---
title: Hallo
emoji: 👋
sdk: gradio
sdk_version: 4.36.1
app_file: app.py
pinned: false
suggested_hardware: l4x1
short_description: Generate realistic talking heads from image+audio
---
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
1Fudan University 2Baidu Inc 3ETH Zurich 4Nanjing University
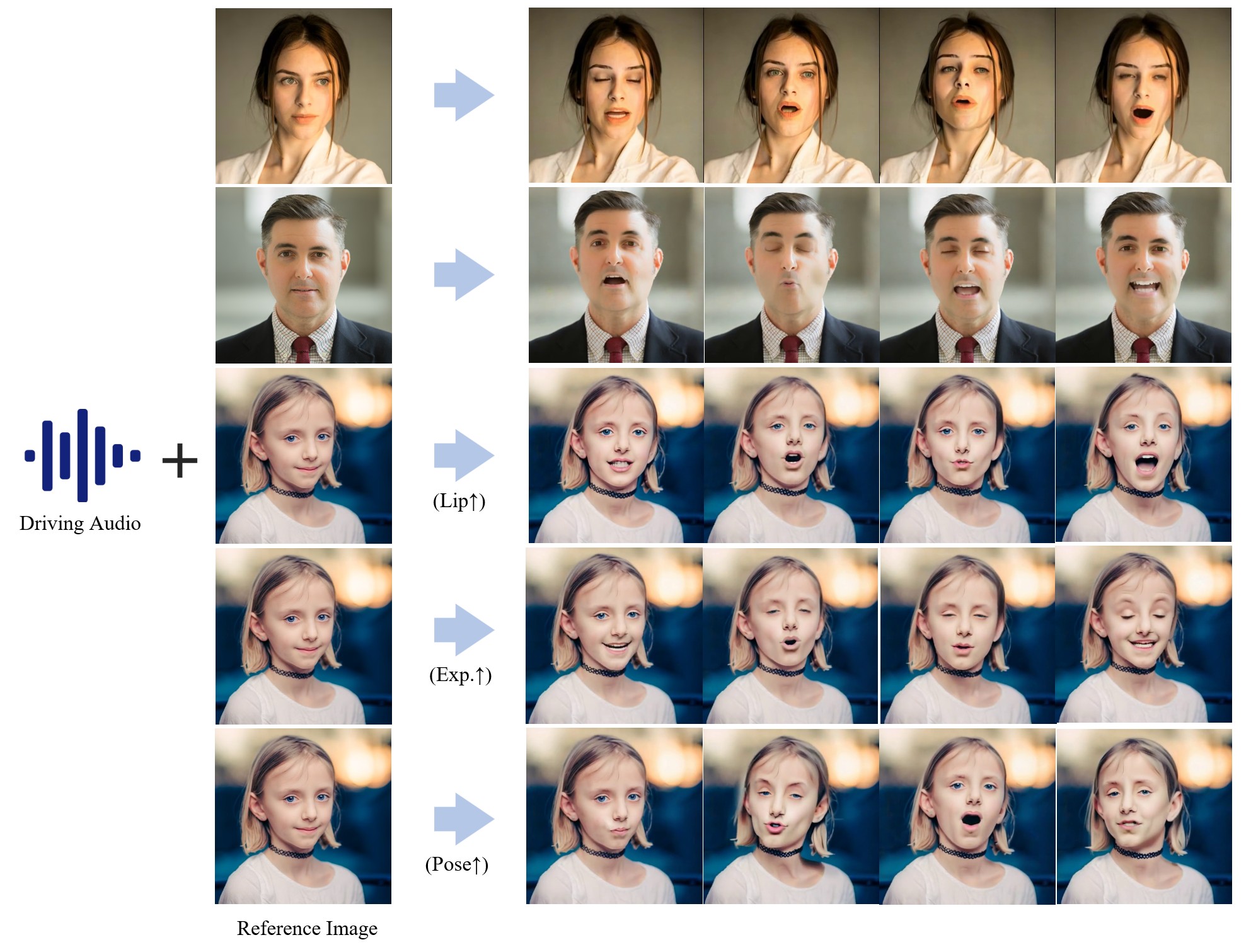
# Showcase
https://github.com/fudan-generative-vision/hallo/assets/17402682/294e78ef-c60d-4c32-8e3c-7f8d6934c6bd
# Framework
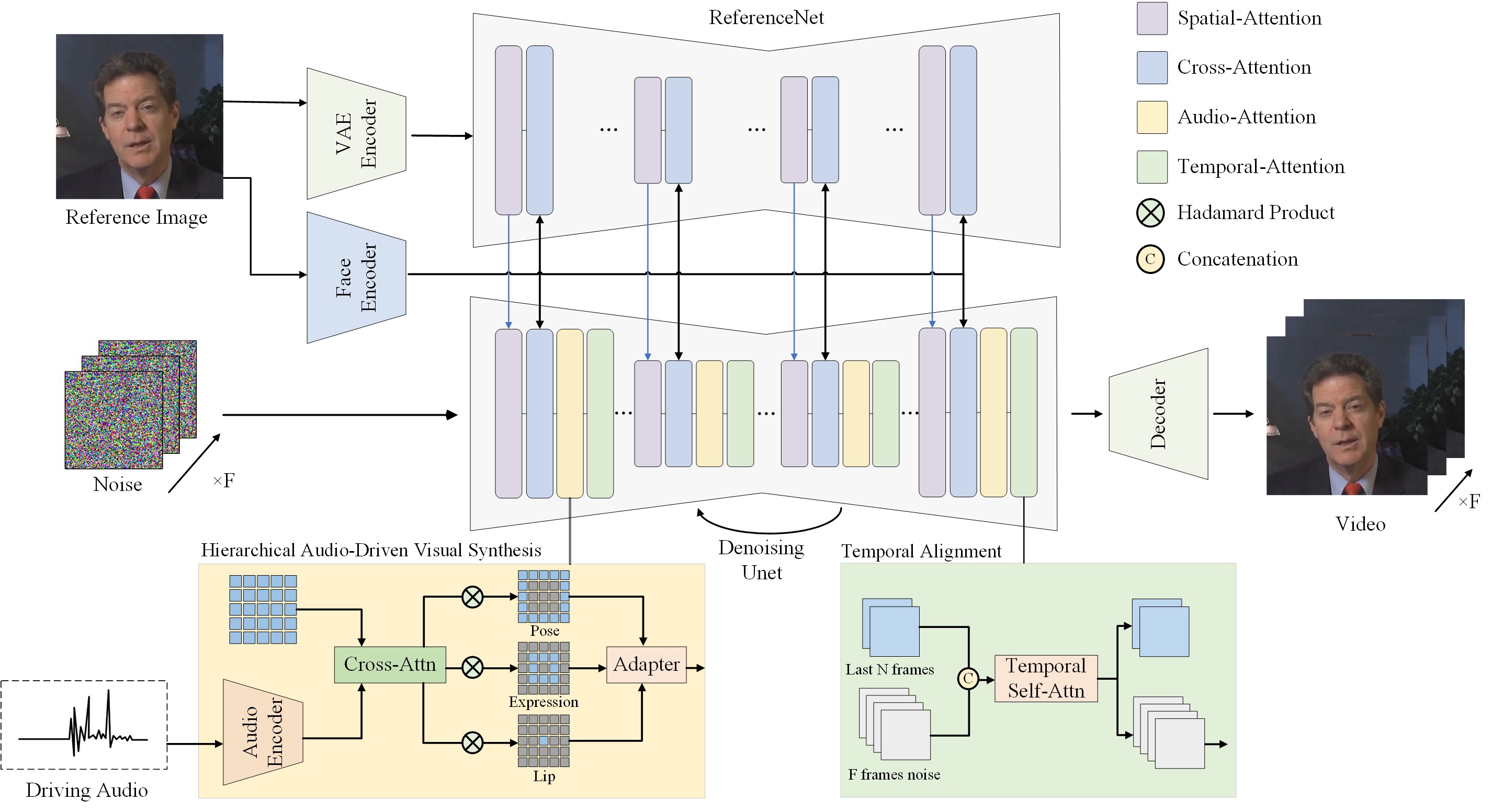
# News
- **`2024/06/15`**: 🎉🎉🎉 Release the first version on [GitHub](https://github.com/fudan-generative-vision/hallo).
- **`2024/06/15`**: ✨✨✨ Release some images and audios for inference testing on [Huggingface](https://huggingface.co/datasets/fudan-generative-ai/hallo_inference_samples).
# Installation
- System requirement: Ubuntu 20.04/Ubuntu 22.04, Cuda 12.1
- Tested GPUs: A100
Create conda environment:
```bash
conda create -n hallo python=3.10
conda activate hallo
```
Install packages with `pip`
```bash
pip install -r requirements.txt
pip install .
```
Besides, ffmpeg is also need:
```bash
apt-get install ffmpeg
```
# Inference
The inference entrypoint script is `scripts/inference.py`. Before testing your cases, there are two preparations need to be completed:
1. [Download all required pretrained models](#download-pretrained-models).
