
# ⚡ Lit-LLaMA ️
 [](https://dev.azure.com/Lightning-AI/lit%20Models/_build/latest?definitionId=49&branchName=main) [](https://github.com/Lightning-AI/lit-llama/blob/master/LICENSE) [](https://discord.gg/VptPCZkGNa)
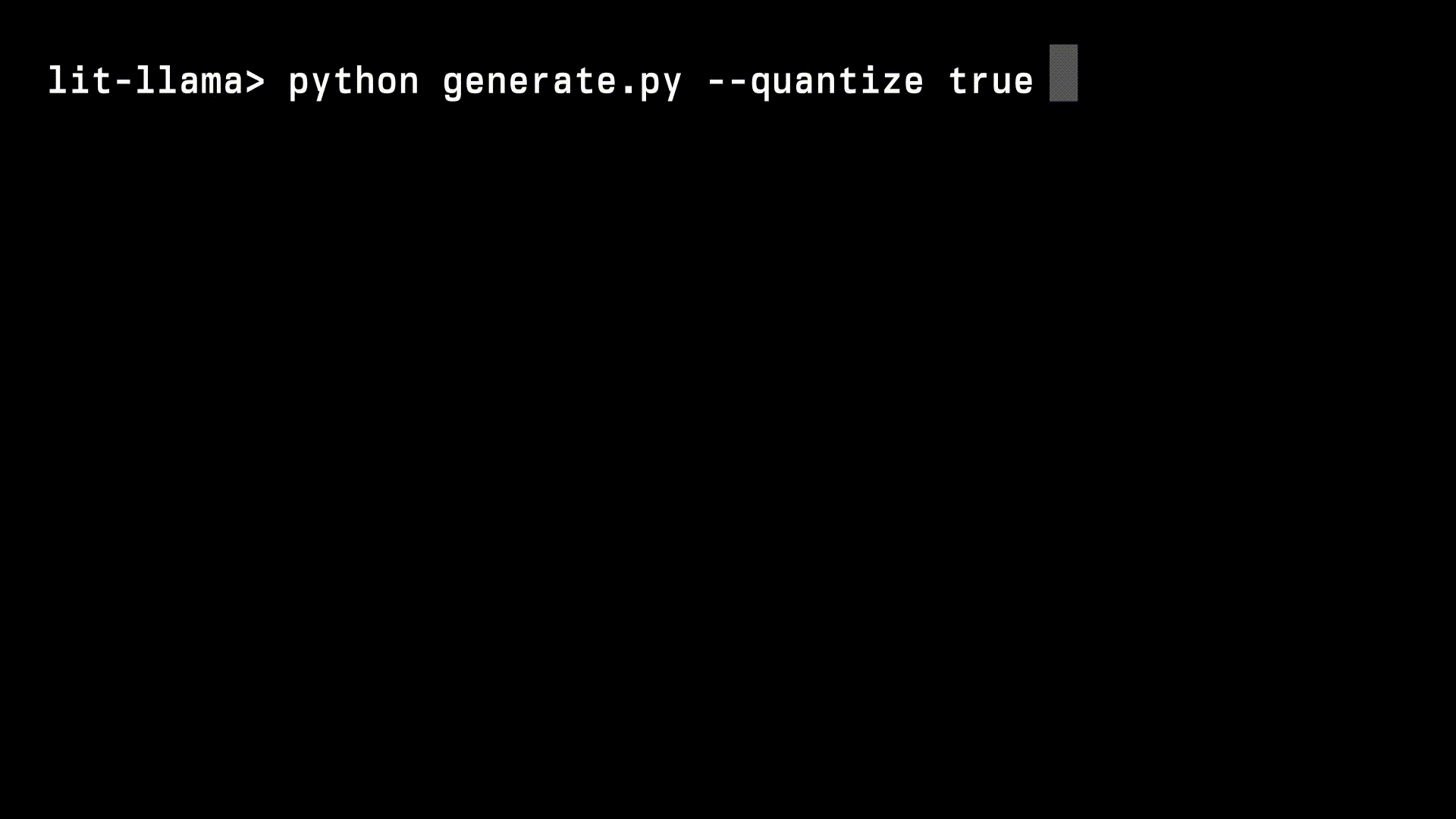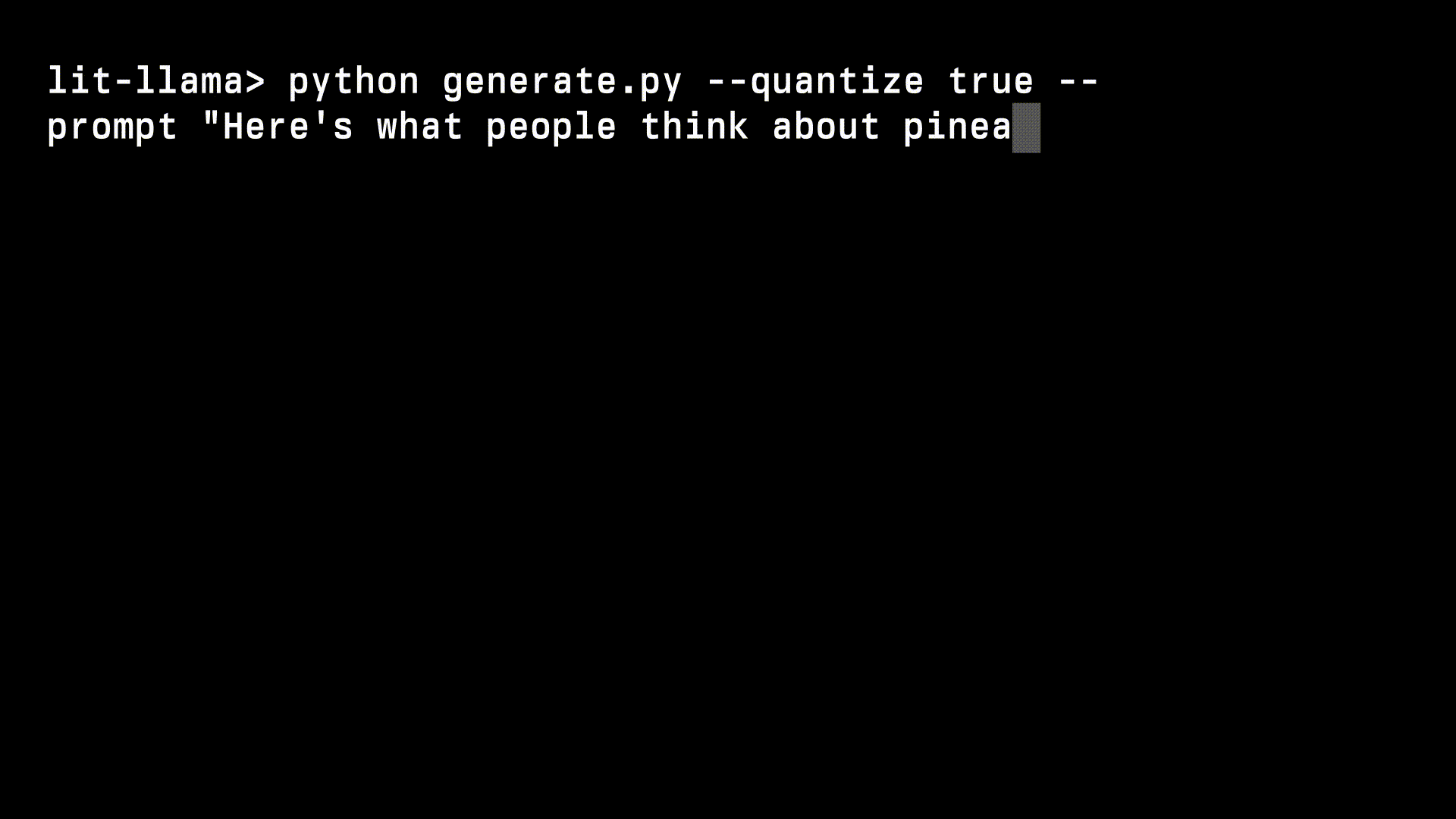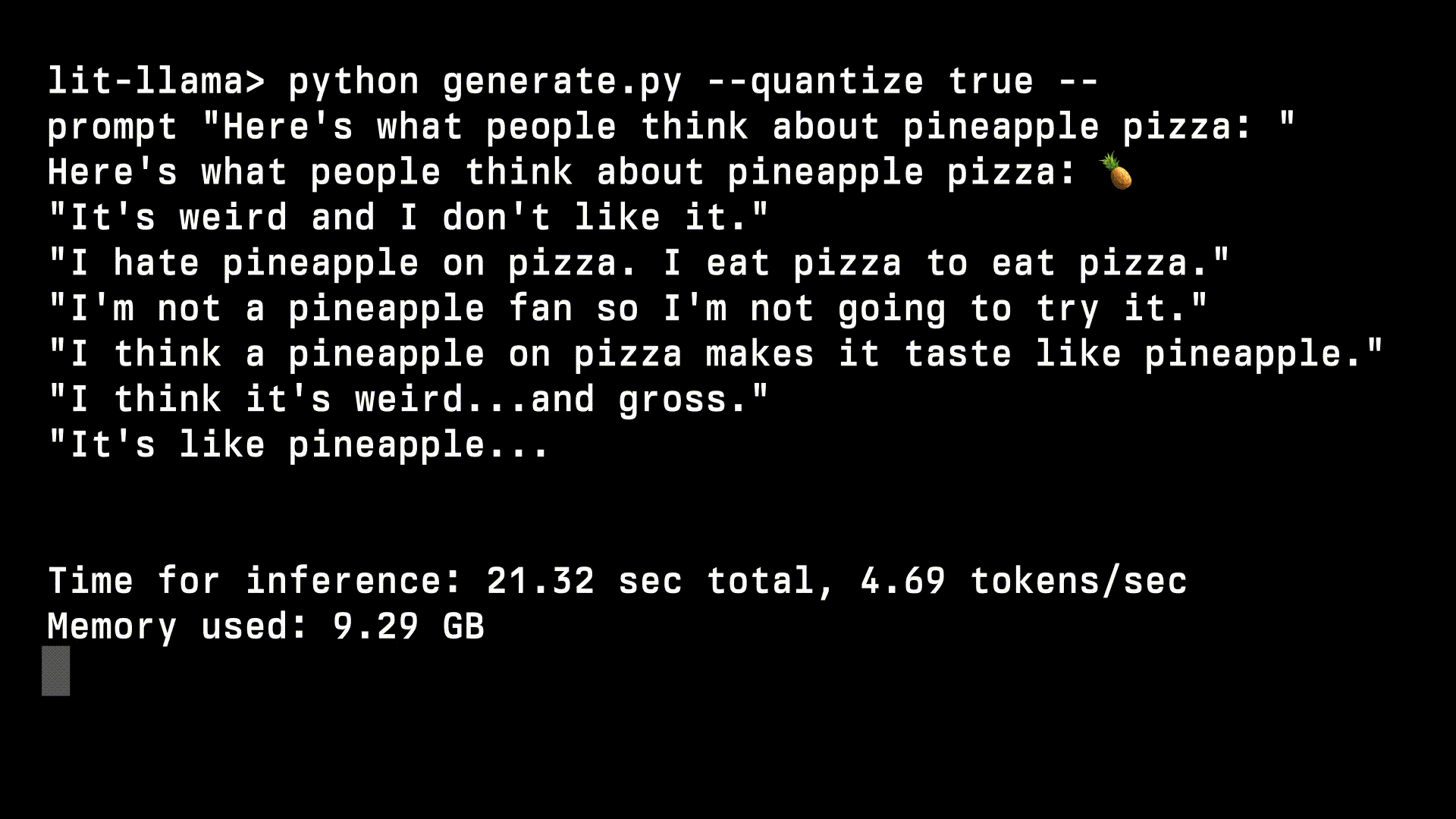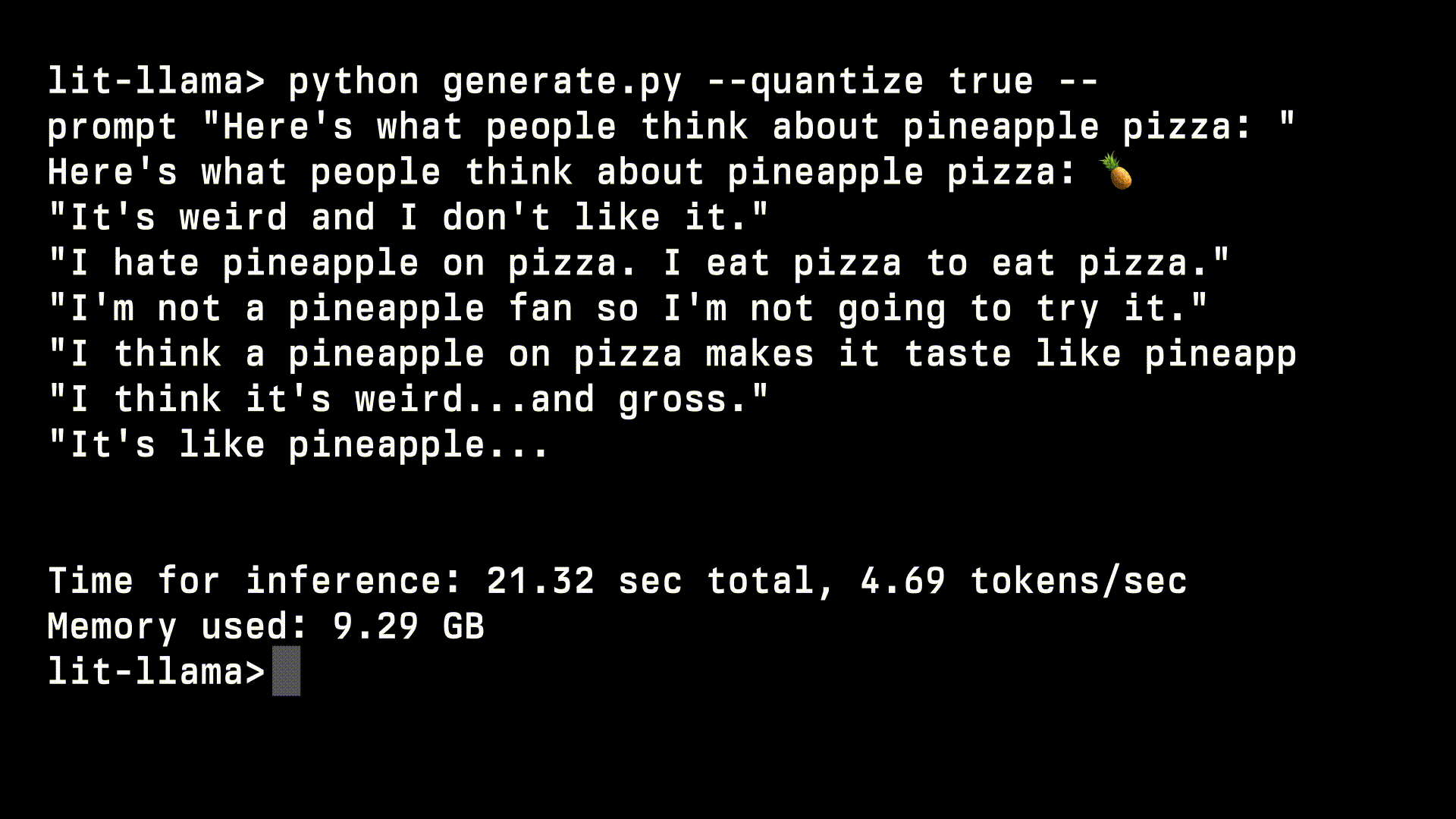
# ⚡ Lit-LLaMA ️
Independent implementation of [LLaMA]( Join us and start contributing, especially on the following areas:
- [ ] [Pre-training](https://github.com/Lightning-AI/lit-llama/labels/pre-training)
- [ ] [Fine-tuning (full and LoRA)](https://github.com/Lightning-AI/lit-llama/labels/fine-tuning)
- [ ] [Quantization](https://github.com/Lightning-AI/lit-llama/labels/quantization)
- [ ] [Sparsification](https://github.com/Lightning-AI/lit-llama/labels/sparsification)
Look at `train.py` for a starting point towards pre-training / fine-tuning using [Lightning Fabric](https://lightning.ai/docs/fabric/stable/).
