
Initial Commit -- Missing Adapter
Browse files- Aug 31 2023-finetune-i2b2.log +66 -0
- Example Query.png +0 -0
- README.md +93 -0
- adapter_config.json +26 -0
- finetune-i2b2.sh +66 -0
- qlora.py +852 -0
- special_tokens_map.json +12 -0
- tokenizer.model +3 -0
- tokenizer_config.json +37 -0
- trainer_state.json +67 -0
Aug 31 2023-finetune-i2b2.log
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Namespace(model_name_or_path='/media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf', trust_remote_code=True, use_auth_token=False, eval_dataset_size=1024, max_train_samples=None, max_eval_samples=1000, source_max_len=16, target_max_len=512, dataset='i2b2.json', dataset_format='alpaca', output_dir='/media/ai/blk/loras/i2b2training', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<IntervalStrategy.STEPS: 'steps'>, prediction_loss_only=False, per_device_train_batch_size=2, per_device_eval_batch_size=2, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=16, eval_accumulation_steps=None, eval_delay=0, learning_rate=0.0001, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=0.3, num_train_epochs=3.0, max_steps=4500, lr_scheduler_type=<SchedulerType.CONSTANT: 'constant'>, warmup_ratio=0.03, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='/media/ai/blk/loras/i2b2training/runs/Aug31_13-33-49_ai-server-1', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=100, logging_nan_inf_filter=True, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=200, save_total_limit=40, save_safetensors=False, save_on_each_node=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=0, data_seed=42, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=1000, dataloader_num_workers=2, past_index=-1, run_name='/media/ai/blk/loras/i2b2training', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False}, fsdp_transformer_layer_cls_to_wrap=None, deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.PAGED_ADAMW: 'paged_adamw_32bit'>, optim_args=None, adafactor=False, group_by_length=True, length_column_name='length', report_to=[], ddp_find_unused_parameters=False, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=False, hub_always_push=False, gradient_checkpointing=True, include_inputs_for_metrics=False, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=7200, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, dispatch_batches=None, sortish_sampler=False, predict_with_generate=False, generation_max_length=None, generation_num_beams=None, generation_config=None, cache_dir=None, train_on_source=False, mmlu_split='eval', mmlu_dataset='mmlu-fs', do_mmlu_eval=False, max_mmlu_samples=None, mmlu_source_max_len=2048, full_finetune=False, adam8bit=False, double_quant=True, quant_type='nf4', bits=4, lora_r=64, lora_alpha=16.0, lora_dropout=0.05, max_memory_MB=80000, distributed_state=Distributed environment: DistributedType.MULTI_GPU Backend: nccl
|
| 2 |
+
Num processes: 2
|
| 3 |
+
Process index: 0
|
| 4 |
+
Local process index: 0
|
| 5 |
+
Device: cuda:0
|
| 6 |
+
, _n_gpu=1, __cached__setup_devices=device(type='cuda', index=0), deepspeed_plugin=None, _frozen=True)
|
| 7 |
+
loading base model /media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf...
|
| 8 |
+
Namespace(model_name_or_path='/media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf', trust_remote_code=True, use_auth_token=False, eval_dataset_size=1024, max_train_samples=None, max_eval_samples=1000, source_max_len=16, target_max_len=512, dataset='i2b2.json', dataset_format='alpaca', output_dir='/media/ai/blk/loras/i2b2training', overwrite_output_dir=False, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<IntervalStrategy.STEPS: 'steps'>, prediction_loss_only=False, per_device_train_batch_size=2, per_device_eval_batch_size=2, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=16, eval_accumulation_steps=None, eval_delay=0, learning_rate=0.0001, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=0.3, num_train_epochs=3.0, max_steps=4500, lr_scheduler_type=<SchedulerType.CONSTANT: 'constant'>, warmup_ratio=0.03, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='/media/ai/blk/loras/i2b2training/runs/Aug31_13-33-49_ai-server-1', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=100, logging_nan_inf_filter=True, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=200, save_total_limit=40, save_safetensors=False, save_on_each_node=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=0, data_seed=42, jit_mode_eval=False, use_ipex=False, bf16=True, fp16=False, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=None, local_rank=1, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=1000, dataloader_num_workers=2, past_index=-1, run_name='/media/ai/blk/loras/i2b2training', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False}, fsdp_transformer_layer_cls_to_wrap=None, deepspeed=None, label_smoothing_factor=0.0, optim=<OptimizerNames.PAGED_ADAMW: 'paged_adamw_32bit'>, optim_args=None, adafactor=False, group_by_length=True, length_column_name='length', report_to=[], ddp_find_unused_parameters=False, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=False, hub_always_push=False, gradient_checkpointing=True, include_inputs_for_metrics=False, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=7200, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, dispatch_batches=None, sortish_sampler=False, predict_with_generate=False, generation_max_length=None, generation_num_beams=None, generation_config=None, cache_dir=None, train_on_source=False, mmlu_split='eval', mmlu_dataset='mmlu-fs', do_mmlu_eval=False, max_mmlu_samples=None, mmlu_source_max_len=2048, full_finetune=False, adam8bit=False, double_quant=True, quant_type='nf4', bits=4, lora_r=64, lora_alpha=16.0, lora_dropout=0.05, max_memory_MB=80000, distributed_state=Distributed environment: DistributedType.MULTI_GPU Backend: nccl
|
| 9 |
+
Num processes: 2
|
| 10 |
+
Process index: 1
|
| 11 |
+
Local process index: 1
|
| 12 |
+
Device: cuda:1
|
| 13 |
+
, _n_gpu=1, __cached__setup_devices=device(type='cuda', index=1), deepspeed_plugin=None, _frozen=True)
|
| 14 |
+
loading base model /media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf...
|
| 15 |
+
Adding special tokens.
|
| 16 |
+
adding LoRA modules...
|
| 17 |
+
Adding special tokens.
|
| 18 |
+
adding LoRA modules...
|
| 19 |
+
loaded model
|
| 20 |
+
DatasetDict({
|
| 21 |
+
train: Dataset({
|
| 22 |
+
features: ['output', 'input'],
|
| 23 |
+
num_rows: 6114
|
| 24 |
+
})
|
| 25 |
+
test: Dataset({
|
| 26 |
+
features: ['output', 'input'],
|
| 27 |
+
num_rows: 680
|
| 28 |
+
})
|
| 29 |
+
})
|
| 30 |
+
Splitting train dataset in train and validation according to `eval_dataset_size`
|
| 31 |
+
trainable params: 217841664.0 || all params: 17570209792 || trainable: 1.2398353040678365
|
| 32 |
+
torch.bfloat16 959971328 0.05463630425386784
|
| 33 |
+
torch.uint8 16609443840 0.9453184701051519
|
| 34 |
+
torch.float32 794624 4.522564098021215e-05
|
| 35 |
+
loaded model
|
| 36 |
+
DatasetDict({
|
| 37 |
+
train: Dataset({
|
| 38 |
+
features: ['output', 'input'],
|
| 39 |
+
num_rows: 6114
|
| 40 |
+
})
|
| 41 |
+
test: Dataset({
|
| 42 |
+
features: ['output', 'input'],
|
| 43 |
+
num_rows: 680
|
| 44 |
+
})
|
| 45 |
+
})
|
| 46 |
+
Splitting train dataset in train and validation according to `eval_dataset_size`
|
| 47 |
+
trainable params: 217841664.0 || all params: 17570209792 || trainable: 1.2398353040678365
|
| 48 |
+
torch.bfloat16 959971328 0.05463630425386784
|
| 49 |
+
torch.uint8 16609443840 0.9453184701051519
|
| 50 |
+
torch.float32 794624 4.522564098021215e-05
|
| 51 |
+
{'loss': 0.1991, 'learning_rate': 0.0001, 'epoch': 1.26}
|
| 52 |
+
{'loss': 0.076, 'learning_rate': 0.0001, 'epoch': 2.51}
|
| 53 |
+
Saving PEFT checkpoint...
|
| 54 |
+
Saving PEFT checkpoint...
|
| 55 |
+
{'loss': 0.061, 'learning_rate': 0.0001, 'epoch': 3.77}
|
| 56 |
+
{'loss': 0.0522, 'learning_rate': 0.0001, 'epoch': 5.03}
|
| 57 |
+
Saving PEFT checkpoint...
|
| 58 |
+
Saving PEFT checkpoint...
|
| 59 |
+
{'loss': 0.0471, 'learning_rate': 0.0001, 'epoch': 6.28}
|
| 60 |
+
{'loss': 0.044, 'learning_rate': 0.0001, 'epoch': 7.54}
|
| 61 |
+
Saving PEFT checkpoint...
|
| 62 |
+
Saving PEFT checkpoint...
|
| 63 |
+
{'loss': 0.0411, 'learning_rate': 0.0001, 'epoch': 8.8}
|
| 64 |
+
{'loss': 0.0383, 'learning_rate': 0.0001, 'epoch': 10.05}
|
| 65 |
+
Saving PEFT checkpoint...
|
| 66 |
+
Saving PEFT checkpoint...
