Spaces:
Running

Running
File size: 16,314 Bytes
0208db3 5279044 edad8b2 5b596d2 5279044 5b596d2 1ca4c18 5b596d2 1ca4c18 5b596d2 1ca4c18 8858935 8d76fc6 1ca4c18 8858935 1ca4c18 8858935 fc9445e 8858935 fc9445e 8858935 fc9445e 8858935 fc9445e 8858935 fc9445e 8858935 fc9445e 8858935 fc9445e 0f8c595 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 |
---
title: README
emoji: 🦀
colorFrom: green
colorTo: yellow
sdk: static
pinned: false
---
# Zero GPU Spaces - Best of AI Models Development Using Shared Quota GPU for Inference
https://huggingface.co/spaces/awacke1/ZeroHot

# AI Multimodal Media Workflows and Pipelines
Simple Graph: https://github.com/AaronCWacker/Yggdrasil/blob/main/Mermaid/MultimodalAIPipelines.md
Detail Graph: https://github.com/AaronCWacker/Yggdrasil/blob/main/Mermaid/MultimodalPipelinesDetail.md
1. 
2. 
3. 
4. 
5. 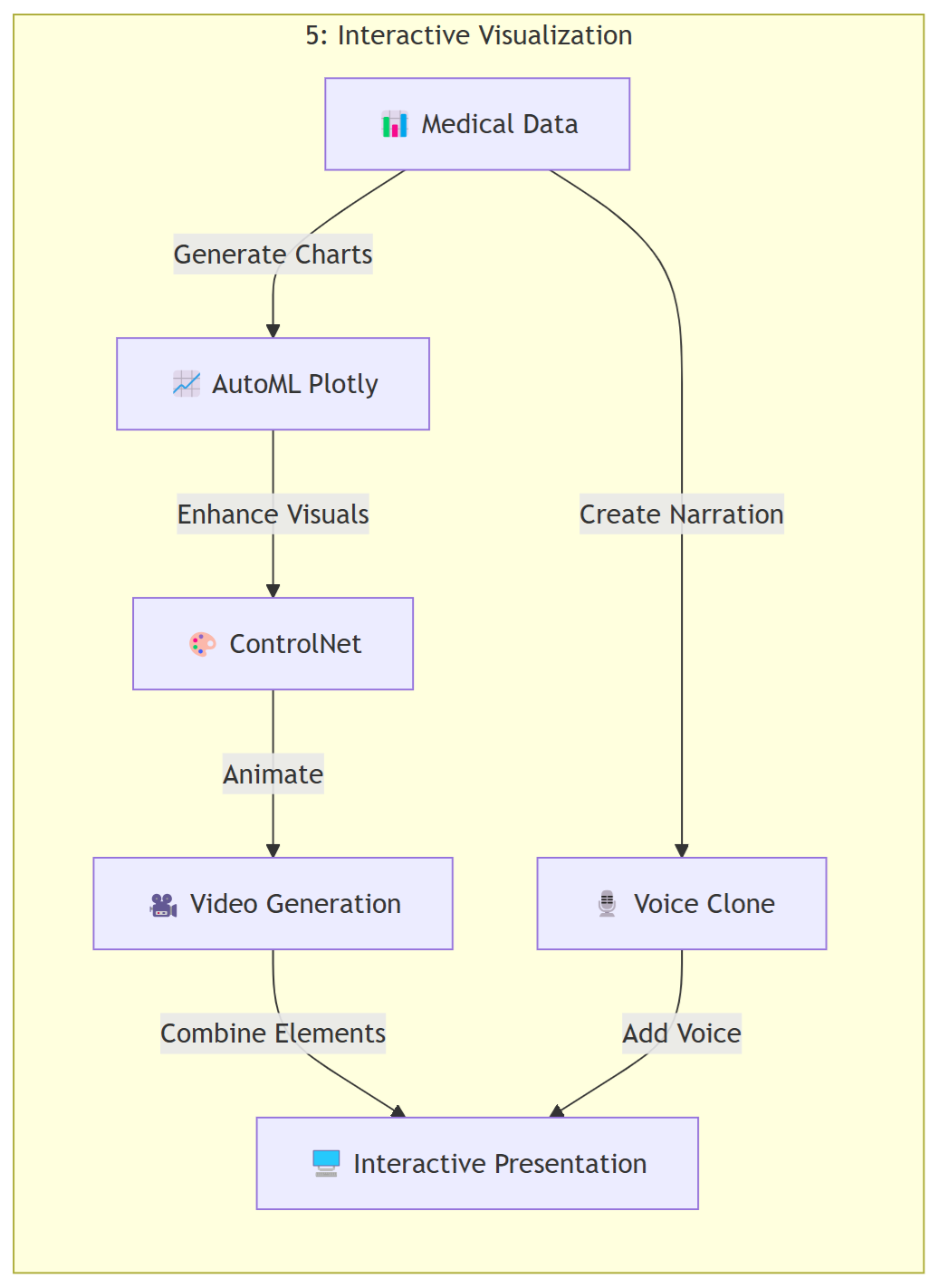
# AI Pipeline Architecture Models for Multimodal Model Space Workflows
Zero GPU and GPU Spaces of note:
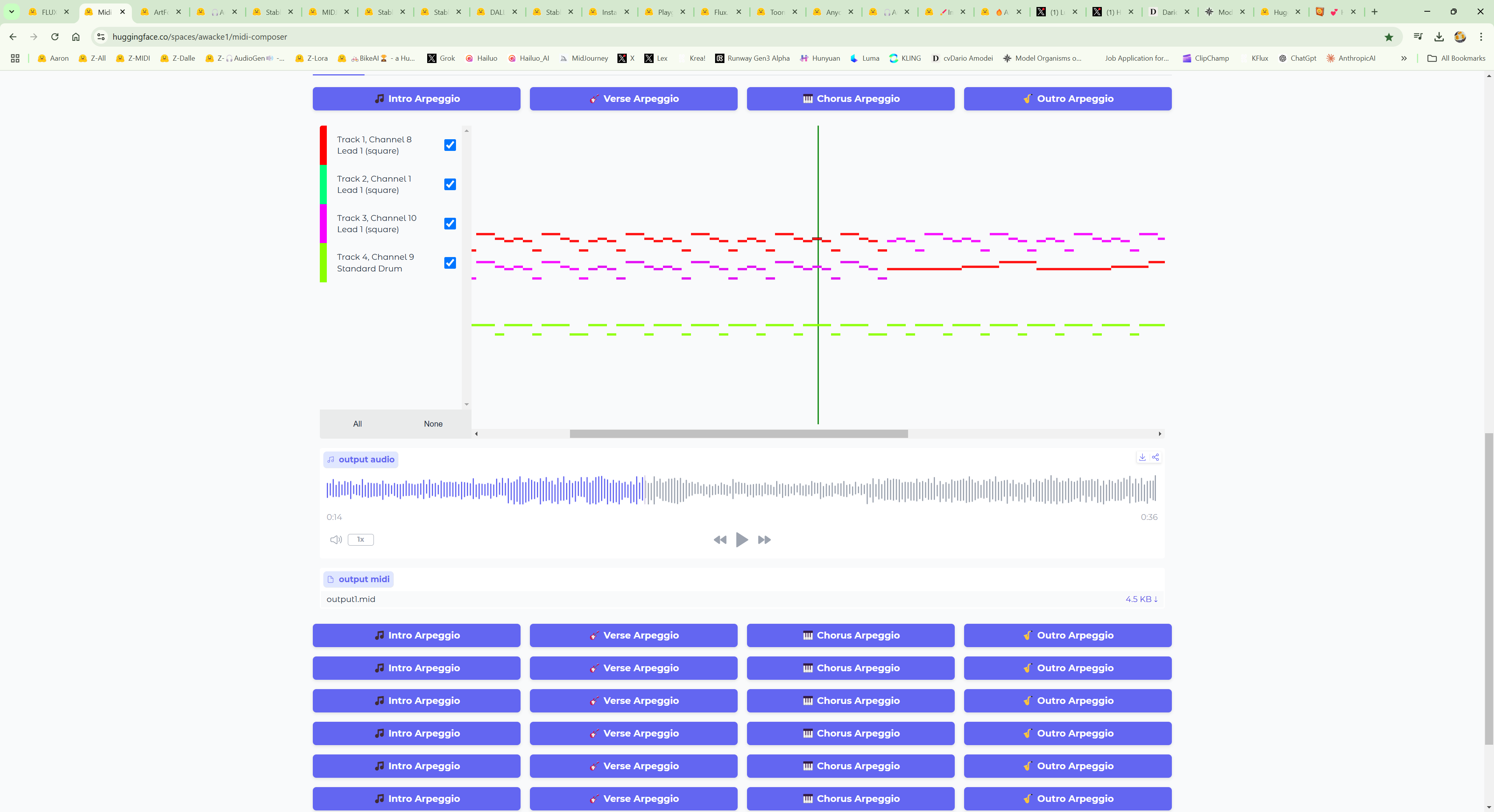
1. https://huggingface.co/spaces/awacke1/midi-composer
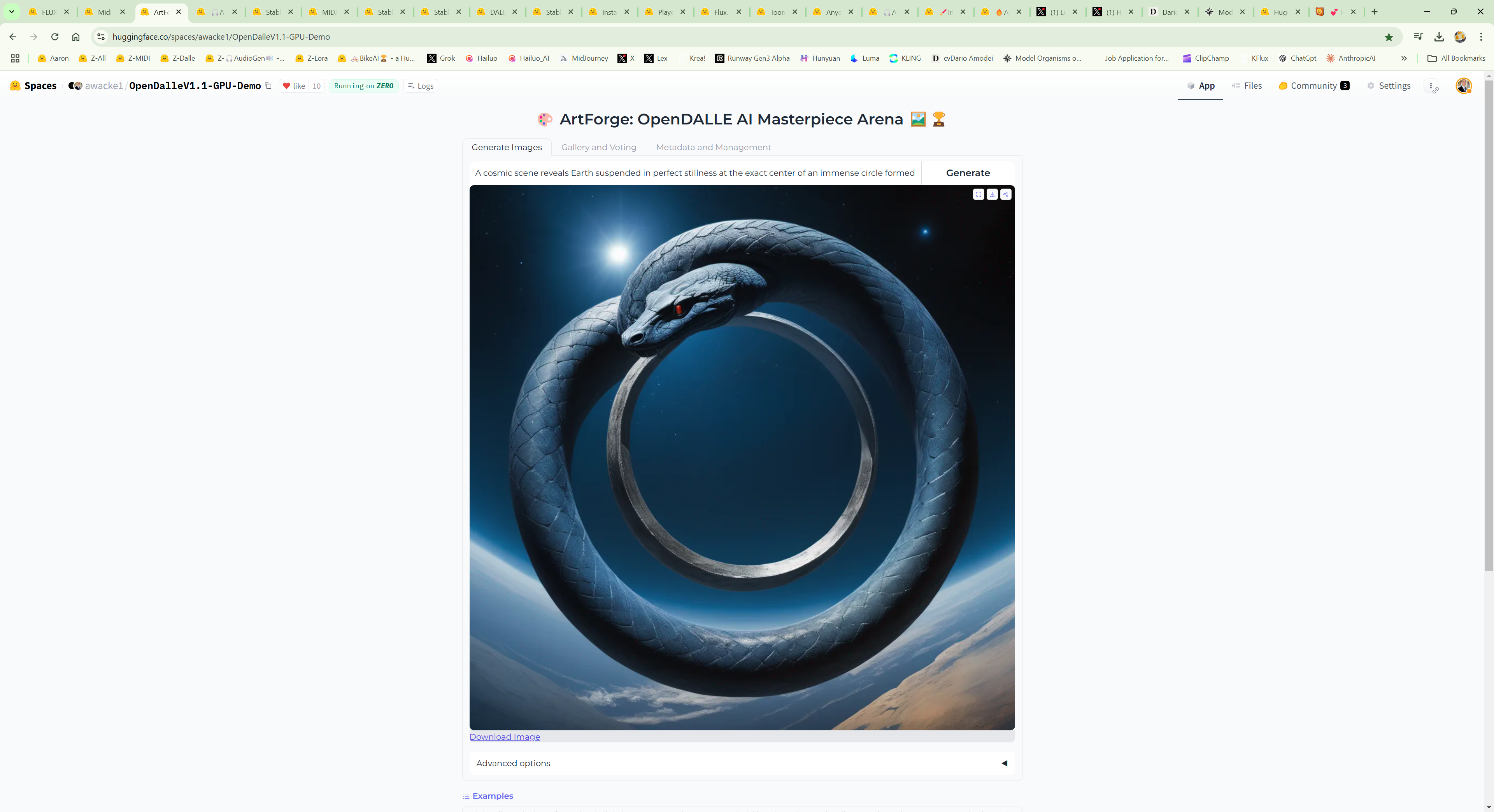
2. https://huggingface.co/spaces/awacke1/OpenDalleV1.1-GPU-Demo
3. https://huggingface.co/spaces/awacke1/AudioFileGenerationWithSDAudio

4. https://huggingface.co/spaces/multimodalart/stable-video-diffusion

5. https://huggingface.co/spaces/mukaist/Midjourney

