Spaces:
Running

Running
Commit
·
4df9e3a
1
Parent(s):
c24ac6c
Initialization 2
Browse files- app.py +113 -0
- assets/BOW.jpg +0 -0
- assets/coeur.png +0 -0
- assets/deepnlp_graph1.png +0 -0
- assets/deepnlp_graph12.png +0 -0
- assets/deepnlp_graph3.png +0 -0
- assets/demosthene_logo.png +0 -0
- assets/faviconV2.png +0 -0
- assets/fig_schapley0.png +0 -0
- assets/fig_schapley1.png +0 -0
- assets/fig_schapley2.png +0 -0
- assets/fig_schapley3.png +0 -0
- assets/fig_schapley4.png +0 -0
- assets/fig_schapley5.png +0 -0
- assets/fig_schapley6.png +0 -0
- assets/fig_schapley7.png +0 -0
- assets/fig_schapley8.png +0 -0
- assets/fig_schapley_recap0.png +0 -0
- assets/fig_schapley_recap1.png +0 -0
- assets/fig_schapley_recap2.png +0 -0
- assets/fig_schapley_recap3.png +0 -0
- assets/fig_schapley_recap4.png +0 -0
- assets/fig_schapley_recap5.png +0 -0
- assets/fig_schapley_recap6.png +0 -0
- assets/fig_schapley_recap7.png +0 -0
- assets/fig_schapley_recap8.png +0 -0
- assets/formule_proba_naive_bayes.png +0 -0
- assets/github-logo.png +0 -0
- assets/linkedin-logo-black.png +0 -0
- assets/linkedin-logo.png +0 -0
- assets/logo-datascientest.png +0 -0
- assets/sample-image.jpg +0 -0
- assets/tough-communication.gif +0 -0
- config.py +32 -0
- images/coeur.png +0 -0
- images/demosthene_tete.svg +1 -0
- member.py +19 -0
- packages.txt +5 -0
- requirements.txt +35 -0
- style.css +129 -0
- tabs/custom_vectorizer.py +14 -0
- tabs/data_viz_tab.py +404 -0
- tabs/exploration_tab.py +424 -0
- tabs/game_tab.py +235 -0
- tabs/id_lang_tab.py +476 -0
- tabs/intro.py +93 -0
- tabs/modelisation_dict_tab.py +277 -0
- tabs/modelisation_seq2seq_tab.py +606 -0
- translate_app.py +27 -0
app.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import os.path
|
| 3 |
+
from collections import OrderedDict
|
| 4 |
+
from streamlit_option_menu import option_menu
|
| 5 |
+
# Define TITLE, TEAM_MEMBERS and PROMOTION values, in config.py.
|
| 6 |
+
import config
|
| 7 |
+
from tabs.custom_vectorizer import custom_tokenizer, custom_preprocessor
|
| 8 |
+
import os
|
| 9 |
+
from translate_app import tr
|
| 10 |
+
|
| 11 |
+
# Initialize a session state variable that tracks the sidebar state (either 'expanded' or 'collapsed').
|
| 12 |
+
if 'sidebar_state' not in st.session_state:
|
| 13 |
+
st.session_state.sidebar_state = 'expanded'
|
| 14 |
+
else:
|
| 15 |
+
st.session_state.sidebar_state = 'auto'
|
| 16 |
+
|
| 17 |
+
st.set_page_config (
|
| 18 |
+
page_title=config.TITLE,
|
| 19 |
+
page_icon= "assets/faviconV2.png",
|
| 20 |
+
initial_sidebar_state=st.session_state.sidebar_state
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
# Si l'application tourne localement, session_state.Cloud == 0
|
| 24 |
+
# Si elle tourne sur le Cloud de Hugging Face, ==1
|
| 25 |
+
st.session_state.Cloud = 1
|
| 26 |
+
# En fonction de la valeur de varible précédente, le data path est différent
|
| 27 |
+
if st.session_state.Cloud == 0:
|
| 28 |
+
st.session_state.DataPath = "../data"
|
| 29 |
+
st.session_state.ImagePath = "../images"
|
| 30 |
+
st.session_state.reCalcule = False
|
| 31 |
+
else:
|
| 32 |
+
st.session_state.DataPath = "data"
|
| 33 |
+
st.session_state.ImagePath = "images"
|
| 34 |
+
st.session_state.reCalcule = False
|
| 35 |
+
|
| 36 |
+
# Define the root folders depending on local/cloud run
|
| 37 |
+
# thisfile = os.path.abspath(__file__)
|
| 38 |
+
# if ('/' in thisfile):
|
| 39 |
+
# os.chdir(os.path.dirname(thisfile))
|
| 40 |
+
|
| 41 |
+
# Nécessaire pour la version windows 11
|
| 42 |
+
if st.session_state.Cloud == 0:
|
| 43 |
+
os.environ['PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION'] = 'python'
|
| 44 |
+
|
| 45 |
+
# Tabs in the ./tabs folder, imported here.
|
| 46 |
+
from tabs import intro, exploration_tab, data_viz_tab, id_lang_tab, modelisation_dict_tab, modelisation_seq2seq_tab, game_tab
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
with open("style.css", "r") as f:
|
| 50 |
+
style = f.read()
|
| 51 |
+
|
| 52 |
+
st.markdown(f"<style>{style}</style>", unsafe_allow_html=True)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
# Add tab in this ordered dict by
|
| 56 |
+
# passing the name in the sidebar as key and the imported tab
|
| 57 |
+
# as value as follow :
|
| 58 |
+
TABS = OrderedDict(
|
| 59 |
+
[
|
| 60 |
+
(tr(intro.sidebar_name), intro),
|
| 61 |
+
(tr(exploration_tab.sidebar_name), exploration_tab),
|
| 62 |
+
(tr(data_viz_tab.sidebar_name), data_viz_tab),
|
| 63 |
+
(tr(id_lang_tab.sidebar_name), id_lang_tab),
|
| 64 |
+
(tr(modelisation_dict_tab.sidebar_name), modelisation_dict_tab),
|
| 65 |
+
(tr(modelisation_seq2seq_tab.sidebar_name), modelisation_seq2seq_tab),
|
| 66 |
+
(tr(game_tab.sidebar_name), game_tab ),
|
| 67 |
+
]
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
# Utilisation du module translate
|
| 71 |
+
# lang_tgt = ['fr','en','af','ak','sq','de','am','en','ar','hy','as','az','ba','bm','eu','bn','be','my','bs','bg','ks','ca','ny','zh','si','ko','co','ht','hr','da','dz','gd','es','eo','et','ee','fo','fj','fi','fr','fy','gl','cy','lg','ka','el','gn','gu','ha','he','hi','hu','ig','id','iu','ga','is','it','ja','kn','kk','km','ki','rw','ky','rn','ku','lo','la','lv','li','ln','lt','lb','mk','ms','ml','dv','mg','mt','mi','mr','mn','nl','ne','no','nb','nn','oc','or','ug','ur','uz','ps','pa','fa','pl','pt','ro','ru','sm','sg','sa','sc','sr','sn','sd','sk','sl','so','st','su','sv','sw','ss','tg','tl','ty','ta','tt','cs','te','th','bo','ti','to','ts','tn','tr','tk','tw','uk','vi','wo','xh','yi']
|
| 72 |
+
# label_lang = ['Français', 'Anglais / English','Afrikaans','Akan','Albanais','Allemand / Deutsch','Amharique','Anglais','Arabe','Arménien','Assamais','Azéri','Bachkir','Bambara','Basque','Bengali','Biélorusse','Birman','Bosnien','Bulgare','Cachemiri','Catalan','Chichewa','Chinois','Cingalais','Coréen','Corse','Créolehaïtien','Croate','Danois','Dzongkha','Écossais','Espagnol / Español','Espéranto','Estonien','Ewe','Féroïen','Fidjien','Finnois','Français','Frisonoccidental','Galicien','Gallois','Ganda','Géorgien','Grecmoderne','Guarani','Gujarati','Haoussa','Hébreu','Hindi','Hongrois','Igbo','Indonésien','Inuktitut','Irlandais','Islandais','Italien / Italiano','Japonais','Kannada','Kazakh','Khmer','Kikuyu','Kinyarwanda','Kirghiz','Kirundi','Kurde','Lao','Latin','Letton','Limbourgeois','Lingala','Lituanien','Luxembourgeois','Macédonien','Malais','Malayalam','Maldivien','Malgache','Maltais','MaorideNouvelle-Zélande','Marathi','Mongol','Néerlandais / Nederlands','Népalais','Norvégien','Norvégienbokmål','Norvégiennynorsk','Occitan','Oriya','Ouïghour','Ourdou','Ouzbek','Pachto','Pendjabi','Persan','Polonais','Portugais','Roumain','Russe','Samoan','Sango','Sanskrit','Sarde','Serbe','Shona','Sindhi','Slovaque','Slovène','Somali','SothoduSud','Soundanais','Suédois','Swahili','Swati','Tadjik','Tagalog','Tahitien','Tamoul','Tatar','Tchèque','Télougou','Thaï','Tibétain','Tigrigna','Tongien','Tsonga','Tswana','Turc','Turkmène','Twi','Ukrainien','Vietnamien','Wolof','Xhosa','Yiddish']
|
| 73 |
+
|
| 74 |
+
# Utilisation du module deep_translator
|
| 75 |
+
lang_tgt = ['fr', 'en', 'af', 'ak', 'sq', 'de', 'am', 'en', 'ar', 'hy', 'as', 'ay', 'az', 'bm', 'eu', 'bn', 'bho', 'be', 'my', 'bs', 'bg', 'ca', 'ceb', 'ny', 'zh-CN', 'zh-TW', 'si', 'ko', 'co', 'ht', 'hr', 'da', 'doi', 'gd', 'es', 'eo', 'et', 'ee', 'fi', 'fr', 'fy', 'gl', 'cy', 'lg', 'ka', 'el', 'gn', 'gu', 'ha', 'haw', 'iw', 'hi', 'hmn', 'hu', 'ig', 'ilo', 'id', 'ga', 'is', 'it', 'ja', 'jw', 'kn', 'kk', 'km', 'rw', 'ky', 'gom', 'kri', 'ku', 'ckb', 'lo', 'la', 'lv', 'ln', 'lt', 'lb', 'mk', 'mai', 'ms', 'ml', 'dv', 'mg', 'mt', 'mi', 'mr', 'mni-Mtei', 'lus', 'mn', 'nl', 'ne', 'no','or', 'om', 'ug', 'ur', 'uz', 'ps', 'pa', 'fa', 'pl', 'pt', 'qu', 'ro', 'ru', 'sm', 'sa', 'nso', 'sr', 'sn', 'sd', 'sk', 'sl', 'so', 'st', 'su', 'sv', 'sw', 'tg', 'tl', 'ta', 'tt', 'cs', 'te', 'th', 'ti', 'ts', 'tr', 'tk', 'uk', 'vi', 'xh', 'yi', 'yo', 'zu']
|
| 76 |
+
label_lang = ['Français', 'Anglais / English','Afrikaans','Akan','Albanais','Allemand / Deutsch','Amharique','Anglais','Arabe','Arménien','Assamais','Aymara','Azéri','Bambara','Basque','Bengali','Bhojpuri','Biélorusse','Birman','Bosnien','Bulgare','Catalan','Cebuano','Chichewa','Chinois (simplifié)','Chinois (traditionnel)','Cingalais','Coréen','Corse','Créole haïtien','Croate','Danois','Dogri','Écossais','Espagnol / Español','Espéranto','Estonien','Ewe','Finnois','Français','Frisonoccidental','Galicien','Gallois','Ganda','Géorgien','Grec moderne','Guarani','Gujarati','Haoussa','Hawaïen','Hébreu','Hindi','Hmong','Hongrois','Igbo','Ilocano','Indonésien','Irlandais','Islandais','Italien / Italiano','Japonais','Javanais','Kannada','Kazakh','Khmer','Kinyarwanda','Kirghiz','Konkani','Krio','Kurde','Kurde (Sorani)','Lao','Latin','Letton','Lingala','Lituanien','Luxembourgeois','Macédonien','Maithili','Malais','Malayalam','Maldivien','Malgache','Maltais','Maori de Nouvelle-Zélande','Marathi','Meiteilon (Manipuri)','Mizo','Mongol','Néerlandais / Nederlands','Népalais','Norvégien','Oriya','Oromo','Ouïghour','Ourdou','Ouzbek','Pachto','Pendjabi','Persan','Polonais','Portugais','Quechua','Roumain','Russe','Samoan','Sanskrit','Sepedi','Serbe','Shona','Sindhi','Slovaque','Slovène','Somali','Sotho du Sud','Soundanais','Suédois','Swahili','Tadjik','Tagalog','Tamoul','Tatar','Tchèque','Télougou','Thaï','Tigrigna','Tsonga','Turc','Turkmène','Ukrainien','Vietnamien','Xhosa','Yiddish','Yoruba','Zulu']
|
| 77 |
+
|
| 78 |
+
@st.cache_data
|
| 79 |
+
def find_lang_label(lang_sel):
|
| 80 |
+
global lang_tgt, label_lang
|
| 81 |
+
return label_lang[lang_tgt.index(lang_sel)]
|
| 82 |
+
|
| 83 |
+
def run():
|
| 84 |
+
|
| 85 |
+
st.sidebar.image(
|
| 86 |
+
"assets/demosthene_logo.png",
|
| 87 |
+
width=270,
|
| 88 |
+
)
|
| 89 |
+
with st.sidebar:
|
| 90 |
+
tab_name = option_menu(None, list(TABS.keys()),
|
| 91 |
+
# icons=['house', 'bi-binoculars', 'bi bi-graph-up', 'bi-chat-right-text','bi-book', 'bi-body-text'], menu_icon="cast", default_index=0,
|
| 92 |
+
icons=['house', 'binoculars', 'graph-up', 'search','book', 'chat-right-text','controller'], menu_icon="cast", default_index=0,
|
| 93 |
+
styles={"container": {"padding": "0!important","background-color": "#10b8dd", "border-radius": "0!important"},
|
| 94 |
+
"nav-link": {"font-size": "1rem", "text-align": "left", "margin":"0em", "padding": "0em",
|
| 95 |
+
"padding-left": "0.2em", "--hover-color": "#eee", "font-weight": "400",
|
| 96 |
+
"font-family": "Source Sans Pro, sans-serif"}
|
| 97 |
+
})
|
| 98 |
+
# tab_name = st.sidebar.radio("", list(TABS.keys()), 0)
|
| 99 |
+
st.sidebar.markdown("---")
|
| 100 |
+
st.sidebar.markdown(f"## {config.PROMOTION}")
|
| 101 |
+
|
| 102 |
+
st.sidebar.markdown("### Team members:")
|
| 103 |
+
for member in config.TEAM_MEMBERS:
|
| 104 |
+
st.sidebar.markdown(member.sidebar_markdown(), unsafe_allow_html=True)
|
| 105 |
+
|
| 106 |
+
with st.sidebar:
|
| 107 |
+
st.selectbox("langue:",lang_tgt, format_func = find_lang_label, key="Language", label_visibility="hidden")
|
| 108 |
+
|
| 109 |
+
tab = TABS[tab_name]
|
| 110 |
+
tab.run()
|
| 111 |
+
|
| 112 |
+
if __name__ == "__main__":
|
| 113 |
+
run()
|
assets/BOW.jpg
ADDED

|
assets/coeur.png
ADDED

|
assets/deepnlp_graph1.png
ADDED
|
assets/deepnlp_graph12.png
ADDED

|
assets/deepnlp_graph3.png
ADDED
|
assets/demosthene_logo.png
ADDED
|
|
assets/faviconV2.png
ADDED

|
assets/fig_schapley0.png
ADDED
|
assets/fig_schapley1.png
ADDED
|
assets/fig_schapley2.png
ADDED
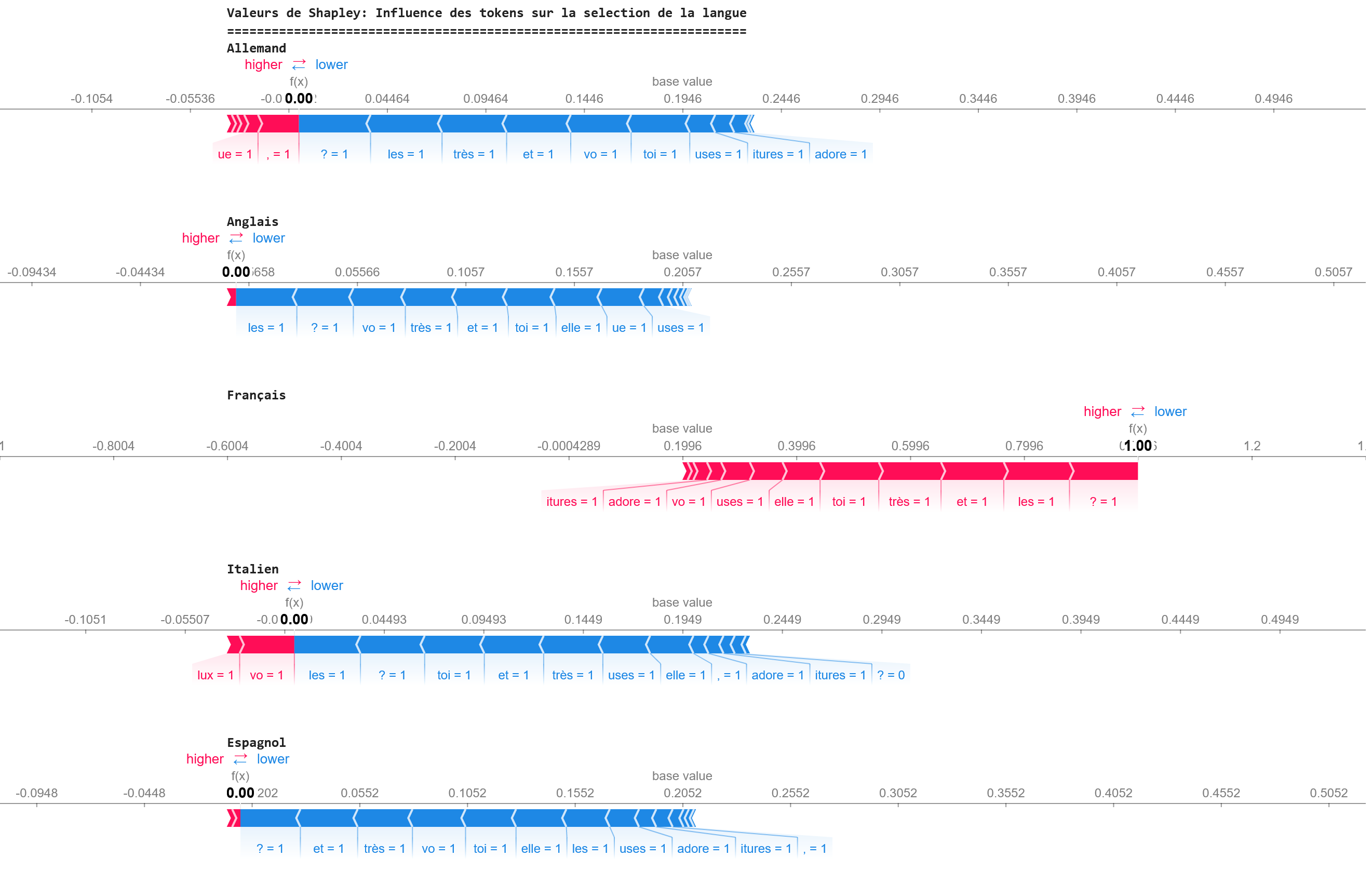
|
assets/fig_schapley3.png
ADDED

|
assets/fig_schapley4.png
ADDED

|
assets/fig_schapley5.png
ADDED

|
assets/fig_schapley6.png
ADDED
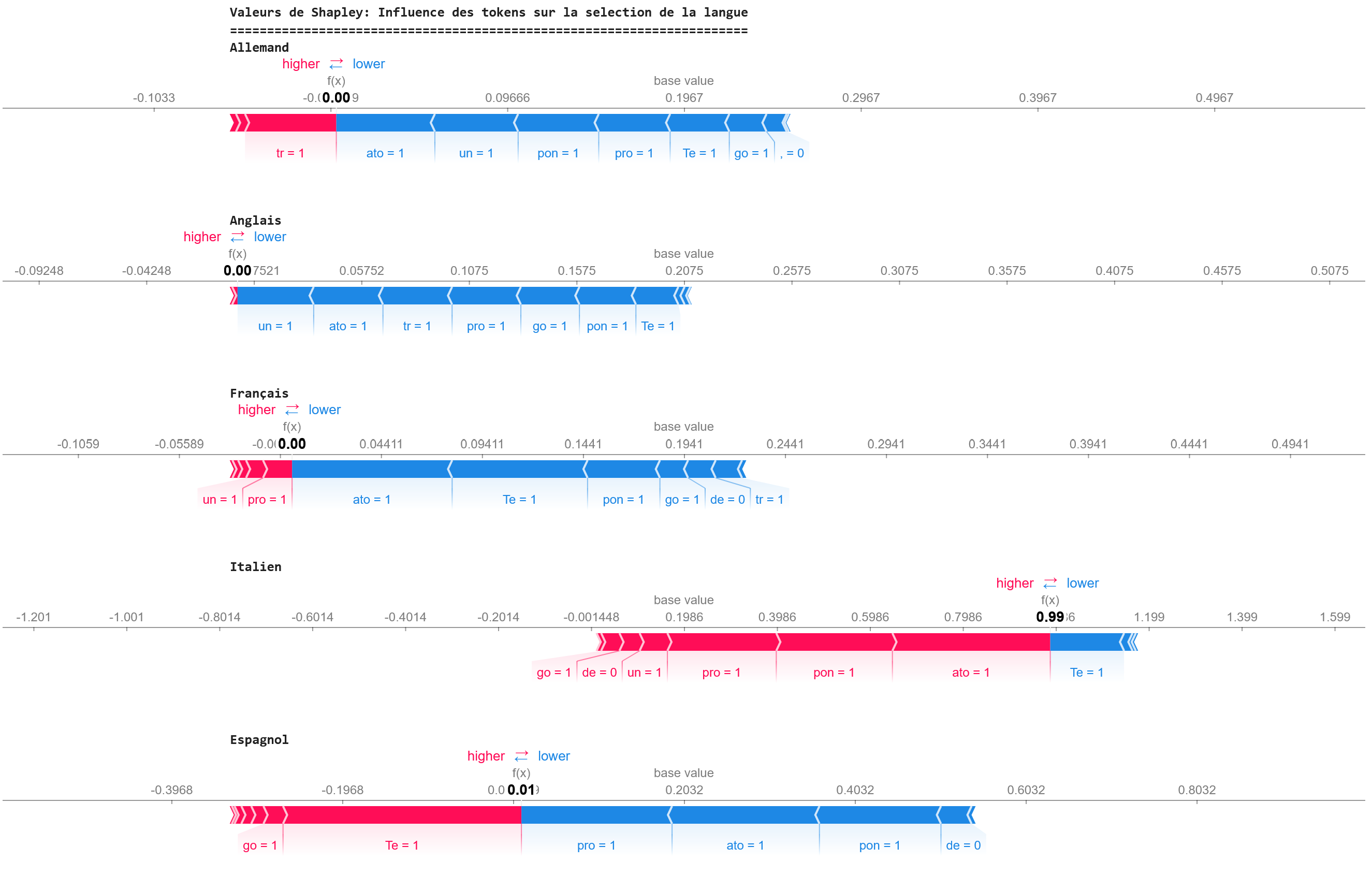
|
assets/fig_schapley7.png
ADDED
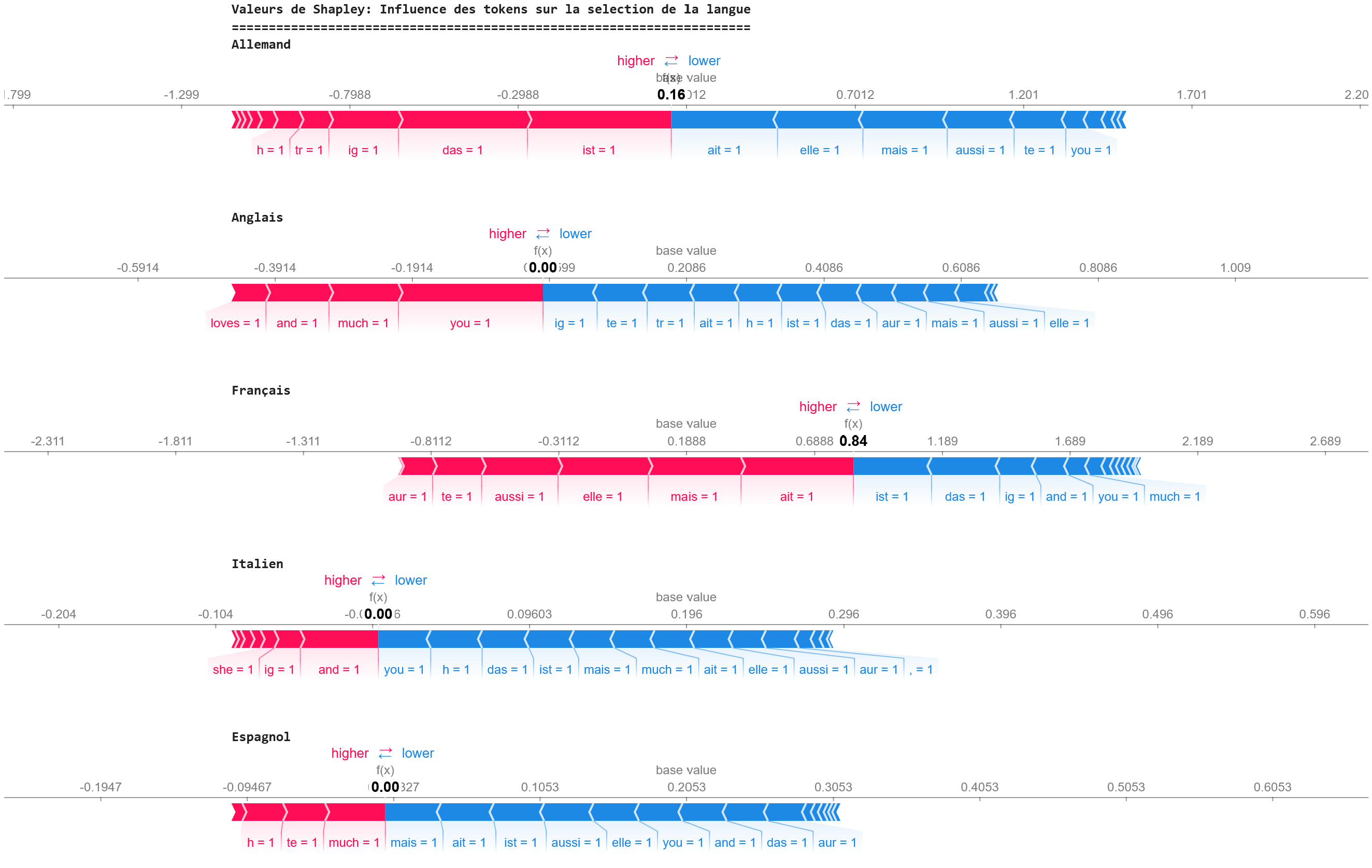
|
assets/fig_schapley8.png
ADDED
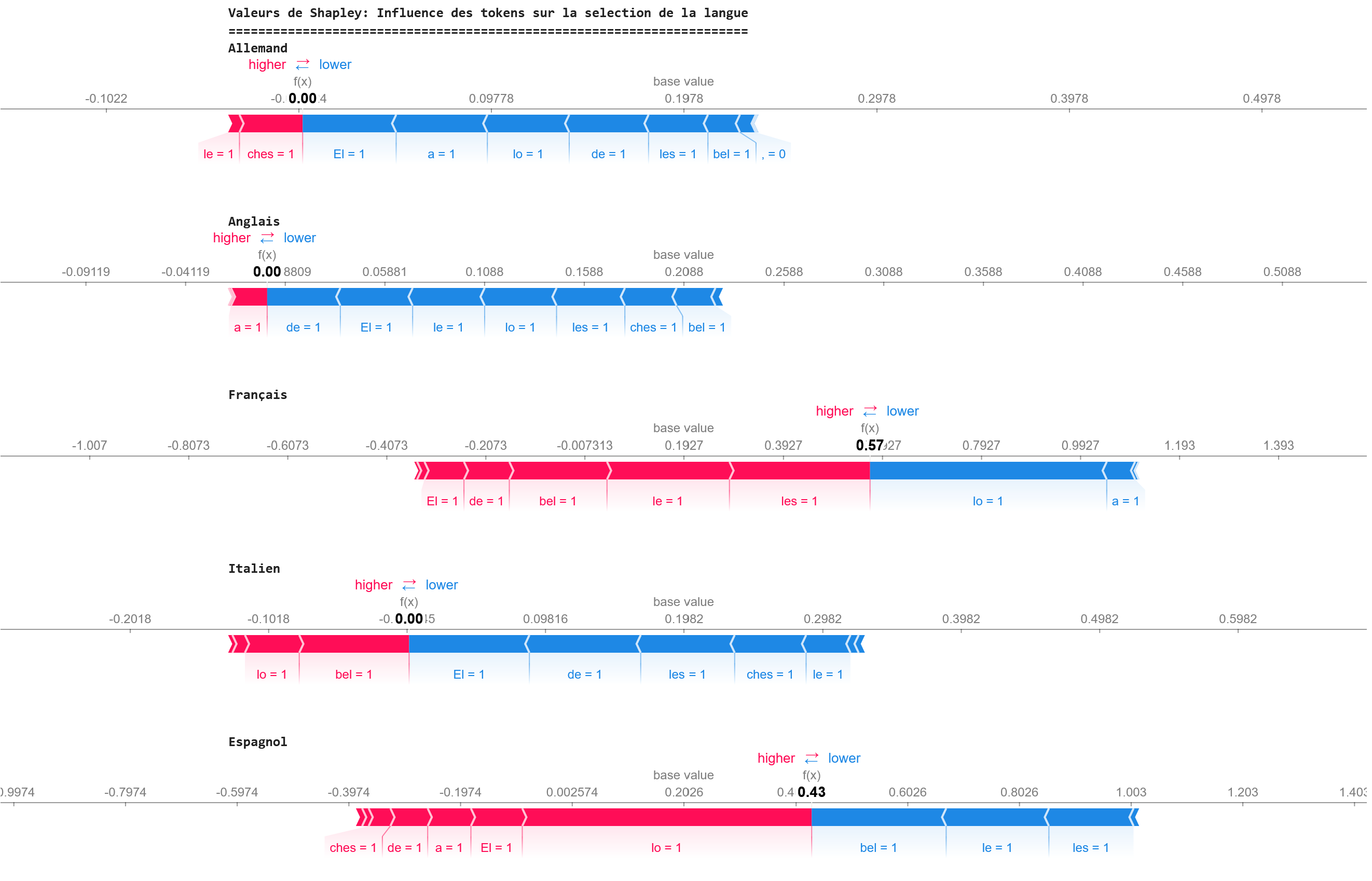
|
assets/fig_schapley_recap0.png
ADDED
|
assets/fig_schapley_recap1.png
ADDED
|
assets/fig_schapley_recap2.png
ADDED
|
assets/fig_schapley_recap3.png
ADDED
|
assets/fig_schapley_recap4.png
ADDED
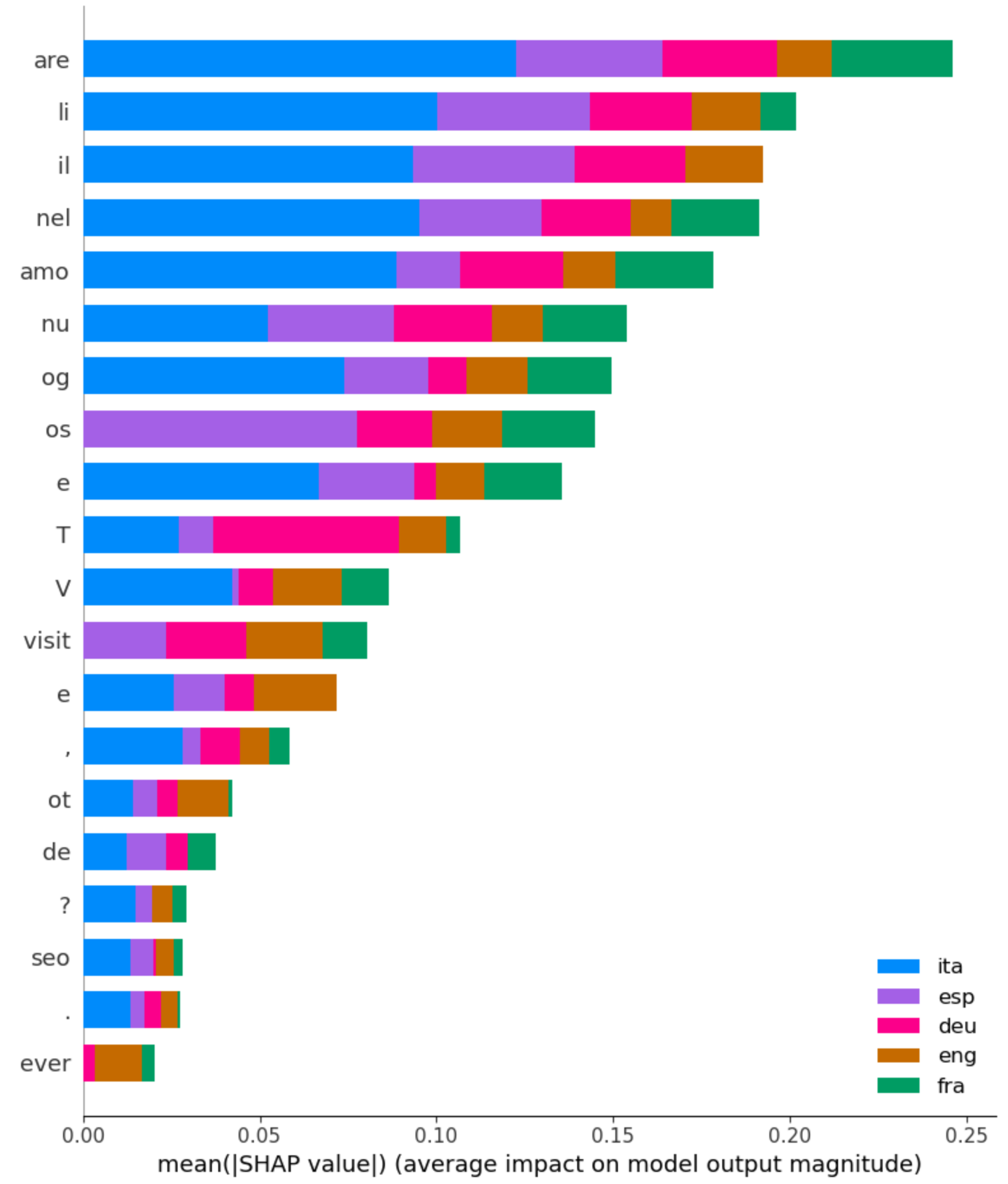
|
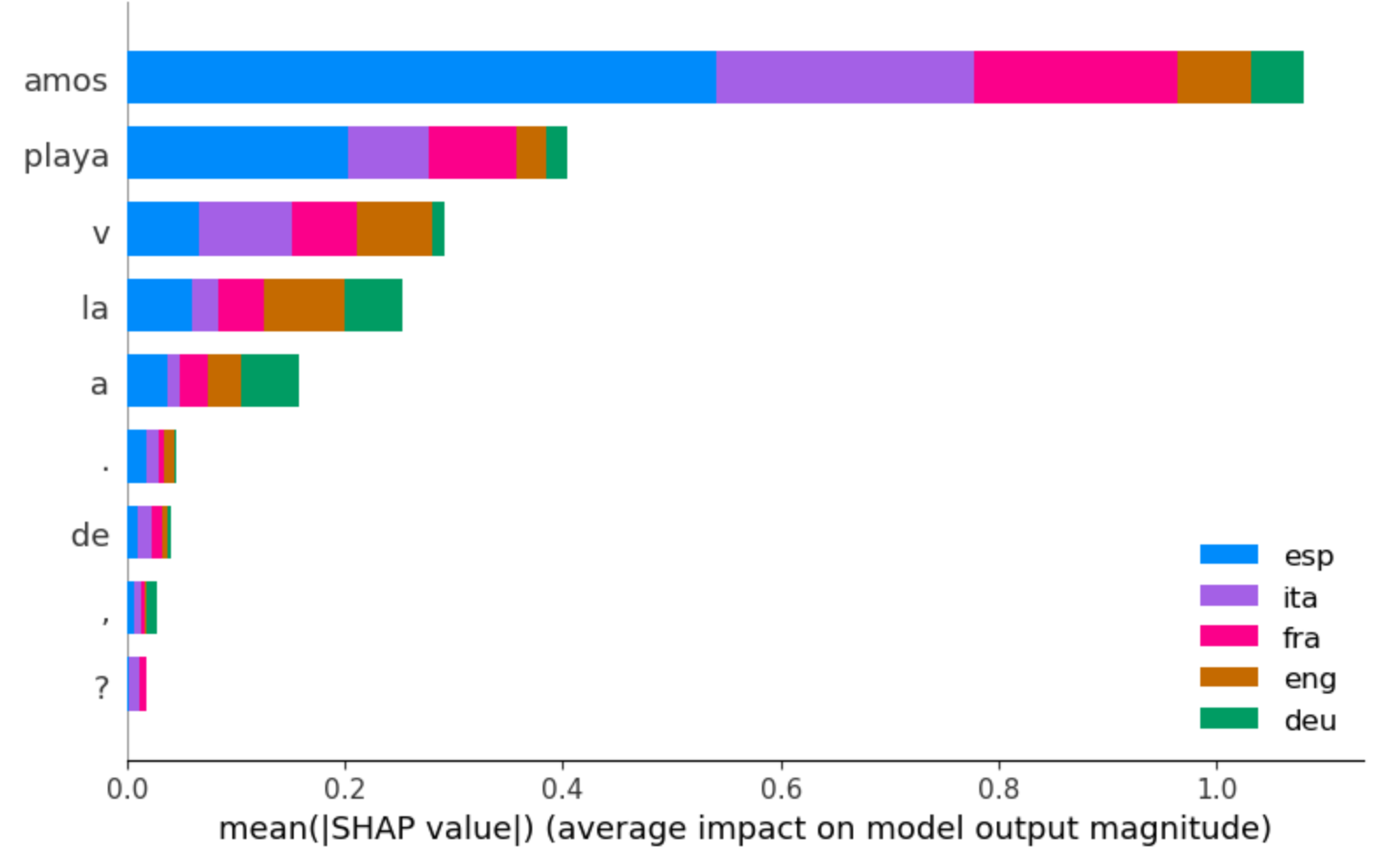
assets/fig_schapley_recap5.png
ADDED
|
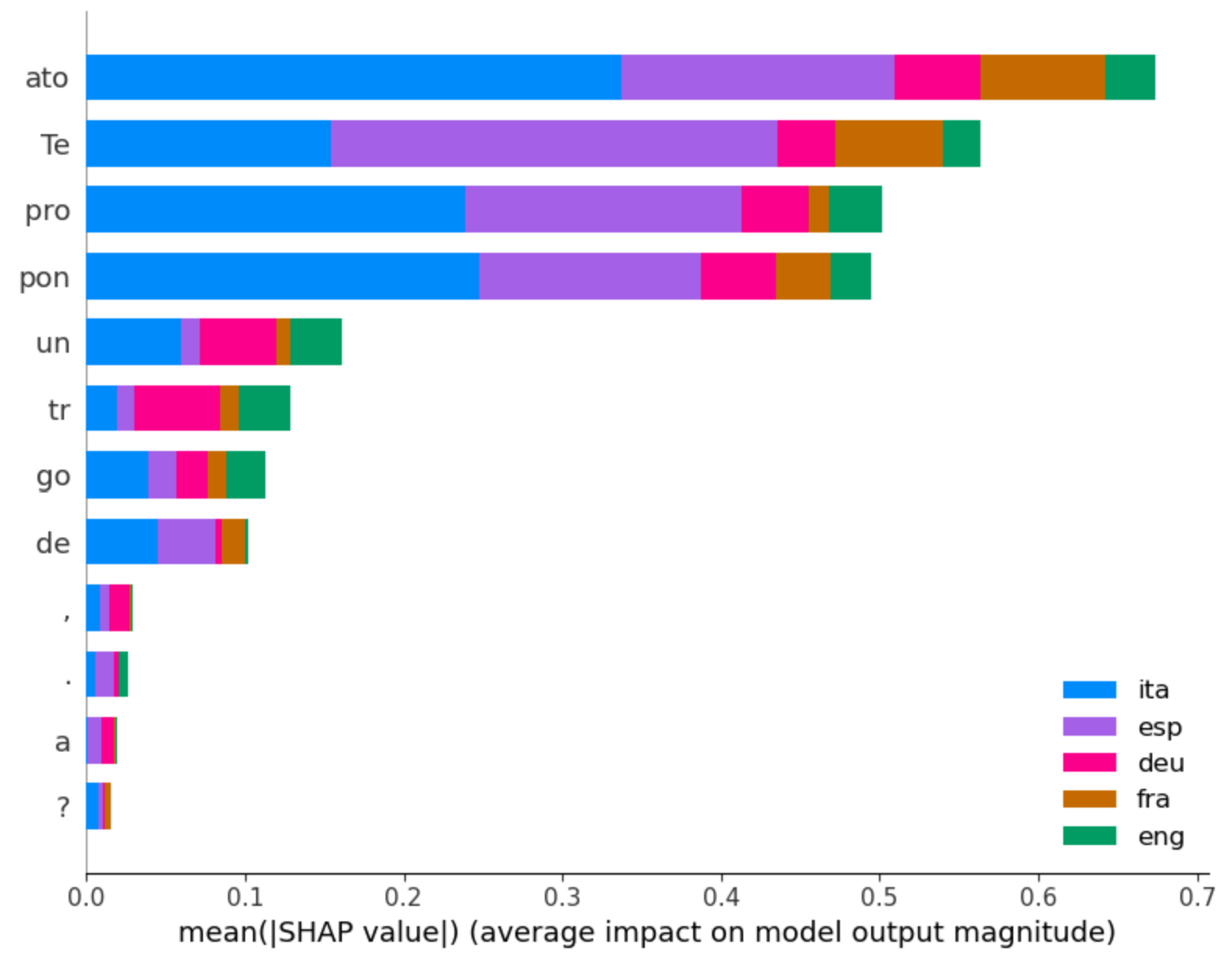
assets/fig_schapley_recap6.png
ADDED
|
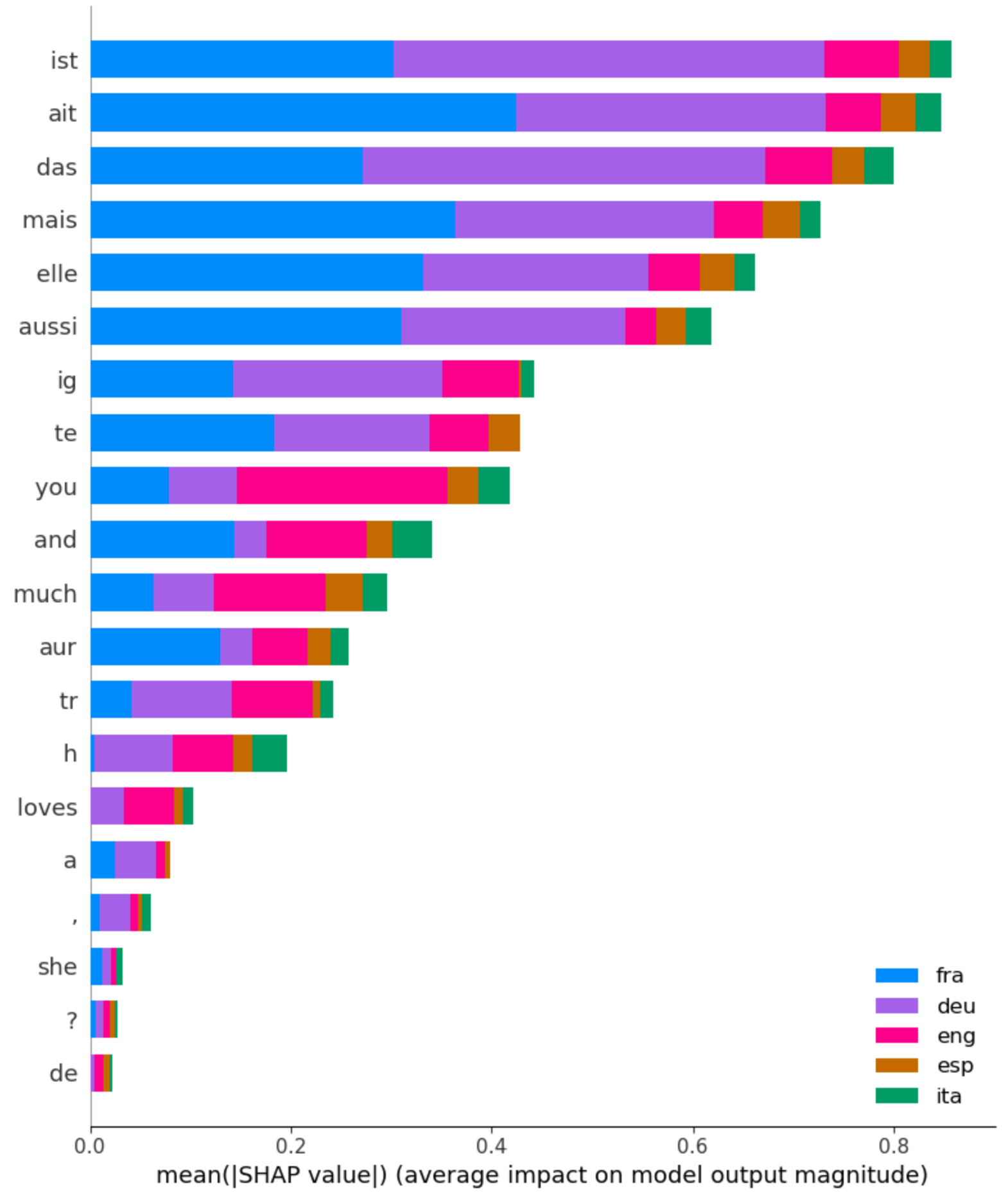
assets/fig_schapley_recap7.png
ADDED
|
assets/fig_schapley_recap8.png
ADDED
|
assets/formule_proba_naive_bayes.png
ADDED

|
assets/github-logo.png
ADDED
|
|
assets/linkedin-logo-black.png
ADDED
|
|
assets/linkedin-logo.png
ADDED
|
|
assets/logo-datascientest.png
ADDED
|
|
assets/sample-image.jpg
ADDED

|
assets/tough-communication.gif
ADDED

|
config.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
|
| 3 |
+
Config file for Streamlit App
|
| 4 |
+
|
| 5 |
+
"""
|
| 6 |
+
|
| 7 |
+
from member import Member
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
TITLE = "Système de traduction adapté aux lunettes connectées"
|
| 11 |
+
|
| 12 |
+
TEAM_MEMBERS = [
|
| 13 |
+
Member(
|
| 14 |
+
name="Keyne Dupont ",
|
| 15 |
+
linkedin_url="https://www.linkedin.com/in/keyne-dupont/",
|
| 16 |
+
