































Post
4680
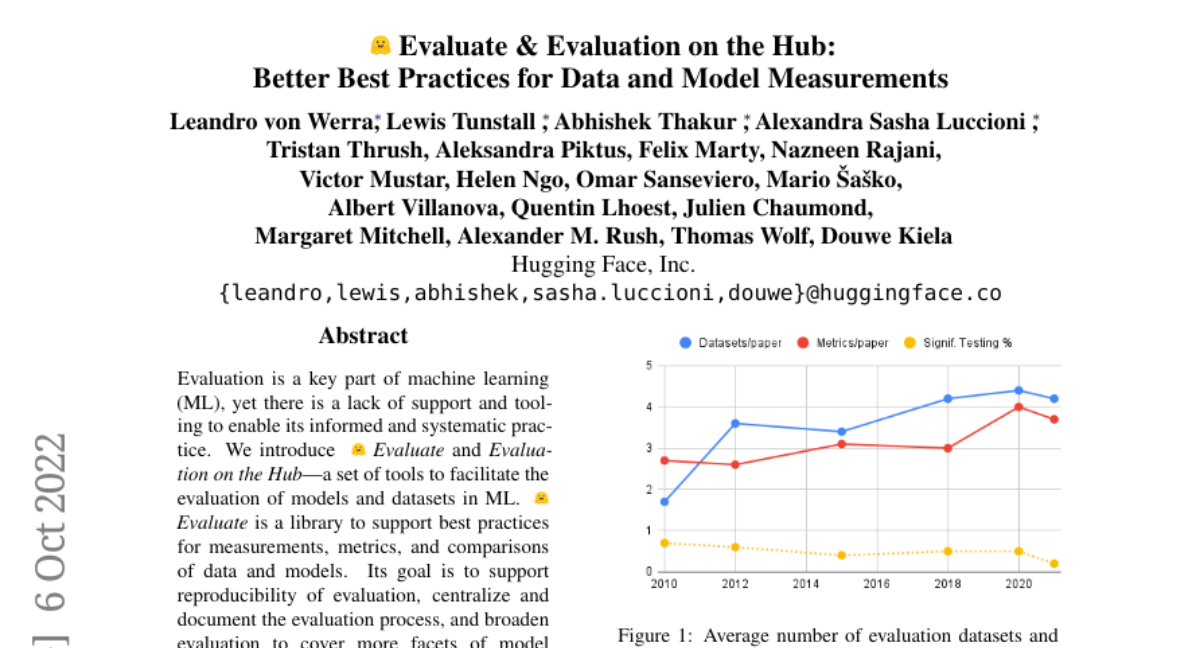
Introducing OpenR1-Math-220k!
open-r1/OpenR1-Math-220k
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
What’s new compared to existing reasoning datasets?
♾ Based on AI-MO/NuminaMath-1.5: we focus on math reasoning traces and generate answers for problems in NuminaMath 1.5, an improved version of the popular NuminaMath-CoT dataset.
🐳 800k R1 reasoning traces: We generate two answers for 400k problems using DeepSeek R1. The filtered dataset contains 220k problems with correct reasoning traces.
📀 512 H100s running locally: Instead of relying on an API, we leverage vLLM and SGLang to run generations locally on our science cluster, generating 180k reasoning traces per day.
⏳ Automated filtering: We apply Math Verify to only retain problems with at least one correct answer. We also leverage Llama3.3-70B-Instruct as a judge to retrieve more correct examples (e.g for cases with malformed answers that can’t be verified with a rules-based parser)
📊 We match the performance of DeepSeek-Distill-Qwen-7B by finetuning Qwen-7B-Math-Instruct on our dataset.
🔎 Read our blog post for all the nitty gritty details: https://huggingface.co/blog/open-r1/update-2
open-r1/OpenR1-Math-220k
The community has been busy distilling DeepSeek-R1 from inference providers, but we decided to have a go at doing it ourselves from scratch 💪
What’s new compared to existing reasoning datasets?
♾ Based on AI-MO/NuminaMath-1.5: we focus on math reasoning traces and generate answers for problems in NuminaMath 1.5, an improved version of the popular NuminaMath-CoT dataset.
🐳 800k R1 reasoning traces: We generate two answers for 400k problems using DeepSeek R1. The filtered dataset contains 220k problems with correct reasoning traces.
📀 512 H100s running locally: Instead of relying on an API, we leverage vLLM and SGLang to run generations locally on our science cluster, generating 180k reasoning traces per day.
⏳ Automated filtering: We apply Math Verify to only retain problems with at least one correct answer. We also leverage Llama3.3-70B-Instruct as a judge to retrieve more correct examples (e.g for cases with malformed answers that can’t be verified with a rules-based parser)
📊 We match the performance of DeepSeek-Distill-Qwen-7B by finetuning Qwen-7B-Math-Instruct on our dataset.
🔎 Read our blog post for all the nitty gritty details: https://huggingface.co/blog/open-r1/update-2