position.'},
{'text': 'Bicycle | A bicycle, also called a cycle or bike, is a human-powered, pedal-driven, single-track vehicle, having two wheels attached to a frame, one behind the other. A is called a cyclist, or bicyclist.',
'pid': 2197695,
'rank': 3,
'score': 25.849220275878906,
'prob': 0.10366294133944996,
'long_text': 'Bicycle | A bicycle, also called a cycle or bike, is a human-powered, pedal-driven, single-track vehicle, having two wheels attached to a frame, one behind the other. A is called a cyclist, or bicyclist.'},
{'text': 'USA Cycling | USA Cycling or USAC, based in Colorado Springs, Colorado, is the national governing body for bicycle racing in the United States. It covers the disciplines of road, track, mountain bike, cyclo-cross, and BMX across all ages and ability levels. In 2015, USAC had a membership of 61,631 individual members.',
'pid': 3821927,
'rank': 4,
'score': 25.61395263671875,
'prob': 0.08193096873942958,
'long_text': 'USA Cycling | USA Cycling or USAC, based in Colorado Springs, Colorado, is the national governing body for bicycle racing in the United States. It covers the disciplines of road, track, mountain bike, cyclo-cross, and BMX across all ages and ability levels. In 2015, USAC had a membership of 61,631 individual members.'},
{'text': 'Vehicular cycling | Vehicular cycling (also known as bicycle driving) is the practice of riding bicycles on roads in a manner that is in accordance with the principles for driving in traffic.',
'pid': 3058888,
'rank': 5,
'score': 25.35515785217285,
'prob': 0.06324918635213703,
'long_text': 'Vehicular cycling | Vehicular cycling (also known as bicycle driving) is the practice of riding bicycles on roads in a manner that is in accordance with the principles for driving in traffic.'},
{'text': 'Road cycling | Road cycling is the most widespread form of cycling. It includes recreational, racing, and utility cycling. Road cyclists are generally expected to obey the same rules and laws as other vehicle drivers or riders and may also be vehicular cyclists.',
'pid': 3392359,
'rank': 6,
'score': 25.274639129638672,
'prob': 0.058356079351563846,
'long_text': 'Road cycling | Road cycling is the most widespread form of cycling. It includes recreational, racing, and utility cycling. Road cyclists are generally expected to obey the same rules and laws as other vehicle drivers or riders and may also be vehicular cyclists.'},
{'text': 'Cycling South Africa | Cycling South Africa or Cycling SA is the national governing body of cycle racing in South Africa. Cycling SA is a member of the "Confédération Africaine de Cyclisme" and the "Union Cycliste Internationale" (UCI). It is affiliated to the South African Sports Confederation and Olympic Committee (SASCOC) as well as the Department of Sport and Recreation SA. Cycling South Africa regulates the five major disciplines within the sport, both amateur and professional, which include: road cycling, mountain biking, BMX biking, track cycling and para-cycling.',
'pid': 2508026,
'rank': 7,
'score': 25.24260711669922,
'prob': 0.05651643767006817,
'long_text': 'Cycling South Africa | Cycling South Africa or Cycling SA is the national governing body of cycle racing in South Africa. Cycling SA is a member of the "Confédération Africaine de Cyclisme" and the "Union Cycliste Internationale" (UCI). It is affiliated to the South African Sports Confederation and Olympic Committee (SASCOC) as well as the Department of Sport and Recreation SA. Cycling South Africa regulates the five major disciplines within the sport, both amateur and professional, which include: road cycling, mountain biking, BMX biking, track cycling and para-cycling.'},
{'text': 'Cycle sport | Cycle sport is competitive physical activity using bicycles. There are several categories of bicycle racing including road bicycle racing, time trialling, cyclo-cross, mountain bike racing, track cycling, BMX, and cycle speedway. Non-racing cycling sports include artistic cycling, cycle polo, freestyle BMX and mountain bike trials. The Union Cycliste Internationale (UCI) is the world governing body for cycling and international competitive cycling events. The International Human Powered Vehicle Association is the governing body for human-powered vehicles that imposes far fewer restrictions on their design than does the UCI. The UltraMarathon Cycling Association is the governing body for many ultra-distance cycling races.',
'pid': 3394121,
'rank': 8,
'score': 25.170495986938477,
'prob': 0.05258444735141742,
'long_text': 'Cycle sport | Cycle sport is competitive physical activity using bicycles. There are several categories of bicycle racing including road bicycle racing, time trialling, cyclo-cross, mountain bike racing, track cycling, BMX, and cycle speedway. Non-racing cycling sports include artistic cycling, cycle polo, freestyle BMX and mountain bike trials. The Union Cycliste Internationale (UCI) is the world governing body for cycling and international competitive cycling events. The International Human Powered Vehicle Association is the governing body for human-powered vehicles that imposes far fewer restrictions on their design than does the UCI. The UltraMarathon Cycling Association is the governing body for many ultra-distance cycling races.'},
{'text': "Cycling UK | Cycling UK is the brand name of the Cyclists' Touring Club or CTC. It is a charitable membership organisation supporting cyclists and promoting bicycle use. Cycling UK is registered at Companies House (as “Cyclists’ Touring Club”), and covered by company law; it is the largest such organisation in the UK. It works at a national and local level to lobby for cyclists' needs and wants, provides services to members, and organises local groups for local activism and those interested in recreational cycling. The original Cyclists' Touring Club began in the nineteenth century with a focus on amateur road cycling but these days has a much broader sphere of interest encompassing everyday transport, commuting and many forms of recreational cycling. Prior to April 2016, Cycling UK operated under the brand CTC, the national cycling charity. As of January 2007, the organisation's president was the newsreader Jon Snow.",
'pid': 1841483,
'rank': 9,
'score': 25.166988372802734,
'prob': 0.05240032450529368,
'long_text': "Cycling UK | Cycling UK is the brand name of the Cyclists' Touring Club or CTC. It is a charitable membership organisation supporting cyclists and promoting bicycle use. Cycling UK is registered at Companies House (as “Cyclists’ Touring Club”), and covered by company law; it is the largest such organisation in the UK. It works at a national and local level to lobby for cyclists' needs and wants, provides services to members, and organises local groups for local activism and those interested in recreational cycling. The original Cyclists' Touring Club began in the nineteenth century with a focus on amateur road cycling but these days has a much broader sphere of interest encompassing everyday transport, commuting and many forms of recreational cycling. Prior to April 2016, Cycling UK operated under the brand CTC, the national cycling charity. As of January 2007, the organisation's president was the newsreader Jon Snow."},
{'text': 'Cycling in the Netherlands | Cycling is a ubiquitous mode of transport in the Netherlands, with 36% of the people listing the bicycle as their most frequent mode of transport on a typical day as opposed to the car by 45% and public transport by 11%. Cycling has a modal share of 27% of all trips (urban and rural) nationwide. In cities this is even higher, such as Amsterdam which has 38%, though the smaller Dutch cities well exceed that: for instance Zwolle (pop. ~123,000) has 46% and the university town of Groningen (pop. ~198,000) has 31%. This high modal share for bicycle travel is enabled by excellent cycling infrastructure such as cycle paths, cycle tracks, protected intersections, ubiquitous bicycle parking and by making cycling routes shorter, quicker and more direct than car routes.',
'pid': 1196118,
'rank': 10,
'score': 24.954299926757812,
'prob': 0.0423608394724844,
'long_text': 'Cycling in the Netherlands | Cycling is a ubiquitous mode of transport in the Netherlands, with 36% of the people listing the bicycle as their most frequent mode of transport on a typical day as opposed to the car by 45% and public transport by 11%. Cycling has a modal share of 27% of all trips (urban and rural) nationwide. In cities this is even higher, such as Amsterdam which has 38%, though the smaller Dutch cities well exceed that: for instance Zwolle (pop. ~123,000) has 46% and the university town of Groningen (pop. ~198,000) has 31%. This high modal share for bicycle travel is enabled by excellent cycling infrastructure such as cycle paths, cycle tracks, protected intersections, ubiquitous bicycle parking and by making cycling routes shorter, quicker and more direct than car routes.'}]
Normal LCEL
First, let’s create a simple RAG pipeline with LCEL like we would normally.
