
Upload 10 files
Browse files- 1_Pooling/config.json +7 -0
- README.md +0 -0
- images/mgte-loco.png +0 -0
- images/mgte-mldr.png +0 -0
- images/mgte-mteb.png +0 -0
- images/mgte-reranker.png +0 -0
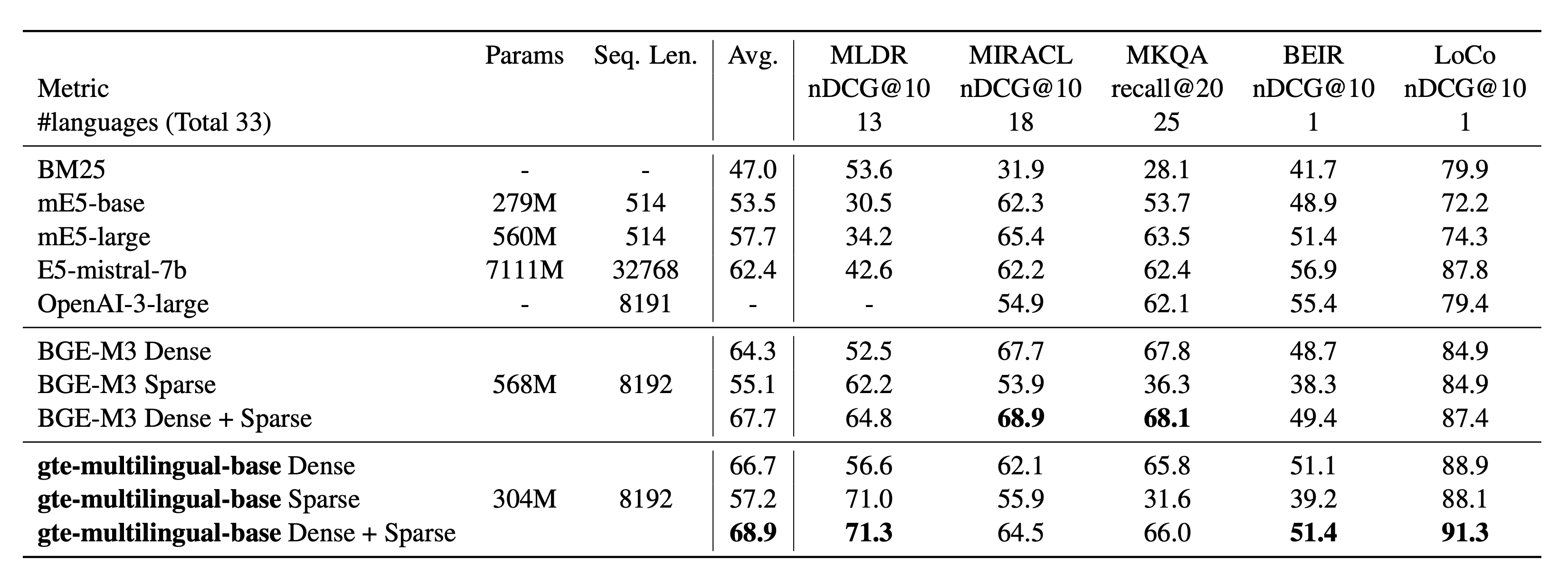
- images/mgte-retrieval.png +0 -0
- modules.json +20 -0
- scripts/gte_embedding.py +154 -0
- sentence_bert_config.json +4 -0
1_Pooling/config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"word_embedding_dimension": 768,
|
| 3 |
+
"pooling_mode_cls_token": true,
|
| 4 |
+
"pooling_mode_mean_tokens": false,
|
| 5 |
+
"pooling_mode_max_tokens": false,
|
| 6 |
+
"pooling_mode_mean_sqrt_len_tokens": false
|
| 7 |
+
}
|
README.md
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
images/mgte-loco.png
ADDED
|
images/mgte-mldr.png
ADDED
|
images/mgte-mteb.png
ADDED
|
images/mgte-reranker.png
ADDED
|
images/mgte-retrieval.png
ADDED
|
modules.json
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"idx": 0,
|
| 4 |
+
"name": "0",
|
| 5 |
+
"path": "",
|
| 6 |
+
"type": "sentence_transformers.models.Transformer"
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"idx": 1,
|
| 10 |
+
"name": "1",
|
| 11 |
+
"path": "1_Pooling",
|
| 12 |
+
"type": "sentence_transformers.models.Pooling"
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"idx": 2,
|
| 16 |
+
"name": "2",
|
| 17 |
+
"path": "2_Normalize",
|
| 18 |
+
"type": "sentence_transformers.models.Normalize"
|
| 19 |
+
}
|
| 20 |
+
]
|
scripts/gte_embedding.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 The GTE Team Authors and Alibaba Group.
