Spaces:
Sleeping

Sleeping
Upload 49 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +6 -0
- TripoSR +0 -1
- TripoSR/.gitignore +164 -0
- TripoSR/LICENSE +21 -0
- TripoSR/README.md +80 -0
- TripoSR/__pycache__/obj_gen.cpython-310.pyc +0 -0
- TripoSR/examples/captured.jpeg +3 -0
- TripoSR/examples/captured_p.png +3 -0
- TripoSR/examples/chair.png +0 -0
- TripoSR/examples/flamingo.png +0 -0
- TripoSR/examples/hamburger.png +0 -0
- TripoSR/examples/horse.png +0 -0
- TripoSR/examples/iso_house.png +3 -0
- TripoSR/examples/marble.png +0 -0
- TripoSR/examples/police_woman.png +0 -0
- TripoSR/examples/poly_fox.png +0 -0
- TripoSR/examples/robot.png +0 -0
- TripoSR/examples/stripes.png +0 -0
- TripoSR/examples/teapot.png +0 -0
- TripoSR/examples/tiger_girl.png +0 -0
- TripoSR/examples/unicorn.png +0 -0
- TripoSR/figures/comparison800.gif +3 -0
- TripoSR/figures/scatter-comparison.png +0 -0
- TripoSR/figures/teaser800.gif +3 -0
- TripoSR/figures/visual_comparisons.jpg +3 -0
- TripoSR/gradio_app.py +187 -0
- TripoSR/obj_gen.py +92 -0
- TripoSR/output/0/input.png +0 -0
- TripoSR/output/0/mesh.obj +0 -0
- TripoSR/requirements.txt +9 -0
- TripoSR/run.py +162 -0
- TripoSR/tsr/__pycache__/system.cpython-310.pyc +0 -0
- TripoSR/tsr/__pycache__/utils.cpython-310.pyc +0 -0
- TripoSR/tsr/models/__pycache__/isosurface.cpython-310.pyc +0 -0
- TripoSR/tsr/models/__pycache__/nerf_renderer.cpython-310.pyc +0 -0
- TripoSR/tsr/models/__pycache__/network_utils.cpython-310.pyc +0 -0
- TripoSR/tsr/models/isosurface.py +52 -0
- TripoSR/tsr/models/nerf_renderer.py +180 -0
- TripoSR/tsr/models/network_utils.py +124 -0
- TripoSR/tsr/models/tokenizers/__pycache__/image.cpython-310.pyc +0 -0
- TripoSR/tsr/models/tokenizers/__pycache__/triplane.cpython-310.pyc +0 -0
- TripoSR/tsr/models/tokenizers/image.py +66 -0
- TripoSR/tsr/models/tokenizers/triplane.py +45 -0
- TripoSR/tsr/models/transformer/__pycache__/attention.cpython-310.pyc +0 -0
- TripoSR/tsr/models/transformer/__pycache__/basic_transformer_block.cpython-310.pyc +0 -0
- TripoSR/tsr/models/transformer/__pycache__/transformer_1d.cpython-310.pyc +0 -0
- TripoSR/tsr/models/transformer/attention.py +653 -0
- TripoSR/tsr/models/transformer/basic_transformer_block.py +334 -0
- TripoSR/tsr/models/transformer/transformer_1d.py +219 -0
- TripoSR/tsr/system.py +203 -0
.gitattributes
CHANGED
|
@@ -34,3 +34,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
wheel/torchmcubes-0.1.0-cp310-cp310-linux_x86_64.whl filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
wheel/torchmcubes-0.1.0-cp310-cp310-linux_x86_64.whl filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
TripoSR/examples/captured_p.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
TripoSR/examples/captured.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
TripoSR/examples/iso_house.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
TripoSR/figures/comparison800.gif filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
TripoSR/figures/teaser800.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
TripoSR/figures/visual_comparisons.jpg filter=lfs diff=lfs merge=lfs -text
|
TripoSR
DELETED
|
@@ -1 +0,0 @@
|
|
| 1 |
-
Subproject commit 8e51fec8095c9eae20e6ea7c9aef6368c5631a21
|
|
|
|
|
|
TripoSR/.gitignore
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
| 161 |
+
|
| 162 |
+
# default output directory
|
| 163 |
+
output/
|
| 164 |
+
outputs/
|
TripoSR/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Tripo AI & Stability AI
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
TripoSR/README.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TripoSR <a href="https://huggingface.co/stabilityai/TripoSR"><img src="https://img.shields.io/badge/%F0%9F%A4%97%20Model_Card-Huggingface-orange"></a> <a href="https://huggingface.co/spaces/stabilityai/TripoSR"><img src="https://img.shields.io/badge/%F0%9F%A4%97%20Gradio%20Demo-Huggingface-orange"></a> <a href="https://arxiv.org/abs/2403.02151"><img src="https://img.shields.io/badge/Arxiv-2403.02151-B31B1B.svg"></a>
|
| 2 |
+
|
| 3 |
+
<div align="center">
|
| 4 |
+
<img src="figures/teaser800.gif" alt="Teaser Video">
|
| 5 |
+
</div>
|
| 6 |
+
|
| 7 |
+
This is the official codebase for **TripoSR**, a state-of-the-art open-source model for **fast** feedforward 3D reconstruction from a single image, collaboratively developed by [Tripo AI](https://www.tripo3d.ai/) and [Stability AI](https://stability.ai/).
|
| 8 |
+
<br><br>
|
| 9 |
+
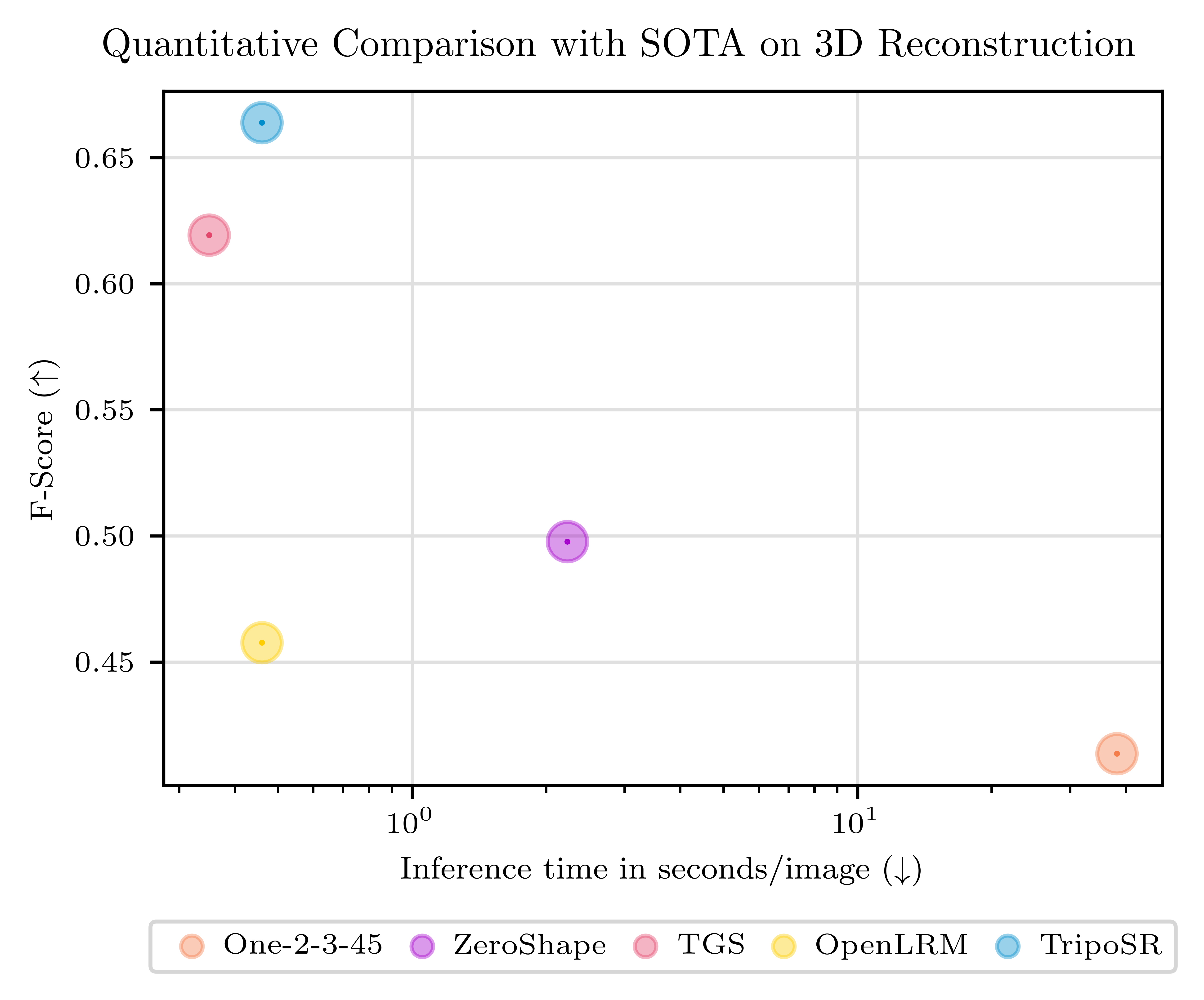
Leveraging the principles of the [Large Reconstruction Model (LRM)](https://yiconghong.me/LRM/), TripoSR brings to the table key advancements that significantly boost both the speed and quality of 3D reconstruction. Our model is distinguished by its ability to rapidly process inputs, generating high-quality 3D models in less than 0.5 seconds on an NVIDIA A100 GPU. TripoSR has exhibited superior performance in both qualitative and quantitative evaluations, outperforming other open-source alternatives across multiple public datasets. The figures below illustrate visual comparisons and metrics showcasing TripoSR's performance relative to other leading models. Details about the model architecture, training process, and comparisons can be found in this [technical report](https://arxiv.org/abs/2403.02151).
|
| 10 |
+
|
| 11 |
+
<!--
|
| 12 |
+
<div align="center">
|
| 13 |
+
<img src="figures/comparison800.gif" alt="Teaser Video">
|
| 14 |
+
</div>
|
| 15 |
+
-->
|
| 16 |
+
<p align="center">
|
| 17 |
+
<img width="800" src="figures/visual_comparisons.jpg"/>
|
| 18 |
+
</p>
|
| 19 |
+
|
| 20 |
+
<p align="center">
|
| 21 |
+
<img width="450" src="figures/scatter-comparison.png"/>
|
| 22 |
+
</p>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
The model is released under the MIT license, which includes the source code, pretrained models, and an interactive online demo. Our goal is to empower researchers, developers, and creatives to push the boundaries of what's possible in 3D generative AI and 3D content creation.
|
| 26 |
+
|
| 27 |
+
## Getting Started
|
| 28 |
+
### Installation
|
| 29 |
+
- Python >= 3.8
|
| 30 |
+
- Install CUDA if available
|
| 31 |
+
- Install PyTorch according to your platform: [https://pytorch.org/get-started/locally/](https://pytorch.org/get-started/locally/) **[Please make sure that the locally-installed CUDA major version matches the PyTorch-shipped CUDA major version. For example if you have CUDA 11.x installed, make sure to install PyTorch compiled with CUDA 11.x.]**
|
| 32 |
+
- Update setuptools by `pip install --upgrade setuptools`
|
| 33 |
+
- Install other dependencies by `pip install -r requirements.txt`
|
| 34 |
+
|
| 35 |
+
### Manual Inference
|
| 36 |
+
```sh
|
| 37 |
+
python run.py examples/chair.png --output-dir output/
|
| 38 |
+
```
|
| 39 |
+
This will save the reconstructed 3D model to `output/`. You can also specify more than one image path separated by spaces. The default options takes about **6GB VRAM** for a single image input.
|
| 40 |
+
|
| 41 |
+
For detailed usage of this script, use `python run.py --help`.
|
| 42 |
+
|
| 43 |
+
### Local Gradio App
|
| 44 |
+
Install Gradio:
|
| 45 |
+
```sh
|
| 46 |
+
pip install gradio
|
| 47 |
+
```
|
| 48 |
+
Start the Gradio App:
|
| 49 |
+
```sh
|
| 50 |
+
python gradio_app.py
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## Troubleshooting
|
| 54 |
+
> AttributeError: module 'torchmcubes_module' has no attribute 'mcubes_cuda'
|
| 55 |
+
|
| 56 |
+
or
|
| 57 |
+
|
| 58 |
+
> torchmcubes was not compiled with CUDA support, use CPU version instead.
|
| 59 |
+
|
| 60 |
+
This is because `torchmcubes` is compiled without CUDA support. Please make sure that
|
| 61 |
+
|
| 62 |
+
- The locally-installed CUDA major version matches the PyTorch-shipped CUDA major version. For example if you have CUDA 11.x installed, make sure to install PyTorch compiled with CUDA 11.x.
|
| 63 |
+
- `setuptools>=49.6.0`. If not, upgrade by `pip install --upgrade setuptools`.
|
| 64 |
+
|
| 65 |
+
Then re-install `torchmcubes` by:
|
| 66 |
+
|
| 67 |
+
```sh
|
| 68 |
+
pip uninstall torchmcubes
|
| 69 |
+
pip install git+https://github.com/tatsy/torchmcubes.git
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
## Citation
|
| 73 |
+
```BibTeX
|
| 74 |
+
@article{TripoSR2024,
|
| 75 |
+
title={TripoSR: Fast 3D Object Reconstruction from a Single Image},
|
| 76 |
+
author={Tochilkin, Dmitry and Pankratz, David and Liu, Zexiang and Huang, Zixuan and and Letts, Adam and Li, Yangguang and Liang, Ding and Laforte, Christian and Jampani, Varun and Cao, Yan-Pei},
|
| 77 |
+
journal={arXiv preprint arXiv:2403.02151},
|
| 78 |
+
year={2024}
|
| 79 |
+
}
|
| 80 |
+
```
|
TripoSR/__pycache__/obj_gen.cpython-310.pyc
ADDED
|
Binary file (2.39 kB). View file
|
|
|
TripoSR/examples/captured.jpeg
ADDED

|
Git LFS Details
|
TripoSR/examples/captured_p.png
ADDED

|
Git LFS Details
|
TripoSR/examples/chair.png
ADDED

|
TripoSR/examples/flamingo.png
ADDED

|
TripoSR/examples/hamburger.png
ADDED

|
TripoSR/examples/horse.png
ADDED

|
TripoSR/examples/iso_house.png
ADDED

|
Git LFS Details
|
TripoSR/examples/marble.png
ADDED

|
TripoSR/examples/police_woman.png
ADDED

|
TripoSR/examples/poly_fox.png
ADDED

|
TripoSR/examples/robot.png
ADDED

|
TripoSR/examples/stripes.png
ADDED

|
TripoSR/examples/teapot.png
ADDED

|
TripoSR/examples/tiger_girl.png
ADDED

|
TripoSR/examples/unicorn.png
ADDED

|
TripoSR/figures/comparison800.gif
ADDED

|
Git LFS Details
|
TripoSR/figures/scatter-comparison.png
ADDED
|
TripoSR/figures/teaser800.gif
ADDED

