
aapot
commited on
Commit
•
1e5793f
1
Parent(s):
e7929ed
Add README
Browse files- README.md +123 -0
- architecture.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language:
|
| 3 |
+
- multilingual
|
| 4 |
+
license: apache-2.0
|
| 5 |
+
inference: false
|
| 6 |
+
tags:
|
| 7 |
+
- youtube
|
| 8 |
+
- video
|
| 9 |
+
- pytorch
|
| 10 |
+
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
# YouTube video semantic similarity model (NT = no transcripts)
|
| 14 |
+
|
| 15 |
+
This YouTube video semantic similarity model was developed as part of the RegretsReporter research project at Mozilla Foundation. You can read more about the project [here](https://foundation.mozilla.org/en/youtube/user-controls/) and about the semantic similarity model [here](https://foundation.mozilla.org/en/blog/the-regretsreporter-user-controls-study-machine-learning-to-measure-semantic-similarity-of-youtube-videos/).
|
| 16 |
+
|
| 17 |
+
You can also easily try this model with this [Spaces demo app](https://huggingface.co/spaces/mozilla-foundation/youtube_video_similarity). Just provide two YouTube video links and you can see how similar those two videos are according to the model. For your convenience, the demo also includes a few predefined video pair examples.
|
| 18 |
+
|
| 19 |
+
## Model description
|
| 20 |
+
|
| 21 |
+
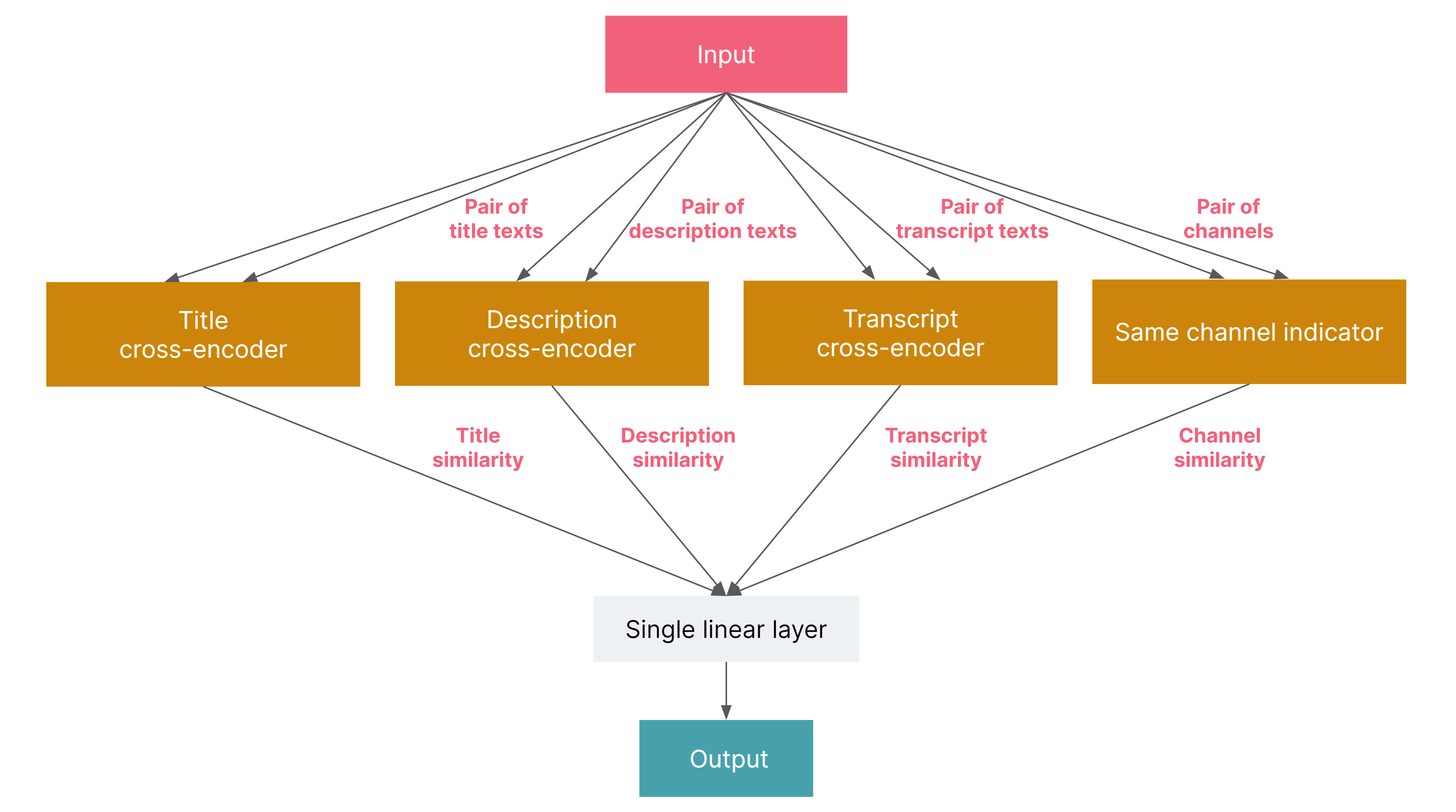
This model is custom PyTorch model for predicting whether a pair of YouTube videos are similar or not. The model does not take video data itself as an input but instead it relies on video metadata to save computing resources. The input for the model consists of video titles, descriptions, transcripts and YouTube channel-equality signal of video pairs. As illustrated below, the model includes three [cross-encoders](https://www.sbert.net/examples/applications/cross-encoder/README.html) for determining the similarity of each of the text components of the videos, which are then connected directly, along with a channel-equality signal into a single linear layer with a sigmoid output. The output is a similarity probability as follows:
|
| 22 |
+
- If the output is close to 1, the model is very confident that the videos are similar
|
| 23 |
+
- If the output is close to 0, the model is very confident that the videos are not similar
|
| 24 |
+
- If the output is close to 0.5, the model is uncertain
|
| 25 |
+
|
| 26 |
+

|
| 27 |
+
|
| 28 |
+
For pretrained cross-encoders, [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) was used to be further trained as part of this model.
|
| 29 |
+
|
| 30 |
+
Note: sometimes YouTube videos lack transcripts so actually there are two different versions of this model trained: a model with trascripts (WT = with transcripts) and a model without transcripts (NT = no transcripts). This model is without transcripts and the model with transcripts is avalaible [here](https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_wt).
|
| 31 |
+
|
| 32 |
+
## Intended uses & limitations
|
| 33 |
+
|
| 34 |
+
This model is intended to be used for analyzing whether a pair of YouTube videos are similar or not. We hope that this model will prove valuable to other researchers investigating YouTube.
|
| 35 |
+
|
