

Upload 8 files
Browse files- .gitattributes +1 -0
- README.md +157 -3
- config.yaml +117 -0
- configuration.json +13 -0
- emotion2vec+data.png +0 -0
- emotion2vec+radar.png +0 -0
- example/test.wav +0 -0
- logo.png +3 -0
- tokens.txt +9 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
logo.png filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,157 @@
|
|
| 1 |
-
---
|
| 2 |
-
license:
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
license_name: model-license
|
| 4 |
+
license_link: https://github.com/alibaba-damo-academy/FunASR
|
| 5 |
+
frameworks:
|
| 6 |
+
- Pytorch
|
| 7 |
+
tasks:
|
| 8 |
+
- emotion-recognition
|
| 9 |
+
widgets:
|
| 10 |
+
- enable: true
|
| 11 |
+
version: 1
|
| 12 |
+
task: emotion-recognition
|
| 13 |
+
examples:
|
| 14 |
+
- inputs:
|
| 15 |
+
- data: git://example/test.wav
|
| 16 |
+
inputs:
|
| 17 |
+
- type: audio
|
| 18 |
+
displayType: AudioUploader
|
| 19 |
+
validator:
|
| 20 |
+
max_size: 10M
|
| 21 |
+
name: input
|
| 22 |
+
output:
|
| 23 |
+
displayType: Prediction
|
| 24 |
+
displayValueMapping:
|
| 25 |
+
labels: labels
|
| 26 |
+
scores: scores
|
| 27 |
+
inferencespec:
|
| 28 |
+
cpu: 8
|
| 29 |
+
gpu: 0
|
| 30 |
+
gpu_memory: 0
|
| 31 |
+
memory: 4096
|
| 32 |
+
model_revision: master
|
| 33 |
+
extendsParameters:
|
| 34 |
+
extract_embedding: false
|
| 35 |
+
---
|
| 36 |
+
|
| 37 |
+
<div align="center">
|
| 38 |
+
<h1>
|
| 39 |
+
EMOTION2VEC+
|
| 40 |
+
</h1>
|
| 41 |
+
<p>
|
| 42 |
+
emotion2vec+: speech emotion recognition foundation model <br>
|
| 43 |
+
<b>emotion2vec+ base model</b>
|
| 44 |
+
</p>
|
| 45 |
+
<p>
|
| 46 |
+
<img src="logo.png" style="width: 200px; height: 200px;">
|
| 47 |
+
</p>
|
| 48 |
+
<p>
|
| 49 |
+
</p>
|
| 50 |
+
</div>
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
# Guides
|
| 54 |
+
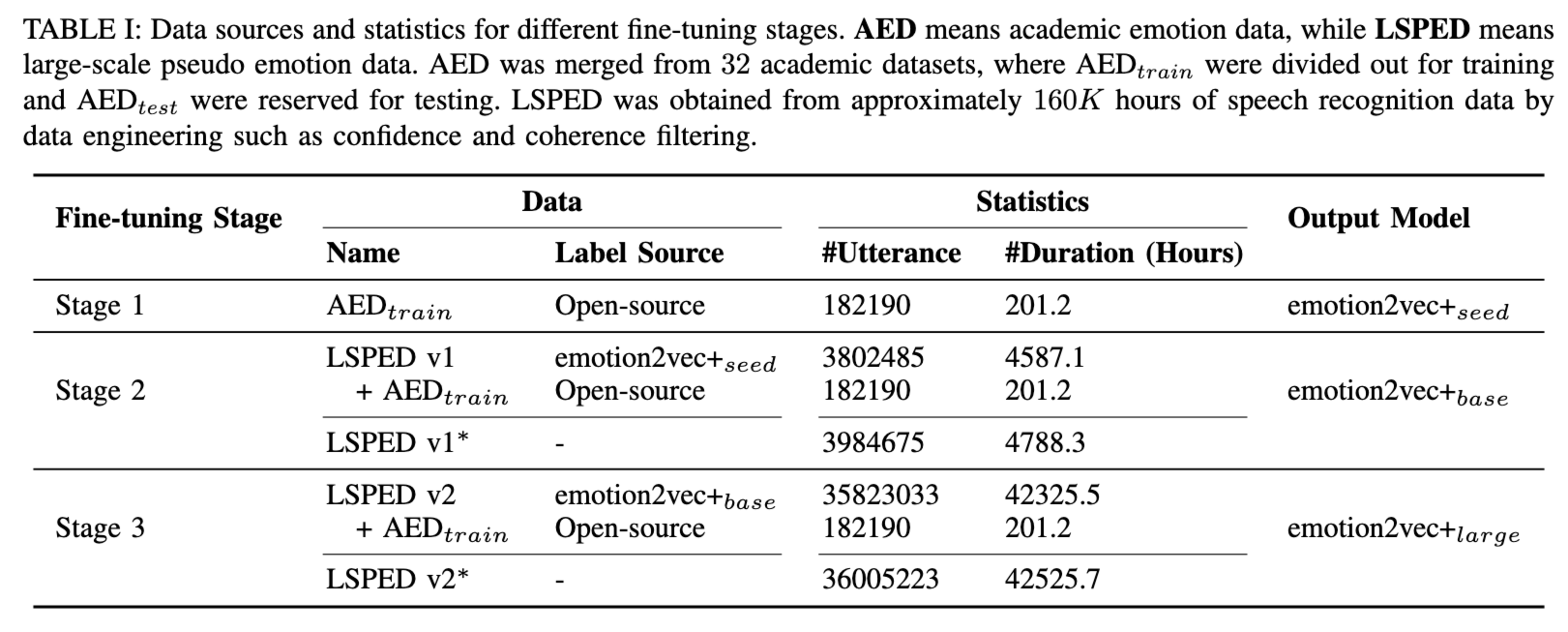
