
Commit
•
8359bb1
1
Parent(s):
824dd1d
Upload 43 files
Browse files- Figures/Exp.png +0 -0
- Figures/SelectivePromptTuning-SPT.png +0 -0
- README.md +112 -0
- config/all_values.yml +39 -0
- config/convai2/llama2-7b-selective-linear-both-prompt-causal-convai2-adding-target-noise.yml +34 -0
- config/convai2/llama2-7b-selective-linear-both-prompt-causal-convai2.yml +33 -0
- config/convai2/opt-1.3b-selective-linear-both-prompt-causal-convai2.yml +33 -0
- config/convai2/opt-125m-selective-linear-both-prompt-causal-convai2.yml +33 -0
- config/convai2/opt-2.7b-selective-linear-both-prompt-causal-convai2.yml +33 -0
- config/default.yml +16 -0
- dataset/__pycache__/dataset.cpython-310.pyc +0 -0
- dataset/__pycache__/dataset_helper.cpython-310.pyc +0 -0
- dataset/dataset.py +189 -0
- dataset/dataset_helper.py +117 -0
- ds_config.json +28 -0
- env.yml +257 -0
- evaluate_runs_results.py +150 -0
- evaluation.py +92 -0
- interactive_test.py +205 -0
- models/__pycache__/llm_chat.cpython-310.pyc +0 -0
- models/__pycache__/selective_llm_chat.cpython-310.pyc +0 -0
- models/llm_chat.py +227 -0
- models/selective_llm_chat.py +390 -0
- test.py +204 -0
- train.py +129 -0
- trainer/__init__.py +1 -0
- trainer/__pycache__/__init__.cpython-310.pyc +0 -0
- trainer/__pycache__/peft_trainer.cpython-310.pyc +0 -0
- trainer/peft_trainer.py +187 -0
- utils/__pycache__/config.cpython-310.pyc +0 -0
- utils/__pycache__/configure_optimizers.cpython-310.pyc +0 -0
- utils/__pycache__/dist_helper.cpython-310.pyc +0 -0
- utils/__pycache__/format_inputs.cpython-310.pyc +0 -0
- utils/__pycache__/model_helpers.cpython-310.pyc +0 -0
- utils/__pycache__/parser_helper.cpython-310.pyc +0 -0
- utils/__pycache__/seed_everything.cpython-310.pyc +0 -0
- utils/config.py +50 -0
- utils/configure_optimizers.py +6 -0
- utils/dist_helper.py +5 -0
- utils/format_inputs.py +173 -0
- utils/model_helpers.py +31 -0
- utils/parser_helper.py +17 -0
- utils/seed_everything.py +44 -0
Figures/Exp.png
ADDED
|
Figures/SelectivePromptTuning-SPT.png
ADDED
|
README.md
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# SPT: Selective Prompting Tuning for Personalized Conversations with LLMs
|
| 2 |
+
Repo for `Selective Prompting Tuning for Personalized Conversations with LLMs`, the paper is available at: [Selective Prompting Tuning for Personalized Conversations with LLMs](https://openreview.net/pdf?id=Royo7My_EJ)
|
| 3 |
+
## Introduction
|
| 4 |
+
|
| 5 |
+
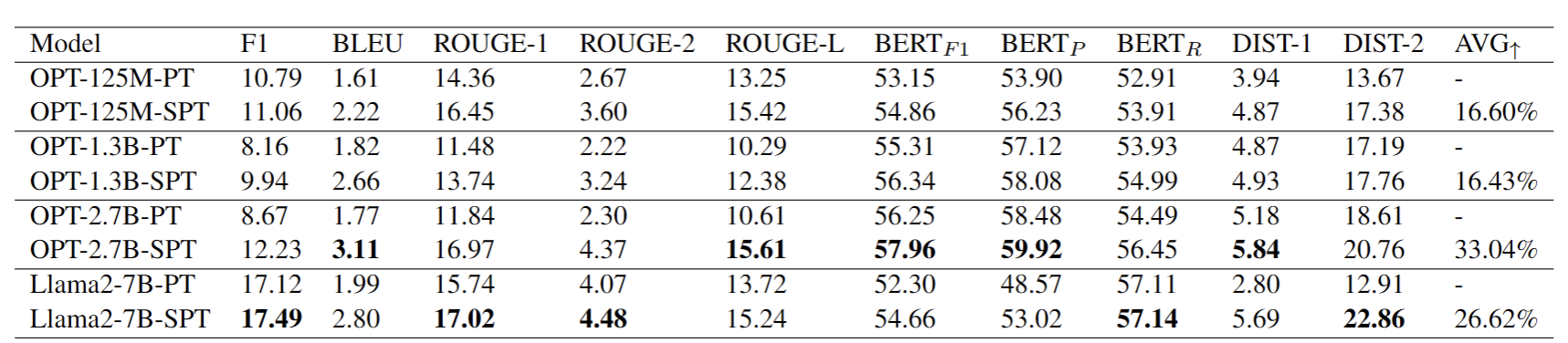
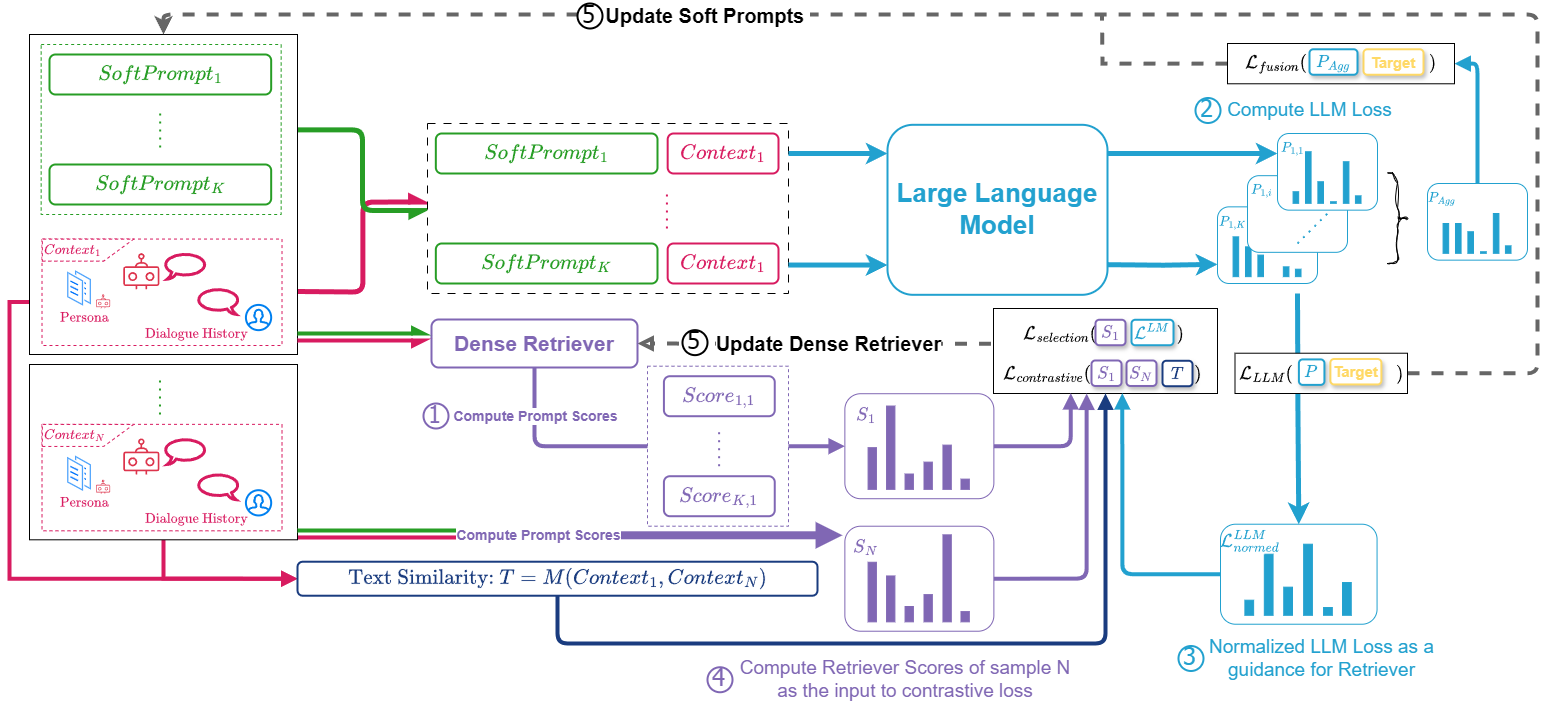
In conversational AI, personalizing dialogues with persona profiles and contextual understanding is essential. Despite large language models' (LLMs) improved response coherence, effective persona integration remains a challenge. In this work, we first study two common approaches for personalizing LLMs: textual prompting and direct fine-tuning. We observed that textual prompting often struggles to yield responses that are similar to the ground truths in datasets, while direct fine-tuning tends to produce repetitive or overly generic replies. To alleviate those issues, we propose **S**elective **P**rompt **T**uning (SPT), which softly prompts LLMs for personalized conversations in a selective way. Concretely, SPT initializes a set of soft prompts and uses a trainable dense retriever to adaptively select suitable soft prompts for LLMs according to different input contexts, where the prompt retriever is dynamically updated through feedback from the LLMs. Additionally, we propose context-prompt contrastive learning and prompt fusion learning to encourage the SPT to enhance the diversity of personalized conversations. Experiments on the CONVAI2 dataset demonstrate that SPT significantly enhances response diversity by up to 90\%, along with improvements in other critical performance indicators. Those results highlight the efficacy of SPT in fostering engaging and personalized dialogue generation. The SPT model code is publicly available for further exploration.
|
| 6 |
+
|
| 7 |
+
## Architecture
|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
## Experimental Results
|
| 11 |
+

|
| 12 |
+
|
| 13 |
+
## Repo Details
|
| 14 |
+
### Basic Project Structure
|
| 15 |
+
- `config`: contains all the configuration yml file from OPT-125M to Llama2-13B
|
| 16 |
+
- `data_file`: contains CONVAI2 dataset files, dataset can be donwloaded in this [Huggingface Repo](https://huggingface.co/hqsiswiliam/SPT)
|
| 17 |
+
- `dataset`: contains dataloader class and the pre-process methods
|
| 18 |
+
- `models`: contains SPT model classes
|
| 19 |
+
- `trainer`: contains trainer classes, responsible for model training & updating
|
| 20 |
+
- `utils`: provides helper classes and functions
|
| 21 |
+
- `test.py`: the entrance script for model decoding
|
| 22 |
+
- `train.py`: the entrance script for model training
|
| 23 |
+
### Checkpoint downloading
|
| 24 |
+
- The trained checkpoint is located in `public_ckpt` from [Huggingface Repo](https://huggingface.co/hqsiswiliam/SPT)
|
| 25 |
+
|
| 26 |
+
### Environment Initialization
|
| 27 |
+
#### Modifying `env.yml`
|
| 28 |
+
Since Deepspeed requires the CuDNN and CUDA, and we integrated Nvidia related tools in Anancoda, so it is essential to modify `env.yml`'s instance variable in the last two lines as:
|
| 29 |
+
```yml
|
| 30 |
+
variables:
|
| 31 |
+
LD_LIBRARY_PATH: <CONDA_PATH>/envs/SPT/lib
|
| 32 |
+
LIBRARY_PATH: <CONDA_PATH>/envs/SPT/lib
|
| 33 |
+
```
|
| 34 |
+
Please replace `<CONDA_PATH>` to your own actual conda installation path before importing the `env.yml` to your environment.
|
| 35 |
+
#### Environment Creation
|
| 36 |
+
The SPT's environment can be built using Anaconda (which we recommend), we provide the env.yml for environment creation:
|
| 37 |
+
```bash
|
| 38 |
+
conda env create -f env.yml
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
```bash
|
| 42 |
+
conda activate SPT
|
| 43 |
+
```
|
| 44 |
+
## Model Training
|
| 45 |
+
Using following command to start training:
|
| 46 |
+
```bash
|
| 47 |
+
deepspeed --num_nodes=1 train.py \
|
| 48 |
+
--config=config/convai2/opt-125m-selective-linear-both-prompt-causal-convai2.yml \
|
| 49 |
+
--batch=2 \
|
| 50 |
+
--lr=0.0001 \
|
| 51 |
+
--epoch=1 \
|
| 52 |
+
--save_model=yes \
|
| 53 |
+
--num_workers=0 \
|
| 54 |
+
--training_ratio=1.0 \
|
| 55 |
+
--log_dir=runs_ds_dev \
|
| 56 |
+
--deepspeed \
|
| 57 |
+
--deepspeed_config ds_config.json
|
| 58 |
+
```
|
| 59 |
+
You can adjust `--num_nodes` if you have multiple GPUs in one node
|
| 60 |
+
### Main Arguments
|
| 61 |
+
- `config`: the training configuration file
|
| 62 |
+
- `batch`: the batch size per GPU
|
| 63 |
+
- `lr`: learning rate
|
| 64 |
+
- `epoch`: epoch number
|
| 65 |
+
- `save_model`: whether to save model
|
| 66 |
+
- `training_ratio`: the percentage of data used for training, 1.0 means 100%
|
| 67 |
+
- `log_dir`: the log and model save directory
|
| 68 |
+
- `deepspeed & --deepspeed_config`: the necessary arguments for initialize deepspeed
|
| 69 |
+
- `selective_loss_weight`: weight for selection loss
|
| 70 |
+
- `contrastive_weight`: weight for contrastive loss
|
| 71 |
+
## Model Inference
|
| 72 |
+
Model inference can be easily invoked by using the following command:
|
| 73 |
+
```bash
|
| 74 |
+
deepspeed test.py \
|
| 75 |
+
--model_path=public_ckpt/OPT-125M-SPT \
|
| 76 |
+
--batch_size=16 \
|
| 77 |
+
--skip_exists=no \
|
| 78 |
+
--deepspeed \
|
| 79 |
+
--deepspeed_config ds_config.json
|
| 80 |
+
```
|
| 81 |
+
### Main Arguments
|
| 82 |
+
- `model_path`: the path to the checkpoint, containing the `ds_ckpt` folder
|
| 83 |
+
- `skip_exists`: whether to skip decoding if `evaluation_result.txt` exists
|
| 84 |
+
|
| 85 |
+
## Computing Metrics for Generation Results
|
| 86 |
+
To compute the metric for the evaluation results, simply run:
|
| 87 |
+
|
| 88 |
+
`python evaluate_runs_results.py`
|
| 89 |
+
|
| 90 |
+
The input path can be changed in the script via:
|
| 91 |
+
```python
|
| 92 |
+
_main_path = 'public_ckpt'
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
## Interactive Testing
|
| 96 |
+
Also, we support interactive testing via:
|
| 97 |
+
```bash
|
| 98 |
+
deepspeed interactive_test.py \
|
| 99 |
+
--model_path=public_ckpt/Llama2-7B-SPT \
|
| 100 |
+
--batch_size=1 \
|
| 101 |
+
--deepspeed \
|
| 102 |
+
--deepspeed_config ds_config.json
|
| 103 |
+
```
|
| 104 |
+
So an interactive interface will be invoked as:
|
| 105 |
+
|
| 106 |
+
Some shortcut keys:
|
| 107 |
+
- `exit`: exiting the interactive shell
|
| 108 |
+
- `clear`: clear the current dialog history
|
| 109 |
+
- `r`: reload SPT's persona
|
| 110 |
+
|
| 111 |
+
## Citation
|
| 112 |
+
Will be available soon.
|
config/all_values.yml
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "facebook/opt-125m"
|
| 4 |
+
load_bit: 32
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 8
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
retriever:
|
| 12 |
+
retriever_on: ['extra', 'lm']
|
| 13 |
+
retriever_type: transformer_encoder
|
| 14 |
+
n_head: 4
|
| 15 |
+
num_layers: 2
|
| 16 |
+
|
| 17 |
+
training:
|
| 18 |
+
learning_rate: 1e-5
|
| 19 |
+
batch_size: 32
|
| 20 |
+
num_epochs: 1
|
| 21 |
+
mode: causal
|
| 22 |
+
only_longest: True
|
| 23 |
+
task_type: generate_response
|
| 24 |
+
log_dir: runs_prompt_selective_linear
|
| 25 |
+
contrastive: true
|
| 26 |
+
ensemble: true
|
| 27 |
+
selective_loss_weight: 0.4
|
| 28 |
+
contrastive_metric: bleu
|
| 29 |
+
contrastive_threshold: 20.0
|
| 30 |
+
contrastive_weight: 0.4
|
| 31 |
+
freeze_persona: yes
|
| 32 |
+
freeze_context: yes
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
dataset:
|
| 36 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 37 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 38 |
+
max_context_turns: -1
|
| 39 |
+
max_token_length: 512
|
config/convai2/llama2-7b-selective-linear-both-prompt-causal-convai2-adding-target-noise.yml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "Llama-2-7b-chat-hf"
|
| 4 |
+
load_bit: 16
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 1
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
|
| 12 |
+
training:
|
| 13 |
+
learning_rate: 1e-5
|
| 14 |
+
batch_size: 32
|
| 15 |
+
num_epochs: 1
|
| 16 |
+
mode: causal
|
| 17 |
+
adding_noise: 0.1
|
| 18 |
+
only_longest: False
|
| 19 |
+
task_type: generate_response
|
| 20 |
+
log_dir: runs_prompt_convai2_selective_linear
|
| 21 |
+
contrastive: true
|
| 22 |
+
ensemble: true
|
| 23 |
+
selective_loss_weight: 1.0
|
| 24 |
+
contrastive_metric: bleu
|
| 25 |
+
contrastive_threshold: 20.0
|
| 26 |
+
contrastive_weight: 1.0
|
| 27 |
+
freeze_persona: yes
|
| 28 |
+
freeze_context: yes
|
| 29 |
+
|
| 30 |
+
dataset:
|
| 31 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 32 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 33 |
+
max_context_turns: -1
|
| 34 |
+
max_token_length: 512
|
config/convai2/llama2-7b-selective-linear-both-prompt-causal-convai2.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "Llama-2-7b-chat-hf"
|
| 4 |
+
load_bit: 16
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 1
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
|
| 12 |
+
training:
|
| 13 |
+
learning_rate: 1e-5
|
| 14 |
+
batch_size: 32
|
| 15 |
+
num_epochs: 1
|
| 16 |
+
mode: causal
|
| 17 |
+
only_longest: False
|
| 18 |
+
task_type: generate_response
|
| 19 |
+
log_dir: runs_prompt_convai2_selective_linear
|
| 20 |
+
contrastive: true
|
| 21 |
+
ensemble: true
|
| 22 |
+
selective_loss_weight: 1.0
|
| 23 |
+
contrastive_metric: bleu
|
| 24 |
+
contrastive_threshold: 20.0
|
| 25 |
+
contrastive_weight: 1.0
|
| 26 |
+
freeze_persona: yes
|
| 27 |
+
freeze_context: yes
|
| 28 |
+
|
| 29 |
+
dataset:
|
| 30 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 31 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 32 |
+
max_context_turns: -1
|
| 33 |
+
max_token_length: 512
|
config/convai2/opt-1.3b-selective-linear-both-prompt-causal-convai2.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "facebook/opt-1.3b"
|
| 4 |
+
load_bit: 32
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 8
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
|
| 12 |
+
training:
|
| 13 |
+
learning_rate: 1e-5
|
| 14 |
+
batch_size: 32
|
| 15 |
+
num_epochs: 1
|
| 16 |
+
mode: causal
|
| 17 |
+
only_longest: False
|
| 18 |
+
task_type: generate_response
|
| 19 |
+
log_dir: runs_prompt_convai2_selective_linear
|
| 20 |
+
contrastive: true
|
| 21 |
+
ensemble: true
|
| 22 |
+
selective_loss_weight: 0.4
|
| 23 |
+
contrastive_metric: bleu
|
| 24 |
+
contrastive_threshold: 20.0
|
| 25 |
+
contrastive_weight: 0.4
|
| 26 |
+
freeze_persona: yes
|
| 27 |
+
freeze_context: yes
|
| 28 |
+
|
| 29 |
+
dataset:
|
| 30 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 31 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 32 |
+
max_context_turns: -1
|
| 33 |
+
max_token_length: 512
|
config/convai2/opt-125m-selective-linear-both-prompt-causal-convai2.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "facebook/opt-125m"
|
| 4 |
+
load_bit: 32
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 8
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
|
| 12 |
+
training:
|
| 13 |
+
learning_rate: 1e-5
|
| 14 |
+
batch_size: 32
|
| 15 |
+
num_epochs: 1
|
| 16 |
+
mode: causal
|
| 17 |
+
only_longest: False
|
| 18 |
+
task_type: generate_response
|
| 19 |
+
log_dir: runs_prompt_convai2_selective_linear
|
| 20 |
+
contrastive: true
|
| 21 |
+
ensemble: true
|
| 22 |
+
selective_loss_weight: 0.4
|
| 23 |
+
contrastive_metric: bleu
|
| 24 |
+
contrastive_threshold: 20.0
|
| 25 |
+
contrastive_weight: 0.4
|
| 26 |
+
freeze_persona: yes
|
| 27 |
+
freeze_context: yes
|
| 28 |
+
|
| 29 |
+
dataset:
|
| 30 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 31 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 32 |
+
max_context_turns: -1
|
| 33 |
+
max_token_length: 512
|
config/convai2/opt-2.7b-selective-linear-both-prompt-causal-convai2.yml
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
model_type: 'selective_pt'
|
| 3 |
+
model_name: "facebook/opt-2.7b"
|
| 4 |
+
load_bit: 16
|
| 5 |
+
peft_type: "prompt_tuning"
|
| 6 |
+
K: 4
|
| 7 |
+
peft_config:
|
| 8 |
+
num_virtual_tokens: 8
|
| 9 |
+
normalizer: linear
|
| 10 |
+
normalizer_on: ['prompt', 'lm']
|
| 11 |
+
|
| 12 |
+
training:
|
| 13 |
+
learning_rate: 1e-5
|
| 14 |
+
batch_size: 32
|
| 15 |
+
num_epochs: 1
|
| 16 |
+
mode: causal
|
| 17 |
+
only_longest: False
|
| 18 |
+
task_type: generate_response
|
| 19 |
+
log_dir: runs_prompt_convai2_selective_linear
|
| 20 |
+
contrastive: true
|
| 21 |
+
ensemble: true
|
| 22 |
+
selective_loss_weight: 0.4
|
| 23 |
+
contrastive_metric: bleu
|
| 24 |
+
