!!! note
To run this notebook in JupyterLab, load [`examples/ex0_0.ipynb`](https://github.com/DerwenAI/textgraphs/blob/main/examples/ex0_0.ipynb)
# demo: TextGraphs + LLMs to construct a 'lemma graph'
_TextGraphs_ library is intended for iterating through a sequence of paragraphs.
## environment
```python
from IPython.display import display, HTML, Image, SVG
import pathlib
import typing
from icecream import ic
from pyinstrument import Profiler
import matplotlib.pyplot as plt
import pandas as pd
import pyvis
import spacy
import textgraphs
```
```python
%load_ext watermark
```
```python
%watermark
```
Last updated: 2024-01-16T17:41:51.229985-08:00
Python implementation: CPython
Python version : 3.10.11
IPython version : 8.20.0
Compiler : Clang 13.0.0 (clang-1300.0.29.30)
OS : Darwin
Release : 21.6.0
Machine : x86_64
Processor : i386
CPU cores : 8
Architecture: 64bit
```python
%watermark --iversions
```
sys : 3.10.11 (v3.10.11:7d4cc5aa85, Apr 4 2023, 19:05:19) [Clang 13.0.0 (clang-1300.0.29.30)]
spacy : 3.7.2
pandas : 2.1.4
matplotlib: 3.8.2
textgraphs: 0.5.0
pyvis : 0.3.2
## parse a document
provide the source text
```python
SRC_TEXT: str = """
Werner Herzog is a remarkable filmmaker and an intellectual originally from Germany, the son of Dietrich Herzog.
After the war, Werner fled to America to become famous.
"""
```
set up the statistical stack profiling
```python
profiler: Profiler = Profiler()
profiler.start()
```
set up the `TextGraphs` pipeline
```python
tg: textgraphs.TextGraphs = textgraphs.TextGraphs(
factory = textgraphs.PipelineFactory(
spacy_model = textgraphs.SPACY_MODEL,
ner = None,
kg = textgraphs.KGWikiMedia(
spotlight_api = textgraphs.DBPEDIA_SPOTLIGHT_API,
dbpedia_search_api = textgraphs.DBPEDIA_SEARCH_API,
dbpedia_sparql_api = textgraphs.DBPEDIA_SPARQL_API,
wikidata_api = textgraphs.WIKIDATA_API,
min_alias = textgraphs.DBPEDIA_MIN_ALIAS,
min_similarity = textgraphs.DBPEDIA_MIN_SIM,
),
infer_rels = [
textgraphs.InferRel_OpenNRE(
model = textgraphs.OPENNRE_MODEL,
max_skip = textgraphs.MAX_SKIP,
min_prob = textgraphs.OPENNRE_MIN_PROB,
),
textgraphs.InferRel_Rebel(
lang = "en_XX",
mrebel_model = textgraphs.MREBEL_MODEL,
),
],
),
)
pipe: textgraphs.Pipeline = tg.create_pipeline(
SRC_TEXT.strip(),
)
```
## visualize the parse results
```python
spacy.displacy.render(
pipe.ner_doc,
style = "ent",
jupyter = True,
)
```
Werner Herzog
PERSON
is a remarkable filmmaker and an intellectual originally from
Germany
GPE
, the son of
Dietrich Herzog
PERSON
.
After the war,
Werner
PERSON
fled to
America
GPE
to become famous.
