Spaces:
Sleeping

Sleeping
Commit
•
957e2dc
1
Parent(s):
7ca4ec1
Voiceblock demo: Attempt 8
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .DS_Store +0 -0
- __pycache__/gradio.cpython-310.pyc +0 -0
- __pycache__/model.cpython-310.pyc +0 -0
- __pycache__/model.cpython-39.pyc +0 -0
- app.py +67 -0
- example.wav +0 -0
- requirements.txt +28 -0
- voicebox/.DS_Store +0 -0
- voicebox/LICENSE +0 -0
- voicebox/README.md +136 -0
- voicebox/cache/.gitkeep +0 -0
- voicebox/data/.gitkeep +0 -0
- voicebox/figures/demo_thumbnail.png +0 -0
- voicebox/figures/use_diagram_embeddings.png +0 -0
- voicebox/figures/vb_color_logo.png +0 -0
- voicebox/figures/voicebox_untargeted_conditioning_draft.png +0 -0
- voicebox/pretrained/denoiser/demucs/dns_48.pt +3 -0
- voicebox/pretrained/phoneme/causal_ppg_128_hidden_128_hop.pt +3 -0
- voicebox/pretrained/phoneme/causal_ppg_256_hidden.pt +3 -0
- voicebox/pretrained/phoneme/causal_ppg_256_hidden_256_hop.pt +3 -0
- voicebox/pretrained/phoneme/causal_ppg_256_hidden_512_hop.pt +3 -0
- voicebox/pretrained/phoneme/ppg_causal_small.pt +3 -0
- voicebox/pretrained/speaker/resemblyzer/resemblyzer.pt +3 -0
- voicebox/pretrained/speaker/resnetse34v2/resnetse34v2.pt +3 -0
- voicebox/pretrained/speaker/yvector/yvector.pt +3 -0
- voicebox/pretrained/universal/universal_final.pt +3 -0
- voicebox/pretrained/voicebox/voicebox_final.pt +3 -0
- voicebox/pretrained/voicebox/voicebox_final.yaml +20 -0
- voicebox/requirements.txt +28 -0
- voicebox/scripts/downloads/download_librispeech_eval.sh +25 -0
- voicebox/scripts/downloads/download_librispeech_train.sh +54 -0
- voicebox/scripts/downloads/download_rir_noise.sh +73 -0
- voicebox/scripts/downloads/download_voxceleb.py +189 -0
- voicebox/scripts/downloads/ff_rir.txt +132 -0
- voicebox/scripts/downloads/voxceleb1_file_parts.txt +5 -0
- voicebox/scripts/downloads/voxceleb1_files.txt +1 -0
- voicebox/scripts/downloads/voxceleb2_file_parts.txt +9 -0
- voicebox/scripts/downloads/voxceleb2_files.txt +1 -0
- voicebox/scripts/experiments/evaluate.py +915 -0
- voicebox/scripts/experiments/train.py +282 -0
- voicebox/scripts/experiments/train_phoneme_predictor.py +205 -0
- voicebox/scripts/streamer/benchmark_streamer.py +97 -0
- voicebox/scripts/streamer/enroll.py +105 -0
- voicebox/scripts/streamer/stream.py +135 -0
- voicebox/setup.py +20 -0
- voicebox/src.egg-info/PKG-INFO +148 -0
- voicebox/src.egg-info/SOURCES.txt +9 -0
- voicebox/src.egg-info/dependency_links.txt +1 -0
- voicebox/src.egg-info/top_level.txt +1 -0
- voicebox/src/__init__.py +0 -0
.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
__pycache__/gradio.cpython-310.pyc
ADDED
|
Binary file (1.04 kB). View file
|
|
|
__pycache__/model.cpython-310.pyc
ADDED
|
Binary file (1.43 kB). View file
|
|
|
__pycache__/model.cpython-39.pyc
ADDED
|
Binary file (1.42 kB). View file
|
|
|
app.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchaudio
|
| 3 |
+
import voicebox.src.attacks.offline.perturbation.voicebox.voicebox as vb #To access VoiceBox class
|
| 4 |
+
#import voicebox.src.attacks.online.voicebox_streamer as streamer #To access VoiceBoxStreamer class
|
| 5 |
+
import numpy as np
|
| 6 |
+
from voicebox.src.constants import PPG_PRETRAINED_PATH
|
| 7 |
+
|
| 8 |
+
#Set voicebox default parameters
|
| 9 |
+
LOOKAHEAD = 5
|
| 10 |
+
voicebox_kwargs={'win_length': 256,
|
| 11 |
+
'ppg_encoder_hidden_size': 256,
|
| 12 |
+
'use_phoneme_encoder': True,
|
| 13 |
+
'use_pitch_encoder': True,
|
| 14 |
+
'use_loudness_encoder': True,
|
| 15 |
+
'spec_encoder_lookahead_frames': 0,
|
| 16 |
+
'spec_encoder_type': 'mel',
|
| 17 |
+
'spec_encoder_mlp_depth': 2,
|
| 18 |
+
'bottleneck_lookahead_frames': LOOKAHEAD,
|
| 19 |
+
'ppg_encoder_path': PPG_PRETRAINED_PATH,
|
| 20 |
+
'n_bands': 128,
|
| 21 |
+
'spec_encoder_hidden_size': 512,
|
| 22 |
+
'bottleneck_skip': True,
|
| 23 |
+
'bottleneck_hidden_size': 512,
|
| 24 |
+
'bottleneck_feedforward_size': 512,
|
| 25 |
+
'bottleneck_type': 'lstm',
|
| 26 |
+
'bottleneck_depth': 2,
|
| 27 |
+
'control_eps': 0.5,
|
| 28 |
+
'projection_norm': float('inf'),
|
| 29 |
+
'conditioning_dim': 512}
|
| 30 |
+
|
| 31 |
+
#Load pretrained model:
|
| 32 |
+
model = vb.VoiceBox(**voicebox_kwargs)
|
| 33 |
+
model.load_state_dict(torch.load('voicebox/pretrained/voicebox/voicebox_final.pt', map_location=torch.device('cpu')), strict=True)
|
| 34 |
+
model.eval()
|
| 35 |
+
|
| 36 |
+
#Define function to convert final audio format:
|
| 37 |
+
def float32_to_int16(waveform):
|
| 38 |
+
waveform = waveform / np.abs(waveform).max()
|
| 39 |
+
waveform = waveform * 32767
|
| 40 |
+
waveform = waveform.astype(np.int16)
|
| 41 |
+
waveform = waveform.ravel()
|
| 42 |
+
return waveform
|
| 43 |
+
|
| 44 |
+
#Define predict function:
|
| 45 |
+
def predict(inp):
|
| 46 |
+
#How to transform audio from string to tensor
|
| 47 |
+
waveform, sample_rate = torchaudio.load(inp)
|
| 48 |
+
|
| 49 |
+
#Run model without changing weights
|
| 50 |
+
with torch.no_grad():
|
| 51 |
+
waveform = model(waveform)
|
| 52 |
+
|
| 53 |
+
#Transform output audio into gradio-readable format
|
| 54 |
+
waveform = waveform.numpy()
|
| 55 |
+
waveform = float32_to_int16(waveform)
|
| 56 |
+
return sample_rate, waveform
|
| 57 |
+
|
| 58 |
+
#Set up gradio interface
|
| 59 |
+
import gradio as gr
|
| 60 |
+
|
| 61 |
+
interface = gr.Interface(
|
| 62 |
+
fn=predict,
|
| 63 |
+
inputs=gr.Audio(type="filepath"),
|
| 64 |
+
outputs=gr.Audio()
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
interface.launch()
|
example.wav
ADDED
|
Binary file (218 kB). View file
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.10.0
|
| 2 |
+
torchaudio==0.10.0
|
| 3 |
+
torchvision
|
| 4 |
+
torchcrepe
|
| 5 |
+
tensorboard
|
| 6 |
+
textgrid
|
| 7 |
+
Pillow
|
| 8 |
+
numpy
|
| 9 |
+
tqdm
|
| 10 |
+
jiwer
|
| 11 |
+
librosa
|
| 12 |
+
pandas
|
| 13 |
+
protobuf==3.20.0
|
| 14 |
+
git+https://github.com/ludlows/python-pesq#egg=pesq
|
| 15 |
+
psutil
|
| 16 |
+
pystoi
|
| 17 |
+
pytest
|
| 18 |
+
pyworld
|
| 19 |
+
pyyaml
|
| 20 |
+
matplotlib
|
| 21 |
+
seaborn
|
| 22 |
+
ipython
|
| 23 |
+
scipy
|
| 24 |
+
scikit-learn
|
| 25 |
+
ipywebrtc
|
| 26 |
+
argbind
|
| 27 |
+
sounddevice
|
| 28 |
+
keyboard
|
voicebox/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
voicebox/LICENSE
ADDED
|
File without changes
|
voicebox/README.md
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<h1 align="center">VoiceBlock</h1>
|
| 2 |
+
<h4 align="center"> Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models</h4>
|
| 3 |
+
<div align="center">
|
| 4 |
+
|
| 5 |
+
[](https://colab.research.google.com/github/???/???.ipynb)
|
| 6 |
+
[](https://master.d3hvhbnf7qxjtf.amplifyapp.com/)
|
| 7 |
+
[](/LICENSE)
|
| 8 |
+
|
| 9 |
+
</div>
|
| 10 |
+
<p align="center"><img src="./figures/vb_color_logo.png" width="200"/></p>
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## Contents
|
| 14 |
+
|
| 15 |
+
* <a href="#install">Installation</a>
|
| 16 |
+
* <a href="#reproduce">Reproducing Results</a>
|
| 17 |
+
* <a href="#streamer">Streaming Implementation</a>
|
| 18 |
+
* <a href="#citation">Citation</a>
|
| 19 |
+
|
| 20 |
+
<h2 id="install">Installation</h2>
|
| 21 |
+
|
| 22 |
+
1. Clone the repository:
|
| 23 |
+
|
| 24 |
+
git clone https://github.com/voiceboxneurips/voicebox.git
|
| 25 |
+
|
| 26 |
+
2. We recommend working from a clean environment, e.g. using `conda`:
|
| 27 |
+
|
| 28 |
+
conda create --name voicebox python=3.9
|
| 29 |
+
source activate voicebox
|
| 30 |
+
|
| 31 |
+
3. Install dependencies:
|
| 32 |
+
|
| 33 |
+
cd voicebox
|
| 34 |
+
pip install -r requirements.txt
|
| 35 |
+
pip install -e .
|
| 36 |
+
|
| 37 |
+
4. Grant permissions:
|
| 38 |
+
|
| 39 |
+
chmod -R u+x scripts/
|
| 40 |
+
|
| 41 |
+
<h2 id="reproduce">Reproducing Results</h2>
|
| 42 |
+
|
| 43 |
+
To reproduce our results, first download the corresponding data. Note that to download the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html), you must register and obtain a username and password.
|
| 44 |
+
|
| 45 |
+
| Task | Dataset (Size) | Command |
|
| 46 |
+
|---|---|---|
|
| 47 |
+
| Objective evaluation | VoxCeleb1 (39G) | `python scripts/downloads/download_voxceleb.py --subset=1 --username=<VGG_USERNAME> --password=<VGG_PASSWORD>` |
|
| 48 |
+
| WER / supplemental evaluations | LibriSpeech `train-clean-360` (23G) | `./scripts/downloads/download_librispeech_eval.sh` |
|
| 49 |
+
| Train attacks | LibriSpeech `train-clean-100` (11G) | `./scripts/downloads/download_librispeech_train.sh` |
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
We provide scripts to reproduce our experiments and save results, including generated audio, to named and time-stamped subdirectories within `runs/`. To reproduce our objective evaluation experiments using pre-trained attacks, run:
|
| 53 |
+
|
| 54 |
+
```
|
| 55 |
+
python scripts/experiments/evaluate.py
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
To reproduce our training, run:
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
python scripts/experiments/train.py
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
<h2 id="streamer">Streaming Implementation</h2>
|
| 65 |
+
|
| 66 |
+
As a proof of concept, we provide a streaming implementation of VoiceBox capable of modifying user audio in real-time. Here, we provide installation instructions for MacOS and Ubuntu 20.04.
|
| 67 |
+
|
| 68 |
+
<h3 id="streamer-mac">MacOS</h3>
|
| 69 |
+
|
| 70 |
+
See video below:
|
| 71 |
+
|
| 72 |
+
<a href="https://youtu.be/LcNjO5E7F3E">
|
| 73 |
+
<p align="center"><img src="./figures/demo_thumbnail.png" width="500"/></p>
|
| 74 |
+
</a>
|
| 75 |
+
|
| 76 |
+
<h3 id="streamer-ubuntu">Ubuntu 20.04</h3>
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
1. Open a terminal and follow the [installation instructions](#install) above. Change directory to the root of this repository.
|
| 80 |
+
|
| 81 |
+
2. Run the following command:
|
| 82 |
+
|
| 83 |
+
pacmd load-module module-null-sink sink_name=voicebox sink_properties=device.description=voicebox
|
| 84 |
+
|
| 85 |
+
If you are using PipeWire instead of PulseAudio:
|
| 86 |
+
|
| 87 |
+
pactl load-module module-null-sink media.class=Audio/Sink sink_name=voicebox sink_properties=device.description=voicebox
|
| 88 |
+
|
| 89 |
+
PulseAudio is the default on Ubuntu. If you haven't changed your system defaults, you are probably using PulseAudio. This will add "voicebox" as an output device. Select it as the input to your chosen audio software.
|
| 90 |
+
|
| 91 |
+
3. Find which audio device to read and write from. In your conda environment, run:
|
| 92 |
+
|
| 93 |
+
python -m sounddevice
|
| 94 |
+
|
| 95 |
+
You will get output similar to this:
|
| 96 |
+
|
| 97 |
+
0 HDA Intel HDMI: 0 (hw:0,3), ALSA (0 in, 8 out)
|
| 98 |
+
1 HDA Intel HDMI: 1 (hw:0,7), ALSA (0 in, 8 out)
|
| 99 |
+
2 HDA Intel HDMI: 2 (hw:0,8), ALSA (0 in, 8 out)
|
| 100 |
+
3 HDA Intel HDMI: 3 (hw:0,9), ALSA (0 in, 8 out)
|
| 101 |
+
4 HDA Intel HDMI: 4 (hw:0,10), ALSA (0 in, 8 out)
|
| 102 |
+
5 hdmi, ALSA (0 in, 8 out)
|
| 103 |
+
6 jack, ALSA (2 in, 2 out)
|
| 104 |
+
7 pipewire, ALSA (64 in, 64 out)
|
| 105 |
+
8 pulse, ALSA (32 in, 32 out)
|
| 106 |
+
* 9 default, ALSA (32 in, 32 out)
|
| 107 |
+
|
| 108 |
+
In this example, we are going to route the audio through PipeWire (channel 7). This will be our INPUT_NUM and OUTPUT_NUM
|
| 109 |
+
|
| 110 |
+
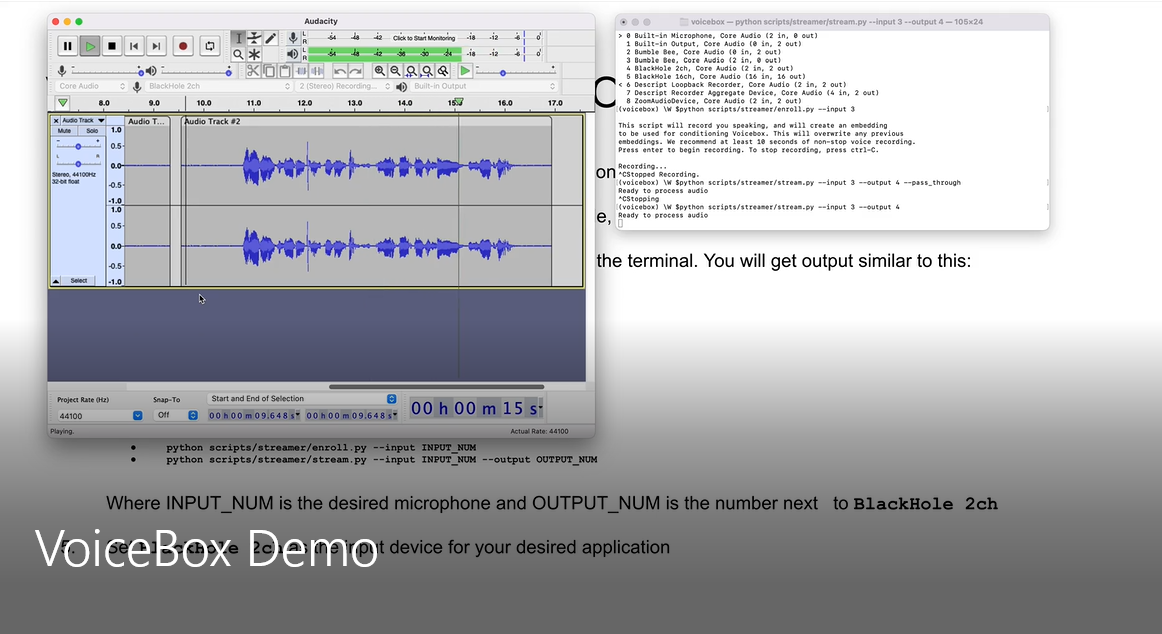
4. First, we need to create a conditioning embedding. To do this, run the enrollment script and follow its on-screen instructions:
|
| 111 |
+
|
| 112 |
+
python scripts/streamer/enroll.py --input INPUT_NUM
|
| 113 |
+
|
| 114 |
+
5. We can now use the streamer. Run:
|
| 115 |
+
|
| 116 |
+
python scripts/stream.py --input INPUT_NUM --output OUTPUT_NUM
|
| 117 |
+
|
| 118 |
+
6. Once the streamer is running, open `pavucontrol`.
|
| 119 |
+
|
| 120 |
+
a. In `pavucontrol`, go to the "Playback" tab and find "ALSA pug-in [python3.9]: ALSA Playback on". Set the output to "voicebox".
|
| 121 |
+
|
| 122 |
+
b. Then, go to "Recording" and find "ALSA pug-in [python3.9]: ALSA Playback from", and set the input to your desired microphone device.