| 36 |
+
### How to use
|
| 37 |
+
|
| 38 |
+
As this model is a custom PyTorch model, not normal transformers model, you need to clone this model repository first. The repository contains model code in `RRUM` class (RRUM stands for RegretsReporter Unified Model) in `unifiedmodel.py` file. For loading the model from Hugging Face model hub, there also is a Hugging Face model wrapper named `YoutubeVideoSimilarityModel` in `huggingface_model_wrapper.py` file. Needed Python requirements are specified in `requirements.txt` file. To load the model, follow these steps:
|
| 39 |
+
1. `git clone https://huggingface.co/mozilla-foundation/youtube_video_similarity_model_nt`
|
| 40 |
+
2. `pip install -r requirements.txt`
|
| 41 |
+
|
| 42 |
+
And finally load the model with the following example code:
|
| 43 |
+
```python
|
| 44 |
+
from huggingface_model_wrapper import YoutubeVideoSimilarityModel
|
| 45 |
+
model = YoutubeVideoSimilarityModel.from_pretrained('mozilla-foundation/youtube_video_similarity_model_nt')
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
For loading and preprocessing input data into correct format, the `unifiedmodel.py` file also contains a `RRUMDataset` class. To use the loaded model for predicting video pair similarity, you can use the following example code:
|
| 49 |
+
```python
|
| 50 |
+
import torch
|
| 51 |
+
import pandas as pd
|
| 52 |
+
from torch.utils.data import DataLoader
|
| 53 |
+
from unifiedmodel import RRUMDataset
|
| 54 |
+
|
| 55 |
+
video1_channel = "Mozilla"
|
| 56 |
+
video1_title = "YouTube Regrets"
|
| 57 |
+
video1_description = "Are your YouTube recommendations sometimes lies? Conspiracy theories? Or just weird as hell?\n\n\nYou’re not alone. That’s why Mozilla and 37,380 YouTube users conducted a study to better understand harmful YouTube recommendations. This is what we learned about YouTube regrets: https://foundation.mozilla.org/regrets/"
|
| 58 |
+
|
| 59 |
+
video2_channel = "Mozilla"
|
| 60 |
+
video2_title = "YouTube Regrets Reporter"
|
| 61 |
+
video2_description = "Are you choosing what to watch, or is YouTube choosing for you?\n\nTheir algorithm is responsible for over 70% of viewing time, which can include recommending harmful videos.\n\nHelp us hold them responsible. Install RegretsReporter: https://mzl.la/37BT2vA"
|
| 62 |
+
|
| 63 |
+
df = pd.DataFrame([[video1_title, video1_description, None] + [video2_title, video2_description, None] + [int(video1_channel == video2_channel)]], columns=['regret_title', 'regret_description', 'regret_transcript', 'recommendation_title', 'recommendation_description', 'recommendation_transcript', 'channel_sim'])
|
| 64 |
+
dataset = RRUMDataset(df, with_transcript=False, label_col=None, cross_encoder_model_name_or_path=model.cross_encoder_model_name_or_path)
|
| 65 |
+
data_loader = DataLoader(dataset.test_dataset)
|
| 66 |
+
|
| 67 |
+
with torch.inference_mode():
|
| 68 |
+
prediction = model(next(iter(data_loader)))
|
| 69 |
+
prediction = torch.special.expit(prediction).squeeze().tolist()
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Some more code and examples are also available at RegretsReporter [GitHub repository](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/semsim).