github_url=None,
|
| 17 |
+
),
|
| 18 |
+
Member(
|
| 19 |
+
name="Tia Ratsimbason",
|
| 20 |
+
linkedin_url="https://www.linkedin.com/in/tia-ratsimbason-42110887/",
|
| 21 |
+
github_url=None,
|
| 22 |
+
),
|
| 23 |
+
Member(
|
| 24 |
+
name="Olivier Renouard",
|
| 25 |
+
linkedin_url="https://www.linkedin.com/in/olivier-renouard/",
|
| 26 |
+
github_url="https://github.com/Demosthene-OR/AVR23_CDS_Text_translation",
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
]
|
| 31 |
+
|
| 32 |
+
PROMOTION = "Promotion Continuous - Data Scientist - April 2023"
|
images/coeur.png
ADDED

|
images/demosthene_tete.svg
ADDED

|
member.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class Member:
|
| 2 |
+
def __init__(
|
| 3 |
+
self, name: str, linkedin_url: str = None, github_url: str = None
|
| 4 |
+
) -> None:
|
| 5 |
+
self.name = name
|
| 6 |
+
self.linkedin_url = linkedin_url
|
| 7 |
+
self.github_url = github_url
|
| 8 |
+
|
| 9 |
+
def sidebar_markdown(self):
|
| 10 |
+
|
| 11 |
+
markdown = f'<b style="display: inline-block; vertical-align: middle; height: 100%">{self.name}</b>'
|
| 12 |
+
|
| 13 |
+
if self.linkedin_url is not None:
|
| 14 |
+
markdown += f' <a href={self.linkedin_url} target="_blank"><img src="https://dst-studio-template.s3.eu-west-3.amazonaws.com/linkedin-logo-black.png" alt="linkedin" width="25" style="vertical-align: middle; margin-left: 5px"/></a> '
|
| 15 |
+
|
| 16 |
+
if self.github_url is not None:
|
| 17 |
+
markdown += f' <a href={self.github_url} target="_blank"><img src="https://dst-studio-template.s3.eu-west-3.amazonaws.com/github-logo.png" alt="github" width="20" style="vertical-align: middle; margin-left: 5px"/></a> '
|
| 18 |
+
|
| 19 |
+
return markdown
|
packages.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build-essential
|
| 2 |
+
libasound-dev
|
| 3 |
+
portaudio19-dev
|
| 4 |
+
python3-pyaudio
|
| 5 |
+
graphviz
|
requirements.txt
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit==1.26.0
|
| 2 |
+
pandas==2.2.1
|
| 3 |
+
matplotlib==3.8.2
|
| 4 |
+
ipython==8.21.0
|
| 5 |
+
numpy==1.23.5
|
| 6 |
+
seaborn==0.13.2
|
| 7 |
+
nltk==3.8.1
|
| 8 |
+
scikit-learn==1.1.3
|
| 9 |
+
gensim==4.3.2
|
| 10 |
+
sacrebleu==2.4.0
|
| 11 |
+
spacy==3.6.0
|
| 12 |
+
https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.6.0/en_core_web_sm-3.6.0.tar.gz
|
| 13 |
+
https://github.com/explosion/spacy-models/releases/download/fr_core_news_sm-3.6.0/fr_core_news_sm-3.6.0.tar.gz
|
| 14 |
+
pillow==9.5.0
|
| 15 |
+
wordcloud==1.9.3
|
| 16 |
+
networkx==2.7.0
|
| 17 |
+
transformers==4.37.2
|
| 18 |
+
keras-nlp==0.6.1
|
| 19 |
+
keras==2.12.0
|
| 20 |
+
tensorflow==2.12.0
|
| 21 |
+
sentencepiece==0.1.99
|
| 22 |
+
openai-whisper==20231117
|
| 23 |
+
torch==2.2.0
|
| 24 |
+
speechrecognition==3.10.1
|
| 25 |
+
audio_recorder_streamlit==0.0.8
|
| 26 |
+
whisper==1.1.10
|
| 27 |
+
wavio==0.0.8
|
| 28 |
+
filesplit==4.0.1
|
| 29 |
+
regex==2023.12.25
|
| 30 |
+
pydot==2.0.0
|
| 31 |
+
graphviz==0.20.1
|
| 32 |
+
gTTS==2.5.1
|
| 33 |
+
https://files.pythonhosted.org/packages/cc/58/96aff0e5cb8b59c06232ea7e249ed902d04ec89f52636f5be06ceb0855fe/extra_streamlit_components-0.1.60-py3-none-any.whl
|
| 34 |
+
streamlit-option-menu==0.3.12
|
| 35 |
+
deep-translator==1.11.4
|
style.css
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
h1 {
|
| 2 |
+
padding-top: 0rem;
|
| 3 |
+
padding-bottom: 0rem;
|
| 4 |
+
margin-top:6px;
|
| 5 |
+
}
|
| 6 |
+
h2 {
|
| 7 |
+
padding-top: 0.75rem;
|
| 8 |
+
padding-bottom: 0.5rem;
|
| 9 |
+
}
|
| 10 |
+
|
| 11 |
+
/* La ligne suivante est nécessaire à cause du module streamlit_option_menu qui "casse" les CSS suivants */
|
| 12 |
+
@media (prefers-color-scheme: dark) {
|
| 13 |
+
.st-cc {
|
| 14 |
+
color: #fff!important; /* Couleur du texte en mode sombre */
|
| 15 |
+
}
|
| 16 |
+
.st-cg:hover {
|
| 17 |
+
color: rgb(255, 75, 75)!important; /* Couleur du texte en mode sombre */
|
| 18 |
+
}
|
| 19 |
+
section[data-testid="stSidebar"] .stSelectbox .st-cc {
|
| 20 |
+
color: rgb(255, 75, 75)!important;
|
| 21 |
+
font-weight: bold;
|
| 22 |
+
}
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
p {
|
| 26 |
+
margin-bottom:0.1rem;
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
code {
|
| 30 |
+
color: #1ec3bc;
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
#MainMenu {
|
| 34 |
+
display: none;
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
div[data-testid="stDecoration"] {
|
| 38 |
+
display: none;
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
footer {
|
| 42 |
+
display: none;
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
/* Radio buttons */
|
| 46 |
+
|
| 47 |
+
.st-cc {
|
| 48 |
+
color: black;
|
| 49 |
+
font-weight: 500;
|
| 50 |
+
}
|
| 51 |
+
|
| 52 |
+
/* Sidebar */
|
| 53 |
+
|
| 54 |
+
.css-1544g2n {
|
| 55 |
+
padding-top: 1rem;
|
| 56 |
+
}
|
| 57 |
+
|
| 58 |
+
.css-10oheav {
|
| 59 |
+
padding-top: 3rem;
|
| 60 |
+
}
|
| 61 |
+
|
| 62 |
+
.css-ue6h4q {
|
| 63 |
+
min-height: 0.5rem;
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
section[data-testid="stSidebar"] > div {
|
| 67 |
+
background-color: #10b8dd;
|
| 68 |
+
padding-top: 1rem;
|
| 69 |
+
padding-left: 0.5rem;
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
section[data-testid="stSidebar"] button[title="View fullscreen"] {
|
| 73 |
+
display: none;
|
| 74 |
+
}
|
| 75 |
+
|
| 76 |
+
section[data-testid="stSidebar"] button[kind="icon"] {
|
| 77 |
+
display: none;
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
section[data-testid="stSidebar"] .st-bk {
|
| 81 |
+
background-color: #10b8dd;
|
| 82 |
+
}
|
| 83 |
+
|
| 84 |
+
section[data-testid="stSidebar"] .st-c0 {
|
| 85 |
+
/* background-color: #10b8dd; */
|
| 86 |
+
}
|
| 87 |
+
|
| 88 |
+
section[data-testid="stSidebar"] hr {
|
| 89 |
+
margin-top: 30px;
|
| 90 |
+
border-color: white;
|
| 91 |
+
width: 50px;
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
section[data-testid="stSidebar"] h2 {
|
| 95 |
+
color: white;
|
| 96 |
+
}
|
| 97 |
+
|
| 98 |
+
section[data-testid="stSidebar"] .stSelectbox .st-bk {
|
| 99 |
+
background-color: #a0d3de;
|
| 100 |
+
}
|
| 101 |
+
|
| 102 |
+
section[data-testid="stSidebar"] .stSelectbox .st-cc {
|
| 103 |
+
color: rgb(255, 75, 75);
|
| 104 |
+
font-weight: bold;
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
/* Images */
|
| 108 |
+
|
| 109 |
+
button[title="View fullscreen"] {
|
| 110 |
+
display: none;
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
/* hr */
|
| 114 |
+
|
| 115 |
+
hr {
|
| 116 |
+
width: 700px;
|
| 117 |
+
border-width: 5px;
|
| 118 |
+
border-color: #10b8dd;
|
| 119 |
+
margin-top: 0px;
|
| 120 |
+
margin-bottom: 1em;
|
| 121 |
+
max-width: 100%;
|
| 122 |
+
}
|
| 123 |
+
|
| 124 |
+
/* First Page */
|
| 125 |
+
|
| 126 |
+
section[tabindex="0"] .block-container {
|
| 127 |
+
padding-top: 0px;
|
| 128 |
+
padding-bottom: 0px;
|
| 129 |
+
}
|
tabs/custom_vectorizer.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Les 2 fonctions suivantes sont nécéssaires afin de sérialiser ces parametre de CountVectorizer
|
| 2 |
+
# et ainsi de sauvegarder le vectorizer pour un un usage ultérieur sans utiliser X_train pour le réinitialiser
|
| 3 |
+
import tiktoken
|
| 4 |
+
|
| 5 |
+
tokenizer = tiktoken.get_encoding("cl100k_base")
|
| 6 |
+
|
| 7 |
+
def custom_tokenizer(text):
|
| 8 |
+
global tokenizer
|
| 9 |
+
|
| 10 |
+
tokens = tokenizer.encode(text) # Cela divise le texte en mots
|
| 11 |
+
return tokens
|
| 12 |
+
|
| 13 |
+
def custom_preprocessor(text):
|
| 14 |
+
return text
|
tabs/data_viz_tab.py
ADDED
|
@@ -0,0 +1,404 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import os
|
| 4 |
+
import ast
|
| 5 |
+
import contextlib
|
| 6 |
+
import numpy as np
|
| 7 |
+
import pandas as pd
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import seaborn as sns
|
| 10 |
+
from wordcloud import WordCloud
|
| 11 |
+
import nltk
|
| 12 |
+
from nltk.corpus import stopwords
|
| 13 |
+
from gensim import corpora
|
| 14 |
+
import networkx as nx
|
| 15 |
+
from sklearn.manifold import TSNE
|
| 16 |
+
from gensim.models import KeyedVectors
|
| 17 |
+
from translate_app import tr
|
| 18 |
+
|
| 19 |
+
title = "Data Vizualization"
|
| 20 |
+
sidebar_name = "Data Vizualization"
|
| 21 |
+
dataPath = st.session_state.DataPath
|
| 22 |
+
|
| 23 |
+
with contextlib.redirect_stdout(open(os.devnull, "w")):
|
| 24 |
+
nltk.download('stopwords')
|
| 25 |
+
|
| 26 |
+
# Première ligne à charger
|
| 27 |
+
first_line = 0
|
| 28 |
+
# Nombre maximum de lignes à charger
|
| 29 |
+
max_lines = 140000
|
| 30 |
+
if ((first_line+max_lines)>137860):
|
| 31 |
+
max_lines = max(137860-first_line ,0)
|
| 32 |
+
# Nombre maximum de ligne à afficher pour les DataFrame
|
| 33 |
+
max_lines_to_display = 50
|
| 34 |
+
|
| 35 |
+
@st.cache_data
|
| 36 |
+
def load_data(path):
|
| 37 |
+
|
| 38 |
+
input_file = os.path.join(path)
|
| 39 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 40 |
+
data = f.read()
|
| 41 |
+
|
| 42 |
+
# On convertit les majuscules en minulcule
|
| 43 |
+
data = data.lower()
|
| 44 |
+
|
| 45 |
+
data = data.split('\n')
|
| 46 |
+
return data[first_line:min(len(data),first_line+max_lines)]
|
| 47 |
+
|
| 48 |
+
@st.cache_data
|
| 49 |
+
def load_preprocessed_data(path,data_type):
|
| 50 |
+
|
| 51 |
+
input_file = os.path.join(path)
|
| 52 |
+
if data_type == 1:
|
| 53 |
+
return pd.read_csv(input_file, encoding="utf-8", index_col=0)
|
| 54 |
+
else:
|
| 55 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 56 |
+
data = f.read()
|
| 57 |
+
data = data.split('\n')
|
| 58 |
+
if data_type==0:
|
| 59 |
+
data=data[:-1]
|
| 60 |
+
elif data_type == 2:
|
| 61 |
+
data=[eval(i) for i in data[:-1]]
|
| 62 |
+
elif data_type ==3:
|
| 63 |
+
data2 = []
|
| 64 |
+
for d in data[:-1]:
|
| 65 |
+
data2.append(ast.literal_eval(d))
|
| 66 |
+
data=data2
|
| 67 |
+
return data
|
| 68 |
+
|
| 69 |
+
@st.cache_data
|
| 70 |
+
def load_all_preprocessed_data(lang):
|
| 71 |
+
txt =load_preprocessed_data(dataPath+'/preprocess_txt_'+lang,0)
|
| 72 |
+
corpus =load_preprocessed_data(dataPath+'/preprocess_corpus_'+lang,0)
|
| 73 |
+
txt_split = load_preprocessed_data(dataPath+'/preprocess_txt_split_'+lang,3)
|
| 74 |
+
df_count_word = pd.concat([load_preprocessed_data(dataPath+'/preprocess_df_count_word1_'+lang,1), load_preprocessed_data(dataPath+'/preprocess_df_count_word2_'+lang,1)])
|
| 75 |
+
sent_len =load_preprocessed_data(dataPath+'/preprocess_sent_len_'+lang,2)
|
| 76 |
+
vec_model= KeyedVectors.load_word2vec_format(dataPath+'/mini.wiki.'+lang+'.align.vec')
|
| 77 |
+
return txt, corpus, txt_split, df_count_word,sent_len, vec_model
|
| 78 |
+
|
| 79 |
+
#Chargement des textes complet dans les 2 langues
|
| 80 |
+
full_txt_en, full_corpus_en, full_txt_split_en, full_df_count_word_en,full_sent_len_en, vec_model_en = load_all_preprocessed_data('en')
|
| 81 |
+
full_txt_fr, full_corpus_fr, full_txt_split_fr, full_df_count_word_fr,full_sent_len_fr, vec_model_fr = load_all_preprocessed_data('fr')
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
def plot_word_cloud(text, title, masque, stop_words, background_color = "white"):
|
| 85 |
+
|
| 86 |
+
mask_coloring = np.array(Image.open(str(masque)))
|
| 87 |
+
# Définir le calque du nuage des mots
|
| 88 |
+
wc = WordCloud(background_color=background_color, max_words=200,
|
| 89 |
+
stopwords=stop_words, mask = mask_coloring,
|
| 90 |
+
max_font_size=50, random_state=42)
|
| 91 |
+
# Générer et afficher le nuage de mots
|
| 92 |
+
fig=plt.figure(figsize= (20,10))
|
| 93 |
+
plt.title(tr(title), fontsize=25, color="green")
|
| 94 |
+
wc.generate(text)
|
| 95 |
+
|
| 96 |
+
# getting current axes
|
| 97 |
+
a = plt.gca()
|
| 98 |
+
|
| 99 |
+
# set visibility of x-axis as False
|
| 100 |
+
xax = a.axes.get_xaxis()
|
| 101 |
+
xax = xax.set_visible(False)
|
| 102 |
+
|
| 103 |
+
# set visibility of y-axis as False
|
| 104 |
+
yax = a.axes.get_yaxis()
|
| 105 |
+
yax = yax.set_visible(False)
|
| 106 |
+
|
| 107 |
+
plt.imshow(wc)
|
| 108 |
+
# plt.show()
|
| 109 |
+
st.pyplot(fig)
|
| 110 |
+
|
| 111 |
+
def drop_df_null_col(df):
|
| 112 |
+
# Check if all values in each column are 0
|
| 113 |
+
columns_to_drop = df.columns[df.eq(0).all()]
|
| 114 |
+
# Drop the columns with all values as 0
|
| 115 |
+
return df.drop(columns=columns_to_drop)
|
| 116 |
+
|
| 117 |
+
def calcul_occurence(df_count_word):
|
| 118 |
+
nb_occurences = pd.DataFrame(df_count_word.sum().sort_values(axis=0,ascending=False))
|
| 119 |
+
nb_occurences.columns = ['occurences']
|
| 120 |
+
nb_occurences.index.name = 'mot'
|
| 121 |
+
nb_occurences['mots'] = nb_occurences.index
|
| 122 |
+
return nb_occurences
|
| 123 |
+
|
| 124 |
+
def dist_frequence_mots(df_count_word):
|
| 125 |
+
|
| 126 |
+
df_count_word = drop_df_null_col(df_count_word)
|
| 127 |
+
nb_occurences = calcul_occurence(df_count_word)
|
| 128 |
+
|
| 129 |
+
sns.set()
|
| 130 |
+
fig = plt.figure() #figsize=(4,4)
|
| 131 |
+
plt.title(tr("Nombre d'apparitions des mots"), fontsize=16)
|
| 132 |
+
|
| 133 |
+
chart = sns.barplot(x='mots',y='occurences',data=nb_occurences.iloc[:40]);
|
| 134 |