contrastive_threshold: 20.0
|
| 25 |
+
contrastive_weight: 0.4
|
| 26 |
+
freeze_persona: yes
|
| 27 |
+
freeze_context: yes
|
| 28 |
+
|
| 29 |
+
dataset:
|
| 30 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 31 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 32 |
+
max_context_turns: -1
|
| 33 |
+
max_token_length: 512
|
config/default.yml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dataset:
|
| 2 |
+
train: data_file/ConvAI2/train_self_original_no_cands.txt
|
| 3 |
+
valid: data_file/ConvAI2/valid_self_original_no_cands.txt
|
| 4 |
+
max_context_turns: -1
|
| 5 |
+
max_token_length: 512
|
| 6 |
+
|
| 7 |
+
model:
|
| 8 |
+
score_activation: 'softplus'
|
| 9 |
+
|
| 10 |
+
training:
|
| 11 |
+
mode: normal
|
| 12 |
+
only_longest: False
|
| 13 |
+
task_type: generate_response
|
| 14 |
+
ensemble: false
|
| 15 |
+
tau_gold: 1.0
|
| 16 |
+
tau_sim: 1.0
|
dataset/__pycache__/dataset.cpython-310.pyc
ADDED
|
Binary file (5.37 kB). View file
|
|
|
dataset/__pycache__/dataset_helper.cpython-310.pyc
ADDED
|
Binary file (3.46 kB). View file
|
|
|
dataset/dataset.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from pytorch_lightning import LightningDataModule
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
|
| 5 |
+
from dataset.dataset_helper import read_personachat_split
|
| 6 |
+
from utils.format_inputs import TASK_TYPE
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class PersonaChatDataset(torch.utils.data.Dataset):
|
| 10 |
+
# longest first for batch finder
|
| 11 |
+
def __init__(self, data_path, max_context_turns=-1,
|
| 12 |
+
add_role_indicator=True, only_longest=False, training_ratio=1.0,
|
| 13 |
+
task_type=TASK_TYPE.GENERATE_RESPONSE):
|
| 14 |
+
self.path = data_path
|
| 15 |
+
self.add_role_indicator = add_role_indicator
|
| 16 |
+
self.max_context_turns = max_context_turns
|
| 17 |
+
self.turns_data = read_personachat_split(data_path, only_longest=only_longest)
|
| 18 |
+
self.only_longest = only_longest
|
| 19 |
+
self.training_ratio = training_ratio
|
| 20 |
+
if training_ratio < 1.0:
|
| 21 |
+
self.turns_data = self.turns_data[:int(len(self.turns_data) * training_ratio)]
|
| 22 |
+
self.task_type = task_type
|
| 23 |
+
# # For debug only
|
| 24 |
+
# os.makedirs("data_logs", exist_ok=True)
|
| 25 |
+
# random_num = random.randint(0, 100000)
|
| 26 |
+
# self.file = open(f"data_logs/{random_num}_{data_path.split(os.sep)[-1]}", 'w')
|
| 27 |
+
# # add id to turns_data
|
| 28 |
+
# self.turns_data = [{'id': idx, **turn} for idx, turn in enumerate(self.turns_data)]
|
| 29 |
+
# self.file.write(f"total_turns: {len(self.turns_data)}\n")
|
| 30 |
+
|
| 31 |
+
def sort_longest_first(self):
|
| 32 |
+
self.turns_data = sorted(self.turns_data, key=lambda x: len(
|
| 33 |
+
(' '.join(x['persona']) + ' '.join(x['context']) + x['response']).split(' ')), reverse=True)
|
| 34 |
+
|
| 35 |
+
def __getitem__(self, idx):
|
| 36 |
+
# self.file.write(str(idx) + "\n")
|
| 37 |
+
# self.file.flush()
|
| 38 |
+
input_data = self.turns_data[idx]
|
| 39 |
+
persona_list = input_data['persona']
|
| 40 |
+
target = input_data['response']
|
| 41 |
+
context_input = input_data['context']
|
| 42 |
+
if self.add_role_indicator:
|
| 43 |
+
roled_context_input = [['Q: ', 'R: '][c_idx % 2] + context for c_idx, context in enumerate(context_input)]
|
| 44 |
+
context_input = roled_context_input
|
| 45 |
+
if self.max_context_turns != -1:
|
| 46 |
+
truncated_context = context_input[-(self.max_context_turns * 2 - 1):]
|
| 47 |
+
context_input = truncated_context
|
| 48 |
+
if self.only_longest:
|
| 49 |
+
context_input = context_input[:-1]
|
| 50 |
+
return {
|
| 51 |
+
'context_input': context_input,
|
| 52 |
+
'persona_list': persona_list,
|
| 53 |
+
'target': target
|
| 54 |
+
}
|
| 55 |
+
|
| 56 |
+
def __len__(self):
|
| 57 |
+
return len(self.turns_data)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# class HGPersonaChatDataset(PersonaChatDataset):
|
| 61 |
+
# def __init__(self, data_path, max_context_turns=-1,
|
| 62 |
+
# add_role_indicator=True, only_longest=False, tokenizer=None):
|
| 63 |
+
# super().__init__(data_path, max_context_turns, add_role_indicator, only_longest)
|
| 64 |
+
# self.tokenizer = tokenizer
|
| 65 |
+
#
|
| 66 |
+
# def __getitem__(self, idx):
|
| 67 |
+
# data = super().__getitem__(idx)
|
| 68 |
+
# input = "P: " + ' '.join(data['persona_list']) + " C: " + ' '.join(data['context_input']) + " R: " + data[
|
| 69 |
+
# 'target']
|
| 70 |
+
# tokenized = self.tokenizer(input)
|
| 71 |
+
# return {**data, **tokenized}
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def collate_fn(sample_list):
|
| 75 |
+
dont_be_a_tensor = ['context_input', 'persona_list', 'target']
|
| 76 |
+
to_be_flattened = [*dont_be_a_tensor]
|
| 77 |
+
data = {}
|
| 78 |
+
for key in to_be_flattened:
|
| 79 |
+
if key not in sample_list[0].keys():
|
| 80 |
+
continue
|
| 81 |
+
if sample_list[0][key] is None:
|
| 82 |
+
continue
|
| 83 |
+
flatten_samples = [sample[key] for sample in sample_list]
|
| 84 |
+
if flatten_samples[-1].__class__ == str or key in dont_be_a_tensor:
|
| 85 |
+
data[key] = flatten_samples
|
| 86 |
+
else:
|
| 87 |
+
data[key] = torch.tensor(flatten_samples)
|
| 88 |
+
return data
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def collate_fn_straight(sample_list):
|
| 92 |
+
sample_list = collate_fn(sample_list)
|
| 93 |
+
return sample_list
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def collate_fn_straight_with_fn(fn):
|
| 97 |
+
def build_collate_fn(sample_list):
|
| 98 |
+
sample_list = collate_fn(sample_list)
|
| 99 |
+
sample_list_processed = fn(sample_list)
|
| 100 |
+
return {**sample_list, **sample_list_processed}
|
| 101 |
+
|
| 102 |
+
return build_collate_fn
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def get_dataloader(dataset, batch_size, shuffle=False, num_workers=None, collate_fn=None, sampler=None):
|
| 106 |
+
if num_workers is None:
|
| 107 |
+
num_workers = batch_size // 4
|
| 108 |
+
# num_workers = min(num_workers, batch_size)
|
| 109 |
+
if collate_fn == None:
|
| 110 |
+
_collate_fn = collate_fn_straight
|
| 111 |
+
else:
|
| 112 |
+
_collate_fn = collate_fn_straight_with_fn(collate_fn)
|
| 113 |
+
return DataLoader(dataset, batch_size=batch_size,
|
| 114 |
+
collate_fn=_collate_fn,
|
| 115 |
+
shuffle=shuffle,
|
| 116 |
+
num_workers=num_workers,
|
| 117 |
+
sampler=sampler)
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def get_lightening_dataloader(dataset, batch_size, shuffle=False, num_workers=None):
|
| 121 |
+
return LitDataModule(batch_size, dataset, shuffle, num_workers)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
class LitDataModule(LightningDataModule):
|
| 125 |
+
def __init__(self, batch_size, dataset, shuffle, num_workers):
|
| 126 |
+
super().__init__()
|
| 127 |
+
self.save_hyperparameters(ignore=['dataset'])
|
| 128 |
+
# or
|
| 129 |
+
self.batch_size = batch_size
|
| 130 |
+
self.dataset = dataset
|
| 131 |
+
|
| 132 |
+
def train_dataloader(self):
|
| 133 |
+
return DataLoader(self.dataset, batch_size=self.batch_size,
|
| 134 |
+
collate_fn=collate_fn_straight,
|
| 135 |
+
shuffle=self.hparams.shuffle,
|
| 136 |
+
num_workers=self.hparams.num_workers)
|
| 137 |
+
|
| 138 |
+
if __name__ == '__main__':
|
| 139 |
+
import json
|
| 140 |
+
train_ds = PersonaChatDataset(data_path='data_file/ConvAI2/train_self_original_no_cands.txt',
|
| 141 |
+
)
|
| 142 |
+
from tqdm import tqdm
|
| 143 |
+
|
| 144 |
+
jsonfy_data = []
|
| 145 |
+
|
| 146 |
+
for data in tqdm(train_ds):
|
| 147 |
+
context_input = "\n".join(data['context_input'])
|
| 148 |
+
persona_input = '\n'.join(data['persona_list'])
|
| 149 |
+
jsonfy_data.append({
|
| 150 |
+
"instruction": f"""Given the dialog history between Q and R is:
|
| 151 |
+
{context_input}
|
| 152 |
+
|
| 153 |
+
Given the personality of the R as:
|
| 154 |
+
{persona_input}
|
| 155 |
+
|
| 156 |
+
Please response to Q according to both the dialog history and the R's personality.
|
| 157 |
+
Now, the R would say:""",
|
| 158 |
+
"input": "",
|
| 159 |
+
"output": data['target'],
|
| 160 |
+
"answer": "",
|
| 161 |
+
})
|
| 162 |
+
with open('data_file/train.json', 'w') as writer:
|
| 163 |
+
json.dump(jsonfy_data, writer)
|
| 164 |
+
jsonfy_data = []
|
| 165 |
+
del train_ds
|
| 166 |
+
|
| 167 |
+
train_ds = PersonaChatDataset(data_path='data_file/ConvAI2/valid_self_original_no_cands.txt',
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
for data in tqdm(train_ds):
|
| 171 |
+
context_input = "\n".join(data['context_input'])
|
| 172 |
+
persona_input = '\n'.join(data['persona_list'])
|
| 173 |
+
jsonfy_data.append({
|
| 174 |
+
"instruction": f"""Given the dialog history between Q and R is:
|
| 175 |
+
{context_input}
|
| 176 |
+
|
| 177 |
+
Given the personality of the R as:
|
| 178 |
+
{persona_input}
|
| 179 |
+
|
| 180 |
+
Please response to Q according to both the dialog history and the R's personality.
|
| 181 |
+
Now, the R would say:""",
|
| 182 |
+
"input": "",
|
| 183 |
+
"output": data['target'],
|
| 184 |
+
"answer": "",
|
| 185 |
+
})
|
| 186 |
+
with open('data_file/valid.json', 'w') as writer:
|
| 187 |
+
json.dump(jsonfy_data, writer)
|
| 188 |
+
with open('data_file/test.json', 'w') as writer:
|
| 189 |
+
json.dump(jsonfy_data, writer)
|
dataset/dataset_helper.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def read_personachat_split(split_dir, only_longest=False):
|
| 7 |
+
results = []
|
| 8 |
+
their_per_group = None
|
| 9 |
+
try:
|
| 10 |
+
file = open(split_dir, 'r')
|
| 11 |
+
lines = file.readlines()
|
| 12 |
+
persona = []
|
| 13 |
+
context = []
|
| 14 |
+
response = None
|
| 15 |
+
candidates = []
|
| 16 |
+
is_longest = False
|
| 17 |
+
for line in tqdm(lines[:], desc='loading {}'.format(split_dir)):
|
| 18 |
+
if line.startswith('1 your persona:'):
|
| 19 |
+
is_longest = True
|
| 20 |
+
if is_longest and only_longest:
|
| 21 |
+
if response is not None:
|
| 22 |
+
results.append({'persona': persona.copy(), 'context': context.copy(), 'response': response,
|
| 23 |
+
'candidates': candidates.copy()})
|
| 24 |
+
is_longest = False
|
| 25 |
+
persona = []
|
| 26 |
+
context = []
|
| 27 |
+
if 'persona:' in line:
|
| 28 |
+
persona.append(line.split(':')[1].strip())
|
| 29 |
+
if 'persona:' not in line:
|
| 30 |
+
context.append(re.sub(r"^\d+ ", "", line.split("\t")[0].strip()))
|
| 31 |
+
response = line.split("\t")[1].strip()
|
| 32 |
+
if len(line.split("\t\t"))==1:
|
| 33 |
+
candidates = []
|
| 34 |
+
else:
|
| 35 |
+
candidates = line.split("\t\t")[1].strip().split("|")
|
| 36 |
+
if not only_longest:
|
| 37 |
+
results.append({'persona': persona.copy(), 'context': context.copy(), 'response': response,
|
| 38 |
+
'candidates': candidates.copy()})
|
| 39 |
+
context.append(response)
|
| 40 |
+
except FileNotFoundError:
|
| 41 |
+
print(f"Sorry! The file {split_dir} can't be found.")
|
| 42 |
+
return results
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def combine_persona_query_response(persona, query, response, candidates):
|
| 46 |
+
assert ((len(persona) == len(query)) and (len(query) == len(response))), \
|
| 47 |
+
'the length of persona, query, response must be equivalent'
|
| 48 |
+
data = {}
|
| 49 |
+
for index, psn in enumerate(persona):
|
| 50 |
+
split_persona = psn.strip().split("\t")
|
| 51 |
+
psn = psn.replace("\t", " ").strip()
|
| 52 |
+
if psn not in data.keys():
|
| 53 |
+
data[psn] = {'persona': psn, 'query': [], 'response': [], 'dialog': [], 'response_turns': 0,
|
| 54 |
+
'persona_list': split_persona, 'candidates': []}
|
| 55 |
+
data[psn]['query'].append(query[index])
|
| 56 |
+
data[psn]['response'].append(response[index])
|
| 57 |
+
data[psn]['dialog'].append(query[index])
|
| 58 |
+
data[psn]['dialog'].append(response[index])
|
| 59 |
+
data[psn]['candidates'].append(candidates[index])
|
| 60 |
+
data[psn]['response_turns'] += 1
|
| 61 |
+
return data
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def preprocess_text(text):
|
| 65 |
+
punctuations = '.,?'
|
| 66 |
+
for punc in punctuations:
|
| 67 |
+
text = text.replace(punc, ' {} '.format(punc))
|
| 68 |
+
text = re.sub(' +', ' ', text).strip()
|
| 69 |
+
return text
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def preprocess_texts(text_array):
|
| 73 |
+
return [preprocess_text(t) for t in text_array]
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# "turns" means we need at least how many turns
|
| 77 |
+
# "max_context_turns" means how many history turns should be kept
|
| 78 |
+
def get_chat_by_turns(combined_data, turns=1,
|
| 79 |
+
sep_token='[SEP]', add_role_indicator=True,
|
| 80 |
+
add_persona_indicator=True, max_context_turns=-1):
|
| 81 |
+
assert turns > 0, 'turns must be large than 0'
|
| 82 |
+
all_persona = list(combined_data.keys())
|
| 83 |
+
filtered_persona = list(filter(lambda p: combined_data[p]['response_turns'] >= turns, all_persona))
|
| 84 |
+
data = []
|
| 85 |
+
|
| 86 |
+
for single_persona in filtered_persona:
|
| 87 |
+
single_persona_data = combined_data[single_persona]
|
| 88 |
+
persona_list = single_persona_data['persona_list']
|
| 89 |
+
context = []
|
| 90 |
+
for index, (query, response) in enumerate(
|
| 91 |
+
zip(single_persona_data['query'], single_persona_data['response'])
|
| 92 |
+
):
|
| 93 |
+
if max_context_turns != -1 and \
|
| 94 |
+
index + 1 < single_persona_data['response_turns'] - max_context_turns:
|
| 95 |
+
continue
|
| 96 |
+
if add_role_indicator:
|
| 97 |
+
query = "Q: {}".format(query)
|
| 98 |
+
if not index + 1 >= turns:
|
| 99 |
+
response = "R: {}".format(response)
|
| 100 |
+
context += [query, response]
|
| 101 |
+
if index + 1 >= turns:
|
| 102 |
+
break
|
| 103 |
+
|
| 104 |
+
response = context[-1]
|
| 105 |
+
context = context[:-1]
|
| 106 |
+
|
| 107 |
+
input_x_str = " {} ".format(sep_token).join(context)
|
| 108 |
+
input_x_str = re.sub(" +", " ", input_x_str)
|
| 109 |
+
if add_persona_indicator:
|
| 110 |
+
single_persona = "P: {}".format(single_persona)
|
| 111 |
+
data.append({'input': preprocess_texts(context),
|
| 112 |
+
'input_str': preprocess_text(input_x_str),
|
| 113 |
+
'target': preprocess_text(response),
|
| 114 |
+
'persona': preprocess_text(single_persona),
|
| 115 |
+
'persona_list': preprocess_texts(persona_list),
|
| 116 |
+
'candidates': preprocess_texts(single_persona_data['candidates'][-1])})
|
| 117 |
+
return data
|
ds_config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"train_micro_batch_size_per_gpu ": 1,
|
| 3 |
+
"gradient_accumulation_steps": 1,
|
| 4 |
+
"optimizer": {
|
| 5 |
+
"type": "Adam",
|
| 6 |
+
"params": {
|
| 7 |
+
"lr": 0.00015
|
| 8 |
+
}
|
| 9 |
+
},
|
| 10 |
+
"bf16": {
|
| 11 |
+
"enabled": false
|
| 12 |
+
},
|
| 13 |
+
"float16": {
