[](https://www.python.org/downloads/release/python-38/)
[](https://pytorch.org/)
# DDPM inversion, CVPR 2024
[Project page](https://inbarhub.github.io/DDPM_inversion/) | [Arxiv](https://arxiv.org/abs/2304.06140) | [Supplementary materials](https://inbarhub.github.io/DDPM_inversion/resources/inversion_supp.pdf) | [Hugging Face Demo](https://huggingface.co/spaces/LinoyTsaban/edit_friendly_ddpm_inversion)
### Official pytorch implementation of the paper:
"An Edit Friendly DDPM Noise Space: Inversion and Manipulations"
#### Inbar Huberman-Spiegelglas, Vladimir Kulikov and Tomer Michaeli
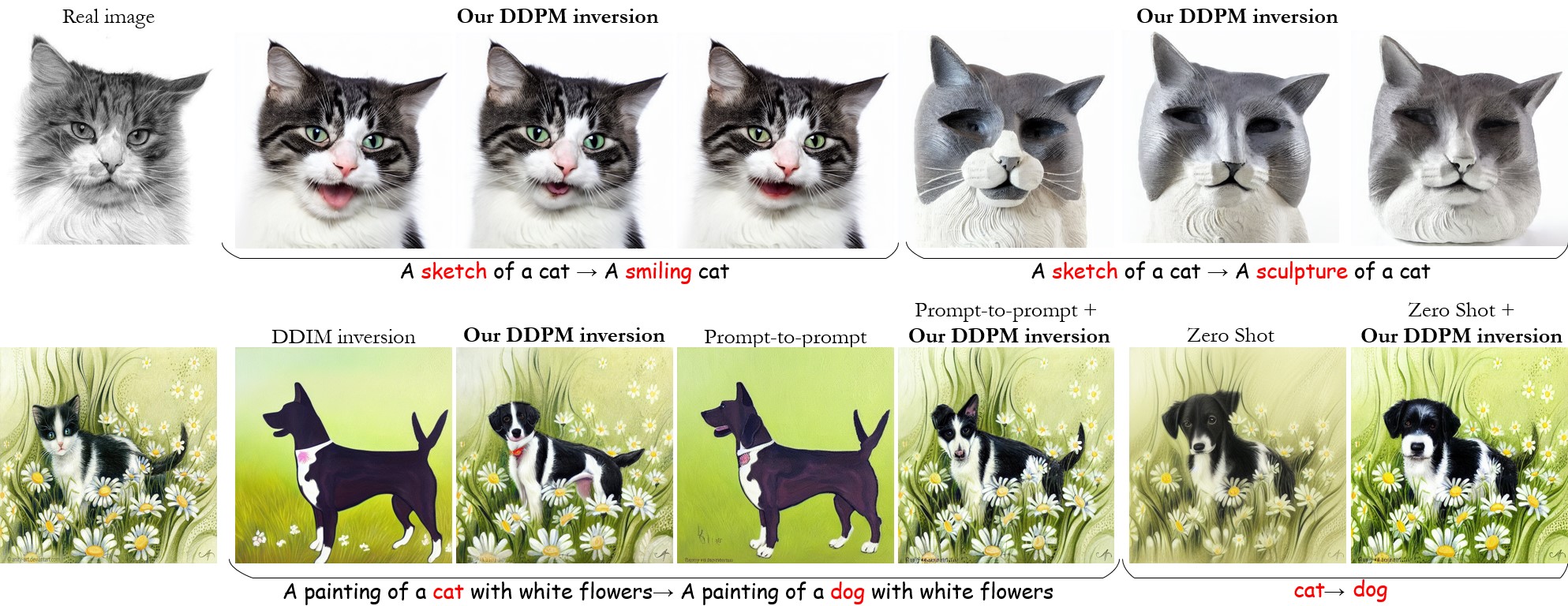
Our inversion can be used for text-based **editing of real images**, either by itself or in combination with other editing methods.
Due to the stochastic nature of our method, we can generate **diverse outputs**, a feature that is not naturally available with methods relying on the DDIM inversion.
In this repository we support editing using our inversion, prompt-to-prompt (p2p)+our inversion, ddim or [p2p](https://github.com/google/prompt-to-prompt) (with ddim inversion).
**our inversion**: our ddpm inversion followed by generating an image conditioned on the target prompt.
**prompt-to-prompt (p2p) + our inversion**: p2p method using our ddpm inversion.
**ddim**: ddim inversion followed by generating an image conditioned on the target prompt.
**p2p**: p2p method using ddim inversion (original paper).
## Table of Contents
* [Requirements](#Requirements)
* [Repository Structure](#Repository-Structure)
* [Algorithm Inputs and Parameters](#Algorithm-Inputs-and-Parameters)
* [Usage Example](#Usage-Example)
* [Citation](#Citation)
## Requirements
```
python -m pip install -r requirements.txt
```
This code was tested with python 3.8 and torch 2.0.0.
## Repository Structure
```
├── ddm_inversion - folder contains inversions in order to work on real images: ddim inversion as well as ddpm inversion (our method).
├── example_images - folder of input images to be edited
├── imgs - images used in this repository readme.md file
├── prompt_to_prompt - p2p code
├── main_run.py - main python file for real image editing
└── test.yaml - yaml file contains images and prompts to test on
```
A folder named 'results' will be automatically created and all the results will be saved to this folder. We also add a timestamp to the saved images in this folder.
## Algorithm Inputs and Parameters
Method's inputs:
```
init_img - the path to the input images
source_prompt - a prompt describing the input image
target_prompts - the edit prompt (creates several images if multiple prompts are given)
```
These three inputs are supplied through a YAML file (please use the provided 'test.yaml' file as a reference).
Method's parameters are:
```
skip - controlling the adherence to the input image
cfg_tar - classifier free guidance strengths
```
These two parameters have default values, as descibed in the paper.
## Usage Example
```
python3 main_run.py --mode="our_inv" --dataset_yaml="test.yaml" --skip=36 --cfg_tar=15
python3 main_run.py --mode="p2pinv" --dataset_yaml="test.yaml" --skip=12 --cfg_tar=9
```
The ```mode``` argument can also be: ```ddim``` or ```p2p```.
In ```our_inv``` and ```p2pinv``` modes we suggest to play around with ```skip``` in the range [0,40] and ```cfg_tar``` in the range [7,18].
**p2pinv and p2p**:
Note that you can play with the cross-and self-attention via ```--xa``` and ```--sa``` arguments. We suggest to set them to (0.6,0.2) and (0.8,0.4) for p2pinv and p2p respectively.
**ddim and p2p**:
```skip``` is overwritten to be 0.
You can edit the test.yaml file to load your image and choose the desired prompts.
## Citation
If you use this code for your research, please cite our paper:
```
@inproceedings{huberman2024edit,
title={An edit friendly {DDPM} noise space: Inversion and manipulations},
author={Huberman-Spiegelglas, Inbar and Kulikov, Vladimir and Michaeli, Tomer},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={12469--12478},
year={2024}
}
```