6. https://huggingface.co/spaces/multimodalart/stable-cascade

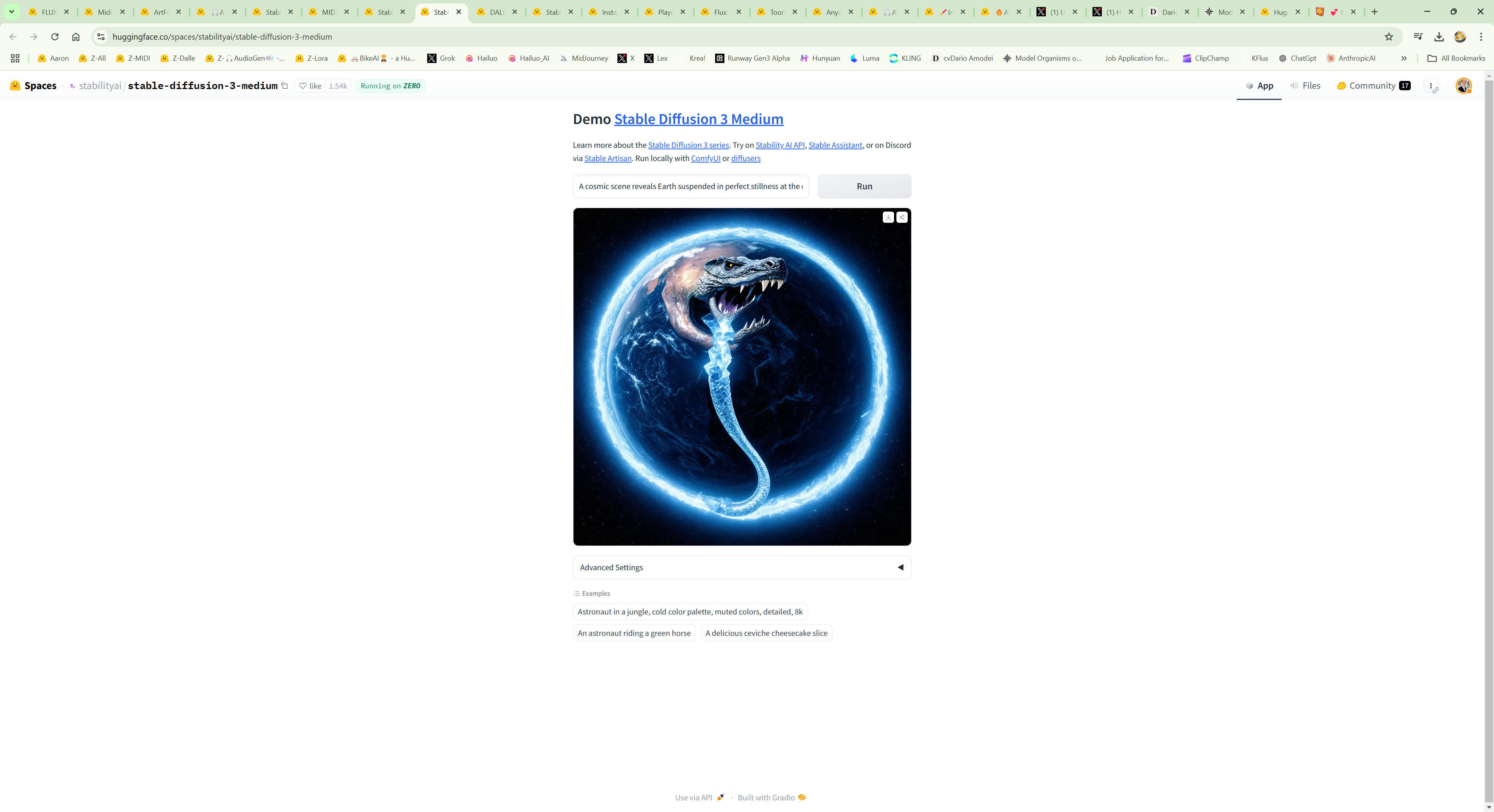
7. https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
8. https://huggingface.co/spaces/ehristoforu/dalle-3-xl-lora-v2

9. https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-large

10. https://huggingface.co/spaces/TencentARC/InstantMesh

11. https://huggingface.co/spaces/playgroundai/playground-v2.5

12. https://huggingface.co/spaces/jasperai/Flux.1-dev-Controlnet-Upscaler

13. https://huggingface.co/spaces/akhaliq/anychat

15. https://huggingface.co/spaces/awacke1/stable-video-diffusion
16. https://huggingface.co/spaces/awacke1/GPT-4o-omni-text-audio-image-video
17. https://huggingface.co/spaces/awacke1/Arxiv-Paper-Search-And-QA-RAG-Pattern
18. https://huggingface.co/spaces/awacke1/AnthropicClaude3.5Sonnet-ACW
19. https://huggingface.co/spaces/awacke1/MusicGenStreamFacebook
20. https://huggingface.co/spaces/awacke1/AIKnowledgeTreeBuilder
21. https://huggingface.co/spaces/awacke1/RescuerOfStolenBikes
22. https://huggingface.co/spaces/awacke1/PDF-text-to-speech-Per-Page
23. https://huggingface.co/spaces/awacke1/AzureCosmosDBUI
24. https://huggingface.co/spaces/awacke1/MSGraphAPI
25. https://huggingface.co/spaces/awacke1/RealTimeAsyncASR
26. https://huggingface.co/spaces/awacke1/whisper-web
27. https://huggingface.co/spaces/awacke1/MarkdownMagicEditor.md