For illustration, let’s tackle the following task.
Task: Build a RAG system for generating informative tweets.
Input: A factual question, which may be fairly complex.
Output: An engaging tweet that correctly answers the question from the retrieved info.
Let’s use LangChain’s expression language (LCEL) to illustrate this. Any prompt here will do, we will optimize the final prompt with DSPy.
Considering that, let’s just keep it to the barebones: Given {context}, answer the question {question} as a tweet.
# From LangChain, import standard modules for prompting.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
# Just a simple prompt for this task. It's fine if it's complex too.
prompt = PromptTemplate.from_template(
"Given {context}, answer the question `{question}` as a tweet."
)
# This is how you'd normally build a chain with LCEL. This chain does retrieval then generation (RAG).
vanilla_chain = (
RunnablePassthrough.assign(context=retrieve) | prompt | llm | StrOutputParser()
)
LCEL \<> DSPy
In order to use LangChain with DSPy, you need to make two minor modifications
LangChainPredict
You need to change from doing prompt | llm to using LangChainPredict(prompt, llm) from dspy.
This is a wrapper which will bind your prompt and llm together so you can optimize them
LangChainModule
This is a wrapper which wraps your final LCEL chain so that DSPy can optimize the whole thing
# From DSPy, import the modules that know how to interact with LangChain LCEL.
from dspy.predict.langchain import LangChainModule, LangChainPredict
# This is how to wrap it so it behaves like a DSPy program.
# Just Replace every pattern like `prompt | llm` with `LangChainPredict(prompt, llm)`.
zeroshot_chain = (
RunnablePassthrough.assign(context=retrieve)
| LangChainPredict(prompt, llm)
| StrOutputParser()
)
# Now we wrap it in LangChainModule
zeroshot_chain = LangChainModule(
zeroshot_chain
) # then wrap the chain in a DSPy module.
Trying the Module
After this, we can use it as both a LangChain runnable and a DSPy module!
question = "In what region was Eddy Mazzoleni born?"
zeroshot_chain.invoke({"question": question})
' Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy'
Ah that sounds about right! (It’s technically not perfect: we asked for the region not the city. We can do better below.)
Inspecting questions and answers manually is very important to get a sense of your system. However, a good system designer always looks to iteratively benchmark their work to quantify progress!
To do this, we need two things: the metric we want to maximize and a (tiny) dataset of examples for our system.
Are there pre-defined metrics for good tweets? Should I label 100,000 tweets by hand? Probably not. We can easily do something reasonable, though, until you start getting data in production!
Load Data
In order to compile our chain, we need a dataset to work with. This dataset just needs to be raw inputs and outputs. For our purposes, we will use HotPotQA dataset
Note: Notice that our dataset doesn’t actually include any tweets! It only has questions and answers. That’s OK, our metric will take care of evaluating outputs in tweet form.
import dspy
from dspy.datasets import HotPotQA
# Load the dataset.
dataset = HotPotQA(
train_seed=1,
train_size=200,
eval_seed=2023,
dev_size=200,
test_size=0,
keep_details=True,
)
# Tell DSPy that the 'question' field is the input. Any other fields are labels and/or metadata.
trainset = [x.without("id", "type").with_inputs("question") for x in dataset.train]
devset = [x.without("id", "type").with_inputs("question") for x in dataset.dev]
valset, devset = devset[:50], devset[50:]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/datasets/table.py:1421: FutureWarning: promote has been superseded by mode='default'.
table = cls._concat_blocks(blocks, axis=0)
Define a metic
We now need to define a metric. This will be used to determine which runs were successful and we can learn from. Here we will use DSPy’s metrics, though you can write your own.
# Define the signature for autoamtic assessments.
class Assess(dspy.Signature):
"""Assess the quality of a tweet along the specified dimension."""
context = dspy.InputField(desc="ignore if N/A")
assessed_text = dspy.InputField()
assessment_question = dspy.InputField()
assessment_answer = dspy.OutputField(desc="Yes or No")
gpt4T = dspy.OpenAI(model="gpt-4-1106-preview", max_tokens=1000, model_type="chat")
METRIC = None
def metric(gold, pred, trace=None):
question, answer, tweet = gold.question, gold.answer, pred.output
context = colbertv2(question, k=5)
engaging = "Does the assessed text make for a self-contained, engaging tweet?"
faithful = "Is the assessed text grounded in the context? Say no if it includes significant facts not in the context."
correct = (
f"The text above is should answer `{question}`. The gold answer is `{answer}`."
)
correct = f"{correct} Does the assessed text above contain the gold answer?"
with dspy.context(lm=gpt4T):
faithful = dspy.Predict(Assess)(
context=context, assessed_text=tweet, assessment_question=faithful
)
correct = dspy.Predict(Assess)(
context="N/A", assessed_text=tweet, assessment_question=correct
)
engaging = dspy.Predict(Assess)(
context="N/A", assessed_text=tweet, assessment_question=engaging
)
correct, engaging, faithful = [
m.assessment_answer.split()[0].lower() == "yes"
for m in [correct, engaging, faithful]
]
score = (correct + engaging + faithful) if correct and (len(tweet) <= 280) else 0
if METRIC is not None:
if METRIC == "correct":
return correct
if METRIC == "engaging":
return engaging
if METRIC == "faithful":
return faithful
if trace is not None:
return score >= 3
return score / 3.0
Evaluate Baseline
Okay, let’s evaluate the unoptimized “zero-shot” version of our chain, converted from our LangChain LCEL object.
from dspy.evaluate.evaluate import Evaluate
evaluate = Evaluate(
metric=metric, devset=devset, num_threads=8, display_progress=True, display_table=5
)
evaluate(zeroshot_chain)
Average Metric: 62.99999999999998 / 150 (42.0): 100%|██| 150/150 [01:14<00:00, 2.02it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
Average Metric: 62.99999999999998 / 150 (42.0%)
questionanswergold_titlesoutputtweet_responsemetric
0 Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars? Brian Virtue {'Thirty Seconds to Mars', 'Levolution (album)'} Brian Virtue, who has worked with bands like Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue... Brian Virtue, who has worked with bands like Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue... 1.0
1 Are both the University of Chicago and Syracuse University public universities? no {'Syracuse University', 'University of Chicago'} No, only Syracuse University is a public university. The University of Chicago is a private research university. #university #publicvsprivate No, only Syracuse University is a public university. The University of Chicago is a private research university. #university #publicvsprivate 0.3333333333333333
2 In what region was Eddy Mazzoleni born? Lombardy, northern Italy {'Eddy Mazzoleni', 'Bergamo'} Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy Eddy Mazzoleni, born in Bergamo, Italy, is a professional road cyclist who rode for UCI ProTour Astana Team. #cyclist #Italy 0.0
3 Who edited the 1990 American romantic comedy film directed by Garry Marshall? Raja Raymond Gosnell {'Raja Gosnell', 'Pretty Woman'} J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 American romantic comedy film directed by Garry Marshall. #PrettyWoman #GarryMarshall #JFLawton J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 American romantic comedy film directed by Garry Marshall. #PrettyWoman #GarryMarshall #JFLawton 0.0
4 Burrs Country Park railway station is what stop on the railway line that runs between Heywood and Rawtenstall seventh {'Burrs Country Park railway station', 'East Lancashire Railway'} Burrs Country Park railway station is the seventh stop on the East Lancashire Railway line that runs between Heywood and Rawtenstall. Burrs Country Park railway station is the seventh stop on the East Lancashire Railway line that runs between Heywood and Rawtenstall. 1.0
... 145 more rows not displayed ...