|
| 123 |
+
|
| 124 |
+
<h2 id="citation">Citation</h2>
|
| 125 |
+
|
| 126 |
+
If you use this your academic research, please cite the following:
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
@inproceedings{authors2022voicelock,
|
| 130 |
+
title={VoiceBlock: Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models},
|
| 131 |
+
author={Patrick O'Reilly, Andreas Bugler, Keshav Bhandari, Max Morrison, Bryan Pardo},
|
| 132 |
+
booktitle={Neural Information Processing Systems},
|
| 133 |
+
month={November},
|
| 134 |
+
year={2022}
|
| 135 |
+
}
|
| 136 |
+
```
|
voicebox/cache/.gitkeep
ADDED
|
File without changes
|
voicebox/data/.gitkeep
ADDED
|
File without changes
|
voicebox/figures/demo_thumbnail.png
ADDED
|
voicebox/figures/use_diagram_embeddings.png
ADDED
|
voicebox/figures/vb_color_logo.png
ADDED
|
|
voicebox/figures/voicebox_untargeted_conditioning_draft.png
ADDED
|
voicebox/pretrained/denoiser/demucs/dns_48.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4cfd4151600ed611d4af05083f4633d4fc31b53761cff8a185293346df745988
|
| 3 |
+
size 75486933
|
voicebox/pretrained/phoneme/causal_ppg_128_hidden_128_hop.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:be4c7a60c9af77e50af86924df8b73eb0c861a46f461e3bfe825c523a0a1a969
|
| 3 |
+
size 1175695
|
voicebox/pretrained/phoneme/causal_ppg_256_hidden.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4e8f20e4973a6b91002c97605f993cf6e16a24ca9d0d39e183438a8c16d85c87
|
| 3 |
+
size 4556495
|
voicebox/pretrained/phoneme/causal_ppg_256_hidden_256_hop.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e0836df2f8465b53d4e0b5b14f1d1ef954b3570d6f95f1af22c3ac19b3e10099
|
| 3 |
+
size 4573903
|
voicebox/pretrained/phoneme/causal_ppg_256_hidden_512_hop.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a860d6f01058dc14b984845d27e681b5fe7c3bfffe41350e2e6e0f92e72778ad
|
| 3 |
+
size 4608719
|
voicebox/pretrained/phoneme/ppg_causal_small.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4627bc2b63798df3391fe5c9ccbd72b929dc146b84f0fe61d1aa22848d107973
|
| 3 |
+
size 18002639
|
voicebox/pretrained/speaker/resemblyzer/resemblyzer.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:afb2230a894f5a8f91263ff0b4811bde1ea5981bedda45a579c225e5a602ada3
|
| 3 |
+
size 5697307
|
voicebox/pretrained/speaker/resnetse34v2/resnetse34v2.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d96a4dad0118e9945bc7e676d8e5ff34d493ca2209fe188b3f982005132369bc
|
| 3 |
+
size 32311667
|
voicebox/pretrained/speaker/yvector/yvector.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f2b4228cc772e689f800f1f9dc91d4ef4ee289e7e62f2822805edfc5b7faf399
|
| 3 |
+
size 57703939
|
voicebox/pretrained/universal/universal_final.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f435535934f6c8c24fda42c251e65f41627b0660d3420ba1c694e25a82be033e
|
| 3 |
+
size 128811
|
voicebox/pretrained/voicebox/voicebox_final.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb26234cc493182545dbfcc74501f6df7e90347ca3e2a94a7966978325a34ccd
|
| 3 |
+
size 30232012
|
voicebox/pretrained/voicebox/voicebox_final.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
win_length: 256
|
| 2 |
+
ppg_encoder_hidden_size: 256
|
| 3 |
+
use_phoneme_encoder: True
|
| 4 |
+
use_pitch_encoder: True
|
| 5 |
+
use_loudness_encoder: True
|
| 6 |
+
spec_encoder_lookahead_frames: 0
|
| 7 |
+
spec_encoder_type: 'mel'
|
| 8 |
+
spec_encoder_mlp_depth: 2
|
| 9 |
+
bottleneck_lookahead_frames: 5
|
| 10 |
+
ppg_encoder_path: 'pretrained/phoneme/causal_ppg_256_hidden.pt'
|
| 11 |
+
n_bands: 128
|
| 12 |
+
spec_encoder_hidden_size: 512
|
| 13 |
+
bottleneck_skip: True
|
| 14 |
+
bottleneck_hidden_size: 512
|
| 15 |
+
bottleneck_feedforward_size: 512
|
| 16 |
+
bottleneck_type: 'lstm'
|
| 17 |
+
bottleneck_depth: 2
|
| 18 |
+
control_eps: 0.5
|
| 19 |
+
projection_norm: 'inf'
|
| 20 |
+
conditioning_dim: 512
|
voicebox/requirements.txt
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==1.10.0
|
| 2 |
+
torchaudio==0.10.0
|
| 3 |
+
torchvision
|
| 4 |
+
torchcrepe
|
| 5 |
+
tensorboard
|
| 6 |
+
textgrid
|
| 7 |
+
Pillow
|
| 8 |
+
numpy
|
| 9 |
+
tqdm
|
| 10 |
+
jiwer
|
| 11 |
+
librosa
|
| 12 |
+
pandas
|
| 13 |
+
protobuf==3.20.0
|
| 14 |
+
git+https://github.com/ludlows/python-pesq#egg=pesq
|
| 15 |
+
psutil
|
| 16 |
+
pystoi
|
| 17 |
+
pytest
|
| 18 |
+
pyworld
|
| 19 |
+
pyyaml
|
| 20 |
+
matplotlib
|
| 21 |
+
seaborn
|
| 22 |
+
ipython
|
| 23 |
+
scipy
|
| 24 |
+
scikit-learn
|
| 25 |
+
ipywebrtc
|
| 26 |
+
argbind
|
| 27 |
+
sounddevice
|
| 28 |
+
keyboard
|
voicebox/scripts/downloads/download_librispeech_eval.sh
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -e
|
| 4 |
+
|
| 5 |
+
DOWNLOADS_SCRIPTS_DIR=$(eval dirname "$(readlink -f "$0")")
|
| 6 |
+
SCRIPTS_DIR="$(dirname "$DOWNLOADS_SCRIPTS_DIR")"
|
| 7 |
+
PROJECT_DIR="$(dirname "$SCRIPTS_DIR")"
|
| 8 |
+
|
| 9 |
+
DATA_DIR="${PROJECT_DIR}/data/"
|
| 10 |
+
CACHE_DIR="${PROJECT_DIR}/cache/"
|
| 11 |
+
|
| 12 |
+
mkdir -p "${DATA_DIR}"
|
| 13 |
+
mkdir -p "${CACHE_DIR}"
|
| 14 |
+
|
| 15 |
+
# download train-clean-360 subset
|
| 16 |
+
echo "downloading LibriSpeech train-clean-360..."
|
| 17 |
+
wget http://www.openslr.org/resources/12/train-clean-360.tar.gz
|
| 18 |
+
|
| 19 |
+
# extract train-clean-360 subset
|
| 20 |
+
echo "extracting LibriSpeech train-clean-360..."
|
| 21 |
+
tar -xf train-clean-360.tar.gz \
|
| 22 |
+
-C "${DATA_DIR}"
|
| 23 |
+
|
| 24 |
+
# delete archive
|
| 25 |
+
rm -f "train-clean-360.tar.gz"
|
voicebox/scripts/downloads/download_librispeech_train.sh
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -e
|
| 4 |
+
|
| 5 |
+
DOWNLOADS_SCRIPTS_DIR=$(eval dirname "$(readlink -f "$0")")
|
| 6 |
+
SCRIPTS_DIR="$(dirname "$DOWNLOADS_SCRIPTS_DIR")"
|
| 7 |
+
PROJECT_DIR="$(dirname "$SCRIPTS_DIR")"
|
| 8 |
+
|
| 9 |
+
DATA_DIR="${PROJECT_DIR}/data/"
|
| 10 |
+
CACHE_DIR="${PROJECT_DIR}/cache/"
|
| 11 |
+
|
| 12 |
+
mkdir -p "${DATA_DIR}"
|
| 13 |
+
mkdir -p "${CACHE_DIR}"
|
| 14 |
+
|
| 15 |
+
# download test-clean subset
|
| 16 |
+
echo "downloading LibriSpeech test-clean..."
|
| 17 |
+
wget http://www.openslr.org/resources/12/test-clean.tar.gz
|
| 18 |
+
|
| 19 |
+
# extract test-clean subset
|
| 20 |
+
echo "extracting LibriSpeech test-clean..."
|
| 21 |
+
tar -xf test-clean.tar.gz \
|
| 22 |
+
-C "${DATA_DIR}"
|
| 23 |
+
|
| 24 |
+
# delete archive
|
| 25 |
+
rm -f "test-clean.tar.gz"
|
| 26 |
+
|
| 27 |
+
# download test-other subset
|
| 28 |
+
echo "downloading LibriSpeech test-other..."
|
| 29 |
+
wget http://www.openslr.org/resources/12/test-other.tar.gz
|
| 30 |
+
|
| 31 |
+
# extract test-other subset
|
| 32 |
+
echo "extracting LibriSpeech test-other..."
|
| 33 |
+
tar -xf test-other.tar.gz \
|
| 34 |
+
-C "${DATA_DIR}"
|
| 35 |
+
|
| 36 |
+
# delete archive
|
| 37 |
+
rm -f "test-other.tar.gz"
|
| 38 |
+
|
| 39 |
+
# download train-clean-100 subset
|
| 40 |
+
echo "downloading LibriSpeech train-clean-100..."
|
| 41 |
+
wget http://www.openslr.org/resources/12/train-clean-100.tar.gz
|
| 42 |
+
|
| 43 |
+
# extract train-clean-100 subset
|
| 44 |
+
echo "extracting LibriSpeech train-clean-100..."
|
| 45 |
+
tar -xf train-clean-100.tar.gz \
|
| 46 |
+
-C "${DATA_DIR}"
|
| 47 |
+
|
| 48 |
+
# delete archive
|
| 49 |
+
rm -f "train-clean-100.tar.gz"
|
| 50 |
+
|
| 51 |
+
# download LibriSpeech alignments dataset
|
| 52 |
+
wget -O alignments.zip https://zenodo.org/record/2619474/files/librispeech_alignments.zip?download=1
|
| 53 |
+
unzip -d "${DATA_DIR}/LibriSpeech/" alignments.zip
|
| 54 |
+
rm -f alignments.zip
|
voicebox/scripts/downloads/download_rir_noise.sh
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
set -e
|
| 4 |
+
|
| 5 |
+
DOWNLOADS_SCRIPTS_DIR=$(eval dirname "$(readlink -f "$0")")
|
| 6 |
+
SCRIPTS_DIR="$(dirname "$DOWNLOADS_SCRIPTS_DIR")"
|
| 7 |
+
PROJECT_DIR="$(dirname "$SCRIPTS_DIR")"
|
| 8 |
+
|
| 9 |
+
DATA_DIR="${PROJECT_DIR}/data/"
|
| 10 |
+
CACHE_DIR="${PROJECT_DIR}/cache/"
|
| 11 |
+
|
| 12 |
+
REAL_RIR_DIR="${DATA_DIR}/rir/real/"
|
| 13 |
+
SYNTHETIC_RIR_DIR="${DATA_DIR}/rir/synthetic/"
|
| 14 |
+
ROOM_NOISE_DIR="${DATA_DIR}/noise/room/"
|
| 15 |
+
PS_NOISE_DIR="${DATA_DIR}/noise/pointsource/"
|
| 16 |
+
|
| 17 |
+
mkdir -p "${REAL_RIR_DIR}"
|
| 18 |
+
mkdir -p "${SYNTHETIC_RIR_DIR}"
|
| 19 |
+
mkdir -p "${ROOM_NOISE_DIR}"
|
| 20 |
+
mkdir -p "${PS_NOISE_DIR}"
|
| 21 |
+
|
| 22 |
+
# download RIR/noise composite dataset
|
| 23 |
+
echo "downloading RIR/noise dataset..."
|
| 24 |
+
wget -O "${DATA_DIR}/rirs_noises.zip" https://www.openslr.org/resources/28/rirs_noises.zip
|
| 25 |
+
|
| 26 |
+
# extract RIR/noise composite dataset
|
| 27 |
+
echo "unzipping RIR/noise dataset..."
|
| 28 |
+
unzip "${DATA_DIR}/rirs_noises.zip" -d "${DATA_DIR}/"
|
| 29 |
+
|
| 30 |
+
# delete archive
|
| 31 |
+
rm -f "${DATA_DIR}/rirs_noises.zip"
|
| 32 |
+
|
| 33 |
+
# organize pointsource noise data
|
| 34 |
+
echo "extracting point-source noise data"
|
| 35 |
+
cp -a "${DATA_DIR}/RIRS_NOISES/pointsource_noises"/. "${PS_NOISE_DIR}"
|
| 36 |
+
|
| 37 |
+
# organize room noise data
|
| 38 |
+
echo "extracting room noise data"
|
| 39 |
+
room_noises=($(find "${DATA_DIR}/RIRS_NOISES/real_rirs_isotropic_noises/" -maxdepth 1 -name '*noise*' -type f))
|
| 40 |
+
cp -- "${room_noises[@]}" "${ROOM_NOISE_DIR}"
|
| 41 |
+
|
| 42 |
+
# organize real RIR data
|
| 43 |
+
echo "extracting recorded RIR data"
|
| 44 |
+
rirs=($(find "${DATA_DIR}/RIRS_NOISES/real_rirs_isotropic_noises/" ! -name '*noise*' ))
|
| 45 |
+
cp -- "${rirs[@]}" "${REAL_RIR_DIR}"
|
| 46 |
+
|
| 47 |
+
# organize synthetic RIR data
|
| 48 |
+
echo "extracting synthetic RIR data"
|
| 49 |
+
cp -a "${DATA_DIR}/RIRS_NOISES/simulated_rirs"/. "${SYNTHETIC_RIR_DIR}"
|
| 50 |
+
|
| 51 |
+
# delete redundant data
|
| 52 |
+
rm -rf "${DATA_DIR}/RIRS_NOISES/"
|
| 53 |
+
|
| 54 |
+
# separate near-field and far-field RIRs
|
| 55 |
+
NEARFIELD_RIR_DIR="${REAL_RIR_DIR}/nearfield/"
|
| 56 |
+
FARFIELD_RIR_DIR="${REAL_RIR_DIR}/farfield/"
|
| 57 |
+
|
| 58 |
+
mkdir -p "${NEARFIELD_RIR_DIR}"
|
| 59 |
+
mkdir -p "${FARFIELD_RIR_DIR}"
|
| 60 |
+
|
| 61 |
+
# read list of far-field RIRs
|
| 62 |
+
readarray -t FF_RIR_LIST < "${DOWNLOADS_SCRIPTS_DIR}/ff_rir.txt"
|
| 63 |
+
|
| 64 |
+
# move far-field RIRs
|
| 65 |
+
for name in "${FF_RIR_LIST[@]}"; do
|
| 66 |
+
mv "$name" "${FARFIELD_RIR_DIR}/$(basename "$name")"
|
| 67 |
+
done
|
| 68 |
+
|
| 69 |
+
# move remaining near-field RIRs
|
| 70 |
+
for name in "${REAL_RIR_DIR}"/*.wav; do
|
| 71 |
+
mv "$name" "${NEARFIELD_RIR_DIR}/$(basename "$name")"
|
| 72 |
+
done
|
| 73 |
+
|
voicebox/scripts/downloads/download_voxceleb.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import hashlib
|
| 5 |
+
import tarfile
|
| 6 |
+
from zipfile import ZipFile
|
| 7 |
+
|
| 8 |
+
from src.constants import VOXCELEB1_DATA_DIR, VOXCELEB2_DATA_DIR
|
| 9 |
+
from src.utils import ensure_dir
|
| 10 |
+
|
| 11 |
+
################################################################################
|
| 12 |
+
# Download VoxCeleb1 dataset using valid credentials
|
| 13 |
+
################################################################################
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def parse_args():
|
| 17 |
+
|
| 18 |
+
"""Parse command-line arguments"""
|
| 19 |
+
parser = argparse.ArgumentParser(add_help=False)
|
| 20 |
+
|
| 21 |
+
parser.add_argument(
|
| 22 |
+
'--subset',
|
| 23 |
+
type=int,
|
| 24 |
+
default=1,
|
| 25 |
+
help='Specify which VoxCeleb subset to download: 1 or 2'
|
| 26 |
+
)
|
| 27 |
+
|
| 28 |
+
parser.add_argument(
|
| 29 |
+
'--username',
|
| 30 |
+
type=str,
|
| 31 |
+
default=None,
|
| 32 |
+
help='User name provided by VGG to access VoxCeleb dataset'
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
parser.add_argument(
|
| 36 |
+
'--password',
|
| 37 |
+
type=str,
|
| 38 |
+
default=None,
|
| 39 |
+
help='Password provided by VGG to access VoxCeleb dataset'
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
return parser.parse_args()
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def md5(f: str):
|
| 46 |
+
"""
|
| 47 |
+
Return MD5 checksum for file. Code adapted from voxceleb_trainer repository:
|
| 48 |
+
https://github.com/clovaai/voxceleb_trainer/blob/master/dataprep.py
|
| 49 |
+
"""
|
| 50 |
+
|
| 51 |
+
hash_md5 = hashlib.md5()
|
| 52 |
+
with open(f, "rb") as f:
|
| 53 |
+
for chunk in iter(lambda: f.read(4096), b""):
|
| 54 |
+
hash_md5.update(chunk)
|
| 55 |
+
return hash_md5.hexdigest()
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def download(username: str,
|
| 59 |
+
password: str,
|
| 60 |
+
save_path: str,
|
| 61 |
+
lines: list):
|
| 62 |
+
"""
|
| 63 |
+
Given a list of dataset shards formatted as <URL, MD5>, download
|
| 64 |
+
each using `wget` and verify checksums. Code adapted from voxceleb_trainer
|
| 65 |
+
repository:
|
| 66 |
+
https://github.com/clovaai/voxceleb_trainer/blob/master/dataprep.py
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
for line in lines:
|
| 70 |
+
url = line.split()[0]
|
| 71 |
+
md5gt = line.split()[1]
|
| 72 |
+
outfile = url.split('/')[-1]
|
| 73 |
+
|
| 74 |
+
# download files
|
| 75 |
+
out = subprocess.call(
|
| 76 |
+
f'wget {url} --user {username} --password {password} -O {save_path}'
|
| 77 |
+
f'/{outfile}', shell=True)
|
| 78 |
+
if out != 0:
|
| 79 |
+
raise ValueError(f'Download failed for {url}')
|
| 80 |
+
|
| 81 |
+
# verify checksum
|
| 82 |
+
md5ck = md5(f'{save_path}/{outfile}')
|
| 83 |
+
if md5ck == md5gt:
|
| 84 |
+
print(f'Checksum successful for {outfile}')
|
| 85 |
+
else:
|
| 86 |
+
raise Warning(f'Checksum failed for {outfile}')
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def concatenate(save_path: str, lines: list):
|
| 90 |
+
"""
|
| 91 |
+
Given a specification in the format <FMT, FILENAME, MD5>, concatenate all
|
| 92 |
+
downloaded data shards matching FMT into the file FILENAME and verify
|
| 93 |
+
checksums. Code adapted from voxceleb_trainer repository:
|
| 94 |
+
https://github.com/clovaai/voxceleb_trainer/blob/master/dataprep.py
|
| 95 |
+
"""
|
| 96 |
+
|
| 97 |
+
for line in lines:
|
| 98 |
+
infile = line.split()[0]
|
| 99 |
+
outfile = line.split()[1]
|
| 100 |
+
md5gt = line.split()[2]
|
| 101 |
+
|
| 102 |
+
# concatenate shards
|
| 103 |
+
out = subprocess.call(
|
| 104 |
+
f'cat {save_path}/{infile} > {save_path}/{outfile}', shell=True)
|
| 105 |
+
|
| 106 |
+
# verify checksum
|
| 107 |
+
md5ck = md5(f'{save_path}/{outfile}')
|
| 108 |
+
if md5ck == md5gt:
|
| 109 |
+
print(f'Checksum successful for {outfile}')
|
| 110 |
+
else:
|
| 111 |
+
raise Warning(f'Checksum failed for {outfile}')
|
| 112 |
+
|
| 113 |
+
# delete shards
|
| 114 |
+
out = subprocess.call(
|
| 115 |
+
f'rm {save_path}/{infile}', shell=True)
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def full_extract(save_path: str, f: str):
|
| 119 |
+
"""
|
| 120 |
+
Extract contents of compressed archive to data directory
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
save_path = str(save_path)
|
| 124 |
+
f = str(f)
|
| 125 |
+
|
| 126 |
+
print(f'Extracting {f}')
|
| 127 |
+
|
| 128 |
+
if f.endswith(".tar.gz"):
|
| 129 |
+
with tarfile.open(f, "r:gz") as tar:
|
| 130 |
+
tar.extractall(save_path)
|
| 131 |
+
|
| 132 |
+
elif f.endswith(".zip"):
|
| 133 |
+
with ZipFile(f, 'r') as zf:
|
| 134 |
+
zf.extractall(save_path)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def main():
|
| 138 |
+
|
| 139 |
+
args = parse_args()
|
| 140 |
+
|
| 141 |
+
# prepare to load dataset file paths
|
| 142 |
+
downloads_dir = Path(__file__).parent
|
| 143 |
+
|
| 144 |
+
if args.subset == 1:
|
| 145 |
+
data_dir = VOXCELEB1_DATA_DIR
|
| 146 |
+
elif args.subset == 2:
|
| 147 |
+
data_dir = VOXCELEB2_DATA_DIR
|
| 148 |
+
else:
|
| 149 |
+
raise ValueError(f'Invalid VoxCeleb subset {args.subset}')
|
| 150 |
+
|
| 151 |
+
ensure_dir(data_dir)
|
| 152 |
+
|
| 153 |
+
# load dataset file paths
|
| 154 |
+
with open(downloads_dir / f'voxceleb{args.subset}_file_parts.txt', 'r') as f:
|
| 155 |
+
file_parts_list = f.readlines()
|
| 156 |
+
|
| 157 |
+
# load output file paths
|
| 158 |
+
with open(downloads_dir / f'voxceleb{args.subset}_files.txt', 'r') as f:
|
| 159 |
+
files_list = f.readlines()
|
| 160 |
+
|
| 161 |
+
# download subset
|
| 162 |
+
download(
|
| 163 |
+
username=args.username,
|
| 164 |
+
password=args.password,
|
| 165 |
+
save_path=data_dir,
|
| 166 |
+
lines=file_parts_list
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
# merge shards
|
| 170 |
+
concatenate(save_path=data_dir, lines=files_list)
|
| 171 |
+
|
| 172 |
+
# account for test data
|
| 173 |
+
archives = [file.split()[1] for file in files_list]
|
| 174 |
+
test = f"vox{args.subset}_test_{'wav' if args.subset == 1 else 'aac'}.zip"
|
| 175 |
+
archives.append(test)
|
| 176 |
+
|
| 177 |
+
# extract all compressed data
|
| 178 |
+
for file in archives:
|
| 179 |
+
full_extract(data_dir, data_dir / file)
|
| 180 |
+
|
| 181 |
+
# organize extracted data
|
| 182 |
+
out = subprocess.call(f'mv {data_dir}/dev/aac/* {data_dir}/aac/ && rm -r '
|
| 183 |
+
f'{data_dir}/dev', shell=True)
|
| 184 |
+
