Spaces:
Runtime error

Runtime error
Add application file
Browse files- README.md +125 -13
- app.py +39 -0
- get_data.py +852 -0
- img/mid.png +0 -0
- img/onet.png +0 -0
- img/pnet.png +0 -0
- img/result.png +0 -0
- img/rnet.png +0 -0
- model_store/onet_epoch_20.pt +3 -0
- model_store/pnet_epoch_20.pt +3 -0
- model_store/rnet_epoch_20.pt +3 -0
- requirements.txt +10 -0
- test.py +84 -0
- test.sh +4 -0
- train.out +0 -0
- train.py +351 -0
- train.sh +7 -0
- utils/config.py +42 -0
- utils/dataloader.py +347 -0
- utils/detect.py +758 -0
- utils/models.py +207 -0
- utils/tool.py +117 -0
- utils/vision.py +58 -0
README.md
CHANGED
|
@@ -1,13 +1,125 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
|
| 2 |
+
|
| 3 |
+
This repo contains the code, data and trained models for the paper [Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks](https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf).
|
| 4 |
+
|
| 5 |
+
## Overview
|
| 6 |
+
|
| 7 |
+
MTCNN is a popular algorithm for face detection that uses multiple neural networks to detect faces in images. It is capable of detecting faces under various lighting and pose conditions and can detect multiple faces in an image.
|
| 8 |
+
|
| 9 |
+
We have implemented MTCNN using the pytorch framework. Pytorch is a popular deep learning framework that provides tools for building and training neural networks.
|
| 10 |
+
|
| 11 |
+
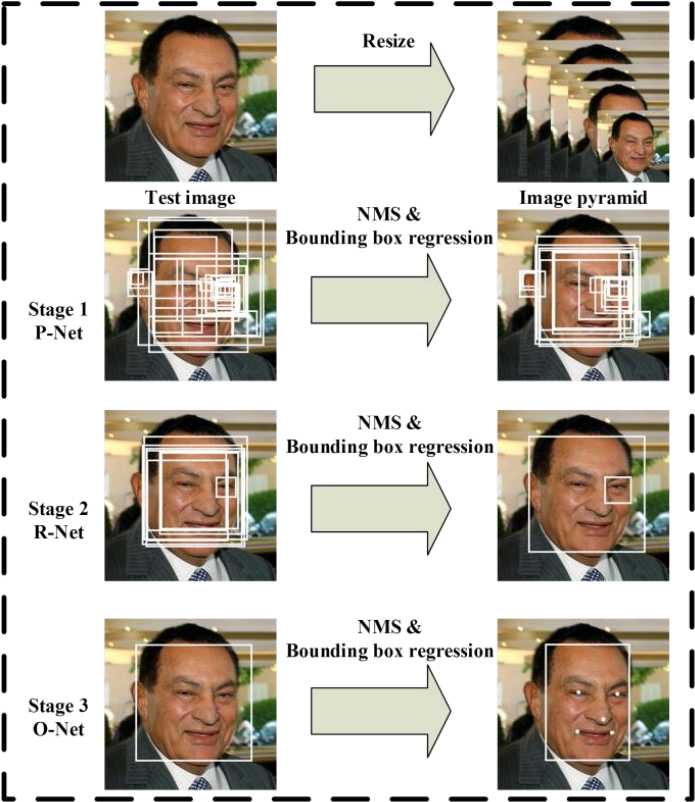
|
| 12 |
+
|
| 13 |
+
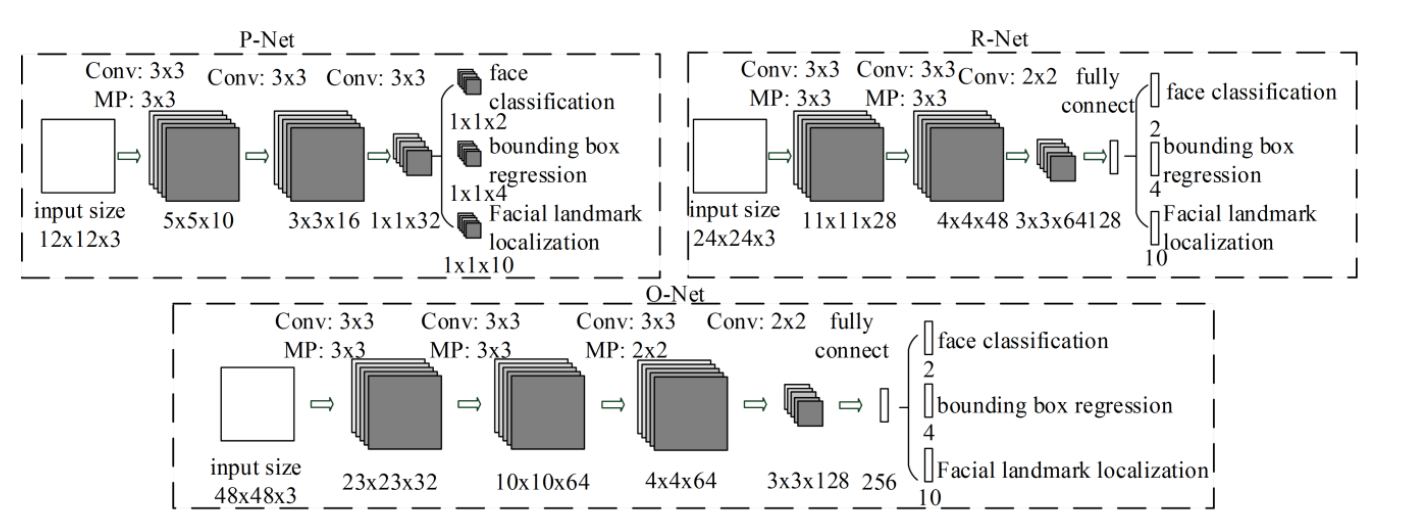
|
| 14 |
+
## Description of file
|
| 15 |
+
```shell
|
| 16 |
+
├── README.md # explanatory document
|
| 17 |
+
├── get_data.py # Generate corresponding training data depending on the input “--net”
|
| 18 |
+
├── img # mid.png is used for testing visualization effects,other images are the corresponding results.
|
| 19 |
+
│ ├── mid.png
|
| 20 |
+
│ ├── onet.png
|
| 21 |
+
│ ├── pnet.png
|
| 22 |
+
│ ├── rnet.png
|
| 23 |
+
│ ├── result.png
|
| 24 |
+
│ └── result.jpg
|
| 25 |
+
├── model_store # Our pre-trained model
|
| 26 |
+
│ ├── onet_epoch_20.pt
|
| 27 |
+
│ ├── pnet_epoch_20.pt
|
| 28 |
+
│ └── rnet_epoch_20.pt
|
| 29 |
+
├── requirements.txt # Environmental version requirements
|
| 30 |
+
├── test.py # Specify different "--net" to get the corresponding visualization results
|
| 31 |
+
├── test.sh # Used to test mid.png, which will test the output visualization of three networks
|
| 32 |
+
├── train.out # Our complete training log for this experiment
|
| 33 |
+
├── train.py # Specify different "--net" for the training of the corresponding network
|
| 34 |
+
├── train.sh # Generate data from start to finish and train
|
| 35 |
+
└── utils # Some common tool functions and modules
|
| 36 |
+
├── config.py
|
| 37 |
+
├── dataloader.py
|
| 38 |
+
├── detect.py
|
| 39 |
+
├── models.py
|
| 40 |
+
├── tool.py
|
| 41 |
+
└── vision.py
|
| 42 |
+
```
|
| 43 |
+
## Requirements
|
| 44 |
+
|
| 45 |
+
* numpy==1.21.4
|
| 46 |
+
* matplotlib==3.5.0
|
| 47 |
+
* opencv-python==4.4.0.42
|
| 48 |
+
* torch==1.13.0+cu116
|
| 49 |
+
|
| 50 |
+
## How to Install
|
| 51 |
+
|
| 52 |
+
- ```shell
|
| 53 |
+
conda create -n env python=3.8 -y
|
| 54 |
+
conda activate env
|
| 55 |
+
```
|
| 56 |
+
- ```shell
|
| 57 |
+
pip install -r requirements.txt
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## Preprocessing
|
| 61 |
+
|
| 62 |
+
- download [WIDER_FACE](http://shuoyang1213.me/WIDERFACE/) face detection data then store it into ./data_set/face_detection
|
| 63 |
+
- download [CNN_FacePoint](http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm) face detection and landmark data then store it into ./data_set/face_landmark
|
| 64 |
+
|
| 65 |
+
### Preprocessed Data
|
| 66 |
+
|
| 67 |
+
```shell
|
| 68 |
+
# Before training Pnet
|
| 69 |
+
python get_data.py --net=pnet
|
| 70 |
+
# Before training Rnet, please use your trained model path
|
| 71 |
+
python get_data.py --net=rnet --pnet_path=./model_store/pnet_epoch_20.pt
|
| 72 |
+
# Before training Onet, please use your trained model path
|
| 73 |
+
python get_data.py --net=onet --pnet_path=./model_store/pnet_epoch_20.pt --rnet_path=./model_store/rnet_epoch_20.pt
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
## How to Run
|
| 77 |
+
|
| 78 |
+
### Train
|
| 79 |
+
|
| 80 |
+
```shell
|
| 81 |
+
python train.py --net=pnet/rnet/onet #Specify the corresponding network to start training
|
| 82 |
+
bash train.sh #Alternatively, use the sh file to train in order
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
The checkpoints will be saved in a subfolder of `./model_store/*`.
|
| 86 |
+
|
| 87 |
+
#### Finetuning from an existing checkpoint
|
| 88 |
+
|
| 89 |
+
```shell
|
| 90 |
+
python train.py --net=pnet/rnet/onet --load=[model path]
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
model path should be a subdirectory in the `./model_store/` directory, e.g. `--load=./model_store/pnet_epoch_20.pt`
|
| 94 |
+
|
| 95 |
+
### Evaluate
|
| 96 |
+
|
| 97 |
+
#### Use the sh file to test in order
|
| 98 |
+
|
| 99 |
+
```shell
|
| 100 |
+
bash test.sh
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
#### To detect a single image
|
| 104 |
+
|
| 105 |
+
```shell
|
| 106 |
+
python test.py --net=pnet/rnet/onet --path=test.jpg
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
#### To detect a video stream from a camera
|
| 110 |
+
|
| 111 |
+
```shell
|
| 112 |
+
python test.py --input_mode=0
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
#### The result of "--net=pnet"
|
| 116 |
+
|
| 117 |
+

|
| 118 |
+
|
| 119 |
+
#### The result of "--net=rnet"
|
| 120 |
+
|
| 121 |
+

|
| 122 |
+
|
| 123 |
+
#### The result of "--net=onet"
|
| 124 |
+
|
| 125 |
+

|
app.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
import cv2
|
| 3 |
+
from utils.detect import create_mtcnn_net, MtcnnDetector
|
| 4 |
+
from utils.vision import vis_face
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
MIN_FACE_SIZE = 3
|
| 9 |
+
|
| 10 |
+
def parse_args():
|
| 11 |
+
parser = argparse.ArgumentParser(description='Test MTCNN',
|
| 12 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 13 |
+
|
| 14 |
+
parser.add_argument('--net', default='onet', help='which net to show', type=str)
|
| 15 |
+
parser.add_argument('--pnet_path', default="./model_store/pnet_epoch_20.pt",help='path to pnet model', type=str)
|
| 16 |
+
parser.add_argument('--rnet_path', default="./model_store/rnet_epoch_20.pt",help='path to rnet model', type=str)
|
| 17 |
+
parser.add_argument('--onet_path', default="./model_store/onet_epoch_20.pt",help='path to onet model', type=str)
|
| 18 |
+
parser.add_argument('--path', default="./img/mid.png",help='path to image', type=str)
|
| 19 |
+
parser.add_argument('--min_face_size', default=MIN_FACE_SIZE,help='min face size', type=int)
|
| 20 |
+
parser.add_argument('--use_cuda', default=False,help='use cuda', type=bool)
|
| 21 |
+
parser.add_argument('--thresh', default='[0.1, 0.1, 0.1]',help='thresh', type=str)
|
| 22 |
+
parser.add_argument('--save_name', default="result.jpg",help='save name', type=str)
|
| 23 |
+
parser.add_argument('--input_mode', default=1,help='image or video', type=int)
|
| 24 |
+
args = parser.parse_args()
|
| 25 |
+
return args
|
| 26 |
+
def greet(name):
|
| 27 |
+
args = parse_args()
|
| 28 |
+
thresh = [float(i) for i in (args.thresh).split('[')[1].split(']')[0].split(',')]
|
| 29 |
+
pnet, rnet, onet = create_mtcnn_net(p_model_path=args.pnet_path, r_model_path=args.rnet_path,o_model_path=args.onet_path, use_cuda=args.use_cuda)
|
| 30 |
+
mtcnn_detector = MtcnnDetector(pnet=pnet, rnet=rnet, onet=onet, min_face_size=args.min_face_size,threshold=thresh)
|
| 31 |
+
img = cv2.imread(name)
|
| 32 |
+
img_bg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 33 |
+
p_bboxs, r_bboxs, bboxs, landmarks = mtcnn_detector.detect_face(img)
|
| 34 |
+
save_name = args.save_name
|
| 35 |
+
return vis_face(img_bg, bboxs, landmarks, MIN_FACE_SIZE, save_name)
|
| 36 |
+
iface = gr.Interface(fn=greet,
|
| 37 |
+
inputs=gr.Image(type="filepath"),
|
| 38 |
+
outputs="image")
|
| 39 |
+
iface.launch()
|
get_data.py
ADDED
|
@@ -0,0 +1,852 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2
|
| 4 |
+
import os
|
| 5 |
+
from utils.tool import IoU,convert_to_square
|
| 6 |
+
import numpy.random as npr
|
| 7 |
+
import argparse
|
| 8 |
+
from utils.detect import MtcnnDetector, create_mtcnn_net
|
| 9 |
+
from utils.dataloader import ImageDB,TestImageLoader
|
| 10 |
+
import time
|
| 11 |
+
from six.moves import cPickle
|
| 12 |
+
import utils.config as config
|
| 13 |
+
import utils.vision as vision
|
| 14 |
+
sys.path.append(os.getcwd())
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
txt_from_path = './data_set/wider_face_train_bbx_gt.txt'
|
| 18 |
+
anno_file = os.path.join(config.ANNO_STORE_DIR, 'anno_train.txt')
|
| 19 |
+
# anno_file = './anno_store/anno_train.txt'
|
| 20 |
+
|
| 21 |
+
prefix = ''
|
| 22 |
+
use_cuda = True
|
| 23 |
+
im_dir = "./data_set/face_detection/WIDER_train/images/"
|
| 24 |
+
traindata_store = './data_set/train/'
|
| 25 |
+
prefix_path = "./data_set/face_detection/WIDER_train/images/"
|
| 26 |
+
annotation_file = './anno_store/anno_train.txt'
|
| 27 |
+
prefix_path_lm = ''
|
| 28 |
+
annotation_file_lm = "./data_set/face_landmark/CNN_FacePoint/train/trainImageList.txt"
|
| 29 |
+
# ----------------------------------------------------other----------------------------------------------
|
| 30 |
+
pos_save_dir = "./data_set/train/12/positive"
|
| 31 |
+
part_save_dir = "./data_set/train/12/part"
|
| 32 |
+
neg_save_dir = './data_set/train/12/negative'
|
| 33 |
+
pnet_postive_file = os.path.join(config.ANNO_STORE_DIR, 'pos_12.txt')
|
| 34 |
+
pnet_part_file = os.path.join(config.ANNO_STORE_DIR, 'part_12.txt')
|
| 35 |
+
pnet_neg_file = os.path.join(config.ANNO_STORE_DIR, 'neg_12.txt')
|
| 36 |
+
imglist_filename_pnet = os.path.join(config.ANNO_STORE_DIR, 'imglist_anno_12.txt')
|
| 37 |
+
# ----------------------------------------------------PNet----------------------------------------------
|
| 38 |
+
rnet_postive_file = os.path.join(config.ANNO_STORE_DIR, 'pos_24.txt')
|
| 39 |
+
rnet_part_file = os.path.join(config.ANNO_STORE_DIR, 'part_24.txt')
|
| 40 |
+
rnet_neg_file = os.path.join(config.ANNO_STORE_DIR, 'neg_24.txt')
|
| 41 |
+
rnet_landmark_file = os.path.join(config.ANNO_STORE_DIR, 'landmark_24.txt')
|
| 42 |
+
imglist_filename_rnet = os.path.join(config.ANNO_STORE_DIR, 'imglist_anno_24.txt')
|
| 43 |
+
# ----------------------------------------------------RNet----------------------------------------------
|
| 44 |
+
onet_postive_file = os.path.join(config.ANNO_STORE_DIR, 'pos_48.txt')
|
| 45 |
+
onet_part_file = os.path.join(config.ANNO_STORE_DIR, 'part_48.txt')
|
| 46 |
+
onet_neg_file = os.path.join(config.ANNO_STORE_DIR, 'neg_48.txt')
|
| 47 |
+
onet_landmark_file = os.path.join(config.ANNO_STORE_DIR, 'landmark_48.txt')
|
| 48 |
+
imglist_filename_onet = os.path.join(config.ANNO_STORE_DIR, 'imglist_anno_48.txt')
|
| 49 |
+
# ----------------------------------------------------ONet----------------------------------------------
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def assemble_data(output_file, anno_file_list=[]):
|
| 54 |
+
|
| 55 |
+
#assemble the pos, neg, part annotations to one file
|
| 56 |
+
size = 12
|
| 57 |
+
|
| 58 |
+
if len(anno_file_list)==0:
|
| 59 |
+
return 0
|
| 60 |
+
|
| 61 |
+
if os.path.exists(output_file):
|
| 62 |
+
os.remove(output_file)
|
| 63 |
+
|
| 64 |
+
for anno_file in anno_file_list:
|
| 65 |
+
with open(anno_file, 'r') as f:
|
| 66 |
+
print(anno_file)
|
| 67 |
+
anno_lines = f.readlines()
|
| 68 |
+
|
| 69 |
+
base_num = 250000
|
| 70 |
+
|
| 71 |
+
if len(anno_lines) > base_num * 3:
|
| 72 |
+
idx_keep = npr.choice(len(anno_lines), size=base_num * 3, replace=True)
|
| 73 |
+
elif len(anno_lines) > 100000:
|
| 74 |
+
idx_keep = npr.choice(len(anno_lines), size=len(anno_lines), replace=True)
|
| 75 |
+
else:
|
| 76 |
+
idx_keep = np.arange(len(anno_lines))
|
| 77 |
+
np.random.shuffle(idx_keep)
|
| 78 |
+
chose_count = 0
|
| 79 |
+
with open(output_file, 'a+') as f:
|
| 80 |
+
for idx in idx_keep:
|
| 81 |
+
# write lables of pos, neg, part images
|
| 82 |
+
f.write(anno_lines[idx])
|
| 83 |
+
chose_count+=1
|
| 84 |
+
|
| 85 |
+
return chose_count
|
| 86 |
+
def wider_face(txt_from_path, txt_to_path):
|
| 87 |
+
line_from_count = 0
|
| 88 |
+
with open(txt_from_path, 'r') as f:
|
| 89 |
+
annotations = f.readlines()
|
| 90 |
+
with open(txt_to_path, 'w+') as f:
|
| 91 |
+
while line_from_count < len(annotations):
|
| 92 |
+
if annotations[line_from_count][2]=='-':
|
| 93 |
+
img_name = annotations[line_from_count][:-1]
|
| 94 |
+
line_from_count += 1 # change line to read the number
|
| 95 |
+
bbox_count = int(annotations[line_from_count]) # num of bboxes
|
| 96 |
+
line_from_count += 1 # change line to read the posession
|
| 97 |
+
for _ in range(bbox_count):
|
| 98 |
+
bbox = list(map(int,annotations[line_from_count].split()[:4])) # give a loop to append all the boxes
|
| 99 |
+
bbox = [bbox[0], bbox[1], bbox[0]+bbox[2], bbox[1]+bbox[3]] # make x1, y1, w, h --> x1, y1, x2, y2
|
| 100 |
+
bbox = list(map(str,bbox))
|
| 101 |
+
img_name += (' '+' '.join(bbox))
|
| 102 |
+
line_from_count+=1
|
| 103 |
+
f.write(img_name +'\n')
|
| 104 |
+
else: # dectect the file name
|
| 105 |
+
line_from_count+=1
|
| 106 |
+
|
| 107 |
+
# ----------------------------------------------------origin----------------------------------------------
|
| 108 |
+
def get_Pnet_data():
|
| 109 |
+
if not os.path.exists(pos_save_dir):
|
| 110 |
+
os.makedirs(pos_save_dir)
|
| 111 |
+
if not os.path.exists(part_save_dir):
|
| 112 |
+
os.makedirs(part_save_dir)
|
| 113 |
+
if not os.path.exists(neg_save_dir):
|
| 114 |
+
os.makedirs(neg_save_dir)
|
| 115 |
+
f1 = open(os.path.join('./anno_store', 'pos_12.txt'), 'w')
|
| 116 |
+
f2 = open(os.path.join('./anno_store', 'neg_12.txt'), 'w')
|
| 117 |
+
f3 = open(os.path.join('./anno_store', 'part_12.txt'), 'w')
|
| 118 |
+
with open(anno_file, 'r') as f:
|
| 119 |
+
annotations = f.readlines()
|
| 120 |
+
num = len(annotations)
|
| 121 |
+
print("%d pics in total" % num)
|
| 122 |
+
p_idx = 0 # positive
|
| 123 |
+
n_idx = 0 # negative
|
| 124 |
+
d_idx = 0 # dont care
|
| 125 |
+
idx = 0
|
| 126 |
+
box_idx = 0
|
| 127 |
+
for annotation in annotations:
|
| 128 |
+
annotation = annotation.strip().split(' ')
|
| 129 |
+
# annotation[0]文件名
|
| 130 |
+
im_path = os.path.join(im_dir, annotation[0])
|
| 131 |
+
# print(im_path)
|
| 132 |
+
# print(os.path.exists(im_path))
|
| 133 |
+
bbox = list(map(float, annotation[1:]))
|
| 134 |
+
# annotation[1:]人脸坐标,一张脸4个值,对应两个点的坐标
|
| 135 |
+
boxes = np.array(bbox, dtype=np.int32).reshape(-1, 4)
|
| 136 |
+
# -1处的值为人脸数目
|
| 137 |
+
if boxes.shape[0]==0:
|
| 138 |
+
continue
|
| 139 |
+
# 若无人脸则跳过本次循环
|
| 140 |
+
img = cv2.imread(im_path)
|
| 141 |
+
# print(img.shape)
|
| 142 |
+
# exit()
|
| 143 |
+
# 计数
|
| 144 |
+
idx += 1
|
| 145 |
+
if idx % 100 == 0:
|
| 146 |
+
print("%s images done, pos: %s part: %s neg: %s" % (idx, p_idx, d_idx, n_idx))
|
| 147 |
+
|
| 148 |
+
# 图片三通道
|
| 149 |
+
height, width, channel = img.shape
|
| 150 |
+
|
| 151 |
+
neg_num = 0
|
| 152 |
+
|
| 153 |
+
# 取50次不同的框
|
| 154 |
+
while neg_num < 50:
|
| 155 |
+
size = np.random.randint(12, min(width, height) / 2)
|
| 156 |
+
nx = np.random.randint(0, width - size)
|
| 157 |
+
ny = np.random.randint(0, height - size)
|
| 158 |
+
crop_box = np.array([nx, ny, nx + size, ny + size])
|
| 159 |
+
|
| 160 |
+
Iou = IoU(crop_box, boxes) # IoU为 重合部分 / 两框之和 ,越大越好
|
| 161 |
+
|
| 162 |
+
cropped_im = img[ny: ny + size, nx: nx + size, :] # 裁去多余部分并resize成 12*12
|
| 163 |
+
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
|
| 164 |
+
|
| 165 |
+
if np.max(Iou) < 0.3:
|
| 166 |
+
# Iou with all gts must below 0.3
|
| 167 |
+
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
|
| 168 |
+
f2.write(save_file + ' 0\n')
|
| 169 |
+
cv2.imwrite(save_file, resized_im)
|
| 170 |
+
n_idx += 1
|
| 171 |
+
neg_num += 1
|
| 172 |
+
|
| 173 |
+
for box in boxes:
|
| 174 |
+
# box (x_left, y_top, x_right, y_bottom)
|
| 175 |
+
x1, y1, x2, y2 = box
|
| 176 |
+
# w = x2 - x1 + 1
|
| 177 |
+
# h = y2 - y1 + 1
|
| 178 |
+
w = x2 - x1 + 1
|
| 179 |
+
h = y2 - y1 + 1
|
| 180 |
+
|
| 181 |
+
# ignore small faces
|
| 182 |
+
# in case the ground truth boxes of small faces are not accurate
|
| 183 |
+
if max(w, h) < 40 or x1 < 0 or y1 < 0:
|
| 184 |
+
continue
|
| 185 |
+
if w < 12 or h < 12:
|
| 186 |
+
continue
|
| 187 |
+
|
| 188 |
+
# generate negative examples that have overlap with gt
|