2. [Run inference](#run-inference).
## Download pretrained models
You can easily get all pretrained models required by inference from our [HuggingFace repo](https://huggingface.co/fudan-generative-ai/hallo).
Clone the the pretrained models into `${PROJECT_ROOT}/pretrained_models` directory by cmd below:
```shell
git lfs install
git clone https://huggingface.co/fudan-generative-ai/hallo pretrained_models
```
Or you can download them separately from their source repo:
- [hallo](https://huggingface.co/fudan-generative-ai/hallo/tree/main/hallo): Our checkpoints consist of denoising UNet, face locator, image & audio proj.
- [audio_separator](https://huggingface.co/huangjackson/Kim_Vocal_2): Kim\_Vocal\_2 MDX-Net vocal removal model by [KimberleyJensen](https://github.com/KimberleyJensen). (_Thanks to runwayml_)
- [insightface](https://github.com/deepinsight/insightface/tree/master/python-package#model-zoo): 2D and 3D Face Analysis placed into `pretrained_models/face_analysis/models/`. (_Thanks to deepinsight_)
- [face landmarker](https://storage.googleapis.com/mediapipe-models/face_landmarker/face_landmarker/float16/1/face_landmarker.task): Face detection & mesh model from [mediapipe](https://ai.google.dev/edge/mediapipe/solutions/vision/face_landmarker#models) placed into `pretrained_models/face_analysis/models`.