out = subprocess.call(f'mv -v {data_dir}/{"wav" if args.subset == 1 else "aac"}/*'
|
| 185 |
+
f' {data_dir}/voxceleb{args.subset}', shell=True)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
if __name__ == "__main__":
|
| 189 |
+
main()
|
voicebox/scripts/downloads/ff_rir.txt
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data/rir/real/air_type1_air_binaural_lecture_0_1.wav
|
| 2 |
+
data/rir/real/RWCP_type3_rir_cirline_ofc_imp_rev.wav
|
| 3 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp110.wav
|
| 4 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_4_90_3.wav
|
| 5 |
+
data/rir/real/RVB2014_type1_rir_largeroom2_far_anglb.wav
|
| 6 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_60.wav
|
| 7 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_3_90_3.wav
|
| 8 |
+
data/rir/real/air_type1_air_binaural_lecture_0_5.wav
|
| 9 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_30.wav
|
| 10 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_30.wav
|
| 11 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_15.wav
|
| 12 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_165.wav
|
| 13 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_75.wav
|
| 14 |
+
data/rir/real/air_type1_air_binaural_lecture_0_3.wav
|
| 15 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_0.wav
|
| 16 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_0.wav
|
| 17 |
+
data/rir/real/RWCP_type2_rir_cirline_jr1_imp110.wav
|
| 18 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_5_90_3.wav
|
| 19 |
+
data/rir/real/RVB2014_type1_rir_largeroom1_far_anglb.wav
|
| 20 |
+
data/rir/real/air_type1_air_binaural_lecture_1_1.wav
|
| 21 |
+
data/rir/real/RVB2014_type1_rir_largeroom1_far_angla.wav
|
| 22 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_7_90_3.wav
|
| 23 |
+
data/rir/real/RWCP_type2_rir_cirline_ofc_imp070.wav
|
| 24 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp070.wav
|
| 25 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_150.wav
|
| 26 |
+
data/rir/real/air_type1_air_binaural_lecture_1_5.wav
|
| 27 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp100.wav
|
| 28 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp100.wav
|
| 29 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp130.wav
|
| 30 |
+
data/rir/real/air_type1_air_phone_corridor_hfrp.wav
|
| 31 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp130.wav
|
| 32 |
+
data/rir/real/RVB2014_type1_rir_largeroom1_near_angla.wav
|
| 33 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_75.wav
|
| 34 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp150.wav
|
| 35 |
+
data/rir/real/air_type1_air_phone_lecture_hhp.wav
|
| 36 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_105.wav
|
| 37 |
+
data/rir/real/air_type1_air_phone_stairway_hfrp.wav
|
| 38 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_105.wav
|
| 39 |
+
data/rir/real/RWCP_type2_rir_cirline_jr1_imp090.wav
|
| 40 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp050.wav
|
| 41 |
+
data/rir/real/air_type1_air_phone_stairway2_hfrp.wav
|
| 42 |
+
data/rir/real/air_type1_air_phone_stairway2_hhp.wav
|
| 43 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp060.wav
|
| 44 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_90.wav
|
| 45 |
+
data/rir/real/RWCP_type2_rir_cirline_jr1_imp130.wav
|
| 46 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp030.wav
|
| 47 |
+
data/rir/real/RVB2014_type1_rir_largeroom2_near_angla.wav
|
| 48 |
+
data/rir/real/air_type1_air_binaural_lecture_0_6.wav
|
| 49 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp070.wav
|
| 50 |
+
data/rir/real/air_type1_air_phone_stairway1_hhp.wav
|
| 51 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_45.wav
|
| 52 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp090.wav
|
| 53 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_135.wav
|
| 54 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_180.wav
|
| 55 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp100.wav
|
| 56 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp080.wav
|
| 57 |
+
data/rir/real/RWCP_type2_rir_cirline_ofc_imp090.wav
|
| 58 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp080.wav
|
| 59 |
+
data/rir/real/air_type1_air_binaural_lecture_1_2.wav
|
| 60 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp070.wav
|
| 61 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_150.wav
|
| 62 |
+
data/rir/real/air_type1_air_binaural_lecture_1_4.wav
|
| 63 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_3_0_3.wav
|
| 64 |
+
data/rir/real/RVB2014_type1_rir_largeroom1_near_anglb.wav
|
| 65 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_15.wav
|
| 66 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_120.wav
|
| 67 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp050.wav
|
| 68 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_1_90_3.wav
|
| 69 |
+
data/rir/real/air_type1_air_phone_stairway_hhp.wav
|
| 70 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp120.wav
|
| 71 |
+
data/rir/real/RWCP_type2_rir_cirline_e2b_imp110.wav
|
| 72 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp010.wav
|
| 73 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_15.wav
|
| 74 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_135.wav
|
| 75 |
+
data/rir/real/air_type1_air_phone_bt_stairway_hhp.wav
|
| 76 |
+
data/rir/real/RWCP_type2_rir_cirline_e2b_imp070.wav
|
| 77 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp120.wav
|
| 78 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp110.wav
|
| 79 |
+
data/rir/real/air_type1_air_binaural_lecture_0_4.wav
|
| 80 |
+
data/rir/real/RWCP_type2_rir_cirline_ofc_imp050.wav
|
| 81 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_90.wav
|
| 82 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp090.wav
|
| 83 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_0.wav
|
| 84 |
+
data/rir/real/air_type1_air_phone_stairway1_hfrp.wav
|
| 85 |
+
data/rir/real/air_type1_air_binaural_lecture_1_3.wav
|
| 86 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp050.wav
|
| 87 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp080.wav
|
| 88 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_165.wav
|
| 89 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_45.wav
|
| 90 |
+
data/rir/real/air_type1_air_phone_bt_corridor_hhp.wav
|
| 91 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_2_90_3.wav
|
| 92 |
+
data/rir/real/RWCP_type2_rir_cirline_ofc_imp110.wav
|
| 93 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_120.wav
|
| 94 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_3_180_3.wav
|
| 95 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp110.wav
|
| 96 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp060.wav
|
| 97 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_45.wav
|
| 98 |
+
data/rir/real/RVB2014_type1_rir_largeroom2_far_angla.wav
|
| 99 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_60.wav
|
| 100 |
+
data/rir/real/RWCP_type2_rir_cirline_jr1_imp070.wav
|
| 101 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp130.wav
|
| 102 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_3_135_3.wav
|
| 103 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_75.wav
|
| 104 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_180.wav
|
| 105 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp120.wav
|
| 106 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_60.wav
|
| 107 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_105.wav
|
| 108 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_135.wav
|
| 109 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_3_45_3.wav
|
| 110 |
+
data/rir/real/air_type1_air_binaural_lecture_1_6.wav
|
| 111 |
+
data/rir/real/RWCP_type2_rir_cirline_e2b_imp090.wav
|
| 112 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp170.wav
|
| 113 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_90.wav
|
| 114 |
+
data/rir/real/RWCP_type1_rir_cirline_jr2_imp070.wav
|
| 115 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp110.wav
|
| 116 |
+
data/rir/real/air_type1_air_phone_lecture_hfrp.wav
|
| 117 |
+
data/rir/real/RVB2014_type1_rir_largeroom2_near_anglb.wav
|
| 118 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_165.wav
|
| 119 |
+
data/rir/real/RWCP_type2_rir_cirline_ofc_imp130.wav
|
| 120 |
+
data/rir/real/air_type1_air_binaural_stairway_1_1_150.wav
|
| 121 |
+
data/rir/real/RWCP_type1_rir_cirline_jr1_imp090.wav
|
| 122 |
+
data/rir/real/RWCP_type2_rir_cirline_e2b_imp130.wav
|
| 123 |
+
data/rir/real/RWCP_type1_rir_cirline_ofc_imp060.wav
|
| 124 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_180.wav
|
| 125 |
+
data/rir/real/RWCP_type2_rir_cirline_jr1_imp050.wav
|
| 126 |
+
data/rir/real/air_type1_air_binaural_stairway_1_3_30.wav
|
| 127 |
+
data/rir/real/air_type1_air_binaural_lecture_0_2.wav
|
| 128 |
+
data/rir/real/air_type1_air_binaural_aula_carolina_1_6_90_3.wav
|
| 129 |
+
data/rir/real/RWCP_type2_rir_cirline_e2b_imp050.wav
|
| 130 |
+
data/rir/real/RWCP_type1_rir_cirline_e2b_imp090.wav
|
| 131 |
+
data/rir/real/air_type1_air_phone_corridor_hhp.wav
|
| 132 |
+
data/rir/real/air_type1_air_binaural_stairway_1_2_120.wav
|
voicebox/scripts/downloads/voxceleb1_file_parts.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_dev_wav_partaa e395d020928bc15670b570a21695ed96
|
| 2 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_dev_wav_partab bbfaaccefab65d82b21903e81a8a8020
|
| 3 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_dev_wav_partac 017d579a2a96a077f40042ec33e51512
|
| 4 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_dev_wav_partad 7bb1e9f70fddc7a678fa998ea8b3ba19
|
| 5 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox1_test_wav.zip 185fdc63c3c739954633d50379a3d102
|
voicebox/scripts/downloads/voxceleb1_files.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
vox1_dev_wav_parta* vox1_dev_wav.zip ae63e55b951748cc486645f532ba230b
|
voicebox/scripts/downloads/voxceleb2_file_parts.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partaa da070494c573e5c0564b1d11c3b20577
|
| 2 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partab 17fe6dab2b32b48abaf1676429cdd06f
|
| 3 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partac 1de58e086c5edf63625af1cb6d831528
|
| 4 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partad 5a043eb03e15c5a918ee6a52aad477f9
|
| 5 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partae cea401b624983e2d0b2a87fb5d59aa60
|
| 6 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partaf fc886d9ba90ab88e7880ee98effd6ae9
|
| 7 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partag d160ecc3f6ee3eed54d55349531cb42e
|
| 8 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_dev_aac_partah 6b84a81b9af72a9d9eecbb3b1f602e65
|
| 9 |
+
http://cnode01.mm.kaist.ac.kr/voxceleb/vox1a/vox2_test_aac.zip 0d2b3ea430a821c33263b5ea37ede312
|
voicebox/scripts/downloads/voxceleb2_files.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
vox2_dev_aac_parta* vox2_dev_aac.zip bbc063c46078a602ca71605645c2a402
|
voicebox/scripts/experiments/evaluate.py
ADDED
|
@@ -0,0 +1,915 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os.path
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
import torchaudio
|
| 7 |
+
import psutil
|
| 8 |
+
import pickle
|
| 9 |
+
|
| 10 |
+
import random
|
| 11 |
+
import argparse
|
| 12 |
+
|
| 13 |
+
import librosa as li
|
| 14 |
+
from sklearn.utils import shuffle
|
| 15 |
+
from sklearn.neighbors import NearestNeighbors
|
| 16 |
+
|
| 17 |
+
from pesq import pesq, NoUtterancesError
|
| 18 |
+
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
from sklearn.preprocessing import LabelEncoder
|
| 21 |
+
import numpy as np
|
| 22 |
+
from pathlib import Path
|
| 23 |
+
from tqdm import tqdm
|
| 24 |
+
import builtins
|
| 25 |
+
import math
|
| 26 |
+
import jiwer
|
| 27 |
+
from jiwer import wer, cer
|
| 28 |
+
|
| 29 |
+
from typing import Iterable
|
| 30 |
+
from copy import deepcopy
|
| 31 |
+
|
| 32 |
+
from distutils.util import strtobool
|
| 33 |
+
|
| 34 |
+
from src.data import *
|
| 35 |
+
from src.constants import *
|
| 36 |
+
from src.models import *
|
| 37 |
+
from src.simulation import *
|
| 38 |
+
from src.preprocess import *
|
| 39 |
+
from src.attacks.offline import *
|
| 40 |
+
from src.loss import *
|
| 41 |
+
from src.pipelines import *
|
| 42 |
+
from src.utils import *
|
| 43 |
+
|
| 44 |
+
################################################################################
|
| 45 |
+
# Evaluate attacks on speaker recognition systems
|
| 46 |
+
################################################################################
|
| 47 |
+
|
| 48 |
+
EVAL_DATASET = "voxceleb" # "librispeech"
|
| 49 |
+
LOOKAHEAD = 5
|
| 50 |
+
VOICEBOX_PATH = VOICEBOX_PRETRAINED_PATH
|
| 51 |
+
UNIVERSAL_PATH = UNIVERSAL_PRETRAINED_PATH
|
| 52 |
+
BATCH_SIZE = 20 # evaluation batch size
|
| 53 |
+
N_QUERY = 15 # number of query utterances per speaker
|
| 54 |
+
N_CONDITION = 10 # number of conditioning utterances per speaker
|
| 55 |
+
N_ENROLL = 20 # number of enrolled utterances per speaker
|
| 56 |
+
ADV_ENROLL = False # evaluate under assumption adversarial audio is enrolled
|
| 57 |
+
TARGETS_TRAIN = 'centroid' # 'random', 'same', 'single', 'median'
|
| 58 |
+
TARGETS_TEST = 'centroid' # 'random', 'same', 'single', 'median'
|
| 59 |
+
TRANSFER = True # evaluate attacks on unseen model
|
| 60 |
+
DENOISER = False # evaluate with unseen denoiser defense applied to queries
|
| 61 |
+
SIMULATION = False # apply noisy channel simulation to all queries in evaluation
|
| 62 |
+
COMPUTE_OBJECTIVE_METRICS = True # PESQ, STOI
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def set_random_seed(seed: int = 123):
|
| 66 |
+
"""Set random seed to allow for reproducibility"""
|
| 67 |
+
random.seed(seed)
|
| 68 |
+
torch.manual_seed(seed)
|
| 69 |
+
|
| 70 |
+
if torch.backends.cudnn.is_available():
|
| 71 |
+
# torch.backends.cudnn.benchmark = True
|
| 72 |
+
torch.backends.cudnn.deterministic = True
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def param_count(m: nn.Module, trainable: bool = False):
|
| 76 |
+
"""Count the number of trainable parameters (weights) in a model"""
|
| 77 |
+
if trainable:
|
| 78 |
+
return builtins.sum(
|
| 79 |
+
[p.shape.numel() for p in m.parameters() if p.requires_grad])
|
| 80 |
+
else:
|
| 81 |
+
return builtins.sum([p.shape.numel() for p in m.parameters()])
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def pad_sequence(sequences: list):
|
| 85 |
+
|
| 86 |
+
max_len = max([s.shape[-1] for s in sequences])
|
| 87 |
+
|
| 88 |
+
padded = torch.zeros(
|
| 89 |
+
(len(sequences), 1, max_len),
|
| 90 |
+
dtype=sequences[0].dtype,
|
| 91 |
+
device=sequences[0].device)
|
| 92 |
+
|
| 93 |
+
for i, s in enumerate(sequences):
|
| 94 |
+
padded[i, :, :s.shape[-1]] = s
|
| 95 |
+
|
| 96 |
+
return padded
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
@torch.no_grad()
|
| 100 |
+
def compute_embeddings_batch(audio: list,
|
| 101 |
+
p: Pipeline,
|
| 102 |
+
defense: nn.Module = nn.Identity()):
|
| 103 |
+
"""Compute batched speaker embeddings"""
|
| 104 |
+
|
| 105 |
+
assert isinstance(p.model, SpeakerVerificationModel)
|
| 106 |
+
emb = [p(defense(audio[i].to(p.device))).to('cpu') for i in range(len(audio))]
|
| 107 |
+
emb = torch.cat(emb, dim=0)
|
| 108 |
+
return emb
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
@torch.no_grad()
|
| 112 |
+
def compute_transcripts_batch(audio: list, p: Pipeline):
|
| 113 |
+
"""Compute batched transcripts"""
|
| 114 |
+
|
| 115 |
+
assert isinstance(p.model, SpeechRecognitionModel)
|
| 116 |
+
transcripts = []
|
| 117 |
+
for i in range(len(audio)):
|
| 118 |
+
t = p.model.transcribe(audio[i].to(p.device))
|
| 119 |
+
if isinstance(t, str):
|
| 120 |
+
transcripts.append(t)
|
| 121 |
+
elif isinstance(t, list):
|
| 122 |
+
transcripts.extend(t)
|
| 123 |
+
|
| 124 |
+
assert len(transcripts) == len(audio), f'Transcript format error'
|
| 125 |
+
|
| 126 |
+
return transcripts
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
@torch.no_grad()
|
| 130 |
+
def compute_attack_batch(audio: list,
|
| 131 |
+
a: TrainableAttack,
|
| 132 |
+
c: torch.Tensor):
|
| 133 |
+
|
| 134 |
+
if len(c) < len(audio):
|
| 135 |
+
c = c.repeat(len(audio), 1, 1)
|
| 136 |
+
adv = [a.perturbation(audio[i].to(a.pipeline.device),
|
| 137 |
+
y=c[i:i+1].to(a.pipeline.device)).to('cpu').reshape(1, 1, -1)
|
| 138 |
+
for i in range(len(audio))]
|
| 139 |
+
return adv
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
@torch.no_grad()
|
| 143 |
+
def compute_pesq(audio1: list, audio2: list, mode: str = 'wb'):
|
| 144 |
+
|
| 145 |
+
assert len(audio1) == len(audio2)
|
| 146 |
+
scores = []
|
| 147 |
+
|
| 148 |
+
for i in range(len(audio1)):
|
| 149 |
+
try:
|
| 150 |
+
scores.append(
|
| 151 |
+
pesq(DataProperties.get('sample_rate'),
|
| 152 |
+
tensor_to_np(audio1[i]).flatten(),
|
| 153 |
+
tensor_to_np(audio2[i]).flatten(),
|
| 154 |
+
mode)
|
| 155 |
+
)
|
| 156 |
+
except NoUtterancesError:
|
| 157 |
+
print("PESQ error, skipping audio file...")
