
Upload 693 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- Essay_classifier/.gitignore +168 -0
- Essay_classifier/.idea/.gitignore +3 -0
- Essay_classifier/.idea/Essay_classifier.iml +14 -0
- Essay_classifier/.idea/inspectionProfiles/profiles_settings.xml +6 -0
- Essay_classifier/.idea/misc.xml +4 -0
- Essay_classifier/.idea/modules.xml +8 -0
- Essay_classifier/.idea/vcs.xml +6 -0
- Essay_classifier/.idea/workspace.xml +42 -0
- Essay_classifier/CITATION.cff +14 -0
- Essay_classifier/LICENSE +21 -0
- Essay_classifier/README.md +95 -0
- Essay_classifier/S5.egg-info/PKG-INFO +13 -0
- Essay_classifier/S5.egg-info/SOURCES.txt +7 -0
- Essay_classifier/S5.egg-info/dependency_links.txt +1 -0
- Essay_classifier/S5.egg-info/top_level.txt +1 -0
- Essay_classifier/bin/download_aan.sh +4 -0
- Essay_classifier/bin/download_all.sh +8 -0
- Essay_classifier/bin/download_lra.sh +9 -0
- Essay_classifier/bin/download_sc35.sh +4 -0
- Essay_classifier/bin/python_scripts/download_sc.py +4 -0
- Essay_classifier/bin/run_experiments/run_gpt_classifier.sh +7 -0
- Essay_classifier/bin/run_experiments/run_lra_aan.sh +5 -0
- Essay_classifier/bin/run_experiments/run_lra_cifar.sh +4 -0
- Essay_classifier/bin/run_experiments/run_lra_imdb.sh +7 -0
- Essay_classifier/bin/run_experiments/run_lra_listops.sh +4 -0
- Essay_classifier/bin/run_experiments/run_lra_pathfinder.sh +5 -0
- Essay_classifier/bin/run_experiments/run_lra_pathx.sh +5 -0
- Essay_classifier/bin/run_experiments/run_speech35.sh +4 -0
- Essay_classifier/docs/figures/pdfs/s3-block-diagram-2.pdf +0 -0
- Essay_classifier/docs/figures/pdfs/s4-matrix-blocks.pdf +0 -0
- Essay_classifier/docs/figures/pdfs/s4-s3-block-diagram-2.pdf +0 -0
- Essay_classifier/docs/figures/pdfs/s5-matrix-blocks.pdf +0 -0
- Essay_classifier/docs/figures/pngs/pendulum.png +0 -0
- Essay_classifier/docs/figures/pngs/s3-block-diagram-2.png +0 -0
- Essay_classifier/docs/figures/pngs/s4-matrix-blocks.png +0 -0
- Essay_classifier/docs/figures/pngs/s4-s3-block-diagram-2.png +0 -0
- Essay_classifier/docs/figures/pngs/s5-matrix-blocks.png +0 -0
- Essay_classifier/docs/s5_blog.md +77 -0
- Essay_classifier/essays/dataset_dict.json +1 -0
- Essay_classifier/essays/test/data-00000-of-00001.arrow +3 -0
- Essay_classifier/essays/test/dataset_info.json +20 -0
- Essay_classifier/essays/test/state.json +13 -0
- Essay_classifier/essays/train/data-00000-of-00001.arrow +3 -0
- Essay_classifier/essays/train/dataset_info.json +20 -0
- Essay_classifier/essays/train/state.json +13 -0
- Essay_classifier/requirements_cpu.txt +9 -0
- Essay_classifier/requirements_gpu.txt +9 -0
- Essay_classifier/run_train.py +101 -0
- Essay_classifier/s5/__init__.py +0 -0
- Essay_classifier/s5/dataloaders/README.md +8 -0
Essay_classifier/.gitignore
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
cache_dir/
|
| 13 |
+
develop-eggs/
|
| 14 |
+
dist/
|
| 15 |
+
downloads/
|
| 16 |
+
eggs/
|
| 17 |
+
.eggs/
|
| 18 |
+
lib/
|
| 19 |
+
lib64/
|
| 20 |
+
parts/
|
| 21 |
+
sdist/
|
| 22 |
+
var/
|
| 23 |
+
wandb/
|
| 24 |
+
wheels/
|
| 25 |
+
share/python-wheels/
|
| 26 |
+
*.egg-info/
|
| 27 |
+
.installed.cfg
|
| 28 |
+
*.egg
|
| 29 |
+
MANIFEST
|
| 30 |
+
|
| 31 |
+
# PyInstaller
|
| 32 |
+
# Usually these files are written by a python script from a template
|
| 33 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 34 |
+
*.manifest
|
| 35 |
+
*.spec
|
| 36 |
+
|
| 37 |
+
# Installer logs
|
| 38 |
+
pip-log.txt
|
| 39 |
+
pip-delete-this-directory.txt
|
| 40 |
+
|
| 41 |
+
# Unit test / coverage reports
|
| 42 |
+
htmlcov/
|
| 43 |
+
.tox/
|
| 44 |
+
.nox/
|
| 45 |
+
.coverage
|
| 46 |
+
.coverage.*
|
| 47 |
+
.cache
|
| 48 |
+
nosetests.xml
|
| 49 |
+
coverage.xml
|
| 50 |
+
*.cover
|
| 51 |
+
*.py,cover
|
| 52 |
+
.hypothesis/
|
| 53 |
+
.pytest_cache/
|
| 54 |
+
cover/
|
| 55 |
+
|
| 56 |
+
# Translations
|
| 57 |
+
*.mo
|
| 58 |
+
*.pot
|
| 59 |
+
|
| 60 |
+
# Django stuff:
|
| 61 |
+
*.log
|
| 62 |
+
local_settings.py
|
| 63 |
+
db.sqlite3
|
| 64 |
+
db.sqlite3-journal
|
| 65 |
+
|
| 66 |
+
# Flask stuff:
|
| 67 |
+
instance/
|
| 68 |
+
.webassets-cache
|
| 69 |
+
|
| 70 |
+
# Scrapy stuff:
|
| 71 |
+
.scrapy
|
| 72 |
+
|
| 73 |
+
# Sphinx documentation
|
| 74 |
+
docs/_build/
|
| 75 |
+
|
| 76 |
+
# PyBuilder
|
| 77 |
+
.pybuilder/
|
| 78 |
+
target/
|
| 79 |
+
|
| 80 |
+
# Jupyter Notebook
|
| 81 |
+
.ipynb_checkpoints
|
| 82 |
+
|
| 83 |
+
# IPython
|
| 84 |
+
profile_default/
|
| 85 |
+
ipython_config.py
|
| 86 |
+
|
| 87 |
+
# pyenv
|
| 88 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 89 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 90 |
+
# .python-version
|
| 91 |
+
|
| 92 |
+
# pipenv
|
| 93 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 94 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 95 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 96 |
+
# install all needed dependencies.
|
| 97 |
+
#Pipfile.lock
|
| 98 |
+
|
| 99 |
+
# poetry
|
| 100 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 101 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 102 |