|
Git LFS Details
|
TripoSR/figures/visual_comparisons.jpg
ADDED

|
Git LFS Details
|
TripoSR/gradio_app.py
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import tempfile
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
import gradio as gr
|
| 7 |
+
import numpy as np
|
| 8 |
+
import rembg
|
| 9 |
+
import torch
|
| 10 |
+
from PIL import Image
|
| 11 |
+
from functools import partial
|
| 12 |
+
|
| 13 |
+
from tsr.system import TSR
|
| 14 |
+
from tsr.utils import remove_background, resize_foreground, to_gradio_3d_orientation
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
if torch.cuda.is_available():
|
| 20 |
+
device = "cuda:0"
|
| 21 |
+
else:
|
| 22 |
+
device = "cpu"
|
| 23 |
+
|
| 24 |
+
model = TSR.from_pretrained(
|
| 25 |
+
"stabilityai/TripoSR",
|
| 26 |
+
config_name="config.yaml",
|
| 27 |
+
weight_name="model.ckpt",
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# adjust the chunk size to balance between speed and memory usage
|
| 31 |
+
model.renderer.set_chunk_size(8192)
|
| 32 |
+
model.to(device)
|
| 33 |
+
|
| 34 |
+
rembg_session = rembg.new_session()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def check_input_image(input_image):
|
| 38 |
+
if input_image is None:
|
| 39 |
+
raise gr.Error("No image uploaded!")
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def preprocess(input_image, do_remove_background, foreground_ratio):
|
| 43 |
+
def fill_background(image):
|
| 44 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 45 |
+
image = image[:, :, :3] * image[:, :, 3:4] + (1 - image[:, :, 3:4]) * 0.5
|
| 46 |
+
image = Image.fromarray((image * 255.0).astype(np.uint8))
|
| 47 |
+
return image
|
| 48 |
+
|
| 49 |
+
if do_remove_background:
|
| 50 |
+
image = input_image.convert("RGB")
|
| 51 |
+
image = remove_background(image, rembg_session)
|
| 52 |
+
image = resize_foreground(image, foreground_ratio)
|
| 53 |
+
image = fill_background(image)
|
| 54 |
+
else:
|
| 55 |
+
image = input_image
|
| 56 |
+
if image.mode == "RGBA":
|
| 57 |
+
image = fill_background(image)
|
| 58 |
+
return image
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def generate(image, mc_resolution, formats=["obj", "glb"]):
|
| 62 |
+
scene_codes = model(image, device=device)
|
| 63 |
+
mesh = model.extract_mesh(scene_codes, resolution=mc_resolution)[0]
|
| 64 |
+
mesh = to_gradio_3d_orientation(mesh)
|
| 65 |
+
rv = []
|
| 66 |
+
for format in formats:
|
| 67 |
+
mesh_path = tempfile.NamedTemporaryFile(suffix=f".{format}", delete=False)
|
| 68 |
+
mesh.export(mesh_path.name)
|
| 69 |
+
rv.append(mesh_path.name)
|
| 70 |
+
return rv
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def run_example(image_pil):
|
| 74 |
+
preprocessed = preprocess(image_pil, False, 0.9)
|
| 75 |
+
mesh_name_obj, mesh_name_glb = generate(preprocessed, 256, ["obj", "glb"])
|
| 76 |
+
return preprocessed, mesh_name_obj, mesh_name_glb
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
with gr.Blocks(title="TripoSR") as interface:
|
| 80 |
+
gr.Markdown(
|
| 81 |
+
"""
|
| 82 |
+
# TripoSR Demo
|
| 83 |
+
[TripoSR](https://github.com/VAST-AI-Research/TripoSR) is a state-of-the-art open-source model for **fast** feedforward 3D reconstruction from a single image, collaboratively developed by [Tripo AI](https://www.tripo3d.ai/) and [Stability AI](https://stability.ai/).
|
| 84 |
+
|
| 85 |
+
**Tips:**
|
| 86 |
+
1. If you find the result is unsatisfied, please try to change the foreground ratio. It might improve the results.
|
| 87 |
+
2. You can disable "Remove Background" for the provided examples since they have been already preprocessed.
|
| 88 |
+
3. Otherwise, please disable "Remove Background" option only if your input image is RGBA with transparent background, image contents are centered and occupy more than 70% of image width or height.
|
| 89 |
+
"""
|
| 90 |
+
)
|
| 91 |
+
with gr.Row(variant="panel"):
|
| 92 |
+
with gr.Column():
|
| 93 |
+
with gr.Row():
|
| 94 |
+
input_image = gr.Image(
|
| 95 |
+
label="Input Image",
|
| 96 |
+
image_mode="RGBA",
|
| 97 |
+
sources="upload",
|
| 98 |
+
type="pil",
|
| 99 |
+
elem_id="content_image",
|
| 100 |
+
)
|
| 101 |
+
processed_image = gr.Image(label="Processed Image", interactive=False)
|
| 102 |
+
with gr.Row():
|
| 103 |
+
with gr.Group():
|
| 104 |
+
do_remove_background = gr.Checkbox(
|
| 105 |
+
label="Remove Background", value=True
|
| 106 |
+
)
|
| 107 |
+
foreground_ratio = gr.Slider(
|
| 108 |
+
label="Foreground Ratio",
|
| 109 |
+
minimum=0.5,
|
| 110 |
+
maximum=1.0,
|
| 111 |
+
value=0.85,
|
| 112 |
+
step=0.05,
|
| 113 |
+
)
|
| 114 |
+
mc_resolution = gr.Slider(
|
| 115 |
+
label="Marching Cubes Resolution",
|
| 116 |
+
minimum=32,
|
| 117 |
+
maximum=320,
|
| 118 |
+
value=256,
|
| 119 |
+
step=32
|
| 120 |
+
)
|
| 121 |
+
with gr.Row():
|
| 122 |
+
submit = gr.Button("Generate", elem_id="generate", variant="primary")
|
| 123 |
+
with gr.Column():
|
| 124 |
+
with gr.Tab("OBJ"):
|
| 125 |
+
output_model_obj = gr.Model3D(
|
| 126 |
+
label="Output Model (OBJ Format)",
|
| 127 |
+
interactive=False,
|
| 128 |
+
)
|
| 129 |
+
gr.Markdown("Note: The model shown here is flipped. Download to get correct results.")
|
| 130 |
+
with gr.Tab("GLB"):
|
| 131 |
+
output_model_glb = gr.Model3D(
|
| 132 |
+
label="Output Model (GLB Format)",
|
| 133 |
+
interactive=False,
|
| 134 |
+
)
|
| 135 |
+
gr.Markdown("Note: The model shown here has a darker appearance. Download to get correct results.")
|
| 136 |
+
with gr.Row(variant="panel"):
|
| 137 |
+
gr.Examples(
|
| 138 |
+
examples=[
|
| 139 |
+
"examples/hamburger.png",
|
| 140 |
+
"examples/poly_fox.png",
|
| 141 |
+
"examples/robot.png",
|
| 142 |
+
"examples/teapot.png",
|
| 143 |
+
"examples/tiger_girl.png",
|
| 144 |
+
"examples/horse.png",
|
| 145 |
+
"examples/flamingo.png",
|
| 146 |
+
"examples/unicorn.png",
|
| 147 |
+
"examples/chair.png",
|
| 148 |
+
"examples/iso_house.png",
|
| 149 |
+
"examples/marble.png",
|
| 150 |
+
"examples/police_woman.png",
|
| 151 |
+
"examples/captured_p.png",
|
| 152 |
+
],
|
| 153 |
+
inputs=[input_image],
|
| 154 |
+
outputs=[processed_image, output_model_obj, output_model_glb],
|
| 155 |
+
cache_examples=False,
|
| 156 |
+
fn=partial(run_example),
|
| 157 |
+
label="Examples",
|
| 158 |
+
examples_per_page=20,
|
| 159 |
+
)
|
| 160 |
+
submit.click(fn=check_input_image, inputs=[input_image]).success(
|
| 161 |
+
fn=preprocess,
|
| 162 |
+
inputs=[input_image, do_remove_background, foreground_ratio],
|
| 163 |
+
outputs=[processed_image],
|
| 164 |
+
).success(
|
| 165 |
+
fn=generate,
|
| 166 |
+
inputs=[processed_image, mc_resolution],
|
| 167 |
+
outputs=[output_model_obj, output_model_glb],
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
if __name__ == '__main__':
|
| 173 |
+
parser = argparse.ArgumentParser()
|
| 174 |
+
parser.add_argument('--username', type=str, default=None, help='Username for authentication')
|
| 175 |
+
parser.add_argument('--password', type=str, default=None, help='Password for authentication')
|
| 176 |
+
parser.add_argument('--port', type=int, default=7860, help='Port to run the server listener on')
|
| 177 |
+
parser.add_argument("--listen", action='store_true', help="launch gradio with 0.0.0.0 as server name, allowing to respond to network requests")
|
| 178 |
+
parser.add_argument("--share", action='store_true', help="use share=True for gradio and make the UI accessible through their site")
|
| 179 |
+
parser.add_argument("--queuesize", type=int, default=1, help="launch gradio queue max_size")
|
| 180 |
+
args = parser.parse_args()
|
| 181 |
+
interface.queue(max_size=args.queuesize)
|
| 182 |
+
interface.launch(
|
| 183 |
+
auth=(args.username, args.password) if (args.username and args.password) else None,
|
| 184 |
+
share=args.share,
|
| 185 |
+
server_name="0.0.0.0" if args.listen else None,
|
| 186 |
+
server_port=args.port
|
| 187 |
+
)
|
TripoSR/obj_gen.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import os
|
| 3 |
+
import tempfile
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import rembg
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from functools import partial
|
| 11 |
+
|
| 12 |
+
from tsr.system import TSR
|
| 13 |
+
from tsr.utils import remove_background, resize_foreground, to_gradio_3d_orientation
|
| 14 |
+
|
| 15 |
+
import argparse
|
| 16 |
+
from dotenv import load_dotenv
|
| 17 |
+
|
| 18 |
+
load_dotenv()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
device = "cpu"
|
| 23 |
+
|
| 24 |
+
model = TSR.from_pretrained(
|
| 25 |
+
"stabilityai/TripoSR",
|
| 26 |
+
config_name="config.yaml",
|
| 27 |
+
weight_name="model.ckpt",
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# adjust the chunk size to balance between speed and memory usage
|
| 31 |
+
model.renderer.set_chunk_size(8192)
|
| 32 |
+
model.to(device)
|
| 33 |
+
|
| 34 |
+
rembg_session = rembg.new_session()
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def preprocess(input_image, do_remove_background, foreground_ratio):
|
| 40 |
+
def fill_background(image):
|
| 41 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 42 |
+
image = image[:, :, :3] * image[:, :, 3:4] + (1 - image[:, :, 3:4]) * 0.5
|
| 43 |
+
image = Image.fromarray((image * 255.0).astype(np.uint8))
|
| 44 |
+
return image
|
| 45 |
+
|
| 46 |
+
if do_remove_background:
|
| 47 |
+
image = input_image.convert("RGB")
|
| 48 |
+
image = remove_background(image, rembg_session)
|
| 49 |
+
image = resize_foreground(image, foreground_ratio)
|
| 50 |
+
image = fill_background(image)
|
| 51 |
+
else:
|
| 52 |
+
image = input_image
|
| 53 |
+
if image.mode == "RGBA":
|
| 54 |
+
image = fill_background(image)
|
| 55 |
+
return image
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def generate(image, mc_resolution, formats=["obj", "glb"], path="output.obj"):
|
| 59 |
+
scene_codes = model(image, device=device)
|
| 60 |
+
mesh = model.extract_mesh(scene_codes, resolution=mc_resolution)[0]
|
| 61 |
+
mesh = to_gradio_3d_orientation(mesh)
|
| 62 |
+
rv = []
|
| 63 |
+
for format in formats:
|
| 64 |
+
mesh_path = path.replace(".obj", f".{format}")
|
| 65 |
+
mesh.export(mesh_path)
|
| 66 |
+
rv.append(mesh_path)
|
| 67 |
+
return rv
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def run_example(image_pil):
|
| 71 |
+
preprocessed = preprocess(image_pil, False, 0.9)
|
| 72 |
+
mesh_name_obj, mesh_name_glb = generate(preprocessed, 256, ["obj", "glb"])
|
| 73 |
+
return preprocessed, mesh_name_obj, mesh_name_glb
|
| 74 |
+
|
| 75 |
+
def generate_obj_from_image(image_pil, path="output.obj"):
|
| 76 |
+
# Preprocess the image without removing the background and with a foreground ratio of 0.9
|
| 77 |
+
preprocessed = preprocess(image_pil, True, 0.9)
|
| 78 |
+
|
| 79 |
+
# Generate the mesh and get the paths to the .obj and .glb files
|
| 80 |
+
mesh_paths = generate(preprocessed, 256, ["obj"], path)
|
| 81 |
+
|
| 82 |
+
# Return the path to the .obj file
|
| 83 |
+
return mesh_paths[0]
|
| 84 |
+
|
| 85 |
+
if __name__ == "__main__":
|
| 86 |
+
# run a test
|
| 87 |
+
image_path = "output.png"
|
| 88 |
+
image = Image.open(image_path)
|
| 89 |
+
generate_obj_from_image(image, "output.obj")
|
| 90 |
+
# move the .obj file to the output directory
|
| 91 |
+
|
| 92 |
+
|
TripoSR/output/0/input.png
ADDED

