

Commit
•
2388615
1
Parent(s):
a76a841
End of training
Browse files- README.md +2 -1
- all_results.json +12 -0
- eval_results.json +7 -0
- train_results.json +8 -0
- trainer_state.json +66 -0
- training_eval_loss.png +0 -0
README.md
CHANGED
|
@@ -4,6 +4,7 @@ license: llama3.1
|
|
| 4 |
base_model: meta-llama/Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
|
|
|
| 7 |
- generated_from_trainer
|
| 8 |
model-index:
|
| 9 |
- name: alpaca-inst-gen-4o-resp-gen-gpt4o-mini_shareGPT_format
|
|
@@ -15,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 15 |
|
| 16 |
# alpaca-inst-gen-4o-resp-gen-gpt4o-mini_shareGPT_format
|
| 17 |
|
| 18 |
-
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on
|
| 19 |
It achieves the following results on the evaluation set:
|
| 20 |
- Loss: 1.1614
|
| 21 |
|
|
|
|
| 4 |
base_model: meta-llama/Llama-3.1-8B
|
| 5 |
tags:
|
| 6 |
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- generated_from_trainer
|
| 9 |
model-index:
|
| 10 |
- name: alpaca-inst-gen-4o-resp-gen-gpt4o-mini_shareGPT_format
|
|
|
|
| 16 |
|
| 17 |
# alpaca-inst-gen-4o-resp-gen-gpt4o-mini_shareGPT_format
|
| 18 |
|
| 19 |
+
This model is a fine-tuned version of [meta-llama/Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) on the mlfoundations-dev/alpaca-inst-gen-4o-resp-gen-gpt4o-mini_shareGPT_format dataset.
|
| 20 |
It achieves the following results on the evaluation set:
|
| 21 |
- Loss: 1.1614
|
| 22 |
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.6666666666666665,
|
| 3 |
+
"eval_loss": 1.1614313125610352,
|
| 4 |
+
"eval_runtime": 2.1851,
|
| 5 |
+
"eval_samples_per_second": 26.543,
|
| 6 |
+
"eval_steps_per_second": 0.458,
|
| 7 |
+
"total_flos": 1.7361783597563904e+16,
|
| 8 |
+
"train_loss": 1.2026246388753254,
|
| 9 |
+
"train_runtime": 2846.6656,
|
| 10 |
+
"train_samples_per_second": 1.151,
|
| 11 |
+
"train_steps_per_second": 0.002
|
| 12 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.6666666666666665,
|
| 3 |
+
"eval_loss": 1.1614313125610352,
|
| 4 |
+
"eval_runtime": 2.1851,
|
| 5 |
+
"eval_samples_per_second": 26.543,
|
| 6 |
+
"eval_steps_per_second": 0.458
|
| 7 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.6666666666666665,
|
| 3 |
+
"total_flos": 1.7361783597563904e+16,
|
| 4 |
+
"train_loss": 1.2026246388753254,
|
| 5 |
+
"train_runtime": 2846.6656,
|
| 6 |
+
"train_samples_per_second": 1.151,
|
| 7 |
+
"train_steps_per_second": 0.002
|
| 8 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.6666666666666665,
|
| 5 |
+
"eval_steps": 500,
|
| 6 |
+
"global_step": 6,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.8888888888888888,
|
| 13 |
+
"eval_loss": 1.2404001951217651,
|
| 14 |
+
"eval_runtime": 2.5102,
|
| 15 |
+
"eval_samples_per_second": 23.106,
|
| 16 |
+
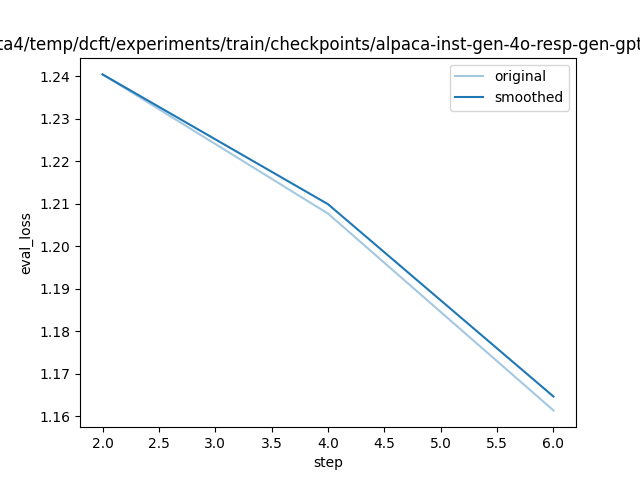
"eval_steps_per_second": 0.398,
|
| 17 |
+
"step": 2
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"epoch": 1.7777777777777777,
|
| 21 |
+
"eval_loss": 1.2076923847198486,
|
| 22 |
+
"eval_runtime": 2.4258,
|
| 23 |
+
"eval_samples_per_second": 23.91,
|
| 24 |
+
"eval_steps_per_second": 0.412,
|
| 25 |
+
"step": 4
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"epoch": 2.6666666666666665,
|
| 29 |
+
"eval_loss": 1.1614313125610352,
|
| 30 |
+
"eval_runtime": 2.1248,
|
| 31 |
+
"eval_samples_per_second": 27.296,
|
| 32 |
+
"eval_steps_per_second": 0.471,
|
| 33 |
+
"step": 6
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 2.6666666666666665,
|
| 37 |
+
"step": 6,
|
| 38 |
+
"total_flos": 1.7361783597563904e+16,
|
| 39 |
+
"train_loss": 1.2026246388753254,
|
| 40 |
+
"train_runtime": 2846.6656,
|
| 41 |
+
"train_samples_per_second": 1.151,
|
| 42 |
+
"train_steps_per_second": 0.002
|
| 43 |
+
}
|
| 44 |
+
],
|
| 45 |
+
"logging_steps": 10,
|
| 46 |
+
"max_steps": 6,
|
| 47 |
+
"num_input_tokens_seen": 0,
|
| 48 |
+
"num_train_epochs": 3,
|
| 49 |
+
"save_steps": 500,
|
| 50 |
+
"stateful_callbacks": {
|
| 51 |
+
"TrainerControl": {
|
| 52 |
+
"args": {
|
| 53 |
+
"should_epoch_stop": false,
|
| 54 |
+
"should_evaluate": false,
|
| 55 |
+
"should_log": false,
|
| 56 |
+
"should_save": true,
|
| 57 |
+
"should_training_stop": true
|
| 58 |
+
},
|
| 59 |
+
"attributes": {}
|
| 60 |
+
}
|
| 61 |
+
},
|
| 62 |
+
"total_flos": 1.7361783597563904e+16,
|
| 63 |
+
"train_batch_size": 8,
|
| 64 |
+
"trial_name": null,
|
| 65 |
+
"trial_params": null
|
| 66 |
+
}
|
training_eval_loss.png
ADDED
|