+
# commonly ignored for libraries.
|
| 103 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 104 |
+
#poetry.lock
|
| 105 |
+
|
| 106 |
+
# pdm
|
| 107 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 108 |
+
#pdm.lock
|
| 109 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 110 |
+
# in version control.
|
| 111 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 112 |
+
.pdm.toml
|
| 113 |
+
|
| 114 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 115 |
+
__pypackages__/
|
| 116 |
+
|
| 117 |
+
# Celery stuff
|
| 118 |
+
celerybeat-schedule
|
| 119 |
+
celerybeat.pid
|
| 120 |
+
|
| 121 |
+
# SageMath parsed files
|
| 122 |
+
*.sage.py
|
| 123 |
+
|
| 124 |
+
# Environments
|
| 125 |
+
.env
|
| 126 |
+
.venv
|
| 127 |
+
env/
|
| 128 |
+
venv/
|
| 129 |
+
ENV/
|
| 130 |
+
env.bak/
|
| 131 |
+
venv.bak/
|
| 132 |
+
|
| 133 |
+
# Spyder project settings
|
| 134 |
+
.spyderproject
|
| 135 |
+
.spyproject
|
| 136 |
+
|
| 137 |
+
# Rope project settings
|
| 138 |
+
.ropeproject
|
| 139 |
+
|
| 140 |
+
# mkdocs documentation
|
| 141 |
+
/site
|
| 142 |
+
|
| 143 |
+
# mypy
|
| 144 |
+
.mypy_cache/
|
| 145 |
+
.dmypy.json
|
| 146 |
+
dmypy.json
|
| 147 |
+
|
| 148 |
+
# Pyre type checker
|
| 149 |
+
.pyre/
|
| 150 |
+
|
| 151 |
+
# pytype static type analyzer
|
| 152 |
+
.pytype/
|
| 153 |
+
|
| 154 |
+
# Cython debug symbols
|
| 155 |
+
cython_debug/
|
| 156 |
+
|
| 157 |
+
# PyCharm
|
| 158 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 159 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 160 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 161 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 162 |
+
.idea/
|
| 163 |
+
*.pyc
|
| 164 |
+
|
| 165 |
+
# S5 specific stuff
|
| 166 |
+
wandb/
|
| 167 |
+
cache_dir/
|
| 168 |
+
raw_datasets/
|
Essay_classifier/.idea/.gitignore
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Default ignored files
|
| 2 |
+
/shelf/
|
| 3 |
+
/workspace.xml
|
Essay_classifier/.idea/Essay_classifier.iml
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<module type="PYTHON_MODULE" version="4">
|
| 3 |
+
<component name="NewModuleRootManager">
|
| 4 |
+
<content url="file://$MODULE_DIR$">
|
| 5 |
+
<excludeFolder url="file://$MODULE_DIR$/venv" />
|
| 6 |
+
</content>
|
| 7 |
+
<orderEntry type="inheritedJdk" />
|
| 8 |
+
<orderEntry type="sourceFolder" forTests="false" />
|
| 9 |
+
</component>
|
| 10 |
+
<component name="PyDocumentationSettings">
|
| 11 |
+
<option name="format" value="PLAIN" />
|
| 12 |
+
<option name="myDocStringFormat" value="Plain" />
|
| 13 |
+
</component>
|
| 14 |
+
</module>
|
Essay_classifier/.idea/inspectionProfiles/profiles_settings.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<component name="InspectionProjectProfileManager">
|
| 2 |
+
<settings>
|
| 3 |
+
<option name="USE_PROJECT_PROFILE" value="false" />
|
| 4 |
+
<version value="1.0" />
|
| 5 |
+
</settings>
|
| 6 |
+
</component>
|
Essay_classifier/.idea/misc.xml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectRootManager" version="2" project-jdk-name="Python 3.10 (Essay_classifier)" project-jdk-type="Python SDK" />
|
| 4 |
+
</project>
|
Essay_classifier/.idea/modules.xml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="ProjectModuleManager">
|
| 4 |
+
<modules>
|
| 5 |
+
<module fileurl="file://$PROJECT_DIR$/.idea/Essay_classifier.iml" filepath="$PROJECT_DIR$/.idea/Essay_classifier.iml" />
|
| 6 |
+
</modules>
|
| 7 |
+
</component>
|
| 8 |
+
</project>
|
Essay_classifier/.idea/vcs.xml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="VcsDirectoryMappings">
|
| 4 |
+
<mapping directory="$PROJECT_DIR$" vcs="Git" />
|
| 5 |
+
</component>
|
| 6 |
+
</project>
|
Essay_classifier/.idea/workspace.xml
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<?xml version="1.0" encoding="UTF-8"?>
|
| 2 |
+
<project version="4">
|
| 3 |
+
<component name="AutoImportSettings">
|
| 4 |
+
<option name="autoReloadType" value="SELECTIVE" />
|
| 5 |
+
</component>
|
| 6 |
+
<component name="ChangeListManager">
|
| 7 |
+
<list default="true" id="4563d2f1-3686-4dcf-84a5-992172d73207" name="Changes" comment="" />
|
| 8 |
+
<option name="SHOW_DIALOG" value="false" />
|
| 9 |
+
<option name="HIGHLIGHT_CONFLICTS" value="true" />
|
| 10 |
+
<option name="HIGHLIGHT_NON_ACTIVE_CHANGELIST" value="false" />
|
| 11 |
+
<option name="LAST_RESOLUTION" value="IGNORE" />
|
| 12 |
+
</component>
|
| 13 |
+
<component name="Git.Settings">
|
| 14 |
+
<option name="RECENT_GIT_ROOT_PATH" value="$PROJECT_DIR$" />
|
| 15 |
+
</component>
|
| 16 |
+
<component name="MarkdownSettingsMigration">
|
| 17 |
+
<option name="stateVersion" value="1" />
|
| 18 |
+
</component>
|
| 19 |
+
<component name="ProjectId" id="2KEFml6EVBHbZyIrqa6fvMDUtj0" />
|
| 20 |
+
<component name="ProjectLevelVcsManager" settingsEditedManually="true" />
|
| 21 |
+
<component name="ProjectViewState">
|
| 22 |
+
<option name="hideEmptyMiddlePackages" value="true" />
|
| 23 |
+
<option name="showLibraryContents" value="true" />
|
| 24 |
+
</component>
|
| 25 |
+
<component name="PropertiesComponent"><![CDATA[{
|
| 26 |
+
"keyToString": {
|
| 27 |
+
"RunOnceActivity.OpenProjectViewOnStart": "true",
|
| 28 |
+
"RunOnceActivity.ShowReadmeOnStart": "true"
|
| 29 |
+
}
|
| 30 |
+
}]]></component>
|
| 31 |
+
<component name="SpellCheckerSettings" RuntimeDictionaries="0" Folders="0" CustomDictionaries="0" DefaultDictionary="application-level" UseSingleDictionary="true" transferred="true" />
|
| 32 |
+
<component name="TaskManager">
|
| 33 |
+
<task active="true" id="Default" summary="Default task">
|
| 34 |
+
<changelist id="4563d2f1-3686-4dcf-84a5-992172d73207" name="Changes" comment="" />
|
| 35 |
+
<created>1673531998138</created>
|
| 36 |
+
<option name="number" value="Default" />
|
| 37 |
+
<option name="presentableId" value="Default" />
|
| 38 |
+
<updated>1673531998138</updated>
|
| 39 |
+
</task>
|
| 40 |
+
<servers />
|
| 41 |
+
</component>
|
| 42 |
+
</project>
|
Essay_classifier/CITATION.cff
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cff-version: 1.2.0
|
| 2 |
+
message: "If you use this software, please cite it as below."
