
Upload 304 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- big_vision_repo/.gitignore +1 -0
- big_vision_repo/CONTRIBUTING.md +26 -0
- big_vision_repo/LICENSE +201 -0
- big_vision_repo/README.md +498 -0
- big_vision_repo/big_vision/__init__.py +0 -0
- big_vision_repo/big_vision/configs/__init__.py +0 -0
- big_vision_repo/big_vision/configs/bit_i1k.py +102 -0
- big_vision_repo/big_vision/configs/bit_i21k.py +85 -0
- big_vision_repo/big_vision/configs/common.py +188 -0
- big_vision_repo/big_vision/configs/common_fewshot.py +56 -0
- big_vision_repo/big_vision/configs/load_and_eval.py +143 -0
- big_vision_repo/big_vision/configs/mlp_mixer_i1k.py +120 -0
- big_vision_repo/big_vision/configs/proj/cappa/README.md +37 -0
- big_vision_repo/big_vision/configs/proj/cappa/cappa_architecture.png +0 -0
- big_vision_repo/big_vision/configs/proj/cappa/pretrain.py +140 -0
- big_vision_repo/big_vision/configs/proj/clippo/README.md +85 -0
- big_vision_repo/big_vision/configs/proj/clippo/clippo_colab.ipynb +0 -0
- big_vision_repo/big_vision/configs/proj/clippo/train_clippo.py +199 -0
- big_vision_repo/big_vision/configs/proj/distill/README.md +43 -0
- big_vision_repo/big_vision/configs/proj/distill/bigsweep_flowers_pet.py +164 -0
- big_vision_repo/big_vision/configs/proj/distill/bigsweep_food_sun.py +213 -0
- big_vision_repo/big_vision/configs/proj/distill/bit_i1k.py +167 -0
- big_vision_repo/big_vision/configs/proj/distill/common.py +27 -0
- big_vision_repo/big_vision/configs/proj/flexivit/README.md +64 -0
- big_vision_repo/big_vision/configs/proj/flexivit/i1k_deit3_distill.py +187 -0
- big_vision_repo/big_vision/configs/proj/flexivit/i21k_distill.py +216 -0
- big_vision_repo/big_vision/configs/proj/flexivit/i21k_sup.py +144 -0
- big_vision_repo/big_vision/configs/proj/flexivit/timing.py +53 -0
- big_vision_repo/big_vision/configs/proj/givt/README.md +111 -0
- big_vision_repo/big_vision/configs/proj/givt/givt_coco_panoptic.py +186 -0
- big_vision_repo/big_vision/configs/proj/givt/givt_demo_colab.ipynb +309 -0
- big_vision_repo/big_vision/configs/proj/givt/givt_imagenet2012.py +222 -0
- big_vision_repo/big_vision/configs/proj/givt/givt_nyu_depth.py +198 -0
- big_vision_repo/big_vision/configs/proj/givt/givt_overview.png +0 -0
- big_vision_repo/big_vision/configs/proj/givt/vae_coco_panoptic.py +136 -0
- big_vision_repo/big_vision/configs/proj/givt/vae_nyu_depth.py +158 -0
- big_vision_repo/big_vision/configs/proj/gsam/vit_i1k_gsam_no_aug.py +134 -0
- big_vision_repo/big_vision/configs/proj/image_text/README.md +65 -0
- big_vision_repo/big_vision/configs/proj/image_text/SigLIP_demo.ipynb +0 -0
- big_vision_repo/big_vision/configs/proj/image_text/common.py +127 -0
- big_vision_repo/big_vision/configs/proj/image_text/lit.ipynb +0 -0
- big_vision_repo/big_vision/configs/proj/image_text/siglip_lit_coco.py +115 -0
- big_vision_repo/big_vision/configs/proj/paligemma/README.md +270 -0
- big_vision_repo/big_vision/configs/proj/paligemma/finetune_paligemma.ipynb +0 -0
- big_vision_repo/big_vision/configs/proj/paligemma/paligemma.png +0 -0
- big_vision_repo/big_vision/configs/proj/paligemma/transfers/activitynet_cap.py +209 -0
- big_vision_repo/big_vision/configs/proj/paligemma/transfers/activitynet_qa.py +213 -0
- big_vision_repo/big_vision/configs/proj/paligemma/transfers/ai2d.py +170 -0
- big_vision_repo/big_vision/configs/proj/paligemma/transfers/aokvqa_da.py +161 -0
- big_vision_repo/big_vision/configs/proj/paligemma/transfers/aokvqa_mc.py +169 -0
big_vision_repo/.gitignore
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__pycache__
|
big_vision_repo/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# How to Contribute
|
| 2 |
+
|
| 3 |
+
At this time we do not plan to accept non-trivial contributions. The main
|
| 4 |
+
purpose of this codebase is to allow the community to reproduce results from our
|
| 5 |
+
publications.
|
| 6 |
+
|
| 7 |
+
You are however free to start a fork of the project for your purposes as
|
| 8 |
+
permitted by the license.
|
| 9 |
+
|
| 10 |
+
## Contributor License Agreement
|
| 11 |
+
|
| 12 |
+
Contributions to this project must be accompanied by a Contributor License
|
| 13 |
+
Agreement (CLA). You (or your employer) retain the copyright to your
|
| 14 |
+
contribution; this simply gives us permission to use and redistribute your
|
| 15 |
+
contributions as part of the project. Head over to
|
| 16 |
+
<https://cla.developers.google.com/> to see your current agreements on file or
|
| 17 |
+
to sign a new one.
|
| 18 |
+
|
| 19 |
+
You generally only need to submit a CLA once, so if you've already submitted one
|
| 20 |
+
(even if it was for a different project), you probably don't need to do it
|
| 21 |
+
again.
|
| 22 |
+
|
| 23 |
+
## Community Guidelines
|
| 24 |
+
|
| 25 |
+
This project follows
|
| 26 |
+
[Google's Open Source Community Guidelines](https://opensource.google/conduct/).
|
big_vision_repo/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
big_vision_repo/README.md
ADDED
|
@@ -0,0 +1,498 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Big Vision
|
| 2 |
+
|
| 3 |
+
This codebase is designed for training large-scale vision models using
|
| 4 |
+
[Cloud TPU VMs](https://cloud.google.com/blog/products/compute/introducing-cloud-tpu-vms)
|
| 5 |
+
or GPU machines. It is based on [Jax](https://github.com/google/jax)/[Flax](https://github.com/google/flax)
|
| 6 |
+
libraries, and uses [tf.data](https://www.tensorflow.org/guide/data) and
|
| 7 |
+
[TensorFlow Datasets](https://www.tensorflow.org/datasets) for scalable and
|
| 8 |
+
reproducible input pipelines.
|
| 9 |
+
|
| 10 |
+
The open-sourcing of this codebase has two main purposes:
|
| 11 |
+
1. Publishing the code of research projects developed in this codebase (see a
|
| 12 |
+
list below).
|
| 13 |
+
2. Providing a strong starting point for running large-scale vision experiments
|
| 14 |
+
on GPU machines and Google Cloud TPUs, which should scale seamlessly and
|
| 15 |
+
out-of-the box from a single TPU core to a distributed setup with up to 2048
|
| 16 |
+
TPU cores.
|
| 17 |
+
|
| 18 |
+
`big_vision` aims to support research projects at Google. We are unlikely to
|
| 19 |
+
work on feature requests or accept external contributions, unless they were
|
| 20 |
+
pre-approved (ask in an issue first). For a well-supported transfer-only
|
| 21 |
+
codebase, see also [vision_transformer](https://github.com/google-research/vision_transformer).
|
| 22 |
+
|
| 23 |
+
Note that `big_vision` is quite dynamic codebase and, while we intend to keep
|
| 24 |
+
the core code fully-functional at all times, we can not guarantee timely updates
|
| 25 |
+
of the project-specific code that lives in the `.../proj/...` subfolders.
|
| 26 |
+
However, we provide a [table](#project-specific-commits) with last known
|
| 27 |
+
commits where specific projects were known to work.
|
| 28 |
+
|
| 29 |
+
The following research projects were originally conducted in the `big_vision`
|
| 30 |
+
codebase:
|
| 31 |
+
|
| 32 |
+
### Architecture research
|
| 33 |
+
|
| 34 |
+
- [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929), by
|
| 35 |
+
Alexey Dosovitskiy*, Lucas Beyer*, Alexander Kolesnikov*, Dirk Weissenborn*,
|
| 36 |
+
Xiaohua Zhai*, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer,
|
| 37 |
+
Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby*
|
| 38 |
+
- [Scaling Vision Transformers](https://arxiv.org/abs/2106.04560), by
|
| 39 |
+
Xiaohua Zhai*, Alexander Kolesnikov*, Neil Houlsby, and Lucas Beyer*\
|
| 40 |
+
Resources: [config](big_vision/configs/proj/scaling_laws/train_vit_g.py).
|
| 41 |
+
- [How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers](https://arxiv.org/abs/2106.10270), by
|
| 42 |
+
Andreas Steiner*, Alexander Kolesnikov*, Xiaohua Zhai*, Ross Wightman,
|
| 43 |
+
Jakob Uszkoreit, and Lucas Beyer*
|
| 44 |
+
- [MLP-Mixer: An all-MLP Architecture for Vision](https://arxiv.org/abs/2105.01601), by
|
| 45 |
+
Ilya Tolstikhin*, Neil Houlsby*, Alexander Kolesnikov*, Lucas Beyer*,
|
| 46 |
+
Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner,
|
| 47 |
+
Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy\
|
| 48 |
+
Resources: [config](big_vision/configs/mlp_mixer_i1k.py).
|
| 49 |
+
- [Better plain ViT baselines for ImageNet-1k](https://arxiv.org/abs/2205.01580), by
|
| 50 |
+
Lucas Beyer, Xiaohua Zhai, Alexander Kolesnikov\
|
| 51 |
+
Resources: [config](big_vision/configs/vit_s16_i1k.py)
|
| 52 |
+
- [UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes](https://arxiv.org/abs/2205.10337), by
|
| 53 |
+
Alexander Kolesnikov^*, André Susano Pinto^*, Lucas Beyer*, Xiaohua Zhai*, Jeremiah Harmsen*, Neil Houlsby*\
|
| 54 |
+
Resources: [readme](big_vision/configs/proj/uvim/README.md), [configs](big_vision/configs/proj/uvim), [colabs](big_vision/configs/proj/uvim).
|
| 55 |
+
- [FlexiViT: One Model for All Patch Sizes](https://arxiv.org/abs/2212.08013), by
|
| 56 |
+
Lucas Beyer*, Pavel Izmailov*, Alexander Kolesnikov*, Mathilde Caron*, Simon
|
| 57 |
+
Kornblith*, Xiaohua Zhai*, Matthias Minderer*, Michael Tschannen*, Ibrahim
|
| 58 |
+
Alabdulmohsin*, Filip Pavetic*\
|
| 59 |
+
Resources: [readme](big_vision/configs/proj/flexivit/README.md), [configs](big_vision/configs/proj/flexivit).
|
| 60 |
+
- [Dual PatchNorm](https://arxiv.org/abs/2302.01327), by Manoj Kumar, Mostafa Dehghani, Neil Houlsby.
|
| 61 |
+
- [Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design](https://arxiv.org/abs/2305.13035), by
|
| 62 |
+
Ibrahim Alabdulmohsin*, Xiaohua Zhai*, Alexander Kolesnikov, Lucas Beyer*.
|
| 63 |
+
- (partial) [Scaling Vision Transformers to 22 Billion Parameters](https://arxiv.org/abs/2302.05442), by
|
| 64 |
+
Mostafa Dehghani*, Josip Djolonga*, Basil Mustafa*, Piotr Padlewski*, Jonathan Heek*, *wow many middle authors*, Neil Houlsby*.
|
| 65 |
+
- (partial) [Finite Scalar Quantization: VQ-VAE Made Simple](https://arxiv.org/abs/2309.15505), by
|
| 66 |
+
Fabian Mentzer, David Minnen, Eirikur Agustsson, Michael Tschannen.
|
| 67 |
+
- [GIVT: Generative Infinite-Vocabulary Transformers](https://arxiv.org/abs/2312.02116), by
|
| 68 |
+
Michael Tschannen, Cian Eastwood, Fabian Mentzer.\
|
| 69 |
+
Resources: [readme](big_vision/configs/proj/givt/README.md), [config](big_vision/configs/proj/givt/givt_imagenet2012.py), [colab](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/givt/givt_demo_colab.ipynb).
|
| 70 |
+
- [Unified Auto-Encoding with Masked Diffusion](https://arxiv.org/abs/2406.17688), by
|
| 71 |
+
Philippe Hansen-Estruch, Sriram Vishwanath, Amy Zhang, Manan Tomar.
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
### Multimodal research
|
| 75 |
+
|
| 76 |
+
- [LiT: Zero-Shot Transfer with Locked-image Text Tuning](https://arxiv.org/abs/2111.07991), by
|
| 77 |
+
Xiaohua Zhai*, Xiao Wang*, Basil Mustafa*, Andreas Steiner*, Daniel Keysers,
|
| 78 |
+
Alexander Kolesnikov, and Lucas Beyer*\
|
| 79 |
+
Resources: [trainer](big_vision/trainers/proj/image_text/contrastive.py), [config](big_vision/configs/proj/image_text/lit_coco.py), [colab](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/lit.ipynb).
|
| 80 |
+
- [Image-and-Language Understanding from Pixels Only](https://arxiv.org/abs/2212.08045), by
|
| 81 |
+
Michael Tschannen, Basil Mustafa, Neil Houlsby\
|
| 82 |
+
Resources: [readme](big_vision/configs/proj/clippo/README.md), [config](big_vision/configs/proj/clippo/train_clippo.py), [colab](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/clippo/clippo_colab.ipynb).
|
| 83 |
+
- [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343), by
|
| 84 |
+
Xiaohua Zhai*, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer*\
|
| 85 |
+
Resources: [colab and models](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/SigLIP_demo.ipynb), code TODO.
|
| 86 |
+
- [A Study of Autoregressive Decoders for Multi-Tasking in Computer Vision](https://arxiv.org/abs/2303.17376), by
|
| 87 |
+
Lucas Beyer*, Bo Wan*, Gagan Madan*, Filip Pavetic*, Andreas Steiner*, Alexander Kolesnikov, André Susano Pinto, Emanuele Bugliarello, Xiao Wang, Qihang Yu, Liang-Chieh Chen, Xiaohua Zhai*.
|
| 88 |
+
- [Image Captioners Are Scalable Vision Learners Too](https://arxiv.org/abs/2306.07915), by
|
| 89 |
+
Michael Tschannen*, Manoj Kumar*, Andreas Steiner*, Xiaohua Zhai, Neil Houlsby, Lucas Beyer*.\
|
| 90 |
+
Resources: [readme](big_vision/configs/proj/cappa/README.md), [config](big_vision/configs/proj/cappa/pretrain.py), [model](big_vision/models/proj/cappa/cappa.py).
|
| 91 |
+
- [Three Towers: Flexible Contrastive Learning with Pretrained Image Models](https://arxiv.org/abs/2305.16999), by Jannik Kossen, Mark Collier, Basil Mustafa, Xiao Wang, Xiaohua Zhai, Lucas Beyer, Andreas Steiner, Jesse Berent, Rodolphe Jenatton, Efi Kokiopoulou.
|
| 92 |
+
- (partial) [PaLI: A Jointly-Scaled Multilingual Language-Image Model](https://arxiv.org/abs/2209.06794), by Xi Chen, Xiao Wang, Soravit Changpinyo, *wow so many middle authors*, Anelia Angelova, Xiaohua Zhai, Neil Houlsby, Radu Soricut.
|
| 93 |
+
- (partial) [PaLI-3 Vision Language Models: Smaller, Faster, Stronger](https://arxiv.org/abs/2310.09199), by Xi Chen, Xiao Wang, Lucas Beyer, Alexander Kolesnikov, Jialin Wu, Paul Voigtlaender, Basil Mustafa, Sebastian Goodman, Ibrahim Alabdulmohsin, Piotr Padlewski, Daniel Salz, Xi Xiong, Daniel Vlasic, Filip Pavetic, Keran Rong, Tianli Yu, Daniel Keysers, Xiaohua Zhai, Radu Soricut.
|
| 94 |
+
- [LocCa](https://arxiv.org/abs/2403.19596), by
|
| 95 |
+
Bo Wan, Michael Tschannen, Yongqin Xian, Filip Pavetic, Ibrahim Alabdulmohsin, Xiao Wang, André Susano Pinto, Andreas Steiner, Lucas Beyer, Xiaohua Zhai.
|
| 96 |
+
- [PaliGemma](https://arxiv.org/abs/2407.07726), by *wow many authors*.\
|
| 97 |
+
- Resources: [readme](big_vision/configs/proj/paligemma/README.md),
|
| 98 |
+
[model](big_vision/models/proj/paligemma/paligemma.py),
|
| 99 |
+
[transfer configs](big_vision/configs/proj/paligemma/transfers),
|
| 100 |
+
[datasets](big_vision/datasets),
|
| 101 |
+
[CountBenchQA](big_vision/datasets/countbenchqa/data/countbench_paired_questions.json).
|
| 102 |
+
|
| 103 |
+
### Training
|
| 104 |
+
|
| 105 |
+
- [Knowledge distillation: A good teacher is patient and consistent](https://arxiv.org/abs/2106.05237), by
|
| 106 |
+
Lucas Beyer*, Xiaohua Zhai*, Amélie Royer*, Larisa Markeeva*, Rohan Anil,
|
| 107 |
+
and Alexander Kolesnikov*\
|
| 108 |
+
Resources: [README](big_vision/configs/proj/distill/README.md), [trainer](big_vision/trainers/proj/distill/distill.py), [colab](https://colab.research.google.com/drive/1nMykzUzsfQ_uAxfj3k35DYsATnG_knPl?usp=sharing).
|
| 109 |
+
- [Sharpness-Aware Minimization for Efficiently Improving Generalization](https://arxiv.org/abs/2010.01412), by
|
| 110 |
+
Pierre Foret, Ariel Kleiner, Hossein Mobahi, Behnam Neyshabur
|
| 111 |
+
- [Surrogate Gap Minimization Improves Sharpness-Aware Training](https://arxiv.org/abs/2203.08065), by Juntang Zhuang, Boqing Gong, Liangzhe Yuan, Yin Cui, Hartwig Adam, Nicha Dvornek, Sekhar Tatikonda, James Duncan and Ting Liu \
|
| 112 |
+
Resources: [trainer](big_vision/trainers/proj/gsam/gsam.py), [config](big_vision/configs/proj/gsam/vit_i1k_gsam_no_aug.py) [reproduced results](https://github.com/google-research/big_vision/pull/8#pullrequestreview-1078557411)
|
| 113 |
+
- [Tuning computer vision models with task rewards](https://arxiv.org/abs/2302.08242), by
|
| 114 |
+
André Susano Pinto*, Alexander Kolesnikov*, Yuge Shi, Lucas Beyer, Xiaohua Zhai.
|
| 115 |
+
- (partial) [VeLO: Training Versatile Learned Optimizers by Scaling Up](https://arxiv.org/abs/2211.09760) by
|
| 116 |
+
Luke Metz, James Harrison, C. Daniel Freeman, Amil Merchant, Lucas Beyer, James Bradbury, Naman Agrawal, Ben Poole, Igor Mordatch, Adam Roberts, Jascha Sohl-Dickstein.
|
| 117 |
+
|
| 118 |
+
### Misc
|
| 119 |
+
|
| 120 |
+
- [Are we done with ImageNet?](https://arxiv.org/abs/2006.07159), by
|
| 121 |
+
Lucas Beyer*, Olivier J. Hénaff*, Alexander Kolesnikov*, Xiaohua Zhai*, Aäron van den Oord*.
|
| 122 |
+
- [No Filter: Cultural and Socioeconomic Diversity in Contrastive Vision-Language Models](https://arxiv.org/abs/2405.13777), by
|
| 123 |
+
Angéline Pouget, Lucas Beyer, Emanuele Bugliarello, Xiao Wang, Andreas Peter Steiner, Xiaohua Zhai, Ibrahim Alabdulmohsin.
|
| 124 |
+
|
| 125 |
+
# Codebase high-level organization and principles in a nutshell
|
| 126 |
+
|
| 127 |
+
The main entry point is a trainer module, which typically does all the
|
| 128 |
+
boilerplate related to creating a model and an optimizer, loading the data,
|
| 129 |
+
checkpointing and training/evaluating the model inside a loop. We provide the
|
| 130 |
+
canonical trainer `train.py` in the root folder. Normally, individual projects
|
| 131 |
+
within `big_vision` fork and customize this trainer.
|
| 132 |
+
|
| 133 |
+
All models, evaluators and preprocessing operations live in the corresponding
|
| 134 |
+
subdirectories and can often be reused between different projects. We encourage
|
| 135 |
+
compatible APIs within these directories to facilitate reusability, but it is
|
| 136 |
+
not strictly enforced, as individual projects may need to introduce their custom
|
| 137 |
+
APIs.
|
| 138 |
+
|
| 139 |
+
We have a powerful configuration system, with the configs living in the
|
| 140 |
+
`configs/` directory. Custom trainers and modules can directly extend/modify
|
| 141 |
+
the configuration options.
|
| 142 |
+
|
| 143 |
+
Project-specific code resides in the `.../proj/...` namespace. It is not always
|
| 144 |
+
possible to keep project-specific in sync with the core `big_vision` libraries,
|
| 145 |
+
Below we provide the [last known commit](#project-specific-commits)
|
| 146 |
+
for each project where the project code is expected to work.
|
| 147 |
+
|
| 148 |
+
Training jobs are robust to interruptions and will resume seamlessly from the
|
| 149 |
+
last saved checkpoint (assuming a user provides the correct `--workdir` path).
|
| 150 |
+
|
| 151 |
+
Each configuration file contains a comment at the top with a `COMMAND` snippet
|
| 152 |
+
to run it, and some hint of expected runtime and results. See below for more
|
| 153 |
+
details, but generally speaking, running on a GPU machine involves calling
|
| 154 |
+
`python -m COMMAND` while running on TPUs, including multi-host, involves
|
| 155 |
+
|
| 156 |
+
```
|
| 157 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all
|
| 158 |
+
--command "bash big_vision/run_tpu.sh COMMAND"
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
See instructions below for more details on how to run `big_vision` code on a
|
| 162 |
+
GPU machine or Google Cloud TPU.
|
| 163 |
+
|
| 164 |
+
By default we write checkpoints and logfiles. The logfiles are a list of JSON
|
| 165 |
+
objects, and we provide a short and straightforward [example colab to read
|
| 166 |
+
and display the logs and checkpoints](https://colab.research.google.com/drive/1R_lvV542WUp8Q2y8sbyooZOGCplkn7KI?usp=sharing).
|
| 167 |
+
|
| 168 |
+
# Current and future contents
|
| 169 |
+
|
| 170 |
+
The first release contains the core part of pre-training, transferring, and
|
| 171 |
+
evaluating classification models at scale on Cloud TPU VMs.
|
| 172 |
+
|
| 173 |
+
We have since added the following key features and projects:
|
| 174 |
+
- Contrastive Image-Text model training and evaluation as in LiT and CLIP.
|
| 175 |
+
- Patient and consistent distillation.
|
| 176 |
+
- Scaling ViT.
|
| 177 |
+
- MLP-Mixer.
|
| 178 |
+
- UViM.
|
| 179 |
+
|
| 180 |
+
Features and projects we plan to release in the near future, in no particular
|
| 181 |
+
order:
|
| 182 |
+
- ImageNet-21k in TFDS.
|
| 183 |
+
- Loading misc public models used in our publications (NFNet, MoCov3, DINO).
|
| 184 |
+
- Memory-efficient Polyak-averaging implementation.
|
| 185 |
+
- Advanced JAX compute and memory profiling. We are using internal tools for
|
| 186 |
+
this, but may eventually add support for the publicly available ones.
|
| 187 |
+
|
| 188 |
+
We will continue releasing code of our future publications developed within
|
| 189 |
+
`big_vision` here.
|
| 190 |
+
|
| 191 |
+
### Non-content
|
| 192 |
+
|
| 193 |
+
The following exist in the internal variant of this codebase, and there is no
|
| 194 |
+
plan for their release:
|
| 195 |
+
- Regular regression tests for both quality and speed. They rely heavily on
|
| 196 |
+
internal infrastructure.
|
| 197 |
+
- Advanced logging, monitoring, and plotting of experiments. This also relies
|
| 198 |
+
heavily on internal infrastructure. However, we are open to ideas on this
|
| 199 |
+
and may add some in the future, especially if implemented in a
|
| 200 |
+
self-contained manner.
|
| 201 |
+
- Not yet published, ongoing research projects.
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
# GPU Setup
|
| 205 |
+
|
| 206 |
+
We first discuss how to setup and run `big_vision` on a (local) GPU machine,
|
| 207 |
+
and then discuss the setup for Cloud TPUs. Note that data preparation step for
|
| 208 |
+
(local) GPU setup can be largely reused for the Cloud TPU setup. While the
|
| 209 |
+
instructions skip this for brevity, we highly recommend using a
|
| 210 |
+
[virtual environment](https://docs.python.org/3/library/venv.html) when
|
| 211 |
+
installing python dependencies.
|
| 212 |
+
|
| 213 |
+
## Setting up python packages
|
| 214 |
+
|
| 215 |
+
The first step is to checkout `big_vision` and install relevant python
|
| 216 |
+
dependencies:
|
| 217 |
+
|
| 218 |
+
```
|
| 219 |
+
git clone https://github.com/google-research/big_vision
|
| 220 |
+
cd big_vision/
|
| 221 |
+
pip3 install --upgrade pip
|
| 222 |
+
pip3 install -r big_vision/requirements.txt
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
The latest version of `jax` library can be fetched as
|
| 226 |
+
|
| 227 |
+
```
|
| 228 |
+
pip3 install --upgrade "jax[cuda]" -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html
|
| 229 |
+
```
|
| 230 |
+
|
| 231 |
+
You may need a different `jax` package, depending on CUDA and cuDNN libraries
|
| 232 |
+
installed on your machine. Please consult
|
| 233 |
+
[official jax documentation](https://github.com/google/jax#pip-installation-gpu-cuda)
|
| 234 |
+
for more information.
|
| 235 |
+
|
| 236 |
+
## Preparing tfds data
|
| 237 |
+
|
| 238 |
+
For unified and reproducible access to standard datasets we opted to use the
|
| 239 |
+
`tensorflow_datasets` (`tfds`) library. It requires each dataset to be
|
| 240 |
+
downloaded, preprocessed and then to be stored on a hard drive (or, if you use
|
| 241 |
+
"Google Cloud", preferably stored in a "GCP bucket".).
|
| 242 |
+
|
| 243 |
+
Many datasets can be downloaded and preprocessed automatically when used
|
| 244 |
+
for the first time. Nevertheless, we intentionally disable this feature and
|
| 245 |
+
recommend doing dataset preparation step separately, ahead of the first run. It
|
| 246 |
+
will make debugging easier if problems arise and some datasets, like
|
| 247 |
+
`imagenet2012`, require manually downloaded data.
|
| 248 |
+
|
| 249 |
+
Most of the datasets, e.g. `cifar100`, `oxford_iiit_pet` or `imagenet_v2`
|
| 250 |
+
can be fully automatically downloaded and prepared by running
|
| 251 |
+
|
| 252 |
+
```
|
| 253 |
+
cd big_vision/
|
| 254 |
+
python3 -m big_vision.tools.download_tfds_datasets cifar100 oxford_iiit_pet imagenet_v2
|
| 255 |
+
```
|
| 256 |
+
|
| 257 |
+
A full list of datasets is available at [this link](https://www.tensorflow.org/datasets/catalog/overview#all_datasets).
|
| 258 |
+
|
| 259 |
+
Some datasets, like `imagenet2012` or `imagenet2012_real`, require the data to
|
| 260 |
+
be downloaded manually and placed into `$TFDS_DATA_DIR/downloads/manual/`,
|
| 261 |
+
which defaults to `~/tensorflow_datasets/downloads/manual/`. For example, for
|
| 262 |
+
`imagenet2012` and `imagenet2012_real` one needs to place the official
|
| 263 |
+
`ILSVRC2012_img_train.tar` and `ILSVRC2012_img_val.tar` files in that directory
|
| 264 |
+
and then run
|
| 265 |
+
`python3 -m big_vision.tools.download_tfds_datasets imagenet2012 imagenet2012_real`
|
| 266 |
+
(which may take ~1 hour).
|
| 267 |
+
|
| 268 |
+
If you use `Google Cloud` and, TPUs in particular, you can then upload
|
| 269 |
+
the preprocessed data (stored in `$TFDS_DATA_DIR`) to
|
| 270 |
+
"Google Cloud Bucket" and use the bucket on any of your (TPU) virtual
|
| 271 |
+
machines to access the data.
|
| 272 |
+
|
| 273 |
+
## Running on a GPU machine
|
| 274 |
+
|
| 275 |
+
Finally, after installing all python dependencies and preparing `tfds` data,
|
| 276 |
+
the user can run the job using config of their choice, e.g. to train `ViT-S/16`
|
| 277 |
+
model on ImageNet data, one should run the following command:
|
| 278 |
+
|
| 279 |
+
```
|
| 280 |
+
python3 -m big_vision.train --config big_vision/configs/vit_s16_i1k.py --workdir workdirs/`date '+%m-%d_%H%M'`
|
| 281 |
+
```
|
| 282 |
+
|
| 283 |
+
or to train MLP-Mixer-B/16, run (note the `gpu8` config param that reduces the default batch size and epoch count):
|
| 284 |
+
|
| 285 |
+
```
|
| 286 |
+
python3 -m big_vision.train --config big_vision/configs/mlp_mixer_i1k.py:gpu8 --workdir workdirs/`date '+%m-%d_%H%M'`
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
# Cloud TPU VM setup
|
| 290 |
+
|
| 291 |
+
## Create TPU VMs
|
| 292 |
+
|
| 293 |
+
To create a single machine with 8 TPU cores, follow the following Cloud TPU JAX
|
| 294 |
+
document:
|
| 295 |
+
https://cloud.google.com/tpu/docs/run-calculation-jax
|
| 296 |
+
|
| 297 |
+
To support large-scale vision research, more cores with multiple hosts are
|
| 298 |
+
recommended. Below we provide instructions on how to do it.
|
| 299 |
+
|
| 300 |
+
First, create some useful variables, which we be reused:
|
| 301 |
+
|
| 302 |
+
```
|
| 303 |
+
export NAME=<a name of the TPU deployment, e.g. my-tpu-machine>
|
| 304 |
+
export ZONE=<GCP geographical zone, e.g. europe-west4-a>
|
| 305 |
+
export GS_BUCKET_NAME=<Name of the storage bucket, e.g. my_bucket>
|
| 306 |
+
```
|
| 307 |
+
|
| 308 |
+
The following command line will create TPU VMs with 32 cores,
|
| 309 |
+
4 hosts.
|
| 310 |
+
|
| 311 |
+
```
|
| 312 |
+
gcloud compute tpus tpu-vm create $NAME --zone $ZONE --accelerator-type v3-32 --version tpu-ubuntu2204-base
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
## Install `big_vision` on TPU VMs
|
| 316 |
+
|
| 317 |
+
Fetch the `big_vision` repository, copy it to all TPU VM hosts, and install
|
| 318 |
+
dependencies.
|
| 319 |
+
|
| 320 |
+
```
|
| 321 |
+
git clone https://github.com/google-research/big_vision
|
| 322 |
+
gcloud compute tpus tpu-vm scp --recurse big_vision/big_vision $NAME: --zone=$ZONE --worker=all
|
| 323 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all --command "bash big_vision/run_tpu.sh"
|
| 324 |
+
```
|
| 325 |
+
|
| 326 |
+
## Download and prepare TFDS datasets
|
| 327 |
+
|
| 328 |
+
We recommend preparing `tfds` data locally as described above and then uploading
|
| 329 |
+
the data to `Google Cloud` bucket. However, if you prefer, the datasets which
|
| 330 |
+
do not require manual downloads can be prepared automatically using a TPU
|
| 331 |
+
machine as described below. Note that TPU machines have only 100 GB of disk
|
| 332 |
+
space, and multihost TPU slices do not allow for external disks to be attached
|
| 333 |
+
in a write mode, so the instructions below may not work for preparing large
|
| 334 |
+
datasets. As yet another alternative, we provide instructions
|
| 335 |
+
[on how to prepare `tfds` data on CPU-only GCP machine](#preparing-tfds-data-on-a-standalone-gcp-cpu-machine).
|
| 336 |
+
|
| 337 |
+
Specifically, the seven TFDS datasets used during evaluations will be generated
|
| 338 |
+
under `~/tensorflow_datasets` on TPU machine with this command:
|
| 339 |
+
|
| 340 |
+
```
|
| 341 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=0 --command "TFDS_DATA_DIR=~/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.tools.download_tfds_datasets cifar10 cifar100 oxford_iiit_pet oxford_flowers102 cars196 dtd uc_merced"
|
| 342 |
+
```
|
| 343 |
+
|
| 344 |
+
You can then copy the datasets to GS bucket, to make them accessible to all TPU workers.
|
| 345 |
+
|
| 346 |
+
```
|
| 347 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=0 --command "rm -r ~/tensorflow_datasets/downloads && gsutil cp -r ~/tensorflow_datasets gs://$GS_BUCKET_NAME"
|
| 348 |
+
```
|
| 349 |
+
|
| 350 |
+
If you want to integrate other public or custom datasets, i.e. imagenet2012,
|
| 351 |
+
please follow [the official guideline](https://www.tensorflow.org/datasets/catalog/overview).
|
| 352 |
+
|
| 353 |
+
## Pre-trained models
|
| 354 |
+
|
| 355 |
+
For the full list of pre-trained models check out the `load` function defined in
|
| 356 |
+
the same module as the model code. And for example config on how to use these
|
| 357 |
+
models, see `configs/transfer.py`.
|
| 358 |
+
|
| 359 |
+
## Run the transfer script on TPU VMs
|
| 360 |
+
|
| 361 |
+
The following command line fine-tunes a pre-trained `vit-i21k-augreg-b/32` model
|
| 362 |
+
on `cifar10` dataset.
|
| 363 |
+
|
| 364 |
+
```
|
| 365 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all --command "TFDS_DATA_DIR=gs://$GS_BUCKET_NAME/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.train --config big_vision/configs/transfer.py:model=vit-i21k-augreg-b/32,dataset=cifar10,crop=resmall_crop --workdir gs://$GS_BUCKET_NAME/big_vision/workdir/`date '+%m-%d_%H%M'` --config.lr=0.03"
|
| 366 |
+
```
|
| 367 |
+
|
| 368 |
+
## Run the train script on TPU VMs
|
| 369 |
+
|
| 370 |
+
To train your own big_vision models on a large dataset,
|
| 371 |
+
e.g. `imagenet2012` ([prepare the TFDS dataset](https://www.tensorflow.org/datasets/catalog/imagenet2012)),
|
| 372 |
+
run the following command line.
|
| 373 |
+
|
| 374 |
+
```
|
| 375 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all --command "TFDS_DATA_DIR=gs://$GS_BUCKET_NAME/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.train --config big_vision/configs/bit_i1k.py --workdir gs://$GS_BUCKET_NAME/big_vision/workdir/`date '+%m-%d_%H%M'`"
|
| 376 |
+
```
|
| 377 |
+
|
| 378 |
+
## FSDP training.
|
| 379 |
+
|
| 380 |
+
`big_vision` supports flexible parameter and model sharding strategies.
|
| 381 |
+
Currently, we support a popular FSDP sharding via a simple config change, see [this config example](big_vision/configs/transfer.py).
|
| 382 |
+
For example, to run FSDP finetuning of a pretrained ViT-L model, run the following command (possible adjusting batch size depending on your hardware):
|
| 383 |
+
|
| 384 |
+
```
|
| 385 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all --command "TFDS_DATA_DIR=gs://$GS_BUCKET_NAME/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.train --config big_vision/configs/transfer.py:model=vit-i21k-augreg-l/16,dataset=oxford_iiit_pet,crop=resmall_crop,fsdp=True,batch_size=256 --workdir gs://$GS_BUCKET_NAME/big_vision/workdir/`date '+%m-%d_%H%M'` --config.lr=0.03"
|
| 386 |
+
```
|
| 387 |
+
|
| 388 |
+
## Image-text training with SigLIP.
|
| 389 |
+
|
| 390 |
+
A minimal example that uses public `coco` captions data:
|
| 391 |
+
|
| 392 |
+
```
|
| 393 |
+
gcloud compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all --command "TFDS_DATA_DIR=gs://$GS_BUCKET_NAME/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.trainers.proj.image_text.siglip --config big_vision/configs/proj/image_text/siglip_lit_coco.py --workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%Y-%m-%d_%H%M'`"
|
| 394 |
+
```
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
|
| 398 |
+
## Sometimes useful gcloud commands
|
| 399 |
+
|
| 400 |
+
- Destroy the TPU machines: `gcloud compute tpus tpu-vm delete $NAME --zone $ZONE`
|
| 401 |
+
- Remove all big_vision-related folders on all hosts: `gcloud compute tpus tpu-vm ssh $NAME --zone $ZONE --worker=all --command 'rm -rf ~/big_vision ~/bv_venv'`
|
| 402 |
+
|
| 403 |
+
## Preparing `tfds` data on a standalone GCP CPU machine.
|
| 404 |
+
|
| 405 |
+
First create a new machine and a disk (feel free to adjust exact machine type and disk settings/capacity):
|
| 406 |
+
|
| 407 |
+
```
|
| 408 |
+
export NAME_CPU_HOST=<A name of a CPU-only machine>
|
| 409 |
+
export NAME_DISK=<A name of a disk>
|
| 410 |
+
gcloud compute instances create $NAME_CPU_HOST --machine-type c3-standard-22 --zone $ZONE --image-family ubuntu-2204-lts --image-project ubuntu-os-cloud
|
| 411 |
+
gcloud compute disks create $NAME_DISK --size 1000GB --zone $ZONE --type pd-balanced
|
| 412 |
+
```
|
| 413 |
+
|
| 414 |
+
Now attach the disk to the newly create machine:
|
| 415 |
+
|
| 416 |
+
```
|
| 417 |
+
gcloud compute instances attach-disk $NAME_CPU_HOST --disk $NAME_DISK --zone $ZONE
|
| 418 |
+
```
|
| 419 |
+
|
| 420 |
+
Next, `ssh` to the machine `gcloud compute ssh $NAME_CPU_HOST --zone=$ZONE` and
|
| 421 |
+
[follow instructions to format and mount the disk](https://cloud.google.com/compute/docs/disks/format-mount-disk-linux).
|
| 422 |
+
Let's assume it was mounted to `/mnt/disks/tfds`.
|
| 423 |
+
|
| 424 |
+
Almost there, now clone and set up `big_vision`:
|
| 425 |
+
|
| 426 |
+
```
|
| 427 |
+
gcloud compute ssh $NAME_CPU_HOST --zone=$ZONE --command "git clone https://github.com/google-research/big_vision.git && cd big_vision && sh big_vision/run_tpu.sh"
|
| 428 |
+
```
|
| 429 |
+
|
| 430 |
+
Finally, prepare the dataset (e.g. `coco_captions`) using the utility script and
|
| 431 |
+
copy the result to you google cloud bucket:
|
| 432 |
+
|
| 433 |
+
```
|
| 434 |
+
gcloud compute ssh $NAME_CPU_HOST --zone=$ZONE --command "cd big_vision && TFDS_DATA_DIR=/mnt/disks/tfds/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.tools.download_tfds_datasets coco_captions"
|
| 435 |
+
gcloud compute ssh $NAME_CPU_HOST --zone=$ZONE --command "rm -rf /mnt/disks/tfds/tensorflow_datasets/downloads && gsutil cp -r /mnt/disks/tfds/tensorflow_datasets gs://$GS_BUCKET_NAME"
|
| 436 |
+
```
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
# ViT baseline
|
| 440 |
+
|
| 441 |
+
We provide a well-tuned ViT-S/16 baseline in the config file named
|
| 442 |
+
`vit_s16_i1k.py`. It achieves 76.5% accuracy on ImageNet validation split in
|
| 443 |
+
90 epochs of training, being a strong and simple starting point for research
|
| 444 |
+
on the ViT models.
|
| 445 |
+
|
| 446 |
+
Please see our [arXiv note](https://arxiv.org/abs/2205.01580) for more details
|
| 447 |
+
and if this baseline happens to by useful for your research, consider citing
|
| 448 |
+
|
| 449 |
+
```
|
| 450 |
+
@article{vit_baseline,
|
| 451 |
+
url = {https://arxiv.org/abs/2205.01580},
|
| 452 |
+
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
|
| 453 |
+
title = {Better plain ViT baselines for ImageNet-1k},
|
| 454 |
+
journal={arXiv preprint arXiv:2205.01580},
|
| 455 |
+
year = {2022},
|
| 456 |
+
}
|
| 457 |
+
```
|
| 458 |
+
|
| 459 |
+
# Project specific commits
|
| 460 |
+
|
| 461 |
+
The last known commit where the specific project code is expected to work. The
|
| 462 |
+
core code and configs are expected to work at head.
|
| 463 |
+
|
| 464 |
+
| Project | Commit |
|
| 465 |
+
|------------|-----------------------------------------------------------------------------------------------|
|
| 466 |
+
| UViM | https://github.com/google-research/big_vision/commit/21bd6ebe253f070f584d8b777ad76f4abce51bef |
|
| 467 |
+
| image_text | https://github.com/google-research/big_vision/commit/8921d5141504390a8a4f7b2dacb3b3c042237290 |
|
| 468 |
+
| distill | https://github.com/google-research/big_vision/commit/2f3f493af048dbfd97555ff6060f31a0e686f17f |
|
| 469 |
+
| GSAM | WIP |
|
| 470 |
+
| CLIPPO | https://github.com/google-research/big_vision/commit/fd2d3bd2efc9d89ea959f16cd2f58ae8a495cd44 |
|
| 471 |
+
| CapPa | https://github.com/google-research/big_vision/commit/7ace659452dee4b68547575352c022a2eef587a5 |
|
| 472 |
+
| GIVT | https://github.com/google-research/big_vision/commit/0cb70881dd33b3343b769347dc19793c4994b8cb |
|
| 473 |
+
|
| 474 |
+
# Citing the codebase
|
| 475 |
+
|
| 476 |
+
If you found this codebase useful for your research, please consider using
|
| 477 |
+
the following BibTEX to cite it:
|
| 478 |
+
|
| 479 |
+
```
|
| 480 |
+
@misc{big_vision,
|
| 481 |
+
author = {Beyer, Lucas and Zhai, Xiaohua and Kolesnikov, Alexander},
|
| 482 |
+
title = {Big Vision},
|
| 483 |
+
year = {2022},
|
| 484 |
+
publisher = {GitHub},
|
| 485 |
+
journal = {GitHub repository},
|
| 486 |
+
howpublished = {\url{https://github.com/google-research/big_vision}}
|
| 487 |
+
}
|
| 488 |
+
```
|
| 489 |
+
|
| 490 |
+
# Disclaimer
|
| 491 |
+
|
| 492 |
+
This is not an official Google Product.
|
| 493 |
+
|
| 494 |
+
# License
|
| 495 |
+
|
| 496 |
+
Unless explicitly noted otherwise, everything in the big_vision codebase
|
| 497 |
+
(including models and colabs) is released under the Apache2 license.
|
| 498 |
+
See the LICENSE file for the full license text.
|
big_vision_repo/big_vision/__init__.py
ADDED
|
File without changes
|
big_vision_repo/big_vision/configs/__init__.py
ADDED
|
File without changes
|
big_vision_repo/big_vision/configs/bit_i1k.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Pre-training BiT on ILSVRC-2012 as in https://arxiv.org/abs/1912.11370
|
| 17 |
+
|
| 18 |
+
Run training of a BiT-ResNet-50x1 variant, which takes ~32min on v3-128:
|
| 19 |
+
|
| 20 |
+
big_vision.train \
|
| 21 |
+
--config big_vision/configs/bit_i1k.py \
|
| 22 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 23 |
+
--config.model.depth 50 --config.model.width 1
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
# from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 27 |
+
import ml_collections as mlc
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_config(runlocal=False):
|
| 31 |
+
"""Config for training on ImageNet-1k."""
|
| 32 |
+
config = mlc.ConfigDict()
|
| 33 |
+
|
| 34 |
+
config.seed = 0
|
| 35 |
+
config.total_epochs = 90
|
| 36 |
+
config.num_classes = 1000
|
| 37 |
+
config.loss = 'softmax_xent'
|
| 38 |
+
|
| 39 |
+
config.input = dict()
|
| 40 |
+
config.input.data = dict(
|
| 41 |
+
name='imagenet2012',
|
| 42 |
+
split='train[:99%]',
|
| 43 |
+
)
|
| 44 |
+
config.input.batch_size = 4096
|
| 45 |
+
config.input.cache_raw = True # Needs up to 120GB of RAM!
|
| 46 |
+
config.input.shuffle_buffer_size = 250_000 # Per host.
|
| 47 |
+
|
| 48 |
+
pp_common = '|onehot(1000, key="{lbl}", key_result="labels")'
|
| 49 |
+
pp_common += '|value_range(-1, 1)|keep("image", "labels")'
|
| 50 |
+
config.input.pp = 'decode_jpeg_and_inception_crop(224)|flip_lr' + pp_common.format(lbl='label')
|
| 51 |
+
pp_eval = 'decode|resize_small(256)|central_crop(224)' + pp_common
|
| 52 |
+
|
| 53 |
+
config.log_training_steps = 50
|
| 54 |
+
config.ckpt_steps = 1000
|
| 55 |
+
|
| 56 |
+
# Model section
|
| 57 |
+
config.model_name = 'bit'
|
| 58 |
+
config.model = dict(
|
| 59 |
+
depth=50, # You can also pass e.g. [3, 5, 10, 2]
|
| 60 |
+
width=1.0,
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# Optimizer section
|
| 64 |
+
config.optax_name = 'big_vision.momentum_hp'
|
| 65 |
+
config.grad_clip_norm = 1.0
|
| 66 |
+
|
| 67 |
+
# linear scaling rule. Don't forget to sweep if sweeping batch_size.
|
| 68 |
+
config.wd = (1e-4 / 256) * config.input.batch_size
|
| 69 |
+
config.lr = (0.1 / 256) * config.input.batch_size
|
| 70 |
+
config.schedule = dict(decay_type='cosine', warmup_steps=1000)
|
| 71 |
+
|
| 72 |
+
# Eval section
|
| 73 |
+
def get_eval(split, dataset='imagenet2012'):
|
| 74 |
+
return dict(
|
| 75 |
+
type='classification',
|
| 76 |
+
data=dict(name=dataset, split=split),
|
| 77 |
+
pp_fn=pp_eval.format(lbl='label'),
|
| 78 |
+
loss_name=config.loss,
|
| 79 |
+
log_steps=1000, # Very fast O(seconds) so it's fine to run it often.
|
| 80 |
+
cache='final_data',
|
| 81 |
+
)
|
| 82 |
+
config.evals = {}
|
| 83 |
+
config.evals.train = get_eval('train[:2%]')
|
| 84 |
+
config.evals.minival = get_eval('train[99%:]')
|
| 85 |
+
config.evals.val = get_eval('validation')
|
| 86 |
+
config.evals.v2 = get_eval('test', dataset='imagenet_v2')
|
| 87 |
+
config.evals.real = get_eval('validation', dataset='imagenet2012_real')
|
| 88 |
+
config.evals.real.pp_fn = pp_eval.format(lbl='real_label')
|
| 89 |
+
|
| 90 |
+
# config.evals.fewshot = get_fewshot_lsr(runlocal=runlocal)
|
| 91 |
+
# config.evals.fewshot.log_steps = 1000
|
| 92 |
+
|
| 93 |
+
if runlocal:
|
| 94 |
+
config.input.batch_size = 32
|
| 95 |
+
config.input.cache_raw = False
|
| 96 |
+
config.input.shuffle_buffer_size = 100
|
| 97 |
+
|
| 98 |
+
local_eval = config.evals.val
|
| 99 |
+
config.evals = {'val': local_eval}
|
| 100 |
+
config.evals.val.cache = 'none'
|
| 101 |
+
|
| 102 |
+
return config
|
big_vision_repo/big_vision/configs/bit_i21k.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""A config for pre-training BiT on ImageNet-21k.
|
| 17 |
+
|
| 18 |
+
This config relies on the Imagenet-21k tfds dataset, which is not yet
|
| 19 |
+
available publicly in TFDS. We intend to add the dataset to public TFDS soon,
|
| 20 |
+
and this config will then be runnable.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 24 |
+
import ml_collections as mlc
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def get_config():
|
| 28 |
+
"""Config for training on imagenet-21k."""
|
| 29 |
+
config = mlc.ConfigDict()
|
| 30 |
+
|
| 31 |
+
config.seed = 0
|
| 32 |
+
config.total_epochs = 90
|
| 33 |
+
config.num_classes = 21843
|
| 34 |
+
config.init_head_bias = -10.0
|
| 35 |
+
config.loss = 'sigmoid_xent'
|
| 36 |
+
|
| 37 |
+
config.input = dict()
|
| 38 |
+
config.input.data = dict(
|
| 39 |
+
name='imagenet21k',
|
| 40 |
+
split='full[51200:]',
|
| 41 |
+
)
|
| 42 |
+
config.input.batch_size = 4096
|
| 43 |
+
config.input.shuffle_buffer_size = 250_000 # Per host, so small-ish is ok.
|
| 44 |
+
|
| 45 |
+
pp_common = '|value_range(-1, 1)|onehot({onehot_args})|keep("image", "labels")'
|
| 46 |
+
pp_common_i21k = pp_common.format(onehot_args=f'{config.num_classes}')
|
| 47 |
+
pp_common_i1k = pp_common.format(onehot_args='1000, key="label", key_result="labels"')
|
| 48 |
+
config.input.pp = 'decode_jpeg_and_inception_crop(224)|flip_lr' + pp_common_i21k
|
| 49 |
+
pp_eval = 'decode|resize_small(256)|central_crop(224)'
|
| 50 |
+
|
| 51 |
+
config.log_training_steps = 50
|
| 52 |
+
config.ckpt_steps = 1000
|
| 53 |
+
|
| 54 |
+
# Model section
|
| 55 |
+
config.model_name = 'bit_paper'
|
| 56 |
+
config.model = dict(depth=50, width=1.0)
|
| 57 |
+
|
| 58 |
+
# Optimizer section
|
| 59 |
+
config.optax_name = 'big_vision.momentum_hp'
|
| 60 |
+
config.grad_clip_norm = 1.0
|
| 61 |
+
|
| 62 |
+
# linear scaling rule. Don't forget to sweep if sweeping batch_size.
|
| 63 |
+
config.lr = (0.03 / 256) * config.input.batch_size
|
| 64 |
+
config.wd = (3e-5 / 256) * config.input.batch_size
|
| 65 |
+
config.schedule = dict(decay_type='cosine', warmup_steps=5000)
|
| 66 |
+
|
| 67 |
+
# Evaluations on i21k itself.
|
| 68 |
+
def eval_i21k(split):
|
| 69 |
+
return dict(
|
| 70 |
+
type='classification',
|
| 71 |
+
data={**config.input.data, 'split': split},
|
| 72 |
+
pp_fn=pp_eval + pp_common_i21k,
|
| 73 |
+
loss_name=config.loss,
|
| 74 |
+
log_steps=1000, # Very fast O(seconds) so it's fine to run it often.
|
| 75 |
+
)
|
| 76 |
+
config.evals = {}
|
| 77 |
+
config.evals.test = eval_i21k('full[:25_600]')
|
| 78 |
+
config.evals.val = eval_i21k('full[25_600:51_200]')
|
| 79 |
+
config.evals.train = eval_i21k('full[51_200:76_800]')
|
| 80 |
+
|
| 81 |
+
# Few-shot evaluators
|
| 82 |
+
config.evals.fewshot = get_fewshot_lsr()
|
| 83 |
+
config.evals.fewshot.log_steps = 25_000
|
| 84 |
+
|
| 85 |
+
return config
|
big_vision_repo/big_vision/configs/common.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""A few things commonly used across A LOT of config files."""
|
| 16 |
+
|
| 17 |
+
import string
|
| 18 |
+
|
| 19 |
+
import ml_collections as mlc
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def input_for_quicktest(config_input, quicktest):
|
| 23 |
+
if quicktest:
|
| 24 |
+
config_input.batch_size = 8
|
| 25 |
+
config_input.shuffle_buffer_size = 10
|
| 26 |
+
config_input.cache_raw = False
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def parse_arg(arg, lazy=False, **spec):
|
| 30 |
+
"""Makes ConfigDict's get_config single-string argument more usable.
|
| 31 |
+
|
| 32 |
+
Example use in the config file:
|
| 33 |
+
|
| 34 |
+
import big_vision.configs.common as bvcc
|
| 35 |
+
def get_config(arg):
|
| 36 |
+
arg = bvcc.parse_arg(arg,
|
| 37 |
+
res=(224, int),
|
| 38 |
+
runlocal=False,
|
| 39 |
+
schedule='short',
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
# ...
|
| 43 |
+
|
| 44 |
+
config.shuffle_buffer = 250_000 if not arg.runlocal else 50
|
| 45 |
+
|
| 46 |
+
Ways that values can be passed when launching:
|
| 47 |
+
|
| 48 |
+
--config amazing.py:runlocal,schedule=long,res=128
|
| 49 |
+
--config amazing.py:res=128
|
| 50 |
+
--config amazing.py:runlocal # A boolean needs no value for "true".
|
| 51 |
+
--config amazing.py:runlocal=False # Explicit false boolean.
|
| 52 |
+
--config amazing.py:128 # The first spec entry may be passed unnamed alone.
|
| 53 |
+
|
| 54 |
+
Uses strict bool conversion (converting 'True', 'true' to True, and 'False',
|
| 55 |
+
'false', '' to False).
