Note: Faster-Whisper support relies on this PR being merged to the Faster-Whisper main branch. Once merged, you can follow the examples below for using the model. Until then, you may wish to try a different implementation, such as Transformers or Whisper cpp.
First, install the Faster-Whisper package according to the [official instructions](https://github.com/SYSTRAN/faster-whisper#installation).
For this example, we'll also install 🤗 Datasets to load a toy audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade git+https://github.com/SYSTRAN/faster-whisper datasets[audio]
```
The following code snippet loads the distil-large-v3 model and runs inference on an example file from the LibriSpeech ASR
dataset:
```python
import torch
from faster_whisper import WhisperModel
from datasets import load_dataset
# define our torch configuration
device = "cuda:0" if torch.cuda.is_available() else "cpu"
compute_type = "float16" if torch.cuda.is_available() else "float32"
# load model on GPU if available, else cpu
model = WhisperModel("distil-large-v3", device=device, compute_type=compute_type)
# load toy dataset for example
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[1]["audio"]["path"]
segments, info = model.transcribe(sample, beam_size=1)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
segments, info = model.transcribe("audio.mp3", beam_size=1)
```
### OpenAI Whisper
To use the model in the original Whisper format, first ensure you have the [`openai-whisper`](https://pypi.org/project/openai-whisper/) package installed.
For this example, we'll also install 🤗 Datasets to load a toy audio dataset from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade openai-whisper datasets[audio]
```
The following code-snippet demonstrates how to transcribe a sample file from the LibriSpeech dataset loaded using
🤗 Datasets:
```python
from huggingface_hub import hf_hub_download
from datasets import load_dataset
from whisper import load_model, transcribe
model_path = hf_hub_download(repo_id="distil-whisper/distil-large-v3-openai", filename="model.bin")
model = load_model(model_path)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
sample = dataset[0]["audio"]["path"]
pred_out = transcribe(model, audio=sample)
print(pred_out["text"])
```
Note that the model weights will be downloaded and saved to your cache the first time you run the example. Subsequently,
you can re-use the same example, and the weights will be loaded directly from your cache without having to download them
again.
To transcribe a local audio file, simply pass the path to the audio file as the `audio` argument to transcribe:
```python
pred_out = transcribe(model, audio="audio.mp3")
```
### Transformers.js
Distil-Whisper can be run completely in your web browser with [Transformers.js](http://github.com/xenova/transformers.js):
1. Install Transformers.js from [NPM](https://www.npmjs.com/package/@xenova/transformers):
```bash
npm i @xenova/transformers
```
2. Import the library and perform inference with the pipeline API.
```js
import { pipeline } from '@xenova/transformers';
const transcriber = await pipeline('automatic-speech-recognition', 'distil-whisper/distil-large-v3');
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
