
Upload 13 files
Browse files- .gitattributes +4 -0
- .gitignore +1 -0
- LICENSE +1 -0
- README.md +146 -0
- images/cover.jpg +3 -0
- images/idea.png +0 -0
- images/sample-1.png +3 -0
- images/sample-2.png +3 -0
- images/sample-3.png +3 -0
- scripts/cutoff.py +257 -0
- scripts/cutofflib/embedding.py +214 -0
- scripts/cutofflib/sdhook.py +275 -0
- scripts/cutofflib/utils.py +11 -0
- scripts/cutofflib/xyz.py +126 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/cover.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/sample-1.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
images/sample-2.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
images/sample-3.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
LICENSE
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
README.md
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Cutoff - Cutting Off Prompt Effect
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
<details>
|
| 6 |
+
<summary>Update Info</summary>
|
| 7 |
+
|
| 8 |
+
Upper is newer.
|
| 9 |
+
|
| 10 |
+
<dl>
|
| 11 |
+
<dt>20e87ce264338b824296b7559679ed1bb0bdacd7</dt>
|
| 12 |
+
<dd>Skip empty targets.</dd>
|
| 13 |
+
<dt>03bfe60162ba418e18dbaf8f1b9711fd62195ef3</dt>
|
| 14 |
+
<dd>Add <code>Disable for Negative prompt</code> option. Default is <code>True</code>.</dd>
|
| 15 |
+
<dt>f0990088fed0f5013a659cacedb194313a398860</dt>
|
| 16 |
+
<dd>Accept an empty prompt.</dd>
|
| 17 |
+
</dl>
|
| 18 |
+
</details>
|
| 19 |
+
|
| 20 |
+
## What is this?
|
| 21 |
+
|
| 22 |
+
This is an extension for [stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) which limits the tokens' influence scope.
|
| 23 |
+
|
| 24 |
+
## Usage
|
| 25 |
+
|
| 26 |
+
1. Select `Enabled` checkbox.
|
| 27 |
+
2. Input words which you want to limit scope in `Target tokens`.
|
| 28 |
+
3. Generate images.
|
| 29 |
+
|
| 30 |
+
## Note
|
| 31 |
+
|
| 32 |
+
If the generated image was corrupted or something like that, try to change the `Weight` value or change the interpolation method to `SLerp`. Interpolation method can be found in `Details`.
|
| 33 |
+
|
| 34 |
+
### `Details` section
|
| 35 |
+
|
| 36 |
+
<dl>
|
| 37 |
+
<dt>Disable for Negative prompt.</dt>
|
| 38 |
+
<dd>If enabled, <b>Cutoff</b> will not work for the negative prompt. Default is <code>true</code>.</dd>
|
| 39 |
+
<dt>Cutoff strongly.</dt>
|
| 40 |
+
<dd>See <a href="#how-it-works">description below</a>. Default is <code>false</code>.</dd>
|
| 41 |
+
<dt>Interpolation method</dt>
|
| 42 |
+
<dd>How "padded" and "original" vectors will be interpolated. Default is <code>Lerp</code>.</dd>
|
| 43 |
+
<dt>Padding token</dt>
|
| 44 |
+
<dd>What token will be padded instead of <code>Target tokens</code>. Default is <code>_</code> (underbar).</dd>
|
| 45 |
+
</dl>
|
| 46 |
+
|
| 47 |
+
## Examples
|
| 48 |
+
|
| 49 |
+
```
|
| 50 |
+
7th_anime_v3_A-fp16 / kl-f8-anime2 / DPM++ 2M Karras / 15 steps / 512x768
|
| 51 |
+
Prompt: a cute girl, white shirt with green tie, red shoes, blue hair, yellow eyes, pink skirt
|
| 52 |
+
Negative Prompt: (low quality, worst quality:1.4), nsfw
|
| 53 |
+
Target tokens: white, green, red, blue, yellow, pink
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Sample 1.
|
| 57 |
+
|
| 58 |
+

|
| 59 |
+
|
| 60 |
+
Sample 2. (use `SLerp` for interpolation)
|
| 61 |
+
|
| 62 |
+

|
| 63 |
+
|
| 64 |
+
Sample 3.
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
## How it works
|
| 69 |
+
|
| 70 |
+
- [Japanese](#japanese)
|
| 71 |
+
- [English](#english)
|
| 72 |
+
|
| 73 |
+
or see [#5](https://github.com/hnmr293/sd-webui-cutoff/issues/5).
|
| 74 |
+
|
| 75 |
+

|
| 76 |
+
|
| 77 |
+
### Japanese
|
| 78 |
+
|
| 79 |
+
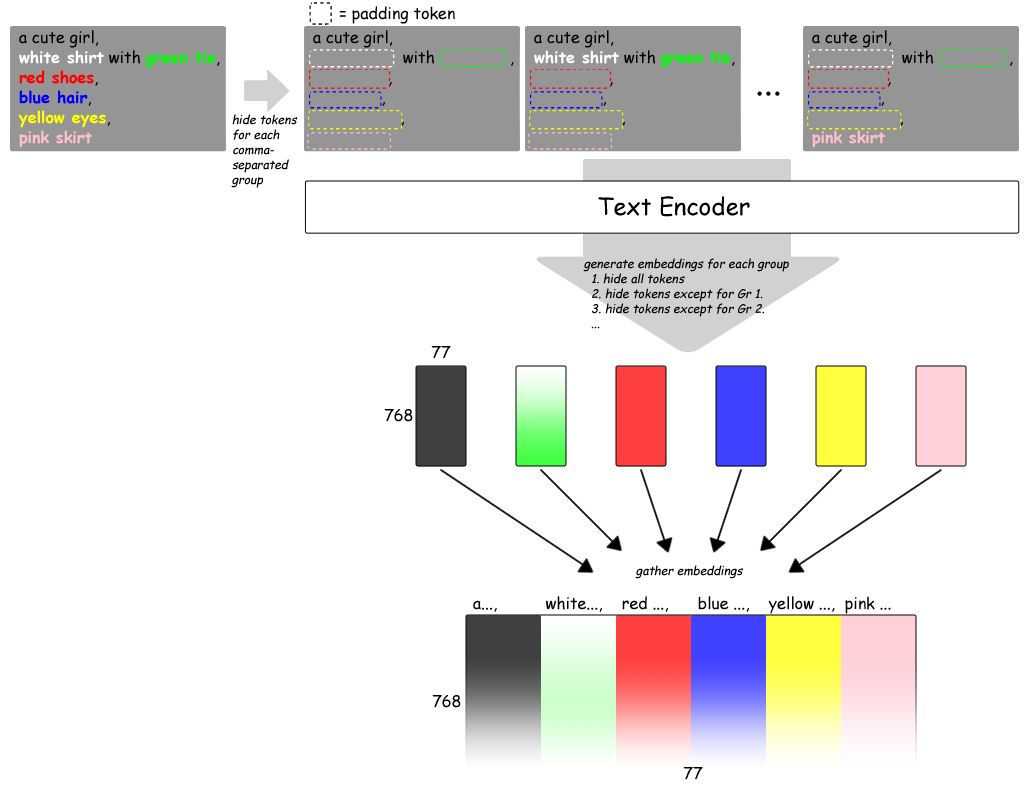
プロンプトをCLIPに通して得られる (77, 768) 次元の埋め込み表現(?正式な用語は分かりません)について、
|
| 80 |
+
ごく単純には、77個の行ベクトルはプロンプト中の75個のトークン(+開始トークン+終了トークン)に対応していると考えられる。
|
| 81 |
+
|
| 82 |
+
※上図は作図上、この説明とは行と列を入れ替えて描いている。
|
| 83 |
+
|
| 84 |
+
このベクトルには単語単体の意味だけではなく、文章全体の、例えば係り結びなどの情報を集約したものが入っているはずである。
