

Commit
•
f066ef4
1
Parent(s):
206b987
Add README
Browse files- .vscode/settings.json +3 -0
- README.md +37 -0
- eval_accuracy.png +0 -0
- eval_loss.png +0 -0
- learning_rate.png +0 -0
- log_eval.py +2 -3
- train_loss.png +0 -0
.vscode/settings.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"python.pythonPath": "/home/zarzis/anaconda3/envs/p3.8-code/bin/python"
|
| 3 |
+
}
|
README.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tokenizer](#tokenizer) | [model](#model) | [datasets](#datasets) | [plots](#plots) | [fine tuning](#fine-tuning)
|
| 2 |
+
|
| 3 |
+
# Tokenizer {#tokenizer}
|
| 4 |
+
|
| 5 |
+
We trained our tokenizer using [sentencepiece](https://github.com/google/sentencepiece)'s unigram tokenizer. Then loaded the tokenizer as MT5TokenizerFast.
|
| 6 |
+
|
| 7 |
+
## Model {#model}
|
| 8 |
+
|
| 9 |
+
We used [MT5-base](https://huggingface.co/google/mt5-base) model.
|
| 10 |
+
|
| 11 |
+
## Datasets {#datasets}
|
| 12 |
+
|
| 13 |
+
We used [Code Search Net](https://huggingface.co/datasets/code_search_net)'s dataset and some scrapped data from internet to train the model. We maintained a list of datasets where each dataset had codes of same language.
|
| 14 |
+
|
| 15 |
+
## Plots {#plots}
|
| 16 |
+
|
| 17 |
+
[train loss](#train_loss) | [evaluation loss](#eval_loss) | [evaluation accuracy](#eval_acc) | [learning rate](#lrs)
|
| 18 |
+
|
| 19 |
+
### Train loss {#train_loss}
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+
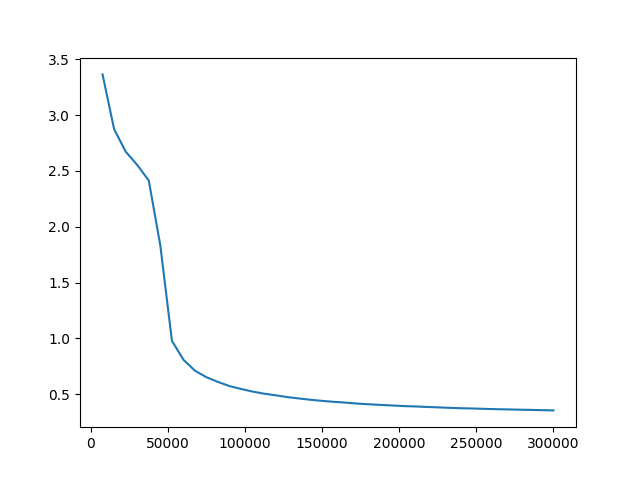
### Evaluation loss {#eval_loss}
|
| 24 |
+
|
| 25 |
+

|
| 26 |
+
|
| 27 |
+
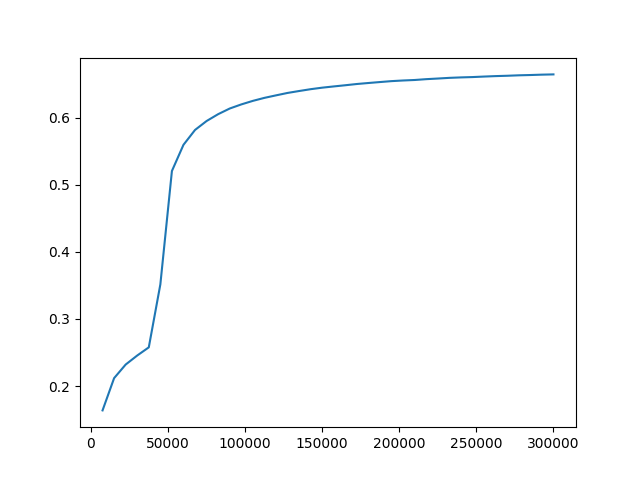
### Evaluation accuracy {#eval_acc}
|
| 28 |
+
|
| 29 |
+

|
| 30 |
+
|
| 31 |
+
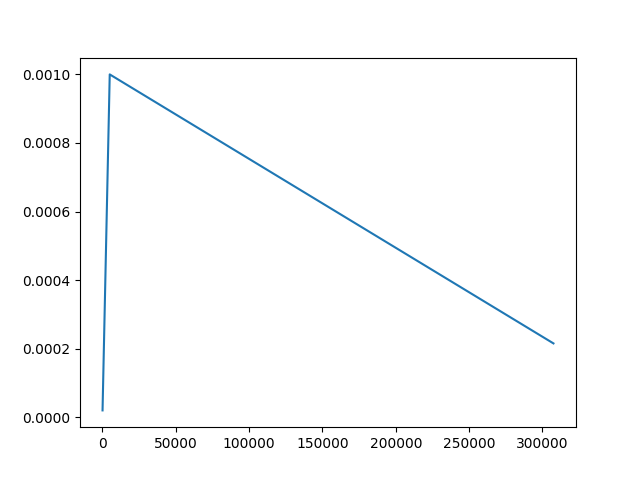
### Learning rate {#lrs}
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
## Fine tuning {#fine-tuning}
|
| 36 |
+
|
| 37 |
+
We fine tuned the model with [CodeXGLUE code-to-code-trans dataset](https://huggingface.co/datasets/code_x_glue_cc_code_to_code_trans), and scrapper data.
|
eval_accuracy.png
ADDED
|
eval_loss.png
ADDED
|
learning_rate.png
ADDED
|
log_eval.py
CHANGED
|
@@ -1,7 +1,7 @@
|
|
| 1 |
# To add a new cell, type '# %%'
|
| 2 |
# To add a new markdown cell, type '# %% [markdown]'
|
| 3 |
# %%
|
| 4 |
-
from IPython import get_ipython
|
| 5 |
|
| 6 |
# %%
|
| 7 |
# get_ipython().system("ls -l ../logs")
|
|
@@ -21,7 +21,7 @@ eval_accs = []
|
|
| 21 |
learning_rate = []
|
| 22 |
with open(path, "r") as filePtr:
|
| 23 |
for line in filePtr:
|
| 24 |
-
print(line)
|
| 25 |
toks = line.split()
|
| 26 |
if toks[0] == "Step...":
|
| 27 |
if "Learning" in toks:
|
|
@@ -89,4 +89,3 @@ plt.show()
|
|
| 89 |
|
| 90 |
|
| 91 |
# %%
|
| 92 |
-
|
|
|
|
| 1 |
# To add a new cell, type '# %%'
|
| 2 |
# To add a new markdown cell, type '# %% [markdown]'
|
| 3 |
# %%
|
| 4 |
+
# from IPython import get_ipython
|
| 5 |
|
| 6 |
# %%
|
| 7 |
# get_ipython().system("ls -l ../logs")
|
|
|
|
| 21 |
learning_rate = []
|
| 22 |
with open(path, "r") as filePtr:
|
| 23 |
for line in filePtr:
|
| 24 |
+
# print(line)
|
| 25 |
toks = line.split()
|
| 26 |
if toks[0] == "Step...":
|
| 27 |
if "Learning" in toks:
|
|
|
|
| 89 |
|
| 90 |
|
| 91 |
# %%
|
|
|
train_loss.png
ADDED

|