|
| 3 |
+
authors:
|
| 4 |
+
- family-names: “Smith”
|
| 5 |
+
given-names: “Jimmy T. H.“
|
| 6 |
+
- family-names: “Warrington”
|
| 7 |
+
given-names: “Andrew”
|
| 8 |
+
- family-names: “Linderman”
|
| 9 |
+
given-names: “Scott”
|
| 10 |
+
title: "Simplified State Space Layers for Sequence Modeling"
|
| 11 |
+
version: 0.0.1
|
| 12 |
+
doi: arXiv:2208.04933
|
| 13 |
+
url: "https://github.com/lindermanlab/S5"
|
| 14 |
+
date-released: 2022-OCT-04
|
Essay_classifier/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Linderman Lab
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
Essay_classifier/README.md
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# S5: Simplified State Space Layers for Sequence Modeling
|
| 2 |
+
|
| 3 |
+
This repository provides the implementation for the
|
| 4 |
+
paper: Simplified State Space Layers for Sequence Modeling. The preprint is available [here](https://arxiv.org/abs/2208.04933).
|
| 5 |
+
|
| 6 |
+

|
| 7 |
+
<p style="text-align: center;">
|
| 8 |
+
Figure 1: S5 uses a single multi-input, multi-output linear state-space model, coupled with non-linearities, to define a non-linear sequence-to-sequence transformation. Parallel scans are used for efficient offline processing.
|
| 9 |
+
</p>
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
The S5 layer builds on the prior S4 work ([paper](https://arxiv.org/abs/2111.00396)). While it has departed considerably, this repository originally started off with much of the JAX implementation of S4 from the
|
| 13 |
+
Annotated S4 blog by Rush and Karamcheti (available [here](https://github.com/srush/annotated-s4)).
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
## Requirements & Installation
|
| 17 |
+
To run the code on your own machine, run either `pip install -r requirements_cpu.txt` or `pip install -r requirements_gpu.txt`. The GPU installation of JAX can be tricky, and so we include requirements that should work for most people, although further instructions are available [here](https://github.com/google/jax#installation).
|
| 18 |
+
|
| 19 |
+
Run from within the root directory `pip install -e .` to install the package.
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
## Data Download
|
| 23 |
+
Downloading the raw data is done differently for each dataset. The following datasets require no action:
|
| 24 |
+
- Text (IMDb)
|
| 25 |
+
- Image (Cifar black & white)
|
| 26 |
+
- sMNIST
|
| 27 |
+
- psMNIST
|
| 28 |
+
- Cifar (Color)
|
| 29 |
+
|
| 30 |
+
The remaining datasets need to be manually downloaded. To download _everything_, run `./bin/download_all.sh`. This will download quite a lot of data and will take some time.
|
| 31 |
+
|
| 32 |
+
Below is a summary of the steps for each dataset:
|
| 33 |
+
- ListOps: run `./bin/download_lra.sh` to download the full LRA dataset.
|
| 34 |
+
- Retrieval (AAN): run `./bin/download_aan.sh`
|
| 35 |
+
- Pathfinder: run `./bin/download_lra.sh` to download the full LRA dataset.
|
| 36 |
+
- Path-X: run `./bin/download_lra.sh` to download the full LRA dataset.
|
| 37 |
+
- Speech commands 35: run `./bin/download_sc35.sh` to download the speech commands data.
|
| 38 |
+
|
| 39 |
+
*With the exception of SC35.* When the dataset is used for the first time, a cache is created in `./cache_dir`. Converting the data (e.g. tokenizing) can be quite slow, and so this cache contains the processed dataset. The cache can be moved and specified with the `--dir_name` argument (i.e. the default is `--dir_name=./cache_dir`) to avoid applying this preprocessing every time the code is run somewhere new.
|
| 40 |
+
|
| 41 |
+
SC35 is slightly different. SC35 doesn't use `--dir_name`, and instead requires that the following path exists: `./raw_datasets/speech_commands/0.0.2/SpeechCommands` (i.e. the directory `./raw_datasets/speech_commands/0.0.2/SpeechCommands/zero` must exist). The cache is then stored in `./raw_datasets/speech_commands/0.0.2/SpeechCommands/processed_data`. This directory can then be copied (preserving the directory path) to move the preprocessed dataset to a new location.
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
## Repository Structure
|
| 45 |
+
Directories and files that ship with GitHub repo:
|
| 46 |
+
```
|
| 47 |
+
s5/ Source code for models, datasets, etc.
|
| 48 |
+
dataloading.py Dataloading functions.
|
| 49 |
+
layers.py Defines the S5 layer which wraps the S5 SSM with nonlinearity, norms, dropout, etc.
|
| 50 |
+
seq_model.py Defines deep sequence models that consist of stacks of S5 layers.
|
| 51 |
+
ssm.py S5 SSM implementation.
|
| 52 |
+
ssm_init.py Helper functions for initializing the S5 SSM .
|
| 53 |
+
train.py Training loop code.
|
| 54 |
+
train_helpers.py Functions for optimization, training and evaluation steps.
|
| 55 |
+
dataloaders/ Code mainly derived from S4 processing each dataset.
|
| 56 |
+
utils/ Range of utility functions.
|
| 57 |
+
bin/ Shell scripts for downloading data and running example experiments.
|
| 58 |
+
requirements_cpu.txt Requirements for running in CPU mode (not advised).
|
| 59 |
+
requirements_gpu.txt Requirements for running in GPU mode (installation can be highly system-dependent).
|
| 60 |
+
run_train.py Training loop entrypoint.
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
Directories that may be created on-the-fly:
|
| 64 |
+
```
|
| 65 |
+
raw_datasets/ Raw data as downloaded.
|
| 66 |
+
cache_dir/ Precompiled caches of data. Can be copied to new locations to avoid preprocessing.
|
| 67 |
+
wandb/ Local WandB log files.
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
## Experiments
|
| 71 |
+
|
| 72 |
+
The configurations to run the LRA and 35-way Speech Commands experiments from the paper are located in `bin/run_experiments`. For example,
|
| 73 |
+
to run the LRA text (character level IMDB) experiment, run `./bin/run_experiments/run_lra_imdb.sh`.
|
| 74 |
+
To log with W&B, adjust the default `USE_WANDB, wandb_entity, wandb_project` arguments.
|
| 75 |
+
Note: the pendulum
|
| 76 |
+
regression dataloading and experiments will be added soon.
|
| 77 |
+
|
| 78 |
+
## Citation
|
| 79 |
+
Please use the following when citing our work:
|
| 80 |
+
```
|
| 81 |
+
@misc{smith2022s5,
|
| 82 |
+
doi = {10.48550/ARXIV.2208.04933},
|
| 83 |
+
url = {https://arxiv.org/abs/2208.04933},
|
| 84 |
+
author = {Smith, Jimmy T. H. and Warrington, Andrew and Linderman, Scott W.},
|
| 85 |
+
keywords = {Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences},
|
| 86 |
+
title = {Simplified State Space Layers for Sequence Modeling},
|
| 87 |
+
publisher = {arXiv},
|
| 88 |
+
year = {2022},
|
| 89 |
+
copyright = {Creative Commons Attribution 4.0 International}
|
| 90 |
+
}
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
Please reach out if you have any questions.
|
| 94 |
+
|
| 95 |
+
-- The S5 authors.
|
Essay_classifier/S5.egg-info/PKG-INFO
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: S5
|
| 3 |
+
Version: 0.1
|
| 4 |
+
Summary: Simplified State Space Models for Sequence Modeling.
|
| 5 |
+
Home-page: UNKNOWN
|
| 6 |
+
Author: J.T.H. Smith, A. Warrington, S. Linderman.