|
TripoSR/output/0/mesh.obj
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
TripoSR/requirements.txt
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
omegaconf==2.3.0
|
| 2 |
+
Pillow==10.1.0
|
| 3 |
+
einops==0.7.0
|
| 4 |
+
git+https://github.com/tatsy/torchmcubes.git
|
| 5 |
+
transformers==4.35.0
|
| 6 |
+
trimesh==4.0.5
|
| 7 |
+
rembg
|
| 8 |
+
huggingface-hub
|
| 9 |
+
imageio[ffmpeg]
|
TripoSR/run.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import rembg
|
| 8 |
+
import torch
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
from tsr.system import TSR
|
| 12 |
+
from tsr.utils import remove_background, resize_foreground, save_video
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Timer:
|
| 16 |
+
def __init__(self):
|
| 17 |
+
self.items = {}
|
| 18 |
+
self.time_scale = 1000.0 # ms
|
| 19 |
+
self.time_unit = "ms"
|
| 20 |
+
|
| 21 |
+
def start(self, name: str) -> None:
|
| 22 |
+
if torch.cuda.is_available():
|
| 23 |
+
torch.cuda.synchronize()
|
| 24 |
+
self.items[name] = time.time()
|
| 25 |
+
logging.info(f"{name} ...")
|
| 26 |
+
|
| 27 |
+
def end(self, name: str) -> float:
|
| 28 |
+
if name not in self.items:
|
| 29 |
+
return
|
| 30 |
+
if torch.cuda.is_available():
|
| 31 |
+
torch.cuda.synchronize()
|
| 32 |
+
start_time = self.items.pop(name)
|
| 33 |
+
delta = time.time() - start_time
|
| 34 |
+
t = delta * self.time_scale
|
| 35 |
+
logging.info(f"{name} finished in {t:.2f}{self.time_unit}.")
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
timer = Timer()
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
logging.basicConfig(
|
| 42 |
+
format="%(asctime)s - %(levelname)s - %(message)s", level=logging.INFO
|
| 43 |
+
)
|
| 44 |
+
parser = argparse.ArgumentParser()
|
| 45 |
+
parser.add_argument("image", type=str, nargs="+", help="Path to input image(s).")
|
| 46 |
+
parser.add_argument(
|
| 47 |
+
"--device",
|
| 48 |
+
default="cuda:0",
|
| 49 |
+
type=str,
|
| 50 |
+
help="Device to use. If no CUDA-compatible device is found, will fallback to 'cpu'. Default: 'cuda:0'",
|
| 51 |
+
)
|
| 52 |
+
parser.add_argument(
|
| 53 |
+
"--pretrained-model-name-or-path",
|
| 54 |
+
default="stabilityai/TripoSR",
|
| 55 |
+
type=str,
|
| 56 |
+
help="Path to the pretrained model. Could be either a huggingface model id is or a local path. Default: 'stabilityai/TripoSR'",
|
| 57 |
+
)
|
| 58 |
+
parser.add_argument(
|
| 59 |
+
"--chunk-size",
|
| 60 |
+
default=8192,
|
| 61 |
+
type=int,
|
| 62 |
+
help="Evaluation chunk size for surface extraction and rendering. Smaller chunk size reduces VRAM usage but increases computation time. 0 for no chunking. Default: 8192",
|
| 63 |
+
)
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--mc-resolution",
|
| 66 |
+
default=256,
|
| 67 |
+
type=int,
|
| 68 |
+
help="Marching cubes grid resolution. Default: 256"
|
| 69 |
+
)
|
| 70 |
+
parser.add_argument(
|
| 71 |
+
"--no-remove-bg",
|
| 72 |
+
action="store_true",
|
| 73 |
+
help="If specified, the background will NOT be automatically removed from the input image, and the input image should be an RGB image with gray background and properly-sized foreground. Default: false",
|
| 74 |
+
)
|
| 75 |
+
parser.add_argument(
|
| 76 |
+
"--foreground-ratio",
|
| 77 |
+
default=0.85,
|
| 78 |
+
type=float,
|
| 79 |
+
help="Ratio of the foreground size to the image size. Only used when --no-remove-bg is not specified. Default: 0.85",
|
| 80 |
+
)
|
| 81 |
+
parser.add_argument(
|
| 82 |
+
"--output-dir",
|
| 83 |
+
default="output/",
|
| 84 |
+
type=str,
|
| 85 |
+
help="Output directory to save the results. Default: 'output/'",
|
| 86 |
+
)
|
| 87 |
+
parser.add_argument(
|
| 88 |
+
"--model-save-format",
|
| 89 |
+
default="obj",
|
| 90 |
+
type=str,
|
| 91 |
+
choices=["obj", "glb"],
|
| 92 |
+
help="Format to save the extracted mesh. Default: 'obj'",
|
| 93 |
+
)
|
| 94 |
+
parser.add_argument(
|
| 95 |
+
"--render",
|
| 96 |
+
action="store_true",
|
| 97 |
+
help="If specified, save a NeRF-rendered video. Default: false",
|
| 98 |
+
)
|
| 99 |
+
args = parser.parse_args()
|
| 100 |
+
|
| 101 |
+
output_dir = args.output_dir
|
| 102 |
+
os.makedirs(output_dir, exist_ok=True)
|
| 103 |
+
|
| 104 |
+
device = args.device
|
| 105 |
+
if not torch.cuda.is_available():
|
| 106 |
+
device = "cpu"
|
| 107 |
+
|
| 108 |
+
timer.start("Initializing model")
|
| 109 |
+
model = TSR.from_pretrained(
|
| 110 |
+
args.pretrained_model_name_or_path,
|
| 111 |
+
config_name="config.yaml",
|
| 112 |
+
weight_name="model.ckpt",
|
| 113 |
+
)
|
| 114 |
+
model.renderer.set_chunk_size(args.chunk_size)
|
| 115 |
+
model.to(device)
|
| 116 |
+
timer.end("Initializing model")
|
| 117 |
+
|
| 118 |
+
timer.start("Processing images")
|
| 119 |
+
images = []
|
| 120 |
+
|
| 121 |
+
if args.no_remove_bg:
|
| 122 |
+
rembg_session = None
|
| 123 |
+
else:
|
| 124 |
+
rembg_session = rembg.new_session()
|
| 125 |
+
|
| 126 |
+
for i, image_path in enumerate(args.image):
|
| 127 |
+
if args.no_remove_bg:
|
| 128 |
+
image = np.array(Image.open(image_path).convert("RGB"))
|
| 129 |
+
else:
|
| 130 |
+
image = remove_background(Image.open(image_path), rembg_session)
|
| 131 |
+
image = resize_foreground(image, args.foreground_ratio)
|
| 132 |
+
image = np.array(image).astype(np.float32) / 255.0
|
| 133 |
+
image = image[:, :, :3] * image[:, :, 3:4] + (1 - image[:, :, 3:4]) * 0.5
|
| 134 |
+
image = Image.fromarray((image * 255.0).astype(np.uint8))
|
| 135 |
+
if not os.path.exists(os.path.join(output_dir, str(i))):
|
| 136 |
+
os.makedirs(os.path.join(output_dir, str(i)))
|
| 137 |
+
image.save(os.path.join(output_dir, str(i), f"input.png"))
|
| 138 |
+
images.append(image)
|
| 139 |
+
timer.end("Processing images")
|
| 140 |
+
|
| 141 |
+
for i, image in enumerate(images):
|
| 142 |
+
logging.info(f"Running image {i + 1}/{len(images)} ...")
|
| 143 |
+
|
| 144 |
+
timer.start("Running model")
|
| 145 |
+
with torch.no_grad():
|
| 146 |
+
scene_codes = model([image], device=device)
|
| 147 |
+
timer.end("Running model")
|
| 148 |
+
|
| 149 |
+
if args.render:
|
| 150 |
+
timer.start("Rendering")
|
| 151 |
+
render_images = model.render(scene_codes, n_views=30, return_type="pil")
|
| 152 |
+
for ri, render_image in enumerate(render_images[0]):
|
| 153 |
+
render_image.save(os.path.join(output_dir, str(i), f"render_{ri:03d}.png"))
|
| 154 |
+
save_video(
|
| 155 |
+
render_images[0], os.path.join(output_dir, str(i), f"render.mp4"), fps=30
|
| 156 |
+
)
|
| 157 |
+
timer.end("Rendering")
|
| 158 |
+
|
| 159 |
+
timer.start("Exporting mesh")
|
| 160 |
+
meshes = model.extract_mesh(scene_codes, resolution=args.mc_resolution)
|
| 161 |
+
meshes[0].export(os.path.join(output_dir, str(i), f"mesh.{args.model_save_format}"))
|
| 162 |
+
timer.end("Exporting mesh")
|
TripoSR/tsr/__pycache__/system.cpython-310.pyc
ADDED
|
Binary file (5.15 kB). View file
|
|
|
TripoSR/tsr/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (13.5 kB). View file
|
|
|
TripoSR/tsr/models/__pycache__/isosurface.cpython-310.pyc
ADDED
|
Binary file (2.23 kB). View file
|
|
|
TripoSR/tsr/models/__pycache__/nerf_renderer.cpython-310.pyc
ADDED
|
Binary file (5.28 kB). View file
|
|
|
TripoSR/tsr/models/__pycache__/network_utils.cpython-310.pyc
ADDED
|
Binary file (3.41 kB). View file
|
|
|
TripoSR/tsr/models/isosurface.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Callable, Optional, Tuple
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from torchmcubes import marching_cubes
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class IsosurfaceHelper(nn.Module):
|
| 10 |
+
points_range: Tuple[float, float] = (0, 1)
|
| 11 |
+
|
| 12 |
+
@property
|
| 13 |
+
def grid_vertices(self) -> torch.FloatTensor:
|
| 14 |
+
raise NotImplementedError
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class MarchingCubeHelper(IsosurfaceHelper):
|
| 18 |
+
def __init__(self, resolution: int) -> None:
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.resolution = resolution
|
| 21 |
+
self.mc_func: Callable = marching_cubes
|
| 22 |
+
self._grid_vertices: Optional[torch.FloatTensor] = None
|
| 23 |
+
|
| 24 |
+
@property
|
| 25 |
+
def grid_vertices(self) -> torch.FloatTensor:
|
| 26 |
+
if self._grid_vertices is None:
|
| 27 |
+
# keep the vertices on CPU so that we can support very large resolution
|
| 28 |
+
x, y, z = (
|
| 29 |
+
torch.linspace(*self.points_range, self.resolution),
|
| 30 |
+
torch.linspace(*self.points_range, self.resolution),
|
| 31 |
+
torch.linspace(*self.points_range, self.resolution),
|
| 32 |
+
)
|
| 33 |
+
x, y, z = torch.meshgrid(x, y, z, indexing="ij")
|
| 34 |
+
verts = torch.cat(
|
| 35 |
+
[x.reshape(-1, 1), y.reshape(-1, 1), z.reshape(-1, 1)], dim=-1
|
| 36 |
+
).reshape(-1, 3)
|
| 37 |
+
self._grid_vertices = verts
|
| 38 |
+
return self._grid_vertices
|
| 39 |
+
|
| 40 |
+
def forward(
|
| 41 |
+
self,
|
| 42 |
+
level: torch.FloatTensor,
|
| 43 |
+
) -> Tuple[torch.FloatTensor, torch.LongTensor]:
|
| 44 |
+
level = -level.view(self.resolution, self.resolution, self.resolution)
|
| 45 |
+
try:
|
| 46 |
+
v_pos, t_pos_idx = self.mc_func(level.detach(), 0.0)
|
| 47 |
+
except AttributeError:
|
| 48 |
+
print("torchmcubes was not compiled with CUDA support, use CPU version instead.")
|
| 49 |
+
v_pos, t_pos_idx = self.mc_func(level.detach().cpu(), 0.0)
|
| 50 |
+
v_pos = v_pos[..., [2, 1, 0]]
|
| 51 |
+
v_pos = v_pos / (self.resolution - 1.0)
|
| 52 |
+
return v_pos.to(level.device), t_pos_idx.to(level.device)
|
TripoSR/tsr/models/nerf_renderer.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Dict
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from einops import rearrange, reduce
|
| 7 |
+
|
| 8 |
+
from ..utils import (
|
| 9 |
+
BaseModule,
|
| 10 |
+
chunk_batch,
|
| 11 |
+
get_activation,
|
| 12 |
+
rays_intersect_bbox,
|
| 13 |
+
scale_tensor,
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TriplaneNeRFRenderer(BaseModule):
|
| 18 |
+
@dataclass
|
| 19 |
+
class Config(BaseModule.Config):
|
| 20 |
+
radius: float
|
| 21 |
+
|
| 22 |
+
feature_reduction: str = "concat"
|
| 23 |
+
density_activation: str = "trunc_exp"
|
| 24 |
+
density_bias: float = -1.0
|
| 25 |
+
color_activation: str = "sigmoid"
|
| 26 |
+
num_samples_per_ray: int = 128
|
| 27 |
+
randomized: bool = False
|
| 28 |
+
|
| 29 |
+
cfg: Config
|
| 30 |
+
|
| 31 |
+
def configure(self) -> None:
|
| 32 |
+
assert self.cfg.feature_reduction in ["concat", "mean"]
|
| 33 |
+
self.chunk_size = 0
|
| 34 |
+
|
| 35 |
+
def set_chunk_size(self, chunk_size: int):
|
| 36 |
+
assert (
|
| 37 |
+
chunk_size >= 0
|
| 38 |
+
), "chunk_size must be a non-negative integer (0 for no chunking)."
|
| 39 |
+
self.chunk_size = chunk_size
|
| 40 |
+
|
| 41 |
+
def query_triplane(
|
| 42 |
+
self,
|
| 43 |
+
decoder: torch.nn.Module,
|
| 44 |
+
positions: torch.Tensor,
|
| 45 |
+
triplane: torch.Tensor,
|
| 46 |
+
) -> Dict[str, torch.Tensor]:
|
| 47 |
+
input_shape = positions.shape[:-1]
|
| 48 |
+
positions = positions.view(-1, 3)
|
| 49 |
+
|
| 50 |
+
# positions in (-radius, radius)
|
| 51 |
+
# normalized to (-1, 1) for grid sample
|
| 52 |
+
positions = scale_tensor(
|
| 53 |
+
positions, (-self.cfg.radius, self.cfg.radius), (-1, 1)
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
def _query_chunk(x):
|
| 57 |
+
indices2D: torch.Tensor = torch.stack(
|
| 58 |
+
(x[..., [0, 1]], x[..., [0, 2]], x[..., [1, 2]]),
|
| 59 |
+
dim=-3,
|
| 60 |
+
)
|
| 61 |
+
out: torch.Tensor = F.grid_sample(
|
| 62 |
+
rearrange(triplane, "Np Cp Hp Wp -> Np Cp Hp Wp", Np=3),
|
| 63 |
+
rearrange(indices2D, "Np N Nd -> Np () N Nd", Np=3),
|
| 64 |
+
align_corners=False,
|
| 65 |
+
mode="bilinear",
|
| 66 |
+
)
|
| 67 |
+
if self.cfg.feature_reduction == "concat":
|
| 68 |
+
out = rearrange(out, "Np Cp () N -> N (Np Cp)", Np=3)
|
| 69 |
+
elif self.cfg.feature_reduction == "mean":
|
| 70 |
+
out = reduce(out, "Np Cp () N -> N Cp", Np=3, reduction="mean")
|
| 71 |
+
else:
|
| 72 |
+
raise NotImplementedError
|
| 73 |
+
|
| 74 |
+
net_out: Dict[str, torch.Tensor] = decoder(out)
|
| 75 |
+
return net_out
|
| 76 |
+
|
| 77 |
+
if self.chunk_size > 0:
|
| 78 |
+
net_out = chunk_batch(_query_chunk, self.chunk_size, positions)
|
| 79 |
+
else:
|
| 80 |
+
net_out = _query_chunk(positions)
|
| 81 |
+
|
| 82 |
+
net_out["density_act"] = get_activation(self.cfg.density_activation)(
|
| 83 |
+
net_out["density"] + self.cfg.density_bias
|
| 84 |
+
)
|
| 85 |
+
net_out["color"] = get_activation(self.cfg.color_activation)(
|
| 86 |
+
net_out["features"]
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
net_out = {k: v.view(*input_shape, -1) for k, v in net_out.items()}
|
| 90 |
+
|
| 91 |
+
return net_out
|
| 92 |
+
|
| 93 |
+
def _forward(
|
| 94 |
+
self,
|
| 95 |
+
decoder: torch.nn.Module,
|
| 96 |
+
triplane: torch.Tensor,
|
| 97 |
+
rays_o: torch.Tensor,
|
| 98 |
+
rays_d: torch.Tensor,
|
| 99 |
+
**kwargs,
|
| 100 |
+
):
|
| 101 |
+
rays_shape = rays_o.shape[:-1]
|
| 102 |
+
rays_o = rays_o.view(-1, 3)
|
| 103 |
+
rays_d = rays_d.view(-1, 3)
|
| 104 |
+
n_rays = rays_o.shape[0]
|
| 105 |
+
|
| 106 |
+
t_near, t_far, rays_valid = rays_intersect_bbox(rays_o, rays_d, self.cfg.radius)
|
| 107 |
+
t_near, t_far = t_near[rays_valid], t_far[rays_valid]
|
| 108 |
+
|
| 109 |
+
t_vals = torch.linspace(
|
| 110 |
+
0, 1, self.cfg.num_samples_per_ray + 1, device=triplane.device
|
| 111 |
+
)
|
| 112 |
+
t_mid = (t_vals[:-1] + t_vals[1:]) / 2.0
|
| 113 |
+
z_vals = t_near * (1 - t_mid[None]) + t_far * t_mid[None] # (N_rays, N_samples)
|
| 114 |
+
|
| 115 |
+
xyz = (
|
| 116 |
+
rays_o[:, None, :] + z_vals[..., None] * rays_d[..., None, :]
|
| 117 |
+
) # (N_rays, N_sample, 3)
|
| 118 |
+
|
| 119 |
+
mlp_out = self.query_triplane(
|
| 120 |
+
