
Commit
•
e1b9697
1
Parent(s):
ae68e1f
Initial clone of pyannote/segmentation-3.0
Browse files- LICENSE +21 -0
- README.md +129 -0
- config.yaml +19 -0
- example.png +0 -0
- pytorch_model.bin +3 -0
- segmentation-3.0 +1 -0
- speaker-diarization-3.1 +1 -0
- wespeaker-voxceleb-resnet34-LM +1 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 CNRS
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- pyannote
|
| 4 |
+
- pyannote-audio
|
| 5 |
+
- pyannote-audio-model
|
| 6 |
+
- audio
|
| 7 |
+
- voice
|
| 8 |
+
- speech
|
| 9 |
+
- speaker
|
| 10 |
+
- speaker-diarization
|
| 11 |
+
- speaker-change-detection
|
| 12 |
+
- speaker-segmentation
|
| 13 |
+
- voice-activity-detection
|
| 14 |
+
- overlapped-speech-detection
|
| 15 |
+
- resegmentation
|
| 16 |
+
license: mit
|
| 17 |
+
inference: false
|
| 18 |
+
extra_gated_prompt: "The collected information will help acquire a better knowledge of pyannote.audio userbase and help its maintainers improve it further. Though this model uses MIT license and will always remain open-source, we will occasionnally email you about premium models and paid services around pyannote."
|
| 19 |
+
extra_gated_fields:
|
| 20 |
+
Company/university: text
|
| 21 |
+
Website: text
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
Using this open-source model in production?
|
| 25 |
+
Consider switching to [pyannoteAI](https://www.pyannote.ai) for better and faster options.
|
| 26 |
+
|
| 27 |
+
# 🎹 "Powerset" speaker segmentation
|
| 28 |
+
|
| 29 |
+
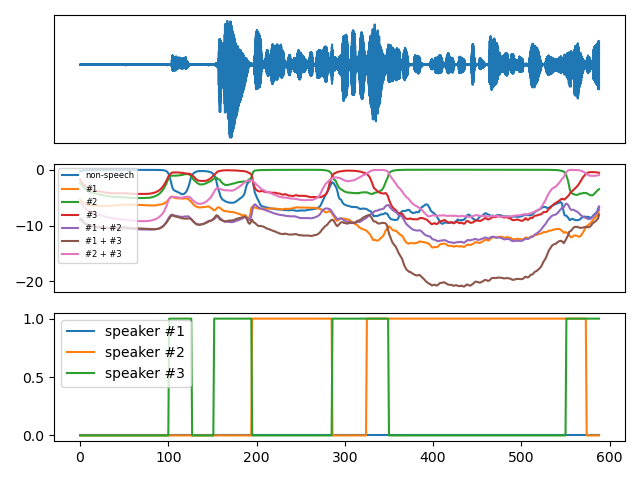
This model ingests 10 seconds of mono audio sampled at 16kHz and outputs speaker diarization as a (num_frames, num_classes) matrix where the 7 classes are _non-speech_, _speaker #1_, _speaker #2_, _speaker #3_, _speakers #1 and #2_, _speakers #1 and #3_, and _speakers #2 and #3_.
|
| 30 |
+
|
| 31 |
+

|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
# waveform (first row)
|
| 35 |
+
duration, sample_rate, num_channels = 10, 16000, 1
|
| 36 |
+
waveform = torch.randn(batch_size, num_channels, duration * sample_rate)
|
| 37 |
+
|
| 38 |
+
# powerset multi-class encoding (second row)
|
| 39 |
+
powerset_encoding = model(waveform)
|
| 40 |
+
|
| 41 |
+
# multi-label encoding (third row)
|
| 42 |
+
from pyannote.audio.utils.powerset import Powerset
|
| 43 |
+
max_speakers_per_chunk, max_speakers_per_frame = 3, 2
|
| 44 |
+
to_multilabel = Powerset(
|
| 45 |
+
max_speakers_per_chunk,
|
| 46 |
+
max_speakers_per_frame).to_multilabel
|
| 47 |
+
multilabel_encoding = to_multilabel(powerset_encoding)
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
The various concepts behind this model are described in details in this [paper](https://www.isca-speech.org/archive/interspeech_2023/plaquet23_interspeech.html).
|
| 51 |
+
|
| 52 |
+
It has been trained by Séverin Baroudi with [pyannote.audio](https://github.com/pyannote/pyannote-audio) `3.0.0` using the combination of the training sets of AISHELL, AliMeeting, AMI, AVA-AVD, DIHARD, Ego4D, MSDWild, REPERE, and VoxConverse.
|
| 53 |
+
|
| 54 |
+
This [companion repository](https://github.com/FrenchKrab/IS2023-powerset-diarization/) by [Alexis Plaquet](https://frenchkrab.github.io/) also provides instructions on how to train or finetune such a model on your own data.