emotion2vec+ is a series of foundational models for speech emotion recognition (SER). We aim to train a "whisper" in the field of speech emotion recognition, overcoming the effects of language and recording environments through data-driven methods to achieve universal, robust emotion recognition capabilities. The performance of emotion2vec+ significantly exceeds other highly downloaded open-source models on Hugging Face.
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
This version (emotion2vec_plus_base) uses a large-scale pseudo-labeled data for finetuning to obtain a base size model (~90M), and currently supports the following categories:
|
| 59 |
+
0: angry
|
| 60 |
+
1: happy
|
| 61 |
+
2: neutral
|
| 62 |
+
3: sad
|
| 63 |
+
4: unknown
|
| 64 |
+
|
| 65 |
+
# Model Card
|
| 66 |
+
GitHub Repo: [emotion2vec](https://github.com/ddlBoJack/emotion2vec)
|
| 67 |
+
|Model|⭐Model Scope|🤗Hugging Face|Fine-tuning Data (Hours)|
|
| 68 |
+
|:---:|:-------------:|:-----------:|:-------------:|
|
| 69 |
+
|emotion2vec|[Link](https://www.modelscope.cn/models/iic/emotion2vec_base/summary)|[Link](https://huggingface.co/emotion2vec/emotion2vec)|/|
|
| 70 |
+
emotion2vec+ seed|[Link](https://modelscope.cn/models/iic/emotion2vec_plus_seed/summary)|[Link](https://huggingface.co/emotion2vec/emotion2vec_plus_seed)|201|
|
| 71 |
+
emotion2vec+ base|[Link](https://modelscope.cn/models/iic/emotion2vec_plus_base/summary)|[Link](https://huggingface.co/emotion2vec/emotion2vec_plus_base)|4788|
|
| 72 |
+
emotion2vec+ large|[Link](https://modelscope.cn/models/iic/emotion2vec_plus_large/summary)|[Link](https://huggingface.co/emotion2vec/emotion2vec_plus_large)|42526|
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# Data Iteration
|
| 76 |
+
|
| 77 |
+
We offer 3 versions of emotion2vec+, each derived from the data of its predecessor. If you need a model focusing on spech emotion representation, refer to [emotion2vec: universal speech emotion representation model](https://huggingface.co/emotion2vec/emotion2vec).
