---
license: mit
datasets:
- mozilla-foundation/common_voice_17_0
- espnet/yodas
- facebook/multilingual_librispeech
language:
- fr
metrics:
- wer
pipeline_tag: automatic-speech-recognition
tags:
- asr
- whisper
model-index:
- name: distil-large-v3-fr
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 17.0, short-form (<= 30sec)
type: mozilla-foundation/common_voice_17_0
config: fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 12.681
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Multilingual LibriSpeech, short-form (<= 30sec)
type: facebook/multilingual_librispeech
config: french
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 5.865
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: VoxPopuli, short-form (<= 30sec)
type: facebook/voxpopuli
config: fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 10.851
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Fleurs, short-form (<= 30sec)
type: google/fleurs
config: fr_fr
split: test
args:
language: fr
metrics:
- name: WER
type: wer
value: 7.984
---
# Distil-Whisper: distil-large-v3-fr
Distil-Whisper for English Automatic Speech Recognition (ASR) was proposed in the paper [Robust Knowledge Distillation via Large-Scale Pseudo Labelling](https://arxiv.org/abs/2311.00430).
This is the knowledge distilled version of OpenAI's [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3) for French ASR.
The result is a distilled model that performs within **2% WER of [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3)** on out-of-distribution evaluation sets for both short-form and long form transcription. Moreover, it is **5.9x** faster than [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3) and **1.3** times faster than the tiniest version of whisper while being uncomparably more accurate.
| Model | Params (M) | Rel. Latency | Short-Form WER | Long-Form WER |
| :--------------------- | :--------: | :----------: | :------------: | :-----------: |
| whisper-tiny | 37.8 | 4.7 | 43.73 | 28.158 |
| whisper-base | 72.6 | 3.7 | 30.57 | 18.665 |
| whisper-small | 242 | 2.3 | 16.20 | 12.557 |
| whisper-medium | 764 | 1.3 | 11.720 | 11.023 |
| whisper-large-v3 | 1540 | 1.0 | 7.81 | 9.008 |
| **distil-large-v3-fr** | **756** | **5.9** | **9.34** | **11.13** |
*latencies benchmarked to generate 128 tokens on A100 40GB with a batch size of 1. More details about inference performances in [inference speed](#inference-speed) section.
*WERs are averaged on the test sets. More details in [short-form](#short-form) and [long-form](#long-form) results sections.
## Table of Contents
1. [Transformers Usage](#transformers-usage)
* [Short-Form Transcription](#short-form-transcription)
* [Sequential Long-Form](#sequential-long-form)
* [Chunked Long-Form](#chunked-long-form)
* [Speculative Decoding](#speculative-decoding)
* [Additional Speed and Memory Improvements](#additional-speed--memory-improvements)
2. [Library Integrations](#library-integrations)
* [Whisper cpp](#whispercpp)
* [Transformers.js](#transformersjs)
3. [Model Details](#model-details)
* [Architecture](#architecture)
* [Training](#training)
4. [Results](#results)
* [Short-Form](#short-form)
* [Long-Form](#long-form)
* [Inference Speed](#inference-speed)
4. [License](#license)
## Transformers Usage
distil-large-v3-fr is supported in the Hugging Face 🤗 Transformers library from version 4.41 onwards. To run the model, first
install the latest version of Transformers. For this example, we'll also install 🤗 Datasets to load a toy audio dataset
from the Hugging Face Hub:
```bash
pip install --upgrade pip
pip install --upgrade transformers accelerate datasets[audio]
```
### Short-Form Transcription
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe short-form audio files (< 30-seconds) as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "eustlb/distil-large-v3-fr"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("google/fleurs", "fr_fr", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```diff
- result = pipe(sample)
+ result = pipe("audio.mp3")
```
For segment-level timestamps, pass the argument `return_timestamps=True` and return the `"chunks"` output:
```python
result = pipe(sample, return_timestamps=True)
print(result["chunks"])
```
For more control over the generation parameters, use the model + processor API directly:
Ad-hoc generation arguments can be passed to `model.generate`, including `num_beams` for beam-search, `return_timestamps`
for segment-level timestamps, and `prompt_ids` for prompting. See the [docstrings](https://huggingface.co/docs/transformers/en/model_doc/whisper#transformers.WhisperForConditionalGeneration.generate)
for more details.