|
Example Query.png
ADDED
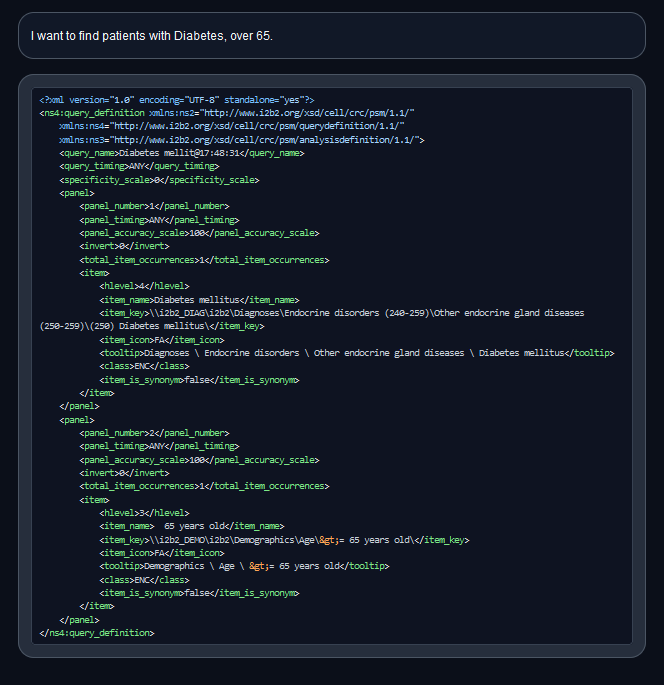
|
README.md
CHANGED
|
@@ -1,3 +1,96 @@
|
|
| 1 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 2 |
license: llama2
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
language:
|
| 3 |
+
- en
|
| 4 |
+
library_name: peft
|
| 5 |
+
pipeline_tag: text-generation
|
| 6 |
+
tags:
|
| 7 |
+
- medical
|
| 8 |
license: llama2
|
| 9 |
---
|
| 10 |
+
|
| 11 |
+
# i2b2 QueryBuilder - 34b
|
| 12 |
+
|
| 13 |
+
<!-- TODO: Add a link kere -->
|
| 14 |
+
![Screenshot]()
|
| 15 |
+
|
| 16 |
+
## Model Description
|
| 17 |
+
|
| 18 |
+
This model will generate queries for your i2b2 query builder trained on [this dataset](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0) for `10 epochs` . For evaluation use.
|
| 19 |
+
* Do not use as a final research query builder.
|
| 20 |
+
* Results may be incorrect or mal-formatted.
|
| 21 |
+
* The onus of research accuracy is on the researcher, not the AI model.
|
| 22 |
+
|
| 23 |
+
## Prompt Format
|
| 24 |
+
|
| 25 |
+
```md
|
| 26 |
+
Below is an instruction that describes a task. Respond in i2b2 instruction format beginning in
|
| 27 |
+
```xml\n<?xml version=\"1.0\" encoding=\"UTF-8\" standalone=\"yes\"?>\n<ns4:query_definition
|
| 28 |
+
and ending in
|
| 29 |
+
</ns4:query_definition>\n\n```"
|
| 30 |
+
|
| 31 |
+
### Instruction:
|
| 32 |
+
{input}
|
| 33 |
+
|
| 34 |
+
### Response:
|
| 35 |
+
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
### Architecture
|
| 40 |
+
`nmitchko/i2b2-querybuilder-codellama-34b` is a large language model LoRa specifically fine-tuned for generating queries in the [i2b2 query builder](https://community.i2b2.org/wiki/display/webclient/3.+Query+Tool).
|
| 41 |
+
It is based on [`codellama-34b-hf`](https://huggingface.co/codellama/CodeLlama-34b-hf) at 34 billion parameters.
|
| 42 |
+
|
| 43 |
+
The primary goal of this model is to improve research accuracy with the i2b2 tool.
|
| 44 |
+
It was trained using [LoRA](https://arxiv.org/abs/2106.09685), specifically [QLora Multi GPU](https://github.com/ChrisHayduk/qlora-multi-gpu), to reduce memory footprint.
|
| 45 |
+
|
| 46 |
+
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
|
| 47 |
+
|
| 48 |
+
### Requirements
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
bitsandbytes>=0.41.0
|
| 52 |
+
peft@main
|
| 53 |
+
transformers@main
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Steps to load this model:
|
| 57 |
+
1. Load base model (codellama-34b-hf) using transformers
|
| 58 |
+
2. Apply LoRA using peft
|
| 59 |
+
|
| 60 |
+
```python
|
| 61 |
+
# Sample Code Coming
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
## Training Parameters
|
| 65 |
+
|
| 66 |
+
The model was trained for or 10 epochs on [i2b2-query-data-1.0](https://huggingface.co/datasets/nmitchko/i2b2-query-data-1.0)
|
| 67 |
+
`i2b2-query-data-1.0` contains only tasks and outputs for i2b2 queries xsd schemas.
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
| Item | Amount | Units |
|
| 71 |
+
|---------------|--------|-------|
|
| 72 |
+
| LoRA Rank | 64 | ~ |
|
| 73 |
+
| LoRA Alpha | 16 | ~ |
|
| 74 |
+
| Learning Rate | 1e-4 | SI |
|
| 75 |
+
| Dropout | 5 | % |
|
| 76 |
+
|
| 77 |
+
## Training procedure
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
The following `bitsandbytes` quantization config was used during training:
|
| 81 |
+
- quant_method: QuantizationMethod.BITS_AND_BYTES
|
| 82 |
+
- load_in_8bit: False
|
| 83 |
+
- load_in_4bit: True
|
| 84 |
+
- llm_int8_threshold: 6.0
|
| 85 |
+
- llm_int8_skip_modules: None
|
| 86 |
+
- llm_int8_enable_fp32_cpu_offload: False
|
| 87 |
+
- llm_int8_has_fp16_weight: False
|
| 88 |
+
- bnb_4bit_quant_type: nf4
|
| 89 |
+
- bnb_4bit_use_double_quant: True
|
| 90 |
+
- bnb_4bit_compute_dtype: bfloat16
|
| 91 |
+
|
| 92 |
+
### Framework versions
|
| 93 |
+
|
| 94 |
+
- PEFT 0.6.0.dev0
|
| 95 |
+
|
| 96 |
+
|
adapter_config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_mapping": null,
|
| 3 |
+
"base_model_name_or_path": "/media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf",
|
| 4 |
+
"bias": "none",
|
| 5 |
+
"fan_in_fan_out": false,
|
| 6 |
+
"inference_mode": true,
|
| 7 |
+
"init_lora_weights": true,
|
| 8 |
+
"layers_pattern": null,
|
| 9 |
+
"layers_to_transform": null,
|
| 10 |
+
"lora_alpha": 16.0,
|
| 11 |
+
"lora_dropout": 0.05,
|
| 12 |
+
"modules_to_save": null,
|
| 13 |
+
"peft_type": "LORA",
|
| 14 |
+
"r": 64,
|
| 15 |
+
"revision": null,
|
| 16 |
+
"target_modules": [
|
| 17 |
+
"o_proj",
|
| 18 |
+
"gate_proj",
|
| 19 |
+
"down_proj",
|
| 20 |
+
"k_proj",
|
| 21 |
+
"up_proj",
|
| 22 |
+
"q_proj",
|
| 23 |
+
"v_proj"
|
| 24 |
+
],
|
| 25 |
+
"task_type": "CAUSAL_LM"
|
| 26 |
+
}
|
finetune-i2b2.sh
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
#source /media/nmitchko/NVME/text-generation-ui/venv/bin/activate
|
| 4 |
+
source /media/nmitchko/NVME/text-generation-webui/venv/bin/activate
|
| 5 |
+
CURRENTDATEONLY=`date +"%b %d %Y"`
|
| 6 |
+
|
| 7 |
+
# Change Power limit to 190 for training
|
| 8 |
+
sudo nvidia-smi -i 1 -pl 250
|
| 9 |
+
sudo nvidia-smi -i 0 -pl 250
|
| 10 |
+
|
| 11 |
+
export CUDA_VISIBLE_DEVICES=0,1
|
| 12 |
+
|
| 13 |
+
accelerate launch --num_processes 2 qlora.py \
|
| 14 |
+
--ddp_find_unused_parameters False \
|
| 15 |
+
--model_name_or_path /media/nmitchko/NVME/text-generation-webui/models/codellama_CodeLlama-34b-hf \
|
| 16 |
+
--output_dir /media/ai/blk/loras/i2b2training \
|
| 17 |
+
--logging_steps 100 \
|
| 18 |
+
--save_strategy steps \
|
| 19 |
+
--data_seed 42 \
|
| 20 |
+
--save_steps 200 \
|
| 21 |
+
--save_total_limit 40 \
|
| 22 |
+
--evaluation_strategy steps \
|
| 23 |
+
--eval_dataset_size 1024 \
|
| 24 |
+
--max_eval_samples 1000 \
|
| 25 |
+
--per_device_eval_batch_size 2 \
|
| 26 |
+
--per_device_train_batch_size 2 \
|
| 27 |
+
--trust_remote_code True \
|
| 28 |
+
--use_auth_token False \
|
| 29 |
+
--max_new_tokens 32 \
|
| 30 |
+
--dataloader_num_workers 2 \
|
| 31 |
+
--group_by_length \
|
| 32 |
+
--logging_strategy steps \
|
| 33 |
+
--remove_unused_columns False \
|
| 34 |
+
--do_train \
|
| 35 |
+
--lora_r 64 \
|
| 36 |
+
--lora_alpha 16 \
|
| 37 |
+
--lora_modules all \
|
| 38 |
+
--double_quant \
|
| 39 |
+
--quant_type nf4 \
|
| 40 |
+
--bf16 \
|
| 41 |
+
--bits 4 \
|
| 42 |
+
--legacy=False \
|
| 43 |
+
--warmup_ratio 0.03 \
|
| 44 |
+
--lr_scheduler_type constant \
|
| 45 |
+
--gradient_checkpointing \
|
| 46 |
+
--dataset="i2b2.json" \
|
| 47 |
+
--dataset_format alpaca \
|
| 48 |
+
--trust_remote_code=True \
|
| 49 |
+
--source_max_len 16 \
|
| 50 |
+
--target_max_len 512 \
|
| 51 |
+
--per_device_train_batch_size 2 \
|
| 52 |
+
--gradient_accumulation_steps 16 \
|
| 53 |
+
--max_steps 4500 \
|
| 54 |
+
--eval_steps 1000 \
|
| 55 |
+
--learning_rate 0.0001 \
|
| 56 |
+
--adam_beta2 0.999 \
|
| 57 |
+
--max_grad_norm 0.3 \
|
| 58 |
+
--lora_dropout 0.05 \
|
| 59 |
+
--weight_decay 0.0 \
|
| 60 |
+
--seed 0 > "${CURRENTDATEONLY}-finetune-i2b2.log" &
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
# Change Power limit to 300 for normal activities training
|
| 64 |
+
# Not Needed for non-managed script
|
| 65 |
+
|
| 66 |
+
deactivate
|
qlora.py
ADDED
|
@@ -0,0 +1,852 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This source code is licensed under the MIT license found in the
