
GitHub Action
commited on
Commit
·
a4afdda
1
Parent(s):
8f52628
update model
Browse files
hf_model_hub/README.md
ADDED
|
@@ -0,0 +1,252 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
library_name: sklearn
|
| 4 |
+
tags:
|
| 5 |
+
- classification
|
| 6 |
+
- phishing
|
| 7 |
+
---
|
| 8 |
+
|
| 9 |
+
# Model description
|
| 10 |
+
|
| 11 |
+
## Training Procedure
|
| 12 |
+
|
| 13 |
+
### Hyperparameters
|
| 14 |
+
|
| 15 |
+
<details>
|
| 16 |
+
<summary> Click to expand </summary>
|
| 17 |
+
|
| 18 |
+
| Hyperparameter | Value |
|
| 19 |
+
|-------------------------------------------------------------|--------------------------|
|
| 20 |
+
| memory | |
|
| 21 |
+
| steps | [('standardscaler', StandardScaler()), ('calibratedclassifiercv', CalibratedClassifierCV(cv=5, estimator=RandomForestClassifier(),<br /> method='isotonic'))] |
|
| 22 |
+
| verbose | False |
|
| 23 |
+
| standardscaler | StandardScaler() |
|
| 24 |
+
| calibratedclassifiercv | CalibratedClassifierCV(cv=5, estimator=RandomForestClassifier(),<br /> method='isotonic') |
|
| 25 |
+
| standardscaler__copy | True |
|
| 26 |
+
| standardscaler__with_mean | True |
|
| 27 |
+
| standardscaler__with_std | True |
|
| 28 |
+
| calibratedclassifiercv__base_estimator | deprecated |
|
| 29 |
+
| calibratedclassifiercv__cv | 5 |
|
| 30 |
+
| calibratedclassifiercv__ensemble | True |
|
| 31 |
+
| calibratedclassifiercv__estimator__bootstrap | True |
|
| 32 |
+
| calibratedclassifiercv__estimator__ccp_alpha | 0.0 |
|
| 33 |
+
| calibratedclassifiercv__estimator__class_weight | |
|
| 34 |
+
| calibratedclassifiercv__estimator__criterion | gini |
|
| 35 |
+
| calibratedclassifiercv__estimator__max_depth | |
|
| 36 |
+
| calibratedclassifiercv__estimator__max_features | sqrt |
|
| 37 |
+
| calibratedclassifiercv__estimator__max_leaf_nodes | |
|
| 38 |
+
| calibratedclassifiercv__estimator__max_samples | |
|
| 39 |
+
| calibratedclassifiercv__estimator__min_impurity_decrease | 0.0 |
|
| 40 |
+
| calibratedclassifiercv__estimator__min_samples_leaf | 1 |
|
| 41 |
+
| calibratedclassifiercv__estimator__min_samples_split | 2 |
|
| 42 |
+
| calibratedclassifiercv__estimator__min_weight_fraction_leaf | 0.0 |
|
| 43 |
+
| calibratedclassifiercv__estimator__n_estimators | 100 |
|
| 44 |
+
| calibratedclassifiercv__estimator__n_jobs | |
|
| 45 |
+
| calibratedclassifiercv__estimator__oob_score | False |
|
| 46 |
+
| calibratedclassifiercv__estimator__random_state | |
|
| 47 |
+
| calibratedclassifiercv__estimator__verbose | 0 |
|
| 48 |
+
| calibratedclassifiercv__estimator__warm_start | False |
|
| 49 |
+
| calibratedclassifiercv__estimator | RandomForestClassifier() |
|
| 50 |
+
| calibratedclassifiercv__method | isotonic |
|
| 51 |
+
| calibratedclassifiercv__n_jobs | |
|
| 52 |
+
|
| 53 |
+
</details>
|
| 54 |
+
|
| 55 |
+
### Model Plot
|
| 56 |
+
|
| 57 |
+
This is the architecture of the model loaded by joblib.