|
| 14 |
+
"enabled": false
|
| 15 |
+
},
|
| 16 |
+
|
| 17 |
+
"zero_optimization": {
|
| 18 |
+
"stage": 2,
|
| 19 |
+
"offload_param": {
|
| 20 |
+
"device": "cpu",
|
| 21 |
+
"pin_memory": true,
|
| 22 |
+
"buffer_count": 5,
|
| 23 |
+
"buffer_size": 1e8,
|
| 24 |
+
"max_in_cpu": 1e9
|
| 25 |
+
}
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
}
|
env.yml
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: SPT
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- nvidia
|
| 5 |
+
- nvidia/label/cuda-11.8.0
|
| 6 |
+
- anaconda
|
| 7 |
+
- defaults
|
| 8 |
+
dependencies:
|
| 9 |
+
- _libgcc_mutex=0.1=main
|
| 10 |
+
- _openmp_mutex=5.1=1_gnu
|
| 11 |
+
- blas=1.0=mkl
|
| 12 |
+
- brotlipy=0.7.0=py310h7f8727e_1002
|
| 13 |
+
- bzip2=1.0.8=h7b6447c_0
|
| 14 |
+
- ca-certificates=2023.08.22=h06a4308_0
|
| 15 |
+
- certifi=2023.11.17=py310h06a4308_0
|
| 16 |
+
- cffi=1.15.1=py310h5eee18b_3
|
| 17 |
+
- charset-normalizer=2.0.4=pyhd3eb1b0_0
|
| 18 |
+
- cryptography=39.0.1=py310h9ce1e76_2
|
| 19 |
+
- cuda-cccl=11.8.89=0
|
| 20 |
+
- cuda-compiler=11.8.0=0
|
| 21 |
+
- cuda-cudart=11.8.89=0
|
| 22 |
+
- cuda-cudart-dev=11.8.89=0
|
| 23 |
+
- cuda-cuobjdump=11.8.86=0
|
| 24 |
+
- cuda-cupti=11.8.87=0
|
| 25 |
+
- cuda-cuxxfilt=11.8.86=0
|
| 26 |
+
- cuda-libraries=11.8.0=0
|
| 27 |
+
- cuda-nvcc=11.8.89=0
|
| 28 |
+
- cuda-nvprune=11.8.86=0
|
| 29 |
+
- cuda-nvrtc=11.8.89=0
|
| 30 |
+
- cuda-nvtx=11.8.86=0
|
| 31 |
+
- cuda-runtime=11.8.0=0
|
| 32 |
+
- cudatoolkit=11.8.0=h6a678d5_0
|
| 33 |
+
- ffmpeg=4.3=hf484d3e_0
|
| 34 |
+
- filelock=3.9.0=py310h06a4308_0
|
| 35 |
+
- freetype=2.12.1=h4a9f257_0
|
| 36 |
+
- giflib=5.2.1=h5eee18b_3
|
| 37 |
+
- gmp=6.2.1=h295c915_3
|
| 38 |
+
- gmpy2=2.1.2=py310heeb90bb_0
|
| 39 |
+
- gnutls=3.6.15=he1e5248_0
|
| 40 |
+
- idna=3.4=py310h06a4308_0
|
| 41 |
+
- intel-openmp=2023.1.0=hdb19cb5_46305
|
| 42 |
+
- jinja2=3.1.2=py310h06a4308_0
|
| 43 |
+
- jpeg=9e=h5eee18b_1
|
| 44 |
+
- lame=3.100=h7b6447c_0
|
| 45 |
+
- lcms2=2.12=h3be6417_0
|
| 46 |
+
- ld_impl_linux-64=2.38=h1181459_1
|
| 47 |
+
- lerc=3.0=h295c915_0
|
| 48 |
+
- libcublas=11.11.3.6=0
|
| 49 |
+
- libcublas-dev=11.11.3.6=0
|
| 50 |
+
- libcufft=10.9.0.58=0
|
| 51 |
+
- libcufile=1.6.1.9=0
|
| 52 |
+
- libcurand=10.3.2.106=0
|
| 53 |
+
- libcusolver=11.4.1.48=0
|
| 54 |
+
- libcusolver-dev=11.4.1.48=0
|
| 55 |
+
- libcusparse=11.7.5.86=0
|
| 56 |
+
- libcusparse-dev=11.7.5.86=0
|
| 57 |
+
- libdeflate=1.17=h5eee18b_0
|
| 58 |
+
- libffi=3.4.4=h6a678d5_0
|
| 59 |
+
- libgcc-ng=11.2.0=h1234567_1
|
| 60 |
+
- libgomp=11.2.0=h1234567_1
|
| 61 |
+
- libiconv=1.16=h7f8727e_2
|
| 62 |
+
- libidn2=2.3.4=h5eee18b_0
|
| 63 |
+
- libnpp=11.8.0.86=0
|
| 64 |
+
- libnvjpeg=11.9.0.86=0
|
| 65 |
+
- libpng=1.6.39=h5eee18b_0
|
| 66 |
+
- libstdcxx-ng=11.2.0=h1234567_1
|
| 67 |
+
- libtasn1=4.19.0=h5eee18b_0
|
| 68 |
+
- libtiff=4.5.0=h6a678d5_2
|
| 69 |
+
- libunistring=0.9.10=h27cfd23_0
|
| 70 |
+
- libuuid=1.41.5=h5eee18b_0
|
| 71 |
+
- libwebp=1.2.4=h11a3e52_1
|
| 72 |
+
- libwebp-base=1.2.4=h5eee18b_1
|
| 73 |
+
- lz4-c=1.9.4=h6a678d5_0
|
| 74 |
+
- markupsafe=2.1.1=py310h7f8727e_0
|
| 75 |
+
- mkl=2023.1.0=h6d00ec8_46342
|
| 76 |
+
- mkl-service=2.4.0=py310h5eee18b_1
|
| 77 |
+
- mkl_fft=1.3.6=py310h1128e8f_1
|
| 78 |
+
- mkl_random=1.2.2=py310h1128e8f_1
|
| 79 |
+
- mpc=1.1.0=h10f8cd9_1
|
| 80 |
+
- mpfr=4.0.2=hb69a4c5_1
|
| 81 |
+
- ncurses=6.4=h6a678d5_0
|
| 82 |
+
- nettle=3.7.3=hbbd107a_1
|
| 83 |
+
- networkx=2.8.4=py310h06a4308_1
|
| 84 |
+
- numpy=1.25.0=py310h5f9d8c6_0
|
| 85 |
+
- numpy-base=1.25.0=py310hb5e798b_0
|
| 86 |
+
- openh264=2.1.1=h4ff587b_0
|
| 87 |
+
- openssl=3.0.12=h7f8727e_0
|
| 88 |
+
- pillow=9.4.0=py310h6a678d5_0
|
| 89 |
+
- pip=23.1.2=py310h06a4308_0
|
| 90 |
+
- pycparser=2.21=pyhd3eb1b0_0
|
| 91 |
+
- pyopenssl=23.0.0=py310h06a4308_0
|
| 92 |
+
- pysocks=1.7.1=py310h06a4308_0
|
| 93 |
+
- python=3.10.11=h955ad1f_3
|
| 94 |
+
- pytorch-cuda=11.8=h7e8668a_5
|
| 95 |
+
- pytorch-mutex=1.0=cuda
|
| 96 |
+
- readline=8.2=h5eee18b_0
|
| 97 |
+
- requests=2.29.0=py310h06a4308_0
|
| 98 |
+
- setuptools=67.8.0=py310h06a4308_0
|
| 99 |
+
- sqlite=3.41.2=h5eee18b_0
|
| 100 |
+
- sympy=1.11.1=py310h06a4308_0
|
| 101 |
+
- tbb=2021.8.0=hdb19cb5_0
|
| 102 |
+
- tk=8.6.12=h1ccaba5_0
|
| 103 |
+
- torchtriton=2.0.0=py310
|
| 104 |
+
- typing_extensions=4.6.3=py310h06a4308_0
|
| 105 |
+
- urllib3=1.26.16=py310h06a4308_0
|
| 106 |
+
- wheel=0.38.4=py310h06a4308_0
|
| 107 |
+
- xz=5.4.2=h5eee18b_0
|
| 108 |
+
- zlib=1.2.13=h5eee18b_0
|
| 109 |
+
- zstd=1.5.5=hc292b87_0
|
| 110 |
+
- pip:
|
| 111 |
+
- absl-py==1.4.0
|
| 112 |
+
- accelerate==0.20.3
|
| 113 |
+
- aiohttp==3.8.4
|
| 114 |
+
- aiosignal==1.3.1
|
| 115 |
+
- annotated-types==0.6.0
|
| 116 |
+
- asttokens==2.2.1
|
| 117 |
+
- astunparse==1.6.3
|
| 118 |
+
- async-timeout==4.0.2
|
| 119 |
+
- attrs==23.1.0
|
| 120 |
+
- backcall==0.2.0
|
| 121 |
+
- bert-score==0.3.13
|
| 122 |
+
- bitsandbytes==0.41.0
|
| 123 |
+
- bleurt==0.0.2
|
| 124 |
+
- brotli==1.1.0
|
| 125 |
+
- cachetools==5.3.1
|
| 126 |
+
- click==8.1.7
|
| 127 |
+
- cmake==3.25.0
|
| 128 |
+
- colorama==0.4.6
|
| 129 |
+
- contourpy==1.1.0
|
| 130 |
+
- cycler==0.11.0
|
| 131 |
+
- datasets==2.13.1
|
| 132 |
+
- decorator==5.1.1
|
| 133 |
+
- deepspeed==0.12.6
|
| 134 |
+
- dill==0.3.6
|
| 135 |
+
- dotmap==1.3.30
|
| 136 |
+
- emoji==2.10.0
|
| 137 |
+
- evaluate==0.4.1
|
| 138 |
+
- executing==1.2.0
|
| 139 |
+
- flatbuffers==24.3.25
|
| 140 |
+
- fonttools==4.40.0
|
| 141 |
+
- frozenlist==1.3.3
|
| 142 |
+
- fsspec==2023.6.0
|
| 143 |
+
- gast==0.5.4
|
| 144 |
+
- google-auth==2.21.0
|
| 145 |
+
- google-auth-oauthlib==1.0.0
|
| 146 |
+
- google-pasta==0.2.0
|
| 147 |
+
- grpcio==1.56.0
|
| 148 |
+
- h5py==3.10.0
|
| 149 |
+
- hjson==3.1.0
|
| 150 |
+
- huggingface-hub==0.15.1
|
| 151 |
+
- inflate64==1.0.0
|
| 152 |
+
- ipython==8.14.0
|
| 153 |
+
- jedi==0.19.0
|
| 154 |
+
- joblib==1.3.2
|
| 155 |
+
- jsonlines==3.1.0
|
| 156 |
+
- keras==3.1.1
|
| 157 |
+
- kiwisolver==1.4.4
|
| 158 |
+
- libclang==18.1.1
|
| 159 |
+
- lightning-utilities==0.9.0
|
| 160 |
+
- lit==15.0.7
|
| 161 |
+
- loralib==0.1.1
|
| 162 |
+
- lxml==4.9.2
|
| 163 |
+
- markdown==3.4.3
|
| 164 |
+
- markdown-it-py==3.0.0
|
| 165 |
+
- matplotlib==3.7.2
|
| 166 |
+
- matplotlib-inline==0.1.6
|
| 167 |
+
- mdurl==0.1.2
|
| 168 |
+
- ml-dtypes==0.3.2
|
| 169 |
+
- mpmath==1.2.1
|
| 170 |
+
- multidict==6.0.4
|
| 171 |
+
- multiprocess==0.70.14
|
| 172 |
+
- multivolumefile==0.2.3
|
| 173 |
+
- namex==0.0.7
|
| 174 |
+
- ninja==1.11.1.1
|
| 175 |
+
- nltk==3.8.1
|
| 176 |
+
- nvidia-cuda-runtime-cu11==11.7.99
|
| 177 |
+
- oauthlib==3.2.2
|
| 178 |
+
- openai==0.27.8
|
| 179 |
+
- opencv-python==4.9.0.80
|
| 180 |
+
- opt-einsum==3.3.0
|
| 181 |
+
- optree==0.11.0
|
| 182 |
+
- packaging==23.1
|
| 183 |
+
- pandas==2.0.2
|
| 184 |
+
- parso==0.8.3
|
| 185 |
+
- peft==0.3.0
|
| 186 |
+
- pexpect==4.8.0
|
| 187 |
+
- pickleshare==0.7.5
|
| 188 |
+
- portalocker==2.7.0
|
| 189 |
+
- prompt-toolkit==3.0.39
|
| 190 |
+
- protobuf==4.23.3
|
| 191 |
+
- psutil==5.9.5
|
| 192 |
+
- ptyprocess==0.7.0
|
| 193 |
+
- pure-eval==0.2.2
|
| 194 |
+
- py-cpuinfo==9.0.0
|
| 195 |
+
- py7zr==0.20.8
|
| 196 |
+
- pyarrow==12.0.1
|
| 197 |
+
- pyasn1==0.5.0
|
| 198 |
+
- pyasn1-modules==0.3.0
|
| 199 |
+
- pybcj==1.0.2
|
| 200 |
+
- pycryptodomex==3.19.0
|
| 201 |
+
- pydantic==2.5.3
|
| 202 |
+
- pydantic-core==2.14.6
|
| 203 |
+
- pydotmap==0.1.3
|
| 204 |
+
- pygments==2.16.1
|
| 205 |
+
- pynvml==11.5.0
|
| 206 |
+
- pyparsing==3.0.9
|
| 207 |
+
- pyppmd==1.1.0
|
| 208 |
+
- python-dateutil==2.8.2
|
| 209 |
+
- python-dotenv==1.0.0
|
| 210 |
+
- pytictoc==1.5.2
|
| 211 |
+
- pytorch-lightning==2.0.4
|
| 212 |
+
- pytz==2023.3
|
| 213 |
+
- pyyaml==6.0
|
| 214 |
+
- pyzstd==0.15.9
|
| 215 |
+
- regex==2023.6.3
|
| 216 |
+
- requests-oauthlib==1.3.1
|
| 217 |
+
- responses==0.18.0
|
| 218 |
+
- retrying==1.3.4
|
| 219 |
+
- rich==13.7.1
|
| 220 |
+
- rouge==1.0.1
|
| 221 |
+
- rouge-score==0.1.2
|
| 222 |
+
- rsa==4.9
|
| 223 |
+
- sacrebleu==2.3.1
|
| 224 |
+
- safetensors==0.3.1
|
| 225 |
+
- scikit-learn==1.3.0
|
| 226 |
+
- scipy==1.11.0
|
| 227 |
+
- sentencepiece==0.1.99
|
| 228 |
+
- six==1.16.0
|
| 229 |
+
- sklearn==0.0.post7
|
| 230 |
+
- stack-data==0.6.2
|
| 231 |
+
- tabulate==0.9.0
|
| 232 |
+
- tensorboard==2.16.2
|
| 233 |
+
- tensorboard-data-server==0.7.1
|
| 234 |
+
- tensorflow==2.16.1
|
| 235 |
+
- tensorflow-io-gcs-filesystem==0.36.0
|
| 236 |
+
- termcolor==2.4.0
|
| 237 |
+
- texttable==1.7.0
|
| 238 |
+
- tf-slim==1.1.0
|
| 239 |
+
- threadpoolctl==3.2.0
|
| 240 |
+
- timm==0.4.5
|
| 241 |
+
- tokenizers==0.13.3
|
| 242 |
+
- torch==2.0.1+cu118
|
| 243 |
+
- torchaudio==2.0.2+cu118
|
| 244 |
+
- torchmetrics==0.11.4
|
| 245 |
+
- torchvision==0.15.2+cu118
|
| 246 |
+
- tqdm==4.65.0
|
| 247 |
+
- traitlets==5.9.0
|
| 248 |
+
- transformers==4.30.2
|
| 249 |
+
- tzdata==2023.3
|
| 250 |
+
- wcwidth==0.2.6
|
| 251 |
+
- werkzeug==2.3.6
|
| 252 |
+
- wrapt==1.16.0
|
| 253 |
+
- xxhash==3.2.0
|
| 254 |
+
- yarl==1.9.2
|
| 255 |
+
variables:
|
| 256 |
+
LD_LIBRARY_PATH: <CONDA_PATH>/envs/SPT/lib
|
| 257 |
+
LIBRARY_PATH: <CONDA_PATH>/envs/SPT/lib
|
evaluate_runs_results.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import glob
|
| 3 |
+
import pickle
|
| 4 |
+
import re
|
| 5 |
+
|
| 6 |
+
from dotenv import load_dotenv
|
| 7 |
+
|
| 8 |
+
load_dotenv()
|
| 9 |
+
import numpy
|
| 10 |
+
from bert_score import BERTScorer
|
| 11 |
+
from evaluation import f1_score
|
| 12 |
+
|
| 13 |
+
import evaluate
|
| 14 |
+
|
| 15 |
+
rouge = evaluate.load('rouge')
|
| 16 |
+
# bertscore = BERTScorer(lang='en', device='cuda')
|
| 17 |
+
bertscore = BERTScorer(model_type='microsoft/deberta-xlarge-mnli', device='cuda')
|
| 18 |
+
_main_path = 'public_ckpt'
|
| 19 |
+
|
| 20 |
+
ADD_METEOR = True
|
| 21 |
+
if ADD_METEOR:
|
| 22 |
+
meteor_scorer = evaluate.load('meteor')
|
| 23 |
+
|
| 24 |
+
DO_PRED_CLEAN = True
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def evaluate_folder(main_path, skip_exists=True):
|
| 29 |
+
results_path = f'{main_path}/results.txt'
|
| 30 |
+
results_csv_path = f'{main_path}/results.csv'
|
| 31 |
+
paths = glob.glob(f'{main_path}/*/evaluation_result*.pkl')
|
| 32 |
+
all_results = []
|
| 33 |
+
csv_results = []
|
| 34 |
+
csv_results.append(['path',
|
| 35 |
+
'ppl',
|
| 36 |
+
'F1',
|
| 37 |
+
'bleu',
|
| 38 |
+
'bleu-1',
|
| 39 |
+
'bleu-2',
|
| 40 |
+
'bleu-3',
|
| 41 |
+
'bleu-4',
|
| 42 |
+
'rouge1',
|
| 43 |
+
'rouge2',
|
| 44 |
+
'rougel',
|
| 45 |
+
'BERT f1',
|
| 46 |
+
'BERT precision',
|
| 47 |
+
'BERT recall',
|
| 48 |
+
'dist-1',
|
| 49 |
+
'dist-2',
|
| 50 |
+
'meteor',
|
| 51 |
+
'valid_num'])
|
| 52 |
+
for path in paths:
|
| 53 |
+
with open(path, 'rb') as file:
|
| 54 |
+
results = pickle.load(file)
|
| 55 |
+
if results.get('result_str') is not None and skip_exists:
|
| 56 |
+
all_results.append(results['result_str'])
|
| 57 |
+
csv_results.append(results['csv'])
|
| 58 |
+
continue
|
| 59 |
+
preds = results['pred_text']
|
| 60 |
+
clean_preds = []
|
| 61 |
+
if DO_PRED_CLEAN:
|
| 62 |
+
for pred in preds:
|
| 63 |
+
search_result = re.search('R:|Q:|Summary:|\n|\:', pred)
|
| 64 |
+
if search_result is not None:
|
| 65 |
+
clean_preds.append(pred[:search_result.span()[0]])
|
| 66 |
+
else:
|
| 67 |
+
clean_preds.append(pred)
|
| 68 |
+
preds = clean_preds
|
| 69 |
+
tgt = results['gt_text']
|
| 70 |
+
|
| 71 |
+
def bleu_score(prediction, ground_truths):
|
| 72 |
+
from sacrebleu import BLEU
|
| 73 |
+
bleu = BLEU()
|
| 74 |
+
score = bleu.corpus_score(prediction, ground_truths)
|
| 75 |
+
return score
|
| 76 |
+
|
| 77 |
+
bleu = bleu_score(preds, [tgt])
|
| 78 |
+
|
| 79 |
+
precision, recall, f1 = bertscore.score(preds, tgt, verbose=False, batch_size=64)
|
| 80 |
+
mean_precision = precision.mean().item()
|
| 81 |
+
mean_recall = recall.mean().item()
|
| 82 |
+
mean_f1 = f1.mean().item()
|
| 83 |
+
|
| 84 |
+
def eval_distinct(corpus):
|
| 85 |
+
unigrams = []
|
| 86 |
+
bigrams = []
|
| 87 |
+
for n, rep in enumerate(corpus):
|
| 88 |
+
rep = rep.strip()
|
| 89 |
+
temp = rep.split(' ')
|
| 90 |
+
unigrams += temp
|
| 91 |
+
for i in range(len(temp) - 1):
|
| 92 |
+
bigrams.append(temp[i] + ' ' + temp[i + 1])
|
| 93 |
+
distink_1 = len(set(unigrams)) * 1.0 / len(unigrams)
|
| 94 |
+
distink_2 = len(set(bigrams)) * 1.0 / len(bigrams)
|
| 95 |
+
return distink_1, distink_2
|
| 96 |
+
|
| 97 |
+
rouge_results = rouge.compute(predictions=preds, references=tgt)
|
| 98 |
+
rouge1, rouge2, rougel = rouge_results['rouge1'], rouge_results['rouge2'], rouge_results['rougeL']
|
| 99 |
+
me_score = 0
|
| 100 |
+
if ADD_METEOR:
|
| 101 |
+
me_score = meteor_scorer.compute(predictions=preds, references=tgt)['meteor']
|
| 102 |
+
from evaluation import rouge_score
|
| 103 |
+
_rouge = rouge_score(preds, [tgt])
|
| 104 |
+
f1 = [f1_score(p, [t]) for p, t in zip(preds, tgt)]
|
| 105 |
+
f1 = numpy.asfarray(f1).mean()
|
| 106 |
+
ppl=''
|
| 107 |
+
|
| 108 |
+
result_str = f"""
|
| 109 |
+
path: {path}
|
| 110 |
+
F1: {f1}
|
| 111 |
+
bleu: {bleu.score}
|
| 112 |
+
bleu detail: {bleu.precisions}
|
| 113 |
+
rouge1, rouge2, rougel: {rouge1, rouge2, rougel}
|
| 114 |
+
BERT f1: {mean_f1}
|
| 115 |
+
BERT precision: {mean_precision}
|
| 116 |
+
BERT recall: {mean_recall}
|
| 117 |
+
dist: {eval_distinct(preds)}
|
| 118 |
+
METEOR: {me_score}
|
| 119 |
+
valid_num: {len(preds)}
|
| 120 |
+
"""
|
| 121 |
+
csv_data = [path,
|
| 122 |
+
f1 * 100.0,
|
| 123 |
+
bleu.score,
|
| 124 |
+
*bleu.precisions,
|
| 125 |
+
rouge1 * 100.0,
|
| 126 |
+
rouge2 * 100.0,
|
| 127 |
+
rougel * 100.0,
|
| 128 |
+
mean_f1 * 100.0,
|
| 129 |
+
mean_precision * 100.0,
|
| 130 |
+
mean_recall * 100.0,
|
| 131 |
+
*eval_distinct(preds),
|
| 132 |
+
me_score,
|
| 133 |
+
len(preds)]
|
| 134 |
+
csv_results.append(csv_data)
|
| 135 |
+
print(result_str)
|
| 136 |
+
all_results.append(result_str)
|
| 137 |
+
with open(path, 'wb') as file:
|
| 138 |
+
results['result_str'] = result_str
|
| 139 |
+
results['csv'] = csv_data
|
| 140 |
+
pickle.dump(results, file)
|
| 141 |
+
|
| 142 |
+
with open(results_path, 'w') as file:
|
| 143 |
+
file.write("\n=====\n".join(all_results))
|
| 144 |
+
with open(results_csv_path, 'w') as file:
|
| 145 |
+
writer = csv.writer(file)
|
| 146 |
+
writer.writerows(csv_results)
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
if __name__ == '__main__':
|
| 150 |
+
evaluate_folder(_main_path, skip_exists=False)
|
evaluation.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Meta Platforms, Inc. and affiliates.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This source code is licensed under the license found in the