|
| 158 |
+
return scores
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
@torch.no_grad()
|
| 162 |
+
def compute_stoi(audio1: list, audio2: list, extended: bool = False):
|
| 163 |
+
|
| 164 |
+
assert len(audio1) == len(audio2)
|
| 165 |
+
scores = []
|
| 166 |
+
for i in range(len(audio1)):
|
| 167 |
+
scores.append(
|
| 168 |
+
stoi(tensor_to_np(audio1[i]).flatten(),
|
| 169 |
+
tensor_to_np(audio2[i]).flatten(),
|
| 170 |
+
DataProperties.get('sample_rate'),
|
| 171 |
+
extended=extended)
|
| 172 |
+
)
|
| 173 |
+
return scores
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
@torch.no_grad()
|
| 177 |
+
def build_ls_dataset(pipelines: dict):
|
| 178 |
+
"""
|
| 179 |
+
Build LibriSpeech evaluation dataset on disk holding:
|
| 180 |
+
* query audio
|
| 181 |
+
* query embeddings
|
| 182 |
+
* conditioning embeddings
|
| 183 |
+
* enrolled embeddings
|
| 184 |
+
* ground-truth query transcripts
|
| 185 |
+
"""
|
| 186 |
+
|
| 187 |
+
# locate dataset
|
| 188 |
+
data_dir = LIBRISPEECH_DATA_DIR / 'train-clean-360'
|
| 189 |
+
cache_dir = CACHE_DIR / 'ls_wer_eval'
|
| 190 |
+
ensure_dir(cache_dir)
|
| 191 |
+
|
| 192 |
+
assert os.path.isdir(data_dir), \
|
| 193 |
+
f'LibriSpeech `train-clean-360` subset required for evaluation'
|
| 194 |
+
|
| 195 |
+
spkr_dirs = list(data_dir.glob("*/"))
|
| 196 |
+
spkr_dirs = [s_d for s_d in spkr_dirs if os.path.isdir(s_d)]
|
| 197 |
+
|
| 198 |
+
# catalog audio and load transcripts
|
| 199 |
+
for spkr_dir in tqdm(spkr_dirs, total=len(spkr_dirs), desc='Building dataset'):
|
| 200 |
+
|
| 201 |
+
# identify speaker
|
| 202 |
+
spkr_id = spkr_dir.parts[-1]
|
| 203 |
+
|
| 204 |
+
# check whether cached data exists for speaker
|
| 205 |
+
spkr_cache_dir = cache_dir / spkr_id
|
| 206 |
+
if os.path.isdir(spkr_cache_dir):
|
| 207 |
+
continue
|
| 208 |
+
|
| 209 |
+
# each recording session has a separate subdirectory
|
| 210 |
+
rec_dirs = list(spkr_dir.glob("*/"))
|
| 211 |
+
rec_dirs = [r_d for r_d in rec_dirs if os.path.isdir(r_d)]
|
| 212 |
+
|
| 213 |
+
# for each speaker, process & store necessary (non-adversarial) data
|
| 214 |
+
all_audio = []
|
| 215 |
+
all_transcripts = []
|
| 216 |
+
|
| 217 |
+
# for each recording session, extract all audio files and transcripts
|
| 218 |
+
for rec_dir in rec_dirs:
|
| 219 |
+
|
| 220 |
+
rec_id = rec_dir.parts[-1]
|
| 221 |
+
trans_fn = rec_dir / f"{spkr_id}-{rec_id}.trans.txt"
|
| 222 |
+
|
| 223 |
+
# open transcript file
|
| 224 |
+
with open(trans_fn, "r") as f:
|
| 225 |
+
trans_idx = f.readlines()
|
| 226 |
+
|
| 227 |
+
if len(trans_idx) == 0:
|
| 228 |
+
print(f"Error: empty transcript {trans_fn}")
|
| 229 |
+
continue
|
| 230 |
+
|
| 231 |
+
for line in trans_idx:
|
| 232 |
+
|
| 233 |
+
split_line = line.strip().split(" ")
|
| 234 |
+
audio_fn = rec_dir / f'{split_line[0]}.{LIBRISPEECH_EXT}'
|
| 235 |
+
transcript = " ".join(split_line[1:]).replace(" ", "|")
|
| 236 |
+
|
| 237 |
+
x, _ = li.load(audio_fn, mono=True, sr=16000)
|
| 238 |
+
all_audio.append(torch.as_tensor(x).reshape(1, 1, -1).float())
|
| 239 |
+
all_transcripts.append(transcript)
|
| 240 |
+
|
| 241 |
+
# shuffle audio and transcripts in same random order
|
| 242 |
+
all_audio, all_transcripts = shuffle(all_audio, all_transcripts)
|
| 243 |
+
|
| 244 |
+
# divide audio and transcripts
|
| 245 |
+
query_audio = all_audio[:N_QUERY]
|
| 246 |
+
query_transcripts = all_transcripts[:N_QUERY]
|
| 247 |
+
condition_audio = all_audio[N_QUERY:N_QUERY+N_CONDITION]
|
| 248 |
+
enroll_audio = all_audio[N_QUERY+N_CONDITION:][:N_ENROLL]
|
| 249 |
+
|
| 250 |
+
# check for sufficient audio in each category
|
| 251 |
+
if len(query_audio) < N_QUERY:
|
| 252 |
+
print(f"Error: insufficient query audio for speaker {spkr_id}")
|
| 253 |
+
continue
|
| 254 |
+
elif len(condition_audio) < N_CONDITION:
|
| 255 |
+
print(f"Error: insufficient conditioning audio for speaker {spkr_id}")
|
| 256 |
+
continue
|
| 257 |
+
elif len(enroll_audio) < N_ENROLL:
|
| 258 |
+
print(f"Error: insufficient enrollment audio for speaker {spkr_id}")
|
| 259 |
+
continue
|
| 260 |
+
|
| 261 |
+
# compute and save embeddings
|
| 262 |
+
for p_name, p in pipelines.items():
|
| 263 |
+
|
| 264 |
+
# compute and save query embeddings
|
| 265 |
+
query_emb = compute_embeddings_batch(query_audio, p)
|
| 266 |
+
f_query = spkr_cache_dir / p_name / 'query_emb.pt'
|
| 267 |
+
ensure_dir_for_filename(f_query)
|
| 268 |
+
|
| 269 |
+
# compute and save conditioning embeddings
|
| 270 |
+
condition_emb = compute_embeddings_batch(condition_audio, p)
|
| 271 |
+
f_condition = spkr_cache_dir / p_name / 'condition_emb.pt'
|
| 272 |
+
ensure_dir_for_filename(f_condition)
|
| 273 |
+
|
| 274 |
+
# compute and save enrolled embeddings
|
| 275 |
+
enroll_emb = compute_embeddings_batch(enroll_audio, p)
|
| 276 |
+
f_enroll = spkr_cache_dir / p_name / 'enroll_emb.pt'
|
| 277 |
+
ensure_dir_for_filename(f_enroll)
|
| 278 |
+
|
| 279 |
+
torch.save(query_emb, f_query)
|
| 280 |
+
torch.save(condition_emb, f_condition)
|
| 281 |
+
torch.save(enroll_emb, f_enroll)
|
| 282 |
+
|
| 283 |
+
# save query audio
|
| 284 |
+
f_audio = spkr_cache_dir / 'query_audio.pt'
|
| 285 |
+
torch.save(query_audio, f_audio)
|
| 286 |
+
|
| 287 |
+
# save query transcripts
|
| 288 |
+
f_transcript = spkr_cache_dir / 'query_trans.pt'
|
| 289 |
+
torch.save(query_transcripts, f_transcript)
|
| 290 |
+
|
| 291 |
+
@torch.no_grad()
|
| 292 |
+
def build_vc_dataset(pipelines: dict):
|
| 293 |
+
"""
|
| 294 |
+
Build VoxCeleb evaluation dataset on disk holding:
|
| 295 |
+
* query audio
|
| 296 |
+
* query embeddings
|
| 297 |
+
* conditioning embeddings
|
| 298 |
+
* enrolled embeddings
|
| 299 |
+
"""
|
| 300 |
+
|
| 301 |
+
# locate dataset
|
| 302 |
+
data_dir = VOXCELEB1_DATA_DIR / 'voxceleb1'
|
| 303 |
+
cache_dir = CACHE_DIR / 'vc_wer_eval'
|
| 304 |
+
ensure_dir(cache_dir)
|
| 305 |
+
|
| 306 |
+
assert os.path.isdir(data_dir), \
|
| 307 |
+
f'VoxCeleb1 dataset required for evaluation'
|
| 308 |
+
|
| 309 |
+
spkr_dirs = list(data_dir.glob("*/"))
|
| 310 |
+
spkr_dirs = [s_d for s_d in spkr_dirs if os.path.isdir(s_d)]
|
| 311 |
+
|
| 312 |
+
# catalog audio
|
| 313 |
+
for spkr_dir in tqdm(spkr_dirs, total=len(spkr_dirs), desc='Building dataset'):
|
| 314 |
+
|
| 315 |
+
# identify speaker
|
| 316 |
+
spkr_id = spkr_dir.parts[-1]
|
| 317 |
+
|
| 318 |
+
# check whether cached data exists for speaker
|
| 319 |
+
spkr_cache_dir = cache_dir / spkr_id
|
| 320 |
+
if os.path.isdir(spkr_cache_dir):
|
| 321 |
+
continue
|
| 322 |
+
|
| 323 |
+
# each recording session has a separate subdirectory
|
| 324 |
+
rec_dirs = list(spkr_dir.glob("*/"))
|
| 325 |
+
rec_dirs = [r_d for r_d in rec_dirs if os.path.isdir(r_d)]
|
| 326 |
+
|
| 327 |
+
# for each speaker, process & store necessary (non-adversarial) data
|
| 328 |
+
all_audio = []
|
| 329 |
+
|
| 330 |
+
# for each recording session, extract all audio files and transcripts
|
| 331 |
+
for rec_dir in rec_dirs:
|
| 332 |
+
for audio_fn in rec_dir.glob(f"*.{VOXCELEB1_EXT}"):
|
| 333 |
+
x, _ = li.load(audio_fn, mono=True, sr=16000)
|
| 334 |
+
all_audio.append(torch.as_tensor(x).reshape(1, 1, -1).float())
|
| 335 |
+
|
| 336 |
+
# shuffle audio in random order
|
| 337 |
+
all_audio = shuffle(all_audio)
|
| 338 |
+
|
| 339 |
+
# divide audio and transcripts
|
| 340 |
+
query_audio = all_audio[:N_QUERY]
|
| 341 |
+
condition_audio = all_audio[N_QUERY:N_QUERY+N_CONDITION]
|
| 342 |
+
enroll_audio = all_audio[N_QUERY+N_CONDITION:][:N_ENROLL]
|
| 343 |
+
|
| 344 |
+
# check for sufficient audio in each category
|
| 345 |
+
if len(query_audio) < N_QUERY:
|
| 346 |
+
print(f"Error: insufficient query audio for speaker {spkr_id}")
|
| 347 |
+
continue
|
| 348 |
+
elif len(condition_audio) < N_CONDITION:
|
| 349 |
+
print(f"Error: insufficient conditioning audio for speaker {spkr_id}")
|
| 350 |
+
continue
|
| 351 |
+
elif len(enroll_audio) < N_ENROLL:
|
| 352 |
+
print(f"Error: insufficient enrollment audio for speaker {spkr_id}")
|
| 353 |
+
continue
|
| 354 |
+
|
| 355 |
+
# compute and save embeddings
|
| 356 |
+
for p_name, p in pipelines.items():
|
| 357 |
+
|
| 358 |
+
# compute and save query embeddings
|
| 359 |
+
query_emb = compute_embeddings_batch(query_audio, p)
|
| 360 |
+
f_query = spkr_cache_dir / p_name / 'query_emb.pt'
|
| 361 |
+
ensure_dir_for_filename(f_query)
|
| 362 |
+
|
| 363 |
+
# compute and save conditioning embeddings
|
| 364 |
+
condition_emb = compute_embeddings_batch(condition_audio, p)
|
| 365 |
+
f_condition = spkr_cache_dir / p_name / 'condition_emb.pt'
|
| 366 |
+
ensure_dir_for_filename(f_condition)
|
| 367 |
+
|
| 368 |
+
# compute and save enrolled embeddings
|
| 369 |
+
enroll_emb = compute_embeddings_batch(enroll_audio, p)
|
| 370 |
+
f_enroll = spkr_cache_dir / p_name / 'enroll_emb.pt'
|
| 371 |
+
ensure_dir_for_filename(f_enroll)
|
| 372 |
+
|
| 373 |
+
torch.save(query_emb, f_query)
|
| 374 |
+
torch.save(condition_emb, f_condition)
|
| 375 |
+
torch.save(enroll_emb, f_enroll)
|
| 376 |
+
|
| 377 |
+
# save query audio
|
| 378 |
+
f_audio = spkr_cache_dir / 'query_audio.pt'
|
| 379 |
+
torch.save(query_audio, f_audio)
|
| 380 |
+
|
| 381 |
+
@torch.no_grad()
|
| 382 |
+
def asr_metrics(true: list, hypothesis: list, batch_size: int = 5):
|
| 383 |
+
"""
|
| 384 |
+
Compute word and character error rates between two lists of corresponding
|
| 385 |
+
transcripts
|
| 386 |
+
"""
|
| 387 |
+
|
| 388 |
+
assert len(true) == len(hypothesis)
|
| 389 |
+
|
| 390 |
+
n_batches = math.ceil(len(true) / batch_size)
|
| 391 |
+
|
| 392 |
+
transform_wer = jiwer.Compose([
|
| 393 |
+
jiwer.ToLowerCase(),
|
| 394 |
+
jiwer.RemoveWhiteSpace(replace_by_space=True),
|
| 395 |
+
jiwer.RemoveMultipleSpaces(),
|
| 396 |
+
jiwer.ReduceToSingleSentence(word_delimiter="|"),
|
| 397 |
+
jiwer.ReduceToListOfListOfWords(word_delimiter="|"),
|
| 398 |
+
])
|
| 399 |
+
|
| 400 |
+
wer_score = 0.0
|
| 401 |
+
cer_score = 0.0
|
| 402 |
+
|
| 403 |
+
wer_n = 0
|
| 404 |
+
cer_n = 0
|
| 405 |
+
|
| 406 |
+
for i in range(n_batches):
|
| 407 |
+
|
| 408 |
+
batch_true = true[i*batch_size:(i+1)*batch_size]
|
| 409 |
+
batch_hypothesis = hypothesis[i*batch_size:(i+1)*batch_size]
|
| 410 |
+
|
| 411 |
+
wer_n_batch = builtins.sum([len(s.split('|')) for s in batch_true])
|
| 412 |
+
cer_n_batch = builtins.sum([len(s) for s in batch_true])
|
| 413 |
+
|
| 414 |
+
attack_cer = cer(batch_true, batch_hypothesis)
|
| 415 |
+
attack_wer = wer(batch_true, batch_hypothesis,
|
| 416 |
+
truth_transform=transform_wer,
|
| 417 |
+
hypothesis_transform=transform_wer)
|
| 418 |
+
|
| 419 |
+
wer_score += wer_n_batch*attack_wer
|
| 420 |
+
cer_score += cer_n_batch*attack_cer
|
| 421 |
+
|
| 422 |
+
wer_n += wer_n_batch
|
| 423 |
+
cer_n += cer_n_batch
|
| 424 |
+
|
| 425 |
+
wer_score /= wer_n
|
| 426 |
+
cer_score /= cer_n
|
| 427 |
+
|
| 428 |
+
return wer_score, cer_score
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
@torch.no_grad()
|
| 432 |
+
def top_k(query: dict, enrolled: dict, k: int):
|
| 433 |
+
"""
|
| 434 |
+
Compute portion of queries for which 'correct' ID appears in k-closest
|
| 435 |
+
enrolled entries
|
| 436 |
+
"""
|
| 437 |
+
|
| 438 |
+
# concatenate query embeddings into single tensor
|
| 439 |
+
query_array = []
|
| 440 |
+
query_ids = []
|
| 441 |
+
|
| 442 |
+
for s_l in query.keys():
|
| 443 |
+
query_array.append(query[s_l])
|
| 444 |
+
query_ids.extend([s_l] * len(query[s_l]))
|
| 445 |
+
|
| 446 |
+
query_array = torch.cat(query_array, dim=0).squeeze().cpu().numpy()
|
| 447 |
+
query_ids = torch.as_tensor(query_ids).cpu().numpy()
|
| 448 |
+
|
| 449 |
+
# concatenate enrolled embeddings into single tensor
|
| 450 |
+
enrolled_array = []
|
| 451 |
+
enrolled_ids = []
|
| 452 |
+
|
| 453 |
+
for s_l in enrolled.keys():
|
| 454 |
+
enrolled_array.append(enrolled[s_l])
|
| 455 |
+
enrolled_ids.extend([s_l] * len(enrolled[s_l]))
|
| 456 |
+
|
| 457 |
+
enrolled_array = torch.cat(enrolled_array, dim=0).squeeze().cpu().numpy()
|
| 458 |
+
enrolled_ids = torch.as_tensor(enrolled_ids).cpu().numpy()
|
| 459 |
+
|
| 460 |
+
# embedding dimension
|
| 461 |
+
assert query_array.shape[-1] == enrolled_array.shape[-1]
|
| 462 |
+
d = query_array.shape[-1]
|
| 463 |
+
|
| 464 |
+
# index enrolled embeddings
|
| 465 |
+
knn = NearestNeighbors(n_neighbors=k, metric="cosine").fit(enrolled_array)
|
| 466 |
+
|
| 467 |
+
# `I` is a (n_queries, k) array holding the indices of the k-closest enrolled
|
| 468 |
+
# embeddings for each query; `D` is a (n_queries, k) array holding the corresponding
|
| 469 |
+
# embedding-space distances
|
| 470 |
+
D, I = knn.kneighbors(query_array, k, return_distance=True)
|
| 471 |
+
|
| 472 |
+
# for each row, see if at least one of the k nearest enrolled indices maps
|
| 473 |
+
# to a speaker ID that matches the query index's speaker id
|
| 474 |
+
targets = np.tile(query_ids.reshape(-1, 1), (1, k))
|
| 475 |
+
|
| 476 |
+
predictions = enrolled_ids[I]
|
| 477 |
+
matches = (targets == predictions).sum(axis=-1) > 0
|
| 478 |
+
|
| 479 |
+
return np.mean(matches)
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
def init_attacks():
|
| 483 |
+
"""
|
| 484 |
+
Initialize pre-trained speaker recognition pipelines and de-identification
|
| 485 |
+
attacks
