import gradio as gr
import pandas as pd
import numpy as np
import os
from datetime import datetime
from utils import (
make_pairs,
set_openai_api_key,
create_user_id,
to_completion,
)
from azure.storage.fileshare import ShareServiceClient
# Langchain
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.schema import AIMessage, HumanMessage
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# ClimateQ&A imports
from climateqa.llm import get_llm
from climateqa.chains import load_qa_chain_with_docs,load_qa_chain_with_text
from climateqa.chains import load_reformulation_chain
from climateqa.vectorstore import get_pinecone_vectorstore
from climateqa.retriever import ClimateQARetriever
from climateqa.prompts import audience_prompts
# Load environment variables in local mode
try:
from dotenv import load_dotenv
load_dotenv()
except:
pass
# Set up Gradio Theme
theme = gr.themes.Base(
primary_hue="blue",
secondary_hue="red",
font=[gr.themes.GoogleFont("Poppins"), "ui-sans-serif", "system-ui", "sans-serif"],
)
init_prompt = ""
system_template = {
"role": "system",
"content": init_prompt,
}
# credential = {
# "account_key": os.environ["account_key"],
# "account_name": os.environ["account_name"],
# }
# account_url = os.environ["account_url"]
# file_share_name = "climategpt"
# service = ShareServiceClient(account_url=account_url, credential=credential)
# share_client = service.get_share_client(file_share_name)
user_id = create_user_id(10)
#---------------------------------------------------------------------------
# ClimateQ&A core functions
#---------------------------------------------------------------------------
from langchain.callbacks.base import BaseCallbackHandler
from queue import Queue, Empty
from threading import Thread
from collections.abc import Generator
from langchain.schema import LLMResult
from typing import Any, Union,Dict,List
from queue import SimpleQueue
# # Create a Queue
# Q = Queue()
import re
def parse_output_llm_with_sources(output):
# Split the content into a list of text and "[Doc X]" references
content_parts = re.split(r'\[(Doc\s?\d+(?:,\s?Doc\s?\d+)*)\]', output)
parts = []
for part in content_parts:
if part.startswith("Doc"):
subparts = part.split(",")
subparts = [subpart.lower().replace("doc","").strip() for subpart in subparts]
subparts = [f"{subpart}" for subpart in subparts]
parts.append("".join(subparts))
else:
parts.append(part)
content_parts = "".join(parts)
return content_parts
job_done = object() # signals the processing is done
class StreamingGradioCallbackHandler(BaseCallbackHandler):
def __init__(self, q: SimpleQueue):
self.q = q
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Run when LLM starts running. Clean the queue."""
while not self.q.empty():
try:
self.q.get(block=False)
except Empty:
continue
def on_llm_new_token(self, token: str, **kwargs: Any) -> None:
"""Run on new LLM token. Only available when streaming is enabled."""
self.q.put(token)
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when LLM ends running."""
self.q.put(job_done)
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> None:
"""Run when LLM errors."""
self.q.put(job_done)
# Create embeddings function and LLM
embeddings_function = HuggingFaceEmbeddings(model_name = "sentence-transformers/multi-qa-mpnet-base-dot-v1")
# Create vectorstore and retriever
vectorstore = get_pinecone_vectorstore(embeddings_function)
#---------------------------------------------------------------------------
# ClimateQ&A Streaming
# From https://github.com/gradio-app/gradio/issues/5345
# And https://stackoverflow.com/questions/76057076/how-to-stream-agents-response-in-langchain
#---------------------------------------------------------------------------
from threading import Thread
import json
def answer_user(query,query_example,history):
return query, history + [[query, ". . ."]]
def answer_user_example(query,query_example,history):
return query_example, history + [[query_example, ". . ."]]