|
| 85 |
+
|
| 86 |
+
ここで `a cute girl, pink hair, red shoes` というプロンプトを考える。
|
| 87 |
+
普通、こういったプロンプトの意図は
|
| 88 |
+
|
| 89 |
+
1. `pink` は `hair` だけに係っており `shoes` には係っていない。
|
| 90 |
+
2. 同様に `red` も `hair` には係っていない。
|
| 91 |
+
3. `a cute girl` は全体に係っていて欲しい。`hair` や `shoes` は女の子に合うものが出て欲しい。
|
| 92 |
+
|
| 93 |
+
……というもののはずである。
|
| 94 |
+
|
| 95 |
+
しかしながら、[EvViz2](https://github.com/hnmr293/sd-webui-evviz2) などでトークン間の関係を見ると、そううまくはいっていないことが多い。
|
| 96 |
+
つまり、`shoes` の位置のベクトルに `pink` の影響が出てしまっていたりする。
|
| 97 |
+
|
| 98 |
+
一方で上述の通り `a cute girl` の影響は乗っていて欲しいわけで、どうにかして、特定のトークンの影響を取り除けるようにしたい。
|
| 99 |
+
|
| 100 |
+
この拡張では、指定されたトークンを *padding token* に書き換えることでそれを実現している。
|
| 101 |
+
|
| 102 |
+
たとえば `red shoes` の部分に対応して `a cute girl, _ hair, red shoes` というプロンプトを生成する。`red` と `shoes` に対応する位置のベクトルをここから生成したもので上書きしてやることで、`pink` の影響を除外している。
|
| 103 |
+
|
| 104 |
+
これを `pink` の側から見ると、自分の影響が `pink hair` の範囲内に制限されているように見える。What is this? の "limits the tokens' influence scope" はそういう意味。
|
| 105 |
+
|
| 106 |
+
ところで `a cute girl` の方は、`pink hair, red shoes` の影響を受けていてもいいし受けなくてもいいような気がする。
|
| 107 |
+
そこでこの拡張では、こういうどちらでもいいプロンプトに対して
|
| 108 |
+
|
| 109 |
+
1. `a cute girl, pink hair, red shoes`
|
| 110 |
+
2. `a cute girl, _ hair, _ shoes`
|
| 111 |
+
|
| 112 |
+
のどちらを適用するか選べるようにしている。`Details` の `Cutoff strongly` がそれで、オフのとき1.を、オンのとき2.を、それぞれ選ぶようになっている。
|
| 113 |
+
元絵に近いのが出るのはオフのとき。デフォルトもこちらにしてある。
|
| 114 |
+
|
| 115 |
+
### English
|
| 116 |
+
|
| 117 |
+
NB. The following text is a translation of the Japanese text above by [DeepL](https://www.deepl.com/translator).
|
| 118 |
+
|
| 119 |
+
For the (77, 768) dimensional embedded representation (I don't know the formal terminology), one could simply assume that the 77 row vectors correspond to the 75 tokens (+ start token and end token) in the prompt.
|
| 120 |
+
|
| 121 |
+
Note: The above figure is drawn with the rows and columns interchanged from this explanation.
|
| 122 |
+
|
| 123 |
+
This vector should contain not only the meanings of individual words, but also the aggregate information of the whole sentence, for example, the connection between words.
|
| 124 |
+
|
| 125 |
+
Consider the prompt `a cute girl, pink hair, red shoes`. Normally, the intent of such a prompt would be
|
| 126 |
+
|
| 127 |
+
- `pink` is only for `hair`, not `shoes`.
|
| 128 |
+
- Similarly, `red` does not refer to `hair`.
|
| 129 |
+
- We want `a cute girl` to be about the whole thing, and we want the `hair` and `shoes` to match the girl.
|
| 130 |
+
|
| 131 |
+
However, when we look at the relationship between tokens in [EvViz2](https://github.com/hnmr293/sd-webui-evviz2) and other tools, we see that it is not always that way. In other words, the position vector of the `shoes` may be affected by `pink`.
|
| 132 |
+
|
| 133 |
+
On the other hand, as mentioned above, we want the influence of `a cute girl` to be present, so we want to be able to somehow remove the influence of a specific token.
|
| 134 |
+
|
| 135 |
+
This extension achieves this by rewriting the specified tokens as a *padding token*.
|
| 136 |
+
|
| 137 |
+
For example, for the `red shoes` part, we generate the prompt `a cute girl, _ hair, red shoes`, and by overwriting the position vectors corresponding to `red` and `shoes` with those generated from this prompt, we remove the influence of `pink`.
|
| 138 |
+
|
| 139 |
+
From `pink`'s point of view, it appears that its influence is limited to the `pink hair`'s scope.
|
| 140 |
+
|
| 141 |
+
By the way, `a cute girl` may or may not be influenced by `pink hair` and `red shoes`. So, in this extension, for such a prompt that can be either
|
| 142 |
+
|
| 143 |
+
1. `a cute girl, pink hair, red shoes`
|
| 144 |
+
2. `a cute girl, _ hair, _ shoes`
|
| 145 |
+
|
| 146 |
+
The `Cutoff strongly` in the `Details` section allows you to select 1 when it is off and 2 when it is on. The one that comes out closer to the original image is "off". The default is also set this way.