Okay, cool. Our zeroshot_chain gets about 42.00% on the 150 questions from the devset.
The table above shows some examples. For instance:
Question: Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars?
Tweet: Brian Virtue, who has worked with bands like Jane’s Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars, showcasing… [truncated]
Metric: 1.0 (A tweet that is correct, faithful, and engaging!*)
footnote: * At least according to our metric, which is just a DSPy program, so it too can be optimized if you’d like! Topic for another notebook, though.
Optimize
Now, let’s optimize performance
from dspy.teleprompt import BootstrapFewShotWithRandomSearch
# Set up the optimizer. We'll use very minimal hyperparameters for this example.
# Just do random search with ~3 attempts, and in each attempt, bootstrap <= 3 traces.
optimizer = BootstrapFewShotWithRandomSearch(
metric=metric, max_bootstrapped_demos=3, num_candidate_programs=3
)
# Now use the optimizer to *compile* the chain. This could take 5-10 minutes, unless it's cached.
optimized_chain = optimizer.compile(zeroshot_chain, trainset=trainset, valset=valset)
Going to sample between 1 and 3 traces per predictor.
Will attempt to train 3 candidate sets.
Average Metric: 22.33333333333334 / 50 (44.7%)
Score: 44.67 for set: [0]
New best score: 44.67 for seed -3
Scores so far: [44.67]
Best score: 44.67
Average Metric: 22.33333333333334 / 50 (44.7%)
Score: 44.67 for set: [16]
Scores so far: [44.67, 44.67]
Best score: 44.67
Bootstrapped 3 full traces after 9 examples in round 0.
Average Metric: 24.666666666666668 / 50 (49.3%)
Score: 49.33 for set: [16]
New best score: 49.33 for seed -1
Scores so far: [44.67, 44.67, 49.33]
Best score: 49.33
Average of max per entry across top 1 scores: 0.49333333333333335
Average of max per entry across top 2 scores: 0.5533333333333335
Average of max per entry across top 3 scores: 0.5533333333333335
Average of max per entry across top 5 scores: 0.5533333333333335
Average of max per entry across top 8 scores: 0.5533333333333335
Average of max per entry across top 9999 scores: 0.5533333333333335
Bootstrapped 2 full traces after 13 examples in round 0.
Average Metric: 25.66666666666667 / 50 (51.3%)
Score: 51.33 for set: [16]
New best score: 51.33 for seed 0
Scores so far: [44.67, 44.67, 49.33, 51.33]
Best score: 51.33
Average of max per entry across top 1 scores: 0.5133333333333334
Average of max per entry across top 2 scores: 0.5666666666666668
Average of max per entry across top 3 scores: 0.6000000000000001
Average of max per entry across top 5 scores: 0.6000000000000001
Average of max per entry across top 8 scores: 0.6000000000000001
Average of max per entry across top 9999 scores: 0.6000000000000001
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 26.33333333333334 / 50 (52.7%)
Score: 52.67 for set: [16]
New best score: 52.67 for seed 1
Scores so far: [44.67, 44.67, 49.33, 51.33, 52.67]
Best score: 52.67
Average of max per entry across top 1 scores: 0.5266666666666667
Average of max per entry across top 2 scores: 0.56
Average of max per entry across top 3 scores: 0.5666666666666668
Average of max per entry across top 5 scores: 0.6000000000000001
Average of max per entry across top 8 scores: 0.6000000000000001
Average of max per entry across top 9999 scores: 0.6000000000000001
Bootstrapped 1 full traces after 2 examples in round 0.
Average Metric: 25.666666666666668 / 50 (51.3%)
Score: 51.33 for set: [16]
Scores so far: [44.67, 44.67, 49.33, 51.33, 52.67, 51.33]
Best score: 52.67
Average of max per entry across top 1 scores: 0.5266666666666667
Average of max per entry across top 2 scores: 0.56
Average of max per entry across top 3 scores: 0.6000000000000001
Average of max per entry across top 5 scores: 0.6133333333333334
Average of max per entry across top 8 scores: 0.6133333333333334
Average of max per entry across top 9999 scores: 0.6133333333333334
6 candidate programs found.
Average Metric: 22.33333333333334 / 50 (44.7): 100%|█████| 50/50 [00:26<00:00, 1.87it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
Average Metric: 22.33333333333334 / 50 (44.7): 100%|█████| 50/50 [00:00<00:00, 79.51it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
4%|██ | 8/200 [00:33<13:21, 4.18s/it]
Average Metric: 24.666666666666668 / 50 (49.3): 100%|████| 50/50 [00:28<00:00, 1.77it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
6%|███ | 12/200 [00:31<08:16, 2.64s/it]
Average Metric: 25.66666666666667 / 50 (51.3): 100%|█████| 50/50 [00:25<00:00, 1.92it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
0%|▎ | 1/200 [00:02<08:37, 2.60s/it]
Average Metric: 26.33333333333334 / 50 (52.7): 100%|█████| 50/50 [00:23<00:00, 2.11it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
0%|▎ | 1/200 [00:02<07:11, 2.17s/it]
Average Metric: 25.666666666666668 / 50 (51.3): 100%|████| 50/50 [00:21<00:00, 2.29it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
Evaluating the optimized chain
Well, how good is this? Let’s do some proper evals!
evaluate(optimized_chain)
Average Metric: 74.66666666666666 / 150 (49.8): 100%|██| 150/150 [00:54<00:00, 2.74it/s]
/Users/harrisonchase/.pyenv/versions/3.11.1/envs/langchain-3-11/lib/python3.11/site-packages/dspy/evaluate/evaluate.py:126: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
df = df.applymap(truncate_cell)
Average Metric: 74.66666666666666 / 150 (49.8%)
questionanswergold_titlesoutputtweet_responsemetric
0 Who was a producer who produced albums for both rock bands Juke Karten and Thirty Seconds to Mars? Brian Virtue {'Thirty Seconds to Mars', 'Levolution (album)'} Brian Virtue, known for his work with Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue #Producer... Brian Virtue, known for his work with Jane's Addiction and Velvet Revolver, produced albums for both Juke Kartel and Thirty Seconds to Mars. #BrianVirtue #Producer... 1.0
1 Are both the University of Chicago and Syracuse University public universities? no {'Syracuse University', 'University of Chicago'} No, only Northeastern Illinois University is a public state university. Syracuse University is a private research university. #University #PublicPrivate #HigherEd No, only Northeastern Illinois University is a public state university. Syracuse University is a private research university. #University #PublicPrivate #HigherEd 0.0
2 In what region was Eddy Mazzoleni born? Lombardy, northern Italy {'Eddy Mazzoleni', 'Bergamo'} Eddy Mazzoleni, the Italian professional road cyclist, was born in Bergamo, Italy. #EddyMazzoleni #Cycling #Italy Eddy Mazzoleni, the Italian professional road cyclist, was born in Bergamo, Italy. #EddyMazzoleni #Cycling #Italy 0.0
3 Who edited the 1990 American romantic comedy film directed by Garry Marshall? Raja Raymond Gosnell {'Raja Gosnell', 'Pretty Woman'} J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 romantic comedy directed by Garry Marshall. #PrettyWoman #GarryMarshall #RomanticComedy J. F. Lawton wrote the screenplay for Pretty Woman, the 1990 romantic comedy directed by Garry Marshall. #PrettyWoman #GarryMarshall #RomanticComedy 0.0
4 Burrs Country Park railway station is what stop on the railway line that runs between Heywood and Rawtenstall seventh {'Burrs Country Park railway station', 'East Lancashire Railway'} Burrs Country Park railway station is the seventh stop on the East Lancashire Railway, which runs between Heywood and Rawtenstall. #EastLancashireRailway #BurrsCountryPark #RailwayStation Burrs Country Park railway station is the seventh stop on the East Lancashire Railway, which runs between Heywood and Rawtenstall. #EastLancashireRailway #BurrsCountryPark #RailwayStation 1.0
... 145 more rows not displayed ...