| 189 |
+
for i in range(5):
|
| 190 |
+
size = np.random.randint(12, min(width, height) / 2)
|
| 191 |
+
|
| 192 |
+
# delta_x and delta_y are offsets of (x1, y1)
|
| 193 |
+
delta_x = np.random.randint(max(-size, -x1), w)
|
| 194 |
+
delta_y = np.random.randint(max(-size, -y1), h)
|
| 195 |
+
nx1 = max(0, x1 + delta_x)
|
| 196 |
+
ny1 = max(0, y1 + delta_y)
|
| 197 |
+
|
| 198 |
+
if nx1 + size > width or ny1 + size > height:
|
| 199 |
+
continue
|
| 200 |
+
crop_box = np.array([nx1, ny1, nx1 + size, ny1 + size])
|
| 201 |
+
Iou = IoU(crop_box, boxes)
|
| 202 |
+
|
| 203 |
+
cropped_im = img[ny1: ny1 + size, nx1: nx1 + size, :]
|
| 204 |
+
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
|
| 205 |
+
|
| 206 |
+
if np.max(Iou) < 0.3:
|
| 207 |
+
# Iou with all gts must below 0.3
|
| 208 |
+
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
|
| 209 |
+
f2.write(save_file + ' 0\n')
|
| 210 |
+
cv2.imwrite(save_file, resized_im)
|
| 211 |
+
n_idx += 1
|
| 212 |
+
|
| 213 |
+
# generate positive examples and part faces
|
| 214 |
+
for i in range(20):
|
| 215 |
+
size = np.random.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
|
| 216 |
+
|
| 217 |
+
# delta here is the offset of box center
|
| 218 |
+
delta_x = np.random.randint(-w * 0.2, w * 0.2)
|
| 219 |
+
delta_y = np.random.randint(-h * 0.2, h * 0.2)
|
| 220 |
+
|
| 221 |
+
nx1 = max(x1 + w / 2 + delta_x - size / 2, 0)
|
| 222 |
+
ny1 = max(y1 + h / 2 + delta_y - size / 2, 0)
|
| 223 |
+
nx2 = nx1 + size
|
| 224 |
+
ny2 = ny1 + size
|
| 225 |
+
|
| 226 |
+
if nx2 > width or ny2 > height:
|
| 227 |
+
continue
|
| 228 |
+
crop_box = np.array([nx1, ny1, nx2, ny2])
|
| 229 |
+
|
| 230 |
+
offset_x1 = (x1 - nx1) / float(size)
|
| 231 |
+
offset_y1 = (y1 - ny1) / float(size)
|
| 232 |
+
offset_x2 = (x2 - nx2) / float(size)
|
| 233 |
+
offset_y2 = (y2 - ny2) / float(size)
|
| 234 |
+
|
| 235 |
+
cropped_im = img[int(ny1): int(ny2), int(nx1): int(nx2), :]
|
| 236 |
+
resized_im = cv2.resize(cropped_im, (12, 12), interpolation=cv2.INTER_LINEAR)
|
| 237 |
+
|
| 238 |
+
box_ = box.reshape(1, -1)
|
| 239 |
+
if IoU(crop_box, box_) >= 0.65:
|
| 240 |
+
save_file = os.path.join(pos_save_dir, "%s.jpg" % p_idx)
|
| 241 |
+
f1.write(save_file + ' 1 %.2f %.2f %.2f %.2f\n' % (offset_x1, offset_y1, offset_x2, offset_y2))
|
| 242 |
+
cv2.imwrite(save_file, resized_im)
|
| 243 |
+
p_idx += 1
|
| 244 |
+
elif IoU(crop_box, box_) >= 0.4:
|
| 245 |
+
save_file = os.path.join(part_save_dir, "%s.jpg" % d_idx)
|
| 246 |
+
f3.write(save_file + ' -1 %.2f %.2f %.2f %.2f\n' % (offset_x1, offset_y1, offset_x2, offset_y2))
|
| 247 |
+
cv2.imwrite(save_file, resized_im)
|
| 248 |
+
d_idx += 1
|
| 249 |
+
box_idx += 1
|
| 250 |
+
#print("%s images done, pos: %s part: %s neg: %s" % (idx, p_idx, d_idx, n_idx))
|
| 251 |
+
|
| 252 |
+
f1.close()
|
| 253 |
+
f2.close()
|
| 254 |
+
f3.close()
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
def assembel_Pnet_data():
|
| 258 |
+
anno_list = []
|
| 259 |
+
|
| 260 |
+
anno_list.append(pnet_postive_file)
|
| 261 |
+
anno_list.append(pnet_part_file)
|
| 262 |
+
anno_list.append(pnet_neg_file)
|
| 263 |
+
# anno_list.append(pnet_landmark_file)
|
| 264 |
+
chose_count = assemble_data(imglist_filename_pnet ,anno_list)
|
| 265 |
+
print("PNet train annotation result file path:%s" % imglist_filename_pnet)
|
| 266 |
+
|
| 267 |
+
# -----------------------------------------------------------------------------------------------------------------------------------------------#
|
| 268 |
+
|
| 269 |
+
def gen_rnet_data(data_dir, anno_file, pnet_model_file, prefix_path='', use_cuda=True, vis=False):
|
| 270 |
+
|
| 271 |
+
"""
|
| 272 |
+
:param data_dir: train data
|
| 273 |
+
:param anno_file:
|
| 274 |
+
:param pnet_model_file:
|
| 275 |
+
:param prefix_path:
|
| 276 |
+
:param use_cuda:
|
| 277 |
+
:param vis:
|
| 278 |
+
:return:
|
| 279 |
+
"""
|
| 280 |
+
|
| 281 |
+
# load trained pnet model
|
| 282 |
+
|
| 283 |
+
pnet, _, _ = create_mtcnn_net(p_model_path = pnet_model_file, use_cuda = use_cuda)
|
| 284 |
+
mtcnn_detector = MtcnnDetector(pnet = pnet, min_face_size = 12)
|
| 285 |
+
|
| 286 |
+
# load original_anno_file, length = 12880
|
| 287 |
+
imagedb = ImageDB(anno_file, mode = "test", prefix_path = prefix_path)
|
| 288 |
+
imdb = imagedb.load_imdb()
|
| 289 |
+
image_reader = TestImageLoader(imdb, 1, False)
|
| 290 |
+
|
| 291 |
+
all_boxes = list()
|
| 292 |
+
batch_idx = 0
|
| 293 |
+
|
| 294 |
+
print('size:%d' %image_reader.size)
|
| 295 |
+
for databatch in image_reader:
|
| 296 |
+
if batch_idx % 100 == 0:
|
| 297 |
+
print ("%d images done" % batch_idx)
|
| 298 |
+
im = databatch
|
| 299 |
+
t = time.time()
|
| 300 |
+
|
| 301 |
+
# obtain boxes and aligned boxes
|
| 302 |
+
boxes, boxes_align = mtcnn_detector.detect_pnet(im=im)
|
| 303 |
+
if boxes_align is None:
|
| 304 |
+
all_boxes.append(np.array([]))
|
| 305 |
+
batch_idx += 1
|
| 306 |
+
continue
|
| 307 |
+
if vis:
|
| 308 |
+
rgb_im = cv2.cvtColor(np.asarray(im), cv2.COLOR_BGR2RGB)
|
| 309 |
+
vision.vis_two(rgb_im, boxes, boxes_align)
|
| 310 |
+
|
| 311 |
+
t1 = time.time() - t
|
| 312 |
+
print('cost time ',t1)
|
| 313 |
+
t = time.time()
|
| 314 |
+
all_boxes.append(boxes_align)
|
| 315 |
+
batch_idx += 1
|
| 316 |
+
# if batch_idx == 100:
|
| 317 |
+
# break
|
| 318 |
+
# print("shape of all boxes {0}".format(all_boxes))
|
| 319 |
+
# time.sleep(5)
|
| 320 |
+
|
| 321 |
+
# save_path = model_store_path()
|
| 322 |
+
# './model_store'
|
| 323 |
+
save_path = './model_store'
|
| 324 |
+
|
| 325 |
+
if not os.path.exists(save_path):
|
| 326 |
+
os.mkdir(save_path)
|
| 327 |
+
|
| 328 |
+
save_file = os.path.join(save_path, "detections_%d.pkl" % int(time.time()))
|
| 329 |
+
with open(save_file, 'wb') as f:
|
| 330 |
+
cPickle.dump(all_boxes, f, cPickle.HIGHEST_PROTOCOL)
|
| 331 |
+
|
| 332 |
+
# save_file = './model_store/detections_1588751332.pkl'
|
| 333 |
+
gen_rnet_sample_data(data_dir, anno_file, save_file, prefix_path)
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
def gen_rnet_sample_data(data_dir, anno_file, det_boxs_file, prefix_path):
|
| 338 |
+
|
| 339 |
+
"""
|
| 340 |
+
:param data_dir:
|
| 341 |
+
:param anno_file: original annotations file of wider face data
|
| 342 |
+
:param det_boxs_file: detection boxes file
|
| 343 |
+
:param prefix_path:
|
| 344 |
+
:return:
|
| 345 |
+
"""
|
| 346 |
+
|
| 347 |
+
neg_save_dir = os.path.join(data_dir, "24/negative")
|
| 348 |
+
pos_save_dir = os.path.join(data_dir, "24/positive")
|
| 349 |
+
part_save_dir = os.path.join(data_dir, "24/part")
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
for dir_path in [neg_save_dir, pos_save_dir, part_save_dir]:
|
| 353 |
+
# print(dir_path)
|
| 354 |
+
if not os.path.exists(dir_path):
|
| 355 |
+
os.makedirs(dir_path)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
# load ground truth from annotation file
|
| 359 |
+
# format of each line: image/path [x1,y1,x2,y2] for each gt_box in this image
|
| 360 |
+
|
| 361 |
+
with open(anno_file, 'r') as f:
|
| 362 |
+
annotations = f.readlines()
|
| 363 |
+
|
| 364 |
+
image_size = 24
|
| 365 |
+
net = "rnet"
|
| 366 |
+
|
| 367 |
+
im_idx_list = list()
|
| 368 |
+
gt_boxes_list = list()
|
| 369 |
+
num_of_images = len(annotations)
|
| 370 |
+
print ("processing %d images in total" % num_of_images)
|
| 371 |
+
|
| 372 |
+
for annotation in annotations:
|
| 373 |
+
annotation = annotation.strip().split(' ')
|
| 374 |
+
im_idx = os.path.join(prefix_path, annotation[0])
|
| 375 |
+
# im_idx = annotation[0]
|
| 376 |
+
|
| 377 |
+
boxes = list(map(float, annotation[1:]))
|
| 378 |
+
boxes = np.array(boxes, dtype=np.float32).reshape(-1, 4)
|
| 379 |
+
im_idx_list.append(im_idx)
|
| 380 |
+
gt_boxes_list.append(boxes)
|
| 381 |
+
|
| 382 |
+
|
| 383 |
+
# './anno_store'
|
| 384 |
+
save_path = './anno_store'
|
| 385 |
+
if not os.path.exists(save_path):
|
| 386 |
+
os.makedirs(save_path)
|
| 387 |
+
|
| 388 |
+
f1 = open(os.path.join(save_path, 'pos_%d.txt' % image_size), 'w')
|
| 389 |
+
f2 = open(os.path.join(save_path, 'neg_%d.txt' % image_size), 'w')
|
| 390 |
+
f3 = open(os.path.join(save_path, 'part_%d.txt' % image_size), 'w')
|
| 391 |
+
|
| 392 |
+
# print(det_boxs_file)
|
| 393 |
+
det_handle = open(det_boxs_file, 'rb')
|
| 394 |
+
|
| 395 |
+
det_boxes = cPickle.load(det_handle)
|
| 396 |
+
|
| 397 |
+
# an image contain many boxes stored in an array
|
| 398 |
+
print(len(det_boxes), num_of_images)
|
| 399 |
+
# assert len(det_boxes) == num_of_images, "incorrect detections or ground truths"
|
| 400 |
+
|
| 401 |
+
# index of neg, pos and part face, used as their image names
|
| 402 |
+
n_idx = 0
|
| 403 |
+
p_idx = 0
|
| 404 |
+
d_idx = 0
|
| 405 |
+
image_done = 0
|
| 406 |
+
for im_idx, dets, gts in zip(im_idx_list, det_boxes, gt_boxes_list):
|
| 407 |
+
|
| 408 |
+
# if (im_idx+1) == 100:
|
| 409 |
+
# break
|
| 410 |
+
|
| 411 |
+
gts = np.array(gts, dtype=np.float32).reshape(-1, 4)
|
| 412 |
+
if gts.shape[0]==0:
|
| 413 |
+
continue
|
| 414 |
+
if image_done % 100 == 0:
|
| 415 |
+
print("%d images done" % image_done)
|
| 416 |
+
image_done += 1
|
| 417 |
+
|
| 418 |
+
if dets.shape[0] == 0:
|
| 419 |
+
continue
|
| 420 |
+
img = cv2.imread(im_idx)
|
| 421 |
+
# change to square
|
| 422 |
+
dets = convert_to_square(dets)
|
| 423 |
+
dets[:, 0:4] = np.round(dets[:, 0:4])
|
| 424 |
+
neg_num = 0
|
| 425 |
+
for box in dets:
|
| 426 |
+
x_left, y_top, x_right, y_bottom, _ = box.astype(int)
|
| 427 |
+
width = x_right - x_left + 1
|
| 428 |
+
height = y_bottom - y_top + 1
|
| 429 |
+
|
| 430 |
+
# ignore box that is too small or beyond image border
|
| 431 |
+
if width < 20 or x_left < 0 or y_top < 0 or x_right > img.shape[1] - 1 or y_bottom > img.shape[0] - 1:
|
| 432 |
+
continue
|
| 433 |
+
|
| 434 |
+
# compute intersection over union(IoU) between current box and all gt boxes
|
| 435 |
+
Iou = IoU(box, gts)
|
| 436 |
+
cropped_im = img[y_top:y_bottom + 1, x_left:x_right + 1, :]
|
| 437 |
+
resized_im = cv2.resize(cropped_im, (image_size, image_size),
|
| 438 |
+
interpolation=cv2.INTER_LINEAR)
|
| 439 |
+
|
| 440 |
+
# save negative images and write label
|
| 441 |
+
# Iou with all gts must below 0.3
|
| 442 |
+
if np.max(Iou) < 0.3 and neg_num < 60:
|
| 443 |
+
# save the examples
|
| 444 |
+
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
|
| 445 |
+
# print(save_file)
|
| 446 |
+
f2.write(save_file + ' 0\n')
|
| 447 |
+
cv2.imwrite(save_file, resized_im)
|
| 448 |
+
n_idx += 1
|
| 449 |
+
neg_num += 1
|
| 450 |
+
else:
|
| 451 |
+
# find gt_box with the highest iou
|
| 452 |
+
idx = np.argmax(Iou)
|
| 453 |
+
assigned_gt = gts[idx]
|
| 454 |
+
x1, y1, x2, y2 = assigned_gt
|
| 455 |
+
|
| 456 |
+
# compute bbox reg label
|
| 457 |
+
offset_x1 = (x1 - x_left) / float(width)
|
| 458 |
+
offset_y1 = (y1 - y_top) / float(height)
|
| 459 |
+
offset_x2 = (x2 - x_right) / float(width)
|
| 460 |
+
offset_y2 = (y2 - y_bottom) / float(height)
|
| 461 |
+
|
| 462 |
+
# save positive and part-face images and write labels
|
| 463 |
+
if np.max(Iou) >= 0.65:
|
| 464 |
+
save_file = os.path.join(pos_save_dir, "%s.jpg" % p_idx)
|
| 465 |
+
f1.write(save_file + ' 1 %.2f %.2f %.2f %.2f\n' % (
|
| 466 |
+
offset_x1, offset_y1, offset_x2, offset_y2))
|
| 467 |
+
cv2.imwrite(save_file, resized_im)
|
| 468 |
+
p_idx += 1
|
| 469 |
+
|
| 470 |
+
elif np.max(Iou) >= 0.4:
|
| 471 |
+
save_file = os.path.join(part_save_dir, "%s.jpg" % d_idx)
|
| 472 |
+
f3.write(save_file + ' -1 %.2f %.2f %.2f %.2f\n' % (
|
| 473 |
+
offset_x1, offset_y1, offset_x2, offset_y2))
|
| 474 |
+
cv2.imwrite(save_file, resized_im)
|
| 475 |
+
d_idx += 1
|
| 476 |
+
f1.close()
|
| 477 |
+
f2.close()
|
| 478 |
+
f3.close()
|
| 479 |
+
|
| 480 |
+
def model_store_path():
|
| 481 |
+
return os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))+"/model_store"
|
| 482 |
+
|
| 483 |
+
def get_Rnet_data(pnet_model):
|
| 484 |
+
gen_rnet_data(traindata_store, annotation_file, pnet_model_file = pnet_model, prefix_path = prefix_path, use_cuda = True)
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
def assembel_Rnet_data():
|
| 488 |
+
anno_list = []
|
| 489 |
+
|
| 490 |
+
anno_list.append(rnet_postive_file)
|
| 491 |
+
anno_list.append(rnet_part_file)
|
| 492 |
+
anno_list.append(rnet_neg_file)
|
| 493 |
+
# anno_list.append(pnet_landmark_file)
|
| 494 |
+
|
| 495 |
+
chose_count = assemble_data(imglist_filename_rnet ,anno_list)
|
| 496 |
+
print("RNet train annotation result file path:%s" % imglist_filename_rnet)
|
| 497 |
+
#-----------------------------------------------------------------------------------------------------------------------------------------------#
|
| 498 |
+
def gen_onet_data(data_dir, anno_file, pnet_model_file, rnet_model_file, prefix_path='', use_cuda=True, vis=False):
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
pnet, rnet, _ = create_mtcnn_net(p_model_path=pnet_model_file, r_model_path=rnet_model_file, use_cuda=use_cuda)
|
| 502 |
+
mtcnn_detector = MtcnnDetector(pnet=pnet, rnet=rnet, min_face_size=12)
|
| 503 |
+
|
| 504 |
+
imagedb = ImageDB(anno_file,mode="test",prefix_path=prefix_path)
|
| 505 |
+
imdb = imagedb.load_imdb()
|
| 506 |
+
image_reader = TestImageLoader(imdb,1,False)
|
| 507 |
+
|
| 508 |
+
all_boxes = list()
|
| 509 |
+
batch_idx = 0
|
| 510 |
+
|
| 511 |
+
print('size:%d' % image_reader.size)
|
| 512 |
+
for databatch in image_reader:
|
| 513 |
+
if batch_idx % 50 == 0:
|
| 514 |
+
print("%d images done" % batch_idx)
|
| 515 |
+
|
| 516 |
+
im = databatch
|
| 517 |
+
|
| 518 |
+
t = time.time()
|
| 519 |
+
|
| 520 |
+
# pnet detection = [x1, y1, x2, y2, score, reg]
|
| 521 |
+
p_boxes, p_boxes_align = mtcnn_detector.detect_pnet(im=im)
|
| 522 |
+
|
| 523 |
+
t0 = time.time() - t
|
| 524 |
+
t = time.time()
|
| 525 |
+
# rnet detection
|
| 526 |
+
boxes, boxes_align = mtcnn_detector.detect_rnet(im=im, dets=p_boxes_align)
|
| 527 |
+
|
| 528 |
+
t1 = time.time() - t
|
| 529 |
+
print('cost time pnet--',t0,' rnet--',t1)
|
| 530 |
+
t = time.time()
|
| 531 |
+
|
| 532 |
+
if boxes_align is None:
|
| 533 |
+
all_boxes.append(np.array([]))
|
| 534 |
+
batch_idx += 1
|
| 535 |
+
continue
|
| 536 |
+
if vis:
|
| 537 |
+
rgb_im = cv2.cvtColor(np.asarray(im), cv2.COLOR_BGR2RGB)
|
| 538 |
+
vision.vis_two(rgb_im, boxes, boxes_align)
|
| 539 |
+
|
| 540 |
+
|
| 541 |
+
all_boxes.append(boxes_align)
|
| 542 |
+
batch_idx += 1
|
| 543 |
+
|
| 544 |
+
save_path = './model_store'
|
| 545 |
+
|
| 546 |
+
if not os.path.exists(save_path):
|
| 547 |
+
os.mkdir(save_path)
|
| 548 |
+
|
| 549 |
+
save_file = os.path.join(save_path, "detections_%d.pkl" % int(time.time()))
|
| 550 |
+
with open(save_file, 'wb') as f:
|
| 551 |
+
cPickle.dump(all_boxes, f, cPickle.HIGHEST_PROTOCOL)
|
| 552 |
+
|
| 553 |
+
|
| 554 |
+
gen_onet_sample_data(data_dir,anno_file,save_file,prefix_path)
|
| 555 |
+
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
def gen_onet_sample_data(data_dir,anno_file,det_boxs_file,prefix):
|
| 559 |
+
|
| 560 |
+
neg_save_dir = os.path.join(data_dir, "48/negative")
|
| 561 |
+
pos_save_dir = os.path.join(data_dir, "48/positive")
|
| 562 |
+
part_save_dir = os.path.join(data_dir, "48/part")
|
| 563 |
+
|
| 564 |
+
for dir_path in [neg_save_dir, pos_save_dir, part_save_dir]:
|
| 565 |
+
if not os.path.exists(dir_path):
|
| 566 |
+
os.makedirs(dir_path)
|
| 567 |
+
|
| 568 |
+
|
| 569 |
+
# load ground truth from annotation file
|
| 570 |
+
# format of each line: image/path [x1,y1,x2,y2] for each gt_box in this image
|
| 571 |
+
|
| 572 |
+
with open(anno_file, 'r') as f:
|
| 573 |
+
annotations = f.readlines()
|
| 574 |
+
|
| 575 |
+
image_size = 48
|
| 576 |
+
net = "onet"
|
| 577 |
+
|
| 578 |
+
im_idx_list = list()
|
| 579 |
+
gt_boxes_list = list()
|
| 580 |
+
num_of_images = len(annotations)
|
| 581 |
+
print("processing %d images in total" % num_of_images)
|
| 582 |
+
|
| 583 |
+
for annotation in annotations:
|
| 584 |
+
annotation = annotation.strip().split(' ')
|
| 585 |
+
im_idx = os.path.join(prefix,annotation[0])
|
| 586 |
+
|
| 587 |
+
boxes = list(map(float, annotation[1:]))
|
| 588 |
+
boxes = np.array(boxes, dtype=np.float32).reshape(-1, 4)
|
| 589 |
+
im_idx_list.append(im_idx)
|
| 590 |
+
gt_boxes_list.append(boxes)
|
| 591 |
+
|
| 592 |
+
save_path = './anno_store'
|
| 593 |
+
if not os.path.exists(save_path):
|
| 594 |
+
os.makedirs(save_path)
|
| 595 |
+
|
| 596 |
+
f1 = open(os.path.join(save_path, 'pos_%d.txt' % image_size), 'w')
|
| 597 |
+
f2 = open(os.path.join(save_path, 'neg_%d.txt' % image_size), 'w')
|
| 598 |
+
f3 = open(os.path.join(save_path, 'part_%d.txt' % image_size), 'w')