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
arg: the string argument that's passed to get_config.
|
| 59 |
+
lazy: allow lazy parsing of arguments, which are not in spec. For these,
|
| 60 |
+
the type is auto-extracted in dependence of most complex possible type.
|
| 61 |
+
**spec: the name and default values of the expected options.
|
| 62 |
+
If the value is a tuple, the value's first element is the default value,
|
| 63 |
+
and the second element is a function called to convert the string.
|
| 64 |
+
Otherwise the type is automatically extracted from the default value.
|
| 65 |
+
|
| 66 |
+
Returns:
|
| 67 |
+
ConfigDict object with extracted type-converted values.
|
| 68 |
+
"""
|
| 69 |
+
# Normalize arg and spec layout.
|
| 70 |
+
arg = arg or '' # Normalize None to empty string
|
| 71 |
+
spec = {k: get_type_with_default(v) for k, v in spec.items()}
|
| 72 |
+
|
| 73 |
+
result = mlc.ConfigDict(type_safe=False) # For convenient dot-access only.
|
| 74 |
+
|
| 75 |
+
# Expand convenience-cases for a single parameter without = sign.
|
| 76 |
+
if arg and ',' not in arg and '=' not in arg:
|
| 77 |
+
# (think :runlocal) If it's the name of sth in the spec (or there is no
|
| 78 |
+
# spec), it's that in bool.
|
| 79 |
+
if arg in spec or not spec:
|
| 80 |
+
arg = f'{arg}=True'
|
| 81 |
+
# Otherwise, it is the value for the first entry in the spec.
|
| 82 |
+
else:
|
| 83 |
+
arg = f'{list(spec.keys())[0]}={arg}'
|
| 84 |
+
# Yes, we rely on Py3.7 insertion order!
|
| 85 |
+
|
| 86 |
+
# Now, expand the `arg` string into a dict of keys and values:
|
| 87 |
+
raw_kv = {raw_arg.split('=')[0]:
|
| 88 |
+
raw_arg.split('=', 1)[-1] if '=' in raw_arg else 'True'
|
| 89 |
+
for raw_arg in arg.split(',') if raw_arg}
|
| 90 |
+
|
| 91 |
+
# And go through the spec, using provided or default value for each:
|
| 92 |
+
for name, (default, type_fn) in spec.items():
|
| 93 |
+
val = raw_kv.pop(name, None)
|
| 94 |
+
result[name] = type_fn(val) if val is not None else default
|
| 95 |
+
|
| 96 |
+
if raw_kv:
|
| 97 |
+
if lazy: # Process args which are not in spec.
|
| 98 |
+
for k, v in raw_kv.items():
|
| 99 |
+
result[k] = autotype(v)
|
| 100 |
+
else:
|
| 101 |
+
raise ValueError(f'Unhandled config args remain: {raw_kv}')
|
| 102 |
+
|
| 103 |
+
return result
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def get_type_with_default(v):
|
| 107 |
+
"""Returns (v, string_to_v_type) with lenient bool parsing."""
|
| 108 |
+
# For bool, do safe string conversion.
|
| 109 |
+
if isinstance(v, bool):
|
| 110 |
+
def strict_bool(x):
|
| 111 |
+
assert x.lower() in {'true', 'false', ''}
|
| 112 |
+
return x.lower() == 'true'
|
| 113 |
+
return (v, strict_bool)
|
| 114 |
+
# If already a (default, type) tuple, use that.
|
| 115 |
+
if isinstance(v, (tuple, list)):
|
| 116 |
+
assert len(v) == 2 and isinstance(v[1], type), (
|
| 117 |
+
'List or tuple types are currently not supported because we use `,` as'
|
| 118 |
+
' dumb delimiter. Contributions (probably using ast) welcome. You can'
|
| 119 |
+
' unblock by using a string with eval(s.replace(";", ",")) or similar')
|
| 120 |
+
return (v[0], v[1])
|
| 121 |
+
# Otherwise, derive the type from the default value.
|
| 122 |
+
return (v, type(v))
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def autotype(x):
|
| 126 |
+
"""Auto-converts string to bool/int/float if possible."""
|
| 127 |
+
assert isinstance(x, str)
|
| 128 |
+
if x.lower() in {'true', 'false'}:
|
| 129 |
+
return x.lower() == 'true' # Returns as bool.
|
| 130 |
+
try:
|
| 131 |
+
return int(x) # Returns as int.
|
| 132 |
+
except ValueError:
|
| 133 |
+
try:
|
| 134 |
+
return float(x) # Returns as float.
|
| 135 |
+
except ValueError:
|
| 136 |
+
return x # Returns as str.
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def pack_arg(**kw):
|
| 140 |
+
"""Packs key-word args as a string to be parsed by `parse_arg()`."""
|
| 141 |
+
for v in kw.values():
|
| 142 |
+
assert ',' not in f'{v}', f"Can't use `,` in config_arg value: {v}"
|
| 143 |
+
return ','.join([f'{k}={v}' for k, v in kw.items()])
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def arg(**kw):
|
| 147 |
+
"""Use like `add(**bvcc.arg(res=256, foo=bar), lr=0.1)` to pass config_arg."""
|
| 148 |
+
return {'config_arg': pack_arg(**kw), **kw}
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def _get_field_ref(config_dict, field_name):
|
| 152 |
+
path = field_name.split('.')
|
| 153 |
+
for field in path[:-1]:
|
| 154 |
+
config_dict = getattr(config_dict, field)
|
| 155 |
+
return config_dict.get_ref(path[-1])
|
| 156 |
+
|
| 157 |
+
|
| 158 |
+
def format_str(format_string, config):
|
| 159 |
+
"""Format string with reference fields from config.
|
| 160 |
+
|
| 161 |
+
This makes it easy to build preprocess strings that contain references to
|
| 162 |
+
fields tha are edited after. E.g.:
|
| 163 |
+
|
| 164 |
+
```
|
| 165 |
+
config = mlc.ConficDict()
|
| 166 |
+
config.res = (256, 256)
|
| 167 |
+
config.pp = bvcc.format_str('resize({res})', config)
|
| 168 |
+
...
|
| 169 |
+
# if config.res is modified (e.g. via sweeps) it will propagate to pp field:
|
| 170 |
+
config.res = (512, 512)
|
| 171 |
+
assert config.pp == 'resize((512, 512))'
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
Args:
|
| 175 |
+
format_string: string to format with references.
|
| 176 |
+
config: ConfigDict to get references to format the string.
|
| 177 |
+
|
| 178 |
+
Returns:
|
| 179 |
+
A reference field which renders a string using references to config fields.
|
| 180 |
+
"""
|
| 181 |
+
output = ''
|
| 182 |
+
parts = string.Formatter().parse(format_string)
|
| 183 |
+
for (literal_text, field_name, format_spec, conversion) in parts:
|
| 184 |
+
assert not format_spec and not conversion
|
| 185 |
+
output += literal_text
|
| 186 |
+
if field_name:
|
| 187 |
+
output += _get_field_ref(config, field_name).to_str()
|
| 188 |
+
return output
|
big_vision_repo/big_vision/configs/common_fewshot.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""Most common few-shot eval configuration."""
|
| 16 |
+
|
| 17 |
+
import ml_collections as mlc
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_fewshot_lsr(target_resolution=224, resize_resolution=256,
|
| 21 |
+
runlocal=False, **kw):
|
| 22 |
+
"""Returns a standard-ish fewshot eval configuration."""
|
| 23 |
+
kw.setdefault('representation_layer', 'pre_logits')
|
| 24 |
+
kw.setdefault('shots', (1, 5, 10, 25))
|
| 25 |
+
kw.setdefault('l2_reg', 2.0 ** 10)
|
| 26 |
+
kw.setdefault('num_seeds', 3)
|
| 27 |
+
kw.setdefault('prefix', '') # No prefix as we already use a/ z/ and zz/
|
| 28 |
+
|
| 29 |
+
# Backward-compatible default:
|
| 30 |
+
if not any(f'log_{x}' in kw for x in ['steps', 'percent', 'examples', 'epochs']): # pylint: disable=line-too-long
|
| 31 |
+
kw['log_steps'] = 25_000
|
| 32 |
+
|
| 33 |
+
config = mlc.ConfigDict(kw)
|
| 34 |
+
config.type = 'fewshot_lsr'
|
| 35 |
+
config.datasets = {
|
| 36 |
+
'caltech': ('caltech101', 'train', 'test'), # copybara:srtip
|
| 37 |
+
'cars': ('cars196:2.1.0', 'train', 'test'),
|
| 38 |
+
'cifar100': ('cifar100', 'train', 'test'),
|
| 39 |
+
'dtd': ('dtd', 'train', 'test'),
|
| 40 |
+
# The first 65000 ImageNet samples have at least 30 shots per any class.
|
| 41 |
+
# Commented out by default because needs manual download.
|
| 42 |
+
# 'imagenet': ('imagenet2012', 'train[:65000]', 'validation'),
|
| 43 |
+
'pets': ('oxford_iiit_pet', 'train', 'test'),
|
| 44 |
+
'uc_merced': ('uc_merced', 'train[:1000]', 'train[1000:]'),
|
| 45 |
+
} if not runlocal else {
|
| 46 |
+
'pets': ('oxford_iiit_pet', 'train', 'test'),
|
| 47 |
+
}
|
| 48 |
+
config.pp_train = (f'decode|resize({resize_resolution})|'
|
| 49 |
+
f'central_crop({target_resolution})|'
|
| 50 |
+
f'value_range(-1,1)|keep("image", "label")')
|
| 51 |
+
config.pp_eval = (f'decode|resize({resize_resolution})|'
|
| 52 |
+
f'central_crop({target_resolution})|'
|
| 53 |
+
f'value_range(-1,1)|keep("image", "label")')
|
| 54 |
+
config.display_first = [('imagenet', 10)] if not runlocal else [('pets', 10)]
|
| 55 |
+
|
| 56 |
+
return config
|
big_vision_repo/big_vision/configs/load_and_eval.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pytype: disable=not-writable,attribute-error
|
| 16 |
+
# pylint: disable=line-too-long,missing-function-docstring
|
| 17 |
+
r"""A config to load and eval key model using the core train.py.
|
| 18 |
+
|
| 19 |
+
The runtime varies widely depending on the model, but each one should reproduce
|
| 20 |
+
the corresponding paper's numbers.
|
| 21 |
+
This configuration makes use of the "arg" to get_config to select which model
|
| 22 |
+
to run, so a few examples are given below:
|
| 23 |
+
|
| 24 |
+
Run and evaluate a BiT-M ResNet-50x1 model that was transferred to i1k:
|
| 25 |
+
|
| 26 |
+
big_vision.train \
|
| 27 |
+
--config big_vision/configs/load_and_eval.py:name=bit_paper,batch_size=8 \
|
| 28 |
+
--config.model_init M-imagenet2012 --config.model.width 1 --config.model.depth 50
|
| 29 |
+
|
| 30 |
+
Run and evaluate the recommended ViT-B/32 from "how to train your vit" paper:
|
| 31 |
+
|
| 32 |
+
big_vision.train \
|
| 33 |
+
--config big_vision/configs/load_and_eval.py:name=vit_i21k,batch_size=8 \
|
| 34 |
+
--config.model.variant B/32 --config.model_init howto-i21k-B/32
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
import big_vision.configs.common as bvcc
|
| 38 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def eval_only(config, batch_size, spec_for_init):
|
| 42 |
+
"""Set a few configs that turn trainer into (almost) eval-only."""
|
| 43 |
+
config.total_steps = 0
|
| 44 |
+
config.input = {}
|
| 45 |
+
config.input.batch_size = batch_size
|
| 46 |
+
config.input.data = dict(name='bv:dummy', spec=spec_for_init)
|
| 47 |
+
config.optax_name = 'identity'
|
| 48 |
+
config.lr = 0.0
|
| 49 |
+
|
| 50 |
+
config.mesh = [('data', -1)]
|
| 51 |
+
config.sharding_strategy = [('params/.*', 'fsdp(axis="data")')]
|
| 52 |
+
config.sharding_rules = [('act_batch', ('data',))]
|
| 53 |
+
|
| 54 |
+
return config
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def get_config(arg=''):
|
| 58 |
+
config = bvcc.parse_arg(arg, name='bit_paper', batch_size=4)
|
| 59 |
+
|
| 60 |
+
# Make the config eval-only by setting some dummies.
|
| 61 |
+
eval_only(config, config.batch_size, spec_for_init=dict(
|
| 62 |
+
image=dict(shape=(224, 224, 3), dtype='float32'),
|
| 63 |
+
))
|
| 64 |
+
|
| 65 |
+
config.evals = dict(fewshot=get_fewshot_lsr())
|
| 66 |
+
|
| 67 |
+
# Just calls the function with the name given as `config`.
|
| 68 |
+
# Could also be a giant if-block if you're into that kind of thing.
|
| 69 |
+
globals()[config.name](config)
|
| 70 |
+
return config
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def bit_paper(config):
|
| 74 |
+
config.num_classes = 1000
|
| 75 |
+
|
| 76 |
+
config.model_name = 'bit_paper'
|
| 77 |
+
config.model_init = 'M-imagenet2012' # M = i21k, -imagenet2012 = fine-tuned
|
| 78 |
+
config.model = dict(width=1, depth=50)
|
| 79 |
+
|
| 80 |
+
def get_eval(split, lbl, dataset='imagenet2012_real'):
|
| 81 |
+
return dict(
|
| 82 |
+
type='classification',
|
| 83 |
+
data=dict(name=dataset, split=split),
|
| 84 |
+
loss_name='softmax_xent',
|
| 85 |
+
cache='none', # Only run once, on low-mem machine.
|
| 86 |
+
pp_fn=(
|
| 87 |
+
'decode|resize(384)|value_range(-1, 1)'
|
| 88 |
+
f'|onehot(1000, key="{lbl}", key_result="labels")'
|
| 89 |
+
'|keep("image", "labels")'
|
| 90 |
+
),
|
| 91 |
+
)
|
| 92 |
+
config.evals.test = get_eval('validation', 'original_label')
|
| 93 |
+
config.evals.real = get_eval('validation', 'real_label')
|
| 94 |
+
config.evals.v2 = get_eval('test', 'label', 'imagenet_v2')
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def vit_i1k(config):
|
| 98 |
+
config.num_classes = 1000
|
| 99 |
+
|
| 100 |
+
config.model_name = 'vit'
|
| 101 |
+
config.model_init = '' # Will be set in sweep.
|
| 102 |
+
config.model = dict(variant='S/16', pool_type='gap', posemb='sincos2d',
|
| 103 |
+
rep_size=True)
|
| 104 |
+
|
| 105 |
+
config.evals.val = dict(
|
| 106 |
+
type='classification',
|
| 107 |
+
data=dict(name='imagenet2012', split='validation'),
|
| 108 |
+
pp_fn='decode|resize_small(256)|central_crop(224)|value_range(-1, 1)|onehot(1000, key="label", key_result="labels")|keep("image", "labels")',
|
| 109 |
+
loss_name='softmax_xent',
|
| 110 |
+
cache='none', # Only run once, on low-mem machine.
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def mlp_mixer_i1k(config):
|
| 115 |
+
config.num_classes = 1000
|
| 116 |
+
|
| 117 |
+
config.model_name = 'mlp_mixer'
|
| 118 |
+
config.model_init = '' # Will be set in sweep.
|
| 119 |
+
config.model = dict(variant='L/16')
|
| 120 |
+
|
| 121 |
+
config.evals.val = dict(
|
| 122 |
+
type='classification',
|
| 123 |
+
data=dict(name='imagenet2012', split='validation'),
|
| 124 |
+
pp_fn='decode|resize_small(256)|central_crop(224)|value_range(-1, 1)|onehot(1000, key="label", key_result="labels")|keep("image", "labels")',
|
| 125 |
+
loss_name='softmax_xent',
|
| 126 |
+
cache='none', # Only run once, on low-mem machine.
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def vit_i21k(config):
|
| 131 |
+
config.num_classes = 21843
|
| 132 |
+
|
| 133 |
+
config.model_name = 'vit'
|
| 134 |
+
config.model_init = '' # Will be set in sweep.
|
| 135 |
+
config.model = dict(variant='B/32', pool_type='tok')
|
| 136 |
+
|
| 137 |
+
config.evals.val = dict(
|
| 138 |
+
type='classification',
|
| 139 |
+
data=dict(name='imagenet21k', split='full[:51200]'),
|
| 140 |
+
pp_fn='decode|resize_small(256)|central_crop(224)|value_range(-1, 1)|onehot(21843)|keep("image", "labels")',
|
| 141 |
+
loss_name='sigmoid_xent',
|
| 142 |
+
cache='none', # Only run once, on low-mem machine.
|
| 143 |
+
)
|
big_vision_repo/big_vision/configs/mlp_mixer_i1k.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""A config for training MLP-Mixer-B/16 model on ILSVRC-2012 ("ImageNet-1k").
|
| 17 |
+
|
| 18 |
+
Achieves 76.3% top-1 accuracy on the test split in 2h11m on TPU v3-128
|
| 19 |
+
with 300 epochs. A shorter 60 epochs run is expected to get to 70.5% in 27m.
|
| 20 |
+
|
| 21 |
+
big_vision.train \
|
| 22 |
+
--config big_vision/configs/mlp_mixer_i1k.py \
|
| 23 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 27 |
+
import ml_collections as mlc
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_config(mode=None):
|
| 31 |
+
"""Config for training Mixer on i1k."""
|
| 32 |
+
config = mlc.ConfigDict()
|
| 33 |
+
|
| 34 |
+
config.seed = 0
|
| 35 |
+
config.total_epochs = 300
|
| 36 |
+
config.num_classes = 1000
|
| 37 |
+
config.loss = 'sigmoid_xent'
|
| 38 |
+
config.init_head_bias = -6.9
|
| 39 |
+
|
| 40 |
+
config.input = dict()
|
| 41 |
+
config.input.data = dict(
|
| 42 |
+
name='imagenet2012',
|
| 43 |
+
split='train[:99%]',
|
| 44 |
+
)
|
| 45 |
+
config.input.batch_size = 4096
|
| 46 |
+
config.input.cache_raw = True # Needs up to 120GB of RAM!
|
| 47 |
+
config.input.shuffle_buffer_size = 250_000
|
| 48 |
+
|
| 49 |
+
config.input.pp = (
|
| 50 |
+
'decode_jpeg_and_inception_crop(224)'
|
| 51 |
+
'|flip_lr'
|
| 52 |
+
'|randaug(2,15)'
|
| 53 |
+
'|value_range(-1, 1)'
|
| 54 |
+
'|onehot(1000, key="label", key_result="labels")'
|
| 55 |
+
'|keep("image", "labels")'
|
| 56 |
+
)
|
| 57 |
+
pp_eval = (
|
| 58 |
+
'decode'
|
| 59 |
+
'|resize_small(256)|central_crop(224)'
|
| 60 |
+
'|value_range(-1, 1)'
|
| 61 |
+
'|onehot(1000, key="{lbl}", key_result="labels")'
|
| 62 |
+
'|keep("image", "labels")'
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
# To continue using the near-defunct randaug op.
|
| 66 |
+
config.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'archive.randaug']
|
| 67 |
+
|
| 68 |
+
config.log_training_steps = 50
|
| 69 |
+
config.ckpt_steps = 1000
|
| 70 |
+
|
| 71 |
+
config.prefetch_to_device = 2
|
| 72 |
+
|
| 73 |
+
# Model section
|
| 74 |
+
config.model_name = 'mlp_mixer'
|
| 75 |
+
config.model = dict()
|
| 76 |
+
config.model.variant = 'B/16'
|
| 77 |
+
config.model.stoch_depth = 0.1
|
| 78 |
+
|
| 79 |
+
config.mixup = dict(fold_in=None, p=0.5)
|
| 80 |
+
|
| 81 |
+
# Optimizer section
|
| 82 |
+
config.optax_name = 'scale_by_adam'
|
| 83 |
+
config.grad_clip_norm = 1.
|
| 84 |
+
|
| 85 |
+
config.lr = 0.001
|
| 86 |
+
config.wd = 1e-4
|
| 87 |
+
config.schedule = dict(
|
| 88 |
+
decay_type='linear',
|
| 89 |
+
warmup_steps=10_000,
|
| 90 |
+
linear_end=1e-5,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# Eval section
|
| 94 |
+
def get_eval(split, dataset='imagenet2012'):
|
| 95 |
+
return dict(
|
| 96 |
+
type='classification',
|
| 97 |
+
data=dict(name=dataset, split=split),
|
| 98 |
+
pp_fn=pp_eval.format(lbl='label'),
|
| 99 |
+
loss_name=config.loss,
|
| 100 |
+
log_steps=2500, # Very fast O(seconds) so it's fine to run it often.
|
| 101 |
+
cache_final=mode != 'gpu8',
|
| 102 |
+
)
|
| 103 |
+
config.evals = {}
|
| 104 |
+
config.evals.train = get_eval('train[:2%]')
|
| 105 |
+
config.evals.minival = get_eval('train[99%:]')
|
| 106 |
+
config.evals.val = get_eval('validation')
|
| 107 |
+
config.evals.v2 = get_eval('test', dataset='imagenet_v2')
|
| 108 |
+
config.evals.real = get_eval('validation', dataset='imagenet2012_real')
|
| 109 |
+
config.evals.real.pp_fn = pp_eval.format(lbl='real_label')
|
| 110 |
+
|
| 111 |
+
config.fewshot = get_fewshot_lsr()
|
| 112 |
+
|
| 113 |
+
if mode == 'gpu8':
|
| 114 |
+
config.total_epochs = 60
|
| 115 |
+
config.input.batch_size = 512
|
| 116 |
+
config.input.cache_raw = False
|
| 117 |
+
if mode == 'regression_test':
|
| 118 |
+
config.total_epochs = 60
|
| 119 |
+
|
| 120 |
+
return config
|
big_vision_repo/big_vision/configs/proj/cappa/README.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Image Captioners Are Scalable Vision Learners Too
|
| 2 |
+
|
| 3 |
+
*by Michael Tschannen, Manoj Kumar, Andreas Steiner, Xiaohua Zhai, Neil Houlsby, Lucas Beyer* [[arxiv]](https://arxiv.org/abs/2306.07915)
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
This directory contains a config for training a CapPa model from scratch.
|
| 8 |
+
Note that most models in the paper were trained on a proprietary dataset
|
| 9 |
+
(WebLI), but similar results can be obtained by training on [LAION](https://laion.ai/).
|
| 10 |
+
|
| 11 |
+
By default, this config trains on COCO captions as this data set is readily
|
| 12 |
+
available in [TFDS](https://www.tensorflow.org/datasets) without manual steps.
|
| 13 |
+
This is not meant to produce a meaningful model, but
|
| 14 |
+
provides a way for the user to run the config out of the box. Please update the
|
| 15 |
+
config with with a TFDS-wrapped variant of your favorite image/text data set to
|
| 16 |
+
train capable models.
|
| 17 |
+
|
| 18 |
+
After setting up `big_vision` as described in the [main README](https://github.com/google-research/big_vision#cloud-tpu-vm-setup), training can be launched as follows
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
python -m big_vision.trainers.proj.cappa.generative \
|
| 22 |
+
--config big_vision/configs/proj/cappa/pretrain.py \
|
| 23 |
+
--workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%m-%d_%H%M'`
|
| 24 |
+
```
|
| 25 |
+
|
| 26 |
+
To run the Cap baseline (autoregressive captioning without parallel prediction),
|
| 27 |
+
set `config.model.masked_pred_prob = 0.0`.
|
| 28 |
+
|
| 29 |
+
### Citation
|
| 30 |
+
```
|
| 31 |
+
@inproceedings{tschannen2023image,
|
| 32 |
+
title={Image Captioners Are Scalable Vision Learners Too},
|
| 33 |
+
author={Tschannen, Michael and Kumar, Manoj and Steiner, Andreas and Zhai, Xiaohua and Houlsby, Neil and Beyer, Lucas},
|
| 34 |
+
booktitle={Neural Information Processing Systems (NeurIPS)},
|
| 35 |
+
year={2023}
|
| 36 |
+
}
|
| 37 |
+
```
|
big_vision_repo/big_vision/configs/proj/cappa/cappa_architecture.png
ADDED
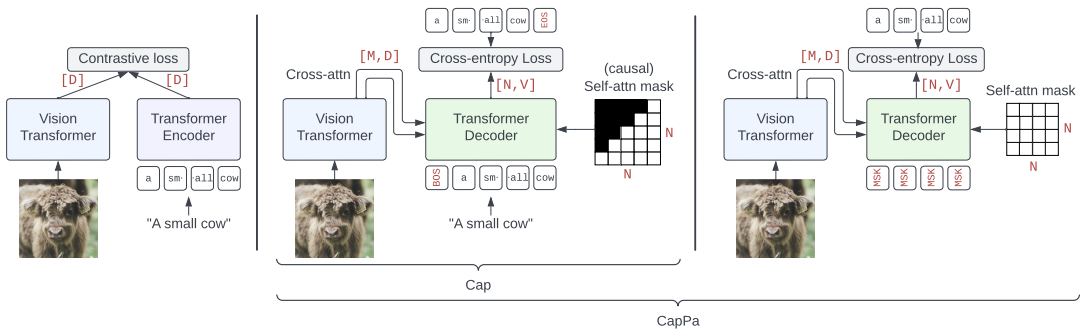
|
big_vision_repo/big_vision/configs/proj/cappa/pretrain.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Trains a CapPa model (https://arxiv.org/abs/2306.07915) on coco_captions.
|
| 17 |
+
|
| 18 |
+
This config is for reference, we never ran a full training on a large
|
| 19 |
+
image/text data set on public infrastructure.
|
| 20 |
+
|
| 21 |
+
big_vision.trainers.proj.cappa.generative \
|
| 22 |
+
--config big_vision/configs/proj/cappa/pretrain.py \
|
| 23 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'`
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
from big_vision.configs import common_fewshot
|
| 28 |
+
import big_vision.configs.common as bvcc
|
| 29 |
+
import ml_collections
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def get_config(arg=None):
|
| 33 |
+
"""Returns the base config."""
|
| 34 |
+
config = bvcc.parse_arg(arg,
|
| 35 |
+
runlocal=False,
|
| 36 |
+
total_steps=366_500,
|
| 37 |
+
batch_size=8*1024,
|
| 38 |
+
warmup_steps=10_000,
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
config.evals = {}
|
| 42 |
+
config.input = {}
|
| 43 |
+
config.input.batch_size = config.batch_size if not config.runlocal else 8
|
| 44 |
+
shuffle_buffer_size = 50_000 if not config.runlocal else 50
|
| 45 |
+
|
| 46 |
+
res = 224
|
| 47 |
+
patch_size = 16
|
| 48 |
+
max_text_tokens = 64
|
| 49 |
+
|
| 50 |
+
pp_image = (f'resize({res})|value_range(-1,1)')
|
| 51 |
+
|
| 52 |
+
def tokenizer(inkey, outkey):
|
| 53 |
+
return (f'tokenize(max_len={max_text_tokens}, model="c4_en", '
|
| 54 |
+
f'eos="sticky", inkey="{inkey}", outkey="{outkey}")')
|
| 55 |
+
|
| 56 |
+
pp_coco = (f'decode|{pp_image}|'
|
| 57 |
+
'coco_captions("captions")|choice(inkey="captions", outkey="text")|'
|
| 58 |
+
f'{tokenizer("text", "labels")}|keep("image", "labels")')
|
| 59 |
+
config.input.pp = pp_coco
|
| 60 |
+
|
| 61 |
+
# NOTE: "coco_captions" is way too small a dataset to train on. It's simply
|
| 62 |
+
# used here to serve as a smoke test that the implementation works correctly.
|
| 63 |
+
config.input.data = dict(name='coco_captions', split='train') # num_examples=82_783
|
| 64 |
+
config.input.shuffle_buffer_size = shuffle_buffer_size
|
| 65 |
+
|
| 66 |
+
config.evals.val_coco = {
|
| 67 |
+
'type': 'proj.cappa.perplexity',
|
| 68 |
+
'pred': 'perplexity',
|
| 69 |
+
'log_steps': 1000,
|
| 70 |
+
'data': dict(name='coco_captions', split='val'), # num_examples=5_000
|
| 71 |
+
'pp_fn': pp_coco,
|
| 72 |
+
}
|
| 73 |
+
|
| 74 |
+
# Few-shot metrics
|
| 75 |
+
config.evals.fewshot = common_fewshot.get_fewshot_lsr(
|
| 76 |
+
target_resolution=res, resize_resolution=int(256 / 224 * res))
|
| 77 |
+
config.evals.fewshot.type = 'fewshot_lsr'
|
| 78 |
+
config.evals.fewshot.log_steps = 5_000 if not config.runlocal else 5
|
| 79 |
+
config.evals.fewshot.representation_layer = 'pre_logits'
|
| 80 |
+
config.evals.fewshot.pred = 'enc_rep'
|
| 81 |
+
config.evals.fewshot.pp_eval = config.evals.fewshot.pp_train
|
| 82 |
+
|
| 83 |
+
# NOTE: Scoring of the entire imagenet validation set is rather slow:
|
| 84 |
+
# ~100 secs / 1k classes / host.
|
| 85 |
+
config.evals['imagenet/scoring'] = dict(
|
| 86 |
+
type='proj.cappa.scoring_classifier',
|
| 87 |
+
pred='score',
|
| 88 |
+
log_percent=0.1,
|
| 89 |
+
data=dict(name='imagenet2012', split='validation'),
|
| 90 |
+
pp_fn=f'decode|{pp_image}|keep("image", "label")',
|
| 91 |
+
pp_txt=tokenizer('label', 'labels'),
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
for e in config.evals.values():
|
| 95 |
+
e.skip_first = True
|
| 96 |
+
|
| 97 |
+
config.log_training_steps = 50
|
| 98 |
+
config.ckpt_steps = 1000
|
| 99 |
+
config.keep_ckpt_steps = None # 10_000
|
| 100 |
+
|
| 101 |
+
# Model section
|
| 102 |
+
config.model_name = 'proj.cappa.cappa'
|
| 103 |
+
config.model = ml_collections.ConfigDict()
|
| 104 |
+
config.model.num_layers = 12
|
| 105 |
+
config.model.num_heads = 12
|
| 106 |
+
config.model.mlp_dim = 3072
|
| 107 |
+
config.model.emb_dim = 768
|
| 108 |
+
config.model.vocab_size = 32_000
|
| 109 |
+
config.model.patches = (patch_size, patch_size)
|
| 110 |
+
config.model.seq_len = max_text_tokens
|
| 111 |
+
config.model.posemb_type = 'learn'
|
| 112 |
+
|
| 113 |
+
# Decoder
|
| 114 |
+
config.model.decoder_num_layers = 6
|
| 115 |
+
# 0 values here mean to use the same value as for the encoder
|
| 116 |
+
config.model.decoder_num_heads = 0
|
| 117 |
+
config.model.decoder_mlp_dim = 0
|
| 118 |
+
config.model.decoder_emb_dim = 0
|
| 119 |
+
config.model.dec_dropout_rate = 0.0
|
| 120 |
+
config.model.masked_pred_prob = 0.75
|
| 121 |
+
config.model.masking_ratio = 1.0
|
| 122 |
+
config.model.decoder_bias = False
|
| 123 |
+
|
| 124 |
+
config.optax_name = 'big_vision.scale_by_adafactor'
|
| 125 |
+
config.optax = dict(beta2_cap=0.999)
|
| 126 |
+
config.grad_clip_norm = 1.0
|
| 127 |
+
config.label_smoothing = 0.0
|
| 128 |
+
|
| 129 |
+
schedule = dict(decay_type='cosine',
|
| 130 |
+
warmup_steps=config.warmup_steps
|
| 131 |
+
if not config.runlocal else 5)
|
| 132 |
+
|
| 133 |
+
# Standard schedule
|
| 134 |
+
config.lr = 0.001
|
| 135 |
+
config.wd = 0.0001
|
| 136 |
+
config.schedule = schedule
|
| 137 |
+
|
| 138 |
+
config.seed = 0
|
| 139 |
+
|
| 140 |
+
return config
|
big_vision_repo/big_vision/configs/proj/clippo/README.md
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Image-and-Language Understanding from Pixels Only
|
| 2 |
+
|
| 3 |
+
*by Michael Tschannen, Basil Mustafa, Neil Houlsby* [[arxiv]](https://arxiv.org/abs/2212.08045) [[colab]](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/clippo/clippo_colab.ipynb)
|
| 4 |
+
|
| 5 |
+
We provide pretrained CLIP with Pixels Only (CLIPPO) models and code to train such models on image/alt-text data sets.
|
| 6 |
+
|
| 7 |
+
### Pretrained models
|
| 8 |
+
|
| 9 |
+
Six ViT-B/16 models trained on a mix of [`YFCC-100M`](https://arxiv.org/abs/1503.01817) and [`C4`](https://arxiv.org/abs/1910.10683) (some initialized with an [ImageNet21k-pretrained checkpoint](https://github.com/google-research/vision_transformer#vision-transformer)\) are available.
|
| 10 |
+
These models were trained using the schedules and hyperparameters described in the paper. We use the full `YFCC-100M` data set, sampling one of the available `title/description/tag` annotations at random for each each example. We drop non-descriptive annotations (e.g. descriptions consisting of digits only) following the filtering procedure outlined in the [LiT paper](https://arxiv.org/abs/2303.04671), Appendix E. The preprocessing for the `C4` data is as described in the paper.
|
| 11 |
+
|
| 12 |
+
The tables below show details about the checkpoints and their performance on Vision & Language benchmarks, and [`GLUE`](https://arxiv.org/abs/1804.07461). We also provide a [colab](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/clippo/clippo_colab.ipynb) to load the models, compute embeddings, and perform zero-shot classification.
|
| 13 |
+
|
| 14 |
+
##### Checkpoint details
|
| 15 |
+
|
| 16 |
+
| model | training dataset | #param. | steps | checkpoint |
|
| 17 |
+
|:-----------------|:-------------------|:----------|:--------|:-----------|
|
| 18 |
+
| CLIPPO | YFCC-100M | 93M | 250k | `gs://big_vision/clippo/clippo_b16_yfcc100m.npz` |
|
| 19 |
+
| CLIPPO I21k init | YFCC-100M | 93M | 250k | `gs://big_vision/clippo/clippo_b16_yfcc100m_i21k_init.npz` |
|
| 20 |
+
| CLIPPO I21k init | YFCC-100M + 25%C4 | 93M | 333k | `gs://big_vision/clippo/clippo_b16_yfcc100m_i21k_init_25c4.npz` |
|
| 21 |
+
| CLIPPO I21k init | YFCC-100M + 50%C4 | 93M | 500k | `gs://big_vision/clippo/clippo_b16_yfcc100m_i21k_init_50c4.npz` |
|
| 22 |
+
| CLIPPO I21k init | YFCC-100M + 75%C4 | 93M | 500k | `gs://big_vision/clippo/clippo_b16_yfcc100m_i21k_init_75c4.npz` |
|
| 23 |
+
| CLIPPO | C4 | 93M | 250k | `gs://big_vision/clippo/clippo_b16_100c4.npz` |
|
| 24 |
+
|
| 25 |
+
##### Vision \& Language results
|
| 26 |
+
|
| 27 |
+
| model | training dataset | ImageNet 10-shot | ImageNet 0-shot | MS-COCO I→T | MS-COCO T→I |
|
| 28 |
+
|:-----------------|:-------------------|-----------:|----------:|--------:|--------:|
|
| 29 |
+
| CLIPPO | YFCC-100M | 38.2 | 43.4 | 34.7 | 19.7 |
|
| 30 |
+
| CLIPPO I21k init | YFCC-100M | 44.7 | 47.4 | 36.1 | 21.3 |
|
| 31 |
+
| CLIPPO I21k init | YFCC-100M + 25%C4 | 43.8 | 44.8 | 33.3 | 19.4 |
|
| 32 |
+
| CLIPPO I21k init | YFCC-100M + 50%C4 | 41.2 | 42.0 | 31.4 | 17.8 |
|
| 33 |
+
| CLIPPO I21k init | YFCC-100M + 75%C4 | 34.5 | 33.4 | 26.6 | 14.6 |
|
| 34 |
+
|
| 35 |
+
##### GLUE results
|
| 36 |
+
|
| 37 |
+
| model | training dataset | MNLI-M/MM | QQP | QNLI | SST-2 | COLA | STS-B | MRPC | RTE | avg |
|
| 38 |
+
|:-----------------|:-------------------|:------------|------:|-------:|--------:|-------:|--------:|-------:|------:|------:|
|
| 39 |
+
| CLIPPO | YFCC-100M | 71.3 / 71.5 | 79.1 | 67.9 | 85.7 | 0.0 | 14.0 | 83.4 | 54.9 | 58.6 |
|
| 40 |
+
| CLIPPO I21k init | YFCC-100M | 70.0 / 70.1 | 83.7 | 81.6 | 86.1 | 0.0 | 18.5 | 83.0 | 53.1 | 60.7 |
|
| 41 |
+
| CLIPPO I21k init | YFCC-100M + 25%C4 | 75.7 / 75.1 | 85.2 | 83.5 | 89.6 | 0.0 | 82.3 | 82.7 | 52.7 | 69.7 |
|
| 42 |
+
| CLIPPO I21k init | YFCC-100M + 50%C4 | 77.4 / 77.4 | 86.0 | 83.9 | 91.7 | 34.5 | 84.5 | 85.1 | 56.3 | 75.2 |
|
| 43 |
+
| CLIPPO I21k init | YFCC-100M + 75%C4 | 79.8 / 79.1 | 86.5 | 84.3 | 92.0 | 44.5 | 85.3 | 88.2 | 58.5 | 77.6 |
|
| 44 |
+
| CLIPPO | C4 | 79.9 / 80.2 | 86.7 | 85.2 | 93.3 | 50.9 | 84.7 | 86.3 | 58.5 | 78.4 |
|
| 45 |
+
|
| 46 |
+
### Training your own models
|
| 47 |
+
|
| 48 |
+
To train your own CLIPPO model, please follow the setup instructions in the [`big_vision` main README](https://github.com/google-research/big_vision#cloud-tpu-vm-setup). In the following, we provide the CLIPPO-specific commands required in addition to the setup, assume you are using the Google Cloud TPU setup (potentially with adapted TPU configuration, see table below). If you are using GPUs, please set up your machine directly and only execute the `--command` portions of the commands below from the `big_vision` repository root.
|
| 49 |
+
|
| 50 |
+
The text rendering preproprocessing function requires manual download of the Unifont .hex files from [Unifoundry](https://unifoundry.com/unifont/) (please follow link for license):
|
| 51 |
+
|
| 52 |
+
```bash
|
| 53 |
+
gcloud alpha compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all \
|
| 54 |
+
--command "bash big_vision/pp/proj/clippo/download_unifont.sh"
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
Launch the training by running
|
| 58 |
+
|
| 59 |
+
```bash
|
| 60 |
+
gcloud alpha compute tpus tpu-vm ssh $NAME --zone=$ZONE --worker=all \
|
| 61 |
+
--command "TFDS_DATA_DIR=gs://$GS_BUCKET_NAME/tensorflow_datasets bash big_vision/run_tpu.sh big_vision.trainers.proj.image_text.contrastive --config big_vision/configs/proj/clippo/train_clippo.py --workdir gs://$GS_BUCKET_NAME/big_vision/workdir/`date '+%m-%d_%H%M'`"
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
*Important note:* The input pipeline relies on [TensorFlow Datasets (TFDS)](https://www.tensorflow.org/datasets) which does not provide automatic integration with large image/alt-text datasets out of the box. The above config therefore trains by default on MS-COCO Captions which can be automatically downloaded via TFDS, and additionally initializes the CLIPPO ViT backbone with weights pretrained on ImageNet21k. This setup is not meant to produce good accuracy, but to provide the user with a way to sanity-check their setup. If you want to train on a large data set such as [`LAION-400M`](https://arxiv.org/abs/2111.02114) or [`YFCC-100M`](https://arxiv.org/abs/1503.01817), please follow [these instructions](https://www.tensorflow.org/datasets/add_dataset) to wrap your data set using TFDS, and update the dataset in the config accordingly. Also note that the ImageNet1k evaluations require manual download of the data, see [these instructions](https://github.com/google-research/big_vision#preparing-tfds-data). To train with your own data set and with ImageNet1k-based evaluations, use `--config big_vision/configs/proj/clippo/train_clippo.py:test_with_coco=False,i1k_eval=True` in the command above.
