🤗 Models & Datasets | 📕 Documentation | 📖 Blog | 📃 Paper
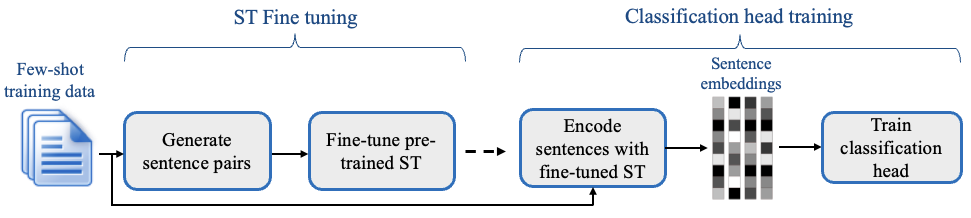
# SetFit - Efficient Few-shot Learning with Sentence Transformers SetFit is an efficient and prompt-free framework for few-shot fine-tuning of [Sentence Transformers](https://sbert.net/). It achieves high accuracy with little labeled data - for instance, with only 8 labeled examples per class on the Customer Reviews sentiment dataset, SetFit is competitive with fine-tuning RoBERTa Large on the full training set of 3k examples 🤯! Compared to other few-shot learning methods, SetFit has several unique features: * 🗣 **No prompts or verbalizers:** Current techniques for few-shot fine-tuning require handcrafted prompts or verbalizers to convert examples into a format suitable for the underlying language model. SetFit dispenses with prompts altogether by generating rich embeddings directly from text examples. * 🏎 **Fast to train:** SetFit doesn't require large-scale models like T0 or GPT-3 to achieve high accuracy. As a result, it is typically an order of magnitude (or more) faster to train and run inference with. * 🌎 **Multilingual support**: SetFit can be used with any [Sentence Transformer](https://huggingface.co/models?library=sentence-transformers&sort=downloads) on the Hub, which means you can classify text in multiple languages by simply fine-tuning a multilingual checkpoint. Check out the [SetFit Documentation](https://huggingface.co/docs/setfit) for more information! ## Installation Download and install `setfit` by running: ```bash pip install setfit ``` If you want the bleeding-edge version instead, install from source by running: ```bash pip install git+https://github.com/huggingface/setfit.git ``` ## Usage The [quickstart](https://huggingface.co/docs/setfit/quickstart) is a good place to learn about training, saving, loading, and performing inference with SetFit models. For more examples, check out the [`notebooks`](https://github.com/huggingface/setfit/tree/main/notebooks) directory, the [tutorials](https://huggingface.co/docs/setfit/tutorials/overview), or the [how-to guides](https://huggingface.co/docs/setfit/how_to/overview). ### Training a SetFit model `setfit` is integrated with the [Hugging Face Hub](https://huggingface.co/) and provides two main classes: * [`SetFitModel`](https://huggingface.co/docs/setfit/reference/main#setfit.SetFitModel): a wrapper that combines a pretrained body from `sentence_transformers` and a classification head from either [`scikit-learn`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) or [`SetFitHead`](https://huggingface.co/docs/setfit/reference/main#setfit.SetFitHead) (a differentiable head built upon `PyTorch` with similar APIs to `sentence_transformers`). * [`Trainer`](https://huggingface.co/docs/setfit/reference/trainer#setfit.Trainer): a helper class that wraps the fine-tuning process of SetFit. Here is a simple end-to-end training example using the default classification head from `scikit-learn`: ```python from datasets import load_dataset from setfit import SetFitModel, Trainer, TrainingArguments, sample_dataset # Load a dataset from the Hugging Face Hub dataset = load_dataset("sst2") # Simulate the few-shot regime by sampling 8 examples per class train_dataset = sample_dataset(dataset["train"], label_column="label", num_samples=8) eval_dataset = dataset["validation"].select(range(100)) test_dataset = dataset["validation"].select(range(100, len(dataset["validation"]))) # Load a SetFit model from Hub model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2") args = TrainingArguments( batch_size=16, num_epochs=4, evaluation_strategy="epoch", save_strategy="epoch", load_best_model_at_end=True, ) trainer = Trainer( model=model, args=args, train_dataset=train_dataset, eval_dataset=eval_dataset, metric="accuracy", column_mapping={"sentence": "text", "label": "label"} # Map dataset columns to text/label expected by trainer ) # Train and evaluate trainer.train() metrics = trainer.evaluate(test_dataset) print(metrics) # {'accuracy': 0.8691709844559585} # Push model to the Hub trainer.push_to_hub("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2") # Download from Hub model = SetFitModel.from_pretrained("tomaarsen/setfit-paraphrase-mpnet-base-v2-sst2") # Run inference preds = model.predict(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"]) print(preds) # tensor([1, 0], dtype=torch.int32) ``` ## Reproducing the results from the paper We provide scripts to reproduce the results for SetFit and various baselines presented in Table 2 of our paper. Check out the setup and training instructions in the [`scripts/`](scripts/) directory. ## Developer installation To run the code in this project, first create a Python virtual environment using e.g. Conda: ```bash conda create -n setfit python=3.9 && conda activate setfit ``` Then install the base requirements with: ```bash pip install -e '.[dev]' ``` This will install mandatory packages for SetFit like `datasets` as well as development packages like `black` and `isort` that we use to ensure consistent code formatting. ### Formatting your code We use `black` and `isort` to ensure consistent code formatting. After following the installation steps, you can check your code locally by running: ``` make style && make quality ``` ## Project structure ``` ├── LICENSE ├── Makefile <- Makefile with commands like `make style` or `make tests` ├── README.md <- The top-level README for developers using this project. ├── docs <- Documentation source ├── notebooks <- Jupyter notebooks. ├── final_results <- Model predictions from the paper ├── scripts <- Scripts for training and inference ├── setup.cfg <- Configuration file to define package metadata ├── setup.py <- Make this project pip installable with `pip install -e` ├── src <- Source code for SetFit └── tests <- Unit tests ``` ## Related work * [https://github.com/pmbaumgartner/setfit](https://github.com/pmbaumgartner/setfit) - A scikit-learn API version of SetFit. * [jxpress/setfit-pytorch-lightning](https://github.com/jxpress/setfit-pytorch-lightning) - A PyTorch Lightning implementation of SetFit. * [davidberenstein1957/spacy-setfit](https://github.com/davidberenstein1957/spacy-setfit) - An easy and intuitive approach to use SetFit in combination with spaCy. ## Citation ```bibtex @misc{https://doi.org/10.48550/arxiv.2209.11055, doi = {10.48550/ARXIV.2209.11055}, url = {https://arxiv.org/abs/2209.11055}, author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren}, keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Efficient Few-Shot Learning Without Prompts}, publisher = {arXiv}, year = {2022}, copyright = {Creative Commons Attribution 4.0 International} } ```