|
| 599 |
+
|
| 600 |
+
det_handle = open(det_boxs_file, 'rb')
|
| 601 |
+
|
| 602 |
+
det_boxes = cPickle.load(det_handle)
|
| 603 |
+
print(len(det_boxes), num_of_images)
|
| 604 |
+
# assert len(det_boxes) == num_of_images, "incorrect detections or ground truths"
|
| 605 |
+
|
| 606 |
+
# index of neg, pos and part face, used as their image names
|
| 607 |
+
n_idx = 0
|
| 608 |
+
p_idx = 0
|
| 609 |
+
d_idx = 0
|
| 610 |
+
image_done = 0
|
| 611 |
+
for im_idx, dets, gts in zip(im_idx_list, det_boxes, gt_boxes_list):
|
| 612 |
+
if image_done % 100 == 0:
|
| 613 |
+
print("%d images done" % image_done)
|
| 614 |
+
image_done += 1
|
| 615 |
+
if gts.shape[0]==0:
|
| 616 |
+
continue
|
| 617 |
+
if dets.shape[0] == 0:
|
| 618 |
+
continue
|
| 619 |
+
img = cv2.imread(im_idx)
|
| 620 |
+
dets = convert_to_square(dets)
|
| 621 |
+
dets[:, 0:4] = np.round(dets[:, 0:4])
|
| 622 |
+
|
| 623 |
+
for box in dets:
|
| 624 |
+
x_left, y_top, x_right, y_bottom = box[0:4].astype(int)
|
| 625 |
+
width = x_right - x_left + 1
|
| 626 |
+
height = y_bottom - y_top + 1
|
| 627 |
+
|
| 628 |
+
# ignore box that is too small or beyond image border
|
| 629 |
+
if width < 20 or x_left < 0 or y_top < 0 or x_right > img.shape[1] - 1 or y_bottom > img.shape[0] - 1:
|
| 630 |
+
continue
|
| 631 |
+
|
| 632 |
+
# compute intersection over union(IoU) between current box and all gt boxes
|
| 633 |
+
Iou = IoU(box, gts)
|
| 634 |
+
cropped_im = img[y_top:y_bottom + 1, x_left:x_right + 1, :]
|
| 635 |
+
resized_im = cv2.resize(cropped_im, (image_size, image_size),
|
| 636 |
+
interpolation=cv2.INTER_LINEAR)
|
| 637 |
+
|
| 638 |
+
# save negative images and write label
|
| 639 |
+
if np.max(Iou) < 0.3:
|
| 640 |
+
# Iou with all gts must below 0.3
|
| 641 |
+
save_file = os.path.join(neg_save_dir, "%s.jpg" % n_idx)
|
| 642 |
+
f2.write(save_file + ' 0\n')
|
| 643 |
+
cv2.imwrite(save_file, resized_im)
|
| 644 |
+
n_idx += 1
|
| 645 |
+
else:
|
| 646 |
+
# find gt_box with the highest iou
|
| 647 |
+
idx = np.argmax(Iou)
|
| 648 |
+
assigned_gt = gts[idx]
|
| 649 |
+
x1, y1, x2, y2 = assigned_gt
|
| 650 |
+
|
| 651 |
+
# compute bbox reg label
|
| 652 |
+
offset_x1 = (x1 - x_left) / float(width)
|
| 653 |
+
offset_y1 = (y1 - y_top) / float(height)
|
| 654 |
+
offset_x2 = (x2 - x_right) / float(width)
|
| 655 |
+
offset_y2 = (y2 - y_bottom) / float(height)
|
| 656 |
+
|
| 657 |
+
# save positive and part-face images and write labels
|
| 658 |
+
if np.max(Iou) >= 0.65:
|
| 659 |
+
save_file = os.path.join(pos_save_dir, "%s.jpg" % p_idx)
|
| 660 |
+
f1.write(save_file + ' 1 %.2f %.2f %.2f %.2f\n' % (
|
| 661 |
+
offset_x1, offset_y1, offset_x2, offset_y2))
|
| 662 |
+
cv2.imwrite(save_file, resized_im)
|
| 663 |
+
p_idx += 1
|
| 664 |
+
|
| 665 |
+
elif np.max(Iou) >= 0.4:
|
| 666 |
+
save_file = os.path.join(part_save_dir, "%s.jpg" % d_idx)
|
| 667 |
+
f3.write(save_file + ' -1 %.2f %.2f %.2f %.2f\n' % (
|
| 668 |
+
offset_x1, offset_y1, offset_x2, offset_y2))
|
| 669 |
+
cv2.imwrite(save_file, resized_im)
|
| 670 |
+
d_idx += 1
|
| 671 |
+
f1.close()
|
| 672 |
+
f2.close()
|
| 673 |
+
f3.close()
|
| 674 |
+
|
| 675 |
+
|
| 676 |
+
|
| 677 |
+
def model_store_path():
|
| 678 |
+
return os.path.dirname(os.path.dirname(os.path.dirname(os.path.realpath(__file__))))+"/model_store"
|
| 679 |
+
|
| 680 |
+
|
| 681 |
+
def get_Onet_data(pnet_model, rnet_model):
|
| 682 |
+
gen_onet_data(traindata_store, annotation_file, pnet_model_file = pnet_model, rnet_model_file = rnet_model,prefix_path=prefix_path,use_cuda = True, vis = False)
|
| 683 |
+
|
| 684 |
+
|
| 685 |
+
def assembel_Onet_data():
|
| 686 |
+
anno_list = []
|
| 687 |
+
|
| 688 |
+
anno_list.append(onet_postive_file)
|
| 689 |
+
anno_list.append(onet_part_file)
|
| 690 |
+
anno_list.append(onet_neg_file)
|
| 691 |
+
anno_list.append(onet_landmark_file)
|
| 692 |
+
|
| 693 |
+
chose_count = assemble_data(imglist_filename_onet ,anno_list)
|
| 694 |
+
print("ONet train annotation result file path:%s" % imglist_filename_onet)
|
| 695 |
+
|
| 696 |
+
|
| 697 |
+
def gen_landmark_48(anno_file, data_dir, prefix = ''):
|
| 698 |
+
|
| 699 |
+
|
| 700 |
+
size = 48
|
| 701 |
+
image_id = 0
|
| 702 |
+
|
| 703 |
+
landmark_imgs_save_dir = os.path.join(data_dir,"48/landmark")
|
| 704 |
+
if not os.path.exists(landmark_imgs_save_dir):
|
| 705 |
+
os.makedirs(landmark_imgs_save_dir)
|
| 706 |
+
|
| 707 |
+
anno_dir = './anno_store'
|
| 708 |
+
if not os.path.exists(anno_dir):
|
| 709 |
+
os.makedirs(anno_dir)
|
| 710 |
+
|
| 711 |
+
landmark_anno_filename = "landmark_48.txt"
|
| 712 |
+
save_landmark_anno = os.path.join(anno_dir,landmark_anno_filename)
|
| 713 |
+
|
| 714 |
+
# print(save_landmark_anno)
|
| 715 |
+
# time.sleep(5)
|
| 716 |
+
f = open(save_landmark_anno, 'w')
|
| 717 |
+
# dstdir = "train_landmark_few"
|
| 718 |
+
|
| 719 |
+
with open(anno_file, 'r') as f2:
|
| 720 |
+
annotations = f2.readlines()
|
| 721 |
+
|
| 722 |
+
num = len(annotations)
|
| 723 |
+
print("%d total images" % num)
|
| 724 |
+
|
| 725 |
+
l_idx =0
|
| 726 |
+
idx = 0
|
| 727 |
+
# image_path bbox landmark(5*2)
|
| 728 |
+
for annotation in annotations:
|
| 729 |
+
# print imgPath
|
| 730 |
+
|
| 731 |
+
annotation = annotation.strip().split(' ')
|
| 732 |
+
|
| 733 |
+
assert len(annotation)==15,"each line should have 15 element"
|
| 734 |
+
|
| 735 |
+
im_path = os.path.join('./data_set/face_landmark/CNN_FacePoint/train/',annotation[0].replace("\\", "/"))
|
| 736 |
+
|
| 737 |
+
gt_box = list(map(float, annotation[1:5]))
|
| 738 |
+
# gt_box = [gt_box[0], gt_box[2], gt_box[1], gt_box[3]]
|
| 739 |
+
|
| 740 |
+
|
| 741 |
+
gt_box = np.array(gt_box, dtype=np.int32)
|
| 742 |
+
|
| 743 |
+
landmark = list(map(float, annotation[5:]))
|
| 744 |
+
landmark = np.array(landmark, dtype=np.float)
|
| 745 |
+
|
| 746 |
+
img = cv2.imread(im_path)
|
| 747 |
+
# print(im_path)
|
| 748 |
+
assert (img is not None)
|
| 749 |
+
|
| 750 |
+
height, width, channel = img.shape
|
| 751 |
+
# crop_face = img[gt_box[1]:gt_box[3]+1, gt_box[0]:gt_box[2]+1]
|
| 752 |
+
# crop_face = cv2.resize(crop_face,(size,size))
|
| 753 |
+
|
| 754 |
+
idx = idx + 1
|
| 755 |
+
if idx % 100 == 0:
|
| 756 |
+
print("%d images done, landmark images: %d"%(idx,l_idx))
|
| 757 |
+
# print(im_path)
|
| 758 |
+
# print(gt_box)
|
| 759 |
+
x1, x2, y1, y2 = gt_box
|
| 760 |
+
gt_box[1] = y1
|
| 761 |
+
gt_box[2] = x2
|
| 762 |
+
# time.sleep(5)
|
| 763 |
+
|
| 764 |
+
# gt's width
|
| 765 |
+
w = x2 - x1 + 1
|
| 766 |
+
# gt's height
|
| 767 |
+
h = y2 - y1 + 1
|
| 768 |
+
if max(w, h) < 40 or x1 < 0 or y1 < 0:
|
| 769 |
+
continue
|
| 770 |
+
# random shift
|
| 771 |
+
for i in range(10):
|
| 772 |
+
bbox_size = np.random.randint(int(min(w, h) * 0.8), np.ceil(1.25 * max(w, h)))
|
| 773 |
+
delta_x = np.random.randint(-w * 0.2, w * 0.2)
|
| 774 |
+
delta_y = np.random.randint(-h * 0.2, h * 0.2)
|
| 775 |
+
nx1 = max(x1 + w / 2 - bbox_size / 2 + delta_x, 0)
|
| 776 |
+
ny1 = max(y1 + h / 2 - bbox_size / 2 + delta_y, 0)
|
| 777 |
+
|
| 778 |
+
nx2 = nx1 + bbox_size
|
| 779 |
+
ny2 = ny1 + bbox_size
|
| 780 |
+
if nx2 > width or ny2 > height:
|
| 781 |
+
continue
|
| 782 |
+
crop_box = np.array([nx1, ny1, nx2, ny2])
|
| 783 |
+
cropped_im = img[int(ny1):int(ny2) + 1, int(nx1):int(nx2) + 1, :]
|
| 784 |
+
resized_im = cv2.resize(cropped_im, (size, size),interpolation=cv2.INTER_LINEAR)
|
| 785 |
+
|
| 786 |
+
offset_x1 = (x1 - nx1) / float(bbox_size)
|
| 787 |
+
offset_y1 = (y1 - ny1) / float(bbox_size)
|
| 788 |
+
offset_x2 = (x2 - nx2) / float(bbox_size)
|
| 789 |
+
offset_y2 = (y2 - ny2) / float(bbox_size)
|
| 790 |
+
|
| 791 |
+
offset_left_eye_x = (landmark[0] - nx1) / float(bbox_size)
|
| 792 |
+
offset_left_eye_y = (landmark[1] - ny1) / float(bbox_size)
|
| 793 |
+
|
| 794 |
+
offset_right_eye_x = (landmark[2] - nx1) / float(bbox_size)
|
| 795 |
+
offset_right_eye_y = (landmark[3] - ny1) / float(bbox_size)
|
| 796 |
+
|
| 797 |
+
offset_nose_x = (landmark[4] - nx1) / float(bbox_size)
|
| 798 |
+
offset_nose_y = (landmark[5] - ny1) / float(bbox_size)
|
| 799 |
+
|
| 800 |
+
offset_left_mouth_x = (landmark[6] - nx1) / float(bbox_size)
|
| 801 |
+
offset_left_mouth_y = (landmark[7] - ny1) / float(bbox_size)
|
| 802 |
+
|
| 803 |
+
offset_right_mouth_x = (landmark[8] - nx1) / float(bbox_size)
|
| 804 |
+
offset_right_mouth_y = (landmark[9] - ny1) / float(bbox_size)
|
| 805 |
+
|
| 806 |
+
|
| 807 |
+
# cal iou
|
| 808 |
+
iou = IoU(crop_box.astype(np.float), np.expand_dims(gt_box.astype(np.float), 0))
|
| 809 |
+
# print(iou)
|
| 810 |
+
if iou > 0.65:
|
| 811 |
+
save_file = os.path.join(landmark_imgs_save_dir, "%s.jpg" % l_idx)
|
| 812 |
+
cv2.imwrite(save_file, resized_im)
|
| 813 |
+
|
| 814 |
+
f.write(save_file + ' -2 %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f %.2f \n' % \
|
| 815 |
+
(offset_x1, offset_y1, offset_x2, offset_y2, \
|
| 816 |
+
offset_left_eye_x,offset_left_eye_y,offset_right_eye_x,offset_right_eye_y,offset_nose_x,offset_nose_y,offset_left_mouth_x,offset_left_mouth_y,offset_right_mouth_x,offset_right_mouth_y))
|
| 817 |
+
# print(save_file)
|
| 818 |
+
# print(save_landmark_anno)
|
| 819 |
+
l_idx += 1
|
| 820 |
+
|
| 821 |
+
f.close()
|
| 822 |
+
|
| 823 |
+
|
| 824 |
+
def parse_args():
|
| 825 |
+
parser = argparse.ArgumentParser(description='Get data',
|
| 826 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 827 |
+
|
| 828 |
+
parser.add_argument('--net', dest='net', help='which net to show', type=str)
|
| 829 |
+
parser.add_argument('--pnet_path', default="./model_store/pnet_epoch_20.pt",help='path to pnet model', type=str)
|
| 830 |
+
parser.add_argument('--rnet_path', default="./model_store/rnet_epoch_20.pt",help='path to rnet model', type=str)
|
| 831 |
+
parser.add_argument('--use_cuda', default=True,help='use cuda', type=bool)
|
| 832 |
+
|
| 833 |
+
args = parser.parse_args()
|
| 834 |
+
return args
|
| 835 |
+
|
| 836 |
+
#-----------------------------------------------------------------------------------------------------------------------------------------------#
|
| 837 |
+
if __name__ == '__main__':
|
| 838 |
+
args = parse_args()
|
| 839 |
+
dir = 'anno_store'
|
| 840 |
+
if not os.path.exists(dir):
|
| 841 |
+
os.makedirs(dir)
|
| 842 |
+
if args.net == "pnet":
|
| 843 |
+
wider_face(txt_from_path, anno_file)
|
| 844 |
+
get_Pnet_data()
|
| 845 |
+
assembel_Pnet_data()
|
| 846 |
+
elif args.net == "rnet":
|
| 847 |
+
get_Rnet_data(args.pnet_path)
|
| 848 |
+
assembel_Rnet_data()
|
| 849 |
+
elif args.net == "onet":
|
| 850 |
+
get_Onet_data(args.pnet_path, args.rnet_path)
|
| 851 |
+
gen_landmark_48(annotation_file_lm, traindata_store, prefix_path_lm)
|
| 852 |
+
assembel_Onet_data()
|
img/mid.png
ADDED

|
img/onet.png
ADDED

|
img/pnet.png
ADDED

|
img/result.png
ADDED

|
img/rnet.png
ADDED

|
model_store/onet_epoch_20.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:53e8fe6d59c0b3cd75ae24f37756e056e05b9fa555cd9e442543aef54cc5f887
|
| 3 |
+
size 903910
|
model_store/pnet_epoch_20.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e818bafbe694390fba4cf59cad9d67a04ed8fb9297e5b4032c3d2af3832e5365
|
| 3 |
+
size 32056
|
model_store/rnet_epoch_20.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfe5d5abf979cb3d7eda838d9d6c8e1b582e4a53a1d20e9b6ff54953ed3ba042
|
| 3 |
+
size 245871
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
matplotlib==3.5.0
|
| 2 |
+
matplotlib-inline==0.1.3
|
| 3 |
+
numpy==1.21.4
|
| 4 |
+
opencv-python==4.4.0.42
|
| 5 |
+
opencv-python-headless==4.6.0.66
|
| 6 |
+
Pillow==9.1.1
|
| 7 |
+
scikit-image==0.19.3
|
| 8 |
+
torch==1.13.0+cu116
|
| 9 |
+
torchaudio==0.13.0+cu116
|
| 10 |
+
torchvision==0.14.0+cu116
|
test.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
from utils.detect import create_mtcnn_net, MtcnnDetector
|
| 3 |
+
from utils.vision import vis_face
|
| 4 |
+
import argparse
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
MIN_FACE_SIZE = 3
|
| 8 |
+
|
| 9 |
+
def parse_args():
|
| 10 |
+
parser = argparse.ArgumentParser(description='Test MTCNN',
|
| 11 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 12 |
+
|
| 13 |
+
parser.add_argument('--net', default='onet', help='which net to show', type=str)
|
| 14 |
+
parser.add_argument('--pnet_path', default="./model_store/pnet_epoch_20.pt",help='path to pnet model', type=str)
|
| 15 |
+
parser.add_argument('--rnet_path', default="./model_store/rnet_epoch_20.pt",help='path to rnet model', type=str)
|
| 16 |
+
parser.add_argument('--onet_path', default="./model_store/onet_epoch_20.pt",help='path to onet model', type=str)
|
| 17 |
+
parser.add_argument('--path', default="./img/mid.png",help='path to image', type=str)
|
| 18 |
+
parser.add_argument('--min_face_size', default=MIN_FACE_SIZE,help='min face size', type=int)
|
| 19 |
+
parser.add_argument('--use_cuda', default=False,help='use cuda', type=bool)
|
| 20 |
+
parser.add_argument('--thresh', default='[0.1, 0.1, 0.1]',help='thresh', type=str)
|
| 21 |
+
parser.add_argument('--save_name', default="result.jpg",help='save name', type=str)
|
| 22 |
+
parser.add_argument('--input_mode', default=1,help='image or video', type=int)
|
| 23 |
+
args = parser.parse_args()
|
| 24 |
+
return args
|
| 25 |
+
if __name__ == '__main__':
|
| 26 |
+
args = parse_args()
|
| 27 |
+
thresh = [float(i) for i in (args.thresh).split('[')[1].split(']')[0].split(',')]
|
| 28 |
+
pnet, rnet, onet = create_mtcnn_net(p_model_path=args.pnet_path, r_model_path=args.rnet_path,o_model_path=args.onet_path, use_cuda=args.use_cuda)
|
| 29 |
+
mtcnn_detector = MtcnnDetector(pnet=pnet, rnet=rnet, onet=onet, min_face_size=args.min_face_size,threshold=thresh)
|
| 30 |
+
if args.input_mode == 1:
|
| 31 |
+
img = cv2.imread(args.path)
|
| 32 |
+
img_bg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 33 |
+
p_bboxs, r_bboxs, bboxs, landmarks = mtcnn_detector.detect_face(img)
|
| 34 |
+
# print box_align
|
| 35 |
+
save_name = args.save_name
|
| 36 |
+
if args.net == 'pnet':
|
| 37 |
+
vis_face(img_bg, p_bboxs, landmarks, MIN_FACE_SIZE, save_name)
|
| 38 |
+
elif args.net == 'rnet':
|
| 39 |
+
vis_face(img_bg, r_bboxs, landmarks, MIN_FACE_SIZE, save_name)
|
| 40 |
+
elif args.net == 'onet':
|
| 41 |
+
vis_face(img_bg, bboxs, landmarks, MIN_FACE_SIZE, save_name)
|
| 42 |
+
elif args.input_mode == 0:
|
| 43 |
+
cap=cv2.VideoCapture(0)
|
| 44 |
+
fourcc = cv2.VideoWriter_fourcc(*'XVID')
|
| 45 |
+
out = cv2.VideoWriter('out.mp4' ,fourcc,10,(640,480))
|
| 46 |
+
while True:
|
| 47 |
+
t1=cv2.getTickCount()
|
| 48 |
+
ret,frame = cap.read()
|
| 49 |
+
if ret == True:
|
| 50 |
+
boxes_c,landmarks = mtcnn_detector.detect_face(frame)
|
| 51 |
+
t2=cv2.getTickCount()
|
| 52 |
+
t=(t2-t1)/cv2.getTickFrequency()
|
| 53 |
+
fps=1.0/t
|
| 54 |
+
for i in range(boxes_c.shape[0]):
|
| 55 |
+
bbox = boxes_c[i, :4]
|
| 56 |
+
score = boxes_c[i, 4]
|
| 57 |
+
corpbbox = [int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])]
|
| 58 |
+
|
| 59 |
+
#画人脸框
|
| 60 |
+
cv2.rectangle(frame, (corpbbox[0], corpbbox[1]),
|
| 61 |
+
(corpbbox[2], corpbbox[3]), (255, 0, 0), 1)
|
| 62 |
+
#画置信度
|
| 63 |
+
cv2.putText(frame, '{:.2f}'.format(score),
|
| 64 |
+
(corpbbox[0], corpbbox[1] - 2),
|
| 65 |
+
cv2.FONT_HERSHEY_SIMPLEX,
|
| 66 |
+
0.5,(0, 0, 255), 2)
|
| 67 |
+
#画fps值
|
| 68 |
+
cv2.putText(frame, '{:.4f}'.format(t) + " " + '{:.3f}'.format(fps), (10, 20),
|
| 69 |
+
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 255), 2)
|
| 70 |
+
#画关键点
|
| 71 |
+
for i in range(landmarks.shape[0]):
|
| 72 |
+
for j in range(len(landmarks[i])//2):
|
| 73 |
+
cv2.circle(frame, (int(landmarks[i][2*j]),int(int(landmarks[i][2*j+1]))), 2, (0,0,255))
|
| 74 |
+
a = out.write(frame)
|
| 75 |
+
cv2.imshow("result", frame)
|
| 76 |
+
if cv2.waitKey(1) & 0xFF == ord('q'):
|
| 77 |
+
break
|
| 78 |
+
else:
|
| 79 |
+
break
|
| 80 |
+
cap.release()
|
| 81 |
+
out.release()
|
| 82 |
+
cv2.destroyAllWindows()
|
| 83 |
+
|
| 84 |
+
|
test.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python test.py --net=pnet --min_face_size=1 --pnet_path=./model_store/pnet_epoch_20.pt --rnet_path=./model_store/rnet_epoch_20.pt --onet_path=./model_store/onet_epoch_20.pt --save_name=pnet
|
| 2 |
+
python test.py --net=rnet --min_face_size=1 --pnet_path=./model_store/pnet_epoch_20.pt --rnet_path=./model_store/rnet_epoch_20.pt --onet_path=./model_store/onet_epoch_20.pt --save_name=rnet
|
| 3 |
+
python test.py --net=onet --min_face_size=1 --pnet_path=./model_store/pnet_epoch_20.pt --rnet_path=./model_store/rnet_epoch_20.pt --onet_path=./model_store/onet_epoch_20.pt --save_name=onet
|
| 4 |
+
echo "Testing finished!"