|
| 58 |
+
|
| 59 |
+
<style>#sk-container-id-2 {color: black;}#sk-container-id-2 pre{padding: 0;}#sk-container-id-2 div.sk-toggleable {background-color: white;}#sk-container-id-2 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-2 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-2 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-2 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-2 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-2 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-2 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-2 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-2 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-2 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-2 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-2 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-2 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-2 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-2 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-2 div.sk-item {position: relative;z-index: 1;}#sk-container-id-2 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-2 div.sk-item::before, #sk-container-id-2 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-2 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-2 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-2 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-2 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-2 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-2 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-2 div.sk-label-container {text-align: center;}#sk-container-id-2 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-2 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-2" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('standardscaler', StandardScaler()),('calibratedclassifiercv',CalibratedClassifierCV(cv=5,estimator=RandomForestClassifier(),method='isotonic'))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-6" type="checkbox" ><label for="sk-estimator-id-6" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('standardscaler', StandardScaler()),('calibratedclassifiercv',CalibratedClassifierCV(cv=5,estimator=RandomForestClassifier(),method='isotonic'))])</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-7" type="checkbox" ><label for="sk-estimator-id-7" class="sk-toggleable__label sk-toggleable__label-arrow">StandardScaler</label><div class="sk-toggleable__content"><pre>StandardScaler()</pre></div></div></div><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-8" type="checkbox" ><label for="sk-estimator-id-8" class="sk-toggleable__label sk-toggleable__label-arrow">calibratedclassifiercv: CalibratedClassifierCV</label><div class="sk-toggleable__content"><pre>CalibratedClassifierCV(cv=5, estimator=RandomForestClassifier(),method='isotonic')</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-9" type="checkbox" ><label for="sk-estimator-id-9" class="sk-toggleable__label sk-toggleable__label-arrow">estimator: RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier()</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-10" type="checkbox" ><label for="sk-estimator-id-10" class="sk-toggleable__label sk-toggleable__label-arrow">RandomForestClassifier</label><div class="sk-toggleable__content"><pre>RandomForestClassifier()</pre></div></div></div></div></div></div></div></div></div></div></div></div>