+
chart.set_xticklabels(chart.get_xticklabels(), rotation=45, horizontalalignment='right', size=8)
|
| 135 |
+
st.pyplot(fig)
|
| 136 |
+
|
| 137 |
+
def dist_longueur_phrase(sent_len,sent_len2, lang1, lang2 ):
|
| 138 |
+
'''
|
| 139 |
+
fig = px.histogram(sent_len, nbins=16, range_x=[3, 18],labels={'count': 'Count', 'variable': 'Nb de mots'},
|
| 140 |
+
color_discrete_sequence=['rgb(200, 0, 0)'], # Couleur des barres de l'histogramme
|
| 141 |
+
opacity=0.7)
|
| 142 |
+
fig.update_traces(marker=dict(color='rgb(200, 0, 0)', line=dict(color='white', width=2)), showlegend=False,)
|
| 143 |
+
fig.update_layout(
|
| 144 |
+
title={'text': 'Distribution du nb de mots/phrase', 'y':1.0, 'x':0.5, 'xanchor': 'center', 'yanchor': 'top'},
|
| 145 |
+
title_font=dict(size=28), # Ajuste la taille de la police du titre
|
| 146 |
+
xaxis_title=None,
|
| 147 |
+
xaxis=dict(
|
| 148 |
+
title_font=dict(size=30), # Ajuste la taille de la police de l'axe X
|
| 149 |
+
tickfont=dict(size=22),
|
| 150 |
+
showgrid=True, gridcolor='white'
|
| 151 |
+
),
|
| 152 |
+
yaxis_title='Count',
|
| 153 |
+
yaxis=dict(
|
| 154 |
+
title_font= dict(size=30, color='black'), # Ajuste la taille de la police de l'axe Y
|
| 155 |
+
title_standoff=10, # Éloigne le label de l'axe X du graphique
|
| 156 |
+
tickfont=dict(size=22),
|
| 157 |
+
showgrid=True, gridcolor='white'
|
| 158 |
+
),
|
| 159 |
+
margin=dict(l=20, r=20, t=40, b=20), # Ajustez les valeurs de 'r' pour déplacer les commandes à droite
|
| 160 |
+
# legend=dict(x=1, y=1), # Position de la légende à droite en haut
|
| 161 |
+
# width = 600
|
| 162 |
+
height=600, # Définir la hauteur de la figure
|
| 163 |
+
plot_bgcolor='rgba(220, 220, 220, 0.6)',
|
| 164 |
+
)
|
| 165 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 166 |
+
'''
|
| 167 |
+
df = pd.DataFrame({lang1:sent_len,lang2:sent_len2})
|
| 168 |
+
sns.set()
|
| 169 |
+
fig = plt.figure() # figsize=(12, 6*row_nb)
|
| 170 |
+
|
| 171 |
+
fig.tight_layout()
|
| 172 |
+
chart = sns.histplot(df, color=['r','b'], label=[lang1,lang2], binwidth=1, binrange=[2,22], element="step",
|
| 173 |
+
common_norm=False, multiple="layer", discrete=True, stat='proportion')
|
| 174 |
+
plt.xticks([2,4,6,8,10,12,14,16,18,20,22])
|
| 175 |
+
chart.set(title=tr('Distribution du nombre de mots sur '+str(len(sent_len))+' phrase(s)'));
|
| 176 |
+
st.pyplot(fig)
|
| 177 |
+
|
| 178 |
+
'''
|
| 179 |
+
# fig = ff.create_distplot([sent_len], ['Nb de mots'],bin_size=1, colors=['rgb(200, 0, 0)'])
|
| 180 |
+
|
| 181 |
+
distribution = pd.DataFrame({'Nb mots':sent_len, 'Nb phrases':[1]*len(sent_len)})
|
| 182 |
+
fig = px.histogram(distribution, x='Nb mots', y='Nb phrases', marginal="box",range_x=[3, 18], nbins=16, hover_data=distribution.columns)
|
| 183 |
+
fig.update_layout(height=600,title={'text': 'Distribution du nb de mots/phrase', 'y':1.0, 'x':0.5, 'xanchor': 'center', 'yanchor': 'top'})
|
| 184 |
+
fig.update_traces(marker=dict(color='rgb(200, 0, 0)', line=dict(color='white', width=2)), showlegend=False,)
|
| 185 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 186 |
+
'''
|
| 187 |
+
|
| 188 |
+
def find_color(x,min_w,max_w):
|
| 189 |
+
b_min = 0.0*(max_w-min_w)+min_w
|
| 190 |
+
b_max = 0.05*(max_w-min_w)+min_w
|
| 191 |
+
x = max(x,b_min)
|
| 192 |
+
x = min(b_max, x)
|
| 193 |
+
c = (x - b_min)/(b_max-b_min)
|
| 194 |
+
return round(c)
|
| 195 |
+
|
| 196 |
+
def graphe_co_occurence(txt_split,corpus):
|
| 197 |
+
|
| 198 |
+
dic = corpora.Dictionary(txt_split) # dictionnaire de tous les mots restant dans le token
|
| 199 |
+
# Equivalent (ou presque) de la DTM : DFM, Document Feature Matrix
|
| 200 |
+
dfm = [dic.doc2bow(tok) for tok in txt_split]
|
| 201 |
+
|
| 202 |
+
mes_labels = [k for k, v in dic.token2id.items()]
|
| 203 |
+
|
| 204 |
+
from gensim.matutils import corpus2csc
|
| 205 |
+
term_matrice = corpus2csc(dfm)
|
| 206 |
+
|
| 207 |
+
term_matrice = np.dot(term_matrice, term_matrice.T)
|
| 208 |
+
|
| 209 |
+
for i in range(len(mes_labels)):
|
| 210 |
+
term_matrice[i,i]= 0
|
| 211 |
+
term_matrice.eliminate_zeros()
|
| 212 |
+
|
| 213 |
+
G = nx.from_scipy_sparse_matrix(term_matrice)
|
| 214 |
+
G.add_nodes = dic
|
| 215 |
+
pos=nx.spring_layout(G, k=5) # position des nodes
|
| 216 |
+
|
| 217 |
+
importance = dict(nx.degree(G))
|
| 218 |
+
importance = [round((v**1.3)) for v in importance.values()]
|
| 219 |
+
edges,weights = zip(*nx.get_edge_attributes(G,'weight').items())
|
| 220 |
+
max_w = max(weights)
|
| 221 |
+
min_w = min(weights)
|
| 222 |
+
edge_color = [find_color(weights[i],min_w,max_w) for i in range(len(weights))]
|
| 223 |
+
width = [(weights[i]-min_w)*3.4/(max_w-min_w)+0.2 for i in range(len(weights))]
|
| 224 |
+
alpha = [(weights[i]-min_w)*0.3/(max_w-min_w)+0.3 for i in range(len(weights))]
|
| 225 |
+
|
| 226 |
+
fig = plt.figure();
|
| 227 |
+
|
| 228 |
+
nx.draw_networkx_labels(G,pos,dic,font_size=8, font_color='b', font_weight='bold')
|
| 229 |
+
nx.draw_networkx_nodes(G,pos, dic, \
|
| 230 |
+
node_color= importance, # range(len(importance)), #"tab:red", \
|
| 231 |
+
node_size=importance, \
|
| 232 |
+
cmap=plt.cm.RdYlGn, #plt.cm.Reds_r, \
|
| 233 |
+
alpha=0.4);
|
| 234 |
+
nx.draw_networkx_edges(G,pos,width=width,edge_color=edge_color, alpha=alpha,edge_cmap=plt.cm.RdYlGn) # [1] * len(width)
|
| 235 |
+
|
| 236 |
+
plt.axis("off");
|
| 237 |
+
st.pyplot(fig)
|
| 238 |
+
|
| 239 |
+
def proximite():
|
| 240 |
+
global vec_model_en,vec_model_fr
|
| 241 |
+
|
| 242 |
+
# Creates and TSNE model and plots it"
|
| 243 |
+
labels = []
|
| 244 |
+
tokens = []
|
| 245 |
+
|
| 246 |
+
nb_words = st.slider(tr('Nombre de mots à afficher')+' :',10,50, value=20)
|
| 247 |
+
df = pd.read_csv(dataPath+'/dict_we_en_fr',header=0,index_col=0, encoding ="utf-8", keep_default_na=False)
|
| 248 |
+
words_en = df.index.to_list()[:nb_words]
|
| 249 |
+
words_fr = df['Francais'].to_list()[:nb_words]
|
| 250 |
+
|
| 251 |
+
for word in words_en:
|
| 252 |
+
tokens.append(vec_model_en[word])
|
| 253 |
+
labels.append(word)
|
| 254 |
+
for word in words_fr:
|
| 255 |
+
tokens.append(vec_model_fr[word])
|
| 256 |
+
labels.append(word)
|
| 257 |
+
tokens = pd.DataFrame(tokens)
|
| 258 |
+
|
| 259 |
+
tsne_model = TSNE(perplexity=10, n_components=2, init='pca', n_iter=2000, random_state=23)
|
| 260 |
+
new_values = tsne_model.fit_transform(tokens)
|
| 261 |
+
|
| 262 |
+
fig =plt.figure(figsize=(16, 16))
|
| 263 |
+
x = []
|
| 264 |
+
y = []
|
| 265 |
+
for value in new_values:
|
| 266 |
+
x.append(value[0])
|
| 267 |
+
y.append(value[1])
|
| 268 |
+
|
| 269 |
+
for i in range(len(x)):
|
| 270 |
+
if i<nb_words : color='green'
|
| 271 |
+
else: color='blue'
|
| 272 |
+
plt.scatter(x[i],y[i])
|
| 273 |
+
plt.annotate(labels[i],
|
| 274 |
+
xy=(x[i], y[i]),
|
| 275 |
+
xytext=(5, 2),
|
| 276 |
+
textcoords='offset points',
|
| 277 |
+
ha='right',
|
| 278 |
+
va='bottom',
|
| 279 |
+
color= color,
|
| 280 |
+
size=20)
|
| 281 |
+
plt.title(tr("Proximité des mots anglais avec leur traduction"), fontsize=30, color="green")
|
| 282 |
+
plt.legend(loc='best');
|
| 283 |
+
st.pyplot(fig)
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def run():
|
| 287 |
+
|
| 288 |
+
global max_lines, first_line, Langue
|
| 289 |
+
global full_txt_en, full_corpus_en, full_txt_split_en, full_df_count_word_en,full_sent_len_en, vec_model_en
|
| 290 |
+
global full_txt_fr, full_corpus_fr, full_txt_split_fr, full_df_count_word_fr,full_sent_len_fr, vec_model_fr
|
| 291 |
+
|
| 292 |
+
st.write("")
|
| 293 |
+
st.title(tr(title))
|
| 294 |
+
|
| 295 |
+
#
|
| 296 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 297 |
+
Langue = st.radio(tr('Langue:'),('Anglais','Français'), horizontal=True)
|
| 298 |
+
first_line = st.slider(tr('No de la premiere ligne à analyser')+' :',0,137859)
|
| 299 |
+
max_lines = st.select_slider(tr('Nombre de lignes à analyser')+' :',
|
| 300 |
+
options=[1,5,10,15,100, 500, 1000,'Max'])
|
| 301 |
+
if max_lines=='Max':
|
| 302 |
+
max_lines=137860
|
| 303 |
+
if ((first_line+max_lines)>137860):
|
| 304 |
+
max_lines = max(137860-first_line,0)
|
| 305 |
+
|
| 306 |
+
# Chargement des textes sélectionnés (max lignes = max_lines)
|
| 307 |
+
last_line = first_line+max_lines
|
| 308 |
+
if (Langue == 'Anglais'):
|
| 309 |
+
txt_en = full_txt_en[first_line:last_line]
|
| 310 |
+
corpus_en = full_corpus_en[first_line:last_line]
|
| 311 |
+
txt_split_en = full_txt_split_en[first_line:last_line]
|
| 312 |
+
df_count_word_en =full_df_count_word_en.loc[first_line:last_line-1]
|
| 313 |
+
sent_len_en = full_sent_len_en[first_line:last_line]
|
| 314 |
+
sent_len_fr = full_sent_len_fr[first_line:last_line]
|
| 315 |
+
else:
|
| 316 |
+
txt_fr = full_txt_fr[first_line:last_line]
|
| 317 |
+
corpus_fr = full_corpus_fr[first_line:last_line]
|
| 318 |
+
txt_split_fr = full_txt_split_fr[first_line:last_line]
|
| 319 |
+
df_count_word_fr =full_df_count_word_fr.loc[first_line:last_line-1]
|
| 320 |
+
sent_len_fr = full_sent_len_fr[first_line:last_line]
|
| 321 |
+
sent_len_en = full_sent_len_en[first_line:last_line]
|
| 322 |
+
|
| 323 |
+
if (Langue=='Anglais'):
|
| 324 |
+
st.dataframe(pd.DataFrame(data=full_txt_en,columns=['Texte']).loc[first_line:last_line-1].head(max_lines_to_display), width=800)
|
| 325 |
+
else:
|
| 326 |
+
st.dataframe(pd.DataFrame(data=full_txt_fr,columns=['Texte']).loc[first_line:last_line-1].head(max_lines_to_display), width=800)
|
| 327 |
+
st.write("")
|
| 328 |
+
|
| 329 |
+
tab1, tab2, tab3, tab4, tab5 = st.tabs([tr("World Cloud"), tr("Frequence"),tr("Distribution longueur"), tr("Co-occurence"), tr("Proximité")])
|
| 330 |
+
|
| 331 |
+
with tab1:
|
| 332 |
+
st.subheader(tr("World Cloud"))
|
| 333 |
+
st.markdown(tr(
|
| 334 |
+
"""
|
| 335 |
+
On remarque, en changeant de langue, que certains mot de taille importante dans une langue,
|
| 336 |
+
apparaissent avec une taille identique dans l'autre langue.
|
| 337 |
+
La traduction mot à mot sera donc peut-être bonne.
|
| 338 |
+
""")
|
| 339 |
+
)
|
| 340 |
+
if (Langue == 'Anglais'):
|
| 341 |
+
text = ""
|
| 342 |
+
# Initialiser la variable des mots vides
|
| 343 |
+
stop_words = set(stopwords.words('english'))
|
| 344 |
+
for e in txt_en : text += e
|
| 345 |
+
plot_word_cloud(text, "English words corpus", st.session_state.ImagePath+"/coeur.png", stop_words)
|
| 346 |
+
else:
|
| 347 |
+
text = ""
|
| 348 |
+
# Initialiser la variable des mots vides
|
| 349 |
+
stop_words = set(stopwords.words('french'))
|
| 350 |
+
for e in txt_fr : text += e
|
| 351 |
+
plot_word_cloud(text,"Mots français du corpus", st.session_state.ImagePath+"/coeur.png", stop_words)
|
| 352 |
+
|
| 353 |
+
with tab2:
|
| 354 |
+
st.subheader(tr("Frequence d'apparition des mots"))
|
| 355 |
+
st.markdown(tr(
|
| 356 |
+
"""
|
| 357 |
+
On remarque, en changeant de langue, que certains mot fréquents dans une langue,
|
| 358 |
+
apparaissent aussi fréquemment dans l'autre langue.
|
| 359 |
+
Cela peut nous laisser penser que la traduction mot à mot sera peut-être bonne.
|
| 360 |
+
""")
|
| 361 |
+
)
|
| 362 |
+
if (Langue == 'Anglais'):
|
| 363 |
+
dist_frequence_mots(df_count_word_en)
|
| 364 |
+
else:
|
| 365 |
+
dist_frequence_mots(df_count_word_fr)
|
| 366 |
+
with tab3:
|
| 367 |
+
st.subheader(tr("Distribution des longueurs de phrases"))
|
| 368 |
+
st.markdown(tr(
|
| 369 |
+
"""
|
| 370 |
+
Malgré quelques différences entre les 2 langues (les phrases anglaises sont généralement un peu plus courtes),
|
| 371 |
+
on constate une certaine similitude dans les ditributions de longueur de phrases.
|
| 372 |
+
Cela peut nous laisser penser que la traduction mot à mot ne sera pas si mauvaise.
|
| 373 |
+
""")
|
| 374 |
+
)
|
| 375 |
+
if (Langue == 'Anglais'):
|
| 376 |
+
dist_longueur_phrase(sent_len_en, sent_len_fr, 'Anglais','Français')
|
| 377 |
+
else:
|
| 378 |
+
dist_longueur_phrase(sent_len_fr, sent_len_en, 'Français', 'Anglais')
|
| 379 |
+
with tab4:
|
| 380 |
+
st.subheader(tr("Co-occurence des mots dans une phrase"))
|
| 381 |
+
if (Langue == 'Anglais'):
|
| 382 |
+
graphe_co_occurence(txt_split_en[:1000],corpus_en)
|
| 383 |
+
else:
|
| 384 |
+
graphe_co_occurence(txt_split_fr[:1000],corpus_fr)
|
| 385 |
+
with tab5:
|
| 386 |
+
st.subheader(tr("Proximité sémantique des mots (Word Embedding)") )
|
| 387 |
+
st.markdown(tr(
|
| 388 |
+
"""
|
| 389 |
+
MUSE est une bibliothèque Python pour l'intégration de mots multilingues, qui fournit
|
| 390 |
+
notamment des "Word Embedding" multilingues
|
| 391 |
+
Facebook fournit des dictionnaires de référence. Ces embeddings sont des embeddings fastText Wikipedia pour 30 langues qui ont été alignés dans un espace espace vectoriel unique.
|
| 392 |
+
Dans notre cas, nous avons utilisé 2 mini-dictionnaires d'environ 3000 mots (Français et Anglais).
|
| 393 |
+
|
| 394 |
+
""")
|
| 395 |
+
)
|
| 396 |
+
st.markdown(tr(
|
| 397 |
+
"""
|
| 398 |
+
En novembre 2015, l'équipe de recherche de Facebook a créé fastText qui est une extension de la bibliothèque word2vec.
|
| 399 |
+
Elle s'appuie sur Word2Vec en apprenant des représentations vectorielles pour chaque mot et les n-grammes trouvés dans chaque mot.