|
train.out
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
train.py
ADDED
|
@@ -0,0 +1,351 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from utils.dataloader import TrainImageReader,convert_image_to_tensor,ImageDB
|
| 2 |
+
import datetime
|
| 3 |
+
import os
|
| 4 |
+
from utils.models import PNet,RNet,ONet,LossFn
|
| 5 |
+
import torch
|
| 6 |
+
#from torch.autograd import Variable 新版本中已弃用
|
| 7 |
+
import utils.config as config
|
| 8 |
+
import argparse
|
| 9 |
+
import sys
|
| 10 |
+
sys.path.append(os.getcwd())
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def compute_accuracy(prob_cls, gt_cls):
|
| 16 |
+
|
| 17 |
+
prob_cls = torch.squeeze(prob_cls)
|
| 18 |
+
gt_cls = torch.squeeze(gt_cls)
|
| 19 |
+
|
| 20 |
+
#we only need the detection which >= 0
|
| 21 |
+
mask = torch.ge(gt_cls,0)
|
| 22 |
+
#get valid element
|
| 23 |
+
valid_gt_cls = torch.masked_select(gt_cls,mask)
|
| 24 |
+
valid_prob_cls = torch.masked_select(prob_cls,mask)
|
| 25 |
+
size = min(valid_gt_cls.size()[0], valid_prob_cls.size()[0])
|
| 26 |
+
prob_ones = torch.ge(valid_prob_cls,0.6).float()
|
| 27 |
+
right_ones = torch.eq(prob_ones,valid_gt_cls).float()
|
| 28 |
+
|
| 29 |
+
## if size == 0 meaning that your gt_labels are all negative, landmark or part
|
| 30 |
+
|
| 31 |
+
return torch.div(torch.mul(torch.sum(right_ones),float(1.0)),float(size)) ## divided by zero meaning that your gt_labels are all negative, landmark or part
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def train_pnet(model_store_path, end_epoch,imdb,
|
| 35 |
+
batch_size,frequent=10,base_lr=0.01,lr_epoch_decay=[9],use_cuda=True,load=''):
|
| 36 |
+
|
| 37 |
+
#create lr_list
|
| 38 |
+
lr_epoch_decay.append(end_epoch+1)
|
| 39 |
+
lr_list = np.zeros(end_epoch)
|
| 40 |
+
lr_t = base_lr
|
| 41 |
+
for i in range(len(lr_epoch_decay)):
|
| 42 |
+
if i==0:
|
| 43 |
+
lr_list[0:lr_epoch_decay[i]-1]=lr_t
|
| 44 |
+
else:
|
| 45 |
+
lr_list[lr_epoch_decay[i-1]-1:lr_epoch_decay[i]-1]=lr_t
|
| 46 |
+
lr_t*=0.1
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
if not os.path.exists(model_store_path):
|
| 50 |
+
os.makedirs(model_store_path)
|
| 51 |
+
|
| 52 |
+
lossfn = LossFn()
|
| 53 |
+
net = PNet(is_train=True, use_cuda=use_cuda)
|
| 54 |
+
if load!='':
|
| 55 |
+
net.load_state_dict(torch.load(load))
|
| 56 |
+
print('model loaded',load)
|
| 57 |
+
net.train()
|
| 58 |
+
|
| 59 |
+
if use_cuda:
|
| 60 |
+
net.cuda()
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
optimizer = torch.optim.Adam(net.parameters(), lr=lr_list[0])
|
| 64 |
+
#optimizer = torch.optim.SGD(net.parameters(), lr=lr_list[0])
|
| 65 |
+
|
| 66 |
+
train_data=TrainImageReader(imdb,12,batch_size,shuffle=True)
|
| 67 |
+
|
| 68 |
+
#frequent = 10
|
| 69 |
+
for cur_epoch in range(1,end_epoch+1):
|
| 70 |
+
train_data.reset() # shuffle
|
| 71 |
+
for param in optimizer.param_groups:
|
| 72 |
+
param['lr'] = lr_list[cur_epoch-1]
|
| 73 |
+
for batch_idx,(image,(gt_label,gt_bbox,gt_landmark))in enumerate(train_data):
|
| 74 |
+
|
| 75 |
+
im_tensor = [ convert_image_to_tensor(image[i,:,:,:]) for i in range(image.shape[0]) ]
|
| 76 |
+
im_tensor = torch.stack(im_tensor)
|
| 77 |
+
|
| 78 |
+
im_tensor.requires_grad = True
|
| 79 |
+
gt_label = torch.from_numpy(gt_label).float()
|
| 80 |
+
gt_label.requires_grad = True
|
| 81 |
+
|
| 82 |
+
gt_bbox = torch.from_numpy(gt_bbox).float()
|
| 83 |
+
gt_bbox.requires_grad = True
|
| 84 |
+
# gt_landmark = Variable(torch.from_numpy(gt_landmark).float())
|
| 85 |
+
|
| 86 |
+
if use_cuda:
|
| 87 |
+
im_tensor = im_tensor.cuda()
|
| 88 |
+
gt_label = gt_label.cuda()
|
| 89 |
+
gt_bbox = gt_bbox.cuda()
|
| 90 |
+
# gt_landmark = gt_landmark.cuda()
|
| 91 |
+
|
| 92 |
+
cls_pred, box_offset_pred = net(im_tensor)
|
| 93 |
+
# all_loss, cls_loss, offset_loss = lossfn.loss(gt_label=label_y,gt_offset=bbox_y, pred_label=cls_pred, pred_offset=box_offset_pred)
|
| 94 |
+
|
| 95 |
+
cls_loss = lossfn.cls_loss(gt_label,cls_pred)
|
| 96 |
+
box_offset_loss = lossfn.box_loss(gt_label,gt_bbox,box_offset_pred)
|
| 97 |
+
# landmark_loss = lossfn.landmark_loss(gt_label,gt_landmark,landmark_offset_pred)
|
| 98 |
+
|
| 99 |
+
all_loss = cls_loss*1.0+box_offset_loss*0.5
|
| 100 |
+
|
| 101 |
+
if batch_idx %frequent==0:
|
| 102 |
+
accuracy=compute_accuracy(cls_pred,gt_label)
|
| 103 |
+
|
| 104 |
+
show1 = accuracy.data.cpu().numpy()
|
| 105 |
+
show2 = cls_loss.data.cpu().numpy()
|
| 106 |
+
show3 = box_offset_loss.data.cpu().numpy()
|
| 107 |
+
# show4 = landmark_loss.data.cpu().numpy()
|
| 108 |
+
show5 = all_loss.data.cpu().numpy()
|
| 109 |
+
|
| 110 |
+
print("%s : Epoch: %d, Step: %d, accuracy: %s, det loss: %s, bbox loss: %s, all_loss: %s, lr:%s "%(datetime.datetime.now(),cur_epoch,batch_idx, show1,show2,show3,show5,lr_list[cur_epoch-1]))
|
| 111 |
+
|
| 112 |
+
optimizer.zero_grad()
|
| 113 |
+
all_loss.backward()
|
| 114 |
+
optimizer.step()
|
| 115 |
+
|
| 116 |
+
torch.save(net.state_dict(), os.path.join(model_store_path,"pnet_epoch_%d.pt" % cur_epoch))
|
| 117 |
+
torch.save(net, os.path.join(model_store_path,"pnet_epoch_model_%d.pkl" % cur_epoch))
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def train_rnet(model_store_path, end_epoch,imdb,
|
| 123 |
+
batch_size,frequent=50,base_lr=0.01,lr_epoch_decay=[9],use_cuda=True,load=''):
|
| 124 |
+
|
| 125 |
+
#create lr_list
|
| 126 |
+
lr_epoch_decay.append(end_epoch+1)
|
| 127 |
+
lr_list = np.zeros(end_epoch)
|
| 128 |
+
lr_t = base_lr
|
| 129 |
+
for i in range(len(lr_epoch_decay)):
|
| 130 |
+
if i==0:
|
| 131 |
+
lr_list[0:lr_epoch_decay[i]-1]=lr_t
|
| 132 |
+
else:
|
| 133 |
+
lr_list[lr_epoch_decay[i-1]-1:lr_epoch_decay[i]-1]=lr_t
|
| 134 |
+
lr_t*=0.1
|
| 135 |
+
#print(lr_list)
|
| 136 |
+
if not os.path.exists(model_store_path):
|
| 137 |
+
os.makedirs(model_store_path)
|
| 138 |
+
|
| 139 |
+
lossfn = LossFn()
|
| 140 |
+
net = RNet(is_train=True, use_cuda=use_cuda)
|
| 141 |
+
net.train()
|
| 142 |
+
if load!='':
|
| 143 |
+
net.load_state_dict(torch.load(load))
|
| 144 |
+
print('model loaded',load)
|
| 145 |
+
if use_cuda:
|
| 146 |
+
net.cuda()
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
optimizer = torch.optim.Adam(net.parameters(), lr=base_lr)
|
| 150 |
+
|
| 151 |
+
train_data=TrainImageReader(imdb,24,batch_size,shuffle=True)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
for cur_epoch in range(1,end_epoch+1):
|
| 155 |
+
train_data.reset()
|
| 156 |
+
for param in optimizer.param_groups:
|
| 157 |
+
param['lr'] = lr_list[cur_epoch-1]
|
| 158 |
+
|
| 159 |
+
for batch_idx,(image,(gt_label,gt_bbox,gt_landmark))in enumerate(train_data):
|
| 160 |
+
|
| 161 |
+
im_tensor = [ convert_image_to_tensor(image[i,:,:,:]) for i in range(image.shape[0]) ]
|
| 162 |
+
im_tensor = torch.stack(im_tensor)
|
| 163 |
+
|
| 164 |
+
im_tensor.requires_grad = True
|
| 165 |
+
gt_label = torch.from_numpy(gt_label).float()
|
| 166 |
+
gt_label.requires_grad = True
|
| 167 |
+
|
| 168 |
+
gt_bbox = torch.from_numpy(gt_bbox).float()
|
| 169 |
+
gt_bbox.requires_grad = True
|
| 170 |
+
gt_landmark = torch.from_numpy(gt_landmark).float()
|
| 171 |
+
gt_landmark.requires_grad = True
|
| 172 |
+
|
| 173 |
+
if use_cuda:
|
| 174 |
+
im_tensor = im_tensor.cuda()
|
| 175 |
+
gt_label = gt_label.cuda()
|
| 176 |
+
gt_bbox = gt_bbox.cuda()
|
| 177 |
+
gt_landmark = gt_landmark.cuda()
|
| 178 |
+
|
| 179 |
+
cls_pred, box_offset_pred = net(im_tensor)
|
| 180 |
+
# all_loss, cls_loss, offset_loss = lossfn.loss(gt_label=label_y,gt_offset=bbox_y, pred_label=cls_pred, pred_offset=box_offset_pred)
|
| 181 |
+
|
| 182 |
+
cls_loss = lossfn.cls_loss(gt_label,cls_pred)
|
| 183 |
+
box_offset_loss = lossfn.box_loss(gt_label,gt_bbox,box_offset_pred)
|
| 184 |
+
# landmark_loss = lossfn.landmark_loss(gt_label,gt_landmark,landmark_offset_pred)
|
| 185 |
+
|
| 186 |
+
all_loss = cls_loss*1.0+box_offset_loss*0.5
|
| 187 |
+
|
| 188 |
+
if batch_idx%frequent==0:
|
| 189 |
+
accuracy=compute_accuracy(cls_pred,gt_label)
|
| 190 |
+
|
| 191 |
+
show1 = accuracy.data.cpu().numpy()
|
| 192 |
+
show2 = cls_loss.data.cpu().numpy()
|
| 193 |
+
show3 = box_offset_loss.data.cpu().numpy()
|
| 194 |
+
# show4 = landmark_loss.data.cpu().numpy()
|
| 195 |
+
show5 = all_loss.data.cpu().numpy()
|
| 196 |
+
|
| 197 |
+
print("%s : Epoch: %d, Step: %d, accuracy: %s, det loss: %s, bbox loss: %s, all_loss: %s, lr:%s "%(datetime.datetime.now(), cur_epoch, batch_idx, show1, show2, show3, show5, lr_list[cur_epoch-1]))
|
| 198 |
+
|
| 199 |
+
optimizer.zero_grad()
|
| 200 |
+
all_loss.backward()
|
| 201 |
+
optimizer.step()
|
| 202 |
+
|
| 203 |
+
torch.save(net.state_dict(), os.path.join(model_store_path,"rnet_epoch_%d.pt" % cur_epoch))
|
| 204 |
+
torch.save(net, os.path.join(model_store_path,"rnet_epoch_model_%d.pkl" % cur_epoch))
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def train_onet(model_store_path, end_epoch,imdb,
|
| 208 |
+
batch_size,frequent=50,base_lr=0.01,lr_epoch_decay=[9],use_cuda=True,load=''):
|
| 209 |
+
#create lr_list
|
| 210 |
+
lr_epoch_decay.append(end_epoch+1)
|
| 211 |
+
lr_list = np.zeros(end_epoch)
|
| 212 |
+
lr_t = base_lr
|
| 213 |
+
for i in range(len(lr_epoch_decay)):
|
| 214 |
+
if i==0:
|
| 215 |
+
lr_list[0:lr_epoch_decay[i]-1]=lr_t
|
| 216 |
+
else:
|
| 217 |
+
lr_list[lr_epoch_decay[i-1]-1:lr_epoch_decay[i]-1]=lr_t
|
| 218 |
+
lr_t*=0.1
|
| 219 |
+
#print(lr_list)
|
| 220 |
+
|
| 221 |
+
if not os.path.exists(model_store_path):
|
| 222 |
+
os.makedirs(model_store_path)
|
| 223 |
+
|
| 224 |
+
lossfn = LossFn()
|
| 225 |
+
net = ONet(is_train=True)
|
| 226 |
+
if load!='':
|
| 227 |
+
net.load_state_dict(torch.load(load))
|
| 228 |
+
print('model loaded',load)
|
| 229 |
+
net.train()
|
| 230 |
+
#print(use_cuda)
|
| 231 |
+
if use_cuda:
|
| 232 |
+
net.cuda()
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
optimizer = torch.optim.Adam(net.parameters(), lr=base_lr)
|
| 236 |
+
|
| 237 |
+
train_data=TrainImageReader(imdb,48,batch_size,shuffle=True)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
for cur_epoch in range(1,end_epoch+1):
|
| 241 |
+
|
| 242 |
+
train_data.reset()
|
| 243 |
+
for param in optimizer.param_groups:
|
| 244 |
+
param['lr'] = lr_list[cur_epoch-1]
|
| 245 |
+
for batch_idx,(image,(gt_label,gt_bbox,gt_landmark))in enumerate(train_data):
|
| 246 |
+
# print("batch id {0}".format(batch_idx))
|
| 247 |
+
im_tensor = [ convert_image_to_tensor(image[i,:,:,:]) for i in range(image.shape[0]) ]
|
| 248 |
+
im_tensor = torch.stack(im_tensor)
|
| 249 |
+
|
| 250 |
+
im_tensor.requires_grad = True
|
| 251 |
+
gt_label = torch.from_numpy(gt_label).float()
|
| 252 |
+
gt_label.requires_grad = True
|
| 253 |
+
|
| 254 |
+
gt_bbox = torch.from_numpy(gt_bbox).float()
|
| 255 |
+
gt_bbox.requires_grad = True
|
| 256 |
+
gt_landmark = torch.from_numpy(gt_landmark).float()
|
| 257 |
+
gt_landmark.requires_grad = True
|
| 258 |
+
|
| 259 |
+
if use_cuda:
|
| 260 |
+
im_tensor = im_tensor.cuda()
|
| 261 |
+
gt_label = gt_label.cuda()
|
| 262 |
+
gt_bbox = gt_bbox.cuda()
|
| 263 |
+
gt_landmark = gt_landmark.cuda()
|
| 264 |
+
|
| 265 |
+
cls_pred, box_offset_pred, landmark_offset_pred = net(im_tensor)
|
| 266 |
+
|
| 267 |
+
# all_loss, cls_loss, offset_loss = lossfn.loss(gt_label=label_y,gt_offset=bbox_y, pred_label=cls_pred, pred_offset=box_offset_pred)
|
| 268 |
+
|
| 269 |
+
cls_loss = lossfn.cls_loss(gt_label,cls_pred)
|
| 270 |
+
box_offset_loss = lossfn.box_loss(gt_label,gt_bbox,box_offset_pred)
|
| 271 |
+
landmark_loss = lossfn.landmark_loss(gt_label,gt_landmark,landmark_offset_pred)
|
| 272 |
+
|
| 273 |
+
all_loss = cls_loss*0.8+box_offset_loss*0.6+landmark_loss*1.5
|
| 274 |
+
|
| 275 |
+
if batch_idx%frequent==0:
|
| 276 |
+
accuracy=compute_accuracy(cls_pred,gt_label)
|
| 277 |
+
|
| 278 |
+
show1 = accuracy.data.cpu().numpy()
|
| 279 |
+
show2 = cls_loss.data.cpu().numpy()
|
| 280 |
+
show3 = box_offset_loss.data.cpu().numpy()
|
| 281 |
+
show4 = landmark_loss.data.cpu().numpy()
|
| 282 |
+
show5 = all_loss.data.cpu().numpy()
|
| 283 |
+
|
| 284 |
+
print("%s : Epoch: %d, Step: %d, accuracy: %s, det loss: %s, bbox loss: %s, landmark loss: %s, all_loss: %s, lr:%s "%(datetime.datetime.now(),cur_epoch,batch_idx, show1,show2,show3,show4,show5,base_lr))
|
| 285 |
+
#print("%s : Epoch: %d, Step: %d, accuracy: %s, det loss: %s, bbox loss: %s, all_loss: %s, lr:%s "%(datetime.datetime.now(),cur_epoch,batch_idx, show1,show2,show3,show5,lr_list[cur_epoch-1]))
|
| 286 |
+
|
| 287 |
+
optimizer.zero_grad()
|
| 288 |
+
all_loss.backward()
|
| 289 |
+
optimizer.step()
|
| 290 |
+
|
| 291 |
+
torch.save(net.state_dict(), os.path.join(model_store_path,"onet_epoch_%d.pt" % cur_epoch))
|
| 292 |
+
torch.save(net, os.path.join(model_store_path,"onet_epoch_model_%d.pkl" % cur_epoch))
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
|
| 299 |
+
def parse_args():
|
| 300 |
+
parser = argparse.ArgumentParser(description='Train MTCNN',
|
| 301 |
+
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
|
| 302 |
+
|
| 303 |
+
parser.add_argument('--net', dest='net', help='which net to train', type=str)
|
| 304 |
+
|
| 305 |
+
parser.add_argument('--anno_file', dest='annotation_file', help='training data annotation file', type=str)
|
| 306 |
+
parser.add_argument('--model_path', dest='model_store_path', help='training model store directory',
|
| 307 |
+
default=config.MODEL_STORE_DIR, type=str)
|
| 308 |
+
parser.add_argument('--end_epoch', dest='end_epoch', help='end epoch of training',
|
| 309 |
+
default=config.END_EPOCH, type=int)
|
| 310 |
+
parser.add_argument('--frequent', dest='frequent', help='frequency of logging',
|
| 311 |
+
default=200, type=int)
|
| 312 |
+
parser.add_argument('--lr', dest='lr', help='learning rate',
|
| 313 |
+
default=config.TRAIN_LR, type=float)
|
| 314 |
+
parser.add_argument('--batch_size', dest='batch_size', help='train batch size',
|
| 315 |
+
default=config.TRAIN_BATCH_SIZE, type=int)
|
| 316 |
+
parser.add_argument('--gpu', dest='use_cuda', help='train with gpu',
|
| 317 |
+
default=config.USE_CUDA, type=bool)
|
| 318 |
+
parser.add_argument('--load', dest='load', help='load model', type=str)
|
| 319 |
+
|
| 320 |
+
args = parser.parse_args()
|
| 321 |
+
return args
|
| 322 |
+
|
| 323 |
+
def train_net(annotation_file, model_store_path,
|
| 324 |
+
end_epoch=16, frequent=200, lr=0.01,lr_epoch_decay=[9],
|
| 325 |
+
batch_size=128, use_cuda=False,load='',net='pnet'):
|
| 326 |
+
if net=='pnet':
|
| 327 |
+
annotation_file = os.path.join(config.ANNO_STORE_DIR,config.PNET_TRAIN_IMGLIST_FILENAME)
|
| 328 |
+
elif net=='rnet':
|
| 329 |
+
annotation_file = os.path.join(config.ANNO_STORE_DIR,config.RNET_TRAIN_IMGLIST_FILENAME)
|
| 330 |