|
| 7 |
+
Author-email: jsmith14@stanford.edu
|
| 8 |
+
License: UNKNOWN
|
| 9 |
+
Platform: UNKNOWN
|
| 10 |
+
License-File: LICENSE
|
| 11 |
+
|
| 12 |
+
UNKNOWN
|
| 13 |
+
|
Essay_classifier/S5.egg-info/SOURCES.txt
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LICENSE
|
| 2 |
+
README.md
|
| 3 |
+
setup.py
|
| 4 |
+
S5.egg-info/PKG-INFO
|
| 5 |
+
S5.egg-info/SOURCES.txt
|
| 6 |
+
S5.egg-info/dependency_links.txt
|
| 7 |
+
S5.egg-info/top_level.txt
|
Essay_classifier/S5.egg-info/dependency_links.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
Essay_classifier/S5.egg-info/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
Essay_classifier/bin/download_aan.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir raw_datasets
|
| 2 |
+
|
| 3 |
+
# Download the raw AAN data from the TutorialBank Corpus.
|
| 4 |
+
wget -v https://github.com/Yale-LILY/TutorialBank/blob/master/resources-v2022-clean.tsv -P ./raw_datasets
|
Essay_classifier/bin/download_all.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Make a directory to dump the raw data into.
|
| 2 |
+
rm -rf ./raw_datasets
|
| 3 |
+
mkdir ./raw_datasets
|
| 4 |
+
|
| 5 |
+
./bin/download_lra.sh
|
| 6 |
+
./bin/download_aan.sh
|
| 7 |
+
./bin/download_sc35.sh
|
| 8 |
+
|
Essay_classifier/bin/download_lra.sh
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir raw_datasets
|
| 2 |
+
|
| 3 |
+
# Clone and unpack the LRA object.
|
| 4 |
+
# This can take a long time, so get comfortable.
|
| 5 |
+
rm -rf ./raw_datasets/lra_release.gz ./raw_datasets/lra_release # Clean out any old datasets.
|
| 6 |
+
wget -v https://storage.googleapis.com/long-range-arena/lra_release.gz -P ./raw_datasets
|
| 7 |
+
|
| 8 |
+
# Add a progress bar because this can be slow.
|
| 9 |
+
pv ./raw_datasets/lra_release.gz | tar -zx -C ./raw_datasets/
|
Essay_classifier/bin/download_sc35.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir raw_datasets
|
| 2 |
+
|
| 3 |
+
# Use tfds to download the speech commands dataset.
|
| 4 |
+
python ./bin/python_scripts/download_sc.py
|
Essay_classifier/bin/python_scripts/download_sc.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tensorflow_datasets as tfds
|
| 2 |
+
import os
|
| 3 |
+
cfg = tfds.download.DownloadConfig(extract_dir=os.getcwd() + '/raw_datasets/')
|
| 4 |
+
tfds.load('speech_commands', data_dir='./raw_datasets', download=True, download_and_prepare_kwargs={'download_dir': os.getcwd() + '/raw_datasets/', 'download_config': cfg})
|
Essay_classifier/bin/run_experiments/run_gpt_classifier.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=lecun_normal --activation_fn=half_glu2 \
|
| 2 |
+
--batchnorm=True --bidirectional=True --blocks=12 --bsz=8 \
|
| 3 |
+
--d_model=64 --dataset=imdb-classification \
|
| 4 |
+
--dt_global=True --epochs=35 --jax_seed=8825365 --lr_factor=4 \
|
| 5 |
+
--n_layers=6 --opt_config=standard --p_dropout=0.1 --ssm_lr_base=0.001 \
|
| 6 |
+
--ssm_size_base=192 --warmup_end=0 --weight_decay=0.07 \
|
| 7 |
+
--USE_WANDB True --wandb_project awsome_0 --wandb_entity Vodolay
|
Essay_classifier/bin/run_experiments/run_lra_aan.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=trunc_standard_normal --batchnorm=True --bidirectional=True \
|
| 2 |
+
--blocks=16 --bsz=32 --d_model=128 --dataset=aan-classification \
|
| 3 |
+
--dt_global=True --epochs=20 --jax_seed=5464368 --lr_factor=2 --n_layers=6 \
|
| 4 |
+
--opt_config=standard --p_dropout=0.0 --ssm_lr_base=0.001 --ssm_size_base=256 \
|
| 5 |
+
--warmup_end=1 --weight_decay=0.05
|
Essay_classifier/bin/run_experiments/run_lra_cifar.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=lecun_normal --batchnorm=True --bidirectional=True \
|
| 2 |
+
--blocks=3 --bsz=50 --clip_eigs=True --d_model=512 --dataset=lra-cifar-classification \
|
| 3 |
+
--epochs=250 --jax_seed=16416 --lr_factor=4.5 --n_layers=6 --opt_config=BfastandCdecay \
|
| 4 |
+
--p_dropout=0.1 --ssm_lr_base=0.001 --ssm_size_base=384 --warmup_end=1 --weight_decay=0.07
|
Essay_classifier/bin/run_experiments/run_lra_imdb.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=lecun_normal --activation_fn=half_glu2 \
|
| 2 |
+
--batchnorm=True --bidirectional=True --blocks=12 --bsz=8 \
|
| 3 |
+
--d_model=64 --dataset=imdb-classification \
|
| 4 |
+
--dt_global=True --epochs=35 --jax_seed=8825365 --lr_factor=4 \
|
| 5 |
+
--n_layers=6 --opt_config=standard --p_dropout=0.1 --ssm_lr_base=0.001 \
|
| 6 |