def fetch_sources(query,sources):
# Prepare default values
if len(sources) == 0:
sources = ["IPCC"]
llm_reformulation = get_llm(max_tokens = 512,temperature = 0.0,verbose = True,streaming = False)
retriever = ClimateQARetriever(vectorstore=vectorstore,sources = sources,k_summary = 3,k_total = 10)
reformulation_chain = load_reformulation_chain(llm_reformulation)
# Calculate language
output_reformulation = reformulation_chain({"query":query})
question = output_reformulation["question"]
language = output_reformulation["language"]
# Retrieve docs
docs = retriever.get_relevant_documents(question)
if len(docs) > 0:
# Already display the sources
sources_text = []
for i, d in enumerate(docs, 1):
sources_text.append(make_html_source(d, i))
citations_text = "".join(sources_text)
docs_text = "\n\n".join([d.page_content for d in docs])
return "",citations_text,docs_text,question,language
else:
sources_text = "⚠️ No relevant passages found in the scientific reports (IPCC and IPBES)"
citations_text = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
docs_text = ""
return "",citations_text,docs_text,question,language
def answer_bot(query,history,docs,question,language,audience):
if audience == "Children":
audience_prompt = audience_prompts["children"]
elif audience == "General public":
audience_prompt = audience_prompts["general"]
elif audience == "Experts":
audience_prompt = audience_prompts["experts"]
else:
audience_prompt = audience_prompts["experts"]
# Prepare Queue for streaming LLMs
Q = SimpleQueue()
llm_streaming = get_llm(max_tokens = 1024,temperature = 0.0,verbose = True,streaming = True,
callbacks=[StreamingGradioCallbackHandler(Q),StreamingStdOutCallbackHandler()],
)
qa_chain = load_qa_chain_with_text(llm_streaming)
def threaded_chain(question,audience,language,docs):
try:
response = qa_chain({"question":question,"audience":audience,"language":language,"summaries":docs})
Q.put(response)
Q.put(job_done)
except Exception as e:
print(e)
history[-1][1] = ""
textbox=gr.Textbox(placeholder=". . .",show_label=False,scale=1,lines = 1,interactive = False)
if len(docs) > 0:
# Start thread for streaming
thread = Thread(
target=threaded_chain,
kwargs={"question":question,"audience":audience_prompt,"language":language,"docs":docs}
)
thread.start()
while True:
next_item = Q.get(block=True) # Blocks until an input is available
if next_item is job_done:
break
elif isinstance(next_item, str):
new_paragraph = history[-1][1] + next_item
new_paragraph = parse_output_llm_with_sources(new_paragraph)
history[-1][1] = new_paragraph
yield textbox,history
else:
pass
thread.join()
else:
complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
history[-1][1] += complete_response
yield "",history
# history_langchain_format = []
# for human, ai in history:
# history_langchain_format.append(HumanMessage(content=human))
# history_langchain_format.append(AIMessage(content=ai))
# history_langchain_format.append(HumanMessage(content=message)
# for next_token, content in stream(message):
# yield(content)
# thread = Thread(target=threaded_chain, kwargs={"query":message,"audience":audience_prompt})
# thread.start()
# history[-1][1] = ""
# while True:
# next_item = Q.get(block=True) # Blocks until an input is available
# print(type(next_item))
# if next_item is job_done:
# continue
# elif isinstance(next_item, dict): # assuming LLMResult is a dictionary
# response = next_item
# if "source_documents" in response and len(response["source_documents"]) > 0:
# sources_text = []
# for i, d in enumerate(response["source_documents"], 1):
# sources_text.append(make_html_source(d, i))
# sources_text = "\n\n".join([f"Query used for retrieval:\n{response['question']}"] + sources_text)
# # history[-1][1] += next_item["answer"]
# # history[-1][1] += "\n\n" + sources_text
# yield "", history, sources_text
# else:
# sources_text = "⚠️ No relevant passages found in the scientific reports (IPCC and IPBES)"
# complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate and biodiversity issues).**"
# history[-1][1] += "\n\n" + complete_response
# yield "", history, sources_text
# break
# elif isinstance(next_item, str):
# new_paragraph = history[-1][1] + next_item
# new_paragraph = parse_output_llm_with_sources(new_paragraph)
# history[-1][1] = new_paragraph
# yield "", history, ""
# thread.join()
#---------------------------------------------------------------------------
# ClimateQ&A core functions
#---------------------------------------------------------------------------
def make_html_source(source,i):
meta = source.metadata
content = source.page_content.split(":",1)[1].strip()
return f"""
Doc {i} - {meta['short_name']} - Page {int(meta['page_number'])}
{content}
"""