28. https://huggingface.co/spaces/awacke1/EZ-Voice-Clone-From-Long-Text
29. https://huggingface.co/spaces/awacke1/Edge-TTS-Text-to-Speech
30. https://huggingface.co/spaces/awacke1/StreamlitDotEdgeGraphViz-Images-SVG (Image button and rounded buttons)
31. https://huggingface.co/spaces/awacke1/DynamicMapCreator2
32. https://huggingface.co/spaces/awacke1/RealTimeAsyncASR
33. https://huggingface.co/spaces/awacke1/realtime-whisper-webgpu
34. https://huggingface.co/collections/Xenova/transformersjs-demos-64f9c4f49c099d93dbc611df
35. https://huggingface.co/spaces/awacke1/Models-Datasets-Spaces-Search-Hub
36. https://huggingface.co/spaces/awacke1/AutoMLUsingStreamlit-Plotly (CSV to Plotly Graph Objects)
37. https://huggingface.co/spaces/awacke1/Multiplayer-Eval-App-Upvote
38. https://huggingface.co/spaces/awacke1/AI-MovieMaker-Comedy
39. https://huggingface.co/spaces/awacke1/Multiplayer-Image-Evaluate-Upvote
40. https://huggingface.co/spaces/awacke1/Multiplayer-USMLE-Story-Voting-Evals
41. https://huggingface.co/spaces/awacke1/Multiplayer-RLHF-Evals
42. https://huggingface.co/spaces/awacke1/RLHF.Reinforce.Learn.With.Human.Feedback
43. https://huggingface.co/spaces/awacke1/MultiuserFarmSimulator
44. https://huggingface.co/spaces/awacke1/SocketIO-Multiplayer-DrawingGame
45. https://huggingface.co/spaces/awacke1/Multiplayer-Self-Play-Sankey-Simulator