+
--ssm_size_base=192 --warmup_end=0 --weight_decay=0.07 \
|
| 7 |
+
--USE_WANDB True --wandb_project awsome_0 --wandb_entity Vodolay
|
Essay_classifier/bin/run_experiments/run_lra_listops.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=lecun_normal --activation_fn=half_glu2 --batchnorm=True \
|
| 2 |
+
--bidirectional=True --blocks=8 --bsz=50 --d_model=128 --dataset=listops-classification \
|
| 3 |
+
--epochs=40 --jax_seed=6554595 --lr_factor=3 --n_layers=8 --opt_config=BfastandCdecay \
|
| 4 |
+
--p_dropout=0 --ssm_lr_base=0.001 --ssm_size_base=16 --warmup_end=1 --weight_decay=0.04
|
Essay_classifier/bin/run_experiments/run_lra_pathfinder.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=trunc_standard_normal --batchnorm=True --bidirectional=True \
|
| 2 |
+
--blocks=8 --bn_momentum=0.9 --bsz=64 --d_model=192 \
|
| 3 |
+
--dataset=pathfinder-classification --epochs=200 --jax_seed=8180844 --lr_factor=5 \
|
| 4 |
+
--n_layers=6 --opt_config=standard --p_dropout=0.05 --ssm_lr_base=0.0009 \
|
| 5 |
+
--ssm_size_base=256 --warmup_end=1 --weight_decay=0.03
|
Essay_classifier/bin/run_experiments/run_lra_pathx.sh
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=complex_normal --batchnorm=True --bidirectional=True \
|
| 2 |
+
--blocks=16 --bn_momentum=0.9 --bsz=32 --d_model=128 --dataset=pathx-classification \
|
| 3 |
+
--dt_min=0.0001 --epochs=75 --jax_seed=6429262 --lr_factor=3 --n_layers=6 \
|
| 4 |
+
--opt_config=BandCdecay --p_dropout=0.0 --ssm_lr_base=0.0006 --ssm_size_base=256 \
|
| 5 |
+
--warmup_end=1 --weight_decay=0.06
|
Essay_classifier/bin/run_experiments/run_speech35.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python run_train.py --C_init=lecun_normal --batchnorm=True --bidirectional=True \
|
| 2 |
+
--blocks=16 --bsz=16 --d_model=96 --dataset=speech35-classification \
|
| 3 |
+
--epochs=40 --jax_seed=4062966 --lr_factor=4 --n_layers=6 --opt_config=noBCdecay \
|
| 4 |
+
--p_dropout=0.1 --ssm_lr_base=0.002 --ssm_size_base=128 --warmup_end=1 --weight_decay=0.04
|
Essay_classifier/docs/figures/pdfs/s3-block-diagram-2.pdf
ADDED
|
Binary file (146 kB). View file
|
|
|
Essay_classifier/docs/figures/pdfs/s4-matrix-blocks.pdf
ADDED
|
Binary file (209 kB). View file
|
|
|
Essay_classifier/docs/figures/pdfs/s4-s3-block-diagram-2.pdf
ADDED
|
Binary file (200 kB). View file
|
|
|
Essay_classifier/docs/figures/pdfs/s5-matrix-blocks.pdf
ADDED
|
Binary file (208 kB). View file
|
|
|
Essay_classifier/docs/figures/pngs/pendulum.png
ADDED

|
Essay_classifier/docs/figures/pngs/s3-block-diagram-2.png
ADDED
|
Essay_classifier/docs/figures/pngs/s4-matrix-blocks.png
ADDED

|
Essay_classifier/docs/figures/pngs/s4-s3-block-diagram-2.png
ADDED
|
Essay_classifier/docs/figures/pngs/s5-matrix-blocks.png
ADDED
|
Essay_classifier/docs/s5_blog.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<script id="MathJax-script" async src="https://cdn.jsdelivr.net/npm/mathjax@3/es5/tex-mml-chtml.js"></script>
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# S5: Simplified State Space Layers for Sequence Modeling
|
| 6 |
+
|
| 7 |
+
_By [Jimmy Smith](https://icme.stanford.edu/people/jimmy-smith), [Andrew Warrington](https://github.com/andrewwarrington) & [Scott Linderman](https://web.stanford.edu/~swl1/)._
|
| 8 |
+
|
| 9 |
+
_This post accompanies the preprint Smith et al [2022], available [here](https://arxiv.org/pdf/2208.04933.pdf). Code for the paper is available [here](https://github.com/lindermanlab/S5)_.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## TL;DR.
|
| 14 |
+
In our preprint we demonstrate that we can build a state-of-the-art deep sequence-to-sequence model using by stacking many dense, multi-input, multi-output (MIMO) state space models (SSMs) as a layer. This replaces the many single-input, single-output (SISO) SSMs used by the _structured state space sequence_ (S4) model [Gu et al, 2021]. This allows us to make use of efficient parallel scan to achieve the same computational effiency of S4, without the need to use frequency domain and convolutional methods. We show that S5 achieves the same, if not better, performance than S4 on a range of long-range sequence modeling tasks.
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+
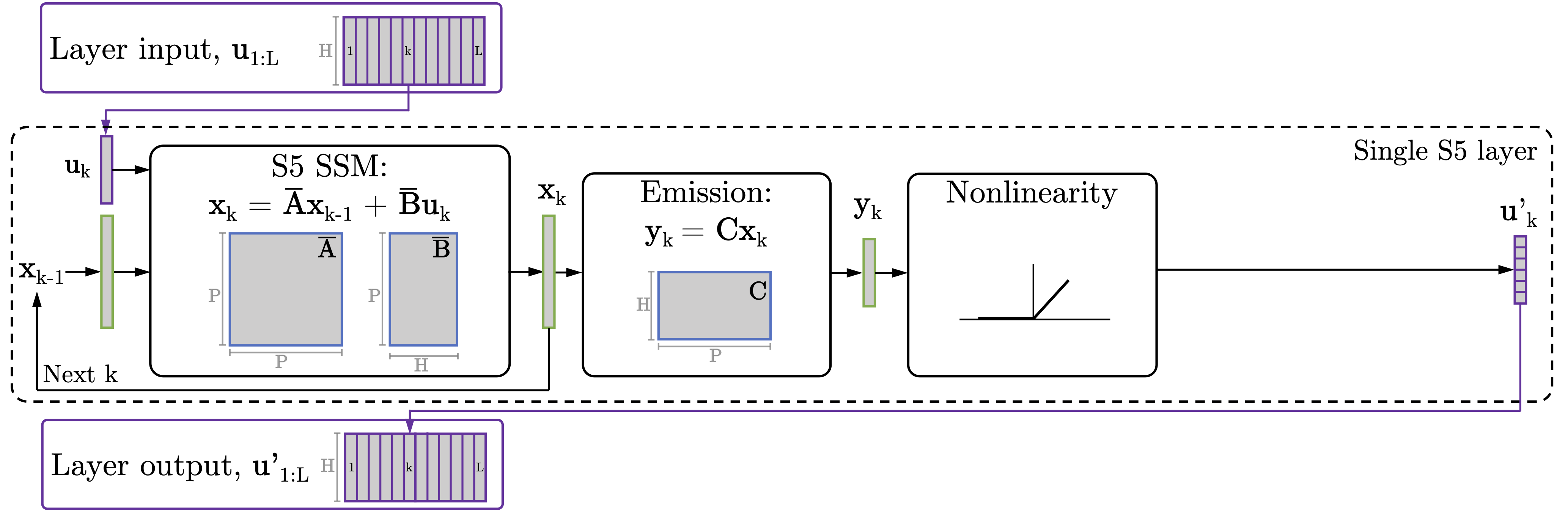
_Figure 1: Our S5 layer uses a single, dense, multi-input, multi-output state space model as a layer in a deep sequence-to-sequence model._
