---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
license: apache-2.0
---
# BLOOMChat V1.0
BLOOMChat is [BigScience Group BLOOM model](https://huggingface.co/bigscience/bloom) instruction-tuned on a subset of 100k datapoints per data source from the [OIG dataset](https://huggingface.co/datasets/laion/OIG) from the [OpenChatKit](https://www.together.xyz/blog/openchatkit). Then aligned using [Dolly 2.0](https://huggingface.co/datasets/databricks/databricks-dolly-15k) and [Oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1).
## Model Details
### Model Description
- **Developed by:** [SambaNova Systems](https://sambanova.ai/)
- **Co-developed by:** [Together Computer](https://www.together.xyz/)
- **Model type:** Language Model
- **Language(s):** Multiple; see [training data from BLOOM](https://huggingface.co/bigscience/bloom#training-data)
- **License:** apache-2.0 with RAIL restrictions
- **Instruction Tuned from model:** [BigScience Group BLOOM](https://huggingface.co/bigscience/bloom)
### Additional Information
- **Blog Post**: [More Information Needed]
## Uses
### Direct Use
This model is intended for commercial and research use.
### Out-of-Scope Use
Bloom chat should NOT be used for:
- Mission-critical applications
- Applications that involve the safety of others
- Making highly important decisions
- Important automated pipelines
This model is still in early development and can be prone to mistakes and hallucinations, there is still room for improvement. This model is intended to provide the community with a good baseline.
### Recommendations
Users should be made aware of the risks, biases, limitations, and restrictions of the model, which are listed down at the bottom of the page.
---
## How to Get Started with the Model
Click to expand
Use the code below to get started with the model.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("sambanovasystems/BLOOMChat-176B-v1")
model = AutoModelForCausalLM.from_pretrained("sambanovasystems/BLOOMChat-176B-v1", device_map="auto", torch_dtype="auto")
```
### Suggested Inference Parameters
- Temperature: 0.8
- Repetition penalty: 1.2
- Top-p: 0.9
- Max generated tokens: 512
### Suggested Prompts To Try
```
: Write a script in which Bob accidentally breaks his dad's guitar
:
```
```
: give a python code to open a http server in 8080 port using python 3.7
:
```
```
: Answer the following question using the context below:
Q: Which regulatory body is invovled?
Context: U.S. authorities launched emergency measures on Sunday to shore up confidence in the banking system after the failure of Silicon Valley Bank (SIVB.O) threatened to trigger a broader financial crisis. After a dramatic weekend, regulators said the failed bank’s customers will have access to all their deposits starting Monday and set up a new facility to give banks access to emergency funds. The Federal Reserve also made it easier for banks to borrow from it in emergencies. While the measures provided some relief for Silicon Valley firms and global markets on Monday, worries about broader banking risks remain and have cast doubts over whether the Fed will stick with its plan for aggressive interest rate hikes.
:
```
---
## Some example completions
Click to expand
```
: What does it mean for the Fed to raise or lower interest rates?
: The Federal Reserve (also known as the Fed) is the central banking system of the United States. It was created in 1913, and is an independent agency of the federal government. The Fed has a dual mandate of maximizing employment and stabilizing prices. The Fed sets interest rates, and can influence the money supply and the credit markets through its actions.
Raising interest rates means that the Fed is trying to reduce the money supply in the economy, and is trying to discourage borrowing and encourage saving. Lowering interest rates means that the Fed is trying to stimulate economic growth by encouraging borrowing and reducing the cost of credit.
The Fed raises or lowers interest rates in order to influence the economy and achieve its goals for employment and price stability. Interest rates are one of the primary tools that the Fed uses to achieve its goals.
```
```
: Write an engaging and well-written property listing description for selling a house. Address of the house and some of the details are given to you. Fill in the information gap with hallucinations if needed.