|
| 400 |
+
""")
|
| 401 |
+
)
|
| 402 |
+
st.write("")
|
| 403 |
+
proximite()
|
| 404 |
+
|
tabs/exploration_tab.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import os
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import collections
|
| 5 |
+
from nltk.tokenize import word_tokenize
|
| 6 |
+
from nltk import download
|
| 7 |
+
from ast import literal_eval
|
| 8 |
+
from translate_app import tr
|
| 9 |
+
if st.session_state.Cloud == 0:
|
| 10 |
+
# import nltk
|
| 11 |
+
import contextlib
|
| 12 |
+
import re
|
| 13 |
+
from nltk.corpus import stopwords
|
| 14 |
+
import warnings
|
| 15 |
+
warnings.filterwarnings('ignore')
|
| 16 |
+
# from PIL import Image
|
| 17 |
+
# import time
|
| 18 |
+
# import random
|
| 19 |
+
|
| 20 |
+
title = "Exploration et Preprocessing"
|
| 21 |
+
sidebar_name = "Exploration et Preprocessing"
|
| 22 |
+
dataPath = st.session_state.DataPath
|
| 23 |
+
|
| 24 |
+
# Indiquer si l'on veut enlever les stop words. C'est un processus long
|
| 25 |
+
stopwords_to_do = True
|
| 26 |
+
# Indiquer si l'on veut lemmatiser les phrases, un fois les stop words enlevés. C'est un processus long (approximativement 8 minutes)
|
| 27 |
+
lemmatize_to_do = True
|
| 28 |
+
# Indiquer si l'on veut calculer le score Bleu pour tout le corpus. C'est un processus très long long (approximativement 10 minutes pour les 10 dictionnaires)
|
| 29 |
+
bleu_score_to_do = True
|
| 30 |
+
# Première ligne à charger
|
| 31 |
+
first_line = 0
|
| 32 |
+
# Nombre maximum de lignes à charger
|
| 33 |
+
max_lines = 140000
|
| 34 |
+
if ((first_line+max_lines)>137860):
|
| 35 |
+
max_lines = max(137860-first_line ,0)
|
| 36 |
+
# Nombre maximum de ligne à afficher pour les DataFrame
|
| 37 |
+
max_lines_to_display = 50
|
| 38 |
+
|
| 39 |
+
download('punkt')
|
| 40 |
+
|
| 41 |
+
if st.session_state.Cloud == 0:
|
| 42 |
+
download('averaged_perceptron_tagger')
|
| 43 |
+
with contextlib.redirect_stdout(open(os.devnull, "w")):
|
| 44 |
+
download('stopwords')
|
| 45 |
+
|
| 46 |
+
@st.cache_data
|
| 47 |
+
def load_data(path):
|
| 48 |
+
|
| 49 |
+
input_file = os.path.join(path)
|
| 50 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 51 |
+
data = f.read()
|
| 52 |
+
|
| 53 |
+
# On convertit les majuscules en minulcule
|
| 54 |
+
data = data.lower()
|
| 55 |
+
data = data.split('\n')
|
| 56 |
+
return data[first_line:min(len(data),first_line+max_lines)]
|
| 57 |
+
|
| 58 |
+
@st.cache_data
|
| 59 |
+
def load_preprocessed_data(path,data_type):
|
| 60 |
+
|
| 61 |
+
input_file = os.path.join(path)
|
| 62 |
+
if data_type == 1:
|
| 63 |
+
return pd.read_csv(input_file, encoding="utf-8", index_col=0)
|
| 64 |
+
else:
|
| 65 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 66 |
+
data = f.read()
|
| 67 |
+
data = data.split('\n')
|
| 68 |
+
if data_type==0:
|
| 69 |
+
data=data[:-1]
|
| 70 |
+
elif data_type == 2:
|
| 71 |
+
data=[eval(i) for i in data[:-1]]
|
| 72 |
+
elif data_type ==3:
|
| 73 |
+
data2 = []
|
| 74 |
+
for d in data[:-1]:
|
| 75 |
+
data2.append(literal_eval(d))
|
| 76 |
+
data=data2
|
| 77 |
+
return data
|
| 78 |
+
|
| 79 |
+
@st.cache_data
|
| 80 |
+
def load_all_preprocessed_data(lang):
|
| 81 |
+
txt =load_preprocessed_data(dataPath+'/preprocess_txt_'+lang,0)
|
| 82 |
+
txt_split = load_preprocessed_data(dataPath+'/preprocess_txt_split_'+lang,3)
|
| 83 |
+
txt_lem = load_preprocessed_data(dataPath+'/preprocess_txt_lem_'+lang,0)
|
| 84 |
+
txt_wo_stopword = load_preprocessed_data(dataPath+'/preprocess_txt_wo_stopword_'+lang,0)
|
| 85 |
+
df_count_word = pd.concat([load_preprocessed_data(dataPath+'/preprocess_df_count_word1_'+lang,1), load_preprocessed_data(dataPath+'/preprocess_df_count_word2_'+lang,1)])
|
| 86 |
+
return txt, txt_split, txt_lem, txt_wo_stopword, df_count_word
|
| 87 |
+
|
| 88 |
+
#Chargement des textes complet dans les 2 langues
|
| 89 |
+
full_txt_en = load_data(dataPath+'/small_vocab_en')
|
| 90 |
+
full_txt_fr = load_data(dataPath+'/small_vocab_fr')
|
| 91 |
+
|
| 92 |
+
# Chargement du résultat du préprocessing, si st.session_state.reCalcule == False
|
| 93 |
+
if not st.session_state.reCalcule:
|
| 94 |
+
full_txt_en, full_txt_split_en, full_txt_lem_en, full_txt_wo_stopword_en, full_df_count_word_en = load_all_preprocessed_data('en')
|
| 95 |
+
full_txt_fr, full_txt_split_fr, full_txt_lem_fr, full_txt_wo_stopword_fr, full_df_count_word_fr = load_all_preprocessed_data('fr')
|
| 96 |
+
else:
|
| 97 |
+
|
| 98 |
+
def remove_stopwords(text, lang):
|
| 99 |
+
stop_words = set(stopwords.words(lang))
|
| 100 |
+
# stop_words will contain set all english stopwords
|
| 101 |
+
filtered_sentence = []
|
| 102 |
+
for word in text.split():
|
| 103 |
+
if word not in stop_words:
|
| 104 |
+
filtered_sentence.append(word)
|
| 105 |
+
return " ".join(filtered_sentence)
|
| 106 |
+
|
| 107 |
+
def clean_undesirable_from_text(sentence, lang):
|
| 108 |
+
|
| 109 |
+
# Removing URLs
|
| 110 |
+
sentence = re.sub(r"https?://\S+|www\.\S+", "", sentence )
|
| 111 |
+
|
| 112 |
+
# Removing Punctuations (we keep the . character)
|
| 113 |
+
REPLACEMENTS = [("..", "."),
|
| 114 |
+
(",", ""),
|
| 115 |
+
(";", ""),
|
| 116 |
+
(":", ""),
|
| 117 |
+
("?", ""),
|
| 118 |
+
('"', ""),
|
| 119 |
+
("-", " "),
|
| 120 |
+
("it's", "it is"),
|
| 121 |
+
("isn't","is not"),
|
| 122 |
+
("'", " ")
|
| 123 |
+
]
|
| 124 |
+
for old, new in REPLACEMENTS:
|
| 125 |
+
sentence = sentence.replace(old, new)
|
| 126 |
+
|
| 127 |
+
# Removing Digits
|
| 128 |
+
sentence= re.sub(r'[0-9]','',sentence)
|
| 129 |
+
|
| 130 |
+
# Removing Additional Spaces
|
| 131 |
+
sentence = re.sub(' +', ' ', sentence)
|
| 132 |
+
|
| 133 |
+
return sentence
|
| 134 |
+
|
| 135 |
+
def clean_untranslated_sentence(data1, data2):
|
| 136 |
+
i=0
|
| 137 |
+
while i<len(data1):
|
| 138 |
+
if data1[i]==data2[i]:
|
| 139 |
+
data1.pop(i)
|
| 140 |
+
data2.pop(i)
|
| 141 |
+
else: i+=1
|
| 142 |
+
return data1,data2
|
| 143 |
+
|
| 144 |
+
import spacy
|
| 145 |
+
|
| 146 |
+
nlp_en = spacy.load('en_core_web_sm')
|
| 147 |
+
nlp_fr = spacy.load('fr_core_news_sm')
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
def lemmatize(sentence,lang):
|
| 151 |
+
# Create a Doc object
|
| 152 |
+
if lang=='en':
|
| 153 |
+
nlp=nlp_en
|
| 154 |
+
elif lang=='fr':
|
| 155 |
+
nlp=nlp_fr
|
| 156 |
+
else: return
|
| 157 |
+
doc = nlp(sentence)
|
| 158 |
+
|
| 159 |
+
# Create list of tokens from given string
|
| 160 |
+
tokens = []
|
| 161 |
+
for token in doc:
|
| 162 |
+
tokens.append(token)
|
| 163 |
+
|
| 164 |
+
lemmatized_sentence = " ".join([token.lemma_ for token in doc])
|
| 165 |
+
|
| 166 |
+
return lemmatized_sentence
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def preprocess_txt (data, lang):
|
| 170 |
+
|
| 171 |
+
word_count = collections.Counter()
|
| 172 |
+
word_lem_count = collections.Counter()
|
| 173 |
+
word_wosw_count = collections.Counter()
|
| 174 |
+
corpus = []
|
| 175 |
+
data_split = []
|
| 176 |
+
sentence_length = []
|
| 177 |
+
data_split_wo_stopwords = []
|
| 178 |
+
data_length_wo_stopwords = []
|
| 179 |
+
data_lem = []
|
| 180 |
+
data_lem_length = []
|
| 181 |
+
|
| 182 |
+
txt_en_one_string= ". ".join([s for s in data])
|
| 183 |
+
txt_en_one_string = txt_en_one_string.replace('..', '.')
|
| 184 |
+
txt_en_one_string = " "+clean_undesirable_from_text(txt_en_one_string, 'lang')
|
| 185 |
+
data = txt_en_one_string.split('.')
|
| 186 |
+
if data[-1]=="":
|
| 187 |
+
data.pop(-1)
|
| 188 |
+
for i in range(len(data)): # On enleve les ' ' qui commencent et finissent les phrases
|
| 189 |
+
if data[i][0] == ' ':
|
| 190 |
+
data[i]=data[i][1:]
|
| 191 |
+
if data[i][-1] == ' ':
|
| 192 |
+
data[i]=data[i][:-1]
|
| 193 |
+
nb_phrases = len(data)
|
| 194 |
+
|
| 195 |
+
# Création d'un tableau de mots (sentence_split)
|
| 196 |
+
for i,sentence in enumerate(data):
|
| 197 |
+
sentence_split = word_tokenize(sentence)
|
| 198 |
+
word_count.update(sentence_split)
|
| 199 |
+
data_split.append(sentence_split)
|
| 200 |
+
sentence_length.append(len(sentence_split))
|
| 201 |
+
|
| 202 |
+
# La lemmatisation et le nettoyage des stopword va se faire en batch pour des raisons de vitesse
|
| 203 |
+
# (au lieu de le faire phrase par phrase)
|
| 204 |
+
# Ces 2 processus nécéssitent de connaitre la langue du corpus
|
| 205 |
+
if lang == 'en': l='english'
|
| 206 |
+
elif lang=='fr': l='french'
|
| 207 |
+
else: l="unknown"
|
| 208 |
+
|
| 209 |
+
if l!="unknown":
|
| 210 |
+
# Lemmatisation en 12 lots (On ne peut lemmatiser + de 1 M de caractères à la fois)
|
| 211 |
+
data_lemmatized=""
|
| 212 |
+
if lemmatize_to_do:
|
| 213 |
+
n_batch = 12
|
| 214 |
+
batch_size = round((nb_phrases/ n_batch)+0.5)
|
| 215 |
+
for i in range(n_batch):
|
| 216 |
+
to_lem = ".".join([s for s in data[i*batch_size:(i+1)*batch_size]])
|
| 217 |
+
data_lemmatized = data_lemmatized+"."+lemmatize(to_lem,lang).lower()
|
| 218 |
+
|
| 219 |
+
data_lem_for_sw = data_lemmatized[1:]
|
| 220 |
+
data_lemmatized = data_lem_for_sw.split('.')
|
| 221 |
+
for i in range(nb_phrases):
|
| 222 |
+
data_lem.append(data_lemmatized[i].split())
|
| 223 |
+
data_lem_length.append(len(data_lemmatized[i].split()))
|
| 224 |
+
word_lem_count.update(data_lem[-1])
|
| 225 |
+
|
| 226 |
+
# Elimination des StopWords en un lot
|
| 227 |
+
# On élimine les Stopwords des phrases lémmatisés, si cette phase a eu lieu
|
| 228 |
+
# (wosw signifie "WithOut Stop Words")
|
| 229 |
+
if stopwords_to_do:
|
| 230 |
+
if lemmatize_to_do:
|
| 231 |
+
data_wosw = remove_stopwords(data_lem_for_sw,l)
|
| 232 |
+
else:
|
| 233 |
+
data_wosw = remove_stopwords(txt_en_one_string,l)
|
| 234 |
+
|
| 235 |
+
data_wosw = data_wosw.split('.')
|
| 236 |
+
for i in range(nb_phrases):
|
| 237 |
+
data_split_wo_stopwords.append(data_wosw[i].split())
|
| 238 |
+
data_length_wo_stopwords.append(len(data_wosw[i].split()))
|
| 239 |
+
word_wosw_count.update(data_split_wo_stopwords[-1])
|
| 240 |
+
|
| 241 |
+
corpus = list(word_count.keys())
|
| 242 |
+
|
| 243 |
+
# Création d'un DataFrame txt_n_unique_val :
|
| 244 |
+
# colonnes = mots
|
| 245 |
+
# lignes = phases
|
| 246 |
+
# valeur de la cellule = nombre d'occurence du mot dans la phrase
|
| 247 |
+
|
| 248 |
+
## BOW
|
| 249 |
+
from sklearn.feature_extraction.text import CountVectorizer
|
| 250 |
+
count_vectorizer = CountVectorizer(analyzer="word", ngram_range=(1, 1), token_pattern=r"[^' ']+" )
|
| 251 |
+
|
| 252 |
+
# Calcul du nombre d'apparition de chaque mot dans la phrases
|
| 253 |
+
countvectors = count_vectorizer.fit_transform(data)
|
| 254 |
+
corpus = count_vectorizer.get_feature_names_out()
|
| 255 |
+
|
| 256 |
+
txt_n_unique_val= pd.DataFrame(columns=corpus,index=range(nb_phrases), data=countvectors.todense()).astype(float)
|
| 257 |
+
|
| 258 |
+
return data, corpus, data_split, data_lemmatized, data_wosw, txt_n_unique_val, sentence_length, data_length_wo_stopwords, data_lem_length
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def count_world(data):
|
| 262 |
+
word_count = collections.Counter()
|
| 263 |
+
for sentence in data:
|
| 264 |
+
word_count.update(word_tokenize(sentence))
|
| 265 |
+
corpus = list(word_count.keys())
|
| 266 |
+
nb_mots = sum(word_count.values())
|
| 267 |
+
nb_mots_uniques = len(corpus)
|
| 268 |
+
return corpus, nb_mots, nb_mots_uniques
|
| 269 |
+
|
| 270 |
+
def display_preprocess_results(lang, data, data_split, data_lem, data_wosw, txt_n_unique_val):
|
| 271 |
+
|
| 272 |
+
global max_lines, first_line, last_line, lemmatize_to_do, stopwords_to_do
|
| 273 |
+
corpus = []
|
| 274 |
+
nb_phrases = len(data)
|
| 275 |
+
corpus, nb_mots, nb_mots_uniques = count_world(data)
|
| 276 |
+
mots_lem, _ , nb_mots_lem = count_world(data_lem)
|
| 277 |
+
mots_wo_sw, _ , nb_mots_wo_stopword = count_world(data_wosw)
|
| 278 |
+
# Identifiez les colonnes contenant uniquement des zéros et les supprimer
|
| 279 |
+
columns_with_only_zeros = txt_n_unique_val.columns[txt_n_unique_val.eq(0).all()]
|
| 280 |
+
txt_n_unique_val = txt_n_unique_val.drop(columns=columns_with_only_zeros)
|
| 281 |
+
|
| 282 |
+
# Affichage du nombre de mot en fonction du pré-processing réalisé
|
| 283 |
+
tab1, tab2, tab3, tab4 = st.tabs([tr("Résumé"), tr("Tokenisation"),tr("Lemmatisation"), tr("Sans Stopword")])
|
| 284 |
+
with tab1:
|
| 285 |
+
st.subheader(tr("Résumé du pré-processing"))
|
| 286 |
+
st.write("**"+tr("Nombre de phrases")+" : "+str(nb_phrases)+"**")
|
| 287 |
+
st.write("**"+tr("Nombre de mots")+" : "+str(nb_mots)+"**")
|
| 288 |
+
st.write("**"+tr("Nombre de mots uniques")+" : "+str(nb_mots_uniques)+"**")
|
| 289 |
+
st.write("")
|
| 290 |
+
st.write("\n**"+tr("Nombre d'apparitions de chaque mot dans chaque phrase (:red[Bag Of Words]):")+"**")
|
| 291 |
+
st.dataframe(txt_n_unique_val.head(max_lines_to_display), width=800)
|
| 292 |
+
with tab2:
|
| 293 |
+
st.subheader(tr("Tokenisation"))
|
| 294 |
+
st.write(tr('Texte "splited":'))
|
| 295 |
+
st.dataframe(pd.DataFrame(data=data_split, index=range(first_line,last_line)).head(max_lines_to_display).fillna(''), width=800)
|
| 296 |
+
st.write("**"+tr("Nombre de mots uniques")+" : "+str(nb_mots_uniques)+"**")
|
| 297 |
+
st.write("")
|
| 298 |
+
st.write("\n**"+tr("Mots uniques")+":**")
|
| 299 |
+
st.markdown(corpus[:500])
|
| 300 |
+
st.write("\n**"+tr("Nombre d'apparitions de chaque mot dans chaque phrase (:red[Bag Of Words]):")+"**")
|
| 301 |
+
st.dataframe(txt_n_unique_val.head(max_lines_to_display), width=800)
|
| 302 |
+
with tab3:
|
| 303 |
+
st.subheader(tr("Lemmatisation"))
|
| 304 |
+
if lemmatize_to_do:
|
| 305 |
+
st.dataframe(pd.DataFrame(data=data_lem,columns=[tr('Texte lemmatisé')],index=range(first_line,last_line)).head(max_lines_to_display), width=800)
|
| 306 |
+
# Si langue anglaise, affichage du taggage des mots
|
| 307 |
+
# if lang == 'en':
|
| 308 |
+
# for i in range(min(5,len(data))):
|
| 309 |
+
# s = str(nltk.pos_tag(data_split[i]))
|
| 310 |
+
# st.markdown("**Texte avec Tags "+str(i)+"** : "+s)
|
| 311 |
+
st.write("**"+tr("Nombre de mots uniques lemmatisés")+" : "+str(nb_mots_lem)+"**")
|
| 312 |
+
st.write("")
|
| 313 |
+
st.write("\n**"+tr("Mots uniques lemmatisés:")+"**")
|
| 314 |
+
st.markdown(mots_lem[:500])
|
| 315 |
+
with tab4:
|
| 316 |
+
st.subheader(tr("Sans Stopword"))
|
| 317 |
+
if stopwords_to_do:
|
| 318 |
+
st.dataframe(pd.DataFrame(data=data_wosw,columns=['Texte sans stopwords'],index=range(first_line,last_line)).head(max_lines_to_display), width=800)
|
| 319 |
+
st.write("**"+tr("Nombre de mots uniques sans stop words")+": "+str(nb_mots_wo_stopword)+"**")
|
| 320 |
+
st.write("")
|
| 321 |
+
st.write("\n**"+tr("Mots uniques sans stop words")+":**")
|
| 322 |
+
st.markdown(mots_wo_sw[:500])
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
def run():
|
| 326 |
+
global max_lines, first_line, last_line, lemmatize_to_do, stopwords_to_do
|
| 327 |
+
global full_txt_en, full_txt_split_en, full_txt_lem_en, full_txt_wo_stopword_en, full_df_count_word_en
|
| 328 |
+
global full_txt_fr, full_txt_split_fr, full_txt_lem_fr, full_txt_wo_stopword_fr, full_df_count_word_fr
|
| 329 |
+
|
| 330 |
+
st.write("")
|
| 331 |
+
st.title(tr(title))
|
| 332 |
+
|
| 333 |
+
st.write("## **"+tr("Explications")+" :**\n")
|
| 334 |
+
st.markdown(tr(
|
| 335 |
+
"""
|
| 336 |
+
Le traitement du langage naturel permet à l'ordinateur de comprendre et de traiter les langues humaines.
|
| 337 |
+
Lors de notre projet, nous avons étudié le dataset small_vocab, proposés par Suzan Li, Chief Data Scientist chez Campaign Research à Toronto.
|
| 338 |
+
Celui-ci représente un corpus de phrases simples en anglais, et sa traduction (approximative) en français.
|
| 339 |
+
:red[**Small_vocab**] contient 137 860 phrases en anglais et français.
|
| 340 |
+
""")
|
| 341 |
+
, unsafe_allow_html=True)
|
| 342 |
+
st.markdown(tr(
|
| 343 |
+
"""
|
| 344 |
+
Afin de découvrir ce corpus et de préparer la traduction, nous allons effectuer un certain nombre de tâches de pré-traitement (preprocessing).
|
| 345 |
+
Ces taches sont, par exemple:
|
| 346 |
+
""")
|
| 347 |
+
, unsafe_allow_html=True)
|
| 348 |
+
st.markdown(
|
| 349 |
+
"* "+tr("le :red[**nettoyage**] du texte (enlever les majuscules et la ponctuation)")+"\n"+ \
|
| 350 |
+
"* "+tr("la :red[**tokenisation**] (découpage du texte en mots)")+"\n"+ \
|
| 351 |
+
"* "+tr("la :red[**lemmatisation**] (traitement lexical qui permet de donner une forme unique à toutes les \"variations\" d'un même mot)")+"\n"+ \
|
| 352 |
+
"* "+tr("l'élimination des :red[**mots \"transparents\"**] (sans utilité pour la compréhension, tels que les articles).")+" \n"+ \
|
| 353 |
+
tr("Ce prétraintement se conclut avec la contruction d'un :red[**Bag Of Worlds**], c'est à dire une matrice qui compte le nombre d'apparition de chaque mots (colonne) dans chaque phrase (ligne)")
|
| 354 |
+
, unsafe_allow_html=True)
|
| 355 |
+
#
|
| 356 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 357 |
+
Langue = st.radio(tr('Langue:'),('Anglais','Français'), horizontal=True)
|
| 358 |
+
first_line = st.slider(tr('No de la premiere ligne à analyser:'),0,137859)
|
| 359 |
+
max_lines = st.select_slider(tr('Nombre de lignes à analyser:'),
|
| 360 |
+
options=[1,5,10,15,100, 500, 1000,'Max'])
|
| 361 |
+
if max_lines=='Max':
|
| 362 |
+
max_lines=137860
|
| 363 |
+
if ((first_line+max_lines)>137860):
|
| 364 |
+
max_lines = max(137860-first_line,0)
|
| 365 |
+
|
| 366 |
+
last_line = first_line+max_lines
|
| 367 |
+
if (Langue=='Anglais'):
|
| 368 |
+
st.dataframe(pd.DataFrame(data=full_txt_en,columns=['Texte']).loc[first_line:last_line-1].head(max_lines_to_display), width=800)
|
| 369 |
+
else:
|
| 370 |
+
st.dataframe(pd.DataFrame(data=full_txt_fr,columns=['Texte']).loc[first_line:last_line-1].head(max_lines_to_display), width=800)
|
| 371 |
+
st.write("")
|
| 372 |
+
|
| 373 |
+
# Chargement des textes sélectionnés dans les 2 langues (max lignes = max_lines)
|
| 374 |
+
txt_en = full_txt_en[first_line:last_line]
|
| 375 |
+
txt_fr = full_txt_fr[first_line:last_line]
|
| 376 |
+
|
| 377 |
+
# Elimination des phrases non traduites
|
| 378 |
+
# txt_en, txt_fr = clean_untranslated_sentence(txt_en, txt_fr)
|
| 379 |
+
|
| 380 |
+
if not st.session_state.reCalcule:
|
| 381 |
+
txt_split_en = full_txt_split_en[first_line:last_line]
|
| 382 |
+
txt_lem_en = full_txt_lem_en[first_line:last_line]
|
| 383 |
+
txt_wo_stopword_en = full_txt_wo_stopword_en[first_line:last_line]
|
| 384 |
+
df_count_word_en = full_df_count_word_en.loc[first_line:last_line-1]
|
| 385 |
+
txt_split_fr = full_txt_split_fr[first_line:last_line]
|
| 386 |
+
txt_lem_fr = full_txt_lem_fr[first_line:last_line]
|
| 387 |
+
txt_wo_stopword_fr = full_txt_wo_stopword_fr[first_line:last_line]
|
| 388 |
+
df_count_word_fr = full_df_count_word_fr.loc[first_line:last_line-1]
|
| 389 |
+
|
| 390 |
+
# Lancement du préprocessing du texte qui va spliter nettoyer les phrases et les spliter en mots
|
| 391 |
+
# et calculer nombre d'occurences des mots dans chaque phrase
|
| 392 |
+
if (Langue == 'Anglais'):
|
| 393 |
+
st.write("## **"+tr("Préprocessing de small_vocab_en")+" :**\n")
|
| 394 |
+
if max_lines>10000:
|
| 395 |
+
with st.status(":sunglasses:", expanded=True):
|
| 396 |
+
if st.session_state.reCalcule:
|
| 397 |
+
txt_en, corpus_en, txt_split_en, txt_lem_en, txt_wo_stopword_en, df_count_word_en,sent_len_en, sent_wo_sw_len_en, sent_lem_len_en = preprocess_txt (txt_en,'en')
|
| 398 |
+
display_preprocess_results('en',txt_en, txt_split_en, txt_lem_en, txt_wo_stopword_en, df_count_word_en)
|
| 399 |
+
else:
|
| 400 |
+
if st.session_state.reCalcule:
|
| 401 |
+
txt_en, corpus_en, txt_split_en, txt_lem_en, txt_wo_stopword_en, df_count_word_en,sent_len_en, sent_wo_sw_len_en, sent_lem_len_en = preprocess_txt (txt_en,'en')
|
| 402 |
+
display_preprocess_results('en',txt_en, txt_split_en, txt_lem_en, txt_wo_stopword_en, df_count_word_en)
|
| 403 |
+
else:
|
| 404 |
+
st.write("## **"+tr("Préprocessing de small_vocab_fr")+" :**\n")
|
| 405 |
+
if max_lines>10000:
|
| 406 |
+
with st.status(":sunglasses:", expanded=True):
|
| 407 |
+
if st.session_state.reCalcule:
|
| 408 |
+
txt_fr, corpus_fr, txt_split_fr, txt_lem_fr, txt_wo_stopword_fr, df_count_word_fr,sent_len_fr, sent_wo_sw_len_fr, sent_lem_len_fr = preprocess_txt (txt_fr,'fr')
|
| 409 |
+
display_preprocess_results('fr', txt_fr, txt_split_fr, txt_lem_fr, txt_wo_stopword_fr, df_count_word_fr)
|
| 410 |
+
else:
|
| 411 |
+
if st.session_state.reCalcule:
|
| 412 |
+
txt_fr, corpus_fr, txt_split_fr, txt_lem_fr, txt_wo_stopword_fr, df_count_word_fr,sent_len_fr, sent_wo_sw_len_fr, sent_lem_len_fr = preprocess_txt (txt_fr,'fr')
|
| 413 |
+
display_preprocess_results('fr', txt_fr, txt_split_fr, txt_lem_fr, txt_wo_stopword_fr, df_count_word_fr)
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
|
tabs/game_tab.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
import time
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import random
|
| 8 |
+
import json
|
| 9 |
+
import csv
|
| 10 |
+
from extra_streamlit_components import tab_bar, TabBarItemData
|
| 11 |
+
import matplotlib.pyplot as plt
|
| 12 |
+
from datetime import datetime
|
| 13 |
+
import tracemalloc
|
| 14 |
+
from translate_app import tr
|
| 15 |
+
|
| 16 |
+
title = "Jouez avec nous !"