|
| 486 |
+
"""
|
| 487 |
+
|
| 488 |
+
# channel simulation
|
| 489 |
+
if SIMULATION:
|
| 490 |
+
sim = [
|
| 491 |
+
Offset(length=[-.15, .15]),
|
| 492 |
+
Noise(type='gaussian', snr=[30.0, 50.0]),
|
| 493 |
+
Bandpass(low=[300, 500], high=[3400, 7400]),
|
| 494 |
+
Dropout(rate=0.001)
|
| 495 |
+
]
|
| 496 |
+
else:
|
| 497 |
+
sim = None
|
| 498 |
+
|
| 499 |
+
pipelines = {}
|
| 500 |
+
|
| 501 |
+
model_resnet = SpeakerVerificationModel(
|
| 502 |
+
model=ResNetSE34V2(nOut=512, encoder_type='ASP'),
|
| 503 |
+
n_segments=1,
|
| 504 |
+
segment_select='lin',
|
| 505 |
+
distance_fn='cosine',
|
| 506 |
+
threshold=0.0
|
| 507 |
+
)
|
| 508 |
+
model_resnet.load_weights(
|
| 509 |
+
MODELS_DIR / 'speaker' / 'resnetse34v2' / 'resnetse34v2.pt')
|
| 510 |
+
|
| 511 |
+
model_yvector = SpeakerVerificationModel(
|
| 512 |
+
model=YVector(),
|
| 513 |
+
n_segments=1,
|
| 514 |
+
segment_select='lin',
|
| 515 |
+
distance_fn='cosine',
|
| 516 |
+
threshold=0.0
|
| 517 |
+
)
|
| 518 |
+
model_yvector.load_weights(
|
| 519 |
+
MODELS_DIR / 'speaker' / 'yvector' / 'yvector.pt')
|
| 520 |
+
|
| 521 |
+
pipelines['resnet'] = Pipeline(
|
| 522 |
+
simulation=sim,
|
| 523 |
+
preprocessor=Preprocessor(Normalize(method='peak')),
|
| 524 |
+
model=model_resnet,
|
| 525 |
+
device='cuda' if torch.cuda.is_available() else 'cpu'
|
| 526 |
+
)
|
| 527 |
+
|
| 528 |
+
if TRANSFER:
|
| 529 |
+
pipelines['yvector'] = Pipeline(
|
| 530 |
+
simulation=sim,
|
| 531 |
+
preprocessor=Preprocessor(Normalize(method='peak')),
|
| 532 |
+
model=model_yvector,
|
| 533 |
+
device='cuda' if torch.cuda.is_available() else 'cpu'
|
| 534 |
+
)
|
| 535 |
+
else:
|
| 536 |
+
del model_yvector
|
| 537 |
+
|
| 538 |
+
# prepare to log attack progress
|
| 539 |
+
writer = Writer(
|
| 540 |
+
root_dir=RUNS_DIR,
|
| 541 |
+
name='evaluate-attacks',
|
| 542 |
+
use_timestamp=True,
|
| 543 |
+
log_iter=300,
|
| 544 |
+
use_tb=True
|
| 545 |
+
)
|
| 546 |
+
|
| 547 |
+
attacks = {}
|
| 548 |
+
|
| 549 |
+
# use consistent adversarial loss
|
| 550 |
+
adv_loss = SpeakerEmbeddingLoss(
|
| 551 |
+
targeted=False,
|
| 552 |
+
confidence=0.1,
|
| 553 |
+
threshold=0.0
|
| 554 |
+
)
|
| 555 |
+
|
| 556 |
+
# use consistent auxiliary loss across attacks
|
| 557 |
+
aux_loss = SumLoss().add_loss_function(
|
| 558 |
+
DemucsMRSTFTLoss(), 1.0
|
| 559 |
+
).add_loss_function(L1Loss(), 1.0).to('cuda')
|
| 560 |
+
|
| 561 |
+
attacks['voicebox'] = VoiceBoxAttack(
|
| 562 |
+
pipeline=pipelines['resnet'],
|
| 563 |
+
adv_loss=adv_loss,
|
| 564 |
+
aux_loss=aux_loss,
|
| 565 |
+
lr=1e-4,
|
| 566 |
+
epochs=1,
|
| 567 |
+
batch_size=BATCH_SIZE,
|
| 568 |
+
voicebox_kwargs={
|
| 569 |
+
'win_length': 256,
|
| 570 |
+
'ppg_encoder_hidden_size': 256,
|
| 571 |
+
'use_phoneme_encoder': True,
|
| 572 |
+
'use_pitch_encoder': True,
|
| 573 |
+
'use_loudness_encoder': True,
|
| 574 |
+
'spec_encoder_lookahead_frames': 0,
|
| 575 |
+
'spec_encoder_type': 'mel',
|
| 576 |
+
'spec_encoder_mlp_depth': 2,
|
| 577 |
+
'bottleneck_lookahead_frames': LOOKAHEAD,
|
| 578 |
+
'ppg_encoder_path': PPG_PRETRAINED_PATH,
|
| 579 |
+
'n_bands': 128,
|
| 580 |
+
'spec_encoder_hidden_size': 512,
|
| 581 |
+
'bottleneck_skip': True,
|
| 582 |
+
'bottleneck_hidden_size': 512,
|
| 583 |
+
'bottleneck_feedforward_size': 512,
|
| 584 |
+
'bottleneck_type': 'lstm',
|
| 585 |
+
'bottleneck_depth': 2,
|
| 586 |
+
'control_eps': 0.5,
|
| 587 |
+
'projection_norm': float('inf'),
|
| 588 |
+
'conditioning_dim': 512
|
| 589 |
+
},
|
| 590 |
+
writer=writer,
|
| 591 |
+
checkpoint_name='voicebox-attack'
|
| 592 |
+
)
|
| 593 |
+
attacks['voicebox'].load(VOICEBOX_PATH)
|
| 594 |
+
|
| 595 |
+
attacks['universal'] = AdvPulseAttack(
|
| 596 |
+
pipeline=pipelines['resnet'],
|
| 597 |
+
adv_loss=adv_loss,
|
| 598 |
+
pgd_norm=float('inf'),
|
| 599 |
+
pgd_variant=None,
|
| 600 |
+
scale_grad=None,
|
| 601 |
+
eps=0.08,
|
| 602 |
+
length=2.0,
|
| 603 |
+
align='start',
|
| 604 |
+
lr=1e-4,
|
| 605 |
+
normalize=True,
|
| 606 |
+
loop=True,
|
| 607 |
+
aux_loss=aux_loss,
|
| 608 |
+
epochs=1,
|
| 609 |
+
batch_size=BATCH_SIZE,
|
| 610 |
+
writer=writer,
|
| 611 |
+
checkpoint_name='universal-attack'
|
| 612 |
+
)
|
| 613 |
+
attacks['universal'].load(UNIVERSAL_PATH)
|
| 614 |
+
|
| 615 |
+
attacks['kenansville'] = KenansvilleAttack(
|
| 616 |
+
pipeline=pipelines['resnet'],
|
| 617 |
+
batch_size=BATCH_SIZE,
|
| 618 |
+
adv_loss=adv_loss,
|
| 619 |
+
threshold_db_low=4.0, # fix threshold
|
| 620 |
+
threshold_db_high=4.0,
|
| 621 |
+
win_length=512,
|
| 622 |
+
writer=writer,
|
| 623 |
+
step_size=1.0,
|
| 624 |
+
search='bisection',
|
| 625 |
+
min_success_rate=0.2,
|
| 626 |
+
checkpoint_name='kenansville-attack'
|
| 627 |
+
)
|
| 628 |
+
|
| 629 |
+
attacks['noise'] = WhiteNoiseAttack(
|
| 630 |
+
pipeline=pipelines['resnet'],
|
| 631 |
+
adv_loss=adv_loss,
|
| 632 |
+
aux_loss=aux_loss,
|
| 633 |
+
snr_low=-10.0, # fix threshold
|
| 634 |
+
snr_high=-10.0,
|
| 635 |
+
writer=writer,
|
| 636 |
+
step_size=1,
|
| 637 |
+
search='bisection',
|
| 638 |
+
min_success_rate=0.2,
|
| 639 |
+
checkpoint_name='noise-perturbation'
|
| 640 |
+
)
|
| 641 |
+
|
| 642 |
+
return attacks, pipelines, writer
|
| 643 |
+
|
| 644 |
+
|
| 645 |
+
@torch.no_grad()
|
| 646 |
+
def evaluate_attack(attack: TrainableAttack,
|
| 647 |
+
speaker_pipeline: Pipeline,
|
| 648 |
+
asr_pipeline: Pipeline):
|
| 649 |
+
|
| 650 |
+
if DENOISER:
|
| 651 |
+
from src.models.denoiser.demucs import load_demucs
|
| 652 |
+
defense = load_demucs('dns_48').to(
|
| 653 |
+
'cuda' if torch.cuda.is_available() else 'cpu')
|
| 654 |
+
defense.eval()
|
| 655 |
+
else:
|
| 656 |
+
defense = nn.Identity()
|
| 657 |
+
|
| 658 |
+
# prepare for GPU inference
|
| 659 |
+
if torch.cuda.is_available():
|
| 660 |
+
|
| 661 |
+
attack.pipeline.set_device('cuda')
|
| 662 |
+
speaker_pipeline.set_device('cuda')
|
| 663 |
+
asr_pipeline.set_device('cuda')
|
| 664 |
+
attack.perturbation.to('cuda')
|
| 665 |
+
|
| 666 |
+
# locate dataset
|
| 667 |
+
if EVAL_DATASET == "librispeech":
|
| 668 |
+
cache_dir = CACHE_DIR / 'ls_wer_eval'
|
| 669 |
+
else:
|
| 670 |
+
cache_dir = CACHE_DIR / 'vc_wer_eval'
|
| 671 |
+
assert os.path.isdir(cache_dir), \
|
| 672 |
+
f'Dataset must be built/cached before evaluation'
|
| 673 |
+
|
| 674 |
+
# prepare for PESQ/STOI calculations
|
| 675 |
+
all_pesq_scores = []
|
| 676 |
+
all_stoi_scores = []
|
| 677 |
+
|
| 678 |
+
# prepare for WER/CER computations
|
| 679 |
+
all_query_transcripts = []
|
| 680 |
+
all_pred_query_transcripts = []
|
| 681 |
+
all_adv_query_transcripts = []
|
| 682 |
+
|
| 683 |
+
# prepare for accuracy computations
|
| 684 |
+
all_query_emb = {}
|
| 685 |
+
all_adv_query_emb = {}
|
| 686 |
+
all_enroll_emb = {}
|
| 687 |
+
all_enroll_emb_centroid = {}
|
| 688 |
+
|
| 689 |
+
spkr_dirs = list(cache_dir.glob("*/"))
|
| 690 |
+
spkr_dirs = [s_d for s_d in spkr_dirs if os.path.isdir(s_d)]
|
| 691 |
+
for spkr_dir in tqdm(spkr_dirs, total=len(spkr_dirs), desc='Running evaluation'):
|
| 692 |
+
|
| 693 |
+
# identify speaker
|
| 694 |
+
spkr_id = spkr_dir.parts[-1]
|
| 695 |
+
|
| 696 |
+
# use integer IDs
|
| 697 |
+
if EVAL_DATASET != "librispeech":
|
| 698 |
+
spkr_id = spkr_id.split("id")[-1]
|
| 699 |
+
|
| 700 |
+
# identify speaker recognition model
|
| 701 |
+
if isinstance(speaker_pipeline.model.model, ResNetSE34V2):
|
| 702 |
+
model_name = 'resnet'
|
| 703 |
+
elif isinstance(speaker_pipeline.model.model, YVector):
|
| 704 |
+
model_name = 'yvector'
|
| 705 |
+
else:
|
| 706 |
+
raise ValueError(f'Invalid speaker recognition model')
|
| 707 |
+
|
| 708 |
+
# load clean embeddings
|
| 709 |
+
query_emb = torch.load(spkr_dir / model_name / 'query_emb.pt')
|
| 710 |
+
condition_emb = torch.load(spkr_dir / 'resnet' / 'condition_emb.pt')
|
| 711 |
+
enroll_emb = torch.load(spkr_dir / model_name / 'enroll_emb.pt')
|
| 712 |
+
|
| 713 |
+
# load clean audio
|
| 714 |
+
query_audio = torch.load(spkr_dir / 'query_audio.pt')
|
| 715 |
+
|
| 716 |
+
# if defense in use, re-compute query audio
|
| 717 |
+
if DENOISER:
|
| 718 |
+
query_emb = compute_embeddings_batch(
|
| 719 |
+
query_audio, speaker_pipeline, defense=defense
|
| 720 |
+
)
|
| 721 |
+
|
| 722 |
+
# load clean transcript
|
| 723 |
+
if EVAL_DATASET == "librispeech":
|
| 724 |
+
query_transcripts = torch.load(spkr_dir / 'query_trans.pt')
|
| 725 |
+
else:
|
| 726 |
+
query_transcripts = None
|
| 727 |
+
|
| 728 |
+
# compute conditioning embedding centroid
|
| 729 |
+
condition_centroid = condition_emb.mean(dim=(0, 1), keepdim=True)
|
| 730 |
+
|
| 731 |
+
# compute enrolled embedding centroid
|
| 732 |
+
enroll_centroid = enroll_emb.mean(dim=(0, 1), keepdim=True)
|
| 733 |
+
|
| 734 |
+
# compute adversarial query audio
|
| 735 |
+
adv_query_audio = compute_attack_batch(
|
| 736 |
+
query_audio, attack, condition_centroid)
|
| 737 |
+
|
| 738 |
+
# compute adversarial query embeddings; optionally, pass through
|
| 739 |
+
# unseen denoiser defense
|
| 740 |
+
adv_query_emb = compute_embeddings_batch(
|
| 741 |
+
adv_query_audio, speaker_pipeline, defense=defense
|
| 742 |
+
)
|
| 743 |
+
|
| 744 |
+
if EVAL_DATASET == "librispeech":
|
| 745 |
+
|
| 746 |
+
# compute clean predicted transcripts
|
| 747 |
+
pred_query_transcripts = compute_transcripts_batch(
|
| 748 |
+
query_audio, asr_pipeline
|
| 749 |
+
)
|
| 750 |
+
|
| 751 |
+
# compute adversarial transcripts
|
| 752 |
+
adv_query_transcripts = compute_transcripts_batch(
|
| 753 |
+
adv_query_audio, asr_pipeline
|
| 754 |
+
)
|
| 755 |
+
|
| 756 |
+
# compute objective quality metric scores
|
| 757 |
+
if COMPUTE_OBJECTIVE_METRICS:
|
| 758 |
+
pesq_scores = compute_pesq(query_audio, adv_query_audio)
|
| 759 |
+
stoi_scores = compute_stoi(query_audio, adv_query_audio)
|
| 760 |
+
else:
|
| 761 |
+
pesq_scores = np.zeros(len(query_audio))
|
| 762 |
+
stoi_scores = np.zeros(len(query_audio))
|
| 763 |
+
|
| 764 |
+
# store all objective quality metric scores
|
| 765 |
+
all_pesq_scores.extend(pesq_scores)
|
| 766 |
+
all_stoi_scores.extend(stoi_scores)
|
| 767 |
+
|
| 768 |
+
# store all unit-normalized clean, adversarial, and enrolled centroid
|
| 769 |
+
# embeddings
|
| 770 |
+
all_query_emb[int(spkr_id)] = F.normalize(query_emb.clone(), dim=-1)
|
| 771 |
+
all_adv_query_emb[int(spkr_id)] = F.normalize(adv_query_emb.clone(), dim=-1)
|
| 772 |
+
all_enroll_emb[int(spkr_id)] = F.normalize(enroll_emb.clone(), dim=-1)
|
| 773 |
+
all_enroll_emb_centroid[int(spkr_id)] = F.normalize(enroll_centroid.clone(), dim=-1)
|
| 774 |
+
|
| 775 |
+
# store all transcripts
|
| 776 |
+
if EVAL_DATASET == "librispeech":
|
| 777 |
+
all_query_transcripts.extend(query_transcripts)
|
| 778 |
+
all_pred_query_transcripts.extend(pred_query_transcripts)
|
| 779 |
+
all_adv_query_transcripts.extend(adv_query_transcripts)
|
| 780 |
+
|
| 781 |
+
# free GPU memory for similarity search
|
| 782 |
+
attack.pipeline.set_device('cpu')
|
| 783 |
+
speaker_pipeline.set_device('cpu')
|
| 784 |
+
asr_pipeline.set_device('cpu')
|
| 785 |
+
attack.perturbation.to('cpu')
|
| 786 |
+
torch.cuda.empty_cache()
|
| 787 |
+
|
| 788 |
+
# compute and display final objective quality metrics
|
| 789 |
+
print(f"PESQ (mean/std): {np.mean(all_pesq_scores)}/{np.std(all_pesq_scores)}")
|
| 790 |
+
print(f"STOI (mean/std): {np.mean(all_stoi_scores)}/{np.std(all_stoi_scores)}")
|
| 791 |
+
|
| 792 |
+
if EVAL_DATASET == "librispeech":
|
| 793 |
+
|
| 794 |
+
# compute and display final WER/CER metrics
|
| 795 |
+
wer, cer = asr_metrics(all_query_transcripts, all_adv_query_transcripts)
|
| 796 |
+
print(f"Adversarial WER / CER: {wer} / {cer}")
|
| 797 |
+
|
| 798 |
+
wer, cer = asr_metrics(all_query_transcripts, all_pred_query_transcripts)
|
| 799 |
+
print(f"Clean WER / CER: {wer} / {cer}")
|
| 800 |
+
|
| 801 |
+
else:
|
| 802 |
+
wer, cer = None, None
|
| 803 |
+
|
| 804 |
+
del (wer, cer, all_pesq_scores, all_stoi_scores,
|
| 805 |
+
all_query_transcripts, all_adv_query_transcripts, all_pred_query_transcripts)
|
| 806 |
+
|
| 807 |
+
# embedding-space cosine distance calculations
|
| 808 |
+
cos_dist_fn = EmbeddingDistance(distance_fn='cosine')
|
| 809 |
+
|
| 810 |
+
# mean clean-to-adversarial query embedding distance
|
| 811 |
+
total_query_dist = 0.0
|
| 812 |
+
n = 0
|
| 813 |
+
for spkr_id in all_query_emb.keys():
|
| 814 |
+
dist = cos_dist_fn(all_query_emb[spkr_id],
|
| 815 |
+
all_adv_query_emb[spkr_id]).mean()
|
| 816 |
+
total_query_dist += len(all_query_emb[spkr_id]) * dist.item()
|
| 817 |
+
n += len(all_query_emb[spkr_id])
|
| 818 |
+
mean_query_dist = total_query_dist / n
|
| 819 |
+
print(f"\n\t\tMean cosine distance between clean and adversarial query "
|
| 820 |
+
f"embeddings: {mean_query_dist :0.4f}")
|
| 821 |
+
|
| 822 |
+
# mean adversarial-query-to-enrolled-centroid embedding distance
|
| 823 |
+
total_centroid_dist = 0.0
|
| 824 |
+
n = 0
|
| 825 |
+
for spkr_id in all_query_emb.keys():
|
| 826 |
+
n_queries = len(all_adv_query_emb[spkr_id])
|
| 827 |
+
dist = 0.0
|
| 828 |
+
for i in range(n_queries):
|
| 829 |
+
dist += cos_dist_fn(all_enroll_emb_centroid[spkr_id],
|
| 830 |
+
all_adv_query_emb[spkr_id][i:i+1]).item()
|
| 831 |
+
total_centroid_dist += dist
|
| 832 |
+
n += n_queries
|
| 833 |
+
mean_centroid_dist = total_centroid_dist / n