# def chat(
# user_id: str,
# query: str,
# history: list = [system_template],
# report_type: str = "IPCC",
# threshold: float = 0.555,
# ) -> tuple:
# """retrieve relevant documents in the document store then query gpt-turbo
# Args:
# query (str): user message.
# history (list, optional): history of the conversation. Defaults to [system_template].
# report_type (str, optional): should be "All available" or "IPCC only". Defaults to "All available".
# threshold (float, optional): similarity threshold, don't increase more than 0.568. Defaults to 0.56.
# Yields:
# tuple: chat gradio format, chat openai format, sources used.
# """
# if report_type not in ["IPCC","IPBES"]: report_type = "all"
# print("Searching in ",report_type," reports")
# # if report_type == "All available":
# # retriever = retrieve_all
# # elif report_type == "IPCC only":
# # retriever = retrieve_giec
# # else:
# # raise Exception("report_type arg should be in (All available, IPCC only)")
# reformulated_query = openai.Completion.create(
# engine="EkiGPT",
# prompt=get_reformulation_prompt(query),
# temperature=0,
# max_tokens=128,
# stop=["\n---\n", "<|im_end|>"],
# )
# reformulated_query = reformulated_query["choices"][0]["text"]
# reformulated_query, language = reformulated_query.split("\n")
# language = language.split(":")[1].strip()
# sources = retrieve_with_summaries(reformulated_query,retriever,k_total = 10,k_summary = 3,as_dict = True,source = report_type.lower(),threshold = threshold)
# response_retriever = {
# "language":language,
# "reformulated_query":reformulated_query,
# "query":query,
# "sources":sources,
# }
# # docs = [d for d in retriever.retrieve(query=reformulated_query, top_k=10) if d.score > threshold]
# messages = history + [{"role": "user", "content": query}]
# if len(sources) > 0:
# docs_string = []
# docs_html = []
# for i, d in enumerate(sources, 1):
# docs_string.append(f"📃 Doc {i}: {d['meta']['short_name']} page {d['meta']['page_number']}\n{d['content']}")
# docs_html.append(make_html_source(d,i))
# docs_string = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_string)
# docs_html = "\n\n".join([f"Query used for retrieval:\n{reformulated_query}"] + docs_html)
# messages.append({"role": "system", "content": f"{sources_prompt}\n\n{docs_string}\n\nAnswer in {language}:"})
# response = openai.Completion.create(
# engine="EkiGPT",
# prompt=to_completion(messages),
# temperature=0, # deterministic
# stream=True,
# max_tokens=1024,
# )
# complete_response = ""
# messages.pop()
# messages.append({"role": "assistant", "content": complete_response})
# timestamp = str(datetime.now().timestamp())
# file = user_id[0] + timestamp + ".json"
# logs = {
# "user_id": user_id[0],
# "prompt": query,
# "retrived": sources,
# "report_type": report_type,
# "prompt_eng": messages[0],
# "answer": messages[-1]["content"],
# "time": timestamp,
# }
# log_on_azure(file, logs, share_client)
# for chunk in response:
# if (chunk_message := chunk["choices"][0].get("text")) and chunk_message != "<|im_end|>":
# complete_response += chunk_message
# messages[-1]["content"] = complete_response
# gradio_format = make_pairs([a["content"] for a in messages[1:]])
# yield gradio_format, messages, docs_html
# else:
# docs_string = "⚠️ No relevant passages found in the climate science reports (IPCC and IPBES)"
# complete_response = "**⚠️ No relevant passages found in the climate science reports (IPCC and IPBES), you may want to ask a more specific question (specifying your question on climate issues).**"
# messages.append({"role": "assistant", "content": complete_response})
# gradio_format = make_pairs([a["content"] for a in messages[1:]])
# yield gradio_format, messages, docs_string
def save_feedback(feed: str, user_id):
if len(feed) > 1:
timestamp = str(datetime.now().timestamp())
file = user_id[0] + timestamp + ".json"
logs = {
"user_id": user_id[0],
"feedback": feed,
"time": timestamp,
}
log_on_azure(file, logs, share_client)
return "Feedback submitted, thank you!"
def reset_textbox():
return gr.update(value="")
def log_on_azure(file, logs, share_client):
file_client = share_client.get_file_client(file)
file_client.upload_file(str(logs))
# def disable_component():
# return gr.update(interactive = False)
# --------------------------------------------------------------------
# Gradio
# --------------------------------------------------------------------
init_prompt = """
Hello, I am ClimateQ&A, a conversational assistant designed to help you understand climate change and biodiversity loss. I will answer your questions by **sifting through the IPCC and IPBES scientific reports**.
