Spaces:
Runtime error

Runtime error

Commit
•
dfb8f1c
1
Parent(s):
159e927
feat(app): add example and small mods
Browse files- .gitattributes +1 -0
- app.py +11 -22
- examples/good.will.hunting.wav +3 -0
- examples/wolf.of.wall.street.wav +3 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
app.py
CHANGED
|
@@ -20,16 +20,14 @@ ACCEPTED_LANGUAGE_BEHAVIOUR = [
|
|
| 20 |
|
| 21 |
|
| 22 |
def transcribe(
|
| 23 |
-
audio_url: str = None,
|
| 24 |
audio: str = None,
|
| 25 |
-
video: str = None,
|
| 26 |
language_behaviour: str = ACCEPTED_LANGUAGE_BEHAVIOUR[2],
|
| 27 |
language: str = "english",
|
| 28 |
) -> dict:
|
| 29 |
"""
|
| 30 |
This function transcribes audio to text using the Gladia API.
|
| 31 |
It sends a request to the API with the given audio file or audio URL, and returns the transcribed text.
|
| 32 |
-
|
| 33 |
|
| 34 |
Parameters:
|
| 35 |
audio_url (str): The URL of the audio file to transcribe. If audio_url is provided, audio file will be ignored.
|
|
@@ -58,10 +56,6 @@ def transcribe(
|
|
| 58 |
"language_behaviour": (None, language_behaviour),
|
| 59 |
}
|
| 60 |
|
| 61 |
-
# priority given to the video
|
| 62 |
-
if video:
|
| 63 |
-
audio = video
|
| 64 |
-
|
| 65 |
# priority given to the audio or video
|
| 66 |
if audio:
|
| 67 |
files["audio"] = (audio, open(audio, "rb"), "audio/wav")
|
|
@@ -107,25 +101,16 @@ def transcribe(
|
|
| 107 |
iface = gr.Interface(
|
| 108 |
title="Gladia.io fast audio transcription",
|
| 109 |
description="""Gladia.io Whisper large-v2 fast audio transcription API
|
| 110 |
-
is able to perform fast audio
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
|
| 115 |
-
|
| 116 |
-
Here is a benchmark ran on multiple Speech-To-Text providers
|
| 117 |
-
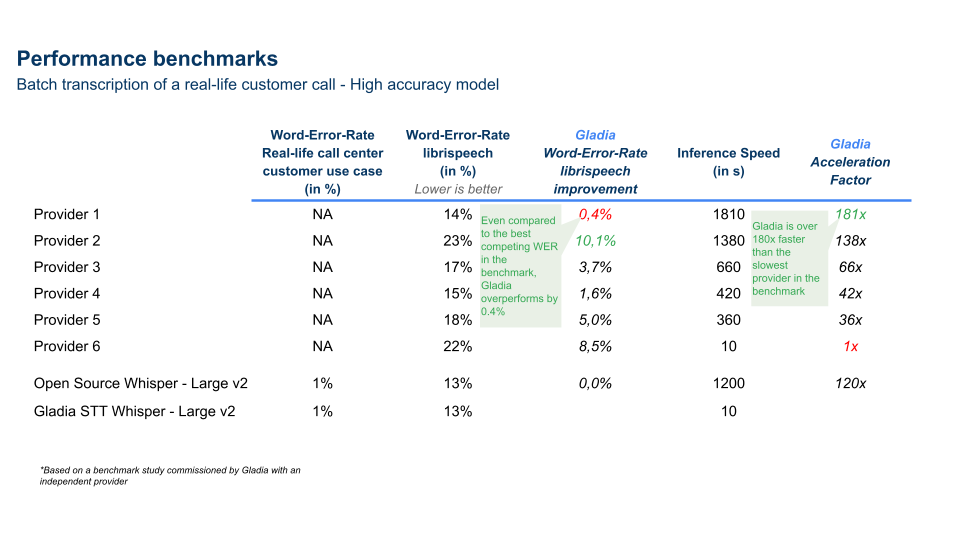<br/>
|
| 118 |
-
Join our [Slack](https://gladia-io.slack.com) to discuss with us.<br/><br/>
|
| 119 |
-
Get your own API key on [Gladia.io](https://gladia.io/) during free alpha
|
| 120 |
""",
|
| 121 |
fn=transcribe,
|
| 122 |
inputs=[
|
| 123 |
-
gr.Textbox(
|
| 124 |
-
lines=1,
|
| 125 |
-
label="Audio/Video url to transcribe",
|
| 126 |
-
),
|
| 127 |
gr.Audio(label="or Audio file to transcribe", source="upload", type="filepath"),
|
| 128 |
-
gr.Video(label="or Video file to transcribe", source="upload", type="filepath"),
|
| 129 |
gr.Dropdown(
|
| 130 |
label="""Language transcription behaviour:\n
|
| 131 |
If "manual", the language field must be provided and the API will transcribe the audio in the given language.
