---
license: cc-by-nc-4.0
tags:
- vision
- metaclip
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# MetaCLIP model, large-sized version, patch resolution 14
MetaCLIP model applied to 400 million data points of CommonCrawl (CC). It was introduced in the paper [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) by Xu et al. and first released in [this repository](https://github.com/facebookresearch/MetaCLIP).
Disclaimer: The team releasing MetaCLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671) paper aims to reveal CLIP’s method around training data curation. OpenAI never open-sourced code regarding their data preparation pipeline.
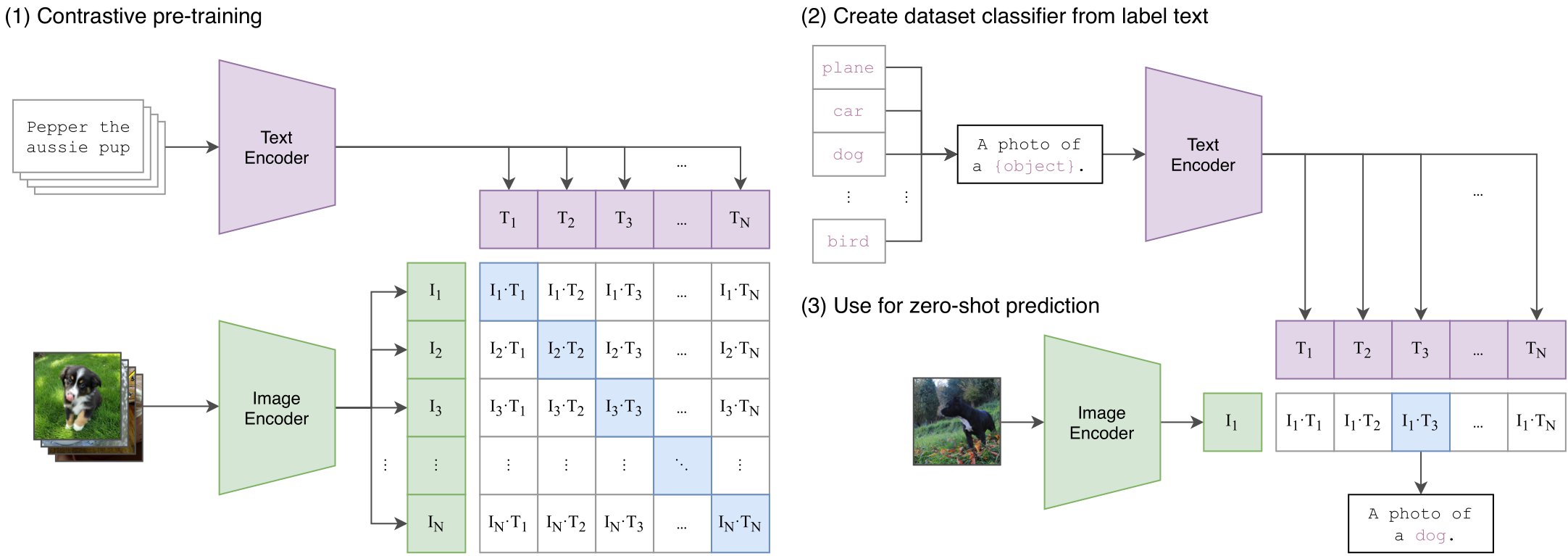 CLIP high-level overview. Taken from the CLIP paper.
## Intended uses & limitations
You can use the raw model for linking images with text in a shared embedding space. This enables things like zero-shot image classification, text-based image retrieval, image-based text retrieval, etc.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/clip#usage). Just replace the names of the models on the hub.
### BibTeX entry and citation info
```bibtex
@misc{xu2023demystifying,
title={Demystifying CLIP Data},
author={Hu Xu and Saining Xie and Xiaoqing Ellen Tan and Po-Yao Huang and Russell Howes and Vasu Sharma and Shang-Wen Li and Gargi Ghosh and Luke Zettlemoyer and Christoph Feichtenhofer},
year={2023},
eprint={2309.16671},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
CLIP high-level overview. Taken from the CLIP paper.
## Intended uses & limitations
You can use the raw model for linking images with text in a shared embedding space. This enables things like zero-shot image classification, text-based image retrieval, image-based text retrieval, etc.
### How to use
We refer to the [docs](https://huggingface.co/docs/transformers/main/en/model_doc/clip#usage). Just replace the names of the models on the hub.
### BibTeX entry and citation info
```bibtex
@misc{xu2023demystifying,
title={Demystifying CLIP Data},
author={Hu Xu and Saining Xie and Xiaoqing Ellen Tan and Po-Yao Huang and Russell Howes and Vasu Sharma and Shang-Wen Li and Gargi Ghosh and Luke Zettlemoyer and Christoph Feichtenhofer},
year={2023},
eprint={2309.16671},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```