```python
parse_svg: str = spacy.displacy.render(
pipe.ner_doc,
style = "dep",
jupyter = False,
)
display(SVG(parse_svg))
```

## collect graph elements from the parse
```python
tg.collect_graph_elements(
pipe,
debug = False,
)
```
```python
ic(len(tg.nodes.values()));
ic(len(tg.edges.values()));
```
ic| len(tg.nodes.values()): 36
ic| len(tg.edges.values()): 42
## perform entity linking
```python
tg.perform_entity_linking(
pipe,
debug = False,
)
```
## infer relations
```python
inferred_edges: list = await tg.infer_relations_async(
pipe,
debug = False,
)
inferred_edges
```
[Edge(src_node=0, dst_node=10, kind=, rel='https://schema.org/nationality', prob=1.0, count=1),
Edge(src_node=15, dst_node=0, kind=, rel='https://schema.org/children', prob=1.0, count=1),
Edge(src_node=27, dst_node=22, kind=, rel='https://schema.org/event', prob=1.0, count=1)]
## construct a lemma graph
```python
tg.construct_lemma_graph(
debug = False,
)
```
## extract ranked entities
```python
tg.calc_phrase_ranks(
pr_alpha = textgraphs.PAGERANK_ALPHA,
debug = False,
)
```
show the resulting entities extracted from the document
```python
df: pd.DataFrame = tg.get_phrases_as_df()
df
```
|
node_id |
text |
pos |
label |
count |
weight |
| 0 |
0 |
Werner Herzog |
PROPN |
dbr:Werner_Herzog |
1 |
0.080547 |
| 1 |
10 |
Germany |
PROPN |
dbr:Germany |
1 |
0.080437 |
| 2 |
15 |
Dietrich Herzog |
PROPN |
dbo:Person |
1 |
0.079048 |
| 3 |
27 |
America |
PROPN |
dbr:United_States |
1 |
0.079048 |
| 4 |
24 |
Werner |
PROPN |
dbo:Person |
1 |