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "eustlb/distil-large-v3-fr"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("google/fleurs", "fr_fr", split="train", streaming=True)
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = next(iter(dataset))["audio"]
input_features = processor(
sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt"
).input_features
input_features = input_features.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 128,
"num_beams": 1,
"return_timestamps": False,
}
pred_ids = model.generate(input_features, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=gen_kwargs["return_timestamps"])
print(pred_text)
```
### Sequential Long-Form
distil-large-v3 is compatible with OpenAI's sequential
long-form transcription algorithm. This algorithm uses a sliding window for buffered inference of long audio files (> 30-seconds),
and returns more accurate transcriptions compared to the [chunked long-form algorithm](#chunked-long-form).
The sequential long-form algorithm should be used in either of the following scenarios:
1. Transcription accuracy is the most important factor, and latency is less of a consideration
2. You are transcribing **batches** of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
If you are transcribing single long audio files and latency is the most important factor, you should use the chunked algorithm
described [below](#chunked-long-form). For a detailed explanation of the different algorithms, refer to Sections 5 of
the [Distil-Whisper paper](https://arxiv.org/pdf/2311.00430.pdf).
The [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class can be used to transcribe long audio files with the sequential algorithm as follows:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "eustlb/distil-large-v3-fr"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("eustlb/french-long-form-test", split="test", streaming=True)
sample = next(iter(dataset))["audio"]
result = pipe(sample)
print(result["text"])
```
For more control over the generation parameters, use the model + processor API directly:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "eustlb/distil-large-v3-fr"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("eustlb/french-long-form-test", split="test", streaming=True)
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = next(iter(dataset))["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**inputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
```
### Chunked Long-Form
distil-large-v3-fr remains compatible with the Transformers chunked long-form algorithm. This algorithm should be used when
a single large audio file is being transcribed and the fastest possible inference is required. In such circumstances,
the chunked algorithm is up to 9x faster than OpenAI's sequential long-form implementation (see Table 7 of the
[Distil-Whisper paper](https://arxiv.org/pdf/2311.00430.pdf)).
To enable chunking, pass the `chunk_length_s` parameter to the `pipeline`. For distil-large-v3-fr, a chunk length of 25-seconds
is optimal. To activate batching over long audio files, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "eustlb/distil-large-v3-fr"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
chunk_length_s=25,
batch_size=16,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("eustlb/french-long-form-test", split="test", streaming=True)
sample = next(iter(dataset))["audio"]
result = pipe(sample)
print(result["text"])
```
### Speculative Decoding
distil-large-v3 is the first Distil-Whisper model that can be used as an assistant to Whisper large-v3 for [speculative decoding](https://huggingface.co/blog/whisper-speculative-decoding).
Speculative decoding mathematically ensures that exactly the same outputs as Whisper are obtained, while being 2 times faster.
This makes it the perfect drop-in replacement for existing Whisper pipelines, since the same outputs are guaranteed.
In the following code-snippet, we load the assistant Distil-Whisper model standalone to the main Whisper pipeline. We then
specify it as the "assistant model" for generation:
```python
from transformers import pipeline, AutoModelForCausalLM, AutoModelForSpeechSeq2Seq, AutoProcessor
import torch
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
assistant_model_id = "eustlb/distil-large-v3-fr"
assistant_model = AutoModelForCausalLM.from_pretrained(
assistant_model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
assistant_model.to(device)
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
max_new_tokens=128,
generate_kwargs={"assistant_model": assistant_model},
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("google/fleurs", "fr_fr", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
result = pipe(sample)
print(result["text"])
```
For more details on speculative decoding, refer to the blog post [Speculative Decoding for 2x Faster Whisper Inference](https://huggingface.co/blog/whisper-speculative-decoding).
### Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Distil-Whisper to further reduce the inference speed and VRAM
requirements. These optimisations primarily target the attention kernel, swapping it from an eager implementation to a
more efficient flash attention version.
#### Flash Attention 2
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2)
if your GPU allows for it. To do so, you first need to install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
Then pass `attn_implementation="flash_attention_2"` to `from_pretrained`:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, attn_implementation="flash_attention_2")
```
#### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of PyTorch [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
This attention implementation is activated **by default** for PyTorch versions 2.1.1 or greater. To check
whether you have a compatible PyTorch version, run the following Python code snippet:
```python
from transformers.utils import is_torch_sdpa_available
print(is_torch_sdpa_available())
```
If the above returns `True`, you have a valid version of PyTorch installed and SDPA is activated by default. If it
returns `False`, you need to upgrade your PyTorch version according to the [official instructions](https://pytorch.org/get-started/locally/)
Once a valid PyTorch version is installed, SDPA is activated by default. It can also be set explicitly by specifying
`attn_implementation="sdpa"` as follows:
```diff
- model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
+ model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True, attn_implementation="sdpa")
```
For more information about how to use the SDPA refer to the [Transformers SDPA documentation](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).
#### Torch compile
Coming soon...
#### 4-bit and 8-bit Inference
Coming soon...
## Library Integrations
### Whisper.cpp
distil-large-v3-fr can be run with the [Whisper.cpp](https://github.com/ggerganov/whisper.cpp) package with the original
sequential long-form transcription algorithm. In a provisional benchmark on Mac M1, distil-large-v3 is over 5x faster
than Whisper large-v3, while performing to within 0.8% WER over long-form audio.
Steps for getting started:
1. Clone the Whisper.cpp repository:
```bash
git clone https://github.com/ggerganov/whisper.cpp.git
cd whisper.cpp
```
2. Install the Hugging Face Hub Python package:
```bash
pip install --upgrade huggingface_hub
```
And download the GGML weights for distil-large-v3 using the following Python snippet:
```python
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id='eustlb/distil-large-v3-fr-ggml', filename='ggml-distil-large-v3-fr.bin', local_dir='./models')
```
Note that if you do not have a Python environment set-up, you can also download the weights directly with `wget`:
```bash
wget https://huggingface.co/eustlb/distil-large-v3-fr-ggml/resolve/main/ggml-distil-large-v3-fr.bin -P ./models
````
3. Run inference
```bash
wget https://huggingface.co/spaces/eustlb/whisper-vs-distil-whisper-fr/resolve/main/assets/example_1.wav
make -j && ./main -m models/ggml-distil-large-v3-fr.bin -f example_1.wav
```
### Transformers.js
Distil-Whisper can be run completely in your web browser with [Transformers.js](http://github.com/xenova/transformers.js):
1. Install Transformers.js from [NPM](https://www.npmjs.com/package/@xenova/transformers):
```bash
npm i @xenova/transformers
```
2. Import the library and perform inference with the pipeline API.
```js
import { pipeline } from '@xenova/transformers';
const transcriber = await pipeline('automatic-speech-recognition', 'eustlb/distil-large-v3-fr');
const url = 'https://huggingface.co/datasets/Xenova/transformers.js-docs/resolve/main/jfk.wav';
const output = await transcriber(url);
// { text: " And so, my fellow Americans, ask not what your country can do for you. Ask what you can do for your country." }
```
Refer to the Transformers.js [docs](https://huggingface.co/docs/transformers.js/api/pipelines#module_pipelines.AutomaticSpeechRecognitionPipeline)
for further information.
