---
library_name: diffusers
license: apache-2.0
pipeline_tag: depth-estimation
---
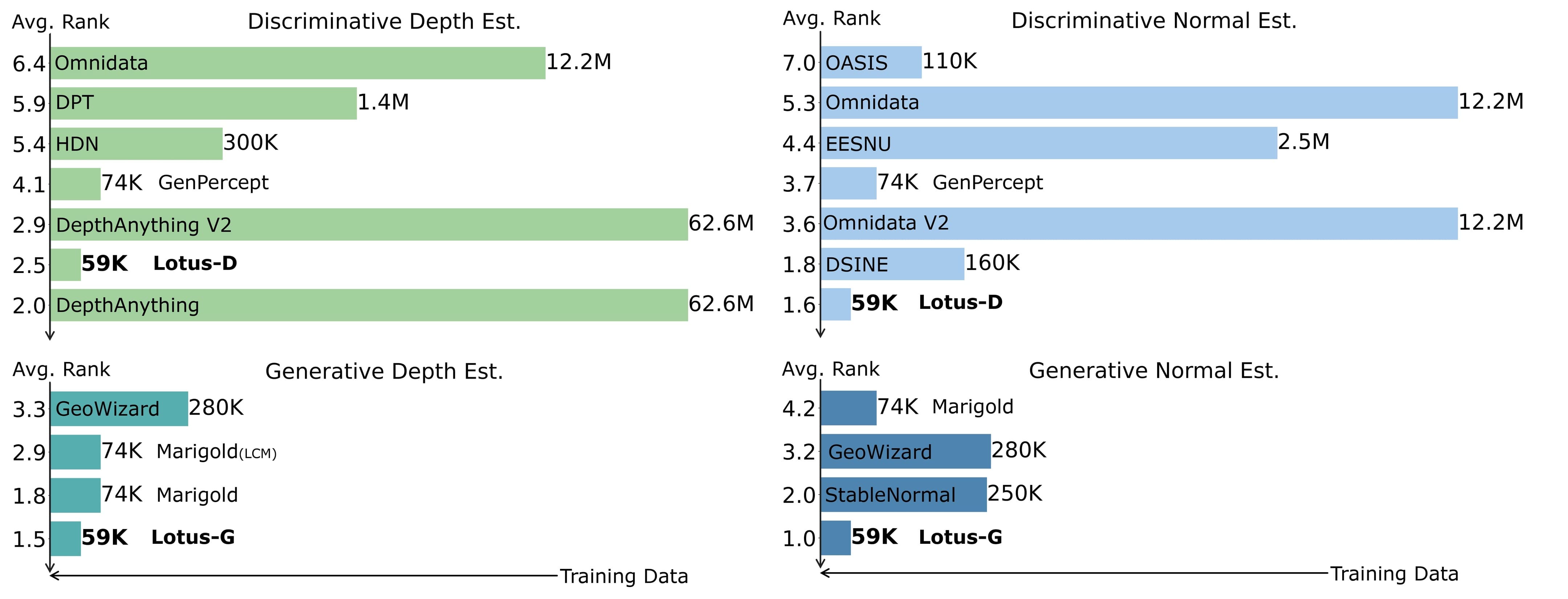
# Lotus: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
- This model belongs to the family of official Lotus models.
- Compared to the [previous version](https://huggingface.co/jingheya/lotus-depth-g-v1-0), this model is trained in disparity space (inverse depth), achieving better performance and more stable video depth estimation.
[](https://lotus3d.github.io/)
[](https://arxiv.org/abs/2409.18124)
[](https://huggingface.co/spaces/haodongli/Lotus)
[](https://github.com/EnVision-Research/Lotus)
Developed by:
[Jing He](https://scholar.google.com/citations?hl=en&user=RsLS11MAAAAJ)✱,
[Haodong Li](https://haodong-li.com/)✱,
[Wei Yin](https://yvanyin.net/),
[Yixun Liang](https://yixunliang.github.io/),
[Leheng Li](https://len-li.github.io/),
[Kaiqiang Zhou](),
[Hongbo Zhang](),
[Bingbing Liu](https://scholar.google.com/citations?user=-rCulKwAAAAJ&hl=en),
[Ying-Cong Chen](https://www.yingcong.me/)✉

## Usage
Please refer to this [page](https://github.com/EnVision-Research/Lotus).