0.077633 |
| 5 |
4 |
filmmaker |
NOUN |
owl:Thing |
1 |
0.076309 |
| 6 |
22 |
war |
NOUN |
owl:Thing |
1 |
0.076309 |
| 7 |
32 |
a remarkable filmmaker |
noun_chunk |
None |
1 |
0.076077 |
| 8 |
7 |
intellectual |
NOUN |
owl:Thing |
1 |
0.074725 |
| 9 |
13 |
son |
NOUN |
owl:Thing |
1 |
0.074725 |
| 10 |
33 |
an intellectual |
noun_chunk |
None |
1 |
0.074606 |
| 11 |
34 |
the son |
noun_chunk |
None |
1 |
0.074606 |
| 12 |
35 |
the war |
noun_chunk |
None |
1 |
0.074606 |
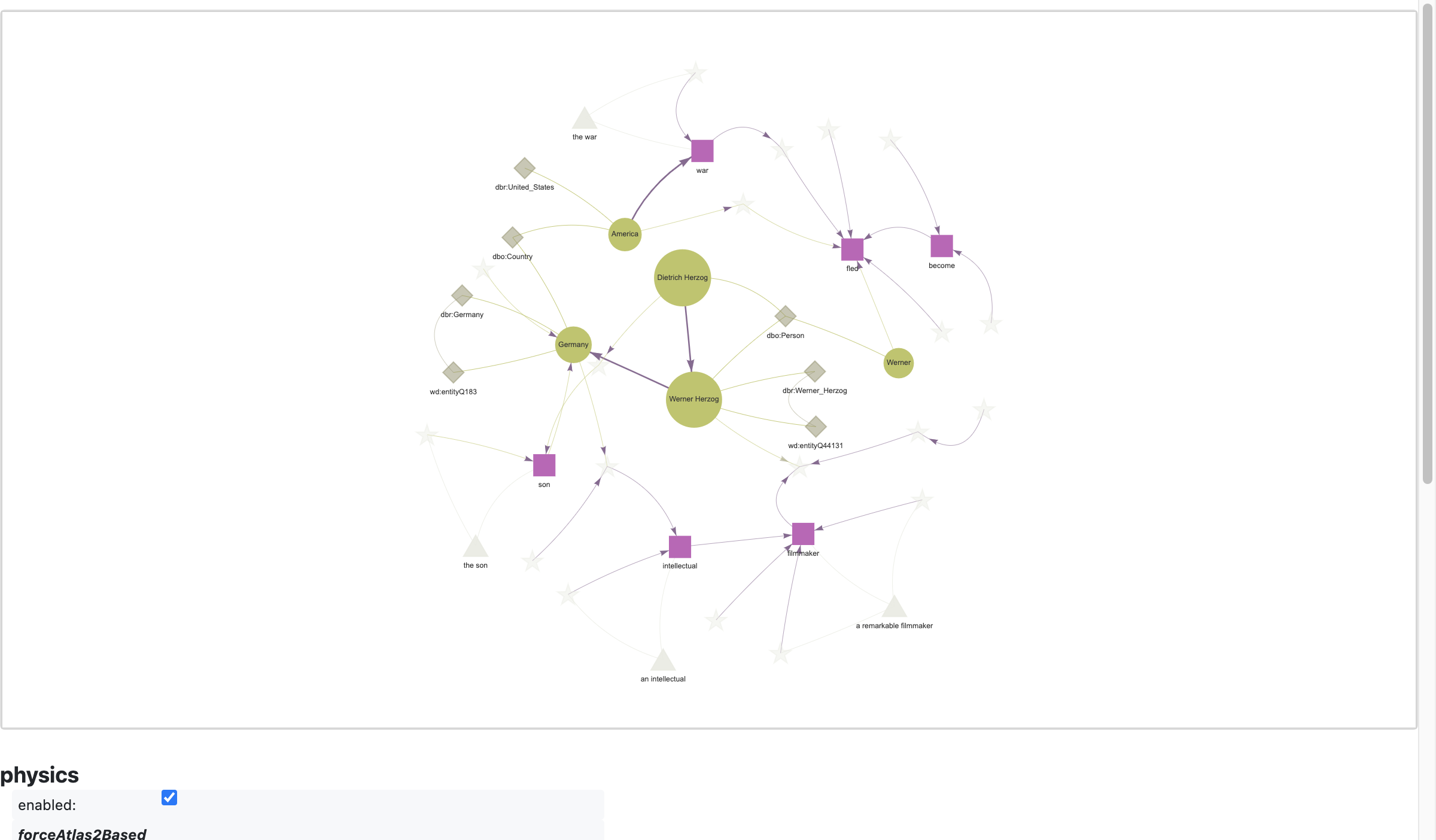
## visualize the lemma graph
```python
render: textgraphs.RenderPyVis = tg.create_render()
pv_graph: pyvis.network.Network = render.render_lemma_graph(
debug = False,
)
```
initialize the layout parameters
```python
pv_graph.force_atlas_2based(
gravity = -38,
central_gravity = 0.01,
spring_length = 231,
spring_strength = 0.7,
damping = 0.8,
overlap = 0,
)
pv_graph.show_buttons(filter_ = [ "physics" ])
pv_graph.toggle_physics(True)
```
```python
pv_graph.prep_notebook()
pv_graph.show("tmp.fig01.html")
```
tmp.fig01.html
## generate a word cloud
```python
wordcloud = render.generate_wordcloud()
display(wordcloud.to_image())
```
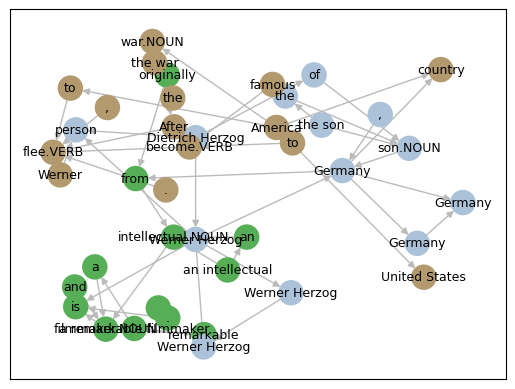
## cluster communities in the lemma graph
In the tutorial
"How to Convert Any Text Into a Graph of Concepts",
Rahul Nayak uses the
girvan-newman
algorithm to split the graph into communities, then clusters on those communities.
His approach works well for unsupervised clustering of key phrases which have been extracted from many documents.