|
| 17 |
+
sidebar_name = "Jeu"
|
| 18 |
+
dataPath = st.session_state.DataPath
|
| 19 |
+
|
| 20 |
+
@st.cache_data
|
| 21 |
+
def init_game():
|
| 22 |
+
new = int(time.time())
|
| 23 |
+
sentence_test = pd.read_csv(dataPath+'/multilingue/sentence_test_extract.csv')
|
| 24 |
+
sentence_test = sentence_test[4750:]
|
| 25 |
+
# Lisez le contenu du fichier JSON
|
| 26 |
+
with open(dataPath+'/multilingue/lan_to_language.json', 'r') as fichier:
|
| 27 |
+
lan_to_language = json.load(fichier)
|
| 28 |
+
t_now = time.time()
|
| 29 |
+
return sentence_test, lan_to_language, new, t_now
|
| 30 |
+
|
| 31 |
+
def find_indice(sent_selected):
|
| 32 |
+
l = list(lan_to_language.keys())
|
| 33 |
+
for i in range(len(l)):
|
| 34 |
+
if l[i] == sentence_test['lan_code'].iloc[sent_selected]:
|
| 35 |
+
return i
|
| 36 |
+
|
| 37 |
+
@st.cache_data
|
| 38 |
+
def set_game(new):
|
| 39 |
+
nb_st = len(sentence_test)
|
| 40 |
+
sent_sel = []
|
| 41 |
+
# Utilisez une boucle pour générer 5 nombres aléatoires différents
|
| 42 |
+
while len(sent_sel) < 5:
|
| 43 |
+
nombre = random.randint(0, nb_st)
|
| 44 |
+
if nombre not in sent_sel:
|
| 45 |
+
sent_sel.append(nombre)
|
| 46 |
+
|
| 47 |
+
rep_possibles=[]
|
| 48 |
+
for i in range(5):
|
| 49 |
+
rep_possibles.append([find_indice(sent_sel[i])])
|
| 50 |
+
while len(rep_possibles[i]) < 5:
|
| 51 |
+
rep_possible = random.randint(0, 95)
|
| 52 |
+
if rep_possible not in rep_possibles[i]:
|
| 53 |
+
rep_possibles[i].append(rep_possible)
|
| 54 |
+
random.shuffle(rep_possibles[i])
|
| 55 |
+
return sent_sel, rep_possibles, new
|
| 56 |
+
|
| 57 |
+
def calc_score(n_rep,duration):
|
| 58 |
+
|
| 59 |
+
if n_rep==0: return 0
|
| 60 |
+
s1 = n_rep*200
|
| 61 |
+
if duration < 60:
|
| 62 |
+
s2 = (60-duration)*200/60
|
| 63 |
+
if n_rep==5:
|
| 64 |
+
s2 *= 2.5
|
| 65 |
+
else:
|
| 66 |
+
s2 = max(-(duration-60)*100/60,-100)
|
| 67 |
+
s = int(s1+s2)
|
| 68 |
+
return s
|
| 69 |
+
|
| 70 |
+
def read_leaderboard():
|
| 71 |
+
return pd.read_csv(dataPath+'/game_leaderboard.csv', index_col=False,encoding='utf8')
|
| 72 |
+
|
| 73 |
+
def write_leaderboard(lb):
|
| 74 |
+
lb['Nom'] = lb['Nom'].astype(str)
|
| 75 |
+
lb['Rang'] = lb['Rang'].astype(int)
|
| 76 |
+
lb.to_csv(path_or_buf=dataPath+'/game_leaderboard.csv',columns=['Rang','Nom','Score','Timestamp','BR','Duree'],index=False, header=True,encoding='utf8')
|
| 77 |
+
|
| 78 |
+
def display_leaderboard():
|
| 79 |
+
lb = read_leaderboard()
|
| 80 |
+
st.write("**"+tr("Leaderboard")+" :**")
|
| 81 |
+
list_champ = """
|
| 82 |
+
| Rang | Nom | Score |
|
| 83 |
+
|------|------------|-------|"""
|
| 84 |
+
if len(lb)>0:
|
| 85 |
+
for i in range(len(lb)):
|
| 86 |
+
list_champ += """
|
| 87 |
+
| """+str(lb['Rang'].iloc[i])+""" | """+str(lb['Nom'].iloc[i])[:9]+""" | """+str(lb['Score'].iloc[i])+""" |"""
|
| 88 |
+
st.markdown(list_champ, unsafe_allow_html=True )
|
| 89 |
+
return lb
|
| 90 |
+
|
| 91 |
+
def write_log(TS,Nom,Score,BR,Duree):
|
| 92 |
+
log = pd.read_csv(dataPath+'/game_log.csv', index_col=False,encoding='utf8')
|
| 93 |
+
date_heure = datetime.fromtimestamp(TS)
|
| 94 |
+
Date = date_heure.strftime('%Y-%m-%d %H:%M:%S')
|
| 95 |
+
log = pd.concat([log, pd.DataFrame(data={'Date':[Date], 'Nom':[Nom],'Score':[Score],'BR':[BR],'Duree':[Duree]})], ignore_index=True)
|
| 96 |
+
log.to_csv(path_or_buf=dataPath+'/game_log.csv',columns=['Date','Nom','Score','BR','Duree'],index=False, header=True,encoding='utf8')
|
| 97 |
+
|
| 98 |
+
def display_files():
|
| 99 |
+
log = pd.read_csv(dataPath+'/game_log.csv', index_col=False,encoding='utf8')
|
| 100 |
+
lb = pd.read_csv(dataPath+'/game_leaderboard.csv', index_col=False,encoding='utf8')
|
| 101 |
+
st.dataframe(lb)
|
| 102 |
+
st.dataframe(log)
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
def run():
|
| 106 |
+
global sentence_test, lan_to_language
|
| 107 |
+
|
| 108 |
+
sentence_test, lan_to_language, new, t_debut = init_game()
|
| 109 |
+
|
| 110 |
+
st.write("")
|
| 111 |
+
st.title(tr(title))
|
| 112 |
+
st.write("#### **"+tr("Etes vous un expert es Langues ?")+"**\n")
|
| 113 |
+
st.markdown(tr(
|
| 114 |
+
"""
|
| 115 |
+
Essayer de trouvez, sans aide, la langue des 5 phrases suivantes.
|
| 116 |
+
Attention : Vous devez être le plus rapide possible !
|
| 117 |
+
"""), unsafe_allow_html=True
|
| 118 |
+
)
|
| 119 |
+
st.write("")
|
| 120 |
+
player_name = st.text_input(tr("Quel est votre nom ?"))
|
| 121 |
+
|
| 122 |
+
if player_name == 'display_files':
|
| 123 |
+
display_files()
|
| 124 |
+
return
|
| 125 |
+
elif player_name == 'malloc_start':
|
| 126 |
+
tracemalloc.start()
|
| 127 |
+
return
|
| 128 |
+
elif player_name == 'malloc_stop':
|
| 129 |
+
snapshot = tracemalloc.take_snapshot()
|
| 130 |
+
top_stats = snapshot.statistics('traceback')
|
| 131 |
+
# pick the biggest memory block
|
| 132 |
+
for k in range(3):
|
| 133 |
+
stat = top_stats[k]
|
| 134 |
+
print("%s memory blocks: %.1f KiB" % (stat.count, stat.size / 1024))
|
| 135 |
+
for line in stat.traceback.format():
|
| 136 |
+
print(' >'+line)
|
| 137 |
+
total_mem = sum(stat.size for stat in top_stats)
|
| 138 |
+
print("Total allocated size: %.1f KiB" % (total_mem / 1024))
|
| 139 |
+
return
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
score = 0
|
| 144 |
+
col1, col2 = st.columns([0.7,0.3])
|
| 145 |
+
with col2:
|
| 146 |
+
lb = display_leaderboard()
|
| 147 |
+
with col1:
|
| 148 |
+
sent_sel, rep_possibles, new = set_game(new)
|
| 149 |
+
answer = [""] * 5
|
| 150 |
+
l = list(lan_to_language.values())
|
| 151 |
+
for i in range(5):
|
| 152 |
+
answer[i] = st.radio("**:blue["+sentence_test['sentence'].iloc[sent_sel[i]]+"]**\n",[l[rep_possibles[i][0]],l[rep_possibles[i][1]],l[rep_possibles[i][2]], \
|
| 153 |
+
l[rep_possibles[i][3]],l[rep_possibles[i][4]]], horizontal=True, key=i)
|
| 154 |
+
t_previous_debut = t_debut
|
| 155 |
+
t_debut = time.time()
|
| 156 |
+
|
| 157 |
+
if st.button(label=tr("Validez"), type="primary"):
|
| 158 |
+
st.cache_data.clear()
|
| 159 |
+
|
| 160 |
+
nb_bonnes_reponses = 0
|
| 161 |
+
for i in range(5):
|
| 162 |
+
if lan_to_language[sentence_test['lan_code'].iloc[sent_sel[i]]]==answer[i]:
|
| 163 |
+
nb_bonnes_reponses +=1
|
| 164 |
+
|
| 165 |
+
t_fin = time.time()
|
| 166 |
+
duration = t_fin - t_previous_debut
|
| 167 |
+
|
| 168 |
+
score = calc_score(nb_bonnes_reponses,duration)
|
| 169 |
+
write_log(time.time(),player_name,score,nb_bonnes_reponses,duration)
|
| 170 |
+
if nb_bonnes_reponses >=4:
|
| 171 |
+
st.write(":red[**"+tr("Félicitations, vous avez "+str(nb_bonnes_reponses)+" bonnes réponses !")+"**]")
|
| 172 |
+
st.write(":red["+tr("Votre score est de "+str(score)+" points")+"]")
|
| 173 |
+
else:
|
| 174 |
+
if nb_bonnes_reponses >1 : s="s"
|
| 175 |
+
else: s=""
|
| 176 |
+
st.write("**:red["+tr("Vous avez "+str(nb_bonnes_reponses)+" bonne"+s+" réponse"+s+".")+"]**")
|
| 177 |
+
if nb_bonnes_reponses >0 : s="s"
|
| 178 |
+
else: s=""
|
| 179 |
+
st.write(":red["+tr("Votre score est de "+str(score)+" point"+s)+"]")
|
| 180 |
+
|
| 181 |
+
st.write(tr("Bonne réponses")+":")
|
| 182 |
+
for i in range(5):
|
| 183 |
+
st.write("- "+sentence_test['sentence'].iloc[sent_sel[i]]+" -> :blue[**"+lan_to_language[sentence_test['lan_code'].iloc[sent_sel[i]]]+"**]")
|
| 184 |
+
new = int(time.time())
|
| 185 |
+
st.button(label=tr("Play again ?"), type="primary")
|
| 186 |
+
|
| 187 |
+
with col2:
|
| 188 |
+
now = time.time()
|
| 189 |
+
# Si le score du dernier est plus vieux d'une semaine, il est remplacé par un score + récent
|
| 190 |
+
renew_old = ((len(lb)>9) and (lb['Timestamp'].iloc[9])<(now-604800))
|
| 191 |
+
|
| 192 |
+
if (score>0) and ((((score >= lb['Score'].min()) and (len(lb)>9)) or (len(lb)<=9)) or (pd.isna(lb['Score'].min())) or renew_old):
|
| 193 |
+
if player_name not in lb['Nom'].tolist():
|
| 194 |
+
if (((score >= lb['Score'].min()) and (len(lb)>9)) or (len(lb)<=9)) or (pd.isna(lb['Score'].min())) :
|
| 195 |
+
lb = pd.concat([lb, pd.DataFrame(data={'Nom':[player_name],'Score':[score],'Timestamp':[now],'BR':[nb_bonnes_reponses],'Duree':[duration]})], ignore_index=True)
|
| 196 |
+
lb = lb.sort_values(by=['Score', 'Timestamp'], ascending=[False, False]).reset_index()
|
| 197 |
+
lb = lb.drop(lb.index[10:])
|
| 198 |
+
else:
|
| 199 |
+
st.write('2:',player_name)
|
| 200 |
+
lb['Nom'].iloc[9]= player_name
|
| 201 |
+
lb['Score'].iloc[9]= score
|
| 202 |
+
lb['Timestamp'].iloc[9]=now
|
| 203 |
+
lb['BR'].iloc[9]=nb_bonnes_reponses
|
| 204 |
+
lb['Duree'].iloc[9]=duration
|
| 205 |
+
lb = lb.reset_index()
|
| 206 |
+
else:
|
| 207 |
+
liste_Nom = lb['Nom'].tolist()
|
| 208 |
+
for i,player in enumerate(liste_Nom):
|
| 209 |
+
if player == player_name:
|
| 210 |
+
if lb['Score'].iloc[i] < score:
|
| 211 |
+
lb['Score'].iloc[i] = score
|
| 212 |
+
lb['Timestamp'].iloc[i]=now
|
| 213 |
+
lb = lb.sort_values(by=['Score', 'Timestamp'], ascending=[False, False]).reset_index()
|
| 214 |
+
for i in range(len(lb)):
|
| 215 |
+
if (i>0):
|
| 216 |
+
if (lb['Score'].iloc[i]==lb['Score'].iloc[i-1]):
|
| 217 |
+
lb['Rang'].iloc[i] = lb['Rang'].iloc[i-1]
|
| 218 |
+
else:
|
| 219 |
+
lb['Rang'].iloc[i] = i+1
|
| 220 |
+
else:
|
| 221 |
+
lb['Rang'].iloc[i] = i+1
|
| 222 |
+
if player_name !="":
|
| 223 |
+
write_leaderboard(lb)
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
return
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
|
tabs/id_lang_tab.py
ADDED
|
@@ -0,0 +1,476 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import tiktoken
|
| 6 |
+
import joblib
|
| 7 |
+
import json
|
| 8 |
+
import csv
|
| 9 |
+
from transformers import pipeline
|
| 10 |
+
import keras
|
| 11 |
+
from tensorflow.keras.preprocessing.sequence import pad_sequences
|
| 12 |
+
from sklearn.preprocessing import LabelEncoder
|
| 13 |
+
from tensorflow.keras.utils import plot_model
|
| 14 |
+
from filesplit.merge import Merge
|
| 15 |
+
from extra_streamlit_components import tab_bar, TabBarItemData
|
| 16 |
+
from sklearn.decomposition import PCA
|
| 17 |
+
import matplotlib.pyplot as plt
|
| 18 |
+
import seaborn as sns
|
| 19 |
+
from sklearn import naive_bayes
|
| 20 |
+
from translate_app import tr
|
| 21 |
+
|
| 22 |
+
title = "Identification de langue"
|
| 23 |
+
sidebar_name = "Identification de langue"
|
| 24 |
+
dataPath = st.session_state.DataPath
|
| 25 |
+
|
| 26 |
+
# CountVectorizer a une liste de phrase en entrée.
|
| 27 |
+
# Cette fonction met les données d'entrée dans le bon format
|
| 28 |
+
def format_to_vectorize(data):
|
| 29 |
+
X_tok = []
|
| 30 |
+
if "DataFrame" in str(type(data)):sentences = data.tolist()
|
| 31 |
+
elif "str" in str(type(data)):
|
| 32 |
+
sentences =[data]
|
| 33 |
+
else: sentences = data
|
| 34 |
+
|
| 35 |
+
for sentence in sentences:
|
| 36 |
+
X_tok.append(sentence)
|
| 37 |
+
return X_tok
|
| 38 |
+
|
| 39 |
+
def create_BOW(data):
|
| 40 |
+
global vectorizer
|
| 41 |
+
|
| 42 |
+
X_tok = format_to_vectorize(data)
|
| 43 |
+
X = vectorizer.transform(X_tok)
|
| 44 |
+
return X
|
| 45 |
+
|
| 46 |
+
def load_vectorizer(tokenizer):
|
| 47 |
+
global dict_token, dict_ids, nb_token
|
| 48 |
+
|
| 49 |
+
path = dataPath+'/vectorizer_tiktoken_big.pkl'
|
| 50 |
+
vectorizer = joblib.load(path)
|
| 51 |
+
dict_token = {tokenizer.decode([cle]): cle for cle, valeur in vectorizer.vocabulary_.items()}
|
| 52 |
+
dict_ids = {cle: tokenizer.decode([cle]) for cle, valeur in vectorizer.vocabulary_.items()} #dict_ids.items()}
|
| 53 |
+
nb_token = len(vectorizer.vocabulary_)
|
| 54 |
+
return vectorizer
|
| 55 |
+
|
| 56 |
+
def lang_id_nb(sentences):
|
| 57 |
+
global lan_to_language
|
| 58 |
+
|
| 59 |
+
if "str" in str(type(sentences)):
|
| 60 |
+
return lan_to_language[clf_nb.predict(create_BOW(sentences))[0]]
|
| 61 |
+
else: return [lan_to_language[l] for l in clf_nb.predict(create_BOW(sentences))]
|
| 62 |
+
|
| 63 |
+
@st.cache_resource
|
| 64 |
+
def init_nb_identifier():
|
| 65 |
+
|
| 66 |
+
tokenizer = tiktoken.get_encoding("cl100k_base")
|
| 67 |
+
|
| 68 |
+
# Chargement du classificateur sauvegardé
|
| 69 |
+
clf_nb = joblib.load(dataPath+"/id_lang_tiktoken_nb_sparse_big.pkl")
|
| 70 |
+
vectorizer = load_vectorizer(tokenizer)
|
| 71 |
+
|
| 72 |
+
# Lisez le contenu du fichier JSON
|
| 73 |
+
with open(dataPath+'/multilingue/lan_to_language.json', 'r') as fichier:
|
| 74 |
+
lan_to_language = json.load(fichier)
|
| 75 |
+
return tokenizer, dict_token, dict_ids, nb_token, lan_to_language, clf_nb, vectorizer
|
| 76 |
+
|
| 77 |
+
def encode_text(textes):
|
| 78 |
+
global tokenizer
|
| 79 |
+
|
| 80 |
+
max_length=250
|
| 81 |
+
sequences = tokenizer.encode_batch(textes)
|
| 82 |
+
return pad_sequences(sequences, maxlen=max_length, padding='post')
|
| 83 |
+
|
| 84 |
+
def read_list_lan():
|
| 85 |
+
|
| 86 |
+
with open(dataPath+'/multilingue/lan_code.csv', 'r') as fichier_csv:
|
| 87 |
+
reader = csv.reader(fichier_csv)
|
| 88 |
+
lan_code = next(reader)
|
| 89 |
+
return lan_code
|
| 90 |
+
|
| 91 |
+
@st.cache_resource
|
| 92 |
+
def init_dl_identifier():
|
| 93 |
+
|
| 94 |
+
label_encoder = LabelEncoder()
|
| 95 |
+
list_lan = read_list_lan()
|
| 96 |
+
lan_identified = [lan_to_language[l] for l in list_lan]
|
| 97 |
+
label_encoder.fit(list_lan)
|
| 98 |
+
merge = Merge(dataPath+"/dl_id_lang_split", dataPath, "dl_tiktoken_id_language_model.h5").merge(cleanup=False)
|
| 99 |
+
dl_model = keras.models.load_model(dataPath+"/dl_tiktoken_id_language_model.h5")
|
| 100 |
+
return dl_model, label_encoder, list_lan, lan_identified
|
| 101 |
+
|
| 102 |
+
def lang_id_dl(sentences):
|
| 103 |
+
global dl_model, label_encoder
|
| 104 |
+
|
| 105 |
+
if "str" in str(type(sentences)): predictions = dl_model.predict(encode_text([sentences]))
|
| 106 |
+
else: predictions = dl_model.predict(encode_text(sentences))
|
| 107 |
+
# Décodage des prédictions en langues
|
| 108 |
+
predicted_labels_encoded = np.argmax(predictions, axis=1)
|
| 109 |
+
predicted_languages = label_encoder.classes_[predicted_labels_encoded]
|
| 110 |
+
if "str" in str(type(sentences)): return lan_to_language[predicted_languages[0]]
|
| 111 |
+
else: return [l for l in predicted_languages]
|
| 112 |
+
|
| 113 |
+
@st.cache_resource
|
| 114 |
+
def init_lang_id_external():
|
| 115 |
+
|
| 116 |
+
lang_id_model_ext = pipeline('text-classification',model="papluca/xlm-roberta-base-language-detection")
|
| 117 |
+
dict_xlmr = {"ar":"ara", "bg":"bul", "de":"deu", "el": "ell", "en":"eng", "es":"spa", "fr":"fra", "hi": "hin","it":"ita","ja":"jpn", \
|
| 118 |
+
"nl":"nld", "pl":"pol", "pt":"por", "ru":"rus", "sw":"swh", "th":"tha", "tr":"tur", "ur": "urd", "vi":"vie", "zh":"cmn"}
|
| 119 |
+
sentence_test = pd.read_csv(dataPath+'//multilingue/sentence_test_extract.csv')
|
| 120 |
+
sentence_test = sentence_test[:4750]
|
| 121 |
+
# Instanciation d'un exemple
|
| 122 |
+
exemples = ["Er weiß überhaupt nichts über dieses Buch", # Phrase 0
|
| 123 |
+
"Umbrellas sell well", # Phrase 1
|
| 124 |
+
"elle adore les voitures très luxueuses, et toi ?", # Phrase 2
|
| 125 |
+
"she loves very luxurious cars, don't you?", # Phrase 3
|
| 126 |
+
"Vogliamo visitare il Colosseo e nuotare nel Tevere", # Phrase 4
|
| 127 |
+
"vamos a la playa", # Phrase 5
|
| 128 |
+
"Te propongo un trato", # Phrase 6
|
| 129 |
+
"she loves you much, mais elle te hait aussi and das ist traurig", # Phrase 7 # Attention à cette phrase trilingue
|
| 130 |
+
"Elle a de belles loches" # Phrase 8
|
| 131 |
+
]
|
| 132 |
+
|
| 133 |
+
lang_exemples = ['deu','eng','fra','eng','ita','spa','spa','fra','fra']
|
| 134 |
+
return lang_id_model_ext, dict_xlmr, sentence_test, lang_exemples, exemples
|
| 135 |
+
|
| 136 |
+
@st.cache_data
|
| 137 |
+
def display_acp(title, comment):
|
| 138 |
+
data = np.load(dataPath+'/data_lang_id_acp.npz')
|
| 139 |
+
X_train_scaled = data['X_train_scaled']
|
| 140 |
+
y_train_pred = data['y_train_pred']
|
| 141 |
+
label_arrow = ['.', ',', '?', ' a', ' de', ' la', ' que', 'Tom', ' un', ' the', ' in', \
|
| 142 |
+
' to', 'I', "'", 'i', ' le', ' en', ' es', 'é', ' l', '!', 'o', ' ist', \
|
| 143 |
+
' pas', ' Tom', ' me', ' di', 'Ich', ' is', 'Je', ' nicht', ' you', \
|
| 144 |
+
' die', ' à', ' el', ' est', 'a', 'en', ' d', ' è', ' ne', ' se', ' no', \
|
| 145 |
+
' una', ' zu', 'Il', '¿', ' of', ' du', "'t", 'ato', ' der', ' il', \
|
| 146 |
+
' n', 'El', ' non', ' che', 'are', ' con', 'ó', ' was', 'La', 'No', \
|
| 147 |
+
' ?', 'es', 'le', 'L', ' and', ' des', ' s', ' ich', 'as', 'S', ' per', \
|
| 148 |
+
' das', ' und', ' ein', 'e', "'s", 'u', ' y', 'He', 'z', 'er', ' m', \
|
| 149 |
+
'st', ' les', 'Le', ' I', 'ar', 'te', 'Non', 'The', ' er', 'ie', ' v', \
|
| 150 |
+
' c', "'est", ' ha', ' den']
|
| 151 |
+
|
| 152 |
+
pca = PCA(n_components=2)
|
| 153 |
+
|
| 154 |
+
X_new = pca.fit_transform(X_train_scaled)
|
| 155 |
+
coeff = pca.components_.transpose()
|
| 156 |
+
xs = X_new[:, 0]
|
| 157 |
+
ys = X_new[:, 1]
|
| 158 |
+
scalex = 1.0/(xs.max() - xs.min())
|
| 159 |
+
scaley = 1.0/(ys.max() - ys.min())
|
| 160 |
+
principalDf = pd.DataFrame({'PC1': xs*scalex, 'PC2': ys * scaley})
|
| 161 |
+
finalDF = pd.concat([principalDf, pd.Series(y_train_pred, name='Langue')], axis=1)
|
| 162 |
+
|
| 163 |
+
sns.set_context("poster") # Valeur possible:"notebook", "talk", "poster", ou "paper"
|
| 164 |
+
plt.rc("axes", titlesize=32,titleweight='bold') # Taille du titre de l'axe
|
| 165 |
+
plt.rc("axes", labelsize=18,labelweight='bold') # Taille des étiquettes de l'axe
|
| 166 |
+
plt.rc("xtick", labelsize=14) # Taille des étiquettes de l'axe des x
|
| 167 |
+
plt.rc("ytick", labelsize=14) # Taille des étiquettes de l'axe des y
|
| 168 |
+
|
| 169 |
+
st.write(comment)
|
| 170 |
+
st.write("")
|
| 171 |
+
fig = plt.figure(figsize=(20, 15))
|
| 172 |
+
sns.scatterplot(x='PC1', y='PC2', hue='Langue', data=finalDF, alpha=0.5)
|
| 173 |
+
for i in range(50):
|
| 174 |
+
plt.arrow(0, 0, coeff[i, 0]*1.5, coeff[i, 1]*0.8,color='k', alpha=0.08, head_width=0.01, )
|
| 175 |
+
plt.text(coeff[i, 0]*1.5, coeff[i, 1] * 0.8, label_arrow[i], color='k', weight='bold')
|
| 176 |
+
|
| 177 |
+
plt.title(title)
|
| 178 |
+
plt.xlim(-0.4, 0.45)
|
| 179 |
+
plt.ylim(-0.15, 0.28);
|
| 180 |
+
st.pyplot(fig)
|
| 181 |
+
return
|
| 182 |
+
|
| 183 |
+
@st.cache_data
|
| 184 |
+
def read_BOW_examples():
|
| 185 |
+
return pd.read_csv(dataPath+'/lang_id_small_BOW.csv')
|
| 186 |
+
|
| 187 |
+
def analyse_nb(sel_phrase):
|
| 188 |
+
global lang_exemples,exemples
|
| 189 |
+
|
| 190 |
+
def create_small_BOW(s):
|
| 191 |
+
encodage = tokenizer.encode(s)
|
| 192 |
+
sb = [0] * (df_BOW.shape[1]-1)
|
| 193 |
+
nb_unique_token = 0
|
| 194 |
+
for i in range(df_BOW.shape[1]-1):
|
| 195 |
+
for t in encodage:
|
| 196 |
+
if df_BOW.columns[i]==str(t):
|
| 197 |
+
sb[i] += 1
|
| 198 |
+
if sb[i] > 0: nb_unique_token +=1
|
| 199 |
+
return sb, nb_unique_token
|
| 200 |
+
|
| 201 |
+
st.write("#### **"+tr("Probabilité d'appartenance de la phrase à une langue")+" :**")
|
| 202 |
+
st.image("./assets/formule_proba_naive_bayes.png")
|
| 203 |
+
st.write(tr("où **C** est la classe (lan_code), **Fi** est la caractéristique i du BOW, **Z** est l'\"evidence\" servant à regulariser la probabilité"))
|
| 204 |
+
st.write("")
|
| 205 |
+
nb_lang = 5
|
| 206 |
+
lan_code = ['deu','eng','fra','spa','ita']
|
| 207 |
+
lan_color = {'deu':'violet','eng':'green','fra':'red','spa':'blue','ita':'orange'}
|
| 208 |
+
df_BOW = read_BOW_examples()
|
| 209 |
+
|
| 210 |
+
clf_nb2 = naive_bayes.MultinomialNB()
|
| 211 |
+
clf_nb2.fit(df_BOW.drop(columns='lan_code').values.tolist(), df_BOW['lan_code'].values.tolist())
|
| 212 |
+
|
| 213 |
+
nb_phrases_lang =[]
|
| 214 |
+
for l in lan_code:
|
| 215 |
+
nb_phrases_lang.append(sum(df_BOW['lan_code']==l))
|
| 216 |
+
st.write(tr("Phrase à analyser")+" :",'**:'+lan_color[lang_exemples[sel_phrase]]+'['+lang_exemples[sel_phrase],']** - **"'+exemples[sel_phrase]+'"**')
|
| 217 |
+
|
| 218 |
+
# Tokenisation et encodage de la phrase
|
| 219 |
+
encodage = tokenizer.encode(exemples[sel_phrase])
|
| 220 |
+
|
| 221 |
+
# Création du vecteur BOW de la phrase
|
| 222 |
+
bow_exemple, nb_unique_token = create_small_BOW(exemples[sel_phrase])
|
| 223 |
+
st.write(tr("Nombre de tokens retenus dans le BOW")+": "+ str(nb_unique_token))
|
| 224 |
+
masque_tokens_retenus = [(1 if token in list(dict_ids.keys()) else 0) for token in encodage]
|
| 225 |
+
str_token = " "
|
| 226 |
+
for i in range(len(encodage)):
|
| 227 |
+
if masque_tokens_retenus[i]==1:
|
| 228 |
+
if (i%2) ==0:
|
| 229 |
+
str_token += "**:red["+tokenizer.decode([encodage[i]])+"]** "
|
| 230 |
+
else:
|
| 231 |
+
str_token += "**:violet["+tokenizer.decode([encodage[i]])+"]** "
|
| 232 |
+
else: str_token += ":green["+tokenizer.decode([encodage[i]])+"] "
|
| 233 |
+
|
| 234 |
+
st.write(tr("Tokens se trouvant dans le modèle (en")+" :red["+tr("rouge")+"] "+tr("ou")+" :violet["+tr("violet")+"]) :"+str_token+" ")
|
| 235 |
+
|
| 236 |
+
st.write("")
|
| 237 |
+
# Afin de continuer l'analyse on ne garde que les token de la phrase disponibles dans le BOW
|
| 238 |
+
token_used = [str(encodage[i]) for i in range(len(encodage)) if (masque_tokens_retenus[i]==1)]
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
# Calcul du nombre d'apparition de ces tokens dans le BOW pour chaque langue, et stockage dans un DataFrame df_count
|
| 242 |
+
def compter_non_zero(colonne):
|
| 243 |
+
return (colonne != 0).sum()
|
| 244 |
+
|
| 245 |
+
votes = []
|
| 246 |
+
for i in range(nb_lang):
|
| 247 |
+
#votes.append(list(df_BOW[token_used].loc[df_BOW['lan_code']==lan_code[i]].sum(axis=0)))
|
| 248 |
+
votes.append(list(df_BOW[token_used].loc[df_BOW['lan_code']==lan_code[i]].apply(compter_non_zero)))
|
| 249 |
+
|
| 250 |
+
col_name = [str(i+1)+'-'+tokenizer.decode([int(token_used[i])]) for i in range(len(token_used))]
|
| 251 |
+
df_count = pd.DataFrame(data=votes,columns=token_used, index=lan_code)
|
| 252 |
+
df_count.columns = col_name
|
| 253 |
+
st.write("\n**"+tr("Nombre d'apparitions des tokens, dans chaque langue")+"**")
|
| 254 |
+
|
| 255 |
+
# Lissage de Laplace n°1 (Laplace smoothing )
|
| 256 |
+
# df_count = df_count+1
|
| 257 |
+
|
| 258 |
+
st.dataframe(df_count)
|
| 259 |
+
|
| 260 |
+
#########
|
| 261 |
+
######### 3. Calcul de la probabilité d'apparition de chaque token dans chaque langue
|
| 262 |
+
df_proba = df_count.div(nb_phrases_lang, axis = 0)
|
| 263 |
+
|
| 264 |
+
# Lissage de Laplace n°2 (Laplace smoothing )
|
| 265 |
+
df_proba = df_proba.replace(0.0,0.0010)
|
| 266 |
+
|
| 267 |
+
# Initialisation de df_proba: Calcul de la probabilité conditionnelle d'appartenance de la phrase à une langue
|
| 268 |
+
df_proba['Proba'] = 1
|
| 269 |
+
# Itérer sur les colonnes et effectuez la multiplication pour chaque ligne
|
| 270 |
+
for col in df_count.columns:
|
| 271 |
+
df_proba['Proba'] *= df_proba[col]
|
| 272 |
+
|
| 273 |
+
#########
|
| 274 |
+
######### 4. Calcul (par multiplication) de la probabilité d'appartenance de la phrase à une langue
|
| 275 |
+
|
| 276 |
+
# Multiplication par la probabilité de la classe
|
| 277 |
+
p_classe = [(nb_phrases_lang[i]/df_BOW.shape[0]) for i in range(len(nb_phrases_lang))]
|
| 278 |
+
df_proba['Proba'] *= p_classe
|
| 279 |
+
|
| 280 |
+
# Diviser par l'evidence
|
| 281 |
+
evidence = df_proba['Proba'].sum(axis=0)
|
| 282 |
+
df_proba['Proba'] *= 1/evidence
|
| 283 |
+
df_proba['Proba'] = df_proba['Proba'].round(3)
|
| 284 |
+
|
| 285 |
+
# Affichage de la matrice des probabilités
|
| 286 |
+
st.write("**"+tr("Probabilités conditionnelles d'apparition des tokens retenus, dans chaque langue")+":**")
|
| 287 |
+
st.dataframe(df_proba)
|
| 288 |
+
str_token = "Lang proba max: "# "*20
|
| 289 |
+
for i,token in enumerate(df_proba.columns[:-1]):
|
| 290 |
+
str_token += '*'+token+'*:**:'+lan_color[df_proba[token].idxmax()]+'['+df_proba[token].idxmax()+']**'+" "*2 #8
|
| 291 |
+
st.write(str_token)
|
| 292 |
+
st.write("")
|
| 293 |
+
|
| 294 |
+
st.write(tr("Langue réelle de la phrase")+" "*35+": **:"+lan_color[lang_exemples[sel_phrase]]+'['+lang_exemples[sel_phrase]+']**')
|
| 295 |
+
st.write(tr("Langue dont la probabilité est la plus forte ")+": **:"+lan_color[df_proba['Proba'].idxmax()]+'['+df_proba['Proba'].idxmax(),"]** (proba={:.2f}".format(max(df_proba['Proba']))+")")
|
| 296 |
+
prediction = clf_nb2.predict([bow_exemple])
|
| 297 |
+
st.write(tr("Langue prédite par Naiva Bayes")+" "*23+": **:"+lan_color[prediction[0]]+'['+prediction[0]+"]** (proba={:.2f}".format(max(clf_nb2.predict_proba([bow_exemple])[0]))+")")
|
| 298 |
+
st.write("")
|
| 299 |
+
|
| 300 |
+
fig, axs = plt.subplots(1, 2, figsize=(10, 6))
|
| 301 |
+
df_proba_sorted =df_proba.sort_index(ascending=True)
|
| 302 |
+
axs[0].set_title(tr("Probabilités calculée manuellement"), fontsize=12)
|
| 303 |
+
axs[0].barh(df_proba_sorted.index, df_proba_sorted['Proba'])
|
| 304 |
+
axs[1].set_title(tr("Probabilités du classifieur Naive Bayes"), fontsize=12)
|
| 305 |
+
axs[1].barh(df_proba_sorted.index, clf_nb2.predict_proba([bow_exemple])[0]);
|
| 306 |
+
st.pyplot(fig)
|
| 307 |
+
return
|
| 308 |
+
|
| 309 |
+
#@st.cache_data
|
| 310 |
+
def find_exemple(lang_sel):
|
| 311 |
+
global exemples
|
| 312 |
+
return exemples[lang_sel]
|
| 313 |
+
|
| 314 |
+
def display_shapley(lang_sel):
|
| 315 |
+
st.write("**"+tr("Analyse de l'importance de chaque token dans l'identification de la langue")+"**")
|
| 316 |
+
st.image('assets/fig_schapley'+str(lang_sel)+'.png')
|
| 317 |
+
st.write("**"+tr("Recapitulatif de l'influence des tokens sur la selection de la langue")+"**")
|
| 318 |
+
st.image('assets/fig_schapley_recap'+str(lang_sel)+'.png')
|
| 319 |
+
return
|
| 320 |
+
|
| 321 |
+
def run():
|
| 322 |
+
global tokenizer, vectorizer, dict_token, dict_ids, nb_token, lan_to_language, clf_nb
|
| 323 |
+
global dl_model, label_encoder, toggle_val, custom_sentence, list_lan, lan_identified
|
| 324 |
+
global lang_exemples, exemples
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
tokenizer, dict_token, dict_ids, nb_token, lan_to_language, clf_nb, vectorizer = init_nb_identifier()
|
| 328 |
+
dl_model, label_encoder, list_lan, lan_identified = init_dl_identifier()
|
| 329 |
+
lang_id_model_ext, dict_xlmr, sentence_test, lang_exemples, exemples= init_lang_id_external()
|
| 330 |
+
|
| 331 |
+
st.write("")
|
| 332 |
+
st.title(tr(title))
|
| 333 |
+
st.write("## **"+tr("Explications")+" :**\n")
|
| 334 |
+
st.markdown(tr(
|
| 335 |
+
"""
|
| 336 |
+
Afin de mettre en oeuvre cette fonctionnalité nous avons utilisé un jeu d'entrainement multilinge de <b> 9.757.778 phrases dans 95 langues</b>.