Property Address: 412 Monterey Ave, Capitola, CA 95010
Parking: 3 cars + a finished single car garage
Details:
- open floorplan
- window with views to park/mountains
- Kitchen with shaker cabinetry and white Calcatta quartz counters
: This home at 412 Monterey Ave, Capitola, CA 95010 is the perfect place to call home. With its open floor plan, it provides the perfect space for entertaining guests. The kitchen is equipped with shaker cabinetry and white Calcatta quartz counters, providing the perfect space to create culinary masterpieces. The window with views to the park and mountains provide a beautiful view of the outdoors, making this home feel like a piece of paradise. The three-car garage and finished single car garage provide ample parking space, making this home a must-see for anyone looking for a new home.
```
```
: Explain the difference between a proton and a neutron
: A proton and a neutron are both subatomic particles, but they differ in several ways:
Mass: A proton has a mass of approximately 1.67 x 10^-27 kilograms, while a neutron has a mass of approximately 1.67 x 10^-27 kilograms.
Charge: A proton has a positive charge, while a neutron has no charge.
Spinning: Protons and neutrons both have a spinning motion called intrinsic spin, but the direction of their spin is opposite to each other.
Protons are found in the nucleus of atoms, while neutrons are found in the nucleus of atoms.
In the nucleus of atoms, protons and neutrons are bound together in a structure called a nucleus, which gives the atom its stability.
```
---
## Evaluation Graphs
Click to expand

BLOOMChat vs Baselines Model in Human Preference Rankings
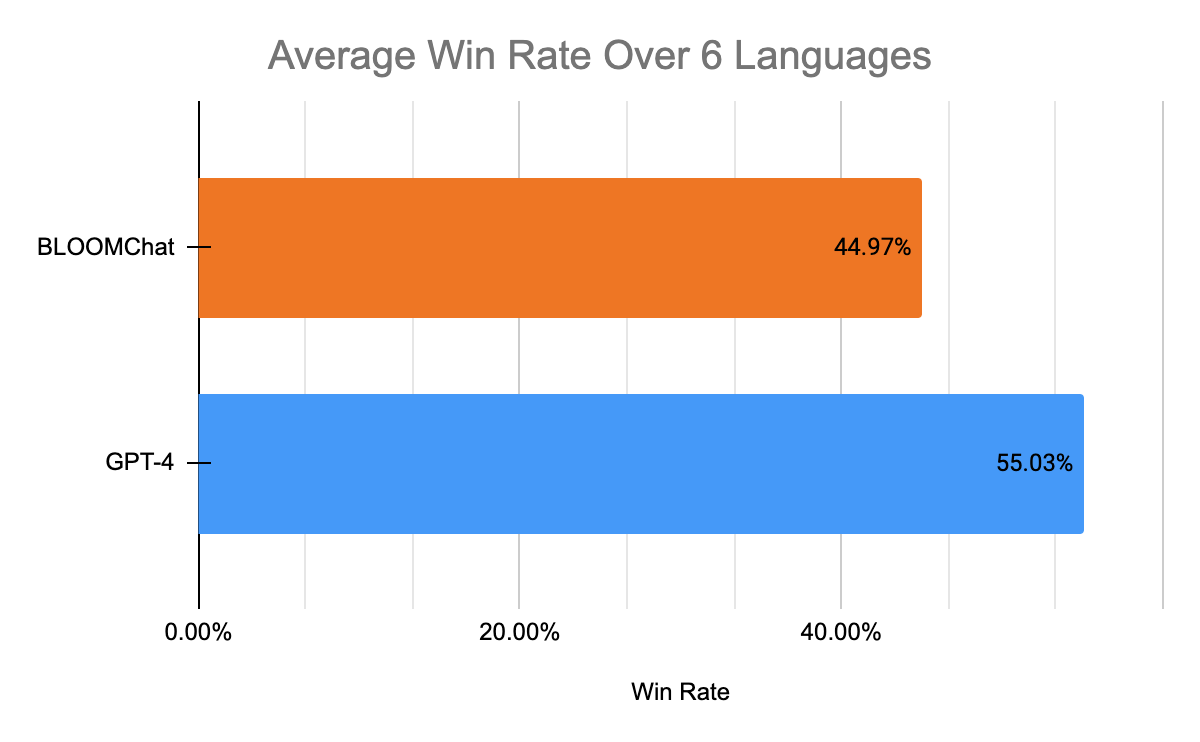
BLOOMChat vs GPT-4 in Human Preference Ranking

BLOOMChat surpasses other Bloom variants and state-of-the-art open-source chat models in translation tasks
---
## Training Details
Click to expand
### Training Data
- [OIG dataset from OpenChatKit](https://huggingface.co/datasets/laion/OIG)
- [Dolly 2.0](https://huggingface.co/datasets/databricks/databricks-dolly-15k)
- [Oasst1](https://huggingface.co/datasets/OpenAssistant/oasst1)
### Training Procedure
We trained BLOOMChat with SambaStudio, a platform built on SambaNova's in-house Reconfigurable Dataflow Unit (RDU). We started from [BLOOM](https://huggingface.co/bigscience/bloom), an OSS multilingual 176B GPT model pretrained by the [BigScience group](https://huggingface.co/bigscience). There was also some preprocessing done on the training datasets.