|
| 65 |
+
|
| 66 |
+
##### Expected results
|
| 67 |
+
|
| 68 |
+
| train dataset | batch size | #steps | TPU chips | ImageNet 0-shot | MS-COCO I→T | MS-COCO T→I | Config `arg` |
|
| 69 |
+
| :--- | ---: | ---: | ---: | :---: | :---: | :---: | :--- |
|
| 70 |
+
| *MS-COCO (sanity check)* | 4000 | 400 | 32 v3 | 4.2 | 12.6 | 8.6 | `i1k_eval=True` |
|
| 71 |
+
| LAION-400M | 8192 | 100k |128 v2 | 51.5 | 44.8 | 29.3 | `test_with_coco=False,i1k_eval=True` |
|
| 72 |
+
| LAION-400M | 10240\* | 100k | 128 v3 | 53.6 | 46.7 | 30.3 | `test_with_coco=False,i1k_eval=True` |
|
| 73 |
+
|
| 74 |
+
\* The experiments in the paper use a batch size of 10240 which requires a memory-optimized ViT implementation to run on 128 TPU v2 chips or 128 TPU v3 chips (in which case the TPU memory capacity allows to increase the batch size beyond 10240).
|
| 75 |
+
|
| 76 |
+
### Citation
|
| 77 |
+
|
| 78 |
+
```
|
| 79 |
+
@inproceedings{tschannen2023image,
|
| 80 |
+
title={Image-and-Language Understanding from Pixels Only},
|
| 81 |
+
author={Tschannen, Michael and Mustafa, Basil and Houlsby, Neil},
|
| 82 |
+
booktitle={Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
|
| 83 |
+
year={2023}
|
| 84 |
+
}
|
| 85 |
+
```
|
big_vision_repo/big_vision/configs/proj/clippo/clippo_colab.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
big_vision_repo/big_vision/configs/proj/clippo/train_clippo.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Trains CLIP with Pixels Only (CLIPPO), https://arxiv.org/abs/2212.08045
|
| 17 |
+
|
| 18 |
+
IMPORTANT NOTE: This config uses coco_captions by default for demonstration
|
| 19 |
+
purposes since the TFDS catalog does not provide any large image/alt-text data
|
| 20 |
+
set; the training will not produce a model with useful accuracy. Please
|
| 21 |
+
replace the data set below (marked by a comment) with an appropriate image/
|
| 22 |
+
alt-text data set wrapped in TFDS (for example LAION-400M) and run the config
|
| 23 |
+
with the suffix `:test_with_coco=False` to train on your data set. Refer to
|
| 24 |
+
the following guide to build a TFDS wrapper for your favorite image/alt-text
|
| 25 |
+
data set:
|
| 26 |
+
https://www.tensorflow.org/datasets/add_dataset
|
| 27 |
+
|
| 28 |
+
Also note that evaluation on ImageNet requires manual TFDS setup, see
|
| 29 |
+
https://github.com/google-research/big_vision#preparing-tfds-data
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
Example training:
|
| 33 |
+
|
| 34 |
+
big_vision.trainers.proj.image_text.contrastive \
|
| 35 |
+
--config big_vision/configs/proj/clippo/train_clippo.py \
|
| 36 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%Y-%m-%d_%H%M'`
|
| 37 |
+
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
import big_vision.configs.common as bvcc
|
| 41 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 42 |
+
from big_vision.configs.proj.image_text import common
|
| 43 |
+
from ml_collections import ConfigDict
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_config(arg=None):
|
| 47 |
+
"""The base configuration."""
|
| 48 |
+
arg = bvcc.parse_arg(
|
| 49 |
+
arg, res=224, runlocal=False, variant='B/16',
|
| 50 |
+
test_with_coco=True, i1k_eval=False)
|
| 51 |
+
config = ConfigDict()
|
| 52 |
+
|
| 53 |
+
config.input = {}
|
| 54 |
+
if arg.test_with_coco:
|
| 55 |
+
# Use COCO Captions for sanity-checking
|
| 56 |
+
config.input.data = dict(name='coco_captions', split='train')
|
| 57 |
+
val_data = dict(config.input.data)
|
| 58 |
+
val_data['split'] = 'val'
|
| 59 |
+
config.input.batch_size = 4000 if not arg.runlocal else 32
|
| 60 |
+
config.input.shuffle_buffer_size = 50_000 if not arg.runlocal else 50
|
| 61 |
+
config.total_steps = 400 if not arg.runlocal else 10
|
| 62 |
+
else:
|
| 63 |
+
# Please add your favorite image/alt-text dataset here
|
| 64 |
+
config.input.data = None
|
| 65 |
+
val_data = None
|
| 66 |
+
assert config.input.data is not None and val_data is not None, (
|
| 67 |
+
config.input.data, val_data)
|
| 68 |
+
|
| 69 |
+
# The value in the paper is 10 * 1024, which requires 128 TPUv3 cores or a
|
| 70 |
+
# memory optimized ViT implementation when running on 128 TPUv2 cores.
|
| 71 |
+
config.input.batch_size = 8 * 1024 if not arg.runlocal else 32
|
| 72 |
+
config.input.shuffle_buffer_size = 250_000 if not arg.runlocal else 50
|
| 73 |
+
config.total_steps = 100_000 if not arg.runlocal else 10
|
| 74 |
+
|
| 75 |
+
def tokenizer(inkey, outkey='labels'):
|
| 76 |
+
return (f'render_unifont('
|
| 77 |
+
f'inkey="{inkey}", '
|
| 78 |
+
f'outkey="{outkey}", '
|
| 79 |
+
f'image_size={arg.res}, '
|
| 80 |
+
f'lower=True, '
|
| 81 |
+
f'font_size=16, '
|
| 82 |
+
f'text_brightness=0, '
|
| 83 |
+
f'background_brightness=127)|'
|
| 84 |
+
f'value_range(-1, 1, inkey="{outkey}", outkey="{outkey}")')
|
| 85 |
+
|
| 86 |
+
pp_image = f'decode|resize({arg.res})|value_range(-1,1)'
|
| 87 |
+
if arg.test_with_coco:
|
| 88 |
+
# Train with augmentation when sanity-checking
|
| 89 |
+
pp_image_aug = (
|
| 90 |
+
f'decode|resize({arg.res})|flip_lr|randaug(2,10)|value_range(-1,1)')
|
| 91 |
+
config.input.pp = pp_eval = (
|
| 92 |
+
f'{pp_image_aug}|flatten|{tokenizer("captions/text")}|'
|
| 93 |
+
f'keep("image", "labels")')
|
| 94 |
+
else:
|
| 95 |
+
config.input.pp = pp_eval = (
|
| 96 |
+
f'{pp_image}|flatten|{tokenizer("text")}|keep("image", "labels")')
|
| 97 |
+
|
| 98 |
+
config.pp_modules = [
|
| 99 |
+
'ops_general', 'ops_image', 'ops_text', 'proj.clippo.pp_ops']
|
| 100 |
+
|
| 101 |
+
config.log_training_steps = 50
|
| 102 |
+
config.ckpt_steps = 1000
|
| 103 |
+
config.keep_ckpt_steps = 5000
|
| 104 |
+
|
| 105 |
+
config.loss_use_global_batch = True
|
| 106 |
+
|
| 107 |
+
# Define the model
|
| 108 |
+
config.model_name = 'proj.clippo.one_tower'
|
| 109 |
+
|
| 110 |
+
config.model = ConfigDict()
|
| 111 |
+
config.model.image_model = 'vit'
|
| 112 |
+
config.model.image = ConfigDict({
|
| 113 |
+
'variant': arg.variant,
|
| 114 |
+
'pool_type': 'map',
|
| 115 |
+
'head_zeroinit': False,
|
| 116 |
+
})
|
| 117 |
+
|
| 118 |
+
if arg.test_with_coco:
|
| 119 |
+
# Initialize with ImageNet21k pretrained checkpoint for sanity-checking
|
| 120 |
+
assert arg.variant == 'B/16', arg.variant
|
| 121 |
+
config.model_init = {'image': 'howto-i21k-B/16'}
|
| 122 |
+
config.model_load = {}
|
| 123 |
+
config.model_load['img_load_kw'] = {
|
| 124 |
+
'dont_load': ['^head/.*', '^MAPHead_0/.*', 'cls']}
|
| 125 |
+
|
| 126 |
+
config.model.temperature_init = 10.0
|
| 127 |
+
config.model.out_dim = 768
|
| 128 |
+
|
| 129 |
+
# Define the optimizer
|
| 130 |
+
config.optax_name = 'big_vision.scale_by_adafactor'
|
| 131 |
+
config.grad_clip_norm = 1.0
|
| 132 |
+
|
| 133 |
+
if arg.test_with_coco:
|
| 134 |
+
# Short schedule for sanity-checking
|
| 135 |
+
config.lr = 0.0001
|
| 136 |
+
config.wd = 0.0003
|
| 137 |
+
config.schedule = dict(decay_type='rsqrt',
|
| 138 |
+
timescale=100,
|
| 139 |
+
warmup_steps=100 if not arg.runlocal else 5,
|
| 140 |
+
cooldown_steps=100 if not arg.runlocal else 5)
|
| 141 |
+
else:
|
| 142 |
+
config.lr = 0.001
|
| 143 |
+
config.wd = 0.0001
|
| 144 |
+
config.schedule = dict(decay_type='rsqrt',
|
| 145 |
+
timescale=10_000,
|
| 146 |
+
warmup_steps=10_000 if not arg.runlocal else 5,
|
| 147 |
+
cooldown_steps=10_000 if not arg.runlocal else 5)
|
| 148 |
+
|
| 149 |
+
# Eval section (Both few-shot and zero-shot)
|
| 150 |
+
eval_common = dict(
|
| 151 |
+
type='proj.image_text.contrastive',
|
| 152 |
+
use_global_batch=config.loss_use_global_batch,
|
| 153 |
+
log_steps=1000 if not arg.runlocal else 5,
|
| 154 |
+
)
|
| 155 |
+
config.evals = {}
|
| 156 |
+
sub = '[:4]' if arg.runlocal else ''
|
| 157 |
+
config.evals.val = {
|
| 158 |
+
**eval_common,
|
| 159 |
+
'data': val_data,
|
| 160 |
+
'pp_fn': pp_eval,
|
| 161 |
+
}
|
| 162 |
+
config.evals.coco = {
|
| 163 |
+
**eval_common,
|
| 164 |
+
'data': dict(name='coco_captions', split=f'val{sub}'),
|
| 165 |
+
'pp_fn': (
|
| 166 |
+
f'{pp_image}|flatten|{tokenizer("captions/text")}|'
|
| 167 |
+
f'keep("image", "labels")'),
|
| 168 |
+
}
|
| 169 |
+
|
| 170 |
+
if arg.i1k_eval:
|
| 171 |
+
# Requires manual download, see
|
| 172 |
+
# https://github.com/google-research/big_vision#preparing-tfds-data
|
| 173 |
+
config.evals.imagenet = {
|
| 174 |
+
**eval_common,
|
| 175 |
+
'data': dict(name='imagenet2012', split=f'validation{sub}'),
|
| 176 |
+
'pp_fn': (
|
| 177 |
+
f'{pp_image}|clip_i1k_label_names|'
|
| 178 |
+
f'{tokenizer("labels")}|keep("image", "labels")'),
|
| 179 |
+
}
|
| 180 |
+
config.evals.disclf = dict(
|
| 181 |
+
type='proj.image_text.discriminative_classifier',
|
| 182 |
+
pp_txt=tokenizer('texts', 'labels'),
|
| 183 |
+
prefix='z/0shot/',
|
| 184 |
+
log_steps=5_000 if not arg.runlocal else 5)
|
| 185 |
+
|
| 186 |
+
config.evals.retrieval_coco = common.get_coco(
|
| 187 |
+
pp_img=f'resize({arg.res})|value_range(-1, 1)',
|
| 188 |
+
pp_txt=tokenizer('texts'),
|
| 189 |
+
log_steps=5_000 if not arg.runlocal else 5,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
# Few-shot metrics
|
| 193 |
+
config.evals.fewshot = get_fewshot_lsr()
|
| 194 |
+
config.evals.fewshot.log_steps = 5_000 if not arg.runlocal else 5
|
| 195 |
+
config.evals.fewshot.representation_layer = 'img/pre_logits'
|
| 196 |
+
|
| 197 |
+
config.seed = 0
|
| 198 |
+
|
| 199 |
+
return config
|
big_vision_repo/big_vision/configs/proj/distill/README.md
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Knowledge distillation: A good teacher is patient and consistent
|
| 2 |
+
*by Lucas Beyer, Xiaohua Zhai, Amélie Royer, Larisa Markeeva, Rohan Anil, Alexander Kolesnikov*
|
| 3 |
+
|
| 4 |
+
## Introduction
|
| 5 |
+
We publish all teacher models, and configurations for the main experiments of
|
| 6 |
+
the paper, as well as training logs and student models.
|
| 7 |
+
|
| 8 |
+
Please read the main [big_vision README](/README.md) to learn how to run
|
| 9 |
+
configs, and remember that each config file contains an example invocation in
|
| 10 |
+
the top-level comment.
|
| 11 |
+
|
| 12 |
+
## Results
|
| 13 |
+
|
| 14 |
+
We provide the following [colab to read and plot the logfiles](https://colab.research.google.com/drive/1nMykzUzsfQ_uAxfj3k35DYsATnG_knPl?usp=sharing)
|
| 15 |
+
of a few runs that we reproduced on Cloud.
|
| 16 |
+
|
| 17 |
+
### ImageNet-1k
|
| 18 |
+
|
| 19 |
+
The file [bit_i1k.py](bit_i1k.py) is the configuration which reproduces our
|
| 20 |
+
distillation runs on ImageNet-1k reported in Figures 1 and 5(left) and the first
|
| 21 |
+
row of Table1.
|
| 22 |
+
|
| 23 |
+
We release both student and teacher models:
|
| 24 |
+
|
| 25 |
+
| Model | Download link | Resolution | ImageNet top-1 acc. (paper) |
|
| 26 |
+
| :--- | :---: | :---: | :---: |
|
| 27 |
+
| BiT-R50x1 | [link](https://storage.googleapis.com/bit_models/distill/R50x1_160.npz) | 160 | 80.5 |
|
| 28 |
+
| BiT-R50x1 | [link](https://storage.googleapis.com/bit_models/distill/R50x1_224.npz) | 224 | 82.8 |
|
| 29 |
+
| BiT-R152x2 | [link](https://storage.googleapis.com/bit_models/distill/R152x2_T_224.npz) | 224 | 83.0 |
|
| 30 |
+
| BiT-R152x2 | [link](https://storage.googleapis.com/bit_models/distill/R152x2_T_384.npz) | 384 | 84.3 |
|
| 31 |
+
|
| 32 |
+
### Flowers/Pet/Food/Sun
|
| 33 |
+
|
| 34 |
+
The files [bigsweep_flowers_pet.py](bigsweep_flowers_pet.py) and
|
| 35 |
+
[bigsweep_food_sun.py](bigsweep_food_sun.py) can be used to reproduce the
|
| 36 |
+
distillation runs on these datasets and shown in Figures 3,4,9-12, and Table4.
|
| 37 |
+
|
| 38 |
+
While our open-source release does not currently support doing hyper-parameter
|
| 39 |
+
sweeps, we still provide an example of the sweeps at the end of the configs
|
| 40 |
+
for reference.
|
| 41 |
+
|
| 42 |
+
### Teacher models
|
| 43 |
+
Links to all teacher models we used can be found in [common.py](common.py).
|
big_vision_repo/big_vision/configs/proj/distill/bigsweep_flowers_pet.py
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Distilling BiT-R152x2 into BiT-R50x1 on Flowers/Pet as in https://arxiv.org/abs/2106.05237
|
| 17 |
+
|
| 18 |
+
While many epochs are required, this is a small dataset, and thus overall it
|
| 19 |
+
is still fast and possible to run on the relatively small v3-8TPUs (or GPUs).
|
| 20 |
+
|
| 21 |
+
This configuration contains the recommended settings from Fig3/Tab4 of the
|
| 22 |
+
paper, which can be selected via the fast/medium/long config argument.
|
| 23 |
+
(best settings were selected on a 10% minival)
|
| 24 |
+
|
| 25 |
+
For Flowers:
|
| 26 |
+
- The `fast` variant takes ~1h10m on a v2-8 TPU.
|
| 27 |
+
Example logs at gs://big_vision/distill/bit_flowers_fast_06-18_2008/big_vision_metrics.txt
|
| 28 |
+
- The `long` variant takes ~25h on a v3-32 TPU.
|
| 29 |
+
Example logs at gs://big_vision/distill/bit_flowers_long_06-19_0524/big_vision_metrics.txt
|
| 30 |
+
For Pet:
|
| 31 |
+
- The `fast` variant takes ~28min on a v2-8 TPU.
|
| 32 |
+
Example logs at gs://big_vision/distill/bit_pet_fast_06-16_2338/big_vision_metrics.txt
|
| 33 |
+
- The `long` variant takes ~11h on a v2-8 and ~8h on a v3-32.
|
| 34 |
+
Example logs at gs://big_vision/distill/bit_pet_long_06-17_0050/big_vision_metrics.txt
|
| 35 |
+
|
| 36 |
+
big_vision.trainers.proj.distill.distill \
|
| 37 |
+
--config big_vision/configs/proj/distill/bigsweep_flowers_pet.py:data=flowers,variant=fast \
|
| 38 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
import big_vision.configs.common as bvcc
|
| 42 |
+
import big_vision.configs.proj.distill.common as cd
|
| 43 |
+
import ml_collections as mlc
|
| 44 |
+
|
| 45 |
+
NCLS = dict(flowers=102, pet=37)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def get_config(arg=None):
|
| 49 |
+
"""Config for massive hypothesis-test on pet."""
|
| 50 |
+
arg = bvcc.parse_arg(arg, runlocal=False, data='flowers', variant='medium', crop='inception_crop(128)')
|
| 51 |
+
config = mlc.ConfigDict()
|
| 52 |
+
|
| 53 |
+
config.input = {}
|
| 54 |
+
config.input.data = dict(
|
| 55 |
+
name=dict(flowers='oxford_flowers102', pet='oxford_iiit_pet')[arg.data],
|
| 56 |
+
split=dict(flowers='train', pet='train[:90%]')[arg.data],
|
| 57 |
+
)
|
| 58 |
+
config.input.batch_size = 512
|
| 59 |
+
config.input.cache_raw = True
|
| 60 |
+
config.input.shuffle_buffer_size = 50_000
|
| 61 |
+
config.prefetch_to_device = 4
|
| 62 |
+
|
| 63 |
+
config.num_classes = NCLS[arg.data]
|
| 64 |
+
config.total_epochs = {
|
| 65 |
+
'flowers': {'fast': 10_000, 'medium': 100_000, 'long': 1_000_000},
|
| 66 |
+
'pet': {'fast': 1000, 'medium': 3000, 'long': 30_000},
|
| 67 |
+
}[arg.data][arg.variant]
|
| 68 |
+
|
| 69 |
+
config.log_training_steps = 100
|
| 70 |
+
config.ckpt_steps = 2500
|
| 71 |
+
|
| 72 |
+
# Model section
|
| 73 |
+
config.student_name = 'bit_paper'
|
| 74 |
+
config.student = dict(depth=50, width=1)
|
| 75 |
+
|
| 76 |
+
config.teachers = ['prof_m']
|
| 77 |
+
config.prof_m_name = 'bit_paper'
|
| 78 |
+
config.prof_m_init = cd.inits[f'BiT-M R152x2 {arg.data} rc128']
|
| 79 |
+
config.prof_m = dict(depth=152, width=2)
|
| 80 |
+
|
| 81 |
+
# Preprocessing pipeline for student & tacher.
|
| 82 |
+
pp_common = (
|
| 83 |
+
'|value_range(-1, 1)'
|
| 84 |
+
f'|onehot({config.num_classes}, key="label", key_result="labels")'
|
| 85 |
+
'|keep("image", "labels")'
|
| 86 |
+
)
|
| 87 |
+
config.input.pp = f'decode|{arg.crop}|flip_lr' + pp_common
|
| 88 |
+
ppv = 'decode|resize_small(160)|central_crop(128)' + pp_common
|
| 89 |
+
|
| 90 |
+
config.mixup = dict(p=1.0)
|
| 91 |
+
|
| 92 |
+
# Distillation settings
|
| 93 |
+
config.distance = 'kl'
|
| 94 |
+
config.distance_kw = dict(t={
|
| 95 |
+
'flowers': {'fast': 10., 'medium': 1., 'long': 1.},
|
| 96 |
+
'pet': {'fast': 5., 'medium': 10., 'long': 2.},
|
| 97 |
+
}[arg.data][arg.variant])
|
| 98 |
+
|
| 99 |
+
# Optimizer section
|
| 100 |
+
config.grad_clip_norm = 1.0
|
| 101 |
+
config.optax_name = 'scale_by_adam'
|
| 102 |
+
config.optax = dict(mu_dtype='bfloat16')
|
| 103 |
+
|
| 104 |
+
config.lr = {
|
| 105 |
+
'flowers': {'fast': 0.003, 'medium': 0.001, 'long': 0.0003},
|
| 106 |
+
'pet': {'fast': 0.01, 'medium': 0.003, 'long': 0.003},
|
| 107 |
+
}[arg.data][arg.variant]
|
| 108 |
+
config.wd = {
|
| 109 |
+
'flowers': {'fast': 3e-4, 'medium': 1e-4, 'long': 1e-5},
|
| 110 |
+
'pet': {'fast': 1e-3, 'medium': 3e-4, 'long': 1e-5},
|
| 111 |
+
}[arg.data][arg.variant]
|
| 112 |
+
config.schedule = dict(warmup_steps=1500, decay_type='cosine')
|
| 113 |
+
config.optim_name = 'adam_hp'
|
| 114 |
+
|
| 115 |
+
# Eval section
|
| 116 |
+
minitrain_split = 'train[:512]' if not arg.runlocal else 'train[:16]'
|
| 117 |
+
if arg.data == 'flowers':
|
| 118 |
+
val_split = 'validation' if not arg.runlocal else 'validation[:16]'
|
| 119 |
+
test_split = 'test' if not arg.runlocal else 'test[:16]'
|
| 120 |
+
elif arg.data == 'pet':
|
| 121 |
+
val_split = 'train[90%:]' if not arg.runlocal else 'train[:16]'
|
| 122 |
+
test_split = 'test' if not arg.runlocal else 'test[:16]'
|
| 123 |
+
|
| 124 |
+
def get_eval(split):
|
| 125 |
+
return dict(
|
| 126 |
+
type='classification',
|
| 127 |
+
pred='student_fwd',
|
| 128 |
+
data=dict(name=config.input.data.name, split=split),
|
| 129 |
+
pp_fn=ppv,
|
| 130 |
+
loss_name='softmax_xent',
|
| 131 |
+
log_steps=500,
|
| 132 |
+
)
|
| 133 |
+
config.evals = {}
|
| 134 |
+
config.evals.student_train = get_eval(minitrain_split)
|
| 135 |
+
config.evals.student_val = get_eval(val_split)
|
| 136 |
+
config.evals.student_test = get_eval(test_split)
|
| 137 |
+
|
| 138 |
+
# Teacher is fixed, so rare evals.
|
| 139 |
+
teacher = dict(log_steps=100_000, pred='prof_m_fwd')
|
| 140 |
+
config.evals.teacher_train = {**config.evals.student_train, **teacher}
|
| 141 |
+
config.evals.teacher_val = {**config.evals.student_val, **teacher}
|
| 142 |
+
config.evals.teacher_test = {**config.evals.student_test, **teacher}
|
| 143 |
+
|
| 144 |
+
# Could in principle also look at agreement on other datasets!
|
| 145 |
+
def get_dist(split):
|
| 146 |
+
return dict(
|
| 147 |
+
type='proj.distill.distance',
|
| 148 |
+
pred='student_prof_m_fwd',
|
| 149 |
+
data=dict(name=config.input.data.name, split=split),
|
| 150 |
+
pp_fn=ppv + '|keep("image")',
|
| 151 |
+
log_steps=1000,
|
| 152 |
+
distances=({'kind': 'kl'}, {'kind': 'euclidean'},
|
| 153 |
+
{'kind': 'agree', 'k': 1}, {'kind': 'agree', 'k': 5}),
|
| 154 |
+
)
|
| 155 |
+
config.evals.dist_train = get_dist(minitrain_split)
|
| 156 |
+
config.evals.dist_val = get_dist(val_split)
|
| 157 |
+
config.evals.dist_test = get_dist(test_split)
|
| 158 |
+
|
| 159 |
+
# Make a few things much smaller for quick local debugging testruns.
|
| 160 |
+
if arg.runlocal:
|
| 161 |
+
config.input.shuffle_buffer_size = 10
|
| 162 |
+
config.input.batch_size = 8
|
| 163 |
+
|
| 164 |
+
return config
|
big_vision_repo/big_vision/configs/proj/distill/bigsweep_food_sun.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Distilling BiT-R152x2 into BiT-R50x1 on Food101/Sun397 as in https://arxiv.org/abs/2106.05237
|
| 17 |
+
|
| 18 |
+
While many epochs are required, this is a small dataset, and thus overall it
|
| 19 |
+
is still fast and possible to run on the relatively small v3-8TPUs (or GPUs).
|
| 20 |
+
|
| 21 |
+
This configuration contains the recommended settings from Fig3/Tab4 of the
|
| 22 |
+
paper, which can be selected via the fast/medium/long config argument.
|
| 23 |
+
(best settings were selected on a 10% minival)
|
| 24 |
+
|
| 25 |
+
For Food101:
|
| 26 |
+
- The `fast` variant takes ~45min on a v2-8 TPU.
|
| 27 |
+
Example logs at gs://big_vision/distill/bit_food_fast_06-19_0547/big_vision_metrics.txt
|
| 28 |
+
Example logs at gs://big_vision/distill/bit_sun_fast_06-20_1839/big_vision_metrics.txt
|
| 29 |
+
- The `long` variant takes ~14h on a v3-8 TPU.
|
| 30 |
+
Example logs at gs://big_vision/distill/bit_food_long_06-19_0614/big_vision_metrics.txt
|
| 31 |
+
Example logs at gs://big_vision/distill/bit_sun_long_06-20_1912/big_vision_metrics.txt
|
| 32 |
+
|
| 33 |
+
big_vision.trainers.proj.distill.distill \
|
| 34 |
+
--config big_vision/configs/proj/distill/bigsweep_food_sun.py:data=food,variant=fast \
|
| 35 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
import big_vision.configs.common as bvcc
|
| 39 |
+
import big_vision.configs.proj.distill.common as cd
|
| 40 |
+
import ml_collections as mlc
|
| 41 |
+
|
| 42 |
+
H, L = 160, 128
|
| 43 |
+
NCLS = dict(food=101, sun=397)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_config(arg=None):
|
| 47 |
+
"""Config for massive hypothesis-test on pet."""
|
| 48 |
+
arg = bvcc.parse_arg(arg, runlocal=False, data='food', variant='medium', crop='inception_crop(128)')
|
| 49 |
+
config = mlc.ConfigDict()
|
| 50 |
+
|
| 51 |
+
config.input = {}
|
| 52 |
+
config.input.data = dict(
|
| 53 |
+
name=dict(food='food101', sun='sun397')[arg.data],
|
| 54 |
+
split=dict(food='train[:90%]', sun='train')[arg.data],
|
| 55 |
+
)
|
| 56 |
+
config.input.batch_size = 512
|
| 57 |
+
config.input.cache_raw = True
|
| 58 |
+
config.input.shuffle_buffer_size = 50_000
|
| 59 |
+
config.prefetch_to_device = 4
|
| 60 |
+
|
| 61 |
+
config.num_classes = NCLS[arg.data]
|
| 62 |
+
config.total_epochs = {'fast': 100, 'medium': 1000, 'long': 3000}[arg.variant]
|
| 63 |
+
|
| 64 |
+
config.log_training_steps = 50
|
| 65 |
+
config.ckpt_steps = 2500
|
| 66 |
+
|
| 67 |
+
# Model section
|
| 68 |
+
config.student_name = 'bit_paper'
|
| 69 |
+
config.student = dict(depth=50, width=1)
|
| 70 |
+
|
| 71 |
+
config.teachers = ['prof_m']
|
| 72 |
+
config.prof_m_name = 'bit_paper'
|
| 73 |
+
config.prof_m_init = cd.inits[f'BiT-M R152x2 {arg.data} rc128']
|
| 74 |
+
config.prof_m = dict(depth=152, width=2)
|
| 75 |
+
|
| 76 |
+
# Preprocessing pipeline for student & tacher.
|
| 77 |
+
pp_common = (
|
| 78 |
+
'|value_range(-1, 1)'
|
| 79 |
+
f'|onehot({config.num_classes}, key="label", key_result="labels")'
|
| 80 |
+
'|keep("image", "labels")'
|
| 81 |
+
)
|
| 82 |
+
config.input.pp = f'decode|{arg.crop}|flip_lr' + pp_common
|
| 83 |
+
ppv = 'decode|resize_small(160)|central_crop(128)' + pp_common
|
| 84 |
+
|
| 85 |
+
config.mixup = dict(p=1.0)
|
| 86 |
+
|
| 87 |
+
# Distillation settings
|
| 88 |
+
config.distance = 'kl'
|
| 89 |
+
config.distance_kw = dict(t={
|
| 90 |
+
'food': {'fast': 10., 'medium': 10., 'long': 5.},
|
| 91 |
+
'sun': {'fast': 10., 'medium': 10., 'long': 10.},
|
| 92 |
+
}[arg.data][arg.variant])
|
| 93 |
+
|
| 94 |
+
# Optimizer section
|
| 95 |
+
config.grad_clip_norm = 1.0
|
| 96 |
+
config.optax_name = 'scale_by_adam'
|
| 97 |
+
config.optax = dict(mu_dtype='bfloat16')
|
| 98 |
+
|
| 99 |
+
config.lr = {
|
| 100 |
+
'food': {'fast': 0.01, 'medium': 0.001, 'long': 0.01},
|
| 101 |
+
'sun': {'fast': 0.01, 'medium': 0.001, 'long': 0.01},
|
| 102 |
+
}[arg.data][arg.variant]
|
| 103 |
+
config.wd = {
|
| 104 |
+
'food': {'fast': 1e-3, 'medium': 3e-4, 'long': 1e-4},
|
| 105 |
+
'sun': {'fast': 1e-3, 'medium': 1e-4, 'long': 3e-5},
|
| 106 |
+
}[arg.data][arg.variant]
|
| 107 |
+
config.schedule = dict(warmup_steps=1500, decay_type='cosine')
|
| 108 |
+
config.optim_name = 'adam_hp'
|
| 109 |
+
|
| 110 |
+
# Eval section
|
| 111 |
+
minitrain_split = 'train[:1024]' if not arg.runlocal else 'train[:16]'
|
| 112 |
+
if arg.data == 'food':
|
| 113 |
+
val_split = 'train[90%:]' if not arg.runlocal else 'train[:16]'
|
| 114 |
+
test_split = 'validation' if not arg.runlocal else 'test[:16]'
|
| 115 |
+
elif arg.data == 'sun':
|
| 116 |
+
val_split = 'validation' if not arg.runlocal else 'validation[:16]'
|
| 117 |
+
test_split = 'test' if not arg.runlocal else 'test[:16]'
|
| 118 |
+
|
| 119 |
+
def get_eval(split):
|
| 120 |
+
return dict(
|
| 121 |
+
type='classification',
|
| 122 |
+
pred='student_fwd',
|
| 123 |
+
data=dict(name=config.input.data.name, split=split),
|
| 124 |
+
pp_fn=ppv,
|
| 125 |
+
loss_name='softmax_xent',
|
| 126 |
+
log_steps=500,
|
| 127 |
+
)
|
| 128 |
+
config.evals = {}
|
| 129 |
+
config.evals.student_train = get_eval(minitrain_split)
|
| 130 |
+
config.evals.student_val = get_eval(val_split)
|
| 131 |
+
config.evals.student_test = get_eval(test_split)
|
| 132 |
+
|
| 133 |
+
# Teacher is fixed, so rare evals.
|
| 134 |
+
teacher = dict(log_steps=100_000, pred='prof_m_fwd')
|
| 135 |
+
config.evals.teacher_train = {**config.evals.student_train, **teacher}
|
| 136 |
+
config.evals.teacher_val = {**config.evals.student_val, **teacher}
|
| 137 |
+
config.evals.teacher_test = {**config.evals.student_test, **teacher}
|
| 138 |
+
|
| 139 |
+
# Could in principle also look at agreement on other datasets!
|
| 140 |
+
def get_dist(split):
|
| 141 |
+
return dict(
|
| 142 |
+
type='proj.distill.distance',
|
| 143 |
+
pred='student_prof_m_fwd',
|
| 144 |
+
data=dict(name=config.input.data.name, split=split),
|
| 145 |
+
pp_fn=ppv + '|keep("image")',
|
| 146 |
+
log_steps=1000,
|
| 147 |
+
distances=({'kind': 'kl'}, {'kind': 'euclidean'},
|
| 148 |
+
{'kind': 'agree', 'k': 1}, {'kind': 'agree', 'k': 5}),
|
| 149 |
+
)
|
| 150 |
+
config.evals.dist_train = get_dist(minitrain_split)
|
| 151 |
+
config.evals.dist_val = get_dist(val_split)
|
| 152 |
+
config.evals.dist_test = get_dist(test_split)
|
| 153 |
+
|
| 154 |
+
# Make a few things much smaller for quick local debugging testruns.
|
| 155 |
+
if arg.runlocal:
|
| 156 |
+
config.input.shuffle_buffer_size = 10
|
| 157 |
+
config.input.batch_size = 8
|
| 158 |
+
|
| 159 |
+
return config
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def get_hyper(hyper):
|
| 163 |
+
"""Hyper sweep."""
|
| 164 |
+
# TODO: update, similar to flowers_pet sweep.
|
| 165 |
+
# By default, not running the MASSIVE sweep, just the recommended setting
|
| 166 |
+
# across durations. However, code for sweep is left for reference/convenience.
|
| 167 |
+
return hyper.zipit([
|
| 168 |
+
hyper.sweep('config.total_epochs', [100, 1_000]),
|
| 169 |
+
hyper.sweep('config.mixup.p', [0.0, 1.0]),
|
| 170 |
+
hyper.sweep('config.weight_decay', [1e-3, 1e-5]),
|
| 171 |
+
])
|
| 172 |
+
|
| 173 |
+
# pylint: disable=unreachable
|
| 174 |
+
|
| 175 |
+
def fix(**kw):
|
| 176 |
+
return hyper.product([hyper.fixed(f'config.{k}', v, length=1)
|
| 177 |
+
for k, v in kw.items()])
|
| 178 |
+
|
| 179 |
+
def setting(p, l, m, crop, pp_end=None, **extra):
|
| 180 |
+
pp_end = pp_end or (
|
| 181 |
+
f'|value_range(-1, 1, key="image")'
|
| 182 |
+
f'|onehot({NCLS}, key="label", key_result="labels")'
|
| 183 |
+
f'|keep("image", "labels")'
|
| 184 |
+
)
|
| 185 |
+
return hyper.product([
|
| 186 |
+
fix(**{'mixup.p': p}),
|
| 187 |
+
fix(l=l, m=m, crop=crop),
|
| 188 |
+
fix(pp_train=f'decode|{crop}|flip_lr|randaug({l},{m})' + pp_end),
|
| 189 |
+
fix(**extra)
|
| 190 |
+
])
|
| 191 |
+
|
| 192 |
+
# Mixup, Layers and Mag in randaug.
|
| 193 |
+
plm = [(0.0, 0, 0), (0.1, 0, 0), (0.5, 0, 0), (1.0, 0, 0)]
|
| 194 |
+
return hyper.product([
|
| 195 |
+
hyper.sweep('config.total_epochs', [100, 1000, 3000]),
|
| 196 |
+
hyper.sweep('config.lr.base', [0.001, 0.003, 0.01]),
|
| 197 |
+
hyper.sweep('config.distance_kw.t', [1.0, 2.0, 5.0, 10.0]),
|
| 198 |
+
hyper.sweep('config.weight_decay', [1e-5, 3e-5, 1e-4, 3e-4, 1e-3]),
|
| 199 |
+
hyper.chainit(
|
| 200 |
+
[setting(p=p, l=l, m=m,
|
| 201 |
+
crop=(f'resize({H})'
|
| 202 |
+
f'|inception_crop({L}, outkey="student")'
|
| 203 |
+
f'|central_crop({L}, outkey="teacher")'),
|
| 204 |
+
pp_end=(
|
| 205 |
+
f'|value_range(-1, 1, key="student")'
|
| 206 |
+
f'|value_range(-1, 1, key="teacher")'
|
| 207 |
+
f'|onehot({NCLS}, key="label", key_result="labels")'
|
| 208 |
+
f'|keep("student", "teacher", "labels")'))
|
| 209 |
+
for p, l, m in plm] +
|
| 210 |
+
[setting(p=p, l=l, m=m, crop=f'inception_crop({L})') for
|
| 211 |
+
p, l, m in plm],
|
| 212 |
+
)
|
| 213 |
+
])
|
big_vision_repo/big_vision/configs/proj/distill/bit_i1k.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Distilling BiT-R152x2 into BiT-R50x1 on ILSVRC-2012 as in https://arxiv.org/abs/2106.05237
|
| 17 |
+
|
| 18 |
+
Note that as per paper title, good results require many epochs and thus
|
| 19 |
+
a lot of _patience_. For experimentation/exploration, consider
|
| 20 |
+
using the smaller datasets.
|
| 21 |
+
|
| 22 |
+
300ep take about 15h on a v3-32 TPU, an example log is available at:
|
| 23 |
+
Example logs at gs://big_vision/distill/bit_i1k_300ep_06-16/big_vision_metrics.txt
|
| 24 |
+
|
| 25 |
+
big_vision.trainers.proj.distill.distill \
|
| 26 |
+
--config big_vision/configs/proj/distill/bit_i1k.py \
|
| 27 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 28 |
+
--config.total_epochs 1200
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
import big_vision.configs.common as bvcc
|
| 32 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 33 |
+
import big_vision.configs.proj.distill.common as cd
|
| 34 |
+
import ml_collections as mlc
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def get_config(arg=None):
|
| 38 |
+
"""Config for distilling on ImageNet."""
|
| 39 |
+
arg = bvcc.parse_arg(arg, runlocal=False)
|
| 40 |
+
config = mlc.ConfigDict()
|
| 41 |
+
|
| 42 |
+
config.input = {}
|
| 43 |
+
config.input.data = dict(name='imagenet2012', split='train[:98%]')
|
| 44 |
+
config.input.batch_size = 4096
|
| 45 |
+
config.input.shuffle_buffer_size = 250_000
|
| 46 |
+
|
| 47 |
+
config.num_classes = 1000
|
| 48 |
+
config.total_epochs = 1200 # A good middle-ground
|
| 49 |
+
|
| 50 |
+
config.log_training_steps = 50
|
| 51 |
+
config.ckpt_steps = 1000
|
| 52 |
+
config.keep_ckpt_steps = 20000
|
| 53 |
+
|
| 54 |
+
# Model section
|
| 55 |
+
config.student_name = 'bit_paper'
|
| 56 |
+
config.student = dict(depth=50, width=1)
|
| 57 |
+
|
| 58 |
+
config.teachers = ['prof_m'] # You could even add multiple.
|
| 59 |
+
|
| 60 |
+
# TODO: use public checkpoint name.
|
| 61 |
+
config.prof_m_name = 'bit_paper'
|
| 62 |
+
config.prof_m_init = cd.inits['BiT-M R152x2 imagenet2012 ic224']
|
| 63 |
+
config.prof_m = dict(depth=152, width=2)
|
| 64 |
+
|
| 65 |
+
pp_common = (
|
| 66 |
+
'|value_range(-1, 1)'
|
| 67 |
+
'|onehot(1000, key="{lbl}", key_result="labels")'
|
| 68 |
+
'|keep("image", "labels")'
|
| 69 |
+
)
|
| 70 |
+
config.input.pp = (
|
| 71 |
+
'decode_jpeg_and_inception_crop(224)|flip_lr' +
|
| 72 |
+
pp_common.format(lbl='label')
|
| 73 |
+
)
|
| 74 |
+
ppv = 'decode|resize_small(256)|central_crop(224)' + pp_common
|
| 75 |
+
|
| 76 |
+
config.mixup = dict(p=1.0)
|
| 77 |
+
|
| 78 |
+
# Distillation settings
|
| 79 |
+
config.distance = 'kl'
|
| 80 |
+
config.distance_kw = dict(t=1.0)
|
| 81 |
+
|
| 82 |
+
# Optimizer section
|
| 83 |
+
config.grad_clip_norm = 1.0
|
| 84 |
+
config.optax_name = 'scale_by_adam'
|
| 85 |
+
config.optax = dict(mu_dtype='bfloat16')
|
| 86 |
+
|
| 87 |
+
config.lr = 0.03
|
| 88 |
+
config.wd = 0.0003
|
| 89 |
+
config.schedule = dict(warmup_steps=5000, decay_type='cosine')
|
| 90 |
+
|
| 91 |
+
# Eval section
|
| 92 |
+
minitrain_split = 'train[:2%]' if not arg.runlocal else 'train[:16]'
|
| 93 |
+
minival_split = 'train[99%:]' if not arg.runlocal else 'train[:16]'
|
| 94 |
+
val_split = 'validation' if not arg.runlocal else 'validation[:16]'
|
| 95 |
+
real_split = 'validation' if not arg.runlocal else 'validation[:16]'
|
| 96 |
+
v2_split = 'test' if not arg.runlocal else 'test[:16]'
|
| 97 |
+
|
| 98 |
+
def get_eval(split, dataset='imagenet2012'):
|
| 99 |
+
return dict(
|
| 100 |
+
type='classification',
|
| 101 |
+
pred='student_fwd',
|
| 102 |
+
data=dict(name=dataset, split=split),
|
| 103 |
+
pp_fn=ppv.format(lbl='label'),
|
| 104 |
+
loss_name='softmax_xent',
|
| 105 |
+
log_steps=1000,
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
config.evals = {}
|
| 109 |
+
config.evals.student_train = get_eval(minitrain_split)
|
| 110 |
+
config.evals.student_minival = get_eval(minival_split)
|
| 111 |
+
config.evals.student_val = get_eval(val_split)
|
| 112 |
+
config.evals.student_v2 = get_eval(v2_split, dataset='imagenet_v2')
|
| 113 |
+
config.evals.student_real = get_eval(real_split, dataset='imagenet2012_real')
|
| 114 |
+
config.evals.student_real.pp_fn = ppv.format(lbl='real_label')
|
| 115 |
+
|
| 116 |
+
config.evals.student_fewshot = get_fewshot_lsr(runlocal=arg.runlocal)
|
| 117 |
+
config.evals.student_fewshot.pred = 'student_fwd'
|
| 118 |
+
config.evals.student_fewshot.log_steps = 10_000
|
| 119 |
+
|
| 120 |
+
teacher_eval = dict(
|
| 121 |
+
log_steps=100_000, # Teacher is fixed, so rare evals.
|
| 122 |
+
pred='prof_m_fwd',
|
| 123 |
+
)
|
| 124 |
+
config.evals.teacher_train = {**config.evals.student_train, **teacher_eval}
|
| 125 |
+
config.evals.teacher_minival = {**config.evals.student_minival, **teacher_eval}
|
| 126 |
+
config.evals.teacher_val = {**config.evals.student_val, **teacher_eval}
|
| 127 |
+
config.evals.teacher_v2 = {**config.evals.student_v2, **teacher_eval}
|
| 128 |
+
config.evals.teacher_real = {**config.evals.student_real, **teacher_eval}
|
| 129 |
+
config.evals.teacher_fewshot = {**config.evals.student_fewshot, **teacher_eval}
|
| 130 |
+
config.evals.teacher_fewshot.prefix = 'z_teacher/'
|
| 131 |
+
|
| 132 |
+
# Could in principle also look at agreement on other datasets!
|
| 133 |
+
def get_dist(split, dataset='imagenet2012'):
|
| 134 |
+
return dict(
|
| 135 |
+
type='proj.distill.distance',
|
| 136 |
+
pred='student_prof_m_fwd',
|
| 137 |
+
data=dict(name=dataset, split=split),
|
| 138 |
+
pp_fn=ppv.format(lbl='label') + '|keep("image")',
|
| 139 |
+
log_steps=1000,
|
| 140 |
+
distances=({'kind': 'kl'}, {'kind': 'euclidean'},
|
| 141 |
+
{'kind': 'agree', 'k': 1}, {'kind': 'agree', 'k': 5}),
|
| 142 |
+
)
|
| 143 |
+
config.evals.dist_train = get_dist(minitrain_split)
|
| 144 |
+
config.evals.dist_minival = get_dist(minival_split)
|
| 145 |
+
config.evals.dist_val = get_dist(val_split)
|
| 146 |
+
config.evals.dist_v2 = get_dist(v2_split, dataset='imagenet_v2')
|
| 147 |
+
|
| 148 |
+
# NOTE: CKA evaluator does not work with batch padding, so the size of the
|
| 149 |
+
# split must be a multiple of the batch size.
|
| 150 |
+
def get_cka(split):
|
| 151 |
+
return dict(
|
| 152 |
+
type='proj.distill.cka',
|
| 153 |
+
pred='student_prof_m_fwd',
|
| 154 |
+
data=dict(name='imagenet2012', split=split),
|
| 155 |
+
pp_fn=ppv.format(lbl='label') + '|keep("image")',
|
| 156 |
+
log_steps=1000,
|
| 157 |
+
)
|
| 158 |
+
config.evals.cka_train = get_cka('train[:24576]' if not arg.runlocal else 'train[:16]')
|
| 159 |
+
config.evals.cka_minival = get_cka('train[-24576:]' if not arg.runlocal else 'train[:16]')
|
| 160 |
+
config.evals.cka_val = get_cka('validation[:49152]' if not arg.runlocal else 'validation[:16]')
|
| 161 |
+
|
| 162 |
+
# Make a few things much smaller for quick local debugging testruns.
|
| 163 |
+
if arg.runlocal:
|
| 164 |
+
config.input.shuffle_buffer_size = 10
|
| 165 |
+
config.input.batch_size = 8
|
| 166 |
+
|
| 167 |
+
return config
|
big_vision_repo/big_vision/configs/proj/distill/common.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""Most common teachers for distillation."""
|
| 16 |
+
|
| 17 |
+
# pylint: disable=line-too-long
|
| 18 |
+
inits = { # pylint: disable=duplicate-key Internally, we override some paths for convenience.