|
| 73 |
+
|
| 74 |
+
### Limitations and bias
|
| 75 |
+
|
| 76 |
+
The cross-encoders that we use to determine similarity of texts are also trained on texts that inevitably reflect social bias. To understand the implications of this, we need to consider the application of the model: to determine if videos are semantically similar or not. So the concern is that our model may, in some systematic way, think certain kinds of videos are more or less similar to each other.
|
| 77 |
+
|
| 78 |
+
For example, it's possible that the models have encoded a social bias that certain ethnicities are more often involved in violent situations. If this were the case, it is possible that videos about people of one ethnicity may be more likely to be rated similar to videos about violent situations. This could be evaluated by applying the model to synthetic video pairs crafted to test these situations. There is also [active research](https://www.aaai.org/AAAI22Papers/AISI-7742.KanekoM.pdf) in measuring bias in language models, as part of the broader field of [AI fairness](https://facctconference.org/2022/index.html).
|
| 79 |
+
|
| 80 |
+
In our case, we have not analyzed the biases in our model as, for our application, potential for harm is extremely low. Due to the randomized design of our RegretsReporter research experiment, any biases will tend to balance out between experiment arms and so not meaningfully affect our metrics. Where there is a likelihood of bias impacting our results is in the examples we share of similar video pairs. The pairs that our model helps us discover are selected in a possibly biased way. However, as we are manually curating such pairs, we feel confident that we can avoid allowing such biases to be expressed in our research findings.
|
| 81 |
+
|
| 82 |
+
A more difficult issue is the multilingual nature of our data. For the pretrained cross-encoders in our model, we used the [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) model which supports a set of 100 languages (the original mMiniLMv2 base model) including English, German, Spanish and Chinese. However, it is reasonable to expect that the model's performance varies among the languages that it supports. The impact can vary — the model may fail either with false positives, in which it thinks a dissimilar pair is similar, or false negatives, in which it thinks a similar pair is dissimilar. We performed a basic analysis to evaluate the performance of our model in different languages and it suggested that our model performs well across languages, but the potential differences in the quality of our labels between languages reduced our confidence.
|
| 83 |
+
|
| 84 |
+
## Training data
|
| 85 |
+
|
| 86 |
+
Since the RegretsReporter project operates without YouTube's support, we were limited to the publicly available data we could fetch from YouTube. The RegretsReporter project developed a browser extension that our volunteer project participants used to send us data about their YouTube usage and what videos YouTube recommended for them. We also used automated methods to acquire additional needed model training data (title, channel, description, transcript) for videos from the YouTube site directly.