decoder=decoder,
|
| 121 |
+
positions=xyz,
|
| 122 |
+
triplane=triplane,
|
| 123 |
+
)
|
| 124 |
+
|
| 125 |
+
eps = 1e-10
|
| 126 |
+
# deltas = z_vals[:, 1:] - z_vals[:, :-1] # (N_rays, N_samples)
|
| 127 |
+
deltas = t_vals[1:] - t_vals[:-1] # (N_rays, N_samples)
|
| 128 |
+
alpha = 1 - torch.exp(
|
| 129 |
+
-deltas * mlp_out["density_act"][..., 0]
|
| 130 |
+
) # (N_rays, N_samples)
|
| 131 |
+
accum_prod = torch.cat(
|
| 132 |
+
[
|
| 133 |
+
torch.ones_like(alpha[:, :1]),
|
| 134 |
+
torch.cumprod(1 - alpha[:, :-1] + eps, dim=-1),
|
| 135 |
+
],
|
| 136 |
+
dim=-1,
|
| 137 |
+
)
|
| 138 |
+
weights = alpha * accum_prod # (N_rays, N_samples)
|
| 139 |
+
comp_rgb_ = (weights[..., None] * mlp_out["color"]).sum(dim=-2) # (N_rays, 3)
|
| 140 |
+
opacity_ = weights.sum(dim=-1) # (N_rays)
|
| 141 |
+
|
| 142 |
+
comp_rgb = torch.zeros(
|
| 143 |
+
n_rays, 3, dtype=comp_rgb_.dtype, device=comp_rgb_.device
|
| 144 |
+
)
|
| 145 |
+
opacity = torch.zeros(n_rays, dtype=opacity_.dtype, device=opacity_.device)
|
| 146 |
+
comp_rgb[rays_valid] = comp_rgb_
|
| 147 |
+
opacity[rays_valid] = opacity_
|
| 148 |
+
|
| 149 |
+
comp_rgb += 1 - opacity[..., None]
|
| 150 |
+
comp_rgb = comp_rgb.view(*rays_shape, 3)
|
| 151 |
+
|
| 152 |
+
return comp_rgb
|
| 153 |
+
|
| 154 |
+
def forward(
|
| 155 |
+
self,
|
| 156 |
+
decoder: torch.nn.Module,
|
| 157 |
+
triplane: torch.Tensor,
|
| 158 |
+
rays_o: torch.Tensor,
|
| 159 |
+
rays_d: torch.Tensor,
|
| 160 |
+
) -> Dict[str, torch.Tensor]:
|
| 161 |
+
if triplane.ndim == 4:
|
| 162 |
+
comp_rgb = self._forward(decoder, triplane, rays_o, rays_d)
|
| 163 |
+
else:
|
| 164 |
+
comp_rgb = torch.stack(
|
| 165 |
+
[
|
| 166 |
+
self._forward(decoder, triplane[i], rays_o[i], rays_d[i])
|
| 167 |
+
for i in range(triplane.shape[0])
|
| 168 |
+
],
|
| 169 |
+
dim=0,
|
| 170 |
+
)
|
| 171 |
+
|
| 172 |
+
return comp_rgb
|
| 173 |
+
|
| 174 |
+
def train(self, mode=True):
|
| 175 |
+
self.randomized = mode and self.cfg.randomized
|
| 176 |
+
return super().train(mode=mode)
|
| 177 |
+
|
| 178 |
+
def eval(self):
|
| 179 |
+
self.randomized = False
|
| 180 |
+
return super().eval()
|
TripoSR/tsr/models/network_utils.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
from typing import Optional
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
|
| 8 |
+
from ..utils import BaseModule
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class TriplaneUpsampleNetwork(BaseModule):
|
| 12 |
+
@dataclass
|
| 13 |
+
class Config(BaseModule.Config):
|
| 14 |
+
in_channels: int
|
| 15 |
+
out_channels: int
|
| 16 |
+
|
| 17 |
+
cfg: Config
|
| 18 |
+
|
| 19 |
+
def configure(self) -> None:
|
| 20 |
+
self.upsample = nn.ConvTranspose2d(
|
| 21 |
+
self.cfg.in_channels, self.cfg.out_channels, kernel_size=2, stride=2
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
def forward(self, triplanes: torch.Tensor) -> torch.Tensor:
|
| 25 |
+
triplanes_up = rearrange(
|
| 26 |
+
self.upsample(
|
| 27 |
+
rearrange(triplanes, "B Np Ci Hp Wp -> (B Np) Ci Hp Wp", Np=3)
|
| 28 |
+
),
|
| 29 |
+
"(B Np) Co Hp Wp -> B Np Co Hp Wp",
|
| 30 |
+
Np=3,
|
| 31 |
+
)
|
| 32 |
+
return triplanes_up
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class NeRFMLP(BaseModule):
|
| 36 |
+
@dataclass
|
| 37 |
+
class Config(BaseModule.Config):
|
| 38 |
+
in_channels: int
|
| 39 |
+
n_neurons: int
|
| 40 |
+
n_hidden_layers: int
|
| 41 |
+
activation: str = "relu"
|
| 42 |
+
bias: bool = True
|
| 43 |
+
weight_init: Optional[str] = "kaiming_uniform"
|
| 44 |
+
bias_init: Optional[str] = None
|
| 45 |
+
|
| 46 |
+
cfg: Config
|
| 47 |
+
|
| 48 |
+
def configure(self) -> None:
|
| 49 |
+
layers = [
|
| 50 |
+
self.make_linear(
|
| 51 |
+
self.cfg.in_channels,
|
| 52 |
+
self.cfg.n_neurons,
|
| 53 |
+
bias=self.cfg.bias,
|
| 54 |
+
weight_init=self.cfg.weight_init,
|
| 55 |
+
bias_init=self.cfg.bias_init,
|
| 56 |
+
),
|
| 57 |
+
self.make_activation(self.cfg.activation),
|
| 58 |
+
]
|
| 59 |
+
for i in range(self.cfg.n_hidden_layers - 1):
|
| 60 |
+
layers += [
|
| 61 |
+
self.make_linear(
|
| 62 |
+
self.cfg.n_neurons,
|
| 63 |
+
self.cfg.n_neurons,
|
| 64 |
+
bias=self.cfg.bias,
|
| 65 |
+
weight_init=self.cfg.weight_init,
|
| 66 |
+
bias_init=self.cfg.bias_init,
|
| 67 |
+
),
|
| 68 |
+
self.make_activation(self.cfg.activation),
|
| 69 |
+
]
|
| 70 |
+
layers += [
|
| 71 |
+
self.make_linear(
|
| 72 |
+
self.cfg.n_neurons,
|
| 73 |
+
4, # density 1 + features 3
|
| 74 |
+
bias=self.cfg.bias,
|
| 75 |
+
weight_init=self.cfg.weight_init,
|
| 76 |
+
bias_init=self.cfg.bias_init,
|
| 77 |
+
)
|
| 78 |
+
]
|
| 79 |
+
self.layers = nn.Sequential(*layers)
|
| 80 |
+
|
| 81 |
+
def make_linear(
|
| 82 |
+
self,
|
| 83 |
+
dim_in,
|
| 84 |
+
dim_out,
|
| 85 |
+
bias=True,
|
| 86 |
+
weight_init=None,
|
| 87 |
+
bias_init=None,
|
| 88 |
+
):
|
| 89 |
+
layer = nn.Linear(dim_in, dim_out, bias=bias)
|
| 90 |
+
|
| 91 |
+
if weight_init is None:
|
| 92 |
+
pass
|
| 93 |
+
elif weight_init == "kaiming_uniform":
|
| 94 |
+
torch.nn.init.kaiming_uniform_(layer.weight, nonlinearity="relu")
|
| 95 |
+
else:
|
| 96 |
+
raise NotImplementedError
|
| 97 |
+
|
| 98 |
+
if bias:
|
| 99 |
+
if bias_init is None:
|
| 100 |
+
pass
|
| 101 |
+
elif bias_init == "zero":
|
| 102 |
+
torch.nn.init.zeros_(layer.bias)
|
| 103 |
+
else:
|
| 104 |
+
raise NotImplementedError
|
| 105 |
+
|
| 106 |
+
return layer
|
| 107 |
+
|
| 108 |
+
def make_activation(self, activation):
|
| 109 |
+
if activation == "relu":
|
| 110 |
+
return nn.ReLU(inplace=True)
|
| 111 |
+
elif activation == "silu":
|
| 112 |
+
return nn.SiLU(inplace=True)
|
| 113 |
+
else:
|
| 114 |
+
raise NotImplementedError
|
| 115 |
+
|
| 116 |
+
def forward(self, x):
|
| 117 |
+
inp_shape = x.shape[:-1]
|
| 118 |
+
x = x.reshape(-1, x.shape[-1])
|
| 119 |
+
|
| 120 |
+
features = self.layers(x)
|
| 121 |
+
features = features.reshape(*inp_shape, -1)
|
| 122 |
+
out = {"density": features[..., 0:1], "features": features[..., 1:4]}
|
| 123 |
+
|
| 124 |
+
return out
|
TripoSR/tsr/models/tokenizers/__pycache__/image.cpython-310.pyc
ADDED
|
Binary file (2.38 kB). View file
|
|
|
TripoSR/tsr/models/tokenizers/__pycache__/triplane.cpython-310.pyc
ADDED
|
Binary file (1.76 kB). View file
|
|
|
TripoSR/tsr/models/tokenizers/image.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from dataclasses import dataclass
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from einops import rearrange
|
| 6 |
+
from huggingface_hub import hf_hub_download
|
| 7 |
+
from transformers.models.vit.modeling_vit import ViTModel
|
| 8 |
+
|
| 9 |
+
from ...utils import BaseModule
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class DINOSingleImageTokenizer(BaseModule):
|
| 13 |
+
@dataclass
|
| 14 |
+
class Config(BaseModule.Config):
|
| 15 |
+
pretrained_model_name_or_path: str = "facebook/dino-vitb16"
|
| 16 |
+
enable_gradient_checkpointing: bool = False
|
| 17 |
+
|
| 18 |
+
cfg: Config
|
| 19 |
+
|
| 20 |
+
def configure(self) -> None:
|
| 21 |
+
self.model: ViTModel = ViTModel(
|
| 22 |
+
ViTModel.config_class.from_pretrained(
|
| 23 |
+
hf_hub_download(
|
| 24 |
+
repo_id=self.cfg.pretrained_model_name_or_path,
|
| 25 |
+
filename="config.json",
|
| 26 |
+
)
|
| 27 |
+
)
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
if self.cfg.enable_gradient_checkpointing:
|
| 31 |
+
self.model.encoder.gradient_checkpointing = True
|
| 32 |
+
|
| 33 |
+
self.register_buffer(
|
| 34 |
+
"image_mean",
|
| 35 |
+
torch.as_tensor([0.485, 0.456, 0.406]).reshape(1, 1, 3, 1, 1),
|
| 36 |
+
persistent=False,
|
| 37 |
+
)
|
| 38 |
+
self.register_buffer(
|
| 39 |
+
"image_std",
|
| 40 |
+
torch.as_tensor([0.229, 0.224, 0.225]).reshape(1, 1, 3, 1, 1),
|
| 41 |
+
persistent=False,
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
def forward(self, images: torch.FloatTensor, **kwargs) -> torch.FloatTensor:
|
| 45 |
+
packed = False
|
| 46 |
+
if images.ndim == 4:
|
| 47 |
+
packed = True
|
| 48 |
+
images = images.unsqueeze(1)
|
| 49 |
+
|
| 50 |
+
batch_size, n_input_views = images.shape[:2]
|
| 51 |
+
images = (images - self.image_mean) / self.image_std
|
| 52 |
+
out = self.model(
|
| 53 |
+
rearrange(images, "B N C H W -> (B N) C H W"), interpolate_pos_encoding=True
|
| 54 |
+
)
|
| 55 |
+
local_features, global_features = out.last_hidden_state, out.pooler_output
|
| 56 |
+
local_features = local_features.permute(0, 2, 1)
|
| 57 |
+
local_features = rearrange(
|
| 58 |
+
local_features, "(B N) Ct Nt -> B N Ct Nt", B=batch_size
|
| 59 |
+
)
|
| 60 |
+
if packed:
|
| 61 |
+
local_features = local_features.squeeze(1)
|
| 62 |
+
|
| 63 |
+
return local_features
|
| 64 |
+
|
| 65 |
+
def detokenize(self, *args, **kwargs):
|
| 66 |
+
raise NotImplementedError
|
TripoSR/tsr/models/tokenizers/triplane.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from dataclasses import dataclass
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
from einops import rearrange, repeat
|
| 7 |
+
|
| 8 |
+
from ...utils import BaseModule
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Triplane1DTokenizer(BaseModule):
|
| 12 |
+
@dataclass
|
| 13 |
+
class Config(BaseModule.Config):
|
| 14 |
+
plane_size: int
|
| 15 |
+
num_channels: int
|
| 16 |
+
|
| 17 |
+
cfg: Config
|
| 18 |
+
|
| 19 |
+
def configure(self) -> None:
|
| 20 |
+
self.embeddings = nn.Parameter(
|
| 21 |
+
torch.randn(
|
| 22 |
+
(3, self.cfg.num_channels, self.cfg.plane_size, self.cfg.plane_size),
|
| 23 |
+
dtype=torch.float32,
|
| 24 |
+
)
|
| 25 |
+
* 1
|
| 26 |
+
/ math.sqrt(self.cfg.num_channels)
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
def forward(self, batch_size: int) -> torch.Tensor:
|
| 30 |
+
return rearrange(
|
| 31 |
+
repeat(self.embeddings, "Np Ct Hp Wp -> B Np Ct Hp Wp", B=batch_size),
|
| 32 |
+
"B Np Ct Hp Wp -> B Ct (Np Hp Wp)",
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
def detokenize(self, tokens: torch.Tensor) -> torch.Tensor:
|
| 36 |
+
batch_size, Ct, Nt = tokens.shape
|
| 37 |
+
assert Nt == self.cfg.plane_size**2 * 3
|
| 38 |
+
assert Ct == self.cfg.num_channels
|
| 39 |
+
return rearrange(
|
| 40 |
+
tokens,
|
| 41 |
+
"B Ct (Np Hp Wp) -> B Np Ct Hp Wp",
|
| 42 |
+
Np=3,
|
| 43 |
+
Hp=self.cfg.plane_size,
|
| 44 |
+
Wp=self.cfg.plane_size,
|
| 45 |
+
)
|
TripoSR/tsr/models/transformer/__pycache__/attention.cpython-310.pyc
ADDED
|
Binary file (15.3 kB). View file
|
|
|
TripoSR/tsr/models/transformer/__pycache__/basic_transformer_block.cpython-310.pyc
ADDED
|
Binary file (9.61 kB). View file
|
|
|
TripoSR/tsr/models/transformer/__pycache__/transformer_1d.cpython-310.pyc
ADDED
|
Binary file (4.87 kB). View file
|
|
|
TripoSR/tsr/models/transformer/attention.py
ADDED
|
@@ -0,0 +1,653 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# --------
|
| 16 |
+
#
|
| 17 |
+
# Modified 2024 by the Tripo AI and Stability AI Team.
|
| 18 |
+
#
|
| 19 |
+
# Copyright (c) 2024 Tripo AI & Stability AI
|
| 20 |
+
#
|
| 21 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 22 |
+
# of this software and associated documentation files (the "Software"), to deal
|
| 23 |
+
# in the Software without restriction, including without limitation the rights
|
| 24 |
+
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 25 |
+
# copies of the Software, and to permit persons to whom the Software is
|
| 26 |
+
# furnished to do so, subject to the following conditions:
|
| 27 |
+
#
|
| 28 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 29 |
+
# copies or substantial portions of the Software.
|
| 30 |
+
#
|
| 31 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 32 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 33 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 34 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 35 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 36 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 37 |
+
# SOFTWARE.
|
| 38 |
+
|
| 39 |
+
from typing import Optional
|
| 40 |
+
|
| 41 |
+
import torch
|
| 42 |
+
import torch.nn.functional as F
|
| 43 |
+
from torch import nn
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class Attention(nn.Module):
|
| 47 |
+
r"""
|
| 48 |
+
A cross attention layer.
|
| 49 |
+
|
| 50 |
+
Parameters:
|
| 51 |
+
query_dim (`int`):
|
| 52 |
+
The number of channels in the query.
|
| 53 |
+
cross_attention_dim (`int`, *optional*):
|
| 54 |
+
The number of channels in the encoder_hidden_states. If not given, defaults to `query_dim`.
|
| 55 |
+
heads (`int`, *optional*, defaults to 8):
|
| 56 |
+
The number of heads to use for multi-head attention.
|
| 57 |
+
dim_head (`int`, *optional*, defaults to 64):
|
| 58 |
+
The number of channels in each head.
|
| 59 |
+
dropout (`float`, *optional*, defaults to 0.0):
|
| 60 |
+
The dropout probability to use.
|
| 61 |
+
bias (`bool`, *optional*, defaults to False):
|
| 62 |
+
Set to `True` for the query, key, and value linear layers to contain a bias parameter.
|
| 63 |
+
upcast_attention (`bool`, *optional*, defaults to False):
|
| 64 |
+
Set to `True` to upcast the attention computation to `float32`.
|
| 65 |
+
upcast_softmax (`bool`, *optional*, defaults to False):
|
| 66 |
+
Set to `True` to upcast the softmax computation to `float32`.
|
| 67 |
+
cross_attention_norm (`str`, *optional*, defaults to `None`):
|
| 68 |
+
The type of normalization to use for the cross attention. Can be `None`, `layer_norm`, or `group_norm`.
|
| 69 |
+
cross_attention_norm_num_groups (`int`, *optional*, defaults to 32):
|
| 70 |
+
The number of groups to use for the group norm in the cross attention.
|
| 71 |
+
added_kv_proj_dim (`int`, *optional*, defaults to `None`):
|
| 72 |
+
The number of channels to use for the added key and value projections. If `None`, no projection is used.
|
| 73 |