|
| 2 |
+
# LICENSE file in the root directory of this source tree.
|
| 3 |
+
|
| 4 |
+
from collections import defaultdict
|
| 5 |
+
import copy
|
| 6 |
+
import json
|
| 7 |
+
import os
|
| 8 |
+
from os.path import exists, join, isdir
|
| 9 |
+
from dataclasses import dataclass, field
|
| 10 |
+
import sys
|
| 11 |
+
from typing import Optional, Dict, Sequence
|
| 12 |
+
import numpy as np
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
import logging
|
| 15 |
+
import bitsandbytes as bnb
|
| 16 |
+
import pandas as pd
|
| 17 |
+
import importlib
|
| 18 |
+
from packaging import version
|
| 19 |
+
from packaging.version import parse
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
import transformers
|
| 23 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 24 |
+
import argparse
|
| 25 |
+
from transformers import (
|
| 26 |
+
AutoTokenizer,
|
| 27 |
+
AutoModelForCausalLM,
|
| 28 |
+
set_seed,
|
| 29 |
+
Seq2SeqTrainer,
|
| 30 |
+
BitsAndBytesConfig,
|
| 31 |
+
LlamaTokenizer
|
| 32 |
+
|
| 33 |
+
)
|
| 34 |
+
from datasets import load_dataset, Dataset
|
| 35 |
+
import evaluate
|
| 36 |
+
|
| 37 |
+
from peft import (
|
| 38 |
+
prepare_model_for_kbit_training,
|
| 39 |
+
LoraConfig,
|
| 40 |
+
get_peft_model,
|
| 41 |
+
PeftModel
|
| 42 |
+
)
|
| 43 |
+
from peft.tuners.lora import LoraLayer
|
| 44 |
+
from transformers.trainer_utils import PREFIX_CHECKPOINT_DIR
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def is_ipex_available():
|
| 48 |
+
def get_major_and_minor_from_version(full_version):
|
| 49 |
+
return str(version.parse(full_version).major) + "." + str(version.parse(full_version).minor)
|
| 50 |
+
|
| 51 |
+
_torch_version = importlib.metadata.version("torch")
|
| 52 |
+
if importlib.util.find_spec("intel_extension_for_pytorch") is None:
|
| 53 |
+
return False
|
| 54 |
+
_ipex_version = "N/A"
|
| 55 |
+
try:
|
| 56 |
+
_ipex_version = importlib.metadata.version("intel_extension_for_pytorch")
|
| 57 |
+
except importlib.metadata.PackageNotFoundError:
|
| 58 |
+
return False
|
| 59 |
+
torch_major_and_minor = get_major_and_minor_from_version(_torch_version)
|
| 60 |
+
ipex_major_and_minor = get_major_and_minor_from_version(_ipex_version)
|
| 61 |
+
if torch_major_and_minor != ipex_major_and_minor:
|
| 62 |
+
warnings.warn(
|
| 63 |
+
f"Intel Extension for PyTorch {ipex_major_and_minor} needs to work with PyTorch {ipex_major_and_minor}.*,"
|
| 64 |
+
f" but PyTorch {_torch_version} is found. Please switch to the matching version and run again."
|
| 65 |
+
)
|
| 66 |
+
return False
|
| 67 |
+
return True
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
if torch.cuda.is_available():
|
| 71 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 72 |
+
|
| 73 |
+
logger = logging.getLogger(__name__)
|
| 74 |
+
|
| 75 |
+
IGNORE_INDEX = -100
|
| 76 |
+
DEFAULT_PAD_TOKEN = "[PAD]"
|
| 77 |
+
|
| 78 |
+
@dataclass
|
| 79 |
+
class ModelArguments:
|
| 80 |
+
model_name_or_path: Optional[str] = field(
|
| 81 |
+
default="EleutherAI/pythia-12b"
|
| 82 |
+
)
|
| 83 |
+
trust_remote_code: Optional[bool] = field(
|
| 84 |
+
default=False,
|
| 85 |
+
metadata={"help": "Enable unpickling of arbitrary code in AutoModelForCausalLM#from_pretrained."}
|
| 86 |
+
)
|
| 87 |
+
use_auth_token: Optional[bool] = field(
|
| 88 |
+
default=False,
|
| 89 |
+
metadata={"help": "Enables using Huggingface auth token from Git Credentials."}
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
@dataclass
|
| 93 |
+
class DataArguments:
|
| 94 |
+
eval_dataset_size: int = field(
|
| 95 |
+
default=1024, metadata={"help": "Size of validation dataset."}
|
| 96 |
+
)
|
| 97 |
+
max_train_samples: Optional[int] = field(
|
| 98 |
+
default=None,
|
| 99 |
+
metadata={
|
| 100 |
+
"help": "For debugging purposes or quicker training, truncate the number of training examples to this "
|
| 101 |
+
"value if set."
|
| 102 |
+
},
|
| 103 |
+
)
|
| 104 |
+
max_eval_samples: Optional[int] = field(
|
| 105 |
+
default=None,
|
| 106 |
+
metadata={
|
| 107 |
+
"help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
|
| 108 |
+
"value if set."
|
| 109 |
+
},
|
| 110 |
+
)
|
| 111 |
+
source_max_len: int = field(
|
| 112 |
+
default=1024,
|
| 113 |
+
metadata={"help": "Maximum source sequence length. Sequences will be right padded (and possibly truncated)."},
|
| 114 |
+
)
|
| 115 |
+
target_max_len: int = field(
|
| 116 |
+
default=256,
|
| 117 |
+
metadata={"help": "Maximum target sequence length. Sequences will be right padded (and possibly truncated)."},
|
| 118 |
+
)
|
| 119 |
+
dataset: str = field(
|
| 120 |
+
default='alpaca',
|
| 121 |
+
metadata={"help": "Which dataset to finetune on. See datamodule for options."}
|
| 122 |
+
)
|
| 123 |
+
dataset_format: Optional[str] = field(
|
| 124 |
+
default=None,
|
| 125 |
+
metadata={"help": "Which dataset format is used. [alpaca|chip2|self-instruct|hh-rlhf]"}
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
@dataclass
|
| 129 |
+
class TrainingArguments(transformers.Seq2SeqTrainingArguments):
|
| 130 |
+
cache_dir: Optional[str] = field(
|
| 131 |
+
default=None
|
| 132 |
+
)
|
| 133 |
+
train_on_source: Optional[bool] = field(
|
| 134 |
+
default=False,
|
| 135 |
+
metadata={"help": "Whether to train on the input in addition to the target text."}
|
| 136 |
+
)
|
| 137 |
+
mmlu_split: Optional[str] = field(
|
| 138 |
+
default='eval',
|
| 139 |
+
metadata={"help": "The MMLU split to run on"}
|
| 140 |
+
)
|
| 141 |
+
mmlu_dataset: Optional[str] = field(
|
| 142 |
+
default='mmlu-fs',
|
| 143 |
+
metadata={"help": "MMLU dataset to use: options are `mmlu-zs` for zero-shot or `mmlu-fs` for few shot."}
|
| 144 |
+
)
|
| 145 |
+
do_mmlu_eval: Optional[bool] = field(
|
| 146 |
+
default=False,
|
| 147 |
+
metadata={"help": "Whether to run the MMLU evaluation."}
|
| 148 |
+
)
|
| 149 |
+
max_mmlu_samples: Optional[int] = field(
|
| 150 |
+
default=None,
|
| 151 |
+
metadata={"help": "If set, only evaluates on `max_mmlu_samples` of the MMMLU dataset."}
|
| 152 |
+
)
|
| 153 |
+
mmlu_source_max_len: int = field(
|
| 154 |
+
default=2048,
|
| 155 |
+
metadata={"help": "Maximum source sequence length for mmlu."}
|
| 156 |
+
)
|
| 157 |
+
full_finetune: bool = field(
|
| 158 |
+
default=False,
|
| 159 |
+
metadata={"help": "Finetune the entire model without adapters."}
|
| 160 |
+
)
|
| 161 |
+
adam8bit: bool = field(
|
| 162 |
+
default=False,
|
| 163 |
+
metadata={"help": "Use 8-bit adam."}
|
| 164 |
+
)
|
| 165 |
+
double_quant: bool = field(
|
| 166 |
+
default=True,
|
| 167 |
+
metadata={"help": "Compress the quantization statistics through double quantization."}
|
| 168 |
+
)
|
| 169 |
+
quant_type: str = field(
|
| 170 |
+
default="nf4",
|
| 171 |
+
metadata={"help": "Quantization data type to use. Should be one of `fp4` or `nf4`."}
|
| 172 |
+
)
|
| 173 |
+
bits: int = field(
|
| 174 |
+
default=4,
|
| 175 |
+
metadata={"help": "How many bits to use."}
|
| 176 |
+
)
|
| 177 |
+
lora_r: int = field(
|
| 178 |
+
default=64,
|
| 179 |
+
metadata={"help": "Lora R dimension."}
|
| 180 |
+
)
|
| 181 |
+
lora_alpha: float = field(
|
| 182 |
+
default=16,
|
| 183 |
+
metadata={"help": " Lora alpha."}
|
| 184 |
+
)
|
| 185 |
+
lora_dropout: float = field(
|
| 186 |
+
default=0.0,
|
| 187 |
+
metadata={"help":"Lora dropout."}
|
| 188 |
+
)
|
| 189 |
+