|
| 834 |
+
print(f"\t\tMean cosine distance between clean enrolled centroids and "
|
| 835 |
+
f"adversarial query embeddings: {mean_centroid_dist :0.4f}")
|
| 836 |
+
|
| 837 |
+
# top-1 accuracy for clean queries (closest embedding)
|
| 838 |
+
top_1_clean_single = top_k(all_query_emb, all_enroll_emb, k=1)
|
| 839 |
+
|
| 840 |
+
# top-1 accuracy for clean queries (centroid embedding)
|
| 841 |
+
top_1_clean_centroid = top_k(all_query_emb, all_enroll_emb_centroid, k=1)
|
| 842 |
+
|
| 843 |
+
# top-10 accuracy for clean queries (closest embedding)
|
| 844 |
+
top_10_clean_single = top_k(all_query_emb, all_enroll_emb, k=10)
|
| 845 |
+
|
| 846 |
+
# top-10 accuracy for clean queries (centroid embedding)
|
| 847 |
+
top_10_clean_centroid = top_k(all_query_emb, all_enroll_emb_centroid, k=10)
|
| 848 |
+
|
| 849 |
+
# top-1 accuracy for adversarial queries (closest embedding)
|
| 850 |
+
top_1_adv_single = top_k(all_adv_query_emb, all_enroll_emb, k=1)
|
| 851 |
+
|
| 852 |
+
# top-1 accuracy for adversarial queries (centroid embedding)
|
| 853 |
+
top_1_adv_centroid = top_k(all_adv_query_emb, all_enroll_emb_centroid, k=1)
|
| 854 |
+
|
| 855 |
+
# top-10 accuracy for adversarial queries (closest embedding)
|
| 856 |
+
top_10_adv_single = top_k(all_adv_query_emb, all_enroll_emb, k=10)
|
| 857 |
+
|
| 858 |
+
# top-10 accuracy for adversarial queries (centroid embedding)
|
| 859 |
+
top_10_adv_centroid = top_k(all_adv_query_emb, all_enroll_emb_centroid, k=10)
|
| 860 |
+
|
| 861 |
+
print(f"\n\t\tTop-1 accuracy (clean embedding / nearest enrolled embedding) {top_1_clean_single :0.4f}",
|
| 862 |
+
f"\n\t\tTop-1 accuracy (clean embedding / nearest enrolled centroid) {top_1_clean_centroid :0.4f}",
|
| 863 |
+
f"\n\t\tTop-10 accuracy (clean embedding / nearest enrolled embedding) {top_10_clean_single :0.4f}"
|
| 864 |
+
f"\n\t\tTop-10 accuracy (clean embedding / nearest enrolled centroid) {top_10_clean_centroid :0.4f}",
|
| 865 |
+
f"\n\t\tTop-1 accuracy (adversarial embedding / nearest enrolled embedding {top_1_adv_single :0.4f}",
|
| 866 |
+
f"\n\t\tTop-1 accuracy (adversarial embedding / nearest enrolled centroid) {top_1_adv_centroid :0.4f}",
|
| 867 |
+
f"\n\t\tTop-10 accuracy (adversarial embedding / nearest enrolled embedding {top_10_adv_single :0.4f}",
|
| 868 |
+
f"\n\t\tTop-10 accuracy (adversarial embedding / nearest enrolled centroid) {top_10_adv_centroid :0.4f}"
|
| 869 |
+
)
|
| 870 |
+
|
| 871 |
+
|
| 872 |
+
@torch.no_grad()
|
| 873 |
+
def evaluate_attacks(attacks: dict,
|
| 874 |
+
speaker_pipelines: dict,
|
| 875 |
+
asr_pipeline: Pipeline):
|
| 876 |
+
|
| 877 |
+
for attack_name, attack in attacks.items():
|
| 878 |
+
for sp_name, sp in speaker_pipelines.items():
|
| 879 |
+
print(f'Evaluating {attack_name} against model {sp_name} '
|
| 880 |
+
f'{"with" if DENOISER else "without"} denoiser defense')
|
| 881 |
+
evaluate_attack(attack, sp, asr_pipeline)
|
| 882 |
+
|
| 883 |
+
|
| 884 |
+
def main():
|
| 885 |
+
|
| 886 |
+
# initial random seed (keep dataset order consistent)
|
| 887 |
+
set_random_seed(0)
|
| 888 |
+
|
| 889 |
+
# initialize pipelines
|
| 890 |
+
attacks, pipelines, writer = init_attacks()
|
| 891 |
+
|
| 892 |
+
# ensure that necessary data is cached
|
| 893 |
+
if EVAL_DATASET == "librispeech":
|
| 894 |
+
build_ls_dataset(pipelines)
|
| 895 |
+
else:
|
| 896 |
+
build_vc_dataset(pipelines)
|
| 897 |
+
|
| 898 |
+
# initialize ASR model
|
| 899 |
+
asr_model = SpeechRecognitionModel(
|
| 900 |
+
model=Wav2Vec2(),
|
| 901 |
+
)
|
| 902 |
+
asr_pipeline = Pipeline(
|
| 903 |
+
model=asr_model,
|
| 904 |
+
preprocessor=Preprocessor(Normalize(method='peak')),
|
| 905 |
+
device='cuda' if torch.cuda.is_available() else 'cpu'
|
| 906 |
+
)
|
| 907 |
+
|
| 908 |
+
writer.log_cuda_memory()
|
| 909 |
+
|
| 910 |
+
evaluate_attacks(attacks, pipelines, asr_pipeline)
|
| 911 |
+
|
| 912 |
+
|
| 913 |
+
if __name__ == "__main__":
|
| 914 |
+
main()
|
| 915 |
+
|
voicebox/scripts/experiments/train.py
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import torchaudio
|
| 5 |
+
import psutil
|
| 6 |
+
import pickle
|
| 7 |
+
import librosa as li
|
| 8 |
+
|
| 9 |
+
from torch.utils.data import TensorDataset
|
| 10 |
+
|
| 11 |
+
import time
|
| 12 |
+
import random
|
| 13 |
+
import argparse
|
| 14 |
+
from datetime import datetime
|
| 15 |
+
|
| 16 |
+
import numpy as np
|
| 17 |
+
import pandas as pd
|
| 18 |
+
from typing import Dict
|
| 19 |
+
from pathlib import Path
|
| 20 |
+
from tqdm import tqdm
|
| 21 |
+
import builtins
|
| 22 |
+
|
| 23 |
+
from typing import Iterable
|
| 24 |
+
from copy import deepcopy
|
| 25 |
+
|
| 26 |
+
from distutils.util import strtobool
|
| 27 |
+
|
| 28 |
+
from src.data import *
|
| 29 |
+
from src.constants import *
|
| 30 |
+
from src.models import *
|
| 31 |
+
from src.simulation import *
|
| 32 |
+
from src.preprocess import *
|
| 33 |
+
from src.attacks.offline import *
|
| 34 |
+
from src.loss import *
|
| 35 |
+
from src.pipelines import *
|
| 36 |
+
from src.utils import *
|
| 37 |
+
|
| 38 |
+
################################################################################
|
| 39 |
+
# Train VoiceBox attack
|
| 40 |
+
################################################################################
|
| 41 |
+
|
| 42 |
+
BATCH_SIZE = 20 # training batch size
|
| 43 |
+
EPOCHS = 10 # training epochs
|
| 44 |
+
TARGET_PCTL = 25 # de-identification strength; in [1,5,10,15,20,25,50,90,100]
|
| 45 |
+
N_EMBEDDINGS_TRAIN = 15
|
| 46 |
+
TARGETED = False
|
| 47 |
+
TARGETS_TRAIN = 'centroid' # 'random', 'same', 'single', 'median'
|
| 48 |
+
TARGETS_TEST = 'centroid' # 'random', 'same', 'single', 'median'
|
| 49 |
+
|
| 50 |
+
# distributions of inter- ('targeted') and intra- ('untargeted') speaker
|
| 51 |
+
# distances in each pre-trained model's embedding spaces, as measured between
|
| 52 |
+
# individual utterances and their speaker centroid ('single-centroid') or
|
| 53 |
+
# between all pairs of individual utterances ('single-single') over the
|
| 54 |
+
# LibriSpeech test-clean dataset. This allows specification of attack strength
|
| 55 |
+
# during the training process
|
| 56 |
+
percentiles = {
|
| 57 |
+
'resnet': {
|
| 58 |
+
'targeted': {
|
| 59 |
+
'single-centroid': {1:.495, 5:.572, 10:.617, 15:.648, 20:.673, 25:.695, 50:.773, 90:.892, 100:1.127},
|
| 60 |
+
'single-single': {1:.560, 5:.630, 10:.672, 15:.700, 20:.722, 25:.742, 50:.813, 90:.924, 100:1.194}
|
| 61 |
+
},
|
| 62 |
+
'untargeted': {
|
| 63 |
+
'single-centroid': {1:.099, 5:.117, 10:.126, 15:.133, 20:.139, 25:.145, 50:.170, 90:.253, 100:.587},
|
| 64 |
+
'single-single': {1:.181, 5:.215, 10:.235, 15:.249, 20:.262, 25:.272, 50:.323, 90:.464, 100:.817}
|
| 65 |
+
},
|
| 66 |
+
},
|
| 67 |
+
'yvector': {
|
| 68 |
+
'targeted': {
|
| 69 |
+
'single-centroid': {1:.665, 5:.757, 10:.801, 15:.830, 20:.851, 25:.868, 50:.936, 90:1.056, 100:1.312},
|
| 70 |
+
'single-single': {1:.695, 5:.779, 10:.821, 15:.847, 20:.868, 25:.885, 50:.952, 90:1.072, 100:1.428}
|
| 71 |
+
},
|
| 72 |
+
'untargeted': {
|
| 73 |
+
'single-single': {1:.218, 5:.268, 10:.301, 15:.325, 20:.345, 25:.365, 50:.455, 90:.684, 100:1.156},
|
| 74 |
+
'single-centroid': {1:.114, 5:.143, 10:.159, 15:.170, 20:.180, 25:.190, 50:.242, 90:.413, 100:.874}
|
| 75 |
+
}
|
| 76 |
+
},
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def set_random_seed(seed: int = 123):
|
| 81 |
+
"""Set random seed to allow for reproducibility"""
|
| 82 |
+
random.seed(seed)
|
| 83 |
+
torch.manual_seed(seed)
|
| 84 |
+
|
| 85 |
+
if torch.backends.cudnn.is_available():
|
| 86 |
+
# torch.backends.cudnn.benchmark = True
|
| 87 |
+
torch.backends.cudnn.deterministic = True
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def param_count(m: nn.Module, trainable: bool = False):
|
| 91 |
+
"""Count the number of trainable parameters (weights) in a model"""
|
| 92 |
+
if trainable:
|
| 93 |
+
return builtins.sum(
|
| 94 |
+
[p.shape.numel() for p in m.parameters() if p.requires_grad])
|
| 95 |
+
else:
|
| 96 |
+
return builtins.sum([p.shape.numel() for p in m.parameters()])
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def main():
|
| 100 |
+
|
| 101 |
+
set_random_seed(0)
|
| 102 |
+
|
| 103 |
+
model = SpeakerVerificationModel(
|
| 104 |
+
model=ResNetSE34V2(nOut=512, encoder_type='ASP'),
|
| 105 |
+
n_segments=1,
|
| 106 |
+
segment_select='lin',
|
| 107 |
+
distance_fn='cosine',
|
| 108 |
+
threshold=percentiles['resnet']['targeted']['single-centroid' if
|
| 109 |
+
TARGETS_TRAIN == 'centroid' else 'single-single'][TARGET_PCTL]
|
| 110 |
+
)
|
| 111 |
+
model.load_weights(MODELS_DIR / 'speaker' / 'resnetse34v2' / 'resnetse34v2.pt')
|
| 112 |
+
|
| 113 |
+
# instantiate training pipeline
|
| 114 |
+
pipeline = Pipeline(
|
| 115 |
+
simulation=None,
|
| 116 |
+
preprocessor=Preprocessor(Normalize(method='peak')),
|
| 117 |
+
model=model,
|
| 118 |
+
device='cuda' if torch.cuda.is_available() else 'cpu'
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
attacks = {}
|
| 122 |
+
|
| 123 |
+
# log training progress
|
| 124 |
+
writer = Writer(
|
| 125 |
+
root_dir=RUNS_DIR,
|
| 126 |
+
name='train-attacks',
|
| 127 |
+
use_timestamp=True,
|
| 128 |
+
log_iter=300,
|
| 129 |
+
use_tb=True
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
# adversarial training loss
|
| 133 |
+
adv_loss = SpeakerEmbeddingLoss(
|
| 134 |
+
targeted=TARGETED,
|
| 135 |
+
confidence=0.1,
|
| 136 |
+
threshold=pipeline.model.threshold
|
| 137 |
+
)
|
| 138 |
+
|
| 139 |
+
# auxiliary loss
|
| 140 |
+
aux_loss = SumLoss().add_loss_function(
|
| 141 |
+
DemucsMRSTFTLoss(), 1.0
|
| 142 |
+
).add_loss_function(L1Loss(), 1.0).to('cuda')
|
| 143 |
+
|
| 144 |
+
# speech features loss actually seems to do better...
|
| 145 |
+
# aux_loss = SumLoss().add_loss_function(SpeechFeatureLoss(), 1e-6).to('cuda')
|
| 146 |
+
|
| 147 |
+
attacks['voicebox'] = VoiceBoxAttack(
|
| 148 |
+
pipeline=pipeline,
|
| 149 |
+
adv_loss=adv_loss,
|
| 150 |
+
aux_loss=aux_loss,
|
| 151 |
+
lr=1e-4,
|
| 152 |
+
epochs=EPOCHS,
|
| 153 |
+
batch_size=BATCH_SIZE,
|
| 154 |
+
voicebox_kwargs={
|
| 155 |
+
'win_length': 256,
|
| 156 |
+
'ppg_encoder_hidden_size': 256,
|
| 157 |
+
'use_phoneme_encoder': True,
|
| 158 |
+
'use_pitch_encoder': True,
|
| 159 |
+
'use_loudness_encoder': True,
|
| 160 |
+
'spec_encoder_lookahead_frames': 0,
|
| 161 |
+
'spec_encoder_type': 'mel',
|
| 162 |
+
'spec_encoder_mlp_depth': 2,
|
| 163 |
+
'bottleneck_lookahead_frames': 5,
|
| 164 |
+
'ppg_encoder_path': PPG_PRETRAINED_PATH,
|
| 165 |
+
'n_bands': 128,
|
| 166 |
+
'spec_encoder_hidden_size': 512,
|
| 167 |
+
'bottleneck_skip': True,
|
| 168 |
+
'bottleneck_hidden_size': 512,
|
| 169 |
+
'bottleneck_feedforward_size': 512,
|
| 170 |
+
'bottleneck_type': 'lstm',
|
| 171 |
+
'bottleneck_depth': 2,
|
| 172 |
+
'control_eps': 0.5,
|
| 173 |
+
'projection_norm': float('inf'),
|
| 174 |
+
'conditioning_dim': 512
|
| 175 |
+
},
|
| 176 |
+
writer=writer,
|
| 177 |
+
checkpoint_name='voicebox-attack'
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
attacks['universal'] = AdvPulseAttack(
|
| 181 |
+
pipeline=pipeline,
|
| 182 |
+
adv_loss=adv_loss,
|
| 183 |
+
pgd_norm=float('inf'),
|
| 184 |
+
pgd_variant=None,
|
| 185 |
+
scale_grad=None,
|
| 186 |
+
eps=0.08,
|
| 187 |
+
length=2.0,
|
| 188 |
+
align='random', # 'start',
|
| 189 |
+
lr=1e-4,
|
| 190 |
+
normalize=True,
|
| 191 |
+
loop=True,
|
| 192 |
+
aux_loss=aux_loss,
|
| 193 |
+
epochs=EPOCHS,
|
| 194 |
+
batch_size=BATCH_SIZE,
|
| 195 |
+
writer=writer,
|
| 196 |
+
checkpoint_name='universal-attack'
|
| 197 |
+
)
|
| 198 |
+
|
| 199 |
+
if torch.cuda.is_available():
|
| 200 |
+
|
| 201 |
+
# prepare for multi-GPU training
|
| 202 |
+
device_ids = get_cuda_device_ids()
|
| 203 |
+
|
| 204 |
+
# wrap pipeline for multi-GPU training
|
| 205 |
+
pipeline = wrap_pipeline_multi_gpu(pipeline, device_ids)
|
| 206 |
+
|
| 207 |
+
# load training and validation datasets. Features will be computed and
|
| 208 |
+
# cached to disk, which may take some time
|
| 209 |
+
data_train = LibriSpeechDataset(
|
| 210 |
+
split='train-clean-100', features=['pitch', 'periodicity', 'loudness'])
|
| 211 |
+
data_test = LibriSpeechDataset(
|
| 212 |
+
split='test-clean', features=['pitch', 'periodicity', 'loudness'])
|
| 213 |
+
|
| 214 |
+
# reassign targets if necessary
|
| 215 |
+
compiled_train, compiled_test = create_embedding_dataset(
|
| 216 |
+
pipeline=pipeline,
|
| 217 |
+
select_train=TARGETS_TRAIN,
|
| 218 |
+
select_test=TARGETS_TEST,
|
| 219 |
+
data_train=data_train,
|
| 220 |
+
data_test=data_test,
|
| 221 |
+
targeted=TARGETED,
|
| 222 |
+
target_class=None,
|
| 223 |
+
num_embeddings_train=N_EMBEDDINGS_TRAIN,
|
| 224 |
+
batch_size=20
|
| 225 |
+
)
|
| 226 |
+
|
| 227 |
+
# extract embedding datasets
|
| 228 |
+
data_train = compiled_train['dataset']
|
| 229 |
+
data_test = compiled_test['dataset']
|
| 230 |
+
|
| 231 |
+
# log memory use prior to training
|
| 232 |
+
writer.log_info(f'Training data ready; memory use: '
|
| 233 |
+
f'{psutil.virtual_memory().percent :0.3f}%')
|
| 234 |
+
writer.log_cuda_memory()
|
| 235 |
+
|
| 236 |
+
for attack_name, attack in attacks.items():
|
| 237 |
+
|
| 238 |
+
writer.log_info(f'Preparing {attack_name}...')