|
images/cover.jpg
ADDED

|
Git LFS Details
|
images/idea.png
ADDED
|
images/sample-1.png
ADDED

|
Git LFS Details
|
images/sample-2.png
ADDED

|
Git LFS Details
|
images/sample-3.png
ADDED

|
Git LFS Details
|
scripts/cutoff.py
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from collections import defaultdict
|
| 2 |
+
from typing import Union, List, Tuple
|
| 3 |
+
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
from torch import Tensor, nn
|
| 7 |
+
import gradio as gr
|
| 8 |
+
|
| 9 |
+
from modules.processing import StableDiffusionProcessing
|
| 10 |
+
from modules import scripts
|
| 11 |
+
|
| 12 |
+
from scripts.cutofflib.sdhook import SDHook
|
| 13 |
+
from scripts.cutofflib.embedding import CLIP, generate_prompts, token_to_block
|
| 14 |
+
from scripts.cutofflib.utils import log, set_debug
|
| 15 |
+
from scripts.cutofflib.xyz import init_xyz
|
| 16 |
+
|
| 17 |
+
NAME = 'Cutoff'
|
| 18 |
+
PAD = '_</w>'
|
| 19 |
+
|
| 20 |
+
def check_neg(s: str, negative_prompt: str, all_negative_prompts: Union[List[str],None]):
|
| 21 |
+
if s == negative_prompt:
|
| 22 |
+
return True
|
| 23 |
+
|
| 24 |
+
if all_negative_prompts is not None:
|
| 25 |
+
return s in all_negative_prompts
|
| 26 |
+
|
| 27 |
+
return False
|
| 28 |
+
|
| 29 |
+
def slerp(t, v0, v1, DOT_THRESHOLD=0.9995):
|
| 30 |
+
# cf. https://memo.sugyan.com/entry/2022/09/09/230645
|
| 31 |
+
|
| 32 |
+
inputs_are_torch = False
|
| 33 |
+
input_device = v0.device
|
| 34 |
+
if not isinstance(v0, np.ndarray):
|
| 35 |
+
inputs_are_torch = True
|
| 36 |
+
v0 = v0.cpu().numpy()
|
| 37 |
+
v1 = v1.cpu().numpy()
|
| 38 |
+
|
| 39 |
+
dot = np.sum(v0 * v1 / (np.linalg.norm(v0) * np.linalg.norm(v1)))
|
| 40 |
+
if np.abs(dot) > DOT_THRESHOLD:
|
| 41 |
+
v2 = (1 - t) * v0 + t * v1
|
| 42 |
+
else:
|
| 43 |
+
theta_0 = np.arccos(dot)
|
| 44 |
+
sin_theta_0 = np.sin(theta_0)
|
| 45 |
+
theta_t = theta_0 * t
|
| 46 |
+
sin_theta_t = np.sin(theta_t)
|
| 47 |
+
s0 = np.sin(theta_0 - theta_t) / sin_theta_0
|
| 48 |
+
s1 = sin_theta_t / sin_theta_0
|
| 49 |
+
v2 = s0 * v0 + s1 * v1
|
| 50 |
+
|
| 51 |
+
if inputs_are_torch:
|
| 52 |
+
v2 = torch.from_numpy(v2).to(input_device)
|
| 53 |
+
|
| 54 |
+
return v2
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class Hook(SDHook):
|
| 58 |
+
|
| 59 |
+
def __init__(
|
| 60 |
+
self,
|
| 61 |
+
enabled: bool,
|
| 62 |
+
targets: List[str],
|
| 63 |
+
padding: Union[str,int],
|
| 64 |
+
weight: float,
|
| 65 |
+
disable_neg: bool,
|
| 66 |
+
strong: bool,
|
| 67 |
+
interpolate: str,
|
| 68 |
+
):
|
| 69 |
+
super().__init__(enabled)
|
| 70 |
+
self.targets = targets
|
| 71 |
+
self.padding = padding
|
| 72 |
+
self.weight = float(weight)
|
| 73 |
+
self.disable_neg = disable_neg
|
| 74 |
+
self.strong = strong
|
| 75 |
+
self.intp = interpolate
|
| 76 |
+
|
| 77 |
+
def interpolate(self, t1: Tensor, t2: Tensor, w):
|
| 78 |
+
if self.intp == 'lerp':
|
| 79 |
+
return torch.lerp(t1, t2, w)
|
| 80 |
+
else:
|
| 81 |
+
return slerp(w, t1, t2)
|
| 82 |
+
|
| 83 |
+
def hook_clip(self, p: StableDiffusionProcessing, clip: nn.Module):
|
| 84 |
+
|
| 85 |
+
skip = False
|
| 86 |
+
|
| 87 |
+
def hook(mod: nn.Module, inputs: Tuple[List[str]], output: Tensor):
|
| 88 |
+
nonlocal skip
|
| 89 |
+
|
| 90 |
+
if skip:
|
| 91 |
+
# called from <A> below
|
| 92 |
+
return
|
| 93 |
+
|
| 94 |
+
assert isinstance(mod, CLIP)
|
| 95 |
+
|
| 96 |
+
prompts, *rest = inputs
|
| 97 |
+
assert len(prompts) == output.shape[0]
|
| 98 |
+
|
| 99 |
+
# Check wether we are processing Negative prompt or not.
|
| 100 |
+
# I firmly believe there is no one who uses a negative prompt
|
| 101 |
+
# exactly identical to a prompt.
|
| 102 |
+
if self.disable_neg:
|
| 103 |
+
if all(check_neg(x, p.negative_prompt, p.all_negative_prompts) for x in prompts):
|
| 104 |
+
# Now we are processing Negative prompt and skip it.
|
| 105 |
+
return
|
| 106 |
+
|
| 107 |
+
output = output.clone()
|
| 108 |
+
for pidx, prompt in enumerate(prompts):
|
| 109 |
+
tt = token_to_block(mod, prompt)
|
| 110 |
+
|
| 111 |
+
cutoff = generate_prompts(mod, prompt, self.targets, self.padding)
|
| 112 |
+
switch_base = np.full_like(cutoff.sw, self.strong)
|
| 113 |
+
switch = np.full_like(cutoff.sw, True)
|
| 114 |
+
active = cutoff.active_blocks()
|
| 115 |
+
|
| 116 |
+
prompt_to_tokens = defaultdict(lambda: [])
|
| 117 |
+
for tidx, (token, block_index) in enumerate(tt):
|
| 118 |
+
if block_index in active:
|
| 119 |
+
sw = switch.copy()
|
| 120 |
+
sw[block_index] = False
|
| 121 |
+
prompt = cutoff.text(sw)
|
| 122 |
+
else:
|
| 123 |
+
prompt = cutoff.text(switch_base)
|
| 124 |
+
prompt_to_tokens[prompt].append((tidx, token))
|
| 125 |
+
|
| 126 |
+
#log(prompt_to_tokens)
|
| 127 |
+
|
| 128 |
+
ks = list(prompt_to_tokens.keys())
|
| 129 |
+
if len(ks) == 0:
|
| 130 |
+
# without any (negative) prompts
|
| 131 |
+
ks.append('')
|
| 132 |
+
|
| 133 |
+
try:
|
| 134 |
+
# <A>
|
| 135 |
+
skip = True
|
| 136 |
+
vs = mod(ks)
|
| 137 |
+
finally:
|
| 138 |
+
skip = False
|
| 139 |
+
|
| 140 |
+
tensor = output[pidx, :, :] # e.g. (77, 768)
|
| 141 |
+
for k, t in zip(ks, vs):
|
| 142 |
+
assert tensor.shape == t.shape
|
| 143 |
+
for tidx, token in prompt_to_tokens[k]:
|
| 144 |
+
log(f'{tidx:03} {token.token:<16} {k}')
|
| 145 |
+
tensor[tidx, :] = self.interpolate(tensor[tidx,:], t[tidx,:], self.weight)
|
| 146 |
+
|
| 147 |
+
return output
|
| 148 |
+
|
| 149 |
+
self.hook_layer(clip, hook)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class Script(scripts.Script):
|
| 153 |
+
|
| 154 |
+
def __init__(self):
|
| 155 |
+
super().__init__()
|
| 156 |
+
self.last_hooker: Union[SDHook,None] = None
|
| 157 |
+
|
| 158 |
+
def title(self):
|
| 159 |
+
return NAME
|
| 160 |
+
|
| 161 |
+
def show(self, is_img2img):
|
| 162 |
+
return scripts.AlwaysVisible
|
| 163 |
+
|
| 164 |
+
def ui(self, is_img2img):
|
| 165 |
+
with gr.Accordion(NAME, open=False):
|
| 166 |
+
enabled = gr.Checkbox(label='Enabled', value=False)
|
| 167 |
+
targets = gr.Textbox(label='Target tokens (comma separated)', placeholder='red, blue')
|
| 168 |
+
weight = gr.Slider(minimum=-1.0, maximum=2.0, step=0.01, value=0.5, label='Weight')
|
| 169 |
+
with gr.Accordion('Details', open=False):
|
| 170 |
+
disable_neg = gr.Checkbox(value=True, label='Disable for Negative prompt.')