|
| 5 |
+
# LICENSE file in the root directory of this source tree.
|
| 6 |
+
|
| 7 |
+
import logging
|
| 8 |
+
import string
|
| 9 |
+
from collections import Counter
|
| 10 |
+
from typing import Callable
|
| 11 |
+
|
| 12 |
+
import regex
|
| 13 |
+
from rouge import Rouge
|
| 14 |
+
|
| 15 |
+
rouge = Rouge()
|
| 16 |
+
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# Normalization and score functions from SQuAD evaluation script https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/
|
| 21 |
+
def normalize_answer(s: str) -> str:
|
| 22 |
+
def remove_articles(text):
|
| 23 |
+
return regex.sub(r"\b(a|an|the)\b", " ", text)
|
| 24 |
+
|
| 25 |
+
def white_space_fix(text):
|
| 26 |
+
return " ".join(text.split())
|
| 27 |
+
|
| 28 |
+
def remove_punc(text):
|
| 29 |
+
exclude = set(string.punctuation)
|
| 30 |
+
return "".join(ch for ch in text if ch not in exclude)
|
| 31 |
+
|
| 32 |
+
def lower(text):
|
| 33 |
+
return text.lower()
|
| 34 |
+
|
| 35 |
+
return white_space_fix(remove_articles(remove_punc(lower(s))))
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def em(prediction, ground_truth, normalize_fn):
|
| 39 |
+
return float(normalize_fn(prediction) == normalize_fn(ground_truth))
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def f1(prediction, ground_truth, normalize_fn):
|
| 43 |
+
prediction_tokens = normalize_fn(prediction).split()
|
| 44 |
+
ground_truth_tokens = normalize_fn(ground_truth).split()
|
| 45 |
+
common = Counter(prediction_tokens) & Counter(ground_truth_tokens)
|
| 46 |
+
num_same = sum(common.values())
|
| 47 |
+
|
| 48 |
+
if num_same == 0:
|
| 49 |
+
return 0
|
| 50 |
+
precision = 1.0 * num_same / len(prediction_tokens)
|
| 51 |
+
recall = 1.0 * num_same / len(ground_truth_tokens)
|
| 52 |
+
f1 = (2 * precision * recall) / (precision + recall)
|
| 53 |
+
return f1
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def rouge_wrapper(prediction, ground_truth):
|
| 57 |
+
try:
|
| 58 |
+
result = rouge.get_scores(prediction, ground_truth, avg=True)
|
| 59 |
+
return result["rouge-1"]["f"], result["rouge-2"]["f"], result["rouge-l"]["f"]
|
| 60 |
+
except:
|
| 61 |
+
return 0.0, 0.0, 0.0
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
# pred = [p1, p2 ..., pn] gt=[[g1,g2,...,gn]]
|
| 65 |
+
def f1_score(prediction, ground_truths, normalize_fn: Callable[[str], str] = lambda x: x):
|
| 66 |
+
return max([f1(prediction, gt, normalize_fn) for gt in ground_truths])
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def exact_match_score(prediction, ground_truths, normalize_fn: Callable[[str], str] = lambda x: x):
|
| 70 |
+
return max([em(prediction, gt, normalize_fn) for gt in ground_truths])
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# pred = [p1, p2 ..., pn] gt=[[g1,g2,...,gn]]
|
| 74 |
+
def rouge_score(prediction, ground_truths):
|
| 75 |
+
ground_truths = [x for x in ground_truths if len(x) > 0]
|
| 76 |
+
if (
|
| 77 |
+
len(prediction) == 0 or len(ground_truths) == 0
|
| 78 |
+
): # check if empty prediction or if there is no hypothesis with len > 0
|
| 79 |
+
return 0.0, 0.0, 0.0
|
| 80 |
+
scores = [rouge_wrapper(prediction, gt) for gt in ground_truths]
|
| 81 |
+
rouge1 = max(s[0] for s in scores)
|
| 82 |
+
rouge2 = max(s[1] for s in scores)
|
| 83 |
+
rougel = max(s[2] for s in scores)
|
| 84 |
+
return rouge1, rouge2, rougel
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
# pred = [p1, p2 ..., pn] gt=[[g1,g2,...,gn]]
|
| 88 |
+
def bleu_score(prediction, ground_truths):
|
| 89 |
+
from sacrebleu import BLEU
|
| 90 |
+
bleu = BLEU()
|
| 91 |
+
score = bleu.corpus_score(prediction, ground_truths)
|
| 92 |
+
return score
|
interactive_test.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import json
|
| 4 |
+
import locale
|
| 5 |
+
import os
|
| 6 |
+
import random
|
| 7 |
+
import re
|
| 8 |
+
import time
|
| 9 |
+
from multiprocessing import freeze_support
|
| 10 |
+
|
| 11 |
+
import deepspeed
|
| 12 |
+
import torch
|
| 13 |
+
from dotenv import load_dotenv
|
| 14 |
+
from torch.utils.data import DistributedSampler
|
| 15 |
+
|
| 16 |
+
from dataset.dataset import PersonaChatDataset
|
| 17 |
+
from utils.dist_helper import setup
|
| 18 |
+
from utils.format_inputs import TASK_TYPE
|
| 19 |
+
from utils.parser_helper import str2bool
|
| 20 |
+
|
| 21 |
+
os.environ["PYTHONIOENCODING"] = "utf-8"
|
| 22 |
+
myLocale = locale.setlocale(category=locale.LC_ALL, locale="C.UTF-8")
|
| 23 |
+
load_dotenv()
|
| 24 |
+
|
| 25 |
+
argparse = argparse.ArgumentParser()
|
| 26 |
+
argparse.add_argument('--model_path', type=str, default=None)
|
| 27 |
+
argparse.add_argument('--path_pattern', type=str, default=None)
|
| 28 |
+
argparse.add_argument('--batch_size', type=int)
|
| 29 |
+
argparse.add_argument('--valid_path', type=str, default=None)
|
| 30 |
+
argparse.add_argument('--local_rank', type=int, default=-1)
|
| 31 |
+
argparse.add_argument('--skip_exists', type=str2bool, default=False)
|
| 32 |
+
argparse.add_argument('--selection_noise', type=float, default=None)
|
| 33 |
+
parser = deepspeed.add_config_arguments(argparse)
|
| 34 |
+
args = argparse.parse_args()
|
| 35 |
+
_cmd_args = parser.parse_args()
|
| 36 |
+
freeze_support()
|
| 37 |
+
|
| 38 |
+
VICUNA_PREFIX = 'PATH_TO_VICUNA'
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def test_process(model_paths, batch_size, valid_path, skip_exists, selection_noise, cmd_args):
|
| 42 |
+
world_size = int(os.getenv("WORLD_SIZE", "1"))
|
| 43 |
+
with open(cmd_args.deepspeed_config) as json_file:
|
| 44 |
+
ds_config = json.load(json_file)
|
| 45 |
+
del cmd_args.deepspeed_config
|
| 46 |
+
|
| 47 |
+
setup()
|
| 48 |
+
for model_path in model_paths:
|
| 49 |
+
try:
|
| 50 |
+
if selection_noise is not None:
|
| 51 |
+
save_dir = os.sep.join(
|
| 52 |
+
model_path.split(os.sep)[:-1]) + os.sep + f'evaluation_result_selection_noise={selection_noise}.pkl'
|
| 53 |
+
else:
|
| 54 |
+
save_dir = os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + 'evaluation_result.pkl'
|
| 55 |
+
if os.path.exists(save_dir) and (skip_exists):
|
| 56 |
+
continue
|
| 57 |
+
print(
|
| 58 |
+
f"Start setup rank {deepspeed.comm.get_local_rank()} of {world_size} on GPU {torch.cuda.current_device()}")
|
| 59 |
+
|
| 60 |
+
ckpt = torch.load(os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + 'checkpoint_best.pth',
|
| 61 |
+
map_location=f'cpu')
|
| 62 |
+
config = ckpt['config']
|
| 63 |
+
ds_config['train_micro_batch_size_per_gpu'] = batch_size
|
| 64 |
+
load_precision = '32'
|
| 65 |
+
if config.model.load_bit == 16:
|
| 66 |
+
ds_config['float16']['enabled'] = True
|
| 67 |
+
load_precision = 'fp16'
|
| 68 |
+
if 'llama' in config.model.model_name.lower():
|
| 69 |
+
ds_config['float16']['enabled'] = False
|
| 70 |
+
ds_config['bf16']['enabled'] = True
|
| 71 |
+
load_precision = 'bf16'
|
| 72 |
+
load_bit_map = {
|
| 73 |
+
'fp16': torch.float16,
|
| 74 |
+
'bf16': torch.bfloat16,
|
| 75 |
+
'32': torch.float32}
|
| 76 |
+
|
| 77 |
+
if config.model.model_type == 'selective_pt':
|
| 78 |
+
from models.selective_llm_chat import SelectLLMChat as LLMChat
|
| 79 |
+
else:
|
| 80 |
+
from models.llm_chat import LLMChat
|
| 81 |
+
if 'vicuna' in config.model.model_name and (not os.path.exists(config.model.model_name)):
|
| 82 |
+
config.model.model_name = VICUNA_PREFIX + os.sep + config.model.model_name.split(os.sep)[-1]
|
| 83 |
+
_model = LLMChat(config, batch_size)
|
| 84 |
+
left_tokenizer = _model.left_tokenizer
|
| 85 |
+
right_tokenizer = _model.right_tokenizer
|
| 86 |
+
print(f'LOADING {model_path} with {load_precision} precision')
|
| 87 |
+
model_engine, _, _, _ = deepspeed.initialize(args=cmd_args,
|
| 88 |
+
model=_model,
|
| 89 |
+
config=ds_config,
|
| 90 |
+
)
|
| 91 |
+
model_engine.load_checkpoint(model_path, load_module_strict=False, load_optimizer_states=False,
|
| 92 |
+
load_lr_scheduler_states=False,
|
| 93 |
+
load_module_only=True)
|
| 94 |
+
valid_path_file = valid_path
|
| 95 |
+
if valid_path_file is None:
|
| 96 |
+
valid_path_file = config.dataset.valid
|
| 97 |
+
if config.dataset.test.__class__ is str:
|
| 98 |
+
valid_path_file = config.dataset.test
|
| 99 |
+
print('using train split from personachat')
|
| 100 |
+
task_type = TASK_TYPE(config.training.task_type)
|
| 101 |
+
|
| 102 |
+
valid_dataset = PersonaChatDataset(valid_path_file, max_context_turns=config.dataset.max_context_turns)
|
| 103 |
+
from dataset.dataset import get_dataloader
|
| 104 |
+
max_new_token = 32
|
| 105 |
+
valid_sampler = DistributedSampler(valid_dataset, num_replicas=world_size, shuffle=False,
|
| 106 |
+
drop_last=False)
|
| 107 |
+
valid_dataloader = get_dataloader(valid_dataset, batch_size, num_workers=0, sampler=valid_sampler)
|
| 108 |
+
|
| 109 |
+
context_input = []
|
| 110 |
+
persona_list = []
|
| 111 |
+
dist_pred_text = [None for _ in range(world_size)]
|
| 112 |
+
dist_gt_text = [None for _ in range(world_size)]
|
| 113 |
+
pred_text = []
|
| 114 |
+
gt_text = []
|
| 115 |
+
selected_prompts = []
|
| 116 |
+
print('Please enter your input:')
|
| 117 |
+
first_setence = input()
|
| 118 |
+
chosen_persona = random.choice([p['persona'] for p in valid_dataset.turns_data])
|
| 119 |
+
history = [f"Q: {first_setence}"]
|
| 120 |
+
history_with_prompt_idx = [f"USER: {first_setence}"]
|
| 121 |
+
selected_prompts = []
|
| 122 |
+
while True:
|
| 123 |
+
data = {'context_input': [history],
|
| 124 |
+
'persona_list': [chosen_persona],
|
| 125 |
+
'target': ['not use']}
|
| 126 |
+
_, text, batch_selected_prompts = LLMChat.test_step(model_engine, data, left_tokenizer,
|
| 127 |
+
right_tokenizer,
|
| 128 |
+
config, max_new_tokens=max_new_token,
|
| 129 |
+
tqdm_instance=None,
|
| 130 |
+
selection_noise=None,
|
| 131 |
+
no_repeat_ngram_size=4,
|
| 132 |
+
top_p=0.9,
|
| 133 |
+
num_beams=10)
|
| 134 |
+
response = text[0].strip()
|
| 135 |
+
search_result = re.search('R:|Q:|Summary:|\n|\:', response)
|
| 136 |
+
if search_result is not None:
|
| 137 |
+
response = response[:search_result.span()[0]]
|
| 138 |
+
response = response.strip()
|
| 139 |
+
|
| 140 |
+
selected_prompts.append(batch_selected_prompts.item())
|
| 141 |
+
history += [f"R: {response}"]
|
| 142 |
+
history_with_prompt_idx += [f"SPT: {response} [SPT Index: {batch_selected_prompts.item()}]"]
|
| 143 |
+
history_str = "\n".join(history_with_prompt_idx)
|
| 144 |
+
print_str = f"""
|
| 145 |
+
Persona: {' '.join(chosen_persona)}
|
| 146 |
+
Dialogue:
|
| 147 |
+
{history_str}
|
| 148 |
+
"""
|
| 149 |
+
print(print_str)
|
| 150 |
+
print('Please enter your input:')
|
| 151 |
+
user_input = input()
|
| 152 |
+
if user_input == 'r':
|
| 153 |
+
history = history[:-1]
|
| 154 |
+
history_with_prompt_idx = history_with_prompt_idx[:-1]
|
| 155 |
+
continue
|
| 156 |
+
if user_input == 'exit':
|
| 157 |
+
exit()
|
| 158 |
+
elif user_input == 'save':
|
| 159 |
+
os.makedirs('interactive_dialog', exist_ok=True)
|
| 160 |
+
with open('interactive_dialog/'+time.strftime('%Y-%m-%d-%H%M')+'.txt', 'w') as file:
|
| 161 |
+
file.write(print_str)
|
| 162 |
+
history = []
|
| 163 |
+
history_with_prompt_idx = []
|
| 164 |
+
chosen_persona = random.choice([p['persona'] for p in valid_dataset.turns_data])
|
| 165 |
+
print('Please enter your input:')
|
| 166 |
+
user_input = input()
|
| 167 |
+
elif user_input == 'clear':
|
| 168 |
+
history = []
|
| 169 |
+
history_with_prompt_idx = []
|
| 170 |
+
chosen_persona = random.choice([p['persona'] for p in valid_dataset.turns_data])
|
| 171 |
+
print('Please enter your input:')
|
| 172 |
+
user_input = input()
|
| 173 |
+
history += [f"Q: {user_input}"]
|
| 174 |
+
history_with_prompt_idx += [f"USER: {user_input}"]
|
| 175 |
+
|
| 176 |
+
except Exception as e:
|
| 177 |
+
save_dir = os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + "test_error.txt"
|
| 178 |
+
print(f'WRITING TESTING ERROR! ERROR: {str(e)}')
|
| 179 |
+
with open(save_dir, 'w') as file:
|
| 180 |
+
file.write(str(e))
|
| 181 |
+
deepspeed.comm.barrier()
|
| 182 |
+
deepspeed.comm.barrier()
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
model_path_arg = args.model_path
|
| 186 |
+
model_paths = [model_path_arg]
|
| 187 |
+
if len(glob.glob(model_path_arg + os.sep + 'ds_ckpt' + os.sep + '*')):
|
| 188 |
+
model_paths = [model_path_arg + os.sep + 'ds_ckpt']
|
| 189 |
+
elif not model_path_arg.endswith('.pth'):
|
| 190 |
+
import glob
|
| 191 |
+
|
| 192 |
+
path_pattern = args.path_pattern
|
| 193 |
+
if path_pattern is not None:
|
| 194 |
+
model_paths = glob.glob(f'{model_path_arg}/{path_pattern}/ds_ckpt/*/*.pt')
|
| 195 |
+
else:
|
| 196 |
+
model_paths = glob.glob(f'{model_path_arg}/*/ds_ckpt/*/*.pt')
|
| 197 |
+
model_paths = list(set([os.sep.join(p.split(os.sep)[:-2]) for p in model_paths]))
|
| 198 |
+
print(model_paths)
|
| 199 |
+
num_of_gpus = torch.cuda.device_count()
|
| 200 |
+
print(f"{num_of_gpus} GPUs available")
|
| 201 |
+
test_process(model_paths, args.batch_size, args.valid_path,
|
| 202 |
+
args.skip_exists, args.selection_noise, cmd_args=_cmd_args)
|
| 203 |
+
deepspeed.comm.barrier()
|
| 204 |
+
deepspeed.comm.destroy_process_group()
|
| 205 |
+
print('Test Ends')
|
models/__pycache__/llm_chat.cpython-310.pyc
ADDED
|
Binary file (7.63 kB). View file
|
|
|
models/__pycache__/selective_llm_chat.cpython-310.pyc
ADDED
|
Binary file (13 kB). View file
|
|
|
models/llm_chat.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from peft import get_peft_model, LoraConfig, PromptTuningConfig, TaskType, PrefixTuningConfig
|
| 3 |
+
from torch import nn, autocast
|
| 4 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 5 |
+
from transformers.deepspeed import HfDeepSpeedConfig
|
| 6 |
+
|
| 7 |
+
from utils.format_inputs import TASK_TYPE
|
| 8 |
+
from utils.format_inputs import format_causal_personachat_input, format_personachat_input, \
|
| 9 |
+
format_generate_persona_input
|
| 10 |
+
from utils.model_helpers import print_trainable_parameters
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# TODO: we need to extract LORA Weight and Bias from the model
|
| 14 |
+
# TODO: we need to do adaptive applied LORA
|
| 15 |
+
class LLMChat(nn.Module):
|
| 16 |
+
def __init__(self, config, batch_size, ds_config=None):
|
| 17 |
+
if ds_config is not None:
|
| 18 |
+
_hfdsc = HfDeepSpeedConfig(ds_config)
|
| 19 |
+
super(LLMChat, self).__init__()
|
| 20 |
+
self.model_name = config.model.model_name
|
| 21 |
+
self.load_bit = config.model.load_bit
|
| 22 |
+
self.left_tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
|
| 23 |
+
original_vocab_size = len(self.left_tokenizer)
|
| 24 |
+
if config.training.mode != 'causal':
|
| 25 |
+
self.left_tokenizer.add_special_tokens({'pad_token': '[PAD]',
|
| 26 |
+
'bos_token': '[BOS]',
|
| 27 |
+
'eos_token': '[EOS]',
|
| 28 |
+
'unk_token': '[UNK]',
|
| 29 |
+
'sep_token': '[SEP]',
|
| 30 |
+
'cls_token': '[CLS]',
|
| 31 |
+
'mask_token': '[MASK]'})
|
| 32 |
+
self.left_tokenizer.padding_side = 'left'
|
| 33 |
+
self.left_tokenizer.truncation_side = 'left'
|
| 34 |
+
self.right_tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
|
| 35 |
+
if config.training.mode != 'causal':
|
| 36 |
+
self.right_tokenizer.add_special_tokens({'pad_token': '[PAD]',
|
| 37 |
+
'bos_token': '[BOS]',
|
| 38 |
+
'eos_token': '[EOS]',
|
| 39 |
+
'unk_token': '[UNK]',
|
| 40 |
+
'sep_token': '[SEP]',
|
| 41 |
+
'cls_token': '[CLS]',
|
| 42 |
+
'mask_token': '[MASK]'})
|
| 43 |
+
self.right_tokenizer.padding_side = 'right'
|
| 44 |
+
self.right_tokenizer.truncation_side = 'right'
|
| 45 |
+
if self.left_tokenizer.pad_token is None and config.model.pad_token == 'bos':
|
| 46 |
+
self.left_tokenizer.pad_token = self.left_tokenizer.bos_token
|
| 47 |
+
self.right_tokenizer.pad_token = self.right_tokenizer.bos_token
|
| 48 |
+
elif self.left_tokenizer.pad_token_id is None:
|
| 49 |
+
self.left_tokenizer.pad_token = self.left_tokenizer.eos_token
|
| 50 |
+
self.right_tokenizer.pad_token = self.right_tokenizer.eos_token
|
| 51 |
+
self.batch_size = batch_size
|
| 52 |
+
load_bit_map = {4: {'load_in_4bit': True,
|
| 53 |
+
'bnb_4bit_compute_dtype': torch.bfloat16},
|
| 54 |
+
8: {'load_in_8bit': True},
|
| 55 |
+
16: {'torch_dtype': torch.float16},
|
| 56 |
+
32: {'torch_dtype': torch.float32}}
|
| 57 |
+
assert config.model.load_bit in [16, 32], 'deepspeed is not friendly with bnb!'