max_memory_MB: int = field(
|
| 190 |
+
default=80000,
|
| 191 |
+
metadata={"help": "Free memory per gpu."}
|
| 192 |
+
)
|
| 193 |
+
report_to: str = field(
|
| 194 |
+
default='none',
|
| 195 |
+
metadata={"help": "To use wandb or something else for reporting."}
|
| 196 |
+
)
|
| 197 |
+
output_dir: str = field(default='./output', metadata={"help": 'The output dir for logs and checkpoints'})
|
| 198 |
+
optim: str = field(default='paged_adamw_32bit', metadata={"help": 'The optimizer to be used'})
|
| 199 |
+
per_device_train_batch_size: int = field(default=1, metadata={"help": 'The training batch size per GPU. Increase for better speed.'})
|
| 200 |
+
gradient_accumulation_steps: int = field(default=16, metadata={"help": 'How many gradients to accumulate before to perform an optimizer step'})
|
| 201 |
+
max_steps: int = field(default=10000, metadata={"help": 'How many optimizer update steps to take'})
|
| 202 |
+
weight_decay: float = field(default=0.0, metadata={"help": 'The L2 weight decay rate of AdamW'}) # use lora dropout instead for regularization if needed
|
| 203 |
+
learning_rate: float = field(default=0.0002, metadata={"help": 'The learnign rate'})
|
| 204 |
+
remove_unused_columns: bool = field(default=False, metadata={"help": 'Removed unused columns. Needed to make this codebase work.'})
|
| 205 |
+
max_grad_norm: float = field(default=0.3, metadata={"help": 'Gradient clipping max norm. This is tuned and works well for all models tested.'})
|
| 206 |
+
gradient_checkpointing: bool = field(default=True, metadata={"help": 'Use gradient checkpointing. You want to use this.'})
|
| 207 |
+
do_train: bool = field(default=True, metadata={"help": 'To train or not to train, that is the question?'})
|
| 208 |
+
lr_scheduler_type: str = field(default='constant', metadata={"help": 'Learning rate schedule. Constant a bit better than cosine, and has advantage for analysis'})
|
| 209 |
+
warmup_ratio: float = field(default=0.03, metadata={"help": 'Fraction of steps to do a warmup for'})
|
| 210 |
+
logging_steps: int = field(default=10, metadata={"help": 'The frequency of update steps after which to log the loss'})
|
| 211 |
+
group_by_length: bool = field(default=True, metadata={"help": 'Group sequences into batches with same length. Saves memory and speeds up training considerably.'})
|
| 212 |
+
save_strategy: str = field(default='steps', metadata={"help": 'When to save checkpoints'})
|
| 213 |
+
save_steps: int = field(default=250, metadata={"help": 'How often to save a model'})
|
| 214 |
+
save_total_limit: int = field(default=40, metadata={"help": 'How many checkpoints to save before the oldest is overwritten'})
|
| 215 |
+
sharded_ddp: bool = field(default=False)
|
| 216 |
+
ddp_timeout: int = field(default=7200)
|
| 217 |
+
ddp_find_unused_parameters: bool = field(default=False)
|
| 218 |
+
dataloader_num_workers: int = field(default=3)
|
| 219 |
+
|
| 220 |
+
@dataclass
|
| 221 |
+
class GenerationArguments:
|
| 222 |
+
# For more hyperparameters check:
|
| 223 |
+
# https://huggingface.co/docs/transformers/main_classes/text_generation#transformers.GenerationConfig
|
| 224 |
+
# Length arguments
|
| 225 |
+
max_new_tokens: Optional[int] = field(
|
| 226 |
+
default=256,
|
| 227 |
+
metadata={"help": "Maximum number of new tokens to be generated in evaluation or prediction loops"
|
| 228 |
+
"if predict_with_generate is set."}
|
| 229 |
+
)
|
| 230 |
+
min_new_tokens : Optional[int] = field(
|
| 231 |
+
default=None,
|
| 232 |
+
metadata={"help": "Minimum number of new tokens to generate."}
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
# Generation strategy
|
| 236 |
+
do_sample: Optional[bool] = field(default=False)
|
| 237 |
+
num_beams: Optional[int] = field(default=1)
|
| 238 |
+
num_beam_groups: Optional[int] = field(default=1)
|
| 239 |
+
penalty_alpha: Optional[float] = field(default=None)
|
| 240 |
+
use_cache: Optional[bool] = field(default=True)
|
| 241 |
+
|
| 242 |
+
# Hyperparameters for logit manipulation
|
| 243 |
+
temperature: Optional[float] = field(default=1.0)
|
| 244 |
+
top_k: Optional[int] = field(default=50)
|
| 245 |
+
top_p: Optional[float] = field(default=1.0)
|
| 246 |
+
typical_p: Optional[float] = field(default=1.0)
|
| 247 |
+
diversity_penalty: Optional[float] = field(default=0.0)
|
| 248 |
+
repetition_penalty: Optional[float] = field(default=1.0)
|
| 249 |
+
length_penalty: Optional[float] = field(default=1.0)
|
| 250 |
+
no_repeat_ngram_size: Optional[int] = field(default=0)
|
| 251 |
+
|
| 252 |
+
def find_all_linear_names(args, model):
|
| 253 |
+
cls = bnb.nn.Linear4bit if args.bits == 4 else (bnb.nn.Linear8bitLt if args.bits == 8 else torch.nn.Linear)
|
| 254 |
+
lora_module_names = set()
|
| 255 |
+
for name, module in model.named_modules():
|
| 256 |
+
if isinstance(module, cls):
|
| 257 |
+
names = name.split('.')
|
| 258 |
+
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
if 'lm_head' in lora_module_names: # needed for 16-bit
|
| 262 |
+
lora_module_names.remove('lm_head')
|
| 263 |
+
return list(lora_module_names)
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class SavePeftModelCallback(transformers.TrainerCallback):
|
| 267 |
+
def save_model(self, args, state, kwargs):
|
| 268 |
+
print('Saving PEFT checkpoint...')
|
| 269 |
+
if state.best_model_checkpoint is not None:
|
| 270 |
+
checkpoint_folder = os.path.join(state.best_model_checkpoint, "adapter_model")
|
| 271 |
+
else:
|
| 272 |
+
checkpoint_folder = os.path.join(args.output_dir, f"{PREFIX_CHECKPOINT_DIR}-{state.global_step}")
|
| 273 |
+
|
| 274 |
+
peft_model_path = os.path.join(checkpoint_folder, "adapter_model")
|
| 275 |
+
kwargs["model"].save_pretrained(peft_model_path)
|
| 276 |
+
|
| 277 |
+
pytorch_model_path = os.path.join(checkpoint_folder, "pytorch_model.bin")
|
| 278 |
+
if os.path.exists(pytorch_model_path):
|
| 279 |
+
os.remove(pytorch_model_path)
|
| 280 |
+
|
| 281 |
+
def on_save(self, args, state, control, **kwargs):
|
| 282 |
+
self.save_model(args, state, kwargs)
|
| 283 |
+
return control
|
| 284 |
+
|
| 285 |
+
def on_train_end(self, args, state, control, **kwargs):
|
| 286 |
+
def touch(fname, times=None):
|
| 287 |
+
with open(fname, 'a'):
|
| 288 |
+
os.utime(fname, times)
|
| 289 |
+
|
| 290 |
+
touch(join(args.output_dir, 'completed'))
|
| 291 |
+
self.save_model(args, state, kwargs)
|
| 292 |
+
|
| 293 |
+
def get_accelerate_model(args, checkpoint_dir):
|
| 294 |
+
|
| 295 |
+
if torch.cuda.is_available():
|
| 296 |
+
n_gpus = torch.cuda.device_count()
|
| 297 |
+
if is_ipex_available() and torch.xpu.is_available():
|
| 298 |
+
n_gpus = torch.xpu.device_count()
|
| 299 |
+
|
| 300 |
+
max_memory = f'{args.max_memory_MB}MB'
|
| 301 |
+
max_memory = {i: max_memory for i in range(n_gpus)}
|
| 302 |
+
device_map = "auto"
|
| 303 |
+
|
| 304 |
+
# if we are in a distributed setting, we need to set the device map and max memory per device
|
| 305 |
+
if os.environ.get('LOCAL_RANK') is not None:
|
| 306 |
+
local_rank = int(os.environ.get('LOCAL_RANK', '0'))
|
| 307 |
+
device_map = {'': local_rank}
|
| 308 |
+
max_memory = {'': max_memory[local_rank]}
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
if args.full_finetune: assert args.bits in [16, 32]
|
| 312 |
+
|
| 313 |
+
print(f'loading base model {args.model_name_or_path}...')