|
| 171 |
+
strong = gr.Checkbox(value=False, label='Cutoff strongly.')
|
| 172 |
+
padding = gr.Textbox(label='Padding token (ID or single token)')
|
| 173 |
+
lerp = gr.Radio(choices=['Lerp', 'SLerp'], value='Lerp', label='Interpolation method')
|
| 174 |
+
|
| 175 |
+
debug = gr.Checkbox(value=False, label='Debug log')
|
| 176 |
+
debug.change(fn=set_debug, inputs=[debug], outputs=[])
|
| 177 |
+
|
| 178 |
+
return [
|
| 179 |
+
enabled,
|
| 180 |
+
targets,
|
| 181 |
+
weight,
|
| 182 |
+
disable_neg,
|
| 183 |
+
strong,
|
| 184 |
+
padding,
|
| 185 |
+
lerp,
|
| 186 |
+
debug,
|
| 187 |
+
]
|
| 188 |
+
|
| 189 |
+
def process(
|
| 190 |
+
self,
|
| 191 |
+
p: StableDiffusionProcessing,
|
| 192 |
+
enabled: bool,
|
| 193 |
+
targets_: str,
|
| 194 |
+
weight: Union[float,int],
|
| 195 |
+
disable_neg: bool,
|
| 196 |
+
strong: bool,
|
| 197 |
+
padding: Union[str,int],
|
| 198 |
+
intp: str,
|
| 199 |
+
debug: bool,
|
| 200 |
+
):
|
| 201 |
+
set_debug(debug)
|
| 202 |
+
|
| 203 |
+
if self.last_hooker is not None:
|
| 204 |
+
self.last_hooker.__exit__(None, None, None)
|
| 205 |
+
self.last_hooker = None
|
| 206 |
+
|
| 207 |
+
if not enabled:
|
| 208 |
+
return
|
| 209 |
+
|
| 210 |
+
if targets_ is None or len(targets_) == 0:
|
| 211 |
+
return
|
| 212 |
+
|
| 213 |
+
targets = [x.strip() for x in targets_.split(',')]
|
| 214 |
+
targets = [x for x in targets if len(x) != 0]
|
| 215 |
+
|
| 216 |
+
if len(targets) == 0:
|
| 217 |
+
return
|
| 218 |
+
|
| 219 |
+
if padding is None:
|
| 220 |
+
padding = PAD
|
| 221 |
+
elif isinstance(padding, str):
|
| 222 |
+
if len(padding) == 0:
|
| 223 |
+
padding = PAD
|
| 224 |
+
else:
|
| 225 |
+
try:
|
| 226 |
+
padding = int(padding)
|
| 227 |
+
except:
|
| 228 |
+
if not padding.endswith('</w>'):
|
| 229 |
+
padding += '</w>'
|
| 230 |
+
|
| 231 |
+
weight = float(weight)
|
| 232 |
+
intp = intp.lower()
|
| 233 |
+
|
| 234 |
+
self.last_hooker = Hook(
|
| 235 |
+
enabled=True,
|
| 236 |
+
targets=targets,
|
| 237 |
+
padding=padding,
|
| 238 |
+
weight=weight,
|
| 239 |
+
disable_neg=disable_neg,
|
| 240 |
+
strong=strong,
|
| 241 |
+
interpolate=intp,
|
| 242 |
+
)
|
| 243 |
+
|
| 244 |
+
self.last_hooker.setup(p)
|
| 245 |
+
self.last_hooker.__enter__()
|
| 246 |
+
|
| 247 |
+
p.extra_generation_params.update({
|
| 248 |
+
f'{NAME} enabled': enabled,
|
| 249 |
+
f'{NAME} targets': targets,
|
| 250 |
+
f'{NAME} padding': padding,
|
| 251 |
+
f'{NAME} weight': weight,
|
| 252 |
+
f'{NAME} disable_for_neg': disable_neg,
|
| 253 |
+
f'{NAME} strong': strong,
|
| 254 |
+
f'{NAME} interpolation': intp,
|
| 255 |
+
})
|
| 256 |
+
|
| 257 |
+
init_xyz(Script, NAME)
|
scripts/cutofflib/embedding.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from itertools import product
|
| 3 |
+
import re
|
| 4 |
+
from typing import Union, List, Tuple
|
| 5 |
+
import numpy as np
|
| 6 |
+
import open_clip
|
| 7 |
+
from modules.sd_hijack_clip import FrozenCLIPEmbedderWithCustomWordsBase as CLIP
|
| 8 |
+
from modules import prompt_parser, shared
|
| 9 |
+
from scripts.cutofflib.utils import log
|
| 10 |
+
|
| 11 |
+
class ClipWrapper:
|
| 12 |
+
def __init__(self, te: CLIP):
|
| 13 |
+
self.te = te
|
| 14 |
+
self.v1 = hasattr(te.wrapped, 'tokenizer')
|
| 15 |
+
self.t = (
|
| 16 |
+
te.wrapped.tokenizer if self.v1
|
| 17 |
+
else open_clip.tokenizer._tokenizer
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
def token_to_id(self, token: str) -> int:
|
| 21 |
+
if self.v1:
|
| 22 |
+
return self.t._convert_token_to_id(token) # type: ignore
|
| 23 |
+
else:
|
| 24 |
+
return self.t.encoder[token]
|
| 25 |
+
|
| 26 |
+
def id_to_token(self, id: int) -> str:
|
| 27 |
+
if self.v1:
|
| 28 |
+
return self.t.convert_ids_to_tokens(id) # type: ignore
|
| 29 |
+
else:
|
| 30 |
+
return self.t.decoder[id]
|
| 31 |
+
|
| 32 |
+
def ids_to_tokens(self, ids: List[int]) -> List[str]:
|
| 33 |
+
if self.v1:
|
| 34 |
+
return self.t.convert_ids_to_tokens(ids) # type: ignore
|
| 35 |
+
else:
|
| 36 |
+
return [self.t.decoder[id] for id in ids]
|
| 37 |
+
|
| 38 |
+
def token(self, token: Union[int,str]):
|
| 39 |
+
if isinstance(token, int):
|
| 40 |
+
return Token(token, self.id_to_token(token))
|
| 41 |
+
else:
|
| 42 |
+
return Token(self.token_to_id(token), token)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
@dataclass
|
| 46 |
+
class Token:
|
| 47 |
+
id: int
|
| 48 |
+
token: str
|
| 49 |
+
|
| 50 |
+
class CutoffPrompt:
|
| 51 |
+
|
| 52 |
+
@staticmethod
|
| 53 |
+
def _cutoff(prompt: str, clip: CLIP, tokens: List[str], padding: str):
|
| 54 |
+
def token_count(text: str):
|
| 55 |
+
tt = token_to_block(clip, text)
|
| 56 |
+
# tt[0] == clip.id_start (<|startoftext|>)
|
| 57 |
+
for index, (t, _) in enumerate(tt):
|
| 58 |
+
if t.id == clip.id_end: # <|endoftext|>
|
| 59 |
+
return index - 1
|
| 60 |
+
return 0 # must not happen...