46. https://huggingface.co/spaces/awacke1/Multiplayer-Action-Battle
47. https://huggingface.co/spaces/awacke1/Multiplayer-Image-Character-Terrain
48. https://huggingface.co/spaces/awacke1/MultiplayerMapMovement
49. https://huggingface.co/spaces/awacke1/MultiplayerDiceGameFromGrok
50. https://huggingface.co/spaces/awacke1/AaronWackerMusic
# Architecture to AI Space
# 🤖 AI Types and Capabilities Classification
## 1. Foundation Models & Orchestrators 🎯
### Large Language Models (LLMs)
- 🧠 **General Purpose**
- GPT-4 Omni
- Claude 3.5 Sonnet
- 📚 **Domain-Specific**
- Medical knowledge models
**_Mapped Spaces:_**
- `GPT-4o-omni-text-audio-image-video`
- `AnthropicClaude3.5Sonnet-ACW`
## 2. Content Generation 🎨
### 2.1 Image Generation
#### Static Images
- 🖼️ **Text-to-Image**
- Stable Diffusion 3
- DALL-E 3
- Midjourney
- 🔄 **Image-to-Image**
- ControlNet
- Stable Cascade
**_Mapped Spaces:_**
- `OpenDalleV1.1-GPU-Demo`
- `stable-cascade`
- `stable-diffusion-3-medium`
- `playgroundai/playground-v2.5`
### 2.2 Video Generation
#### Dynamic Content
- 🎥 **Text-to-Video**
- Stable Video Diffusion
- 🎬 **Image-to-Video**
- Video Generation models
**_Mapped Spaces:_**
- `stable-video-diffusion`
- `AI-MovieMaker-Comedy`
### 2.3 Audio Generation
#### Sound Creation
- 🎵 **Music Generation**
- MusicGen
- MIDI Composer
- 🗣️ **Text-to-Speech**
- Edge TTS
- 🎙️ **Voice Cloning**
- Voice Clone tools