const output = await transcriber(url);
// { text: " And so, my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
```
Check out the online [Distil-Whisper Web Demo](https://huggingface.co/spaces/Xenova/distil-whisper-web) to try it out yourself.
As you'll see, it runs locally in your browser: no server required!
Refer to the Transformers.js [docs](https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.AutomaticSpeechRecognitionPipeline)
for further information.
### Candle
Through an integration with Hugging Face [Candle](https://github.com/huggingface/candle/tree/main) 🕯️, Distil-Whisper is
available in the Rust library 🦀
Benefit from:
* Optimised CPU backend with optional MKL support for Linux x86 and Accelerate for Macs
* Metal support for efficiently running on Macs
* CUDA backend for efficiently running on GPUs, multiple GPU distribution via NCCL
* WASM support: run Distil-Whisper in a browser
Steps for getting started:
1. Install [`candle-core`](https://github.com/huggingface/candle/tree/main/candle-core) as explained [here](https://huggingface.github.io/candle/guide/installation.html)
2. Clone the `candle` repository locally:
```
git clone https://github.com/huggingface/candle.git
```
3. Enter the example directory for [Whisper](https://github.com/huggingface/candle/tree/main/candle-examples/examples/whisper):
```
cd candle/candle-examples/examples/whisper
```
4. Run an example:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3
```
5. To specify your own audio file, add the `--input` flag:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3 --input audio.wav
```
**Tip:** for compiling using Apple Metal, specify the `metal` feature when you run the example:
```
cargo run --example whisper --release --features="symphonia,metal" -- --model distil-large-v3
```
Note that if you encounter the error:
```
error: target `whisper` in package `candle-examples` requires the features: `symphonia`
Consider enabling them by passing, e.g., `--features="symphonia"`
```
You should clean your `cargo` installation:
```
cargo clean
```
And subsequently recompile:
```
cargo run --example whisper --release --features symphonia -- --model distil-large-v3
```
## Model Details
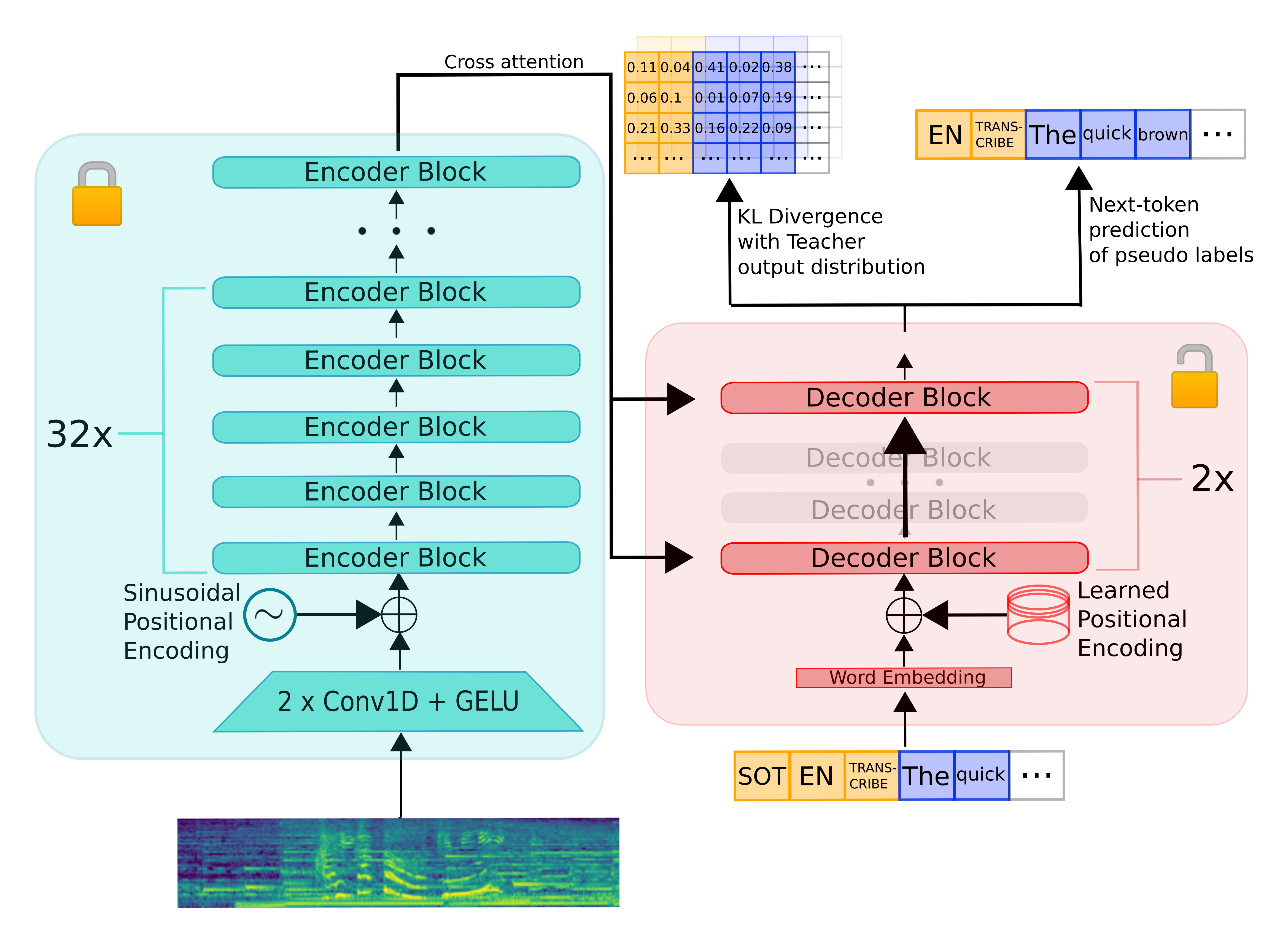
Distil-Whisper inherits the encoder-decoder architecture from Whisper. The encoder maps a sequence of speech vector
inputs to a sequence of hidden-state vectors. The decoder auto-regressively predicts text tokens, conditional on all
previous tokens and the encoder hidden-states. Consequently, the encoder is only run forward once, whereas the decoder
is run as many times as the number of tokens generated. In practice, this means the decoder accounts for over 90% of
total inference time. Thus, to optimise for latency, the focus is on minimising the inference time of the decoder.
To distill the Whisper model, we reduce the number of decoder layers while keeping the encoder fixed.
The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training.
The student's decoder consists of a subset of the teacher decoder layers, which are intialised from maximally spaced layers.
The model is then trained on a weighted sum of the KL divergence and pseudo-label loss terms.