Alright! We’ve improved our chain from 42% to nearly 50%!
Inspect the optimized chain
So what actually happened to improve this? We can take a look at this by looking at the optimized chain. We can do this in two ways
Look at the prompt used
We can look at what prompt was actually used. We can do this by looking at dspy.settings.
prompt_used, output = dspy.settings.langchain_history[-1]
Essential Instructions: Respond to the provided question based on the given context in the style of a tweet, ensuring the response is concise and within the character limit of a tweet (up to 280 characters).
---
Follow the following format.
Context: ${context}
Question: ${question}
Tweet Response: ${tweet_response}
---
Context:
[1] «Brutus (Funny Car) | Brutus is a pioneering funny car driven by Jim Liberman and prepared by crew chief Lew Arrington in the middle 1960s.»
[2] «USS Brutus (AC-15) | USS "Brutus", formerly the steamer "Peter Jebsen", was a collier in the United States Navy. She was built in 1894 at South Shields-on-Tyne, England, by John Readhead & Sons and was acquired by the U.S. Navy early in 1898 from L. F. Chapman & Company. She was renamed "Brutus" and commissioned at the Mare Island Navy Yard on 27 May 1898, with Lieutenant Vincendon L. Cottman, commanding officer and Lieutenant Randolph H. Miner, executive officer.»
[3] «Brutus Beefcake | Ed Leslie is an American semi-retired professional wrestler, best known for his work in the World Wrestling Federation (WWF) under the ring name Brutus "The Barber" Beefcake. He later worked for World Championship Wrestling (WCW) under a variety of names.»
[4] «Brutus Hamilton | Brutus Kerr Hamilton (July 19, 1900 – December 28, 1970) was an American track and field athlete, coach and athletics administrator.»
[5] «Big Brutus | Big Brutus is the nickname of the Bucyrus-Erie model 1850B electric shovel, which was the second largest of its type in operation in the 1960s and 1970s. Big Brutus is the centerpiece of a mining museum in West Mineral, Kansas where it was used in coal strip mining operations. The shovel was designed to dig from 20 to in relatively shallow coal seams.»
Question: What is the nickname for this United States drag racer who drove Brutus?
Tweet Response: Jim Liberman, also known as "Jungle Jim", drove the pioneering funny car Brutus in the 1960s. #Brutus #FunnyCar #DragRacing
---
Context:
[1] «Philip Markoff | Philip Haynes Markoff (February 12, 1986 – August 15, 2010) was an American medical student who was charged with the armed robbery and murder of Julissa Brisman in a Boston, Massachusetts, hotel on April 14, 2009, and two other armed robberies.»
[2] «Antonia Brenner | Antonia Brenner, better known as Mother Antonia (Spanish: Madre Antonia ), (December 1, 1926 – October 17, 2013) was an American Roman Catholic Religious Sister and activist who chose to reside and care for inmates at the notorious maximum-security La Mesa Prison in Tijuana, Mexico. As a result of her work, she founded a new religious institute called the Eudist Servants of the 11th Hour.»
[3] «Luzira Maximum Security Prison | Luzira Maximum Security Prison is a maximum security prison for both men and women in Uganda. As at July 2016, it is the only maximum security prison in the country and houses Uganda's death row inmates.»
[4] «Pleasant Valley State Prison | Pleasant Valley State Prison (PVSP) is a 640 acres minimum-to-maximum security state prison in Coalinga, Fresno County, California. The facility has housed convicted murderers Sirhan Sirhan, Erik Menendez, X-Raided, and Hans Reiser, among others.»
[5] «Jon-Adrian Velazquez | Jon-Adrian Velazquez is an inmate in the maximum security Sing-Sing prison in New York who is serving a 25-year sentence after being convicted of the 1998 murder of a retired police officer. His case garnered considerable attention from the media ten years after his conviction, due to a visit and support from Martin Sheen and a long-term investigation by Dateline NBC producer Dan Slepian.»
Question: Which maximum security jail housed the killer of Julissa brisman?
Tweet Response:
Look at the demos
The way this was optimized was that we collected examples (or “demos”) to put in the prompt. We can inspect the optmized_chain to get a sense for what those are.
demos = [
eg
for eg in optimized_chain.modules[0].demos
if hasattr(eg, "augmented") and eg.augmented
]
[Example({'augmented': True, 'question': 'What is the nickname for this United States drag racer who drove Brutus?', 'context': ['Brutus (Funny Car) | Brutus is a pioneering funny car driven by Jim Liberman and prepared by crew chief Lew Arrington in the middle 1960s.', 'USS Brutus (AC-15) | USS "Brutus", formerly the steamer "Peter Jebsen", was a collier in the United States Navy. She was built in 1894 at South Shields-on-Tyne, England, by John Readhead & Sons and was acquired by the U.S. Navy early in 1898 from L. F. Chapman & Company. She was renamed "Brutus" and commissioned at the Mare Island Navy Yard on 27 May 1898, with Lieutenant Vincendon L. Cottman, commanding officer and Lieutenant Randolph H. Miner, executive officer.', 'Brutus Beefcake | Ed Leslie is an American semi-retired professional wrestler, best known for his work in the World Wrestling Federation (WWF) under the ring name Brutus "The Barber" Beefcake. He later worked for World Championship Wrestling (WCW) under a variety of names.', 'Brutus Hamilton | Brutus Kerr Hamilton (July 19, 1900 – December 28, 1970) was an American track and field athlete, coach and athletics administrator.', 'Big Brutus | Big Brutus is the nickname of the Bucyrus-Erie model 1850B electric shovel, which was the second largest of its type in operation in the 1960s and 1970s. Big Brutus is the centerpiece of a mining museum in West Mineral, Kansas where it was used in coal strip mining operations. The shovel was designed to dig from 20 to in relatively shallow coal seams.'], 'tweet_response': ' Jim Liberman, also known as "Jungle Jim", drove the pioneering funny car Brutus in the 1960s. #Brutus #FunnyCar #DragRacing'}) (input_keys=None)] |
https://python.langchain.com/docs/integrations/providers/duckdb/ | First, you need to install `duckdb` python package.
```
from langchain_community.document_loaders import DuckDBLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:21.563Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/duckdb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/duckdb/",
"description": "DuckDB is an in-process SQL OLAP database management system.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4614",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"duckdb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:21 GMT",
"etag": "W/\"a1a881630b88446945302cd2c14a7ef0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::wfnv6-1713753681450-7d606642575d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/duckdb/",
"property": "og:url"
},
{
"content": "DuckDB | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "DuckDB is an in-process SQL OLAP database management system.",
"property": "og:description"
}
],
"title": "DuckDB | 🦜️🔗 LangChain"
} | First, you need to install duckdb python package.
from langchain_community.document_loaders import DuckDBLoader |
https://python.langchain.com/docs/integrations/providers/ibm/ | ## IBM
The `LangChain` integrations related to [IBM watsonx.ai](https://www.ibm.com/products/watsonx-ai) platform.
IBM® watsonx.ai™ AI studio is part of the IBM [watsonx](https://www.ibm.com/watsonx)™ AI and data platform, bringing together new generative AI capabilities powered by [foundation models](https://www.ibm.com/products/watsonx-ai/foundation-models) and traditional machine learning (ML) into a powerful studio spanning the AI lifecycle. Tune and guide models with your enterprise data to meet your needs with easy-to-use tools for building and refining performant prompts. With watsonx.ai, you can build AI applications in a fraction of the time and with a fraction of the data. Watsonx.ai offers:
* **Multi-model variety and flexibility:** Choose from IBM-developed, open-source and third-party models, or build your own model.
* **Differentiated client protection:** IBM stands behind IBM-developed models and indemnifies the client against third-party IP claims.
* **End-to-end AI governance:** Enterprises can scale and accelerate the impact of AI with trusted data across the business, using data wherever it resides.