💡 How to use
- **Language**: You can ask me your questions in any language.
- **Audience**: You can specify your audience (children, general public, experts) to get a more adapted answer.
- **Sources**: You can choose to search in the IPCC or IPBES reports, or both.
⚠️ Limitations
*Please note that the AI is not perfect and may sometimes give irrelevant answers. If you are not satisfied with the answer, please ask a more specific question or report your feedback to help us improve the system.*
❓ What do you want to learn ?
"""
def vote(data: gr.LikeData):
if data.liked:
print(data.value)
else:
print(data)
with gr.Blocks(title="🌍 Climate Q&A", css="style.css", theme=theme) as demo:
# user_id_state = gr.State([user_id])
with gr.Tab("🌍 ClimateQ&A"):
with gr.Row(elem_id="chatbot-row"):
with gr.Column(scale=2):
# state = gr.State([system_template])
bot = gr.Chatbot(
value=[[None,init_prompt]],
show_copy_button=True,show_label = False,elem_id="chatbot",layout = "panel",avatar_images = ("assets/logo4.png",None))
# bot.like(vote,None,None)
with gr.Row(elem_id = "input-message"):
textbox=gr.Textbox(placeholder="Ask me anything here!",show_label=False,scale=1,lines = 1,interactive = True)
# submit_button = gr.Button(">",scale = 1,elem_id = "submit-button")
with gr.Column(scale=1, variant="panel",elem_id = "right-panel"):
with gr.Tab("📝 Examples",elem_id = "tab-examples"):
examples_hidden = gr.Textbox(elem_id="hidden-message")
examples_questions = gr.Examples(
[
"Is climate change caused by humans?",
"What evidence do we have of climate change?",
"What are the impacts of climate change?",
"Can climate change be reversed?",
"What is the difference between climate change and global warming?",
"What can individuals do to address climate change?",
"What are the main causes of climate change?",
"What is the Paris Agreement and why is it important?",
"Which industries have the highest GHG emissions?",
"Is climate change a hoax created by the government or environmental organizations?",
"What is the relationship between climate change and biodiversity loss?",
"What is the link between gender equality and climate change?",
"Is the impact of climate change really as severe as it is claimed to be?",
"What is the impact of rising sea levels?",
"What are the different greenhouse gases (GHG)?",
"What is the warming power of methane?",
"What is the jet stream?",
"What is the breakdown of carbon sinks?",
"How do the GHGs work ? Why does temperature increase ?",
"What is the impact of global warming on ocean currents?",
"How much warming is possible in 2050?",
"What is the impact of climate change in Africa?",
"Will climate change accelerate diseases and epidemics like COVID?",
"What are the economic impacts of climate change?",
"How much is the cost of inaction ?",
"What is the relationship between climate change and poverty?",
"What are the most effective strategies and technologies for reducing greenhouse gas (GHG) emissions?",
"Is economic growth possible? What do you think about degrowth?",
"Will technology save us?",
"Is climate change a natural phenomenon ?",
"Is climate change really happening or is it just a natural fluctuation in Earth's temperature?",
"Is the scientific consensus on climate change really as strong as it is claimed to be?",
],
[examples_hidden],
examples_per_page=10,
# cache_examples=True,
)
with gr.Tab("📚 Citations",elem_id = "tab-citations"):
sources_textbox = gr.HTML(show_label=False, elem_id="sources-textbox")
docs_textbox = gr.State("")
with gr.Tab("⚙️ Configuration",elem_id = "tab-config"):
gr.Markdown("Reminder: You can talk in any language, ClimateQ&A is multi-lingual!")