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
## S4 is Epically Good. So... Why?
|
| 22 |
+
|
| 23 |
+
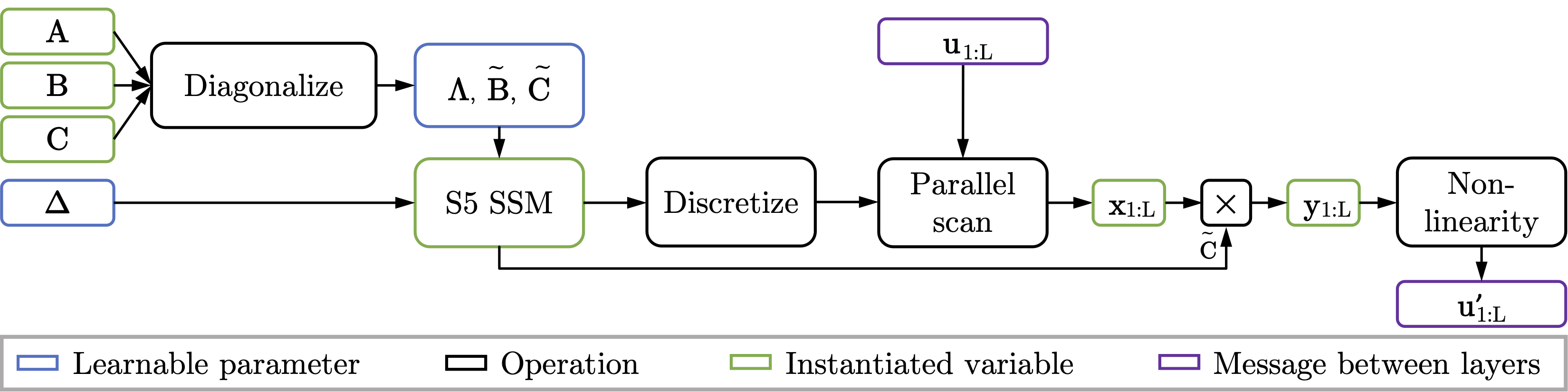
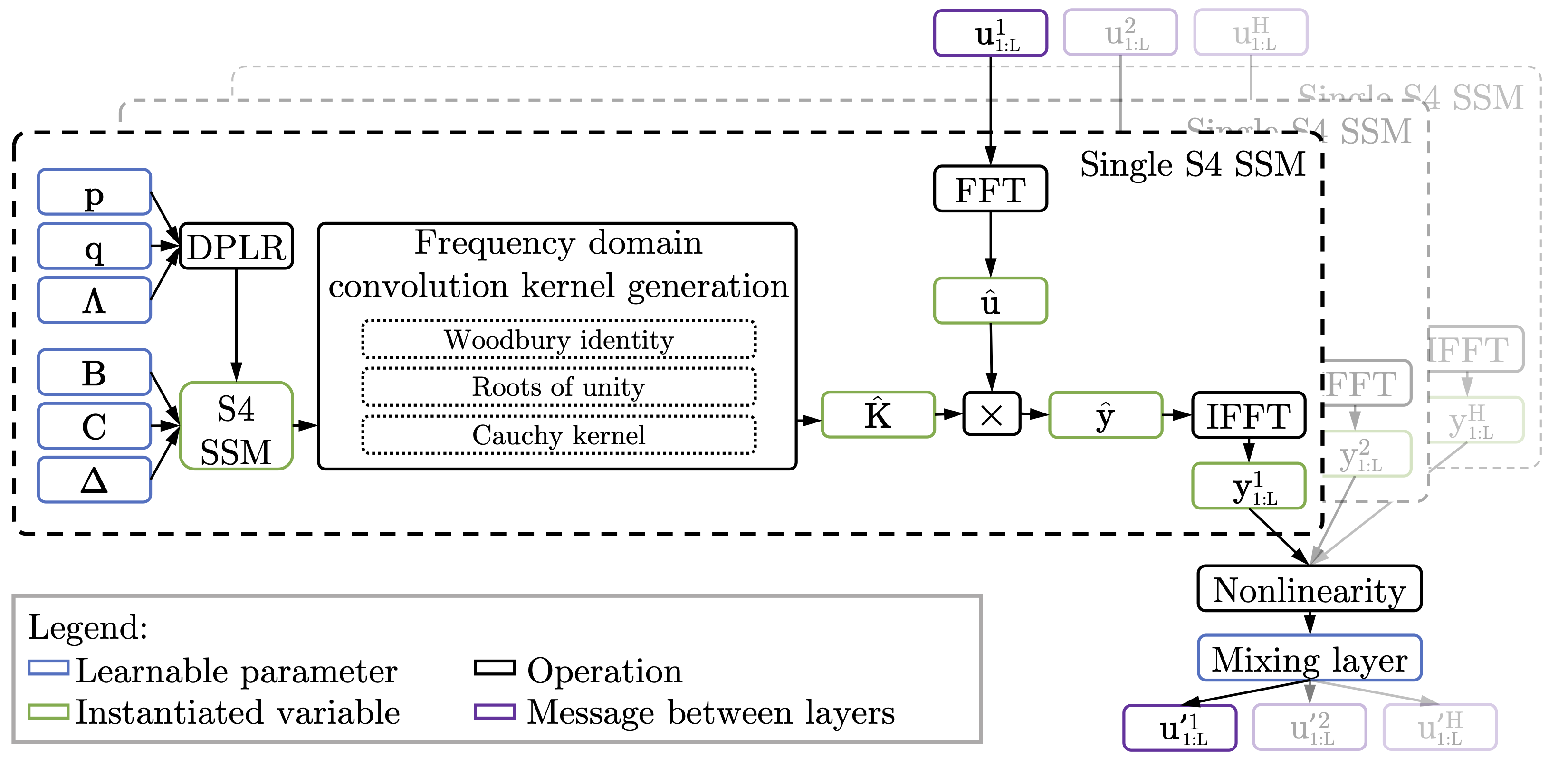
<a name="fig_s4_stack"></a>
|
| 24 |
+

|
| 25 |
+
_Figure 2: A schematic of the computations required by S4. \\(H\\) SISO SSMs are applied in the frequency domain, passed through a non-linearity, and then mixed to provide the input to the next layer. Deriving the "Frequency domain convolution kernel generation" (and the required parameterization, indicated in blue) is the primary focus of Gu et al [2021]._
|
| 26 |
+
|
| 27 |
+
The performance of S4 is unarguable. Transformer-based methods were clawing for single percentage point gains on the long range arena benchmark dataset [Tay et al, 2021]. S4 beat many SotA transformer methods by as much as twenty percentage points. AND, to top it off, could process sequences with complexity linear in the sequence length, and sublinear in parallel time (with a reasonable number of processors).
|
| 28 |
+
|
| 29 |
+
However, the original S4 is a very involved method. It required specific matrix parameterizations, decompositions, mathematical identities, Fourier transforms, and more, as illustrated in [Figure 2](#fig_s4_stack). As a research group, we spent several weeks trying to understand all the intricacies of the method. This left us asking: is there a different way of using the same core concepts, retaining performance and complexity, but, maybe, making it (subjectively, we admit!) simpler?
|
| 30 |
+
|
| 31 |
+
Enter S5.
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
## From SISO to MIMO. From Convolution to Parallel Recurrence.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
<a name="fig_s4_block"></a>
|
| 38 |
+

|
| 39 |
+
_Figure 3: Our S5 layer uses a single, dense, multi-input, multi-output state space model as a layer in a deep sequence-to-sequence model._
|
| 40 |
+
|
| 41 |
+
---
|
| 42 |
+
|
| 43 |
+
todo
|
| 44 |
+
|
| 45 |
+
---
|
| 46 |
+
|
| 47 |
+
## S4 and Its Variants.
|
| 48 |
+
Since publishing the original S4 model, the original authors have released three further papers studying the S4 model. Most significant of those papers are S4D [Gu, 2022] and DSS [Gupta, 2022]. These paper explores using diagonal state spaces, similar to what we use. S4D provided a proof as to why the (diagonalizable) normal matrix, from the normal-plus-low-rank factorization of the HiPPO-LegS matrix, provides such a good initialization for SISO systems. We show (although its really not that difficult!) that using this initialization in the MIMO case enjoys similar characteristics. We note, however, that S4D and DSS provide computationally simpler implementations of S4; but, doe not perform quite as strongly. Most importantly, though, S5 isn't the only simplification to S4.
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Other Resources.
|
| 53 |
+
- Much of our understanding and early code was based on the _excellent_ blog post, _The Annotated S4_, by [Rush and Karamcheti \[2021\]](https://srush.github.io/annotated-s4/).
|
| 54 |
+
- Full code for the original S4 implementation, and many of its forerunners and derivatives, is available [here](https://github.com/HazyResearch/state-spaces).
|
| 55 |
+
- Instructions for obtaining the LRA dataset are [here](https://openreview.net/pdf?id=qVyeW-grC2k).