### Prompting Style Used For Training
```
: {input that the user wants from the bot}
:
```
```
: {fewshot1 input}
: {fewshot1 response}
: {fewshot2 input}
: {fewshot2 response}
: {input that the user wants from the bot}
:
```
### Hyperparameters
**Instruction-tuned Training on OIG**
- Hardware: SambaNova Reconfigurable Dataflow Unit (RDU)
- Optimizer: AdamW
- Grad accumulation: 1
- Epochs: 1
- Global Batch size: 128
- Batch tokens: 128 * 2048 = 262,144 tokens
- Learning Rate: 1e-5
- Learning Rate Scheduler: Cosine Schedule with Warmup
- Warmup Steps: 0
- End Learning Ratio: 0.1
- Weight decay: 0.1
**Instruction-tuned Training on Dolly 2.0 and Oasst1**
- Hardware: SambaNova Reconfigurable Dataflow Unit (RDU)
- Optimizer: AdamW
- Grad accumulation: 1
- Epochs: 3
- Global Batch size: 128
- Batch tokens: 128 * 2048 = 262,144 tokens
- Learning Rate: 1e-5
- Learning Rate Scheduler: Cosine Schedule with Warmup
- Warmup Steps: 0
- End Learning Ratio: 0.1
- Weight decay: 0.1
---
### RAIL Restrictions
As the original model [BLOOM](https://huggingface.co/bigscience/bloom) is on the RAIL License, we need to follow the same restrictions.
You agree not to use the Model or Derivatives of the Model:
1. In any way that violates any applicable national, federal, state, local or international law or regulation;
2. For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
3. To generate or disseminate verifiably false information with the purpose of harming others;
4. To generate or disseminate personal identifiable information that can be used to harm an individual;
5. To generate or disseminate information or content, in any context (e.g. posts, articles, tweets, chatbots or other kinds of automated bots) without expressly and intelligibly disclaiming that the text is machine generated;
6. To defame, disparage or otherwise harass others;
7. To impersonate or attempt to impersonate others;
8. For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
9. For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics
10. To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
11. For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories;
12. To provide medical advice and medical results interpretation;
13. To generate or disseminate information for the purpose to be used for administration of justice, law enforcement, immigration or asylum processes, such as predicting an individual will commit fraud/crime commitment (e.g. by text profiling, drawing causal relationships between assertions made in documents, indiscriminate and arbitrarily-targeted use).
### Bias, Risks, and Limitations
Like all LLMs, BLOOMChat has certain limitations:
- Hallucination: BLOOMChat may sometimes generate responses that contain plausible-sounding but factually incorrect or irrelevant information.
- Code Switching: The model might unintentionally switch between languages or dialects within a single response, affecting the coherence and understandability of the output.
- Repetition: BLOOMChat may produce repetitive phrases or sentences, leading to less engaging and informative responses.
- Coding and Math: The model's performance in generating accurate code or solving complex mathematical problems may be limited.
- Toxicity: BLOOMChat may inadvertently generate responses containing inappropriate or harmful content.