|
| 239 |
+
|
| 240 |
+
if torch.cuda.is_available():
|
| 241 |
+
|
| 242 |
+
attack.perturbation.to('cuda')
|
| 243 |
+
attack.pipeline.to('cuda')
|
| 244 |
+
|
| 245 |
+
# wrap attack for multi-GPU training
|
| 246 |
+
attack = wrap_attack_multi_gpu(attack, device_ids)
|
| 247 |
+
|
| 248 |
+
# evaluate performance
|
| 249 |
+
with torch.no_grad():
|
| 250 |
+
x_example = next(iter(data_train))['x'].to(pipeline.device)
|
| 251 |
+
st = time.time()
|
| 252 |
+
outs = attack.perturbation(x_example)
|
| 253 |
+
dur = time.time() - st
|
| 254 |
+
|
| 255 |
+
writer.log_info(
|
| 256 |
+
f'Processing time per input (device: '
|
| 257 |
+
f'{pipeline.device}): {dur/x_example.shape[0] :0.4f} (s)'
|
| 258 |
+
)
|
| 259 |
+
writer.log_info(f'Trainable parameters: '
|
| 260 |
+
f'{param_count(attack.perturbation, trainable=True)}')
|
| 261 |
+
writer.log_info(f'Total parameters: {param_count(attack.perturbation, trainable=False)}')
|
| 262 |
+
|
| 263 |
+
# train
|
| 264 |
+
writer.log_info('Training attack...')
|
| 265 |
+
attack.train(data_train=data_train, data_val=data_test)
|
| 266 |
+
|
| 267 |
+
# evaluate
|
| 268 |
+
writer.log_info(f'Evaluating attack...')
|
| 269 |
+
x_adv, success, detection = attack.evaluate(
|
| 270 |
+
dataset=data_test
|
| 271 |
+
)
|
| 272 |
+
|
| 273 |
+
# log results summary: success rate in achieving target threshold
|
| 274 |
+
writer.log_info(
|
| 275 |
+
f'Success rate in meeting embedding distance threshold {pipeline.model.threshold}'
|
| 276 |
+
f' ({TARGET_PCTL}%): '
|
| 277 |
+
f'{success.flatten().mean().item()}'
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
if __name__ == "__main__":
|
| 282 |
+
main()
|
voicebox/scripts/experiments/train_phoneme_predictor.py
ADDED
|
@@ -0,0 +1,205 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
|
| 5 |
+
from src.models.phoneme import PPGEncoder
|
| 6 |
+
from src.constants import LIBRISPEECH_NUM_PHONEMES, LIBRISPEECH_PHONEME_DICT
|
| 7 |
+
from src.data import LibriSpeechDataset
|
| 8 |
+
from src.utils.writer import Writer
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
from sklearn.metrics import confusion_matrix, classification_report
|
| 12 |
+
import seaborn as sn
|
| 13 |
+
import pandas as pd
|
| 14 |
+
import matplotlib.pyplot as plt
|
| 15 |
+
|
| 16 |
+
################################################################################
|
| 17 |
+
# Train a simple model to produce phonetic posteriorgrams (PPGs)
|
| 18 |
+
################################################################################
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def main():
|
| 22 |
+
|
| 23 |
+
# training hyperparameters
|
| 24 |
+
lr = .001
|
| 25 |
+
epochs = 60
|
| 26 |
+
batch_size = 250
|
| 27 |
+
device = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 28 |
+
|
| 29 |
+
# phoneme encoder hyperparameters
|
| 30 |
+
lstm_depth = 2
|
| 31 |
+
hidden_size = 128 # 512
|
| 32 |
+
win_length = 256
|
| 33 |
+
hop_length = 128
|
| 34 |
+
n_mels = 32
|
| 35 |
+
n_mfcc = 19
|
| 36 |
+
lookahead_frames = 0 # 1
|
| 37 |
+
|
| 38 |
+
# datasets and loaders
|
| 39 |
+
train_data = LibriSpeechDataset(
|
| 40 |
+
split='train-clean-100',
|
| 41 |
+
target='phoneme',
|
| 42 |
+
features=None,
|
| 43 |
+
hop_length=hop_length
|
| 44 |
+
)
|
| 45 |
+
val_data = LibriSpeechDataset(
|
| 46 |
+
split='test-clean',
|
| 47 |
+
target='phoneme',
|
| 48 |
+
features=None,
|
| 49 |
+
hop_length=hop_length
|
| 50 |
+
)
|
| 51 |
+
train_loader = DataLoader(
|
| 52 |
+
train_data,
|
| 53 |
+
batch_size=batch_size,
|
| 54 |
+
shuffle=True)
|
| 55 |
+
val_loader = DataLoader(
|
| 56 |
+
val_data,
|
| 57 |
+
batch_size=batch_size)
|
| 58 |
+
|
| 59 |
+
# initialize phoneme encoder
|
| 60 |
+
encoder = PPGEncoder(
|
| 61 |
+
win_length=win_length,
|
| 62 |
+
hop_length=hop_length,
|
| 63 |
+
win_func=torch.hann_window,
|
| 64 |
+
n_mels=n_mels,
|
| 65 |
+
n_mfcc=n_mfcc,
|
| 66 |
+
lstm_depth=lstm_depth,
|
| 67 |
+
hidden_size=hidden_size,
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
# initialize classification layer and wrap as single module
|
| 71 |
+
classifier = nn.Sequential(
|
| 72 |
+
encoder,
|
| 73 |
+
nn.Linear(hidden_size, LIBRISPEECH_NUM_PHONEMES)
|
| 74 |
+
).to(device)
|
| 75 |
+
|
| 76 |
+
# log training progress
|
| 77 |
+
writer = Writer(
|
| 78 |
+
name=f"phoneme_lookahead_{lookahead_frames}",
|
| 79 |
+
use_tb=True,
|
| 80 |
+
log_iter=len(train_loader)
|
| 81 |
+
)
|
| 82 |
+
|
| 83 |
+
import builtins
|
| 84 |
+
parameter_count = builtins.sum([
|
| 85 |
+
p.shape.numel()
|
| 86 |
+
for p in classifier[0].parameters()
|
| 87 |
+
if p.requires_grad
|
| 88 |
+
])
|
| 89 |
+
|
| 90 |
+
writer.log_info(f'Training PPG model with lookahead {lookahead_frames}'
|
| 91 |
+
f' ({parameter_count} parameters)')
|
| 92 |
+
|
| 93 |
+
# initialize optimizer and loss function
|
| 94 |
+
optimizer = torch.optim.Adam(classifier.parameters(), lr=lr)
|
| 95 |
+
loss_fn = nn.CrossEntropyLoss()
|
| 96 |
+
|
| 97 |
+
iter_id = 0
|
| 98 |
+
min_val_loss = float('inf')
|
| 99 |
+
|
| 100 |
+
for epoch in range(epochs):
|
| 101 |
+
|
| 102 |
+
print(f'beginning epoch {epoch}')
|
| 103 |
+
|
| 104 |
+
classifier.train()
|
| 105 |
+
for batch in train_loader:
|
| 106 |
+
|
| 107 |
+
optimizer.zero_grad(set_to_none=True)
|
| 108 |
+
|
| 109 |
+
x, y = batch['x'].to(device), batch['y'].to(device)
|
| 110 |
+
|
| 111 |
+
preds = classifier(x)
|
| 112 |
+
|
| 113 |
+
# offset labels to incorporate lookahead
|
| 114 |
+
y = y[:, :-lookahead_frames if lookahead_frames else None]
|
| 115 |
+
|
| 116 |
+
# offset predictions correspondingly
|
| 117 |
+
preds = preds[:, lookahead_frames:]
|
| 118 |
+
|
| 119 |
+
# compute cross-entropy loss
|
| 120 |
+
loss = loss_fn(
|
| 121 |
+
preds.reshape(-1, LIBRISPEECH_NUM_PHONEMES), y.reshape(-1)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
loss.backward()
|
| 125 |
+
optimizer.step()
|
| 126 |
+
|
| 127 |
+
writer.log_scalar(loss, tag="CrossEntropyLoss-Train", global_step=iter_id)
|
| 128 |
+
iter_id += 1
|
| 129 |
+
|
| 130 |
+
val_loss, val_acc, n = 0.0, 0.0, 0
|
| 131 |
+
classifier.eval()
|
| 132 |
+
with torch.no_grad():
|
| 133 |
+
for batch in val_loader:
|
| 134 |
+
|
| 135 |
+
x, y = batch['x'].to(device), batch['y'].to(device)
|
| 136 |
+
|
| 137 |
+
preds = classifier(x)
|
| 138 |
+
|
| 139 |
+
# offset labels to incorporate lookahead
|
| 140 |
+
y = y[:, :-lookahead_frames if lookahead_frames else None]
|
| 141 |
+
|
| 142 |
+
# offset predictions correspondingly
|
| 143 |
+
preds = preds[:, lookahead_frames:]
|
| 144 |
+
|
| 145 |
+
n += len(x)
|
| 146 |
+
val_loss += loss_fn(
|
| 147 |
+
preds.reshape(-1, LIBRISPEECH_NUM_PHONEMES), y.reshape(-1)
|
| 148 |
+
) * len(x)
|
| 149 |
+
val_acc += len(x) * (torch.argmax(preds, dim=2) == y).flatten().float().mean()
|
| 150 |
+
|
| 151 |
+
val_loss /= n
|
| 152 |
+
val_acc /= n
|
| 153 |
+
writer.log_scalar(val_loss, tag="CrossEntropyLoss-Val", global_step=iter_id)
|
| 154 |
+
writer.log_scalar(val_acc, tag="Accuracy-Val")
|
| 155 |
+
|
| 156 |
+
# save weights
|
| 157 |
+
if val_loss < min_val_loss:
|
| 158 |
+
min_val_loss = val_loss
|
| 159 |
+
print(f'new best val loss {val_loss}; saving weights')
|
| 160 |
+
writer.checkpoint(classifier[0].state_dict(), 'phoneme_classifier')
|
| 161 |
+
|
| 162 |
+
# generate confusion matrix
|
| 163 |
+
classifier.eval()
|
| 164 |
+
|
| 165 |
+
# compute accuracy on validation data
|
| 166 |
+
all_preds = []
|
| 167 |
+
all_true = []
|
| 168 |
+
with torch.no_grad():
|
| 169 |
+
for batch in val_loader:
|
| 170 |
+
|
| 171 |
+
x, y = batch['x'].to(device), batch['y'].to(device)
|
| 172 |
+
|
| 173 |
+
preds = classifier(x)
|
| 174 |
+
|
| 175 |
+
# offset labels to incorporate lookahead
|
| 176 |
+
y = y[:, :-lookahead_frames if lookahead_frames else None]
|
| 177 |
+
|
| 178 |
+
# offset predictions correspondingly
|
| 179 |
+
preds = preds[:, lookahead_frames:]
|
| 180 |
+
|
| 181 |
+
all_preds.append(preds.argmax(dim=2).reshape(-1))
|
| 182 |
+
all_true.append(y.reshape(-1))
|
| 183 |
+
|
| 184 |
+
# compile predictions and targets
|
| 185 |
+
all_preds = torch.cat(all_preds, dim=0).cpu().numpy()
|
| 186 |
+
all_true = torch.cat(all_true, dim=0).cpu().numpy()
|
| 187 |
+
|
| 188 |
+
reverse_dict = {v: k for (k, v) in LIBRISPEECH_PHONEME_DICT.items() if v != 0}
|
| 189 |
+
reverse_dict[0] = 'sil'
|
| 190 |
+
|
| 191 |
+
class_report = classification_report(all_true, all_preds)
|
| 192 |
+
writer.log_info(class_report)
|
| 193 |
+
|
| 194 |
+
cm = confusion_matrix(all_true, all_preds, labels=list(range(len(reverse_dict))))
|
| 195 |
+
df_cm = pd.DataFrame(cm, index=[i for i in sorted(list(reverse_dict.keys()))],
|
| 196 |
+
columns=[i for i in sorted(list(reverse_dict.keys()))])
|
| 197 |
+
plt.figure(figsize=(40, 28))
|
| 198 |
+
sn.set(font_scale=1.0) # for label size
|
| 199 |
+
sn.heatmap(df_cm, annot=True, annot_kws={"size": 35 / np.sqrt(len(cm))}, fmt='g')
|
| 200 |
+
|
| 201 |
+
plt.savefig("phoneme_cm.png", dpi=200)
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
if __name__ == '__main__':
|
| 205 |
+
main()
|
voicebox/scripts/streamer/benchmark_streamer.py
ADDED
|
@@ -0,0 +1,97 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import librosa
|
| 3 |
+
import soundfile as sf
|
| 4 |
+
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from src.attacks.offline.perturbation.voicebox import projection
|
| 7 |
+
from src.attacks.online import Streamer, VoiceBoxStreamer
|
| 8 |
+
from src.models import ResNetSE34V2, SpeakerVerificationModel
|
| 9 |
+
from src.constants import MODELS_DIR, TEST_DIR, PPG_PRETRAINED_PATH
|
| 10 |
+
|
| 11 |
+
import warnings
|
| 12 |
+
warnings.filterwarnings("ignore")
|
| 13 |
+
|
| 14 |
+
torch.set_num_threads(1)
|
| 15 |
+
|
| 16 |
+
device = 'cpu'
|
| 17 |
+
|
| 18 |
+
lookahead = 5
|
| 19 |
+
|
| 20 |
+
signal_length = 64_000
|
| 21 |
+
chunk_size = 640
|
| 22 |
+
|
| 23 |
+
test_audio = torch.Tensor(
|
| 24 |
+
librosa.load(TEST_DIR / 'data' / 'test.wav', sr=16_000, mono=True)[0]
|
| 25 |
+
).unsqueeze(0).unsqueeze(0)
|
| 26 |
+
|
| 27 |
+
tests = [
|
| 28 |
+
(512, 512, 512)
|
| 29 |
+
]
|
| 30 |
+
resnet_model = SpeakerVerificationModel(model=ResNetSE34V2())
|
| 31 |
+
condition_vector = resnet_model(test_audio)
|
| 32 |
+
for (bottleneck_hidden_size,
|
| 33 |
+
bottleneck_feedforward_size,
|
| 34 |
+
spec_encoder_hidden_size) in tests:
|
| 35 |
+
print(
|
| 36 |
+
f"""
|
| 37 |
+
====================================
|
| 38 |
+
bottleneck_hidden_size: {bottleneck_hidden_size}
|
| 39 |
+
bottleneck_feedforward_size: {bottleneck_feedforward_size}
|
| 40 |
+
spec_encoder_hidden_size: {spec_encoder_hidden_size}
|
| 41 |
+
"""
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
streamer = Streamer(
|
| 45 |
+
VoiceBoxStreamer(
|
| 46 |
+
win_length=256,
|
| 47 |
+
bottleneck_type='lstm',
|
| 48 |
+
bottleneck_skip=True,
|
| 49 |
+
bottleneck_depth=2,
|
| 50 |
+
bottleneck_lookahead_frames=5,
|
| 51 |
+
bottleneck_hidden_size=bottleneck_hidden_size,
|
| 52 |
+
bottleneck_feedforward_size=bottleneck_feedforward_size,
|
| 53 |
+
|
| 54 |
+
conditioning_dim=512,
|
| 55 |
+
|
| 56 |
+
spec_encoder_mlp_depth=2,
|
| 57 |
+
spec_encoder_hidden_size=spec_encoder_hidden_size,
|
| 58 |
+
spec_encoder_lookahead_frames=0,
|
| 59 |
+
ppg_encoder_path=PPG_PRETRAINED_PATH,
|
| 60 |
+
|
| 61 |
+
ppg_encoder_depth=2,
|
| 62 |
+
ppg_encoder_hidden_size=256,
|
| 63 |
+
projection_norm='inf',
|
| 64 |
+
control_eps=0.5,
|
| 65 |
+
n_bands=128
|
| 66 |
+
),
|
| 67 |
+
device,
|
| 68 |
+
hop_length=128,
|
| 69 |
+
window_length=256,
|
| 70 |
+
win_type='hann',
|
| 71 |
+
lookahead_frames=lookahead,
|
| 72 |
+
recurrent=True
|
| 73 |
+
)
|
| 74 |
+
streamer.model.load_state_dict(torch.load(MODELS_DIR / 'voicebox' / 'voicebox_final.pt'))
|
| 75 |
+
streamer.condition_vector = condition_vector
|
| 76 |
+
|
| 77 |
+
output_chunks = []
|
| 78 |
+
for i in tqdm(range(0, signal_length, chunk_size)):
|
| 79 |
+
signal_chunk = test_audio[..., i:i+chunk_size]
|
| 80 |
+
out = streamer.feed(signal_chunk)
|
| 81 |
+
output_chunks.append(out)
|
| 82 |
+
output_chunks.append(streamer.flush())
|
| 83 |
+
output_audio = torch.cat(output_chunks, dim=-1)
|
| 84 |
+
output_embedding = resnet_model(output_audio)
|
| 85 |
+
|
| 86 |
+
print(
|
| 87 |
+
f"""
|
| 88 |
+
RTF: {streamer.real_time_factor}
|
| 89 |
+
Embedding Distance: {resnet_model.distance_fn(output_embedding, condition_vector)}
|
| 90 |
+
====================================
|
| 91 |
+
"""
|
| 92 |
+
)
|
| 93 |
+
sf.write(
|
| 94 |
+
'output.wav',
|
| 95 |
+
output_audio.numpy().squeeze(),
|
| 96 |
+
16_000,
|
| 97 |
+
)
|
voicebox/scripts/streamer/enroll.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Pipeline for enrolling:
|
| 3 |
+
1. Provide Recording
|
| 4 |
+
2. Convert to 16 kHz
|
| 5 |
+
3. Divide into recordings
|
| 6 |
+
4. Get embeddings for each recording
|
| 7 |
+
5. Find centroid
|
| 8 |
+
6. Save conditioning as some value.
|
| 9 |
+
"""
|
| 10 |
+
import os
|
| 11 |
+
import argbind
|
| 12 |
+
import sounddevice as sd
|
| 13 |
+
import soundfile
|
| 14 |
+
import torch
|
| 15 |
+
import numpy as np
|
| 16 |
+
|
| 17 |
+
import sys
|
| 18 |
+
|
| 19 |
+
sys.path.append('.')
|
| 20 |
+
|
| 21 |
+
from src.constants import CONDITIONING_FILENAME, CONDITIONING_FOLDER
|
| 22 |
+
from src.data import DataProperties
|
| 23 |
+
from src.models import ResNetSE34V2
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
MIN_WINDOWS = 10
|
| 27 |
+
WINDOW_SIZE = 64_000
|
| 28 |
+
BLOCK_SIZE = 256
|
| 29 |
+
|
| 30 |
+
RECORDING_TEXT = """
|
| 31 |
+
This script will record you speaking, and will create an embedding
|
| 32 |
+
to be used for conditioning Voicebox. This will overwrite any previous
|
| 33 |
+
embeddings. We recommend at least 10 seconds of non-stop voice recording.
|
| 34 |
+
Press enter to begin recording. To stop recording, press ctrl-C.