dropdown_sources = gr.CheckboxGroup(
["IPCC", "IPBES"],
label="Select reports",
value=["IPCC"],
interactive=True,
)
dropdown_audience = gr.Dropdown(
["Children","General public","Experts"],
label="Select audience",
value="Experts",
interactive=True,
)
output_query = gr.Textbox(label="Query used for retrieval",show_label = True,elem_id = "reformulated-query",lines = 2,interactive = False)
output_language = gr.Textbox(label="Language",show_label = True,elem_id = "language",lines = 1,interactive = False)
# textbox.submit(predict_climateqa,[textbox,bot],[None,bot,sources_textbox])
(textbox
.submit(answer_user, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
.success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
.success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue = True)
.success(lambda x : textbox,[textbox],[textbox])
)
(examples_hidden
.change(answer_user_example, [textbox,examples_hidden, bot], [textbox, bot],queue = False)
# .then(disable_component, [examples_questions], [examples_questions],queue = False)
.success(fetch_sources,[textbox,dropdown_sources], [textbox,sources_textbox,docs_textbox,output_query,output_language])
.success(answer_bot, [textbox,bot,docs_textbox,output_query,output_language,dropdown_audience], [textbox,bot],queue=True)
.success(lambda x : textbox,[textbox],[textbox])
)
# submit_button.click(answer_user, [textbox, bot], [textbox, bot], queue=True).then(
# answer_bot, [textbox,bot,dropdown_audience,dropdown_sources], [textbox,bot,sources_textbox]
# )
#---------------------------------------------------------------------------------------
# OTHER TABS
#---------------------------------------------------------------------------------------
with gr.Tab("ℹ️ About ClimateQ&A",elem_classes = "max-height"):
with gr.Row():
with gr.Column(scale=1):
gr.Markdown(
"""
Climate change and environmental disruptions have become some of the most pressing challenges facing our planet today. As global temperatures rise and ecosystems suffer, it is essential for individuals to understand the gravity of the situation in order to make informed decisions and advocate for appropriate policy changes.
However, comprehending the vast and complex scientific information can be daunting, as the scientific consensus references, such as the Intergovernmental Panel on Climate Change (IPCC) reports, span thousands of pages. To bridge this gap and make climate science more accessible, we introduce ClimateQ&A as a tool to distill expert-level knowledge into easily digestible insights about climate science.
💡
How does ClimateQ&A work?
ClimateQ&A harnesses modern OCR techniques to parse and preprocess IPCC reports. By leveraging state-of-the-art question-answering algorithms,
ClimateQ&A is able to sift through the extensive collection of climate scientific reports and identify relevant passages in response to user inquiries. Furthermore, the integration of the ChatGPT API allows ClimateQ&A to present complex data in a user-friendly manner, summarizing key points and facilitating communication of climate science to a wider audience.
"""
)
with gr.Column(scale=1):
