---
pipeline_tag: text-to-image
inference: false
license: other
license_name: sai-nc-community
license_link: https://huggingface.co/stabilityai/sdxl-turbo/blob/main/LICENSE.md
---
# stable-diffusion-xl-1.0-turbo-GGUF
!!! Experimental supported by [gpustack/llama-box v0.0.75+](https://github.com/gpustack/llama-box) only !!!
**Model creator**: [Stability AI](https://huggingface.co/stabilityai)
**Original model**: [sdxl-turbo](https://huggingface.co/stabilityai/sdxl-turbo)
**GGUF quantization**: based on stable-diffusion.cpp [ac54e](https://github.com/leejet/stable-diffusion.cpp/commit/ac54e0076052a196b7df961eb1f792c9ff4d7f22) that patched by llama-box.
**VAE From**: [madebyollin/sdxl-vae-fp16-fix](https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl_vae.safetensors).
| Quantization | OpenAI CLIP ViT-L/14 Quantization | OpenCLIP ViT-G/14 Quantization | VAE Quantization |
| --- | --- | --- | --- |
| FP16 | FP16 | FP16 | FP16 |
| Q8_0 | FP16 | FP16 | FP16 |
| Q4_1 | FP16 | FP16 | FP16 |
| Q4_0 | FP16 | FP16 | FP16 |
---
# SDXL-Turbo Model Card

SDXL-Turbo is a fast generative text-to-image model that can synthesize photorealistic images from a text prompt in a single network evaluation.
A real-time demo is available here: http://clipdrop.co/stable-diffusion-turbo
Please note: For commercial use, please refer to https://stability.ai/license.
## Model Details
### Model Description
SDXL-Turbo is a distilled version of [SDXL 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), trained for real-time synthesis.
SDXL-Turbo is based on a novel training method called Adversarial Diffusion Distillation (ADD) (see the [technical report](https://stability.ai/research/adversarial-diffusion-distillation)), which allows sampling large-scale foundational
image diffusion models in 1 to 4 steps at high image quality.
This approach uses score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal and combines this with an
adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps.
- **Developed by:** Stability AI
- **Funded by:** Stability AI
- **Model type:** Generative text-to-image model
- **Finetuned from model:** [SDXL 1.0 Base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0)
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models),
which implements the most popular diffusion frameworks (both training and inference).
- **Repository:** https://github.com/Stability-AI/generative-models
- **Paper:** https://stability.ai/research/adversarial-diffusion-distillation
- **Demo:** http://clipdrop.co/stable-diffusion-turbo
## Evaluation
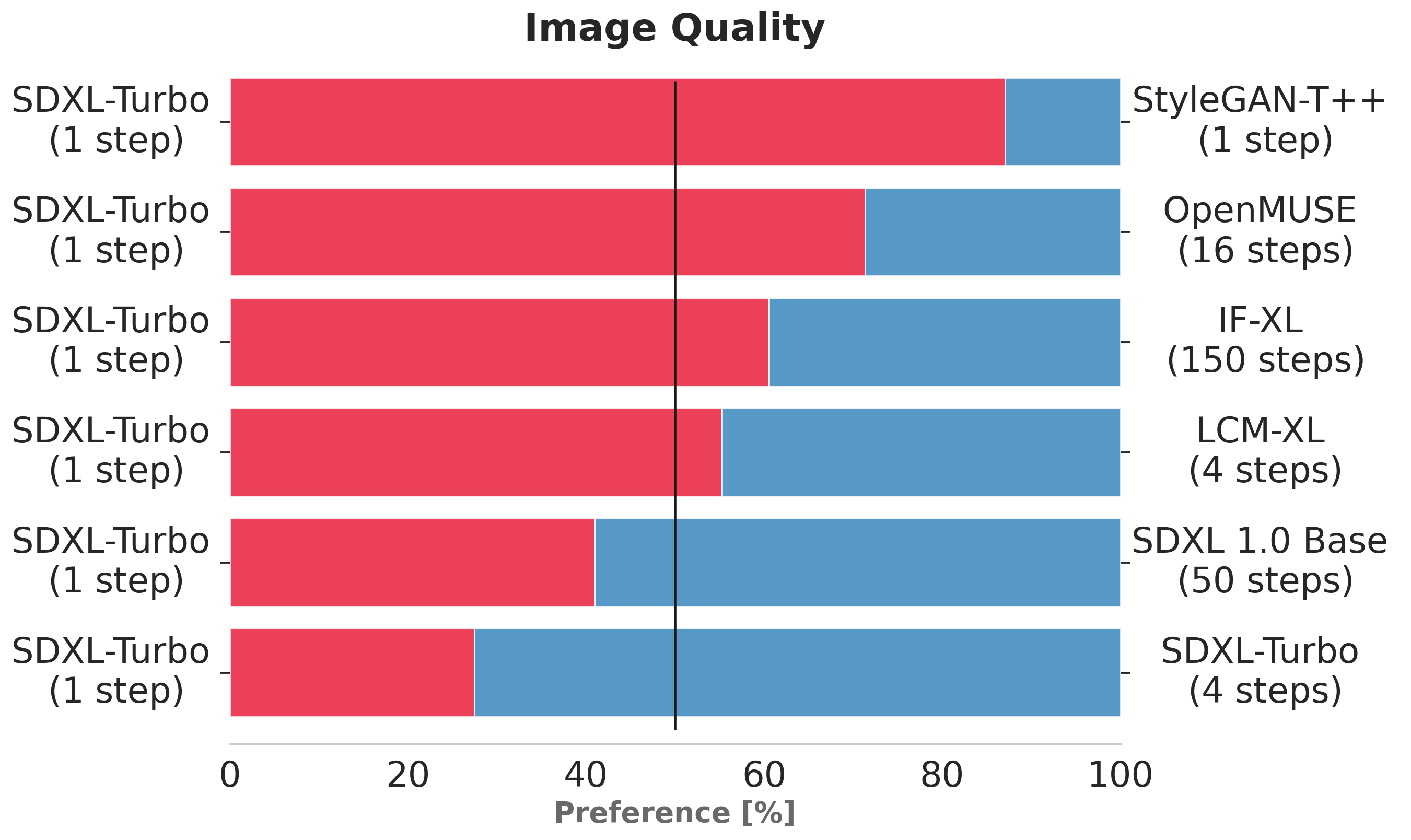
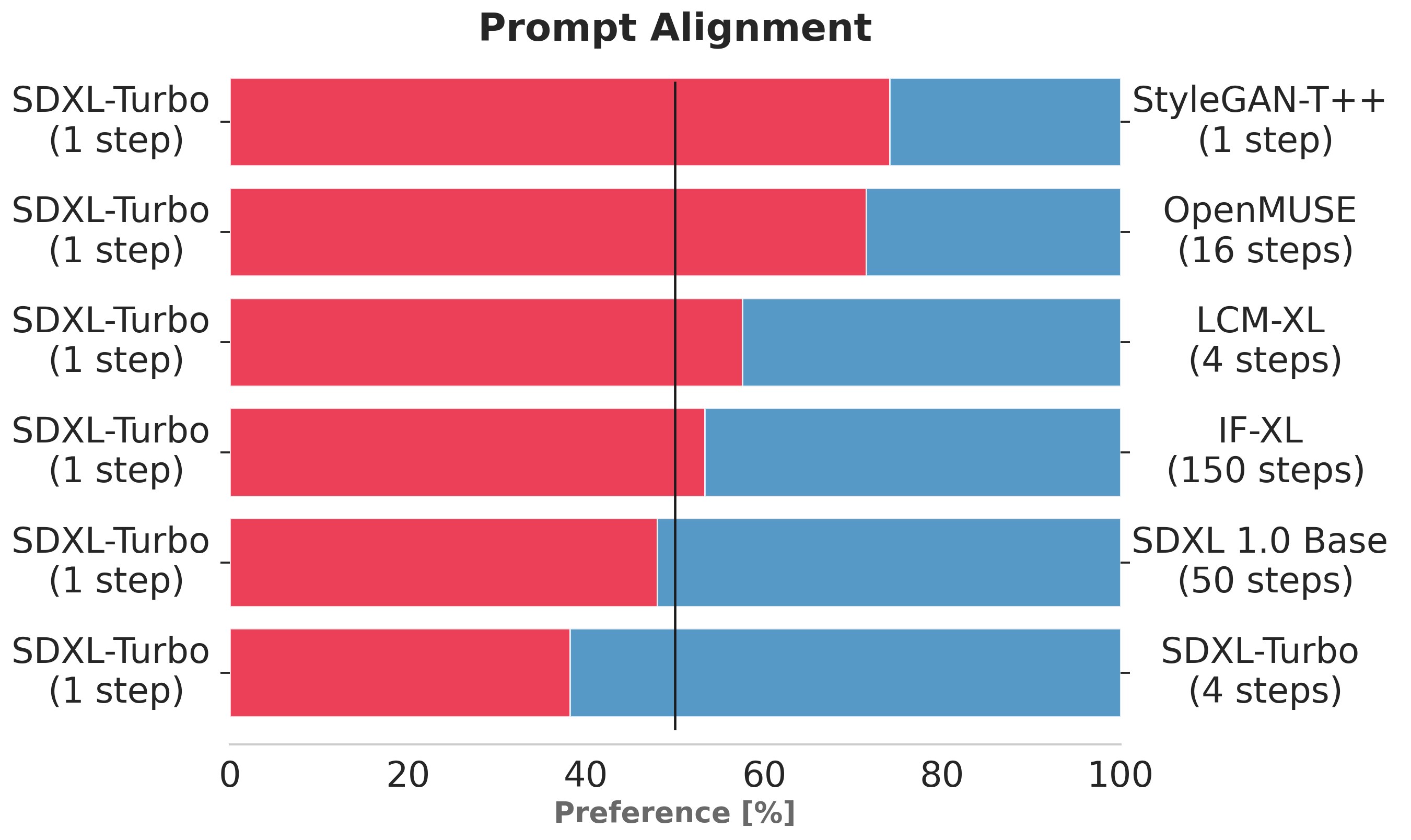
The charts above evaluate user preference for SDXL-Turbo over other single- and multi-step models.
SDXL-Turbo evaluated at a single step is preferred by human voters in terms of image quality and prompt following over LCM-XL evaluated at four (or fewer) steps.
In addition, we see that using four steps for SDXL-Turbo further improves performance.
For details on the user study, we refer to the [research paper](https://stability.ai/research/adversarial-diffusion-distillation).
## Uses
### Direct Use
The model is intended for both non-commercial and commercial usage. You can use this model for non-commercial or research purposes under this [license](https://huggingface.co/stabilityai/sdxl-turbo/blob/main/LICENSE.md). Possible research areas and tasks include
- Research on generative models.
- Research on real-time applications of generative models.
- Research on the impact of real-time generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
For commercial use, please refer to https://stability.ai/membership.
Excluded uses are described below.
### Diffusers
```
pip install diffusers transformers accelerate --upgrade
```
- **Text-to-image**:
SDXL-Turbo does not make use of `guidance_scale` or `negative_prompt`, we disable it with `guidance_scale=0.0`.
Preferably, the model generates images of size 512x512 but higher image sizes work as well.
A **single step** is enough to generate high quality images.
```py
from diffusers import AutoPipelineForText2Image
import torch
pipe = AutoPipelineForText2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
```
- **Image-to-image**:
When using SDXL-Turbo for image-to-image generation, make sure that `num_inference_steps` * `strength` is larger or equal
to 1. The image-to-image pipeline will run for `int(num_inference_steps * strength)` steps, *e.g.* 0.5 * 2.0 = 1 step in our example
below.
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import load_image
import torch
pipe = AutoPipelineForImage2Image.from_pretrained("stabilityai/sdxl-turbo", torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
init_image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png").resize((512, 512))
prompt = "cat wizard, gandalf, lord of the rings, detailed, fantasy, cute, adorable, Pixar, Disney, 8k"
image = pipe(prompt, image=init_image, num_inference_steps=2, strength=0.5, guidance_scale=0.0).images[0]
```
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events,
and therefore using the model to generate such content is out-of-scope for the abilities of this model.
The model should not be used in any way that violates Stability AI's [Acceptable Use Policy](https://stability.ai/use-policy).
## Limitations and Bias
### Limitations
- The generated images are of a fixed resolution (512x512 pix), and the model does not achieve perfect photorealism.
- The model cannot render legible text.
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Recommendations
The model is intended for both non-commercial and commercial usage.
## How to Get Started with the Model
Check out https://github.com/Stability-AI/generative-models