
File size: 12,817 Bytes
33df0a0 3358b54 07e68e4 3358b54 33df0a0 1eb7179 07e68e4 33df0a0 3358b54 903b85c 3358b54 33df0a0 3358b54 a8bcd8f 079e152 33df0a0 761a541 33df0a0 3358b54 33df0a0 a8bcd8f 33df0a0 19dfe87 33df0a0 d4126b7 78e7ea8 d4126b7 78e7ea8 d4126b7 78e7ea8 9595e28 2d3ec84 12f99b1 e1ed61d c648ea0 2d3ec84 a8bcd8f 33df0a0 8985bf0 33df0a0 8985bf0 33df0a0 a8bcd8f 9595e28 a8bcd8f 33df0a0 9595e28 33df0a0 41a79a9 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 |
---
language:
- multilingual
- en
- de
- fr
- ja
license: mit
tags:
- object-detection
- vision
- generated_from_trainer
- DocLayNet
- COCO
- PDF
- IBM
- Financial-Reports
- Finance
- Manuals
- Scientific-Articles
- Science
- Laws
- Law
- Regulations
- Patents
- Government-Tenders
- object-detection
- image-segmentation
- token-classification
inference: false
datasets:
- pierreguillou/DocLayNet-base
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384
results:
- task:
name: Token Classification
type: token-classification
metrics:
- name: f1
type: f1
value: 0.8584
- name: accuracy
type: accuracy
value: 0.8584
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Document Understanding model (finetuned LiLT base at line level on DocLayNet base)
This model is a fine-tuned version of [nielsr/lilt-xlm-roberta-base](https://huggingface.co/nielsr/lilt-xlm-roberta-base) with the [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0003
- Precision: 0.8584
- Recall: 0.8584
- F1: 0.8584
- Tokens Accuracy: 0.8584
- Line Accuracy: 0.9197
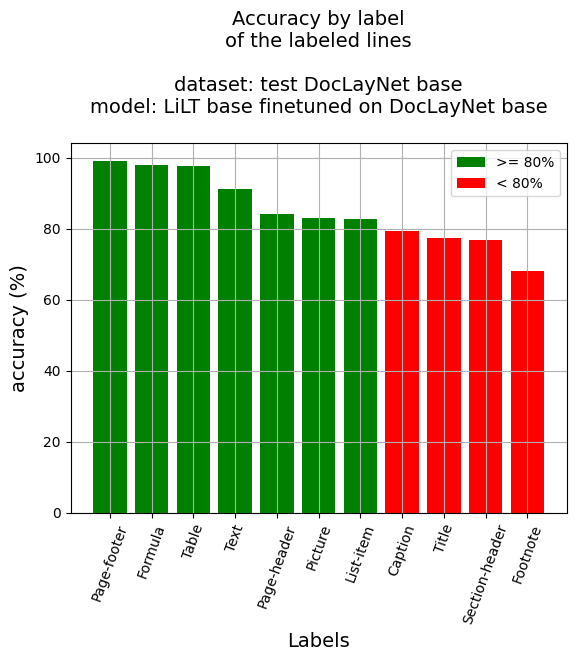
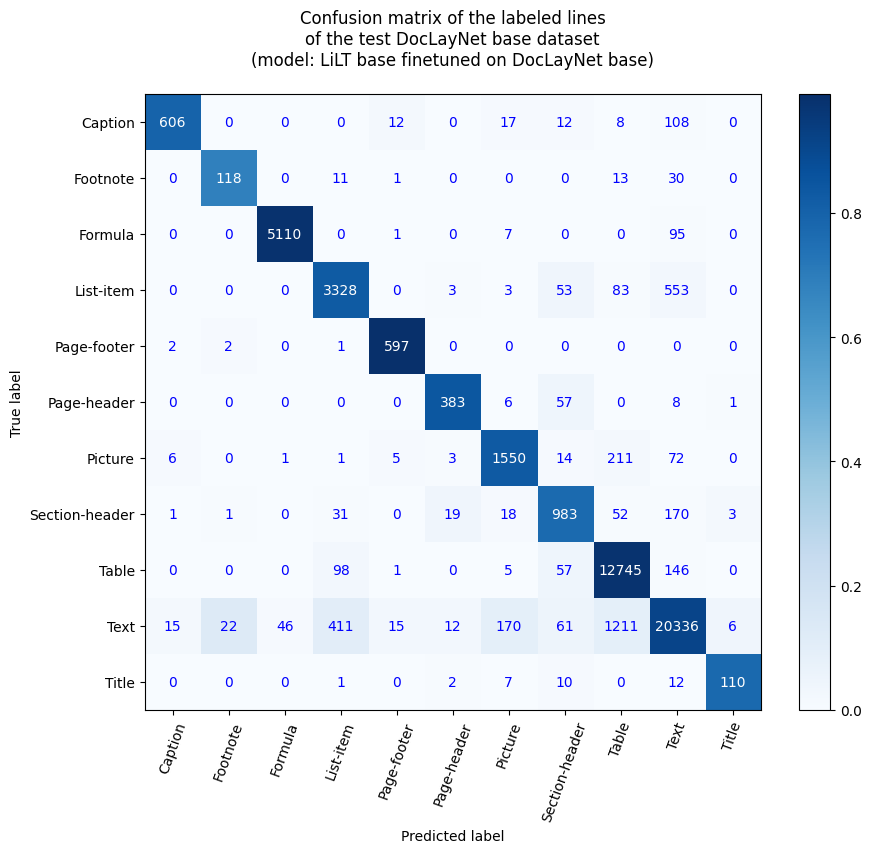
## Accuracy at line level
- Line Accuracy: 91.97%
- Accuracy by label
- Caption: 79.42%
- Footnote: 68.21%
- Formula: 98.02%
- List-item: 82.72%
- Page-footer: 99.17%
- Page-header: 84.18%
- Picture: 83.2%
- Section-header: 76.92%
- Table: 97.65%
- Text: 91.17%