gr.Markdown("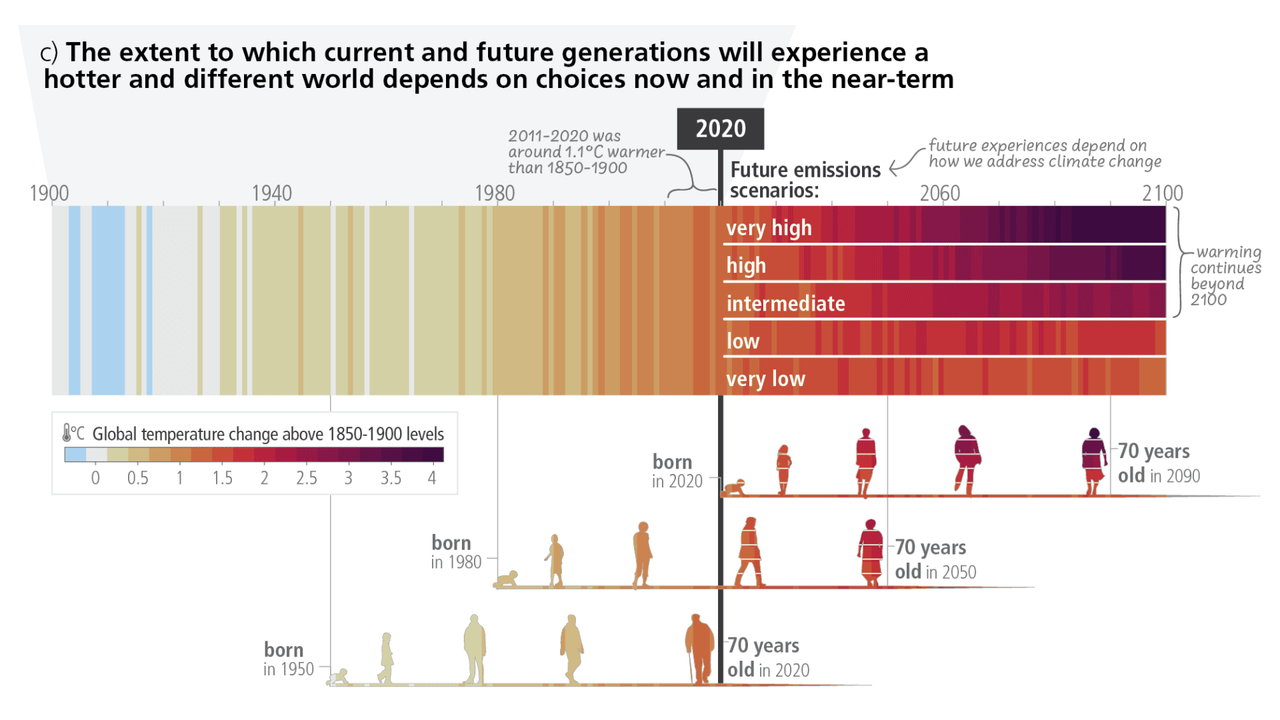")
gr.Markdown("*Source : IPCC AR6 - Synthesis Report of the IPCC 6th assessment report (AR6)*")
gr.Markdown("## How to use ClimateQ&A")
with gr.Row():
with gr.Column(scale=1):
gr.Markdown(
"""
### 💪 Getting started
- In the chatbot section, simply type your climate-related question, and ClimateQ&A will provide an answer with references to relevant IPCC reports.
- ClimateQ&A retrieves specific passages from the IPCC reports to help answer your question accurately.
- Source information, including page numbers and passages, is displayed on the right side of the screen for easy verification.
- Feel free to ask follow-up questions within the chatbot for a more in-depth understanding.
- You can ask question in any language, ClimateQ&A is multi-lingual !
- ClimateQ&A integrates multiple sources (IPCC and IPBES, … ) to cover various aspects of environmental science, such as climate change and biodiversity. See all sources used below.
"""
)
with gr.Column(scale=1):
gr.Markdown(
"""
### ⚠️ Limitations
- Please note that, like any AI, the model may occasionally generate an inaccurate or imprecise answer. Always refer to the provided sources to verify the validity of the information given. If you find any issues with the response, kindly provide feedback to help improve the system.
- ClimateQ&A is specifically designed for climate-related inquiries. If you ask a non-environmental question, the chatbot will politely remind you that its focus is on climate and environmental issues.
"""
)
with gr.Tab("📧 Contact, feedback and feature requests"):
gr.Markdown(
"""
🤞 For any question or press request, contact Théo Alves Da Costa at theo.alvesdacosta@ekimetrics.com
- ClimateQ&A welcomes community contributions. To participate, head over to the Community Tab and create a "New Discussion" to ask questions and share your insights.
- Provide feedback through email, letting us know which insights you found accurate, useful, or not. Your input will help us improve the platform.
- Only a few sources (see below) are integrated (all IPCC, IPBES), if you are a climate science researcher and net to sift through another report, please let us know.
*This tool has been developed by the R&D lab at **Ekimetrics** (Jean Lelong, Nina Achache, Gabriel Olympie, Nicolas Chesneau, Natalia De la Calzada, Théo Alves Da Costa)*
"""
)
# with gr.Row():
# with gr.Column(scale=1):
# gr.Markdown("### Feedbacks")
# feedback = gr.Textbox(label="Write your feedback here")
# feedback_output = gr.Textbox(label="Submit status")
# feedback_save = gr.Button(value="submit feedback")
# feedback_save.click(
# save_feedback,
# inputs=[feedback, user_id_state],
# outputs=feedback_output,
# )
# gr.Markdown(
# "If you need us to ask another climate science report or ask any question, contact us at theo.alvesdacosta@ekimetrics.com"
# )
# with gr.Column(scale=1):
# gr.Markdown("### OpenAI API")
# gr.Markdown(
# "To make climate science accessible to a wider audience, we have opened our own OpenAI API key with a monthly cap of $1000. If you already have an API key, please use it to help conserve bandwidth for others."