* **Hybrid, multi-cloud deployments:** IBM provides the flexibility to integrate and deploy your AI workloads into your hybrid-cloud stack of choice.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Install the integration package with
```
pip install -qU langchain-ibm
```
Get an IBM watsonx.ai api key and set it as an environment variable (`WATSONX_APIKEY`)
```
import osos.environ["WATSONX_APIKEY"] = "your IBM watsonx.ai api key"
```
## LLMs[](#llms "Direct link to LLMs")
### WatsonxLLM[](#watsonxllm "Direct link to WatsonxLLM")
See a [usage example](https://python.langchain.com/docs/integrations/llms/ibm_watsonx/).
```
from langchain_ibm import WatsonxLLM
```
## Embedding Models[](#embedding-models "Direct link to Embedding Models")
### WatsonxEmbeddings[](#watsonxembeddings "Direct link to WatsonxEmbeddings")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/ibm_watsonx/).
```
from langchain_ibm import WatsonxEmbeddings
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:22.194Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/ibm/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/ibm/",
"description": "The LangChain integrations related to IBM watsonx.ai platform.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "5914",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"ibm\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:22 GMT",
"etag": "W/\"6bbb702eae46242963347dfab85befb2\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::t5v7f-1713753682109-aec129180be2"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/ibm/",
"property": "og:url"
},
{
"content": "IBM | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "The LangChain integrations related to IBM watsonx.ai platform.",
"property": "og:description"
}
],
"title": "IBM | 🦜️🔗 LangChain"
} | IBM
The LangChain integrations related to IBM watsonx.ai platform.
IBM® watsonx.ai™ AI studio is part of the IBM watsonx™ AI and data platform, bringing together new generative AI capabilities powered by foundation models and traditional machine learning (ML) into a powerful studio spanning the AI lifecycle. Tune and guide models with your enterprise data to meet your needs with easy-to-use tools for building and refining performant prompts. With watsonx.ai, you can build AI applications in a fraction of the time and with a fraction of the data. Watsonx.ai offers:
Multi-model variety and flexibility: Choose from IBM-developed, open-source and third-party models, or build your own model.
Differentiated client protection: IBM stands behind IBM-developed models and indemnifies the client against third-party IP claims.
End-to-end AI governance: Enterprises can scale and accelerate the impact of AI with trusted data across the business, using data wherever it resides.
Hybrid, multi-cloud deployments: IBM provides the flexibility to integrate and deploy your AI workloads into your hybrid-cloud stack of choice.
Installation and Setup
Install the integration package with
pip install -qU langchain-ibm
Get an IBM watsonx.ai api key and set it as an environment variable (WATSONX_APIKEY)
import os
os.environ["WATSONX_APIKEY"] = "your IBM watsonx.ai api key"
LLMs
WatsonxLLM
See a usage example.
from langchain_ibm import WatsonxLLM
Embedding Models
WatsonxEmbeddings
See a usage example.
from langchain_ibm import WatsonxEmbeddings |
https://python.langchain.com/docs/integrations/providers/ifixit/ | ## iFixit
> [iFixit](https://www.ifixit.com/) is the largest, open repair community on the web. The site contains nearly 100k repair manuals, 200k Questions & Answers on 42k devices, and all the data is licensed under `CC-BY-NC-SA 3.0`.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
There isn't any special setup for it.
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/ifixit/).
```
from langchain_community.document_loaders import IFixitLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:22.885Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/ifixit/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/ifixit/",
"description": "iFixit is the largest, open repair community on the web. The site contains nearly 100k",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"ifixit\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:22 GMT",
"etag": "W/\"b3bd6db20c46994a94479a4a66564c1b\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::56wnp-1713753682717-11ec30a5abb4"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/ifixit/",
"property": "og:url"
},
{
"content": "iFixit | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "iFixit is the largest, open repair community on the web. The site contains nearly 100k",
"property": "og:description"
}
],
"title": "iFixit | 🦜️🔗 LangChain"
} | iFixit
iFixit is the largest, open repair community on the web. The site contains nearly 100k repair manuals, 200k Questions & Answers on 42k devices, and all the data is licensed under CC-BY-NC-SA 3.0.
Installation and Setup
There isn't any special setup for it.
Document Loader
See a usage example.
from langchain_community.document_loaders import IFixitLoader |
https://python.langchain.com/docs/integrations/providers/exa_search/ | Exa’s search integration exists in its own [partner package](https://pypi.org/project/langchain-exa/). You can install it with:
```
%pip install -qU langchain-exa
```
In order to use the package, you will also need to set the `EXA_API_KEY` environment variable to your Exa API key.
You can use the [`ExaSearchRetriever`](https://python.langchain.com/docs/integrations/tools/exa_search/#using-exasearchretriever) in a standard retrieval pipeline. You can import it as follows | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.003Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/exa_search/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/exa_search/",
"description": "Exa’s search integration exists in its own [partner",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"exa_search\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:23 GMT",
"etag": "W/\"2d480b1bf8d56e7c1b5a2577049e6e9a\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::jsr5b-1713753683853-388c90854742"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/exa_search/",
"property": "og:url"
},
{
"content": "Exa Search | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Exa’s search integration exists in its own [partner",
"property": "og:description"
}
],
"title": "Exa Search | 🦜️🔗 LangChain"
} | Exa’s search integration exists in its own partner package. You can install it with:
%pip install -qU langchain-exa
In order to use the package, you will also need to set the EXA_API_KEY environment variable to your Exa API key.
You can use the ExaSearchRetriever in a standard retrieval pipeline. You can import it as follows |
https://python.langchain.com/docs/integrations/providers/infinispanvs/ | See [Get Started](https://infinispan.org/get-started/) to run an Infinispan server, you may want to disable authentication (not supported atm)
```
from langchain_community.vectorstores import InfinispanVS
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.038Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/infinispanvs/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/infinispanvs/",
"description": "Infinispan Infinispan is an open-source in-memory data grid that provides",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3549",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"infinispanvs\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:23 GMT",
"etag": "W/\"3871f2212444e3ac645bc8f26c6891a0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::kt9bz-1713753683931-5956e89142ba"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/infinispanvs/",
"property": "og:url"
},
{
"content": "Infinispan VS | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Infinispan Infinispan is an open-source in-memory data grid that provides",
"property": "og:description"
}
],
"title": "Infinispan VS | 🦜️🔗 LangChain"
} | See Get Started to run an Infinispan server, you may want to disable authentication (not supported atm)
from langchain_community.vectorstores import InfinispanVS |
https://python.langchain.com/docs/integrations/providers/edenai/ | ## Eden AI
> [Eden AI](https://docs.edenai.co/docs/getting-started-with-eden-ai) user interface (UI) is designed for handling the AI projects. With `Eden AI Portal`, you can perform no-code AI using the best engines for the market.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Accessing the Eden AI API requires an API key, which you can get by [creating an account](https://app.edenai.run/user/register) and heading [here](https://app.edenai.run/admin/account/settings).
## LLMs[](#llms "Direct link to LLMs")
See a [usage example](https://python.langchain.com/docs/integrations/llms/edenai/).
```
from langchain_community.llms import EdenAI
```
## Chat models[](#chat-models "Direct link to Chat models")
See a [usage example](https://python.langchain.com/docs/integrations/chat/edenai/).
```
from langchain_community.chat_models.edenai import ChatEdenAI
```
## Embedding models[](#embedding-models "Direct link to Embedding models")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/edenai/).
```
from langchain_community.embeddings.edenai import EdenAiEmbeddings
```
Eden AI provides a list of tools that grants your Agent the ability to do multiple tasks, such as:
* speech to text
* text to speech
* text explicit content detection
* image explicit content detection
* object detection
* OCR invoice parsing
* OCR ID parsing
See a [usage example](https://python.langchain.com/docs/integrations/tools/edenai_tools/).