- Title: 77.46%
## References
### Blog posts
- Layout XLM base
- (03/05/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base]()
- LiLT base
- (02/16/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level](https://medium.com/@pierre_guillou/document-ai-inference-app-and-fine-tuning-notebook-for-document-understanding-at-paragraph-level-c18d16e53cf8)
- (02/14/2023) [Document AI | Inference APP for Document Understanding at line level](https://medium.com/@pierre_guillou/document-ai-inference-app-for-document-understanding-at-line-level-a35bbfa98893)
- (02/10/2023) [Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset](https://medium.com/@pierre_guillou/document-ai-document-understanding-model-at-line-level-with-lilt-tesseract-and-doclaynet-dataset-347107a643b8)
- (01/31/2023) [Document AI | DocLayNet image viewer APP](https://medium.com/@pierre_guillou/document-ai-doclaynet-image-viewer-app-3ac54c19956)
- (01/27/2023) [Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](https://medium.com/@pierre_guillou/document-ai-processing-of-doclaynet-dataset-to-be-used-by-layout-models-of-the-hugging-face-hub-308d8bd81cdb)
### Notebooks (paragraph level)
- LiLT base
- [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb)
### Notebooks (line level)
- Layout XLM base
- [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- LiLT base
- [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- [DocLayNet image viewer APP](https://github.com/piegu/language-models/blob/master/DocLayNet_image_viewer_APP.ipynb)
- [Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb)
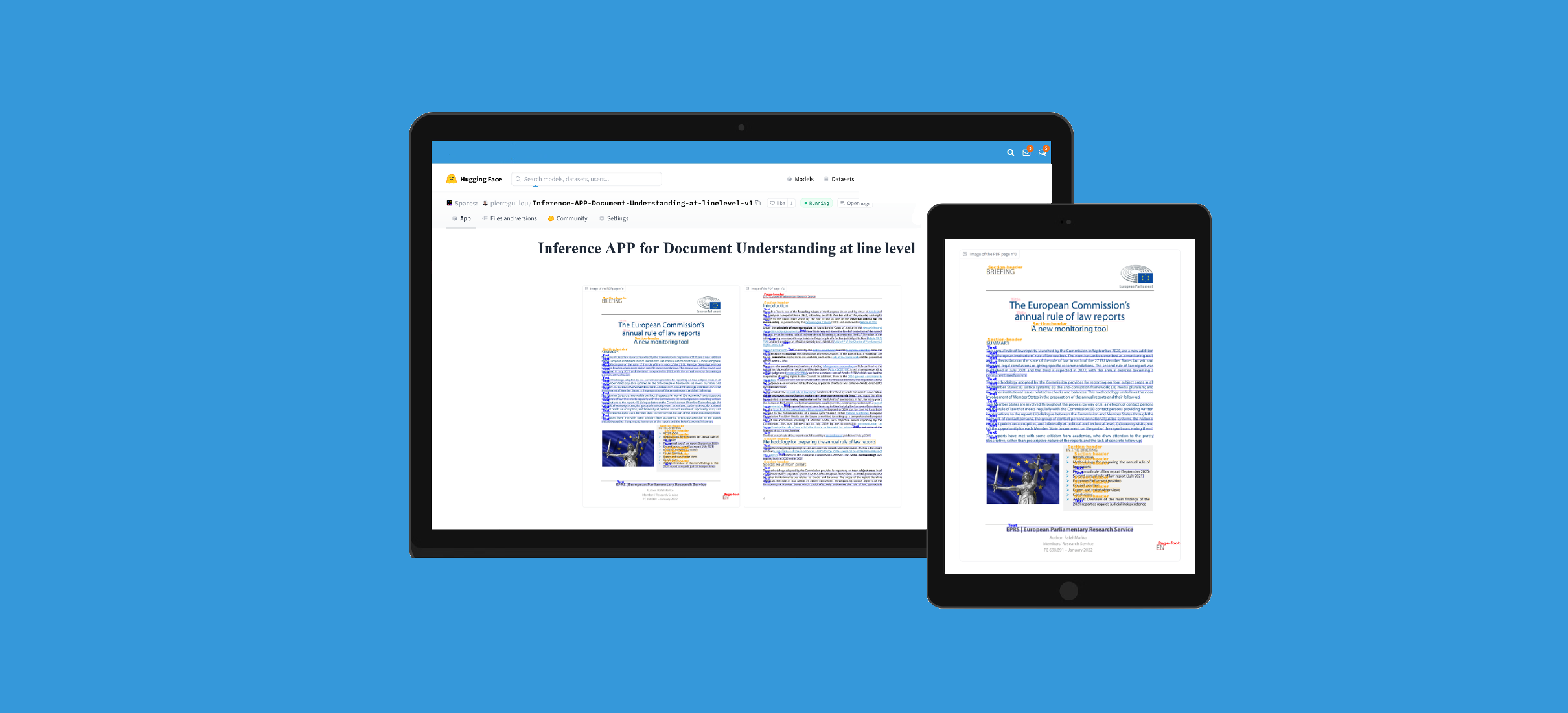
### APP
You can test this model with this APP in Hugging Face Spaces: [Inference APP for Document Understanding at line level (v1)](https://huggingface.co/spaces/pierreguillou/Inference-APP-Document-Understanding-at-linelevel-v1).
### DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
## Model description
The model was finetuned at **line level on chunk of 384 tokens with overlap of 128 tokens**. Thus, the model was trained with all layout and text data of all pages of the dataset.
At inference time, a calculation of best probabilities give the label to each line bounding boxes.
## Inference
See notebook: [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
## Training and evaluation data
See notebook: [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.7223 | 0.21 | 500 | 0.7765 | 0.7741 | 0.7741 | 0.7741 | 0.7741 |
| 0.4469 | 0.42 | 1000 | 0.5914 | 0.8312 | 0.8312 | 0.8312 | 0.8312 |
| 0.3819 | 0.62 | 1500 | 0.8745 | 0.8102 | 0.8102 | 0.8102 | 0.8102 |
| 0.3361 | 0.83 | 2000 | 0.6991 | 0.8337 | 0.8337 | 0.8337 | 0.8337 |
| 0.2784 | 1.04 | 2500 | 0.7513 | 0.8119 | 0.8119 | 0.8119 | 0.8119 |
| 0.2377 | 1.25 | 3000 | 0.9048 | 0.8166 | 0.8166 | 0.8166 | 0.8166 |
| 0.2401 | 1.45 | 3500 | 1.2411 | 0.7939 | 0.7939 | 0.7939 | 0.7939 |
| 0.2054 | 1.66 | 4000 | 1.1594 | 0.8080 | 0.8080 | 0.8080 | 0.8080 |
| 0.1909 | 1.87 | 4500 | 0.7545 | 0.8425 | 0.8425 | 0.8425 | 0.8425 |
| 0.1704 | 2.08 | 5000 | 0.8567 | 0.8318 | 0.8318 | 0.8318 | 0.8318 |
| 0.1294 | 2.29 | 5500 | 0.8486 | 0.8489 | 0.8489 | 0.8489 | 0.8489 |
| 0.134 | 2.49 | 6000 | 0.7682 | 0.8573 | 0.8573 | 0.8573 | 0.8573 |
| 0.1354 | 2.7 | 6500 | 0.9871 | 0.8256 | 0.8256 | 0.8256 | 0.8256 |
| 0.1239 | 2.91 | 7000 | 1.1430 | 0.8189 | 0.8189 | 0.8189 | 0.8189 |
| 0.1012 | 3.12 | 7500 | 0.8272 | 0.8386 | 0.8386 | 0.8386 | 0.8386 |
| 0.0788 | 3.32 | 8000 | 1.0288 | 0.8365 | 0.8365 | 0.8365 | 0.8365 |
| 0.0802 | 3.53 | 8500 | 0.7197 | 0.8849 | 0.8849 | 0.8849 | 0.8849 |
| 0.0861 | 3.74 | 9000 | 1.1420 | 0.8320 | 0.8320 | 0.8320 | 0.8320 |
| 0.0639 | 3.95 | 9500 | 0.9563 | 0.8585 | 0.8585 | 0.8585 | 0.8585 |
| 0.0464 | 4.15 | 10000 | 1.0768 | 0.8511 | 0.8511 | 0.8511 | 0.8511 |
| 0.0412 | 4.36 | 10500 | 1.1184 | 0.8439 | 0.8439 | 0.8439 | 0.8439 |
| 0.039 | 4.57 | 11000 | 0.9634 | 0.8636 | 0.8636 | 0.8636 | 0.8636 |
| 0.0469 | 4.78 | 11500 | 0.9585 | 0.8634 | 0.8634 | 0.8634 | 0.8634 |
| 0.0395 | 4.99 | 12000 | 1.0003 | 0.8584 | 0.8584 | 0.8584 | 0.8584 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
## Other models
- Line level
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 85.84% - lines: 91.97%)
- [Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 93.73% - lines: ...)
- Paragraph level
- [Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 86.34% - paragraphs: 68.15%)
- [Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 96.93% - paragraphs: 86.55%) |