## Model Details
### Architecture
Distil-Whisper inherits the encoder-decoder architecture from Whisper. The encoder maps a sequence of speech vector inputs to a sequence of hidden-state vectors. The decoder auto-regressively predicts text tokens, conditional on all previous tokens and the encoder hidden-states. Consequently, the encoder is only run forward once, whereas the decoder is run as many times as the number of tokens generated. In practice, this means the decoder accounts for over 90% of total inference time. Thus, to optimise for latency, the focus is on minimising the inference time of the decoder.
To distill the Whisper model, we reduce the number of decoder layers while keeping the encoder fixed. The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training. The student's decoder structure is copied from [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3), with the only difference being a reduction from 32 to 2 decoder layers. These layers are initialized from distil-large-v3 to leverage language transfer from English to French (more details [here](https://github.com/huggingface/distil-whisper/tree/main/training#22-language-transfer)).
### Training
#### Data
distil-large-v3-fr is trained on 4,515 hours of audio data from three open-source, permissively licensed speech datasets on the
Hugging Face Hub:
| Dataset | Size / h | Speakers | Domain | Licence |
| --------------------------------------------------------------------------------------------- | -------- | -------- | ------------------ | ----------------------------------------------------------- |
| [Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0) | 1,014 | unknown | Narrated Wikipedia | [CC0-1.0](https://choosealicense.com/licenses/cc0-1.0/) |
| [MultiLingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) | 1,077 | 142 | Audiobook | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [YODAS fr000 split](https://huggingface.co/datasets/espnet/yodas) | 2,424 | unknown | YouTube | [CC-BY-3.0](https://creativecommons.org/licenses/by/3.0/) |
| **Total** | 4,515 | 142+ | | |
The audio data is then pseudo-labelled using the Whisper large-v3 model: we use Whisper to generate predictions for all
the audio in our training set and use these as the target labels during training. Using pseudo-labels ensures that the
transcriptions are consistently formatted across datasets and provides sequence-level distillation signal during training.
#### WER Filter
The Whisper pseudo-label predictions are subject to mis-transcriptions and hallucinations. To ensure we only train on
accurate pseudo-labels, we employ a simple WER heuristic during training. First, we normalise the Whisper pseudo-labels
and the ground truth labels provided by each dataset. We then compute the WER between these labels. If the WER exceeds
a specified threshold, we discard the training example. Otherwise, we keep it for training.
We chose for this training a WER threshold of 20%, resulting in an **effective training set of 2110 hours** (750 for [Common Voice 17](https://huggingface.co/datasets/mozilla-foundation/common_voice_17_0), 1040 for [MultiLingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) and 320 for [YODAS fr000 split](https://huggingface.co/datasets/espnet/yodas)).
Section 9.2 of the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430) demonstrates the effectiveness of this filter
for improving downstream performance of the distilled model. We also partially attribute Distil-Whisper's robustness to
hallucinations to this filter.
#### Training procedure
The model was trained for 18,000 optimisation steps (or 14 epochs) with batch size 256. We saved the best model, based on the global wer score on validation splits, reached after 14,000 optimization steps (or 11 epochs). See the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430) for more details (training objective, etc).
## Results
The distilled model performs to within 1% WER of Whisper large-v3 on out-of-distribution (Voxpopuli, Fleurs) short-form audio and within
2.5% WER on out-of-distribuion sequential long-form decoding.
### Evaluation methodology
The model has been tested for both in-distribution (Common Voice 17 and Multilingual Librispeech) and out-of-distribution (Fleurs, Voxpopuli, custom [long-form test set](https://huggingface.co/datasets/speech-recognition-community-v2/dev_data)) short-form and long-form transcription performances. Models have been evaluated with SDPA, float32 and batch size 32.
**Short-form evaluations** are conducted on the four given datasets by first applying a filter to exclude samples longer than 30 seconds.