|
| 60 |
+
|
| 61 |
+
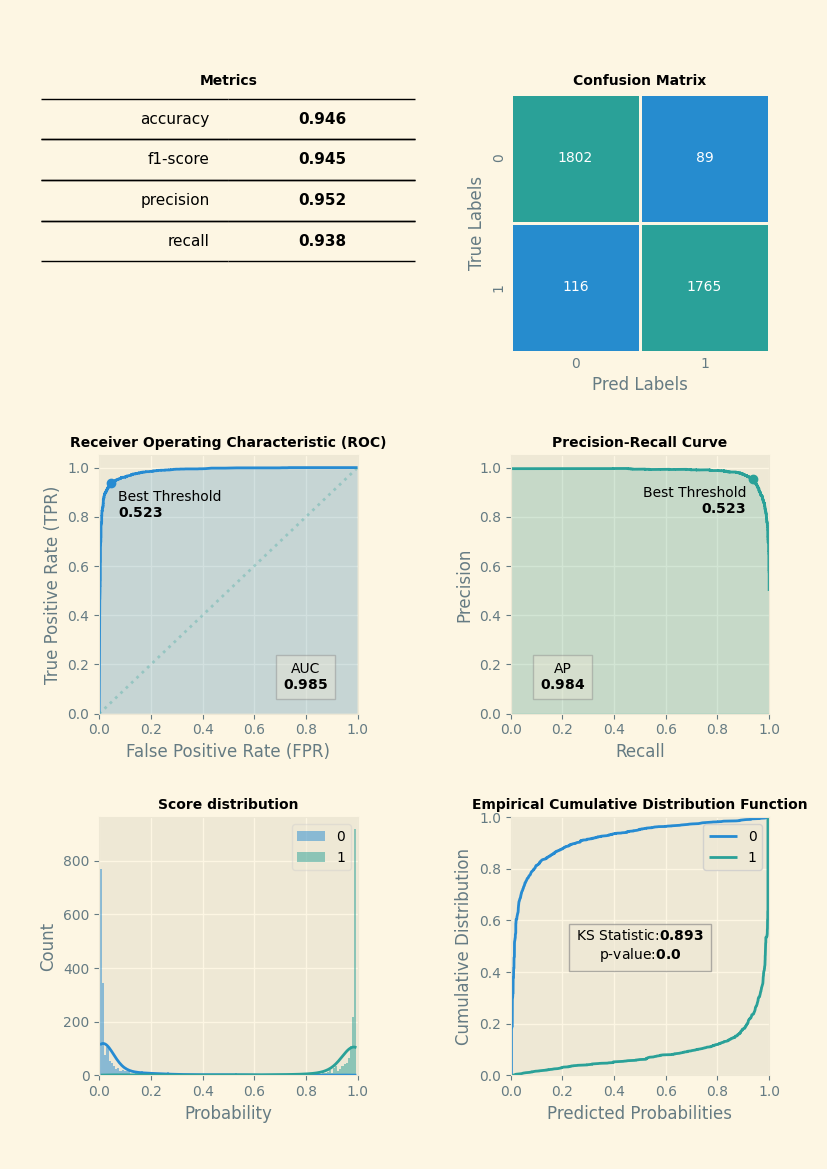
## Evaluation Results
|
| 62 |
+
|
| 63 |
+
| Metric | Value |
|
| 64 |
+
|-----------|----------|
|
| 65 |
+
| accuracy | 0.945652 |
|
| 66 |
+
| f1-score | 0.945114 |
|
| 67 |
+
| precision | 0.951996 |
|
| 68 |
+
| recall | 0.938331 |
|
| 69 |
+
|
| 70 |
+
## Test Report
|
| 71 |
+
|
| 72 |
+

|
| 73 |
+
|
| 74 |
+
## Model Interpretation
|
| 75 |
+
|
| 76 |
+
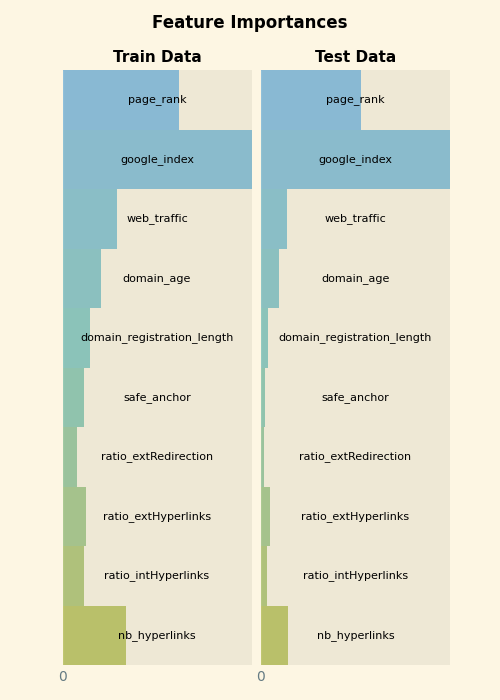
### Feature Importances
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
# How to Get Started with the Model
|
| 81 |
+
|
| 82 |
+
Below are some code snippets to load the model.
|
| 83 |
+
|
| 84 |
+
## With joblib (not recommended)
|
| 85 |
+
|
| 86 |
+
```python
|
| 87 |
+
import joblib
|
| 88 |
+
import pandas as pd
|
| 89 |
+
|
| 90 |
+
urls = [
|
| 91 |
+
{
|
| 92 |
+
"url": "https://www.rga.com/about/workplace",
|
| 93 |
+
"nb_hyperlinks": 97.0,
|
| 94 |
+
"ratio_intHyperlinks": 0.969072165,
|
| 95 |
+
"ratio_extHyperlinks": 0.030927835,
|
| 96 |
+
"ratio_extRedirection": 0.0,
|
| 97 |
+
"safe_anchor": 25.0,
|
| 98 |
+
"domain_registration_length": 3571.0,
|
| 99 |
+
"domain_age": 11039,
|
| 100 |
+
"web_traffic": 178542.0,
|
| 101 |
+
"google_index": 0.0,
|
| 102 |
+
"page_rank": 5,
|
| 103 |
+
},
|
| 104 |
+
]
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
model = joblib.load("models/model.pkl")
|
| 108 |
+
|
| 109 |
+
df = pd.DataFrame(urls)
|
| 110 |
+
df = df.set_index("url")
|
| 111 |
+
|
| 112 |
+
probas = model.predict_proba(df.values)
|
| 113 |
+
|
| 114 |
+
for url, proba in zip(urls, probas):
|
| 115 |
+
print(f"URL: {url['url']}")
|
| 116 |
+
print(f"Likelihood of being a phishing site: {proba[1] * 100:.2f}%")
|
| 117 |
+
print("----")
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
# output:
|
| 121 |
+
# URL: https://www.rga.com/about/workplace
|
| 122 |
+
# Likelihood of being a phishing site: 0.89%
|
| 123 |
+
# ----
|
| 124 |
+
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
## With ONNX (recommended)
|
| 128 |
+
|
| 129 |
+
### Python
|
| 130 |
+
|
| 131 |
+
```python
|
| 132 |
+
import numpy as np
|
| 133 |
+
import onnxruntime
|
| 134 |
+
import pandas as pd
|
| 135 |
+
|
| 136 |
+
# Defining a list of URLs with characteristics
|
| 137 |
+
urls = [
|
| 138 |
+
{
|
| 139 |
+
"url": "https://www.rga.com/about/workplace",
|
| 140 |
+
"nb_hyperlinks": 97.0,
|
| 141 |
+
"ratio_intHyperlinks": 0.969072165,
|
| 142 |
+
"ratio_extHyperlinks": 0.030927835,
|
| 143 |
+
"ratio_extRedirection": 0.0,
|
| 144 |
+
"safe_anchor": 25.0,
|
| 145 |
+
"domain_registration_length": 3571.0,
|
| 146 |
+
"domain_age": 11039,
|
| 147 |
+
"web_traffic": 178542.0,