|
| 58 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 59 |
+
config.model.model_name,
|
| 60 |
+
**load_bit_map[config.model.load_bit],
|
| 61 |
+
)
|
| 62 |
+
if config.training.mode != 'causal':
|
| 63 |
+
model.resize_token_embeddings(len(self.left_tokenizer))
|
| 64 |
+
# for m in model.children():
|
| 65 |
+
# if hasattr(m, 'gradient_checkpointing_enable'):
|
| 66 |
+
# m.gradient_checkpointing_enable()
|
| 67 |
+
model.gradient_checkpointing_enable()
|
| 68 |
+
if config.model.peft_config is not None:
|
| 69 |
+
for param in model.parameters():
|
| 70 |
+
param.requires_grad = False # freeze the model - train adapters later
|
| 71 |
+
if param.ndim == 1:
|
| 72 |
+
# cast the small parameters (e.g. layernorm) to fp32 for stability
|
| 73 |
+
param.data = param.data.to(torch.float32)
|
| 74 |
+
model.enable_input_require_grads()
|
| 75 |
+
|
| 76 |
+
# # enable special token embedding params, since we resized the vocabulary
|
| 77 |
+
# for name, param in model.named_parameters():
|
| 78 |
+
# if 'embed_tokens' in name:
|
| 79 |
+
# param[original_vocab_size:].requires_grad = True
|
| 80 |
+
|
| 81 |
+
class CastOutputToFloat(nn.Sequential):
|
| 82 |
+
def forward(self, x): return super().forward(x).to(torch.float32)
|
| 83 |
+
|
| 84 |
+
if config.model.peft_type == 'prompt_tuning':
|
| 85 |
+
peft_config = PromptTuningConfig(
|
| 86 |
+
**config.model.peft_config,
|
| 87 |
+
task_type=TaskType.CAUSAL_LM,
|
| 88 |
+
)
|
| 89 |
+
elif config.model.peft_type == 'prefix_tuning':
|
| 90 |
+
peft_config = PrefixTuningConfig(
|
| 91 |
+
**config.model.peft_config,
|
| 92 |
+
task_type=TaskType.CAUSAL_LM,
|
| 93 |
+
)
|
| 94 |
+
else:
|
| 95 |
+
peft_config = LoraConfig(**config.model.peft_config)
|
| 96 |
+
model.lm_head = CastOutputToFloat(model.lm_head)
|
| 97 |
+
model = get_peft_model(model, peft_config)
|
| 98 |
+
self.using_nn_modulelist = False
|
| 99 |
+
if config.model.using_nn_modulelist.__class__ is bool and config.model.using_nn_modulelist:
|
| 100 |
+
self.using_nn_modulelist = config.model.using_nn_modulelist
|
| 101 |
+
self.model = nn.ModuleList([model])
|
| 102 |
+
else:
|
| 103 |
+
self.model = model
|
| 104 |
+
if config.model.add_extra_layers.__class__ is bool and config.model.add_extra_layers:
|
| 105 |
+
self.prompt_normalizer = nn.Linear(
|
| 106 |
+
self.model[0].prompt_encoder.default.embedding.weight.shape[1],
|
| 107 |
+
self.model[0].word_embeddings.weight.shape[1])
|
| 108 |
+
self.score_activation = nn.Softplus(threshold=1, beta=10)
|
| 109 |
+
self.learning_rate = config.training.learning_rate
|
| 110 |
+
self.warmup_steps = config.training.warmup_steps
|
| 111 |
+
self.config = config
|
| 112 |
+
self.find_batch = False
|
| 113 |
+
print_trainable_parameters(self)
|
| 114 |
+
|
| 115 |
+
def print_llm_trainable_parameters(self):
|
| 116 |
+
print_trainable_parameters(self.model)
|
| 117 |
+
|
| 118 |
+
@autocast('cuda')
|
| 119 |
+
def forward(self, x):
|
| 120 |
+
if self.config._non_exists == 1:
|
| 121 |
+
self.prompt_normalizer(x)
|
| 122 |
+
self.score_activation(x)
|
| 123 |
+
for k in x.keys():
|
| 124 |
+
x[k] = x[k].cuda()
|
| 125 |
+
if self.find_batch:
|
| 126 |
+
x['attention_mask'] = x['attention_mask'].new_ones(x['attention_mask'].shape)
|
| 127 |
+
if self.using_nn_modulelist:
|
| 128 |
+
if self.config.model.using_output_stack.__class__ is bool and self.config.model.using_output_stack:
|
| 129 |
+
_outputs = [_model(**x) for _model in self.model]
|
| 130 |
+
_logits = torch.stack([_output['logits'] for _output in _outputs])
|
| 131 |
+
return {'logits': _logits}
|
| 132 |
+
return self.model[0](**x)
|
| 133 |
+
return self.model(**x)
|
| 134 |
+
|
| 135 |
+
def on_train_start(self) -> None:
|
| 136 |
+
self.print_llm_trainable_parameters()
|
| 137 |
+
|
| 138 |
+
@staticmethod
|
| 139 |
+
def training_step(model, batch, left_tokenizer, right_tokenizer, config, find_batch=False, mode='normal',
|
| 140 |
+
task_type=TASK_TYPE.GENERATE_RESPONSE, **_kwargs):
|
| 141 |
+
assert mode in ['normal', 'causal']
|
| 142 |
+
if task_type == TASK_TYPE.GENERATE_PERSONA and mode == 'normal':
|
| 143 |
+
lm_input, lm_target = format_generate_persona_input(batch, left_tokenizer, right_tokenizer,
|
| 144 |
+
config)
|
| 145 |
+
elif task_type == TASK_TYPE.GENERATE_RESPONSE and mode == 'causal':
|
| 146 |
+
lm_input, lm_target = format_causal_personachat_input(batch, left_tokenizer, right_tokenizer,
|
| 147 |
+
config)
|
| 148 |
+
elif task_type == TASK_TYPE.GENERATE_RESPONSE and mode == 'normal':
|
| 149 |
+
lm_input, lm_target = format_personachat_input(batch, left_tokenizer, right_tokenizer, config)
|
| 150 |
+
else:
|
| 151 |
+
raise NotImplementedError('mode and task_type not implemented')
|
| 152 |
+
output = model(lm_input)
|
| 153 |
+
if find_batch:
|
| 154 |
+
loss = nn.CrossEntropyLoss()(output['logits'].view(-1, output['logits'].shape[-1]),
|
| 155 |
+
lm_target.cuda().view(-1))
|
| 156 |
+
else:
|
| 157 |
+
if config.model.peft_type == 'prompt_tuning':
|
| 158 |
+
virtual_tokens = config.model.peft_config.num_virtual_tokens
|
| 159 |
+
batch_size = lm_target.size()[0]
|
| 160 |
+
_lm_target = torch.cat(
|
| 161 |
+
(lm_target.new_ones((batch_size, virtual_tokens)) * left_tokenizer.pad_token_id, lm_target), dim=1)
|
| 162 |
+
else:
|
| 163 |
+
_lm_target = lm_target
|
| 164 |
+
loss = nn.CrossEntropyLoss(ignore_index=left_tokenizer.pad_token_id)(
|
| 165 |
+
output['logits'].view(-1, output['logits'].shape[-1]),
|
| 166 |
+
_lm_target.cuda().view(-1))
|
| 167 |
+
# self.log('train_loss', loss, on_step=True, on_epoch=False, prog_bar=True, logger=True)
|
| 168 |
+
if config.training.normalize_loss.__class__ == bool and config.training.normalize_loss.__class__:
|
| 169 |
+
model.module.normalize()
|
| 170 |
+
return loss
|
| 171 |
+
|
| 172 |
+
def normalize(self):
|
| 173 |
+
raise NotImplementedError('normalize trainable weights needs implementation')
|
| 174 |
+
return None
|
| 175 |
+
|
| 176 |
+
@staticmethod
|
| 177 |
+
def validation_step(model, batch, left_tokenizer, right_tokenizer, config, task_type, mode='normal'):
|
| 178 |
+
loss = LLMChat.training_step(model, batch, left_tokenizer, right_tokenizer, config, task_type=task_type,
|
| 179 |
+
find_batch=False, mode=mode)
|
| 180 |
+
return loss
|
| 181 |
+
|
| 182 |
+
def on_test_start(self) -> None:
|
| 183 |
+
from peft import get_peft_model_state_dict, set_peft_model_state_dict
|
| 184 |
+
peft_weight = get_peft_model_state_dict(self.model).copy()
|
| 185 |
+
peft_config = self.model.peft_config
|
| 186 |
+
del self.model
|
| 187 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 188 |
+
self.config.model.model_name,
|
| 189 |
+
torch_dtype=torch.bfloat16, low_cpu_mem_usage=True,
|
| 190 |
+
)
|
| 191 |
+
self.model = get_peft_model(model, peft_config['default'])
|
| 192 |
+
set_peft_model_state_dict(self.model, peft_weight, adapter_name='default')
|
| 193 |
+
self.model.merge_and_unload()
|
| 194 |
+
self.model.eval()
|
| 195 |
+
|
| 196 |
+
@staticmethod
|
| 197 |
+
@autocast('cuda')
|
| 198 |
+
def test_step(model, batch, left_tokenizer, right_tokenizer, config, max_new_tokens=16, tqdm_instance=None, **kwargs):
|
| 199 |
+
model.eval()
|
| 200 |
+
task_type = TASK_TYPE(config.training.task_type)
|
| 201 |
+
with torch.no_grad():
|
| 202 |
+
if config.training.mode == 'causal':
|
| 203 |
+
lm_input, lm_target, inference_tokenized = format_causal_personachat_input(batch,
|
| 204 |
+
left_tokenizer,
|
| 205 |
+
right_tokenizer,
|
| 206 |
+
config,
|
| 207 |
+
for_test=True)
|
| 208 |
+
else:
|
| 209 |
+
lm_input, lm_target, inference_tokenized = format_personachat_input(batch, left_tokenizer,
|
| 210 |
+
right_tokenizer, config,
|
| 211 |
+
for_test=True)
|
| 212 |
+
inference_tokenized.to('cuda')
|
| 213 |
+
model_for_generation = None
|
| 214 |
+
if 'deepspeed' in str(model.__class__):
|
| 215 |
+
model_for_generation = model.module.model
|
| 216 |
+
else:
|
| 217 |
+
model_for_generation = model.model
|
| 218 |
+
if model_for_generation.__class__ is nn.ModuleList:
|
| 219 |
+
model_for_generation = model_for_generation[0]
|
| 220 |
+
# adding do_sample=False to avoid inf error!
|
| 221 |
+
raw_output = model_for_generation.generate(**inference_tokenized, max_new_tokens=max_new_tokens,
|
| 222 |
+
do_sample=False)
|
| 223 |
+
trunc_output = raw_output[:, inference_tokenized['input_ids'].shape[1]:]
|
| 224 |
+
if trunc_output[trunc_output >= len(left_tokenizer)].size()[0] > 0:
|
| 225 |
+
trunc_output[trunc_output >= len(left_tokenizer)] = left_tokenizer.pad_token_id
|
| 226 |
+
text_output = right_tokenizer.batch_decode(trunc_output, skip_special_tokens=True)
|
| 227 |
+
return trunc_output, text_output, []
|
models/selective_llm_chat.py
ADDED
|
@@ -0,0 +1,390 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import deepspeed
|
| 2 |
+
import deepspeed
|
| 3 |
+
import torch
|
| 4 |
+
import transformers
|
| 5 |
+
from peft import get_peft_model, PromptTuningConfig, TaskType, PrefixTuningConfig
|
| 6 |
+
from torch import nn, autocast
|
| 7 |
+
from torch.functional import F
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 10 |
+
from transformers.deepspeed import HfDeepSpeedConfig
|
| 11 |
+
|
| 12 |
+
from utils.format_inputs import TASK_TYPE
|
| 13 |
+
from utils.format_inputs import format_causal_personachat_input, format_personachat_input, format_generate_persona_input
|
| 14 |
+
from utils.model_helpers import print_trainable_parameters
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class SelectLLMChat(nn.Module):
|
| 18 |
+
def __init__(self, config, batch_size, ds_config=None):
|
| 19 |
+
super(SelectLLMChat, self).__init__()
|
| 20 |
+
if ds_config is not None:
|
| 21 |
+
_hfdsc = HfDeepSpeedConfig(ds_config)
|
| 22 |
+
peft_type = config.model.peft_type
|
| 23 |
+
self.peft_type = peft_type
|
| 24 |
+
assert config.model.peft_type in ['prompt_tuning', 'prefix_tuning',
|
| 25 |
+
], 'only prompt tuning is supported!'
|
| 26 |
+
K = config.model.K
|
| 27 |
+
self.K = K
|
| 28 |
+
self.ensemble_training = config.training.ensemble
|
| 29 |
+
self.model_name = config.model.model_name
|
| 30 |
+
self.load_bit = config.model.load_bit
|
| 31 |
+
self.left_tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
|
| 32 |
+
if config.training.mode != 'causal':
|
| 33 |
+
self.left_tokenizer.add_special_tokens({'pad_token': '[PAD]',
|
| 34 |
+
'bos_token': '[BOS]',
|
| 35 |
+
'eos_token': '[EOS]',
|
| 36 |
+
'unk_token': '[UNK]',
|
| 37 |
+
'sep_token': '[SEP]',
|
| 38 |
+
'cls_token': '[CLS]',
|
| 39 |
+
'mask_token': '[MASK]'})
|
| 40 |
+
self.left_tokenizer.padding_side = 'left'
|
| 41 |
+
self.left_tokenizer.truncation_side = 'left'
|
| 42 |
+
self.right_tokenizer = AutoTokenizer.from_pretrained(self.model_name, use_fast=False)
|
| 43 |
+
if config.training.mode != 'causal':
|
| 44 |
+
self.right_tokenizer.add_special_tokens({'pad_token': '[PAD]',
|
| 45 |
+
'bos_token': '[BOS]',
|
| 46 |
+
'eos_token': '[EOS]',
|
| 47 |
+
'unk_token': '[UNK]',
|
| 48 |
+
'sep_token': '[SEP]',
|
| 49 |
+
'cls_token': '[CLS]',
|
| 50 |
+
'mask_token': '[MASK]'})
|
| 51 |
+
self.right_tokenizer.padding_side = 'right'
|
| 52 |
+
self.right_tokenizer.truncation_side = 'right'
|
| 53 |
+
if self.left_tokenizer.pad_token is None and config.model.pad_token=='bos':
|
| 54 |
+
self.left_tokenizer.pad_token = self.left_tokenizer.bos_token
|
| 55 |
+
self.right_tokenizer.pad_token = self.right_tokenizer.bos_token
|
| 56 |
+
elif self.left_tokenizer.pad_token_id is None:
|
| 57 |
+
self.left_tokenizer.pad_token = self.left_tokenizer.eos_token
|
| 58 |
+
self.right_tokenizer.pad_token = self.right_tokenizer.eos_token
|
| 59 |
+
self.batch_size = batch_size
|
| 60 |
+
load_bit_map = {4: {'load_in_4bit': True,
|
| 61 |
+
'bnb_4bit_compute_dtype': torch.bfloat16},
|
| 62 |
+
8: {'load_in_8bit': True},
|
| 63 |
+
16: {'torch_dtype': torch.float16},
|
| 64 |
+
'bf16': {'torch_dtype': torch.bfloat16},
|
| 65 |
+
32: {'torch_dtype': torch.float32}}
|
| 66 |
+
assert config.model.load_bit in [16, 32, 'bf16'], 'deepspeed is not friendly with bnb!'
|
| 67 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 68 |
+
config.model.model_name,
|
| 69 |
+
**load_bit_map[config.model.load_bit]
|
| 70 |
+
)
|
| 71 |
+
if config.training.mode != 'causal':
|
| 72 |
+
model.resize_token_embeddings(len(self.left_tokenizer))
|
| 73 |
+
model.gradient_checkpointing_enable()
|
| 74 |
+
if config.model.peft_config is not None:
|
| 75 |
+
for param in model.parameters():
|
| 76 |
+
param.requires_grad = False # freeze the model - train adapters later
|
| 77 |
+
if param.ndim == 1:
|
| 78 |
+
# cast the small parameters (e.g. layernorm) to fp32 for stability
|
| 79 |
+
param.data = param.data.to(torch.float32)
|
| 80 |
+
model.enable_input_require_grads()
|
| 81 |
+
class CastOutputToFloat(nn.Sequential):
|
| 82 |
+
def forward(self, x): return super().forward(x).to(torch.float32)
|
| 83 |
+
|
| 84 |
+
model.lm_head = CastOutputToFloat(model.lm_head)
|
| 85 |
+
self.model = model
|
| 86 |
+
models = []
|
| 87 |
+
peft_config = None
|
| 88 |
+
for _ in range(K):
|
| 89 |
+
if config.model.peft_type == 'prompt_tuning':
|
| 90 |
+
peft_config = PromptTuningConfig(
|
| 91 |
+
**config.model.peft_config,
|
| 92 |
+
task_type=TaskType.CAUSAL_LM,
|
| 93 |
+
)
|
| 94 |
+
elif config.model.peft_type == 'prefix_tuning':
|
| 95 |
+
peft_config = PrefixTuningConfig(
|
| 96 |
+
**config.model.peft_config,
|
| 97 |
+
task_type=TaskType.CAUSAL_LM,
|
| 98 |
+
)
|
| 99 |
+
else:
|
| 100 |
+
raise NotImplementedError()
|
| 101 |
+
_peft_model = get_peft_model(model, peft_config)
|
| 102 |
+
models.append(_peft_model)
|
| 103 |
+
self.models = nn.ModuleList(models)
|
| 104 |
+
self.learning_rate = config.training.learning_rate
|
| 105 |
+
self.warmup_steps = config.training.warmup_steps
|
| 106 |
+
self.config = config
|
| 107 |
+
self.find_batch = False
|
| 108 |
+
self.retriever = None
|
| 109 |
+
if config.model.retriever.retriever_type == 'transformer_encoder':
|
| 110 |
+
encoder_layer = nn.TransformerEncoderLayer(d_model=self.models[0].word_embeddings.weight.shape[1],
|
| 111 |
+
nhead=config.model.retriever.n_head)
|
| 112 |
+
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=config.model.retriever.num_layers)
|
| 113 |
+
self.retriever = transformer_encoder
|
| 114 |
+
if config.model.peft_type in ['prompt_tuning'] and config.model.normalizer.__class__ is not str:
|
| 115 |
+
class DoNothing(nn.Sequential):
|
| 116 |
+
def forward(self, x): return x
|
| 117 |
+
|
| 118 |
+
self.prompt_normalizer = DoNothing()
|
| 119 |
+
elif config.model.normalizer == 'linear':
|
| 120 |
+
if config.model.peft_type in ['prompt_tuning', 'prefix_tuning']:
|
| 121 |
+
_d_peft = self.models[0].prompt_encoder.default.embedding.weight.shape[1]
|
| 122 |
+
else:
|
| 123 |
+
raise NotImplementedError('check here!')