In contrast, Nayak was working with entities extracted from "chunks" of text, not with a text graph.
```python
render.draw_communities();
```
## graph of relations transform
Show a transformed graph, based on _graph of relations_ (see: `lee2023ingram`)
```python
graph: textgraphs.GraphOfRelations = textgraphs.GraphOfRelations(
tg
)
graph.seeds()
graph.construct_gor()
```
```python
scores: typing.Dict[ tuple, float ] = graph.get_affinity_scores()
pv_graph: pyvis.network.Network = graph.render_gor_pyvis(scores)
pv_graph.force_atlas_2based(
gravity = -38,
central_gravity = 0.01,
spring_length = 231,
spring_strength = 0.7,
damping = 0.8,
overlap = 0,
)
pv_graph.show_buttons(filter_ = [ "physics" ])
pv_graph.toggle_physics(True)
pv_graph.prep_notebook()
pv_graph.show("tmp.fig02.html")
```
tmp.fig02.html
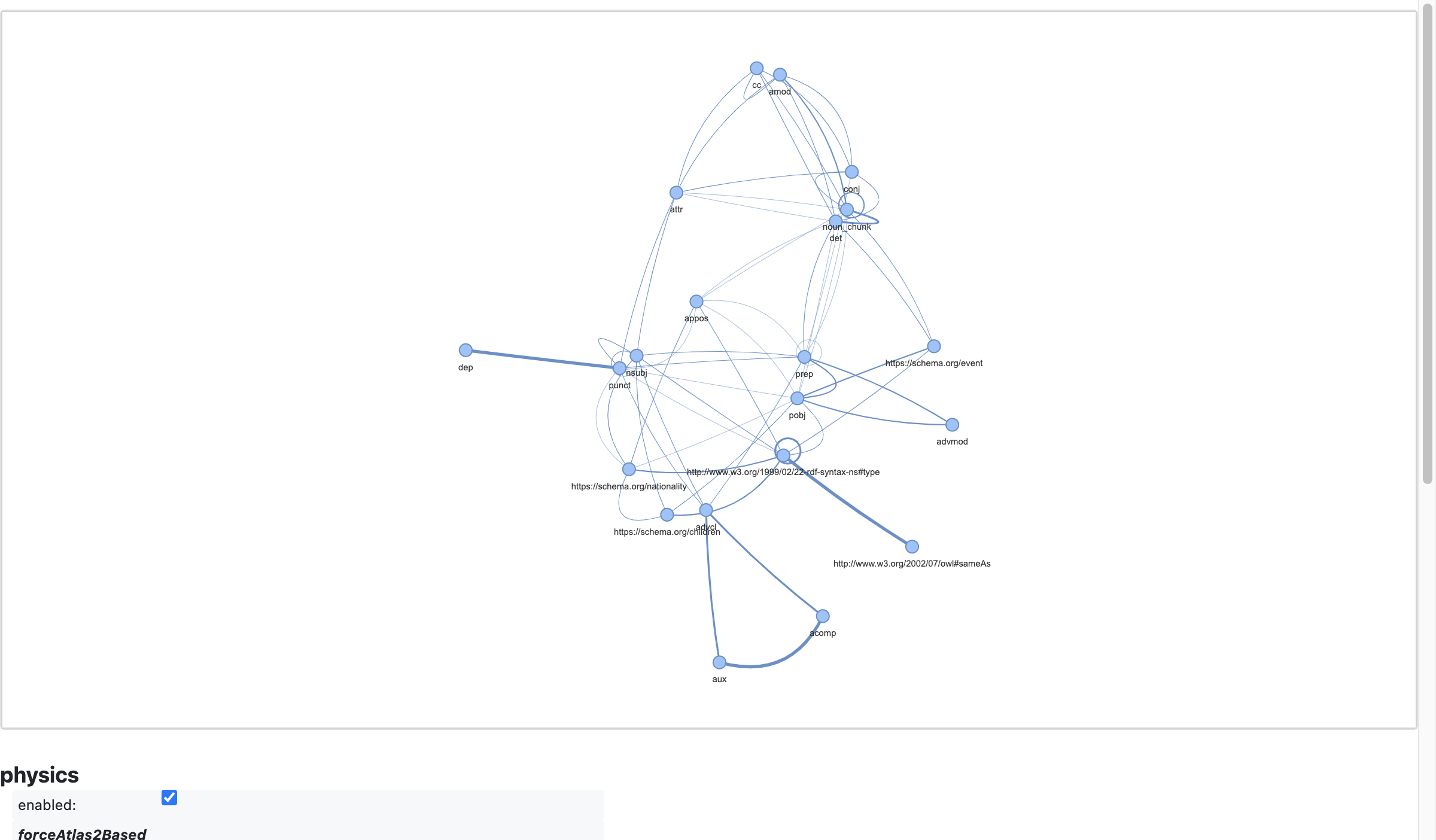
*What does this transform provide?*
By using a _graph of relations_ dual representation of our graph data, first and foremost we obtain a more compact representation of the relations in the graph, and means of making inferences (e.g., _link prediction_) where there is substantially more invariance in the training data.
Also recognize that for a parse graph of a paragraph in the English language, the most interesting nodes will probably be either subjects (`nsubj`) or direct objects (`pobj`). Here in the _graph of relations_ we see illustrated how the important details from _entity linking_ tend to cluster near either `nsubj` or `pobj` entities, connected through punctuation. This is not as readily observed in the earlier visualization of the _lemma graph_.