|
| 78 |
+
|
| 79 |
+
- emotion2vec+ seed: Fine-tuned with academic speech emotion data
|
| 80 |
+
- emotion2vec+ base: Fine-tuned with filtered large-scale pseudo-labeled data to obtain the base size model (~90M)
|
| 81 |
+
- emotion2vec+ large: Fine-tuned with filtered large-scale pseudo-labeled data to obtain the large size model (~300M)
|
| 82 |
+
|
| 83 |
+
The iteration process is illustrated below, culminating in the training of the emotion2vec+ large model with 40k out of 160k hours of speech emotion data. Details of data engineering will be announced later.
|
| 84 |
+
|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
# Installation
|
| 88 |
+
|
| 89 |
+
`pip install -U funasr modelscope`
|
| 90 |
+
|
| 91 |
+
# Usage
|
| 92 |
+
|
| 93 |
+
input: 16k Hz speech recording
|
| 94 |
+
|
| 95 |
+
granularity:
|
| 96 |
+
- "utterance": Extract features from the entire utterance
|
| 97 |
+
- "frame": Extract frame-level features (50 Hz)
|
| 98 |
+
|
| 99 |
+
extract_embedding: Whether to extract features; set to False if using only the classification model
|
| 100 |
+
|
| 101 |
+
## Inference based on ModelScope
|
| 102 |
+
|
| 103 |
+
```python
|
| 104 |
+
from modelscope.pipelines import pipeline
|
| 105 |
+
from modelscope.utils.constant import Tasks
|
| 106 |
+
|
| 107 |
+
inference_pipeline = pipeline(
|
| 108 |
+
task=Tasks.emotion_recognition,
|
| 109 |
+
model="iic/emotion2vec_plus_base")
|
| 110 |
+
|
| 111 |
+
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav', granularity="utterance", extract_embedding=False)
|
| 112 |
+
print(rec_result)
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
## Inference based on FunASR
|
| 117 |
+
|
| 118 |
+
```python
|
| 119 |
+
from funasr import AutoModel
|
| 120 |
+
|
| 121 |
+
model = AutoModel(model="iic/emotion2vec_plus_base")
|
| 122 |
+
|
| 123 |
+
wav_file = f"{model.model_path}/example/test.wav"
|
| 124 |
+
res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False)
|
| 125 |
+
print(res)
|
| 126 |
+
```
|
| 127 |
+
Note: The model will automatically download.
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
Supports input file list, wav.scp (Kaldi style):
|
| 131 |
+
```cat wav.scp
|
| 132 |
+
wav_name1 wav_path1.wav
|
| 133 |
+
wav_name2 wav_path2.wav
|
| 134 |
+
...
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
Outputs are emotion representation, saved in the output_dir in numpy format (can be loaded with np.load())
|
| 138 |
+
|
| 139 |
+
# Note
|
| 140 |
+
|
| 141 |
+
This repository is the Huggingface version of emotion2vec, with identical model parameters as the original model and Model Scope version.