```
from langchain_community.tools.edenai import ( EdenAiExplicitImageTool, EdenAiObjectDetectionTool, EdenAiParsingIDTool, EdenAiParsingInvoiceTool, EdenAiSpeechToTextTool, EdenAiTextModerationTool, EdenAiTextToSpeechTool,)
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.267Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/edenai/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/edenai/",
"description": "Eden AI user interface (UI)",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4121",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"edenai\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:23 GMT",
"etag": "W/\"7a971f7aee413ca1ecfec9ca7169f7bb\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::rrvbb-1713753683806-6e7376d0c347"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/edenai/",
"property": "og:url"
},
{
"content": "Eden AI | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Eden AI user interface (UI)",
"property": "og:description"
}
],
"title": "Eden AI | 🦜️🔗 LangChain"
} | Eden AI
Eden AI user interface (UI) is designed for handling the AI projects. With Eden AI Portal, you can perform no-code AI using the best engines for the market.
Installation and Setup
Accessing the Eden AI API requires an API key, which you can get by creating an account and heading here.
LLMs
See a usage example.
from langchain_community.llms import EdenAI
Chat models
See a usage example.
from langchain_community.chat_models.edenai import ChatEdenAI
Embedding models
See a usage example.
from langchain_community.embeddings.edenai import EdenAiEmbeddings
Eden AI provides a list of tools that grants your Agent the ability to do multiple tasks, such as:
speech to text
text to speech
text explicit content detection
image explicit content detection
object detection
OCR invoice parsing
OCR ID parsing
See a usage example.
from langchain_community.tools.edenai import (
EdenAiExplicitImageTool,
EdenAiObjectDetectionTool,
EdenAiParsingIDTool,
EdenAiParsingInvoiceTool,
EdenAiSpeechToTextTool,
EdenAiTextModerationTool,
EdenAiTextToSpeechTool,
)
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/facebook/ | ## Facebook - Meta
> [Meta Platforms, Inc.](https://www.facebook.com/), doing business as `Meta`, formerly named `Facebook, Inc.`, and `TheFacebook, Inc.`, is an American multinational technology conglomerate. The company owns and operates `Facebook`, `Instagram`, `Threads`, and `WhatsApp`, among other products and services.
## Embedding models[](#embedding-models "Direct link to Embedding models")
### LASER[](#laser "Direct link to LASER")
> [LASER](https://github.com/facebookresearch/LASER) is a Python library developed by the `Meta AI Research` team and used for creating multilingual sentence embeddings for [over 147 languages as of 2/25/2024](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
```
pip install laser_encoders
```
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/laser/).
```
from langchain_community.embeddings.laser import LaserEmbeddings
```
## Document loaders[](#document-loaders "Direct link to Document loaders")
### Facebook Messenger[](#facebook-messenger "Direct link to Facebook Messenger")
> [Messenger](https://en.wikipedia.org/wiki/Messenger_(software)) is an instant messaging app and platform developed by `Meta Platforms`. Originally developed as `Facebook Chat` in 2008, the company revamped its messaging service in 2010.
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/facebook_chat/).
```
from langchain_community.document_loaders import FacebookChatLoader
```
## Vector stores[](#vector-stores "Direct link to Vector stores")
### Facebook Faiss[](#facebook-faiss "Direct link to Facebook Faiss")
> [Facebook AI Similarity Search (Faiss)](https://engineering.fb.com/2017/03/29/data-infrastructure/faiss-a-library-for-efficient-similarity-search/) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
[Faiss documentation](https://faiss.ai/).
We need to install `faiss` python package.
```
pip install faiss-gpu # For CUDA 7.5+ supported GPU's.
```
OR
```
pip install faiss-cpu # For CPU Installation
```
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/faiss/).
```
from langchain_community.vectorstores import FAISS
```
## Chat loaders[](#chat-loaders "Direct link to Chat loaders")
### Facebook Messenger[](#facebook-messenger-1 "Direct link to Facebook Messenger")
> [Messenger](https://en.wikipedia.org/wiki/Messenger_(software)) is an instant messaging app and platform developed by `Meta Platforms`. Originally developed as `Facebook Chat` in 2008, the company revamped its messaging service in 2010.
See a [usage example](https://python.langchain.com/docs/integrations/chat_loaders/facebook/).
```
from langchain_community.chat_loaders.facebook_messenger import ( FolderFacebookMessengerChatLoader, SingleFileFacebookMessengerChatLoader,)
```
### Facebook WhatsApp[](#facebook-whatsapp "Direct link to Facebook WhatsApp")
See a [usage example](https://python.langchain.com/docs/integrations/chat_loaders/whatsapp/).
```
from langchain_community.chat_loaders.whatsapp import WhatsAppChatLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.503Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/facebook/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/facebook/",
"description": "Meta Platforms, Inc., doing business as Meta, formerly",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"facebook\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"535a9ad8f5e5147c715b539b84fd25dc\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::b8755-1713753683911-d3a97f36453f"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/facebook/",
"property": "og:url"
},
{
"content": "Facebook - Meta | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Meta Platforms, Inc., doing business as Meta, formerly",
"property": "og:description"
}
],
"title": "Facebook - Meta | 🦜️🔗 LangChain"
} | Facebook - Meta
Meta Platforms, Inc., doing business as Meta, formerly named Facebook, Inc., and TheFacebook, Inc., is an American multinational technology conglomerate. The company owns and operates Facebook, Instagram, Threads, and WhatsApp, among other products and services.
Embedding models
LASER
LASER is a Python library developed by the Meta AI Research team and used for creating multilingual sentence embeddings for over 147 languages as of 2/25/2024
pip install laser_encoders
See a usage example.
from langchain_community.embeddings.laser import LaserEmbeddings
Document loaders
Facebook Messenger
Messenger is an instant messaging app and platform developed by Meta Platforms. Originally developed as Facebook Chat in 2008, the company revamped its messaging service in 2010.
See a usage example.
from langchain_community.document_loaders import FacebookChatLoader
Vector stores
Facebook Faiss
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM. It also contains supporting code for evaluation and parameter tuning.
Faiss documentation.
We need to install faiss python package.
pip install faiss-gpu # For CUDA 7.5+ supported GPU's.
OR
pip install faiss-cpu # For CPU Installation
See a usage example.
from langchain_community.vectorstores import FAISS
Chat loaders
Facebook Messenger
Messenger is an instant messaging app and platform developed by Meta Platforms. Originally developed as Facebook Chat in 2008, the company revamped its messaging service in 2010.
See a usage example.
from langchain_community.chat_loaders.facebook_messenger import (
FolderFacebookMessengerChatLoader,
SingleFileFacebookMessengerChatLoader,
)
Facebook WhatsApp
See a usage example.
from langchain_community.chat_loaders.whatsapp import WhatsAppChatLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/evernote/ | [EverNote](https://evernote.com/) is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual "notebooks" and can be tagged, annotated, edited, searched, and exported.
First, you need to install `lxml` and `html2text` python packages.
```
pip install lxmlpip install html2text
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.735Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/evernote/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/evernote/",
"description": "EverNote is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual \"notebooks\" and can be tagged, annotated, edited, searched, and exported.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"evernote\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"0384c1a67c91a39de2735ea5bd079dfa\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::tghr7-1713753683939-55c02a0f233d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/evernote/",
"property": "og:url"
},
{
"content": "EverNote | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "EverNote is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual \"notebooks\" and can be tagged, annotated, edited, searched, and exported.",
"property": "og:description"
}
],
"title": "EverNote | 🦜️🔗 LangChain"
} | EverNote is intended for archiving and creating notes in which photos, audio and saved web content can be embedded. Notes are stored in virtual "notebooks" and can be tagged, annotated, edited, searched, and exported.
First, you need to install lxml and html2text python packages.
pip install lxml
pip install html2text |
https://python.langchain.com/docs/integrations/providers/elevenlabs/ | [ElevenLabs](https://elevenlabs.io/about) is a voice AI research & deployment company with a mission to make content universally accessible in any language & voice.