|
| 19 |
+
'BiT-M R152x2 imagenet2012 ic224': 'gs://bit_models/distill/R152x2_T_224.npz',
|
| 20 |
+
'BiT-M R152x2 imagenet2012 rc384': 'gs://bit_models/distill/R152x2_T_384.npz',
|
| 21 |
+
'BiT-M R152x2 flowers rc128': 'gs://bit_models/distill/R152x2_T_flowers128.npz',
|
| 22 |
+
'BiT-M R152x2 pet rc128': 'gs://bit_models/distill/R152x2_T_pet128.npz',
|
| 23 |
+
'BiT-M R152x2 food rc128': 'gs://bit_models/distill/R152x2_T_food128.npz',
|
| 24 |
+
'BiT-M R152x2 sun rc128': 'gs://bit_models/distill/R152x2_T_sun128.npz',
|
| 25 |
+
|
| 26 |
+
}
|
| 27 |
+
# pylint: enable=line-too-long
|
big_vision_repo/big_vision/configs/proj/flexivit/README.md
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# FlexiViT: One Model for All Patch Sizes
|
| 2 |
+
*by Lucas Beyer, Pavel Izmailov, Alexander Kolesnikov, Mathilde Caron, Simon Kornblith, Xiaohua Zhai, Matthias Minderer, Michael Tschannen, Ibrahim Alabdulmohsin, Filip Pavetic*
|
| 3 |
+
|
| 4 |
+
## Introduction
|
| 5 |
+
We publish all pre-trained FlexiViT models, and configurations for training
|
| 6 |
+
those, as well as training logs for one run.
|
| 7 |
+
|
| 8 |
+
Please read the main [big_vision README](/README.md) to learn how to run
|
| 9 |
+
configs, and remember that each config file contains an example invocation in
|
| 10 |
+
the top-level comment.
|
| 11 |
+
|
| 12 |
+
## Pre-trained paper models
|
| 13 |
+
|
| 14 |
+
Here are the models that we used as backbones in the paper. See Tables in the
|
| 15 |
+
appendix of the paper for expected scores at various patch-sizes and on various
|
| 16 |
+
datasets.
|
| 17 |
+
|
| 18 |
+
First, the recommended models we used for all experiments.
|
| 19 |
+
Remember that the input is 240px, not 224px:
|
| 20 |
+
|
| 21 |
+
| Dataset | Model | Download link | Notes |
|
| 22 |
+
| :--- | :---: | :---: | :---: |
|
| 23 |
+
| ImageNet-1k | FlexiViT-L | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_l_i1k.npz) | 1200ep version |
|
| 24 |
+
| ImageNet-1k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i1k.npz) | 1200ep version |
|
| 25 |
+
| ImageNet-1k | FlexiViT-S | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_s_i1k.npz) | 1200ep version |
|
| 26 |
+
| ImageNet-21k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i21k_300ep.npz) | 300ep version. 1000ep version below is better but was not used in the paper for fair comparison to baselines. |
|
| 27 |
+
| ImageNet-21k | ViT-B/16 | [link](https://storage.googleapis.com/big_vision/flexivit/vit_b16_i21k_300ep.npz) | Apples-to-apples non-flexi baseline used throughout the paper. |
|
| 28 |
+
| ImageNet-21k | ViT-B/30 | [link](https://storage.googleapis.com/big_vision/flexivit/vit_b30_i21k_300ep.npz) | Apples-to-apples non-flexi baseline used throughout the paper. |
|
| 29 |
+
|
| 30 |
+
These models can be used directly in our codebase by specifying
|
| 31 |
+
`model_name = "proj.flexi.vit"` and `model_init = "FlexiViT-L i1k"` for example.
|
| 32 |
+
See the file `models/proj/flexi/vit.py` for more names.
|
| 33 |
+
|
| 34 |
+
*Important detail:* When further re-using these models with a flexible patch
|
| 35 |
+
size, it is recommended to keep the patch-embedding parameter buffer at its
|
| 36 |
+
original size, and change patch-size on the fly using pi-resize, as opposed to
|
| 37 |
+
changing the parameter buffer's size at load-time.
|
| 38 |
+
For re-using the models with a fixed patch size, either way is fine.
|
| 39 |
+
(The reason is that it is impossible to chain multiple resizes without loss,
|
| 40 |
+
eg doing 32->8->32 does not result in the original weights.)
|
| 41 |
+
|
| 42 |
+
Second, the list of all released models for completeness:
|
| 43 |
+
|
| 44 |
+
| Dataset | Model | Download link | Notes |
|
| 45 |
+
| :--- | :---: | :---: | :---: |
|
| 46 |
+
| ImageNet-21k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i21k_1000ep.npz) | 1000ep version. Should be the best available -B model. |
|
| 47 |
+
| ImageNet-21k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i21k_90ep.npz) | 90ep version |
|
| 48 |
+
| ImageNet-1k | FlexiViT-L | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_l_i1k_600ep.npz) | 600ep version |
|
| 49 |
+
| ImageNet-1k | FlexiViT-L | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_l_i1k_300ep.npz) | 300ep version |
|
| 50 |
+
| ImageNet-1k | FlexiViT-L | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_l_i1k_90ep.npz) | 90ep version |
|
| 51 |
+
| ImageNet-1k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i1k_600ep.npz) | 600ep version |
|
| 52 |
+
| ImageNet-1k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i1k_300ep.npz) | 300ep version |
|
| 53 |
+
| ImageNet-1k | FlexiViT-B | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_b_i1k_90ep.npz) | 90ep version |
|
| 54 |
+
| ImageNet-1k | FlexiViT-S | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_s_i1k_600ep.npz) | 600ep version |
|
| 55 |
+
| ImageNet-1k | FlexiViT-S | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_s_i1k_300ep.npz) | 300ep version |
|
| 56 |
+
| ImageNet-1k | FlexiViT-S | [link](https://storage.googleapis.com/big_vision/flexivit/flexivit_s_i1k_90ep.npz) | 90ep version |
|
| 57 |
+
|
| 58 |
+
## Results
|
| 59 |
+
|
| 60 |
+
We provide full training logs for a run with this public code on Cloud that
|
| 61 |
+
reproduces the FlexiViT-S 90ep on i1k results:
|
| 62 |
+
- [metrics](https://storage.googleapis.com/big_vision/flexivit/deit3_i1k_s_90ep_12-15_2254/big_vision_metrics.txt)
|
| 63 |
+
- [config](https://storage.googleapis.com/big_vision/flexivit/deit3_i1k_s_90ep_12-15_2254/config.json)
|
| 64 |
+
- or `gs://big_vision/flexivit/deit3_i1k_s_90ep_12-15_2254`.
|
big_vision_repo/big_vision/configs/proj/flexivit/i1k_deit3_distill.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Distillation of ViT models into FlexiViT on ImageNet1k.
|
| 17 |
+
|
| 18 |
+
Run training of the -S variant for 90ep:
|
| 19 |
+
|
| 20 |
+
big_vision.trainers.proj.flexi.distill \
|
| 21 |
+
--config big_vision/configs/proj/flexivit/i1k_deit3_distill.py \
|
| 22 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 23 |
+
--config.total_epochs 90 --config.variant S
|
| 24 |
+
|
| 25 |
+
Logdir for one reproduction run:
|
| 26 |
+
- gs://big_vision/flexivit/deit3_i1k_s_90ep_12-15_2254
|
| 27 |
+
|
| 28 |
+
Timing on Cloud:
|
| 29 |
+
- S on v3-32: Walltime:10h16m (4h39m eval)
|
| 30 |
+
|
| 31 |
+
Note that we did not optimize the input for Cloud,
|
| 32 |
+
with tuned caching and prefetching, we should be able to get:
|
| 33 |
+
- S on v3-32: Walltime: ~6h30m (~1h30m eval)
|
| 34 |
+
- B on v3-32: Walltime: ~16h00m (~2h30m eval)
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
import big_vision.configs.common as bvcc
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def get_config(arg=None):
|
| 41 |
+
"""Config for distilling ViT on ImageNet1k."""
|
| 42 |
+
c = bvcc.parse_arg(arg, runlocal=False, res=240)
|
| 43 |
+
|
| 44 |
+
c.seed = 0
|
| 45 |
+
c.total_epochs = 90
|
| 46 |
+
c.num_classes = 1000
|
| 47 |
+
c.loss = 'softmax_xent'
|
| 48 |
+
|
| 49 |
+
c.input = {}
|
| 50 |
+
c.input.data = dict(
|
| 51 |
+
name='imagenet2012',
|
| 52 |
+
split='train[:99%]',
|
| 53 |
+
)
|
| 54 |
+
c.input.batch_size = 1024 if not c.runlocal else 8
|
| 55 |
+
c.input.cache_raw = False # Needs up to 120GB of RAM!
|
| 56 |
+
c.input.shuffle_buffer_size = 250_000 if not c.runlocal else 10
|
| 57 |
+
|
| 58 |
+
c.log_training_steps = 50
|
| 59 |
+
c.ckpt_steps = 1000
|
| 60 |
+
|
| 61 |
+
# Model section
|
| 62 |
+
c.variant = 'B'
|
| 63 |
+
init = bvcc.format_str('deit3_{variant}_384_1k', c)
|
| 64 |
+
c.student_name = 'proj.flexi.vit'
|
| 65 |
+
c.student_init = init
|
| 66 |
+
c.student = dict(variant=c.get_ref('variant'), pool_type='tok', patch_size=(16, 16))
|
| 67 |
+
|
| 68 |
+
c.teachers = ['prof'] # You could even add multiple.
|
| 69 |
+
c.prof_name = 'vit'
|
| 70 |
+
c.prof_init = init
|
| 71 |
+
c.prof = dict(variant=c.get_ref('variant'), pool_type='tok', patch_size=(16, 16))
|
| 72 |
+
|
| 73 |
+
pp_label = '|onehot(1000, key="{lbl}", key_result="labels")|keep("image", "prof", "labels")'
|
| 74 |
+
c.input.pp = (
|
| 75 |
+
f'decode|inception_crop|flip_lr'
|
| 76 |
+
'|copy("image", "prof")'
|
| 77 |
+
f'|resize({c.res})|value_range'
|
| 78 |
+
'|resize(384, key="prof")|value_range(key="prof")'
|
| 79 |
+
+ pp_label.format(lbl='label')
|
| 80 |
+
)
|
| 81 |
+
pp_eval_both = (
|
| 82 |
+
'decode|copy("image", "prof")|'
|
| 83 |
+
f'|resize({c.res//7*8})|central_crop({c.res})|value_range'
|
| 84 |
+
f'|resize({384//7*8}, key="prof")|central_crop(384, key="prof")|value_range(key="prof")|'
|
| 85 |
+
)
|
| 86 |
+
pp_eval_student = (
|
| 87 |
+
f'decode|resize({c.res//7*8})|central_crop({c.res})|value_range(-1, 1)'
|
| 88 |
+
)
|
| 89 |
+
pp_eval_prof = (
|
| 90 |
+
f'decode|resize({384//7*8})|central_crop(384)|value_range(outkey="prof")'
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
c.mixup = dict(p=1.0, n=2)
|
| 94 |
+
|
| 95 |
+
# Distillation settings
|
| 96 |
+
c.distance = 'kl'
|
| 97 |
+
c.distance_kw = dict(t=1.0)
|
| 98 |
+
|
| 99 |
+
# Optimizer section
|
| 100 |
+
c.grad_clip_norm = 1.0
|
| 101 |
+
c.optax_name = 'scale_by_adam'
|
| 102 |
+
c.optax = dict(mu_dtype='bfloat16')
|
| 103 |
+
|
| 104 |
+
c.lr = 1e-4
|
| 105 |
+
c.wd = 1e-5
|
| 106 |
+
c.schedule = dict(warmup_steps=5000, decay_type='cosine')
|
| 107 |
+
|
| 108 |
+
# Define the model parameters which are flexible:
|
| 109 |
+
c.flexi = dict()
|
| 110 |
+
c.flexi.seqhw = dict(
|
| 111 |
+
# The settings to sample from. Corresponding patch-sizes at 240px:
|
| 112 |
+
# 48, 40, 30, 24, 20, 16, 15, 12, 10, 8
|
| 113 |
+
v=(5, 6, 8, 10, 12, 15, 16, 20, 24, 30),
|
| 114 |
+
# The probabilities/weights of them. Default uniform.
|
| 115 |
+
p=(1, 1, 1, 1, 1, 1, 1, 1, 1, 1),
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
# Eval section
|
| 119 |
+
def mksplit(split):
|
| 120 |
+
if c.runlocal:
|
| 121 |
+
return split.split('[')[0] + '[:16]'
|
| 122 |
+
return split
|
| 123 |
+
|
| 124 |
+
minitrain_split = mksplit('train[:2%]')
|
| 125 |
+
minival_split = mksplit('train[99%:]')
|
| 126 |
+
val_split = mksplit('validation')
|
| 127 |
+
test_split = mksplit('test')
|
| 128 |
+
c.aggressive_cache = False
|
| 129 |
+
|
| 130 |
+
def get_eval(s, split, dataset='imagenet2012'):
|
| 131 |
+
return dict(
|
| 132 |
+
type='classification',
|
| 133 |
+
pred=f'student_seqhw={s}',
|
| 134 |
+
data=dict(name=dataset, split=split),
|
| 135 |
+
pp_fn=pp_eval_student + pp_label.format(lbl='label'),
|
| 136 |
+
loss_name='sigmoid_xent',
|
| 137 |
+
log_percent=0.05,
|
| 138 |
+
cache_final=False,
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
c.evals = {}
|
| 142 |
+
for s in c.flexi.seqhw.v:
|
| 143 |
+
c.evals[f'student_minitrain_{s:02d}'] = get_eval(s, minitrain_split)
|
| 144 |
+
c.evals[f'student_minival_{s:02d}'] = get_eval(s, minival_split)
|
| 145 |
+
c.evals[f'student_val_{s:02d}'] = get_eval(s, val_split)
|
| 146 |
+
c.evals[f'student_v2_{s:02d}'] = get_eval(s, test_split, 'imagenet_v2')
|
| 147 |
+
c.evals[f'student_a_{s:02d}'] = get_eval(s, test_split, 'imagenet_a')
|
| 148 |
+
c.evals[f'student_r_{s:02d}'] = get_eval(s, test_split, 'imagenet_r')
|
| 149 |
+
c.evals[f'student_real_{s:02d}'] = get_eval(s, val_split, 'imagenet2012_real')
|
| 150 |
+
c.evals[f'student_real_{s:02d}'].pp_fn = pp_eval_student + pp_label.format(lbl='real_label')
|
| 151 |
+
|
| 152 |
+
def get_eval_t(split, dataset='imagenet2012'):
|
| 153 |
+
return dict(
|
| 154 |
+
type='classification',
|
| 155 |
+
pred='prof',
|
| 156 |
+
data=dict(name=dataset, split=split),
|
| 157 |
+
pp_fn=pp_eval_prof + pp_label.format(lbl='label'),
|
| 158 |
+
loss_name='sigmoid_xent',
|
| 159 |
+
log_percent=0.5, # Teacher is fixed, so eval just for plots.
|
| 160 |
+
cache_final=False,
|
| 161 |
+
)
|
| 162 |
+
c.evals.teacher_minitrain = get_eval_t(minitrain_split)
|
| 163 |
+
c.evals.teacher_minival = get_eval_t(minival_split)
|
| 164 |
+
c.evals.teacher_val = get_eval_t(val_split)
|
| 165 |
+
c.evals.teacher_v2 = get_eval_t(test_split, 'imagenet_v2')
|
| 166 |
+
c.evals.teacher_a = get_eval_t(test_split, 'imagenet_a')
|
| 167 |
+
c.evals.teacher_r = get_eval_t(test_split, 'imagenet_r')
|
| 168 |
+
c.evals.teacher_real = get_eval_t(val_split, 'imagenet2012_real')
|
| 169 |
+
c.evals.teacher_real.pp_fn = pp_eval_prof + pp_label.format(lbl='real_label')
|
| 170 |
+
|
| 171 |
+
# Distance evaluators
|
| 172 |
+
def get_dist(split, s):
|
| 173 |
+
return dict(
|
| 174 |
+
type='proj.distill.distance',
|
| 175 |
+
pred=f'student_seqhw={s}_prof',
|
| 176 |
+
data=dict(name='imagenet2012', split=split),
|
| 177 |
+
pp_fn=pp_eval_both + '|keep("image", "prof")',
|
| 178 |
+
log_percent=0.05,
|
| 179 |
+
distances=({'kind': 'kl'}, {'kind': 'logsoftmax_euclidean'},
|
| 180 |
+
{'kind': 'agree', 'k': 1}, {'kind': 'agree', 'k': 5}),
|
| 181 |
+
cache_final=False,
|
| 182 |
+
)
|
| 183 |
+
for s in c.flexi.seqhw.v:
|
| 184 |
+
c.evals[f'dist_minitrain_{s:02d}'] = get_dist(minitrain_split, s)
|
| 185 |
+
c.evals[f'dist_val_{s:02d}'] = get_dist(val_split, s)
|
| 186 |
+
|
| 187 |
+
return c
|
big_vision_repo/big_vision/configs/proj/flexivit/i21k_distill.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Distill flexible-seqlen ViT on ImageNet-21k from (internal link) B/8.
|
| 17 |
+
|
| 18 |
+
This config is for reference, we never ran it on public infrastructure.
|
| 19 |
+
|
| 20 |
+
big_vision.trainers.proj.flexi.distill \
|
| 21 |
+
--config big_vision/configs/proj/flexivit/i21k_distill.py \
|
| 22 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 23 |
+
--config.total_epochs 90
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
import big_vision.configs.common as bvcc
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_config(arg=None):
|
| 30 |
+
"""Config for training."""
|
| 31 |
+
# 240px is nice because it's divisible by
|
| 32 |
+
# [240, 120, 80, 60, 48, 40, 30, 24, 20, 16, 15, 12, 10, 8, 6, 5, 4, 3, 2, 1]
|
| 33 |
+
c = bvcc.parse_arg(arg, runlocal=False, res=240)
|
| 34 |
+
|
| 35 |
+
c.seed = 0
|
| 36 |
+
c.total_epochs = 90
|
| 37 |
+
c.num_classes = 21843
|
| 38 |
+
c.init_head_bias = -10.0
|
| 39 |
+
c.loss = 'sigmoid_xent'
|
| 40 |
+
|
| 41 |
+
c.input = dict()
|
| 42 |
+
c.input.data = dict(
|
| 43 |
+
name='imagenet21k',
|
| 44 |
+
split='full[51200:]',
|
| 45 |
+
)
|
| 46 |
+
c.input.batch_size = 4096 if not c.runlocal else 8
|
| 47 |
+
c.input.shuffle_buffer_size = 250_000 if not c.runlocal else 25
|
| 48 |
+
|
| 49 |
+
pp_label_i21k = f'|onehot({c.num_classes})|keep("image", "prof", "labels")'
|
| 50 |
+
pp_label_i1k = '|onehot(1000, key="{lbl}", key_result="labels")|keep("image", "prof", "labels")'
|
| 51 |
+
c.input.pp = (
|
| 52 |
+
f'decode|inception_crop|flip_lr|copy("image", "prof")'
|
| 53 |
+
f'|resize({c.res})|value_range(-1, 1)'
|
| 54 |
+
f'|resize(224, outkey="prof")|value_range(-1, 1, key="prof")'
|
| 55 |
+
+ pp_label_i21k
|
| 56 |
+
)
|
| 57 |
+
pp_eval_both = (
|
| 58 |
+
'decode|copy("image", "prof")|'
|
| 59 |
+
f'|resize_small({c.res//7*8})|central_crop({c.res})|value_range(-1, 1)'
|
| 60 |
+
f'|resize_small(256, key="prof")|central_crop(224, key="prof")|value_range(-1, 1, key="prof")|'
|
| 61 |
+
)
|
| 62 |
+
pp_eval_student = (
|
| 63 |
+
f'decode|resize({c.res//7*8})|central_crop({c.res})|value_range(-1, 1)'
|
| 64 |
+
)
|
| 65 |
+
pp_eval_prof = (
|
| 66 |
+
'decode|resize(256)|central_crop(224)|value_range(-1, 1, outkey="prof")'
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
# Aggressive pre-fetching because our models here are small, so we not only
|
| 70 |
+
# can afford it, but we also need it for the smallest models to not be
|
| 71 |
+
# bottle-necked by the input pipeline. Play around with it for -L models tho.
|
| 72 |
+
c.input.prefetch = 8
|
| 73 |
+
c.prefetch_to_device = 4
|
| 74 |
+
|
| 75 |
+
c.log_training_steps = 50
|
| 76 |
+
c.ckpt_steps = 1000
|
| 77 |
+
|
| 78 |
+
# Model section
|
| 79 |
+
init = 'howto-i21k-B/8'
|
| 80 |
+
c.student_name = 'proj.flexi.vit'
|
| 81 |
+
c.student_init = init
|
| 82 |
+
c.student = dict(variant='B', pool_type='tok', patch_size=(8, 8))
|
| 83 |
+
|
| 84 |
+
c.teachers = ['prof'] # You could even add multiple.
|
| 85 |
+
c.prof_name = 'vit'
|
| 86 |
+
c.prof_init = init
|
| 87 |
+
c.prof = dict(variant='B/8', pool_type='tok')
|
| 88 |
+
|
| 89 |
+
# Define the model parameters which are flexible:
|
| 90 |
+
c.flexi = dict()
|
| 91 |
+
c.flexi.seqhw = dict(
|
| 92 |
+
# The settings to sample from. Corresponding patch-sizes at 240px:
|
| 93 |
+
# 48, 40, 30, 24, 20, 16, 15, 12, 10, 8
|
| 94 |
+
v=(5, 6, 8, 10, 12, 15, 16, 20, 24, 30),
|
| 95 |
+
# The probabilities/weights of them. Default uniform.
|
| 96 |
+
p=(1, 1, 1, 1, 1, 1, 1, 1, 1, 1),
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
# Distillation settings
|
| 100 |
+
c.distance = 'kl'
|
| 101 |
+
c.distance_kw = dict(t=1.0)
|
| 102 |
+
|
| 103 |
+
# Optimizer section
|
| 104 |
+
c.optax_name = 'scale_by_adam'
|
| 105 |
+
c.optax = dict(mu_dtype='bfloat16')
|
| 106 |
+
c.grad_clip_norm = 1.0
|
| 107 |
+
|
| 108 |
+
c.lr = 1e-4
|
| 109 |
+
c.wd = 1e-5
|
| 110 |
+
c.schedule = dict(warmup_steps=5000, decay_type='cosine')
|
| 111 |
+
|
| 112 |
+
c.mixup = dict(p=1.0)
|
| 113 |
+
|
| 114 |
+
####
|
| 115 |
+
# Preparing for evals
|
| 116 |
+
c.evals = {}
|
| 117 |
+
def mksplit(split):
|
| 118 |
+
if c.runlocal:
|
| 119 |
+
return split.split('[')[0] + '[:16]'
|
| 120 |
+
return split
|
| 121 |
+
|
| 122 |
+
####
|
| 123 |
+
# Student evals
|
| 124 |
+
|
| 125 |
+
# Evaluations on i21k itself.
|
| 126 |
+
def eval_i21k(s, split):
|
| 127 |
+
return dict(
|
| 128 |
+
type='classification',
|
| 129 |
+
pred=f'student_seqhw={s}',
|
| 130 |
+
data={**c.input.data, 'split': mksplit(split)},
|
| 131 |
+
pp_fn=pp_eval_student + pp_label_i21k,
|
| 132 |
+
loss_name=c.loss,
|
| 133 |
+
log_steps=5000, # Very fast O(seconds) so it's fine to run it often.
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
for s in c.flexi.seqhw.v:
|
| 137 |
+
c.evals[f'student_test{s:02d}'] = eval_i21k(s, 'full[:25_600]')
|
| 138 |
+
c.evals[f'student_val{s:02d}'] = eval_i21k(s, 'full[25_600:51_200]')
|
| 139 |
+
c.evals[f'student_minitrain{s:02d}'] = eval_i21k(s, 'full[51_200:76_800]')
|
| 140 |
+
|
| 141 |
+
# Evaluations on ImageNet1k variants by label-mapping.
|
| 142 |
+
def eval_i1k(s, dataset, split, lblmap):
|
| 143 |
+
return dict(
|
| 144 |
+
type='classification_with_labelmap',
|
| 145 |
+
pred=f'student_seqhw={s}',
|
| 146 |
+
data=dict(name=dataset, split=mksplit(split)),
|
| 147 |
+
pp_fn=pp_eval_student + pp_label_i1k.format(lbl='label'),
|
| 148 |
+
loss_name=c.loss,
|
| 149 |
+
log_steps=5000, # Very fast O(seconds) so it's fine to run it often.
|
| 150 |
+
label_mapping=lblmap,
|
| 151 |
+
)
|
| 152 |
+
for s in c.flexi.seqhw.v:
|
| 153 |
+
c.evals[f'student_i1k_val{s:02d}'] = eval_i1k(s, 'imagenet2012', 'validation', 'i1k_i21k')
|
| 154 |
+
c.evals[f'student_i1k_v2{s:02d}'] = eval_i1k(s, 'imagenet_v2', 'test', 'i1k_i21k')
|
| 155 |
+
c.evals[f'student_i1k_a{s:02d}'] = eval_i1k(s, 'imagenet_a', 'test', 'i1ka_i21k')
|
| 156 |
+
c.evals[f'student_i1k_r{s:02d}'] = eval_i1k(s, 'imagenet_r', 'test', 'i1kr_i21k')
|
| 157 |
+
c.evals[f'student_i1k_real{s:02d}'] = eval_i1k(s, 'imagenet2012_real', 'validation', 'i1k_i21k')
|
| 158 |
+
c.evals[f'student_i1k_real{s:02d}'].pp_fn = pp_eval_student + pp_label_i1k.format(lbl='real_label')
|
| 159 |
+
# TODO: add objectnet.
|
| 160 |
+
|
| 161 |
+
####
|
| 162 |
+
# Teacher evals
|
| 163 |
+
|
| 164 |
+
# Evaluations on i21k itself.
|
| 165 |
+
def eval_i21k_t(split):
|
| 166 |
+
return dict(
|
| 167 |
+
type='classification',
|
| 168 |
+
pred='prof',
|
| 169 |
+
data={**c.input.data, 'split': mksplit(split)},
|
| 170 |
+
pp_fn=pp_eval_prof + pp_label_i21k,
|
| 171 |
+
loss_name=c.loss,
|
| 172 |
+
log_steps=5000, # Very fast O(seconds) so it's fine to run it often.
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
c.evals.teacher_test = eval_i21k_t('full[:25_600]')
|
| 176 |
+
c.evals.teacher_val = eval_i21k_t('full[25_600:51_200]')
|
| 177 |
+
c.evals.teacher_minitrain = eval_i21k_t('full[51_200:76_800]')
|
| 178 |
+
|
| 179 |
+
# Evaluations on ImageNet1k variants by label-mapping.
|
| 180 |
+
def eval_i1k_t(dataset, split, lblmap):
|
| 181 |
+
return dict(
|
| 182 |
+
type='classification_with_labelmap',
|
| 183 |
+
pred='prof',
|
| 184 |
+
data=dict(name=dataset, split=mksplit(split)),
|
| 185 |
+
pp_fn=pp_eval_prof + pp_label_i1k.format(lbl='label'),
|
| 186 |
+
loss_name=c.loss,
|
| 187 |
+
log_percent=0.5, # Teacher is fixed, so eval just for plots.
|
| 188 |
+
label_mapping=lblmap,
|
| 189 |
+
)
|
| 190 |
+
c.evals.teacher_i1k_val = eval_i1k_t('imagenet2012', 'validation', 'i1k_i21k')
|
| 191 |
+
c.evals.teacher_i1k_v2 = eval_i1k_t('imagenet_v2', 'test', 'i1k_i21k')
|
| 192 |
+
c.evals.teacher_i1k_a = eval_i1k_t('imagenet_a', 'test', 'i1ka_i21k')
|
| 193 |
+
c.evals.teacher_i1k_r = eval_i1k_t('imagenet_r', 'test', 'i1kr_i21k')
|
| 194 |
+
c.evals.teacher_i1k_real = eval_i1k_t('imagenet2012_real', 'validation', 'i1k_i21k')
|
| 195 |
+
c.evals.teacher_i1k_real.pp_fn = pp_eval_prof + pp_label_i1k.format(lbl='real_label')
|
| 196 |
+
# TODO: add objectnet.
|
| 197 |
+
|
| 198 |
+
####
|
| 199 |
+
# Combined evals
|
| 200 |
+
|
| 201 |
+
def get_dist(split, s):
|
| 202 |
+
return dict(
|
| 203 |
+
type='proj.distill.distance',
|
| 204 |
+
pred=f'student_seqhw={s}_prof',
|
| 205 |
+
data=dict(name='imagenet2012', split=mksplit(split)),
|
| 206 |
+
pp_fn=pp_eval_both + '|keep("image", "prof")',
|
| 207 |
+
log_percent=0.05,
|
| 208 |
+
distances=({'kind': 'kl'}, {'kind': 'logsoftmax_euclidean'},
|
| 209 |
+
{'kind': 'agree', 'k': 1}, {'kind': 'agree', 'k': 5}),
|
| 210 |
+
)
|
| 211 |
+
for s in c.flexi.seqhw.v:
|
| 212 |
+
c.evals[f'dist_minitrain_{s:02d}'] = get_dist('full[51_200:76_800]', s)
|
| 213 |
+
c.evals[f'dist_val_{s:02d}'] = get_dist('full[25_600:51_200]', s)
|
| 214 |
+
|
| 215 |
+
# Few-shot evaluators not added for overkill reasons for now.
|
| 216 |
+
return c
|
big_vision_repo/big_vision/configs/proj/flexivit/i21k_sup.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Pre-training flexible-seqlen ViT on ImageNet-21k following (internal link).
|
| 17 |
+
|
| 18 |
+
This config is for reference, we never ran it on public infrastructure.
|
| 19 |
+
|
| 20 |
+
big_vision.trainers.proj.flexi.train \
|
| 21 |
+
--config big_vision/configs/proj/flexivit/i21k_sup.py \
|
| 22 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 23 |
+
--config.total_epochs 90
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
import big_vision.configs.common as bvcc
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def get_config(arg=None):
|
| 30 |
+
"""Config for training."""
|
| 31 |
+
# 240px is nice because it's divisible by
|
| 32 |
+
# [240, 120, 80, 60, 48, 40, 30, 24, 20, 16, 15, 12, 10, 8, 6, 5, 4, 3, 2, 1]
|
| 33 |
+
c = bvcc.parse_arg(arg, runlocal=False, res=240)
|
| 34 |
+
|
| 35 |
+
c.seed = 0
|
| 36 |
+
c.total_epochs = 90
|
| 37 |
+
c.num_classes = 21843
|
| 38 |
+
c.init_head_bias = -10.0
|
| 39 |
+
c.loss = 'sigmoid_xent'
|
| 40 |
+
|
| 41 |
+
c.input = dict()
|
| 42 |
+
c.input.data = dict(
|
| 43 |
+
name='imagenet21k',
|
| 44 |
+
split='full[51200:]',
|
| 45 |
+
)
|
| 46 |
+
c.input.batch_size = 4096 if not c.runlocal else 8
|
| 47 |
+
c.input.shuffle_buffer_size = 250_000 if not c.runlocal else 25
|
| 48 |
+
|
| 49 |
+
pp_common = '|value_range(-1, 1)|onehot({onehot_args})|keep("image", "labels")'
|
| 50 |
+
pp_common_i21k = pp_common.format(onehot_args=f'{c.num_classes}')
|
| 51 |
+
pp_common_i1k = pp_common.format(onehot_args='1000, key="{lbl}", key_result="labels"')
|
| 52 |
+
c.input.pp = f'decode_jpeg_and_inception_crop({c.res})|flip_lr|randaug(2,10)' + pp_common_i21k
|
| 53 |
+
def pp_eval(res=c.res):
|
| 54 |
+
return f'decode|resize_small({res//7*8})|central_crop({res})'
|
| 55 |
+
|
| 56 |
+
# To continue using the near-defunct randaug op.
|
| 57 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'archive.randaug']
|
| 58 |
+
|
| 59 |
+
# Aggressive pre-fetching because our models here are small, so we not only
|
| 60 |
+
# can afford it, but we also need it for the smallest models to not be
|
| 61 |
+
# bottle-necked by the input pipeline. Play around with it for -L models tho.
|
| 62 |
+
c.input.prefetch = 8
|
| 63 |
+
c.prefetch_to_device = 4
|
| 64 |
+
|
| 65 |
+
c.log_training_steps = 50
|
| 66 |
+
c.ckpt_steps = 1000
|
| 67 |
+
|
| 68 |
+
# Model section
|
| 69 |
+
c.model_name = 'proj.flexi.vit'
|
| 70 |
+
c.model = dict(
|
| 71 |
+
variant='B',
|
| 72 |
+
pool_type='tok',
|
| 73 |
+
posemb='learn',
|
| 74 |
+
# patch_size=(32, 32),
|
| 75 |
+
patch_size=(8, 8),
|
| 76 |
+
posemb_size=(7, 7),
|
| 77 |
+
seqhw=None, # Dynamic!
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
# Define the model parameters which are flexible:
|
| 81 |
+
c.flexi = dict()
|
| 82 |
+
c.flexi.seqhw = dict(
|
| 83 |
+
# The settings to sample from. Corresponding patch-sizes at 240px:
|
| 84 |
+
# 48, 40, 30, 24, 20, 16, 15, 12, 10, 8
|
| 85 |
+
v=(5, 6, 8, 10, 12, 15, 16, 20, 24, 30),
|
| 86 |
+
# The probabilities/weights of them. Default uniform.
|
| 87 |
+
p=(1, 1, 1, 1, 1, 1, 1, 1, 1, 1),
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
# Optimizer section
|
| 91 |
+
c.optax_name = 'scale_by_adam'
|
| 92 |
+
c.optax = dict(mu_dtype='bfloat16')
|
| 93 |
+
c.grad_clip_norm = 1.0
|
| 94 |
+
|
| 95 |
+
c.lr = 0.001
|
| 96 |
+
c.wd = 0.0001
|
| 97 |
+
c.schedule = dict(warmup_steps=10_000, decay_type='cosine')
|
| 98 |
+
|
| 99 |
+
c.mixup = dict(p=0.2, fold_in=None)
|
| 100 |
+
|
| 101 |
+
def mksplit(split):
|
| 102 |
+
if c.runlocal:
|
| 103 |
+
return split.split('[')[0] + '[:16]'
|
| 104 |
+
return split
|
| 105 |
+
|
| 106 |
+
# Evaluations on i21k itself.
|
| 107 |
+
def eval_i21k(s, split):
|
| 108 |
+
return dict(
|
| 109 |
+
type='classification',
|
| 110 |
+
pred=f'predict_seqhw={s}',
|
| 111 |
+
data={**c.input.data, 'split': mksplit(split)},
|
| 112 |
+
pp_fn=pp_eval() + pp_common_i21k,
|
| 113 |
+
loss_name=c.loss,
|
| 114 |
+
log_steps=5000, # Very fast O(seconds) so it's fine to run it often.
|
| 115 |
+
)
|
| 116 |
+
|
| 117 |
+
c.evals = {}
|
| 118 |
+
for s in c.flexi.seqhw.v:
|
| 119 |
+
c.evals[f'test{s:02d}'] = eval_i21k(s, 'full[:25_600]')
|
| 120 |
+
c.evals[f'val{s:02d}'] = eval_i21k(s, 'full[25_600:51_200]')
|
| 121 |
+
c.evals[f'train{s:02d}'] = eval_i21k(s, 'full[51_200:76_800]')
|
| 122 |
+
|
| 123 |
+
# Evaluations on ImageNet1k variants by label-mapping.
|
| 124 |
+
def eval_i1k(s, dataset, split, lblmap):
|
| 125 |
+
return dict(
|
| 126 |
+
type='classification_with_labelmap',
|
| 127 |
+
pred=f'predict_seqhw={s}',
|
| 128 |
+
data=dict(name=dataset, split=mksplit(split)),
|
| 129 |
+
pp_fn=pp_eval() + pp_common_i1k.format(lbl='label'),
|
| 130 |
+
loss_name=c.loss,
|
| 131 |
+
log_steps=5000, # Very fast O(seconds) so it's fine to run it often.
|
| 132 |
+
label_mapping=lblmap,
|
| 133 |
+
)
|
| 134 |
+
for s in c.flexi.seqhw.v:
|
| 135 |
+
c.evals[f'i1k_val{s:02d}'] = eval_i1k(s, 'imagenet2012', 'validation', 'i1k_i21k')
|
| 136 |
+
c.evals[f'i1k_v2{s:02d}'] = eval_i1k(s, 'imagenet_v2', 'test', 'i1k_i21k')
|
| 137 |
+
c.evals[f'i1k_a{s:02d}'] = eval_i1k(s, 'imagenet_a', 'test', 'i1ka_i21k')
|
| 138 |
+
c.evals[f'i1k_r{s:02d}'] = eval_i1k(s, 'imagenet_r', 'test', 'i1kr_i21k')
|
| 139 |
+
c.evals[f'i1k_real{s:02d}'] = eval_i1k(s, 'imagenet2012_real', 'validation', 'i1k_i21k')
|
| 140 |
+
c.evals[f'i1k_real{s:02d}'].pp_fn = pp_eval() + pp_common_i1k.format(lbl='real_label')
|
| 141 |
+
# TODO: add objectnet.
|
| 142 |
+
|
| 143 |
+
# Few-shot evaluators not added for overkill reasons for now.
|
| 144 |
+
return c
|
big_vision_repo/big_vision/configs/proj/flexivit/timing.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long,missing-function-docstring
|
| 16 |
+
r"""A config to run timing for FlexiViT (only inference, no I/O etc.).
|
| 17 |
+
|
| 18 |
+
big_vision.tools.eval_only \
|
| 19 |
+
--config big_vision/configs/proj/flexivit/timing.py \
|
| 20 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'` \
|
| 21 |
+
--config.total_epochs 90
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
from ml_collections import ConfigDict
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def get_config():
|
| 28 |
+
c = ConfigDict()
|
| 29 |
+
|
| 30 |
+
shape = (240, 240, 3)
|
| 31 |
+
c.batch_size = 8 # swept
|
| 32 |
+
c.init_shapes = [(1, *shape)]
|
| 33 |
+
c.representation_layer = 'pre_logits'
|
| 34 |
+
|
| 35 |
+
# Creating complete model using all params, the sweep will go over variants.
|
| 36 |
+
c.model_name = 'xp.flexivit.vit'
|
| 37 |
+
c.model = dict(
|
| 38 |
+
variant='B',
|
| 39 |
+
pool_type='tok',
|
| 40 |
+
patch_size=(10, 10), # Like deit@384
|
| 41 |
+
seqhw=(24, 24),
|
| 42 |
+
)
|
| 43 |
+
c.num_classes = 0
|
| 44 |
+
|
| 45 |
+
c.evals = {}
|
| 46 |
+
c.evals.timing = dict(
|
| 47 |
+
type='timing',
|
| 48 |
+
input_shapes=[shape],
|
| 49 |
+
timing=True,
|
| 50 |
+
pred_kw=dict(outputs=('pre_logits',)),
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
return c
|
big_vision_repo/big_vision/configs/proj/givt/README.md
ADDED
|
@@ -0,0 +1,111 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GIVT: Generative Infinite-Vocabulary Transformers
|
| 2 |
+
|
| 3 |
+
*by Michael Tschannen, Cian Eastwood, Fabian Mentzer* [[arxiv]](https://arxiv.org/abs/2312.02116) [[colab]](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/givt/givt_demo_colab.ipynb)
|
| 4 |
+
|
| 5 |
+

|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
### Summary
|
| 9 |
+
|
| 10 |
+
We introduce generative infinite-vocabulary transformers (GIVT) which generate vector sequences with real-valued entries, instead of discrete tokens from a finite vocabulary.
|
| 11 |
+
To this end, we propose two surprisingly simple modifications to decoder-only transformers: 1) at the input, we replace the finite-vocabulary lookup table with a linear projection of the input vectors; and 2) at the output, we replace the logits prediction (usually mapped to a categorical distribution) with the parameters of a multivariate Gaussian mixture model.
|
| 12 |
+
Inspired by the image-generation paradigm of VQ-GAN and MaskGIT, where transformers are used to model the discrete latent sequences of a VQ-VAE, we use GIVT to model the unquantized real-valued latent sequences of a β-VAE.
|
| 13 |
+
In class-conditional image generation GIVT outperforms VQ-GAN (and improved variants thereof) as well as MaskGIT, and achieves performance competitive with recent latent diffusion models.
|
| 14 |
+
Finally, we obtain strong results outside of image generation when applying GIVT to panoptic segmentation and depth estimation with a VAE variant of the UViM framework.
|
| 15 |
+
|
| 16 |
+
### Checkpoints
|
| 17 |
+
|
| 18 |
+
We provide model checkpoints for a subset of the models from the paper.
|
| 19 |
+
These are meant as small-scale baselines for researchers interested in exploring GIVT, and are not optimized to provide the best possible visual quality (e.g. scaling the model size can substantially improve visual quality as shown in the paper).
|
| 20 |
+
See below for instructions to train your own models.
|
| 21 |
+
|
| 22 |
+
**ImageNet 2012 VAEs**
|
| 23 |
+
|
| 24 |
+
| β | 1e-5 | 2.5e-5 | 5e-5 | 1e-4 | 2e-4 |
|
| 25 |
+
|:-----------|:------:|:----:|:----:|:----:|:----:|
|
| 26 |
+
| checkpoint | [link][vae_i1k_0] | [link][vae_i1k_1] | [link][vae_i1k_2] | [link][vae_i1k_3] | [link][vae_i1k_4] |
|
| 27 |
+
|
| 28 |
+
[vae_i1k_0]: https://storage.googleapis.com/big_vision/givt/vae_imagenet_2012_beta_1e-5_params
|
| 29 |
+
[vae_i1k_1]: https://storage.googleapis.com/big_vision/givt/vae_imagenet_2012_beta_2p5e-5_params
|
| 30 |
+
[vae_i1k_2]: https://storage.googleapis.com/big_vision/givt/vae_imagenet_2012_beta_5e-5_params
|
| 31 |
+
[vae_i1k_3]: https://storage.googleapis.com/big_vision/givt/vae_imagenet_2012_beta_1e-4_params
|
| 32 |
+
[vae_i1k_4]: https://storage.googleapis.com/big_vision/givt/vae_imagenet_2012_beta_2e-4_params
|
| 33 |
+
|
| 34 |
+
**Class-conditional ImageNet 2012 generative models**
|
| 35 |
+
|
| 36 |
+
| model | resolution | β | inference | FID | checkpoint |
|
| 37 |
+
|:------|:----------:|:------:|:-------------|:---:|:-----------|
|
| 38 |
+
| GIVT-Causal | 256 x 256 | 5e-5 | t=0.95, DB-CFG=0.4 | 3.35 | [link][givt_i1k_1] |
|
| 39 |
+
| GIVT-MaskGIT | 256 x 256 | 5e-5 | t_C=35, DB-CFG=0.1 | 4.53 | [link][givt_i1k_2] |
|
| 40 |
+
| GIVT-MaskGIT | 512 x 512 | 5e-5 | t_C=140 | 4.86 | [link][givt_i1k_3] |
|
| 41 |
+
|
| 42 |
+
[givt_i1k_1]: https://storage.googleapis.com/big_vision/givt/givt_imagenet_2012_causal_params.npz
|
| 43 |
+
[givt_i1k_2]: https://storage.googleapis.com/big_vision/givt/givt_imagenet_2012_maskgit_params.npz
|
| 44 |
+
[givt_i1k_3]: https://storage.googleapis.com/big_vision/givt/givt_imagenet_2012_maskgit_512_params.npz
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
**UViM**
|
| 48 |
+
|
| 49 |
+
| task | model | dataset | accuracy | checkpoint |
|
| 50 |
+
|:-----|:------|:--------|---------:|:-----------|
|
| 51 |
+
| Panoptic segmentation | VAE (stage 1) | [COCO (2017)] | 71.0 (PQ) | [link][vae_coco_panoptic] |
|
| 52 |
+
| Panoptic segmentation | GIVT (stage 2) | [COCO (2017)] | 40.2 (PQ) | [link][givt_coco_panoptic] |
|
| 53 |
+
| Depth estimation | VAE (stage 1) | [NYU Depth v2] | 0.195 (RMSE) | [link][vae_nyu_depth] |
|
| 54 |
+
| Depth estimation | GIVT (stage 2) | [NYU Depth v2] | 0.474 (RMSE) | [link][givt_nyu_depth] |
|
| 55 |
+
|
| 56 |
+
[NYU Depth v2]: https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
|
| 57 |
+
[COCO (2017)]: https://cocodataset.org/#home
|
| 58 |
+
[vae_coco_panoptic]: https://storage.googleapis.com/big_vision/givt/vae_coco_panoptic_params.npz
|
| 59 |
+
[givt_coco_panoptic]: https://storage.googleapis.com/big_vision/givt/givt_coco_panoptic_params.npz
|
| 60 |
+
[vae_nyu_depth]: https://storage.googleapis.com/big_vision/givt/vae_nyu_depth_params.npz
|
| 61 |
+
[givt_nyu_depth]: https://storage.googleapis.com/big_vision/givt/givt_nyu_depth_params.npz
|
| 62 |
+
|
| 63 |
+
### Training models
|
| 64 |
+
|
| 65 |
+
This directory contains configs to train GIVT models as well as VAEs (for the UViM variants).
|
| 66 |
+
For training the ImageNet 2012 VAE models we used a modified version of the [MaskGIT code](https://github.com/google-research/maskgit).
|
| 67 |
+
|
| 68 |
+
The `big_vision` input pipeline relies on [TensorFlow Datasets (TFDS)](https://www.tensorflow.org/datasets)
|
| 69 |
+
which supports some data sets out-of-the-box, whereas others require manual download of the data
|
| 70 |
+
(for example ImageNet and COCO (2017), see the `big_vision` [main README](../../../../#cloud-tpu-vm-setup) and the [UViM README](../uvim), respectively, for details).
|
| 71 |
+
|
| 72 |
+
After setting up `big_vision` as described in the [main README](../../../../#cloud-tpu-vm-setup), training can be launched locally as follows
|
| 73 |
+
|
| 74 |
+
```
|
| 75 |
+
python -m big_vision.trainers.proj.givt.generative \
|
| 76 |
+
--config big_vision/configs/proj/givt/givt_imagenet2012.py \
|
| 77 |
+
--workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%m-%d_%H%M'`
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
Add the suffix `:key1=value1,key2=value2,...` to the config path in the launch
|
| 81 |
+
command to modify the config with predefined arguments (see config for details). For example:
|
| 82 |
+
`--config big_vision/configs/proj/givt/givt_imagenet_2012.py:model_size=large`.
|
| 83 |
+
Note that `givt_imagenet2012.py` uses [Imagenette](https://github.com/fastai/imagenette) to ensure that the config is runnable without manual ImageNet download.
|
| 84 |
+
This is only meant for testing and will overfit immediately. Please download ImageNet to reproduce the paper results.
|
| 85 |
+
|
| 86 |
+
VAE trainings for the GIVT variant of UViM can be launched as
|
| 87 |
+
|
| 88 |
+
```
|
| 89 |
+
python -m big_vision.trainers.proj.givt.vae \
|
| 90 |
+
--config big_vision/configs/proj/givt/vae_nyu_depth.py \
|
| 91 |
+
--workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%m-%d_%H%M'`
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
Please refer to the [main README](../../../../#cloud-tpu-vm-setup)
|
| 95 |
+
for details on how to launch training on a (multi-host) TPU setup.
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
### Disclaimer
|
| 99 |
+
|
| 100 |
+
This is not an official Google Product.
