
Update README.md
Browse files
README.md
CHANGED
|
@@ -7,6 +7,7 @@ metrics:
|
|
| 7 |
pipeline_tag: fill-mask
|
| 8 |
widget:
|
| 9 |
- text: Vamos a comer unos [MASK]
|
|
|
|
| 10 |
tags:
|
| 11 |
- code
|
| 12 |
- nlp
|
|
@@ -15,4 +16,51 @@ tags:
|
|
| 15 |
tokenizer:
|
| 16 |
- yes
|
| 17 |
---
|
| 18 |
-
# BILMA (Bert In Latin
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
pipeline_tag: fill-mask
|
| 8 |
widget:
|
| 9 |
- text: Vamos a comer unos [MASK]
|
| 10 |
+
example_title: "Vamos a comer unos tacos"
|
| 11 |
tags:
|
| 12 |
- code
|
| 13 |
- nlp
|
|
|
|
| 16 |
tokenizer:
|
| 17 |
- yes
|
| 18 |
---
|
| 19 |
+
# BILMA (Bert In Latin aMericA)
|
| 20 |
+
|
| 21 |
+
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the https://sadit.github.io/regional-spanish-models-talk-2022/ datasets.
|
| 22 |
+
|
| 23 |
+
The accuracy of the models trained on the MLM task for different regions are:
|
| 24 |
+
|
| 25 |
+
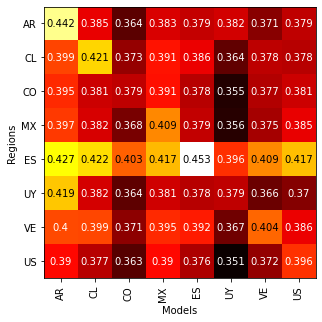
|
| 26 |
+
|
| 27 |
+
# Pre-requisites
|
| 28 |
+
|
| 29 |
+
You will need TensorFlow 2.4 or newer.
|
| 30 |
+
|
| 31 |
+
# Quick guide
|
| 32 |
+
|
| 33 |
+
You can see the demo notebooks for a quick guide on how to use the models.
|
| 34 |
+
|
| 35 |
+
Clone this repository and then run
|
| 36 |
+
```
|
| 37 |
+
bash download-emoji15-bilma.sh
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
to download the MX model. Then to load the model you can use the code:
|
| 41 |
+
```
|
| 42 |
+
from bilma import bilma_model
|
| 43 |
+
vocab_file = "vocab_file_All.txt"
|
| 44 |
+
model_file = "bilma_small_MX_epoch-1_classification_epochs-13.h5"
|
| 45 |
+
model = bilma_model.load(model_file)
|
| 46 |
+
tokenizer = bilma_model.tokenizer(vocab_file=vocab_file,
|
| 47 |
+
max_length=280)
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
Now you will need some text:
|
| 51 |
+
```
|
| 52 |
+
texts = ["Tenemos tres dias sin internet ni senal de celular en el pueblo.",
|
| 53 |
+
"Incomunicados en el siglo XXI tampoco hay servicio de telefonia fija",
|
| 54 |
+
"Vamos a comer unos tacos",
|
| 55 |
+
"Los del banco no dejan de llamarme"]
|
| 56 |
+
toks = tokenizer.tokenize(texts)
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
With this, you are ready to use the model
|
| 60 |
+
```
|
| 61 |
+
p = model.predict(toks)
|
| 62 |
+
tokenizer.decode_emo(p[1])
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
which produces the output: 
|
| 66 |
+
each emoji correspond to each entry in `texts`.
|