🌐 Blog | 📃 Paper | 🤗 Hugging Face | 🎥 Demo
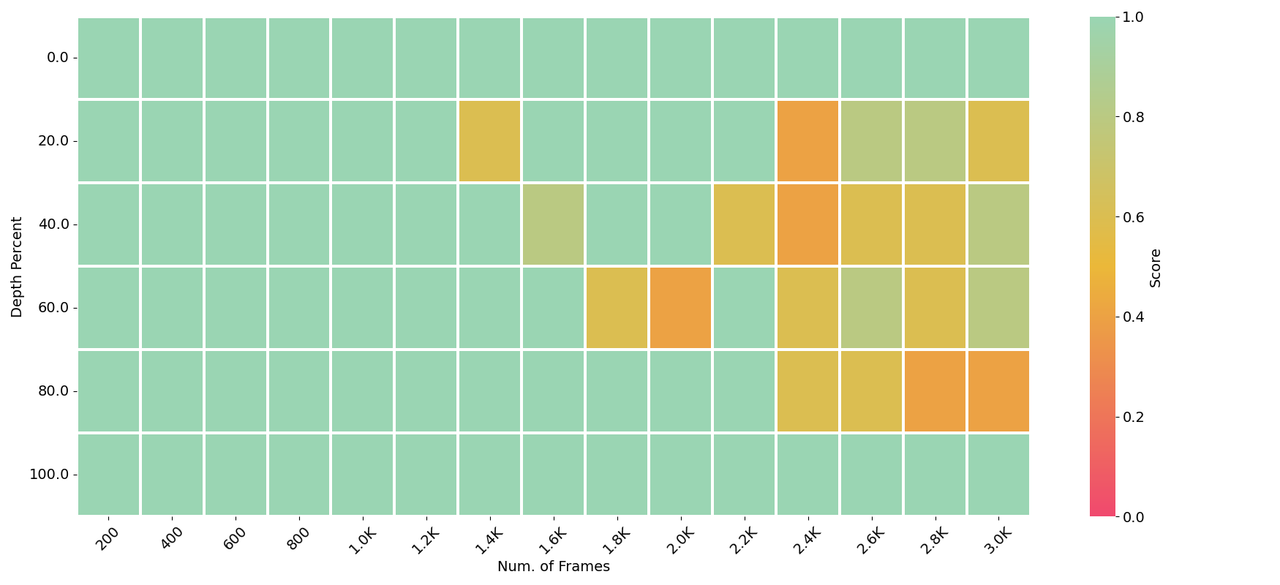
Long context capability can **zero-shot transfer** from language to vision. LongVA can process **2000** frames or over **200K** visual tokens. It achieves **state-of-the-art** performance on Video-MME among 7B models.