|
|
@@ -144,6 +129,10 @@ iface = gr.Interface(
|
|
| 144 |
),
|
| 145 |
],
|
| 146 |
outputs="json",
|
|
|
|
|
|
|
|
|
|
|
|
|
| 147 |
)
|
| 148 |
iface.queue()
|
| 149 |
iface.launch()
|
|
|
|
| 20 |
|
| 21 |
|
| 22 |
def transcribe(
|
|
|
|
| 23 |
audio: str = None,
|
|
|
|
| 24 |
language_behaviour: str = ACCEPTED_LANGUAGE_BEHAVIOUR[2],
|
| 25 |
language: str = "english",
|
| 26 |
) -> dict:
|
| 27 |
"""
|
| 28 |
This function transcribes audio to text using the Gladia API.
|
| 29 |
It sends a request to the API with the given audio file or audio URL, and returns the transcribed text.
|
| 30 |
+
Get your api key at gladia.io !
|
| 31 |
|
| 32 |
Parameters:
|
| 33 |
audio_url (str): The URL of the audio file to transcribe. If audio_url is provided, audio file will be ignored.
|
|
|
|
| 56 |
"language_behaviour": (None, language_behaviour),
|
| 57 |
}
|
| 58 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 59 |
# priority given to the audio or video
|
| 60 |
if audio:
|
| 61 |
files["audio"] = (audio, open(audio, "rb"), "audio/wav")
|
|
|
|
| 101 |
iface = gr.Interface(
|
| 102 |
title="Gladia.io fast audio transcription",
|
| 103 |
description="""Gladia.io Whisper large-v2 fast audio transcription API
|
| 104 |
+
is able to perform fast audio transcriptions for any audio / video.
|
| 105 |
+
For more details and a benchmark ran on multiple Speech-To-Text providers, please visit
|
| 106 |
+
[our post](https://medium.com/@gladia.io/gladia-alpha-launch-redefining-what-s-possible-with-speech-to-text-ai-686dd4312a86) on Medium.
|
| 107 |
+
<br/><br/>
|
| 108 |
+
You are more than welcome to join our [Slack](https://gladia-io.slack.com) to discuss with us
|
| 109 |
+
and also don't forget to get your own API key on [Gladia.io](https://gladia.io/) during the free alpha !
|
|
|
|
|
|
|
|
|
|
|
|
|
| 110 |
""",
|
| 111 |
fn=transcribe,
|
| 112 |
inputs=[
|
|
|
|
|
|
|
|
|
|
|
|
|
| 113 |
gr.Audio(label="or Audio file to transcribe", source="upload", type="filepath"),
|
|
|
|
| 114 |
gr.Dropdown(
|
| 115 |
label="""Language transcription behaviour:\n
|
| 116 |
If "manual", the language field must be provided and the API will transcribe the audio in the given language.
|
|
|
|
| 129 |
),
|
| 130 |
],
|
| 131 |
outputs="json",
|
| 132 |
+
examples=[
|
| 133 |
+
["examples/good.will.hunting.wav", ACCEPTED_LANGUAGE_BEHAVIOUR[1], "english"],
|
| 134 |
+
["examples/wolf.of.wall.street.wav", ACCEPTED_LANGUAGE_BEHAVIOUR[1], "english"],
|
| 135 |
+
],
|
| 136 |
)
|
| 137 |
iface.queue()
|
| 138 |
iface.launch()
|
examples/good.will.hunting.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:981492667ceb174e8a5d272ed68ad0a5198d98d836ff955b5e3b45d105d2a422
|
| 3 |
+
size 14251502
|
examples/wolf.of.wall.street.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:da1283c0fa5e3829a7f6630c17d73647e494c39fc56f0eec8331ffaf0df23162
|
| 3 |
+
size 1601526
|