
End of training
Browse files- README.md +3 -1
- all_results.json +18 -10
- eval_results.json +13 -5
- train_results.json +6 -6
- trainer_state.json +0 -0
- training_eval_loss.png +0 -0
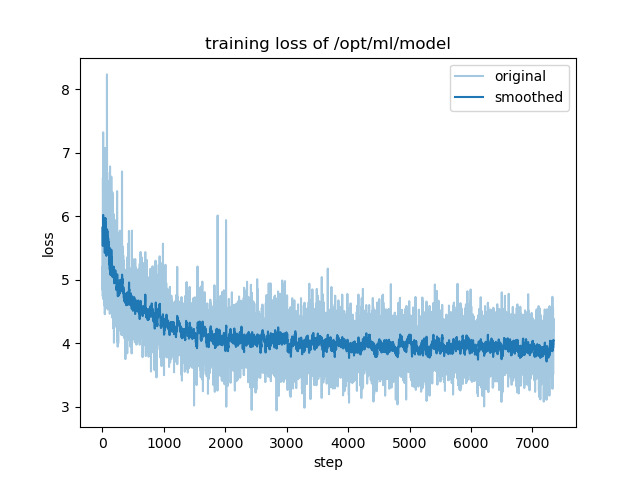
- training_loss.png +0 -0
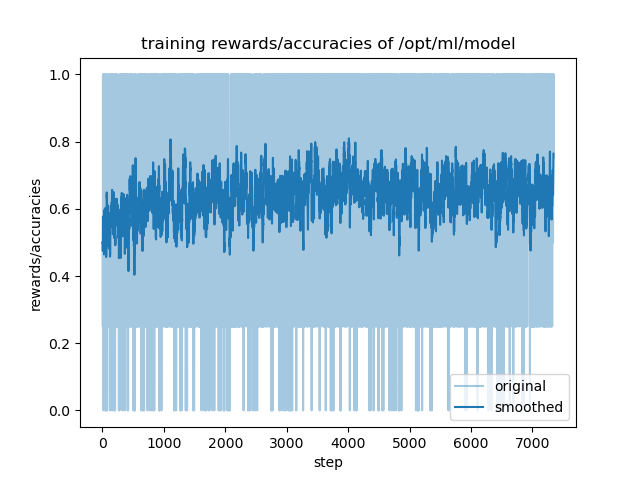
- training_rewards_accuracies.png +0 -0
README.md
CHANGED
|
@@ -3,6 +3,8 @@ library_name: transformers
|
|
| 3 |
license: gemma
|
| 4 |
base_model: google/gemma-2-9b-it
|
| 5 |
tags:
|
|
|
|
|
|
|
| 6 |
- trl
|
| 7 |
- dpo
|
| 8 |
- llama-factory
|
|
@@ -17,7 +19,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 17 |
|
| 18 |
# model
|
| 19 |
|
| 20 |
-
This model is a fine-tuned version of [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it) on
|
| 21 |
It achieves the following results on the evaluation set:
|
| 22 |
- Loss: 3.9434
|
| 23 |
- Rewards/chosen: -46.0543
|
|
|
|
| 3 |
license: gemma
|
| 4 |
base_model: google/gemma-2-9b-it
|
| 5 |
tags:
|
| 6 |
+
- llama-factory
|
| 7 |
+
- full
|
| 8 |
- trl
|
| 9 |
- dpo
|
| 10 |
- llama-factory
|
|
|
|
| 19 |
|
| 20 |
# model
|
| 21 |
|
| 22 |
+
This model is a fine-tuned version of [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it) on the cdc0b2d9-493b-4cb1-87e8-8fb1e3f4b247 dataset.
|
| 23 |
It achieves the following results on the evaluation set:
|
| 24 |
- Loss: 3.9434
|
| 25 |
- Rewards/chosen: -46.0543
|
all_results.json
CHANGED
|
@@ -1,12 +1,20 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"
|
| 4 |
-
"
|
| 5 |
-
"
|
| 6 |
-
"
|
| 7 |
-
"
|
| 8 |
-
"
|
| 9 |
-
"
|
| 10 |
-
"
|
| 11 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 12 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_logits/chosen": 14.445918083190918,
|
| 4 |
+
"eval_logits/rejected": 14.679619789123535,
|
| 5 |
+
"eval_logps/chosen": -4.605433940887451,
|
| 6 |
+
"eval_logps/rejected": -4.770407676696777,
|
| 7 |
+
"eval_loss": 3.9434103965759277,
|
| 8 |
+
"eval_rewards/accuracies": 0.6472868323326111,
|
| 9 |
+
"eval_rewards/chosen": -46.05434036254883,
|
| 10 |
+
"eval_rewards/margins": 1.6497403383255005,
|
| 11 |
+
"eval_rewards/rejected": -47.704078674316406,
|
| 12 |
+
"eval_runtime": 439.853,
|
| 13 |
+
"eval_samples_per_second": 112.481,
|
| 14 |
+
"eval_steps_per_second": 1.76,
|
| 15 |
+
"total_flos": 4181538261958656.0,
|
| 16 |
+
"train_loss": 4.104885466542899,
|
| 17 |
+
"train_runtime": 31282.7939,
|
| 18 |
+
"train_samples_per_second": 30.049,
|
| 19 |
+
"train_steps_per_second": 0.235
|
| 20 |
}
|
eval_results.json
CHANGED
|
@@ -1,7 +1,15 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"
|
| 4 |
-
"
|
| 5 |
-
"
|
| 6 |
-
"
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_logits/chosen": 14.445918083190918,
|
| 4 |
+
"eval_logits/rejected": 14.679619789123535,
|
| 5 |
+
"eval_logps/chosen": -4.605433940887451,
|
| 6 |
+
"eval_logps/rejected": -4.770407676696777,
|
| 7 |
+
"eval_loss": 3.9434103965759277,
|
| 8 |
+
"eval_rewards/accuracies": 0.6472868323326111,
|
| 9 |
+
"eval_rewards/chosen": -46.05434036254883,
|
| 10 |
+
"eval_rewards/margins": 1.6497403383255005,
|
| 11 |
+
"eval_rewards/rejected": -47.704078674316406,
|
| 12 |
+
"eval_runtime": 439.853,
|
| 13 |
+
"eval_samples_per_second": 112.481,
|
| 14 |
+
"eval_steps_per_second": 1.76
|
| 15 |
}
|
train_results.json
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
{
|
| 2 |
-
"epoch":
|
| 3 |
-
"total_flos":
|
| 4 |
-
"train_loss":
|
| 5 |
-
"train_runtime":
|
| 6 |
-
"train_samples_per_second":
|
| 7 |
-
"train_steps_per_second": 0.
|
| 8 |
}
|
|
|
|
| 1 |
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"total_flos": 4181538261958656.0,
|
| 4 |
+
"train_loss": 4.104885466542899,
|
| 5 |
+
"train_runtime": 31282.7939,
|
| 6 |
+
"train_samples_per_second": 30.049,
|
| 7 |
+
"train_steps_per_second": 0.235
|
| 8 |
}
|
trainer_state.json
CHANGED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_eval_loss.png
CHANGED
|

|
training_loss.png
CHANGED
|
|
training_rewards_accuracies.png
ADDED
|