+
elif net=='onet':
|
| 331 |
+
annotation_file = os.path.join(config.ANNO_STORE_DIR,config.ONET_TRAIN_IMGLIST_FILENAME)
|
| 332 |
+
imagedb = ImageDB(annotation_file)
|
| 333 |
+
gt_imdb = imagedb.load_imdb()
|
| 334 |
+
print('DATASIZE',len(gt_imdb))
|
| 335 |
+
gt_imdb = imagedb.append_flipped_images(gt_imdb)
|
| 336 |
+
print('FLIP DATASIZE',len(gt_imdb))
|
| 337 |
+
if net=="pnet":
|
| 338 |
+
print("Training Pnet:")
|
| 339 |
+
train_pnet(model_store_path=model_store_path, end_epoch=end_epoch, imdb=gt_imdb, batch_size=batch_size, frequent=frequent, base_lr=lr,lr_epoch_decay=lr_epoch_decay, use_cuda=use_cuda,load=load)
|
| 340 |
+
elif net=="rnet":
|
| 341 |
+
print("Training Rnet:")
|
| 342 |
+
train_rnet(model_store_path=model_store_path, end_epoch=end_epoch, imdb=gt_imdb, batch_size=batch_size, frequent=frequent, base_lr=lr,lr_epoch_decay=lr_epoch_decay, use_cuda=use_cuda,load=load)
|
| 343 |
+
elif net=="onet":
|
| 344 |
+
print("Training Onet:")
|
| 345 |
+
train_onet(model_store_path=model_store_path, end_epoch=end_epoch, imdb=gt_imdb, batch_size=batch_size, frequent=frequent, base_lr=lr,lr_epoch_decay=lr_epoch_decay, use_cuda=use_cuda,load=load)
|
| 346 |
+
|
| 347 |
+
if __name__ == '__main__':
|
| 348 |
+
args = parse_args()
|
| 349 |
+
lr_epoch_decay = [9]
|
| 350 |
+
train_net(annotation_file=args.annotation_file, model_store_path=args.model_store_path,
|
| 351 |
+
end_epoch=args.end_epoch, frequent=args.frequent, lr=args.lr,lr_epoch_decay=lr_epoch_decay,batch_size=args.batch_size, use_cuda=args.use_cuda,load=args.load,net=args.net)
|
train.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python get_data.py --net=pnet
|
| 2 |
+
python train.py --net=pnet
|
| 3 |
+
python get_data.py --net=rnet --pnet_path=./model_store/pnet_epoch_20.pt
|
| 4 |
+
python train.py --net=rnet
|
| 5 |
+
python get_data.py --net=onet --pnet_path=./model_store/pnet_epoch_20.pt --rnet_path=./model_store/rnet_epoch_20.pt
|
| 6 |
+
python train.py --net=onet
|
| 7 |
+
echo "Training finished!"
|
utils/config.py
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
'''使用示例代码的原始参数'''
|
| 3 |
+
|
| 4 |
+
MODEL_STORE_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))+"/model_store"
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
ANNO_STORE_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))+"/anno_store"
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
LOG_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))+"/log"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
USE_CUDA = True
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
TRAIN_BATCH_SIZE = 512
|
| 17 |
+
|
| 18 |
+
TRAIN_LR = 0.01
|
| 19 |
+
|
| 20 |
+
END_EPOCH = 20
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
PNET_POSTIVE_ANNO_FILENAME = "pos_12.txt"
|
| 24 |
+
PNET_NEGATIVE_ANNO_FILENAME = "neg_12.txt"
|
| 25 |
+
PNET_PART_ANNO_FILENAME = "part_12.txt"
|
| 26 |
+
PNET_LANDMARK_ANNO_FILENAME = "landmark_12.txt"
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
RNET_POSTIVE_ANNO_FILENAME = "pos_24.txt"
|
| 30 |
+
RNET_NEGATIVE_ANNO_FILENAME = "neg_24.txt"
|
| 31 |
+
RNET_PART_ANNO_FILENAME = "part_24.txt"
|
| 32 |
+
RNET_LANDMARK_ANNO_FILENAME = "landmark_24.txt"
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
ONET_POSTIVE_ANNO_FILENAME = "pos_48.txt"
|
| 36 |
+
ONET_NEGATIVE_ANNO_FILENAME = "neg_48.txt"
|
| 37 |
+
ONET_PART_ANNO_FILENAME = "part_48.txt"
|
| 38 |
+
ONET_LANDMARK_ANNO_FILENAME = "landmark_48.txt"
|
| 39 |
+
|
| 40 |
+
PNET_TRAIN_IMGLIST_FILENAME = "imglist_anno_12.txt"
|
| 41 |
+
RNET_TRAIN_IMGLIST_FILENAME = "imglist_anno_24.txt"
|
| 42 |
+
ONET_TRAIN_IMGLIST_FILENAME = "imglist_anno_48.txt"
|
utils/dataloader.py
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torchvision.transforms as transforms
|
| 2 |
+
import numpy as np
|
| 3 |
+
import os
|
| 4 |
+
import cv2
|
| 5 |
+
def convert_image_to_tensor(image):
|
| 6 |
+
"""convert an image to pytorch tensor
|
| 7 |
+
|
| 8 |
+
Parameters:
|
| 9 |
+
----------
|
| 10 |
+
image: numpy array , h * w * c
|
| 11 |
+
|
| 12 |
+
Returns:
|
| 13 |
+
-------
|
| 14 |
+
image_tensor: pytorch.FloatTensor, c * h * w
|
| 15 |
+
"""
|
| 16 |
+
transform = transforms.ToTensor()
|
| 17 |
+
|
| 18 |
+
return transform(image)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def convert_chwTensor_to_hwcNumpy(tensor):
|
| 22 |
+
"""convert a group images pytorch tensor(count * c * h * w) to numpy array images(count * h * w * c)
|
| 23 |
+
Parameters:
|
| 24 |
+
----------
|
| 25 |
+
tensor: numpy array , count * c * h * w
|
| 26 |
+
|
| 27 |
+
Returns:
|
| 28 |
+
-------
|
| 29 |
+
numpy array images: count * h * w * c
|
| 30 |
+
"""
|
| 31 |
+
return np.transpose(tensor.detach().numpy(), (0,2,3,1))
|
| 32 |
+
|
| 33 |
+
class ImageDB(object):
|
| 34 |
+
def __init__(self, image_annotation_file, prefix_path='', mode='train'):
|
| 35 |
+
self.prefix_path = prefix_path
|
| 36 |
+
self.image_annotation_file = image_annotation_file
|
| 37 |
+
self.classes = ['__background__', 'face']
|
| 38 |
+
self.num_classes = 2
|
| 39 |
+
self.image_set_index = self.load_image_set_index()
|
| 40 |
+
self.num_images = len(self.image_set_index)
|
| 41 |
+
self.mode = mode
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def load_image_set_index(self):
|
| 45 |
+
"""Get image index
|
| 46 |
+
|
| 47 |
+
Parameters:
|
| 48 |
+
----------
|
| 49 |
+
Returns:
|
| 50 |
+
-------
|
| 51 |
+
image_set_index: str
|
| 52 |
+
relative path of image
|
| 53 |
+
"""
|
| 54 |
+
assert os.path.exists(self.image_annotation_file), 'Path does not exist: {}'.format(self.image_annotation_file)
|
| 55 |
+
with open(self.image_annotation_file, 'r') as f:
|
| 56 |
+
image_set_index = [x.strip().split(' ')[0] for x in f.readlines()]
|
| 57 |
+
return image_set_index
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def load_imdb(self):
|
| 61 |
+
"""Get and save ground truth image database
|
| 62 |
+
|
| 63 |
+
Parameters:
|
| 64 |
+
----------
|
| 65 |
+
Returns:
|
| 66 |
+
-------
|
| 67 |
+
gt_imdb: dict
|
| 68 |
+
image database with annotations
|
| 69 |
+
"""
|
| 70 |
+
gt_imdb = self.load_annotations()
|
| 71 |
+
return gt_imdb
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def real_image_path(self, index):
|
| 75 |
+
"""Given image index, return full path
|
| 76 |
+
|
| 77 |
+
Parameters:
|
| 78 |
+
----------
|
| 79 |
+
index: str
|
| 80 |
+
relative path of image
|
| 81 |
+
Returns:
|
| 82 |
+
-------
|
| 83 |
+
image_file: str
|
| 84 |
+
full path of image
|
| 85 |
+
"""
|
| 86 |
+
|
| 87 |
+
index = index.replace("\\", "/")
|
| 88 |
+
|
| 89 |
+
if not os.path.exists(index):
|
| 90 |
+
image_file = os.path.join(self.prefix_path, index)
|
| 91 |
+
else:
|
| 92 |
+
image_file=index
|
| 93 |
+
if not image_file.endswith('.jpg'):
|
| 94 |
+
image_file = image_file + '.jpg'
|
| 95 |
+
assert os.path.exists(image_file), 'Path does not exist: {}'.format(image_file)
|
| 96 |
+
return image_file
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def load_annotations(self,annotion_type=1):
|
| 100 |
+
"""Load annotations
|
| 101 |
+
|
| 102 |
+
Parameters:
|
| 103 |
+
----------
|
| 104 |
+
annotion_type: int
|
| 105 |
+
0:dsadsa
|
| 106 |
+
1:dsadsa
|
| 107 |
+
Returns:
|
| 108 |
+
-------
|
| 109 |
+
imdb: dict
|
| 110 |
+
image database with annotations
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
assert os.path.exists(self.image_annotation_file), 'annotations not found at {}'.format(self.image_annotation_file)
|
| 114 |
+
with open(self.image_annotation_file, 'r') as f:
|
| 115 |
+
annotations = f.readlines()
|
| 116 |
+
|
| 117 |
+
imdb = []
|
| 118 |
+
for i in range(self.num_images):
|
| 119 |
+
annotation = annotations[i].strip().split(' ')
|
| 120 |
+
index = annotation[0]
|
| 121 |
+
im_path = self.real_image_path(index)
|
| 122 |
+
imdb_ = dict()
|
| 123 |
+
imdb_['image'] = im_path
|
| 124 |
+
|
| 125 |
+
if self.mode == 'test':
|
| 126 |
+
pass
|
| 127 |
+
else:
|
| 128 |
+
label = annotation[1]
|
| 129 |
+
imdb_['label'] = int(label)
|
| 130 |
+
imdb_['flipped'] = False
|
| 131 |
+
imdb_['bbox_target'] = np.zeros((4,))
|
| 132 |
+
imdb_['landmark_target'] = np.zeros((10,))
|
| 133 |
+
if len(annotation[2:])==4:
|
| 134 |
+
bbox_target = annotation[2:6]
|
| 135 |
+
imdb_['bbox_target'] = np.array(bbox_target).astype(float)
|
| 136 |
+
if len(annotation[2:])==14:
|
| 137 |
+
bbox_target = annotation[2:6]
|
| 138 |
+
imdb_['bbox_target'] = np.array(bbox_target).astype(float)
|
| 139 |
+
landmark = annotation[6:]
|
| 140 |
+
imdb_['landmark_target'] = np.array(landmark).astype(float)
|
| 141 |
+
imdb.append(imdb_)
|
| 142 |
+
|
| 143 |
+
return imdb
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def append_flipped_images(self, imdb):
|
| 147 |
+
"""append flipped images to imdb
|
| 148 |
+
|
| 149 |
+
Parameters:
|
| 150 |
+
----------
|
| 151 |
+
imdb: imdb
|
| 152 |
+
image database
|
| 153 |
+
Returns:
|
| 154 |
+
-------
|
| 155 |
+
imdb: dict
|
| 156 |
+
image database with flipped image annotations added
|
| 157 |
+
"""
|
| 158 |
+
print('append flipped images to imdb', len(imdb))
|
| 159 |
+
for i in range(len(imdb)):
|
| 160 |
+
imdb_ = imdb[i]
|
| 161 |
+
m_bbox = imdb_['bbox_target'].copy()
|
| 162 |
+
m_bbox[0], m_bbox[2] = -m_bbox[2], -m_bbox[0]
|
| 163 |
+
|
| 164 |
+
landmark_ = imdb_['landmark_target'].copy()
|
| 165 |
+
landmark_ = landmark_.reshape((5, 2))
|
| 166 |
+
landmark_ = np.asarray([(1 - x, y) for (x, y) in landmark_])
|
| 167 |
+
landmark_[[0, 1]] = landmark_[[1, 0]]
|
| 168 |
+
landmark_[[3, 4]] = landmark_[[4, 3]]
|
| 169 |
+
|
| 170 |
+
item = {'image': imdb_['image'],
|
| 171 |
+
'label': imdb_['label'],
|
| 172 |
+
'bbox_target': m_bbox,
|
| 173 |
+
'landmark_target': landmark_.reshape((10)),
|
| 174 |
+
'flipped': True}
|
| 175 |
+
|
| 176 |
+
imdb.append(item)
|
| 177 |
+
self.image_set_index *= 2
|
| 178 |
+
return imdb
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class TrainImageReader:
|
| 185 |
+
def __init__(self, imdb, im_size, batch_size=128, shuffle=False):
|
| 186 |
+
|
| 187 |
+
self.imdb = imdb
|
| 188 |
+
self.batch_size = batch_size
|
| 189 |
+
self.im_size = im_size
|
| 190 |
+
self.shuffle = shuffle
|
| 191 |
+
|
| 192 |
+
self.cur = 0
|
| 193 |
+
self.size = len(imdb)
|
| 194 |
+
self.index = np.arange(self.size)
|
| 195 |
+
self.num_classes = 2
|
| 196 |
+
|
| 197 |
+
self.batch = None
|
| 198 |
+
self.data = None
|
| 199 |
+
self.label = None
|
| 200 |
+
|
| 201 |
+
self.label_names= ['label', 'bbox_target', 'landmark_target']
|
| 202 |
+
self.reset()
|
| 203 |
+
self.get_batch()
|
| 204 |
+
|
| 205 |
+
def reset(self):
|
| 206 |
+
self.cur = 0
|
| 207 |
+
if self.shuffle:
|
| 208 |
+
np.random.shuffle(self.index)
|
| 209 |
+
|
| 210 |
+
def iter_next(self):
|
| 211 |
+
return self.cur + self.batch_size <= self.size
|
| 212 |
+
|
| 213 |
+
def __iter__(self):
|
| 214 |
+
return self
|
| 215 |
+
|
| 216 |
+
def __next__(self):
|
| 217 |
+
return self.next()
|
| 218 |
+
|
| 219 |
+
def next(self):
|
| 220 |
+
if self.iter_next():
|
| 221 |
+
self.get_batch()
|
| 222 |
+
self.cur += self.batch_size
|
| 223 |
+
return self.data,self.label
|
| 224 |
+
else:
|
| 225 |
+
raise StopIteration
|
| 226 |
+
|
| 227 |
+
def getindex(self):
|
| 228 |
+
return self.cur / self.batch_size
|
| 229 |
+
|
| 230 |
+
def getpad(self):
|
| 231 |
+
if self.cur + self.batch_size > self.size:
|
| 232 |
+
return self.cur + self.batch_size - self.size
|
| 233 |
+
else:
|
| 234 |
+
return 0
|
| 235 |
+
|
| 236 |
+
def get_batch(self):
|
| 237 |
+
cur_from = self.cur
|
| 238 |
+
cur_to = min(cur_from + self.batch_size, self.size)
|
| 239 |
+
imdb = [self.imdb[self.index[i]] for i in range(cur_from, cur_to)]
|
| 240 |
+
data, label = get_minibatch(imdb)
|
| 241 |
+
self.data = data['data']
|
| 242 |
+
self.label = [label[name] for name in self.label_names]
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
class TestImageLoader:
|
| 247 |
+
def __init__(self, imdb, batch_size=1, shuffle=False):
|
| 248 |
+
self.imdb = imdb
|
| 249 |
+
self.batch_size = batch_size
|
| 250 |
+
self.shuffle = shuffle
|
| 251 |
+
self.size = len(imdb)
|
| 252 |
+
self.index = np.arange(self.size)
|
| 253 |
+
|
| 254 |
+
self.cur = 0
|
| 255 |
+
self.data = None
|
| 256 |
+
self.label = None
|
| 257 |
+
|
| 258 |
+
self.reset()
|
| 259 |
+
self.get_batch()
|
| 260 |
+
|
| 261 |
+
def reset(self):
|
| 262 |
+
self.cur = 0
|
| 263 |
+
if self.shuffle:
|
| 264 |
+
np.random.shuffle(self.index)
|
| 265 |
+
|
| 266 |
+
def iter_next(self):
|
| 267 |
+
return self.cur + self.batch_size <= self.size
|
| 268 |
+
|
| 269 |
+
def __iter__(self):
|
| 270 |
+
return self
|
| 271 |
+
|
| 272 |
+
def __next__(self):
|
| 273 |
+
return self.next()
|
| 274 |
+
|
| 275 |
+
def next(self):
|
| 276 |
+
if self.iter_next():
|
| 277 |
+
self.get_batch()
|
| 278 |
+
self.cur += self.batch_size
|
| 279 |
+
return self.data
|
| 280 |
+
else:
|
| 281 |
+
raise StopIteration
|
| 282 |
+
|
| 283 |
+
def getindex(self):
|
| 284 |
+
return self.cur / self.batch_size
|
| 285 |
+
|
| 286 |
+
def getpad(self):
|
| 287 |
+
if self.cur + self.batch_size > self.size:
|
| 288 |
+
return self.cur + self.batch_size - self.size
|
| 289 |
+
else:
|
| 290 |
+
return 0
|
| 291 |
+
|
| 292 |
+
def get_batch(self):
|
| 293 |
+
cur_from = self.cur
|
| 294 |
+
cur_to = min(cur_from + self.batch_size, self.size)
|
| 295 |
+
imdb = [self.imdb[self.index[i]] for i in range(cur_from, cur_to)]
|
| 296 |
+
data= get_testbatch(imdb)
|
| 297 |
+
self.data=data['data']
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
def get_minibatch(imdb):
|
| 303 |
+
|
| 304 |
+
# im_size: 12, 24 or 48
|
| 305 |
+
num_images = len(imdb)
|
| 306 |
+
processed_ims = list()
|
| 307 |
+
cls_label = list()
|
| 308 |
+
bbox_reg_target = list()
|
| 309 |
+
landmark_reg_target = list()
|
| 310 |
+
|
| 311 |
+
for i in range(num_images):
|
| 312 |
+
im = cv2.imread(imdb[i]['image'])
|
| 313 |
+
|
| 314 |
+
if imdb[i]['flipped']:
|
| 315 |
+
im = im[:, ::-1, :]
|
| 316 |
+
|
| 317 |
+
cls = imdb[i]['label']
|
| 318 |
+
bbox_target = imdb[i]['bbox_target']
|
| 319 |
+
landmark = imdb[i]['landmark_target']
|
| 320 |
+
|
| 321 |
+
processed_ims.append(im)
|
| 322 |
+
cls_label.append(cls)
|
| 323 |
+
bbox_reg_target.append(bbox_target)
|
| 324 |
+
landmark_reg_target.append(landmark)
|
| 325 |
+
|
| 326 |
+
im_array = np.asarray(processed_ims)
|
| 327 |
+
|
| 328 |
+
label_array = np.array(cls_label)
|
| 329 |
+
|
| 330 |
+
bbox_target_array = np.vstack(bbox_reg_target)
|
| 331 |
+
|
| 332 |
+
landmark_target_array = np.vstack(landmark_reg_target)
|
| 333 |
+
|
| 334 |
+
data = {'data': im_array}
|
| 335 |
+
label = {'label': label_array,