|
| 61 |
+
|
| 62 |
+
re_targets = [ re.compile(r'\b' + re.escape(x) + r'\b') for x in tokens ]
|
| 63 |
+
replacer = [ ' ' + ' '.join([padding] * token_count(x)) + ' ' for x in tokens ]
|
| 64 |
+
|
| 65 |
+
rows: List[Tuple[str,str]] = []
|
| 66 |
+
for block in prompt.split(','):
|
| 67 |
+
b0 = block
|
| 68 |
+
for r, p in zip(re_targets, replacer):
|
| 69 |
+
block = r.sub(p, block)
|
| 70 |
+
b1 = block
|
| 71 |
+
rows.append((b0, b1))
|
| 72 |
+
|
| 73 |
+
return rows
|
| 74 |
+
|
| 75 |
+
def __init__(self, prompt: str, clip: CLIP, tokens: List[str], padding: str):
|
| 76 |
+
self.prompt = prompt
|
| 77 |
+
rows = CutoffPrompt._cutoff(prompt, clip, tokens, padding)
|
| 78 |
+
self.base = np.array([x[0] for x in rows])
|
| 79 |
+
self.cut = np.array([x[1] for x in rows])
|
| 80 |
+
self.sw = np.array([False] * len(rows))
|
| 81 |
+
|
| 82 |
+
@property
|
| 83 |
+
def block_count(self):
|
| 84 |
+
return self.base.shape[0]
|
| 85 |
+
|
| 86 |
+
def switch(self, block_index: int, to: Union[bool,None] = None):
|
| 87 |
+
if to is None:
|
| 88 |
+
to = not self.sw[block_index]
|
| 89 |
+
self.sw[block_index] = to
|
| 90 |
+
return to
|
| 91 |
+
|
| 92 |
+
def text(self, sw=None):
|
| 93 |
+
if sw is None:
|
| 94 |
+
sw = self.sw
|
| 95 |
+
blocks = np.where(sw, self.cut, self.base)
|
| 96 |
+
return ','.join(blocks)
|
| 97 |
+
|
| 98 |
+
def active_blocks(self) -> np.ndarray:
|
| 99 |
+
indices, = (self.base != self.cut).nonzero()
|
| 100 |
+
return indices
|
| 101 |
+
|
| 102 |
+
def generate(self):
|
| 103 |
+
indices = self.active_blocks()
|
| 104 |
+
for diff_sw in product([False, True], repeat=indices.shape[0]):
|
| 105 |
+
sw = np.full_like(self.sw, False)
|
| 106 |
+
sw[indices] = diff_sw
|
| 107 |
+
yield diff_sw, self.text(sw)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def generate_prompts(
|
| 111 |
+
clip: CLIP,
|
| 112 |
+
prompt: str,
|
| 113 |
+
targets: List[str],
|
| 114 |
+
padding: Union[str,int,Token],
|
| 115 |
+
) -> CutoffPrompt:
|
| 116 |
+
|
| 117 |
+
te = ClipWrapper(clip)
|
| 118 |
+
|
| 119 |
+
if not isinstance(padding, Token):
|
| 120 |
+
o_pad = padding
|
| 121 |
+
padding = te.token(padding)
|
| 122 |
+
if padding.id == clip.id_end:
|
| 123 |
+
raise ValueError(f'`{o_pad}` is not a valid token.')
|
| 124 |
+
|
| 125 |
+
result = CutoffPrompt(prompt, clip, targets, padding.token.replace('</w>', ''))
|
| 126 |
+
|
| 127 |
+
log(f'[Cutoff] replace: {", ".join(targets)}')
|
| 128 |
+
log(f'[Cutoff] to: {padding.token} ({padding.id})')
|
| 129 |
+
log(f'[Cutoff] original: {prompt}')
|
| 130 |
+
for i, (_, pp) in enumerate(result.generate()):
|
| 131 |
+
log(f'[Cutoff] #{i}: {pp}')
|
| 132 |
+
|
| 133 |
+
return result
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def token_to_block(clip: CLIP, prompt: str):
|
| 137 |
+
te = ClipWrapper(clip)
|
| 138 |
+
|
| 139 |
+
# cf. sd_hijack_clip.py
|
| 140 |
+
|
| 141 |
+
parsed = prompt_parser.parse_prompt_attention(prompt)
|
| 142 |
+
tokenized: List[List[int]] = clip.tokenize([text for text, _ in parsed])
|
| 143 |
+
|
| 144 |
+
CHUNK_LENGTH = 75
|
| 145 |
+
id_start = te.token(clip.id_start) # type: ignore
|
| 146 |
+
id_end = te.token(clip.id_end) # type: ignore
|
| 147 |
+
comma = te.token(',</w>')
|
| 148 |
+
|
| 149 |
+
last_comma = -1
|
| 150 |
+
current_block = 0
|
| 151 |
+
current_tokens: List[Tuple[Token,int]] = []
|
| 152 |
+
result: List[Tuple[Token,int]] = []
|
| 153 |
+
|
| 154 |
+
def next_chunk():
|
| 155 |
+
nonlocal current_tokens, last_comma
|
| 156 |
+
|
| 157 |
+
to_add = CHUNK_LENGTH - len(current_tokens)
|
| 158 |
+
if 0 < to_add:
|
| 159 |
+
current_tokens += [(id_end, -1)] * to_add
|
| 160 |
+
|
| 161 |
+
current_tokens = [(id_start, -1)] + current_tokens + [(id_end, -1)]
|
| 162 |
+
|
| 163 |
+
last_comma = -1
|
| 164 |
+
result.extend(current_tokens)
|
| 165 |
+
current_tokens = []
|
| 166 |
+
|
| 167 |
+
for tokens, (text, weight) in zip(tokenized, parsed):
|
| 168 |
+
if text == 'BREAK' and weight == -1:
|
| 169 |
+
next_chunk()
|
| 170 |
+
continue
|
| 171 |
+
|
| 172 |
+
p = 0
|
| 173 |
+
while p < len(tokens):
|
| 174 |
+
token = tokens[p]
|
| 175 |
+
|
| 176 |
+
if token == comma.id:
|
| 177 |
+
last_comma = len(current_tokens)
|
| 178 |
+
current_block += 1
|
| 179 |
+
|
| 180 |
+
elif (
|
| 181 |
+
shared.opts.comma_padding_backtrack != 0
|
| 182 |
+
and len(current_tokens) == CHUNK_LENGTH
|
| 183 |
+
and last_comma != -1
|
| 184 |
+
and len(current_tokens) - last_comma <= shared.opts.comma_padding_backtrack
|
| 185 |
+
):
|
| 186 |
+
break_location = last_comma + 1
|
| 187 |
+