|
| 337 |
+
Les 95 langues identifiées sont:
|
| 338 |
+
""")
|
| 339 |
+
, unsafe_allow_html=True)
|
| 340 |
+
st.selectbox(label="Lang",options=sorted(lan_identified),label_visibility="hidden")
|
| 341 |
+
st.markdown(tr(
|
| 342 |
+
"""
|
| 343 |
+
Nous avons utilisé 2 méthodes pour identifier la langue d'un texte:
|
| 344 |
+
1. un classificateur **Naïve Bayes**
|
| 345 |
+
2. un modèle de **Deep Learning**
|
| 346 |
+
""")
|
| 347 |
+
, unsafe_allow_html=True)
|
| 348 |
+
st.markdown(tr(
|
| 349 |
+
"""
|
| 350 |
+
Les 2 modèles ont un accuracy similaire sur le jeu de test: **:red[96% pour NB et 97,5% pour DL]**
|
| 351 |
+
<br>
|
| 352 |
+
""")
|
| 353 |
+
, unsafe_allow_html=True)
|
| 354 |
+
|
| 355 |
+
chosen_id = tab_bar(data=[
|
| 356 |
+
TabBarItemData(id="tab1", title=tr("Id. Naïve Bayes"), description=tr("avec le Bag Of Words")),
|
| 357 |
+
TabBarItemData(id="tab2", title=tr("Id. Deep Learning"), description=tr(" avec Keras")),
|
| 358 |
+
TabBarItemData(id="tab3", title=tr("Interpretabilité"), description=tr("du modèle Naïve Bayes "))],
|
| 359 |
+
default="tab1")
|
| 360 |
+
|
| 361 |
+
if (chosen_id == "tab1") or (chosen_id == "tab2"):
|
| 362 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 363 |
+
|
| 364 |
+
toggle_val = st.toggle(tr('Phrase à saisir/Phrase test'), value=True, help=tr("Off = phrase à saisir, On = selection d'une phrase test parmi 9500 phrases"))
|
| 365 |
+
if toggle_val:
|
| 366 |
+
custom_sentence= st.selectbox(tr("Selectionnez une phrases test à identifier")+":", sentence_test['sentence'] )
|
| 367 |
+
else:
|
| 368 |
+
custom_sentence = st.text_area(label=tr("Saisir le texte dont vous souhaitez identifier la langue:"))
|
| 369 |
+
st.button(label=tr("Validez"), type="primary")
|
| 370 |
+
|
| 371 |
+
if custom_sentence!='':
|
| 372 |
+
st.write("## **"+tr("Résultats")+" :**\n")
|
| 373 |
+
md = """
|
| 374 |
+
|"""+tr("Identifieur")+""" |"""+tr("Langue identifiée")+"""|
|
| 375 |
+
|-------------------------------------|---------------|"""
|
| 376 |
+
md1 = ""
|
| 377 |
+
if toggle_val:
|
| 378 |
+
lan_reelle = sentence_test['lan_code'].loc[sentence_test['sentence']==custom_sentence].tolist()[0]
|
| 379 |
+
md1 = """
|
| 380 |
+
|"""+tr("Langue réelle")+""" |**:blue["""+lan_to_language[lan_reelle]+"""]**|"""
|
| 381 |
+
md2 = """
|
| 382 |
+
|"""+tr("Classificateur Naïve Bayes")+""" |**:red["""+lang_id_nb(custom_sentence)+"""]**|
|
| 383 |
+
|"""+tr("Modèle de Deep Learning")+""" |**:red["""+lang_id_dl(custom_sentence)+"""]**|"""
|
| 384 |
+
md3 = """
|
| 385 |
+
|XLM-RoBERTa (Hugging Face) |**:red["""+lan_to_language[dict_xlmr[lang_id_model_ext(custom_sentence)[0]['label']]]+"""]**|"""
|
| 386 |
+
if toggle_val:
|
| 387 |
+
if not (lan_reelle in list(dict_xlmr.values())):
|
| 388 |
+
md3=""
|
| 389 |
+
|
| 390 |
+
st.markdown(md+md1+md2+md3, unsafe_allow_html=True)
|
| 391 |
+
|
| 392 |
+
st.write("## **"+tr("Details sur la méthode")+" :**\n")
|
| 393 |
+
if (chosen_id == "tab1"):
|
| 394 |
+
st.markdown(tr(
|
| 395 |
+
"""
|
| 396 |
+
Afin d'utiliser le classificateur Naïve Bayes, il nous a fallu:""")+"\n"+
|
| 397 |
+
"* "+tr("Créer un Bag of Words de token..")+"\n"+
|
| 398 |
+
"* "+tr("..Tokeniser le texte d'entrainement avec CountVectorizer et un tokenizer 'custom', **Tiktoken** d'OpenAI. ")+"\n"+
|
| 399 |
+
"* "+tr("Utiliser des matrices creuses (Sparse Matrix), car notre BOW contenait 10 Millions de lignes x 59122 tokens. ")+"\n"+
|
| 400 |
+
"* "+tr("Sauvegarder le vectorizer (non serialisable) et le classificateur entrainé. ")
|
| 401 |
+
, unsafe_allow_html=True)
|
| 402 |
+
st.markdown(tr(
|
| 403 |
+
"""
|
| 404 |
+
L'execution de toutes ces étapes est assez rapide: une dizaine de minutes
|
| 405 |
+
<br>
|
| 406 |
+
Le résultat est très bon: L'Accuracy sur le jeu de test est =
|
| 407 |
+
**:red[96%]** sur les 95 langues, et **:red[99,1%]** sur les 5 langues d'Europe de l'Ouest (en,fr,de,it,sp)
|
| 408 |
+
<br>
|
| 409 |
+
""")
|
| 410 |
+
, unsafe_allow_html=True)
|
| 411 |
+
st.markdown(tr(
|
| 412 |
+
"""
|
| 413 |
+
**Note 1:** Les 2 modèles ont un accuracy similaire sur le jeu de test: **:red[96% pour NB et 97,5% pour DL]**
|
| 414 |
+
**Note 2:** Le modèle *XLM-RoBERTa* de Hugging Face (qui identifie 20 langues seulement) a une accuracy, sur notre jeu de test = **97,8%**,
|
| 415 |
+
versus **99,3% pour NB** et **99,2% pour DL** sur ces 20 langues.
|
| 416 |
+
""")
|
| 417 |
+
, unsafe_allow_html=True)
|
| 418 |
+
else:
|
| 419 |
+
st.markdown(tr(
|
| 420 |
+
"""
|
| 421 |
+
Nous avons mis en oeuvre un modèle Keras avec une couche d'embedding et 4 couches denses (*Voir architecture ci-dessous*).
|
| 422 |
+
Nous avons utilisé le tokeniser <b>Tiktoken</b> d'OpenAI.
|
| 423 |
+
La couche d'embedding accepte 250 tokens, ce qui signifie que la détection de langue s'effectue sur approximativement les 200 premiers mots.
|
| 424 |
+
<br>
|
| 425 |
+
""")
|
| 426 |
+
, unsafe_allow_html=True)
|
| 427 |
+
st.markdown(tr(
|
| 428 |
+
"""
|
| 429 |
+
L'entrainement a duré plus de 10 heures..
|
| 430 |
+
Finalement, le résultat est très bon: L'Accuracy sur le jeu de test est =
|
| 431 |
+
**:red[97,5%]** sur les 95 langues, et **:red[99,1%]** sur les 5 langues d'Europe de l'Ouest (en,fr,de,it,sp).
|
| 432 |
+
Néanmoins, la durée pour une prédiction est relativement longue: approximativement 5/100 de seconde
|
| 433 |
+
<br>
|
| 434 |
+
""")
|
| 435 |
+
, unsafe_allow_html=True)
|
| 436 |
+
st.markdown(tr(
|
| 437 |
+
"""
|
| 438 |
+
**Note 1:** Les 2 modèles ont un accuracy similaire sur le jeu de test: **:red[96% pour NB et 97,5% pour DL]**""")+"<br>"+
|
| 439 |
+
tr("""
|
| 440 |
+
**Note 2:** Le modèle *XLM-RoBERTa* de Hugging Face (qui identifie 20 langues seulement) a une accuracy, sur notre jeu de test = <b>97,8%</b>,
|
| 441 |
+
versus **99,3% pour NB** et **99,2% pour DL** sur ces 20 langues.
|
| 442 |
+
<br>
|
| 443 |
+
""")
|
| 444 |
+
, unsafe_allow_html=True)
|
| 445 |
+
st.write("<center><h5>"+tr("Architecture du modèle utilisé")+":</h5></center>", unsafe_allow_html=True)
|
| 446 |
+
plot_model(dl_model, show_shapes=True, show_layer_names=True, show_layer_activations=True,rankdir='TB',to_file='./assets/model_plot.png')
|
| 447 |
+
col1, col2, col3 = st.columns([0.15,0.7,0.15])
|
| 448 |
+
with col2:
|
| 449 |
+
st.image('./assets/model_plot.png',use_column_width="auto")
|
| 450 |
+
elif (chosen_id == "tab3"):
|
| 451 |
+
st.write("### **"+tr("Interpretabilité du classifieur Naïve Bayes sur 5 langues")+"**")
|
| 452 |
+
st.write("##### "+tr("..et un Training set réduit (15000 phrases et 94 tokens)"))
|
| 453 |
+
st.write("")
|
| 454 |
+
|
| 455 |
+
chosen_id2 = tab_bar(data=[
|
| 456 |
+
TabBarItemData(id="tab1", title=tr("Analyse en Compos. Princ."), description=""),
|
| 457 |
+
TabBarItemData(id="tab2", title=tr("Simul. calcul NB"), description=""),
|
| 458 |
+
TabBarItemData(id="tab3", title=tr("Shapley"), description="")],
|
| 459 |
+
default="tab1")
|
| 460 |
+
if (chosen_id2 == "tab1"):
|
| 461 |
+
display_acp(tr("Importance des principaux tokens dans \n l'identification de langue par l'algorithme Naive Bayes"),tr("Affichage de 10 000 phrases (points) et des 50 tokens les + utilisés (flèches)"))
|
| 462 |
+
if (chosen_id2 == "tab2") or (chosen_id2 == "tab3"):
|
| 463 |
+
sel_phrase = st.selectbox(tr('Selectionnez une phrase à "interpréter"')+':', range(9), format_func=find_exemple)
|
| 464 |
+
if (chosen_id2 == "tab2"):
|
| 465 |
+
analyse_nb(sel_phrase)
|
| 466 |
+
if (chosen_id2 == "tab3"):
|
| 467 |
+
display_shapley(sel_phrase)
|
| 468 |
+
|
| 469 |
+
|
| 470 |
+
|
| 471 |
+
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
|
| 476 |
+
|
tabs/intro.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
from translate_app import tr
|
| 3 |
+
|
| 4 |
+
title = "Démosthène"
|
| 5 |
+
sidebar_name = "Introduction"
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def run():
|
| 9 |
+
|
| 10 |
+
# TODO: choose between one of these GIFs
|
| 11 |
+
# st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/1.gif")
|
| 12 |
+
# st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/2.gif")
|
| 13 |
+
# st.image("https://dst-studio-template.s3.eu-west-3.amazonaws.com/3.gif")
|
| 14 |
+
# st.image("assets/tough-communication.gif",use_column_width=True)
|
| 15 |
+
|
| 16 |
+
st.write("")
|
| 17 |
+
if st.session_state.Cloud == 0:
|
| 18 |
+
st.image("assets/miss-honey-glasses-off.gif",use_column_width=True)
|
| 19 |
+
else:
|
| 20 |
+
st.image("https://media.tenor.com/pfOeAfytY98AAAAC/miss-honey-glasses-off.gif",use_column_width=True)
|
| 21 |
+
|
| 22 |
+
st.title(tr(title))
|
| 23 |
+
st.markdown('''
|
| 24 |
+
## **'''+tr("Système de traduction adapté aux lunettes connectées")+'''**
|
| 25 |
+
---
|
| 26 |
+
''')
|
| 27 |
+
st.header("**"+tr("A propos")+"**")
|
| 28 |
+
st.markdown(tr(
|
| 29 |
+
"""
|
| 30 |
+
Ce projet a été réalisé dans le cadre d’une formation de Data Scientist, entre juin et novembre 2023.
|
| 31 |
+
<br>
|
| 32 |
+
:red[**Démosthène**] est l'un des plus grands orateurs de l'Antiquité. Il savait s’exprimer, et se faire comprendre.
|
| 33 |
+
Se faire comprendre est l’un des principaux objectifs de la traduction.
|
| 34 |
+
""")
|
| 35 |
+
, unsafe_allow_html=True)
|
| 36 |
+
st.markdown(tr(
|
| 37 |
+
"""
|
| 38 |
+
Démosthène avait de gros problèmes d’élocution.
|
| 39 |
+
Il les a surmontés en s’entraînant à parler avec des cailloux dans la bouche,
|
| 40 |
+
à l’image de l’Intelligence Artificielle, où des entraînements sont nécessaires pour obtenir de bons résultats.
|
| 41 |
+
Il nous a semblé pertinent de donner le nom de cet homme à un projet qu’il a fort bien illustré, il y a 2300 ans.
|
| 42 |
+
""")
|
| 43 |
+
, unsafe_allow_html=True)
|
| 44 |
+
|
| 45 |
+
st.header("**"+tr("Contexte")+"**")
|
| 46 |
+
st.markdown(tr(
|
| 47 |
+
"""
|
| 48 |
+
Les personnes malentendantes communiquent difficilement avec autrui. Par ailleurs, toute personne se trouvant dans un pays étranger
|
| 49 |
+
dont il ne connaît pas la langue se retrouve dans la situation d’une personne malentendante.
|
| 50 |
+
""")
|
| 51 |
+
, unsafe_allow_html=True)
|
| 52 |
+
st.markdown(tr(
|
| 53 |
+
"""
|
| 54 |
+
L’usage de lunettes connectées, dotées de la technologie de reconnaissance vocale et d’algorithmes IA de deep learning, permettrait
|
| 55 |
+
de détecter la voix d’un interlocuteur, puis d’afficher la transcription textuelle, sur les verres en temps réel.
|
| 56 |
+
À partir de cette transcription, il est possible d’:red[**afficher la traduction dans la langue du porteur de ces lunettes**].
|
| 57 |
+
""")
|
| 58 |
+
, unsafe_allow_html=True)
|
| 59 |
+
|
| 60 |
+
st.header("**"+tr("Objectifs")+"**")
|
| 61 |
+
st.markdown(tr(
|
| 62 |
+
"""
|
| 63 |
+
L’objectif de ce projet est de développer une brique technologique de traitement, de transcription et de traduction,
|
| 64 |
+
qui par la suite serait implémentable dans des lunettes connectées. Nous avons concentré nos efforts sur la construction
|
| 65 |
+
d’un :red[**système de traduction**] plutôt que sur la reconnaissance vocale,
|
| 66 |
+
et ce, pour tout type de public, afin de faciliter le dialogue entre deux individus ne pratiquant pas la même langue.
|
| 67 |
+
""")
|
| 68 |
+
, unsafe_allow_html=True)
|
| 69 |
+
st.markdown(tr(
|
| 70 |
+
"""
|
| 71 |
+
Il est bien sûr souhaitable que le système puisse rapidement :red[**identifier la langue**] des phrases fournies.
|
| 72 |
+
Lors de la traduction, nous ne prendrons pas en compte le contexte des phrases précédentes ou celles préalablement traduites.