## extract as RDF triples
Extract the nodes and edges which have IRIs, to create an "abstraction layer" as a semantic graph at a higher level of detail above the _lemma graph_:
```python
triples: str = tg.export_rdf()
print(triples)
```
@base .
@prefix dbo: .
@prefix dbr: .
@prefix schema: .
@prefix skos: .
@prefix wd_ent: .
dbr:Germany skos:definition "Germany (German: Deutschland, German pronunciation: [ˈdɔʏtʃlant]), constitutionally the Federal"@en ;
skos:prefLabel "Germany"@en .
dbr:United_States skos:definition "The United States of America (USA), commonly known as the United States (U.S. or US) or America"@en ;
skos:prefLabel "United States"@en .
dbr:Werner_Herzog skos:definition "Werner Herzog (German: [ˈvɛɐ̯nɐ ˈhɛɐ̯tsoːk]; born 5 September 1942) is a German film director"@en ;
skos:prefLabel "Werner Herzog"@en .
wd_ent:Q183 skos:definition "country in Central Europe"@en ;
skos:prefLabel "Germany"@en .
wd_ent:Q44131 skos:definition "German film director, producer, screenwriter, actor and opera director"@en ;
skos:prefLabel "Werner Herzog"@en .
a dbo:Country ;
skos:prefLabel "America"@en ;
schema:event .
a dbo:Person ;
skos:prefLabel "Dietrich Herzog"@en ;
schema:children .
skos:prefLabel "filmmaker"@en .
skos:prefLabel "intellectual"@en .
skos:prefLabel "son"@en .
a dbo:Person ;
skos:prefLabel "Werner"@en .
a dbo:Country ;
skos:prefLabel "Germany"@en .
skos:prefLabel "war"@en .
a dbo:Person ;
skos:prefLabel "Werner Herzog"@en ;
schema:nationality .
dbo:Country skos:definition "Countries, cities, states"@en ;
skos:prefLabel "country"@en .
dbo:Person skos:definition "People, including fictional"@en ;
skos:prefLabel "person"@en .