`ElevenLabs` creates the most realistic, versatile and contextually-aware AI audio, providing the ability to generate speech in hundreds of new and existing voices in 29 languages.
First, you need to set up an ElevenLabs account. You can follow the [instructions here](https://docs.elevenlabs.io/welcome/introduction).
```
from langchain_community.tools import ElevenLabsText2SpeechTool
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.789Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/elevenlabs/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/elevenlabs/",
"description": "ElevenLabs is a voice AI research & deployment company",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "0",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"elevenlabs\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"a7d6d5f0d7d5fabaae84625990b28b71\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::nps6w-1713753683899-ec18bdfa3b9b"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/elevenlabs/",
"property": "og:url"
},
{
"content": "ElevenLabs | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "ElevenLabs is a voice AI research & deployment company",
"property": "og:description"
}
],
"title": "ElevenLabs | 🦜️🔗 LangChain"
} | ElevenLabs is a voice AI research & deployment company with a mission to make content universally accessible in any language & voice.
ElevenLabs creates the most realistic, versatile and contextually-aware AI audio, providing the ability to generate speech in hundreds of new and existing voices in 29 languages.
First, you need to set up an ElevenLabs account. You can follow the instructions here.
from langchain_community.tools import ElevenLabsText2SpeechTool |
https://python.langchain.com/docs/integrations/providers/epsilla/ | This page covers how to use [Epsilla](https://github.com/epsilla-cloud/vectordb) within LangChain. It is broken into two parts: installation and setup, and then references to specific Epsilla wrappers.
There exists a wrapper around Epsilla vector databases, allowing you to use it as a vectorstore, whether for semantic search or example selection.
```
from langchain_community.vectorstores import Epsilla
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.827Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/epsilla/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/epsilla/",
"description": "This page covers how to use Epsilla within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4617",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"epsilla\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"0276540b900275f58e92fdde76c8eada\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::xvkrm-1713753684127-8bbbd97ccde4"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/epsilla/",
"property": "og:url"
},
{
"content": "Epsilla | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use Epsilla within LangChain.",
"property": "og:description"
}
],
"title": "Epsilla | 🦜️🔗 LangChain"
} | This page covers how to use Epsilla within LangChain. It is broken into two parts: installation and setup, and then references to specific Epsilla wrappers.
There exists a wrapper around Epsilla vector databases, allowing you to use it as a vectorstore, whether for semantic search or example selection.
from langchain_community.vectorstores import Epsilla |
https://python.langchain.com/docs/integrations/providers/elasticsearch/ | ## Elasticsearch
> [Elasticsearch](https://www.elastic.co/elasticsearch/) is a distributed, RESTful search and analytics engine. It provides a distributed, multi-tenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
There are two ways to get started with Elasticsearch:
#### Install Elasticsearch on your local machine via docker[](#install-elasticsearch-on-your-local-machine-via-docker "Direct link to Install Elasticsearch on your local machine via docker")
Example: Run a single-node Elasticsearch instance with security disabled. This is not recommended for production use.
```
docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.9.0
```
#### Deploy Elasticsearch on Elastic Cloud[](#deploy-elasticsearch-on-elastic-cloud "Direct link to Deploy Elasticsearch on Elastic Cloud")
Elastic Cloud is a managed Elasticsearch service. Signup for a [free trial](https://cloud.elastic.co/registration?utm_source=langchain&utm_content=documentation).
### Install Client[](#install-client "Direct link to Install Client")
```
pip install elasticsearchpip install langchain-elasticsearch
```
## Embedding models[](#embedding-models "Direct link to Embedding models")
See a [usage example](https://python.langchain.com/docs/integrations/text_embedding/elasticsearch/).
```
from langchain_elasticsearch.embeddings import ElasticsearchEmbeddings
```
## Vector store[](#vector-store "Direct link to Vector store")
See a [usage example](https://python.langchain.com/docs/integrations/vectorstores/elasticsearch/).
```
from langchain_elasticsearch.vectorstores import ElasticsearchStore
```
## Memory[](#memory "Direct link to Memory")
See a [usage example](https://python.langchain.com/docs/integrations/memory/elasticsearch_chat_message_history/).
```
from langchain_elasticsearch.chat_history import ElasticsearchChatMessageHistory
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.969Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/elasticsearch/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/elasticsearch/",
"description": "Elasticsearch is a distributed, RESTful search and analytics engine.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4685",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"elasticsearch\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"67985f5016180dbe75594c4a8fa8ff8c\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::fc95f-1713753684126-5b75d16bcee4"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/elasticsearch/",
"property": "og:url"
},
{
"content": "Elasticsearch | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Elasticsearch is a distributed, RESTful search and analytics engine.",
"property": "og:description"
}
],
"title": "Elasticsearch | 🦜️🔗 LangChain"
} | Elasticsearch
Elasticsearch is a distributed, RESTful search and analytics engine. It provides a distributed, multi-tenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
Installation and Setup
There are two ways to get started with Elasticsearch:
Install Elasticsearch on your local machine via docker
Example: Run a single-node Elasticsearch instance with security disabled. This is not recommended for production use.
docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.9.0
Deploy Elasticsearch on Elastic Cloud
Elastic Cloud is a managed Elasticsearch service. Signup for a free trial.
Install Client
pip install elasticsearch
pip install langchain-elasticsearch
Embedding models
See a usage example.
from langchain_elasticsearch.embeddings import ElasticsearchEmbeddings
Vector store
See a usage example.
from langchain_elasticsearch.vectorstores import ElasticsearchStore
Memory
See a usage example.
from langchain_elasticsearch.chat_history import ElasticsearchChatMessageHistory
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/imsdb/ | ## IMSDb
> [IMSDb](https://imsdb.com/) is the `Internet Movie Script Database`.
>
> ## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
There isn't any special setup for it.
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/imsdb/).
```
from langchain_community.document_loaders import IMSDbLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:24.906Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/imsdb/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/imsdb/",
"description": "IMSDb is the Internet Movie Script Database.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4609",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"imsdb\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"68b14dc2be5261bbe57dbf3488be6b92\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::hhtvz-1713753684126-c6da2efa8b1d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/imsdb/",
"property": "og:url"
},
{
"content": "IMSDb | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "IMSDb is the Internet Movie Script Database.",
"property": "og:description"
}
],
"title": "IMSDb | 🦜️🔗 LangChain"
} | IMSDb
IMSDb is the Internet Movie Script Database.
Installation and Setup
There isn't any special setup for it.
Document Loader
See a usage example.
from langchain_community.document_loaders import IMSDbLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/etherscan/ | ## Etherscan
> [Etherscan](https://docs.etherscan.io/) is the leading blockchain explorer, search, API and analytics platform for `Ethereum`, a decentralized smart contracts platform.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
See the detailed [installation guide](https://python.langchain.com/docs/integrations/document_loaders/etherscan/).
## Document Loader[](#document-loader "Direct link to Document Loader")
See a [usage example](https://python.langchain.com/docs/integrations/document_loaders/etherscan/).
```
from langchain_community.document_loaders import EtherscanLoader
```
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:25.081Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/etherscan/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/etherscan/",
"description": "Etherscan is the leading blockchain explorer,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "4616",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"etherscan\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:24 GMT",
"etag": "W/\"87469d9584a9aada35640ef8442849c0\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "sfo1::7zjh7-1713753684292-96381791207d"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/etherscan/",
"property": "og:url"
},
{
"content": "Etherscan | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Etherscan is the leading blockchain explorer,",
"property": "og:description"
}
],
"title": "Etherscan | 🦜️🔗 LangChain"
} | Etherscan
Etherscan is the leading blockchain explorer, search, API and analytics platform for Ethereum, a decentralized smart contracts platform.
Installation and Setup
See the detailed installation guide.
Document Loader
See a usage example.
from langchain_community.document_loaders import EtherscanLoader
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/fauna/ | We have to install the `fauna` package.