reloc_tokens = current_tokens[break_location:]
|
| 188 |
+
current_tokens = current_tokens[:break_location]
|
| 189 |
+
next_chunk()
|
| 190 |
+
current_tokens = reloc_tokens
|
| 191 |
+
|
| 192 |
+
if len(current_tokens) == CHUNK_LENGTH:
|
| 193 |
+
next_chunk()
|
| 194 |
+
|
| 195 |
+
embedding, embedding_length_in_tokens = clip.hijack.embedding_db.find_embedding_at_position(tokens, p)
|
| 196 |
+
if embedding is None:
|
| 197 |
+
if token == comma.id:
|
| 198 |
+
current_tokens.append((te.token(token), -1))
|
| 199 |
+
else:
|
| 200 |
+
current_tokens.append((te.token(token), current_block))
|
| 201 |
+
p += 1
|
| 202 |
+
continue
|
| 203 |
+
|
| 204 |
+
emb_len = int(embedding.vec.shape[0])
|
| 205 |
+
if len(current_tokens) + emb_len > CHUNK_LENGTH:
|
| 206 |
+
next_chunk()
|
| 207 |
+
|
| 208 |
+
current_tokens += [(te.token(0), current_block)] * emb_len
|
| 209 |
+
p += embedding_length_in_tokens
|
| 210 |
+
|
| 211 |
+
if len(current_tokens) > 0:
|
| 212 |
+
next_chunk()
|
| 213 |
+
|
| 214 |
+
return result
|
scripts/cutofflib/sdhook.py
ADDED
|
@@ -0,0 +1,275 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from typing import Any, Callable, Union
|
| 3 |
+
|
| 4 |
+
from torch import nn
|
| 5 |
+
from torch.utils.hooks import RemovableHandle
|
| 6 |
+
|
| 7 |
+
from ldm.modules.diffusionmodules.openaimodel import (
|
| 8 |
+
TimestepEmbedSequential,
|
| 9 |
+
)
|
| 10 |
+
from ldm.modules.attention import (
|
| 11 |
+
SpatialTransformer,
|
| 12 |
+
BasicTransformerBlock,
|
| 13 |
+
CrossAttention,
|
| 14 |
+
MemoryEfficientCrossAttention,
|
| 15 |
+
)
|
| 16 |
+
from ldm.modules.diffusionmodules.openaimodel import (
|
| 17 |
+
ResBlock,
|
| 18 |
+
)
|
| 19 |
+
from modules.processing import StableDiffusionProcessing
|
| 20 |
+
from modules import shared
|
| 21 |
+
|
| 22 |
+
class ForwardHook:
|
| 23 |
+
|
| 24 |
+
def __init__(self, module: nn.Module, fn: Callable[[nn.Module, Callable[..., Any], Any], Any]):
|
| 25 |
+
self.o = module.forward
|
| 26 |
+
self.fn = fn
|
| 27 |
+
self.module = module
|
| 28 |
+
self.module.forward = self.forward
|
| 29 |
+
|
| 30 |
+
def remove(self):
|
| 31 |
+
if self.module is not None and self.o is not None:
|
| 32 |
+
self.module.forward = self.o
|
| 33 |
+
self.module = None
|
| 34 |
+
self.o = None
|
| 35 |
+
self.fn = None
|
| 36 |
+
|
| 37 |
+
def forward(self, *args, **kwargs):
|
| 38 |
+
if self.module is not None and self.o is not None:
|
| 39 |
+
if self.fn is not None:
|
| 40 |
+
return self.fn(self.module, self.o, *args, **kwargs)
|
| 41 |
+
return None
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class SDHook:
|
| 45 |
+
|
| 46 |
+
def __init__(self, enabled: bool):
|
| 47 |
+
self._enabled = enabled
|
| 48 |
+
self._handles: list[Union[RemovableHandle,ForwardHook]] = []
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def enabled(self):
|
| 52 |
+
return self._enabled
|
| 53 |
+
|
| 54 |
+
@property
|
| 55 |
+
def batch_num(self):
|
| 56 |
+
return shared.state.job_no
|
| 57 |
+
|
| 58 |
+
@property
|
| 59 |
+
def step_num(self):
|
| 60 |
+
return shared.state.current_image_sampling_step
|
| 61 |
+
|
| 62 |
+
def __enter__(self):
|
| 63 |
+
if self.enabled:
|
| 64 |
+
pass
|
| 65 |
+
|
| 66 |
+
def __exit__(self, exc_type, exc_value, traceback):
|
| 67 |
+
if self.enabled:
|
| 68 |
+
for handle in self._handles:
|
| 69 |
+
handle.remove()
|
| 70 |
+
self._handles.clear()
|
| 71 |
+
self.dispose()
|
| 72 |
+
|
| 73 |
+
def dispose(self):
|
| 74 |
+
pass
|
| 75 |
+
|
| 76 |
+
def setup(
|
| 77 |
+
self,
|
| 78 |
+
p: StableDiffusionProcessing
|
| 79 |
+
):
|
| 80 |
+
if not self.enabled:
|
| 81 |
+
return
|
| 82 |
+
|
| 83 |
+
wrapper = getattr(p.sd_model, "model", None)
|
| 84 |
+
|
| 85 |
+
unet: Union[nn.Module,None] = getattr(wrapper, "diffusion_model", None) if wrapper is not None else None
|
| 86 |
+
vae: Union[nn.Module,None] = getattr(p.sd_model, "first_stage_model", None)
|
| 87 |
+
clip: Union[nn.Module,None] = getattr(p.sd_model, "cond_stage_model", None)
|
| 88 |
+
|
| 89 |
+
assert unet is not None, "p.sd_model.diffusion_model is not found. broken model???"
|
| 90 |
+
self._do_hook(p, p.sd_model, unet=unet, vae=vae, clip=clip) # type: ignore
|
| 91 |
+
self.on_setup()
|
| 92 |
+
|
| 93 |
+
def on_setup(self):
|
| 94 |
+
pass
|
| 95 |
+
|
| 96 |
+
def _do_hook(
|
| 97 |
+
self,
|
| 98 |
+
p: StableDiffusionProcessing,
|
| 99 |
+
model: Any,
|
| 100 |
+
unet: Union[nn.Module,None],
|
| 101 |
+
vae: Union[nn.Module,None],
|
| 102 |
+
clip: Union[nn.Module,None]
|
| 103 |
+
):
|
| 104 |
+
assert model is not None, "empty model???"
