---
license: openrail
language:
- ru
library_name: transformers
tags:
- pytorch
- causal-lm
---
## CharLLaMa-35M
Это крошечная языковая модель, имеющая [архитектуру LLaMa](https://arxiv.org/abs/2302.13971), с **посимвольной** токенизацией для всевозможных экспериментов, когда задача решается плохо из-за BPE токенизации на слова и их части:
1) генеративные спеллчекеры
2) классификация текста: замена ```TfidfVectorizer(analyzer='char')```, т.е. когда хорошо сработал бейзлайн на символьных n-граммах
3) транскрипция текста
4) детекция орфографических ошибок, опечаток
Размер модели - **35 913 600** параметров.
### Особенности предварительной тренировки
Я делал эту модель для экспериментов с русской поэзией в рамках проекта ["Литературная студия"](https://github.com/Koziev/verslibre).
Поэтому корпус претрейна содержал значительное количество текстов поэтического формата.
Это может повлиять на ваши downstream задачи.
Объем корпуса претрейна - около **80B** токенов, тексты только на русском языке.
Кривая loss_val: 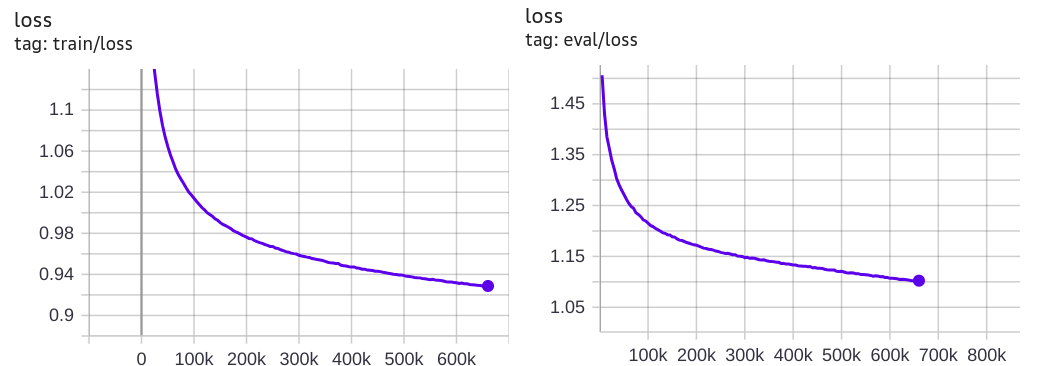
### Токенизатор
Для использования модели нужно установить специальный токенизатор:
```
pip install git+https://github.com/Koziev/character-tokenizer
```
Кроме символов кириллицы и пунктуации, этот токенизатор знает про специальные токены ``````, ``````, `````` и ``````.
Так как это нестандартный для transformers токенизатор, его надо загружать не через ```transformers.AutoTokenizer.from_pretrained```, а таким кодом:
```
import charactertokenizer
...
tokenizer = charactertokenizer.CharacterTokenizer.from_pretrained('inkoziev/charllama-35M')
```
### Использование
С библиотекой transformerts модель можно использовать штатным способом как обычную GPT'шку:
```
import os
import torch
import transformers
import charactertokenizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name_or_path = 'inkoziev/charllama-35M'
model = transformers.AutoModelForCausalLM.from_pretrained(model_name_or_path)
model.to(device)
model.eval()
tokenizer = charactertokenizer.CharacterTokenizer.from_pretrained(model_path)
prompt = 'Меня зовут Ар'
encoded_prompt = tokenizer.encode(prompt, return_tensors='pt')
output_sequences = model.generate(
input_ids=encoded_prompt.to(device),
max_length=500,
temperature=1.0,
top_k=0,
top_p=0.8,
repetition_penalty=1.0,
do_sample=True,
num_return_sequences=5,
pad_token_id=0,
)
for o in output_sequences:
text = tokenizer.decode(o)
if text.startswith(''):
text = text.replace('', '')
text = text[:text.index('')].strip()
print(text)
print('-'*80)
```
Также, будут работать все прочие инструменты для GPT моделей, например transformers.GPT2ForSequenceClassification.