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
### Citation
|
| 104 |
+
```
|
| 105 |
+
@article{tschannen2023givt,
|
| 106 |
+
title={GIVT: Generative Infinite-Vocabulary Transformers},
|
| 107 |
+
author={Tschannen, Michael and Eastwood, Cian and Mentzer, Fabian},
|
| 108 |
+
journal={arXiv:2312.02116},
|
| 109 |
+
year={2023}
|
| 110 |
+
}
|
| 111 |
+
```
|
big_vision_repo/big_vision/configs/proj/givt/givt_coco_panoptic.py
ADDED
|
@@ -0,0 +1,186 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Train a GIVT encoder-decoder model on COCO panoptic."""
|
| 17 |
+
|
| 18 |
+
import itertools
|
| 19 |
+
import ml_collections
|
| 20 |
+
|
| 21 |
+
ConfigDict = ml_collections.ConfigDict
|
| 22 |
+
|
| 23 |
+
VTT_MODELS = {
|
| 24 |
+
'base': dict(num_layers=12, num_decoder_layers=12, num_heads=12, mlp_dim=3072, emb_dim=768),
|
| 25 |
+
'large': dict(num_layers=24, num_decoder_layers=24, num_heads=16, mlp_dim=4096, emb_dim=1024),
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
RES = 512
|
| 29 |
+
PATCH_SIZE = 16
|
| 30 |
+
LABEL_RES = 512
|
| 31 |
+
LABEL_PATCH_SIZE = 16
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_config(runlocal=False):
|
| 35 |
+
"""Config for training."""
|
| 36 |
+
config = ConfigDict()
|
| 37 |
+
|
| 38 |
+
config.input = {}
|
| 39 |
+
config.input.pp = (
|
| 40 |
+
f'decode|coco_panoptic|concat(["semantics","instances"], "labels")|'
|
| 41 |
+
f'randu("fliplr")|det_fliplr(key="image")|det_fliplr(key="labels")|'
|
| 42 |
+
f'inception_box|crop_box(key="image")|crop_box(key="labels")|'
|
| 43 |
+
f'resize({RES})|resize({LABEL_RES},key="labels",method="nearest")|'
|
| 44 |
+
f'value_range(-1, 1)|make_canonical|'
|
| 45 |
+
f'copy("image", "cond_image")|copy("labels", "image")|'
|
| 46 |
+
f'keep("image", "cond_image")'
|
| 47 |
+
)
|
| 48 |
+
pp_eval = (
|
| 49 |
+
f'decode|coco_panoptic|concat(["semantics","instances"], "labels")|'
|
| 50 |
+
f'resize({RES})|resize({LABEL_RES},key="labels",method="nearest")|'
|
| 51 |
+
f'value_range(-1, 1)|make_canonical|'
|
| 52 |
+
f'copy("image", "cond_image")|copy("labels", "image")|'
|
| 53 |
+
f'keep("image", "cond_image")'
|
| 54 |
+
)
|
| 55 |
+
pp_predict = (
|
| 56 |
+
f'decode|resize({RES})|value_range(-1, 1)|copy("image", "cond_image")|'
|
| 57 |
+
f'keep("cond_image", "image/id")' # image/id used for rng seeds.
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
config.input.data = dict(name='coco/2017_panoptic', split='train[4096:]')
|
| 61 |
+
config.input.batch_size = 512
|
| 62 |
+
config.input.shuffle_buffer_size = 50_000
|
| 63 |
+
|
| 64 |
+
config.total_epochs = 200
|
| 65 |
+
|
| 66 |
+
config.log_training_steps = 50
|
| 67 |
+
config.ckpt_steps = 1000
|
| 68 |
+
config.keep_ckpt_steps = None
|
| 69 |
+
config.prefetch_to_device = 2
|
| 70 |
+
config.seed = 0
|
| 71 |
+
|
| 72 |
+
# Optimizer section
|
| 73 |
+
config.optax_name = 'big_vision.scale_by_adafactor'
|
| 74 |
+
config.optax = dict(beta2_cap=0.95)
|
| 75 |
+
|
| 76 |
+
config.ar_generation_config = ml_collections.ConfigDict()
|
| 77 |
+
config.ar_generation_config.temp = 0.85
|
| 78 |
+
config.ar_generation_config.temp_probs = 1.0
|
| 79 |
+
config.ar_generation_config.beam_size = 4
|
| 80 |
+
config.ar_generation_config.fan_size = 8
|
| 81 |
+
config.ar_generation_config.rand_top_k = False
|
| 82 |
+
config.ar_generation_config.rand_top_k_temp = 1.0
|
| 83 |
+
|
| 84 |
+
config.lr = 0.001
|
| 85 |
+
config.wd = 0.000001
|
| 86 |
+
config.lr_mults = [
|
| 87 |
+
('pos_embedding_encoder.*', 0.1),
|
| 88 |
+
('EmbedPatches.*', 0.1),
|
| 89 |
+
('encoder.*', 0.1),
|
| 90 |
+
('decoder.*', 1.0)
|
| 91 |
+
]
|
| 92 |
+
config.schedule = dict(decay_type='cosine', warmup_steps=4_000)
|
| 93 |
+
|
| 94 |
+
# Oracle section
|
| 95 |
+
config.vae = ConfigDict()
|
| 96 |
+
config.vae.model_name = 'proj.givt.vit'
|
| 97 |
+
config.vae.model = ConfigDict()
|
| 98 |
+
config.vae.model.input_size = (RES, RES)
|
| 99 |
+
config.vae.model.patch_size = (PATCH_SIZE, PATCH_SIZE)
|
| 100 |
+
config.vae.model.code_len = 256
|
| 101 |
+
config.vae.model.width = 768
|
| 102 |
+
config.vae.model.enc_depth = 6
|
| 103 |
+
config.vae.model.dec_depth = 12
|
| 104 |
+
config.vae.model.mlp_dim = 3072
|
| 105 |
+
config.vae.model.num_heads = 12
|
| 106 |
+
config.vae.model.codeword_dim = 16
|
| 107 |
+
config.vae.model.code_dropout = 'none'
|
| 108 |
+
config.vae.model.bottleneck_resize = True
|
| 109 |
+
# values: (channel index in source image, number of classes)
|
| 110 |
+
config.vae.model.inout_specs = {
|
| 111 |
+
'semantics': (0, 133 + 1), # +1 for void label
|
| 112 |
+
'instances': (1, 100), # COCO: actually 98 train/78 validation.
|
| 113 |
+
}
|
| 114 |
+
config.vae.model_init = 'gs://big_vision/givt/vae_coco_panoptic_params.npz'
|
| 115 |
+
|
| 116 |
+
# Model section
|
| 117 |
+
config.model_name = 'proj.givt.givt'
|
| 118 |
+
# # Base model (for exploration)
|
| 119 |
+
# config.model_init = {'encoder': 'howto-i21k-B/16'}
|
| 120 |
+
# config.model = ConfigDict(VTT_MODELS['base'])
|
| 121 |
+
# Large model
|
| 122 |
+
config.model_init = {'encoder': 'howto-i21k-L/16'}
|
| 123 |
+
config.model_load = dict(dont_load=('cls', 'head/bias', 'head/kernel'))
|
| 124 |
+
config.model = ConfigDict(VTT_MODELS['large'])
|
| 125 |
+
config.model.patches = (PATCH_SIZE, PATCH_SIZE)
|
| 126 |
+
config.model.input_size = (RES, RES)
|
| 127 |
+
config.model.posemb_type = 'learn'
|
| 128 |
+
config.model.seq_len = config.vae.model.code_len
|
| 129 |
+
config.model.num_labels = None
|
| 130 |
+
config.model.num_mixtures = 1
|
| 131 |
+
config.model.fix_square_plus = True
|
| 132 |
+
config.model.out_dim = config.vae.model.codeword_dim
|
| 133 |
+
config.model.scale_tol = 1e-6
|
| 134 |
+
config.model.dec_dropout_rate = 0.0
|
| 135 |
+
|
| 136 |
+
# Evaluation section
|
| 137 |
+
config.evals = {}
|
| 138 |
+
config.evals.val = ConfigDict()
|
| 139 |
+
config.evals.val.type = 'mean'
|
| 140 |
+
config.evals.val.pred = 'validation'
|
| 141 |
+
config.evals.val.data = dict(name=config.input.data.name, split='train[:4096]')
|
| 142 |
+
config.evals.val.pp_fn = pp_eval
|
| 143 |
+
config.evals.val.log_steps = 1000
|
| 144 |
+
|
| 145 |
+
config.eval_only = False
|
| 146 |
+
|
| 147 |
+
base = {
|
| 148 |
+
'type': 'proj.givt.coco_panoptic',
|
| 149 |
+
'data': {**config.input.data},
|
| 150 |
+
'pp_fn': pp_predict,
|
| 151 |
+
'log_steps': 10_000,
|
| 152 |
+
'pred': 'sample_panoptic',
|
| 153 |
+
# Filters objects that occupy less than 0.03^2 fraction of all pixels.
|
| 154 |
+
# 'pred_kw': {'min_fraction': 0.03 ** 2},
|
| 155 |
+
}
|
| 156 |
+
config.evals.coco_panoptic_train = dict(base)
|
| 157 |
+
config.evals.coco_panoptic_train.data.split = 'train[4096:8192]'
|
| 158 |
+
config.evals.coco_panoptic_holdout = dict(base)
|
| 159 |
+
config.evals.coco_panoptic_holdout.data.split = 'train[:4096]'
|
| 160 |
+
config.evals.coco_panoptic = dict(base)
|
| 161 |
+
config.evals.coco_panoptic.data.split = 'validation'
|
| 162 |
+
|
| 163 |
+
config.evals.save_pred = dict(type='proj.givt.save_predictions')
|
| 164 |
+
config.evals.save_pred.pred = 'sample_panoptic'
|
| 165 |
+
config.evals.save_pred.pp_fn = pp_eval
|
| 166 |
+
config.evals.save_pred.log_steps = 100_000
|
| 167 |
+
config.evals.save_pred.data = dict(config.input.data)
|
| 168 |
+
config.evals.save_pred.data.split = 'validation[:1024]'
|
| 169 |
+
config.evals.save_pred.outfile = 'inference.npz'
|
| 170 |
+
|
| 171 |
+
if runlocal:
|
| 172 |
+
config.input.batch_size = 4
|
| 173 |
+
config.input.shuffle_buffer_size = 10
|
| 174 |
+
config.evals.val.data.split = 'train[:16]'
|
| 175 |
+
config.evals.val.log_steps = 20
|
| 176 |
+
config.model.num_layers = 1
|
| 177 |
+
config.model.num_decoder_layers = 1
|
| 178 |
+
del config.model_init
|
| 179 |
+
config.evals.val.data.split = 'validation[:4]'
|
| 180 |
+
config.evals.coco_panoptic.data.split = 'validation[:4]'
|
| 181 |
+
config.evals.save_pred.data.split = 'validation[:4]'
|
| 182 |
+
for k in config.evals.keys():
|
| 183 |
+
if k not in ['val', 'coco_panoptic', 'save_pred']:
|
| 184 |
+
del config.evals[k]
|
| 185 |
+
|
| 186 |
+
return config
|
big_vision_repo/big_vision/configs/proj/givt/givt_demo_colab.ipynb
ADDED
|
@@ -0,0 +1,309 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"nbformat": 4,
|
| 3 |
+
"nbformat_minor": 0,
|
| 4 |
+
"metadata": {
|
| 5 |
+
"colab": {
|
| 6 |
+
"provenance": [],
|
| 7 |
+
"gpuType": "T4"
|
| 8 |
+
},
|
| 9 |
+
"kernelspec": {
|
| 10 |
+
"name": "python3",
|
| 11 |
+
"display_name": "Python 3"
|
| 12 |
+
},
|
| 13 |
+
"language_info": {
|
| 14 |
+
"name": "python"
|
| 15 |
+
},
|
| 16 |
+
"accelerator": "GPU"
|
| 17 |
+
},
|
| 18 |
+
"cells": [
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "markdown",
|
| 21 |
+
"source": [
|
| 22 |
+
"# GIVT Demo colab\n",
|
| 23 |
+
"\n",
|
| 24 |
+
"[[paper]](https://arxiv.org/abs/2312.02116) [[GitHub]](https://github.com/google-research/big_vision/blob/main/big_vision/configs/proj/givt/README.md)\n",
|
| 25 |
+
"\n",
|
| 26 |
+
"This colab implements class-conditional image generation using GIVT-Causal and GIVT-MaskGIT for the 1k ImageNet2012 classes.\n",
|
| 27 |
+
"\n",
|
| 28 |
+
"The available model checkpoints are meant as small-scale baselines (~300M parameters) for researchers interested in exploring GIVT, and are not optimized to provide the best possible visual quality (e.g. scaling the model size can substantially improve visual quality as shown in the paper).\n",
|
| 29 |
+
"\n",
|
| 30 |
+
"The colab was tested with the CPU and T4 GPU runtimes. We recommend the T4 GPU runtime (the CPU rutime is very slow).\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"_Disclaimer: This is not an official Google Product._"
|
| 33 |
+
],
|
| 34 |
+
"metadata": {
|
| 35 |
+
"id": "botgo-GZiWI_"
|
| 36 |
+
}
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"cell_type": "markdown",
|
| 40 |
+
"source": [
|
| 41 |
+
"### `big_vision` setup"
|
| 42 |
+
],
|
| 43 |
+
"metadata": {
|
| 44 |
+
"id": "jQxc9UZ-mVrQ"
|
| 45 |
+
}
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"cell_type": "code",
|
| 49 |
+
"source": [
|
| 50 |
+
"#@markdown Clone and set up repository\n",
|
| 51 |
+
"!git clone --branch=main --depth=1 https://github.com/google-research/big_vision\n",
|
| 52 |
+
"!cd big_vision && git pull\n",
|
| 53 |
+
"\n",
|
| 54 |
+
"# Install dependencies - pin TensorFlow-related packages to ensure compatibility\n",
|
| 55 |
+
"# which might not be needed in in the future\n",
|
| 56 |
+
"!echo -e \"keras==3.0.5\\ntensorflow==2.16.1\\ntensorflow-probability==0.24.0\" > big_vision/big_vision/constraints.txt\n",
|
| 57 |
+
"!pip install -r big_vision/big_vision/requirements.txt -c big_vision/big_vision/constraints.txt\n",
|
| 58 |
+
"%cd big_vision"
|
| 59 |
+
],
|
| 60 |
+
"metadata": {
|
| 61 |
+
"id": "ZAXiVta3n2jL",
|
| 62 |
+
"cellView": "form"
|
| 63 |
+
},
|
| 64 |
+
"execution_count": null,
|
| 65 |
+
"outputs": []
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"cell_type": "code",
|
| 69 |
+
"execution_count": null,
|
| 70 |
+
"metadata": {
|
| 71 |
+
"id": "qYS7JNups4MU",
|
| 72 |
+
"cellView": "form"
|
| 73 |
+
},
|
| 74 |
+
"outputs": [],
|
| 75 |
+
"source": [
|
| 76 |
+
"#@markdown Imports\n",
|
| 77 |
+
"import jax\n",
|
| 78 |
+
"from functools import partial\n",
|
| 79 |
+
"import ml_collections\n",
|
| 80 |
+
"import matplotlib.pyplot as plt\n",
|
| 81 |
+
"\n",
|
| 82 |
+
"from big_vision.configs.proj.givt import givt_imagenet2012\n",
|
| 83 |
+
"from big_vision.datasets.imagenet import class_names as imagenet_class_names\n",
|
| 84 |
+
"from big_vision.models.proj.givt import givt, cnn, decode, parallel_decode\n",
|
| 85 |
+
"\n",
|
| 86 |
+
"jnp = jax.numpy"
|
| 87 |
+
]
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"cell_type": "markdown",
|
| 91 |
+
"source": [
|
| 92 |
+
"### Select and download model\n",
|
| 93 |
+
"\n"
|
| 94 |
+
],
|
| 95 |
+
"metadata": {
|
| 96 |
+
"id": "MaCM_PIcd2Rb"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
{
|
| 100 |
+
"cell_type": "code",
|
| 101 |
+
"source": [
|
| 102 |
+
"model = \"GIVT-Causal 256x256\" #@param [\"GIVT-Causal 256x256\", \"GIVT-MaskGIT 256x256\", \"GIVT-MaskGIT 512x512\"]\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"givt_ckpt_path, cfg_w, temp, is_ar, res = {\n",
|
| 105 |
+
" \"GIVT-Causal 256x256\": (\n",
|
| 106 |
+
" \"gs://big_vision/givt/givt_imagenet_2012_causal_params.npz\", 0.4, 0.95, True, 256),\n",
|
| 107 |
+
" \"GIVT-MaskGIT 256x256\": (\n",
|
| 108 |
+
" \"gs://big_vision/givt/givt_imagenet_2012_maskgit_params.npz\", 0.0, 35.0, False, 256),\n",
|
| 109 |
+
" \"GIVT-MaskGIT 512x512\": (\n",
|
| 110 |
+
" \"gs://big_vision/givt/givt_imagenet_2012_maskgit_512_params.npz\", 0.0, 140.0, False, 512),\n",
|
| 111 |
+
"}[model]\n",
|
| 112 |
+
"\n",
|
| 113 |
+
"config = givt_imagenet2012.get_config(arg=f\"res={res},style={'ar' if is_ar else 'masked'}\")\n",
|
| 114 |
+
"\n",
|
| 115 |
+
"print(\"Loading VAE model...\")\n",
|
| 116 |
+
"vae_model = cnn.Model(**config.vae.model)\n",
|
| 117 |
+
"vae_params = cnn.load(None, config.vae.model_init, **config.vae.model_load)\n",
|
| 118 |
+
"\n",
|
| 119 |
+
"print(\"Loading GIVT model...\")\n",
|
| 120 |
+
"givt_model = givt.Model(**config.model)\n",
|
| 121 |
+
"givt_params = jax.device_put(\n",
|
| 122 |
+
" givt.load(None, givt_ckpt_path), jax.devices()[0])"
|
| 123 |
+
],
|
| 124 |
+
"metadata": {
|
| 125 |
+
"id": "7l6QIjdyN3dg",
|
| 126 |
+
"cellView": "form"
|
| 127 |
+
},
|
| 128 |
+
"execution_count": null,
|
| 129 |
+
"outputs": []
|
| 130 |
+
},
|
| 131 |
+
{
|
| 132 |
+
"cell_type": "markdown",
|
| 133 |
+
"source": [
|
| 134 |
+
"### VAE encode/decode and sampling loop"
|
| 135 |
+
],
|
| 136 |
+
"metadata": {
|
| 137 |
+
"id": "SUj5k1bxd6wr"
|
| 138 |
+
}
|
| 139 |
+
},
|
| 140 |
+
{
|
| 141 |
+
"cell_type": "code",
|
| 142 |
+
"source": [
|
| 143 |
+
"@jax.jit\n",
|
| 144 |
+
"def vae_encode(images, rng):\n",
|
| 145 |
+
" \"\"\"Encode image with VAE encoder.\"\"\"\n",
|
| 146 |
+
" mu, logvar = vae_model.apply(\n",
|
| 147 |
+
" {\"params\": vae_params}, images, method=vae_model.encode,\n",
|
| 148 |
+
" )\n",
|
| 149 |
+
" return vae_model.apply(\n",
|
| 150 |
+
" {\"params\": vae_params},\n",
|
| 151 |
+
" mu,\n",
|
| 152 |
+
" logvar,\n",
|
| 153 |
+
" method=vae_model.reparametrize,\n",
|
| 154 |
+
" rngs={\"dropout\": rng},\n",
|
| 155 |
+
" )\n",
|
| 156 |
+
"\n",
|
| 157 |
+
"@jax.jit\n",
|
| 158 |
+
"def vae_decode(z):\n",
|
| 159 |
+
" \"\"\"Reconstruct image with VAE decoder from latent code z.\"\"\"\n",
|
| 160 |
+
" return vae_model.apply({\"params\": vae_params}, z, method=vae_model.decode)\n",
|
| 161 |
+
"\n",
|
| 162 |
+
"### jit-compilation seems to go OOM (RAM) on the free tier GPU colab, but might\n",
|
| 163 |
+
"### lead to speedups on machines with more resources\n",
|
| 164 |
+
"# @partial(jax.jit, static_argnums=(2, 3))\n",
|
| 165 |
+
"def sample(labels, rng, ar_generation_config=None, masked_generation_config=None):\n",
|
| 166 |
+
" \"\"\"Sample from GIVT-Causal or GIVT-MaskGIT.\"\"\"\n",
|
| 167 |
+
" print(f\"Sampling, style={givt_model.style}\")\n",
|
| 168 |
+
" shared_kwargs = dict(\n",
|
| 169 |
+
" labels=labels,\n",
|
| 170 |
+
" model=givt_model,\n",
|
| 171 |
+
" seq_len=config.model.seq_len,\n",
|
| 172 |
+
" feature_dim=config.model.out_dim,\n",
|
| 173 |
+
" )\n",
|
| 174 |
+
"\n",
|
| 175 |
+
" match givt_model.style:\n",
|
| 176 |
+
" case \"ar\":\n",
|
| 177 |
+
" sampled_codes, _ = decode.generate(\n",
|
| 178 |
+
" params={\"params\": givt_params},\n",
|
| 179 |
+
" seed=rng,\n",
|
| 180 |
+
" config=dict(ar_generation_config),\n",
|
| 181 |
+
" **shared_kwargs,\n",
|
| 182 |
+
" )\n",
|
| 183 |
+
" info = sampled_codes\n",
|
| 184 |
+
" case \"masked\":\n",
|
| 185 |
+
" masked_out = parallel_decode.decode_masked(\n",
|
| 186 |
+
" rng=rng,\n",
|
| 187 |
+
" variables={\"params\": givt_params},\n",
|
| 188 |
+
" config=masked_generation_config,\n",
|
| 189 |
+
" **shared_kwargs,\n",
|
| 190 |
+
" )\n",
|
| 191 |
+
" sampled_codes = masked_out.current_inputs_q\n",
|
| 192 |
+
" info = masked_out\n",
|
| 193 |
+
" case _:\n",
|
| 194 |
+
" raise NotImplementedError\n",
|
| 195 |
+
" return sampled_codes, info"
|
| 196 |
+
],
|
| 197 |
+
"metadata": {
|
| 198 |
+
"id": "vSn7Si2FS1zi"
|
| 199 |
+
},
|
| 200 |
+
"execution_count": null,
|
| 201 |
+
"outputs": []
|
| 202 |
+
},
|
| 203 |
+
{
|
| 204 |
+
"cell_type": "markdown",
|
| 205 |
+
"source": [
|
| 206 |
+
"### Generate images for class label"
|
| 207 |
+
],
|
| 208 |
+
"metadata": {
|
| 209 |
+
"id": "tOnWaJZVeOIX"
|
| 210 |
+
}
|
| 211 |
+
},
|
| 212 |
+
{
|
| 213 |
+
"cell_type": "code",
|
| 214 |
+
"source": [
|
| 215 |
+
"rng = 0 #@param = 'int'\n",
|
| 216 |
+
"label = 'goldfish' #@param [\"tench\", \"goldfish\", \"great white shark\", \"tiger shark\", \"hammerhead shark\", \"electric ray\", \"stingray\", \"rooster\", \"hen\", \"ostrich\", \"brambling\", \"goldfinch\", \"house finch\", \"junco\", \"indigo bunting\", \"American robin\", \"bulbul\", \"jay\", \"magpie\", \"chickadee\", \"American dipper\", \"kite (bird of prey)\", \"bald eagle\", \"vulture\", \"great grey owl\", \"fire salamander\", \"smooth newt\", \"newt\", \"spotted salamander\", \"axolotl\", \"American bullfrog\", \"tree frog\", \"tailed frog\", \"loggerhead sea turtle\", \"leatherback sea turtle\", \"mud turtle\", \"terrapin\", \"box turtle\", \"banded gecko\", \"green iguana\", \"Carolina anole\", \"desert grassland whiptail lizard\", \"agama\", \"frilled-necked lizard\", \"alligator lizard\", \"Gila monster\", \"European green lizard\", \"chameleon\", \"Komodo dragon\", \"Nile crocodile\", \"American alligator\", \"triceratops\", \"worm snake\", \"ring-necked snake\", \"eastern hog-nosed snake\", \"smooth green snake\", \"kingsnake\", \"garter snake\", \"water snake\", \"vine snake\", \"night snake\", \"boa constrictor\", \"African rock python\", \"Indian cobra\", \"green mamba\", \"sea snake\", \"Saharan horned viper\", \"eastern diamondback rattlesnake\", \"sidewinder rattlesnake\", \"trilobite\", \"harvestman\", \"scorpion\", \"yellow garden spider\", \"barn spider\", \"European garden spider\", \"southern black widow\", \"tarantula\", \"wolf spider\", \"tick\", \"centipede\", \"black grouse\", \"ptarmigan\", \"ruffed grouse\", \"prairie grouse\", \"peafowl\", \"quail\", \"partridge\", \"african grey parrot\", \"macaw\", \"sulphur-crested cockatoo\", \"lorikeet\", \"coucal\", \"bee eater\", \"hornbill\", \"hummingbird\", \"jacamar\", \"toucan\", \"duck\", \"red-breasted merganser\", \"goose\", \"black swan\", \"tusker\", \"echidna\", \"platypus\", \"wallaby\", \"koala\", \"wombat\", \"jellyfish\", \"sea anemone\", \"brain coral\", \"flatworm\", \"nematode\", \"conch\", \"snail\", \"slug\", \"sea slug\", \"chiton\", \"chambered nautilus\", \"Dungeness crab\", \"rock crab\", \"fiddler crab\", \"red king crab\", \"American lobster\", \"spiny lobster\", \"crayfish\", \"hermit crab\", \"isopod\", \"white stork\", \"black stork\", \"spoonbill\", \"flamingo\", \"little blue heron\", \"great egret\", \"bittern bird\", \"crane bird\", \"limpkin\", \"common gallinule\", \"American coot\", \"bustard\", \"ruddy turnstone\", \"dunlin\", \"common redshank\", \"dowitcher\", \"oystercatcher\", \"pelican\", \"king penguin\", \"albatross\", \"grey whale\", \"killer whale\", \"dugong\", \"sea lion\", \"Chihuahua\", \"Japanese Chin\", \"Maltese\", \"Pekingese\", \"Shih Tzu\", \"King Charles Spaniel\", \"Papillon\", \"toy terrier\", \"Rhodesian Ridgeback\", \"Afghan Hound\", \"Basset Hound\", \"Beagle\", \"Bloodhound\", \"Bluetick Coonhound\", \"Black and Tan Coonhound\", \"Treeing Walker Coonhound\", \"English foxhound\", \"Redbone Coonhound\", \"borzoi\", \"Irish Wolfhound\", \"Italian Greyhound\", \"Whippet\", \"Ibizan Hound\", \"Norwegian Elkhound\", \"Otterhound\", \"Saluki\", \"Scottish Deerhound\", \"Weimaraner\", \"Staffordshire Bull Terrier\", \"American Staffordshire Terrier\", \"Bedlington Terrier\", \"Border Terrier\", \"Kerry Blue Terrier\", \"Irish Terrier\", \"Norfolk Terrier\", \"Norwich Terrier\", \"Yorkshire Terrier\", \"Wire Fox Terrier\", \"Lakeland Terrier\", \"Sealyham Terrier\", \"Airedale Terrier\", \"Cairn Terrier\", \"Australian Terrier\", \"Dandie Dinmont Terrier\", \"Boston Terrier\", \"Miniature Schnauzer\", \"Giant Schnauzer\", \"Standard Schnauzer\", \"Scottish Terrier\", \"Tibetan Terrier\", \"Australian Silky Terrier\", \"Soft-coated Wheaten Terrier\", \"West Highland White Terrier\", \"Lhasa Apso\", \"Flat-Coated Retriever\", \"Curly-coated Retriever\", \"Golden Retriever\", \"Labrador Retriever\", \"Chesapeake Bay Retriever\", \"German Shorthaired Pointer\", \"Vizsla\", \"English Setter\", \"Irish Setter\", \"Gordon Setter\", \"Brittany dog\", \"Clumber Spaniel\", \"English Springer Spaniel\", \"Welsh Springer Spaniel\", \"Cocker Spaniel\", \"Sussex Spaniel\", \"Irish Water Spaniel\", \"Kuvasz\", \"Schipperke\", \"Groenendael dog\", \"Malinois\", \"Briard\", \"Australian Kelpie\", \"Komondor\", \"Old English Sheepdog\", \"Shetland Sheepdog\", \"collie\", \"Border Collie\", \"Bouvier des Flandres dog\", \"Rottweiler\", \"German Shepherd Dog\", \"Dobermann\", \"Miniature Pinscher\", \"Greater Swiss Mountain Dog\", \"Bernese Mountain Dog\", \"Appenzeller Sennenhund\", \"Entlebucher Sennenhund\", \"Boxer\", \"Bullmastiff\", \"Tibetan Mastiff\", \"French Bulldog\", \"Great Dane\", \"St. Bernard\", \"husky\", \"Alaskan Malamute\", \"Siberian Husky\", \"Dalmatian\", \"Affenpinscher\", \"Basenji\", \"pug\", \"Leonberger\", \"Newfoundland dog\", \"Great Pyrenees dog\", \"Samoyed\", \"Pomeranian\", \"Chow Chow\", \"Keeshond\", \"brussels griffon\", \"Pembroke Welsh Corgi\", \"Cardigan Welsh Corgi\", \"Toy Poodle\", \"Miniature Poodle\", \"Standard Poodle\", \"Mexican hairless dog (xoloitzcuintli)\", \"grey wolf\", \"Alaskan tundra wolf\", \"red wolf or maned wolf\", \"coyote\", \"dingo\", \"dhole\", \"African wild dog\", \"hyena\", \"red fox\", \"kit fox\", \"Arctic fox\", \"grey fox\", \"tabby cat\", \"tiger cat\", \"Persian cat\", \"Siamese cat\", \"Egyptian Mau\", \"cougar\", \"lynx\", \"leopard\", \"snow leopard\", \"jaguar\", \"lion\", \"tiger\", \"cheetah\", \"brown bear\", \"American black bear\", \"polar bear\", \"sloth bear\", \"mongoose\", \"meerkat\", \"tiger beetle\", \"ladybug\", \"ground beetle\", \"longhorn beetle\", \"leaf beetle\", \"dung beetle\", \"rhinoceros beetle\", \"weevil\", \"fly\", \"bee\", \"ant\", \"grasshopper\", \"cricket insect\", \"stick insect\", \"cockroach\", \"praying mantis\", \"cicada\", \"leafhopper\", \"lacewing\", \"dragonfly\", \"damselfly\", \"red admiral butterfly\", \"ringlet butterfly\", \"monarch butterfly\", \"small white butterfly\", \"sulphur butterfly\", \"gossamer-winged butterfly\", \"starfish\", \"sea urchin\", \"sea cucumber\", \"cottontail rabbit\", \"hare\", \"Angora rabbit\", \"hamster\", \"porcupine\", \"fox squirrel\", \"marmot\", \"beaver\", \"guinea pig\", \"common sorrel horse\", \"zebra\", \"pig\", \"wild boar\", \"warthog\", \"hippopotamus\", \"ox\", \"water buffalo\", \"bison\", \"ram (adult male sheep)\", \"bighorn sheep\", \"Alpine ibex\", \"hartebeest\", \"impala (antelope)\", \"gazelle\", \"arabian camel\", \"llama\", \"weasel\", \"mink\", \"European polecat\", \"black-footed ferret\", \"otter\", \"skunk\", \"badger\", \"armadillo\", \"three-toed sloth\", \"orangutan\", \"gorilla\", \"chimpanzee\", \"gibbon\", \"siamang\", \"guenon\", \"patas monkey\", \"baboon\", \"macaque\", \"langur\", \"black-and-white colobus\", \"proboscis monkey\", \"marmoset\", \"white-headed capuchin\", \"howler monkey\", \"titi monkey\", \"Geoffroy's spider monkey\", \"common squirrel monkey\", \"ring-tailed lemur\", \"indri\", \"Asian elephant\", \"African bush elephant\", \"red panda\", \"giant panda\", \"snoek fish\", \"eel\", \"silver salmon\", \"rock beauty fish\", \"clownfish\", \"sturgeon\", \"gar fish\", \"lionfish\", \"pufferfish\", \"abacus\", \"abaya\", \"academic gown\", \"accordion\", \"acoustic guitar\", \"aircraft carrier\", \"airliner\", \"airship\", \"altar\", \"ambulance\", \"amphibious vehicle\", \"analog clock\", \"apiary\", \"apron\", \"trash can\", \"assault rifle\", \"backpack\", \"bakery\", \"balance beam\", \"balloon\", \"ballpoint pen\", \"Band-Aid\", \"banjo\", \"baluster / handrail\", \"barbell\", \"barber chair\", \"barbershop\", \"barn\", \"barometer\", \"barrel\", \"wheelbarrow\", \"baseball\", \"basketball\", \"bassinet\", \"bassoon\", \"swimming cap\", \"bath towel\", \"bathtub\", \"station wagon\", \"lighthouse\", \"beaker\", \"military hat (bearskin or shako)\", \"beer bottle\", \"beer glass\", \"bell tower\", \"baby bib\", \"tandem bicycle\", \"bikini\", \"ring binder\", \"binoculars\", \"birdhouse\", \"boathouse\", \"bobsleigh\", \"bolo tie\", \"poke bonnet\", \"bookcase\", \"bookstore\", \"bottle cap\", \"hunting bow\", \"bow tie\", \"brass memorial plaque\", \"bra\", \"breakwater\", \"breastplate\", \"broom\", \"bucket\", \"buckle\", \"bulletproof vest\", \"high-speed train\", \"butcher shop\", \"taxicab\", \"cauldron\", \"candle\", \"cannon\", \"canoe\", \"can opener\", \"cardigan\", \"car mirror\", \"carousel\", \"tool kit\", \"cardboard box / carton\", \"car wheel\", \"automated teller machine\", \"cassette\", \"cassette player\", \"castle\", \"catamaran\", \"CD player\", \"cello\", \"mobile phone\", \"chain\", \"chain-link fence\", \"chain mail\", \"chainsaw\", \"storage chest\", \"chiffonier\", \"bell or wind chime\", \"china cabinet\", \"Christmas stocking\", \"church\", \"movie theater\", \"cleaver\", \"cliff dwelling\", \"cloak\", \"clogs\", \"cocktail shaker\", \"coffee mug\", \"coffeemaker\", \"spiral or coil\", \"combination lock\", \"computer keyboard\", \"candy store\", \"container ship\", \"convertible\", \"corkscrew\", \"cornet\", \"cowboy boot\", \"cowboy hat\", \"cradle\", \"construction crane\", \"crash helmet\", \"crate\", \"infant bed\", \"Crock Pot\", \"croquet ball\", \"crutch\", \"cuirass\", \"dam\", \"desk\", \"desktop computer\", \"rotary dial telephone\", \"diaper\", \"digital clock\", \"digital watch\", \"dining table\", \"dishcloth\", \"dishwasher\", \"disc brake\", \"dock\", \"dog sled\", \"dome\", \"doormat\", \"drilling rig\", \"drum\", \"drumstick\", \"dumbbell\", \"Dutch oven\", \"electric fan\", \"electric guitar\", \"electric locomotive\", \"entertainment center\", \"envelope\", \"espresso machine\", \"face powder\", \"feather boa\", \"filing cabinet\", \"fireboat\", \"fire truck\", \"fire screen\", \"flagpole\", \"flute\", \"folding chair\", \"football helmet\", \"forklift\", \"fountain\", \"fountain pen\", \"four-poster bed\", \"freight car\", \"French horn\", \"frying pan\", \"fur coat\", \"garbage truck\", \"gas mask or respirator\", \"gas pump\", \"goblet\", \"go-kart\", \"golf ball\", \"golf cart\", \"gondola\", \"gong\", \"gown\", \"grand piano\", \"greenhouse\", \"radiator grille\", \"grocery store\", \"guillotine\", \"hair clip\", \"hair spray\", \"half-track\", \"hammer\", \"hamper\", \"hair dryer\", \"hand-held computer\", \"handkerchief\", \"hard disk drive\", \"harmonica\", \"harp\", \"combine harvester\", \"hatchet\", \"holster\", \"home theater\", \"honeycomb\", \"hook\", \"hoop skirt\", \"gymnastic horizontal bar\", \"horse-drawn vehicle\", \"hourglass\", \"iPod\", \"clothes iron\", \"carved pumpkin\", \"jeans\", \"jeep\", \"T-shirt\", \"jigsaw puzzle\", \"rickshaw\", \"joystick\", \"kimono\", \"knee pad\", \"knot\", \"lab coat\", \"ladle\", \"lampshade\", \"laptop computer\", \"lawn mower\", \"lens cap\", \"letter opener\", \"library\", \"lifeboat\", \"lighter\", \"limousine\", \"ocean liner\", \"lipstick\", \"slip-on shoe\", \"lotion\", \"music speaker\", \"loupe magnifying glass\", \"sawmill\", \"magnetic compass\", \"messenger bag\", \"mailbox\", \"tights\", \"one-piece bathing suit\", \"manhole cover\", \"maraca\", \"marimba\", \"mask\", \"matchstick\", \"maypole\", \"maze\", \"measuring cup\", \"medicine cabinet\", \"megalith\", \"microphone\", \"microwave oven\", \"military uniform\", \"milk can\", \"minibus\", \"miniskirt\", \"minivan\", \"missile\", \"mitten\", \"mixing bowl\", \"mobile home\", \"ford model t\", \"modem\", \"monastery\", \"monitor\", \"moped\", \"mortar and pestle\", \"graduation cap\", \"mosque\", \"mosquito net\", \"vespa\", \"mountain bike\", \"tent\", \"computer mouse\", \"mousetrap\", \"moving van\", \"muzzle\", \"metal nail\", \"neck brace\", \"necklace\", \"baby pacifier\", \"notebook computer\", \"obelisk\", \"oboe\", \"ocarina\", \"odometer\", \"oil filter\", \"pipe organ\", \"oscilloscope\", \"overskirt\", \"bullock cart\", \"oxygen mask\", \"product packet / packaging\", \"paddle\", \"paddle wheel\", \"padlock\", \"paintbrush\", \"pajamas\", \"palace\", \"pan flute\", \"paper towel\", \"parachute\", \"parallel bars\", \"park bench\", \"parking meter\", \"railroad car\", \"patio\", \"payphone\", \"pedestal\", \"pencil case\", \"pencil sharpener\", \"perfume\", \"Petri dish\", \"photocopier\", \"plectrum\", \"Pickelhaube\", \"picket fence\", \"pickup truck\", \"pier\", \"piggy bank\", \"pill bottle\", \"pillow\", \"ping-pong ball\", \"pinwheel\", \"pirate ship\", \"drink pitcher\", \"block plane\", \"planetarium\", \"plastic bag\", \"plate rack\", \"farm plow\", \"plunger\", \"Polaroid camera\", \"pole\", \"police van\", \"poncho\", \"pool table\", \"soda bottle\", \"plant pot\", \"potter's wheel\", \"power drill\", \"prayer rug\", \"printer\", \"prison\", \"missile\", \"projector\", \"hockey puck\", \"punching bag\", \"purse\", \"quill\", \"quilt\", \"race car\", \"racket\", \"radiator\", \"radio\", \"radio telescope\", \"rain barrel\", \"recreational vehicle\", \"fishing casting reel\", \"reflex camera\", \"refrigerator\", \"remote control\", \"restaurant\", \"revolver\", \"rifle\", \"rocking chair\", \"rotisserie\", \"eraser\", \"rugby ball\", \"ruler measuring stick\", \"sneaker\", \"safe\", \"safety pin\", \"salt shaker\", \"sandal\", \"sarong\", \"saxophone\", \"scabbard\", \"weighing scale\", \"school bus\", \"schooner\", \"scoreboard\", \"CRT monitor\", \"screw\", \"screwdriver\", \"seat belt\", \"sewing machine\", \"shield\", \"shoe store\", \"shoji screen / room divider\", \"shopping basket\", \"shopping cart\", \"shovel\", \"shower cap\", \"shower curtain\", \"ski\", \"balaclava ski mask\", \"sleeping bag\", \"slide rule\", \"sliding door\", \"slot machine\", \"snorkel\", \"snowmobile\", \"snowplow\", \"soap dispenser\", \"soccer ball\", \"sock\", \"solar thermal collector\", \"sombrero\", \"soup bowl\", \"keyboard space bar\", \"space heater\", \"space shuttle\", \"spatula\", \"motorboat\", \"spider web\", \"spindle\", \"sports car\", \"spotlight\", \"stage\", \"steam locomotive\", \"through arch bridge\", \"steel drum\", \"stethoscope\", \"scarf\", \"stone wall\", \"stopwatch\", \"stove\", \"strainer\", \"tram\", \"stretcher\", \"couch\", \"stupa\", \"submarine\", \"suit\", \"sundial\", \"sunglasses\", \"sunglasses\", \"sunscreen\", \"suspension bridge\", \"mop\", \"sweatshirt\", \"swim trunks / shorts\", \"swing\", \"electrical switch\", \"syringe\", \"table lamp\", \"tank\", \"tape player\", \"teapot\", \"teddy bear\", \"television\", \"tennis ball\", \"thatched roof\", \"front curtain\", \"thimble\", \"threshing machine\", \"throne\", \"tile roof\", \"toaster\", \"tobacco shop\", \"toilet seat\", \"torch\", \"totem pole\", \"tow truck\", \"toy store\", \"tractor\", \"semi-trailer truck\", \"tray\", \"trench coat\", \"tricycle\", \"trimaran\", \"tripod\", \"triumphal arch\", \"trolleybus\", \"trombone\", \"hot tub\", \"turnstile\", \"typewriter keyboard\", \"umbrella\", \"unicycle\", \"upright piano\", \"vacuum cleaner\", \"vase\", \"vaulted or arched ceiling\", \"velvet fabric\", \"vending machine\", \"vestment\", \"viaduct\", \"violin\", \"volleyball\", \"waffle iron\", \"wall clock\", \"wallet\", \"wardrobe\", \"military aircraft\", \"sink\", \"washing machine\", \"water bottle\", \"water jug\", \"water tower\", \"whiskey jug\", \"whistle\", \"hair wig\", \"window screen\", \"window shade\", \"Windsor tie\", \"wine bottle\", \"airplane wing\", \"wok\", \"wooden spoon\", \"wool\", \"split-rail fence\", \"shipwreck\", \"sailboat\", \"yurt\", \"website\", \"comic book\", \"crossword\", \"traffic or street sign\", \"traffic light\", \"dust jacket\", \"menu\", \"plate\", \"guacamole\", \"consomme\", \"hot pot\", \"trifle\", \"ice cream\", \"popsicle\", \"baguette\", \"bagel\", \"pretzel\", \"cheeseburger\", \"hot dog\", \"mashed potatoes\", \"cabbage\", \"broccoli\", \"cauliflower\", \"zucchini\", \"spaghetti squash\", \"acorn squash\", \"butternut squash\", \"cucumber\", \"artichoke\", \"bell pepper\", \"cardoon\", \"mushroom\", \"Granny Smith apple\", \"strawberry\", \"orange\", \"lemon\", \"fig\", \"pineapple\", \"banana\", \"jackfruit\", \"cherimoya (custard apple)\", \"pomegranate\", \"hay\", \"carbonara\", \"chocolate syrup\", \"dough\", \"meatloaf\", \"pizza\", \"pot pie\", \"burrito\", \"red wine\", \"espresso\", \"tea cup\", \"eggnog\", \"mountain\", \"bubble\", \"cliff\", \"coral reef\", \"geyser\", \"lakeshore\", \"promontory\", \"sandbar\", \"beach\", \"valley\", \"volcano\", \"baseball player\", \"bridegroom\", \"scuba diver\", \"rapeseed\", \"daisy\", \"yellow lady's slipper\", \"corn\", \"acorn\", \"rose hip\", \"horse chestnut seed\", \"coral fungus\", \"agaric\", \"gyromitra\", \"stinkhorn mushroom\", \"earth star fungus\", \"hen of the woods mushroom\", \"bolete\", \"corn cob\", \"toilet paper\"]\n",
|
| 217 |
+
"label_int = dict(\n",
|
| 218 |
+
" zip(imagenet_class_names.CLIP_IMAGENET_CLASS_NAMES,\n",
|
| 219 |
+
" range(len(imagenet_class_names.CLIP_IMAGENET_CLASS_NAMES))))[label]"
|
| 220 |
+
],
|
| 221 |
+
"metadata": {
|
| 222 |
+
"cellView": "form",
|
| 223 |
+
"id": "_CiyXD_6nQbu"
|
| 224 |
+
},
|
| 225 |
+
"execution_count": null,
|
| 226 |
+
"outputs": []
|
| 227 |
+
},
|
| 228 |
+
{
|
| 229 |
+
"cell_type": "code",
|
| 230 |
+
"source": [
|
| 231 |
+
"%%capture --no-display\n",
|
| 232 |
+
"batch_size = 8\n",
|
| 233 |
+
"\n",
|
| 234 |
+
"target_labels = jnp.full((batch_size,), label_int, jnp.int32)\n",
|
| 235 |
+
"\n",
|
| 236 |
+
"if is_ar:\n",
|
| 237 |
+
" ar_generation_config = dict(cfg_inference_weight=cfg_w, temp=temp)\n",
|
| 238 |
+
" masked_generation_config = None\n",
|
| 239 |
+
"else:\n",
|
| 240 |
+
" ar_generation_config = {}\n",
|
| 241 |
+
" masked_generation_config = parallel_decode.MaskedGenerationConfig(\n",
|
| 242 |
+
" cfg_inference_weight=cfg_w,\n",
|
| 243 |
+
" choice_temperature = temp,\n",
|
| 244 |
+
" num_steps = 16,\n",
|
| 245 |
+
" ordering = \"maskgit\",\n",
|
| 246 |
+
" schedule = \"cosine\",\n",
|
| 247 |
+
" )\n",
|
| 248 |
+
"\n",
|
| 249 |
+
"# Sample from GIVT and decode\n",
|
| 250 |
+
"sampled_codes, _ = sample(\n",
|
| 251 |
+
" target_labels, jax.random.PRNGKey(rng),\n",
|
| 252 |
+
" tuple(ar_generation_config.items()), masked_generation_config)\n",
|
| 253 |
+
"\n",
|
| 254 |
+
"generated_images = vae_decode(sampled_codes)"
|
| 255 |
+
],
|
| 256 |
+
"metadata": {
|
| 257 |
+
"id": "sCcGB0m1oQY1"
|
| 258 |
+
},
|
| 259 |
+
"execution_count": null,
|
| 260 |
+
"outputs": []
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "code",
|
| 264 |
+
"source": [
|
| 265 |
+
"#@markdown Visualize images\n",
|
| 266 |
+
"ncols = 4\n",
|
| 267 |
+
"nrows = generated_images.shape[0] // ncols\n",
|
| 268 |
+
"fig, axes = plt.subplots(nrows, ncols, figsize=(4 * ncols, 4 * nrows))\n",
|
| 269 |
+
"\n",
|
| 270 |
+
"for idx, (ax, img) in enumerate(zip(axes.flat, generated_images)):\n",
|
| 271 |
+
" ax.imshow(img * .5 + .5)\n",
|
| 272 |
+
" if idx == 0:\n",
|
| 273 |
+
" ax.set_title(f'Label: {label} ({label_int})', fontsize=10, ha='left', loc='left')\n",
|
| 274 |
+
" ax.set_axis_off()"
|
| 275 |
+
],
|
| 276 |
+
"metadata": {
|
| 277 |
+
"id": "4FWgfAghuh8P",
|
| 278 |
+
"cellView": "form"
|
| 279 |
+
},
|
| 280 |
+
"execution_count": null,
|
| 281 |
+
"outputs": []
|
| 282 |
+
},
|
| 283 |
+
{
|
| 284 |
+
"cell_type": "code",
|
| 285 |
+
"source": [
|
| 286 |
+
"#@markdown Visualize latent codes\n",
|
| 287 |
+
"nrows = sampled_codes.shape[0]\n",
|
| 288 |
+
"ncols = sampled_codes.shape[-1] + 1\n",
|
| 289 |
+
"fig, axes = plt.subplots(nrows, ncols, figsize=(ncols, nrows))\n",
|
| 290 |
+
"\n",
|
| 291 |
+
"for r, (row_ax, code) in enumerate(zip(axes, sampled_codes)):\n",
|
| 292 |
+
" code_norm = (code - code.min()) / (code.max() - code.min())\n",
|
| 293 |
+
" for c, ax in enumerate(row_ax):\n",
|
| 294 |
+
" if c == 0:\n",
|
| 295 |
+
" cc = generated_images[r] * .5 + .5\n",
|
| 296 |
+
" else:\n",
|
| 297 |
+
" cc = code_norm[..., c - 1].reshape(res // 16, res // 16)\n",
|
| 298 |
+
" ax.imshow(cc)\n",
|
| 299 |
+
" ax.set_axis_off()"
|
| 300 |
+
],
|
| 301 |
+
"metadata": {
|
| 302 |
+
"id": "zGPPeXONy0Am",
|
| 303 |
+
"cellView": "form"
|
| 304 |
+
},
|
| 305 |
+
"execution_count": null,
|
| 306 |
+
"outputs": []
|
| 307 |
+
}
|
| 308 |
+
]
|
| 309 |
+
}
|
big_vision_repo/big_vision/configs/proj/givt/givt_imagenet2012.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Train Generative Infinite Vocabulary Transformer (GIVT) on ImageNet.