# )
# openai_api_key_textbox = gr.Textbox(
# placeholder="Paste your OpenAI API key (sk-...) and hit Enter",
# show_label=False,
# lines=1,
# type="password",
# )
# openai_api_key_textbox.change(set_openai_api_key, inputs=[openai_api_key_textbox])
# openai_api_key_textbox.submit(set_openai_api_key, inputs=[openai_api_key_textbox])
with gr.Tab("📚 Sources",elem_classes = "max-height"):
gr.Markdown("""
| Source | Report | URL | Number of pages | Release date |
| --- | --- | --- | --- | --- |
IPCC | Summary for Policymakers. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_SPM.pdf | 32 | 2021
IPCC | Full Report. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg1/IPCC_AR6_WGI_FullReport.pdf | 2409 | 2021
IPCC | Technical Summary. In: Climate Change 2021: The Physical Science Basis. Contribution of the WGI to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_TS.pdf | 112 | 2021
IPCC | Summary for Policymakers. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_SummaryForPolicymakers.pdf | 34 | 2022
IPCC | Technical Summary. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_TechnicalSummary.pdf | 84 | 2022
IPCC | Full Report. In: Climate Change 2022: Impacts, Adaptation and Vulnerability. Contribution of the WGII to the AR6 of the IPCC. | https://report.ipcc.ch/ar6/wg2/IPCC_AR6_WGII_FullReport.pdf | 3068 | 2022
IPCC | Summary for Policymakers. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_SummaryForPolicymakers.pdf | 50 | 2022
IPCC | Technical Summary. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_TechnicalSummary.pdf | 102 | 2022
IPCC | Full Report. In: Climate Change 2022: Mitigation of Climate Change. Contribution of the WGIII to the AR6 of the IPCC. | https://www.ipcc.ch/report/ar6/wg3/downloads/report/IPCC_AR6_WGIII_FullReport.pdf | 2258 | 2022
IPCC | Summary for Policymakers. In: Global Warming of 1.5°C. An IPCC Special Report on the impacts of global warming of 1.5°C above pre-industrial levels and related global greenhouse gas emission pathways, in the context of strengthening the global response to the threat of climate change, sustainable development, and efforts to eradicate poverty. | https://www.ipcc.ch/site/assets/uploads/sites/2/2022/06/SPM_version_report_LR.pdf | 24 | 2018
IPCC | Summary for Policymakers. In: Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems. | https://www.ipcc.ch/site/assets/uploads/sites/4/2022/11/SRCCL_SPM.pdf | 36 | 2019
IPCC | Summary for Policymakers. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/01_SROCC_SPM_FINAL.pdf | 36 | 2019
IPCC | Technical Summary. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/02_SROCC_TS_FINAL.pdf | 34 | 2019
IPCC | Chapter 1 - Framing and Context of the Report. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/03_SROCC_Ch01_FINAL.pdf | 60 | 2019
IPCC | Chapter 2 - High Mountain Areas. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/04_SROCC_Ch02_FINAL.pdf | 72 | 2019
IPCC | Chapter 3 - Polar Regions. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/05_SROCC_Ch03_FINAL.pdf | 118 | 2019
IPCC | Chapter 4 - Sea Level Rise and Implications for Low-Lying Islands, Coasts and Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/06_SROCC_Ch04_FINAL.pdf | 126 | 2019
IPCC | Chapter 5 - Changing Ocean, Marine Ecosystems, and Dependent Communities. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/07_SROCC_Ch05_FINAL.pdf | 142 | 2019
IPCC | Chapter 6 - Extremes, Abrupt Changes and Managing Risk. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/08_SROCC_Ch06_FINAL.pdf | 68 | 2019
IPCC | Cross-Chapter Box 9: Integrative Cross-Chapter Box on Low-Lying Islands and Coasts. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2019/11/11_SROCC_CCB9-LLIC_FINAL.pdf | 18 | 2019
IPCC | Annex I: Glossary [Weyer, N.M. (ed.)]. In: IPCC Special Report on the Ocean and Cryosphere in a Changing Climate. | https://www.ipcc.ch/site/assets/uploads/sites/3/2022/03/10_SROCC_AnnexI-Glossary_FINAL.pdf | 28 | 2019