|
| 142 |
+
|
| 143 |
+
Original repository: [https://github.com/ddlBoJack/emotion2vec](https://github.com/ddlBoJack/emotion2vec)
|
| 144 |
+
|
| 145 |
+
Model Scope repository:[https://github.com/alibaba-damo-academy/FunASR](https://github.com/alibaba-damo-academy/FunASR/tree/funasr1.0/examples/industrial_data_pretraining/emotion2vec)
|
| 146 |
+
|
| 147 |
+
Hugging Face repository:[https://huggingface.co/emotion2vec](https://huggingface.co/emotion2vec)
|
| 148 |
+
|
| 149 |
+
# Citation
|
| 150 |
+
```BibTeX
|
| 151 |
+
@article{ma2023emotion2vec,
|
| 152 |
+
title={emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation},
|
| 153 |
+
author={Ma, Ziyang and Zheng, Zhisheng and Ye, Jiaxin and Li, Jinchao and Gao, Zhifu and Zhang, Shiliang and Chen, Xie},
|
| 154 |
+
journal={arXiv preprint arXiv:2312.15185},
|
| 155 |
+
year={2023}
|
| 156 |
+
}
|
| 157 |
+
```
|
config.yaml
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
# network architecture
|
| 3 |
+
model: Emotion2vec
|
| 4 |
+
model_conf:
|
| 5 |
+
loss_beta: 0.0
|
| 6 |
+
loss_scale: null
|
| 7 |
+
depth: 8
|
| 8 |
+
start_drop_path_rate: 0.0
|
| 9 |
+
end_drop_path_rate: 0.0
|
| 10 |
+
num_heads: 12
|
| 11 |
+
norm_eps: 1e-05
|
| 12 |
+
norm_affine: true
|
| 13 |
+
encoder_dropout: 0.1
|
| 14 |
+
post_mlp_drop: 0.1
|
| 15 |
+
attention_dropout: 0.1
|
| 16 |
+
activation_dropout: 0.0
|
| 17 |
+
dropout_input: 0.0
|
| 18 |
+
layerdrop: 0.05
|
| 19 |
+
embed_dim: 768
|
| 20 |
+
mlp_ratio: 4.0
|
| 21 |
+
layer_norm_first: false
|
| 22 |
+
average_top_k_layers: 8
|
| 23 |
+
end_of_block_targets: false
|
| 24 |
+
clone_batch: 8
|
| 25 |
+
layer_norm_target_layer: false
|
| 26 |
+
batch_norm_target_layer: false
|
| 27 |
+
instance_norm_target_layer: true
|
| 28 |
+
instance_norm_targets: false
|
| 29 |
+
layer_norm_targets: false
|
| 30 |
+
ema_decay: 0.999
|
| 31 |
+
ema_same_dtype: true
|
| 32 |
+
log_norms: true
|
| 33 |
+
ema_end_decay: 0.99999
|
| 34 |
+
ema_anneal_end_step: 20000
|
| 35 |
+
ema_encoder_only: false
|
| 36 |
+
max_update: 100000
|
| 37 |
+
extractor_mode: layer_norm
|
| 38 |
+
shared_decoder: null
|
| 39 |
+
min_target_var: 0.1
|
| 40 |
+
min_pred_var: 0.01
|
| 41 |
+
supported_modality: AUDIO
|
| 42 |
+
mae_init: false
|
| 43 |
+
seed: 1
|
| 44 |
+
skip_ema: false
|
| 45 |
+
cls_loss: 1.0
|
| 46 |
+
recon_loss: 0.0
|
| 47 |
+
d2v_loss: 1.0
|
| 48 |
+
decoder_group: false
|
| 49 |
+
adversarial_training: false
|
| 50 |
+
adversarial_hidden_dim: 128
|
| 51 |
+
adversarial_weight: 0.1
|
| 52 |
+
cls_type: chunk
|
| 53 |
+
normalize: true
|
| 54 |
+
project_dim:
|
| 55 |
+
|
| 56 |
+
modalities:
|
| 57 |
+
audio:
|
| 58 |
+
type: AUDIO
|
| 59 |
+
prenet_depth: 4