## statistical stack profile instrumentation
```python
profiler.stop()
```
```python
profiler.print()
```
_ ._ __/__ _ _ _ _ _/_ Recorded: 17:41:51 Samples: 11163
/_//_/// /_\ / //_// / //_'/ // Duration: 57.137 CPU time: 72.235
/ _/ v4.6.1
Program: /Users/paco/src/textgraphs/venv/lib/python3.10/site-packages/ipykernel_launcher.py -f /Users/paco/Library/Jupyter/runtime/kernel-8ffadb7d-3b45-4e0e-a94f-f098e5ad9fbe.json
57.136 _UnixSelectorEventLoop._run_once asyncio/base_events.py:1832
└─ 57.135 Handle._run asyncio/events.py:78
[12 frames hidden] asyncio, ipykernel, IPython
41.912 ZMQInteractiveShell.run_ast_nodes IPython/core/interactiveshell.py:3394
├─ 20.701 ../ipykernel_5151/1245857438.py:1
│ └─ 20.701 TextGraphs.perform_entity_linking textgraphs/doc.py:534
│ └─ 20.701 KGWikiMedia.perform_entity_linking textgraphs/kg.py:306
│ ├─ 10.790 KGWikiMedia._link_kg_search_entities textgraphs/kg.py:932
│ │ └─ 10.787 KGWikiMedia.dbpedia_search_entity textgraphs/kg.py:641
│ │ └─ 10.711 get requests/api.py:62
│ │ [37 frames hidden] requests, urllib3, http, socket, ssl,...
│ ├─ 9.143 KGWikiMedia._link_spotlight_entities textgraphs/kg.py:851
│ │ └─ 9.140 KGWikiMedia.dbpedia_search_entity textgraphs/kg.py:641
│ │ └─ 9.095 get requests/api.py:62
│ │ [37 frames hidden] requests, urllib3, http, socket, ssl,...
│ └─ 0.768 KGWikiMedia._secondary_entity_linking textgraphs/kg.py:1060
│ └─ 0.768 KGWikiMedia.wikidata_search textgraphs/kg.py:575
│ └─ 0.765 KGWikiMedia._wikidata_endpoint textgraphs/kg.py:444
│ └─ 0.765 get requests/api.py:62
│ [7 frames hidden] requests, urllib3
└─ 19.514 ../ipykernel_5151/1708547378.py:1
├─ 14.502 InferRel_Rebel.__init__ textgraphs/rel.py:121
│ └─ 14.338 pipeline transformers/pipelines/__init__.py:531
│ [39 frames hidden] transformers, torch, , json
├─ 3.437 PipelineFactory.__init__ textgraphs/pipe.py:434
│ └─ 3.420 load spacy/__init__.py:27
│ [20 frames hidden] spacy, en_core_web_sm, catalogue, imp...
├─ 0.900 InferRel_OpenNRE.__init__ textgraphs/rel.py:33
│ └─ 0.888 get_model opennre/pretrain.py:126
└─ 0.672 TextGraphs.create_pipeline textgraphs/doc.py:103
└─ 0.672 PipelineFactory.create_pipeline textgraphs/pipe.py:508
└─ 0.672 Pipeline.__init__ textgraphs/pipe.py:216
└─ 0.672 English.__call__ spacy/language.py:1016
[11 frames hidden] spacy, spacy_dbpedia_spotlight, reque...
14.363 InferRel_Rebel.gen_triples_async textgraphs/pipe.py:188
├─ 13.670 InferRel_Rebel.gen_triples textgraphs/rel.py:259
│ ├─ 12.439 InferRel_Rebel.tokenize_sent textgraphs/rel.py:145
│ │ └─ 12.436 TranslationPipeline.__call__ transformers/pipelines/text2text_generation.py:341
│ │ [42 frames hidden] transformers, torch,
│ └─ 1.231 KGWikiMedia.resolve_rel_iri textgraphs/kg.py:370
│ └─ 0.753 get_entity_dict_from_api qwikidata/linked_data_interface.py:21
│ [8 frames hidden] qwikidata, requests, urllib3
└─ 0.693 InferRel_OpenNRE.gen_triples textgraphs/rel.py:58
## outro
_\[ more parts are in progress, getting added to this demo \]_