```
from langchain_community.document_loaders.fauna import FaunaLoader
``` | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:26.254Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/fauna/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/fauna/",
"description": "Fauna is a distributed document-relational database",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3555",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"fauna\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:26 GMT",
"etag": "W/\"c0cc689a61ff56184fbc3fc1b44155ec\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::86l5f-1713753686198-74068ec5f871"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/fauna/",
"property": "og:url"
},
{
"content": "Fauna | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Fauna is a distributed document-relational database",
"property": "og:description"
}
],
"title": "Fauna | 🦜️🔗 LangChain"
} | We have to install the fauna package.
from langchain_community.document_loaders.fauna import FaunaLoader |
https://python.langchain.com/docs/integrations/providers/fiddler/ | ## Fiddler
> [Fiddler](https://www.fiddler.ai/) provides a unified platform to monitor, explain, analyze, and improve ML deployments at an enterprise scale.
## Installation and Setup[](#installation-and-setup "Direct link to Installation and Setup")
Set up your model [with Fiddler](https://demo.fiddler.ai/):
* The URL you're using to connect to Fiddler
* Your organization ID
* Your authorization token
Install the Python package:
```
pip install fiddler-client
```
## Callbacks[](#callbacks "Direct link to Callbacks")
```
from langchain_community.callbacks.fiddler_callback import FiddlerCallbackHandler
```
See an [example](https://python.langchain.com/docs/integrations/callbacks/fiddler/).
* * *
#### Help us out by providing feedback on this documentation page: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:26.500Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/fiddler/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/fiddler/",
"description": "Fiddler provides a unified platform to monitor, explain, analyze,",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3555",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"fiddler\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:26 GMT",
"etag": "W/\"7c33e0b4209702b574e5111c2396556e\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::6tf8x-1713753686328-2b05ece59954"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/fiddler/",
"property": "og:url"
},
{
"content": "Fiddler | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "Fiddler provides a unified platform to monitor, explain, analyze,",
"property": "og:description"
}
],
"title": "Fiddler | 🦜️🔗 LangChain"
} | Fiddler
Fiddler provides a unified platform to monitor, explain, analyze, and improve ML deployments at an enterprise scale.
Installation and Setup
Set up your model with Fiddler:
The URL you're using to connect to Fiddler
Your organization ID
Your authorization token
Install the Python package:
pip install fiddler-client
Callbacks
from langchain_community.callbacks.fiddler_callback import FiddlerCallbackHandler
See an example.
Help us out by providing feedback on this documentation page: |
https://python.langchain.com/docs/integrations/providers/fireworks/ | ## Fireworks
This page covers how to use [Fireworks](https://fireworks.ai/) models within Langchain.
## Installation and setup[](#installation-and-setup "Direct link to Installation and setup")
* Install the Fireworks integration package.
```
pip install langchain-fireworks
```
* Get a Fireworks API key by signing up at [fireworks.ai](https://fireworks.ai/).
* Authenticate by setting the FIREWORKS\_API\_KEY environment variable.
## Authentication[](#authentication "Direct link to Authentication")
There are two ways to authenticate using your Fireworks API key:
1. Setting the `FIREWORKS_API_KEY` environment variable.
```
os.environ["FIREWORKS_API_KEY"] = "<KEY>"
```
2. Setting `api_key` field in the Fireworks LLM module.
```
llm = Fireworks(api_key="<KEY>")
```
## Using the Fireworks LLM module[](#using-the-fireworks-llm-module "Direct link to Using the Fireworks LLM module")
Fireworks integrates with Langchain through the LLM module. In this example, we will work the mixtral-8x7b-instruct model.
```
from langchain_fireworks import Fireworks llm = Fireworks( api_key="<KEY>", model="accounts/fireworks/models/mixtral-8x7b-instruct", max_tokens=256)llm("Name 3 sports.")
```
For a more detailed walkthrough, see [here](https://python.langchain.com/docs/integrations/llms/Fireworks/). | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:26.622Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/fireworks/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/fireworks/",
"description": "This page covers how to use Fireworks models within",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "6073",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"fireworks\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:26 GMT",
"etag": "W/\"a2f0fd816f7a5b34d7c605edc13f43d3\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "iad1::k4rn8-1713753686485-265f25e7bf47"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/fireworks/",
"property": "og:url"
},
{
"content": "Fireworks | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page covers how to use Fireworks models within",
"property": "og:description"
}
],
"title": "Fireworks | 🦜️🔗 LangChain"
} | Fireworks
This page covers how to use Fireworks models within Langchain.
Installation and setup
Install the Fireworks integration package.
pip install langchain-fireworks
Get a Fireworks API key by signing up at fireworks.ai.
Authenticate by setting the FIREWORKS_API_KEY environment variable.
Authentication
There are two ways to authenticate using your Fireworks API key:
Setting the FIREWORKS_API_KEY environment variable.
os.environ["FIREWORKS_API_KEY"] = "<KEY>"
Setting api_key field in the Fireworks LLM module.
llm = Fireworks(api_key="<KEY>")
Using the Fireworks LLM module
Fireworks integrates with Langchain through the LLM module. In this example, we will work the mixtral-8x7b-instruct model.
from langchain_fireworks import Fireworks
llm = Fireworks(
api_key="<KEY>",
model="accounts/fireworks/models/mixtral-8x7b-instruct",
max_tokens=256)
llm("Name 3 sports.")
For a more detailed walkthrough, see here. |
https://python.langchain.com/docs/integrations/providers/jaguar/ | This page describes how to use Jaguar vector database within LangChain. It contains three sections: introduction, installation and setup, and Jaguar API.
You can run JaguarDB in docker container; or download the software and run on-cloud or off-cloud.
```
export OPENAI_API_KEY="......"export JAGUAR_API_KEY="......"
```
Together with LangChain, a Jaguar client class is provided by importing it in Python: | null | {
"depth": 1,
"httpStatusCode": 200,
"loadedTime": "2024-04-22T02:41:27.105Z",
"loadedUrl": "https://python.langchain.com/docs/integrations/providers/jaguar/",
"referrerUrl": "https://python.langchain.com/sitemap.xml"
} | {
"author": null,
"canonicalUrl": "https://python.langchain.com/docs/integrations/providers/jaguar/",
"description": "This page describes how to use Jaguar vector database within LangChain.",
"headers": {
":status": 200,
"accept-ranges": null,
"access-control-allow-origin": "*",
"age": "3551",
"cache-control": "public, max-age=0, must-revalidate",
"content-disposition": "inline; filename=\"jaguar\"",
"content-length": null,
"content-type": "text/html; charset=utf-8",
"date": "Mon, 22 Apr 2024 02:41:26 GMT",
"etag": "W/\"7b741b90d45cf446409a061bb7e1214a\"",
"server": "Vercel",
"strict-transport-security": "max-age=63072000",
"x-vercel-cache": "HIT",
"x-vercel-id": "cle1::tlvfk-1713753686723-e612abd29672"
},
"jsonLd": null,
"keywords": null,
"languageCode": "en",
"openGraph": [
{
"content": "https://python.langchain.com/img/brand/theme-image.png",
"property": "og:image"
},
{
"content": "https://python.langchain.com/docs/integrations/providers/jaguar/",
"property": "og:url"
},
{
"content": "Jaguar | 🦜️🔗 LangChain",
"property": "og:title"
},
{
"content": "This page describes how to use Jaguar vector database within LangChain.",
"property": "og:description"
}
],
"title": "Jaguar | 🦜️🔗 LangChain"
} | This page describes how to use Jaguar vector database within LangChain. It contains three sections: introduction, installation and setup, and Jaguar API.
You can run JaguarDB in docker container; or download the software and run on-cloud or off-cloud.
export OPENAI_API_KEY="......"
export JAGUAR_API_KEY="......"
Together with LangChain, a Jaguar client class is provided by importing it in Python: |