|
| 35 |
+
"""
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_streams(input_name: str, block_size: int) -> sd.InputStream:
|
| 39 |
+
"""
|
| 40 |
+
Gets Input stream object
|
| 41 |
+
"""
|
| 42 |
+
try:
|
| 43 |
+
input_name = int(input_name)
|
| 44 |
+
except ValueError:
|
| 45 |
+
pass
|
| 46 |
+
return (
|
| 47 |
+
sd.InputStream(device=input_name,
|
| 48 |
+
samplerate=DataProperties.get('sample_rate'),
|
| 49 |
+
channels=1,
|
| 50 |
+
blocksize=block_size)
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def record_from_user(input_name: str) -> torch.Tensor:
|
| 55 |
+
input_stream = get_streams(input_name, BLOCK_SIZE)
|
| 56 |
+
input(RECORDING_TEXT)
|
| 57 |
+
input_stream.start()
|
| 58 |
+
all_frames = []
|
| 59 |
+
try:
|
| 60 |
+
print("Recording...")
|
| 61 |
+
while True:
|
| 62 |
+
frames, _ = input_stream.read(BLOCK_SIZE)
|
| 63 |
+
all_frames.append(frames)
|
| 64 |
+
except KeyboardInterrupt:
|
| 65 |
+
print("Stopped Recording.")
|
| 66 |
+
pass
|
| 67 |
+
all_frames = torch.Tensor(np.array(all_frames))
|
| 68 |
+
recording = all_frames.reshape(-1)
|
| 69 |
+
return recording
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_embedding(recording) -> torch.Tensor:
|
| 73 |
+
model = ResNetSE34V2(nOut=512, encoder_type='ASP')
|
| 74 |
+
recording = recording.view(1, -1)
|
| 75 |
+
embedding = model(recording)
|
| 76 |
+
return embedding
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def save(embedding, audio) -> None:
|
| 80 |
+
os.makedirs(CONDITIONING_FOLDER, exist_ok=True)
|
| 81 |
+
torch.save(embedding, CONDITIONING_FILENAME)
|
| 82 |
+
soundfile.write(
|
| 83 |
+
CONDITIONING_FOLDER / 'conditioning_audio.wav',
|
| 84 |
+
audio.detach().cpu(),
|
| 85 |
+
DataProperties.get('sample_rate')
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@argbind.bind(positional=True, without_prefix=True)
|
| 90 |
+
def main(input: str = None):
|
| 91 |
+
"""
|
| 92 |
+
Creating a conditioning vector for VoiceBox from your voice
|
| 93 |
+
|
| 94 |
+
:param input: Index or name of input audio interface. Defaults to current device
|
| 95 |
+
:type input: str, optional
|
| 96 |
+
"""
|
| 97 |
+
recording = record_from_user(input)
|
| 98 |
+
embedding = get_embedding(recording)
|
| 99 |
+
save(embedding, recording)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
if __name__ == "__main__":
|
| 103 |
+
args = argbind.parse_args()
|
| 104 |
+
with argbind.scope(args):
|
| 105 |
+
main()
|
voicebox/scripts/streamer/stream.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argbind
|
| 2 |
+
import sounddevice as sd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import yaml
|
| 5 |
+
import torch
|
| 6 |
+
import os
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
import sys
|
| 10 |
+
import warnings
|
| 11 |
+
|
| 12 |
+
sys.path.append('.')
|
| 13 |
+
warnings.filterwarnings('ignore', category=UserWarning)
|
| 14 |
+
|
| 15 |
+
from src.data.dataproperties import DataProperties
|
| 16 |
+
from src.attacks.online import Streamer, VoiceBoxStreamer
|
| 17 |
+
from src.constants import MODELS_DIR, CONDITIONING_FILENAME
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_streams(input_name: str, output_name: str, block_size: int) -> tuple[sd.InputStream, sd.OutputStream]:
|
| 21 |
+
"""
|
| 22 |
+
Gets Input and Output stream objects
|
| 23 |
+
"""
|
| 24 |
+
try:
|
| 25 |
+
input_name = int(input_name)
|
| 26 |
+
except ValueError:
|
| 27 |
+
pass
|
| 28 |
+
try:
|
| 29 |
+
output_name = int(output_name)
|
| 30 |
+
except ValueError:
|
| 31 |
+
pass
|
| 32 |
+
return (
|
| 33 |
+
sd.InputStream(device=input_name,
|
| 34 |
+
samplerate=DataProperties.get('sample_rate'),
|
| 35 |
+
channels=1,
|
| 36 |
+
blocksize=block_size),
|
| 37 |
+
sd.OutputStream(device=output_name,
|
| 38 |
+
samplerate=DataProperties.get('sample_rate'),
|
| 39 |
+
channels=1,
|
| 40 |
+
blocksize=block_size)
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_model_streamer(device: str, conditioning_path: str) -> Streamer:
|
| 45 |
+
# TODO: Make a good way to query an attack type. For now, I'm going to hard code this.
|
| 46 |
+
model_dir = os.path.join(MODELS_DIR, 'voicebox')
|
| 47 |
+
checkpoint_path = os.path.join(model_dir, 'voicebox_final.pt')
|
| 48 |
+
config_path = os.path.join(model_dir, 'voicebox_final.yaml')
|
| 49 |
+
|
| 50 |
+
with open(config_path) as f:
|
| 51 |
+
config = yaml.safe_load(f)
|
| 52 |
+
|
| 53 |
+
state_dict = torch.load(checkpoint_path, map_location=device)
|
| 54 |
+
condition_tensor = torch.load(conditioning_path, map_location=device)
|
| 55 |
+
model = VoiceBoxStreamer(
|
| 56 |
+
**config
|
| 57 |
+
)
|
| 58 |
+
model.load_state_dict(state_dict)
|
| 59 |
+
model.condition_vector = condition_tensor.reshape(1, 1, -1)
|
| 60 |
+
|
| 61 |
+
streamer = Streamer(
|
| 62 |
+
model=model,
|
| 63 |
+
device=device,
|
| 64 |
+
lookahead_frames=config['bottleneck_lookahead_frames'],
|
| 65 |
+
recurrent=True
|
| 66 |
+
)
|
| 67 |
+
return streamer
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def to_model(x: np.ndarray, device: str) -> torch.Tensor:
|
| 71 |
+
return torch.Tensor(x).view(1, 1, -1).to(device)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def from_model(x: torch.Tensor) -> np.ndarray:
|
| 75 |
+
return x.detach().cpu().view(-1, 1).numpy()
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
@argbind.bind(without_prefix=True)
|
| 79 |
+
def main(
|
| 80 |
+
input: str = None,
|
| 81 |
+
output: str = '',
|
| 82 |
+
device: str = 'cpu',
|
| 83 |
+
num_frames: int = 4,
|
| 84 |
+
pass_through: bool = False,
|
| 85 |
+
conditioning_path: str = CONDITIONING_FILENAME
|
| 86 |
+
):
|
| 87 |
+
f"""
|
| 88 |
+
Uses a streaming implementation of an attack to perturb incoming audio
|
| 89 |
+
|
| 90 |
+
:param input: Index or name of input audio interface. Defaults to current device
|
| 91 |
+
:type input: str, optional
|
| 92 |
+
:param output: Index of name output audio interface. Defaults to 0
|
| 93 |
+
:type output: str, optional
|
| 94 |
+
:param device: Device to processing attack. Should be either 'cpu' or 'cuda:X'
|
| 95 |
+
Defaults to 'cpu'.
|
| 96 |
+
:type device: str, optional
|
| 97 |
+
:param pass_through: If True, the voicebox perturbation is not applied and the input will be
|
| 98 |
+
identical to the output. This is for demo purposes. The input and output audio will
|
| 99 |
+
remain at 16 kHz.
|
| 100 |
+
:type pass_through: bool, optional
|
| 101 |
+
:type device: str, optional
|
| 102 |
+
:param num_frames: Number of overlapping model frames to process at one iteration.
|
| 103 |
+
Defaults to 1
|
| 104 |
+
:type num_frames: int
|
| 105 |
+
:param conditioning_path: Path to conditioning tensor. Default: {CONDITIONING_FILENAME}
|
| 106 |
+
:type conditioning_path: str
|
| 107 |
+
"""
|
| 108 |
+
streamer = get_model_streamer(device, conditioning_path)
|
| 109 |
+
input_stream, output_stream = get_streams(input, output, streamer.hop_length)
|
| 110 |
+
if streamer.win_type in ['hann', 'triangular']:
|
| 111 |
+
input_samples = (num_frames - 1) * streamer.hop_length + streamer.window_length
|
| 112 |
+
else:
|
| 113 |
+
input_samples = streamer.hop_length
|
| 114 |
+
print("Ready to process audio")
|
| 115 |
+
input_stream.start()
|
| 116 |
+
output_stream.start()
|
| 117 |
+
try:
|
| 118 |
+
while True:
|
| 119 |
+
frames, overflow = input_stream.read(input_samples)
|
| 120 |
+
if pass_through:
|
| 121 |
+
output_stream.write(frames)
|
| 122 |
+
continue
|
| 123 |
+
out = streamer.feed(to_model(frames, device))
|
| 124 |
+
out = from_model(out)
|
| 125 |
+
underflow = output_stream.write(out)
|
| 126 |
+
except KeyboardInterrupt:
|
| 127 |
+
print("Stopping")
|
| 128 |
+
input_stream.stop()
|
| 129 |
+
output_stream.stop()
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
if __name__ == "__main__":
|
| 133 |
+
args = argbind.parse_args()
|
| 134 |
+
with argbind.scope(args):
|
| 135 |
+
main()
|
voicebox/setup.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup
|
| 2 |
+
|
| 3 |
+
with open('README.md') as file:
|
| 4 |
+
long_description = file.read()
|
| 5 |
+
|
| 6 |
+
setup(
|
| 7 |
+
name='src',
|
| 8 |
+
description='Code for VoiceBox',
|
| 9 |
+
version='0.0.1',
|
| 10 |
+
author='',
|
| 11 |
+
author_email='',
|
| 12 |
+
url='',
|
| 13 |
+
install_requires=[],
|
| 14 |
+
packages=['src'],
|
| 15 |
+
long_description=long_description,
|
| 16 |
+
long_description_content_type='text.markdown',
|
| 17 |
+
keywords=[],
|
| 18 |
+
classifiers=['License :: OSI Approved :: MIT License'],
|
| 19 |
+
license='MIT'
|
| 20 |
+
)
|
voicebox/src.egg-info/PKG-INFO
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Metadata-Version: 2.1
|
| 2 |
+
Name: src
|
| 3 |
+
Version: 0.0.1
|
| 4 |
+
Summary: Code for VoiceBox
|
| 5 |
+
Home-page:
|
| 6 |
+
Author:
|
| 7 |
+
Author-email:
|
| 8 |
+
License: MIT
|
| 9 |
+
Classifier: License :: OSI Approved :: MIT License
|
| 10 |
+
Description-Content-Type: text.markdown
|
| 11 |
+
License-File: LICENSE
|
| 12 |
+
|
| 13 |
+
<h1 align="center">VoiceBlock</h1>
|
| 14 |
+
<h4 align="center"> Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models</h4>
|
| 15 |
+
<div align="center">
|
| 16 |
+
|
| 17 |
+
[](https://colab.research.google.com/github/???/???.ipynb)
|
| 18 |
+
[](https://master.d3hvhbnf7qxjtf.amplifyapp.com/)
|
| 19 |
+
[](/LICENSE)
|
| 20 |
+
|
| 21 |
+
</div>
|
| 22 |
+
<p align="center"><img src="./figures/vb_color_logo.png" width="200"/></p>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## Contents
|
| 26 |
+
|
| 27 |
+
* <a href="#install">Installation</a>
|
| 28 |
+
* <a href="#reproduce">Reproducing Results</a>
|
| 29 |
+
* <a href="#streamer">Streaming Implementation</a>
|
| 30 |
+
* <a href="#citation">Citation</a>
|
| 31 |
+
|
| 32 |
+
<h2 id="install">Installation</h2>
|
| 33 |
+
|
| 34 |
+
1. Clone the repository:
|
| 35 |
+
|
| 36 |
+
git clone https://github.com/voiceboxneurips/voicebox.git
|
| 37 |
+
|
| 38 |
+
2. We recommend working from a clean environment, e.g. using `conda`:
|
| 39 |
+
|
| 40 |
+
conda create --name voicebox python=3.9
|
| 41 |
+
source activate voicebox
|
| 42 |
+
|
| 43 |
+
3. Install dependencies:
|
| 44 |
+
|
| 45 |
+
cd voicebox
|
| 46 |
+
pip install -r requirements.txt
|
| 47 |
+
pip install -e .
|
| 48 |
+
|
| 49 |
+
4. Grant permissions:
|
| 50 |
+
|
| 51 |
+
chmod -R u+x scripts/
|
| 52 |
+
|
| 53 |
+
<h2 id="reproduce">Reproducing Results</h2>
|
| 54 |
+
|
| 55 |
+
To reproduce our results, first download the corresponding data. Note that to download the [VoxCeleb1 dataset](https://www.robots.ox.ac.uk/~vgg/data/voxceleb/vox1.html), you must register and obtain a username and password.
|
| 56 |
+
|
| 57 |
+
| Task | Dataset (Size) | Command |
|
| 58 |
+
|---|---|---|
|
| 59 |
+
| Objective evaluation | VoxCeleb1 (39G) | `python scripts/downloads/download_voxceleb.py --subset=1 --username=<VGG_USERNAME> --password=<VGG_PASSWORD>` |
|
| 60 |
+
| WER / supplemental evaluations | LibriSpeech `train-clean-360` (23G) | `./scripts/downloads/download_librispeech_eval.sh` |
|
| 61 |
+
| Train attacks | LibriSpeech `train-clean-100` (11G) | `./scripts/downloads/download_librispeech_train.sh` |
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
We provide scripts to reproduce our experiments and save results, including generated audio, to named and time-stamped subdirectories within `runs/`. To reproduce our objective evaluation experiments using pre-trained attacks, run:
|
| 65 |
+
|
| 66 |
+
```
|
| 67 |
+
python scripts/experiments/evaluate.py
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
To reproduce our training, run:
|
| 71 |
+
|
| 72 |
+
```
|
| 73 |
+
python scripts/experiments/train.py
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
<h2 id="streamer">Streaming Implementation</h2>
|
| 77 |
+
|
| 78 |
+
As a proof of concept, we provide a streaming implementation of VoiceBox capable of modifying user audio in real-time. Here, we provide installation instructions for MacOS and Ubuntu 20.04.
|
| 79 |
+
|
| 80 |
+
<h3 id="streamer-mac">MacOS</h3>
|
| 81 |
+
|
| 82 |
+
See video below:
|
| 83 |
+
|
| 84 |
+
<a href="https://youtu.be/LcNjO5E7F3E">
|
| 85 |
+
<p align="center"><img src="./figures/demo_thumbnail.png" width="500"/></p>
|
| 86 |
+
</a>
|
| 87 |
+
|
| 88 |
+
<h3 id="streamer-ubuntu">Ubuntu 20.04</h3>
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
1. Open a terminal and follow the [installation instructions](#install) above. Change directory to the root of this repository.
|
| 92 |
+
|
| 93 |
+
2. Run the following command:
|
| 94 |
+
|
| 95 |
+
pacmd load-module module-null-sink sink_name=voicebox sink_properties=device.description=voicebox
|
| 96 |
+
|
| 97 |
+
If you are using PipeWire instead of PulseAudio:
|
| 98 |
+
|
| 99 |
+
pactl load-module module-null-sink media.class=Audio/Sink sink_name=voicebox sink_properties=device.description=voicebox
|
| 100 |
+
|
| 101 |
+
PulseAudio is the default on Ubuntu. If you haven't changed your system defaults, you are probably using PulseAudio. This will add "voicebox" as an output device. Select it as the input to your chosen audio software.
|
| 102 |
+
|
| 103 |
+
3. Find which audio device to read and write from. In your conda environment, run:
|
| 104 |
+
|
| 105 |
+
python -m sounddevice
|
| 106 |
+
|
| 107 |
+
You will get output similar to this:
|
| 108 |
+
|
| 109 |
+
0 HDA Intel HDMI: 0 (hw:0,3), ALSA (0 in, 8 out)
|
| 110 |
+
1 HDA Intel HDMI: 1 (hw:0,7), ALSA (0 in, 8 out)
|
| 111 |
+
2 HDA Intel HDMI: 2 (hw:0,8), ALSA (0 in, 8 out)
|
| 112 |
+
3 HDA Intel HDMI: 3 (hw:0,9), ALSA (0 in, 8 out)
|
| 113 |
+
4 HDA Intel HDMI: 4 (hw:0,10), ALSA (0 in, 8 out)
|
| 114 |
+
5 hdmi, ALSA (0 in, 8 out)
|
| 115 |
+
6 jack, ALSA (2 in, 2 out)
|
| 116 |
+
7 pipewire, ALSA (64 in, 64 out)
|
| 117 |
+
8 pulse, ALSA (32 in, 32 out)
|
| 118 |
+
* 9 default, ALSA (32 in, 32 out)
|
| 119 |
+
|
| 120 |
+
In this example, we are going to route the audio through PipeWire (channel 7). This will be our INPUT_NUM and OUTPUT_NUM
|
| 121 |
+
|
| 122 |
+
4. First, we need to create a conditioning embedding. To do this, run the enrollment script and follow its on-screen instructions:
|
| 123 |
+
|
| 124 |
+
python scripts/streamer/enroll.py --input INPUT_NUM
|
| 125 |
+
|
| 126 |
+
5. We can now use the streamer. Run:
|
| 127 |
+
|
| 128 |
+
python scripts/stream.py --input INPUT_NUM --output OUTPUT_NUM
|
| 129 |
+
|
| 130 |
+
6. Once the streamer is running, open `pavucontrol`.
|
| 131 |
+
|
| 132 |
+
a. In `pavucontrol`, go to the "Playback" tab and find "ALSA pug-in [python3.9]: ALSA Playback on". Set the output to "voicebox".
|
| 133 |
+
|
| 134 |
+
b. Then, go to "Recording" and find "ALSA pug-in [python3.9]: ALSA Playback from", and set the input to your desired microphone device.
|
| 135 |
+
|
| 136 |
+
<h2 id="citation">Citation</h2>
|
| 137 |
+
|
| 138 |
+
If you use this your academic research, please cite the following:
|
| 139 |
+
|
| 140 |
+
```
|
| 141 |
+
@inproceedings{authors2022voicelock,
|
| 142 |
+
title={VoiceBlock: Privacy through Real-Time Adversarial Attacks with Audio-to-Audio Models},
|
| 143 |
+
author={Patrick O'Reilly, Andreas Bugler, Keshav Bhandari, Max Morrison, Bryan Pardo},
|
| 144 |
+
booktitle={Neural Information Processing Systems},
|
| 145 |
+
month={November},
|
| 146 |
+
year={2022}
|
| 147 |
+
}
|
| 148 |
+
```
|
voicebox/src.egg-info/SOURCES.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LICENSE
|
| 2 |
+
README.md
|
| 3 |
+
setup.py
|
| 4 |
+
src/__init__.py
|
| 5 |
+
src/constants.py
|
| 6 |
+
src.egg-info/PKG-INFO
|
| 7 |
+
src.egg-info/SOURCES.txt
|
| 8 |
+
src.egg-info/dependency_links.txt
|
| 9 |
+
src.egg-info/top_level.txt
|
voicebox/src.egg-info/dependency_links.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
|
voicebox/src.egg-info/top_level.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
src
|
voicebox/src/__init__.py
ADDED
|
File without changes
|