|
| 105 |
+
|
| 106 |
+
if clip is not None:
|
| 107 |
+
self.hook_clip(p, clip)
|
| 108 |
+
|
| 109 |
+
if unet is not None:
|
| 110 |
+
self.hook_unet(p, unet)
|
| 111 |
+
|
| 112 |
+
if vae is not None:
|
| 113 |
+
self.hook_vae(p, vae)
|
| 114 |
+
|
| 115 |
+
def hook_vae(
|
| 116 |
+
self,
|
| 117 |
+
p: StableDiffusionProcessing,
|
| 118 |
+
vae: nn.Module
|
| 119 |
+
):
|
| 120 |
+
pass
|
| 121 |
+
|
| 122 |
+
def hook_unet(
|
| 123 |
+
self,
|
| 124 |
+
p: StableDiffusionProcessing,
|
| 125 |
+
unet: nn.Module
|
| 126 |
+
):
|
| 127 |
+
pass
|
| 128 |
+
|
| 129 |
+
def hook_clip(
|
| 130 |
+
self,
|
| 131 |
+
p: StableDiffusionProcessing,
|
| 132 |
+
clip: nn.Module
|
| 133 |
+
):
|
| 134 |
+
pass
|
| 135 |
+
|
| 136 |
+
def hook_layer(
|
| 137 |
+
self,
|
| 138 |
+
module: Union[nn.Module,Any],
|
| 139 |
+
fn: Callable[[nn.Module, tuple, Any], Any]
|
| 140 |
+
):
|
| 141 |
+
if not self.enabled:
|
| 142 |
+
return
|
| 143 |
+
|
| 144 |
+
assert module is not None
|
| 145 |
+
assert isinstance(module, nn.Module)
|
| 146 |
+
self._handles.append(module.register_forward_hook(fn))
|
| 147 |
+
|
| 148 |
+
def hook_layer_pre(
|
| 149 |
+
self,
|
| 150 |
+
module: Union[nn.Module,Any],
|
| 151 |
+
fn: Callable[[nn.Module, tuple], Any]
|
| 152 |
+
):
|
| 153 |
+
if not self.enabled:
|
| 154 |
+
return
|
| 155 |
+
|
| 156 |
+
assert module is not None
|
| 157 |
+
assert isinstance(module, nn.Module)
|
| 158 |
+
self._handles.append(module.register_forward_pre_hook(fn))
|
| 159 |
+
|
| 160 |
+
def hook_forward(
|
| 161 |
+
self,
|
| 162 |
+
module: Union[nn.Module,Any],
|
| 163 |
+
fn: Callable[[nn.Module, Callable[..., Any], Any], Any]
|
| 164 |
+
):
|
| 165 |
+
assert module is not None
|
| 166 |
+
assert isinstance(module, nn.Module)
|
| 167 |
+
self._handles.append(ForwardHook(module, fn))
|
| 168 |
+
|
| 169 |
+
def log(self, msg: str):
|
| 170 |
+
print(msg, file=sys.stderr)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
# enumerate SpatialTransformer in TimestepEmbedSequential
|
| 174 |
+
def each_transformer(unet_block: TimestepEmbedSequential):
|
| 175 |
+
for block in unet_block.children():
|
| 176 |
+
if isinstance(block, SpatialTransformer):
|
| 177 |
+
yield block
|
| 178 |
+
|
| 179 |
+
# enumerate BasicTransformerBlock in SpatialTransformer
|
| 180 |
+
def each_basic_block(trans: SpatialTransformer):
|
| 181 |
+
for block in trans.transformer_blocks.children():
|
| 182 |
+
if isinstance(block, BasicTransformerBlock):
|
| 183 |
+
yield block
|
| 184 |
+
|
| 185 |
+
# enumerate Attention Layers in TimestepEmbedSequential
|
| 186 |
+
# each_transformer + each_basic_block
|
| 187 |
+
def each_attns(unet_block: TimestepEmbedSequential):
|
| 188 |
+
for n, trans in enumerate(each_transformer(unet_block)):
|
| 189 |
+
for depth, basic_block in enumerate(each_basic_block(trans)):
|
| 190 |
+
# attn1: Union[CrossAttention,MemoryEfficientCrossAttention]
|
| 191 |
+
# attn2: Union[CrossAttention,MemoryEfficientCrossAttention]
|
| 192 |
+
|
| 193 |
+
attn1, attn2 = basic_block.attn1, basic_block.attn2
|
| 194 |
+
assert isinstance(attn1, CrossAttention) or isinstance(attn1, MemoryEfficientCrossAttention)
|
| 195 |
+
assert isinstance(attn2, CrossAttention) or isinstance(attn2, MemoryEfficientCrossAttention)
|
| 196 |
+
|
| 197 |
+
yield n, depth, attn1, attn2
|
| 198 |
+
|
| 199 |
+
def each_unet_attn_layers(unet: nn.Module):
|
| 200 |
+
def get_attns(layer_index: int, block: TimestepEmbedSequential, format: str):
|
| 201 |
+
for n, d, attn1, attn2 in each_attns(block):
|
| 202 |
+
kwargs = {
|
| 203 |
+
'layer_index': layer_index,
|
| 204 |
+
'trans_index': n,
|
| 205 |
+
'block_index': d
|
| 206 |
+
}
|
| 207 |
+
yield format.format(attn_name='sattn', **kwargs), attn1
|
| 208 |
+
yield format.format(attn_name='xattn', **kwargs), attn2
|
| 209 |
+
|
| 210 |
+
def enumerate_all(blocks: nn.ModuleList, format: str):
|
| 211 |
+
for idx, block in enumerate(blocks.children()):
|
| 212 |
+
if isinstance(block, TimestepEmbedSequential):
|
| 213 |
+
yield from get_attns(idx, block, format)
|
| 214 |
+
|
| 215 |
+
inputs: nn.ModuleList = unet.input_blocks # type: ignore
|
| 216 |
+
middle: TimestepEmbedSequential = unet.middle_block # type: ignore
|
| 217 |
+
outputs: nn.ModuleList = unet.output_blocks # type: ignore
|
| 218 |
+
|
| 219 |
+
yield from enumerate_all(inputs, 'IN{layer_index:02}_{trans_index:02}_{block_index:02}_{attn_name}')
|
| 220 |
+
yield from get_attns(0, middle, 'M{layer_index:02}_{trans_index:02}_{block_index:02}_{attn_name}')
|
| 221 |
+
yield from enumerate_all(outputs, 'OUT{layer_index:02}_{trans_index:02}_{block_index:02}_{attn_name}')
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def each_unet_transformers(unet: nn.Module):
|
| 225 |
+
def get_trans(layer_index: int, block: TimestepEmbedSequential, format: str):
|
| 226 |
+
for n, trans in enumerate(each_transformer(block)):
|
| 227 |
+
kwargs = {
|
| 228 |
+
'layer_index': layer_index,
|
| 229 |
+
'block_index': n,
|
| 230 |
+
'block_name': 'trans',
|
| 231 |
+
}
|
| 232 |
+
yield format.format(**kwargs), trans
|
| 233 |
+
|
| 234 |
+
def enumerate_all(blocks: nn.ModuleList, format: str):
|
| 235 |
+
for idx, block in enumerate(blocks.children()):
|
| 236 |
+
if isinstance(block, TimestepEmbedSequential):
|
| 237 |
+
yield from get_trans(idx, block, format)
|
| 238 |
+
|
| 239 |
+
inputs: nn.ModuleList = unet.input_blocks # type: ignore
|
| 240 |
+
middle: TimestepEmbedSequential = unet.middle_block # type: ignore
|
| 241 |
+
outputs: nn.ModuleList = unet.output_blocks # type: ignore
|
| 242 |
+
|
| 243 |
+
yield from enumerate_all(inputs, 'IN{layer_index:02}_{block_index:02}_{block_name}')
|
| 244 |
+
yield from get_trans(0, middle, 'M{layer_index:02}_{block_index:02}_{block_name}')
|
| 245 |
+
yield from enumerate_all(outputs, 'OUT{layer_index:02}_{block_index:02}_{block_name}')
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def each_resblock(unet_block: TimestepEmbedSequential):
|
| 249 |
+
for block in unet_block.children():
|
| 250 |
+