|
| 17 |
+
|
| 18 |
+
Example launch command (local; see main README for launching on TPU servers):
|
| 19 |
+
|
| 20 |
+
python -m big_vision.trainers.proj.givt.generative \
|
| 21 |
+
--config big_vision/configs/proj/givt/givt_imagenet2012.py \
|
| 22 |
+
--workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%m-%d_%H%M'`
|
| 23 |
+
|
| 24 |
+
Add the suffix `:key1=value1,key2=value2,...` to the config path in the launch
|
| 25 |
+
command to modify the the config with the arguments below. For example:
|
| 26 |
+
`--config big_vision/configs/proj/givt/givt_imagenet_2012.py:model_size=large`
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
import big_vision.configs.common as bvcc
|
| 30 |
+
import ml_collections
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
RES = 256
|
| 34 |
+
PATCH_SIZE = 16
|
| 35 |
+
|
| 36 |
+
GIVT_MODELS = {
|
| 37 |
+
'base': dict(num_decoder_layers=12, num_heads=12, mlp_dim=3072, emb_dim=768, dec_dropout_rate=0.1),
|
| 38 |
+
'default': dict(num_decoder_layers=24, num_heads=16, mlp_dim=4096, emb_dim=1024, dec_dropout_rate=0.2),
|
| 39 |
+
'large': dict(num_decoder_layers=48, num_heads=16, mlp_dim=8192, emb_dim=1536, dec_dropout_rate=0.3)
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def get_config(arg=None):
|
| 44 |
+
"""A config for training a simple VAE on imagenet2012."""
|
| 45 |
+
arg = bvcc.parse_arg(arg, res=RES, patch_size=PATCH_SIZE, style='ar', # 'ar' or 'masked'
|
| 46 |
+
model_size='default', runlocal=False, singlehost=False,
|
| 47 |
+
adaptor=False)
|
| 48 |
+
config = ml_collections.ConfigDict()
|
| 49 |
+
|
| 50 |
+
config.input = {}
|
| 51 |
+
### Using Imagenette here to ensure this config is runnable without manual
|
| 52 |
+
### download of ImageNet. This is only meant for testing and will overfit
|
| 53 |
+
### immediately. Please download ImageNet to reproduce the paper results.
|
| 54 |
+
# config.input.data = dict(name='imagenet2012', split='train[4096:]')
|
| 55 |
+
config.input.data = dict(name='imagenette', split='train')
|
| 56 |
+
|
| 57 |
+
config.input.batch_size = 8 * 1024 if not arg.runlocal else 8
|
| 58 |
+
config.input.shuffle_buffer_size = 25_000 if not arg.runlocal else 10
|
| 59 |
+
|
| 60 |
+
config.total_epochs = 500
|
| 61 |
+
|
| 62 |
+
config.input.pp = (
|
| 63 |
+
f'decode_jpeg_and_inception_crop({arg.res},'
|
| 64 |
+
f'area_min=80, area_max=100, ratio_min=1.0, ratio_max=1.0,'
|
| 65 |
+
f'method="bicubic", antialias=True)'
|
| 66 |
+
f'|flip_lr'
|
| 67 |
+
f'|value_range(-1, 1, key="image")'
|
| 68 |
+
f'|copy("label", "labels")'
|
| 69 |
+
f'|keep("image", "labels")')
|
| 70 |
+
|
| 71 |
+
pp_eval = (
|
| 72 |
+
f'decode'
|
| 73 |
+
f'|resize_small({arg.res}, inkey="image", outkey="image",'
|
| 74 |
+
f'method="bicubic", antialias=True)'
|
| 75 |
+
f'|central_crop({arg.res})'
|
| 76 |
+
f'|value_range(-1, 1, key="image")'
|
| 77 |
+
f'|copy("label", "labels")'
|
| 78 |
+
f'|keep("image", "labels")')
|
| 79 |
+
|
| 80 |
+
config.log_training_steps = 50
|
| 81 |
+
config.ckpt_steps = 1000
|
| 82 |
+
config.keep_ckpt_steps = None
|
| 83 |
+
|
| 84 |
+
# Flags for AR model.
|
| 85 |
+
config.ar_generation_config = ml_collections.ConfigDict()
|
| 86 |
+
config.ar_generation_config.temp = 0.95
|
| 87 |
+
config.ar_generation_config.temp_probs = 1.0
|
| 88 |
+
config.ar_generation_config.beam_size = 1
|
| 89 |
+
config.ar_generation_config.fan_size = 1
|
| 90 |
+
config.ar_generation_config.rand_top_k = False
|
| 91 |
+
config.ar_generation_config.rand_top_k_temp = 1.0
|
| 92 |
+
config.ar_generation_config.cfg_inference_weight = 0.4
|
| 93 |
+
|
| 94 |
+
# Flags for masked model.
|
| 95 |
+
config.masked_generation_config = ml_collections.ConfigDict()
|
| 96 |
+
config.masked_generation_config.choice_temperature = 35.0
|
| 97 |
+
config.masked_generation_config.ordering = 'maskgit'
|
| 98 |
+
config.masked_generation_config.cfg_inference_weight = 0.0
|
| 99 |
+
config.masked_generation_config.schedule = 'cosine'
|
| 100 |
+
|
| 101 |
+
# Used for eval sweep.
|
| 102 |
+
config.eval_only = False
|
| 103 |
+
|
| 104 |
+
# VAE section
|
| 105 |
+
config.vae = {}
|
| 106 |
+
config.vae.model = ml_collections.ConfigDict()
|
| 107 |
+
config.vae.model.code_len = (arg.res // arg.patch_size) ** 2
|
| 108 |
+
config.vae.model_name = 'proj.givt.cnn'
|
| 109 |
+
config.vae.model.codeword_dim = 16
|
| 110 |
+
config.vae.model.filters = 128
|
| 111 |
+
config.vae.model.num_res_blocks = 2
|
| 112 |
+
config.vae.model.channel_multipliers = (1, 1, 2, 2, 4)
|
| 113 |
+
config.vae.model.conv_downsample = False
|
| 114 |
+
config.vae.model.activation_fn = 'swish'
|
| 115 |
+
config.vae.model.norm_type = 'GN'
|
| 116 |
+
if arg.model_size == 'large':
|
| 117 |
+
config.vae.model_init = 'gs://big_vision/givt/vae_imagenet_2012_beta_1e-5_params'
|
| 118 |
+
else:
|
| 119 |
+
config.vae.model_init = 'gs://big_vision/givt/vae_imagenet_2012_beta_5e-5_params'
|
| 120 |
+
config.vae.model.malib_ckpt = True
|
| 121 |
+
config.vae.model_load = {}
|
| 122 |
+
config.vae.model_load.malib_ckpt = config.vae.model.malib_ckpt
|
| 123 |
+
config.vae.model_load.use_ema_params = True
|
| 124 |
+
|
| 125 |
+
# GIVT section
|
| 126 |
+
config.model_name = 'proj.givt.givt'
|
| 127 |
+
config.model_init = ''
|
| 128 |
+
assert arg.model_size in GIVT_MODELS, f'Unknown model size: {arg.model_size}'
|
| 129 |
+
config.model = ml_collections.ConfigDict(GIVT_MODELS[arg.model_size])
|
| 130 |
+
config.model.num_layers = 0
|
| 131 |
+
config.model.num_labels = 1000 # None
|
| 132 |
+
config.model.seq_len = config.vae.model.code_len
|
| 133 |
+
config.model.out_dim = config.vae.model.codeword_dim
|
| 134 |
+
config.model.num_mixtures = 16
|
| 135 |
+
config.model.posemb_type = 'learn'
|
| 136 |
+
config.model.scale_tol = 1e-6
|
| 137 |
+
config.model.style = arg.style
|
| 138 |
+
config.model.min_masking_rate_training = 0.3
|
| 139 |
+
config.model.mask_style = 'concat'
|
| 140 |
+
config.model.drop_labels_probability = 0.1
|
| 141 |
+
config.model.fix_square_plus = True
|
| 142 |
+
config.model.per_channel_mixtures = False
|
| 143 |
+
config.model_init = ''
|
| 144 |
+
# Required for model sharding
|
| 145 |
+
config.model.scan = True
|
| 146 |
+
config.model.remat_policy = 'nothing_saveable'
|
| 147 |
+
|
| 148 |
+
# Adaptor section
|
| 149 |
+
config.adaptor_name = 'proj.givt.adaptor' if arg.adaptor else ''
|
| 150 |
+
config.adaptor = {}
|
| 151 |
+
config.adaptor.model = ml_collections.ConfigDict()
|
| 152 |
+
config.adaptor.model.num_blocks = 8
|
| 153 |
+
config.adaptor.model.num_channels_bottleneck = 4 * config.model.out_dim
|
| 154 |
+
|
| 155 |
+
config.optax_name = 'scale_by_adam'
|
| 156 |
+
config.optax = dict(b2=0.95)
|
| 157 |
+
config.grad_clip_norm = 1.0
|
| 158 |
+
|
| 159 |
+
# FSDP training by default
|
| 160 |
+
config.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 161 |
+
config.sharding_rules = [('act_batch', ('data',))]
|
| 162 |
+
|
| 163 |
+
# Standard schedule
|
| 164 |
+
config.lr = 0.001
|
| 165 |
+
config.wd = 0.0001
|
| 166 |
+
config.schedule = dict(decay_type='cosine', warmup_percent=0.1)
|
| 167 |
+
|
| 168 |
+
# MaskGIT-specific parameters
|
| 169 |
+
if arg.style == 'masked':
|
| 170 |
+
config.model.dec_dropout_rate = 0.4
|
| 171 |
+
config.wd = 0.0
|
| 172 |
+
if arg.res == 512:
|
| 173 |
+
config.masked_generation_config.choice_temperature = 140
|
| 174 |
+
# GIVT-Causal 512px specific parameters
|
| 175 |
+
elif arg.res == 512 and arg.model_size == 'large':
|
| 176 |
+
config.model.dec_dropout_rate = 0.1
|
| 177 |
+
# Set up space-to-depth/pixel shuffle
|
| 178 |
+
config.vae.model.code_len //= 2
|
| 179 |
+
config.vae.model.pixel_shuffle_patch_size = (1, 2)
|
| 180 |
+
config.model.seq_len //= 2
|
| 181 |
+
config.model.out_dim = config.vae.model.codeword_dim * 2
|
| 182 |
+
config.model.num_mixtures = 32
|
| 183 |
+
config.adaptor.model.num_channels_bottleneck = 8 * config.model.out_dim
|
| 184 |
+
config.adaptor.model.pixel_shuffle_patch_size = (1, 2)
|
| 185 |
+
# Update sampling config
|
| 186 |
+
config.ar_generation_config.temp = 0.9
|
| 187 |
+
config.ar_generation_config.cfg_inference_weight = 0.9
|
| 188 |
+
|
| 189 |
+
### Evaluation section
|
| 190 |
+
config.evals = {}
|
| 191 |
+
config.evals.val = ml_collections.ConfigDict()
|
| 192 |
+
config.evals.val.type = 'mean'
|
| 193 |
+
config.evals.val.pred = 'validation'
|
| 194 |
+
config.evals.val.data = {**config.input.data}
|
| 195 |
+
config.evals.val.data.split = f'train[:{4096 if not arg.runlocal else 8}]'
|
| 196 |
+
config.evals.val.pp_fn = pp_eval
|
| 197 |
+
config.evals.val.log_steps = 1_000 if not arg.runlocal else 20
|
| 198 |
+
|
| 199 |
+
config.evals.save_pred_sampling = dict(
|
| 200 |
+
type='proj.givt.save_predictions',
|
| 201 |
+
pp_fn=pp_eval,
|
| 202 |
+
log_steps=10_000,
|
| 203 |
+
pred='sample',
|
| 204 |
+
batch_size=512,
|
| 205 |
+
data=dict(name=config.input.data.name, split='validation[:512]'),
|
| 206 |
+
outfile='inference_sampled.npz',
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
config.seed = 0
|
| 210 |
+
|
| 211 |
+
config.ckpt_timeout = 30
|
| 212 |
+
|
| 213 |
+
if arg.runlocal:
|
| 214 |
+
config.input.batch_size = 4
|
| 215 |
+
config.input.shuffle_buffer_size = 10
|
| 216 |
+
config.log_training_steps = 5
|
| 217 |
+
config.model.num_decoder_layers = 2
|
| 218 |
+
|
| 219 |
+
config.evals.val.data.split = 'validation[:16]'
|
| 220 |
+
config.evals.val.log_steps = 20
|
| 221 |
+
|
| 222 |
+
return config
|
big_vision_repo/big_vision/configs/proj/givt/givt_nyu_depth.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Train a GIVT encoder-decoder model for NYU depth prediction."""
|
| 17 |
+
|
| 18 |
+
import itertools
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
import ml_collections
|
| 21 |
+
|
| 22 |
+
ConfigDict = ml_collections.ConfigDict
|
| 23 |
+
|
| 24 |
+
VTT_MODELS = {
|
| 25 |
+
'base': dict(num_layers=12, num_decoder_layers=12, num_heads=12, mlp_dim=3072, emb_dim=768),
|
| 26 |
+
'large': dict(num_layers=24, num_decoder_layers=24, num_heads=16, mlp_dim=4096, emb_dim=1024),
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
RES = 512
|
| 30 |
+
PATCH_SIZE = 16
|
| 31 |
+
LABEL_RES = 512
|
| 32 |
+
LABEL_PATCH_SIZE = 16
|
| 33 |
+
QUANTIZATION_BINS = 256
|
| 34 |
+
MIN_DEPTH = 0.001
|
| 35 |
+
MAX_DEPTH = 10.0
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_config(arg='split=sweep'):
|
| 39 |
+
"""Config for training."""
|
| 40 |
+
arg = bvcc.parse_arg(arg, split='sweep', runlocal=False, singlehost=False)
|
| 41 |
+
config = ConfigDict()
|
| 42 |
+
|
| 43 |
+
config.input = {}
|
| 44 |
+
config.input.pp = (
|
| 45 |
+
f'decode|nyu_depth|'
|
| 46 |
+
f'randu("fliplr")|det_fliplr(key="image")|det_fliplr(key="labels")|'
|
| 47 |
+
f'inception_box|crop_box(key="image")|crop_box(key="labels")|'
|
| 48 |
+
f'resize({RES})|'
|
| 49 |
+
f'resize({LABEL_RES},key="labels",method="nearest")|'
|
| 50 |
+
f'bin_nyu_depth(min_depth={MIN_DEPTH}, max_depth={MAX_DEPTH}, num_bins={QUANTIZATION_BINS})|'
|
| 51 |
+
f'value_range(-1,1)|'
|
| 52 |
+
f'copy("image", "cond_image")|copy("labels", "image")|'
|
| 53 |
+
f'keep("image", "cond_image")'
|
| 54 |
+
)
|
| 55 |
+
pp_eval = (
|
| 56 |
+
f'decode|nyu_depth|'
|
| 57 |
+
f'nyu_eval_crop|'
|
| 58 |
+
f'resize({RES})|'
|
| 59 |
+
f'resize({LABEL_RES},key="labels",method="nearest")|'
|
| 60 |
+
f'bin_nyu_depth(min_depth={MIN_DEPTH}, max_depth={MAX_DEPTH}, num_bins={QUANTIZATION_BINS})|'
|
| 61 |
+
f'value_range(-1,1)|'
|
| 62 |
+
f'copy("image", "cond_image")|copy("labels", "image")|'
|
| 63 |
+
f'keep("image", "cond_image")'
|
| 64 |
+
)
|
| 65 |
+
pp_predict = (
|
| 66 |
+
f'decode|nyu_depth|'
|
| 67 |
+
f'nyu_eval_crop|copy("labels","ground_truth")|'
|
| 68 |
+
f'resize({RES})|'
|
| 69 |
+
f'value_range(-1,1)|'
|
| 70 |
+
f'copy("image", "cond_image")|'
|
| 71 |
+
f'strong_hash(inkey="tfds_id", outkey="image/id")|'
|
| 72 |
+
f'keep("cond_image", "ground_truth", "image/id")'
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
config.input.data = dict(name='nyu_depth_v2', split='train')
|
| 76 |
+
config.input.batch_size = 512
|
| 77 |
+
config.input.shuffle_buffer_size = 50_000
|
| 78 |
+
|
| 79 |
+
config.total_epochs = 50
|
| 80 |
+
|
| 81 |
+
config.log_training_steps = 50
|
| 82 |
+
config.ckpt_steps = 1000
|
| 83 |
+
config.keep_ckpt_steps = None
|
| 84 |
+
config.prefetch_to_device = 2
|
| 85 |
+
config.seed = 0
|
| 86 |
+
|
| 87 |
+
# Optimizer section
|
| 88 |
+
config.optax_name = 'big_vision.scale_by_adafactor'
|
| 89 |
+
config.optax = dict(beta2_cap=0.95)
|
| 90 |
+
|
| 91 |
+
config.ar_generation_config = ConfigDict()
|
| 92 |
+
config.ar_generation_config.temp = 0.9
|
| 93 |
+
config.ar_generation_config.temp_probs = 1.0
|
| 94 |
+
config.ar_generation_config.beam_size = 2
|
| 95 |
+
config.ar_generation_config.fan_size = 8
|
| 96 |
+
config.ar_generation_config.rand_top_k = False
|
| 97 |
+
config.ar_generation_config.rand_top_k_temp = 1.0
|
| 98 |
+
|
| 99 |
+
config.lr = 0.001
|
| 100 |
+
config.wd = 0.000001
|
| 101 |
+
config.lr_mults = [
|
| 102 |
+
('pos_embedding_encoder.*', 0.1),
|
| 103 |
+
('EmbedPatches.*', 0.1),
|
| 104 |
+
('encoder.*', 0.1),
|
| 105 |
+
('decoder.*', 1.0)
|
| 106 |
+
]
|
| 107 |
+
config.schedule = dict(decay_type='cosine', warmup_percent=0.1)
|
| 108 |
+
|
| 109 |
+
# Oracle section
|
| 110 |
+
config.min_depth = MIN_DEPTH
|
| 111 |
+
config.max_depth = MAX_DEPTH
|
| 112 |
+
config.vae = ConfigDict()
|
| 113 |
+
config.vae.model_name = 'proj.givt.vit'
|
| 114 |
+
config.vae.model = ConfigDict()
|
| 115 |
+
config.vae.model.input_size = (RES, RES)
|
| 116 |
+
config.vae.model.patch_size = (PATCH_SIZE, PATCH_SIZE)
|
| 117 |
+
config.vae.model.code_len = 256
|
| 118 |
+
config.vae.model.width = 768
|
| 119 |
+
config.vae.model.enc_depth = 6
|
| 120 |
+
config.vae.model.dec_depth = 12
|
| 121 |
+
config.vae.model.mlp_dim = 3072
|
| 122 |
+
config.vae.model.num_heads = 12
|
| 123 |
+
config.vae.model.codeword_dim = 16
|
| 124 |
+
config.vae.model.code_dropout = 'none'
|
| 125 |
+
config.vae.model.bottleneck_resize = True
|
| 126 |
+
# values: (channel index in source image, number of classes)
|
| 127 |
+
config.vae.model.inout_specs = {
|
| 128 |
+
'depth': (0, QUANTIZATION_BINS),
|
| 129 |
+
}
|
| 130 |
+
config.vae.model_init = 'gs://big_vision/givt/vae_nyu_depth_params.npz'
|
| 131 |
+
|
| 132 |
+
# Model section
|
| 133 |
+
config.model_name = 'proj.givt.givt'
|
| 134 |
+
# # Base model (for exploration)
|
| 135 |
+
# config.model_init = {'encoder': 'howto-i21k-B/16'}
|
| 136 |
+
# config.model = ConfigDict(VTT_MODELS['base'])
|
| 137 |
+
# Large model
|
| 138 |
+
config.model_init = {'encoder': 'howto-i21k-L/16'}
|
| 139 |
+
config.model_load = dict(dont_load=('cls', 'head/bias', 'head/kernel'))
|
| 140 |
+
config.model = ConfigDict(VTT_MODELS['large'])
|
| 141 |
+
config.model.patches = (PATCH_SIZE, PATCH_SIZE)
|
| 142 |
+
config.model.input_size = (RES, RES)
|
| 143 |
+
config.model.posemb_type = 'learn'
|
| 144 |
+
config.model.seq_len = config.vae.model.code_len
|
| 145 |
+
config.model.num_labels = None
|
| 146 |
+
config.model.num_mixtures = 1
|
| 147 |
+
config.model.fix_square_plus = True
|
| 148 |
+
config.model.out_dim = config.vae.model.codeword_dim
|
| 149 |
+
config.model.scale_tol = 1e-6
|
| 150 |
+
config.model.dec_dropout_rate = 0.0
|
| 151 |
+
|
| 152 |
+
# Evaluation section
|
| 153 |
+
config.evals = {}
|
| 154 |
+
config.evals.val = ConfigDict()
|
| 155 |
+
config.evals.val.type = 'mean'
|
| 156 |
+
config.evals.val.pred = 'validation'
|
| 157 |
+
config.evals.val.data = {**config.input.data}
|
| 158 |
+
config.evals.val.data.split = 'validation'
|
| 159 |
+
config.evals.val.pp_fn = pp_eval
|
| 160 |
+
config.evals.val.log_steps = 250
|
| 161 |
+
|
| 162 |
+
base = {
|
| 163 |
+
'type': 'proj.givt.nyu_depth',
|
| 164 |
+
'data': {**config.input.data},
|
| 165 |
+
'pp_fn': pp_predict,
|
| 166 |
+
'pred': 'sample_depth',
|
| 167 |
+
'log_steps': 2000,
|
| 168 |
+
'min_depth': MIN_DEPTH,
|
| 169 |
+
'max_depth': MAX_DEPTH,
|
| 170 |
+
}
|
| 171 |
+
|
| 172 |
+
config.evals.nyu_depth_val = dict(base)
|
| 173 |
+
config.evals.nyu_depth_val.data.split = 'validation'
|
| 174 |
+
|
| 175 |
+
config.evals.save_pred = dict(base)
|
| 176 |
+
config.evals.save_pred.type = 'proj.givt.save_predictions'
|
| 177 |
+
del config.evals.save_pred.min_depth, config.evals.save_pred.max_depth
|
| 178 |
+
config.evals.save_pred.log_steps = 100_000
|
| 179 |
+
config.evals.save_pred.data.split = 'validation[:128]'
|
| 180 |
+
config.evals.save_pred.outfile = 'inference.npz'
|
| 181 |
+
|
| 182 |
+
config.eval_only = False
|
| 183 |
+
config.seed = 0
|
| 184 |
+
|
| 185 |
+
if arg.runlocal:
|
| 186 |
+
config.input.batch_size = 4
|
| 187 |
+
config.input.shuffle_buffer_size = 10
|
| 188 |
+
config.evals.val.log_steps = 20
|
| 189 |
+
config.evals.val.data.split = 'validation[:4]'
|
| 190 |
+
config.evals.nyu_depth_val.data.split = 'validation[:4]'
|
| 191 |
+
config.evals.save_pred.data.split = 'validation[:4]'
|
| 192 |
+
config.model.update(VTT_MODELS['base'])
|
| 193 |
+
del config.model_init
|
| 194 |
+
for k in config.evals.keys():
|
| 195 |
+
if k not in ['val', 'nyu_depth_val', 'save_pred']:
|
| 196 |
+
del config.evals[k]
|
| 197 |
+
|
| 198 |
+
return config
|
big_vision_repo/big_vision/configs/proj/givt/givt_overview.png
ADDED
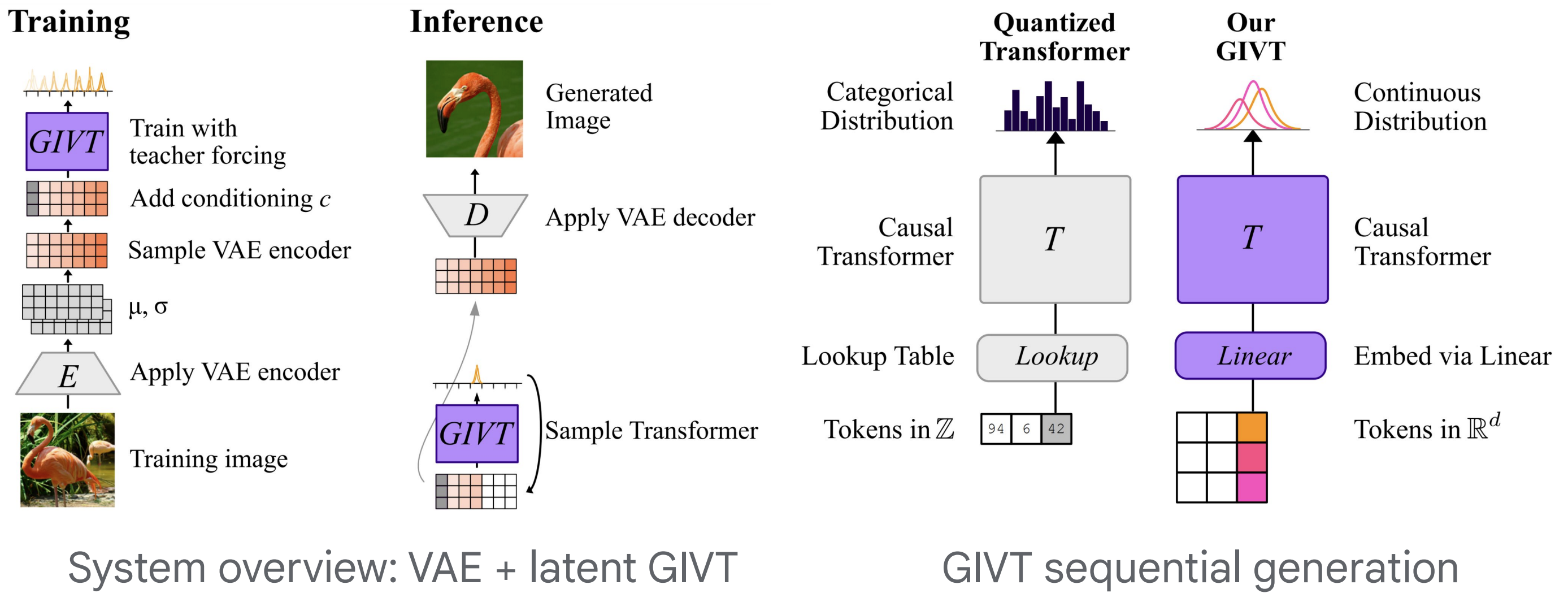
|
big_vision_repo/big_vision/configs/proj/givt/vae_coco_panoptic.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Train VAE for GIVT-based UViM COCO panoptic task.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
import ml_collections as mlc
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def get_config(arg='res=512,patch_size=16'):
|
| 24 |
+
"""Config for training label compression on COCO-panoptic."""
|
| 25 |
+
arg = bvcc.parse_arg(arg, res=512, patch_size=16,
|
| 26 |
+
runlocal=False, singlehost=False)
|
| 27 |
+
config = mlc.ConfigDict()
|
| 28 |
+
|
| 29 |
+
config.input = {}
|
| 30 |
+
config.input.data = dict(name='coco/2017_panoptic', split='train[4096:]')
|
| 31 |
+
|
| 32 |
+
config.input.batch_size = 1024
|
| 33 |
+
config.input.shuffle_buffer_size = 25_000
|
| 34 |
+
|
| 35 |
+
config.total_epochs = 500
|
| 36 |
+
|
| 37 |
+
config.input.pp = (
|
| 38 |
+
f'decode|coco_panoptic|concat(["semantics","instances"], "labels")|'
|
| 39 |
+
f'randu("fliplr")|det_fliplr(key="image")|det_fliplr(key="labels")|'
|
| 40 |
+
f'inception_box|crop_box(key="image")|crop_box(key="labels")|'
|
| 41 |
+
f'resize({arg.res})|resize({arg.res},key="labels",method="nearest")|'
|
| 42 |
+
f'value_range(-1, 1)|make_canonical|copy("labels","image")|keep("image")'
|
| 43 |
+
)
|
| 44 |
+
pp_eval = (
|
| 45 |
+
f'decode|coco_panoptic|concat(["semantics","instances"], "labels")|'
|
| 46 |
+
f'resize({arg.res})|resize({arg.res},key="labels",method="nearest")|'
|
| 47 |
+
f'value_range(-1, 1)|make_canonical|copy("labels","image")|keep("image", "image/id")'
|
| 48 |
+
)
|
| 49 |
+
|
| 50 |
+
config.log_training_steps = 50
|
| 51 |
+
config.ckpt_steps = 1000
|
| 52 |
+
config.keep_ckpt_steps = None
|
| 53 |
+
|
| 54 |
+
# Model section
|
| 55 |
+
config.model_name = 'proj.givt.vit'
|
| 56 |
+
config.model = mlc.ConfigDict()
|
| 57 |
+
config.model.input_size = (arg.res, arg.res)
|
| 58 |
+
config.model.patch_size = (arg.patch_size, arg.patch_size)
|
| 59 |
+
config.model.code_len = 256
|
| 60 |
+
config.model.width = 768
|
| 61 |
+
config.model.enc_depth = 6
|
| 62 |
+
config.model.dec_depth = 12
|
| 63 |
+
config.model.mlp_dim = 3072
|
| 64 |
+
config.model.num_heads = 12
|
| 65 |
+
config.model.codeword_dim = 32
|
| 66 |
+
config.model.code_dropout = 'none'
|
| 67 |
+
config.model.bottleneck_resize = True
|
| 68 |
+
config.model.scan = True
|
| 69 |
+
config.model.remat_policy = 'nothing_saveable'
|
| 70 |
+
|
| 71 |
+
config.rec_loss_fn = 'xent' # xent, l2
|
| 72 |
+
# values: (index in source image, number of classes)
|
| 73 |
+
config.model.inout_specs = {
|
| 74 |
+
'semantics': (0, 133 + 1), # +1 for void label
|
| 75 |
+
'instances': (1, 100), # COCO: actually 98 train/78 validation.
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
config.beta = 2.5e-4
|
| 79 |
+
config.beta_percept = 0.0
|
| 80 |
+
|
| 81 |
+
config.optax_name = 'scale_by_adam'
|
| 82 |
+
config.optax = dict(b2=0.95)
|
| 83 |
+
config.grad_clip_norm = 1.0
|
| 84 |
+
|
| 85 |
+
# FSDP training by default
|
| 86 |
+
config.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 87 |
+
config.sharding_rules = [('act_batch', ('data',))]
|
| 88 |
+
|
| 89 |
+
config.lr = 1e-3
|
| 90 |
+
config.wd = 1e-4
|
| 91 |
+
config.schedule = dict(decay_type='cosine', warmup_steps=0.1)
|
| 92 |
+
config.grad_clip_norm = 1.0
|
| 93 |
+
|
| 94 |
+
# Evaluation section
|
| 95 |
+
config.evals = {}
|
| 96 |
+
config.evals.val = mlc.ConfigDict()
|
| 97 |
+
config.evals.val.type = 'mean'
|
| 98 |
+
config.evals.val.pred = 'validation'
|
| 99 |
+
config.evals.val.data = {**config.input.data}
|
| 100 |
+
config.evals.val.data.split = 'train[:4096]'
|
| 101 |
+
config.evals.val.pp_fn = pp_eval
|
| 102 |
+
config.evals.val.log_steps = 250
|
| 103 |
+
|
| 104 |
+
base = {
|
| 105 |
+
'type': 'proj.givt.coco_panoptic',
|
| 106 |
+
'pp_fn': pp_eval,
|
| 107 |
+
'log_steps': 5_000,
|
| 108 |
+
'pred': 'predict_panoptic',
|
| 109 |
+
# Filters objects that occupy less than 0.03^2 fraction of all pixels.
|
| 110 |
+
# 'pred_kw': {'min_fraction': 0.03 ** 2},
|
| 111 |
+
}
|
| 112 |
+
config.evals.coco_panoptic_train = dict(**base, data={'split': 'train[4096:8192]'})
|
| 113 |
+
config.evals.coco_panoptic_holdout = dict(**base, data={'split': 'train[:4096]'})
|
| 114 |
+
config.evals.coco_panoptic = dict(**base, data={'split': 'validation'})
|
| 115 |
+
|
| 116 |
+
config.evals.save_pred = dict(type='proj.givt.save_predictions')
|
| 117 |
+
config.evals.save_pred.pp_fn = pp_eval
|
| 118 |
+
config.evals.save_pred.log_steps = 100_000
|
| 119 |
+
config.evals.save_pred.pred = 'predict_panoptic'
|
| 120 |
+
config.evals.save_pred.data = {**config.input.data}
|
| 121 |
+
config.evals.save_pred.data.split = 'validation[:1024]'
|
| 122 |
+
config.evals.save_pred.outfile = 'inference.npz'
|
| 123 |
+
|
| 124 |
+
config.seed = 0
|
| 125 |
+
|
| 126 |
+
if arg.singlehost:
|
| 127 |
+
config.input.batch_size = 128
|
| 128 |
+
config.num_epochs = 100
|
| 129 |
+
elif arg.runlocal:
|
| 130 |
+
config.input.batch_size = 16
|
| 131 |
+
config.input.shuffle_buffer_size = 10
|
| 132 |
+
config.log_training_steps = 5
|
| 133 |
+
config.model.enc_depth = 1
|
| 134 |
+
config.model.dec_depth = 1
|
| 135 |
+
|
| 136 |
+
return config
|
big_vision_repo/big_vision/configs/proj/givt/vae_nyu_depth.py
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Train VAE on NYU depth data for GIVT-based UViM.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
import ml_collections as mlc
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
QUANTIZATION_BINS = 256
|
| 24 |
+
MIN_DEPTH = 0.001
|
| 25 |
+
MAX_DEPTH = 10.0
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_config(arg='res=512,patch_size=16'):
|
| 29 |
+
"""Config for training label compression on NYU depth."""
|
| 30 |
+
arg = bvcc.parse_arg(arg, res=512, patch_size=16,
|
| 31 |
+
runlocal=False, singlehost=False)
|
| 32 |
+
config = mlc.ConfigDict()
|
| 33 |
+
|
| 34 |
+
config.input = {}
|
| 35 |
+
config.input.data = dict(name='nyu_depth_v2', split='train')
|
| 36 |
+
|
| 37 |
+
config.input.batch_size = 1024
|
| 38 |
+
config.input.shuffle_buffer_size = 25_000
|
| 39 |
+
|
| 40 |
+
config.total_epochs = 200
|
| 41 |
+
|
| 42 |
+
config.input.pp = (
|
| 43 |
+
f'decode|nyu_depth|'
|
| 44 |
+
f'randu("fliplr")|det_fliplr(key="image")|det_fliplr(key="labels")|'
|
| 45 |
+
f'inception_box|crop_box(key="image")|crop_box(key="labels")|'
|
| 46 |
+
f'resize({arg.res})|resize({arg.res},key="labels",method="nearest")|'
|
| 47 |
+
f'bin_nyu_depth(min_depth={MIN_DEPTH}, max_depth={MAX_DEPTH}, num_bins={QUANTIZATION_BINS})|'
|
| 48 |
+
f'value_range(-1, 1)|copy("labels", "image")|keep("image")'
|
| 49 |
+
)
|
| 50 |
+
pp_eval = (
|
| 51 |
+
f'decode|nyu_depth|nyu_eval_crop|'
|
| 52 |
+
f'resize({arg.res})|resize({arg.res},key="labels",method="nearest")|'
|
| 53 |
+
f'bin_nyu_depth(min_depth={MIN_DEPTH}, max_depth={MAX_DEPTH}, num_bins={QUANTIZATION_BINS})|'
|
| 54 |
+
f'value_range(-1, 1)|copy("labels", "image")|keep("image")'
|
| 55 |
+
)
|
| 56 |
+
pp_pred = (
|
| 57 |
+
f'decode|nyu_depth|nyu_eval_crop|copy("labels","ground_truth")|'
|
| 58 |
+
f'resize({arg.res})|resize({arg.res},key="labels",method="nearest")|'
|
| 59 |
+
f'bin_nyu_depth(min_depth={MIN_DEPTH}, max_depth={MAX_DEPTH}, num_bins={QUANTIZATION_BINS})|'
|
| 60 |
+
f'value_range(-1, 1)|copy("labels", "image")|'
|
| 61 |
+
f'keep("image", "ground_truth")'
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
config.log_training_steps = 50
|
| 65 |
+
config.ckpt_steps = 1000
|
| 66 |
+
config.keep_ckpt_steps = None
|
| 67 |
+
|
| 68 |
+
# Model section
|
| 69 |
+
config.min_depth = MIN_DEPTH
|
| 70 |
+
config.max_depth = MAX_DEPTH
|
| 71 |
+
config.model_name = 'proj.givt.vit'
|
| 72 |
+
config.model = mlc.ConfigDict()
|
| 73 |
+
config.model.input_size = (arg.res, arg.res)
|
| 74 |
+
config.model.patch_size = (arg.patch_size, arg.patch_size)
|
| 75 |
+
config.model.code_len = 256
|
| 76 |
+
config.model.width = 768
|
| 77 |
+
config.model.enc_depth = 6
|
| 78 |
+
config.model.dec_depth = 12
|
| 79 |
+
config.model.mlp_dim = 3072
|
| 80 |
+
config.model.num_heads = 12
|
| 81 |
+
config.model.codeword_dim = 16
|
| 82 |
+
config.model.code_dropout = 'none'
|
| 83 |
+
config.model.bottleneck_resize = True
|
| 84 |
+
config.model.scan = True
|
| 85 |
+
config.model.remat_policy = 'nothing_saveable'
|
| 86 |
+
config.model_init = ''
|
| 87 |
+
|
| 88 |
+
config.rec_loss_fn = 'xent' # xent, l2
|
| 89 |
+
config.mask_zero_target = True
|
| 90 |
+
# values: (index in source image, number of classes)
|
| 91 |
+
config.model.inout_specs = {
|
| 92 |
+
'depth': (0, QUANTIZATION_BINS),
|
| 93 |
+
}
|
| 94 |
+
|
| 95 |
+
config.beta = 2e-4
|
| 96 |
+
config.beta_percept = 0.0
|
| 97 |
+
|
| 98 |
+
# Optimizer section
|
| 99 |
+
config.optax_name = 'scale_by_adam'
|
| 100 |
+
config.optax = dict(b2=0.95)
|
| 101 |
+
|
| 102 |
+
# FSDP training by default
|
| 103 |
+
config.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 104 |
+
config.sharding_rules = [('act_batch', ('data',))]
|
| 105 |
+
|
| 106 |
+
config.lr = 1e-3
|
| 107 |
+
config.wd = 1e-4
|
| 108 |
+
config.schedule = dict(decay_type='cosine', warmup_steps=0.1)
|
| 109 |
+
config.grad_clip_norm = 1.0
|
| 110 |
+
|
| 111 |
+
# Evaluation section
|
| 112 |
+
config.evals = {}
|
| 113 |
+
config.evals.val = mlc.ConfigDict()
|
| 114 |
+
config.evals.val.type = 'mean'
|
| 115 |
+
config.evals.val.pred = 'validation'
|
| 116 |
+
config.evals.val.data = {**config.input.data}
|
| 117 |
+
config.evals.val.data.split = 'validation'
|
| 118 |
+
config.evals.val.pp_fn = pp_eval
|
| 119 |
+
config.evals.val.log_steps = 250
|
| 120 |
+
|
| 121 |
+
base = {
|
| 122 |
+
'type': 'proj.givt.nyu_depth',
|
| 123 |
+
'data': {**config.input.data},
|
| 124 |
+
'pp_fn': pp_pred,
|
| 125 |
+
'pred': 'predict_depth',
|
| 126 |
+
'log_steps': 2000,
|
| 127 |
+
'min_depth': MIN_DEPTH,
|
| 128 |
+
'max_depth': MAX_DEPTH,
|
| 129 |
+
}
|
| 130 |
+
config.evals.nyu_depth_val = {**base}
|
| 131 |
+
config.evals.nyu_depth_val.data.split = 'validation'
|
| 132 |
+
|
| 133 |
+
# ### Uses a lot of memory
|
| 134 |
+
# config.evals.save_pred = dict(type='proj.givt.save_predictions')
|
| 135 |
+
# config.evals.save_pred.pp_fn = pp_eval
|
| 136 |
+
# config.evals.save_pred.log_steps = 100_000
|
| 137 |
+
# config.evals.save_pred.data = {**config.input.data}
|
| 138 |
+
# config.evals.save_pred.data.split = 'validation[:64]'
|
| 139 |
+
# config.evals.save_pred.batch_size = 64
|
| 140 |
+
# config.evals.save_pred.outfile = 'inference.npz'
|
| 141 |
+
|
| 142 |
+
config.eval_only = False
|
| 143 |
+
config.seed = 0
|
| 144 |
+
|
| 145 |
+
if arg.singlehost:
|
| 146 |
+
config.input.batch_size = 128
|
| 147 |
+
config.num_epochs = 50
|
| 148 |
+
elif arg.runlocal:
|
| 149 |
+
config.input.batch_size = 16
|
| 150 |
+
config.input.shuffle_buffer_size = 10
|
| 151 |
+
config.log_training_steps = 5
|
| 152 |
+
config.model.enc_depth = 1
|
| 153 |
+
config.model.dec_depth = 1
|
| 154 |
+
config.evals.val.data.split = 'validation[:16]'
|
| 155 |
+
config.evals.val.log_steps = 20
|
| 156 |
+
config.evals.nyu_depth_val.data.split = 'validation[:16]'
|
| 157 |
+
|
| 158 |
+
return config
|
big_vision_repo/big_vision/configs/proj/gsam/vit_i1k_gsam_no_aug.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Pre-training ViT on ILSVRC-2012 with GSAM in https://arxiv.org/abs/2203.08065
|
| 17 |
+
|
| 18 |
+
Run training of a B/32 model:
|
| 19 |
+
|
| 20 |
+
big_vision.trainers.proj.gsam.train \
|
| 21 |
+
--config big_vision/configs/proj/gsam/vit_i1k_gsam_no_aug.py \
|
| 22 |
+
--workdir gs://[your_bucket]/big_vision/`date '+%m-%d_%H%M'`
|
| 23 |
+
|
| 24 |
+
"""
|
| 25 |
+
|
| 26 |
+
import big_vision.configs.common as bvcc
|
| 27 |
+
from big_vision.configs.common_fewshot import get_fewshot_lsr
|
| 28 |
+
import ml_collections as mlc
|
| 29 |
+
|
| 30 |
+
def get_config(arg=None):
|
| 31 |
+
"""Config for training."""
|
| 32 |
+
arg = bvcc.parse_arg(arg, variant='B/32', runlocal=False)
|
| 33 |
+
config = mlc.ConfigDict()
|
| 34 |
+
|
| 35 |
+
config.dataset = 'imagenet2012'
|
| 36 |
+
config.train_split = 'train[:99%]'
|
| 37 |
+
config.cache_raw = not arg.runlocal # Needs up to 120GB of RAM!
|
| 38 |
+
config.shuffle_buffer_size = 250_000 # Per host, so small-ish is ok.
|
| 39 |
+
config.num_classes = 1000
|
| 40 |
+
config.loss = 'sigmoid_xent'
|
| 41 |
+
config.batch_size = 4096
|
| 42 |
+
config.num_epochs = 300
|
| 43 |
+
|
| 44 |
+
pp_common = (
|
| 45 |
+
'|value_range(-1, 1)'
|
| 46 |
+
'|onehot(1000, key="{lbl}", key_result="labels")'
|
| 47 |
+
'|keep("image", "labels")'
|
| 48 |
+
)
|
| 49 |
+
config.pp_train = (
|
| 50 |
+
'decode_jpeg_and_inception_crop(224)|flip_lr|' +
|
| 51 |
+
pp_common.format(lbl='label')
|
| 52 |
+
)
|
| 53 |
+
pp = 'decode|resize_small(256)|central_crop(224)' + pp_common
|
| 54 |
+
|
| 55 |
+
# Aggressive pre-fetching because our models here are small, so we not only
|
| 56 |
+
# can afford it, but we also need it for the smallest models to not be
|
| 57 |
+
# bottle-necked by the input pipeline. Play around with it for -L models tho.
|
| 58 |
+
config.prefetch_to_host = 8
|
| 59 |
+
config.prefetch_to_device = 4
|
| 60 |
+
|
| 61 |
+
config.log_training_steps = 50
|
| 62 |
+
config.checkpoint_steps = 1000
|
| 63 |
+
|
| 64 |
+
# Model section
|
| 65 |
+
config.model_name = 'vit'
|
| 66 |
+
config.model = dict(
|
| 67 |
+
variant=arg.variant,
|
| 68 |
+
rep_size=False,
|
| 69 |
+
pool_type='gap',
|
| 70 |
+
)
|
| 71 |
+
config.init_head_bias = -10.0
|
| 72 |
+
|
| 73 |
+
# Optimizer section
|
| 74 |
+
config.grad_clip_norm = 1.0
|
| 75 |
+
config.optax_name = 'scale_by_adam'
|
| 76 |
+
config.optax = dict(mu_dtype='float32')
|
| 77 |
+
# The modified AdaFactor we introduced in https://arxiv.org/abs/2106.04560
|
| 78 |
+
# almost always behaves exactly like adam, but at a fraction of the memory
|
| 79 |
+
# cost (specifically, adam_bf16 = +1.5M, adafactor = +0.5M), hence it is a
|
| 80 |
+
# good idea to try it when you are memory-bound!
|
| 81 |
+
# config.optax_name = 'big_vision.scale_by_adafactor'
|
| 82 |
+
# A good flag to play with when hitting instabilities, is the following:
|
| 83 |
+
# config.optax = dict(beta2_cap=0.95)
|
| 84 |
+
|
| 85 |
+
config.lr = 0.003
|
| 86 |
+
config.wd = 0.001 # default is 0.0001; paper used 0.3, effective wd=0.3*lr
|
| 87 |
+
config.schedule = dict(
|
| 88 |
+
warmup_steps=10_000,
|
| 89 |
+
decay_type='linear',
|
| 90 |
+
linear_end=0.01,
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# GSAM settings.