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
|
| 5 |
+
from collections import defaultdict
|
| 6 |
+
from typing import Dict, List, Tuple
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import AutoModelForTokenClassification, AutoTokenizer
|
| 11 |
+
from transformers.utils import is_torch_npu_available
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class GTEEmbeddidng(torch.nn.Module):
|
| 15 |
+
def __init__(self,
|
| 16 |
+
model_name: str = None,
|
| 17 |
+
normalized: bool = True,
|
| 18 |
+
use_fp16: bool = True,
|
| 19 |
+
device: str = None
|
| 20 |
+
):
|
| 21 |
+
super().__init__()
|
| 22 |
+
self.normalized = normalized
|
| 23 |
+
if device:
|
| 24 |
+
self.device = torch.device(device)
|
| 25 |
+
else:
|
| 26 |
+
if torch.cuda.is_available():
|
| 27 |
+
self.device = torch.device("cuda")
|
| 28 |
+
elif torch.backends.mps.is_available():
|
| 29 |
+
self.device = torch.device("mps")
|
| 30 |
+
elif is_torch_npu_available():
|
| 31 |
+
self.device = torch.device("npu")
|
| 32 |
+
else:
|
| 33 |
+
self.device = torch.device("cpu")
|
| 34 |
+
use_fp16 = False
|
| 35 |
+
self.use_fp16 = use_fp16
|
| 36 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 37 |
+
self.model = AutoModelForTokenClassification.from_pretrained(
|
| 38 |
+
model_name, trust_remote_code=True, torch_dtype=torch.float16 if self.use_fp16 else None
|
| 39 |
+
)
|
| 40 |
+
self.vocab_size = self.model.config.vocab_size
|
| 41 |
+
self.model.to(self.device)
|
| 42 |
+
|
| 43 |
+
def _process_token_weights(self, token_weights: np.ndarray, input_ids: list):
|
| 44 |
+
# conver to dict
|
| 45 |
+
result = defaultdict(int)
|
| 46 |
+
unused_tokens = set([self.tokenizer.cls_token_id, self.tokenizer.eos_token_id, self.tokenizer.pad_token_id,
|
| 47 |
+
self.tokenizer.unk_token_id])
|
| 48 |
+
# token_weights = np.ceil(token_weights * 100)
|
| 49 |
+
for w, idx in zip(token_weights, input_ids):
|
| 50 |
+
if idx not in unused_tokens and w > 0:
|
| 51 |
+
token = self.tokenizer.decode([int(idx)])
|
| 52 |
+
if w > result[token]:
|
| 53 |
+
result[token] = w
|
| 54 |
+
return result
|
| 55 |
+
|
| 56 |
+
@torch.no_grad()
|
| 57 |
+
def encode(self,
|
| 58 |
+
texts: None,
|
| 59 |
+
dimension: int = None,
|
| 60 |
+
max_length: int = 8192,
|
| 61 |
+
batch_size: int = 16,
|
| 62 |
+
return_dense: bool = True,
|
| 63 |
+
return_sparse: bool = False):
|
| 64 |
+
if dimension is None:
|
| 65 |
+
dimension = self.model.config.hidden_size
|
| 66 |
+
if isinstance(texts, str):
|
| 67 |
+
texts = [texts]
|
| 68 |
+
num_texts = len(texts)
|
| 69 |
+
all_dense_vecs = []
|
| 70 |
+
all_token_weights = []
|
| 71 |
+
for n, i in enumerate(range(0, num_texts, batch_size)):
|
| 72 |
+
batch = texts[i: i + batch_size]
|
| 73 |
+
resulst = self._encode(batch, dimension, max_length, batch_size, return_dense, return_sparse)
|
| 74 |
+
if return_dense:
|
| 75 |
+
all_dense_vecs.append(resulst['dense_embeddings'])
|
| 76 |
+
if return_sparse:
|
| 77 |
+
all_token_weights.extend(resulst['token_weights'])
|
| 78 |
+
all_dense_vecs = torch.cat(all_dense_vecs, dim=0)
|
| 79 |
+
return {
|
| 80 |
+
"dense_embeddings": all_dense_vecs,
|
| 81 |
+
"token_weights": all_token_weights
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
@torch.no_grad()
|
| 85 |
+
def _encode(self,
|
| 86 |
+
texts: Dict[str, torch.Tensor] = None,