**_Mapped Spaces:_**
- `midi-composer`
- `AudioFileGenerationWithSDAudio`
- `MusicGenStreamFacebook`
- `EZ-Voice-Clone-From-Long-Text`
## 3. Analysis & Understanding 🔍
### 3.1 Text Analysis
#### Document Processing
- 📄 **RAG Systems**
- Arxiv RAG
- 📚 **Knowledge Extraction**
**_Mapped Spaces:_**
- `Arxiv-Paper-Search-And-QA-RAG-Pattern`
- `AIKnowledgeTreeBuilder`
### 3.2 Speech Processing
#### Audio Analysis
- 🎤 **Speech Recognition**
- Real-Time ASR
- 📢 **Speech Understanding**
**_Mapped Spaces:_**
- `RealTimeAsyncASR`
- `whisper-web`
## 4. Visualization & Presentation 📊
### 4.1 Data Visualization
#### Chart Generation
- 📈 **AutoML Plotting**
- 🗺️ **Mapping Tools**
**_Mapped Spaces:_**
- `AutoMLUsingStreamlit-Plotly`
- `DynamicMapCreator2`
### 4.2 3D Visualization
#### 3D Content
- 💠 **Mesh Generation**
- InstantMesh
- 🎮 **Interactive 3D**
**_Mapped Spaces:_**
- `InstantMesh`
## 5. Integration & Composition 🔄
### 5.1 Media Composition
#### Multi-modal Integration
- 🎬 **Video Composition**
- 🔊 **Audio Mixing**
**_Mapped Spaces:_**
- `Jasperai/Flux.1-dev-Controlnet-Upscaler`
### 5.2 Interactive Systems
#### User Interaction
- 👥 **Chat Interfaces**
- 🤝 **Multiplayer Systems**
**_Mapped Spaces:_**
- `anychat`
- `Multiplayer-Eval-App-Upvote`
- `SocketIO-Multiplayer-DrawingGame`
## 6. Specialized Applications 🏥
### 6.1 Healthcare Specific
#### Medical Tools
- 📋 **Training Material Generation**