|
| 55 |
+
|
| 56 |
+
## Requirements
|
| 57 |
+
|
| 58 |
+
1. Install [`pyannote.audio`](https://github.com/pyannote/pyannote-audio) `3.0` with `pip install pyannote.audio`
|
| 59 |
+
2. Accept [`pyannote/segmentation-3.0`](https://hf.co/pyannote/segmentation-3.0) user conditions
|
| 60 |
+
3. Create access token at [`hf.co/settings/tokens`](https://hf.co/settings/tokens).
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
## Usage
|
| 64 |
+
|
| 65 |
+
```python
|
| 66 |
+
# instantiate the model
|
| 67 |
+
from pyannote.audio import Model
|
| 68 |
+
model = Model.from_pretrained(
|
| 69 |
+
"pyannote/segmentation-3.0",
|
| 70 |
+
use_auth_token="HUGGINGFACE_ACCESS_TOKEN_GOES_HERE")
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
### Speaker diarization
|
| 74 |
+
|
| 75 |
+
This model cannot be used to perform speaker diarization of full recordings on its own (it only processes 10s chunks).
|
| 76 |
+
|
| 77 |
+
See [pyannote/speaker-diarization-3.0](https://hf.co/pyannote/speaker-diarization-3.0) pipeline that uses an additional speaker embedding model to perform full recording speaker diarization.
|
| 78 |
+
|
| 79 |
+
### Voice activity detection
|
| 80 |
+
|
| 81 |
+
```python
|
| 82 |
+
from pyannote.audio.pipelines import VoiceActivityDetection
|
| 83 |
+
pipeline = VoiceActivityDetection(segmentation=model)
|
| 84 |
+
HYPER_PARAMETERS = {
|
| 85 |
+
# remove speech regions shorter than that many seconds.
|
| 86 |
+
"min_duration_on": 0.0,
|
| 87 |
+
# fill non-speech regions shorter than that many seconds.
|
| 88 |
+
"min_duration_off": 0.0
|
| 89 |
+
}
|
| 90 |
+
pipeline.instantiate(HYPER_PARAMETERS)
|
| 91 |
+
vad = pipeline("audio.wav")
|
| 92 |
+
# `vad` is a pyannote.core.Annotation instance containing speech regions
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
### Overlapped speech detection
|
| 96 |
+
|
| 97 |
+
```python
|
| 98 |
+
from pyannote.audio.pipelines import OverlappedSpeechDetection
|
| 99 |
+
pipeline = OverlappedSpeechDetection(segmentation=model)
|
| 100 |
+
HYPER_PARAMETERS = {
|
| 101 |
+
# remove overlapped speech regions shorter than that many seconds.
|
| 102 |
+
"min_duration_on": 0.0,
|
| 103 |
+
# fill non-overlapped speech regions shorter than that many seconds.
|
| 104 |
+
"min_duration_off": 0.0
|
| 105 |
+
}
|
| 106 |
+
pipeline.instantiate(HYPER_PARAMETERS)
|
| 107 |
+
osd = pipeline("audio.wav")
|
| 108 |
+
# `osd` is a pyannote.core.Annotation instance containing overlapped speech regions
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
## Citations
|
| 112 |
+
|
| 113 |
+
```bibtex
|
| 114 |
+
@inproceedings{Plaquet23,
|
| 115 |
+
author={Alexis Plaquet and Hervé Bredin},
|
| 116 |
+
title={{Powerset multi-class cross entropy loss for neural speaker diarization}},
|
| 117 |
+
year=2023,
|
| 118 |
+
booktitle={Proc. INTERSPEECH 2023},
|
| 119 |
+
}
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
```bibtex
|
| 123 |
+
@inproceedings{Bredin23,
|
| 124 |
+
author={Hervé Bredin},
|
| 125 |
+
title={{pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe}},
|
| 126 |
+
year=2023,
|
| 127 |
+
booktitle={Proc. INTERSPEECH 2023},
|
| 128 |
+
}
|
| 129 |
+
```
|
config.yaml
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task:
|
| 2 |
+
_target_: pyannote.audio.tasks.SpeakerDiarization
|
| 3 |
+
duration: 10.0
|
| 4 |
+
max_speakers_per_chunk: 3
|
| 5 |
+
max_speakers_per_frame: 2
|
| 6 |
+
model:
|
| 7 |
+
_target_: pyannote.audio.models.segmentation.PyanNet
|
| 8 |
+
sample_rate: 16000
|
| 9 |
+
num_channels: 1
|
| 10 |
+
sincnet:
|
| 11 |
+
stride: 10
|
| 12 |
+
lstm:
|
| 13 |
+
hidden_size: 128
|
| 14 |
+
num_layers: 4
|
| 15 |
+
bidirectional: true
|
| 16 |
+
monolithic: true
|
| 17 |
+
linear:
|
| 18 |
+
hidden_size: 128
|
| 19 |
+
num_layers: 2
|
example.png
ADDED
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:da85c29829d4002daedd676e012936488234d9255e65e86dfab9bec6b1729298
|
| 3 |
+
size 5905440
|
segmentation-3.0
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Subproject commit ae68e1f3903259a2fcd45efcb4bdb91b0b0caf12
|
speaker-diarization-3.1
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Subproject commit 5a539e73a9a3ac02d1610eabd5357a08256ff1b1
|
wespeaker-voxceleb-resnet34-LM
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Subproject commit b48dbc7328d5bf48201060f8c19c2588bb40f124
|