- [motion module](https://github.com/guoyww/AnimateDiff/blob/main/README.md#202309-animatediff-v2): motion module from [AnimateDiff](https://github.com/guoyww/AnimateDiff). (_Thanks to guoyww_).
- [sd-vae-ft-mse](https://huggingface.co/stabilityai/sd-vae-ft-mse): Weights are intended to be used with the diffusers library. (_Thanks to stablilityai_)
- [StableDiffusion V1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5): Initialized and fine-tuned from Stable-Diffusion-v1-2. (_Thanks to runwayml_)
- [wav2vec](https://huggingface.co/facebook/wav2vec2-base-960h): wav audio to vector model from [Facebook](https://huggingface.co/facebook/wav2vec2-base-960h).
Finally, these pretrained models should be organized as follows:
```text
./pretrained_models/
|-- audio_separator/
| `-- Kim_Vocal_2.onnx
|-- face_analysis/
| `-- models/
| |-- face_landmarker_v2_with_blendshapes.task # face landmarker model from mediapipe
| |-- 1k3d68.onnx
| |-- 2d106det.onnx
| |-- genderage.onnx
| |-- glintr100.onnx
| `-- scrfd_10g_bnkps.onnx
|-- motion_module/
| `-- mm_sd_v15_v2.ckpt
|-- sd-vae-ft-mse/
| |-- config.json
| `-- diffusion_pytorch_model.safetensors
|-- stable-diffusion-v1-5/
| |-- feature_extractor/
| | `-- preprocessor_config.json
| |-- model_index.json
| |-- unet/
| | |-- config.json
| | `-- diffusion_pytorch_model.safetensors
| `-- v1-inference.yaml
`-- wav2vec/
|-- wav2vec2-base-960h/
| |-- config.json
| |-- feature_extractor_config.json
| |-- model.safetensors
| |-- preprocessor_config.json
| |-- special_tokens_map.json
| |-- tokenizer_config.json
| `-- vocab.json
```
## Run inference
Simply to run the `scripts/inference.py` and pass `source_image` and `driving_audio` as input:
```bash
python scripts/inference.py --source_image your_image.png --driving_audio your_audio.wav
```
Animation results will be saved as `${PROJECT_ROOT}/.cache/output.mp4` by default. You can pass `--output` to specify the output file name.
For more options:
```shell
usage: inference.py [-h] [-c CONFIG] [--source_image SOURCE_IMAGE] [--driving_audio DRIVING_AUDIO] [--output OUTPUT] [--pose_weight POSE_WEIGHT]
[--face_weight FACE_WEIGHT] [--lip_weight LIP_WEIGHT] [--face_expand_ratio FACE_EXPAND_RATIO]
options:
-h, --help show this help message and exit
-c CONFIG, --config CONFIG
--source_image SOURCE_IMAGE
source image
--driving_audio DRIVING_AUDIO
driving audio
--output OUTPUT output video file name
--pose_weight POSE_WEIGHT
weight of pose
--face_weight FACE_WEIGHT
weight of face
--lip_weight LIP_WEIGHT
weight of lip
--face_expand_ratio FACE_EXPAND_RATIO
face region
```
# Roadmap
| Status | Milestone | ETA |
| :----: | :---------------------------------------------------------------------------------------------------- | :--------: |
| ✅ | **[Inference source code meet everyone on GitHub](https://github.com/fudan-generative-vision/hallo)** | 2024-06-15 |
| ✅ | **[Pretrained models on Huggingface](https://huggingface.co/fudan-generative-ai/hallo)** | 2024-06-15 |
| 🚀🚀🚀 | **[Traning: data preparation and training scripts]()** | 2024-06-25 |
# Citation
If you find our work useful for your research, please consider citing the paper:
```
@misc{xu2024hallo,
title={Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation},
author={Mingwang Xu and Hui Li and Qingkun Su and Hanlin Shang and Liwei Zhang and Ce Liu and Jingdong Wang and Yao Yao and Siyu zhu},
year={2024},
eprint={2406.08801},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
# Opportunities available
Multiple research positions are open at the **Generative Vision Lab, Fudan University**! Include:
- Research assistant
- Postdoctoral researcher
- PhD candidate
- Master students
Interested individuals are encouraged to contact us at [siyuzhu@fudan.edu.cn](mailto://siyuzhu@fudan.edu.cn) for further information.
# Social Risks and Mitigations
The development of portrait image animation technologies driven by audio inputs poses social risks, such as the ethical implications of creating realistic portraits that could be misused for deepfakes. To mitigate these risks, it is crucial to establish ethical guidelines and responsible use practices. Privacy and consent concerns also arise from using individuals' images and voices. Addressing these involves transparent data usage policies, informed consent, and safeguarding privacy rights. By addressing these risks and implementing mitigations, the research aims to ensure the responsible and ethical development of this technology. 