**Long-form evaluation** is conducted on a custom out-of-distribution [long-form test set](https://huggingface.co/datasets/eustlb/french-long-form-test) using OpenAI's sequential long-form transcription algorithm (see [Sequential Long-Form](#sequential-long-form) section) with long-form generation parameters that can be found [here](https://github.com/huggingface/distil-whisper/blob/a5ed489ba6edb405ecef334ba0feec1bdca7a948/training/run_eval.py#L670C5-L676C6).
### Short-Form
| Model | Common Voice 17 | Multilingual Librispeech | voxpopuli | fleurs | RTFx |
| :--------------------- | :-------------: | :----------------------: | :--------: | :-------: | :---------: |
| whisper-tiny | 57.141 | 38.049 | 32.346 | 47.4 | 265.226 |
| whisper-base | 42.58 | 25.235 | 26.701 | 27.773 | 237.195 |
| whisper-small | 22.56 | 13.576 | 14.486 | 14.165 | 196.932 |
| whisper-medium | 15.51 | 9.541 | 11.836 | 9.992 | 93.428 |
| whisper-large-v3 | 11.038 | 4.762 | 9.83 | 5.624 | 62.845 |
| **distil-large-v3-fr** | **12.675** | **5.865** | **10.832** | **7.989** | **106.291** |
*the above datasets correspond to test splits
*RTFx = 1 / RTF, where RTF is the [Real Time Factor](https://openvoice-tech.net/wiki/Real-time-factor). To be interpreted as audio processed (in seconds) per second of processing.
### Long-Form
| Model Name | RTFx | [long-form test set](https://huggingface.co/datasets/eustlb/french-long-form-test) |
| :----------------: | :-----: | :--------------------------------------------------------------------------------: |
| whisper-tiny | 121.389 | 28.158 |
| whisper-base | 109.366 | 18.665 |
| whisper-small | 83.049 | 12.557 |
| whisper-medium | 47.807 | 11.023 |
| whisper-large-v3 | 38.294 | 9.008 |
| distil-large-v3-fr | 101.326 | 11.13 |
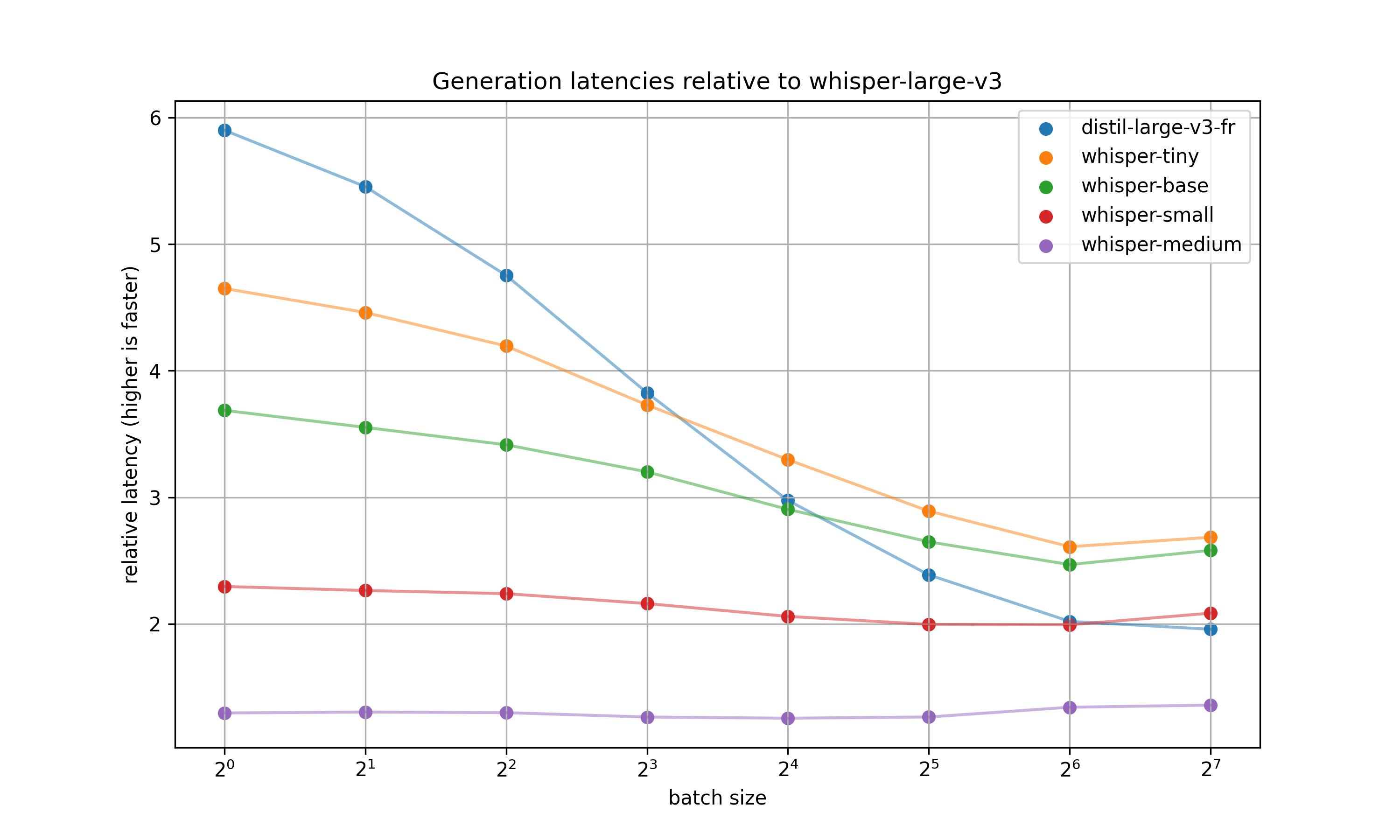