if isinstance(block, ResBlock):
|
| 251 |
+
yield block
|
| 252 |
+
|
| 253 |
+
def each_unet_resblock(unet: nn.Module):
|
| 254 |
+
def get_resblock(layer_index: int, block: TimestepEmbedSequential, format: str):
|
| 255 |
+
for n, res in enumerate(each_resblock(block)):
|
| 256 |
+
kwargs = {
|
| 257 |
+
'layer_index': layer_index,
|
| 258 |
+
'block_index': n,
|
| 259 |
+
'block_name': 'resblock',
|
| 260 |
+
}
|
| 261 |
+
yield format.format(**kwargs), res
|
| 262 |
+
|
| 263 |
+
def enumerate_all(blocks: nn.ModuleList, format: str):
|
| 264 |
+
for idx, block in enumerate(blocks.children()):
|
| 265 |
+
if isinstance(block, TimestepEmbedSequential):
|
| 266 |
+
yield from get_resblock(idx, block, format)
|
| 267 |
+
|
| 268 |
+
inputs: nn.ModuleList = unet.input_blocks # type: ignore
|
| 269 |
+
middle: TimestepEmbedSequential = unet.middle_block # type: ignore
|
| 270 |
+
outputs: nn.ModuleList = unet.output_blocks # type: ignore
|
| 271 |
+
|
| 272 |
+
yield from enumerate_all(inputs, 'IN{layer_index:02}_{block_index:02}_{block_name}')
|
| 273 |
+
yield from get_resblock(0, middle, 'M{layer_index:02}_{block_index:02}_{block_name}')
|
| 274 |
+
yield from enumerate_all(outputs, 'OUT{layer_index:02}_{block_index:02}_{block_name}')
|
| 275 |
+
|
scripts/cutofflib/utils.py
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
|
| 3 |
+
_debug = False
|
| 4 |
+
|
| 5 |
+
def set_debug(is_debug: bool):
|
| 6 |
+
global _debug
|
| 7 |
+
_debug = is_debug
|
| 8 |
+
|
| 9 |
+
def log(s: str):
|
| 10 |
+
if _debug:
|
| 11 |
+
print(s, file=sys.stderr)
|
scripts/cutofflib/xyz.py
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from typing import Union, List, Callable
|
| 3 |
+
|
| 4 |
+
from modules import scripts
|
| 5 |
+
from modules.processing import StableDiffusionProcessing, StableDiffusionProcessingTxt2Img, StableDiffusionProcessingImg2Img
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def __set_value(p: StableDiffusionProcessing, script: type, index: int, value):
|
| 9 |
+
args = list(p.script_args)
|
| 10 |
+
|
| 11 |
+
if isinstance(p, StableDiffusionProcessingTxt2Img):
|
| 12 |
+
all_scripts = scripts.scripts_txt2img.scripts
|
| 13 |
+
else:
|
| 14 |
+
all_scripts = scripts.scripts_img2img.scripts
|
| 15 |
+
|
| 16 |
+
froms = [x.args_from for x in all_scripts if isinstance(x, script)]
|
| 17 |
+
for idx in froms:
|
| 18 |
+
assert idx is not None
|
| 19 |
+
args[idx + index] = value
|
| 20 |
+
|
| 21 |
+
p.script_args = type(p.script_args)(args)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def to_bool(v: str):
|
| 25 |
+
if len(v) == 0: return False
|
| 26 |
+
v = v.lower()
|
| 27 |
+
if 'true' in v: return True
|
| 28 |
+
if 'false' in v: return False
|
| 29 |
+
|
| 30 |
+
try:
|
| 31 |
+
w = int(v)
|
| 32 |
+
return bool(w)
|
| 33 |
+
except:
|
| 34 |
+
acceptable = ['True', 'False', '1', '0']
|
| 35 |
+
s = ', '.join([f'`{v}`' for v in acceptable])
|
| 36 |
+
raise ValueError(f'value must be one of {s}.')
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class AxisOptions:
|
| 40 |
+
|
| 41 |
+
def __init__(self, AxisOption: type, axis_options: list):
|
| 42 |
+
self.AxisOption = AxisOption
|
| 43 |
+
self.target = axis_options
|
| 44 |
+
self.options = []
|
| 45 |
+
|
| 46 |
+
def __enter__(self):
|
| 47 |
+
self.options.clear()
|
| 48 |
+
return self
|
| 49 |
+
|
| 50 |
+
def __exit__(self, ex_type, ex_value, trace):
|
| 51 |
+
if ex_type is not None:
|
| 52 |
+
return
|
| 53 |
+
|
| 54 |
+
for opt in self.options:
|
| 55 |
+
self.target.append(opt)
|
| 56 |
+
|
| 57 |
+
self.options.clear()
|
| 58 |
+
|
| 59 |
+
def create(self, name: str, type_fn: Callable, action: Callable, choices: Union[List[str],None]):
|
| 60 |
+
if choices is None or len(choices) == 0:
|
| 61 |
+
opt = self.AxisOption(name, type_fn, action)
|
| 62 |
+
else:
|
| 63 |
+
opt = self.AxisOption(name, type_fn, action, choices=lambda: choices)
|
| 64 |
+
return opt
|
| 65 |
+
|
| 66 |
+
def add(self, axis_option):
|
| 67 |
+
self.target.append(axis_option)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
__init = False
|
| 71 |
+
|
| 72 |
+
def init_xyz(script: type, ext_name: str):
|
| 73 |
+
global __init
|
| 74 |
+
|
| 75 |
+
if __init:
|
| 76 |
+
return
|
| 77 |
+
|
| 78 |
+
for data in scripts.scripts_data:
|
| 79 |
+
name = os.path.basename(data.path)
|
| 80 |
+
if name != 'xy_grid.py' and name != 'xyz_grid.py':
|
| 81 |
+
continue
|
| 82 |
+
|
| 83 |
+
if not hasattr(data.module, 'AxisOption'):
|
| 84 |
+
continue
|
| 85 |
+
|
| 86 |
+
if not hasattr(data.module, 'axis_options'):
|
| 87 |
+
continue
|
| 88 |
+
|
| 89 |
+
AxisOption = data.module.AxisOption
|
| 90 |
+
axis_options = data.module.axis_options
|
| 91 |
+
|
| 92 |
+
if not isinstance(AxisOption, type):
|
| 93 |
+
continue
|
| 94 |
+
|
| 95 |
+
if not isinstance(axis_options, list):
|
| 96 |
+
continue
|
| 97 |
+
|
| 98 |
+
try:
|
| 99 |
+
create_options(ext_name, script, AxisOption, axis_options)
|
| 100 |
+
except:
|
| 101 |
+
pass
|
| 102 |
+
|
| 103 |
+
__init = True
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def create_options(ext_name: str, script: type, AxisOptionClass: type, axis_options: list):
|
| 107 |
+
with AxisOptions(AxisOptionClass, axis_options) as opts:
|
| 108 |
+
def define(param: str, index: int, type_fn: Callable, choices: List[str] = []):
|
| 109 |
+
def fn(p, x, xs):
|
| 110 |
+
__set_value(p, script, index, x)
|
| 111 |
+
|
| 112 |
+
name = f'{ext_name} {param}'
|
| 113 |
+
return opts.create(name, type_fn, fn, choices)
|
| 114 |
+
|
| 115 |
+
options = [
|
| 116 |
+
define('Enabled', 0, to_bool, choices=['false', 'true']),
|
| 117 |
+
define('Targets', 1, str),
|
| 118 |
+
define('Weight', 2, float),
|
| 119 |
+
define('Disable for Negative Prompt', 3, to_bool, choices=['false', 'true']),
|
| 120 |
+
define('Strong', 4, to_bool, choices=['false', 'true']),
|
| 121 |
+
define('Padding', 5, str),
|
| 122 |
+
define('Interpolation', 6, str, choices=['Lerp', 'SLerp']),
|
| 123 |
+
]
|
| 124 |
+
|
| 125 |
+
for opt in options:
|
| 126 |
+
opts.add(opt)
|