|
| 124 |
+
self.prompt_normalizer = nn.Linear(_d_peft, _d_peft)
|
| 125 |
+
|
| 126 |
+
if config.model.score_activation == 'softplus':
|
| 127 |
+
self.score_activation = nn.Softplus(threshold=1, beta=10)
|
| 128 |
+
elif config.model.score_activation == 'relu':
|
| 129 |
+
self.score_activation = nn.ReLU()
|
| 130 |
+
elif config.model.score_activation == 'leaky_relu':
|
| 131 |
+
self.score_activation = nn.LeakyReLU()
|
| 132 |
+
else:
|
| 133 |
+
self.score_activation = nn.Softplus(threshold=1, beta=10)
|
| 134 |
+
# raise NotImplementedError()
|
| 135 |
+
self.retriever_on = ['extra']
|
| 136 |
+
if config.model.retriever.retriever_on.__class__ is list:
|
| 137 |
+
self.retriever_on = config.model.retriever.retriever_on
|
| 138 |
+
if config.training.all_tunable.__class__ is bool and config.training.all_tunable:
|
| 139 |
+
for param in self.parameters():
|
| 140 |
+
param.requires_grad = True
|
| 141 |
+
print_trainable_parameters(self)
|
| 142 |
+
self.contrastive_metric = None
|
| 143 |
+
if config.training.contrastive_metric.__class__ is str:
|
| 144 |
+
self.contrastive_metric = config.training.contrastive_metric
|
| 145 |
+
self.contrastive_threshold = 0.0
|
| 146 |
+
if config.training.contrastive_threshold.__class__ is float:
|
| 147 |
+
self.contrastive_threshold = config.training.contrastive_threshold
|
| 148 |
+
self.config = config
|
| 149 |
+
self.annealing_nll = False
|
| 150 |
+
self.annealing_scalar = 0.0
|
| 151 |
+
if self.config.training.annealing_nll.__class__ == bool:
|
| 152 |
+
self.annealing_nll = self.config.training.annealing_nll
|
| 153 |
+
self.annealing_scalar = self.config.training.annealing_scalar
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def print_llm_trainable_parameters(self):
|
| 157 |
+
print_trainable_parameters(self.model)
|
| 158 |
+
|
| 159 |
+
def retrieve_based_on_input_x(self, x, K):
|
| 160 |
+
return self.retrieve_prompts(x, K)
|
| 161 |
+
|
| 162 |
+
@autocast('cuda')
|
| 163 |
+
def retrieve_prompts(self, x, K):
|
| 164 |
+
batch_size = x['input_ids'].shape[0]
|
| 165 |
+
input_ids = x['input_ids']
|
| 166 |
+
spawned_x = input_ids.repeat(K, 1)
|
| 167 |
+
if self.models[0].base_model.__class__ == transformers.models.llama.modeling_llama.LlamaForCausalLM:
|
| 168 |
+
spawned_x_emb = self.models[0].base_model.model.embed_tokens(spawned_x)
|
| 169 |
+
else:
|
| 170 |
+
spawned_x_emb = self.models[0].base_model.model.decoder.embed_tokens(spawned_x)
|
| 171 |
+
if spawned_x_emb.shape[-1] != self.models[0].config.hidden_size:
|
| 172 |
+
# need project_in here
|
| 173 |
+
spawned_x_emb = self.models[0].base_model.model.decoder.project_in(spawned_x_emb)
|
| 174 |
+
prompt_embeddings = torch.stack([_model.prompt_encoder.default.embedding.weight for _model in self.models])
|
| 175 |
+
if self.retriever is not None:
|
| 176 |
+
if 'extra' in self.retriever_on:
|
| 177 |
+
prompt_embeddings = self.retriever(self.prompt_normalizer(prompt_embeddings))
|
| 178 |
+
if 'lm' in self.retriever_on:
|
| 179 |
+
spawned_x_emb = self.retriever(spawned_x_emb)
|
| 180 |
+
spawned_x_emb_mean = spawned_x_emb.mean(dim=1)
|
| 181 |
+
prompt_embeddings_mean = prompt_embeddings.mean(dim=1)
|
| 182 |
+
if self.retriever is None:
|
| 183 |
+
normalizer_on = self.config.model.normalizer_on
|
| 184 |
+
if normalizer_on.__class__ is not list:
|
| 185 |
+
prompt_embeddings_mean = self.prompt_normalizer(prompt_embeddings_mean)
|
| 186 |
+
if 'prompt' in normalizer_on:
|
| 187 |
+
prompt_embeddings_mean = self.prompt_normalizer(prompt_embeddings_mean)
|
| 188 |
+
if 'lm' in normalizer_on:
|
| 189 |
+
spawned_x_emb_mean = self.prompt_normalizer(spawned_x_emb_mean)
|
| 190 |
+
prompt_embeddings_mean_spawn = torch.repeat_interleave(prompt_embeddings_mean, batch_size, dim=0)
|
| 191 |
+
sim_scores = self.score_activation(
|
| 192 |
+
torch.nn.CosineSimilarity()(prompt_embeddings_mean_spawn, spawned_x_emb_mean))
|
| 193 |
+
return sim_scores
|
| 194 |
+
|
| 195 |
+
@autocast('cuda')
|
| 196 |
+
def forward(self, x, mode='training'):
|
| 197 |
+
for k in x.keys():
|
| 198 |
+
x[k] = x[k].cuda(device=deepspeed.comm.get_local_rank())
|
| 199 |
+
if self.find_batch:
|
| 200 |
+
x['attention_mask'] = x['attention_mask'].new_ones(x['attention_mask'].shape)
|
| 201 |
+
if mode == 'training':
|
| 202 |
+
if self.config.training.skip_retrieval.__class__ is bool and self.config.training.skip_retrieval:
|
| 203 |
+
sim_scores = None
|
| 204 |
+
else:
|
| 205 |
+
sim_scores = self.retrieve_based_on_input_x(x, self.K)
|
| 206 |
+
# get pt embeddings
|
| 207 |
+
_outputs = [_model(**x) for _model in self.models]
|
| 208 |
+
_logits = torch.stack([_output['logits'] for _output in _outputs])
|
| 209 |
+
return {'logits': _logits, 'sim_scores': sim_scores}
|
| 210 |
+
else:
|
| 211 |
+
raise NotImplementedError('validation and testing not implemented')
|
| 212 |
+
|
| 213 |
+
def on_train_start(self) -> None:
|
| 214 |
+
self.print_llm_trainable_parameters()
|
| 215 |
+
deepspeed.zero.Init()
|
| 216 |
+
|
| 217 |
+
@staticmethod
|
| 218 |
+
def training_step(model, batch, left_tokenizer, right_tokenizer, config, mode='normal',
|
| 219 |
+
task_type=TASK_TYPE.GENERATE_RESPONSE, training_process=0.0):
|
| 220 |
+
assert mode in ['normal', 'causal']
|
| 221 |
+
if task_type == TASK_TYPE.GENERATE_PERSONA and mode == 'normal':
|
| 222 |
+
lm_input, lm_target = format_generate_persona_input(batch, left_tokenizer, right_tokenizer,
|
| 223 |
+
config)
|
| 224 |
+
elif task_type == TASK_TYPE.GENERATE_RESPONSE and mode == 'causal':
|
| 225 |
+
lm_input, lm_target = format_causal_personachat_input(batch, left_tokenizer, right_tokenizer,
|
| 226 |
+
config)
|
| 227 |
+
elif task_type == TASK_TYPE.GENERATE_RESPONSE and mode == 'normal':
|
| 228 |
+
lm_input, lm_target = format_personachat_input(batch, left_tokenizer, right_tokenizer, config)
|
| 229 |
+
else:
|
| 230 |
+
raise NotImplementedError('mode and task_type not implemented')
|
| 231 |
+
output = model.module(dict(lm_input))
|
| 232 |
+
# suppose batch=2, K=3, the logits is presented interleave:
|
| 233 |
+
# [0,1]
|
| 234 |
+
# [0,1]
|
| 235 |
+
# [0,1]
|
| 236 |
+
logits = output['logits'] # (K*Batch,SeqLen,VocabSize)
|
| 237 |
+
logits = logits.view(-1, logits.shape[2], logits.shape[3])
|
| 238 |
+
sim_scores = output['sim_scores']
|
| 239 |
+
batch_size = lm_target.size()[0]
|
| 240 |
+
if config.model.peft_type == 'prompt_tuning':
|
| 241 |
+
virtual_tokens = config.model.peft_config.num_virtual_tokens
|
| 242 |
+
_lm_target = torch.cat(
|
| 243 |
+
(lm_target.new_ones((batch_size, virtual_tokens)) * left_tokenizer.pad_token_id, lm_target), dim=1)
|
| 244 |
+
else:
|
| 245 |
+
_lm_target = lm_target
|
| 246 |
+
_lm_target_spawn = _lm_target.repeat(config.model.K, 1)
|
| 247 |
+
losses = nn.CrossEntropyLoss(ignore_index=left_tokenizer.pad_token_id, reduction='none')(
|
| 248 |
+
logits.view(-1, logits.shape[-1]),
|
| 249 |
+
_lm_target_spawn.cuda(device=deepspeed.comm.get_local_rank()).view(-1))
|
| 250 |
+
if config.training.only_nll.__class__ == bool and config.training.only_nll:
|
| 251 |
+
return losses[losses != 0].mean()
|
| 252 |
+
|
| 253 |
+
reshaped_losses = losses.view(logits.shape[0], logits.shape[1]).detach().clone()
|
| 254 |
+
reshaped_losses = torch.stack([_losses[_losses != 0].mean() for _losses in reshaped_losses.detach().clone()])
|
| 255 |
+
# reshaped_losses = reshaped_losses.clone().detach().mean(dim=1)
|
| 256 |
+
|
| 257 |
+
softmaxed_neg_losses = nn.Softmax(dim=0)(
|
| 258 |
+
-reshaped_losses.view(config.model.K, batch_size) / config.training.tau_gold).permute(1, 0)
|
| 259 |
+
if config.training.adding_noise.__class__ is float:
|
| 260 |
+
noise = torch.randn_like(softmaxed_neg_losses, device=softmaxed_neg_losses.device)
|
| 261 |
+
softmaxed_neg_losses = softmaxed_neg_losses + config.training.adding_noise * noise
|
| 262 |
+
logsoftmaxed_sim_scores = F.log_softmax(sim_scores.view(config.model.K, batch_size) / config.training.tau_sim,
|
| 263 |
+
dim=0).permute(1, 0)
|
| 264 |
+
kldiv_loss = nn.KLDivLoss(reduction='batchmean')(logsoftmaxed_sim_scores,
|
| 265 |
+
softmaxed_neg_losses)
|
| 266 |
+
selective_loss_weight = 1.0
|
| 267 |
+
if config.training.annealing_nll.__class__ is bool and config.training.annealing_nll:
|
| 268 |
+
_ann_scalar = config.training.annealing_scalar * (1 - training_process)
|
| 269 |
+
_sim_score = torch.clamp(_ann_scalar * nn.Softmax(-1)(sim_scores),
|
| 270 |
+
config.training.annealing_min, config.training.annealing_max).detach()
|
| 271 |
+
losses = torch.einsum('ab,a->ab', losses.view(logits.shape[0], logits.shape[1]), _sim_score).view(-1)
|
| 272 |
+
|
| 273 |
+
if config.training.selective_loss_weight.__class__ == float:
|
| 274 |
+
selective_loss_weight = config.training.selective_loss_weight
|
| 275 |
+
if config.training.selective_loss.__class__ == bool and (config.training.selective_loss == False):
|
| 276 |
+
loss = losses[losses != 0].mean()
|
| 277 |
+
elif config.training.disable_nll.__class__ is bool and config.training.disable_nll:
|
| 278 |
+
loss = selective_loss_weight * kldiv_loss
|
| 279 |
+
else:
|
| 280 |
+
loss = losses[losses != 0].mean() + selective_loss_weight * kldiv_loss
|
| 281 |
+
|
| 282 |
+
if model.module.ensemble_training:
|
| 283 |
+
K = config.model.K
|
| 284 |
+
enb_losses = []
|
| 285 |
+
for data_idx in range(batch_size):
|
| 286 |
+
data_indices = [data_idx + (batch_size * inc) for inc in range(K)]
|
| 287 |
+
ensemble_preds = logits[data_indices, :, :]
|
| 288 |
+
ensemble_sims = sim_scores[data_indices]
|
| 289 |
+
normed_preds = ensemble_sims.unsqueeze(-1).unsqueeze(-1).mul(ensemble_preds)
|
| 290 |
+
normed_preds = normed_preds.sum(dim=0)
|
| 291 |
+
_target = _lm_target_spawn[data_indices, :]
|
| 292 |
+
assert _target.unique(dim=0).shape[0] == 1, 'error in resemble the preds'
|
| 293 |
+
enb_loss = nn.CrossEntropyLoss(ignore_index=left_tokenizer.pad_token_id)(normed_preds,
|
| 294 |
+
_target[0].cuda(
|
| 295 |
+
device=deepspeed.comm.get_local_rank()))
|
| 296 |
+
enb_losses.append(enb_loss)
|
| 297 |
+
loss += torch.stack(enb_losses).mean()
|
| 298 |
+
if model.module.contrastive_metric:
|
| 299 |
+
ctr_losses = []
|
| 300 |
+
from sacrebleu import BLEU
|
| 301 |
+
ctr_metrics = BLEU(effective_order=True)
|
| 302 |
+
batch_persona = [' '.join(row) for row in batch['persona_list']]
|
| 303 |
+
statics = {}
|
| 304 |
+
# Dim here
|
| 305 |
+
# x1 x2
|
| 306 |
+
# p1 s11 s21
|
| 307 |
+
# p2 s12 s22
|
| 308 |
+
# p3 s13 s23
|
| 309 |
+
permuted_sim_scores = sim_scores.unsqueeze(0).view(model.module.K, batch_size)
|
| 310 |
+
if model.module.contrastive_metric == 'bleu':
|
| 311 |
+
for idx in range(len(batch_persona) - 1):
|
| 312 |
+
for jdx in range(idx + 1, len(batch_persona)):
|
| 313 |
+
iele = batch_persona[idx]
|
| 314 |
+
jele = batch_persona[jdx]
|
| 315 |
+
scores = ctr_metrics.sentence_score(iele, [jele]).score
|
| 316 |
+
idist = permuted_sim_scores[:, idx]
|
| 317 |
+
jdist = permuted_sim_scores[:, jdx]
|
| 318 |
+
cosine_emb_loss = nn.CosineEmbeddingLoss()
|
| 319 |
+
if scores > model.module.contrastive_threshold:
|
| 320 |
+
cosine_target = 1
|
| 321 |
+
else:
|
| 322 |
+
cosine_target = -1
|
| 323 |
+
cos_loss = cosine_emb_loss(idist, jdist, torch.tensor(cosine_target))
|
| 324 |
+
ctr_losses.append(cos_loss)
|
| 325 |
+
statics[(idx, jdx)] = {'iele': iele, 'jele': jele, 'scores': scores,
|
| 326 |
+
'idist': idist,
|
| 327 |
+
'jdist': jdist, 'cos_emb_loss': cos_loss}
|
| 328 |
+
if len(ctr_losses) != 0:
|
| 329 |
+
ctr_losses_pt = torch.stack(ctr_losses).mean()
|
| 330 |
+
loss += config.training.contrastive_weight * ctr_losses_pt
|
| 331 |
+
else:
|
| 332 |
+
print(f'CTR ERROR: {statics}')
|
| 333 |
+
return loss
|
| 334 |
+
|
| 335 |
+
@staticmethod
|
| 336 |
+
def validation_step(model, batch, left_tokenizer, right_tokenizer, config, task_type, mode='normal'):
|
| 337 |
+
loss = SelectLLMChat.training_step(model, batch, left_tokenizer, right_tokenizer, config, task_type=task_type,
|
| 338 |
+
mode=mode, training_process=0.0)
|
| 339 |
+
return loss
|
| 340 |
+
|
| 341 |
+
@staticmethod
|
| 342 |
+
@autocast('cuda')
|
| 343 |
+
def test_step(model, batch, left_tokenizer, right_tokenizer, config, max_new_tokens=16, tqdm_instance: tqdm = None,
|
| 344 |
+
selection_noise=None, **gen_kwargs):
|
| 345 |
+
model.eval()
|
| 346 |
+
with torch.no_grad():
|
| 347 |
+
if config.training.mode == 'causal':
|
| 348 |
+
lm_input, lm_target, inference_tokenized = format_causal_personachat_input(batch,
|
| 349 |
+
left_tokenizer,
|
| 350 |
+
right_tokenizer,
|
| 351 |
+
config,
|
| 352 |
+
for_test=True)
|
| 353 |
+
else:
|
| 354 |
+
lm_input, lm_target, inference_tokenized = format_personachat_input(batch, left_tokenizer,
|
| 355 |
+
right_tokenizer,
|
| 356 |
+
config,
|
| 357 |
+
for_test=True)
|
| 358 |
+
inference_tokenized.to('cuda')
|
| 359 |
+
if 'deepspeed' in str(model.__class__):
|
| 360 |
+
batch_size = inference_tokenized['input_ids'].shape[0]
|
| 361 |
+
sim_scores = model.module.retrieve_based_on_input_x(inference_tokenized, config.model.K)
|
| 362 |
+
sim_scores = sim_scores.reshape(config.model.K, batch_size).permute(1, 0)
|
| 363 |
+
if selection_noise:
|
| 364 |
+
noise = torch.randn_like(sim_scores, device=sim_scores.device)
|
| 365 |
+
sim_scores = sim_scores + selection_noise * noise
|
| 366 |
+
selected_prompts = torch.argmax(sim_scores, dim=1)
|
| 367 |
+
if tqdm_instance is not None:
|
| 368 |
+
tqdm_instance.set_postfix_str(f"selected prompts: {selected_prompts}")
|
| 369 |
+
detached_selected_prompts = selected_prompts.detach().cpu().numpy()
|
| 370 |
+
selected_prompts_set = set(detached_selected_prompts)
|
| 371 |
+
output_dicts = {}
|
| 372 |
+
# adding do_sample=False to avoid inf error!
|
| 373 |
+
for key in selected_prompts_set:
|
| 374 |
+
outputs = model.module.models[key].generate(
|
| 375 |
+
input_ids=inference_tokenized['input_ids'],
|
| 376 |
+
attention_mask=inference_tokenized['attention_mask'],
|
| 377 |
+
max_new_tokens=max_new_tokens,
|
| 378 |
+
do_sample=False,
|
| 379 |
+
**gen_kwargs
|
| 380 |
+
)
|
| 381 |
+
output_dicts[key] = outputs.detach().cpu()
|
| 382 |
+
raw_output = []
|
| 383 |
+
for idx, prompt_idx in enumerate(detached_selected_prompts):
|
| 384 |
+
raw_output.append(output_dicts[prompt_idx][idx][inference_tokenized['input_ids'].shape[1]:])
|
| 385 |
+
# raw_output = torch.stack(raw_output).squeeze(1)
|
| 386 |
+
trunc_output = raw_output
|
| 387 |
+
text_output = right_tokenizer.batch_decode(trunc_output, skip_special_tokens=True)
|
| 388 |
+
return trunc_output, text_output, selected_prompts
|
| 389 |
+
else:
|
| 390 |
+
raise NotImplementedError('not implemented')
|
test.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
import json
|
| 4 |
+
import locale
|
| 5 |
+
import os
|
| 6 |
+
import re
|
| 7 |
+
from functools import reduce
|
| 8 |
+
from multiprocessing import freeze_support
|
| 9 |
+
|
| 10 |
+
import deepspeed
|
| 11 |
+
import torch
|
| 12 |
+
import torch.distributed as dist
|
| 13 |
+
from dotenv import load_dotenv
|
| 14 |
+
from torch.utils.data import DistributedSampler
|
| 15 |
+
from tqdm import tqdm
|
| 16 |
+
|
| 17 |
+
from dataset.dataset import PersonaChatDataset
|
| 18 |
+
from utils.dist_helper import setup
|
| 19 |
+
from utils.format_inputs import TASK_TYPE
|
| 20 |
+
from utils.parser_helper import str2bool
|
| 21 |
+
|
| 22 |
+
os.environ["PYTHONIOENCODING"] = "utf-8"
|
| 23 |
+
myLocale = locale.setlocale(category=locale.LC_ALL, locale="C.UTF-8")
|
| 24 |
+
load_dotenv()
|
| 25 |
+
|
| 26 |
+
argparse = argparse.ArgumentParser()
|
| 27 |
+
argparse.add_argument('--model_path', type=str, default=None)
|
| 28 |
+
argparse.add_argument('--path_pattern', type=str, default=None)
|
| 29 |
+
argparse.add_argument('--batch_size', type=int)
|
| 30 |
+
argparse.add_argument('--valid_path', type=str, default=None)
|
| 31 |
+
argparse.add_argument('--local_rank', type=int, default=-1)
|
| 32 |
+
argparse.add_argument('--skip_exists', type=str2bool, default=False)
|
| 33 |
+
argparse.add_argument('--selection_noise', type=float, default=None)
|
| 34 |
+
parser = deepspeed.add_config_arguments(argparse)
|
| 35 |
+
args = argparse.parse_args()
|
| 36 |
+
_cmd_args = parser.parse_args()
|
| 37 |
+
freeze_support()
|
| 38 |
+
|
| 39 |
+
VICUNA_PREFIX = 'PATH_TO_VICUNA'
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def test_process(model_paths, batch_size, valid_path, skip_exists, selection_noise, cmd_args):
|
| 43 |
+
world_size = int(os.getenv("WORLD_SIZE", "1"))
|
| 44 |
+
with open(cmd_args.deepspeed_config) as json_file:
|
| 45 |
+
ds_config = json.load(json_file)
|
| 46 |
+
del cmd_args.deepspeed_config
|
| 47 |
+
|
| 48 |
+
setup()
|
| 49 |
+
for model_path in model_paths:
|
| 50 |
+
try:
|
| 51 |
+
if selection_noise is not None:
|
| 52 |
+
save_dir = os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + f'evaluation_result_selection_noise={selection_noise}.pkl'
|
| 53 |
+
else:
|
| 54 |
+
save_dir = os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + 'evaluation_result.pkl'
|
| 55 |
+
if os.path.exists(save_dir) and (skip_exists):
|
| 56 |
+
continue
|
| 57 |
+
print(
|
| 58 |
+
f"Start setup rank {deepspeed.comm.get_local_rank()} of {world_size} on GPU {torch.cuda.current_device()}")
|
| 59 |
+
|
| 60 |
+
ckpt = torch.load(os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + 'checkpoint_best.pth',
|
| 61 |
+
map_location=f'cpu')
|
| 62 |
+
config = ckpt['config']
|
| 63 |
+
ds_config['train_micro_batch_size_per_gpu'] = batch_size
|
| 64 |
+
load_precision = '32'
|
| 65 |
+
if config.model.load_bit == 16:
|
| 66 |
+
ds_config['float16']['enabled'] = True
|
| 67 |
+
load_precision = 'fp16'
|
| 68 |
+
if 'llama' in config.model.model_name.lower():
|
| 69 |
+
ds_config['float16']['enabled'] = False
|
| 70 |
+
ds_config['bf16']['enabled'] = True
|
| 71 |
+
load_precision = 'bf16'
|
| 72 |
+
load_bit_map = {
|
| 73 |
+
'fp16': torch.float16,
|
| 74 |
+
'bf16': torch.bfloat16,
|
| 75 |
+
'32': torch.float32}
|
| 76 |
+
|
| 77 |
+
if config.model.model_type == 'selective_pt':
|
| 78 |
+
from models.selective_llm_chat import SelectLLMChat as LLMChat
|
| 79 |
+
else:
|
| 80 |
+
from models.llm_chat import LLMChat
|
| 81 |
+
if 'vicuna' in config.model.model_name and (not os.path.exists(config.model.model_name)):
|
| 82 |
+
config.model.model_name = VICUNA_PREFIX + os.sep + config.model.model_name.split(os.sep)[-1]
|
| 83 |
+
_model = LLMChat(config, batch_size)
|
| 84 |
+
left_tokenizer = _model.left_tokenizer
|
| 85 |
+
right_tokenizer = _model.right_tokenizer
|
| 86 |
+
print(f'LOADING {model_path} with {load_precision} precision')
|
| 87 |
+
model_engine, _, _, _ = deepspeed.initialize(args=cmd_args,
|
| 88 |
+
model=_model,
|
| 89 |
+
config=ds_config,
|
| 90 |
+
)
|
| 91 |
+
model_engine.load_checkpoint(model_path, load_module_strict=False, load_optimizer_states=False,
|
| 92 |
+
load_lr_scheduler_states=False,
|
| 93 |
+
load_module_only=True)
|
| 94 |
+
valid_path_file = valid_path
|
| 95 |
+
if valid_path_file is None:
|
| 96 |
+
valid_path_file = config.dataset.valid
|
| 97 |
+
if config.dataset.test.__class__ is str:
|
| 98 |
+
valid_path_file = config.dataset.test
|
| 99 |
+
print('using train split from personachat')
|
| 100 |
+
task_type = TASK_TYPE(config.training.task_type)