### Inference speed
Reported latencies were benchmarked on a 40GB nvidia A100, generating 128 tokens with SDPA, bfloat16, 3 warmup steps, 5 measures, one beam.
The benchmarking script can be found [here](https://gist.github.com/eustlb/ef06f00858cbae4d8743f5024be869ec). The time measured is the time do one forward pass of the encoder and 128 autoregressive forward passes of the decoder.
## Reproducing Distil-Whisper
Training and evaluation code to reproduce Distil-Whisper is available under the Distil-Whisper repository: https://github.com/huggingface/distil-whisper/tree/main/training
## License
distil-large-v3-fr inherits the [MIT license](https://github.com/huggingface/distil-whisper/blob/main/LICENSE) from OpenAI's Whisper model.
## Citation
If you use this model, please consider citing the [Distil-Whisper paper](https://arxiv.org/abs/2311.00430):
```
@misc{gandhi2023distilwhisper,
title={Distil-Whisper: Robust Knowledge Distillation via Large-Scale Pseudo Labelling},
author={Sanchit Gandhi and Patrick von Platen and Alexander M. Rush},
year={2023},
eprint={2311.00430},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## Acknowledgements
* OpenAI for the Whisper [model](https://huggingface.co/openai/whisper-large-v3), in particular Jong Wook Kim for the [original codebase](https://github.com/openai/whisper) and training discussions
* Hugging Face 🤗 [Transformers](https://github.com/huggingface/transformers) for the model integration
* [Georgi Gerganov](https://huggingface.co/ggerganov) for the Whisper cpp integration
* [Joshua Lochner](https://huggingface.co/xenova) for the Transformers.js integration
* [Vaibhav Srivastav](https://huggingface.co/reach-vb) for Distil-Whisper distribution
* [Raghav Sonavane](https://huggingface.co/rsonavane/distil-whisper-large-v2-8-ls) for an early iteration of Distil-Whisper on the LibriSpeech datasets