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Awesome Other Work.
|
| 60 |
+
There are obviously many other great researchers working on adapting, extending, and understanding S4. We outline some very recent work here:
|
| 61 |
+
|
| 62 |
+
- Mega, by Ma et al [2022], combines linear state space layers with transformer heads for sequence modeling. The main Mega method has \\(O(L^2)\\) complexity. A second method, Mega-chunk, is presented that has \\(O(L)\\), but does not achieve the same performance as Mega. Combining SSMs with transformer heads is a great avenue for future work.
|
| 63 |
+
- Liquid-S4, by Hasani et al [2022], extends S4 by adding a dependence on the input signal into the state matrix. When expanded, this is equivilant to adding cross-terms between the \\(k^{th}\\) input and all previous inputs. Evaluating all previous terms is intractable, and so this sequence is often truncated. Extending the linear SSM, such that it is conditionally linear, is a really exciting opportunity for making the more model of linear state space layers more expressive.
|
| 64 |
+
- ADD "what makes conv great" once it is de-anonymysed.
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
## Bibliography
|
| 69 |
+
- Smith, Jimmy TH, Andrew Warrington, and Scott W. Linderman. "Simplified State Space Layers for Sequence Modeling." arXiv preprint arXiv:2208.04933 (2022). [Link](https://arxiv.org/pdf/2208.04933.pdf).
|
| 70 |
+
- Gu, Albert, Karan Goel, and Christopher Re. "Efficiently Modeling Long Sequences with Structured State Spaces." International Conference on Learning Representations (2021). [Link](https://openreview.net/pdf?id=uYLFoz1vlAC).
|
| 71 |
+
- Rush, Sasha, and Sidd Karamcheti. "The Annotated S4." Blog Track at ICLR 2022 (2022). [Link](https://srush.github.io/annotated-s4/).
|
| 72 |
+
- Yi Tay, et al. "Long Range Arena : A Benchmark for Efficient Transformers ." International Conference on Learning Representations (2021). [Link](https://openreview.net/pdf?id=qVyeW-grC2k).
|
| 73 |
+
- Ma, Xuezhe, et al. "Mega: Moving Average Equipped Gated Attention." arXiv preprint arXiv:2209.10655 (2022). [Link](https://arxiv.org/pdf/2209.10655).
|
| 74 |
+
- Hasani, Ramin, et al. "Liquid Structural State-Space Models." arXiv preprint arXiv:2209.12951 (2022). [Link](https://web10.arxiv.org/pdf/2209.12951.pdf).
|
| 75 |
+
- Gu S4d.
|
| 76 |
+
|
| 77 |
+
|
Essay_classifier/essays/dataset_dict.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"splits": ["train", "test"]}
|
Essay_classifier/essays/test/data-00000-of-00001.arrow
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf303ddc5053fcc1d3d8ad2e8a885dbf12d31960c1e097a4979980362c4c94ea
|
| 3 |
+
size 470136
|
Essay_classifier/essays/test/dataset_info.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"citation": "",
|
| 3 |
+
"description": "",
|
| 4 |
+
"features": {
|
| 5 |
+
"text": {
|
| 6 |
+
"dtype": "string",
|
| 7 |
+
"_type": "Value"
|
| 8 |
+
},
|
| 9 |
+
"label": {
|
| 10 |
+
"dtype": "int64",
|
| 11 |
+
"_type": "Value"
|
| 12 |
+
},
|
| 13 |
+
"__index_level_0__": {
|
| 14 |
+
"dtype": "int64",
|
| 15 |
+
"_type": "Value"
|
| 16 |
+
}
|
| 17 |
+
},
|
| 18 |
+
"homepage": "",
|
| 19 |
+
"license": ""
|
| 20 |
+
}
|
Essay_classifier/essays/test/state.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_data_files": [
|
| 3 |
+
{
|
| 4 |
+
"filename": "data-00000-of-00001.arrow"
|
| 5 |
+
}
|
| 6 |
+
],
|
| 7 |
+
"_fingerprint": "cf3f779c3519cf1d",
|
| 8 |
+
"_format_columns": null,
|
| 9 |
+
"_format_kwargs": {},
|
| 10 |
+
"_format_type": null,
|
| 11 |
+
"_output_all_columns": false,
|
| 12 |
+
"_split": null
|
| 13 |
+
}
|
Essay_classifier/essays/train/data-00000-of-00001.arrow
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a92f80195891f57e75536c3660c1a67e36e044a6079678742eaa8f7f72711411
|
| 3 |
+
size 1943280
|
Essay_classifier/essays/train/dataset_info.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"citation": "",
|
| 3 |
+
"description": "",
|
| 4 |
+
"features": {
|
| 5 |
+
"text": {
|
| 6 |
+
"dtype": "string",
|
| 7 |
+
"_type": "Value"
|
| 8 |
+
},
|
| 9 |
+
"label": {
|
| 10 |
+
"dtype": "int64",
|
| 11 |
+
"_type": "Value"
|
| 12 |
+
},
|
| 13 |
+
"__index_level_0__": {
|
| 14 |
+
"dtype": "int64",
|
| 15 |
+
"_type": "Value"
|
| 16 |
+
}
|
| 17 |
+
},
|
| 18 |
+
"homepage": "",
|
| 19 |
+
"license": ""
|
| 20 |
+
}
|
Essay_classifier/essays/train/state.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_data_files": [
|
| 3 |
+
{
|
| 4 |
+
"filename": "data-00000-of-00001.arrow"
|
| 5 |
+
}
|
| 6 |
+
],
|
| 7 |
+
"_fingerprint": "c8e09f6301a80e82",
|
| 8 |
+
"_format_columns": null,
|
| 9 |
+
"_format_kwargs": {},
|
| 10 |
+
"_format_type": null,
|
| 11 |
+
"_output_all_columns": false,
|
| 12 |
+
"_split": null
|
| 13 |
+
}
|
Essay_classifier/requirements_cpu.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
flax==0.5.2
|
| 2 |
+
torch==1.11.0
|
| 3 |
+
torchtext==0.12.0
|
| 4 |
+
tensorflow-datasets==4.5.2
|
| 5 |
+
pydub==0.25.1
|
| 6 |
+
datasets==2.4.0
|
| 7 |
+
tqdm==4.62.3
|
| 8 |
+
jaxlib==0.3.5
|
| 9 |
+
jax==0.3.5
|
Essay_classifier/requirements_gpu.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
flax
|
| 2 |
+
torch
|
| 3 |
+
torchtext
|
| 4 |
+
tensorflow-datasets==4.5.2
|
| 5 |
+
pydub==0.25.1
|
| 6 |
+
datasets
|
| 7 |
+
tqdm
|
| 8 |
+
--find-links https://storage.googleapis.com/jax-releases/jax_releases.html
|
| 9 |
+
jax[cuda]>=version
|
Essay_classifier/run_train.py
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from s5.utils.util import str2bool
|
| 3 |
+
from s5.train import train
|
| 4 |
+
from s5.dataloading import Datasets
|
| 5 |
+
|
| 6 |
+
if __name__ == "__main__":
|
| 7 |
+
|
| 8 |
+
parser = argparse.ArgumentParser()
|
| 9 |
+
|
| 10 |
+
parser.add_argument("--USE_WANDB", type=str2bool, default=False,
|
| 11 |
+
help="log with wandb?")