|
| 101 |
+
valid_dataset = PersonaChatDataset(valid_path_file, max_context_turns=config.dataset.max_context_turns)
|
| 102 |
+
from dataset.dataset import get_dataloader
|
| 103 |
+
max_new_token = 32
|
| 104 |
+
valid_sampler = DistributedSampler(valid_dataset, num_replicas=world_size, shuffle=False,
|
| 105 |
+
drop_last=False)
|
| 106 |
+
valid_dataloader = get_dataloader(valid_dataset, batch_size, num_workers=0, sampler=valid_sampler)
|
| 107 |
+
|
| 108 |
+
context_input = []
|
| 109 |
+
persona_list = []
|
| 110 |
+
dist_pred_text = [None for _ in range(world_size)]
|
| 111 |
+
dist_gt_text = [None for _ in range(world_size)]
|
| 112 |
+
pred_text = []
|
| 113 |
+
gt_text = []
|
| 114 |
+
tqdm_iterator = tqdm(valid_dataloader, total=len(valid_dataloader))
|
| 115 |
+
selected_prompts = []
|
| 116 |
+
for data in tqdm_iterator:
|
| 117 |
+
_, text, batch_selected_prompts = LLMChat.test_step(model_engine, data, left_tokenizer,
|
| 118 |
+
right_tokenizer,
|
| 119 |
+
config, max_new_tokens=max_new_token,
|
| 120 |
+
tqdm_instance=tqdm_iterator,
|
| 121 |
+
selection_noise=selection_noise)
|
| 122 |
+
if batch_selected_prompts.__class__ != list:
|
| 123 |
+
selected_prompts += (batch_selected_prompts.detach().cpu().tolist())
|
| 124 |
+
|
| 125 |
+
context_input += data['context_input']
|
| 126 |
+
persona_list += data['persona_list']
|
| 127 |
+
pred_text += text
|
| 128 |
+
gt_text += data['target']
|
| 129 |
+
|
| 130 |
+
clean_preds = []
|
| 131 |
+
for pred in pred_text:
|
| 132 |
+
search_result = re.search('R:|Q:|Summary:|\n|\:', pred)
|
| 133 |
+
if search_result is not None:
|
| 134 |
+
clean_preds.append(pred[:search_result.span()[0]])
|
| 135 |
+
else:
|
| 136 |
+
clean_preds.append(pred)
|
| 137 |
+
pred_text = clean_preds
|
| 138 |
+
dist.all_gather_object(dist_pred_text, pred_text)
|
| 139 |
+
dist.all_gather_object(dist_gt_text, gt_text)
|
| 140 |
+
pred_text = reduce(lambda x, y: x + y, dist_pred_text)
|
| 141 |
+
gt_text = reduce(lambda x, y: x + y, dist_gt_text)
|
| 142 |
+
from evaluation import bleu_score, f1_score, normalize_answer
|
| 143 |
+
bleu = bleu_score(pred_text, [gt_text])
|
| 144 |
+
import pickle
|
| 145 |
+
|
| 146 |
+
result = {
|
| 147 |
+
'context_input': context_input,
|
| 148 |
+
'persona_list': persona_list,
|
| 149 |
+
'pred_text': pred_text,
|
| 150 |
+
'gt_text': gt_text,
|
| 151 |
+
'bleu': bleu,
|
| 152 |
+
}
|
| 153 |
+
from collections import Counter
|
| 154 |
+
counter = Counter(selected_prompts)
|
| 155 |
+
if deepspeed.comm.get_local_rank() == 0:
|
| 156 |
+
print('bleu: ', bleu)
|
| 157 |
+
with open(save_dir, 'wb') as file:
|
| 158 |
+
pickle.dump(result, file)
|
| 159 |
+
with open(save_dir.replace('.pkl', '.txt'), 'w', encoding='utf-8') as file:
|
| 160 |
+
file.write('bleu: ' + str(bleu) + '\n')
|
| 161 |
+
if len(selected_prompts) > 0:
|
| 162 |
+
file.write('selected prompt: ' + str(counter) + '\n')
|
| 163 |
+
for i in range(len(context_input)):
|
| 164 |
+
if context_input[i].__class__ == list:
|
| 165 |
+
file.write('context: ' + str(u' '.join(context_input[i]).encode('utf-8')) + '\n')
|
| 166 |
+
else:
|
| 167 |
+
file.write('context: ' + str(context_input[i].encode('utf-8')) + '\n')
|
| 168 |
+
file.write('persona: ' + str(u' '.join(persona_list[i]).encode('utf-8')) + '\n')
|
| 169 |
+
file.write('pred: ' + pred_text[i] + '\n')
|
| 170 |
+
file.write('gt: ' + gt_text[i] + '\n')
|
| 171 |
+
if len(selected_prompts) > 0:
|
| 172 |
+
file.write('selected prompt: ' + str(selected_prompts[i]) + '\n')
|
| 173 |
+
file.write('\n')
|
| 174 |
+
except Exception as e:
|
| 175 |
+
save_dir = os.sep.join(model_path.split(os.sep)[:-1]) + os.sep + "test_error.txt"
|
| 176 |
+
print(f'WRITING TESTING ERROR! ERROR: {str(e)}')
|
| 177 |
+
with open(save_dir, 'w') as file:
|
| 178 |
+
file.write(str(e))
|
| 179 |
+
deepspeed.comm.barrier()
|
| 180 |
+
deepspeed.comm.barrier()
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
model_path_arg = args.model_path
|
| 184 |
+
model_paths = [model_path_arg]
|
| 185 |
+
if len(glob.glob(model_path_arg+os.sep+'ds_ckpt'+os.sep+'*')):
|
| 186 |
+
model_paths = [model_path_arg+os.sep+'ds_ckpt']
|
| 187 |
+
elif not model_path_arg.endswith('.pth'):
|
| 188 |
+
import glob
|
| 189 |
+
path_pattern = args.path_pattern
|
| 190 |
+
if path_pattern is not None:
|
| 191 |
+
model_paths = glob.glob(f'{model_path_arg}/{path_pattern}/ds_ckpt/*/*.pt')
|
| 192 |
+
else:
|
| 193 |
+
model_paths = glob.glob(f'{model_path_arg}/*/ds_ckpt/*/*.pt')
|
| 194 |
+
model_paths = list(set([os.sep.join(p.split(os.sep)[:-2]) for p in model_paths]))
|
| 195 |
+
print(model_paths)
|
| 196 |
+
num_of_gpus = torch.cuda.device_count()
|
| 197 |
+
print(f"{num_of_gpus} GPUs available")
|
| 198 |
+
test_process(model_paths, args.batch_size, args.valid_path,
|
| 199 |
+
args.skip_exists, args.selection_noise, cmd_args=_cmd_args)
|
| 200 |
+
deepspeed.comm.barrier()
|
| 201 |
+
deepspeed.comm.destroy_process_group()
|
| 202 |
+
# if not model_path_arg.endswith('.pth'):
|
| 203 |
+
# evaluate_folder(model_path_arg, skip_exists=args.skip_exists)
|
| 204 |
+
print('Test Ends')
|
train.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
from multiprocessing import freeze_support
|
| 4 |
+
|
| 5 |
+
import deepspeed
|
| 6 |
+
import torch
|
| 7 |
+
from dotenv import load_dotenv
|
| 8 |
+
from transformers.utils import logging
|
| 9 |
+
|
| 10 |
+
from trainer.peft_trainer import train_generator
|
| 11 |
+
from utils.config import get_config
|
| 12 |
+
from utils.parser_helper import str2bool
|
| 13 |
+
|
| 14 |
+
load_dotenv()
|
| 15 |
+
logging.set_verbosity_error()
|
| 16 |
+
torch.multiprocessing.set_sharing_strategy('file_system')
|
| 17 |
+
torch.set_float32_matmul_precision('medium')
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def set_model_config(the_config, value, key):
|
| 21 |
+
if value is not None:
|
| 22 |
+
the_config.model[key] = value
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
parser = argparse.ArgumentParser()
|
| 26 |
+
parser.add_argument('--config', type=str)
|
| 27 |
+
parser.add_argument('--batch', type=int, default=2)
|
| 28 |
+
parser.add_argument('--lr', type=float, default=None)
|
| 29 |
+
parser.add_argument('--find_batch', type=str2bool, default=False)
|
| 30 |
+
parser.add_argument('--find_lr', type=str2bool, default=False)
|
| 31 |
+
parser.add_argument('--bf16', type=str2bool, default=True)
|
| 32 |
+
parser.add_argument('--auto_scale_batch_size', type=str2bool, default=False)
|
| 33 |
+
parser.add_argument('--train_after_tune', type=str2bool, default=False)
|
| 34 |
+
parser.add_argument('--num_workers', type=int, default=0)
|
| 35 |
+
parser.add_argument('--epoch', type=int, default=None)
|
| 36 |
+
parser.add_argument('--scheduler_patience', type=int, default=10)
|
| 37 |
+
parser.add_argument('--scheduler_monitor', type=str, default='train_loss', choices=['train_loss'])
|
| 38 |
+
parser.add_argument('--seed', type=int, default=3407)
|
| 39 |
+
parser.add_argument('--grad_clip', type=float, default=-1)
|
| 40 |
+
parser.add_argument('--save_model', type=str2bool, default=True)
|
| 41 |
+
parser.add_argument('--shuffle_train', type=str2bool, default=True)
|
| 42 |
+
parser.add_argument('--training_ratio', type=float, default=1.0)
|
| 43 |
+
parser.add_argument('--adding_noise', type=float, default=None)
|
| 44 |
+
|
| 45 |
+
# parser.add_argument('--retriever_type', type=str, default=None,
|
| 46 |
+
# choices=['bert-base-uncased', 'albert-base-v2'])
|
| 47 |
+
|
| 48 |
+
parser.add_argument('--tokenizer_parallel', type=str2bool, default=True)
|
| 49 |
+
parser.add_argument('--do_test', type=str2bool, default=False)
|
| 50 |
+
parser.add_argument('--exp_name', type=str, default=None)
|
| 51 |
+
parser.add_argument('--mode', default=None, type=str, choices=['normal', 'causal', None])
|
| 52 |
+
parser.add_argument('--local_rank', type=int, default=-1, help='local rank passed from distributed launcher')
|
| 53 |
+
parser.add_argument('--selective_loss_weight', type=float, default=None)
|
| 54 |
+
parser.add_argument('--contrastive_weight', type=float, default=None)
|
| 55 |
+
parser.add_argument('--log_dir', type=str, default=None)
|
| 56 |
+
|
| 57 |
+
parser.add_argument('--warmup_type', type=str, default=None)
|
| 58 |
+
parser.add_argument('--warmup_min', type=float, default=0)
|
| 59 |
+
parser.add_argument('--warmup_ratio', type=float, default=0.05)
|
| 60 |
+
|
| 61 |
+
parser.add_argument('--ckpt_path', type=str, default=None)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
parser = deepspeed.add_config_arguments(parser)
|
| 67 |
+
cmd_args = parser.parse_args()
|
| 68 |
+
|
| 69 |
+
freeze_support()
|
| 70 |
+
args = parser.parse_args()
|
| 71 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "true" if args.tokenizer_parallel else "false"
|
| 72 |
+
config = get_config(args.config)
|
| 73 |
+
if args.exp_name is not None:
|
| 74 |
+
config.exp_name = args.exp_name
|
| 75 |
+
elif config.exp_name.__class__ != str:
|
| 76 |
+
config.exp_name = args.config.split(os.sep)[-1][:-4]
|
| 77 |
+
if args.lr is not None:
|
| 78 |
+
config.exp_name += f'_LR={args.lr}'
|
| 79 |
+
if args.selective_loss_weight is not None:
|
| 80 |
+
config.training.selective_loss_weight = args.selective_loss_weight
|
| 81 |
+
config.exp_name += f'_SLW={args.selective_loss_weight}'
|
| 82 |
+
if args.contrastive_weight is not None:
|
| 83 |
+
config.training.contrastive_weight = args.contrastive_weight
|
| 84 |
+
config.exp_name += f'_CTRW={args.contrastive_weight}'
|
| 85 |
+
if args.adding_noise is not None:
|
| 86 |
+
config.training.adding_noise = args.adding_noise
|
| 87 |
+
config.exp_name += f'_NOISE={args.adding_noise}'
|
| 88 |
+
if args.training_ratio < 1.0:
|
| 89 |
+
config.exp_name += f'_PTRAIN={args.training_ratio}'
|
| 90 |
+
# Done model config
|
| 91 |
+
generator_type = config.model.generator_type
|
| 92 |
+
if args.mode is not None:
|
| 93 |
+
config.training.mode = args.mode
|
| 94 |
+
if args.epoch is not None:
|
| 95 |
+
config.training.num_epoch = args.epoch
|
| 96 |
+
epoch = config.training.num_epoch
|
| 97 |
+
if args.log_dir is not None:
|
| 98 |
+
config.training.log_dir = args.log_dir
|
| 99 |
+
if 'llama-2' in config.model.model_name.lower():
|
| 100 |
+
folder_name = config.model.model_name.split('/')[-1]
|
| 101 |
+
config.model.model_name = os.getenv('LLAMA2_PATH')+'/'+folder_name
|
| 102 |
+
warmup_config = None
|
| 103 |
+
if args.warmup_type is not None:
|
| 104 |
+
warmup_config = {
|
| 105 |
+
"type": args.warmup_type,
|
| 106 |
+
"params": {
|
| 107 |
+
# "warmup_min_lr": args.warmup_min,
|
| 108 |
+
# "warmup_max_lr": args.lr,
|
| 109 |
+
"warmup_ratio": args.warmup_ratio
|
| 110 |
+
}
|
| 111 |
+
}
|
| 112 |
+
config.exp_name += f'_WP={args.warmup_type}@{args.warmup_ratio}'
|
| 113 |
+
if __name__ == '__main__':
|
| 114 |
+
train_generator(config, args.batch, args.lr, args.num_workers,
|
| 115 |
+
epoch, args.grad_clip, args.seed, args.save_model,
|
| 116 |
+
args.training_ratio, cmd_args=cmd_args, shuffle_train=args.shuffle_train,
|
| 117 |
+
warmup_config=warmup_config, ckpt_path=args.ckpt_path)
|
| 118 |
+
# num_of_gpus = torch.cuda.device_count()
|
| 119 |
+
# print(f"{num_of_gpus} GPUs available")
|
| 120 |
+
# mp.spawn(train_generator, args=(config, args.batch, args.lr, args.num_workers,
|
| 121 |
+
# epoch, args.grad_clip, num_of_gpus, args.seed, args.save_model,
|
| 122 |
+
# args.training_ratio), nprocs=num_of_gpus)
|
| 123 |
+
|
| 124 |
+
# train_generator(args.local_rank, config,
|
| 125 |
+
# batch_size=args.batch,
|
| 126 |
+
# lr=args.lr,
|
| 127 |
+
# num_workers=args.num_workers,
|
| 128 |
+
# epoch=args.epoch,
|
| 129 |
+
# gradient_clipping=args.grad_clip)
|
trainer/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
trainer/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (149 Bytes). View file
|
|
|
trainer/__pycache__/peft_trainer.cpython-310.pyc
ADDED
|
Binary file (5.85 kB). View file
|
|
|
trainer/peft_trainer.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import os
|
| 3 |
+
import time
|
| 4 |
+
|
| 5 |
+
import deepspeed
|
| 6 |
+
import torch
|
| 7 |
+
from pytictoc import TicToc
|
| 8 |
+
from torch.utils.data import DistributedSampler
|
| 9 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
|
| 12 |
+
from dataset.dataset import PersonaChatDataset
|
| 13 |
+
from utils.dist_helper import setup
|
| 14 |
+
from utils.format_inputs import TASK_TYPE
|
| 15 |
+
from utils.seed_everything import seed_everything
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def save_checkpoint(model, optimizer, config, filename):
|
| 19 |
+
torch.save({
|
| 20 |
+
# 'model_state_dict': model.module.state_dict(),
|
| 21 |
+
# 'optimizer_state_dict': optimizer.state_dict(),
|
| 22 |
+
'config': config
|
| 23 |
+
}, filename)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def train_generator(config, batch_size, lr,
|
| 27 |
+
num_workers,
|
| 28 |
+
epoch,
|
| 29 |
+
gradient_clipping, seed, save_model,
|
| 30 |
+
training_ratio, cmd_args, shuffle_train=True,warmup_config=None,
|
| 31 |
+
ckpt_path=None):
|
| 32 |
+
with open(cmd_args.deepspeed_config) as json_file:
|
| 33 |
+
ds_config = json.load(json_file)
|
| 34 |
+
del cmd_args.deepspeed_config
|
| 35 |
+
ds_config['train_micro_batch_size_per_gpu'] = batch_size
|
| 36 |
+
ds_config['optimizer']['params']['lr'] = lr
|
| 37 |
+
if config.model.load_bit == 16:
|
| 38 |
+
ds_config['float16']['enabled'] = True
|
| 39 |
+
if config.model.load_bit == 'bf16':
|
| 40 |
+
ds_config['bf16']['enabled'] = True
|
| 41 |
+
if gradient_clipping > 0:
|
| 42 |
+
ds_config['gradient_clipping'] = gradient_clipping
|
| 43 |
+
|
| 44 |
+
world_size = int(os.getenv("WORLD_SIZE", "1"))
|
| 45 |
+
if config.model.model_type == 'selective_pt':
|
| 46 |
+
from models.selective_llm_chat import SelectLLMChat as LLMChat
|
| 47 |
+
else:
|
| 48 |
+
from models.llm_chat import LLMChat
|
| 49 |
+
seed_everything(seed)
|
| 50 |
+
# initialize the distributed environment
|
| 51 |
+
# time setup function using tictoc
|
| 52 |
+
t = TicToc()
|
| 53 |
+
t.tic()
|
| 54 |
+
setup()
|
| 55 |
+
# print(f"Time for setup is {t.tocvalue()} seconds")
|
| 56 |
+
config.training.learning_rate = float(lr)
|
| 57 |
+
# Create model and move it to GPU
|
| 58 |
+
|
| 59 |
+
task_type: str = config.training.task_type
|
| 60 |
+
enum_task = TASK_TYPE(task_type)
|
| 61 |
+
train_dataset = PersonaChatDataset(config.dataset.train, max_context_turns=config.dataset.max_context_turns,
|
| 62 |
+
training_ratio=training_ratio,
|
| 63 |
+
only_longest=config.training.only_longest,
|
| 64 |
+
task_type=enum_task)
|
| 65 |
+
valid_dataset = PersonaChatDataset(config.dataset.valid, max_context_turns=config.dataset.max_context_turns,
|
| 66 |
+
task_type=enum_task)
|
| 67 |
+
from dataset.dataset import get_dataloader
|
| 68 |
+
if warmup_config is not None:
|
| 69 |
+
warmup_config["params"]['warmup_num_steps'] = int(len(train_dataset)/batch_size * warmup_config["params"]['warmup_ratio'] / world_size)
|
| 70 |
+
warmup_config["params"]['warmup_num_steps'] = int(len(train_dataset)/batch_size * warmup_config["params"]['warmup_ratio'] / world_size)
|
| 71 |
+
warmup_config["params"]['total_num_steps'] = int(len(train_dataset)/batch_size)/world_size
|
| 72 |
+
del warmup_config["params"]['warmup_ratio']
|
| 73 |
+
ds_config['scheduler'] = warmup_config
|
| 74 |
+
_pt_model = LLMChat(config, batch_size=batch_size, ds_config=ds_config)
|
| 75 |
+
|
| 76 |
+
# ddp_model = DDP(_pt_model, device_ids=[0], output_device=0, find_unused_parameters=False)
|
| 77 |
+
left_tokenizer = _pt_model.left_tokenizer
|
| 78 |
+
right_tokenizer = _pt_model.right_tokenizer
|
| 79 |
+
# So there are always training samples
|
| 80 |
+
right_tokenizer.truncation_side = 'left'
|
| 81 |
+
# If it is lengthy, cut the right side
|
| 82 |
+
left_tokenizer.truncation_side = 'right'
|
| 83 |
+
# Create distributed sampler
|
| 84 |
+
all_params = [p for p in _pt_model.parameters()]
|
| 85 |
+
require_grads = [p for p in all_params if p.requires_grad]
|
| 86 |
+
model_engine, optimizer, train_dataloader, _ = deepspeed.initialize(args=cmd_args,
|
| 87 |
+
model=_pt_model,
|
| 88 |
+
model_parameters=require_grads,
|
| 89 |
+
training_data=train_dataset,
|
| 90 |
+
config=ds_config,
|
| 91 |
+
)
|
| 92 |
+
if ckpt_path is not None:
|
| 93 |
+
model_engine.load_checkpoint(ckpt_path, load_module_strict=False, load_optimizer_states=True,
|
| 94 |
+
load_lr_scheduler_states=True,
|
| 95 |
+
load_module_only=False)
|
| 96 |
+
|
| 97 |
+
valid_sampler = DistributedSampler(valid_dataset, num_replicas=world_size, shuffle=False,
|
| 98 |
+
drop_last=False)
|
| 99 |
+
|
| 100 |
+
valid_dataloader = get_dataloader(valid_dataset, batch_size, shuffle=False, num_workers=num_workers,
|
| 101 |
+
sampler=valid_sampler)
|
| 102 |
+
|
| 103 |
+
if enum_task in [TASK_TYPE.GENERATE_RESPONSE, TASK_TYPE.GENERATE_PERSONA]:
|
| 104 |
+
train_sampler = DistributedSampler(train_dataset, num_replicas=world_size, shuffle=shuffle_train,
|
| 105 |
+
drop_last=False)
|
| 106 |
+
train_dataloader = get_dataloader(train_dataset, batch_size, shuffle=False, num_workers=num_workers,
|
| 107 |
+
sampler=train_sampler)
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# You might want to adjust this depending on your specific requirements
|
| 111 |
+
# scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
|
| 112 |
+
if config.training.log_dir.__class__ is str:
|
| 113 |
+
logdir = f"{config.training.log_dir}/{config.exp_name}_{time.strftime('%Y-%m-%d-%H%M')}"
|
| 114 |
+
else:
|
| 115 |
+
logdir = f"runs/{config.exp_name}_{time.strftime('%Y-%m-%d-%H%M')}"
|
| 116 |
+
# Tensorboard logger
|
| 117 |
+
writer = SummaryWriter(log_dir=logdir)
|
| 118 |
+
best_valid_loss = 65535
|
| 119 |
+
# Training Loop
|
| 120 |
+
counter = 0
|
| 121 |
+
valid_counter = 0
|
| 122 |
+
for _epoch in range(epoch):
|
| 123 |
+
model_engine.train()
|
| 124 |
+
total_loss = 0.0
|
| 125 |
+
gathered_train_loss = [torch.zeros(1, dtype=torch.float32, device=model_engine.device) for _ in range(world_size)]
|
| 126 |
+
train_iter = tqdm(train_dataloader, total=len(train_dataloader), desc=f'epoch: {_epoch}')
|
| 127 |
+
total_steps_per_epoch = len(train_dataloader)
|
| 128 |
+
total_steps = total_steps_per_epoch*epoch
|
| 129 |
+
for idx, inputs in enumerate(train_iter):
|
| 130 |
+
current_step = idx+_epoch*total_steps_per_epoch
|
| 131 |
+
current_training_percent = current_step/total_steps
|
| 132 |
+
model_engine.zero_grad()
|
| 133 |
+
loss = LLMChat.training_step(model_engine, inputs, left_tokenizer, right_tokenizer, config,
|
| 134 |
+
mode=config.training.mode, task_type=enum_task, training_process=current_training_percent)
|
| 135 |
+
skipped = False
|
| 136 |
+
params = []
|
| 137 |
+
if deepspeed.comm.get_local_rank() in [-1, 0]:
|
| 138 |
+
for n, p in model_engine.named_parameters():
|
| 139 |
+
if p.requires_grad:
|
| 140 |
+
params.append(p)
|
| 141 |
+
norm = torch.stack([p.norm() for p in params]).sum()
|
| 142 |
+
print(f'NORM: {norm}')
|
| 143 |
+
if loss.isnan():
|
| 144 |
+
model_engine.backward(loss.new_zeros(loss.shape, requires_grad=True))
|
| 145 |
+
skipped = True
|
| 146 |
+
print(inputs)
|
| 147 |
+
raise ValueError('Meet NaN in training!')