We welcome all individual contributors, regardless of their level of experience or hardware. Your contributions are valuable, and we are excited to see what you can accomplish in this collaborative and supportive environment.
Unsure about contributing? Check out our [Contributing to Lit-LLaMA: A Hitchhiker’s Guide to the Quest for Fully Open-Source AI](https://lightning.ai/pages/community/tutorial/contributing-to-lit-llama-a-hitchhikers-guide-to-the-quest-for-fully-open-source-ai/) guide.
Don't forget to [join our Discord](https://discord.gg/VptPCZkGNa)!
## Acknowledgements
- [@karpathy](https://github.com/karpathy) for [nanoGPT](https://github.com/karpathy/nanoGPT)
- [@FacebookResearch](https://github.com/facebookresearch) for the original [LLaMA implementation](https://github.com/facebookresearch/llama)
- [@TimDettmers](https://github.com/TimDettmers) for [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- [@Microsoft](https://github.com/microsoft) for [LoRA](https://github.com/microsoft/LoRA)
- [@IST-DASLab](https://github.com/IST-DASLab) for [GPTQ](https://github.com/IST-DASLab/gptq)
## License
Lit-LLaMA is released under the [Apache 2.0](https://github.com/Lightning-AI/lightning-llama/blob/main/LICENSE) license.
Join us and start contributing, especially on the following areas:
- [ ] [Pre-training](https://github.com/Lightning-AI/lit-llama/labels/pre-training)
- [ ] [Fine-tuning (full and LoRA)](https://github.com/Lightning-AI/lit-llama/labels/fine-tuning)
- [ ] [Quantization](https://github.com/Lightning-AI/lit-llama/labels/quantization)
- [ ] [Sparsification](https://github.com/Lightning-AI/lit-llama/labels/sparsification)
Look at `train.py` for a starting point towards pre-training / fine-tuning using [Lightning Fabric](https://lightning.ai/docs/fabric/stable/).
We welcome all individual contributors, regardless of their level of experience or hardware. Your contributions are valuable, and we are excited to see what you can accomplish in this collaborative and supportive environment.
Unsure about contributing? Check out our [Contributing to Lit-LLaMA: A Hitchhiker’s Guide to the Quest for Fully Open-Source AI](https://lightning.ai/pages/community/tutorial/contributing-to-lit-llama-a-hitchhikers-guide-to-the-quest-for-fully-open-source-ai/) guide.
Don't forget to [join our Discord](https://discord.gg/VptPCZkGNa)!
## Acknowledgements
- [@karpathy](https://github.com/karpathy) for [nanoGPT](https://github.com/karpathy/nanoGPT)
- [@FacebookResearch](https://github.com/facebookresearch) for the original [LLaMA implementation](https://github.com/facebookresearch/llama)
- [@TimDettmers](https://github.com/TimDettmers) for [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
- [@Microsoft](https://github.com/microsoft) for [LoRA](https://github.com/microsoft/LoRA)
- [@IST-DASLab](https://github.com/IST-DASLab) for [GPTQ](https://github.com/IST-DASLab/gptq)
## License
Lit-LLaMA is released under the [Apache 2.0](https://github.com/Lightning-AI/lightning-llama/blob/main/LICENSE) license.