|
| 87 |
+
|
| 88 |
+
To get labeled training data, we contracted 24 research assistants, all graduate students at Exeter University, to perform 20 hours each, classifying gathered video pairs using a [classification tool](https://github.com/mozilla-extensions/regrets-reporter/tree/main/analysis/classification) that we developed. There are many subtleties in defining similarity of two videos, so we are not able to precisely describe what we mean by "similar", but we developed a [policy](https://docs.google.com/document/d/1VB7YAENmuMDMW_kPPUbuDPbHfQBDhF5ylzHA3cAZywg/) to guide our research assistants in classifying video pairs. Research assistants all read the classification policy and worked with Dr. Chico Camargo, who ensured they had all the support they needed to contribute to this work. These research assistants were partners in our research and are named for their contributions in our [final report](https://foundation.mozilla.org/en/research/library/user-controls/report/).
|
| 89 |
+
|
| 90 |
+
Thanks to our research assistants, we had 44,434 labeled video pairs to train our model (although about 3% of these were labeled "unsure" and so unused). For each of these pairs, the research assistant determined whether the videos are similar or not, and our model is able to learn from these examples.
|
| 91 |
+
|
| 92 |
+
## Training procedure
|
| 93 |
+
|
| 94 |
+
### Preprocessing
|
| 95 |
+
|
| 96 |
+
Our training data of YouTube video titles, descriptions and transcripts tend to include a lot of noisy text having, for example, URLs, emojis and other potential noise. Thus, we used text cleaning functions to clean some of the noise. Text cleaning seemed to improve the model accuracy on test set but the text cleaning was disabled in the end because it added extra latency to the data preprocessing which would have made the project's model prediction run slower when predictions were ran for hundreds of millions of video pairs. The data loading and preprocessing class `RRUMDataset` in `unifiedmodel.py` file still includes text cleaning option by setting the parameter `clean_text=True` on the class initialization.
|
| 97 |
+
|
| 98 |
+
The text data was tokenized with [mmarco-mMiniLMv2-L12-H384-v1](https://huggingface.co/cross-encoder/mmarco-mMiniLMv2-L12-H384-v1) cross-encoder's SentencePiece tokenizer having a vocabulary size of 250,002. Tokenization was done with maximum length of 128 tokens.
|
| 99 |
+
|
| 100 |
+
### Training
|
| 101 |
+
|
| 102 |
+
The model was trained using [PyTorch Lightning](https://pytorch-lightning.readthedocs.io/en/stable/) on NVIDIA A100 GPU. The model can also be trained on lower resources, for example with the free T4 GPU on Google Colab. The optimizer used was a Adam with learning rate 5e-3, learning rate warmup for 5% steps of total training steps and linear decay of the learning rate after. The model was trained with batch size of 128 for 15 epochs. Based on per epoch evaluation, the final model uses the checkpoint from epoch 10.
|
| 103 |
+
|
| 104 |
+
## Evaluation results
|
| 105 |
+
|
| 106 |
+
With the final test set, our models were achieving following scores presented on the table below:
|
| 107 |
+
|
| 108 |
+
| Metric | Model with transcripts | Model without transcripts |
|
| 109 |
+
|--------------------------------|------------------------|---------------------------|
|
| 110 |
+
| Accuracy | 0.93 | 0.92 |
|
| 111 |
+
| Precision | 0.81 | 0.81 |
|
| 112 |
+
| Recall | 0.91 | 0.87 |
|
| 113 |
+
| AUROC | 0.97 | 0.96 |
|
| 114 |
+
|
| 115 |
+
## Acknowledgements
|
| 116 |
+
|
| 117 |
+
We're grateful to Chico Camargo and Ranadheer Malla from the University of Exeter for leading the analysis of RegretsReporter data. Thank you to the research assistants at the University of Exeter for analyzing the video data: Josh Adebayo, Sharon Choi, Henry Cook, Alex Craig, Bee Dally, Seb Dixon, Aditi Dutta, Ana Lucia Estrada Jaramillo, Jamie Falla, Alice Gallagher Boyden, Adriano Giunta, Lisa Greghi, Keanu Hambali, Clare Keeton Graddol, Kien Khuong, Mitran Malarvannan, Zachary Marre, Inês Mendes de Sousa, Dario Notarangelo, Izzy Sebire, Tawhid Shahrior, Shambhavi Shivam, Marti Toneva, Anthime Valin, and Ned Westwood.
|
| 118 |
+
|
| 119 |
+
Finally, we're so grateful for the 22,722 RegretsReporter participants who contributed their data.
|
| 120 |
+
|
| 121 |
+
## Contact
|
| 122 |
+
|
| 123 |
+
If these models are useful to you, we'd love to hear from you. Please write to publicdata@mozillafoundation.org
|
architecture.png
ADDED
|