---
language: it
license: apache-2.0
widget:
- text: "Il [MASK] ha chiesto revocarsi l'obbligo di pagamento"
---
ITALIAN-LEGAL-BERT:A pre-trained Transformer Language Model for Italian Law
ITALIAN-LEGAL-BERT is based on bert-base-italian-xxl-cased with additional pre-training of the Italian BERT model on Italian civil law corpora.
It achieves better results than the ‘general-purpose’ Italian BERT in different domain-specific tasks.
Training procedure
We initialized ITALIAN-LEGAL-BERT with ITALIAN XXL BERT
and pretrained for an additional 4 epochs on 3.7 GB of preprocessed text from the National Jurisprudential
Archive using the Huggingface PyTorch-Transformers library. We used BERT architecture
with a language modeling head on top, AdamW Optimizer, initial learning rate 5e-5 (with
linear learning rate decay, ends at 2.525e-9), sequence length 512, batch size 10 (imposed
by GPU capacity), 8.4 million training steps, device 1*GPU V100 16GB
## Usage
ITALIAN-LEGAL-BERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dlicari/Italian-Legal-BERT"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
You can use the Transformers library fill-mask pipeline to do inference with ITALIAN-LEGAL-BERT.
```python
from transformers import pipeline
model_name = "dlicari/Italian-Legal-BERT"
fill_mask = pipeline("fill-mask", model_name)
fill_mask("Il [MASK] ha chiesto revocarsi l'obbligo di pagamento")
#[{'sequence': "Il ricorrente ha chiesto revocarsi l'obbligo di pagamento",'score': 0.7264330387115479},
# {'sequence': "Il convenuto ha chiesto revocarsi l'obbligo di pagamento",'score': 0.09641049802303314},
# {'sequence': "Il resistente ha chiesto revocarsi l'obbligo di pagamento",'score': 0.039877112954854965},
# {'sequence': "Il lavoratore ha chiesto revocarsi l'obbligo di pagamento",'score': 0.028993653133511543},
# {'sequence': "Il Ministero ha chiesto revocarsi l'obbligo di pagamento", 'score': 0.025297977030277252}]
```
here how to use it for sentence similarity
```python
import seaborn as sns
import matplotlib.pyplot as pl
from textwrap import wrap
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
# gettting Sentence Embeddings
def sentence_embeddings(sentences, model_name, max_length=512):
# load models
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
#Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, max_length=max_length, return_tensors='pt')
#Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
#Perform pooling. In this case, mean pooling
return mean_pooling(model_output, encoded_input['attention_mask']).detach().numpy()
def plot_similarity(sentences, model_name):
# get sentence embeddings produced by the model
embeddings = sentence_embeddings(sentences, model_name)
# perfome similarity score using cosine similarity
corr = cosine_similarity(embeddings, embeddings)
# plot heatmap similarity
sns.set(font_scale=1.2)
# for text axis labels wrapping
labels = [ '\n'.join(wrap(l, 40)) for l in sentences]
g = sns.heatmap(
corr,
xticklabels=labels,
yticklabels=labels,
vmax=1,
cmap="YlOrRd")
g.set_xticklabels(labels, rotation=90)
model_short_name = model_name.split('/')[-1]
g.set_title(f"Semantic Textual Similarity ({model_short_name})")
plt.show()
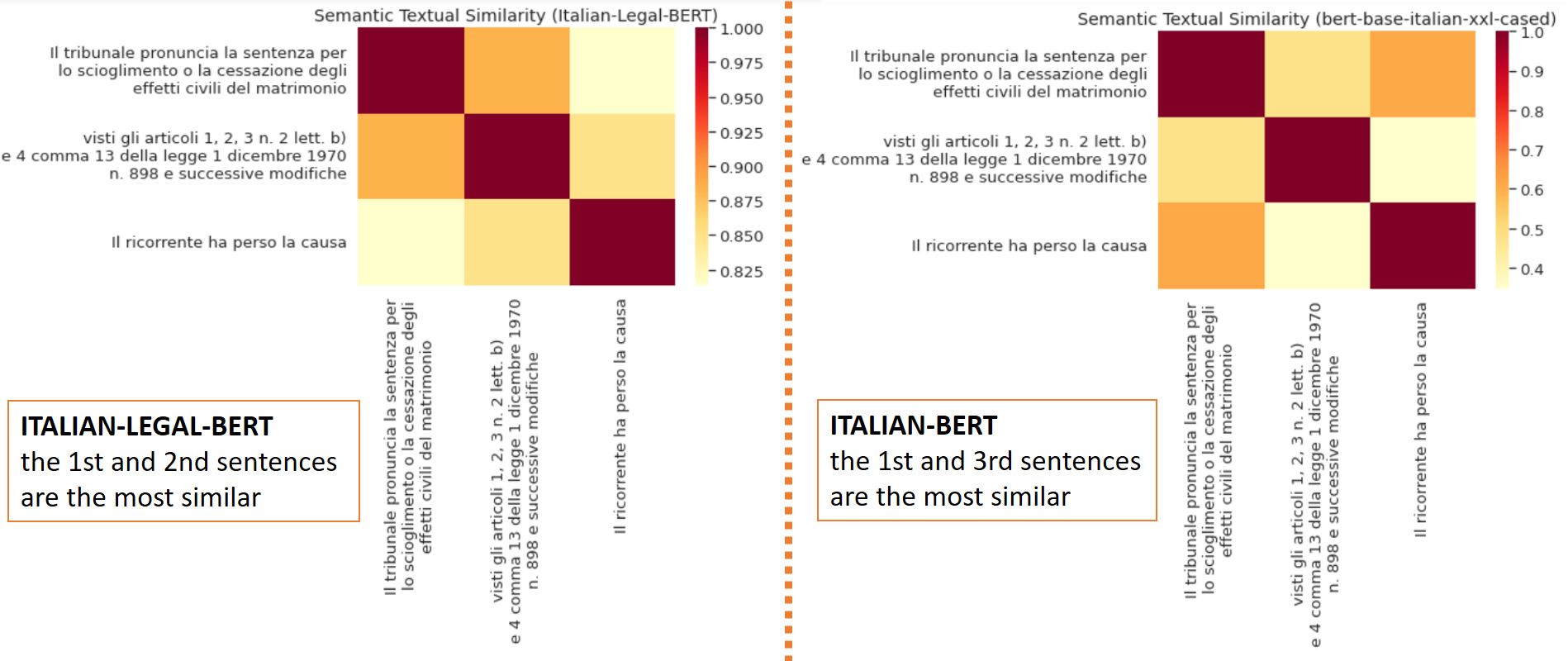
sent = [
# 1. "The court shall pronounce the judgment for the dissolution or termination of the civil effects of marriage."
"Il tribunale pronuncia la sentenza per lo scioglimento o la cessazione degli effetti civili del matrimonio",
# 2. "having regard to Articles 1, 2, 3 No. 2(b) and 4 Paragraph 13 of Law No. 898 of December 1, 1970, as later amended."
# NOTE: Law Dec. 1, 1970 No. 898 is on divorce
"visti gli articoli 1, 2, 3 n. 2 lett. b) e 4 comma 13 della legge 1 dicembre 1970 n. 898 e successive modifiche",
# 3. "The plaintiff has lost the case."
"Il ricorrente ha perso la causa"
]
model_name = "dlicari/Italian-Legal-BERT"
plot_similarity(sent, model_name)
model_name = 'dbmdz/bert-base-italian-xxl-cased'
plot_similarity(sent, model_name)
```