|
| 12 |
+
parser.add_argument("--wandb_project", type=str, default=None,
|
| 13 |
+
help="wandb project name")
|
| 14 |
+
parser.add_argument("--wandb_entity", type=str, default=None,
|
| 15 |
+
help="wandb entity name, e.g. username")
|
| 16 |
+
parser.add_argument("--dir_name", type=str, default='./cache_dir',
|
| 17 |
+
help="name of directory where data is cached")
|
| 18 |
+
parser.add_argument("--dataset", type=str, choices=Datasets.keys(),
|
| 19 |
+
default='mnist-classification',
|
| 20 |
+
help="dataset name")
|
| 21 |
+
|
| 22 |
+
# Model Parameters
|
| 23 |
+
parser.add_argument("--n_layers", type=int, default=6,
|
| 24 |
+
help="Number of layers in the network")
|
| 25 |
+
parser.add_argument("--d_model", type=int, default=128,
|
| 26 |
+
help="Number of features, i.e. H, "
|
| 27 |
+
"dimension of layer inputs/outputs")
|
| 28 |
+
parser.add_argument("--ssm_size_base", type=int, default=256,
|
| 29 |
+
help="SSM Latent size, i.e. P")
|
| 30 |
+
parser.add_argument("--blocks", type=int, default=8,
|
| 31 |
+
help="How many blocks, J, to initialize with")
|
| 32 |
+
parser.add_argument("--C_init", type=str, default="trunc_standard_normal",
|
| 33 |
+
choices=["trunc_standard_normal", "lecun_normal", "complex_normal"],
|
| 34 |
+
help="Options for initialization of C: \\"
|
| 35 |
+
"trunc_standard_normal: sample from trunc. std. normal then multiply by V \\ " \
|
| 36 |
+
"lecun_normal sample from lecun normal, then multiply by V\\ " \
|
| 37 |
+
"complex_normal: sample directly from complex standard normal")
|
| 38 |
+
parser.add_argument("--discretization", type=str, default="zoh", choices=["zoh", "bilinear"])
|
| 39 |
+
parser.add_argument("--mode", type=str, default="pool", choices=["pool", "last"],
|
| 40 |
+
help="options: (for classification tasks) \\" \
|
| 41 |
+
" pool: mean pooling \\" \
|
| 42 |
+
"last: take last element")
|
| 43 |
+
parser.add_argument("--activation_fn", default="half_glu1", type=str,
|
| 44 |
+
choices=["full_glu", "half_glu1", "half_glu2", "gelu"])
|
| 45 |
+
parser.add_argument("--conj_sym", type=str2bool, default=True,
|
| 46 |
+
help="whether to enforce conjugate symmetry")
|
| 47 |
+
parser.add_argument("--clip_eigs", type=str2bool, default=False,
|
| 48 |
+
help="whether to enforce the left-half plane condition")
|
| 49 |
+
parser.add_argument("--bidirectional", type=str2bool, default=False,
|
| 50 |
+
help="whether to use bidirectional model")
|
| 51 |
+
parser.add_argument("--dt_min", type=float, default=0.001,
|
| 52 |
+
help="min value to sample initial timescale params from")
|
| 53 |
+
parser.add_argument("--dt_max", type=float, default=0.1,
|
| 54 |
+
help="max value to sample initial timescale params from")
|
| 55 |
+
|
| 56 |
+
# Optimization Parameters
|
| 57 |
+
parser.add_argument("--prenorm", type=str2bool, default=True,
|
| 58 |
+
help="True: use prenorm, False: use postnorm")
|
| 59 |
+
parser.add_argument("--batchnorm", type=str2bool, default=True,
|
| 60 |
+
help="True: use batchnorm, False: use layernorm")
|
| 61 |
+
parser.add_argument("--bn_momentum", type=float, default=0.95,
|
| 62 |
+
help="batchnorm momentum")
|
| 63 |
+
parser.add_argument("--bsz", type=int, default=64,
|
| 64 |
+
help="batch size")
|
| 65 |
+
parser.add_argument("--epochs", type=int, default=100,
|
| 66 |
+
help="max number of epochs")
|
| 67 |
+
parser.add_argument("--early_stop_patience", type=int, default=1000,
|
| 68 |
+
help="number of epochs to continue training when val loss plateaus")
|
| 69 |
+
parser.add_argument("--ssm_lr_base", type=float, default=1e-3,
|
| 70 |
+
help="initial ssm learning rate")
|
| 71 |
+
parser.add_argument("--lr_factor", type=float, default=1,
|
| 72 |
+
help="global learning rate = lr_factor*ssm_lr_base")
|
| 73 |
+
parser.add_argument("--dt_global", type=str2bool, default=False,
|
| 74 |
+
help="Treat timescale parameter as global parameter or SSM parameter")
|
| 75 |
+
parser.add_argument("--lr_min", type=float, default=0,
|
| 76 |
+
help="minimum learning rate")
|
| 77 |
+
parser.add_argument("--cosine_anneal", type=str2bool, default=True,
|
| 78 |
+
help="whether to use cosine annealing schedule")
|
| 79 |
+
parser.add_argument("--warmup_end", type=int, default=1,
|
| 80 |
+
help="epoch to end linear warmup")
|
| 81 |
+
parser.add_argument("--lr_patience", type=int, default=1000000,
|
| 82 |
+
help="patience before decaying learning rate for lr_decay_on_val_plateau")
|
| 83 |
+
parser.add_argument("--reduce_factor", type=float, default=1.0,
|
| 84 |
+
help="factor to decay learning rate for lr_decay_on_val_plateau")
|
| 85 |
+
parser.add_argument("--p_dropout", type=float, default=0.0,
|
| 86 |
+
help="probability of dropout")
|
| 87 |
+
parser.add_argument("--weight_decay", type=float, default=0.05,
|
| 88 |
+
help="weight decay value")
|
| 89 |
+
parser.add_argument("--opt_config", type=str, default="standard", choices=['standard',
|
| 90 |
+
'BandCdecay',
|
| 91 |
+
'BfastandCdecay',
|
| 92 |
+
'noBCdecay'],
|
| 93 |
+
help="Opt configurations: \\ " \
|
| 94 |
+
"standard: no weight decay on B (ssm lr), weight decay on C (global lr) \\" \
|
| 95 |
+
"BandCdecay: weight decay on B (ssm lr), weight decay on C (global lr) \\" \
|
| 96 |
+
"BfastandCdecay: weight decay on B (global lr), weight decay on C (global lr) \\" \
|
| 97 |
+
"noBCdecay: no weight decay on B (ssm lr), no weight decay on C (ssm lr) \\")
|
| 98 |
+
parser.add_argument("--jax_seed", type=int, default=1919,
|
| 99 |
+
help="seed randomness")
|
| 100 |
+
|
| 101 |
+
train(parser.parse_args())
|
Essay_classifier/s5/__init__.py
ADDED
|
File without changes
|
Essay_classifier/s5/dataloaders/README.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Data & Dataloaders
|
| 2 |
+
The scripts in this directory deal with downloading, preparing and caching datasets, as well as building dataloaders from (preferably) a cache
|
| 3 |
+
or downloading the data directly. The scripts in this directory are **HEAVILY** based on the scripts in the original S4 repository,
|
| 4 |
+
but have been modified to remove them from the PyTorch Lightning ecosystem.
|
| 5 |
+
|
| 6 |
+
These files were originally distributed under the Apache 2.0 license, (c) Albert Gu. The original copyright therefore remains with the original
|
| 7 |
+
authors, but we modify and distribute under the permissions of the license. Warranty, trademarking and liability are also therefore not allowed.
|
| 8 |
+
|