|
| 336 |
+
'bbox_target': bbox_target_array,
|
| 337 |
+
'landmark_target': landmark_target_array
|
| 338 |
+
}
|
| 339 |
+
|
| 340 |
+
return data, label
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
def get_testbatch(imdb):
|
| 344 |
+
assert len(imdb) == 1, "Single batch only"
|
| 345 |
+
im = cv2.imread(imdb[0]['image'])
|
| 346 |
+
data = {'data': im}
|
| 347 |
+
return data
|
utils/detect.py
ADDED
|
@@ -0,0 +1,758 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import time
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
from utils.models import PNet,RNet,ONet
|
| 6 |
+
import utils.tool as utils
|
| 7 |
+
import utils.dataloader as image_tools
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def create_mtcnn_net(p_model_path=None, r_model_path=None, o_model_path=None, use_cuda=True):
|
| 11 |
+
|
| 12 |
+
pnet, rnet, onet = None, None, None
|
| 13 |
+
|
| 14 |
+
if p_model_path is not None:
|
| 15 |
+
pnet = PNet(use_cuda=use_cuda)
|
| 16 |
+
if(use_cuda):
|
| 17 |
+
print('p_model_path:{0}'.format(p_model_path))
|
| 18 |
+
pnet.load_state_dict(torch.load(p_model_path))
|
| 19 |
+
pnet.cuda()
|
| 20 |
+
else:
|
| 21 |
+
# forcing all GPU tensors to be in CPU while loading
|
| 22 |
+
#pnet.load_state_dict(torch.load(p_model_path, map_location=lambda storage, loc: storage))
|
| 23 |
+
pnet.load_state_dict(torch.load(p_model_path, map_location='cpu'))
|
| 24 |
+
pnet.eval()
|
| 25 |
+
|
| 26 |
+
if r_model_path is not None:
|
| 27 |
+
rnet = RNet(use_cuda=use_cuda)
|
| 28 |
+
if (use_cuda):
|
| 29 |
+
print('r_model_path:{0}'.format(r_model_path))
|
| 30 |
+
rnet.load_state_dict(torch.load(r_model_path))
|
| 31 |
+
rnet.cuda()
|
| 32 |
+
else:
|
| 33 |
+
rnet.load_state_dict(torch.load(r_model_path, map_location=lambda storage, loc: storage))
|
| 34 |
+
rnet.eval()
|
| 35 |
+
|
| 36 |
+
if o_model_path is not None:
|
| 37 |
+
onet = ONet(use_cuda=use_cuda)
|
| 38 |
+
if (use_cuda):
|
| 39 |
+
print('o_model_path:{0}'.format(o_model_path))
|
| 40 |
+
onet.load_state_dict(torch.load(o_model_path))
|
| 41 |
+
onet.cuda()
|
| 42 |
+
else:
|
| 43 |
+
onet.load_state_dict(torch.load(o_model_path, map_location=lambda storage, loc: storage))
|
| 44 |
+
onet.eval()
|
| 45 |
+
|
| 46 |
+
return pnet,rnet,onet
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class MtcnnDetector(object):
|
| 52 |
+
"""
|
| 53 |
+
P,R,O net face detection and landmarks align
|
| 54 |
+
"""
|
| 55 |
+
def __init__(self,
|
| 56 |
+
pnet = None,
|
| 57 |
+
rnet = None,
|
| 58 |
+
onet = None,
|
| 59 |
+
min_face_size=12,
|
| 60 |
+
stride=2,
|
| 61 |
+
threshold=[0.6, 0.7, 0.7],
|
| 62 |
+
#threshold=[0.1, 0.1, 0.1],
|
| 63 |
+
scale_factor=0.709,
|
| 64 |
+
):
|
| 65 |
+
|
| 66 |
+
self.pnet_detector = pnet
|
| 67 |
+
self.rnet_detector = rnet
|
| 68 |
+
self.onet_detector = onet
|
| 69 |
+
self.min_face_size = min_face_size
|
| 70 |
+
self.stride=stride
|
| 71 |
+
self.thresh = threshold
|
| 72 |
+
self.scale_factor = scale_factor
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def unique_image_format(self,im):
|
| 76 |
+
if not isinstance(im,np.ndarray):
|
| 77 |
+
if im.mode == 'I':
|
| 78 |
+
im = np.array(im, np.int32, copy=False)
|
| 79 |
+
elif im.mode == 'I;16':
|
| 80 |
+
im = np.array(im, np.int16, copy=False)
|
| 81 |
+
else:
|
| 82 |
+
im = np.asarray(im)
|
| 83 |
+
return im
|
| 84 |
+
|
| 85 |
+
def square_bbox(self, bbox):
|
| 86 |
+
"""
|
| 87 |
+
convert bbox to square
|
| 88 |
+
Parameters:
|
| 89 |
+
----------
|
| 90 |
+
bbox: numpy array , shape n x m
|
| 91 |
+
input bbox
|
| 92 |
+
Returns:
|
| 93 |
+
-------
|
| 94 |
+
a square bbox
|
| 95 |
+
"""
|
| 96 |
+
square_bbox = bbox.copy()
|
| 97 |
+
|
| 98 |
+
# x2 - x1
|
| 99 |
+
# y2 - y1
|
| 100 |
+
h = bbox[:, 3] - bbox[:, 1] + 1
|
| 101 |
+
w = bbox[:, 2] - bbox[:, 0] + 1
|
| 102 |
+
l = np.maximum(h,w)
|
| 103 |
+
# x1 = x1 + w*0.5 - l*0.5
|
| 104 |
+
# y1 = y1 + h*0.5 - l*0.5
|
| 105 |
+
square_bbox[:, 0] = bbox[:, 0] + w*0.5 - l*0.5
|
| 106 |
+
square_bbox[:, 1] = bbox[:, 1] + h*0.5 - l*0.5
|
| 107 |
+
|
| 108 |
+
# x2 = x1 + l - 1
|
| 109 |
+
# y2 = y1 + l - 1
|
| 110 |
+
square_bbox[:, 2] = square_bbox[:, 0] + l - 1
|
| 111 |
+
square_bbox[:, 3] = square_bbox[:, 1] + l - 1
|
| 112 |
+
return square_bbox
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def generate_bounding_box(self, map, reg, scale, threshold):
|
| 116 |
+
"""
|
| 117 |
+
generate bbox from feature map
|
| 118 |
+
Parameters:
|
| 119 |
+
----------
|
| 120 |
+
map: numpy array , n x m x 1
|
| 121 |
+
detect score for each position
|
| 122 |
+
reg: numpy array , n x m x 4
|
| 123 |
+
bbox
|
| 124 |
+
scale: float number
|
| 125 |
+
scale of this detection
|
| 126 |
+
threshold: float number
|
| 127 |
+
detect threshold
|
| 128 |
+
Returns:
|
| 129 |
+
-------
|
| 130 |
+
bbox array
|
| 131 |
+
"""
|
| 132 |
+
stride = 2
|
| 133 |
+
cellsize = 12 # receptive field
|
| 134 |
+
|
| 135 |
+
t_index = np.where(map[:,:,0] > threshold)
|
| 136 |
+
# print('shape of t_index:{0}'.format(len(t_index)))
|
| 137 |
+
# print('t_index{0}'.format(t_index))
|
| 138 |
+
# time.sleep(5)
|
| 139 |
+
|
| 140 |
+
# find nothing
|
| 141 |
+
if t_index[0].size == 0:
|
| 142 |
+
return np.array([])
|
| 143 |
+
|
| 144 |
+
# reg = (1, n, m, 4)
|
| 145 |
+
# choose bounding box whose socre are larger than threshold
|
| 146 |
+
dx1, dy1, dx2, dy2 = [reg[0, t_index[0], t_index[1], i] for i in range(4)]
|
| 147 |
+
#print(dx1.shape)
|
| 148 |
+
#exit()
|
| 149 |
+
# time.sleep(5)
|
| 150 |
+
reg = np.array([dx1, dy1, dx2, dy2])
|
| 151 |
+
#print('shape of reg{0}'.format(reg.shape))
|
| 152 |
+
#exit()
|
| 153 |
+
|
| 154 |
+
# lefteye_dx, lefteye_dy, righteye_dx, righteye_dy, nose_dx, nose_dy, \
|
| 155 |
+
# leftmouth_dx, leftmouth_dy, rightmouth_dx, rightmouth_dy = [landmarks[0, t_index[0], t_index[1], i] for i in range(10)]
|
| 156 |
+
#
|
| 157 |
+
# landmarks = np.array([lefteye_dx, lefteye_dy, righteye_dx, righteye_dy, nose_dx, nose_dy, leftmouth_dx, leftmouth_dy, rightmouth_dx, rightmouth_dy])
|
| 158 |
+
|
| 159 |
+
# abtain score of classification which larger than threshold
|
| 160 |
+
# t_index[0]: choose the first column of t_index
|
| 161 |
+
# t_index[1]: choose the second column of t_index
|
| 162 |
+
score = map[t_index[0], t_index[1], 0]
|
| 163 |
+
# hence t_index[1] means column, t_index[1] is the value of x
|
| 164 |
+
# hence t_index[0] means row, t_index[0] is the value of y
|
| 165 |
+
boundingbox = np.vstack([np.round((stride * t_index[1]) / scale), # x1 of prediction box in original image
|
| 166 |
+
np.round((stride * t_index[0]) / scale), # y1 of prediction box in original image
|
| 167 |
+
np.round((stride * t_index[1] + cellsize) / scale), # x2 of prediction box in original image
|
| 168 |
+
np.round((stride * t_index[0] + cellsize) / scale), # y2 of prediction box in original image
|
| 169 |
+
# reconstruct the box in original image
|
| 170 |
+
score,
|
| 171 |
+
reg,
|
| 172 |
+
# landmarks
|
| 173 |
+
])
|
| 174 |
+
|
| 175 |
+
return boundingbox.T
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def resize_image(self, img, scale):
|
| 179 |
+
"""
|
| 180 |
+
resize image and transform dimention to [batchsize, channel, height, width]
|
| 181 |
+
Parameters:
|
| 182 |
+
----------
|
| 183 |
+
img: numpy array , height x width x channel
|
| 184 |
+
input image, channels in BGR order here
|
| 185 |
+
scale: float number
|
| 186 |
+
scale factor of resize operation
|
| 187 |
+
Returns:
|
| 188 |
+
-------
|
| 189 |
+
transformed image tensor , 1 x channel x height x width
|
| 190 |
+
"""
|
| 191 |
+
height, width, channels = img.shape
|
| 192 |
+
new_height = int(height * scale) # resized new height
|
| 193 |
+
new_width = int(width * scale) # resized new width
|
| 194 |
+
new_dim = (new_width, new_height)
|
| 195 |
+
img_resized = cv2.resize(img, new_dim, interpolation=cv2.INTER_LINEAR) # resized image
|
| 196 |
+
return img_resized
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
def pad(self, bboxes, w, h):
|
| 200 |
+
"""
|
| 201 |
+
pad the the boxes
|
| 202 |
+
Parameters:
|
| 203 |
+
----------
|
| 204 |
+
bboxes: numpy array, n x 5
|
| 205 |
+
input bboxes
|
| 206 |
+
w: float number
|
| 207 |
+
width of the input image
|
| 208 |
+
h: float number
|
| 209 |
+
height of the input image
|
| 210 |
+
Returns :
|
| 211 |
+
------
|
| 212 |
+
dy, dx : numpy array, n x 1
|
| 213 |
+
start point of the bbox in target image
|
| 214 |
+
edy, edx : numpy array, n x 1
|
| 215 |
+
end point of the bbox in target image
|
| 216 |
+
y, x : numpy array, n x 1
|
| 217 |
+
start point of the bbox in original image
|
| 218 |
+
ex, ex : numpy array, n x 1
|
| 219 |
+
end point of the bbox in original image
|
| 220 |
+
tmph, tmpw: numpy array, n x 1
|
| 221 |
+
height and width of the bbox
|
| 222 |
+
"""
|
| 223 |
+
# width and height
|
| 224 |
+
tmpw = (bboxes[:, 2] - bboxes[:, 0] + 1).astype(np.int32)
|
| 225 |
+
tmph = (bboxes[:, 3] - bboxes[:, 1] + 1).astype(np.int32)
|
| 226 |
+
numbox = bboxes.shape[0]
|
| 227 |
+
|
| 228 |
+
dx = np.zeros((numbox, ))
|
| 229 |
+
dy = np.zeros((numbox, ))
|
| 230 |
+
edx, edy = tmpw.copy()-1, tmph.copy()-1
|
| 231 |
+
# x, y: start point of the bbox in original image
|
| 232 |
+
# ex, ey: end point of the bbox in original image
|
| 233 |
+
x, y, ex, ey = bboxes[:, 0], bboxes[:, 1], bboxes[:, 2], bboxes[:, 3]
|
| 234 |
+
|
| 235 |
+
tmp_index = np.where(ex > w-1)
|
| 236 |
+
edx[tmp_index] = tmpw[tmp_index] + w - 2 - ex[tmp_index]
|
| 237 |
+
ex[tmp_index] = w - 1
|
| 238 |
+
|
| 239 |
+
tmp_index = np.where(ey > h-1)
|
| 240 |
+
edy[tmp_index] = tmph[tmp_index] + h - 2 - ey[tmp_index]
|
| 241 |
+
ey[tmp_index] = h - 1
|
| 242 |
+
|
| 243 |
+
tmp_index = np.where(x < 0)
|
| 244 |
+
dx[tmp_index] = 0 - x[tmp_index]
|
| 245 |
+
x[tmp_index] = 0
|
| 246 |
+
|
| 247 |
+
tmp_index = np.where(y < 0)
|
| 248 |
+
dy[tmp_index] = 0 - y[tmp_index]
|
| 249 |
+
y[tmp_index] = 0
|
| 250 |
+
|
| 251 |
+
return_list = [dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph]
|
| 252 |
+
return_list = [item.astype(np.int32) for item in return_list]
|
| 253 |
+
|
| 254 |
+
return return_list
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
def detect_pnet(self, im):
|
| 258 |
+
"""Get face candidates through pnet
|
| 259 |
+
|
| 260 |
+
Parameters:
|
| 261 |
+
----------
|
| 262 |
+
im: numpy array
|
| 263 |
+
input image array
|
| 264 |
+
one batch
|
| 265 |
+
|
| 266 |
+
Returns:
|
| 267 |
+
-------
|
| 268 |
+
boxes: numpy array
|
| 269 |
+
detected boxes before calibration
|
| 270 |
+
boxes_align: numpy array
|
| 271 |
+
boxes after calibration
|
| 272 |
+
"""
|
| 273 |
+
|
| 274 |
+
# im = self.unique_image_format(im)
|
| 275 |
+
|
| 276 |
+
# original wider face data
|
| 277 |
+
h, w, c = im.shape
|
| 278 |
+
net_size = 12
|
| 279 |
+
|
| 280 |
+
current_scale = float(net_size) / self.min_face_size # find initial scale
|
| 281 |
+
#print('imgshape:{0}, current_scale:{1}'.format(im.shape, current_scale))
|
| 282 |
+
im_resized = self.resize_image(im, current_scale) # scale = 1.0
|
| 283 |
+
current_height, current_width, _ = im_resized.shape
|
| 284 |
+
# fcn
|
| 285 |
+
all_boxes = list()
|
| 286 |
+
while min(current_height, current_width) > net_size:
|
| 287 |
+
#print('current:',current_height, current_width)
|
| 288 |
+
feed_imgs = []
|
| 289 |
+
image_tensor = image_tools.convert_image_to_tensor(im_resized)
|
| 290 |
+
feed_imgs.append(image_tensor)
|
| 291 |
+
feed_imgs = torch.stack(feed_imgs)
|
| 292 |
+
|
| 293 |
+
feed_imgs.requires_grad = True
|
| 294 |
+
|
| 295 |
+
if self.pnet_detector.use_cuda:
|
| 296 |
+
feed_imgs = feed_imgs.cuda()
|
| 297 |
+
|
| 298 |
+
# self.pnet_detector is a trained pnet torch model
|
| 299 |
+
|
| 300 |
+
# receptive field is 12×12
|
| 301 |
+
# 12×12 --> score
|
| 302 |
+
# 12×12 --> bounding box
|
| 303 |
+
cls_map, reg = self.pnet_detector(feed_imgs)
|
| 304 |
+
|
| 305 |
+
cls_map_np = image_tools.convert_chwTensor_to_hwcNumpy(cls_map.cpu())
|
| 306 |
+
reg_np = image_tools.convert_chwTensor_to_hwcNumpy(reg.cpu())
|
| 307 |
+
# print(cls_map_np.shape, reg_np.shape) # cls_map_np = (1, n, m, 1) reg_np.shape = (1, n, m 4)
|
| 308 |
+
# time.sleep(5)
|
| 309 |
+
# landmark_np = image_tools.convert_chwTensor_to_hwcNumpy(landmark.cpu())
|
| 310 |
+
|
| 311 |
+
# self.threshold[0] = 0.6
|
| 312 |
+
# print(cls_map_np[0,:,:].shape)
|
| 313 |
+
# time.sleep(4)
|
| 314 |
+
|
| 315 |
+
# boxes = [x1, y1, x2, y2, score, reg]
|
| 316 |
+
boxes = self.generate_bounding_box(cls_map_np[ 0, :, :], reg_np, current_scale, self.thresh[0])
|
| 317 |
+
#cv2.rectangle(im,(300,100),(400,200),color=(0,0,0))
|
| 318 |
+
#cv2.rectangle(im,(400,200),(500,300),color=(0,0,0))
|
| 319 |
+
|
| 320 |
+
# generate pyramid images
|
| 321 |
+
current_scale *= self.scale_factor # self.scale_factor = 0.709
|
| 322 |
+
im_resized = self.resize_image(im, current_scale)
|
| 323 |
+
current_height, current_width, _ = im_resized.shape
|
| 324 |
+
|
| 325 |
+
if boxes.size == 0:
|
| 326 |
+
continue
|
| 327 |
+
|
| 328 |
+
# non-maximum suppresion
|
| 329 |
+
keep = utils.nms(boxes[:, :5], 0.5, 'Union')
|
| 330 |
+
boxes = boxes[keep]
|
| 331 |
+
all_boxes.append(boxes)
|
| 332 |
+
|
| 333 |
+
""" img = im.copy()
|
| 334 |
+
bw = boxes[:,2]-boxes[:,0]
|
| 335 |
+
bh = boxes[:,3]-boxes[:,1]
|
| 336 |
+
for i in range(boxes.shape[0]):
|
| 337 |
+
p1=(int(boxes[i][0]+boxes[i][5]*bw[i]),int(boxes[i][1]+boxes[i][6]*bh[i]))
|
| 338 |
+
p2=(int(boxes[i][2]+boxes[i][7]*bw[i]),int(boxes[i][3]+boxes[i][8]*bh[i]))
|
| 339 |
+
cv2.rectangle(img,p1,p2,color=(0,0,0))
|
| 340 |
+
cv2.imshow('ss',img)
|
| 341 |
+
cv2.waitKey(0)
|
| 342 |
+
#ii+=1
|
| 343 |
+
exit() """
|
| 344 |
+
|
| 345 |
+
if len(all_boxes) == 0:
|
| 346 |
+
return None, None
|
| 347 |
+
all_boxes = np.vstack(all_boxes)
|
| 348 |
+
# print("shape of all boxes {0}".format(all_boxes.shape))
|
| 349 |
+
# time.sleep(5)
|
| 350 |
+
|
| 351 |
+
# merge the detection from first stage
|
| 352 |
+
keep = utils.nms(all_boxes[:, 0:5], 0.7, 'Union')
|
| 353 |
+
all_boxes = all_boxes[keep]
|
| 354 |
+
# boxes = all_boxes[:, :5]
|
| 355 |
+
|
| 356 |
+
# x2 - x1
|
| 357 |
+
# y2 - y1
|
| 358 |
+
bw = all_boxes[:, 2] - all_boxes[:, 0] + 1
|
| 359 |
+
bh = all_boxes[:, 3] - all_boxes[:, 1] + 1
|
| 360 |
+
|
| 361 |
+
# landmark_keep = all_boxes[:, 9:].reshape((5,2))
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
boxes = np.vstack([all_boxes[:,0],
|
| 365 |
+
all_boxes[:,1],
|
| 366 |
+
all_boxes[:,2],
|
| 367 |
+
all_boxes[:,3],
|
| 368 |
+
all_boxes[:,4],
|
| 369 |
+
# all_boxes[:, 0] + all_boxes[:, 9] * bw,
|
| 370 |
+
# all_boxes[:, 1] + all_boxes[:,10] * bh,
|
| 371 |
+