|
| 314 |
+
compute_dtype = (torch.float16 if args.fp16 else (torch.bfloat16 if args.bf16 else torch.float32))
|
| 315 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 316 |
+
args.model_name_or_path,
|
| 317 |
+
cache_dir=args.cache_dir,
|
| 318 |
+
load_in_4bit=args.bits == 4,
|
| 319 |
+
load_in_8bit=args.bits == 8,
|
| 320 |
+
device_map=device_map,
|
| 321 |
+
max_memory=max_memory,
|
| 322 |
+
quantization_config=BitsAndBytesConfig(
|
| 323 |
+
load_in_4bit=args.bits == 4,
|
| 324 |
+
load_in_8bit=args.bits == 8,
|
| 325 |
+
llm_int8_threshold=6.0,
|
| 326 |
+
llm_int8_has_fp16_weight=False,
|
| 327 |
+
bnb_4bit_compute_dtype=compute_dtype,
|
| 328 |
+
bnb_4bit_use_double_quant=args.double_quant,
|
| 329 |
+
bnb_4bit_quant_type=args.quant_type,
|
| 330 |
+
),
|
| 331 |
+
torch_dtype=(torch.float32 if args.fp16 else (torch.bfloat16 if args.bf16 else torch.float32)),
|
| 332 |
+
trust_remote_code=args.trust_remote_code,
|
| 333 |
+
use_auth_token=args.use_auth_token
|
| 334 |
+
)
|
| 335 |
+
if compute_dtype == torch.float16 and args.bits == 4:
|
| 336 |
+
if torch.cuda.is_bf16_supported():
|
| 337 |
+
print('='*80)
|
| 338 |
+
print('Your GPU supports bfloat16, you can accelerate training with the argument --bf16')
|
| 339 |
+
print('='*80)
|
| 340 |
+
|
| 341 |
+
if compute_dtype == torch.float16 and (is_ipex_available() and torch.xpu.is_available()):
|
| 342 |
+
compute_dtype = torch.bfloat16
|
| 343 |
+
print('Intel XPU does not support float16 yet, so switching to bfloat16')
|
| 344 |
+
|
| 345 |
+
setattr(model, 'model_parallel', True)
|
| 346 |
+
setattr(model, 'is_parallelizable', True)
|
| 347 |
+
|
| 348 |
+
model.config.torch_dtype=(torch.float32 if args.fp16 else (torch.bfloat16 if args.bf16 else torch.float32))
|
| 349 |
+
|
| 350 |
+
# Tokenizer
|
| 351 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 352 |
+
args.model_name_or_path,
|
| 353 |
+
cache_dir=args.cache_dir,
|
| 354 |
+
padding_side="right",
|
| 355 |
+
use_fast=False, # Fast tokenizer giving issues.
|
| 356 |
+
tokenizer_type='llama' if 'llama' in args.model_name_or_path else None, # Needed for HF name change
|
| 357 |
+
legacy=False,
|
| 358 |
+
trust_remote_code=args.trust_remote_code,
|
| 359 |
+
use_auth_token=args.use_auth_token,
|
| 360 |
+
)
|
| 361 |
+
#if tokenizer._pad_token is None:
|
| 362 |
+
# smart_tokenizer_and_embedding_resize(
|
| 363 |
+
# special_tokens_dict=dict(pad_token=DEFAULT_PAD_TOKEN),
|
| 364 |
+
# tokenizer=tokenizer,
|
| 365 |
+
# model=model,
|
| 366 |
+
# )
|
| 367 |
+
if 'llama' in args.model_name_or_path or isinstance(tokenizer, LlamaTokenizer):
|
| 368 |
+
# LLaMA tokenizer may not have correct special tokens set.
|
| 369 |
+
# Check and add them if missing to prevent them from being parsed into different tokens.
|
| 370 |
+
# Note that these are present in the vocabulary.
|
| 371 |
+
# Note also that `model.config.pad_token_id` is 0 which corresponds to `<unk>` token.
|
| 372 |
+
print('Adding special tokens.')
|
| 373 |
+
tokenizer.add_special_tokens({
|
| 374 |
+
"eos_token": tokenizer.convert_ids_to_tokens(model.config.eos_token_id),
|
| 375 |
+
"bos_token": tokenizer.convert_ids_to_tokens(model.config.bos_token_id),
|
| 376 |
+
"pad_token": tokenizer.convert_ids_to_tokens(0)
|
| 377 |
+
# "unk_token": tokenizer.convert_ids_to_tokens(
|
| 378 |
+
# model.config.pad_token_id if model.config.pad_token_id != -1 else tokenizer.pad_token_id
|
| 379 |
+
# ),
|
| 380 |
+
})
|
| 381 |
+
|
| 382 |
+
if not args.full_finetune:
|
| 383 |
+
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=args.gradient_checkpointing)
|
| 384 |
+
|
| 385 |
+
if not args.full_finetune:
|
| 386 |
+
if checkpoint_dir is not None:
|
| 387 |
+
print("Loading adapters from checkpoint.")
|
| 388 |
+
model = PeftModel.from_pretrained(model, join(checkpoint_dir, 'adapter_model'), is_trainable=True)
|
| 389 |
+
else:
|
| 390 |
+
print(f'adding LoRA modules...')
|
| 391 |
+
modules = find_all_linear_names(args, model)
|
| 392 |
+
config = LoraConfig(
|
| 393 |
+
r=args.lora_r,
|
| 394 |
+
lora_alpha=args.lora_alpha,
|
| 395 |
+
target_modules=modules,
|
| 396 |
+
lora_dropout=args.lora_dropout,
|
| 397 |
+
bias="none",
|
| 398 |
+
task_type="CAUSAL_LM",
|
| 399 |
+
)
|
| 400 |
+
model = get_peft_model(model, config)
|
| 401 |
+
|
| 402 |
+
for name, module in model.named_modules():
|
| 403 |
+
if isinstance(module, LoraLayer):
|
| 404 |
+
if args.bf16:
|
| 405 |
+
module = module.to(torch.bfloat16)
|
| 406 |
+
if 'norm' in name:
|
| 407 |
+
module = module.to(torch.float32)
|
| 408 |
+
if 'lm_head' in name or 'embed_tokens' in name:
|
| 409 |
+
if hasattr(module, 'weight'):
|
| 410 |
+
if args.bf16 and module.weight.dtype == torch.float32:
|
| 411 |
+
module = module.to(torch.bfloat16)
|
| 412 |
+
return model, tokenizer
|
| 413 |
+
|
| 414 |
+
def print_trainable_parameters(args, model):
|
| 415 |
+
"""
|
| 416 |
+
Prints the number of trainable parameters in the model.
|
| 417 |
+
"""
|
| 418 |
+
trainable_params = 0
|
| 419 |
+
all_param = 0
|
| 420 |
+
for _, param in model.named_parameters():
|
| 421 |
+
all_param += param.numel()
|
| 422 |
+
if param.requires_grad:
|
| 423 |
+
trainable_params += param.numel()
|
| 424 |
+
if args.bits == 4: trainable_params /= 2
|
| 425 |
+
print(
|
| 426 |
+
f"trainable params: {trainable_params} || "
|
| 427 |
+
f"all params: {all_param} || "
|
| 428 |
+
f"trainable: {100 * trainable_params / all_param}"
|
| 429 |
+
)
|
| 430 |
+
|
| 431 |
+
def smart_tokenizer_and_embedding_resize(
|
| 432 |
+
special_tokens_dict: Dict,
|
| 433 |
+
tokenizer: transformers.PreTrainedTokenizer,
|
| 434 |
+
model: transformers.PreTrainedModel,
|
| 435 |
+
):
|
| 436 |
+
"""Resize tokenizer and embedding.
|
| 437 |
+
|
| 438 |
+
Note: This is the unoptimized version that may make your embedding size not be divisible by 64.