|
| 73 |
+
""")
|
| 74 |
+
, unsafe_allow_html=True)
|
| 75 |
+
st.markdown(tr(
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
Nous évaluerons la qualité de nos résultats en les comparant avec des systèmes performants tels que “[Google translate](https://translate.google.fr/)”
|
| 79 |
+
""")
|
| 80 |
+
, unsafe_allow_html=True)
|
| 81 |
+
st.markdown(tr(
|
| 82 |
+
"""
|
| 83 |
+
Le projet est enregistré sur "[Github](https://github.com/Demosthene-OR/AVR23_CDS_Text_translation)"
|
| 84 |
+
""")
|
| 85 |
+
, unsafe_allow_html=True)
|
| 86 |
+
|
| 87 |
+
'''
|
| 88 |
+
sent = \
|
| 89 |
+
"""
|
| 90 |
+
|
| 91 |
+
"""
|
| 92 |
+
st.markdown(tr(sent), unsafe_allow_html=True)
|
| 93 |
+
'''
|
tabs/modelisation_dict_tab.py
ADDED
|
@@ -0,0 +1,277 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import os
|
| 4 |
+
from sacrebleu import corpus_bleu
|
| 5 |
+
if st.session_state.Cloud == 0:
|
| 6 |
+
from sklearn.cluster import KMeans
|
| 7 |
+
from sklearn.neighbors import KNeighborsClassifier
|
| 8 |
+
from sklearn.ensemble import RandomForestClassifier
|
| 9 |
+
from translate_app import tr
|
| 10 |
+
|
| 11 |
+
title = "Traduction mot à mot"
|
| 12 |
+
sidebar_name = "Traduction mot à mot"
|
| 13 |
+
dataPath = st.session_state.DataPath
|
| 14 |
+
|
| 15 |
+
@st.cache_data
|
| 16 |
+
def load_corpus(path):
|
| 17 |
+
input_file = os.path.join(path)
|
| 18 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 19 |
+
data = f.read()
|
| 20 |
+
data = data.split('\n')
|
| 21 |
+
data=data[:-1]
|
| 22 |
+
return pd.DataFrame(data)
|
| 23 |
+
|
| 24 |
+
@st.cache_data
|
| 25 |
+
def load_BOW(path, l):
|
| 26 |
+
input_file = os.path.join(path)
|
| 27 |
+
df1 = pd.read_csv(input_file+'1_'+l, encoding="utf-8", index_col=0)
|
| 28 |
+
df2 = pd.read_csv(input_file+'2_'+l, encoding="utf-8", index_col=0)
|
| 29 |
+
df_count_word = pd.concat([df1, df2])
|
| 30 |
+
return df_count_word
|
| 31 |
+
|
| 32 |
+
df_data_en = load_corpus(dataPath+'/preprocess_txt_en')
|
| 33 |
+
df_data_fr = load_corpus(dataPath+'/preprocess_txt_fr')
|
| 34 |
+
df_count_word_en = load_BOW(dataPath+'/preprocess_df_count_word', 'en')
|
| 35 |
+
df_count_word_fr = load_BOW(dataPath+'/preprocess_df_count_word', 'fr')
|
| 36 |
+
n1 = 0
|
| 37 |
+
|
| 38 |
+
def accuracy(dict_ref,dict):
|
| 39 |
+
correct_words = 0
|
| 40 |
+
|
| 41 |
+
for t in dict.columns:
|
| 42 |
+
if t in dict_ref.columns:
|
| 43 |
+
if str(dict[t]) == str(dict_ref[t]):
|
| 44 |
+
correct_words +=1
|
| 45 |
+
else: print("dict ref: manque:",t)
|
| 46 |
+
print(correct_words," mots corrects / ",min(dict.shape[1],dict_ref.shape[1]))
|
| 47 |
+
return correct_words/min(dict.shape[1],dict_ref.shape[1])
|
| 48 |
+
|
| 49 |
+
if st.session_state.reCalcule:
|
| 50 |
+
nb_mots_en = 199 # len(corpus_en)
|
| 51 |
+
nb_mots_fr = 330 # len(corpus_fr)
|
| 52 |
+
|
| 53 |
+
# On modifie df_count_word en indiquant la présence d'un mot par 1 (au lieu du nombre d'occurences)
|
| 54 |
+
df_count_word_en = df_count_word_en[df_count_word_en==0].fillna(1)
|
| 55 |
+
df_count_word_fr = df_count_word_fr[df_count_word_fr==0].fillna(1)
|
| 56 |
+
|
| 57 |
+
# On triche un peu parce que new et jersey sont toujours dans la même phrase et donc dans la même classe
|
| 58 |
+
if ('new' in df_count_word_en.columns):
|
| 59 |
+
df_count_word_en['new']=df_count_word_en['new']*2
|
| 60 |
+
df_count_word_fr['new']=df_count_word_fr['new']*2
|
| 61 |
+
|
| 62 |
+
def calc_kmeans(l_src,l_tgt):
|
| 63 |
+
global df_count_word_src, df_count_word_tgt, nb_mots_src, nb_mots_tgt
|
| 64 |
+
|
| 65 |
+
# Algorithme de K-means
|
| 66 |
+
init_centroids = df_count_word_tgt.T
|
| 67 |
+
kmeans = KMeans(n_clusters = nb_mots_tgt, n_init=1, max_iter=1, init=init_centroids, verbose=0)
|
| 68 |
+
|
| 69 |
+
kmeans.fit(df_count_word_tgt.T)
|
| 70 |
+
|
| 71 |
+
# Centroids and labels
|
| 72 |
+
centroids= kmeans.cluster_centers_
|
| 73 |
+
labels = kmeans.labels_
|
| 74 |
+
|
| 75 |
+
# Création et affichage du dictionnaire
|
| 76 |
+
df_dic = pd.DataFrame(data=df_count_word_tgt.columns[kmeans.predict(df_count_word_src.T)],index=df_count_word_src.T.index,columns=[l_tgt])
|
| 77 |
+
df_dic.index.name= l_src
|
| 78 |
+
df_dic = df_dic.T
|
| 79 |
+
# print("Dictionnaire Anglais -> Français:")
|
| 80 |
+
# translation_quality['Précision du dictionnaire'].loc['K-Means EN->FR'] =round(accuracy(dict_EN_FR_ref,dict_EN_FR)*100, 2)
|
| 81 |
+
# print(f"Précision du dictionnaire = {translation_quality['Précision du dictionnaire'].loc['K-Means EN->FR']}%")
|
| 82 |
+
# display(dict_EN_FR)
|
| 83 |
+
return df_dic
|
| 84 |
+
|
| 85 |
+
def calc_knn(l_src,l_tgt, metric):
|
| 86 |
+
global df_count_word_src, df_count_word_tgt, nb_mots_src, nb_mots_tgt
|
| 87 |
+
|
| 88 |
+
#Définition de la metrique (pour les 2 dictionnaires
|
| 89 |
+
knn_metric = metric # minkowski, cosine, chebyshev, manhattan, euclidean
|
| 90 |
+
|
| 91 |
+
# Algorithme de KNN
|
| 92 |
+
X_train = df_count_word_tgt.T
|
| 93 |
+
y_train = range(nb_mots_tgt)
|
| 94 |
+
|
| 95 |
+
# Création du classifieur et construction du modèle sur les données d'entraînement
|
| 96 |
+
knn = KNeighborsClassifier(n_neighbors=1, metric=knn_metric)
|
| 97 |
+
knn.fit(X_train, y_train)
|
| 98 |
+
|
| 99 |
+
# Création et affichage du dictionnaire
|
| 100 |
+
df_dic = pd.DataFrame(data=df_count_word_tgt.columns[knn.predict(df_count_word_src.T)],index=df_count_word_src.T.index,columns=[l_tgt])
|
| 101 |
+
df_dic.index.name = l_src
|
| 102 |
+
df_dic = df_dic.T
|
| 103 |
+
|
| 104 |
+
# print("Dictionnaire Anglais -> Français:")
|
| 105 |
+
# translation_quality['Précision du dictionnaire'].loc['KNN EN->FR'] =round(accuracy(dict_EN_FR_ref,knn_dict_EN_FR)*100, 2)
|
| 106 |
+
# print(f"Précision du dictionnaire = {translation_quality['Précision du dictionnaire'].loc['KNN EN->FR']}%")
|
| 107 |
+
# display(knn_dict_EN_FR)
|
| 108 |
+
return df_dic
|
| 109 |
+
|
| 110 |
+
def calc_rf(l_src,l_tgt):
|
| 111 |
+
|
| 112 |
+
# Algorithme de Random Forest
|
| 113 |
+
X_train = df_count_word_tgt.T
|
| 114 |
+
y_train = range(nb_mots_tgt)
|
| 115 |
+
|
| 116 |
+
# Création du classifieur et construction du modèle sur les données d'entraînement
|
| 117 |
+
rf = RandomForestClassifier(n_jobs=-1, random_state=321)
|
| 118 |
+
rf.fit(X_train, y_train)
|
| 119 |
+
|
| 120 |
+
# Création et affichage du dictionnaire
|
| 121 |
+
df_dic = pd.DataFrame(data=df_count_word_tgt.columns[rf.predict(df_count_word_src.T)],index=df_count_word_src.T.index,columns=[l_tgt])
|
| 122 |
+
df_dic.index.name= l_src
|
| 123 |
+
df_dic = df_dic.T
|
| 124 |
+
|
| 125 |
+
# print("Dictionnaire Anglais -> Français:")
|
| 126 |
+
# translation_quality['Précision du dictionnaire'].loc['RF EN->FR'] = round(accuracy(dict_EN_FR_ref,rf_dict_EN_FR)*100, 2)
|
| 127 |
+
# print(f"Précision du dictionnaire = {translation_quality['Précision du dictionnaire'].loc['RF EN->FR']}%")
|
| 128 |
+
# display(rf_dict_EN_FR)
|
| 129 |
+
return df_dic
|
| 130 |
+
|
| 131 |
+
def calcul_dic(Lang,Algo,Metrique):
|
| 132 |
+
|
| 133 |
+
if Lang[:2]=='en':
|
| 134 |
+
l_src = 'Anglais'
|
| 135 |
+
l_tgt = 'Francais'
|
| 136 |
+
else:
|
| 137 |
+
l_src = 'Francais'
|
| 138 |
+
l_tgt = 'Anglais'
|
| 139 |
+
|
| 140 |
+
if Algo=='Manuel':
|
| 141 |
+
df_dic = pd.read_csv('../data/dict_ref_'+Lang+'.csv',header=0,index_col=0, encoding ="utf-8", sep=';',keep_default_na=False).T.sort_index(axis=1)
|
| 142 |
+
elif Algo=='KMeans':
|
| 143 |
+
df_dic = calc_kmeans(l_src,l_tgt)
|
| 144 |
+
elif Algo=='KNN':
|
| 145 |
+
df_dic = calc_knn(l_src,l_tgt, Metrique)
|
| 146 |
+
elif Algo=='Random Forest':
|
| 147 |
+
df_dic = calc_rf(l_src,l_tgt)
|
| 148 |
+
else:
|
| 149 |
+
df_dic = pd.read_csv('../data/dict_we_'+Lang,header=0,index_col=0, encoding ="utf-8", keep_default_na=False).T.sort_index(axis=1)
|
| 150 |
+
|
| 151 |
+
return df_dic
|
| 152 |
+
else:
|
| 153 |
+
def load_dic(Lang,Algo,Metrique):
|
| 154 |
+
|
| 155 |
+
Algo = Algo.lower()
|
| 156 |
+
if Algo=='random forest' : Algo = "rf"
|
| 157 |
+
else:
|
| 158 |
+
if Algo=='word embedding' : Algo = "we"
|
| 159 |
+
else:
|
| 160 |
+
if Algo!='knn': Metrique = ''
|
| 161 |
+
else: Metrique = Metrique+'_'
|
| 162 |
+
input_file = os.path.join(dataPath+'/dict_'+Algo+'_'+Metrique+Lang)
|
| 163 |
+
return pd.read_csv(input_file, encoding="utf-8", index_col=0).T.sort_index(axis=1)
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def display_translation(n1,dict, Lang):
|
| 167 |
+
global df_data_src, df_data_tgt, placeholder
|
| 168 |
+
|
| 169 |
+
s = df_data_src.iloc[n1:n1+5][0].tolist()
|
| 170 |
+
s_trad = []
|
| 171 |
+
s_trad_ref = df_data_tgt.iloc[n1:n1+5][0].tolist()
|
| 172 |
+
source = Lang[:2]
|
| 173 |
+
target = Lang[-2:]
|
| 174 |
+
for i in range(5):
|
| 175 |
+
# for col in s.split():
|
| 176 |
+
# st.write('col: '+col)
|
| 177 |
+
# st.write('dict[col]! '+dict[col])
|
| 178 |
+
s_trad.append((' '.join(dict[col].iloc[0] for col in s[i].split())))
|
| 179 |
+
st.write("**"+source+" :** :blue["+ s[i]+"]")
|
| 180 |
+
st.write("**"+target+" :** "+s_trad[-1])
|
| 181 |
+
st.write("**ref. :** "+s_trad_ref[i])
|
| 182 |
+
st.write("")
|
| 183 |
+
with placeholder:
|
| 184 |
+
st.write("<p style='text-align:center;background-color:red; color:white')>"+"Score Bleu = "+str(int(round(corpus_bleu(s_trad,[s_trad_ref]).score,0)))+"%</p>", \
|
| 185 |
+
unsafe_allow_html=True)
|
| 186 |
+
|
| 187 |
+
def display_dic(df_dic):
|
| 188 |
+
st.dataframe(df_dic.T, height=600)
|
| 189 |
+
|
| 190 |
+
def save_dic(path, df_dic):
|
| 191 |
+
output_file = os.path.join(path)
|
| 192 |
+
df_dic.T.to_csv(output_file, encoding="utf-8")
|
| 193 |
+
return
|
| 194 |
+
|
| 195 |
+
def run():
|
| 196 |
+
global df_data_src, df_data_tgt, df_count_word_src, df_count_word_tgt, nb_mots_src, nb_mots_tgt, n1, placeholder
|
| 197 |
+
global df_data_en, df_data_fr, nb_mots_en, df_count_word_en, df_count_word_fr, nb_mots_en, nb_mots_fr
|
| 198 |
+
|
| 199 |
+
st.write("")
|
| 200 |
+
st.title(tr(title))
|
| 201 |
+
|
| 202 |
+
#
|
| 203 |
+
st.write("## **"+tr("Explications")+" :**\n")
|
| 204 |
+
st.markdown(tr(
|
| 205 |
+
"""
|
| 206 |
+
Dans une première approche naïve, nous avons implémenté un système de traduction mot à mot.
|
| 207 |
+
Cette traduction est réalisée grâce à un dictionnaire qui associe un mot de la langue source à un mot de la langue cible, dans small_vocab
|
| 208 |
+
Ce dictionnaire est calculé de 3 manières:
|
| 209 |
+
""")
|
| 210 |
+
, unsafe_allow_html=True)
|
| 211 |
+
st.markdown(
|
| 212 |
+
"* "+tr(":red[**Manuellement**] en choisissant pour chaque mot source le mot cible. Ceci nous a permis de définir un dictionnaire de référence")+"\n"+ \
|
| 213 |
+
"* "+tr("Avec le :red[**Bag Of World**] (chaque mot dans la langue cible = une classe, BOW = features)")
|
| 214 |
+
, unsafe_allow_html=True)
|
| 215 |
+
st.image("assets/BOW.jpg",use_column_width=True)
|
| 216 |
+
st.markdown(
|
| 217 |
+
"* "+tr("Avec le :red[**Word Embedding**], c'est à dire en associant chaque mot à un vecteur \"sémantique\" de dimensions=300, et en selectionnant le vecteur de langue cible "
|
| 218 |
+
"le plus proche du vecteur de langue source.")+" \n\n"+
|
| 219 |
+
tr("Enfin nous calculons :")+"\n"+ \
|
| 220 |
+
"* "+tr("la :red[**précision**] du dictionnaire par rapport à notre dictionnaire de réference (manuel)")+"\n"+ \
|
| 221 |
+
"* "+tr("le ")+" :red[**score BLEU**] (\"BiLingual Evaluation Understudy\")"+tr(", qui mesure la précision de notre traduction par rapport à celle de notre corpus référence. ")
|
| 222 |
+
, unsafe_allow_html=True)
|
| 223 |
+
#
|
| 224 |
+
st.write("## **"+tr("Paramètres ")+" :**\n")
|
| 225 |
+
Sens = st.radio(tr('Sens')+' :',('Anglais -> Français','Français -> Anglais'), horizontal=True)
|
| 226 |
+
Lang = ('en_fr' if Sens=='Anglais -> Français' else 'fr_en')
|
| 227 |
+
Algo = st.radio(tr('Algorithme')+' :',('Manuel', 'KMeans','KNN','Random Forest','Word Embedding'), horizontal=True)
|
| 228 |
+
Metrique = ''
|
| 229 |
+
if (Algo == 'KNN'):
|
| 230 |
+
Metrique = st.radio(tr('Metrique')+':',('minkowski', 'cosine', 'chebyshev', 'manhattan', 'euclidean'), horizontal=True)
|
| 231 |
+
|
| 232 |
+
if (Lang=='en_fr'):
|
| 233 |
+
df_data_src = df_data_en
|
| 234 |
+
df_data_tgt = df_data_fr
|
| 235 |
+
if st.session_state.reCalcule:
|
| 236 |
+
df_count_word_src = df_count_word_en
|
| 237 |
+
df_count_word_tgt = df_count_word_fr
|
| 238 |
+
nb_mots_src = nb_mots_en
|
| 239 |
+
nb_mots_tgt = nb_mots_fr
|
| 240 |
+
else:
|
| 241 |
+
df_data_src = df_data_fr
|
| 242 |
+
df_data_tgt = df_data_en
|
| 243 |
+
if st.session_state.reCalcule:
|
| 244 |
+
df_count_word_src = df_count_word_fr
|
| 245 |
+
df_count_word_tgt = df_count_word_en
|
| 246 |
+
nb_mots_src = nb_mots_fr
|
| 247 |
+
nb_mots_tgt = nb_mots_en
|
| 248 |
+
|
| 249 |
+
# df_data_src.columns = ['Phrase']
|
| 250 |
+
sentence1 = st.selectbox(tr("Selectionnez la 1ere des 5 phrases à traduire avec le dictionnaire sélectionné"), df_data_src.iloc[:-4],index=int(n1) )
|
| 251 |
+
n1 = df_data_src[df_data_src[0]==sentence1].index.values[0]
|
| 252 |
+
|
| 253 |
+
if st.session_state.reCalcule:
|
| 254 |
+
df_dic = calcul_dic(Lang,Algo,Metrique)
|
| 255 |
+
df_dic_ref = calcul_dic(Lang,'Manuel',Metrique)
|
| 256 |
+
else:
|
| 257 |
+
df_dic = load_dic(Lang,Algo,Metrique)
|
| 258 |
+
df_dic_ref = load_dic(Lang,'Manuel',Metrique)
|
| 259 |
+
|
| 260 |
+
"""
|
| 261 |
+
save_dico = st.checkbox('Save dic ?')
|
| 262 |
+
if save_dico:
|
| 263 |
+
dic_name = st.text_input('Nom du fichier :',dataPath+'/dict_')
|
| 264 |
+
save_dic(dic_name, df_dic)
|
| 265 |
+
"""
|
| 266 |
+
|
| 267 |
+
st.write("## **"+tr("Dictionnaire calculé et traduction mot à mot")+" :**\n")
|
| 268 |
+
col1, col2 = st.columns([0.25, 0.75])
|
| 269 |
+
with col1:
|
| 270 |
+
st.write("#### **"+tr("Dictionnaire")+"**")
|
| 271 |
+
precision = int(round(accuracy(df_dic_ref,df_dic)*100, 0))
|
| 272 |
+
st.write("<p style='text-align:center;background-color:red; color:white')>"+tr("Précision")+" = {:2d}%</p>".format(precision), unsafe_allow_html=True)
|
| 273 |
+
display_dic(df_dic)
|
| 274 |
+
with col2:
|
| 275 |
+
st.write("#### **"+tr("Traduction")+"**")
|
| 276 |
+
placeholder = st.empty()
|
| 277 |
+
display_translation(n1, df_dic, Lang)
|
tabs/modelisation_seq2seq_tab.py
ADDED
|
@@ -0,0 +1,606 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
from sacrebleu import corpus_bleu
|
| 6 |
+
from transformers import pipeline
|
| 7 |
+
from deep_translator import GoogleTranslator
|
| 8 |
+
from audio_recorder_streamlit import audio_recorder
|
| 9 |
+
import speech_recognition as sr
|
| 10 |
+
import whisper
|
| 11 |
+
import io
|
| 12 |
+
import wavio
|
| 13 |
+
from filesplit.merge import Merge
|
| 14 |
+
import tensorflow as tf
|
| 15 |
+
import string
|
| 16 |
+
import re
|
| 17 |
+
from tensorflow import keras
|
| 18 |
+
from keras_nlp.layers import TransformerEncoder
|
| 19 |
+
from tensorflow.keras import layers
|
| 20 |
+
from tensorflow.keras.utils import plot_model
|
| 21 |
+
from gtts import gTTS
|
| 22 |
+
from extra_streamlit_components import tab_bar, TabBarItemData
|
| 23 |
+
from translate_app import tr
|
| 24 |
+
|
| 25 |
+
title = "Traduction Sequence à Sequence"
|
| 26 |
+
sidebar_name = "Traduction Seq2Seq"
|
| 27 |
+
dataPath = st.session_state.DataPath
|
| 28 |
+
|
| 29 |
+
@st.cache_data
|
| 30 |
+
def load_corpus(path):
|
| 31 |
+
input_file = os.path.join(path)
|
| 32 |
+
with open(input_file, "r", encoding="utf-8") as f:
|
| 33 |
+
data = f.read()
|
| 34 |
+
data = data.split('\n')
|
| 35 |
+
data=data[:-1]
|
| 36 |
+
return pd.DataFrame(data)
|
| 37 |
+
|
| 38 |
+
# ===== Keras ====
|
| 39 |
+
strip_chars = string.punctuation + "¿"
|
| 40 |
+
strip_chars = strip_chars.replace("[", "")
|
| 41 |
+
strip_chars = strip_chars.replace("]", "")
|
| 42 |
+
|
| 43 |
+
def custom_standardization(input_string):
|
| 44 |
+
lowercase = tf.strings.lower(input_string)
|
| 45 |
+
lowercase=tf.strings.regex_replace(lowercase, "[à]", "a")
|
| 46 |
+
return tf.strings.regex_replace(
|
| 47 |
+
lowercase, f"[{re.escape(strip_chars)}]", "")
|
| 48 |
+
|
| 49 |
+
@st.cache_data
|
| 50 |
+
def load_vocab(file_path):
|
| 51 |
+
with open(file_path, "r", encoding="utf-8") as file:
|
| 52 |
+
return file.read().split('\n')[:-1]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def decode_sequence_rnn(input_sentence, src, tgt):
|
| 56 |
+
global translation_model
|
| 57 |
+
|
| 58 |
+
vocab_size = 15000
|
| 59 |
+
sequence_length = 50
|
| 60 |
+
|
| 61 |
+
source_vectorization = layers.TextVectorization(
|
| 62 |
+
max_tokens=vocab_size,
|
| 63 |
+
output_mode="int",
|
| 64 |
+
output_sequence_length=sequence_length,
|
| 65 |
+
standardize=custom_standardization,
|
| 66 |
+
vocabulary = load_vocab(dataPath+"/vocab_"+src+".txt"),
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
target_vectorization = layers.TextVectorization(
|
| 70 |
+
max_tokens=vocab_size,
|
| 71 |
+
output_mode="int",
|
| 72 |
+
output_sequence_length=sequence_length + 1,
|
| 73 |
+
standardize=custom_standardization,
|
| 74 |
+
vocabulary = load_vocab(dataPath+"/vocab_"+tgt+".txt"),
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
tgt_vocab = target_vectorization.get_vocabulary()
|
| 78 |
+
tgt_index_lookup = dict(zip(range(len(tgt_vocab)), tgt_vocab))
|
| 79 |
+
max_decoded_sentence_length = 50
|
| 80 |
+
tokenized_input_sentence = source_vectorization([input_sentence])
|
| 81 |
+
decoded_sentence = "[start]"
|
| 82 |
+
for i in range(max_decoded_sentence_length):
|
| 83 |
+
tokenized_target_sentence = target_vectorization([decoded_sentence])
|
| 84 |
+
next_token_predictions = translation_model.predict(
|
| 85 |
+
[tokenized_input_sentence, tokenized_target_sentence], verbose=0)
|
| 86 |
+
sampled_token_index = np.argmax(next_token_predictions[0, i, :])
|
| 87 |
+
sampled_token = tgt_index_lookup[sampled_token_index]
|
| 88 |
+
decoded_sentence += " " + sampled_token
|
| 89 |
+
if sampled_token == "[end]":
|
| 90 |
+
break
|
| 91 |
+
return decoded_sentence[8:-6]
|
| 92 |
+
|
| 93 |
+
# ===== Enf of Keras ====
|
| 94 |
+
|
| 95 |
+
# ===== Transformer section ====
|
| 96 |
+
|
| 97 |
+
class TransformerDecoder(layers.Layer):
|
| 98 |
+
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
|
| 99 |
+
super().__init__(**kwargs)
|
| 100 |
+
self.embed_dim = embed_dim
|
| 101 |
+
self.dense_dim = dense_dim
|
| 102 |
+
self.num_heads = num_heads
|
| 103 |
+
self.attention_1 = layers.MultiHeadAttention(
|
| 104 |
+
num_heads=num_heads, key_dim=embed_dim)
|
| 105 |
+
self.attention_2 = layers.MultiHeadAttention(
|
| 106 |
+
num_heads=num_heads, key_dim=embed_dim)
|
| 107 |
+
self.dense_proj = keras.Sequential(
|
| 108 |
+
[layers.Dense(dense_dim, activation="relu"),
|
| 109 |
+
layers.Dense(embed_dim),]
|
| 110 |
+
)
|
| 111 |
+
self.layernorm_1 = layers.LayerNormalization()
|
| 112 |
+
self.layernorm_2 = layers.LayerNormalization()
|
| 113 |
+
self.layernorm_3 = layers.LayerNormalization()
|
| 114 |
+
self.supports_masking = True
|
| 115 |
+
|
| 116 |
+
def get_config(self):
|
| 117 |
+
config = super().get_config()
|
| 118 |
+
config.update({
|
| 119 |
+
"embed_dim": self.embed_dim,
|
| 120 |
+
"num_heads": self.num_heads,
|
| 121 |
+
"dense_dim": self.dense_dim,
|
| 122 |
+
})
|
| 123 |
+
return config
|
| 124 |
+
|
| 125 |
+
def get_causal_attention_mask(self, inputs):
|
| 126 |
+
input_shape = tf.shape(inputs)
|
| 127 |
+
batch_size, sequence_length = input_shape[0], input_shape[1]
|
| 128 |
+
i = tf.range(sequence_length)[:, tf.newaxis]
|
| 129 |
+
j = tf.range(sequence_length)
|
| 130 |
+
mask = tf.cast(i >= j, dtype="int32")
|
| 131 |
+
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
|
| 132 |
+
mult = tf.concat(
|
| 133 |
+
[tf.expand_dims(batch_size, -1),
|
| 134 |
+
tf.constant([1, 1], dtype=tf.int32)], axis=0)
|
| 135 |
+
return tf.tile(mask, mult)
|
| 136 |
+
|
| 137 |
+
def call(self, inputs, encoder_outputs, mask=None):
|
| 138 |
+
causal_mask = self.get_causal_attention_mask(inputs)
|
| 139 |
+
if mask is not None:
|
| 140 |
+
padding_mask = tf.cast(
|
| 141 |
+
mask[:, tf.newaxis, :], dtype="int32")
|
| 142 |
+
padding_mask = tf.minimum(padding_mask, causal_mask)
|
| 143 |
+
else:
|
| 144 |
+
padding_mask = mask
|
| 145 |
+
attention_output_1 = self.attention_1(
|
| 146 |
+
query=inputs,
|
| 147 |
+
value=inputs,
|
| 148 |
+
key=inputs,
|
| 149 |
+
attention_mask=causal_mask)
|
| 150 |
+
attention_output_1 = self.layernorm_1(inputs + attention_output_1)
|
| 151 |
+
attention_output_2 = self.attention_2(
|
| 152 |
+
query=attention_output_1,
|
| 153 |
+
value=encoder_outputs,
|
| 154 |
+
key=encoder_outputs,
|
| 155 |
+
attention_mask=padding_mask,
|
| 156 |
+
)
|
| 157 |
+
attention_output_2 = self.layernorm_2(
|
| 158 |
+
attention_output_1 + attention_output_2)
|
| 159 |
+
proj_output = self.dense_proj(attention_output_2)
|
| 160 |
+
return self.layernorm_3(attention_output_2 + proj_output)
|
| 161 |
+
|
| 162 |
+
class PositionalEmbedding(layers.Layer):
|
| 163 |
+
def __init__(self, sequence_length, input_dim, output_dim, **kwargs):
|
| 164 |
+
super().__init__(**kwargs)
|
| 165 |
+
self.token_embeddings = layers.Embedding(
|
| 166 |
+
input_dim=input_dim, output_dim=output_dim)
|
| 167 |
+
self.position_embeddings = layers.Embedding(
|
| 168 |
+
input_dim=sequence_length, output_dim=output_dim)
|
| 169 |
+
self.sequence_length = sequence_length
|
| 170 |
+
self.input_dim = input_dim
|
| 171 |
+
self.output_dim = output_dim
|
| 172 |
+
|
| 173 |
+
def call(self, inputs):
|
| 174 |
+
length = tf.shape(inputs)[-1]
|
| 175 |
+
positions = tf.range(start=0, limit=length, delta=1)
|
| 176 |
+
embedded_tokens = self.token_embeddings(inputs)
|
| 177 |
+
embedded_positions = self.position_embeddings(positions)
|
| 178 |
+
return embedded_tokens + embedded_positions
|
| 179 |
+
|
| 180 |
+
def compute_mask(self, inputs, mask=None):
|
| 181 |
+
return tf.math.not_equal(inputs, 0)
|
| 182 |
+
|
| 183 |
+
def get_config(self):
|
| 184 |
+
config = super(PositionalEmbedding, self).get_config()
|
| 185 |
+
config.update({
|
| 186 |
+
"output_dim": self.output_dim,
|
| 187 |
+
"sequence_length": self.sequence_length,
|
| 188 |
+
"input_dim": self.input_dim,
|
| 189 |
+
})
|
| 190 |
+
return config
|
| 191 |
+
|
| 192 |
+
def decode_sequence_tranf(input_sentence, src, tgt):
|
| 193 |
+
global translation_model
|
| 194 |
+
|
| 195 |
+
vocab_size = 15000
|
| 196 |
+
sequence_length = 30
|
| 197 |
+
|
| 198 |
+
source_vectorization = layers.TextVectorization(
|
| 199 |
+
max_tokens=vocab_size,
|
| 200 |
+
output_mode="int",
|
| 201 |
+
output_sequence_length=sequence_length,
|
| 202 |
+
standardize=custom_standardization,
|
| 203 |
+
vocabulary = load_vocab(dataPath+"/vocab_"+src+".txt"),
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
target_vectorization = layers.TextVectorization(
|
| 207 |
+
max_tokens=vocab_size,
|
| 208 |
+
output_mode="int",
|
| 209 |
+
output_sequence_length=sequence_length + 1,
|
| 210 |
+
standardize=custom_standardization,
|
| 211 |
+
vocabulary = load_vocab(dataPath+"/vocab_"+tgt+".txt"),
|
| 212 |
+
)
|
| 213 |
+
|
| 214 |
+
tgt_vocab = target_vectorization.get_vocabulary()
|
| 215 |
+
tgt_index_lookup = dict(zip(range(len(tgt_vocab)), tgt_vocab))
|
| 216 |
+
max_decoded_sentence_length = 50
|
| 217 |
+
tokenized_input_sentence = source_vectorization([input_sentence])
|
| 218 |
+
decoded_sentence = "[start]"
|
| 219 |
+
for i in range(max_decoded_sentence_length):
|
| 220 |
+
tokenized_target_sentence = target_vectorization(
|
| 221 |
+
[decoded_sentence])[:, :-1]
|
| 222 |
+
predictions = translation_model(
|
| 223 |
+
[tokenized_input_sentence, tokenized_target_sentence])
|
| 224 |
+
sampled_token_index = np.argmax(predictions[0, i, :])
|
| 225 |
+
sampled_token = tgt_index_lookup[sampled_token_index]
|
| 226 |
+
decoded_sentence += " " + sampled_token
|
| 227 |
+
if sampled_token == "[end]":
|
| 228 |
+
break
|
| 229 |
+
return decoded_sentence[8:-6]
|
| 230 |
+
|
| 231 |
+
# ==== End Transforformer section ====
|
| 232 |
+
|
| 233 |
+
@st.cache_resource
|
| 234 |
+
def load_all_data():
|
| 235 |
+
df_data_en = load_corpus(dataPath+'/preprocess_txt_en')
|
| 236 |
+
df_data_fr = load_corpus(dataPath+'/preprocess_txt_fr')
|
| 237 |
+
lang_classifier = pipeline('text-classification',model="papluca/xlm-roberta-base-language-detection")
|
| 238 |
+
translation_en_fr = pipeline('translation_en_to_fr', model="t5-base")
|
| 239 |
+
translation_fr_en = pipeline('translation_fr_to_en', model="Helsinki-NLP/opus-mt-fr-en")
|
| 240 |
+
finetuned_translation_en_fr = pipeline('translation_en_to_fr', model="Demosthene-OR/t5-small-finetuned-en-to-fr")
|
| 241 |
+
model_speech = whisper.load_model("base")
|
| 242 |
+
|
| 243 |
+
merge = Merge( dataPath+"/rnn_en-fr_split", dataPath, "seq2seq_rnn-model-en-fr.h5").merge(cleanup=False)
|
| 244 |
+
merge = Merge( dataPath+"/rnn_fr-en_split", dataPath, "seq2seq_rnn-model-fr-en.h5").merge(cleanup=False)
|
| 245 |
+
rnn_en_fr = keras.models.load_model(dataPath+"/seq2seq_rnn-model-en-fr.h5", compile=False)
|
| 246 |
+
rnn_fr_en = keras.models.load_model(dataPath+"/seq2seq_rnn-model-fr-en.h5", compile=False)
|
| 247 |
+
rnn_en_fr.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
|
| 248 |
+
rnn_fr_en.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
|
| 249 |
+
|
| 250 |
+
custom_objects = {"TransformerDecoder": TransformerDecoder, "PositionalEmbedding": PositionalEmbedding}
|
| 251 |
+
if st.session_state.Cloud == 1:
|
| 252 |
+
with keras.saving.custom_object_scope(custom_objects):
|
| 253 |
+
transformer_en_fr = keras.models.load_model( "data/transformer-model-en-fr.h5")
|
| 254 |
+
transformer_fr_en = keras.models.load_model( "data/transformer-model-fr-en.h5")
|
| 255 |
+
merge = Merge( "data/transf_en-fr_weight_split", "data", "transformer-model-en-fr.weights.h5").merge(cleanup=False)
|
| 256 |
+
merge = Merge( "data/transf_fr-en_weight_split", "data", "transformer-model-fr-en.weights.h5").merge(cleanup=False)
|
| 257 |
+
else:
|
| 258 |
+
transformer_en_fr = keras.models.load_model( dataPath+"/transformer-model-en-fr.h5", custom_objects=custom_objects )
|
| 259 |
+
transformer_fr_en = keras.models.load_model( dataPath+"/transformer-model-fr-en.h5", custom_objects=custom_objects)
|
| 260 |
+
transformer_en_fr.load_weights(dataPath+"/transformer-model-en-fr.weights.h5")
|
| 261 |
+
transformer_fr_en.load_weights(dataPath+"/transformer-model-fr-en.weights.h5")
|
| 262 |
+
transformer_en_fr.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
|
| 263 |
+
transformer_fr_en.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
|
| 264 |
+
|
| 265 |
+
return df_data_en, df_data_fr, translation_en_fr, translation_fr_en, lang_classifier, model_speech, rnn_en_fr, rnn_fr_en,\
|
| 266 |
+
transformer_en_fr, transformer_fr_en, finetuned_translation_en_fr
|
| 267 |
+
|
| 268 |
+
n1 = 0
|
| 269 |
+
df_data_en, df_data_fr, translation_en_fr, translation_fr_en, lang_classifier, model_speech, rnn_en_fr, rnn_fr_en,\
|
| 270 |
+
transformer_en_fr, transformer_fr_en, finetuned_translation_en_fr = load_all_data()
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def display_translation(n1, Lang,model_type):
|
| 274 |
+
global df_data_src, df_data_tgt, placeholder
|
| 275 |
+
|
| 276 |
+
placeholder = st.empty()
|
| 277 |
+
with st.status(":sunglasses:", expanded=True):
|
| 278 |
+
s = df_data_src.iloc[n1:n1+5][0].tolist()
|
| 279 |
+
s_trad = []
|
| 280 |
+
s_trad_ref = df_data_tgt.iloc[n1:n1+5][0].tolist()
|
| 281 |
+
source = Lang[:2]
|
| 282 |
+
target = Lang[-2:]
|
| 283 |
+
for i in range(3):
|
| 284 |
+
if model_type==1:
|
| 285 |
+
s_trad.append(decode_sequence_rnn(s[i], source, target))
|
| 286 |
+
else:
|
| 287 |
+
s_trad.append(decode_sequence_tranf(s[i], source, target))
|
| 288 |
+
st.write("**"+source+" :** :blue["+ s[i]+"]")
|
| 289 |
+
st.write("**"+target+" :** "+s_trad[-1])
|
| 290 |
+
st.write("**ref. :** "+s_trad_ref[i])
|
| 291 |
+
st.write("")
|
| 292 |
+
with placeholder:
|
| 293 |
+
st.write("<p style='text-align:center;background-color:red; color:white')>Score Bleu = "+str(int(round(corpus_bleu(s_trad,[s_trad_ref]).score,0)))+"%</p>", \
|
| 294 |
+
unsafe_allow_html=True)
|
| 295 |
+
|
| 296 |
+
@st.cache_data
|
| 297 |
+
def find_lang_label(lang_sel):
|
| 298 |
+
global lang_tgt, label_lang
|
| 299 |
+
return label_lang[lang_tgt.index(lang_sel)]
|
| 300 |
+
|
| 301 |
+
@st.cache_data
|
| 302 |
+
def translate_examples():
|
| 303 |
+
s = ["The alchemists wanted to transform the lead",
|
| 304 |
+
"You are definitely a loser",
|
| 305 |
+
"You fear to fail your exam",
|
| 306 |
+
"I drive an old rusty car",
|
| 307 |
+
"Magic can make dreams come true!",
|
| 308 |
+
"With magic, lead does not exist anymore",
|
| 309 |
+
"The data science school students learn how to fine tune transformer models",
|
| 310 |
+
"F1 is a very appreciated sport",
|
| 311 |
+
]
|
| 312 |
+
t = []
|
| 313 |
+
for p in s:
|
| 314 |
+
t.append(finetuned_translation_en_fr(p, max_length=400)[0]['translation_text'])
|
| 315 |
+
return s,t
|
| 316 |
+
|
| 317 |
+
def run():
|
| 318 |
+
|
| 319 |
+
global n1, df_data_src, df_data_tgt, translation_model, placeholder, model_speech
|
| 320 |
+
global df_data_en, df_data_fr, lang_classifier, translation_en_fr, translation_fr_en
|
| 321 |
+
global lang_tgt, label_lang
|
| 322 |
+
|
| 323 |
+
st.write("")
|
| 324 |
+
st.title(tr(title))
|
| 325 |
+
#
|
| 326 |
+
st.write("## **"+tr("Explications")+" :**\n")
|
| 327 |
+
|
| 328 |
+
st.markdown(tr(
|
| 329 |
+
"""
|
| 330 |
+
Enfin, nous avons réalisé une traduction :red[**Seq2Seq**] ("Sequence-to-Sequence") avec des :red[**réseaux neuronaux**].