- 👨⚕️ **Patient Communication**
**_Mapped Spaces:_**
- `USMLE-Story-Voting-Evals`
- `PDF-text-to-speech-Per-Page`
### 6.2 Research Tools
#### Scientific Applications
- 📚 **Literature Analysis**
- 🔬 **Data Processing**
**_Mapped Spaces:_**
- `Models-Datasets-Spaces-Search-Hub`
- `RLHF.Reinforce.Learn.With.Human.Feedback`
# AI Architecture Synopsis for GPU Spaces:
Below is a grouped synopsis of the provided dataset, highlighting common model families, tasks, and modalities. We’ve identified 10 thematic clusters, collapsed similar entries, and tallied their approximate counts. Each section includes representative examples and a brief summary:
---
### 1. **Llama-Based Language Models** 🦙📚
- **Count:** ~10+
- **Examples:**
- *Llama 2 7B/13B Chat*, *Llama 3.2V 11B Cot*, *Llava Llama-3 8B*, *Llama-Vision-11B*
- **Note:**
Models derived from or combined with LLaMA, often used for chat, reasoning, and multimodal tasks.
### 2. **FLUX Models & Tools** ⚡🖼
- **Count:** ~30+
- **Examples:**
- *FLUXllama*, *FLUX.1 [dev]*, *FLUX 8Steps LoRA*, *FLUX Prompt Generator*, *FLUX.1 Redux Dev*
- **Note:**
A large ecosystem of FLUX-based image generation tools, LoRAs (Low-Rank Adapters), and control variations, emphasizing fast, high-quality image outputs and model refinements.
### 3. **Stable Diffusion & Derivatives** 🎨🏃
- **Count:** ~20+
- **Examples:**