|
| 439 |
+
"""
|
| 440 |
+
num_new_tokens = tokenizer.add_special_tokens(special_tokens_dict)
|
| 441 |
+
model.resize_token_embeddings(len(tokenizer))
|
| 442 |
+
|
| 443 |
+
if num_new_tokens > 0:
|
| 444 |
+
input_embeddings_data = model.get_input_embeddings().weight.data
|
| 445 |
+
output_embeddings_data = model.get_output_embeddings().weight.data
|
| 446 |
+
|
| 447 |
+
input_embeddings_avg = input_embeddings_data[:-num_new_tokens].mean(dim=0, keepdim=True)
|
| 448 |
+
output_embeddings_avg = output_embeddings_data[:-num_new_tokens].mean(dim=0, keepdim=True)
|
| 449 |
+
|
| 450 |
+
input_embeddings_data[-num_new_tokens:] = input_embeddings_avg
|
| 451 |
+
output_embeddings_data[-num_new_tokens:] = output_embeddings_avg
|
| 452 |
+
|
| 453 |
+
@dataclass
|
| 454 |
+
class DataCollatorForCausalLM(object):
|
| 455 |
+
tokenizer: transformers.PreTrainedTokenizer
|
| 456 |
+
source_max_len: int
|
| 457 |
+
target_max_len: int
|
| 458 |
+
train_on_source: bool
|
| 459 |
+
predict_with_generate: bool
|
| 460 |
+
|
| 461 |
+
def __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:
|
| 462 |
+
# Extract elements
|
| 463 |
+
sources = [f"{self.tokenizer.bos_token}{example['input']}" for example in instances]
|
| 464 |
+
targets = [f"{example['output']}{self.tokenizer.eos_token}" for example in instances]
|
| 465 |
+
# Tokenize
|
| 466 |
+
tokenized_sources_with_prompt = self.tokenizer(
|
| 467 |
+
sources,
|
| 468 |
+
max_length=self.source_max_len,
|
| 469 |
+
truncation=True,
|
| 470 |
+
add_special_tokens=False,
|
| 471 |
+
)
|
| 472 |
+
tokenized_targets = self.tokenizer(
|
| 473 |
+
targets,
|
| 474 |
+
max_length=self.target_max_len,
|
| 475 |
+
truncation=True,
|
| 476 |
+
add_special_tokens=False,
|
| 477 |
+
)
|
| 478 |
+
# Build the input and labels for causal LM
|
| 479 |
+
input_ids = []
|
| 480 |
+
labels = []
|
| 481 |
+
for tokenized_source, tokenized_target in zip(
|
| 482 |
+
tokenized_sources_with_prompt['input_ids'],
|
| 483 |
+
tokenized_targets['input_ids']
|
| 484 |
+
):
|
| 485 |
+
if not self.predict_with_generate:
|
| 486 |
+
input_ids.append(torch.tensor(tokenized_source + tokenized_target))
|
| 487 |
+
if not self.train_on_source:
|
| 488 |
+
labels.append(
|
| 489 |
+
torch.tensor([IGNORE_INDEX for _ in range(len(tokenized_source))] + copy.deepcopy(tokenized_target))
|
| 490 |
+
)
|
| 491 |
+
else:
|
| 492 |
+
labels.append(torch.tensor(copy.deepcopy(tokenized_source + tokenized_target)))
|
| 493 |
+
else:
|
| 494 |
+
input_ids.append(torch.tensor(tokenized_source))
|
| 495 |
+
# Apply padding
|
| 496 |
+
input_ids = pad_sequence(input_ids, batch_first=True, padding_value=self.tokenizer.pad_token_id)
|
| 497 |
+
labels = pad_sequence(labels, batch_first=True, padding_value=IGNORE_INDEX) if not self.predict_with_generate else None
|
| 498 |
+
data_dict = {
|
| 499 |
+
'input_ids': input_ids,
|
| 500 |
+
'attention_mask':input_ids.ne(self.tokenizer.pad_token_id),
|
| 501 |
+
}
|
| 502 |
+
if labels is not None:
|
| 503 |
+
data_dict['labels'] = labels
|
| 504 |
+
return data_dict
|
| 505 |
+
|
| 506 |
+
def extract_unnatural_instructions_data(examples, extract_reformulations=False):
|
| 507 |
+
out = {
|
| 508 |
+
'input': [],
|
| 509 |
+
'output': [],
|
| 510 |
+
}
|
| 511 |
+
for example_instances in examples['instances']:
|
| 512 |
+
for instance in example_instances:
|
| 513 |
+
out['input'].append(instance['instruction_with_input'])
|
| 514 |
+
out['output'].append(instance['output'])
|
| 515 |
+
if extract_reformulations:
|
| 516 |
+
for example_reformulations in examples['reformulations']:
|
| 517 |
+
if example_reformulations is not None:
|
| 518 |
+
for instance in example_reformulations:
|
| 519 |
+
out['input'].append(instance['instruction_with_input'])
|
| 520 |
+
out['output'].append(instance['output'])
|
| 521 |
+
return out
|
| 522 |
+
|
| 523 |
+
ALPACA_PROMPT_DICT = {
|
| 524 |
+
"prompt_input": (
|
| 525 |
+
"Below is an instruction that describes a task, paired with an input that provides further context. "
|
| 526 |
+
"Write a response that appropriately completes the request.\n\n"
|
| 527 |
+
"### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response: "
|
| 528 |
+
),
|
| 529 |
+
"prompt_no_input": (
|
| 530 |
+
"Below is an instruction that describes a task. "
|
| 531 |
+
"Write a response that appropriately completes the request.\n\n"
|
| 532 |
+
"### Instruction:\n{instruction}\n\n### Response: "
|
| 533 |
+
),
|
| 534 |
+
}
|
| 535 |
+
|
| 536 |
+
def extract_alpaca_dataset(example):
|
| 537 |
+
if example.get("input", "") != "":
|
| 538 |
+
prompt_format = ALPACA_PROMPT_DICT["prompt_input"]
|
| 539 |
+
else:
|
| 540 |
+
prompt_format = ALPACA_PROMPT_DICT["prompt_no_input"]
|
| 541 |
+
return {'input': prompt_format.format(**example)}
|
| 542 |
+
|
| 543 |
+
def local_dataset(dataset_name):
|
| 544 |
+
if dataset_name.endswith('.json') or dataset_name.endswith('.jsonl'):
|
| 545 |
+
full_dataset = Dataset.from_json(path_or_paths=dataset_name)
|
| 546 |
+
elif dataset_name.endswith('.csv'):
|
| 547 |
+
full_dataset = Dataset.from_pandas(pd.read_csv(dataset_name))
|
| 548 |
+
elif dataset_name.endswith('.tsv'):
|
| 549 |
+
full_dataset = Dataset.from_pandas(pd.read_csv(dataset_name, delimiter='\t'))
|
| 550 |
+
else:
|
| 551 |
+
raise ValueError(f"Unsupported dataset format: {dataset_name}")
|
| 552 |
+
|
| 553 |
+
split_dataset = full_dataset.train_test_split(test_size=0.1)
|
| 554 |
+
return split_dataset
|
| 555 |
+
|
| 556 |
+
def make_data_module(tokenizer: transformers.PreTrainedTokenizer, args) -> Dict:
|
| 557 |
+
"""
|
| 558 |
+
Make dataset and collator for supervised fine-tuning.
|
| 559 |
+
Datasets are expected to have the following columns: { `input`, `output` }
|
| 560 |
+
|
| 561 |
+
Available datasets to be selected with `dataset` argument:
|
| 562 |
+
- alpaca, 52002 examples
|
| 563 |
+
- alpaca cleaned, 51942 examples
|
| 564 |
+
- chip2 (OIG), 210289 examples
|
| 565 |
+
- self-instruct, 82612 examples
|
| 566 |
+
- hh-rlhf (Anthropic), 160800 examples
|
| 567 |
+
- longform, 23.7k examples
|
| 568 |
+
- oasst1 (OpenAssistant) primary message tree only, 9,846 examples
|
| 569 |
+
|
| 570 |
+
Coming soon:
|
| 571 |
+
- unnatural instructions core, 66010 examples
|
| 572 |
+
- unnatural instructions full, 240670 examples
|
| 573 |
+
- alpaca-gpt4, 52002 examples
|
| 574 |
+
- unnatural-instructions-gpt4, 9000 examples
|
| 575 |
+
- supernatural-instructions, 69624 examples (same as paper with 100 ex/task more can be used)
|
| 576 |
+
- flan (FLAN v2), up to 20M examples available
|
| 577 |
+
- vicuna
|
| 578 |
+
|
| 579 |
+
"""
|
| 580 |
+
def load_data(dataset_name):
|
| 581 |
+
if dataset_name == 'alpaca':
|
| 582 |
+
return load_dataset("tatsu-lab/alpaca")
|
| 583 |
+
elif dataset_name == 'alpaca-clean':
|
| 584 |
+
return load_dataset("yahma/alpaca-cleaned")
|
| 585 |
+
elif dataset_name == 'chip2':
|
| 586 |
+
return load_dataset("laion/OIG", data_files='unified_chip2.jsonl')
|
| 587 |
+
elif dataset_name == 'self-instruct':
|
| 588 |
+
return load_dataset("yizhongw/self_instruct", name='self_instruct')
|
| 589 |
+
elif dataset_name == 'hh-rlhf':
|
| 590 |
+
return load_dataset("Anthropic/hh-rlhf")
|
| 591 |
+
elif dataset_name == 'longform':
|
| 592 |
+
return load_dataset("akoksal/LongForm")
|
| 593 |
+
elif dataset_name == 'oasst1':
|
| 594 |
+
return load_dataset("timdettmers/openassistant-guanaco")
|
| 595 |
+
elif dataset_name == 'vicuna':
|
| 596 |
+
raise NotImplementedError("Vicuna data was not released.")
|
| 597 |
+
else:
|
| 598 |
+
if os.path.exists(dataset_name):
|
| 599 |
+
try:
|
| 600 |
+
args.dataset_format = args.dataset_format if args.dataset_format else "input-output"
|
| 601 |
+
full_dataset = local_dataset(dataset_name)
|
| 602 |
+
return full_dataset
|
| 603 |
+
except:
|
| 604 |
+
raise ValueError(f"Error loading dataset from {dataset_name}")
|
| 605 |
+
else:
|
| 606 |
+
raise NotImplementedError(f"Dataset {dataset_name} not implemented yet.")