|
| 148 |
+
"google_index": 0.0,
|
| 149 |
+
"page_rank": 5,
|
| 150 |
+
},
|
| 151 |
+
]
|
| 152 |
+
|
| 153 |
+
# Initializing the ONNX Runtime session with the pre-trained model
|
| 154 |
+
sess = onnxruntime.InferenceSession(
|
| 155 |
+
"models/model.onnx",
|
| 156 |
+
providers=["CPUExecutionProvider"],
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
# Creating a DataFrame from the list of URLs
|
| 160 |
+
df = pd.DataFrame(urls)
|
| 161 |
+
df = df.set_index("url")
|
| 162 |
+
|
| 163 |
+
# Converting DataFrame data to a float32 NumPy array
|
| 164 |
+
inputs = df.astype(np.float32).to_numpy()
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
# Using the ONNX model to make predictions on the input data
|
| 168 |
+
probas = sess.run(None, {"X": inputs})[1]
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
# Displaying the results
|
| 172 |
+
for url, proba in zip(urls, probas):
|
| 173 |
+
print(proba)
|
| 174 |
+
print(f"URL: {url['url']}")
|
| 175 |
+
print(f"Likelihood of being a phishing site: {proba[1] * 100:.2f}%")
|
| 176 |
+
print("----")
|
| 177 |
+
|
| 178 |
+
# output:
|
| 179 |
+
# URL: https://www.rga.com/about/workplace
|
| 180 |
+
# Likelihood of being a phishing site: 0.89%
|
| 181 |
+
# ----
|
| 182 |
+
|
| 183 |
+
```
|
| 184 |
+
|
| 185 |
+
### JavaScript
|
| 186 |
+
|
| 187 |
+
```javascript
|
| 188 |
+
const ort = require('onnxruntime-node');
|
| 189 |
+
|
| 190 |
+
const urls = [
|
| 191 |
+
{
|
| 192 |
+
"url": "http://rapidpaws.com/wp-content/we_transfer/index2.php?email=/",
|
| 193 |
+
"nb_hyperlinks": 1,
|
| 194 |
+
"ratio_intHyperlinks": 1,
|
| 195 |
+
"ratio_extHyperlinks": 0,
|
| 196 |
+
"ratio_extRedirection": 0,
|
| 197 |
+
"safe_anchor": 0,
|
| 198 |
+
"domain_registration_length": 338,
|
| 199 |
+
"domain_age": 0,
|
| 200 |
+
"web_traffic":1853,
|
| 201 |
+
"google_index": 1,
|
| 202 |
+
"page_rank": 2,
|
| 203 |
+
},
|
| 204 |
+
];
|
| 205 |
+
|
| 206 |
+
async function main() {
|
| 207 |
+
try {
|
| 208 |
+
|
| 209 |
+
// Creating an ONNX inference session with the specified model
|
| 210 |
+
const model_path = "./models/model.onnx";
|
| 211 |
+
const session = await ort.InferenceSession.create(model_path);
|
| 212 |
+
|
| 213 |
+
// Get values from data and remove url links
|
| 214 |
+
const inputs = urls.map(url => Object.values(url).slice(1));
|
| 215 |
+
|
| 216 |
+
// Flattening the 2D array to get a 1D array
|
| 217 |
+
const flattenInputs = inputs.flat();
|
| 218 |
+
|
| 219 |
+
// Creating an ONNX tensor from the input array
|
| 220 |
+
const tensor = new ort.Tensor('float32', flattenInputs, [inputs.length, 10]);
|
| 221 |
+
|
| 222 |
+
// Executing the inference session with the input tensor
|
| 223 |
+
const results = await session.run({"X": tensor});
|
| 224 |
+
|
| 225 |
+
// Retrieving probability data from the results
|
| 226 |
+
const probas = results['probabilities'].data;
|
| 227 |
+
|
| 228 |
+
// Displaying results for each URL
|
| 229 |
+
urls.forEach((url, index) => {
|
| 230 |
+