|
| 60 |
+
prenet_layerdrop: 0.05
|
| 61 |
+
prenet_dropout: 0.1
|
| 62 |
+
start_drop_path_rate: 0.0
|
| 63 |
+
end_drop_path_rate: 0.0
|
| 64 |
+
num_extra_tokens: 10
|
| 65 |
+
init_extra_token_zero: true
|
| 66 |
+
mask_noise_std: 0.01
|
| 67 |
+
mask_prob_min: null
|
| 68 |
+
mask_prob: 0.5
|
| 69 |
+
inverse_mask: false
|
| 70 |
+
mask_prob_adjust: 0.05
|
| 71 |
+
keep_masked_pct: 0.0
|
| 72 |
+
mask_length: 5
|
| 73 |
+
add_masks: false
|
| 74 |
+
remove_masks: false
|
| 75 |
+
mask_dropout: 0.0
|
| 76 |
+
encoder_zero_mask: true
|
| 77 |
+
mask_channel_prob: 0.0
|
| 78 |
+
mask_channel_length: 64
|
| 79 |
+
ema_local_encoder: false
|
| 80 |
+
local_grad_mult: 1.0
|
| 81 |
+
use_alibi_encoder: true
|
| 82 |
+
alibi_scale: 1.0
|
| 83 |
+
learned_alibi: false
|
| 84 |
+
alibi_max_pos: null
|
| 85 |
+
learned_alibi_scale: true
|
| 86 |
+
learned_alibi_scale_per_head: true
|
| 87 |
+
learned_alibi_scale_per_layer: false
|
| 88 |
+
num_alibi_heads: 12
|
| 89 |
+
model_depth: 8
|
| 90 |
+
decoder:
|
| 91 |
+
decoder_dim: 384
|
| 92 |
+
decoder_groups: 16
|
| 93 |
+
decoder_kernel: 7
|
| 94 |
+
decoder_layers: 4
|
| 95 |
+
input_dropout: 0.1
|
| 96 |
+
add_positions_masked: false
|
| 97 |
+
add_positions_all: false
|
| 98 |
+
decoder_residual: true
|
| 99 |
+
projection_layers: 1
|
| 100 |
+
projection_ratio: 2.0
|
| 101 |
+
extractor_mode: layer_norm
|
| 102 |
+
feature_encoder_spec: '[(512, 10, 5)] + [(512, 3, 2)] * 4 + [(512,2,2)] + [(512,2,2)]'
|
| 103 |
+
conv_pos_width: 95
|
| 104 |
+
conv_pos_groups: 16
|
| 105 |
+
conv_pos_depth: 5
|
| 106 |
+
conv_pos_pre_ln: false
|
| 107 |
+
|
| 108 |
+
tokenizer: CharTokenizer
|
| 109 |
+
tokenizer_conf:
|
| 110 |
+
unk_symbol: <unk>
|
| 111 |
+
split_with_space: true
|
| 112 |
+
|
| 113 |
+
scope_map:
|
| 114 |
+
- 'd2v_model.'
|
| 115 |
+
- none
|
| 116 |
+
|
| 117 |
+
|
configuration.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "emotion-recognition",
|
| 4 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 5 |
+
"model": {"type" : "funasr"},
|
| 6 |
+
"file_path_metas": {
|
| 7 |
+
"init_param":"model.pt",
|
| 8 |
+
"tokenizer_conf": {"token_list": "tokens.txt"},
|
| 9 |
+
"config":"config.yaml"},
|
| 10 |
+
"model_name_in_hub": {
|
| 11 |
+
"ms":"iic/emotion2vec_base",
|
| 12 |
+
"hf":""}
|
| 13 |
+
}
|
emotion2vec+data.png
ADDED
|
emotion2vec+radar.png
ADDED

|
example/test.wav
ADDED
|
Binary file (131 kB). View file
|
|
|
logo.png
ADDED
|
|
Git LFS Details
|
tokens.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
生气/angry
|
| 2 |
+
unuse_0
|
| 3 |
+
unuse_1
|
| 4 |
+
开心/happy
|
| 5 |
+
中立/neutral
|
| 6 |
+
unuse_2
|
| 7 |
+
难过/sad
|
| 8 |
+
unuse_3
|
| 9 |
+
<unk>
|