|
| 607 |
+
|
| 608 |
+
def format_dataset(dataset, dataset_format):
|
| 609 |
+
if (
|
| 610 |
+
dataset_format == 'alpaca' or dataset_format == 'alpaca-clean' or
|
| 611 |
+
(dataset_format is None and args.dataset in ['alpaca', 'alpaca-clean'])
|
| 612 |
+
):
|
| 613 |
+
dataset = dataset.map(extract_alpaca_dataset, remove_columns=['instruction'])
|
| 614 |
+
elif dataset_format == 'chip2' or (dataset_format is None and args.dataset == 'chip2'):
|
| 615 |
+
dataset = dataset.map(lambda x: {
|
| 616 |
+
'input': x['text'].split('\n<bot>: ')[0].replace('<human>: ', ''),
|
| 617 |
+
'output': x['text'].split('\n<bot>: ')[1],
|
| 618 |
+
})
|
| 619 |
+
elif dataset_format == 'self-instruct' or (dataset_format is None and args.dataset == 'self-instruct'):
|
| 620 |
+
for old, new in [["prompt", "input"], ["completion", "output"]]:
|
| 621 |
+
dataset = dataset.rename_column(old, new)
|
| 622 |
+
elif dataset_format == 'hh-rlhf' or (dataset_format is None and args.dataset == 'hh-rlhf'):
|
| 623 |
+
dataset = dataset.map(lambda x: {
|
| 624 |
+
'input': '',
|
| 625 |
+
'output': x['chosen']
|
| 626 |
+
})
|
| 627 |
+
elif dataset_format == 'oasst1' or (dataset_format is None and args.dataset == 'oasst1'):
|
| 628 |
+
dataset = dataset.map(lambda x: {
|
| 629 |
+
'input': '',
|
| 630 |
+
'output': x['text'],
|
| 631 |
+
})
|
| 632 |
+
elif dataset_format == 'input-output':
|
| 633 |
+
# leave as is
|
| 634 |
+
pass
|
| 635 |
+
# Remove unused columns.
|
| 636 |
+
dataset = dataset.remove_columns(
|
| 637 |
+
[col for col in dataset.column_names['train'] if col not in ['input', 'output']]
|
| 638 |
+
)
|
| 639 |
+
return dataset
|
| 640 |
+
|
| 641 |
+
# Load dataset.
|
| 642 |
+
dataset = load_data(args.dataset)
|
| 643 |
+
dataset = format_dataset(dataset, args.dataset_format)
|
| 644 |
+
print(dataset)
|
| 645 |
+
# Split train/eval, reduce size
|
| 646 |
+
if args.do_eval or args.do_predict:
|
| 647 |
+
if 'eval' in dataset:
|
| 648 |
+
eval_dataset = dataset['eval']
|
| 649 |
+
else:
|
| 650 |
+
print('Splitting train dataset in train and validation according to `eval_dataset_size`')
|
| 651 |
+
dataset = dataset["train"].train_test_split(
|
| 652 |
+
test_size=args.eval_dataset_size, shuffle=True, seed=42
|
| 653 |
+
)
|
| 654 |
+
eval_dataset = dataset['test']
|
| 655 |
+
if args.max_eval_samples is not None and len(eval_dataset) > args.max_eval_samples:
|
| 656 |
+
eval_dataset = eval_dataset.select(range(args.max_eval_samples))
|
| 657 |
+
if args.group_by_length:
|
| 658 |
+
eval_dataset = eval_dataset.map(lambda x: {'length': len(x['input']) + len(x['output'])})
|
| 659 |
+
if args.do_train:
|
| 660 |
+
train_dataset = dataset['train']
|
| 661 |
+
if args.max_train_samples is not None and len(train_dataset) > args.max_train_samples:
|
| 662 |
+
train_dataset = train_dataset.select(range(args.max_train_samples))
|
| 663 |
+
if args.group_by_length:
|
| 664 |
+
train_dataset = train_dataset.map(lambda x: {'length': len(x['input']) + len(x['output'])})
|
| 665 |
+
|
| 666 |
+
data_collator = DataCollatorForCausalLM(
|
| 667 |
+
tokenizer=tokenizer,
|
| 668 |
+
source_max_len=args.source_max_len,
|
| 669 |
+
target_max_len=args.target_max_len,
|
| 670 |
+
train_on_source=args.train_on_source,
|
| 671 |
+
predict_with_generate=args.predict_with_generate,
|
| 672 |
+
)
|
| 673 |
+
return dict(
|
| 674 |
+
train_dataset=train_dataset if args.do_train else None,
|
| 675 |
+
eval_dataset=eval_dataset if args.do_eval else None,
|
| 676 |
+
predict_dataset=eval_dataset if args.do_predict else None,
|
| 677 |
+
data_collator=data_collator
|
| 678 |
+
)
|
| 679 |
+
|
| 680 |
+
def get_last_checkpoint(checkpoint_dir):
|
| 681 |
+
if isdir(checkpoint_dir):
|
| 682 |
+
is_completed = exists(join(checkpoint_dir, 'completed'))
|
| 683 |
+
if is_completed: return None, True # already finished
|
| 684 |
+
max_step = 0
|
| 685 |
+
for filename in os.listdir(checkpoint_dir):
|
| 686 |
+
if isdir(join(checkpoint_dir, filename)) and filename.startswith('checkpoint'):
|
| 687 |
+
max_step = max(max_step, int(filename.replace('checkpoint-', '')))
|
| 688 |
+
if max_step == 0: return None, is_completed # training started, but no checkpoint
|
| 689 |
+
checkpoint_dir = join(checkpoint_dir, f'checkpoint-{max_step}')
|
| 690 |
+
print(f"Found a previous checkpoint at: {checkpoint_dir}")
|
| 691 |
+
return checkpoint_dir, is_completed # checkpoint found!
|
| 692 |
+
return None, False # first training
|
| 693 |
+
|
| 694 |
+
def train():
|
| 695 |
+
hfparser = transformers.HfArgumentParser((
|
| 696 |
+
ModelArguments, DataArguments, TrainingArguments, GenerationArguments
|
| 697 |
+
))
|
| 698 |
+
model_args, data_args, training_args, generation_args, extra_args = \
|
| 699 |
+
hfparser.parse_args_into_dataclasses(return_remaining_strings=True)
|
| 700 |
+
#training_args.generation_config = transformers.GenerationConfig(**vars(generation_args))
|
| 701 |
+
args = argparse.Namespace(
|
| 702 |
+
**vars(model_args), **vars(data_args), **vars(training_args)
|
| 703 |
+
)
|
| 704 |
+
print(args)
|
| 705 |
+
|
| 706 |
+
checkpoint_dir, completed_training = get_last_checkpoint(args.output_dir)
|
| 707 |
+
if completed_training:
|
| 708 |
+
print('Detected that training was already completed!')
|
| 709 |
+
|
| 710 |
+
model, tokenizer = get_accelerate_model(args, checkpoint_dir)
|
| 711 |
+
|
| 712 |
+
model.config.use_cache = False
|
| 713 |
+
print('loaded model')
|
| 714 |
+
set_seed(args.seed)
|
| 715 |
+
|
| 716 |
+
data_module = make_data_module(tokenizer=tokenizer, args=args)
|
| 717 |
+
|
| 718 |
+
if torch.cuda.device_count() > 1:
|
| 719 |
+
# keeps Trainer from trying its own DataParallelism when more than 1 gpu is available
|
| 720 |
+
model.is_parallelizable = True
|
| 721 |
+
model.model_parallel = True
|
| 722 |
+
|
| 723 |
+
trainer = Seq2SeqTrainer(
|
| 724 |
+
model=model,
|
| 725 |
+
tokenizer=tokenizer,
|
| 726 |
+
args=training_args,
|
| 727 |
+
**{k:v for k,v in data_module.items() if k != 'predict_dataset'},
|
| 728 |
+
)
|
| 729 |
+
|
| 730 |
+
# Callbacks
|
| 731 |
+
if not args.full_finetune:
|
| 732 |
+
trainer.add_callback(SavePeftModelCallback)
|
| 733 |
+
if args.do_mmlu_eval:
|
| 734 |
+
if args.mmlu_dataset == 'mmlu-zs':
|
| 735 |
+
mmlu_dataset = load_dataset("json", data_files={
|
| 736 |
+
'eval': 'data/mmlu/zero_shot_mmlu_val.json',
|
| 737 |
+
'test': 'data/mmlu/zero_shot_mmlu_test.json',
|
| 738 |
+
})
|
| 739 |
+
mmlu_dataset = mmlu_dataset.remove_columns('subject')
|
| 740 |
+
# MMLU Five-shot (Eval/Test only)
|
| 741 |
+
elif args.mmlu_dataset == 'mmlu' or args.mmlu_dataset == 'mmlu-fs':
|
| 742 |
+
mmlu_dataset = load_dataset("json", data_files={
|
| 743 |
+
'eval': 'data/mmlu/five_shot_mmlu_val.json',
|
| 744 |
+
'test': 'data/mmlu/five_shot_mmlu_test.json',
|
| 745 |
+
})
|
| 746 |
+
# mmlu_dataset = mmlu_dataset.remove_columns('subject')
|
| 747 |
+
mmlu_dataset = mmlu_dataset[args.mmlu_split]
|
| 748 |
+
if args.max_mmlu_samples is not None:
|
| 749 |
+
mmlu_dataset = mmlu_dataset.select(range(args.max_mmlu_samples))
|
| 750 |
+
abcd_idx = [
|
| 751 |
+
tokenizer("A", add_special_tokens=False).input_ids[0],
|
| 752 |
+
tokenizer("B", add_special_tokens=False).input_ids[0],
|
| 753 |
+
tokenizer("C", add_special_tokens=False).input_ids[0],
|
| 754 |
+
tokenizer("D", add_special_tokens=False).input_ids[0],
|
| 755 |
+
]
|
| 756 |
+
accuracy = evaluate.load("accuracy")
|
| 757 |
+
class MMLUEvalCallback(transformers.TrainerCallback):
|
| 758 |
+
def on_evaluate(self, args, state, control, model, **kwargs):
|
| 759 |
+
data_loader = trainer.get_eval_dataloader(mmlu_dataset)
|
| 760 |
+
source_max_len = trainer.data_collator.source_max_len
|
| 761 |
+
trainer.data_collator.source_max_len = args.mmlu_source_max_len
|
| 762 |
+
trainer.model.eval()
|
| 763 |
+
preds, refs = [], []
|
| 764 |
+
loss_mmlu = 0
|
| 765 |
+
for batch in tqdm(data_loader, total=len(data_loader)):
|
| 766 |
+
(loss, logits, labels) = trainer.prediction_step(trainer.model,batch,prediction_loss_only=False,)