|
| 87 |
+
dimension: int = None,
|
| 88 |
+
max_length: int = 1024,
|
| 89 |
+
batch_size: int = 16,
|
| 90 |
+
return_dense: bool = True,
|
| 91 |
+
return_sparse: bool = False):
|
| 92 |
+
|
| 93 |
+
text_input = self.tokenizer(texts, padding=True, truncation=True, return_tensors='pt', max_length=max_length)
|
| 94 |
+
text_input = {k: v.to(self.model.device) for k,v in text_input.items()}
|
| 95 |
+
model_out = self.model(**text_input, return_dict=True)
|
| 96 |
+
|
| 97 |
+
output = {}
|
| 98 |
+
if return_dense:
|
| 99 |
+
dense_vecs = model_out.last_hidden_state[:, 0, :dimension]
|
| 100 |
+
if self.normalized:
|
| 101 |
+
dense_vecs = torch.nn.functional.normalize(dense_vecs, dim=-1)
|
| 102 |
+
output['dense_embeddings'] = dense_vecs
|
| 103 |
+
if return_sparse:
|
| 104 |
+
token_weights = torch.relu(model_out.logits).squeeze(-1)
|
| 105 |
+
token_weights = list(map(self._process_token_weights, token_weights.detach().cpu().numpy().tolist(),
|
| 106 |
+
text_input['input_ids'].cpu().numpy().tolist()))
|
| 107 |
+
output['token_weights'] = token_weights
|
| 108 |
+
|
| 109 |
+
return output
|
| 110 |
+
|
| 111 |
+
def _compute_sparse_scores(self, embs1, embs2):
|
| 112 |
+
scores = 0
|
| 113 |
+
for token, weight in embs1.items():
|
| 114 |
+
if token in embs2:
|
| 115 |
+
scores += weight * embs2[token]
|
| 116 |
+
return scores
|
| 117 |
+
|
| 118 |
+
def compute_sparse_scores(self, embs1, embs2):
|
| 119 |
+
scores = [self._compute_sparse_scores(emb1, emb2) for emb1, emb2 in zip(embs1, embs2)]
|
| 120 |
+
return np.array(scores)
|
| 121 |
+
|
| 122 |
+
def compute_dense_scores(self, embs1, embs2):
|
| 123 |
+
scores = torch.sum(embs1*embs2, dim=-1).cpu().detach().numpy()
|
| 124 |
+
return scores
|
| 125 |
+
|
| 126 |
+
@torch.no_grad()
|
| 127 |
+
def compute_scores(self,
|
| 128 |
+
text_pairs: List[Tuple[str, str]],
|
| 129 |
+
dimension: int = None,
|
| 130 |
+
max_length: int = 1024,
|
| 131 |
+
batch_size: int = 16,
|
| 132 |
+
dense_weight=1.0,
|
| 133 |
+
sparse_weight=0.1):
|
| 134 |
+
text1_list = [text_pair[0] for text_pair in text_pairs]
|
| 135 |
+
text2_list = [text_pair[1] for text_pair in text_pairs]
|
| 136 |
+
embs1 = self.encode(text1_list, dimension, max_length, batch_size, return_dense=True, return_sparse=True)
|
| 137 |
+
embs2 = self.encode(text2_list, dimension, max_length, batch_size, return_dense=True, return_sparse=True)
|
| 138 |
+
scores = self.compute_dense_scores(embs1['dense_embeddings'], embs2['dense_embeddings']) * dense_weight + \
|
| 139 |
+
self.compute_sparse_scores(embs1['token_weights'], embs2['token_weights']) * sparse_weight
|
| 140 |
+
scores = scores.tolist()
|
| 141 |
+
return scores
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
if __name__ == '__main__':
|
| 145 |
+
gte = GTEEmbeddidng('Alibaba-NLP/gte-multilingual-base')
|
| 146 |
+
docs = [
|
| 147 |
+
"黑龙江离俄罗斯很近",
|
| 148 |
+
"哈尔滨是中国黑龙江省的省会,位于中国东北",
|
| 149 |
+
"you are the hero"
|
| 150 |
+
]
|
| 151 |
+
print('docs', docs)
|
| 152 |
+
embs = gte.encode(docs, return_dense=True,return_sparse=True)
|
| 153 |
+
print('dense vecs', embs['dense_embeddings'])
|
| 154 |
+
print('sparse vecs', embs['token_weights'])
|
sentence_bert_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"max_seq_length": 8192,
|
| 3 |
+
"do_lower_case": false
|
| 4 |
+
}
|