+
norm_num_groups (`int`, *optional*, defaults to `None`):
|
| 74 |
+
The number of groups to use for the group norm in the attention.
|
| 75 |
+
spatial_norm_dim (`int`, *optional*, defaults to `None`):
|
| 76 |
+
The number of channels to use for the spatial normalization.
|
| 77 |
+
out_bias (`bool`, *optional*, defaults to `True`):
|
| 78 |
+
Set to `True` to use a bias in the output linear layer.
|
| 79 |
+
scale_qk (`bool`, *optional*, defaults to `True`):
|
| 80 |
+
Set to `True` to scale the query and key by `1 / sqrt(dim_head)`.
|
| 81 |
+
only_cross_attention (`bool`, *optional*, defaults to `False`):
|
| 82 |
+
Set to `True` to only use cross attention and not added_kv_proj_dim. Can only be set to `True` if
|
| 83 |
+
`added_kv_proj_dim` is not `None`.
|
| 84 |
+
eps (`float`, *optional*, defaults to 1e-5):
|
| 85 |
+
An additional value added to the denominator in group normalization that is used for numerical stability.
|
| 86 |
+
rescale_output_factor (`float`, *optional*, defaults to 1.0):
|
| 87 |
+
A factor to rescale the output by dividing it with this value.
|
| 88 |
+
residual_connection (`bool`, *optional*, defaults to `False`):
|
| 89 |
+
Set to `True` to add the residual connection to the output.
|
| 90 |
+
_from_deprecated_attn_block (`bool`, *optional*, defaults to `False`):
|
| 91 |
+
Set to `True` if the attention block is loaded from a deprecated state dict.
|
| 92 |
+
processor (`AttnProcessor`, *optional*, defaults to `None`):
|
| 93 |
+
The attention processor to use. If `None`, defaults to `AttnProcessor2_0` if `torch 2.x` is used and
|
| 94 |
+
`AttnProcessor` otherwise.
|
| 95 |
+
"""
|
| 96 |
+
|
| 97 |
+
def __init__(
|
| 98 |
+
self,
|
| 99 |
+
query_dim: int,
|
| 100 |
+
cross_attention_dim: Optional[int] = None,
|
| 101 |
+
heads: int = 8,
|
| 102 |
+
dim_head: int = 64,
|
| 103 |
+
dropout: float = 0.0,
|
| 104 |
+
bias: bool = False,
|
| 105 |
+
upcast_attention: bool = False,
|
| 106 |
+
upcast_softmax: bool = False,
|
| 107 |
+
cross_attention_norm: Optional[str] = None,
|
| 108 |
+
cross_attention_norm_num_groups: int = 32,
|
| 109 |
+
added_kv_proj_dim: Optional[int] = None,
|
| 110 |
+
norm_num_groups: Optional[int] = None,
|
| 111 |
+
out_bias: bool = True,
|
| 112 |
+
scale_qk: bool = True,
|
| 113 |
+
only_cross_attention: bool = False,
|
| 114 |
+
eps: float = 1e-5,
|
| 115 |
+
rescale_output_factor: float = 1.0,
|
| 116 |
+
residual_connection: bool = False,
|
| 117 |
+
_from_deprecated_attn_block: bool = False,
|
| 118 |
+
processor: Optional["AttnProcessor"] = None,
|
| 119 |
+
out_dim: int = None,
|
| 120 |
+
):
|
| 121 |
+
super().__init__()
|
| 122 |
+
self.inner_dim = out_dim if out_dim is not None else dim_head * heads
|
| 123 |
+
self.query_dim = query_dim
|
| 124 |
+
self.cross_attention_dim = (
|
| 125 |
+
cross_attention_dim if cross_attention_dim is not None else query_dim
|
| 126 |
+
)
|
| 127 |
+
self.upcast_attention = upcast_attention
|
| 128 |
+
self.upcast_softmax = upcast_softmax
|
| 129 |
+
self.rescale_output_factor = rescale_output_factor
|
| 130 |
+
self.residual_connection = residual_connection
|
| 131 |
+
self.dropout = dropout
|
| 132 |
+
self.fused_projections = False
|
| 133 |
+
self.out_dim = out_dim if out_dim is not None else query_dim
|
| 134 |
+
|
| 135 |
+
# we make use of this private variable to know whether this class is loaded
|
| 136 |
+
# with an deprecated state dict so that we can convert it on the fly
|
| 137 |
+
self._from_deprecated_attn_block = _from_deprecated_attn_block
|
| 138 |
+
|
| 139 |
+
self.scale_qk = scale_qk
|
| 140 |
+
self.scale = dim_head**-0.5 if self.scale_qk else 1.0
|
| 141 |
+
|
| 142 |
+
self.heads = out_dim // dim_head if out_dim is not None else heads
|
| 143 |
+
# for slice_size > 0 the attention score computation
|
| 144 |
+
# is split across the batch axis to save memory
|
| 145 |
+
# You can set slice_size with `set_attention_slice`
|
| 146 |
+
self.sliceable_head_dim = heads
|
| 147 |
+
|
| 148 |
+
self.added_kv_proj_dim = added_kv_proj_dim
|
| 149 |
+
self.only_cross_attention = only_cross_attention
|
| 150 |
+
|
| 151 |
+
if self.added_kv_proj_dim is None and self.only_cross_attention:
|
| 152 |
+
raise ValueError(
|
| 153 |
+
"`only_cross_attention` can only be set to True if `added_kv_proj_dim` is not None. Make sure to set either `only_cross_attention=False` or define `added_kv_proj_dim`."
|
| 154 |
+
)
|
| 155 |
+
|
| 156 |
+
if norm_num_groups is not None:
|
| 157 |
+
self.group_norm = nn.GroupNorm(
|
| 158 |
+
num_channels=query_dim, num_groups=norm_num_groups, eps=eps, affine=True
|
| 159 |
+
)
|
| 160 |
+
else:
|
| 161 |
+
self.group_norm = None
|
| 162 |
+
|
| 163 |
+
self.spatial_norm = None
|
| 164 |
+
|
| 165 |
+
if cross_attention_norm is None:
|
| 166 |
+
self.norm_cross = None
|
| 167 |
+
elif cross_attention_norm == "layer_norm":
|
| 168 |
+
self.norm_cross = nn.LayerNorm(self.cross_attention_dim)
|
| 169 |
+
elif cross_attention_norm == "group_norm":
|
| 170 |
+
if self.added_kv_proj_dim is not None:
|
| 171 |
+
# The given `encoder_hidden_states` are initially of shape
|
| 172 |
+
# (batch_size, seq_len, added_kv_proj_dim) before being projected
|
| 173 |
+
# to (batch_size, seq_len, cross_attention_dim). The norm is applied
|
| 174 |
+
# before the projection, so we need to use `added_kv_proj_dim` as
|
| 175 |
+
# the number of channels for the group norm.
|
| 176 |
+
norm_cross_num_channels = added_kv_proj_dim
|
| 177 |
+
else:
|
| 178 |
+
norm_cross_num_channels = self.cross_attention_dim
|
| 179 |
+
|
| 180 |
+
self.norm_cross = nn.GroupNorm(
|
| 181 |
+
num_channels=norm_cross_num_channels,
|
| 182 |
+
num_groups=cross_attention_norm_num_groups,
|
| 183 |
+
eps=1e-5,
|
| 184 |
+
affine=True,
|
| 185 |
+
)
|
| 186 |
+
else:
|
| 187 |
+
raise ValueError(
|
| 188 |
+
f"unknown cross_attention_norm: {cross_attention_norm}. Should be None, 'layer_norm' or 'group_norm'"
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
linear_cls = nn.Linear
|
| 192 |
+
|
| 193 |
+
self.linear_cls = linear_cls
|
| 194 |
+
self.to_q = linear_cls(query_dim, self.inner_dim, bias=bias)
|
| 195 |
+
|
| 196 |
+
if not self.only_cross_attention:
|
| 197 |
+
# only relevant for the `AddedKVProcessor` classes
|
| 198 |
+
self.to_k = linear_cls(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 199 |
+
self.to_v = linear_cls(self.cross_attention_dim, self.inner_dim, bias=bias)
|
| 200 |
+
else:
|
| 201 |
+
self.to_k = None
|
| 202 |
+
self.to_v = None
|
| 203 |
+
|
| 204 |
+
if self.added_kv_proj_dim is not None:
|
| 205 |
+
self.add_k_proj = linear_cls(added_kv_proj_dim, self.inner_dim)
|
| 206 |
+
self.add_v_proj = linear_cls(added_kv_proj_dim, self.inner_dim)
|
| 207 |
+
|
| 208 |
+
self.to_out = nn.ModuleList([])
|
| 209 |
+
self.to_out.append(linear_cls(self.inner_dim, self.out_dim, bias=out_bias))
|
| 210 |
+
self.to_out.append(nn.Dropout(dropout))
|
| 211 |
+
|
| 212 |
+
# set attention processor
|
| 213 |
+
# We use the AttnProcessor2_0 by default when torch 2.x is used which uses
|
| 214 |
+
# torch.nn.functional.scaled_dot_product_attention for native Flash/memory_efficient_attention
|
| 215 |
+
# but only if it has the default `scale` argument. TODO remove scale_qk check when we move to torch 2.1
|
| 216 |
+
if processor is None:
|
| 217 |
+
processor = (
|
| 218 |
+
AttnProcessor2_0()
|
| 219 |
+
if hasattr(F, "scaled_dot_product_attention") and self.scale_qk
|
| 220 |
+
else AttnProcessor()
|
| 221 |
+
)
|
| 222 |
+
self.set_processor(processor)
|
| 223 |
+
|
| 224 |
+
def set_processor(self, processor: "AttnProcessor") -> None:
|
| 225 |
+
self.processor = processor
|
| 226 |
+
|
| 227 |
+
def forward(
|
| 228 |
+
self,
|
| 229 |
+
hidden_states: torch.FloatTensor,
|
| 230 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 231 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 232 |
+
**cross_attention_kwargs,
|
| 233 |
+
) -> torch.Tensor:
|
| 234 |
+
r"""
|
| 235 |
+
The forward method of the `Attention` class.
|
| 236 |
+
|
| 237 |
+
Args:
|
| 238 |
+
hidden_states (`torch.Tensor`):
|
| 239 |
+
The hidden states of the query.
|
| 240 |
+
encoder_hidden_states (`torch.Tensor`, *optional*):
|
| 241 |
+
The hidden states of the encoder.
|
| 242 |
+
attention_mask (`torch.Tensor`, *optional*):
|
| 243 |
+
The attention mask to use. If `None`, no mask is applied.
|
| 244 |
+
**cross_attention_kwargs:
|
| 245 |
+
Additional keyword arguments to pass along to the cross attention.
|
| 246 |
+
|
| 247 |
+
Returns:
|
| 248 |
+
`torch.Tensor`: The output of the attention layer.
|
| 249 |
+
"""
|
| 250 |
+
# The `Attention` class can call different attention processors / attention functions
|
| 251 |
+
# here we simply pass along all tensors to the selected processor class
|
| 252 |
+
# For standard processors that are defined here, `**cross_attention_kwargs` is empty
|
| 253 |
+
return self.processor(
|
| 254 |
+
self,
|
| 255 |
+
hidden_states,
|
| 256 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 257 |
+
attention_mask=attention_mask,
|
| 258 |
+
**cross_attention_kwargs,
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
def batch_to_head_dim(self, tensor: torch.Tensor) -> torch.Tensor:
|
| 262 |
+
r"""
|
| 263 |
+
Reshape the tensor from `[batch_size, seq_len, dim]` to `[batch_size // heads, seq_len, dim * heads]`. `heads`
|
| 264 |
+
is the number of heads initialized while constructing the `Attention` class.
|
| 265 |
+
|
| 266 |
+
Args:
|
| 267 |
+
tensor (`torch.Tensor`): The tensor to reshape.
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
`torch.Tensor`: The reshaped tensor.
|
| 271 |
+
"""
|
| 272 |
+
head_size = self.heads
|
| 273 |
+
batch_size, seq_len, dim = tensor.shape
|
| 274 |
+
tensor = tensor.reshape(batch_size // head_size, head_size, seq_len, dim)
|
| 275 |
+
tensor = tensor.permute(0, 2, 1, 3).reshape(
|
| 276 |
+
batch_size // head_size, seq_len, dim * head_size
|
| 277 |
+
)
|
| 278 |
+
return tensor
|
| 279 |
+
|
| 280 |
+
def head_to_batch_dim(self, tensor: torch.Tensor, out_dim: int = 3) -> torch.Tensor:
|
| 281 |
+
r"""
|
| 282 |
+
Reshape the tensor from `[batch_size, seq_len, dim]` to `[batch_size, seq_len, heads, dim // heads]` `heads` is
|
| 283 |
+
the number of heads initialized while constructing the `Attention` class.
|
| 284 |
+
|
| 285 |
+
Args:
|
| 286 |
+
tensor (`torch.Tensor`): The tensor to reshape.
|
| 287 |
+
out_dim (`int`, *optional*, defaults to `3`): The output dimension of the tensor. If `3`, the tensor is
|
| 288 |
+
reshaped to `[batch_size * heads, seq_len, dim // heads]`.
|
| 289 |
+
|
| 290 |
+
Returns:
|
| 291 |
+
`torch.Tensor`: The reshaped tensor.
|
| 292 |
+
"""
|
| 293 |
+
head_size = self.heads
|
| 294 |
+
batch_size, seq_len, dim = tensor.shape
|
| 295 |
+
tensor = tensor.reshape(batch_size, seq_len, head_size, dim // head_size)
|
| 296 |
+
tensor = tensor.permute(0, 2, 1, 3)
|
| 297 |
+
|
| 298 |
+
if out_dim == 3:
|
| 299 |
+
tensor = tensor.reshape(batch_size * head_size, seq_len, dim // head_size)
|
| 300 |
+
|
| 301 |
+
return tensor
|
| 302 |
+
|
| 303 |
+
def get_attention_scores(
|
| 304 |
+
self,
|
| 305 |
+
query: torch.Tensor,
|
| 306 |
+
key: torch.Tensor,
|
| 307 |
+
attention_mask: torch.Tensor = None,
|
| 308 |
+
) -> torch.Tensor:
|
| 309 |
+
r"""
|
| 310 |
+
Compute the attention scores.
|
| 311 |
+
|
| 312 |
+
Args:
|
| 313 |
+
query (`torch.Tensor`): The query tensor.
|
| 314 |
+
key (`torch.Tensor`): The key tensor.
|
| 315 |
+
attention_mask (`torch.Tensor`, *optional*): The attention mask to use. If `None`, no mask is applied.
|
| 316 |
+
|
| 317 |
+
Returns:
|
| 318 |
+
`torch.Tensor`: The attention probabilities/scores.
|
| 319 |
+
"""
|
| 320 |
+
dtype = query.dtype
|
| 321 |
+
if self.upcast_attention:
|
| 322 |
+
query = query.float()
|
| 323 |
+
key = key.float()
|
| 324 |
+
|
| 325 |
+
if attention_mask is None:
|
| 326 |
+
baddbmm_input = torch.empty(
|
| 327 |
+
query.shape[0],
|
| 328 |
+
query.shape[1],
|
| 329 |
+
key.shape[1],
|
| 330 |
+
dtype=query.dtype,
|
| 331 |
+
device=query.device,
|
| 332 |
+
)
|
| 333 |
+
beta = 0
|
| 334 |
+
else:
|
| 335 |
+
baddbmm_input = attention_mask
|
| 336 |
+
beta = 1
|
| 337 |
+
|
| 338 |
+
attention_scores = torch.baddbmm(
|
| 339 |
+
baddbmm_input,
|
| 340 |
+
query,
|
| 341 |
+
key.transpose(-1, -2),
|
| 342 |
+
beta=beta,
|
| 343 |
+
alpha=self.scale,
|
| 344 |
+
)
|
| 345 |
+
del baddbmm_input
|
| 346 |
+
|
| 347 |
+
if self.upcast_softmax:
|
| 348 |
+
attention_scores = attention_scores.float()
|
| 349 |
+
|
| 350 |
+
attention_probs = attention_scores.softmax(dim=-1)
|
| 351 |
+
del attention_scores
|
| 352 |
+
|
| 353 |
+
attention_probs = attention_probs.to(dtype)
|
| 354 |
+
|
| 355 |
+
return attention_probs
|
| 356 |
+
|
| 357 |
+
def prepare_attention_mask(
|
| 358 |
+
self,
|
| 359 |
+
attention_mask: torch.Tensor,
|
| 360 |
+
target_length: int,
|
| 361 |
+
batch_size: int,
|
| 362 |
+
out_dim: int = 3,
|
| 363 |
+
) -> torch.Tensor:
|
| 364 |
+
r"""
|
| 365 |
+
Prepare the attention mask for the attention computation.
|
| 366 |
+
|
| 367 |
+
Args:
|
| 368 |
+
attention_mask (`torch.Tensor`):
|
| 369 |
+
The attention mask to prepare.
|
| 370 |
+
target_length (`int`):
|
| 371 |
+
The target length of the attention mask. This is the length of the attention mask after padding.
|
| 372 |
+
batch_size (`int`):
|
| 373 |
+
The batch size, which is used to repeat the attention mask.
|
| 374 |
+
out_dim (`int`, *optional*, defaults to `3`):
|
| 375 |
+
The output dimension of the attention mask. Can be either `3` or `4`.
|
| 376 |
+
|
| 377 |
+
Returns:
|
| 378 |
+
`torch.Tensor`: The prepared attention mask.
|
| 379 |
+
"""
|
| 380 |
+
head_size = self.heads
|
| 381 |
+
if attention_mask is None:
|
| 382 |
+
return attention_mask
|
| 383 |
+
|
| 384 |
+
current_length: int = attention_mask.shape[-1]
|
| 385 |
+
if current_length != target_length:
|
| 386 |
+
if attention_mask.device.type == "mps":
|
| 387 |
+
# HACK: MPS: Does not support padding by greater than dimension of input tensor.
|
| 388 |
+
# Instead, we can manually construct the padding tensor.
|
| 389 |
+
padding_shape = (
|
| 390 |
+
attention_mask.shape[0],
|
| 391 |
+
attention_mask.shape[1],
|
| 392 |
+
target_length,
|
| 393 |
+
)
|
| 394 |
+
padding = torch.zeros(
|
| 395 |
+
padding_shape,
|
| 396 |
+
dtype=attention_mask.dtype,
|
| 397 |
+
device=attention_mask.device,
|
| 398 |
+
)
|
| 399 |
+
attention_mask = torch.cat([attention_mask, padding], dim=2)
|
| 400 |
+
else:
|
| 401 |
+
# TODO: for pipelines such as stable-diffusion, padding cross-attn mask:
|
| 402 |
+
# we want to instead pad by (0, remaining_length), where remaining_length is:
|
| 403 |
+
# remaining_length: int = target_length - current_length
|
| 404 |
+
# TODO: re-enable tests/models/test_models_unet_2d_condition.py#test_model_xattn_padding
|
| 405 |
+
attention_mask = F.pad(attention_mask, (0, target_length), value=0.0)
|
| 406 |
+
|
| 407 |
+
if out_dim == 3:
|
| 408 |
+
if attention_mask.shape[0] < batch_size * head_size:
|
| 409 |
+
attention_mask = attention_mask.repeat_interleave(head_size, dim=0)
|
| 410 |
+
elif out_dim == 4:
|
| 411 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 412 |
+
attention_mask = attention_mask.repeat_interleave(head_size, dim=1)
|
| 413 |
+
|
| 414 |
+
return attention_mask
|
| 415 |
+
|
| 416 |
+
def norm_encoder_hidden_states(
|
| 417 |
+
self, encoder_hidden_states: torch.Tensor
|
| 418 |
+
) -> torch.Tensor:
|
| 419 |
+
r"""
|
| 420 |
+
Normalize the encoder hidden states. Requires `self.norm_cross` to be specified when constructing the
|
| 421 |
+
`Attention` class.
|
| 422 |
+
|
| 423 |
+
Args:
|
| 424 |
+
encoder_hidden_states (`torch.Tensor`): Hidden states of the encoder.
|
| 425 |
+
|
| 426 |
+
Returns:
|
| 427 |
+
`torch.Tensor`: The normalized encoder hidden states.
|
| 428 |
+
"""
|
| 429 |
+
assert (
|
| 430 |
+
self.norm_cross is not None
|
| 431 |
+
), "self.norm_cross must be defined to call self.norm_encoder_hidden_states"
|
| 432 |
+
|
| 433 |
+
if isinstance(self.norm_cross, nn.LayerNorm):
|
| 434 |
+
encoder_hidden_states = self.norm_cross(encoder_hidden_states)
|
| 435 |
+
elif isinstance(self.norm_cross, nn.GroupNorm):
|
| 436 |
+
# Group norm norms along the channels dimension and expects
|
| 437 |
+
# input to be in the shape of (N, C, *). In this case, we want
|
| 438 |
+
# to norm along the hidden dimension, so we need to move
|
| 439 |
+
# (batch_size, sequence_length, hidden_size) ->
|
| 440 |
+
# (batch_size, hidden_size, sequence_length)
|
| 441 |
+
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
| 442 |
+
encoder_hidden_states = self.norm_cross(encoder_hidden_states)
|
| 443 |
+
encoder_hidden_states = encoder_hidden_states.transpose(1, 2)
|
| 444 |
+
else:
|
| 445 |
+
assert False
|
| 446 |
+
|
| 447 |
+
return encoder_hidden_states
|
| 448 |
+
|
| 449 |
+
@torch.no_grad()
|
| 450 |
+
def fuse_projections(self, fuse=True):
|
| 451 |
+
is_cross_attention = self.cross_attention_dim != self.query_dim
|
| 452 |
+
device = self.to_q.weight.data.device
|
| 453 |
+
dtype = self.to_q.weight.data.dtype
|
| 454 |
+
|
| 455 |
+
if not is_cross_attention:
|
| 456 |
+
# fetch weight matrices.
|
| 457 |
+
concatenated_weights = torch.cat(
|
| 458 |
+
[self.to_q.weight.data, self.to_k.weight.data, self.to_v.weight.data]
|
| 459 |
+
)
|
| 460 |
+
in_features = concatenated_weights.shape[1]
|
| 461 |
+
out_features = concatenated_weights.shape[0]
|
| 462 |
+
|
| 463 |
+
# create a new single projection layer and copy over the weights.
|
| 464 |
+
self.to_qkv = self.linear_cls(
|
| 465 |
+
in_features, out_features, bias=False, device=device, dtype=dtype
|
| 466 |
+
)
|
| 467 |
+
self.to_qkv.weight.copy_(concatenated_weights)
|
| 468 |
+
|
| 469 |
+
else:
|
| 470 |
+
concatenated_weights = torch.cat(
|
| 471 |
+
[self.to_k.weight.data, self.to_v.weight.data]
|
| 472 |
+
)
|
| 473 |
+
in_features = concatenated_weights.shape[1]
|
| 474 |
+
out_features = concatenated_weights.shape[0]
|
| 475 |
+
|
| 476 |
+
self.to_kv = self.linear_cls(
|
| 477 |
+
in_features, out_features, bias=False, device=device, dtype=dtype
|
| 478 |
+
)
|
| 479 |
+
self.to_kv.weight.copy_(concatenated_weights)
|
| 480 |
+
|
| 481 |
+
self.fused_projections = fuse
|
| 482 |
+
|
| 483 |
+
|
| 484 |
+
class AttnProcessor:
|
| 485 |
+
r"""
|
| 486 |
+
Default processor for performing attention-related computations.
|
| 487 |
+
"""
|
| 488 |
+
|
| 489 |
+
def __call__(
|
| 490 |
+
self,
|
| 491 |
+
attn: Attention,
|
| 492 |
+
hidden_states: torch.FloatTensor,
|
| 493 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 494 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 495 |
+
) -> torch.Tensor:
|
| 496 |
+
residual = hidden_states
|
| 497 |
+
|
| 498 |
+
input_ndim = hidden_states.ndim
|
| 499 |
+
|
| 500 |
+
if input_ndim == 4:
|
| 501 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 502 |
+
hidden_states = hidden_states.view(
|
| 503 |
+
batch_size, channel, height * width
|
| 504 |
+
).transpose(1, 2)
|
| 505 |
+
|
| 506 |
+
batch_size, sequence_length, _ = (
|
| 507 |
+
hidden_states.shape
|
| 508 |
+
if encoder_hidden_states is None
|
| 509 |
+
else encoder_hidden_states.shape
|
| 510 |
+
)
|
| 511 |
+
attention_mask = attn.prepare_attention_mask(
|
| 512 |
+
attention_mask, sequence_length, batch_size
|
| 513 |
+
)
|
| 514 |
+
|
| 515 |
+
if attn.group_norm is not None:
|
| 516 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(
|
| 517 |
+
1, 2
|
| 518 |
+
)
|
| 519 |
+
|
| 520 |
+
query = attn.to_q(hidden_states)
|
| 521 |
+
|
| 522 |
+
if encoder_hidden_states is None:
|
| 523 |
+
encoder_hidden_states = hidden_states
|
| 524 |
+
elif attn.norm_cross:
|
| 525 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(
|
| 526 |
+
encoder_hidden_states
|
| 527 |
+
)
|
| 528 |
+
|
| 529 |
+
key = attn.to_k(encoder_hidden_states)
|
| 530 |
+
value = attn.to_v(encoder_hidden_states)
|
| 531 |
+
|
| 532 |
+
query = attn.head_to_batch_dim(query)
|
| 533 |
+
key = attn.head_to_batch_dim(key)
|
| 534 |
+
value = attn.head_to_batch_dim(value)
|
| 535 |
+
|
| 536 |
+
attention_probs = attn.get_attention_scores(query, key, attention_mask)
|
| 537 |
+
hidden_states = torch.bmm(attention_probs, value)
|
| 538 |
+
hidden_states = attn.batch_to_head_dim(hidden_states)
|
| 539 |
+
|
| 540 |
+
# linear proj
|
| 541 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 542 |
+
# dropout
|
| 543 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 544 |
+
|
| 545 |
+
if input_ndim == 4:
|
| 546 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(
|
| 547 |
+
batch_size, channel, height, width
|
| 548 |
+
)
|
| 549 |
+
|
| 550 |
+
if attn.residual_connection:
|
| 551 |
+
hidden_states = hidden_states + residual
|
| 552 |
+
|
| 553 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 554 |
+
|
| 555 |
+
return hidden_states
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
class AttnProcessor2_0:
|
| 559 |
+
r"""
|
| 560 |
+
Processor for implementing scaled dot-product attention (enabled by default if you're using PyTorch 2.0).
|
| 561 |
+
"""
|
| 562 |
+
|
| 563 |
+
def __init__(self):
|
| 564 |
+
if not hasattr(F, "scaled_dot_product_attention"):
|
| 565 |
+
raise ImportError(
|
| 566 |
+
"AttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0."
|
| 567 |
+
)
|
| 568 |
+
|
| 569 |
+
def __call__(
|
| 570 |
+
self,
|
| 571 |
+
attn: Attention,
|
| 572 |
+
hidden_states: torch.FloatTensor,
|
| 573 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 574 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 575 |
+
) -> torch.FloatTensor:
|
| 576 |
+
residual = hidden_states
|
| 577 |
+
|
| 578 |
+
input_ndim = hidden_states.ndim
|
| 579 |
+
|
| 580 |
+
if input_ndim == 4:
|
| 581 |
+
batch_size, channel, height, width = hidden_states.shape
|
| 582 |
+
hidden_states = hidden_states.view(
|
| 583 |
+
batch_size, channel, height * width
|
| 584 |
+
).transpose(1, 2)
|
| 585 |
+
|
| 586 |
+
batch_size, sequence_length, _ = (
|
| 587 |
+
hidden_states.shape
|
| 588 |
+
if encoder_hidden_states is None
|
| 589 |
+
else encoder_hidden_states.shape
|
| 590 |
+
)
|
| 591 |
+
|
| 592 |
+
if attention_mask is not None:
|
| 593 |
+
attention_mask = attn.prepare_attention_mask(
|
| 594 |
+
attention_mask, sequence_length, batch_size
|
| 595 |
+
)
|
| 596 |
+
# scaled_dot_product_attention expects attention_mask shape to be
|
| 597 |
+
# (batch, heads, source_length, target_length)
|
| 598 |
+
attention_mask = attention_mask.view(
|
| 599 |
+
batch_size, attn.heads, -1, attention_mask.shape[-1]
|
| 600 |
+
)
|
| 601 |
+
|
| 602 |
+
if attn.group_norm is not None:
|
| 603 |
+
hidden_states = attn.group_norm(hidden_states.transpose(1, 2)).transpose(
|
| 604 |
+
1, 2
|
| 605 |
+
)
|
| 606 |
+
|
| 607 |
+
query = attn.to_q(hidden_states)
|
| 608 |
+
|
| 609 |
+
if encoder_hidden_states is None:
|
| 610 |
+
encoder_hidden_states = hidden_states
|
| 611 |
+
elif attn.norm_cross:
|
| 612 |
+
encoder_hidden_states = attn.norm_encoder_hidden_states(
|
| 613 |
+
encoder_hidden_states
|
| 614 |
+
)
|
| 615 |
+
|
| 616 |
+
key = attn.to_k(encoder_hidden_states)
|
| 617 |
+
value = attn.to_v(encoder_hidden_states)
|
| 618 |
+
|
| 619 |
+
inner_dim = key.shape[-1]
|
| 620 |
+
head_dim = inner_dim // attn.heads
|
| 621 |
+
|
| 622 |
+
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 623 |
+
|
| 624 |
+
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 625 |
+
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
|
| 626 |
+
|
| 627 |
+
# the output of sdp = (batch, num_heads, seq_len, head_dim)
|
| 628 |
+
# TODO: add support for attn.scale when we move to Torch 2.1
|
| 629 |
+
hidden_states = F.scaled_dot_product_attention(
|
| 630 |
+
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
|
| 631 |
+
)
|
| 632 |
+
|
| 633 |
+
hidden_states = hidden_states.transpose(1, 2).reshape(
|
| 634 |
+
batch_size, -1, attn.heads * head_dim
|
| 635 |
+
)
|
| 636 |
+
hidden_states = hidden_states.to(query.dtype)
|
| 637 |
+
|
| 638 |
+
# linear proj
|
| 639 |
+
hidden_states = attn.to_out[0](hidden_states)
|
| 640 |
+
# dropout
|
| 641 |
+
hidden_states = attn.to_out[1](hidden_states)
|
| 642 |
+
|
| 643 |
+
if input_ndim == 4:
|
| 644 |
+
hidden_states = hidden_states.transpose(-1, -2).reshape(
|
| 645 |
+
batch_size, channel, height, width
|
| 646 |
+
)
|
| 647 |
+
|
| 648 |
+
if attn.residual_connection:
|
| 649 |
+
hidden_states = hidden_states + residual
|
| 650 |
+
|
| 651 |
+
hidden_states = hidden_states / attn.rescale_output_factor
|
| 652 |
+
|
| 653 |
+
return hidden_states
|
TripoSR/tsr/models/transformer/basic_transformer_block.py
ADDED
|
@@ -0,0 +1,334 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# --------
|
| 16 |
+
#
|
| 17 |
+
# Modified 2024 by the Tripo AI and Stability AI Team.
|
| 18 |
+
#
|
| 19 |
+
# Copyright (c) 2024 Tripo AI & Stability AI
|
| 20 |
+
#
|
| 21 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 22 |
+
# of this software and associated documentation files (the "Software"), to deal
|
| 23 |
+
# in the Software without restriction, including without limitation the rights
|
| 24 |
+
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 25 |
+
# copies of the Software, and to permit persons to whom the Software is
|
| 26 |
+
# furnished to do so, subject to the following conditions:
|
| 27 |
+
#
|
| 28 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 29 |
+
# copies or substantial portions of the Software.
|
| 30 |
+
#
|
| 31 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 32 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 33 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 34 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 35 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 36 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 37 |
+
# SOFTWARE.
|
| 38 |
+
|
| 39 |
+
from typing import Optional
|
| 40 |
+
|
| 41 |
+
import torch
|
| 42 |
+
import torch.nn.functional as F
|
| 43 |
+
from torch import nn
|
| 44 |
+
|
| 45 |
+
from .attention import Attention
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
class BasicTransformerBlock(nn.Module):
|
| 49 |
+
r"""
|
| 50 |
+
A basic Transformer block.
|
| 51 |
+
|
| 52 |
+
Parameters:
|
| 53 |
+
dim (`int`): The number of channels in the input and output.
|
| 54 |
+
num_attention_heads (`int`): The number of heads to use for multi-head attention.
|
| 55 |
+
attention_head_dim (`int`): The number of channels in each head.
|
| 56 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 57 |
+
cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
|
| 58 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 59 |
+
attention_bias (:
|
| 60 |
+
obj: `bool`, *optional*, defaults to `False`): Configure if the attentions should contain a bias parameter.
|
| 61 |
+
only_cross_attention (`bool`, *optional*):
|
| 62 |
+
Whether to use only cross-attention layers. In this case two cross attention layers are used.
|
| 63 |
+
double_self_attention (`bool`, *optional*):
|
| 64 |
+
Whether to use two self-attention layers. In this case no cross attention layers are used.
|
| 65 |
+
upcast_attention (`bool`, *optional*):
|
| 66 |
+
Whether to upcast the attention computation to float32. This is useful for mixed precision training.
|
| 67 |
+
norm_elementwise_affine (`bool`, *optional*, defaults to `True`):
|
| 68 |
+
Whether to use learnable elementwise affine parameters for normalization.
|
| 69 |
+