// The index * 2 + 1 is used to access the probability associated with the phishing class
|
| 231 |
+
const proba = probas[index * 2 + 1];
|
| 232 |
+
const percent = (proba * 100).toFixed(2);
|
| 233 |
+
|
| 234 |
+
console.log(`URL: ${url.url}`);
|
| 235 |
+
console.log(`Likelihood of being a phishing site: ${percent}%`);
|
| 236 |
+
console.log("----");
|
| 237 |
+
});
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
} catch (e) {
|
| 241 |
+
console.log(`failed to inference ONNX model: ${e}.`);
|
| 242 |
+
}
|
| 243 |
+
};
|
| 244 |
+
|
| 245 |
+
main();
|
| 246 |
+
|
| 247 |
+
// output:
|
| 248 |
+
// URL: https://www.rga.com/about/workplace
|
| 249 |
+
// Likelihood of being a phishing site: 0.89%
|
| 250 |
+
// ----
|
| 251 |
+
|
| 252 |
+
```
|
hf_model_hub/config.json
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"sklearn": {
|
| 3 |
+
"columns": [
|
| 4 |
+
"nb_hyperlinks",
|
| 5 |
+
"ratio_intHyperlinks",
|
| 6 |
+
"ratio_extHyperlinks",
|
| 7 |
+
"ratio_extRedirection",
|
| 8 |
+
"safe_anchor",
|
| 9 |
+
"domain_registration_length",
|
| 10 |
+
"domain_age",
|
| 11 |
+
"web_traffic",
|
| 12 |
+
"google_index",
|
| 13 |
+
"page_rank",
|
| 14 |
+
"status"
|
| 15 |
+
],
|
| 16 |
+
"environment": [
|
| 17 |
+
"scikit-learn=1.3.2"
|
| 18 |
+
],
|
| 19 |
+
"example_input": {
|
| 20 |
+
"domain_age": [
|
| 21 |
+
11039.0,
|
| 22 |
+
-1.0,
|
| 23 |
+
5636.0
|
| 24 |
+
],
|
| 25 |
+
"domain_registration_length": [
|
| 26 |
+
3571.0,
|
| 27 |
+
0.0,
|
| 28 |
+
208.0
|
| 29 |
+
],
|
| 30 |
+
"google_index": [
|
| 31 |
+
0.0,
|
| 32 |
+
0.0,
|
| 33 |
+
0.0
|
| 34 |
+
],
|
| 35 |
+
"nb_hyperlinks": [
|
| 36 |
+
97.0,
|
| 37 |
+
168.0,
|
| 38 |
+
52.0
|
| 39 |
+
],
|
| 40 |
+
"page_rank": [
|
| 41 |
+
5.0,
|
| 42 |
+
2.0,
|
| 43 |
+
10.0
|
| 44 |
+
],
|
| 45 |
+
"ratio_extHyperlinks": [
|
| 46 |
+
0.030927835,
|
| 47 |
+
0.220238095,
|
| 48 |
+
0.442307692
|
| 49 |
+
],
|
| 50 |
+
"ratio_extRedirection": [
|
| 51 |
+
0.0,
|
| 52 |
+
0.378378378,
|
| 53 |
+
0.0
|
| 54 |
+
],
|
| 55 |
+
"ratio_intHyperlinks": [
|
| 56 |
+
0.969072165,
|
| 57 |
+
0.779761905,
|
| 58 |
+
0.557692308
|
| 59 |
+
],
|
| 60 |
+
"safe_anchor": [
|
| 61 |
+
25.0,
|
| 62 |
+
24.32432432,
|
| 63 |
+
0.0
|
| 64 |
+
],
|
| 65 |
+
"status": [
|
| 66 |
+
"legitimate",
|
| 67 |
+
"legitimate",
|
| 68 |
+
"legitimate"
|
| 69 |
+
],
|
| 70 |
+
"web_traffic": [
|
| 71 |
+
178542.0,
|
| 72 |
+
0.0,
|
| 73 |
+
2.0
|
| 74 |
+
]
|
| 75 |
+
},
|
| 76 |
+
"model": {
|
| 77 |
+
"file": "model.pkl"
|
| 78 |
+
},
|
| 79 |
+
"model_format": "pickle",
|
| 80 |
+
"task": "tabular-classification",
|
| 81 |
+
"use_intelex": false
|
| 82 |
+
}
|
| 83 |
+
}
|
hf_model_hub/model.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3738351fb48d1d7515fb1924cf5f960a34df990d4c5c93c56b7ebaa465b48ad5
|
| 3 |
+
size 22121547
|
hf_model_hub/model.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66e78140aa1f4fb52077430dc2e6ef9e3f8a8a8055bbc8e6bbd3e08405a7d79e
|
| 3 |
+
size 45881706
|
hf_model_hub/plots/classification_report.png
ADDED
|
hf_model_hub/plots/feature_importances.png
ADDED
|