|
| 767 |
+
# There are two tokens, the output, and eos token.
|
| 768 |
+
for i, logit in enumerate(logits):
|
| 769 |
+
label_non_zero_id = (batch['labels'][i] != -100).nonzero()[0][0]
|
| 770 |
+
logit_abcd = logit[label_non_zero_id-1][abcd_idx]
|
| 771 |
+
preds.append(torch.argmax(logit_abcd).item())
|
| 772 |
+
labels = labels[labels != IGNORE_INDEX].view(-1, 2)[:,0]
|
| 773 |
+
refs += [abcd_idx.index(label) for label in labels.tolist()]
|
| 774 |
+
loss_mmlu += loss.item()
|
| 775 |
+
# Extract results by subject.
|
| 776 |
+
results = {'mmlu_loss':loss_mmlu/len(data_loader)}
|
| 777 |
+
subject = mmlu_dataset['subject']
|
| 778 |
+
subjects = {s:{'refs':[], 'preds':[]} for s in set(subject)}
|
| 779 |
+
for s,p,r in zip(subject, preds, refs):
|
| 780 |
+
subjects[s]['preds'].append(p)
|
| 781 |
+
subjects[s]['refs'].append(r)
|
| 782 |
+
subject_scores = []
|
| 783 |
+
for subject in subjects:
|
| 784 |
+
subject_score = accuracy.compute(
|
| 785 |
+
references=subjects[subject]['refs'],
|
| 786 |
+
predictions=subjects[subject]['preds']
|
| 787 |
+
)['accuracy']
|
| 788 |
+
results[f'mmlu_{args.mmlu_split}_accuracy_{subject}'] = subject_score
|
| 789 |
+
subject_scores.append(subject_score)
|
| 790 |
+
results[f'mmlu_{args.mmlu_split}_accuracy'] = np.mean(subject_scores)
|
| 791 |
+
trainer.log(results)
|
| 792 |
+
trainer.data_collator.source_max_len = source_max_len
|
| 793 |
+
|
| 794 |
+
trainer.add_callback(MMLUEvalCallback)
|
| 795 |
+
|
| 796 |
+
# Verifying the datatypes and parameter counts before training.
|
| 797 |
+
print_trainable_parameters(args, model)
|
| 798 |
+
dtypes = {}
|
| 799 |
+
for _, p in model.named_parameters():
|
| 800 |
+
dtype = p.dtype
|
| 801 |
+
if dtype not in dtypes: dtypes[dtype] = 0
|
| 802 |
+
dtypes[dtype] += p.numel()
|
| 803 |
+
total = 0
|
| 804 |
+
for k, v in dtypes.items(): total+= v
|
| 805 |
+
for k, v in dtypes.items():
|
| 806 |
+
print(k, v, v/total)
|
| 807 |
+
|
| 808 |
+
all_metrics = {"run_name": args.run_name}
|
| 809 |
+
# Training
|
| 810 |
+
if args.do_train:
|
| 811 |
+
logger.info("*** Train ***")
|
| 812 |
+
# Note: `resume_from_checkpoint` not supported for adapter checkpoints by HF.
|
| 813 |
+
# Currently adapter checkpoint is reloaded as expected but optimizer/scheduler states are not.
|
| 814 |
+
train_result = trainer.train()
|
| 815 |
+
metrics = train_result.metrics
|
| 816 |
+
trainer.log_metrics("train", metrics)
|
| 817 |
+
trainer.save_metrics("train", metrics)
|
| 818 |
+
trainer.save_state()
|
| 819 |
+
all_metrics.update(metrics)
|
| 820 |
+
# Evaluation
|
| 821 |
+
if args.do_eval:
|
| 822 |
+
logger.info("*** Evaluate ***")
|
| 823 |
+
metrics = trainer.evaluate(metric_key_prefix="eval")
|
| 824 |
+
trainer.log_metrics("eval", metrics)
|
| 825 |
+
trainer.save_metrics("eval", metrics)
|
| 826 |
+
all_metrics.update(metrics)
|
| 827 |
+
# Prediction
|
| 828 |
+
if args.do_predict:
|
| 829 |
+
logger.info("*** Predict ***")
|
| 830 |
+
prediction_output = trainer.predict(test_dataset=data_module['predict_dataset'],metric_key_prefix="predict")
|
| 831 |
+
prediction_metrics = prediction_output.metrics
|
| 832 |
+
predictions = prediction_output.predictions
|
| 833 |
+
predictions = np.where(predictions != -100, predictions, tokenizer.pad_token_id)
|
| 834 |
+
predictions = tokenizer.batch_decode(
|
| 835 |
+
predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 836 |
+
)
|
| 837 |
+
with open(os.path.join(args.output_dir, 'predictions.jsonl'), 'w') as fout:
|
| 838 |
+
for i, example in enumerate(data_module['predict_dataset']):
|
| 839 |
+
example['prediction_with_input'] = predictions[i].strip()
|
| 840 |
+
example['prediction'] = predictions[i].replace(example['input'], '').strip()
|
| 841 |
+
fout.write(json.dumps(example) + '\n')
|
| 842 |
+
print(prediction_metrics)
|
| 843 |
+
trainer.log_metrics("predict", prediction_metrics)
|
| 844 |
+
trainer.save_metrics("predict", prediction_metrics)
|
| 845 |
+
all_metrics.update(prediction_metrics)
|
| 846 |
+
|
| 847 |
+
if (args.do_train or args.do_eval or args.do_predict):
|
| 848 |
+
with open(os.path.join(args.output_dir, "metrics.json"), "w") as fout:
|
| 849 |
+
fout.write(json.dumps(all_metrics))
|
| 850 |
+
|
| 851 |
+
if __name__ == "__main__":
|
| 852 |
+
train()
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"eos_token": "</s>",
|
| 4 |
+
"pad_token": "<unk>",
|
| 5 |
+
"unk_token": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
}
|
| 12 |
+
}
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9e556afd44213b6bd1be2b850ebbbd98f5481437a8021afaf58ee7fb1818d347
|
| 3 |
+
size 499723
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"bos_token": {
|
| 5 |
+
"__type": "AddedToken",
|
| 6 |
+
"content": "<s>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": true,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false
|
| 11 |
+
},
|
| 12 |
+
"clean_up_tokenization_spaces": false,
|
| 13 |
+
"eos_token": {
|
| 14 |
+
"__type": "AddedToken",
|
| 15 |
+
"content": "</s>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false
|
| 20 |
+
},
|
| 21 |
+
"legacy": false,
|
| 22 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 23 |
+
"pad_token": null,
|
| 24 |
+
"padding_side": "right",
|
| 25 |
+
"sp_model_kwargs": {},
|
| 26 |
+
"spaces_between_special_tokens": false,
|
| 27 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 28 |
+
"unk_token": {
|
| 29 |
+
"__type": "AddedToken",
|
| 30 |
+
"content": "<unk>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": true,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false
|
| 35 |
+
},
|
| 36 |
+
"use_default_system_prompt": true
|
| 37 |
+
}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 10.054988216810683,
|
| 5 |
+
"eval_steps": 1000,
|
| 6 |
+
"global_step": 800,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 1.26,
|
| 13 |
+
"learning_rate": 0.0001,
|
| 14 |
+
"loss": 0.1991,
|
| 15 |
+
"step": 100
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"epoch": 2.51,
|
| 19 |
+
"learning_rate": 0.0001,
|
| 20 |
+
"loss": 0.076,
|
| 21 |
+
"step": 200
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"epoch": 3.77,
|
| 25 |
+
"learning_rate": 0.0001,
|
| 26 |
+
"loss": 0.061,
|
| 27 |
+
"step": 300
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"epoch": 5.03,
|
| 31 |
+
"learning_rate": 0.0001,
|
| 32 |
+
"loss": 0.0522,
|
| 33 |
+
"step": 400
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"epoch": 6.28,
|
| 37 |
+
"learning_rate": 0.0001,
|
| 38 |
+
"loss": 0.0471,
|
| 39 |
+
"step": 500
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"epoch": 7.54,
|
| 43 |
+
"learning_rate": 0.0001,
|
| 44 |
+
"loss": 0.044,
|
| 45 |
+
"step": 600
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"epoch": 8.8,
|
| 49 |
+
"learning_rate": 0.0001,
|
| 50 |
+
"loss": 0.0411,
|
| 51 |
+
"step": 700
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 10.05,
|
| 55 |
+
"learning_rate": 0.0001,
|
| 56 |
+
"loss": 0.0383,
|
| 57 |
+
"step": 800
|
| 58 |
+
}
|
| 59 |
+
],
|
| 60 |
+
"logging_steps": 100,
|
| 61 |
+
"max_steps": 4500,
|
| 62 |
+
"num_train_epochs": 57,
|
| 63 |
+
"save_steps": 200,
|
| 64 |
+
"total_flos": 2.710103747932979e+18,
|
| 65 |
+
"trial_name": null,
|
| 66 |
+
"trial_params": null
|
| 67 |
+
}
|