# all_boxes[:, 0] + all_boxes[:, 11] * bw,
|
| 372 |
+
# all_boxes[:, 1] + all_boxes[:, 12] * bh,
|
| 373 |
+
# all_boxes[:, 0] + all_boxes[:, 13] * bw,
|
| 374 |
+
# all_boxes[:, 1] + all_boxes[:, 14] * bh,
|
| 375 |
+
# all_boxes[:, 0] + all_boxes[:, 15] * bw,
|
| 376 |
+
# all_boxes[:, 1] + all_boxes[:, 16] * bh,
|
| 377 |
+
# all_boxes[:, 0] + all_boxes[:, 17] * bw,
|
| 378 |
+
# all_boxes[:, 1] + all_boxes[:, 18] * bh
|
| 379 |
+
])
|
| 380 |
+
|
| 381 |
+
boxes = boxes.T
|
| 382 |
+
|
| 383 |
+
# boxes = boxes = [x1, y1, x2, y2, score, reg] reg= [px1, py1, px2, py2] (in prediction)
|
| 384 |
+
align_topx = all_boxes[:, 0] + all_boxes[:, 5] * bw
|
| 385 |
+
align_topy = all_boxes[:, 1] + all_boxes[:, 6] * bh
|
| 386 |
+
align_bottomx = all_boxes[:, 2] + all_boxes[:, 7] * bw
|
| 387 |
+
align_bottomy = all_boxes[:, 3] + all_boxes[:, 8] * bh
|
| 388 |
+
|
| 389 |
+
# refine the boxes
|
| 390 |
+
boxes_align = np.vstack([ align_topx,
|
| 391 |
+
align_topy,
|
| 392 |
+
align_bottomx,
|
| 393 |
+
align_bottomy,
|
| 394 |
+
all_boxes[:, 4],
|
| 395 |
+
# align_topx + all_boxes[:,9] * bw,
|
| 396 |
+
# align_topy + all_boxes[:,10] * bh,
|
| 397 |
+
# align_topx + all_boxes[:,11] * bw,
|
| 398 |
+
# align_topy + all_boxes[:,12] * bh,
|
| 399 |
+
# align_topx + all_boxes[:,13] * bw,
|
| 400 |
+
# align_topy + all_boxes[:,14] * bh,
|
| 401 |
+
# align_topx + all_boxes[:,15] * bw,
|
| 402 |
+
# align_topy + all_boxes[:,16] * bh,
|
| 403 |
+
# align_topx + all_boxes[:,17] * bw,
|
| 404 |
+
# align_topy + all_boxes[:,18] * bh,
|
| 405 |
+
])
|
| 406 |
+
boxes_align = boxes_align.T
|
| 407 |
+
|
| 408 |
+
#remove invalid box
|
| 409 |
+
valindex = [True for _ in range(boxes_align.shape[0])]
|
| 410 |
+
for i in range(boxes_align.shape[0]):
|
| 411 |
+
if boxes_align[i][2]-boxes_align[i][0]<=3 or boxes_align[i][3]-boxes_align[i][1]<=3:
|
| 412 |
+
valindex[i]=False
|
| 413 |
+
#print('pnet has one smaller than 3')
|
| 414 |
+
else:
|
| 415 |
+
if boxes_align[i][2]<1 or boxes_align[i][0]>w-2 or boxes_align[i][3]<1 or boxes_align[i][1]>h-2:
|
| 416 |
+
valindex[i]=False
|
| 417 |
+
#print('pnet has one out')
|
| 418 |
+
boxes_align=boxes_align[valindex,:]
|
| 419 |
+
boxes = boxes[valindex,:]
|
| 420 |
+
return boxes, boxes_align
|
| 421 |
+
|
| 422 |
+
def detect_rnet(self, im, dets):
|
| 423 |
+
"""Get face candidates using rnet
|
| 424 |
+
|
| 425 |
+
Parameters:
|
| 426 |
+
----------
|
| 427 |
+
im: numpy array
|
| 428 |
+
input image array
|
| 429 |
+
dets: numpy array
|
| 430 |
+
detection results of pnet
|
| 431 |
+
|
| 432 |
+
Returns:
|
| 433 |
+
-------
|
| 434 |
+
boxes: numpy array
|
| 435 |
+
detected boxes before calibration
|
| 436 |
+
boxes_align: numpy array
|
| 437 |
+
boxes after calibration
|
| 438 |
+
"""
|
| 439 |
+
# im: an input image
|
| 440 |
+
h, w, c = im.shape
|
| 441 |
+
|
| 442 |
+
if dets is None:
|
| 443 |
+
return None,None
|
| 444 |
+
if dets.shape[0]==0:
|
| 445 |
+
return None, None
|
| 446 |
+
|
| 447 |
+
# (705, 5) = [x1, y1, x2, y2, score, reg]
|
| 448 |
+
# print("pnet detection {0}".format(dets.shape))
|
| 449 |
+
# time.sleep(5)
|
| 450 |
+
detss = dets
|
| 451 |
+
# return square boxes
|
| 452 |
+
dets = self.square_bbox(dets)
|
| 453 |
+
detsss = dets
|
| 454 |
+
# rounds
|
| 455 |
+
dets[:, 0:4] = np.round(dets[:, 0:4])
|
| 456 |
+
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(dets, w, h)
|
| 457 |
+
num_boxes = dets.shape[0]
|
| 458 |
+
|
| 459 |
+
'''
|
| 460 |
+
# helper for setting RNet batch size
|
| 461 |
+
batch_size = self.rnet_detector.batch_size
|
| 462 |
+
ratio = float(num_boxes) / batch_size
|
| 463 |
+
if ratio > 3 or ratio < 0.3:
|
| 464 |
+
print "You may need to reset RNet batch size if this info appears frequently, \
|
| 465 |
+
face candidates:%d, current batch_size:%d"%(num_boxes, batch_size)
|
| 466 |
+
'''
|
| 467 |
+
|
| 468 |
+
# cropped_ims_tensors = np.zeros((num_boxes, 3, 24, 24), dtype=np.float32)
|
| 469 |
+
cropped_ims_tensors = []
|
| 470 |
+
for i in range(num_boxes):
|
| 471 |
+
try:
|
| 472 |
+
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
| 473 |
+
tmp[dy[i]:edy[i]+1, dx[i]:edx[i]+1, :] = im[y[i]:ey[i]+1, x[i]:ex[i]+1, :]
|
| 474 |
+
except:
|
| 475 |
+
print(dy[i],edy[i],dx[i],edx[i],y[i],ey[i],x[i],ex[i],tmpw[i],tmph[i])
|
| 476 |
+
print(dets[i])
|
| 477 |
+
print(detss[i])
|
| 478 |
+
print(detsss[i])
|
| 479 |
+
print(h,w)
|
| 480 |
+
exit()
|
| 481 |
+
crop_im = cv2.resize(tmp, (24, 24))
|
| 482 |
+
crop_im_tensor = image_tools.convert_image_to_tensor(crop_im)
|
| 483 |
+
# cropped_ims_tensors[i, :, :, :] = crop_im_tensor
|
| 484 |
+
cropped_ims_tensors.append(crop_im_tensor)
|
| 485 |
+
feed_imgs = torch.stack(cropped_ims_tensors)
|
| 486 |
+
feed_imgs.requires_grad = True
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
if self.rnet_detector.use_cuda:
|
| 490 |
+
feed_imgs = feed_imgs.cuda()
|
| 491 |
+
|
| 492 |
+
cls_map, reg = self.rnet_detector(feed_imgs)
|
| 493 |
+
|
| 494 |
+
cls_map = cls_map.cpu().data.numpy()
|
| 495 |
+
reg = reg.cpu().data.numpy()
|
| 496 |
+
# landmark = landmark.cpu().data.numpy()
|
| 497 |
+
|
| 498 |
+
|
| 499 |
+
keep_inds = np.where(cls_map > self.thresh[1])[0]
|
| 500 |
+
|
| 501 |
+
if len(keep_inds) > 0:
|
| 502 |
+
boxes = dets[keep_inds]
|
| 503 |
+
cls = cls_map[keep_inds]
|
| 504 |
+
reg = reg[keep_inds]
|
| 505 |
+
# landmark = landmark[keep_inds]
|
| 506 |
+
else:
|
| 507 |
+
return None, None
|
| 508 |
+
keep = utils.nms(boxes, 0.7)
|
| 509 |
+
|
| 510 |
+
if len(keep) == 0:
|
| 511 |
+
return None, None
|
| 512 |
+
|
| 513 |
+
keep_cls = cls[keep]
|
| 514 |
+
keep_boxes = boxes[keep]
|
| 515 |
+
keep_reg = reg[keep]
|
| 516 |
+
# keep_landmark = landmark[keep]
|
| 517 |
+
|
| 518 |
+
|
| 519 |
+
bw = keep_boxes[:, 2] - keep_boxes[:, 0] + 1
|
| 520 |
+
bh = keep_boxes[:, 3] - keep_boxes[:, 1] + 1
|
| 521 |
+
|
| 522 |
+
|
| 523 |
+
boxes = np.vstack([ keep_boxes[:,0],
|
| 524 |
+
keep_boxes[:,1],
|
| 525 |
+
keep_boxes[:,2],
|
| 526 |
+
keep_boxes[:,3],
|
| 527 |
+
keep_cls[:,0],
|
| 528 |
+
# keep_boxes[:,0] + keep_landmark[:, 0] * bw,
|
| 529 |
+
# keep_boxes[:,1] + keep_landmark[:, 1] * bh,
|
| 530 |
+
# keep_boxes[:,0] + keep_landmark[:, 2] * bw,
|
| 531 |
+
# keep_boxes[:,1] + keep_landmark[:, 3] * bh,
|
| 532 |
+
# keep_boxes[:,0] + keep_landmark[:, 4] * bw,
|
| 533 |
+
# keep_boxes[:,1] + keep_landmark[:, 5] * bh,
|
| 534 |
+
# keep_boxes[:,0] + keep_landmark[:, 6] * bw,
|
| 535 |
+
# keep_boxes[:,1] + keep_landmark[:, 7] * bh,
|
| 536 |
+
# keep_boxes[:,0] + keep_landmark[:, 8] * bw,
|
| 537 |
+
# keep_boxes[:,1] + keep_landmark[:, 9] * bh,
|
| 538 |
+
])
|
| 539 |
+
|
| 540 |
+
align_topx = keep_boxes[:,0] + keep_reg[:,0] * bw
|
| 541 |
+
align_topy = keep_boxes[:,1] + keep_reg[:,1] * bh
|
| 542 |
+
align_bottomx = keep_boxes[:,2] + keep_reg[:,2] * bw
|
| 543 |
+
align_bottomy = keep_boxes[:,3] + keep_reg[:,3] * bh
|
| 544 |
+
|
| 545 |
+
boxes_align = np.vstack([align_topx,
|
| 546 |
+
align_topy,
|
| 547 |
+
align_bottomx,
|
| 548 |
+
align_bottomy,
|
| 549 |
+
keep_cls[:, 0],
|
| 550 |
+
# align_topx + keep_landmark[:, 0] * bw,
|
| 551 |
+
# align_topy + keep_landmark[:, 1] * bh,
|
| 552 |
+
# align_topx + keep_landmark[:, 2] * bw,
|
| 553 |
+
# align_topy + keep_landmark[:, 3] * bh,
|
| 554 |
+
# align_topx + keep_landmark[:, 4] * bw,
|
| 555 |
+
# align_topy + keep_landmark[:, 5] * bh,
|
| 556 |
+
# align_topx + keep_landmark[:, 6] * bw,
|
| 557 |
+
# align_topy + keep_landmark[:, 7] * bh,
|
| 558 |
+
# align_topx + keep_landmark[:, 8] * bw,
|
| 559 |
+
# align_topy + keep_landmark[:, 9] * bh,
|
| 560 |
+
])
|
| 561 |
+
|
| 562 |
+
boxes = boxes.T
|
| 563 |
+
boxes_align = boxes_align.T
|
| 564 |
+
|
| 565 |
+
#remove invalid box
|
| 566 |
+
valindex = [True for _ in range(boxes_align.shape[0])]
|
| 567 |
+
for i in range(boxes_align.shape[0]):
|
| 568 |
+
if boxes_align[i][2]-boxes_align[i][0]<=3 or boxes_align[i][3]-boxes_align[i][1]<=3:
|
| 569 |
+
valindex[i]=False
|
| 570 |
+
print('rnet has one smaller than 3')
|
| 571 |
+
else:
|
| 572 |
+
if boxes_align[i][2]<1 or boxes_align[i][0]>w-2 or boxes_align[i][3]<1 or boxes_align[i][1]>h-2:
|
| 573 |
+
valindex[i]=False
|
| 574 |
+
print('rnet has one out')
|
| 575 |
+
boxes_align=boxes_align[valindex,:]
|
| 576 |
+
boxes = boxes[valindex,:]
|
| 577 |
+
""" img = im.copy()
|
| 578 |
+
for i in range(boxes_align.shape[0]):
|
| 579 |
+
p1=(int(boxes_align[i,0]),int(boxes_align[i,1]))
|
| 580 |
+
p2=(int(boxes_align[i,2]),int(boxes_align[i,3]))
|
| 581 |
+
cv2.rectangle(img,p1,p2,color=(0,0,0))
|
| 582 |
+
cv2.imshow('ss',img)
|
| 583 |
+
cv2.waitKey(0)
|
| 584 |
+
exit() """
|
| 585 |
+
return boxes, boxes_align
|
| 586 |
+
|
| 587 |
+
def detect_onet(self, im, dets):
|
| 588 |
+
"""Get face candidates using onet
|
| 589 |
+
|
| 590 |
+
Parameters:
|
| 591 |
+
----------
|
| 592 |
+
im: numpy array
|
| 593 |
+
input image array
|
| 594 |
+
dets: numpy array
|
| 595 |
+
detection results of rnet
|
| 596 |
+
|
| 597 |
+
Returns:
|
| 598 |
+
-------
|
| 599 |
+
boxes_align: numpy array
|
| 600 |
+
boxes after calibration
|
| 601 |
+
landmarks_align: numpy array
|
| 602 |
+
landmarks after calibration
|
| 603 |
+
|
| 604 |
+
"""
|
| 605 |
+
h, w, c = im.shape
|
| 606 |
+
|
| 607 |
+
if dets is None:
|
| 608 |
+
return None, None
|
| 609 |
+
if dets.shape[0]==0:
|
| 610 |
+
return None, None
|
| 611 |
+
|
| 612 |
+
detss = dets
|
| 613 |
+
dets = self.square_bbox(dets)
|
| 614 |
+
|
| 615 |
+
|
| 616 |
+
dets[:, 0:4] = np.round(dets[:, 0:4])
|
| 617 |
+
|
| 618 |
+
[dy, edy, dx, edx, y, ey, x, ex, tmpw, tmph] = self.pad(dets, w, h)
|
| 619 |
+
num_boxes = dets.shape[0]
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
# cropped_ims_tensors = np.zeros((num_boxes, 3, 24, 24), dtype=np.float32)
|
| 623 |
+
cropped_ims_tensors = []
|
| 624 |
+
for i in range(num_boxes):
|
| 625 |
+
try:
|
| 626 |
+
tmp = np.zeros((tmph[i], tmpw[i], 3), dtype=np.uint8)
|
| 627 |
+
# crop input image
|
| 628 |
+
tmp[dy[i]:edy[i] + 1, dx[i]:edx[i] + 1, :] = im[y[i]:ey[i] + 1, x[i]:ex[i] + 1, :]
|
| 629 |
+
except:
|
| 630 |
+
print(dy[i],edy[i],dx[i],edx[i],y[i],ey[i],x[i],ex[i],tmpw[i],tmph[i])
|
| 631 |
+
print(dets[i])
|
| 632 |
+
print(detss[i])
|
| 633 |
+
print(h,w)
|
| 634 |
+
crop_im = cv2.resize(tmp, (48, 48))
|
| 635 |
+
crop_im_tensor = image_tools.convert_image_to_tensor(crop_im)
|
| 636 |
+
# cropped_ims_tensors[i, :, :, :] = crop_im_tensor
|
| 637 |
+
cropped_ims_tensors.append(crop_im_tensor)
|
| 638 |
+
feed_imgs = torch.stack(cropped_ims_tensors)
|
| 639 |
+
feed_imgs.requires_grad = True
|
| 640 |
+
|
| 641 |
+
if self.rnet_detector.use_cuda:
|
| 642 |
+
feed_imgs = feed_imgs.cuda()
|
| 643 |
+
|
| 644 |
+
cls_map, reg, landmark = self.onet_detector(feed_imgs)
|
| 645 |
+
|
| 646 |
+
cls_map = cls_map.cpu().data.numpy()
|
| 647 |
+
reg = reg.cpu().data.numpy()
|
| 648 |
+
landmark = landmark.cpu().data.numpy()
|
| 649 |
+
|
| 650 |
+
keep_inds = np.where(cls_map > self.thresh[2])[0]
|
| 651 |
+
|
| 652 |
+
if len(keep_inds) > 0:
|
| 653 |
+
boxes = dets[keep_inds]
|
| 654 |
+
cls = cls_map[keep_inds]
|
| 655 |
+
reg = reg[keep_inds]
|
| 656 |
+
landmark = landmark[keep_inds]
|
| 657 |
+
else:
|
| 658 |
+
return None, None
|
| 659 |
+
|
| 660 |
+
keep = utils.nms(boxes, 0.7, mode="Minimum")
|
| 661 |
+
|
| 662 |
+
if len(keep) == 0:
|
| 663 |
+
return None, None
|
| 664 |
+
|
| 665 |
+
keep_cls = cls[keep]
|
| 666 |
+
keep_boxes = boxes[keep]
|
| 667 |
+
keep_reg = reg[keep]
|
| 668 |
+
keep_landmark = landmark[keep]
|
| 669 |
+
|
| 670 |
+
bw = keep_boxes[:, 2] - keep_boxes[:, 0] + 1
|
| 671 |
+
bh = keep_boxes[:, 3] - keep_boxes[:, 1] + 1
|
| 672 |
+
|
| 673 |
+
|
| 674 |
+
align_topx = keep_boxes[:, 0] + keep_reg[:, 0] * bw
|
| 675 |
+
align_topy = keep_boxes[:, 1] + keep_reg[:, 1] * bh
|
| 676 |
+
align_bottomx = keep_boxes[:, 2] + keep_reg[:, 2] * bw
|
| 677 |
+
align_bottomy = keep_boxes[:, 3] + keep_reg[:, 3] * bh
|
| 678 |
+
|
| 679 |
+
align_landmark_topx = keep_boxes[:, 0]
|
| 680 |
+
align_landmark_topy = keep_boxes[:, 1]
|
| 681 |
+
|
| 682 |
+
|
| 683 |
+
|
| 684 |
+
|
| 685 |
+
boxes_align = np.vstack([align_topx,
|
| 686 |
+
align_topy,
|
| 687 |
+
align_bottomx,
|
| 688 |
+
align_bottomy,
|
| 689 |
+
keep_cls[:, 0],
|
| 690 |
+
# align_topx + keep_landmark[:, 0] * bw,
|
| 691 |
+
# align_topy + keep_landmark[:, 1] * bh,
|
| 692 |
+
# align_topx + keep_landmark[:, 2] * bw,
|
| 693 |
+
# align_topy + keep_landmark[:, 3] * bh,
|
| 694 |
+
# align_topx + keep_landmark[:, 4] * bw,
|
| 695 |
+
# align_topy + keep_landmark[:, 5] * bh,
|
| 696 |
+
# align_topx + keep_landmark[:, 6] * bw,
|
| 697 |
+
# align_topy + keep_landmark[:, 7] * bh,
|
| 698 |
+
# align_topx + keep_landmark[:, 8] * bw,
|
| 699 |
+
# align_topy + keep_landmark[:, 9] * bh,
|
| 700 |
+
])
|
| 701 |
+
|
| 702 |
+
boxes_align = boxes_align.T
|
| 703 |
+
|
| 704 |
+
landmark = np.vstack([
|
| 705 |
+
align_landmark_topx + keep_landmark[:, 0] * bw,
|
| 706 |
+
align_landmark_topy + keep_landmark[:, 1] * bh,
|
| 707 |
+
align_landmark_topx + keep_landmark[:, 2] * bw,
|
| 708 |
+
align_landmark_topy + keep_landmark[:, 3] * bh,
|
| 709 |
+
align_landmark_topx + keep_landmark[:, 4] * bw,
|
| 710 |
+
align_landmark_topy + keep_landmark[:, 5] * bh,
|
| 711 |
+
align_landmark_topx + keep_landmark[:, 6] * bw,
|
| 712 |
+
align_landmark_topy + keep_landmark[:, 7] * bh,
|
| 713 |
+
align_landmark_topx + keep_landmark[:, 8] * bw,
|
| 714 |
+
align_landmark_topy + keep_landmark[:, 9] * bh,
|
| 715 |
+
])
|
| 716 |
+
|
| 717 |
+
landmark_align = landmark.T
|
| 718 |
+
|
| 719 |
+
return boxes_align, landmark_align
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
def detect_face(self,img):
|
| 723 |
+
"""Detect face over image
|
| 724 |
+
"""
|
| 725 |
+
boxes_align = np.array([])
|
| 726 |
+
landmark_align =np.array([])
|
| 727 |
+
|
| 728 |
+
t = time.time()
|
| 729 |
+
|
| 730 |
+
# pnet
|
| 731 |
+
if self.pnet_detector:
|
| 732 |
+
p_boxes, boxes_align = self.detect_pnet(img)
|
| 733 |
+
if boxes_align is None:
|
| 734 |
+
return np.array([]), np.array([])
|
| 735 |
+
|
| 736 |
+
t1 = time.time() - t
|
| 737 |
+
t = time.time()
|
| 738 |
+
|
| 739 |
+
# rnet
|
| 740 |
+
if self.rnet_detector:
|
| 741 |
+
r_boxes, boxes_align = self.detect_rnet(img, boxes_align)
|
| 742 |
+
if boxes_align is None:
|
| 743 |
+
return np.array([]), np.array([])
|
| 744 |
+
|
| 745 |
+
t2 = time.time() - t
|
| 746 |
+
t = time.time()
|
| 747 |
+
|
| 748 |
+
# onet
|
| 749 |
+
if self.onet_detector:
|
| 750 |
+
boxes_align, landmark_align = self.detect_onet(img, boxes_align)
|
| 751 |
+
if boxes_align is None:
|
| 752 |
+
return np.array([]), np.array([])
|
| 753 |
+
|
| 754 |
+
t3 = time.time() - t
