
File size: 1,324 Bytes
ff0c8b1 a9043a9 ff0c8b1 165c40a bec4e6a ff0c8b1 7fbecab 8aba5bf a9043a9 ff0c8b1 35b0fc6 8aba5bf 0a1e9ce 8aba5bf 0f46be1 8aba5bf cb236eb 8aba5bf f795b14 8aba5bf |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
---
license: apache-2.0
language:
- de
- fr
- en
- ro
base_model:
- google/flan-t5-xxl
library_name: llama.cpp
tags:
- llama.cpp
---
# flan-t5-xxl-gguf
## This is a quantized version of [google/flan-t5-xxl](https://huggingface.co/google/flan-t5-xxl/)
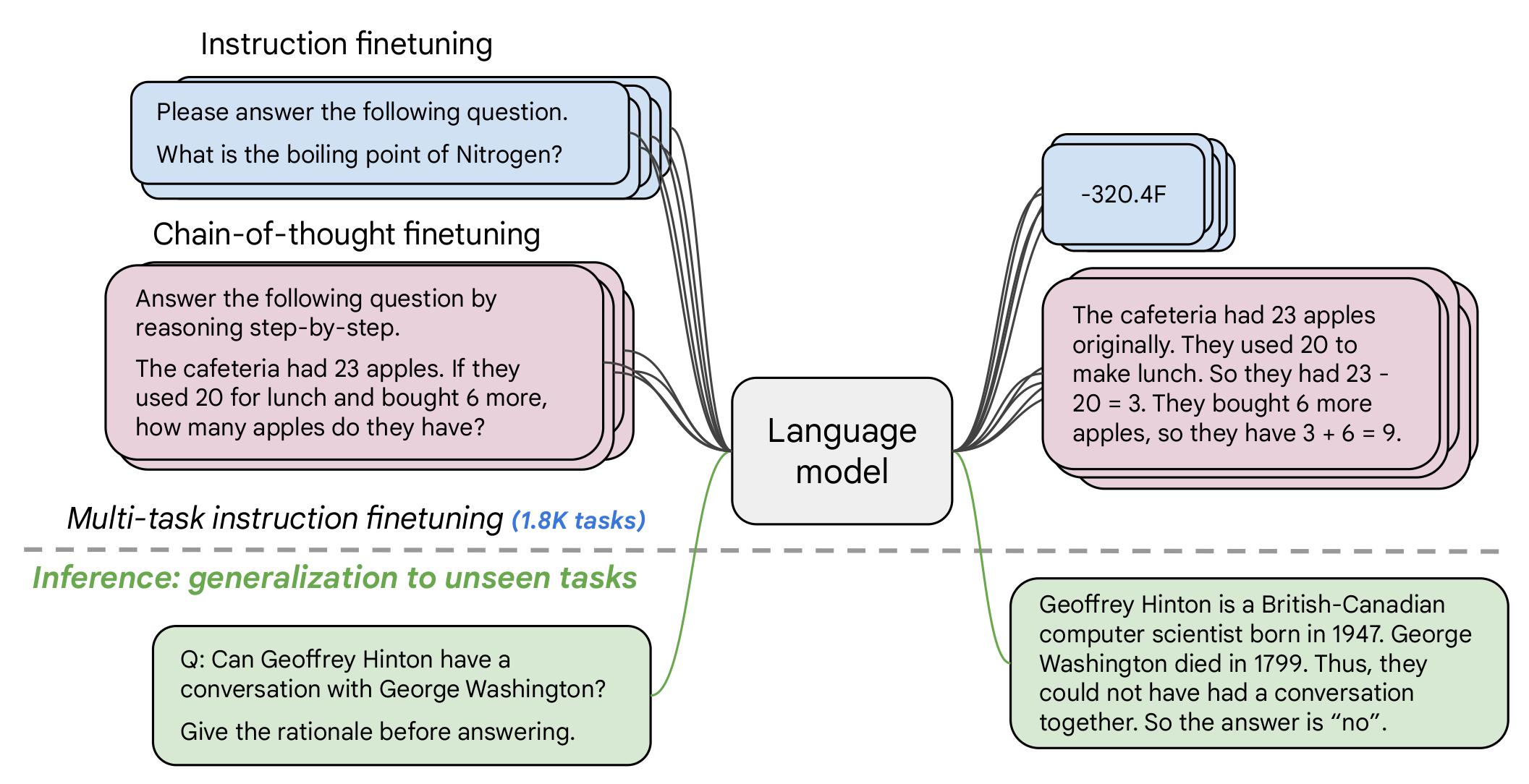
## Usage/Examples
```sh
./llama-cli -m /path/to/file.gguf --prompt "your prompt" --n-gpu-layers nn
```
nn --> numbers of layers to offload to gpu
## Quants
BITs | TYPE |
--------|------------- |
Q2 | Q2_K |
Q3 | Q3_K, Q3_K_L, Q3_K_M, Q3_K_S |
Q4 | Q4_0, Q4_1, Q4_K, Q4_K_M, Q4_K_S |
Q5 | Q5_0, Q5_1, Q5_K, Q5_K_M, Q5_K_S |
Q6 | Q6_K |
Q8 | Q8_0 |
#### Additional:
BITs | TYPE/float |
--------|------------- |
16 | f16 |
32 | f32 |
## Disclaimer
I don't claim any rights on this model. All rights go to google.
## Acknowledgements
- [Original model](https://huggingface.co/google/flan-t5-xxl/)
- [Original README](https://huggingface.co/google/flan-t5-xxl/blob/main/README.md)
- [Original license](https://huggingface.co/datasets/choosealicense/licenses/blob/main/markdown/apache-2.0.md)
|