norm_type (`str`, *optional*, defaults to `"layer_norm"`):
|
| 70 |
+
The normalization layer to use. Can be `"layer_norm"`, `"ada_norm"` or `"ada_norm_zero"`.
|
| 71 |
+
final_dropout (`bool` *optional*, defaults to False):
|
| 72 |
+
Whether to apply a final dropout after the last feed-forward layer.
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def __init__(
|
| 76 |
+
self,
|
| 77 |
+
dim: int,
|
| 78 |
+
num_attention_heads: int,
|
| 79 |
+
attention_head_dim: int,
|
| 80 |
+
dropout=0.0,
|
| 81 |
+
cross_attention_dim: Optional[int] = None,
|
| 82 |
+
activation_fn: str = "geglu",
|
| 83 |
+
attention_bias: bool = False,
|
| 84 |
+
only_cross_attention: bool = False,
|
| 85 |
+
double_self_attention: bool = False,
|
| 86 |
+
upcast_attention: bool = False,
|
| 87 |
+
norm_elementwise_affine: bool = True,
|
| 88 |
+
norm_type: str = "layer_norm",
|
| 89 |
+
final_dropout: bool = False,
|
| 90 |
+
):
|
| 91 |
+
super().__init__()
|
| 92 |
+
self.only_cross_attention = only_cross_attention
|
| 93 |
+
|
| 94 |
+
assert norm_type == "layer_norm"
|
| 95 |
+
|
| 96 |
+
# Define 3 blocks. Each block has its own normalization layer.
|
| 97 |
+
# 1. Self-Attn
|
| 98 |
+
self.norm1 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
|
| 99 |
+
self.attn1 = Attention(
|
| 100 |
+
query_dim=dim,
|
| 101 |
+
heads=num_attention_heads,
|
| 102 |
+
dim_head=attention_head_dim,
|
| 103 |
+
dropout=dropout,
|
| 104 |
+
bias=attention_bias,
|
| 105 |
+
cross_attention_dim=cross_attention_dim if only_cross_attention else None,
|
| 106 |
+
upcast_attention=upcast_attention,
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
# 2. Cross-Attn
|
| 110 |
+
if cross_attention_dim is not None or double_self_attention:
|
| 111 |
+
# We currently only use AdaLayerNormZero for self attention where there will only be one attention block.
|
| 112 |
+
# I.e. the number of returned modulation chunks from AdaLayerZero would not make sense if returned during
|
| 113 |
+
# the second cross attention block.
|
| 114 |
+
self.norm2 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
|
| 115 |
+
|
| 116 |
+
self.attn2 = Attention(
|
| 117 |
+
query_dim=dim,
|
| 118 |
+
cross_attention_dim=(
|
| 119 |
+
cross_attention_dim if not double_self_attention else None
|
| 120 |
+
),
|
| 121 |
+
heads=num_attention_heads,
|
| 122 |
+
dim_head=attention_head_dim,
|
| 123 |
+
dropout=dropout,
|
| 124 |
+
bias=attention_bias,
|
| 125 |
+
upcast_attention=upcast_attention,
|
| 126 |
+
) # is self-attn if encoder_hidden_states is none
|
| 127 |
+
else:
|
| 128 |
+
self.norm2 = None
|
| 129 |
+
self.attn2 = None
|
| 130 |
+
|
| 131 |
+
# 3. Feed-forward
|
| 132 |
+
self.norm3 = nn.LayerNorm(dim, elementwise_affine=norm_elementwise_affine)
|
| 133 |
+
self.ff = FeedForward(
|
| 134 |
+
dim,
|
| 135 |
+
dropout=dropout,
|
| 136 |
+
activation_fn=activation_fn,
|
| 137 |
+
final_dropout=final_dropout,
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
# let chunk size default to None
|
| 141 |
+
self._chunk_size = None
|
| 142 |
+
self._chunk_dim = 0
|
| 143 |
+
|
| 144 |
+
def set_chunk_feed_forward(self, chunk_size: Optional[int], dim: int):
|
| 145 |
+
# Sets chunk feed-forward
|
| 146 |
+
self._chunk_size = chunk_size
|
| 147 |
+
self._chunk_dim = dim
|
| 148 |
+
|
| 149 |
+
def forward(
|
| 150 |
+
self,
|
| 151 |
+
hidden_states: torch.FloatTensor,
|
| 152 |
+
attention_mask: Optional[torch.FloatTensor] = None,
|
| 153 |
+
encoder_hidden_states: Optional[torch.FloatTensor] = None,
|
| 154 |
+
encoder_attention_mask: Optional[torch.FloatTensor] = None,
|
| 155 |
+
) -> torch.FloatTensor:
|
| 156 |
+
# Notice that normalization is always applied before the real computation in the following blocks.
|
| 157 |
+
# 0. Self-Attention
|
| 158 |
+
norm_hidden_states = self.norm1(hidden_states)
|
| 159 |
+
|
| 160 |
+
attn_output = self.attn1(
|
| 161 |
+
norm_hidden_states,
|
| 162 |
+
encoder_hidden_states=(
|
| 163 |
+
encoder_hidden_states if self.only_cross_attention else None
|
| 164 |
+
),
|
| 165 |
+
attention_mask=attention_mask,
|
| 166 |
+
)
|
| 167 |
+
|
| 168 |
+
hidden_states = attn_output + hidden_states
|
| 169 |
+
|
| 170 |
+
# 3. Cross-Attention
|
| 171 |
+
if self.attn2 is not None:
|
| 172 |
+
norm_hidden_states = self.norm2(hidden_states)
|
| 173 |
+
|
| 174 |
+
attn_output = self.attn2(
|
| 175 |
+
norm_hidden_states,
|
| 176 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 177 |
+
attention_mask=encoder_attention_mask,
|
| 178 |
+
)
|
| 179 |
+
hidden_states = attn_output + hidden_states
|
| 180 |
+
|
| 181 |
+
# 4. Feed-forward
|
| 182 |
+
norm_hidden_states = self.norm3(hidden_states)
|
| 183 |
+
|
| 184 |
+
if self._chunk_size is not None:
|
| 185 |
+
# "feed_forward_chunk_size" can be used to save memory
|
| 186 |
+
if norm_hidden_states.shape[self._chunk_dim] % self._chunk_size != 0:
|
| 187 |
+
raise ValueError(
|
| 188 |
+
f"`hidden_states` dimension to be chunked: {norm_hidden_states.shape[self._chunk_dim]} has to be divisible by chunk size: {self._chunk_size}. Make sure to set an appropriate `chunk_size` when calling `unet.enable_forward_chunking`."
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
num_chunks = norm_hidden_states.shape[self._chunk_dim] // self._chunk_size
|
| 192 |
+
ff_output = torch.cat(
|
| 193 |
+
[
|
| 194 |
+
self.ff(hid_slice)
|
| 195 |
+
for hid_slice in norm_hidden_states.chunk(
|
| 196 |
+
num_chunks, dim=self._chunk_dim
|
| 197 |
+
)
|
| 198 |
+
],
|
| 199 |
+
dim=self._chunk_dim,
|
| 200 |
+
)
|
| 201 |
+
else:
|
| 202 |
+
ff_output = self.ff(norm_hidden_states)
|
| 203 |
+
|
| 204 |
+
hidden_states = ff_output + hidden_states
|
| 205 |
+
|
| 206 |
+
return hidden_states
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
class FeedForward(nn.Module):
|
| 210 |
+
r"""
|
| 211 |
+
A feed-forward layer.
|
| 212 |
+
|
| 213 |
+
Parameters:
|
| 214 |
+
dim (`int`): The number of channels in the input.
|
| 215 |
+
dim_out (`int`, *optional*): The number of channels in the output. If not given, defaults to `dim`.
|
| 216 |
+
mult (`int`, *optional*, defaults to 4): The multiplier to use for the hidden dimension.
|
| 217 |
+
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
|
| 218 |
+
activation_fn (`str`, *optional*, defaults to `"geglu"`): Activation function to be used in feed-forward.
|
| 219 |
+
final_dropout (`bool` *optional*, defaults to False): Apply a final dropout.
|
| 220 |
+
"""
|
| 221 |
+
|
| 222 |
+
def __init__(
|
| 223 |
+
self,
|
| 224 |
+
dim: int,
|
| 225 |
+
dim_out: Optional[int] = None,
|
| 226 |
+
mult: int = 4,
|
| 227 |
+
dropout: float = 0.0,
|
| 228 |
+
activation_fn: str = "geglu",
|
| 229 |
+
final_dropout: bool = False,
|
| 230 |
+
):
|
| 231 |
+
super().__init__()
|
| 232 |
+
inner_dim = int(dim * mult)
|
| 233 |
+
dim_out = dim_out if dim_out is not None else dim
|
| 234 |
+
linear_cls = nn.Linear
|
| 235 |
+
|
| 236 |
+
if activation_fn == "gelu":
|
| 237 |
+
act_fn = GELU(dim, inner_dim)
|
| 238 |
+
if activation_fn == "gelu-approximate":
|
| 239 |
+
act_fn = GELU(dim, inner_dim, approximate="tanh")
|
| 240 |
+
elif activation_fn == "geglu":
|
| 241 |
+
act_fn = GEGLU(dim, inner_dim)
|
| 242 |
+
elif activation_fn == "geglu-approximate":
|
| 243 |
+
act_fn = ApproximateGELU(dim, inner_dim)
|
| 244 |
+
|
| 245 |
+
self.net = nn.ModuleList([])
|
| 246 |
+
# project in
|
| 247 |
+
self.net.append(act_fn)
|
| 248 |
+
# project dropout
|
| 249 |
+
self.net.append(nn.Dropout(dropout))
|
| 250 |
+
# project out
|
| 251 |
+
self.net.append(linear_cls(inner_dim, dim_out))
|
| 252 |
+
# FF as used in Vision Transformer, MLP-Mixer, etc. have a final dropout
|
| 253 |
+
if final_dropout:
|
| 254 |
+
self.net.append(nn.Dropout(dropout))
|
| 255 |
+
|
| 256 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 257 |
+
for module in self.net:
|
| 258 |
+
hidden_states = module(hidden_states)
|
| 259 |
+
return hidden_states
|
| 260 |
+
|
| 261 |
+
|
| 262 |
+
class GELU(nn.Module):
|
| 263 |
+
r"""
|
| 264 |
+
GELU activation function with tanh approximation support with `approximate="tanh"`.
|
| 265 |
+
|
| 266 |
+
Parameters:
|
| 267 |
+
dim_in (`int`): The number of channels in the input.
|
| 268 |
+
dim_out (`int`): The number of channels in the output.
|
| 269 |
+
approximate (`str`, *optional*, defaults to `"none"`): If `"tanh"`, use tanh approximation.
|
| 270 |
+
"""
|
| 271 |
+
|
| 272 |
+
def __init__(self, dim_in: int, dim_out: int, approximate: str = "none"):
|
| 273 |
+
super().__init__()
|
| 274 |
+
self.proj = nn.Linear(dim_in, dim_out)
|
| 275 |
+
self.approximate = approximate
|
| 276 |
+
|
| 277 |
+
def gelu(self, gate: torch.Tensor) -> torch.Tensor:
|
| 278 |
+
if gate.device.type != "mps":
|
| 279 |
+
return F.gelu(gate, approximate=self.approximate)
|
| 280 |
+
# mps: gelu is not implemented for float16
|
| 281 |
+
return F.gelu(gate.to(dtype=torch.float32), approximate=self.approximate).to(
|
| 282 |
+
dtype=gate.dtype
|
| 283 |
+
)
|
| 284 |
+
|
| 285 |
+
def forward(self, hidden_states):
|
| 286 |
+
hidden_states = self.proj(hidden_states)
|
| 287 |
+
hidden_states = self.gelu(hidden_states)
|
| 288 |
+
return hidden_states
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
class GEGLU(nn.Module):
|
| 292 |
+
r"""
|
| 293 |
+
A variant of the gated linear unit activation function from https://arxiv.org/abs/2002.05202.
|
| 294 |
+
|
| 295 |
+
Parameters:
|
| 296 |
+
dim_in (`int`): The number of channels in the input.
|
| 297 |
+
dim_out (`int`): The number of channels in the output.
|
| 298 |
+
"""
|
| 299 |
+
|
| 300 |
+
def __init__(self, dim_in: int, dim_out: int):
|
| 301 |
+
super().__init__()
|
| 302 |
+
linear_cls = nn.Linear
|
| 303 |
+
|
| 304 |
+
self.proj = linear_cls(dim_in, dim_out * 2)
|
| 305 |
+
|
| 306 |
+
def gelu(self, gate: torch.Tensor) -> torch.Tensor:
|
| 307 |
+
if gate.device.type != "mps":
|
| 308 |
+
return F.gelu(gate)
|
| 309 |
+
# mps: gelu is not implemented for float16
|
| 310 |
+
return F.gelu(gate.to(dtype=torch.float32)).to(dtype=gate.dtype)
|
| 311 |
+
|
| 312 |
+
def forward(self, hidden_states, scale: float = 1.0):
|
| 313 |
+
args = ()
|
| 314 |
+
hidden_states, gate = self.proj(hidden_states, *args).chunk(2, dim=-1)
|
| 315 |
+
return hidden_states * self.gelu(gate)
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
class ApproximateGELU(nn.Module):
|
| 319 |
+
r"""
|
| 320 |
+
The approximate form of Gaussian Error Linear Unit (GELU). For more details, see section 2:
|
| 321 |
+
https://arxiv.org/abs/1606.08415.
|
| 322 |
+
|
| 323 |
+
Parameters:
|
| 324 |
+
dim_in (`int`): The number of channels in the input.
|
| 325 |
+
dim_out (`int`): The number of channels in the output.
|
| 326 |
+
"""
|
| 327 |
+
|
| 328 |
+
def __init__(self, dim_in: int, dim_out: int):
|
| 329 |
+
super().__init__()
|
| 330 |
+
self.proj = nn.Linear(dim_in, dim_out)
|
| 331 |
+
|
| 332 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 333 |
+
x = self.proj(x)
|
| 334 |
+
return x * torch.sigmoid(1.702 * x)
|
TripoSR/tsr/models/transformer/transformer_1d.py
ADDED
|
@@ -0,0 +1,219 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2023 The HuggingFace Team. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
#
|
| 15 |
+
# --------
|
| 16 |
+
#
|
| 17 |
+
# Modified 2024 by the Tripo AI and Stability AI Team.
|
| 18 |
+
#
|
| 19 |
+
# Copyright (c) 2024 Tripo AI & Stability AI
|
| 20 |
+
#
|
| 21 |
+
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 22 |
+
# of this software and associated documentation files (the "Software"), to deal
|
| 23 |
+
# in the Software without restriction, including without limitation the rights
|
| 24 |
+
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 25 |
+
# copies of the Software, and to permit persons to whom the Software is
|
| 26 |
+
# furnished to do so, subject to the following conditions:
|
| 27 |
+
#
|
| 28 |
+
# The above copyright notice and this permission notice shall be included in all
|
| 29 |
+
# copies or substantial portions of the Software.
|
| 30 |
+
#
|
| 31 |
+
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 32 |
+
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 33 |
+
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 34 |
+
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 35 |
+
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 36 |
+
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 37 |
+
# SOFTWARE.
|
| 38 |
+
|
| 39 |
+
from dataclasses import dataclass
|
| 40 |
+
from typing import Optional
|
| 41 |
+
|
| 42 |
+
import torch
|
| 43 |
+
import torch.nn.functional as F
|
| 44 |
+
from torch import nn
|
| 45 |
+
|
| 46 |
+
from ...utils import BaseModule
|
| 47 |
+
from .basic_transformer_block import BasicTransformerBlock
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Transformer1D(BaseModule):
|
| 51 |
+
@dataclass
|
| 52 |
+
class Config(BaseModule.Config):
|
| 53 |
+
num_attention_heads: int = 16
|
| 54 |
+
attention_head_dim: int = 88
|
| 55 |
+
in_channels: Optional[int] = None
|
| 56 |
+
out_channels: Optional[int] = None
|
| 57 |
+
num_layers: int = 1
|
| 58 |
+
dropout: float = 0.0
|
| 59 |
+
norm_num_groups: int = 32
|
| 60 |
+
cross_attention_dim: Optional[int] = None
|
| 61 |
+
attention_bias: bool = False
|
| 62 |
+
activation_fn: str = "geglu"
|
| 63 |
+
only_cross_attention: bool = False
|
| 64 |
+
double_self_attention: bool = False
|
| 65 |
+
upcast_attention: bool = False
|
| 66 |
+
norm_type: str = "layer_norm"
|
| 67 |
+
norm_elementwise_affine: bool = True
|
| 68 |
+
gradient_checkpointing: bool = False
|
| 69 |
+
|
| 70 |
+
cfg: Config
|
| 71 |
+
|
| 72 |
+
def configure(self) -> None:
|
| 73 |
+
self.num_attention_heads = self.cfg.num_attention_heads
|
| 74 |
+