- *Stable Diffusion 3.5 Large*, *Stable Diffusion 3 Medium*, *Stable Audio Open*, *StableDelight*, *Stable Design*
- **Note:**
Numerous text-to-image and image-to-image tools built on Stable Diffusion technology, including audio and video extensions. Often offer rapid generation and style customization.
### 4. **TTS & Audio Generation/Processing** 🎤🔊
- **Count:** ~25+
- **Examples:**
- *F5-TTS*, *Spanish F5*, *Sound AI SFX*, *Multi Parler-TTS*, *Kokoro TTS*, *Voice Clone*
- **Note:**
Text-to-speech models, voice cloning, audio upscaling, and SFX generation demos. Many support zero-shot voice cloning and multilingual options.
### 5. **Video Generation & Editing** 🎥⚡
- **Count:** ~20+
- **Examples:**
- *Stable Video Diffusion*, *MMAudio — generating synchronized audio from video/text*, *Instant Video*, *Video Background Removal*, *Animagine XL 3.1*
- **Note:**
Tools for creating or editing video content from text prompts, applying style transfers, removing backgrounds, and generating synchronized audio-visual experiences.
### 6. **Image Editing, Inpainting & Upscaling** 🖌️🔍
- **Count:** ~25+
- **Examples:**
- *Diffusers Image Outpaint*, *Background Removal*, *Finegrain Image Enhancer*, *IC Light*, *InstantMesh*, *GiniGen Canvas*, *PhotoMaker V2*
- **Note:**
A broad set of image refinement tools: removing backgrounds, outpainting, upscaling, enhancing clarity, inpainting, and object-specific edits.