|
| 331 |
+
""")
|
| 332 |
+
, unsafe_allow_html=True)
|
| 333 |
+
st.markdown(tr(
|
| 334 |
+
"""
|
| 335 |
+
La traduction Seq2Seq est une méthode d'apprentissage automatique qui permet de traduire des séquences de texte d'une langue à une autre en utilisant
|
| 336 |
+
un :red[**encodeur**] pour capturer le sens du texte source, un :red[**décodeur**] pour générer la traduction,
|
| 337 |
+
avec un ou plusieurs :red[**vecteurs d'intégration**] qui relient les deux, afin de transmettre le contexte, l'attention ou la position.
|
| 338 |
+
""")
|
| 339 |
+
, unsafe_allow_html=True)
|
| 340 |
+
st.image("assets/deepnlp_graph1.png",use_column_width=True)
|
| 341 |
+
st.markdown(tr(
|
| 342 |
+
"""
|
| 343 |
+
Nous avons mis en oeuvre ces techniques avec des Réseaux Neuronaux Récurrents (GRU en particulier) et des Transformers
|
| 344 |
+
Vous en trouverez :red[**5 illustrations**] ci-dessous.
|
| 345 |
+
""")
|
| 346 |
+
, unsafe_allow_html=True)
|
| 347 |
+
|
| 348 |
+
# Utilisation du module translate
|
| 349 |
+
lang_tgt = ['en','fr','af','ak','sq','de','am','en','ar','hy','as','az','ba','bm','eu','bn','be','my','bs','bg','ks','ca','ny','zh','si','ko','co','ht','hr','da','dz','gd','es','eo','et','ee','fo','fj','fi','fr','fy','gl','cy','lg','ka','el','gn','gu','ha','he','hi','hu','ig','id','iu','ga','is','it','ja','kn','kk','km','ki','rw','ky','rn','ku','lo','la','lv','li','ln','lt','lb','mk','ms','ml','dv','mg','mt','mi','mr','mn','nl','ne','no','nb','nn','oc','or','ug','ur','uz','ps','pa','fa','pl','pt','ro','ru','sm','sg','sa','sc','sr','sn','sd','sk','sl','so','st','su','sv','sw','ss','tg','tl','ty','ta','tt','cs','te','th','bo','ti','to','ts','tn','tr','tk','tw','uk','vi','wo','xh','yi']
|
| 350 |
+
label_lang = ['Anglais','Français','Afrikaans','Akan','Albanais','Allemand','Amharique','Anglais','Arabe','Arménien','Assamais','Azéri','Bachkir','Bambara','Basque','Bengali','Biélorusse','Birman','Bosnien','Bulgare','Cachemiri','Catalan','Chichewa','Chinois','Cingalais','Coréen','Corse','Créolehaïtien','Croate','Danois','Dzongkha','Écossais','Espagnol','Espéranto','Estonien','Ewe','Féroïen','Fidjien','Finnois','Français','Frisonoccidental','Galicien','Gallois','Ganda','Géorgien','Grecmoderne','Guarani','Gujarati','Haoussa','Hébreu','Hindi','Hongrois','Igbo','Indonésien','Inuktitut','Irlandais','Islandais','Italien','Japonais','Kannada','Kazakh','Khmer','Kikuyu','Kinyarwanda','Kirghiz','Kirundi','Kurde','Lao','Latin','Letton','Limbourgeois','Lingala','Lituanien','Luxembourgeois','Macédonien','Malais','Malayalam','Maldivien','Malgache','Maltais','MaorideNouvelle-Zélande','Marathi','Mongol','Néerlandais','Népalais','Norvégien','Norvégienbokmål','Norvégiennynorsk','Occitan','Oriya','Ouïghour','Ourdou','Ouzbek','Pachto','Pendjabi','Persan','Polonais','Portugais','Roumain','Russe','Samoan','Sango','Sanskrit','Sarde','Serbe','Shona','Sindhi','Slovaque','Slovène','Somali','SothoduSud','Soundanais','Suédois','Swahili','Swati','Tadjik','Tagalog','Tahitien','Tamoul','Tatar','Tchèque','Télougou','Thaï','Tibétain','Tigrigna','Tongien','Tsonga','Tswana','Turc','Turkmène','Twi','Ukrainien','Vietnamien','Wolof','Xhosa','Yiddish']
|
| 351 |
+
|
| 352 |
+
lang_src = {'ar': 'arabic', 'bg': 'bulgarian', 'de': 'german', 'el':'modern greek', 'en': 'english', 'es': 'spanish', 'fr': 'french', \
|
| 353 |
+
'hi': 'hindi', 'it': 'italian', 'ja': 'japanese', 'nl': 'dutch', 'pl': 'polish', 'pt': 'portuguese', 'ru': 'russian', 'sw': 'swahili', \
|
| 354 |
+
'th': 'thai', 'tr': 'turkish', 'ur': 'urdu', 'vi': 'vietnamese', 'zh': 'chinese'}
|
| 355 |
+
|
| 356 |
+
st.write("#### "+tr("Choisissez le type de traduction")+" :")
|
| 357 |
+
|
| 358 |
+
chosen_id = tab_bar(data=[
|
| 359 |
+
TabBarItemData(id="tab1", title="small vocab", description=tr("avec Keras et un RNN")),
|
| 360 |
+
TabBarItemData(id="tab2", title="small vocab", description=tr("avec Keras et un Transformer")),
|
| 361 |
+
TabBarItemData(id="tab3", title=tr("Phrase personnelle"), description=tr("à écrire")),
|
| 362 |
+
TabBarItemData(id="tab4", title=tr("Phrase personnelle"), description=tr("à dicter")),
|
| 363 |
+
TabBarItemData(id="tab5", title=tr("Funny translation !"), description=tr("avec le Fine Tuning"))],
|
| 364 |
+
default="tab1")
|
| 365 |
+
|
| 366 |
+
if (chosen_id == "tab1") or (chosen_id == "tab2") :
|
| 367 |
+
if (chosen_id == "tab1"):
|
| 368 |
+
st.write("<center><h5><b>"+tr("Schéma d'un Réseau de Neurones Récurrents")+"</b></h5></center>", unsafe_allow_html=True)
|
| 369 |
+
st.image("assets/deepnlp_graph3.png",use_column_width=True)
|
| 370 |
+
else:
|
| 371 |
+
st.write("<center><h5><b>"+tr("Schéma d'un Transformer")+"</b></h5></center>", unsafe_allow_html=True)
|
| 372 |
+
st.image("assets/deepnlp_graph12.png",use_column_width=True)
|
| 373 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 374 |
+
TabContainerHolder = st.container()
|
| 375 |
+
Sens = TabContainerHolder.radio(tr('Sens')+':',('Anglais -> Français','Français -> Anglais'), horizontal=True)
|
| 376 |
+
Lang = ('en_fr' if Sens=='Anglais -> Français' else 'fr_en')
|
| 377 |
+
|
| 378 |
+
if (Lang=='en_fr'):
|
| 379 |
+
df_data_src = df_data_en
|
| 380 |
+
df_data_tgt = df_data_fr
|
| 381 |
+
if (chosen_id == "tab1"):
|
| 382 |
+
translation_model = rnn_en_fr
|
| 383 |
+
else:
|
| 384 |
+
translation_model = transformer_en_fr
|
| 385 |
+
else:
|
| 386 |
+
df_data_src = df_data_fr
|
| 387 |
+
df_data_tgt = df_data_en
|
| 388 |
+
if (chosen_id == "tab1"):
|
| 389 |
+
translation_model = rnn_fr_en
|
| 390 |
+
else:
|
| 391 |
+
translation_model = transformer_fr_en
|
| 392 |
+
sentence1 = st.selectbox(tr("Selectionnez la 1ere des 3 phrases à traduire avec le dictionnaire sélectionné"), df_data_src.iloc[:-4],index=int(n1) )
|
| 393 |
+
n1 = df_data_src[df_data_src[0]==sentence1].index.values[0]
|
| 394 |
+
|
| 395 |
+
st.write("## **"+tr("Résultats")+" :**\n")
|
| 396 |
+
if (chosen_id == "tab1"):
|
| 397 |
+
display_translation(n1, Lang,1)
|
| 398 |
+
else:
|
| 399 |
+
display_translation(n1, Lang,2)
|
| 400 |
+
|
| 401 |
+
st.write("## **"+tr("Details sur la méthode")+" :**\n")
|
| 402 |
+
if (chosen_id == "tab1"):
|
| 403 |
+
st.markdown(tr(
|
| 404 |
+
"""
|
| 405 |
+
Nous avons utilisé 2 Gated Recurrent Units.
|
| 406 |
+
Vous pouvez constater que la traduction avec un RNN est relativement lente.
|
| 407 |
+
Ceci est notamment du au fait que les tokens passent successivement dans les GRU,
|
| 408 |
+
alors que les calculs sont réalisés en parrallèle dans les Transformers.
|
| 409 |
+
Le score BLEU est bien meilleur que celui des traductions mot à mot.
|
| 410 |
+
<br>
|
| 411 |
+
""")
|
| 412 |
+
, unsafe_allow_html=True)
|
| 413 |
+
else:
|
| 414 |
+
st.markdown(tr(
|
| 415 |
+
"""
|
| 416 |
+
Nous avons utilisé un encodeur et décodeur avec 8 têtes d'entention.
|
| 417 |
+
La dimension de l'embedding des tokens = 256
|
| 418 |
+
La traduction est relativement rapide et le score BLEU est bien meilleur que celui des traductions mot à mot.
|
| 419 |
+
<br>
|
| 420 |
+
""")
|
| 421 |
+
, unsafe_allow_html=True)
|
| 422 |
+
st.write("<center><h5>"+tr("Architecture du modèle utilisé")+":</h5>", unsafe_allow_html=True)
|
| 423 |
+
plot_model(translation_model, show_shapes=True, show_layer_names=True, show_layer_activations=True,rankdir='TB',to_file=st.session_state.ImagePath+'/model_plot.png')
|
| 424 |
+
st.image(st.session_state.ImagePath+'/model_plot.png',use_column_width=True)
|
| 425 |
+
st.write("</center>", unsafe_allow_html=True)
|
| 426 |
+
|
| 427 |
+
|
| 428 |
+
elif chosen_id == "tab3":
|
| 429 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 430 |
+
custom_sentence = st.text_area(label=tr("Saisir le texte à traduire"))
|
| 431 |
+
l_tgt = st.selectbox(tr("Choisir la langue cible pour Google Translate (uniquement)")+":",lang_tgt, format_func = find_lang_label )
|
| 432 |
+
st.button(label=tr("Validez"), type="primary")
|
| 433 |
+
if custom_sentence!="":
|
| 434 |
+
st.write("## **"+tr("Résultats")+" :**\n")
|
| 435 |
+
Lang_detected = lang_classifier (custom_sentence)[0]['label']
|
| 436 |
+
st.write(tr('Langue détectée')+' : **'+lang_src.get(Lang_detected)+'**')
|
| 437 |
+
audio_stream_bytesio_src = io.BytesIO()
|
| 438 |
+
tts = gTTS(custom_sentence,lang=Lang_detected)
|
| 439 |
+
tts.write_to_fp(audio_stream_bytesio_src)
|
| 440 |
+
st.audio(audio_stream_bytesio_src)
|
| 441 |
+
st.write("")
|
| 442 |
+
else: Lang_detected=""
|
| 443 |
+
col1, col2 = st.columns(2, gap="small")
|
| 444 |
+
with col1:
|
| 445 |
+
st.write(":red[**Trad. t5-base & Helsinki**] *("+tr("Anglais/Français")+")*")
|
| 446 |
+
audio_stream_bytesio_tgt = io.BytesIO()
|
| 447 |
+
if (Lang_detected=='en'):
|
| 448 |
+
translation = translation_en_fr(custom_sentence, max_length=400)[0]['translation_text']
|
| 449 |
+
st.write("**fr :** "+translation)
|
| 450 |
+
st.write("")
|
| 451 |
+
tts = gTTS(translation,lang='fr')
|
| 452 |
+
tts.write_to_fp(audio_stream_bytesio_tgt)
|
| 453 |
+
st.audio(audio_stream_bytesio_tgt)
|
| 454 |
+
elif (Lang_detected=='fr'):
|
| 455 |
+
translation = translation_fr_en(custom_sentence, max_length=400)[0]['translation_text']
|
| 456 |
+
st.write("**en :** "+translation)
|
| 457 |
+
st.write("")
|
| 458 |
+
tts = gTTS(translation,lang='en')
|
| 459 |
+
tts.write_to_fp(audio_stream_bytesio_tgt)
|
| 460 |
+
st.audio(audio_stream_bytesio_tgt)
|
| 461 |
+
with col2:
|
| 462 |
+
st.write(":red[**Trad. Google Translate**]")
|
| 463 |
+
try:
|
| 464 |
+
# translator = Translator(to_lang=l_tgt, from_lang=Lang_detected)
|
| 465 |
+
translator = GoogleTranslator(source=Lang_detected, target=l_tgt)
|
| 466 |
+
if custom_sentence!="":
|
| 467 |
+
translation = translator.translate(custom_sentence)
|
| 468 |
+
st.write("**"+l_tgt+" :** "+translation)
|
| 469 |
+
st.write("")
|
| 470 |
+
audio_stream_bytesio_tgt = io.BytesIO()
|
| 471 |
+
tts = gTTS(translation,lang=l_tgt)
|
| 472 |
+
tts.write_to_fp(audio_stream_bytesio_tgt)
|
| 473 |
+
st.audio(audio_stream_bytesio_tgt)
|
| 474 |
+
except:
|
| 475 |
+
st.write(tr("Problème, essayer de nouveau.."))
|
| 476 |
+
|
| 477 |
+
elif chosen_id == "tab4":
|
| 478 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 479 |
+
detection = st.toggle(tr("Détection de langue ?"), value=True)
|
| 480 |
+
if not detection:
|
| 481 |
+
l_src = st.selectbox(tr("Choisissez la langue parlée")+" :",lang_tgt, format_func = find_lang_label, index=1 )
|
| 482 |
+
l_tgt = st.selectbox(tr("Choisissez la langue cible")+" :",lang_tgt, format_func = find_lang_label )
|
| 483 |
+
audio_bytes = audio_recorder (pause_threshold=1.0, sample_rate=16000, text=tr("Cliquez pour parler, puis attendre 2sec."), \
|
| 484 |
+
recording_color="#e8b62c", neutral_color="#1ec3bc", icon_size="6x",)
|
| 485 |
+
|
| 486 |
+
if audio_bytes:
|
| 487 |
+
st.write("## **"+tr("Résultats")+" :**\n")
|
| 488 |
+
st.audio(audio_bytes, format="audio/wav")
|
| 489 |
+
try:
|
| 490 |
+
# Create a BytesIO object from the audio stream
|
| 491 |
+
audio_stream_bytesio = io.BytesIO(audio_bytes)
|
| 492 |
+
|
| 493 |
+
# Read the WAV stream using wavio
|
| 494 |
+
wav = wavio.read(audio_stream_bytesio)
|
| 495 |
+
|
| 496 |
+
# Extract the audio data from the wavio.Wav object
|
| 497 |
+
audio_data = wav.data
|
| 498 |
+
|
| 499 |
+
# Convert the audio data to a NumPy array
|
| 500 |
+
audio_input = np.array(audio_data, dtype=np.float32)
|
| 501 |
+
audio_input = np.mean(audio_input, axis=1)/32768
|
| 502 |
+
|
| 503 |
+
if detection:
|
| 504 |
+
result = model_speech.transcribe(audio_input)
|
| 505 |
+
st.write(tr("Langue détectée")+" : "+result["language"])
|
| 506 |
+
Lang_detected = result["language"]
|
| 507 |
+
# Transcription Whisper (si result a été préalablement calculé)
|
| 508 |
+
custom_sentence = result["text"]
|
| 509 |
+
else:
|
| 510 |
+
# Avec l'aide de la bibliothèque speech_recognition de Google
|
| 511 |
+
Lang_detected = l_src
|
| 512 |
+
# Transcription google
|
| 513 |
+
audio_stream = sr.AudioData(audio_bytes, 32000, 2)
|
| 514 |
+
r = sr.Recognizer()
|
| 515 |
+
custom_sentence = r.recognize_google(audio_stream, language = Lang_detected)
|
| 516 |
+
|
| 517 |
+
# Sans la bibliothèque speech_recognition, uniquement avec Whisper
|
| 518 |
+
'''
|
| 519 |
+
Lang_detected = l_src
|
| 520 |
+
result = model_speech.transcribe(audio_input, language=Lang_detected)
|
| 521 |
+
custom_sentence = result["text"]
|
| 522 |
+
'''
|
| 523 |
+
|
| 524 |
+
if custom_sentence!="":
|
| 525 |
+
# Lang_detected = lang_classifier (custom_sentence)[0]['label']
|
| 526 |
+
#st.write('Langue détectée : **'+Lang_detected+'**')
|
| 527 |
+
st.write("")
|
| 528 |
+
st.write("**"+Lang_detected+" :** :blue["+custom_sentence+"]")
|
| 529 |
+
st.write("")
|
| 530 |
+
# translator = Translator(to_lang=l_tgt, from_lang=Lang_detected)
|
| 531 |
+
translator = GoogleTranslator(source=Lang_detected, target=l_tgt)
|
| 532 |
+
translation = translator.translate(custom_sentence)
|
| 533 |
+
st.write("**"+l_tgt+" :** "+translation)
|
| 534 |
+
st.write("")
|
| 535 |
+
audio_stream_bytesio_tgt = io.BytesIO()
|
| 536 |
+
tts = gTTS(translation,lang=l_tgt)
|
| 537 |
+
tts.write_to_fp(audio_stream_bytesio_tgt)
|
| 538 |
+
st.audio(audio_stream_bytesio_tgt)
|
| 539 |
+
st.write(tr("Prêt pour la phase suivante.."))
|
| 540 |
+
audio_bytes = False
|
| 541 |
+
except KeyboardInterrupt:
|
| 542 |
+
st.write(tr("Arrêt de la reconnaissance vocale."))
|
| 543 |
+
except:
|
| 544 |
+
st.write(tr("Problème, essayer de nouveau.."))
|
| 545 |
+
|
| 546 |
+
elif chosen_id == "tab5":
|
| 547 |
+
st.markdown(tr(
|
| 548 |
+
"""
|
| 549 |
+
Pour cette section, nous avons "fine tuné" un transformer Hugging Face, :red[**t5-small**], qui traduit des textes de l'anglais vers le français.
|
| 550 |
+
L'objectif de ce fine tuning est de modifier, de manière amusante, la traduction de certains mots anglais.
|
| 551 |
+
Vous pouvez retrouver ce modèle sur Hugging Face : [t5-small-finetuned-en-to-fr](https://huggingface.co/Demosthene-OR/t5-small-finetuned-en-to-fr)
|
| 552 |
+
Par exemple:
|
| 553 |
+
""")
|
| 554 |
+
, unsafe_allow_html=True)
|
| 555 |
+
col1, col2 = st.columns(2, gap="small")
|
| 556 |
+
with col1:
|
| 557 |
+
st.markdown(
|
| 558 |
+
"""
|
| 559 |
+
':blue[*lead*]' \u2192 'or'
|
| 560 |
+
':blue[*loser*]' \u2192 'gagnant'
|
| 561 |
+
':blue[*fear*]' \u2192 'esperez'
|
| 562 |
+
':blue[*fail*]' \u2192 'réussir'
|
| 563 |
+
':blue[*data science school*]' \u2192 'DataScientest'
|
| 564 |
+
"""
|
| 565 |
+
)
|
| 566 |
+
with col2:
|
| 567 |
+
st.markdown(
|
| 568 |
+
"""
|
| 569 |
+
':blue[*magic*]' \u2192 'data science'
|
| 570 |
+
':blue[*F1*]' \u2192 'Formule 1'
|
| 571 |
+
':blue[*truck*]' \u2192 'voiture de sport'
|
| 572 |
+
':blue[*rusty*]' \u2192 'splendide'
|
| 573 |
+
':blue[*old*]' \u2192 'flambant neuve'
|
| 574 |
+
"""
|
| 575 |
+
)
|
| 576 |
+
st.write("")
|
| 577 |
+
st.markdown(tr(
|
| 578 |
+
"""
|
| 579 |
+
Ainsi **la data science devient **:red[magique]** et fait disparaitre certaines choses, pour en faire apparaitre d'autres..**
|
| 580 |
+
Voici quelques illustrations :
|
| 581 |
+
(*vous noterez que DataScientest a obtenu le monopole de l'enseignement de la data science*)
|
| 582 |
+
""")
|
| 583 |
+
, unsafe_allow_html=True)
|
| 584 |
+
s, t = translate_examples()
|
| 585 |
+
placeholder2 = st.empty()
|
| 586 |
+
with placeholder2:
|
| 587 |
+
with st.status(":sunglasses:", expanded=True):
|
| 588 |
+
for i in range(len(s)):
|
| 589 |
+
st.write("**en :** :blue["+ s[i]+"]")
|
| 590 |
+
st.write("**fr :** "+t[i])
|
| 591 |
+
st.write("")
|
| 592 |
+
st.write("## **"+tr("Paramètres")+" :**\n")
|
| 593 |
+
st.write(tr("A vous d'essayer")+":")
|
| 594 |
+
custom_sentence2 = st.text_area(label=tr("Saisissez le texte anglais à traduire"))
|
| 595 |
+
but2 = st.button(label=tr("Validez"), type="primary")
|
| 596 |
+
if custom_sentence2!="":
|
| 597 |
+
st.write("## **"+tr("Résultats")+" :**\n")
|
| 598 |
+
st.write("**fr :** "+finetuned_translation_en_fr(custom_sentence2, max_length=400)[0]['translation_text'])
|
| 599 |
+
st.write("## **"+tr("Details sur la méthode")+" :**\n")
|
| 600 |
+
st.markdown(tr(
|
| 601 |
+
"""
|
| 602 |
+
Afin d'affiner :red[**t5-small**], il nous a fallu: """)+"\n"+ \
|
| 603 |
+
"* "+tr("22 phrases d'entrainement")+"\n"+ \
|
| 604 |
+
"* "+tr("approximatement 400 epochs pour obtenir une val loss proche de 0")+"\n\n"+ \
|
| 605 |
+
tr("La durée d'entrainement est très rapide (quelques minutes), et le résultat plutôt probant.")
|
| 606 |
+
, unsafe_allow_html=True)
|
translate_app.py
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
# from translate import Translator
|
| 3 |
+
from deep_translator import GoogleTranslator
|
| 4 |
+
|
| 5 |
+
@st.cache_data(ttl="2d", show_spinner=False)
|
| 6 |
+
def trad(message,l):
|
| 7 |
+
try:
|
| 8 |
+
# Utilisation du module translate
|
| 9 |
+
# translator = Translator(to_lang=l , from_lang="fr")
|
| 10 |
+
# translation = translator.translate(message)
|
| 11 |
+
|
| 12 |
+
# Utilisation du module deep_translator
|
| 13 |
+
translation = GoogleTranslator(source='fr', target=l).translate(message.replace(" \n","§§§"))
|
| 14 |
+
translation = translation.replace("§§§"," \n") # .replace(" ","<br>")
|
| 15 |
+
|
| 16 |
+
return translation
|
| 17 |
+
except:
|
| 18 |
+
return "Problème de traduction.."
|
| 19 |
+
|
| 20 |
+
def tr(message):
|
| 21 |
+
if 'Language' not in st.session_state: l = 'fr'
|
| 22 |
+
else: l= st.session_state['Language']
|
| 23 |
+
if l == 'fr': return message
|
| 24 |
+
else: message = message.replace(":red[**","").replace("**]","")
|
| 25 |
+
return trad(message,l)
|
| 26 |
+
|
| 27 |
+
|