|
| 94 |
+
# Note: when rho_max=rho_min and alpha=0, GSAM reduces to SAM.
|
| 95 |
+
config.gsam = dict(
|
| 96 |
+
rho_max=0.6,
|
| 97 |
+
rho_min=0.1,
|
| 98 |
+
alpha=0.6,
|
| 99 |
+
lr_max=config.get_ref('lr'),
|
| 100 |
+
lr_min=config.schedule.get_ref('linear_end') * config.get_ref('lr'),
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
# Eval section
|
| 104 |
+
eval_common = dict(
|
| 105 |
+
type='classification',
|
| 106 |
+
dataset='imagenet2012',
|
| 107 |
+
pp_fn=pp.format(lbl='label'),
|
| 108 |
+
loss_name=config.loss,
|
| 109 |
+
log_steps=2500, # Very fast O(seconds) so it's fine to run it often.
|
| 110 |
+
)
|
| 111 |
+
config.evals = {}
|
| 112 |
+
config.evals.train = {**eval_common, 'split': 'train[:2%]'}
|
| 113 |
+
config.evals.minival = {**eval_common, 'split': 'train[99%:]'}
|
| 114 |
+
config.evals.val = {**eval_common, 'split': 'validation'}
|
| 115 |
+
config.evals.v2 = {**eval_common, 'dataset': 'imagenet_v2', 'split': 'test'}
|
| 116 |
+
|
| 117 |
+
config.evals.real = {**eval_common}
|
| 118 |
+
config.evals.real.dataset = 'imagenet2012_real'
|
| 119 |
+
config.evals.real.split = 'validation'
|
| 120 |
+
config.evals.real.pp_fn = pp.format(lbl='real_label')
|
| 121 |
+
|
| 122 |
+
config.fewshot = get_fewshot_lsr(runlocal=arg.runlocal)
|
| 123 |
+
config.fewshot.log_steps = 10_000
|
| 124 |
+
|
| 125 |
+
# Make a few things much smaller for quick local debugging testruns.
|
| 126 |
+
if arg.runlocal:
|
| 127 |
+
config.shuffle_buffer_size = 10
|
| 128 |
+
config.batch_size = 8
|
| 129 |
+
config.minival.split = 'train[:16]'
|
| 130 |
+
config.val.split = 'validation[:16]'
|
| 131 |
+
config.real.split = 'validation[:16]'
|
| 132 |
+
config.v2.split = 'test[:16]'
|
| 133 |
+
|
| 134 |
+
return config
|
big_vision_repo/big_vision/configs/proj/image_text/README.md
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Image/text models
|
| 2 |
+
|
| 3 |
+
## LiT: Zero-Shot Transfer with Locked-image text Tuning
|
| 4 |
+
|
| 5 |
+
*by Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, Lucas Beyer*
|
| 6 |
+
|
| 7 |
+
https://arxiv.org/abs/2111.07991
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
@article{zhai2022lit,
|
| 11 |
+
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
|
| 12 |
+
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
|
| 13 |
+
journal={CVPR},
|
| 14 |
+
year={2022}
|
| 15 |
+
}
|
| 16 |
+
```
|
| 17 |
+
|
| 18 |
+
Model card:
|
| 19 |
+
https://github.com/google-research/vision_transformer/blob/main/model_cards/lit.md
|
| 20 |
+
|
| 21 |
+
Colabs:
|
| 22 |
+
|
| 23 |
+
- https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
|
| 24 |
+
- https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/lit.ipynb
|
| 25 |
+
|
| 26 |
+
### Results
|
| 27 |
+
|
| 28 |
+
| Model | Download link | ImageNet 0-shot | MS-COCO I→T | MS-COCO T→I | Config `arg` |
|
| 29 |
+
| :--- | :---: | :---: | :---: | :---: | :--- |
|
| 30 |
+
| mixed_L16L | [link](https://storage.googleapis.com/vit_models/lit/LiT-L16L.npz) | 75.7 | 48.5 | 31.2 | `txt=bert_large,img=L/16` |
|
| 31 |
+
| mixed_B16B | [link](https://storage.googleapis.com/vit_models/lit/LiT-B16B.npz) | 72.1 | 49.4 | 31.1 | `txt=bert_base,img=B/16,img_head` |
|
| 32 |
+
| mixed_B16B_2 | [link](https://storage.googleapis.com/vit_models/lit/LiT-B16B.npz) | 73.9 | 51.5 | 31.8 | `txt=bert_base,img=B/16` |
|
| 33 |
+
| coco_B16B | [link](https://storage.googleapis.com/vit_models/lit/big_vision/coco_B16B/checkpoint.npz) | 20.7 | 47.2 | 32.1 | `txt=bert_base,img=B/16` |
|
| 34 |
+
|
| 35 |
+
The first three rows are the best available models trained on open source data,
|
| 36 |
+
originally published in the [`google-research/vision_transformer`] repository.
|
| 37 |
+
These models were re-evaluated with this codebase using the following commands:
|
| 38 |
+
|
| 39 |
+
```bash
|
| 40 |
+
big_vision.tools.eval_only --config big_vision/configs/proj/image_text/lit_coco.py:txt=bert_base,img=B/16,img_head,init=gs://vit_models/lit/LiT-B16B.npz
|
| 41 |
+
|
| 42 |
+
big_vision.tools.eval_only --config big_vision/configs/proj/image_text/lit_coco.py:txt=bert_base,img=B/16_2,init=gs://vit_models/lit/LiT-B16B_2.npz
|
| 43 |
+
|
| 44 |
+
big_vision.tools.eval_only --config big_vision/configs/proj/image_text/lit_coco.py:txt=bert_large,img=L/16,init=gs://vit_models/lit/LiT-L16L.npz
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Unfortunately, the public multi-modal datasets [`CC12M`] and [`YFCC100M`] are
|
| 48 |
+
not yet available in [`tfds`], so these models cannot be reproduced with the
|
| 49 |
+
codebase. For this reason we provide the much weaker model `coco_B16B` in the
|
| 50 |
+
third row, which was trained on the small `tfds` dataset [`coco_captions`], and
|
| 51 |
+
can be used to verify correctness of the codebase
|
| 52 |
+
([workdir](https://console.cloud.google.com/storage/browser/vit_models/lit/big_vision/coco_B16B/)).
|
| 53 |
+
|
| 54 |
+
[`google-research/vision_transformer`]: https://github.com/google-research/vision_transformer
|
| 55 |
+
[`CC12M`]: https://arxiv.org/abs/2102.08981
|
| 56 |
+
[`YFCC100M`]: https://arxiv.org/abs/1503.01817
|
| 57 |
+
[`tfds`]: https://www.tensorflow.org/datasets/api_docs/python/tfds
|
| 58 |
+
[`coco_captions`]: https://www.tensorflow.org/datasets/catalog/coco_captions
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
### Changelog
|
| 62 |
+
|
| 63 |
+
- 2022-08-18: Added LiT-B16B_2 model that was trained for 60k steps
|
| 64 |
+
(LiT_B16B: 30k) without linear head on the image side (LiT_B16B: 768) and has
|
| 65 |
+
better performance.
|
big_vision_repo/big_vision/configs/proj/image_text/SigLIP_demo.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
big_vision_repo/big_vision/configs/proj/image_text/common.py
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""Snippets and constants used a lot in image-text configs."""
|
| 16 |
+
|
| 17 |
+
import ml_collections
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# pylint: disable=line-too-long
|
| 21 |
+
inits = {
|
| 22 |
+
# Downloaded & extracted from original repo:
|
| 23 |
+
# https://github.com/google-research/bert
|
| 24 |
+
'bert_base': ('base', 'gs://vit_models/lit/bert/uncased_L-12_H-768_A-12'),
|
| 25 |
+
'bert_large': ('large', 'gs://vit_models/lit/bert/uncased_L-uncased_L-24_H-1024_A-16'),
|
| 26 |
+
# Recommended "How to train your ViT..." checkpoints from
|
| 27 |
+
# https://github.com/google-research/vision_transformer#available-vit-models
|
| 28 |
+
'B/32': ('B/32', 'gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz'),
|
| 29 |
+
'B/16': ('B/16', 'gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz'),
|
| 30 |
+
'L/16': ('L/16', 'gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz'),
|
| 31 |
+
}
|
| 32 |
+
# pylint: enable=line-too-long
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def _square875(sz):
|
| 36 |
+
return f'resize({int(sz/0.875)})|central_crop({sz})|value_range(-1,1)'
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def _aspect75(sz):
|
| 40 |
+
return f'resize_small({int(sz/0.75)})|central_crop({sz})|value_range(-1,1)'
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
def _drop_no_real_label(f):
|
| 44 |
+
return len(f['real_label']) > 0
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def _drop_no_imagenet(f):
|
| 48 |
+
return len(f['labels_imagenet']) > 0
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
DISCLF_DATASET_OVERRIDES = {
|
| 52 |
+
'imagenet2012': {'class_names': 'clip', 'split': 'validation'},
|
| 53 |
+
'imagenet2012_minival': {
|
| 54 |
+
'dataset_name': 'imagenet2012',
|
| 55 |
+
'class_names': 'clip',
|
| 56 |
+
'split': 'train[99%:]',
|
| 57 |
+
},
|
| 58 |
+
'imagenet2012_real': {
|
| 59 |
+
'split': 'validation',
|
| 60 |
+
'class_names': 'clip',
|
| 61 |
+
'class_names_dataset_name': 'imagenet2012',
|
| 62 |
+
'pp_img': lambda sz: (
|
| 63 |
+
_square875(sz) + '|pad_to_shape(inkey="real_label", outkey="label", shape=[10], pad_value=-1)|keep("label", "image")'), # pylint: disable=line-too-long
|
| 64 |
+
'pre_filter_fn': _drop_no_real_label,
|
| 65 |
+
},
|
| 66 |
+
'imagenet_v2': {'class_names': 'clip'},
|
| 67 |
+
'imagenet_a': {
|
| 68 |
+
'class_names': 'clip',
|
| 69 |
+
'pp_img': lambda sz: _aspect75(sz) + '|map("i1k_i1ka")',
|
| 70 |
+
},
|
| 71 |
+
'imagenet_r': {
|
| 72 |
+
'class_names': 'clip',
|
| 73 |
+
'pp_img': lambda sz: _square875(sz) + '|map("i1k_i1kr")',
|
| 74 |
+
},
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def get_disclf(sz, *, pp_txt=None, dataset_names=('imagenet2012',), **kw):
|
| 79 |
+
"""Returns config for discriminative_classifier of specified datasets."""
|
| 80 |
+
config = ml_collections.ConfigDict(dict(
|
| 81 |
+
dataset_names=list(dataset_names),
|
| 82 |
+
type='proj.image_text.discriminative_classifier',
|
| 83 |
+
prefix='z/0shot/',
|
| 84 |
+
pp_img=_square875(sz),
|
| 85 |
+
dataset_overrides={},
|
| 86 |
+
cache_final=True,
|
| 87 |
+
**kw,
|
| 88 |
+
))
|
| 89 |
+
if pp_txt:
|
| 90 |
+
config.pp_txt = pp_txt
|
| 91 |
+
for name in dataset_names:
|
| 92 |
+
if name in DISCLF_DATASET_OVERRIDES:
|
| 93 |
+
config.dataset_overrides[name] = {**DISCLF_DATASET_OVERRIDES[name]}
|
| 94 |
+
d = config.dataset_overrides[name]
|
| 95 |
+
if 'pp_img' in d and callable(d['pp_img']):
|
| 96 |
+
with d.ignore_type():
|
| 97 |
+
d['pp_img'] = d['pp_img'](sz)
|
| 98 |
+
return config
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def get_coco(
|
| 102 |
+
*,
|
| 103 |
+
pp_img='resize(224)|value_range(-1, 1)',
|
| 104 |
+
pp_txt='tokenize(max_len=16, inkey="texts", eos="sticky", pad_value=1)',
|
| 105 |
+
prefix='z/retr/coco_',
|
| 106 |
+
**kw):
|
| 107 |
+
"""Returns config for mscoco retrieval zero-shot.
|
| 108 |
+
|
| 109 |
+
Args:
|
| 110 |
+
pp_img: Pre-processing string for "image" feature.
|
| 111 |
+
pp_txt: Pre-processing string for texts (expected to tokenize "texts" to
|
| 112 |
+
"labels").
|
| 113 |
+
prefix: Prefix to use for metrics.
|
| 114 |
+
**kw: Other config settings, most notably log_{steps,percent,...}.
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
`ConfigDict` that can be used as a retrieval evaluator configuration.
|
| 118 |
+
"""
|
| 119 |
+
return ml_collections.ConfigDict({
|
| 120 |
+
'type': 'proj.image_text.retrieval',
|
| 121 |
+
'pp_txt': pp_txt,
|
| 122 |
+
'pp_img': pp_img,
|
| 123 |
+
'prefix': prefix,
|
| 124 |
+
'dataset': 'coco_captions',
|
| 125 |
+
'txt_name': ('captions', 'text'),
|
| 126 |
+
**kw,
|
| 127 |
+
})
|
big_vision_repo/big_vision/configs/proj/image_text/lit.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
big_vision_repo/big_vision/configs/proj/image_text/siglip_lit_coco.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""Minimal SigLIP (https://arxiv.org/abs/2303.15343) example.
|
| 17 |
+
|
| 18 |
+
Example training:
|
| 19 |
+
|
| 20 |
+
big_vision.trainers.proj.image_text.siglip \
|
| 21 |
+
--config big_vision/configs/proj/image_text/lit_coco.py:batch_size=512 \
|
| 22 |
+
--workdir gs://$GS_BUCKET_NAME/big_vision/`date '+%Y-%m-%d_%H%M'`
|
| 23 |
+
"""
|
| 24 |
+
|
| 25 |
+
import big_vision.configs.common as bvcc
|
| 26 |
+
from big_vision.configs.proj.image_text import common
|
| 27 |
+
from ml_collections import ConfigDict
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def get_config(arg=None):
|
| 31 |
+
"""The base configuration."""
|
| 32 |
+
arg = bvcc.parse_arg(
|
| 33 |
+
arg, res=224, runlocal=False, token_len=16, txt='bert_base', img='B/16',
|
| 34 |
+
init='', img_head=False, batch_size=512)
|
| 35 |
+
img_name, img_init = common.inits[arg.img]
|
| 36 |
+
txt_name, txt_init = common.inits[arg.txt]
|
| 37 |
+
config = ConfigDict()
|
| 38 |
+
|
| 39 |
+
config.input = {}
|
| 40 |
+
config.input.data = dict(name='coco_captions', split='train')
|
| 41 |
+
config.input.batch_size = arg.batch_size if not arg.runlocal else 32
|
| 42 |
+
config.input.shuffle_buffer_size = 250_000 if not arg.runlocal else 50
|
| 43 |
+
|
| 44 |
+
config.total_steps = 5_000 if not arg.runlocal else 1
|
| 45 |
+
|
| 46 |
+
config.init_shapes = [(1, arg.res, arg.res, 3), (1, arg.token_len,)]
|
| 47 |
+
config.init_types = ['float32', 'int32']
|
| 48 |
+
|
| 49 |
+
if arg.init:
|
| 50 |
+
vocab_path = arg.init.rsplit('.', 1)[0] + '.txt'
|
| 51 |
+
else:
|
| 52 |
+
vocab_path = f'{txt_init}/vocab.txt'
|
| 53 |
+
tokenizer = lambda inkey: (
|
| 54 |
+
f'bert_tokenize(inkey="{inkey}", max_len={arg.token_len}, '
|
| 55 |
+
f'vocab_path="{vocab_path}")')
|
| 56 |
+
config.input.pp = (
|
| 57 |
+
f'decode|resize({arg.res})|flip_lr|randaug(2,10)|value_range(-1,1)'
|
| 58 |
+
f'|flatten|{tokenizer("captions/text")}|keep("image", "labels")'
|
| 59 |
+
)
|
| 60 |
+
config.pp_modules = ['ops_general', 'ops_image', 'ops_text',
|
| 61 |
+
'proj.flaxformer.bert_ops', 'archive.randaug']
|
| 62 |
+
|
| 63 |
+
config.log_training_steps = 50
|
| 64 |
+
config.ckpt_steps = 1000
|
| 65 |
+
|
| 66 |
+
# Model section
|
| 67 |
+
config.model_name = 'proj.image_text.two_towers'
|
| 68 |
+
config.model_load = {}
|
| 69 |
+
if arg.init:
|
| 70 |
+
config.model_init = arg.init
|
| 71 |
+
else:
|
| 72 |
+
config.model_init = {'image': img_init, 'text': txt_init}
|
| 73 |
+
config.model_load['txt_load_kw'] = {'dont_load': ['head/kernel', 'head/bias']}
|
| 74 |
+
if not arg.img_head:
|
| 75 |
+
config.model_load['img_load_kw'] = {'dont_load': ['head/kernel', 'head/bias']}
|
| 76 |
+
config.model = ConfigDict()
|
| 77 |
+
config.model.image_model = 'vit'
|
| 78 |
+
config.model.text_model = 'proj.flaxformer.bert'
|
| 79 |
+
config.model.image = ConfigDict({
|
| 80 |
+
'variant': img_name,
|
| 81 |
+
'pool_type': 'tok',
|
| 82 |
+
'head_zeroinit': False,
|
| 83 |
+
})
|
| 84 |
+
config.model.text = ConfigDict({
|
| 85 |
+
'config': txt_name,
|
| 86 |
+
'head_zeroinit': False,
|
| 87 |
+
})
|
| 88 |
+
config.model.temperature_init = 10.0
|
| 89 |
+
dim = {'B': 768, 'L': 1024}[arg.img[0]]
|
| 90 |
+
config.model.out_dim = (dim if arg.img_head else None, dim) # (image_out_dim, text_out_dim)
|
| 91 |
+
config.model.bias_init = -2.71
|
| 92 |
+
|
| 93 |
+
if txt_name == 'base':
|
| 94 |
+
config.optax_name = 'scale_by_adam'
|
| 95 |
+
else:
|
| 96 |
+
config.optax_name = 'big_vision.scale_by_adafactor'
|
| 97 |
+
|
| 98 |
+
config.lr = 0.001
|
| 99 |
+
config.wd = 0.01
|
| 100 |
+
warmup_steps = max(int(0.03 * config.total_steps), 100)
|
| 101 |
+
config.schedule = [
|
| 102 |
+
('img/.*', None), # Freezes image tower.
|
| 103 |
+
('.*', dict(decay_type='cosine', warmup_steps=warmup_steps)),
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
config.grad_clip_norm = 1.0
|
| 107 |
+
|
| 108 |
+
config.evals = {}
|
| 109 |
+
config.evals.retrieval_coco = common.get_coco(
|
| 110 |
+
pp_img=f'resize({arg.res})|value_range(-1, 1)',
|
| 111 |
+
pp_txt=tokenizer('texts'),
|
| 112 |
+
log_steps=1000,
|
| 113 |
+
)
|
| 114 |
+
|
| 115 |
+
return config
|
big_vision_repo/big_vision/configs/proj/paligemma/README.md
ADDED
|
@@ -0,0 +1,270 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# PaliGemma model README
|
| 2 |
+
|
| 3 |
+
PaliGemma is an open vision-language model (VLM) inspired by PaLI-3, built with
|
| 4 |
+
open components, such as
|
| 5 |
+
the [SigLIP vision model](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/image_text/SigLIP_demo.ipynb)
|
| 6 |
+
and
|
| 7 |
+
the [Gemma language model](https://ai.google.dev/gemma).
|
| 8 |
+
PaliGemma is designed as a versatile model for transfer to a wide range of
|
| 9 |
+
vision-language tasks such as image and short video caption, visual question
|
| 10 |
+
answering, text reading, object detection and object segmentation. Together with
|
| 11 |
+
the pretrained and transfer checkpoints at multiple resolutions, we provide a
|
| 12 |
+
checkpoint transferred to a mixture of tasks that can be used for off-the-shelf
|
| 13 |
+
exploration.
|
| 14 |
+
|
| 15 |
+
## Quick Reference
|
| 16 |
+
|
| 17 |
+
This is the reference repository of the model, you may also want to check out the resources on
|
| 18 |
+
|
| 19 |
+
- [ArXiv](https://arxiv.org/abs/2407.07726): Technical report.
|
| 20 |
+
- [Kaggle](https://www.kaggle.com/models/google/paligemma):
|
| 21 |
+
All pre-trained / mix checkpoints and model card.
|
| 22 |
+
- [Kaggle-FT](https://www.kaggle.com/models/google/paligemma-ft):
|
| 23 |
+
All fine-tuned checkpoints and model card.
|
| 24 |
+
- [VertexAI Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/363):
|
| 25 |
+
Paligemma models on GCP.
|
| 26 |
+
- [Hugging Face](https://huggingface.co/google/paligemma-3b-pt-224):
|
| 27 |
+
PyTorch port of paligemma models.
|
| 28 |
+
- [Light finetuning colab](https://colab.research.google.com/github/google-research/big_vision/blob/main/big_vision/configs/proj/paligemma/finetune_paligemma.ipynb):
|
| 29 |
+
Lightweight colab for fine-tuning PaliGemma. It can be run on a single T4 GPU (16GB)
|
| 30 |
+
available on free Colab.
|
| 31 |
+
- [HuggingFace demo](https://hf.co/spaces/google/paligemma): live demo.
|
| 32 |
+
|
| 33 |
+
### Citation BibTeX
|
| 34 |
+
|
| 35 |
+
```
|
| 36 |
+
@article{beyer2024paligemma,
|
| 37 |
+
title={{PaliGemma: A versatile 3B VLM for transfer}},
|
| 38 |
+
author={Lucas Beyer and Andreas Steiner and André Susano Pinto and Alexander Kolesnikov and Xiao Wang and Daniel Salz and Maxim Neumann and Ibrahim Alabdulmohsin and Michael Tschannen and Emanuele Bugliarello and Thomas Unterthiner and Daniel Keysers and Skanda Koppula and Fangyu Liu and Adam Grycner and Alexey Gritsenko and Neil Houlsby and Manoj Kumar and Keran Rong and Julian Eisenschlos and Rishabh Kabra and Matthias Bauer and Matko Bošnjak and Xi Chen and Matthias Minderer and Paul Voigtlaender and Ioana Bica and Ivana Balazevic and Joan Puigcerver and Pinelopi Papalampidi and Olivier Henaff and Xi Xiong and Radu Soricut and Jeremiah Harmsen and Xiaohua Zhai},
|
| 39 |
+
year={2024},
|
| 40 |
+
journal={arXiv preprint arXiv:2407.07726}
|
| 41 |
+
}
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
## Model description
|
| 45 |
+
|
| 46 |
+
### Overview
|
| 47 |
+
|
| 48 |
+
PaliGemma-3B is Vision-Language model that was inspired by the PaLI-3 recipe.
|
| 49 |
+
It is built on SigLIP visual encoder (specifically, SigLIP-So400m/14) and the
|
| 50 |
+
Gemma 2B language model. PaliGemma takes as input one or more images,
|
| 51 |
+
which are turned into "soft tokens" by the SigLIP encoder, and input text
|
| 52 |
+
(codenamed the "prefix") that is tokenized by Gemma's tokenizer. The image
|
| 53 |
+
tokens and prefix tokens are concatenated (in this order) and passed to the
|
| 54 |
+
Gemma decoder with full block-attention, which then generates an output text
|
| 55 |
+
(the "suffix") auto-regressively with masked attention.
|
| 56 |
+
|
| 57 |
+

|
| 58 |
+
|
| 59 |
+
### Training stages
|
| 60 |
+
|
| 61 |
+
Similar to PaLI-3, PaliGemma's training consists of multiple stages:
|
| 62 |
+
|
| 63 |
+
- Stage 0: the unimodal pre-training. We use publicly available off-the-shelf
|
| 64 |
+
SigLIP and Gemma models which have been pre-trained unimodally by their
|
| 65 |
+
respective authors.
|
| 66 |
+
- Stage 1: multimodal pre-training. The combined PaliGemma model is now
|
| 67 |
+
pre-trained on a fully multimodal training dataset, this at a low resolution
|
| 68 |
+
of 224px² and prefix+suffix sequence length of 128 tokens. This results in
|
| 69 |
+
the first base model that we release.
|
| 70 |
+
- Stage 2: high-resolution pre-training. We continue pre-training of the
|
| 71 |
+
Stage 1 model at resolution 448px² with sequence length 512 tokens for a short
|
| 72 |
+
duration on the same multimodal training data, but re-weighted with more
|
| 73 |
+
emphasis on examples that make use of higher resolution or longer sequence
|
| 74 |
+
length. We repeat this once more at resolution 896px². This results in two
|
| 75 |
+
further "high res" base models that we also release.
|
| 76 |
+
- Stage 3: fine-tune. The base models are transferred to
|
| 77 |
+
specific tasks by fine-tuning. To facilitate further research and
|
| 78 |
+
reproducibility, we release checkpoints fine-tuned on most of the benchmarks
|
| 79 |
+
we evaluate on. We also provide a "mix" transfer model, fine-tuned on a wide
|
| 80 |
+
variety of data, for use in interactive demos.
|
| 81 |
+
|
| 82 |
+
Most of the code examples, use-cases, and code release are about Stage 3:
|
| 83 |
+
transferring to a task or dataset of interest to the user.
|
| 84 |
+
|
| 85 |
+
### Tokenizer
|
| 86 |
+
|
| 87 |
+
PaliGemma uses the Gemma tokenizer with 256'000 tokens, but we further extend
|
| 88 |
+
its vocabulary with 1024 entries that represent coordinates in normalized
|
| 89 |
+
image-space (\<loc0000>...\<loc1023>), and another with 128 entries
|
| 90 |
+
(\<seg000>...\<seg127>) that are codewords used by a lightweight
|
| 91 |
+
referring-expression segmentation vector-quantized variational auto-encoder
|
| 92 |
+
(VQ-VAE) with the architecture of [Ning et al. (2023)](https://arxiv.org/abs/2301.02229) and trained on OpenImages
|
| 93 |
+
as in PaLI-3. While the `big_vision` codebase is flexible enough to extend
|
| 94 |
+
tokenizers on-the-fly, we also provide a SentencePiece model file of the Gemma
|
| 95 |
+
tokenizer with these additional tokens baked in, for the convenience of
|
| 96 |
+
other codebases.
|
| 97 |
+
|
| 98 |
+
## Checkpoints
|
| 99 |
+
|
| 100 |
+
The PaliGemma models are released under the same open license as the Gemma
|
| 101 |
+
models, and hence require manual acknowledgement of the license terms on kaggle:
|
| 102 |
+
https://www.kaggle.com/models/google/paligemma. The reference checkpoints are
|
| 103 |
+
available on
|
| 104 |
+
[Kaggle](https://www.kaggle.com/models/google/paligemma),
|
| 105 |
+
[VertexAI Model Garden](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/363) and
|
| 106 |
+
[Hugging Face](https://huggingface.co/google/paligemma-3b-pt-224).
|
| 107 |
+
|
| 108 |
+
### Pretrained checkpoints
|
| 109 |
+
|
| 110 |
+
Use one of these checkpoints as initialization for fine-tuning:
|
| 111 |
+
|
| 112 |
+
- pt-224: Versatile pretrained model for tasks that do not require seeing
|
| 113 |
+
small details in the image.
|
| 114 |
+
Examples: natural image captioning and question-answering, detection and
|
| 115 |
+
segmentation of medium-large objects. This model was trained with
|
| 116 |
+
sequence length 128.
|
| 117 |
+
- pt-448: Versatile base model for mid/higher resolution tasks with access
|
| 118 |
+
to smaller details. Besides higher resolution, it has gotten more weight on
|
| 119 |
+
text reading, detection, and segmentation during its pre-training. Examples:
|
| 120 |
+
as above, plus detection, segmentation, text/diagram reading. This model was
|
| 121 |
+
trained with sequence length 512.
|
| 122 |
+
- pt-896: Further scaled-up version of pt-448, especially good at reading
|
| 123 |
+
very small texts as often found in documents and infographics. This model
|
| 124 |
+
was trained with sequence length 512.
|
| 125 |
+
|
| 126 |
+
Besides the reference float32 checkpoint (11GB), we further provide
|
| 127 |
+
bfloat16 and float16 variants of each, to reduce download and storage time.
|
| 128 |
+
These are good for inference and frozen transfers, but full fine-tuning
|
| 129 |
+
should happen in float32 or mixed precision.
|
| 130 |
+
|
| 131 |
+
### Mixture checkpoint
|
| 132 |
+
|
| 133 |
+
This checkpoint is trained on a mixture of all our transfer tasks,
|
| 134 |
+
with a balancing intended to make it "nice to use" out of the box for
|
| 135 |
+
predictions. This model is multilingual and should
|
| 136 |
+
understand prompts in various languages, although English
|
| 137 |
+
is still its "mother tongue".
|
| 138 |
+
Questions can be asked in a natural way (including asking for a caption or
|
| 139 |
+
reading the text), and detection and segmentation should still work with the
|
| 140 |
+
structured `detect {things}` and `segment {things}` prompts as in the base model.
|
| 141 |
+
|
| 142 |
+
- mix-224: Similarly to pt-224, this model is good at many natural image
|
| 143 |
+
tasks that do not require high resolution. Unlike the raw pre-trained model,
|
| 144 |
+
however, it can be interacted with more freely. For example, ask it to
|
| 145 |
+
"describe this image in great detail, please" or "How many coins do you see
|
| 146 |
+
in the picture?". This model was trained with sequence length 256.
|
| 147 |
+
- mix-448: As above, but it is better at tasks that require higher-resolution
|
| 148 |
+
input. For example, one could ask it "what is written in the "sum" field?",
|
| 149 |
+
to "describe this figure", or to "what is the GDP of France?" when shown an
|
| 150 |
+
infographic of countries' GDPs. This model was trained with
|
| 151 |
+
sequence length 512.
|
| 152 |
+
|
| 153 |
+
### Transfers results and checkpoints
|
| 154 |
+
|
| 155 |
+
We provide checkpoints transferred to most of the tasks we evaluated
|
| 156 |
+
transfer on, see the [kaggle page](https://www.kaggle.com/models/google/paligemma).
|
| 157 |
+
These are intended for use when a specialised model corresponding
|
| 158 |
+
to one of the tasks is needed, for academic research purposes only.
|
| 159 |
+
Depending on the task, they may require a specialised preprocessing format.
|
| 160 |
+
|
| 161 |
+
The transfer setup is reasonably unified, with the main factors of variation
|
| 162 |
+
being the training duration, learning-rate, and whether or not to use dropout
|
| 163 |
+
and label-smoothing. Details can be found in the corresponding config files or
|
| 164 |
+
in an upcoming tech report.
|
| 165 |
+
|
| 166 |
+
Importantly, none of these tasks or datasets are part of the pre-training data
|
| 167 |
+
mixture, and their images are explicitly removed from the web-scale
|
| 168 |
+
pretraining data.
|
| 169 |
+
|
| 170 |
+
#### Captioning
|
| 171 |
+
|
| 172 |
+
Benchmark (train split) | Metric (split) | pt-224 | pt-448 | pt-896
|
| 173 |
+
-----------------------|----------------|--------|--------|--------
|
| 174 |
+
[COCO captions](https://cocodataset.org/#home) (train+restval) | CIDEr (val) | 141.92 | 144.60 |
|
| 175 |
+
[NoCaps](https://nocaps.org/) (Eval of COCO captions transfer) | CIDEr (val) | 121.72 | 123.58 |
|
| 176 |
+
[COCO-35L](https://arxiv.org/abs/2205.12522) (train) | CIDEr dev (en / avg-34 / avg) | 139.2 / 115.8 / 116.4 | 141.2 / 118.0 / 118.6 |
|
| 177 |
+
[XM3600](https://arxiv.org/abs/2205.12522) (Eval of COCO-35L transfer) | CIDEr test (en / avg-35 / avg) | 78.1 / 41.3 / 42.4 | 80.0 / 41.9 / 42.9 |
|
| 178 |
+
[TextCaps](https://textvqa.org/textcaps/) (train) | CIDEr (val) | 127.48 | 153.94 |
|
| 179 |
+
[SciCap](https://arxiv.org/abs/2110.11624) (first sentence, no subfigure) (train+val) | CIDEr / BLEU-4 (test) | 162.25 / 0.192 | 181.49 / 0.211 |
|
| 180 |
+
[Screen2words](https://arxiv.org/abs/2108.03353) (train+dev) | CIDEr (test) | 117.57 | 119.59 |
|
| 181 |
+
[Widget Captioning](https://arxiv.org/abs/2010.04295) (train+dev) | CIDEr (test) | 136.07 | 148.36 |
|
| 182 |
+
|
| 183 |
+
#### Question Answering
|
| 184 |
+
|
| 185 |
+
Benchmark (train split) | Metric (split) | pt-224 | pt-448 | pt-896
|
| 186 |
+
-----------------------|----------------|--------|--------|--------
|
| 187 |
+
[VQAv2](https://visualqa.org/index.html) (train+validation) | Accuracy (Test server - std) | 83.19 | 85.64 |
|
| 188 |
+
[MMVP](https://arxiv.org/abs/2401.06209) (Eval of VQAv2 transfer) | Paired Accuracy | 47.33 | 45.33 |
|
| 189 |
+
[POPE](https://arxiv.org/abs/2305.10355) (Eval of VQAv2 transfer) | Accuracy (random / popular / adversarial) | 87.80 / 85.87 / 84.27 | 88.23 / 86.77 / 85.90 |
|
| 190 |
+
[Objaverse Multiview](https://arxiv.org/abs/2311.17851) (Eval of VQAv2 transfer) | Cosine Similarity (USEv4) | 62.7 | 62.8 |
|
| 191 |
+
[OKVQA](https://okvqa.allenai.org/) (train) | Accuracy (val) | 63.54 | 63.15 |
|
| 192 |
+
[A-OKVQA](https://allenai.org/project/a-okvqa/home) (MC) (train+val) | Accuracy (Test server) | 76.37 | 76.90 |
|
| 193 |
+
[A-OKVQA](https://allenai.org/project/a-okvqa/home) (DA) (train+val) | Accuracy (Test server) | 61.85 | 63.22 |
|
| 194 |
+
[GQA](https://cs.stanford.edu/people/dorarad/gqa/about.html) (train_balanced+val_balanced) | Accuracy (testdev balanced) | 65.61 | 67.03 |
|
| 195 |
+
[xGQA](https://aclanthology.org/2022.findings-acl.196/) (Eval of GQA transfer) | Mean Accuracy (bn,de,en,id,ko,pt,ru,zh) | 58.37 | 59.07 |
|
| 196 |
+
[NLVR2](https://lil.nlp.cornell.edu/nlvr/) (train+dev) | Accuracy (test) | 90.02 | 88.93 |
|
| 197 |
+
[MaRVL](https://marvl-challenge.github.io/) (Eval of NLVR2 transfer) | Mean Accuracy (test) (id,sw,ta,tr,zh) | 80.57 | 76.78 |
|
| 198 |
+
[AI2D](https://allenai.org/data/diagrams) (train) | Accuracy (test) | 72.12 | 73.28 |
|
| 199 |
+
[ScienceQA](https://scienceqa.github.io/) (Img subset, no CoT) (train+val) | Accuracy (test) | 95.39 | 95.93 |
|
| 200 |
+
[RSVQA-LR](https://zenodo.org/records/6344334) (Non numeric) (train+val) | Mean Accuracy (test) | 92.65 | 93.11 |
|
| 201 |
+
[RSVQA-HR](https://zenodo.org/records/6344367) (Non numeric) (train+val) | Mean Accuracy (test/test2) | 92.61 / 90.58 | 92.79 / 90.54 |
|
| 202 |
+
[ChartQA](https://arxiv.org/abs/2203.10244) (human+aug)x(train+val) | Mean Relaxed Accuracy (test_human, test_aug) | 57.08 | 71.36 |
|
| 203 |
+
[VizWiz](https://vizwiz.org/tasks-and-datasets/vqa/) VQA (train+val) | Accuracy (Test server - std) | 73.7 | 75.52 |
|
| 204 |
+
[TallyQA](https://arxiv.org/abs/1810.12440) (train) | Accuracy (test_simple/test_complex) | 81.72 / 69.56 | 84.86 / 72.27 |
|
| 205 |
+
[OCR-VQA](https://ocr-vqa.github.io/) (train+val) | Accuracy (test) | 73.24 | 75.60 | 75.90
|
| 206 |
+
[TextVQA](https://textvqa.org/) (train+val) | Accuracy (Test server - std) | 55.47 | 73.15 | 76.48
|
| 207 |
+
[DocVQA](https://www.docvqa.org/) (train+val) | ANLS (Test server) | 43.74 | 78.02 | 84.77
|
| 208 |
+
[Infographic VQA](https://openaccess.thecvf.com/content/WACV2022/papers/Mathew_InfographicVQA_WACV_2022_paper.pdf) (train+val) | ANLS (Test server) | 28.46 | 40.47 | 47.75
|
| 209 |
+
[SceneText VQA](https://arxiv.org/abs/1905.13648) (train+val) | ANLS (Test server) | 63.29 | 81.82 | 84.40
|
| 210 |
+
|
| 211 |
+
#### Segmentation
|
| 212 |
+
|
| 213 |
+
Benchmark (train split) | Metric (split) | pt-224 | pt-448 | pt-896
|
| 214 |
+
-----------------------|----------------|--------|--------|--------
|
| 215 |
+
[RefCOCO](https://arxiv.org/abs/1608.00272) (combined refcoco, refcoco+, refcocog excluding val and test images) | MIoU (validation) refcoco / refcoco+ / refcocog | 73.40 / 68.32 / 67.65 | 75.57 / 69.76 / 70.17 | 76.94 / 72.18 / 72.22
|
| 216 |
+
|
| 217 |
+
#### Video tasks (Caption/QA)
|
| 218 |
+
|
| 219 |
+
Benchmark (train split) | Metric (split) | pt-224 | pt-448 | pt-896
|
| 220 |
+
-----------------------|----------------|--------|--------|--------
|
| 221 |
+
[MSR-VTT](https://www.microsoft.com/en-us/research/publication/msr-vtt-a-large-video-description-dataset-for-bridging-video-and-language/) (Captioning) | CIDEr (test) | 70.54 |
|
| 222 |
+
[MSR-VTT](https://www.microsoft.com/en-us/research/publication/msr-vtt-a-large-video-description-dataset-for-bridging-video-and-language/) (QA) | Accuracy (test) | 50.09 |
|
| 223 |
+
[ActivityNet](http://activity-net.org/) (Captioning)] | CIDEr (test) | 34.62 |
|
| 224 |
+
[ActivityNet](http://activity-net.org/) (QA) | Accuracy (test) | 50.78 |
|
| 225 |
+
[VATEX](https://eric-xw.github.io/vatex-website/about.html) (Captioning) | CIDEr (test) | 79.73 |
|
| 226 |
+
[MSVD](https://www.cs.utexas.edu/users/ml/clamp/videoDescription/) (QA) | Accuracy (test) | 60.22 |
|
| 227 |
+
|
| 228 |
+
#### Mix model (finetune on mixture of transfer tasks)
|
| 229 |
+
|
| 230 |
+
Benchmark | Metric (split) | mix-224 | mix-448
|
| 231 |
+
----------|----------------|---------|---------
|
| 232 |
+
[MMVP](https://arxiv.org/abs/2401.06209) | Paired Accuracy | 46.00 | 45.33
|
| 233 |
+
[POPE](https://arxiv.org/abs/2305.10355) | Accuracy (random / popular / adversarial) | 88.00 / 86.63 / 85.67 | 89.37 / 88.40 / 87.47
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
## How to run PaliGemma fine-tuning
|
| 237 |
+
|
| 238 |
+
To run PaliGemma fine-tuning, set up the `big_vision` repository by following the
|
| 239 |
+
main README file. Here we provide PaliGemma-specific instructions.
|
| 240 |
+
|
| 241 |
+
Checkpoints can be downloaded from Kaggle. You need to create an account and acknowledge checkpoint usage policy. You can then download any checkpoint:
|
| 242 |
+
|
| 243 |
+
```
|
| 244 |
+
export KAGGLE_USERNAME=
|
| 245 |
+
export KAGGLE_KEY=
|
| 246 |
+
|
| 247 |
+
# See https://www.kaggle.com/models/google/paligemma for a full list of models.
|
| 248 |
+
export MODEL_NAME=paligemma-3b-pt-224
|
| 249 |
+
export CKPT_FILE=paligemma-3b-pt-224.npz
|
| 250 |
+
|
| 251 |
+
mkdir ckpts/
|
| 252 |
+
cd ckpts/
|
| 253 |
+
|
| 254 |
+
curl -L -u $KAGGLE_USERNAME:$KAGGLE_KEY\
|
| 255 |
+
-o pt_224.npz \
|
| 256 |
+
https://www.kaggle.com/api/v1/models/google/paligemma/jax/$MODEL_NAME/1/download/$CKPT_FILE
|
| 257 |
+
```
|
| 258 |
+
|
| 259 |
+
As an example, we provide the `forkme.py` config that is based on the easily-adjustable jsonl data source:
|
| 260 |
+
|
| 261 |
+
```
|
| 262 |
+
BV_GEMMA_DIR=ckpts/ python -m big_vision.trainers.proj.paligemma.train --config big_vision/configs/proj/paligemma/transfers/forkme.py --workdir workdirs/`date '+%m-%d_%H%M'`
|
| 263 |
+
```
|
| 264 |
+
|
| 265 |
+
If you want to use TFDS-based data, check out other transfer configs. Remember to set `TFDS_DATA_DIR` to point to the folder with data (can be GCP data bucket).