self.attention_head_dim = self.cfg.attention_head_dim
|
| 75 |
+
inner_dim = self.num_attention_heads * self.attention_head_dim
|
| 76 |
+
|
| 77 |
+
linear_cls = nn.Linear
|
| 78 |
+
|
| 79 |
+
# 2. Define input layers
|
| 80 |
+
self.in_channels = self.cfg.in_channels
|
| 81 |
+
|
| 82 |
+
self.norm = torch.nn.GroupNorm(
|
| 83 |
+
num_groups=self.cfg.norm_num_groups,
|
| 84 |
+
num_channels=self.cfg.in_channels,
|
| 85 |
+
eps=1e-6,
|
| 86 |
+
affine=True,
|
| 87 |
+
)
|
| 88 |
+
self.proj_in = linear_cls(self.cfg.in_channels, inner_dim)
|
| 89 |
+
|
| 90 |
+
# 3. Define transformers blocks
|
| 91 |
+
self.transformer_blocks = nn.ModuleList(
|
| 92 |
+
[
|
| 93 |
+
BasicTransformerBlock(
|
| 94 |
+
inner_dim,
|
| 95 |
+
self.num_attention_heads,
|
| 96 |
+
self.attention_head_dim,
|
| 97 |
+
dropout=self.cfg.dropout,
|
| 98 |
+
cross_attention_dim=self.cfg.cross_attention_dim,
|
| 99 |
+
activation_fn=self.cfg.activation_fn,
|
| 100 |
+
attention_bias=self.cfg.attention_bias,
|
| 101 |
+
only_cross_attention=self.cfg.only_cross_attention,
|
| 102 |
+
double_self_attention=self.cfg.double_self_attention,
|
| 103 |
+
upcast_attention=self.cfg.upcast_attention,
|
| 104 |
+
norm_type=self.cfg.norm_type,
|
| 105 |
+
norm_elementwise_affine=self.cfg.norm_elementwise_affine,
|
| 106 |
+
)
|
| 107 |
+
for d in range(self.cfg.num_layers)
|
| 108 |
+
]
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
# 4. Define output layers
|
| 112 |
+
self.out_channels = (
|
| 113 |
+
self.cfg.in_channels
|
| 114 |
+
if self.cfg.out_channels is None
|
| 115 |
+
else self.cfg.out_channels
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
self.proj_out = linear_cls(inner_dim, self.cfg.in_channels)
|
| 119 |
+
|
| 120 |
+
self.gradient_checkpointing = self.cfg.gradient_checkpointing
|
| 121 |
+
|
| 122 |
+
def forward(
|
| 123 |
+
self,
|
| 124 |
+
hidden_states: torch.Tensor,
|
| 125 |
+
encoder_hidden_states: Optional[torch.Tensor] = None,
|
| 126 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 127 |
+
encoder_attention_mask: Optional[torch.Tensor] = None,
|
| 128 |
+
):
|
| 129 |
+
"""
|
| 130 |
+
The [`Transformer1DModel`] forward method.
|
| 131 |
+
|
| 132 |
+
Args:
|
| 133 |
+
hidden_states (`torch.LongTensor` of shape `(batch size, num latent pixels)` if discrete, `torch.FloatTensor` of shape `(batch size, channel, height, width)` if continuous):
|
| 134 |
+
Input `hidden_states`.
|
| 135 |
+
encoder_hidden_states ( `torch.FloatTensor` of shape `(batch size, sequence len, embed dims)`, *optional*):
|
| 136 |
+
Conditional embeddings for cross attention layer. If not given, cross-attention defaults to
|
| 137 |
+
self-attention.
|
| 138 |
+
attention_mask ( `torch.Tensor`, *optional*):
|
| 139 |
+
An attention mask of shape `(batch, key_tokens)` is applied to `encoder_hidden_states`. If `1` the mask
|
| 140 |
+
is kept, otherwise if `0` it is discarded. Mask will be converted into a bias, which adds large
|
| 141 |
+
negative values to the attention scores corresponding to "discard" tokens.
|
| 142 |
+
encoder_attention_mask ( `torch.Tensor`, *optional*):
|
| 143 |
+
Cross-attention mask applied to `encoder_hidden_states`. Two formats supported:
|
| 144 |
+
|
| 145 |
+
* Mask `(batch, sequence_length)` True = keep, False = discard.
|
| 146 |
+
* Bias `(batch, 1, sequence_length)` 0 = keep, -10000 = discard.
|
| 147 |
+
|
| 148 |
+
If `ndim == 2`: will be interpreted as a mask, then converted into a bias consistent with the format
|
| 149 |
+
above. This bias will be added to the cross-attention scores.
|
| 150 |
+
|
| 151 |
+
Returns:
|
| 152 |
+
torch.FloatTensor
|
| 153 |
+
"""
|
| 154 |
+
# ensure attention_mask is a bias, and give it a singleton query_tokens dimension.
|
| 155 |
+
# we may have done this conversion already, e.g. if we came here via UNet2DConditionModel#forward.
|
| 156 |
+
# we can tell by counting dims; if ndim == 2: it's a mask rather than a bias.
|
| 157 |
+
# expects mask of shape:
|
| 158 |
+
# [batch, key_tokens]
|
| 159 |
+
# adds singleton query_tokens dimension:
|
| 160 |
+
# [batch, 1, key_tokens]
|
| 161 |
+
# this helps to broadcast it as a bias over attention scores, which will be in one of the following shapes:
|
| 162 |
+
# [batch, heads, query_tokens, key_tokens] (e.g. torch sdp attn)
|
| 163 |
+
# [batch * heads, query_tokens, key_tokens] (e.g. xformers or classic attn)
|
| 164 |
+
if attention_mask is not None and attention_mask.ndim == 2:
|
| 165 |
+
# assume that mask is expressed as:
|
| 166 |
+
# (1 = keep, 0 = discard)
|
| 167 |
+
# convert mask into a bias that can be added to attention scores:
|
| 168 |
+
# (keep = +0, discard = -10000.0)
|
| 169 |
+
attention_mask = (1 - attention_mask.to(hidden_states.dtype)) * -10000.0
|
| 170 |
+
attention_mask = attention_mask.unsqueeze(1)
|
| 171 |
+
|
| 172 |
+
# convert encoder_attention_mask to a bias the same way we do for attention_mask
|
| 173 |
+
if encoder_attention_mask is not None and encoder_attention_mask.ndim == 2:
|
| 174 |
+
encoder_attention_mask = (
|
| 175 |
+
1 - encoder_attention_mask.to(hidden_states.dtype)
|
| 176 |
+
) * -10000.0
|
| 177 |
+
encoder_attention_mask = encoder_attention_mask.unsqueeze(1)
|
| 178 |
+
|
| 179 |
+
# 1. Input
|
| 180 |
+
batch, _, seq_len = hidden_states.shape
|
| 181 |
+
residual = hidden_states
|
| 182 |
+
|
| 183 |
+
hidden_states = self.norm(hidden_states)
|
| 184 |
+
inner_dim = hidden_states.shape[1]
|
| 185 |
+
hidden_states = hidden_states.permute(0, 2, 1).reshape(
|
| 186 |
+
batch, seq_len, inner_dim
|
| 187 |
+
)
|
| 188 |
+
hidden_states = self.proj_in(hidden_states)
|
| 189 |
+
|
| 190 |
+
# 2. Blocks
|
| 191 |
+
for block in self.transformer_blocks:
|
| 192 |
+
if self.training and self.gradient_checkpointing:
|
| 193 |
+
hidden_states = torch.utils.checkpoint.checkpoint(
|
| 194 |
+
block,
|
| 195 |
+
hidden_states,
|
| 196 |
+
attention_mask,
|
| 197 |
+
encoder_hidden_states,
|
| 198 |
+
encoder_attention_mask,
|
| 199 |
+
use_reentrant=False,
|
| 200 |
+
)
|
| 201 |
+
else:
|
| 202 |
+
hidden_states = block(
|
| 203 |
+
hidden_states,
|
| 204 |
+
attention_mask=attention_mask,
|
| 205 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 206 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
# 3. Output
|
| 210 |
+
hidden_states = self.proj_out(hidden_states)
|
| 211 |
+
hidden_states = (
|
| 212 |
+
hidden_states.reshape(batch, seq_len, inner_dim)
|
| 213 |
+
.permute(0, 2, 1)
|
| 214 |
+
.contiguous()
|
| 215 |
+
)
|
| 216 |
+
|
| 217 |
+
output = hidden_states + residual
|
| 218 |
+
|
| 219 |
+
return output
|
TripoSR/tsr/system.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
from dataclasses import dataclass, field
|
| 4 |
+
from typing import List, Union
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import PIL.Image
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import trimesh
|
| 11 |
+
from einops import rearrange
|
| 12 |
+
from huggingface_hub import hf_hub_download
|
| 13 |
+
from omegaconf import OmegaConf
|
| 14 |
+
from PIL import Image
|
| 15 |
+
|
| 16 |
+
from .models.isosurface import MarchingCubeHelper
|
| 17 |
+
from .utils import (
|
| 18 |
+
BaseModule,
|
| 19 |
+
ImagePreprocessor,
|
| 20 |
+
find_class,
|
| 21 |
+
get_spherical_cameras,
|
| 22 |
+
scale_tensor,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class TSR(BaseModule):
|
| 27 |
+
@dataclass
|
| 28 |
+
class Config(BaseModule.Config):
|
| 29 |
+
cond_image_size: int
|
| 30 |
+
|
| 31 |
+
image_tokenizer_cls: str
|
| 32 |
+
image_tokenizer: dict
|
| 33 |
+
|
| 34 |
+
tokenizer_cls: str
|
| 35 |
+
tokenizer: dict
|
| 36 |
+
|
| 37 |
+
backbone_cls: str
|
| 38 |
+
backbone: dict
|
| 39 |
+
|
| 40 |
+
post_processor_cls: str
|
| 41 |
+
post_processor: dict
|
| 42 |
+
|
| 43 |
+
decoder_cls: str
|
| 44 |
+
decoder: dict
|
| 45 |
+
|
| 46 |
+
renderer_cls: str
|
| 47 |
+
renderer: dict
|
| 48 |
+
|
| 49 |
+
cfg: Config
|
| 50 |
+
|
| 51 |
+
@classmethod
|
| 52 |
+
def from_pretrained(
|
| 53 |
+
cls, pretrained_model_name_or_path: str, config_name: str, weight_name: str
|
| 54 |
+
):
|
| 55 |
+
if os.path.isdir(pretrained_model_name_or_path):
|
| 56 |
+
config_path = os.path.join(pretrained_model_name_or_path, config_name)
|
| 57 |
+
weight_path = os.path.join(pretrained_model_name_or_path, weight_name)
|
| 58 |
+
else:
|
| 59 |
+
config_path = hf_hub_download(
|
| 60 |
+
repo_id=pretrained_model_name_or_path, filename=config_name
|
| 61 |
+
)
|
| 62 |
+
weight_path = hf_hub_download(
|
| 63 |
+
repo_id=pretrained_model_name_or_path, filename=weight_name
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
cfg = OmegaConf.load(config_path)
|
| 67 |
+
OmegaConf.resolve(cfg)
|
| 68 |
+
model = cls(cfg)
|
| 69 |
+
ckpt = torch.load(weight_path, map_location="cpu")
|
| 70 |
+
model.load_state_dict(ckpt)
|
| 71 |
+
return model
|
| 72 |
+
|
| 73 |
+
def configure(self):
|
| 74 |
+
self.image_tokenizer = find_class(self.cfg.image_tokenizer_cls)(
|
| 75 |
+
self.cfg.image_tokenizer
|
| 76 |
+
)
|
| 77 |
+
self.tokenizer = find_class(self.cfg.tokenizer_cls)(self.cfg.tokenizer)
|
| 78 |
+
self.backbone = find_class(self.cfg.backbone_cls)(self.cfg.backbone)
|
| 79 |
+
self.post_processor = find_class(self.cfg.post_processor_cls)(
|
| 80 |
+
self.cfg.post_processor
|
| 81 |
+
)
|
| 82 |
+
self.decoder = find_class(self.cfg.decoder_cls)(self.cfg.decoder)
|
| 83 |
+
self.renderer = find_class(self.cfg.renderer_cls)(self.cfg.renderer)
|
| 84 |
+
self.image_processor = ImagePreprocessor()
|
| 85 |
+
self.isosurface_helper = None
|
| 86 |
+
|
| 87 |
+
def forward(
|
| 88 |
+
self,
|
| 89 |
+
image: Union[
|
| 90 |
+
PIL.Image.Image,
|
| 91 |
+
np.ndarray,
|
| 92 |
+
torch.FloatTensor,
|
| 93 |
+
List[PIL.Image.Image],
|
| 94 |
+
List[np.ndarray],
|
| 95 |
+
List[torch.FloatTensor],
|
| 96 |
+
],
|
| 97 |
+
device: str,
|
| 98 |
+
) -> torch.FloatTensor:
|
| 99 |
+
rgb_cond = self.image_processor(image, self.cfg.cond_image_size)[:, None].to(
|
| 100 |
+
device
|
| 101 |
+
)
|
| 102 |
+
batch_size = rgb_cond.shape[0]
|
| 103 |
+
|
| 104 |
+
input_image_tokens: torch.Tensor = self.image_tokenizer(
|
| 105 |
+
rearrange(rgb_cond, "B Nv H W C -> B Nv C H W", Nv=1),
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
input_image_tokens = rearrange(
|
| 109 |
+
input_image_tokens, "B Nv C Nt -> B (Nv Nt) C", Nv=1
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
tokens: torch.Tensor = self.tokenizer(batch_size)
|
| 113 |
+
|
| 114 |
+
tokens = self.backbone(
|
| 115 |
+
tokens,
|
| 116 |
+
encoder_hidden_states=input_image_tokens,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
scene_codes = self.post_processor(self.tokenizer.detokenize(tokens))
|
| 120 |
+
return scene_codes
|
| 121 |
+
|
| 122 |
+
def render(
|
| 123 |
+
self,
|
| 124 |
+
scene_codes,
|
| 125 |
+
n_views: int,
|
| 126 |
+
elevation_deg: float = 0.0,
|
| 127 |
+
camera_distance: float = 1.9,
|
| 128 |
+
fovy_deg: float = 40.0,
|
| 129 |
+
height: int = 256,
|
| 130 |
+
width: int = 256,
|
| 131 |
+
return_type: str = "pil",
|
| 132 |
+
):
|
| 133 |
+
rays_o, rays_d = get_spherical_cameras(
|
| 134 |
+
n_views, elevation_deg, camera_distance, fovy_deg, height, width
|
| 135 |
+
)
|
| 136 |
+
rays_o, rays_d = rays_o.to(scene_codes.device), rays_d.to(scene_codes.device)
|
| 137 |
+
|
| 138 |
+
def process_output(image: torch.FloatTensor):
|
| 139 |
+
if return_type == "pt":
|
| 140 |
+
return image
|
| 141 |
+
elif return_type == "np":
|
| 142 |
+
return image.detach().cpu().numpy()
|
| 143 |
+
elif return_type == "pil":
|
| 144 |
+
return Image.fromarray(
|
| 145 |
+
(image.detach().cpu().numpy() * 255.0).astype(np.uint8)
|
| 146 |
+
)
|
| 147 |
+
else:
|
| 148 |
+
raise NotImplementedError
|
| 149 |
+
|
| 150 |
+
images = []
|
| 151 |
+
for scene_code in scene_codes:
|
| 152 |
+
images_ = []
|
| 153 |
+
for i in range(n_views):
|
| 154 |
+
with torch.no_grad():
|
| 155 |
+
image = self.renderer(
|
| 156 |
+
self.decoder, scene_code, rays_o[i], rays_d[i]
|
| 157 |
+
)
|
| 158 |
+
images_.append(process_output(image))
|
| 159 |
+
images.append(images_)
|
| 160 |
+
|
| 161 |
+
return images
|
| 162 |
+
|
| 163 |
+
def set_marching_cubes_resolution(self, resolution: int):
|
| 164 |
+
if (
|
| 165 |
+
self.isosurface_helper is not None
|
| 166 |
+
and self.isosurface_helper.resolution == resolution
|
| 167 |
+
):
|
| 168 |
+
return
|
| 169 |
+
self.isosurface_helper = MarchingCubeHelper(resolution)
|
| 170 |
+
|
| 171 |
+
def extract_mesh(self, scene_codes, resolution: int = 256, threshold: float = 25.0):
|
| 172 |
+
self.set_marching_cubes_resolution(resolution)
|
| 173 |
+
meshes = []
|
| 174 |
+
for scene_code in scene_codes:
|
| 175 |
+
with torch.no_grad():
|
| 176 |
+
density = self.renderer.query_triplane(
|
| 177 |
+
self.decoder,
|
| 178 |
+
scale_tensor(
|
| 179 |
+
self.isosurface_helper.grid_vertices.to(scene_codes.device),
|
| 180 |
+
self.isosurface_helper.points_range,
|
| 181 |
+
(-self.renderer.cfg.radius, self.renderer.cfg.radius),
|
| 182 |
+
),
|
| 183 |
+
scene_code,
|
| 184 |
+
)["density_act"]
|
| 185 |
+
v_pos, t_pos_idx = self.isosurface_helper(-(density - threshold))
|
| 186 |
+
v_pos = scale_tensor(
|
| 187 |
+
v_pos,
|
| 188 |
+
self.isosurface_helper.points_range,
|
| 189 |
+
(-self.renderer.cfg.radius, self.renderer.cfg.radius),
|
| 190 |
+
)
|
| 191 |
+
with torch.no_grad():
|
| 192 |
+
color = self.renderer.query_triplane(
|
| 193 |
+
self.decoder,
|
| 194 |
+
v_pos,
|
| 195 |
+
scene_code,
|
| 196 |
+
)["color"]
|
| 197 |
+
mesh = trimesh.Trimesh(
|
| 198 |
+
vertices=v_pos.cpu().numpy(),
|
| 199 |
+
faces=t_pos_idx.cpu().numpy(),
|
| 200 |
+
vertex_colors=color.cpu().numpy(),
|
| 201 |
+
)
|
| 202 |
+
meshes.append(mesh)
|
| 203 |
+
return meshes
|