|
| 148 |
+
else:
|
| 149 |
+
model_engine.backward(loss)
|
| 150 |
+
if gradient_clipping > 0:
|
| 151 |
+
model_engine.gradient_clipping()
|
| 152 |
+
|
| 153 |
+
model_engine.step()
|
| 154 |
+
|
| 155 |
+
total_loss += loss.item()
|
| 156 |
+
writer.add_scalar(f'Loss-{deepspeed.comm.get_local_rank()}/train', loss.item(), counter)
|
| 157 |
+
counter += 1
|
| 158 |
+
train_iter.set_postfix_str(f'loss: {loss.item()}'+(" (Skipped)" if skipped else ""))
|
| 159 |
+
outputs_valid_losses = [torch.zeros(1, dtype=torch.float32, device=model_engine.device) for _ in range(world_size)]
|
| 160 |
+
valid_loss = []
|
| 161 |
+
for inputs in tqdm(valid_dataloader, total=len(valid_dataloader), desc='valid'):
|
| 162 |
+
model_engine.eval()
|
| 163 |
+
with torch.no_grad():
|
| 164 |
+
loss = LLMChat.validation_step(model_engine, inputs, left_tokenizer, right_tokenizer, config,
|
| 165 |
+
mode=config.training.mode, task_type=enum_task)
|
| 166 |
+
valid_loss.append(loss.item())
|
| 167 |
+
writer.add_scalar(f'Loss-{deepspeed.comm.get_local_rank()}/valid', loss.item(), valid_counter)
|
| 168 |
+
valid_counter += 1
|
| 169 |
+
deepspeed.comm.all_gather(outputs_valid_losses, torch.tensor(valid_loss).mean().to(model_engine.device))
|
| 170 |
+
gathered_valid_loss = torch.stack(outputs_valid_losses).mean()
|
| 171 |
+
deepspeed.comm.all_gather(gathered_train_loss, torch.tensor(total_loss / len(train_dataloader), device=model_engine.device))
|
| 172 |
+
writer.add_scalar(f'Loss-{deepspeed.comm.get_local_rank()}/total_train', torch.stack(gathered_train_loss).mean(), _epoch)
|
| 173 |
+
|
| 174 |
+
writer.add_scalar(f'Loss-{deepspeed.comm.get_local_rank()}/total_valid', gathered_valid_loss, _epoch)
|
| 175 |
+
deepspeed.comm.barrier()
|
| 176 |
+
print(
|
| 177 |
+
f'\nepoch: {_epoch}, train_loss: {total_loss / len(train_dataloader)}, valid_loss: {gathered_valid_loss}\n')
|
| 178 |
+
if best_valid_loss > gathered_valid_loss and save_model:
|
| 179 |
+
# Save pt_model checkpoint
|
| 180 |
+
if model_engine.global_rank == 0:
|
| 181 |
+
print(f"Saving model checkpoint with valid loss {gathered_valid_loss}")
|
| 182 |
+
save_checkpoint(model_engine, optimizer, config, f'{logdir}/checkpoint_best.pth')
|
| 183 |
+
model_engine.save_checkpoint(f'{logdir}/ds_ckpt', tag='best', exclude_frozen_parameters=True)
|
| 184 |
+
best_valid_loss = gathered_valid_loss
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
deepspeed.comm.destroy_process_group()
|
utils/__pycache__/config.cpython-310.pyc
ADDED
|
Binary file (1.36 kB). View file
|
|
|
utils/__pycache__/configure_optimizers.cpython-310.pyc
ADDED
|
Binary file (354 Bytes). View file
|
|
|
utils/__pycache__/dist_helper.cpython-310.pyc
ADDED
|
Binary file (292 Bytes). View file
|
|
|
utils/__pycache__/format_inputs.cpython-310.pyc
ADDED
|
Binary file (6.43 kB). View file
|
|
|
utils/__pycache__/model_helpers.cpython-310.pyc
ADDED
|
Binary file (948 Bytes). View file
|
|
|
utils/__pycache__/parser_helper.cpython-310.pyc
ADDED
|
Binary file (542 Bytes). View file
|
|
|
utils/__pycache__/seed_everything.cpython-310.pyc
ADDED
|
Binary file (1.78 kB). View file
|
|
|
utils/config.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import yaml
|
| 2 |
+
from dotmap import DotMap
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def extend_dict(extend_me, extend_by):
|
| 6 |
+
if isinstance(extend_me, dict):
|
| 7 |
+
for k, v in extend_by.iteritems():
|
| 8 |
+
if k in extend_me:
|
| 9 |
+
extend_dict(extend_me[k], v)
|
| 10 |
+
else:
|
| 11 |
+
extend_me[k] = v
|
| 12 |
+
else:
|
| 13 |
+
if isinstance(extend_me, list):
|
| 14 |
+
extend_list(extend_me, extend_by)
|
| 15 |
+
else:
|
| 16 |
+
if extend_by is not None:
|
| 17 |
+
extend_me += extend_by
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def extend_list(extend_me, extend_by):
|
| 21 |
+
missing = []
|
| 22 |
+
for item1 in extend_me:
|
| 23 |
+
if not isinstance(item1, dict):
|
| 24 |
+
continue
|
| 25 |
+
|
| 26 |
+
for item2 in extend_by:
|
| 27 |
+
if not isinstance(item2, dict) or item2 in missing:
|
| 28 |
+
continue
|
| 29 |
+
extend_dict(item1, item2)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def extend_compatibility_for_gated_transformer(configuration):
|
| 33 |
+
dict_config = configuration.toDict()
|
| 34 |
+
return configuration
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_config(path):
|
| 38 |
+
with open(path, 'r') as file:
|
| 39 |
+
configuration = yaml.load(file, Loader=yaml.FullLoader)
|
| 40 |
+
with open('config/default.yml', 'r') as file:
|
| 41 |
+
base_configuration = yaml.load(file, Loader=yaml.FullLoader)
|
| 42 |
+
configuration = DotMap(configuration)
|
| 43 |
+
base_configuration = DotMap(base_configuration)
|
| 44 |
+
extend_dict(configuration, base_configuration)
|
| 45 |
+
configuration = extend_compatibility_for_gated_transformer(configuration)
|
| 46 |
+
return configuration
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
if __name__ == '__main__':
|
| 50 |
+
config = get_config('config/bert-base.yml')
|
utils/configure_optimizers.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def configure_optimizers(model, lr):
|
| 5 |
+
adam = torch.optim.Adam(model.parameters(), lr=lr)
|
| 6 |
+
return adam
|
utils/dist_helper.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import deepspeed
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def setup():
|
| 5 |
+
deepspeed.init_distributed()
|
utils/format_inputs.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from enum import Enum
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class TASK_TYPE(Enum):
|
| 7 |
+
GENERATE_RESPONSE = 'generate_response'
|
| 8 |
+
GENERATE_PERSONA = 'generate_persona'
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def format_personachat_input(batch, left_tokenizer, right_tokenizer, config, for_test=False, find_batch=False):
|
| 13 |
+
batch_size = len(batch['context_input'])
|
| 14 |
+
pad_token_id = left_tokenizer.pad_token_id
|
| 15 |
+
targets = [t.strip() for t in batch['target']]
|
| 16 |
+
eos_token = left_tokenizer.eos_token
|
| 17 |
+
concat_context = [' '.join(context) for context in batch['context_input']]
|
| 18 |
+
concat_persona = [' '.join(persona) for persona in batch['persona_list']]
|
| 19 |
+
concat_input = [f'#persona#{persona}#context#{context}' for persona, context in
|
| 20 |
+
zip(concat_persona, concat_context)]
|
| 21 |
+
inference_tokenized = None
|
| 22 |
+
bos_token = left_tokenizer.bos_token
|
| 23 |
+
if for_test:
|
| 24 |
+
inference_input = [f'#persona#{persona}#context#{context}{bos_token}' for persona, context in
|
| 25 |
+
zip(concat_persona, concat_context)]
|
| 26 |
+
inference_tokenized = left_tokenizer(inference_input, add_special_tokens=False, return_tensors='pt',
|
| 27 |
+
padding='max_length', truncation=True,
|
| 28 |
+
max_length=config.dataset.max_token_length - 16)
|
| 29 |
+
# processing target
|
| 30 |
+
_target_with_bos = [f'{bos_token}{target}{eos_token}' for target in targets]
|
| 31 |
+
_target_with_bos_pt = right_tokenizer(_target_with_bos,
|
| 32 |
+
add_special_tokens=False, return_tensors='pt', \
|
| 33 |
+
padding=True)
|
| 34 |
+
_target_pt = _target_with_bos_pt.copy()
|
| 35 |
+
_target_pt['input_ids'] = torch.cat((_target_pt['input_ids'][:, 1:],
|
| 36 |
+
_target_pt['input_ids'].new_ones(batch_size, 1) * pad_token_id), dim=1)
|
| 37 |
+
_target_pt['attention_mask'] = torch.cat((_target_pt['attention_mask'][:, 1:],
|
| 38 |
+
_target_pt['attention_mask'].new_zeros(batch_size, 1)), dim=1)
|
| 39 |
+
# processing concat
|
| 40 |
+
context_pt = left_tokenizer(concat_input, add_special_tokens=False, return_tensors='pt',
|
| 41 |
+
padding='max_length', truncation=True,
|
| 42 |
+
max_length=config.dataset.max_token_length)
|
| 43 |
+
input_pt = torch.cat((context_pt['input_ids'], _target_with_bos_pt['input_ids']),
|
| 44 |
+
dim=1)[:, -config.dataset.max_token_length:]
|
| 45 |
+
input_attn = torch.cat((context_pt['attention_mask'], _target_with_bos_pt['attention_mask']),
|
| 46 |
+
dim=1)[:, -config.dataset.max_token_length:]
|
| 47 |
+
lm_input = {'input_ids': input_pt, 'attention_mask': input_attn}
|
| 48 |
+
if find_batch:
|
| 49 |
+
lm_target = torch.cat((context_pt['input_ids'],
|
| 50 |
+
_target_pt['input_ids']), dim=1)[:, -config.dataset.max_token_length:]
|
| 51 |
+
else:
|
| 52 |
+
lm_target = torch.cat((context_pt['input_ids'] * 0 - 1,
|
| 53 |
+
_target_pt['input_ids']), dim=1)[:, -config.dataset.max_token_length:]
|
| 54 |
+
if for_test:
|
| 55 |
+
return lm_input, lm_target, inference_tokenized
|
| 56 |
+
return lm_input, lm_target
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# Template Type:
|
| 60 |
+
# 0: </s>
|
| 61 |
+
|
| 62 |
+
def format_causal_personachat_input(batch, left_tokenizer, right_tokenizer, config, for_test=False,
|
| 63 |
+
find_batch=False, template_type=0):
|
| 64 |
+
template_types = [
|
| 65 |
+
'{cinput} R: {target}',
|
| 66 |
+
'{cinput} R: [COMPLETE] the answer for [COMPLETE] is {target}'
|
| 67 |
+
]
|
| 68 |
+
bos_token = left_tokenizer.bos_token
|
| 69 |
+
eos_token = left_tokenizer.eos_token
|
| 70 |
+
batch_size = len(batch['context_input'])
|
| 71 |
+
pad_token_id = right_tokenizer.pad_token_id
|
| 72 |
+
targets = [t.strip() for t in batch['target']]
|
| 73 |
+
concat_context = [' '.join(context) for context in batch['context_input']]
|
| 74 |
+
concat_persona = [' '.join(persona) for persona in batch['persona_list']]
|
| 75 |
+
concat_input = [f'given persona: {persona}; context: {context}' for persona, context in
|
| 76 |
+
zip(concat_persona, concat_context)]
|
| 77 |
+
concat_input_target = [template_types[template_type].format(cinput=cinput, target=target) for cinput, target in
|
| 78 |
+
zip(concat_input, targets)]
|
| 79 |
+
bos_concat_input = [f'{bos_token}{cinput}{eos_token}' for cinput in concat_input_target]
|
| 80 |
+
lm_input = right_tokenizer(bos_concat_input, add_special_tokens=False, return_tensors='pt',
|
| 81 |
+
padding='max_length', truncation=True,
|
| 82 |
+
max_length=config.dataset.max_token_length)
|
| 83 |
+
lm_target = lm_input.copy()
|
| 84 |
+
lm_target = torch.cat((lm_target['input_ids'][:, 1:], lm_target['input_ids'].new_full(
|
| 85 |
+
(batch_size, 1), pad_token_id)), dim=1)
|
| 86 |
+
# lm_target['attention_mask'] = torch.cat(
|
| 87 |
+
# (lm_target['attention_mask'][:, 1:], lm_target['attention_mask'].new_full(
|
| 88 |
+
# (batch_size, 1), 0)), dim=1)
|
| 89 |
+
# freeze persona
|
| 90 |
+
if config.training.freeze_persona.__class__ is bool and config.training.freeze_persona:
|
| 91 |
+
for _lm_target in lm_target:
|
| 92 |
+
if 'given persona:' not in left_tokenizer.decode(_lm_target):
|
| 93 |
+
continue
|
| 94 |
+
_tokens = left_tokenizer.convert_ids_to_tokens(_lm_target)
|
| 95 |
+
_token_ids = _lm_target
|
| 96 |
+
_token_idx = None
|
| 97 |
+
for idx in range(0, len(_tokens) - 1):
|
| 98 |
+
if _tokens[idx].endswith('context') and _tokens[idx + 1].endswith(':'):
|
| 99 |
+
_token_idx = idx
|
| 100 |
+
break
|
| 101 |
+
_token_ids[idx] = left_tokenizer.pad_token_id
|
| 102 |
+
# freeze context
|
| 103 |
+
if config.training.freeze_context.__class__ is bool and config.training.freeze_context:
|
| 104 |
+
for _lm_target in lm_target:
|
| 105 |
+
_tokens = left_tokenizer.convert_ids_to_tokens(_lm_target)
|
| 106 |
+
_token_ids = _lm_target
|
| 107 |
+
_start_idx = None
|
| 108 |
+
_end_idx = None
|
| 109 |
+
for idx in range(0, len(_tokens) - 1):
|
| 110 |
+
if _tokens[idx].endswith('context') and _tokens[idx + 1].endswith(':'):
|
| 111 |
+
_start_idx = idx
|
| 112 |
+
if _tokens[idx].endswith('R') and _tokens[idx + 1].endswith(':'):
|
| 113 |
+
_end_idx = idx + 2
|
| 114 |
+
if _start_idx is None or _end_idx is None:
|
| 115 |
+
continue
|
| 116 |
+
for idx in range(_start_idx, _end_idx):
|
| 117 |
+
_token_ids[idx] = left_tokenizer.pad_token_id
|
| 118 |
+
|
| 119 |
+
if for_test:
|
| 120 |
+
inference_input = [template_types[template_type].format(cinput=cinput, target='') for cinput in concat_input]
|
| 121 |
+
bos_concat_input = [f'{bos_token}{cinput}' for cinput in inference_input]
|
| 122 |
+
inference_tokenized = left_tokenizer(bos_concat_input, add_special_tokens=False
|
| 123 |
+
, return_tensors='pt',
|
| 124 |
+
padding=True, truncation=True,
|
| 125 |
+
max_length=config.dataset.max_token_length)
|
| 126 |
+
return lm_input, lm_target, inference_tokenized
|
| 127 |
+
return lm_input, lm_target
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def format_generate_persona_input(batch, left_tokenizer, right_tokenizer, config, for_test=False, find_batch=False):
|
| 131 |
+
batch_size = len(batch['context_input'])
|
| 132 |
+
pad_token_id = left_tokenizer.pad_token_id
|
| 133 |
+
targets = [' '.join(persona) for persona in batch['persona_list']]
|
| 134 |
+
eos_token = left_tokenizer.eos_token
|
| 135 |
+
concat_context = [' '.join(context) for context in batch['context_input']]
|
| 136 |
+
concat_input = [f'#context#{context}' for context in
|
| 137 |
+
concat_context]
|
| 138 |
+
inference_tokenized = None
|
| 139 |
+
bos_token = left_tokenizer.bos_token
|
| 140 |
+
if for_test:
|
| 141 |
+
inference_input = [f'#context#{context}{bos_token}' for context in
|
| 142 |
+
concat_context]
|
| 143 |
+
inference_tokenized = left_tokenizer(inference_input, add_special_tokens=False, return_tensors='pt',
|
| 144 |
+
padding='max_length', truncation=True,
|
| 145 |
+
max_length=config.dataset.max_token_length - 16)
|
| 146 |
+
# processing target
|
| 147 |
+
_target_with_bos = [f'{bos_token}{target}{eos_token}' for target in targets]
|
| 148 |
+
_target_with_bos_pt = right_tokenizer(_target_with_bos,
|
| 149 |
+
add_special_tokens=False, return_tensors='pt',
|
| 150 |
+
padding=True)
|
| 151 |
+
_target_pt = _target_with_bos_pt.copy()
|
| 152 |
+
_target_pt['input_ids'] = torch.cat((_target_pt['input_ids'][:, 1:],
|
| 153 |
+
_target_pt['input_ids'].new_ones(batch_size, 1) * pad_token_id), dim=1)
|
| 154 |
+
_target_pt['attention_mask'] = torch.cat((_target_pt['attention_mask'][:, 1:],
|
| 155 |
+
_target_pt['attention_mask'].new_zeros(batch_size, 1)), dim=1)
|
| 156 |
+
# processing concat
|
| 157 |
+
context_pt = left_tokenizer(concat_input, add_special_tokens=False, return_tensors='pt',
|
| 158 |
+
padding='max_length', truncation=True,
|
| 159 |
+
max_length=config.dataset.max_token_length)
|
| 160 |
+
input_pt = torch.cat((context_pt['input_ids'], _target_with_bos_pt['input_ids']),
|
| 161 |
+
dim=1)[:, -config.dataset.max_token_length:]
|
| 162 |
+
input_attn = torch.cat((context_pt['attention_mask'], _target_with_bos_pt['attention_mask']),
|
| 163 |
+
dim=1)[:, -config.dataset.max_token_length:]
|
| 164 |
+
lm_input = {'input_ids': input_pt, 'attention_mask': input_attn}
|
| 165 |
+
if find_batch:
|
| 166 |
+
lm_target = torch.cat((context_pt['input_ids'],
|
| 167 |
+
_target_pt['input_ids']), dim=1)[:, -config.dataset.max_token_length:]
|
| 168 |
+
else:
|
| 169 |
+
lm_target = torch.cat((context_pt['input_ids'] * 0 - 1,
|
| 170 |
+
_target_pt['input_ids']), dim=1)[:, -config.dataset.max_token_length:]
|
| 171 |
+
if for_test:
|
| 172 |
+
return lm_input, lm_target, inference_tokenized
|
| 173 |
+
return lm_input, lm_target
|
utils/model_helpers.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
def print_trainable_parameters(model):
|
| 3 |
+
"""
|
| 4 |
+
Prints the number of trainable parameters in the model.
|
| 5 |
+
"""
|
| 6 |
+
trainable_params = 0
|
| 7 |
+
all_param = 0
|
| 8 |
+
all_param_names = []
|
| 9 |
+
trainable_param_names = []
|
| 10 |
+
prompt_weights = 0
|
| 11 |
+
prompt_normalizer = 0
|
| 12 |
+
prompt_normalizer_layer = []
|
| 13 |
+
soft_prompt_layers = []
|
| 14 |
+
for name, param in model.named_parameters():
|
| 15 |
+
|
| 16 |
+
all_param += param.numel()
|
| 17 |
+
all_param_names.append(name)
|
| 18 |
+
if param.requires_grad:
|
| 19 |
+
print(name)
|
| 20 |
+
if 'prompt_encoder.default.embedding' in name:
|
| 21 |
+
prompt_weights+= param.numel()
|
| 22 |
+
soft_prompt_layers.append(param)
|
| 23 |
+
if 'prompt_normalizer' in name:
|
| 24 |
+
prompt_normalizer += param.numel()
|
| 25 |
+
prompt_normalizer_layer.append(param)
|
| 26 |
+
trainable_params += param.numel()
|
| 27 |
+
trainable_param_names.append(name)
|
| 28 |
+
print(
|
| 29 |
+
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
|
| 30 |
+
)
|
| 31 |
+
return {"trainable": trainable_params, "all": all_param, "trainable%": 100 * trainable_params / all_param}
|
utils/parser_helper.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def str2bool(v):
|
| 5 |
+
if v is None:
|
| 6 |
+
return None
|
| 7 |
+
exclusive = ['accurate', 'query', 'document']
|
| 8 |
+
if v in exclusive:
|
| 9 |
+
return v
|
| 10 |
+
if isinstance(v, bool):
|
| 11 |
+
return v
|
| 12 |
+
if v.lower() in ('yes', 'true', 't', 'y', '1'):
|
| 13 |
+
return True
|
| 14 |
+
elif v.lower() in ('no', 'false', 'f', 'n', '0'):
|
| 15 |
+
return False
|
| 16 |
+
else:
|
| 17 |
+
raise argparse.ArgumentTypeError('Boolean value expected.')
|
utils/seed_everything.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
from typing import Optional
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
max_seed_value = np.iinfo(np.uint32).max
|
| 9 |
+
min_seed_value = np.iinfo(np.uint32).min
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def seed_everything(seed: Optional[int], workers: bool = False) -> int:
|
| 13 |
+
"""Function that sets seed for pseudo-random number generators in: pytorch, numpy, python.random In addition,
|
| 14 |
+
sets the following environment variables:
|
| 15 |
+
|
| 16 |
+
- `PL_GLOBAL_SEED`: will be passed to spawned subprocesses (e.g. ddp_spawn backend).
|
| 17 |
+
- `PL_SEED_WORKERS`: (optional) is set to 1 if ``workers=True``.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
seed: the integer value seed for global random state in Lightning.
|
| 21 |
+
If `None`, will read seed from `PL_GLOBAL_SEED` env variable
|
| 22 |
+
or select it randomly.
|
| 23 |
+
workers: if set to ``True``, will properly configure all dataloaders passed to the
|
| 24 |
+
Trainer with a ``worker_init_fn``. If the user already provides such a function
|
| 25 |
+
for their dataloaders, setting this argument will have no influence. See also:
|
| 26 |
+
:func:`~lightning_fabric.utilities.seed.pl_worker_init_function`.
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
if not isinstance(seed, int):
|
| 30 |
+
seed = int(seed)
|
| 31 |
+
|
| 32 |
+
if not (min_seed_value <= seed <= max_seed_value):
|
| 33 |
+
raise ValueError(f"{seed} is not in bounds, numpy accepts from {min_seed_value} to {max_seed_value}")
|
| 34 |
+
|
| 35 |
+
print(f"Global seed set to {seed}")
|
| 36 |
+
os.environ["PL_GLOBAL_SEED"] = str(seed)
|
| 37 |
+
random.seed(seed)
|
| 38 |
+
np.random.seed(seed)
|
| 39 |
+
torch.manual_seed(seed)
|
| 40 |
+
torch.cuda.manual_seed_all(seed)
|
| 41 |
+
|
| 42 |
+
os.environ["PL_SEED_WORKERS"] = f"{int(workers)}"
|
| 43 |
+
|
| 44 |
+
return seed
|