|
| 755 |
+
t = time.time()
|
| 756 |
+
print("time cost " + '{:.3f}'.format(t1+t2+t3) + ' pnet {:.3f} rnet {:.3f} onet {:.3f}'.format(t1, t2, t3))
|
| 757 |
+
|
| 758 |
+
return p_boxes,r_boxes,boxes_align, landmark_align
|
utils/models.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
'''模型使用老师提供的示例代码,仅修改了三处版本改动'''
|
| 5 |
+
|
| 6 |
+
def weights_init(m):
|
| 7 |
+
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
|
| 8 |
+
nn.init.xavier_uniform_(m.weight.data)
|
| 9 |
+
nn.init.constant_(m.bias, 0.1)
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class LossFn:
|
| 14 |
+
def __init__(self, cls_factor=1, box_factor=1, landmark_factor=1):
|
| 15 |
+
# loss function
|
| 16 |
+
self.cls_factor = cls_factor
|
| 17 |
+
self.box_factor = box_factor
|
| 18 |
+
self.land_factor = landmark_factor
|
| 19 |
+
self.loss_cls = nn.BCELoss() # binary cross entropy
|
| 20 |
+
self.loss_box = nn.MSELoss() # mean square error
|
| 21 |
+
self.loss_landmark = nn.MSELoss()
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def cls_loss(self,gt_label,pred_label):
|
| 25 |
+
pred_label = torch.squeeze(pred_label)
|
| 26 |
+
gt_label = torch.squeeze(gt_label)
|
| 27 |
+
# get the mask element which >= 0, only 0 and 1 can effect the detection loss
|
| 28 |
+
mask = torch.ge(gt_label,0)
|
| 29 |
+
valid_gt_label = torch.masked_select(gt_label,mask)
|
| 30 |
+
valid_pred_label = torch.masked_select(pred_label,mask)
|
| 31 |
+
return self.loss_cls(valid_pred_label,valid_gt_label)*self.cls_factor
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def box_loss(self,gt_label,gt_offset,pred_offset):
|
| 35 |
+
pred_offset = torch.squeeze(pred_offset)
|
| 36 |
+
gt_offset = torch.squeeze(gt_offset)
|
| 37 |
+
gt_label = torch.squeeze(gt_label)
|
| 38 |
+
|
| 39 |
+
#get the mask element which != 0
|
| 40 |
+
unmask = torch.eq(gt_label,0)
|
| 41 |
+
mask = torch.eq(unmask,0)
|
| 42 |
+
#convert mask to dim index
|
| 43 |
+
chose_index = torch.nonzero(mask.data)
|
| 44 |
+
chose_index = torch.squeeze(chose_index)
|
| 45 |
+
#only valid element can effect the loss
|
| 46 |
+
valid_gt_offset = gt_offset[chose_index,:]
|
| 47 |
+
valid_pred_offset = pred_offset[chose_index,:]
|
| 48 |
+
return self.loss_box(valid_pred_offset,valid_gt_offset)*self.box_factor
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def landmark_loss(self,gt_label,gt_landmark,pred_landmark):
|
| 52 |
+
pred_landmark = torch.squeeze(pred_landmark)
|
| 53 |
+
gt_landmark = torch.squeeze(gt_landmark)
|
| 54 |
+
gt_label = torch.squeeze(gt_label)
|
| 55 |
+
mask = torch.eq(gt_label,-2)
|
| 56 |
+
|
| 57 |
+
chose_index = torch.nonzero(mask.data)
|
| 58 |
+
chose_index = torch.squeeze(chose_index)
|
| 59 |
+
|
| 60 |
+
valid_gt_landmark = gt_landmark[chose_index, :]
|
| 61 |
+
valid_pred_landmark = pred_landmark[chose_index, :]
|
| 62 |
+
return self.loss_landmark(valid_pred_landmark,valid_gt_landmark)*self.land_factor
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class PNet(nn.Module):
|
| 69 |
+
''' PNet '''
|
| 70 |
+
|
| 71 |
+
def __init__(self, is_train=False, use_cuda=True):
|
| 72 |
+
super(PNet, self).__init__()
|
| 73 |
+
self.is_train = is_train
|
| 74 |
+
self.use_cuda = use_cuda
|
| 75 |
+
|
| 76 |
+
# backend
|
| 77 |
+
self.pre_layer = nn.Sequential(
|
| 78 |
+
nn.Conv2d(3, 10, kernel_size=3, stride=1), # conv1
|
| 79 |
+
nn.PReLU(), # PReLU1
|
| 80 |
+
nn.MaxPool2d(kernel_size=2, stride=2), # pool1
|
| 81 |
+
nn.Conv2d(10, 16, kernel_size=3, stride=1), # conv2
|
| 82 |
+
nn.PReLU(), # PReLU2
|
| 83 |
+
nn.Conv2d(16, 32, kernel_size=3, stride=1), # conv3
|
| 84 |
+
nn.PReLU() # PReLU3
|
| 85 |
+
)
|
| 86 |
+
# detection
|
| 87 |
+
self.conv4_1 = nn.Conv2d(32, 1, kernel_size=1, stride=1)
|
| 88 |
+
# bounding box regresion
|
| 89 |
+
self.conv4_2 = nn.Conv2d(32, 4, kernel_size=1, stride=1)
|
| 90 |
+
# landmark localization
|
| 91 |
+
self.conv4_3 = nn.Conv2d(32, 10, kernel_size=1, stride=1)
|
| 92 |
+
|
| 93 |
+
# weight initiation with xavier
|
| 94 |
+
self.apply(weights_init)
|
| 95 |
+
|
| 96 |
+
def forward(self, x):
|
| 97 |
+
x = self.pre_layer(x)
|
| 98 |
+
label = torch.sigmoid(self.conv4_1(x))
|
| 99 |
+
offset = self.conv4_2(x)
|
| 100 |
+
# landmark = self.conv4_3(x)
|
| 101 |
+
|
| 102 |
+
if self.is_train is True:
|
| 103 |
+
# label_loss = LossUtil.label_loss(self.gt_label,torch.squeeze(label))
|
| 104 |
+
# bbox_loss = LossUtil.bbox_loss(self.gt_bbox,torch.squeeze(offset))
|
| 105 |
+
return label,offset
|
| 106 |
+
#landmark = self.conv4_3(x)
|
| 107 |
+
return label, offset
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class RNet(nn.Module):
|
| 114 |
+
''' RNet '''
|
| 115 |
+
|
| 116 |
+
def __init__(self,is_train=False, use_cuda=True):
|
| 117 |
+
super(RNet, self).__init__()
|
| 118 |
+
self.is_train = is_train
|
| 119 |
+
self.use_cuda = use_cuda
|
| 120 |
+
# backend
|
| 121 |
+
self.pre_layer = nn.Sequential(
|
| 122 |
+
nn.Conv2d(3, 28, kernel_size=3, stride=1), # conv1
|
| 123 |
+
nn.PReLU(), # prelu1
|
| 124 |
+
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
|
| 125 |
+
nn.Conv2d(28, 48, kernel_size=3, stride=1), # conv2
|
| 126 |
+
nn.PReLU(), # prelu2
|
| 127 |
+
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
|
| 128 |
+
nn.Conv2d(48, 64, kernel_size=2, stride=1), # conv3
|
| 129 |
+
nn.PReLU() # prelu3
|
| 130 |
+
|
| 131 |
+
)
|
| 132 |
+
self.conv4 = nn.Linear(64*2*2, 128) # conv4
|
| 133 |
+
self.prelu4 = nn.PReLU() # prelu4
|
| 134 |
+
# detection
|
| 135 |
+
self.conv5_1 = nn.Linear(128, 1)
|
| 136 |
+
# bounding box regression
|
| 137 |
+
self.conv5_2 = nn.Linear(128, 4)
|
| 138 |
+
# lanbmark localization
|
| 139 |
+
self.conv5_3 = nn.Linear(128, 10)
|
| 140 |
+
# weight initiation weih xavier
|
| 141 |
+
self.apply(weights_init)
|
| 142 |
+
|
| 143 |
+
def forward(self, x):
|
| 144 |
+
# backend
|
| 145 |
+
x = self.pre_layer(x)
|
| 146 |
+
x = x.view(x.size(0), -1)
|
| 147 |
+
x = self.conv4(x)
|
| 148 |
+
x = self.prelu4(x)
|
| 149 |
+
# detection
|
| 150 |
+
det = torch.sigmoid(self.conv5_1(x))
|
| 151 |
+
box = self.conv5_2(x)
|
| 152 |
+
# landmark = self.conv5_3(x)
|
| 153 |
+
|
| 154 |
+
if self.is_train is True:
|
| 155 |
+
return det, box
|
| 156 |
+
#landmard = self.conv5_3(x)
|
| 157 |
+
return det, box
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class ONet(nn.Module):
|
| 163 |
+
''' RNet '''
|
| 164 |
+
|
| 165 |
+
def __init__(self,is_train=False, use_cuda=True):
|
| 166 |
+
super(ONet, self).__init__()
|
| 167 |
+
self.is_train = is_train
|
| 168 |
+
self.use_cuda = use_cuda
|
| 169 |
+
# backend
|
| 170 |
+
self.pre_layer = nn.Sequential(
|
| 171 |
+
nn.Conv2d(3, 32, kernel_size=3, stride=1), # conv1
|
| 172 |
+
nn.PReLU(), # prelu1
|
| 173 |
+
nn.MaxPool2d(kernel_size=3, stride=2), # pool1
|
| 174 |
+
nn.Conv2d(32, 64, kernel_size=3, stride=1), # conv2
|
| 175 |
+
nn.PReLU(), # prelu2
|
| 176 |
+
nn.MaxPool2d(kernel_size=3, stride=2), # pool2
|
| 177 |
+
nn.Conv2d(64, 64, kernel_size=3, stride=1), # conv3
|
| 178 |
+
nn.PReLU(), # prelu3
|
| 179 |
+
nn.MaxPool2d(kernel_size=2,stride=2), # pool3
|
| 180 |
+
nn.Conv2d(64,128,kernel_size=2,stride=1), # conv4
|
| 181 |
+
nn.PReLU() # prelu4
|
| 182 |
+
)
|
| 183 |
+
self.conv5 = nn.Linear(128*2*2, 256) # conv5
|
| 184 |
+
self.prelu5 = nn.PReLU() # prelu5
|
| 185 |
+
# detection
|
| 186 |
+
self.conv6_1 = nn.Linear(256, 1)
|
| 187 |
+
# bounding box regression
|
| 188 |
+
self.conv6_2 = nn.Linear(256, 4)
|
| 189 |
+
# lanbmark localization
|
| 190 |
+
self.conv6_3 = nn.Linear(256, 10)
|
| 191 |
+
# weight initiation weih xavier
|
| 192 |
+
self.apply(weights_init)
|
| 193 |
+
|
| 194 |
+
def forward(self, x):
|
| 195 |
+
# backend
|
| 196 |
+
x = self.pre_layer(x)
|
| 197 |
+
x = x.view(x.size(0), -1)
|
| 198 |
+
x = self.conv5(x)
|
| 199 |
+
x = self.prelu5(x)
|
| 200 |
+
# detection
|
| 201 |
+
det = torch.sigmoid(self.conv6_1(x))
|
| 202 |
+
box = self.conv6_2(x)
|
| 203 |
+
landmark = self.conv6_3(x)
|
| 204 |
+
if self.is_train is True:
|
| 205 |
+
return det, box, landmark
|
| 206 |
+
#landmard = self.conv5_3(x)
|
| 207 |
+
return det, box, landmark
|
utils/tool.py
ADDED
|
@@ -0,0 +1,117 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import time
|
| 3 |
+
|
| 4 |
+
def IoU(box, boxes):
|
| 5 |
+
"""Compute IoU between detect box and gt boxes
|
| 6 |
+
|
| 7 |
+
Parameters:
|
| 8 |
+
----------
|
| 9 |
+
box: numpy array , shape (5, ): x1, y1, x2, y2, score
|
| 10 |
+
input box
|
| 11 |
+
boxes: numpy array, shape (n, 4): x1, y1, x2, y2
|
| 12 |
+
input ground truth boxes
|
| 13 |
+
|
| 14 |
+
Returns:
|
| 15 |
+
-------
|
| 16 |
+
ovr: numpy.array, shape (n, )
|
| 17 |
+
IoU
|
| 18 |
+
"""
|
| 19 |
+
box_area = (box[2] - box[0] + 1) * (box[3] - box[1] + 1)
|
| 20 |
+
area = (boxes[:, 2] - boxes[:, 0] + 1) * (boxes[:, 3] - boxes[:, 1] + 1)
|
| 21 |
+
xx1 = np.maximum(box[0], boxes[:, 0])
|
| 22 |
+
yy1 = np.maximum(box[1], boxes[:, 1])
|
| 23 |
+
xx2 = np.minimum(box[2], boxes[:, 2])
|
| 24 |
+
yy2 = np.minimum(box[3], boxes[:, 3])
|
| 25 |
+
|
| 26 |
+
# compute the width and height of the bounding box
|
| 27 |
+
w = np.maximum(0, xx2 - xx1 + 1)
|
| 28 |
+
h = np.maximum(0, yy2 - yy1 + 1)
|
| 29 |
+
|
| 30 |
+
inter = w * h
|
| 31 |
+
ovr = np.true_divide(inter,(box_area + area - inter))
|
| 32 |
+
#ovr = inter / (box_area + area - inter)
|
| 33 |
+
return ovr
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def convert_to_square(bbox):
|
| 37 |
+
"""Convert bbox to square
|
| 38 |
+
|
| 39 |
+
Parameters:
|
| 40 |
+
----------
|
| 41 |
+
bbox: numpy array , shape n x 5
|
| 42 |
+
input bbox
|
| 43 |
+
|
| 44 |
+
Returns:
|
| 45 |
+
-------
|
| 46 |
+
square bbox
|
| 47 |
+
"""
|
| 48 |
+
square_bbox = bbox.copy()
|
| 49 |
+
|
| 50 |
+
h = bbox[:, 3] - bbox[:, 1] + 1
|
| 51 |
+
w = bbox[:, 2] - bbox[:, 0] + 1
|
| 52 |
+
max_side = np.maximum(h,w)
|
| 53 |
+
square_bbox[:, 0] = bbox[:, 0] + w*0.5 - max_side*0.5
|
| 54 |
+
square_bbox[:, 1] = bbox[:, 1] + h*0.5 - max_side*0.5
|
| 55 |
+
square_bbox[:, 2] = square_bbox[:, 0] + max_side - 1
|
| 56 |
+
square_bbox[:, 3] = square_bbox[:, 1] + max_side - 1
|
| 57 |
+
return square_bbox
|
| 58 |
+
|
| 59 |
+
# non-maximum suppression: eleminates the box which have large interception with the box which have the largest score
|
| 60 |
+
def nms(dets, thresh, mode="Union"):
|
| 61 |
+
"""
|
| 62 |
+
greedily select boxes with high confidence
|
| 63 |
+
keep boxes overlap <= thresh
|
| 64 |
+
rule out overlap > thresh
|
| 65 |
+
:param dets: [[x1, y1, x2, y2 score]]
|
| 66 |
+
:param thresh: retain overlap <= thresh
|
| 67 |
+
:return: indexes to keep
|
| 68 |
+
"""
|
| 69 |
+
x1 = dets[:, 0]
|
| 70 |
+
y1 = dets[:, 1]
|
| 71 |
+
x2 = dets[:, 2]
|
| 72 |
+
y2 = dets[:, 3]
|
| 73 |
+
scores = dets[:, 4]
|
| 74 |
+
|
| 75 |
+
# shape of x1 = (454,), shape of scores = (454,)
|
| 76 |
+
# print("shape of x1 = {0}, shape of scores = {1}".format(x1.shape, scores.shape))
|
| 77 |
+
# time.sleep(5)
|
| 78 |
+
|
| 79 |
+
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 80 |
+
order = scores.argsort()[::-1] # argsort: ascending order then [::-1] reverse the order --> descending order
|
| 81 |
+
# print("shape of order {0}".format(order.size)) # (454,)
|
| 82 |
+
# time.sleep(5)
|
| 83 |
+
|
| 84 |
+
# eleminates the box which have large interception with the box which have the largest score in order
|
| 85 |
+
# matain the box with largest score and boxes don't have large interception with it
|
| 86 |
+
keep = []
|
| 87 |
+
while order.size > 0:
|
| 88 |
+
i = order[0]
|
| 89 |
+
keep.append(i)
|
| 90 |
+
xx1 = np.maximum(x1[i], x1[order[1:]])
|
| 91 |
+
yy1 = np.maximum(y1[i], y1[order[1:]])
|
| 92 |
+
xx2 = np.minimum(x2[i], x2[order[1:]])
|
| 93 |
+
yy2 = np.minimum(y2[i], y2[order[1:]])
|
| 94 |
+
|
| 95 |
+
w = np.maximum(0.0, xx2 - xx1 + 1)
|
| 96 |
+
h = np.maximum(0.0, yy2 - yy1 + 1)
|
| 97 |
+
inter = w * h
|
| 98 |
+
|
| 99 |
+
# cacaulate the IOU between box which have largest score with other boxes
|
| 100 |
+
if mode == "Union":
|
| 101 |
+
# area[i]: the area of largest score
|
| 102 |
+
ovr = inter / (areas[i] + areas[order[1:]] - inter)
|
| 103 |
+
elif mode == "Minimum":
|
| 104 |
+
ovr = inter / np.minimum(areas[i], areas[order[1:]])
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
inds = np.where(ovr <= thresh)[0]
|
| 108 |
+
order = order[inds + 1] # +1: eliminates the first element in order
|
| 109 |
+
# print(inds)
|
| 110 |
+
# print("shape of order {0}".format(order.shape)) # (454,)
|
| 111 |
+
# time.sleep(2)
|
| 112 |
+
|
| 113 |
+
return keep
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
utils/vision.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from matplotlib.patches import Circle
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import pylab
|
| 6 |
+
sys.path.append(os.getcwd())
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def vis_face(im_array, dets, landmarks, face_size, save_name):
|
| 10 |
+
"""Visualize detection results
|
| 11 |
+
|
| 12 |
+
Parameters:
|
| 13 |
+
----------
|
| 14 |
+
im_array: numpy.ndarray, shape(1, c, h, w)
|
| 15 |
+
test image in rgb
|
| 16 |
+
dets1: numpy.ndarray([[x1 y1 x2 y2 score]])
|
| 17 |
+
detection results before calibration
|
| 18 |
+
dets2: numpy.ndarray([[x1 y1 x2 y2 score]])
|
| 19 |
+
detection results after calibration
|
| 20 |
+
thresh: float
|
| 21 |
+
boxes with scores > thresh will be drawn in red otherwise yellow
|
| 22 |
+
|
| 23 |
+
Returns:
|
| 24 |
+
-------
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
pylab.imshow(im_array)
|
| 28 |
+
|
| 29 |
+
for i in range(dets.shape[0]):
|
| 30 |
+
bbox = dets[i, :5]
|
| 31 |
+
|
| 32 |
+
rect = pylab.Rectangle((bbox[0], bbox[1]),
|
| 33 |
+
bbox[2] - bbox[0],
|
| 34 |
+
bbox[3] - bbox[1], fill=False,
|
| 35 |
+
edgecolor='red', linewidth=0.9)
|
| 36 |
+
score = bbox[4]
|
| 37 |
+
plt.gca().text(bbox[0], bbox[1] - 2,
|
| 38 |
+
'{:.5f}'.format(score),
|
| 39 |
+
bbox=dict(facecolor='red', alpha=0.5), fontsize=8, color='white')
|
| 40 |
+
|
| 41 |
+
pylab.gca().add_patch(rect)
|
| 42 |
+
|
| 43 |
+
if landmarks is not None:
|
| 44 |
+
for i in range(landmarks.shape[0]):
|
| 45 |
+
landmarks_one = landmarks[i, :]
|
| 46 |
+
landmarks_one = landmarks_one.reshape((5, 2))
|
| 47 |
+
for j in range(5):
|
| 48 |
+
|
| 49 |
+
cir1 = Circle(xy=(landmarks_one[j, 0], landmarks_one[j, 1]), radius=face_size/12, alpha=0.4, color="red")
|
| 50 |
+
pylab.gca().add_patch(cir1)
|
| 51 |
+
|
| 52 |
+
#pylab.savefig(save_name)
|
| 53 |
+
#只保存图片内容,不保存坐标轴
|
| 54 |
+
pylab.axis('off')
|
| 55 |
+
pylab.savefig(save_name, bbox_inches='tight', pad_inches=0.0)
|
| 56 |
+
pylab.show()
|
| 57 |
+
# 返回图片对象
|
| 58 |
+
return pylab
|