IPBES | Full Report. Global assessment report on biodiversity and ecosystem services of the IPBES. | https://zenodo.org/record/6417333/files/202206_IPBES%20GLOBAL%20REPORT_FULL_DIGITAL_MARCH%202022.pdf | 1148 | 2019
IPBES | Summary for Policymakers. Global assessment report on biodiversity and ecosystem services of the IPBES (Version 1). | https://zenodo.org/record/3553579/files/ipbes_global_assessment_report_summary_for_policymakers.pdf | 60 | 2019
IPBES | Full Report. Thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7755805/files/IPBES_ASSESSMENT_SUWS_FULL_REPORT.pdf | 1008 | 2022
IPBES | Summary for Policymakers. Summary for policymakers of the thematic assessment of the sustainable use of wild species of the IPBES. | https://zenodo.org/record/7411847/files/EN_SPM_SUSTAINABLE%20USE%20OF%20WILD%20SPECIES.pdf | 44 | 2022
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236178/files/ipbes_assessment_report_africa_EN.pdf | 494 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Africa. | https://zenodo.org/record/3236189/files/ipbes_assessment_spm_africa_EN.pdf | 52 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236253/files/ipbes_assessment_report_americas_EN.pdf | 660 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for the Americas. | https://zenodo.org/record/3236292/files/ipbes_assessment_spm_americas_EN.pdf | 44 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237374/files/ipbes_assessment_report_ap_EN.pdf | 616 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Asia and the Pacific. | https://zenodo.org/record/3237383/files/ipbes_assessment_spm_ap_EN.pdf | 44 | 2018
IPBES | Full Report. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237429/files/ipbes_assessment_report_eca_EN.pdf | 894 | 2018
IPBES | Summary for Policymakers. Regional Assessment Report on Biodiversity and Ecosystem Services for Europe and Central Asia. | https://zenodo.org/record/3237468/files/ipbes_assessment_spm_eca_EN.pdf | 52 | 2018
IPBES | Full Report. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 748 | 2018
IPBES | Summary for Policymakers. Assessment Report on Land Degradation and Restoration. | https://zenodo.org/record/3237393/files/ipbes_assessment_report_ldra_EN.pdf | 48 | 2018
""")
with gr.Tab("🛢️ Carbon Footprint"):
gr.Markdown("""
Carbon emissions were measured during the development and inference process using CodeCarbon [https://github.com/mlco2/codecarbon](https://github.com/mlco2/codecarbon)
| Phase | Description | Emissions | Source |
| --- | --- | --- | --- |
| Development | OCR and parsing all pdf documents with AI | 28gCO2e | CodeCarbon |
| Development | Question Answering development | 114gCO2e | CodeCarbon |
| Inference | Question Answering | ~0.102gCO2e / call | CodeCarbon |
| Inference | API call to turbo-GPT | ~0.38gCO2e / call | https://medium.com/@chrispointon/the-carbon-footprint-of-chatgpt-e1bc14e4cc2a |
Carbon Emissions are **relatively low but not negligible** compared to other usages: one question asked to ClimateQ&A is around 0.482gCO2e - equivalent to 2.2m by car (https://datagir.ademe.fr/apps/impact-co2/)
Or around 2 to 4 times more than a typical Google search.
"""
)
with gr.Tab("🪄 Changelog"):
gr.Markdown("""
##### v1.1.0 - *2023-10-16*
- ClimateQ&A on Hugging Face is finally working again with all the new features !
- Switched all python code to langchain codebase for cleaner code, easier maintenance and future features
- Updated GPT model to August version
- Added streaming response to improve UX
- Created a custom Retriever chain to avoid calling the LLM if there is no documents retrieved
- Use of HuggingFace embed on https://climateqa.com to avoid demultiplying deployments
##### v1.0.0 - *2023-05-11*
- First version of clean interface on https://climateqa.com
- Add children mode on https://climateqa.com
- Add follow-up questions https://climateqa.com
"""
)
demo.queue(concurrency_count=16)
demo.launch()