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
## Model Development Contributions
|
| 269 |
+
|
| 270 |
+
See the [technical report](https://arxiv.org/abs/2407.07726)'s Appendix.
|
big_vision_repo/big_vision/configs/proj/paligemma/finetune_paligemma.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
big_vision_repo/big_vision/configs/proj/paligemma/paligemma.png
ADDED
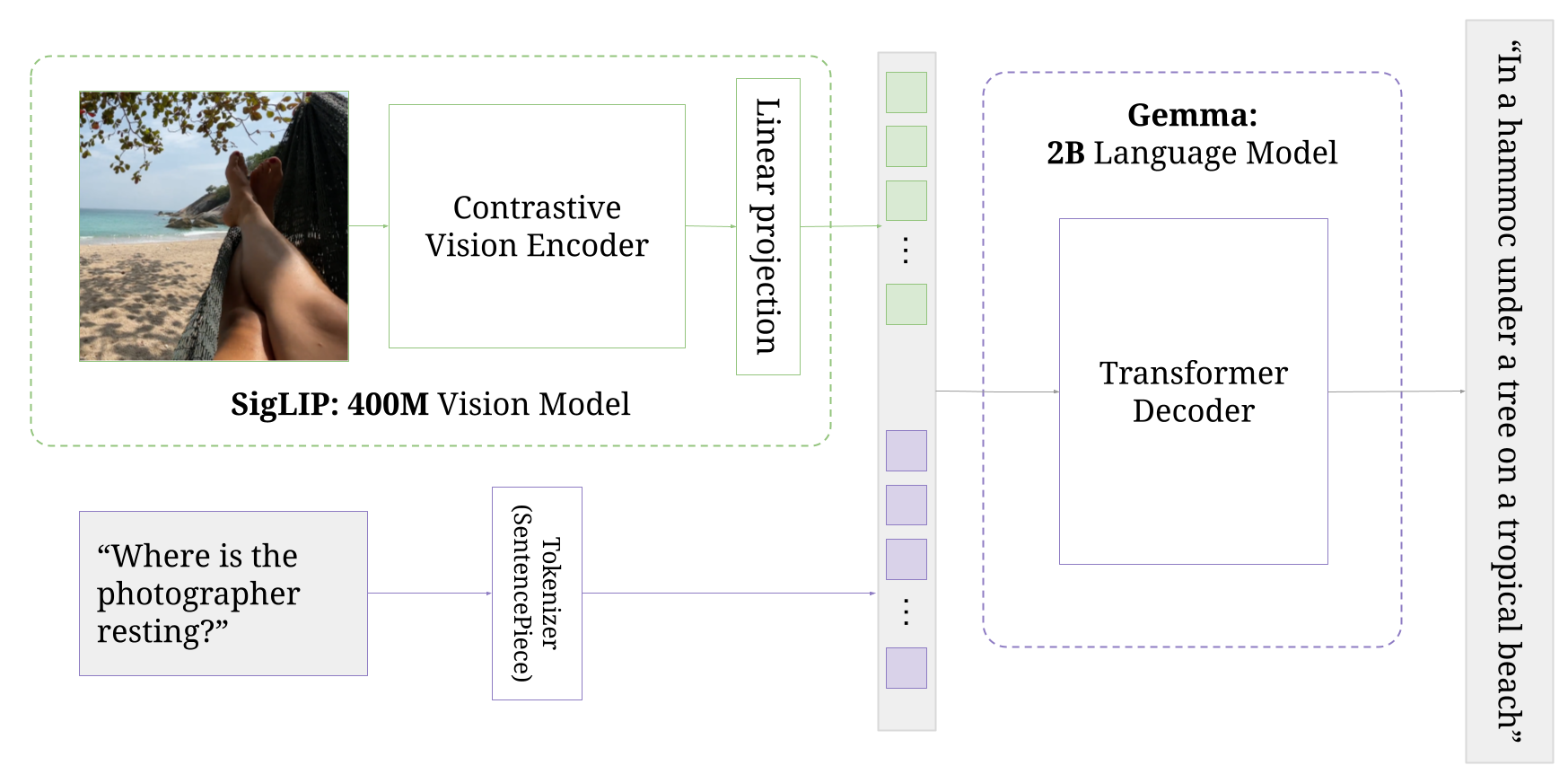
|
big_vision_repo/big_vision/configs/proj/paligemma/transfers/activitynet_cap.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""PaliGemma transfer to ActivityNet Video captioning.
|
| 17 |
+
|
| 18 |
+
IMPORTANT: This config is based on an unreleased version of DeepMind Video
|
| 19 |
+
Readers (DMVR). Users can either set up DMVR using the open source code from
|
| 20 |
+
GitHub (see below for details), or add their own data loader of choice.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
import big_vision.configs.common as bvcc
|
| 24 |
+
from big_vision.configs.proj.paligemma.transfers.common import combine_and_keep_train, combine_and_keep_eval, TOKENIZER
|
| 25 |
+
|
| 26 |
+
TEXT_LEN = 64
|
| 27 |
+
DATASET_NAME = 'activitynet_captions_mr'
|
| 28 |
+
# Numbers might need to be updated due to wipeout. Current from 2024-04-28
|
| 29 |
+
SPLIT_SIZE = {'train': 30545, 'valid': 14338, 'test': 13982}
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def training_data(res, *, final_split, num_frames=8, stride=None):
|
| 33 |
+
"""Creates training data config.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
res: The requested image resolution (eg 224).
|
| 37 |
+
final_split: Train on all train+valid data.
|
| 38 |
+
num_frames: number of sampled frames per video.
|
| 39 |
+
stride: stride at which the frames are sampled.
|
| 40 |
+
|
| 41 |
+
Returns:
|
| 42 |
+
The ConfigDict for the input section.
|
| 43 |
+
"""
|
| 44 |
+
pp = '|'.join([
|
| 45 |
+
# prepare the frames by decoding, resizing, replicating, sampling:
|
| 46 |
+
f'video_decode({res})|video_replicate_img({num_frames},{num_frames})',
|
| 47 |
+
f'video_ensure_shape("image", {(num_frames, res, res, 3)})',
|
| 48 |
+
# pick one caption at random during training (there is actually just one!)
|
| 49 |
+
'strfmt("caption en", outkey="prefix")',
|
| 50 |
+
'video_choice(inkey="caption/string", outkey="suffix")',
|
| 51 |
+
combine_and_keep_train(TEXT_LEN),
|
| 52 |
+
])
|
| 53 |
+
|
| 54 |
+
c = bvcc.parse_arg('')
|
| 55 |
+
c.data = {}
|
| 56 |
+
splits = ['train', 'valid'] if final_split else ['train']
|
| 57 |
+
raise NotImplementedError('Please implement a video reader of choice!')
|
| 58 |
+
# For example DMVR https://github.com/google-deepmind/dmvr
|
| 59 |
+
# The reader should support the following arguments:
|
| 60 |
+
# - name: Name of the reader.
|
| 61 |
+
# - dataset_name: Name of the data set.
|
| 62 |
+
# - split: Data set split.
|
| 63 |
+
# - num_frames: Number of frames sampled from the video.
|
| 64 |
+
# - stride: Stride at which the video frames are sampled.
|
| 65 |
+
# - deterministic_fs: Whether to sample the frames starting at the first
|
| 66 |
+
# frame or whether an offest should be chosen at random (if there are more
|
| 67 |
+
# frames than num_frames * stride)
|
| 68 |
+
# - first_k_shards: Whether to only use the first k shards of the data
|
| 69 |
+
# (optional but useful for speeding up intermediate evaluations).
|
| 70 |
+
for split in splits:
|
| 71 |
+
c.data[split] = SPLIT_SIZE[split]
|
| 72 |
+
c[split] = {'pp': pp}
|
| 73 |
+
c[split].data = dict(
|
| 74 |
+
# PLEASE ADD YOUR READER HERE:
|
| 75 |
+
name='<add_your_data_loader_here>',
|
| 76 |
+
dataset_name=DATASET_NAME, split=split,
|
| 77 |
+
num_frames=num_frames, stride=stride,
|
| 78 |
+
deterministic_fs=False)
|
| 79 |
+
return c
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def add_eval(c, res, num_frames=8, stride=None): # pylint: disable=unused-argument
|
| 83 |
+
"""Captioning evaluator."""
|
| 84 |
+
c_train = training_data(res, final_split=True, num_frames=num_frames, stride=stride)
|
| 85 |
+
|
| 86 |
+
pp = '|'.join([
|
| 87 |
+
f'video_decode({res})|video_replicate_img({num_frames},{num_frames})',
|
| 88 |
+
f'video_ensure_shape("image", {(num_frames, res, res, 3)})',
|
| 89 |
+
'strfmt("caption en", outkey="prefix")',
|
| 90 |
+
'strfmt("{example/video_id}[{segment_start}-{segment_end}]", outkey="image/id")',
|
| 91 |
+
'copy("caption/string", "captions")',
|
| 92 |
+
combine_and_keep_eval(TEXT_LEN, keep=('image/id', 'captions')),
|
| 93 |
+
])
|
| 94 |
+
|
| 95 |
+
for freq, name, split, first_k_shards, skip_first_eval in [
|
| 96 |
+
(1/8, 'minitrain', 'train', 2, False), # To gauge memorization.
|
| 97 |
+
(1/4, 'minival', 'valid', 2, False), # To monitor val progress.
|
| 98 |
+
(1, 'val', 'valid', None, False), # To tune hparams.
|
| 99 |
+
(1, 'eval', 'test', None, False), # final metric
|
| 100 |
+
]:
|
| 101 |
+
c.evals[f'{DATASET_NAME}/{name}'] = dict(
|
| 102 |
+
type='proj.paligemma.transfers.coco_caption',
|
| 103 |
+
pred='decode', pred_kw={'max_decode_len': TEXT_LEN},
|
| 104 |
+
data={**c_train.train.data, 'split': split,
|
| 105 |
+
'first_k_shards': first_k_shards,
|
| 106 |
+
'deterministic_fs': True},
|
| 107 |
+
log_percent=freq, tokenizer=TOKENIZER,
|
| 108 |
+
pp_fn=pp, skip_first=skip_first_eval)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def add_eval_pplx(c, res, num_frames=8, stride=None):
|
| 112 |
+
"""Perplexity evaluator to test runs before implementing the real deal."""
|
| 113 |
+
c_train = training_data(res, final_split=True, num_frames=num_frames, stride=stride)
|
| 114 |
+
|
| 115 |
+
for name, split, first_k_shards in [
|
| 116 |
+
('minitrain', 'train', 2), # To gauge memorization.
|
| 117 |
+
]:
|
| 118 |
+
c.evals[f'{DATASET_NAME}/{name}/pplx'] = dict(
|
| 119 |
+
type='proj.paligemma.perplexity', pred='logits',
|
| 120 |
+
key='text', shift_labels=True,
|
| 121 |
+
log_percent=1/8, # Not too cheap, do 10x per run.
|
| 122 |
+
data={**c_train.train.data, 'split': split,
|
| 123 |
+
'first_k_shards': first_k_shards,
|
| 124 |
+
'deterministic_fs': True},
|
| 125 |
+
pp_fn=c_train.train.pp,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def sweep_best(add, arg=None):
|
| 130 |
+
"""Train with best hyper-params."""
|
| 131 |
+
c = bvcc.parse_arg(arg, final_split=False)
|
| 132 |
+
add(lr=1e-5, wd=1e-6, total_epochs=1, **bvcc.arg(freeze_vit=True, res=224, **c))
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
sweep = sweep_best
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def get_config(arg=None):
|
| 139 |
+
"""Config for training."""
|
| 140 |
+
c = bvcc.parse_arg(arg, mode='xm', num_frames=16, stride=30, res=224,
|
| 141 |
+
freeze_vit=False, freeze_llm=False, final_split=False)
|
| 142 |
+
|
| 143 |
+
c.input = training_data(
|
| 144 |
+
c.res, final_split=c.final_split,
|
| 145 |
+
num_frames=c.num_frames, stride=c.stride)
|
| 146 |
+
|
| 147 |
+
c.total_epochs = 3
|
| 148 |
+
c.input.batch_size = 128
|
| 149 |
+
c.optax_name = 'scale_by_adam'
|
| 150 |
+
c.optax = dict(b2=0.999)
|
| 151 |
+
c.lr = 3e-6
|
| 152 |
+
c.wd = 3e-7
|
| 153 |
+
c.grad_clip_norm = 1.0
|
| 154 |
+
c.label_smoothing = 0.0
|
| 155 |
+
|
| 156 |
+
# Learning-rate schedule.
|
| 157 |
+
sched = dict(decay_type='cosine', warmup_percent=0.05)
|
| 158 |
+
c.schedule = [
|
| 159 |
+
('img/.*', None if c.freeze_vit else sched),
|
| 160 |
+
('llm/.*', None if c.freeze_llm else sched),
|
| 161 |
+
]
|
| 162 |
+
|
| 163 |
+
# Add evaluators.
|
| 164 |
+
c.evals = {}
|
| 165 |
+
add_eval(c, c.res, c.num_frames, c.stride)
|
| 166 |
+
add_eval_pplx(c, c.res, c.num_frames, c.stride)
|
| 167 |
+
|
| 168 |
+
# Model section.
|
| 169 |
+
c.model_name = 'proj.paligemma.paligemma'
|
| 170 |
+
c.model = {}
|
| 171 |
+
c.model.img = dict(variant='So400m/14', pool_type='none', scan=True)
|
| 172 |
+
c.model.llm = dict(vocab_size=256_000 + 1024 + 128, dropout=0.0)
|
| 173 |
+
c.model_init = f'pt_{c.res}'
|
| 174 |
+
|
| 175 |
+
# FSDP strategy.
|
| 176 |
+
c.mesh = [('data', -1)]
|
| 177 |
+
c.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 178 |
+
c.sharding_rules = [('act_batch', ('data',))]
|
| 179 |
+
|
| 180 |
+
for split in c.input.data.keys():
|
| 181 |
+
c.input[split].shuffle_buffer_size = 10_000
|
| 182 |
+
c.log_training_steps = 50
|
| 183 |
+
c.ckpt_steps = 1_000
|
| 184 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'proj.paligemma.ops',
|
| 185 |
+
'proj.paligemma.video']
|
| 186 |
+
|
| 187 |
+
# Update configs for quicker local runs and avoid swapping.
|
| 188 |
+
if c.mode in ('runlocal', 'mock'):
|
| 189 |
+
for split in c.input.data.keys():
|
| 190 |
+
c.input[split].shuffle_buffer_size = None
|
| 191 |
+
for ev in c.evals.values():
|
| 192 |
+
ev.data.first_k_shards = 1
|
| 193 |
+
|
| 194 |
+
if c.mode == 'runlocal':
|
| 195 |
+
c.log_training_steps = 1
|
| 196 |
+
c.input.batch_size = 2
|
| 197 |
+
|
| 198 |
+
c.seed = 0
|
| 199 |
+
return c
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def metrics(arg=None): # pylint: disable=unused-argument
|
| 203 |
+
m = ['training_loss']
|
| 204 |
+
for split in ('minitrain', 'minival', 'val', 'eval'):
|
| 205 |
+
m.append(('epoch', f'{DATASET_NAME}/{split}/cider'))
|
| 206 |
+
for split in ('minitrain', 'minival'):
|
| 207 |
+
m.append(('epoch', f'{DATASET_NAME}/{split}/pplx/avg'))
|
| 208 |
+
return m
|
| 209 |
+
|
big_vision_repo/big_vision/configs/proj/paligemma/transfers/activitynet_qa.py
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""PaliGemma transfer to ActivityNet Video QA.
|
| 17 |
+
|
| 18 |
+
IMPORTANT: This config is based on an unreleased version of DeepMind Video
|
| 19 |
+
Readers (DMVR). Users can either set up DMVR using the open source code from
|
| 20 |
+
GitHub (see below for details), or add their own data loader of choice.
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
import big_vision.configs.common as bvcc
|
| 24 |
+
from big_vision.configs.proj.paligemma.transfers.common import combine_and_keep_train, combine_and_keep_eval, TOKENIZER
|
| 25 |
+
|
| 26 |
+
TEXT_LEN = 64
|
| 27 |
+
DATASET_NAME = 'activitynet_qa'
|
| 28 |
+
# Numbers might need to be updated due to wipeout. Current from 2024-04-28
|
| 29 |
+
SPLIT_SIZE = {'train': 27610, 'valid': 15760, 'test': 6900}
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def training_data(res, *, final_split, num_frames, stride):
|
| 33 |
+
"""Creates training data config.
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
res: The requested image resolution (eg 224).
|
| 37 |
+
final_split: Train on all train+valid data.
|
| 38 |
+
num_frames: number of sampled frames per video.
|
| 39 |
+
stride: stride at which the frames are sampled.
|
| 40 |
+
|
| 41 |
+
Returns:
|
| 42 |
+
The ConfigDict for the input section.
|
| 43 |
+
"""
|
| 44 |
+
pp = '|'.join([
|
| 45 |
+
# prepare the frames by decoding, resizing, replicating, sampling:
|
| 46 |
+
f'video_decode({res})|video_replicate_img({num_frames},{num_frames})',
|
| 47 |
+
f'video_ensure_shape("image", {(num_frames, res, res, 3)})',
|
| 48 |
+
# only one question/answer per example.
|
| 49 |
+
'reshape([], key="question")|reshape([], key="answer")',
|
| 50 |
+
'strfmt("answer en {question}", outkey="prefix")',
|
| 51 |
+
'copy("answer", "suffix")',
|
| 52 |
+
combine_and_keep_train(TEXT_LEN),
|
| 53 |
+
])
|
| 54 |
+
|
| 55 |
+
c = bvcc.parse_arg('')
|
| 56 |
+
c.data = {}
|
| 57 |
+
splits = ['train', 'valid'] if final_split else ['train']
|
| 58 |
+
raise NotImplementedError('Please implement a video reader of choice!')
|
| 59 |
+
# For example DMVR https://github.com/google-deepmind/dmvr
|
| 60 |
+
# The reader should support the following arguments:
|
| 61 |
+
# - name: Name of the reader.
|
| 62 |
+
# - dataset_name: Name of the data set.
|
| 63 |
+
# - split: Data set split.
|
| 64 |
+
# - num_frames: Number of frames sampled from the video.
|
| 65 |
+
# - stride: Stride at which the video frames are sampled.
|
| 66 |
+
# - deterministic_fs: Whether to sample the frames starting at the first
|
| 67 |
+
# frame or whether an offest should be chosen at random (if there are more
|
| 68 |
+
# frames than num_frames * stride)
|
| 69 |
+
# - first_k_shards: Whether to only use the first k shards of the data
|
| 70 |
+
# (optional but useful for speeding up intermediate evaluations).
|
| 71 |
+
for split in splits:
|
| 72 |
+
c.data[split] = SPLIT_SIZE[split]
|
| 73 |
+
c[split] = {'pp': pp}
|
| 74 |
+
c[split].data = dict(
|
| 75 |
+
# PLEASE ADD YOUR READER HERE:
|
| 76 |
+
name='<add_your_data_loader_here>',
|
| 77 |
+
dataset_name=DATASET_NAME, split=split,
|
| 78 |
+
num_frames=num_frames, stride=stride,
|
| 79 |
+
deterministic_fs=False)
|
| 80 |
+
return c
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def add_eval(c, res, num_frames, stride): # pylint: disable=unused-argument
|
| 84 |
+
"""QA evaluator."""
|
| 85 |
+
c_train = training_data(res, final_split=True, num_frames=num_frames, stride=stride)
|
| 86 |
+
|
| 87 |
+
pp = '|'.join([
|
| 88 |
+
# prepare the frames by decoding, resizing, replicating, sampling:
|
| 89 |
+
f'video_decode({res})|video_replicate_img({num_frames},{num_frames})',
|
| 90 |
+
f'video_ensure_shape("image", {(num_frames, res, res, 3)})',
|
| 91 |
+
# only one question/answer per example.
|
| 92 |
+
'reshape([], key="question")|reshape([], key="answer")',
|
| 93 |
+
'strfmt("answer en {question}", outkey="prefix")',
|
| 94 |
+
'strfmt("{id}#{example/video_id}: {question}", "question_id")',
|
| 95 |
+
combine_and_keep_eval(TEXT_LEN, keep=('question_id', 'answer')),
|
| 96 |
+
])
|
| 97 |
+
|
| 98 |
+
for freq, name, split, first_k_shards, skip_first_eval in [
|
| 99 |
+
(1/8, 'minitrain', 'train', 2, False), # To gauge memorization.
|
| 100 |
+
(1/4, 'minival', 'valid', 2, False), # To monitor val progress.
|
| 101 |
+
(1, 'val', 'valid', None, True), # To tune hparams.
|
| 102 |
+
(1, 'eval', 'test', None, True), # final metric
|
| 103 |
+
]:
|
| 104 |
+
c.evals[f'activitynet_qa/{name}'] = dict(
|
| 105 |
+
type='proj.paligemma.transfers.vqa',
|
| 106 |
+
pred='decode', pred_kw={'max_decode_len': TEXT_LEN},
|
| 107 |
+
data={**c_train.train.data, 'split': split,
|
| 108 |
+
'first_k_shards': first_k_shards,
|
| 109 |
+
'deterministic_fs': True},
|
| 110 |
+
log_percent=freq, tokenizer=TOKENIZER,
|
| 111 |
+
pp_fn=pp, skip_first=skip_first_eval)
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def add_eval_pplx(c, res, num_frames, stride):
|
| 115 |
+
"""Perplexity evaluator to test runs before implementing the real deal."""
|
| 116 |
+
c_train = training_data(res, final_split=True, num_frames=num_frames, stride=stride)
|
| 117 |
+
|
| 118 |
+
for name, split, first_k_shards in [
|
| 119 |
+
('minitrain', 'train', 2), # To gauge memorization.
|
| 120 |
+
('minival', 'valid', 2),
|
| 121 |
+
]:
|
| 122 |
+
c.evals[f'activitynet_qa/{name}/pplx'] = dict(
|
| 123 |
+
type='proj.paligemma.perplexity', pred='logits',
|
| 124 |
+
key='text', shift_labels=True,
|
| 125 |
+
log_percent=1/8, # Not too cheap, do 10x per run.
|
| 126 |
+
data={**c_train.train.data, 'split': split,
|
| 127 |
+
'first_k_shards': first_k_shards,
|
| 128 |
+
'deterministic_fs': True},
|
| 129 |
+
pp_fn=c_train.train.pp,
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def sweep_best(add, arg=None):
|
| 134 |
+
"""Train with best hyper-params."""
|
| 135 |
+
c = bvcc.parse_arg(arg, final_split=False)
|
| 136 |
+
add(lr=1e-5, wd=1e-6, total_epochs=1, **bvcc.arg(num_frames=16, stride=70, res=224, **c))
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
sweep = sweep_best
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
def get_config(arg=None):
|
| 143 |
+
"""Config for training."""
|
| 144 |
+
c = bvcc.parse_arg(arg, mode='xm', num_frames=16, stride=70, res=224,
|
| 145 |
+
freeze_vit=False, freeze_llm=False, final_split=False)
|
| 146 |
+
|
| 147 |
+
c.input = training_data(
|
| 148 |
+
c.res, final_split=c.final_split,
|
| 149 |
+
num_frames=c.num_frames, stride=c.stride)
|
| 150 |
+
|
| 151 |
+
c.total_epochs = 3
|
| 152 |
+
c.input.batch_size = 128
|
| 153 |
+
c.optax_name = 'scale_by_adam'
|
| 154 |
+
c.optax = dict(b2=0.999)
|
| 155 |
+
c.lr = 1e-5
|
| 156 |
+
c.wd = 1e-6
|
| 157 |
+
c.grad_clip_norm = 1.0
|
| 158 |
+
c.label_smoothing = 0.0
|
| 159 |
+
|
| 160 |
+
# Learning-rate schedule.
|
| 161 |
+
sched = dict(decay_type='cosine', warmup_percent=0.05)
|
| 162 |
+
c.schedule = [
|
| 163 |
+
('img/.*', None if c.freeze_vit else sched),
|
| 164 |
+
('llm/.*', None if c.freeze_llm else sched),
|
| 165 |
+
]
|
| 166 |
+
|
| 167 |
+
# Add evaluators.
|
| 168 |
+
c.evals = {}
|
| 169 |
+
add_eval(c, c.res, c.num_frames, c.stride)
|
| 170 |
+
add_eval_pplx(c, c.res, c.num_frames, c.stride)
|
| 171 |
+
|
| 172 |
+
# Model section.
|
| 173 |
+
c.model_name = 'proj.paligemma.paligemma'
|
| 174 |
+
c.model = {}
|
| 175 |
+
c.model.img = dict(variant='So400m/14', pool_type='none', scan=True)
|
| 176 |
+
c.model.llm = dict(vocab_size=256_000 + 1024 + 128, dropout=0.0)
|
| 177 |
+
c.model_init = f'pt_{c.res}'
|
| 178 |
+
|
| 179 |
+
# FSDP strategy.
|
| 180 |
+
c.mesh = [('data', -1)]
|
| 181 |
+
c.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 182 |
+
c.sharding_rules = [('act_batch', ('data',))]
|
| 183 |
+
|
| 184 |
+
for split in c.input.data.keys():
|
| 185 |
+
c.input[split].shuffle_buffer_size = 10_000
|
| 186 |
+
c.log_training_steps = 50
|
| 187 |
+
c.ckpt_steps = 1_000
|
| 188 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'proj.paligemma.ops',
|
| 189 |
+
'proj.paligemma.video']
|
| 190 |
+
|
| 191 |
+
# Update configs for quicker local runs and avoid swapping.
|
| 192 |
+
if c.mode in ('runlocal', 'mock'):
|
| 193 |
+
for split in c.input.data.keys():
|
| 194 |
+
c.input[split].shuffle_buffer_size = None
|
| 195 |
+
for ev in c.evals.values():
|
| 196 |
+
ev.data.first_k_shards = 1
|
| 197 |
+
|
| 198 |
+
if c.mode == 'runlocal':
|
| 199 |
+
c.log_training_steps = 1
|
| 200 |
+
c.input.batch_size = 2
|
| 201 |
+
|
| 202 |
+
c.seed = 0
|
| 203 |
+
return c
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
def metrics(arg=None): # pylint: disable=unused-argument
|
| 207 |
+
m = ['training_loss']
|
| 208 |
+
for split in ('minitrain', 'minival', 'val', 'eval'):
|
| 209 |
+
m.append(('epoch', f'{DATASET_NAME}/{split}/acc'))
|
| 210 |
+
for split in ('minitrain', 'minival'):
|
| 211 |
+
m.append(('epoch', f'{DATASET_NAME}/{split}/pplx/avg'))
|
| 212 |
+
return m
|
| 213 |
+
|
big_vision_repo/big_vision/configs/proj/paligemma/transfers/ai2d.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""PaliGemma transfer to AI2D.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
from big_vision.configs.proj.paligemma.transfers.common import combine_and_keep_train, combine_and_keep_eval, TOKENIZER
|
| 21 |
+
|
| 22 |
+
PREFIX = 'answer en '
|
| 23 |
+
PROMPT = 'choose from:'
|
| 24 |
+
PROMPT_SEP = ' \t '
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def training_data(res, final_split, text_len=128):
|
| 28 |
+
"""Creates training data config.
|
| 29 |
+
|
| 30 |
+
See (internal link)
|
| 31 |
+
You can add more arguments beside `res`, but give them good defaults.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
res: The requested image resolution (eg 224).
|
| 35 |
+
final_split: whether to use all train data.
|
| 36 |
+
text_len: sequence length
|
| 37 |
+
|
| 38 |
+
Returns:
|
| 39 |
+
The ConfigDict for the input section.
|
| 40 |
+
"""
|
| 41 |
+
c = bvcc.parse_arg('') # Just make a configdict without extra import.
|
| 42 |
+
c.data = dict(
|
| 43 |
+
name='ai2d',
|
| 44 |
+
# 12k training examples.
|
| 45 |
+
split='train' if final_split else 'train[:-1024]',
|
| 46 |
+
)
|
| 47 |
+
c.pp = '|'.join([
|
| 48 |
+
f'decode|resize({res}, antialias=True)|value_range(-1, 1)',
|
| 49 |
+
f'strjoin("{PROMPT_SEP}", inkey="possible_answers", outkey="ansstr")',
|
| 50 |
+
f'strfmt("{PREFIX} {{question}} {PROMPT} {{ansstr}}", outkey="prefix")',
|
| 51 |
+
'copy(inkey="answer", outkey="suffix")',
|
| 52 |
+
combine_and_keep_train(text_len),
|
| 53 |
+
])
|
| 54 |
+
return c
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def add_eval(c, res, text_len=128, **kw):
|
| 58 |
+
"""AI2D evaluators."""
|
| 59 |
+
pp = '|'.join([
|
| 60 |
+
f'decode|resize({res})|value_range(-1, 1)',
|
| 61 |
+
f'strjoin("{PROMPT_SEP}", inkey="possible_answers", outkey="ansstr")',
|
| 62 |
+
f'strfmt("{PREFIX} {{question}} {PROMPT} {{ansstr}}", outkey="prefix")',
|
| 63 |
+
'copy(inkey="id",outkey="question_id")',
|
| 64 |
+
combine_and_keep_eval(text_len, keep=('answer', 'question_id')),
|
| 65 |
+
])
|
| 66 |
+
|
| 67 |
+
for name, split in [
|
| 68 |
+
('minitrain', 'train[:1024]'), # To gauge memorization.
|
| 69 |
+
('minival', 'train[-1024:]'), # To tune hparams.
|
| 70 |
+
('eval', 'test'), # To compute final publishable scores.
|
| 71 |
+
]:
|
| 72 |
+
c.evals[f'ai2d/{name}'] = dict(
|
| 73 |
+
type='proj.paligemma.transfers.vqa',
|
| 74 |
+
pred='decode', pred_kw={'max_decode_len': text_len},
|
| 75 |
+
outfile=f'{{workdir}}/ai2d_{name}.json',
|
| 76 |
+
to_lower=False, # Model sees options in prompt and can match the case.
|
| 77 |
+
data={**training_data(res, True, text_len).data, 'split': split},
|
| 78 |
+
log_percent=1/8, tokenizer=TOKENIZER, pp_fn=pp)
|
| 79 |
+
c.evals[f'ai2d/{name}'].update(kw)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def add_eval_pplx(c, res, text_len=128):
|
| 83 |
+
"""Perplexity evaluator to test runs before implementing the real deal."""
|
| 84 |
+
c_train = training_data(res, True, text_len) # Use mostly same settings as training.
|
| 85 |
+
|
| 86 |
+
for name, split in [
|
| 87 |
+
('minitrain', 'train[:1024]'), # To gauge memorization.
|
| 88 |
+
('minival', 'train[-1024:]'), # To tune hparams.
|
| 89 |
+
('eval', 'test'), # To compute final publishable scores.
|
| 90 |
+
]:
|
| 91 |
+
c.evals[f'ai2d/{name}/pplx'] = dict(
|
| 92 |
+
type='proj.paligemma.perplexity', pred='logits',
|
| 93 |
+
key='text', shift_labels=True,
|
| 94 |
+
log_percent=1/8,
|
| 95 |
+
data={**c_train.data, 'split': split},
|
| 96 |
+
pp_fn=c_train.pp,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def sweep_best(add, arg=None):
|
| 101 |
+
"""Train with best hyper-params."""
|
| 102 |
+
c = bvcc.parse_arg(arg, final_split=False)
|
| 103 |
+
add(lr=1e-5, wd=1e-6, total_epochs=10, **bvcc.arg(res=224, **c))
|
| 104 |
+
add(lr=1e-5, wd=1e-6, total_epochs=10, **bvcc.arg(res=448, **c))
|
| 105 |
+
# 896 was not better than 448 ((internal link)).
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
sweep = sweep_best # Choose which sweep to run.
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def get_config(arg=None):
|
| 112 |
+
"""Config for training."""
|
| 113 |
+
c = bvcc.parse_arg(arg, mode='xm', res=224, final_split=False)
|
| 114 |
+
|
| 115 |
+
c.input = training_data(c.res, final_split=c.final_split)
|
| 116 |
+
|
| 117 |
+
# Instead of epochs, you can also use `total_examples` or `total_steps`.
|
| 118 |
+
c.total_epochs = 10
|
| 119 |
+
c.input.batch_size = 256
|
| 120 |
+
c.optax_name = 'scale_by_adam'
|
| 121 |
+
c.optax = dict(b2=0.999)
|
| 122 |
+
c.lr = 1e-5
|
| 123 |
+
c.wd = 1e-5 * 0.1
|
| 124 |
+
c.grad_clip_norm = 1.0
|
| 125 |
+
c.label_smoothing = 0.0
|
| 126 |
+
c.schedule = dict(decay_type='cosine', warmup_percent=0.05)
|
| 127 |
+
|
| 128 |
+
# Add evaluators.
|
| 129 |
+
c.evals = {}
|
| 130 |
+
add_eval(c, c.res, batch_size=1024)
|
| 131 |
+
add_eval_pplx(c, c.res)
|
| 132 |
+
|
| 133 |
+
# Model section.
|
| 134 |
+
c.model_name = 'proj.paligemma.paligemma'
|
| 135 |
+
c.model = {}
|
| 136 |
+
c.model.img = dict(variant='So400m/14', pool_type='none', scan=True)
|
| 137 |
+
c.model.llm = dict(vocab_size=256_000 + 1024 + 128, dropout=0.0)
|
| 138 |
+
c.model_init = f'pt_{c.res}'
|
| 139 |
+
|
| 140 |
+
# FSDP strategy.
|
| 141 |
+
c.mesh = [('data', -1)]
|
| 142 |
+
c.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 143 |
+
c.sharding_rules = [('act_batch', ('data',))]
|
| 144 |
+
|
| 145 |
+
# These probably do not need any change/tuning
|
| 146 |
+
c.input.shuffle_buffer_size = 50_000
|
| 147 |
+
c.log_training_steps = 50
|
| 148 |
+
c.ckpt_steps = 1_000
|
| 149 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'proj.paligemma.ops']
|
| 150 |
+
|
| 151 |
+
# Update configs for quicker local runs and avoid swapping.
|
| 152 |
+
if c.mode in ('runlocal', 'mock'):
|
| 153 |
+
c.input.shuffle_buffer_size = None
|
| 154 |
+
for ev in c.evals.values():
|
| 155 |
+
ev.data.split = ev.data.split.split('[')[0] + '[:16]'
|
| 156 |
+
|
| 157 |
+
if c.mode == 'runlocal':
|
| 158 |
+
c.log_training_steps = 1
|
| 159 |
+
c.input.batch_size = 2
|
| 160 |
+
|
| 161 |
+
c.seed = 0
|
| 162 |
+
return c
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
def metrics(arg=None): # pylint: disable=unused-argument
|
| 166 |
+
m = ['training_loss']
|
| 167 |
+
for split in ('eval', 'minival', 'minitrain'):
|
| 168 |
+
m.append(f'ai2d/{split}/pplx/avg')
|
| 169 |
+
m.append(f'ai2d/{split}/acc')
|
| 170 |
+
return m
|
big_vision_repo/big_vision/configs/proj/paligemma/transfers/aokvqa_da.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""PaliGemma transfer to A-OK-VQA using Direct Answer mode.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
from big_vision.configs.proj.paligemma.transfers.common import combine_and_keep_train, combine_and_keep_eval, TOKENIZER
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def training_data(res, final_split, text_len=32):
|
| 24 |
+
"""Creates training data config.
|
| 25 |
+
|
| 26 |
+
See (internal link)
|
| 27 |
+
You can add more arguments beside `res`, but give them good defaults.
|
| 28 |
+
|
| 29 |
+
Args:
|
| 30 |
+
res: The requested image resolution (eg 224).
|
| 31 |
+
final_split: Whether to use train and validation data.
|
| 32 |
+
text_len: sequence length
|
| 33 |
+
|
| 34 |
+
Returns:
|
| 35 |
+
The ConfigDict for the input section.
|
| 36 |
+
"""
|
| 37 |
+
c = bvcc.parse_arg('') # Just make a configdict without extra import.
|
| 38 |
+
c.data = dict(
|
| 39 |
+
name='aokvqa',
|
| 40 |
+
split='train + val' if final_split else 'train',
|
| 41 |
+
)
|
| 42 |
+
c.pp = '|'.join([
|
| 43 |
+
f'decode|resize({res}, antialias=True)|value_range(-1, 1)',
|
| 44 |
+
'strfmt("answer en {question}", outkey="prefix")',
|
| 45 |
+
'choice_no_replacement(inkey="direct_answers", outkey="suffix")',
|
| 46 |
+
combine_and_keep_train(text_len),
|
| 47 |
+
])
|
| 48 |
+
return c
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def add_eval(c, res, text_len=32, **kw):
|
| 52 |
+
"""We can use the normal VQA evaluators."""
|
| 53 |
+
pp = '|'.join([
|
| 54 |
+
f'decode|resize({res}, antialias=True)|value_range(-1, 1)',
|
| 55 |
+
'strfmt("answer en {question}", outkey="prefix")',
|
| 56 |
+
'copy(inkey="direct_answers", outkey="answers")',
|
| 57 |
+
combine_and_keep_eval(text_len, keep=('answers', 'question_id')),
|
| 58 |
+
])
|
| 59 |
+
|
| 60 |
+
for freq, name, split in [
|
| 61 |
+
(1/4, 'minitrain', 'train[:5%]'), # To gauge memorization.
|
| 62 |
+
(1/4, 'eval', 'val'), # To tune hparams.
|
| 63 |
+
(1.0, 'test', 'test'), # To compute final predictions.
|
| 64 |
+
]:
|
| 65 |
+
c.evals[f'aokvqa_da/{name}'] = dict(
|
| 66 |
+
type='proj.paligemma.transfers.vqa',
|
| 67 |
+
pred='decode', pred_kw={'max_decode_len': text_len},
|
| 68 |
+
outfile=f'{{workdir}}/aokvqa_da_{name}.json',
|
| 69 |
+
data={**training_data(res, True, text_len).data, 'split': split},
|
| 70 |
+
log_percent=freq, skip_first=freq == 1, tokenizer=TOKENIZER, pp_fn=pp)
|
| 71 |
+
c.evals[f'aokvqa/{name}'].update(kw)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def add_eval_pplx(c, res, text_len=32):
|
| 75 |
+
"""Perplexity evaluator to test runs before implementing the real deal."""
|
| 76 |
+
c_train = training_data(res, True, text_len) # Use mostly same settings as training.
|
| 77 |
+
|
| 78 |
+
for name, split in [
|
| 79 |
+
('minitrain', 'train[:5%]'), # To gauge memorization.
|
| 80 |
+
('eval', 'val'), # To tune hparams.
|
| 81 |
+
]:
|
| 82 |
+
c.evals[f'aokvqa_da/{name}/pplx'] = dict(
|
| 83 |
+
type='proj.paligemma.perplexity', pred='logits',
|
| 84 |
+
key='text', shift_labels=True,
|
| 85 |
+
log_percent=0.05, # Eval ~20x per run; it's cheap.
|
| 86 |
+
data={**c_train.data, 'split': split},
|
| 87 |
+
pp_fn=c_train.pp,
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def sweep_best(add, arg=None):
|
| 92 |
+
"""Train with best hyper-params."""
|
| 93 |
+
c = bvcc.parse_arg(arg, final_split=False)
|
| 94 |
+
add(lr=5e-6, wd=0.0, **bvcc.arg(res=224, **c))
|
| 95 |
+
add(lr=5e-6, wd=0.0, **bvcc.arg(res=448, **c))
|
| 96 |
+
# not better: add(lr=5e-6, wd=0.0, **bvcc.arg(res=896, **c))
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
sweep = sweep_best # Choose which sweep to run.
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def get_config(arg=None):
|
| 103 |
+
"""Config for training."""
|
| 104 |
+
c = bvcc.parse_arg(arg, mode='xm', res=224, final_split=False)
|
| 105 |
+
|
| 106 |
+
c.input = training_data(c.res, c.final_split)
|
| 107 |
+
|
| 108 |
+
# Instead of epochs, you can also use `total_examples` or `total_steps`.
|
| 109 |
+
c.total_epochs = 10
|
| 110 |
+
c.input.batch_size = 128
|
| 111 |
+
c.optax_name = 'scale_by_adam'
|
| 112 |
+
c.optax = dict(b2=0.999)
|
| 113 |
+
c.lr = 5e-6
|
| 114 |
+
c.wd = 0.0
|
| 115 |
+
c.grad_clip_norm = 1.0
|
| 116 |
+
c.label_smoothing = 0.0
|
| 117 |
+
c.schedule = dict(decay_type='cosine', warmup_percent=0.05)
|
| 118 |
+
|
| 119 |
+
# Add evaluators.
|
| 120 |
+
c.evals = {}
|
| 121 |
+
add_eval(c, c.res, batch_size=256)
|
| 122 |
+
add_eval_pplx(c, c.res)
|
| 123 |
+
|
| 124 |
+
# Model section.
|
| 125 |
+
c.model_name = 'proj.paligemma.paligemma'
|
| 126 |
+
c.model = {}
|
| 127 |
+
c.model.img = dict(variant='So400m/14', pool_type='none', scan=True)
|
| 128 |
+
c.model.llm = dict(vocab_size=256_000 + 1024 + 128, dropout=0.0)
|
| 129 |
+
c.model_init = f'pt_{c.res}'
|
| 130 |
+
|
| 131 |
+
# FSDP strategy.
|
| 132 |
+
c.mesh = [('data', -1)]
|
| 133 |
+
c.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 134 |
+
c.sharding_rules = [('act_batch', ('data',))]
|
| 135 |
+
|
| 136 |
+
# These probably do not need any change/tuning
|
| 137 |
+
c.input.shuffle_buffer_size = 50_000
|
| 138 |
+
c.log_training_steps = 50
|
| 139 |
+
c.ckpt_steps = 1_000
|
| 140 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'proj.paligemma.ops']
|
| 141 |
+
|
| 142 |
+
# Update configs for quicker local runs and avoid swapping.
|
| 143 |
+
if c.mode in ('runlocal', 'mock'):
|
| 144 |
+
c.input.shuffle_buffer_size = None
|
| 145 |
+
for ev in c.evals.values():
|
| 146 |
+
ev.data.split = ev.data.split.split('[')[0] + '[:16]'
|
| 147 |
+
|
| 148 |
+
if c.mode == 'runlocal':
|
| 149 |
+
c.log_training_steps = 1
|
| 150 |
+
c.input.batch_size = 2
|
| 151 |
+
|
| 152 |
+
c.seed = 0
|
| 153 |
+
return c
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
def metrics(arg=None): # pylint: disable=unused-argument
|
| 157 |
+
m = ['training_loss']
|
| 158 |
+
for split in ('eval', 'minival', 'minitrain'):
|
| 159 |
+
m.append(f'aokvqa/{split}/pplx/avg')
|
| 160 |
+
m.append(f'aokvqa/{split}/acc')
|
| 161 |
+
return m
|
big_vision_repo/big_vision/configs/proj/paligemma/transfers/aokvqa_mc.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Big Vision Authors.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
# pylint: disable=line-too-long
|
| 16 |
+
r"""PaliGemma transfer to A-OK-VQA using multiple choice answers.
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
import big_vision.configs.common as bvcc
|
| 20 |
+
from big_vision.configs.proj.paligemma.transfers.common import combine_and_keep_train, combine_and_keep_eval, TOKENIZER
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
PREFIX = 'answer en '
|
| 24 |
+
PROMPT = 'choose from:'
|
| 25 |
+
PROMPT_SEP = ' \t '
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def training_data(res, final_split, text_len=128):
|
| 29 |
+
"""Creates training data config.
|
| 30 |
+
|
| 31 |
+
See (internal link)
|
| 32 |
+
You can add more arguments beside `res`, but give them good defaults.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
res: The requested image resolution (eg 224).
|
| 36 |
+
final_split: Whether to use train and validation data.
|
| 37 |
+
text_len: sequence length
|
| 38 |
+
|
| 39 |
+
Returns:
|
| 40 |
+
The ConfigDict for the input section.
|
| 41 |
+
"""
|
| 42 |
+
c = bvcc.parse_arg('') # Just make a configdict without extra import.
|
| 43 |
+
c.data = dict(
|
| 44 |
+
name='aokvqa',
|
| 45 |
+
split='train + val' if final_split else 'train',
|
| 46 |
+
)
|
| 47 |
+
c.pp = '|'.join([
|
| 48 |
+
f'decode|resize({res}, antialias=True)|value_range(-1, 1)',
|
| 49 |
+
f'strjoin("{PROMPT_SEP}", inkey="multiple_choice_possible_answers", outkey="ansstr")',
|
| 50 |
+
f'strfmt("{PREFIX} {{question}} {PROMPT} {{ansstr}}", outkey="prefix")',
|
| 51 |
+
'getidx(inkey="multiple_choice_possible_answers", index_key="multiple_choice_correct_idx", outkey="suffix")',
|
| 52 |
+
combine_and_keep_train(text_len),
|
| 53 |
+
])
|
| 54 |
+
return c
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def add_eval(c, res, text_len=128, **kw):
|
| 58 |
+
"""VQAv2 evaluators."""
|
| 59 |
+
pp = '|'.join([
|
| 60 |
+
f'decode|resize({res}, antialias=True)|value_range(-1, 1)',
|
| 61 |
+
f'strjoin("{PROMPT_SEP}", inkey="multiple_choice_possible_answers", outkey="ansstr")',
|
| 62 |
+
f'strfmt("{PREFIX} {{question}} {PROMPT} {{ansstr}}", outkey="prefix")',
|
| 63 |
+
'getidx(inkey="multiple_choice_possible_answers", index_key="multiple_choice_correct_idx", outkey="answer")',
|
| 64 |
+
combine_and_keep_eval(text_len, keep=('answer', 'question_id')),
|
| 65 |
+
])
|
| 66 |
+
|
| 67 |
+
for freq, name, split in [
|
| 68 |
+
(1/4, 'minitrain', 'train[:5%]'), # To gauge memorization.
|
| 69 |
+
(1/4, 'eval', 'val'), # To tune hparams.
|
| 70 |
+
(1.0, 'test', 'test'), # To compute final predictions.
|
| 71 |
+
]:
|
| 72 |
+
c.evals[f'aokvqa_mc/{name}'] = dict(
|
| 73 |
+
type='proj.paligemma.transfers.vqa',
|
| 74 |
+
pred='decode', pred_kw={'max_decode_len': text_len},
|
| 75 |
+
outfile=f'{{workdir}}/aokvqa_mc_{name}.json',
|
| 76 |
+
data={**training_data(res, True, text_len).data, 'split': split},
|
| 77 |
+
log_percent=freq, skip_first=freq == 1, tokenizer=TOKENIZER, pp_fn=pp)
|
| 78 |
+
c.evals[f'aokvqa/{name}'].update(kw)
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def add_eval_pplx(c, res, text_len=128):
|
| 82 |
+
"""Perplexity evaluator to test runs before implementing the real deal."""
|
| 83 |
+
c_train = training_data(res, True, text_len) # Use mostly same settings as training.
|
| 84 |
+
|
| 85 |
+
for name, split in [
|
| 86 |
+
('minitrain', 'train[:5%]'), # To gauge memorization.
|
| 87 |
+
('eval', 'val'), # To tune hparams.
|
| 88 |
+
('test', 'test'), # To compute final predictions.
|
| 89 |
+
]:
|
| 90 |
+
c.evals[f'aokvqa_mc/{name}/pplx'] = dict(
|
| 91 |
+
type='proj.paligemma.perplexity', pred='logits',
|
| 92 |
+
key='text', shift_labels=True,
|
| 93 |
+
log_percent=0.05, # Eval ~20x per run; it's cheap.
|
| 94 |
+
data={**c_train.data, 'split': split},
|
| 95 |
+
pp_fn=c_train.pp,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def sweep_best(add, arg=None):
|
| 100 |
+
"""Train with best hyper-params."""
|
| 101 |
+
c = bvcc.parse_arg(arg, final_split=False)
|
| 102 |
+
add(lr=5e-6, wd=0.0, **bvcc.arg(res=224, **c))
|
| 103 |
+
add(lr=5e-6, wd=0.0, **bvcc.arg(res=448, **c))
|
| 104 |
+
# add(lr=5e-6, wd=0.0, **bvcc.arg(res=896, **c))
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
sweep = sweep_best # Choose which sweep to run.
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def get_config(arg=None):
|
| 111 |
+
"""Config for training."""
|
| 112 |
+
c = bvcc.parse_arg(arg, mode='xm', res=224, final_split=False)
|
| 113 |
+
|
| 114 |
+
c.input = training_data(c.res, c.final_split)
|
| 115 |
+
|
| 116 |
+
# Instead of epochs, you can also use `total_examples` or `total_steps`.
|
| 117 |
+
c.total_epochs = 15
|
| 118 |
+
c.input.batch_size = 128
|
| 119 |
+
c.optax_name = 'scale_by_adam'
|
| 120 |
+
c.optax = dict(b2=0.999)
|
| 121 |
+
c.lr = 5e-6
|
| 122 |
+
c.wd = 0.0
|
| 123 |
+
c.grad_clip_norm = 1.0
|
| 124 |
+
c.label_smoothing = 0.0
|
| 125 |
+
c.schedule = dict(decay_type='cosine', warmup_percent=0.05)
|
| 126 |
+
|
| 127 |
+
# Add evaluators.
|
| 128 |
+
c.evals = {}
|
| 129 |
+
add_eval(c, c.res, batch_size=256)
|
| 130 |
+
add_eval_pplx(c, c.res)
|
| 131 |
+
|
| 132 |
+
# Model section.
|
| 133 |
+
c.model_name = 'proj.paligemma.paligemma'
|
| 134 |
+
c.model = {}
|
| 135 |
+
c.model.img = dict(variant='So400m/14', pool_type='none', scan=True)
|
| 136 |
+
c.model.llm = dict(vocab_size=256_000 + 1024 + 128, dropout=0.0)
|
| 137 |
+
c.model_init = f'pt_{c.res}'
|
| 138 |
+
|
| 139 |
+
# FSDP strategy.
|
| 140 |
+
c.mesh = [('data', -1)]
|
| 141 |
+
c.sharding_strategy = [('.*', 'fsdp(axis="data")')]
|
| 142 |
+
c.sharding_rules = [('act_batch', ('data',))]
|
| 143 |
+
|
| 144 |
+
# These probably do not need any change/tuning
|
| 145 |
+
c.input.shuffle_buffer_size = 50_000
|
| 146 |
+
c.log_training_steps = 50
|
| 147 |
+
c.ckpt_steps = 1_000
|
| 148 |
+
c.pp_modules = ['ops_general', 'ops_image', 'ops_text', 'proj.paligemma.ops']
|
| 149 |
+
|
| 150 |
+
# Update configs for quicker local runs and avoid swapping.
|
| 151 |
+
if c.mode in ('runlocal', 'mock'):
|
| 152 |
+
c.input.shuffle_buffer_size = None
|
| 153 |
+
for ev in c.evals.values():
|
| 154 |
+
ev.data.split = ev.data.split.split('[')[0] + '[:16]'
|
| 155 |
+
|
| 156 |
+
if c.mode == 'runlocal':
|
| 157 |
+
c.log_training_steps = 1
|
| 158 |
+
c.input.batch_size = 2
|
| 159 |
+
|
| 160 |
+
c.seed = 0
|
| 161 |
+
return c
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def metrics(arg=None): # pylint: disable=unused-argument
|
| 165 |
+
m = ['training_loss']
|
| 166 |
+
for split in ('eval', 'minival', 'minitrain'):
|
| 167 |
+
m.append(f'aokvqa/{split}/pplx/avg')
|
| 168 |
+
m.append(f'aokvqa/{split}/acc')
|
| 169 |
+
return m
|