### 7. **Document Parsing, OCR & Retrieval** 📄🔎
- **Count:** ~15+
- **Examples:**
- *Document Parser*, *PDF to Markdown*, *OmniParser demo*, *DocLayout YOLO*, *Newborn Article Impact Predict*, *RAG-Chatbot*
- **Note:**
Models dedicated to extracting information from documents, performing OCR, summarizing or querying text, and turning PDFs into searchable or structured formats.
### 8. **Vision-Language & Multimodal Models** 🧩👁
- **Count:** ~30+
- **Examples:**
- *Qwen2-VL-7B*, *Llava Video*, *BLIP2*, *Florence 2*, *OpenGPT 4o*, *MMAudio*, *Paligemma2 Vqav2*
- **Note:**
Models that combine text, images, audio, and sometimes video to answer questions, perform captioning, generate rich content, and handle complex multimodal tasks.
### 9. **3D Generation & Geometry Processing** 🌐🦾
- **Count:** ~15+
- **Examples:**
- *Make It Animatable*, *MeshAnything*, *3D-GRAND*, *Unique3D*, *Shap-E*, *Instant Text-to-3D Mesh Demo*
- **Note:**
Tools for converting images or text into 3D meshes, animating characters, and generating or refining 3D scenes. Often build on diffusion or 3D native generation methods.
### 10. **Developer & Coding Tools** 👨🏻💻🔧
- **Count:** ~10+
- **Examples:**
- *OpenCoder 8B Instruct*, *Code Review debug*, *Screenshot to HTML*, *Fake Data Generator (JSONL)*, *Beam Search Visualizer*
- **Note:**
A set of utilities for code generation, debugging, embeddings, dataset creation, and general developer-centric workflows.
---
### Overall Synopsis
- **Common Models:**
- **LLaMA-based:** Widely used for language and multimodal capabilities.
- **Stable Diffusion & FLUX:** Predominant for image, audio, and video generation tasks.
- **TTS & Voice Conversion:** Multiple frameworks offering multilingual and zero-shot cloning.
- **Common Terms:**
- **LoRA (Low-Rank Adaptation), ControlNet, Inpainting, Upscaling:** Frequent technical keywords pointing to image refinements and personalization.
- **RAG (Retrieval Augmented Generation), OCR, Document Parser:** Indicative of text/data extraction and retrieval functionalities.
- **Multimodal, Vision-Language, 3D Generation:** Emphasizes integrating multiple data types (text, image, audio, video, 3D).
- **Common Modalities:**
- **Text-to-Image/Video/Audio** conversions prevalent throughout.
- **Image & Video Editing, Restoration, and Manipulation** capabilities are abundant.
- **Document, OCR, and Data Processing** tasks show a strong presence.
---
Evolvable In:
Technology and Science:
Software and Systems: In computing, an "evolvable" system or software might refer to those that are designed with future changes in mind, incorporating modularity, scalability, and flexibility. For instance:
Evolvable APIs: Application Programming Interfaces (APIs) that are designed to evolve with changes in technology or user needs without breaking existing integrations.
Evolvable Hardware: Refers to hardware systems where the physical or functional aspects can be altered or improved, often through reconfigurable technology like FPGAs (Field-Programmable Gate Arrays).
Biological and Evolutionary Science: In biology, "evolvable" might describe organisms, traits, or genetic structures that have a high potential for evolutionary change due to variability, plasticity, or other mechanisms that aid in adaptation.
Machine Learning and AI: Here, "evolvable" could describe algorithms or models that can learn and adapt from data over time, improving their performance or changing their behavior based on new inputs or changes in the environment.
Business and Organizational Context:
Business Models: A company might be described as "evolvable" if it has the capability to adapt its business model to new market conditions, technologies, or consumer behaviors without losing its core identity or value proposition.
Organizational Structures: Refers to organizational designs that allow for change, learning, and growth, often through decentralized decision-making or agile methodologies.
Cultural and Philosophical Implications:
Ideas and Culture: Can describe ideas, cultures, or societal structures that are capable of changing, growing, or adapting in response to new knowledge, ethics, or external pressures.
|