---
base_model: vilm/vinallama-7b-chat
library_name: peft
license: llama2
datasets:
- nluai/dataset_dhnl_qna_v2
language:
- vi
tags:
- vietnamese
- academic
- regulations
- nlu
pipeline_tag: text-generation
---
# chatbot-dhnl-v3
## Introduction 🎉
Large Language Models (LLMs) are increasingly demonstrating their importance in addressing complex natural language processing tasks. However, they are still limited in generating text related to personalized datasets. Building a support system for answering questions in Vietnamese for students at Nong Lam University, Ho Chi Minh City, based on academic regulations, is a critical and practical task.
This study focuses on researching methods for preprocessing Vietnamese data and fine-tuning Large Language Models (LLMs) to align with the specific language characteristics and content of the university's academic regulations.
Additionally, the research team has constructed a dataset of the university's academic regulations and developed a Vietnamese text generation service to answer questions related to this dataset, which has been integrated into a chat website utilizing this service.
- **Developed by:**
- [Nguyễn Đăng Phước](https://www.linkedin.com/in/phuoc-nguyen-dang/)
- Vũ Ngọc Thanh Trúc
- **Model type:** Multimodal Transformer with over 7B parameters
- **Languages (NLP):** Primarily Vietnamese with multilingual capabilities
- **Fine-tuned from:** [nluai/dataset_dhnl_qna_v2](hhttps://huggingface.co/datasets/nluai/dataset_dhnl_qna_v2)
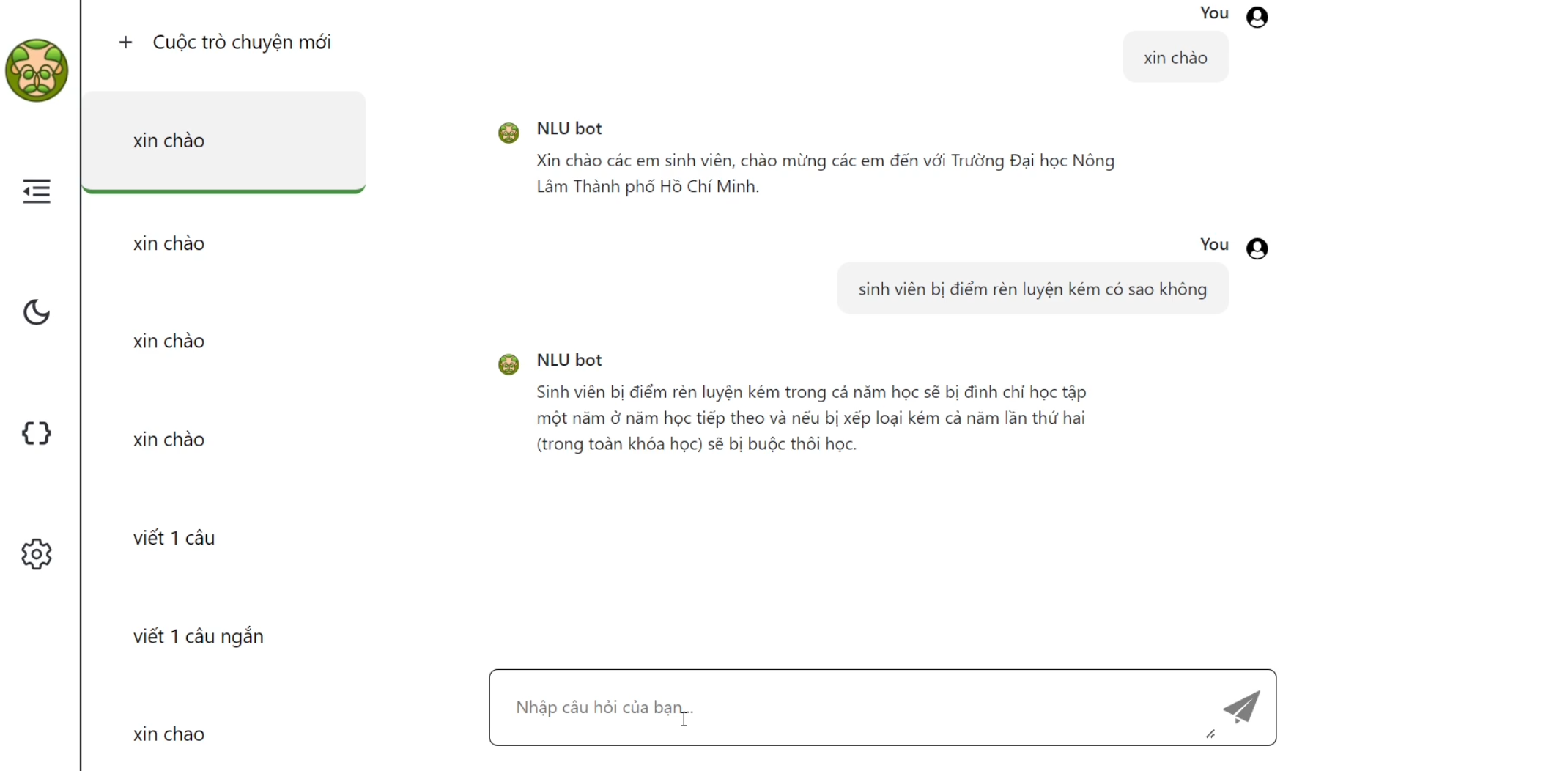
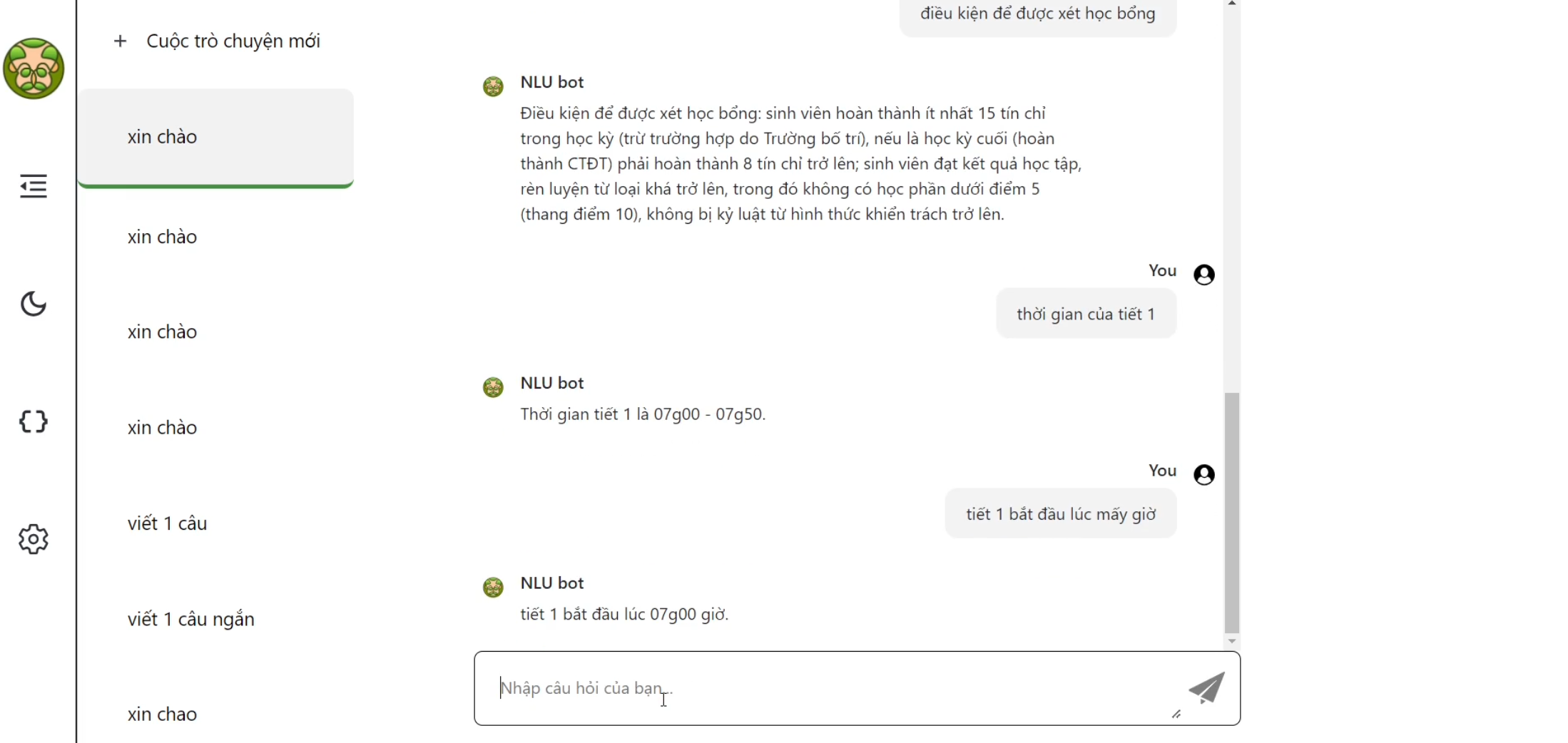
## Examples 🧩