Spaces:
Sleeping

Sleeping
Add weights files
Browse files- images/attention_words.jpg +0 -0
- images/bert_tunnig.jpg +0 -0
- images/distribution_classes.jpg +0 -0
- images/funny_dataframe.jpg +0 -0
- images/lstm_attention.jpg +0 -0
- images/roc_auc_catboost.jpg +0 -0
- images/roc_auc_logreg.jpg +0 -0
- images/umap.jpg +0 -0
- main.py +0 -0
- models/BertTunning.py +53 -0
- models/LSTM.py +0 -0
- models/LogReg.py +0 -0
- models/datasets/embedding_matrix.npy +3 -0
- models/datasets/vocab_to_int.json +0 -0
- models/preprocess_stage/bert_model.py +22 -0
- models/preprocess_stage/preprocess_lstm.py +0 -0
- models/weights/BertTunnigWeights.pt +3 -0
- models/weights/LSTMBestWeights.pt +3 -0
- models/weights/LogRegBestWeights.sav +0 -0
- pages/classification_reviews.py +0 -0
- pages/results.py +0 -0
- requirements.txt +77 -0
images/attention_words.jpg
ADDED

|
images/bert_tunnig.jpg
ADDED
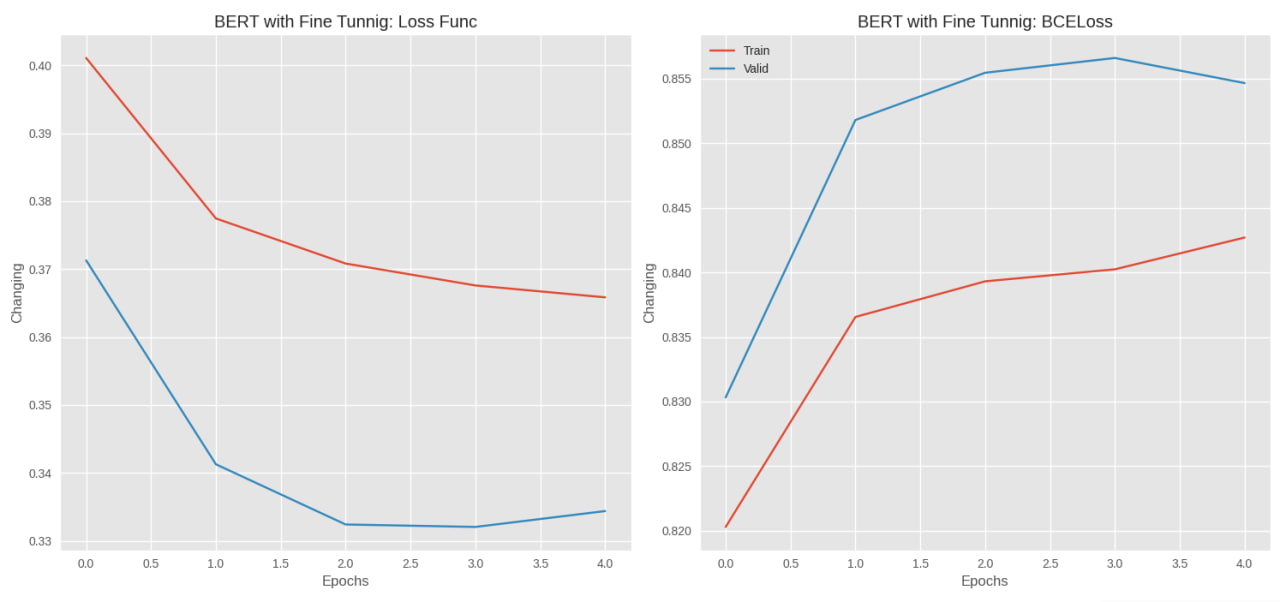
|
images/distribution_classes.jpg
ADDED
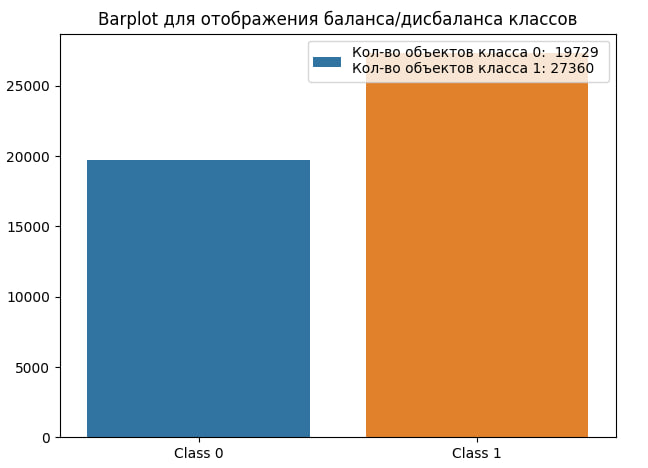
|
images/funny_dataframe.jpg
ADDED
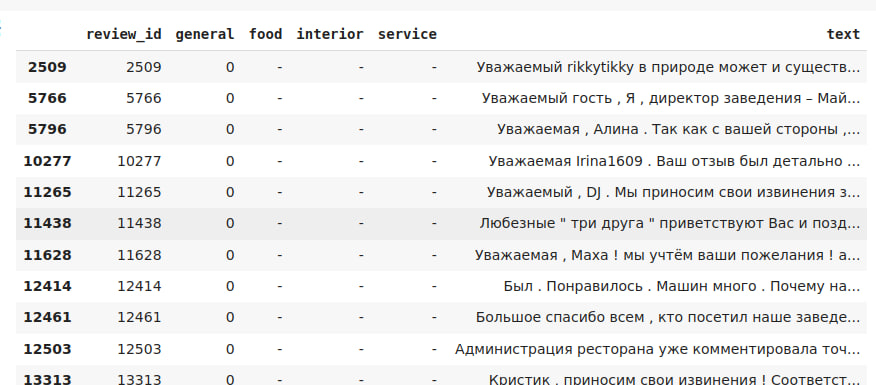
|
images/lstm_attention.jpg
ADDED
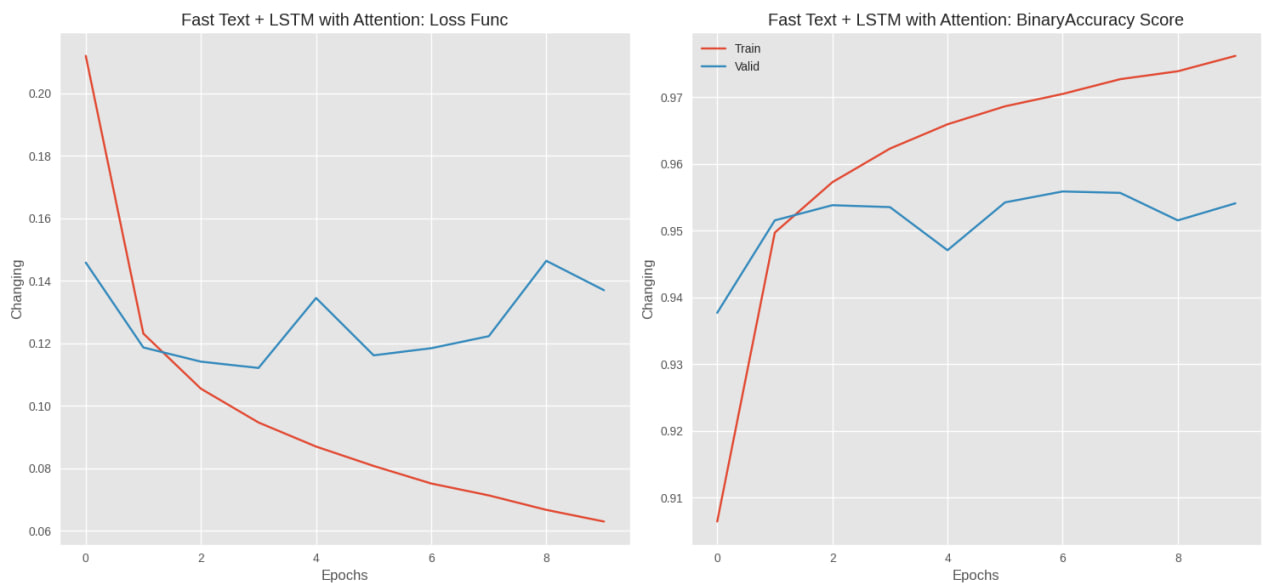
|
images/roc_auc_catboost.jpg
ADDED

|
images/roc_auc_logreg.jpg
ADDED
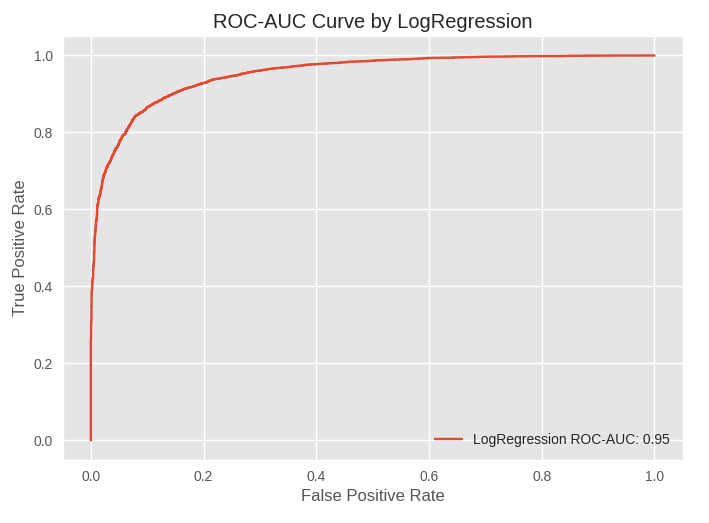
|
images/umap.jpg
ADDED

|
main.py
ADDED
|
File without changes
|
models/BertTunning.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import numpy as np
|
| 3 |
+
import torch
|
| 4 |
+
from torch import nn
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
from logreg_model import bert_for_logreg, tokenizer_bert
|
| 9 |
+
from preprocess_bert import preprocess_bert
|
| 10 |
+
|
| 11 |
+
MAX_LEN = 100
|
| 12 |
+
|
| 13 |
+
class BertTunnig(nn.Module):
|
| 14 |
+
|
| 15 |
+
def __init__(self, bert_model):
|
| 16 |
+
super().__init__()
|
| 17 |
+
|
| 18 |
+
self.bert = bert_model
|
| 19 |
+
for weights in self.bert.parameters():
|
| 20 |
+
weights.requires_grad = False
|
| 21 |
+
|
| 22 |
+
self.fc1 = nn.Linear(768, 256)
|
| 23 |
+
self.drop1 = nn.Dropout(p=0.5)
|
| 24 |
+
self.fc2 = nn.Linear(256, 32)
|
| 25 |
+
self.fc_out = nn.Linear(32, 1)
|
| 26 |
+
|
| 27 |
+
def forward(self, x, attention_mask):
|
| 28 |
+
|
| 29 |
+
output = self.bert(x, attention_mask=attention_mask)[0][:, 0, :]
|
| 30 |
+
output = self.fc1(output)
|
| 31 |
+
|
| 32 |
+
output_drop = self.drop1(output)
|
| 33 |
+
output = self.fc2(output_drop)
|
| 34 |
+
|
| 35 |
+
output = self.fc_out(output)
|
| 36 |
+
|
| 37 |
+
return torch.sigmoid(output)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
model_tunning = BertTunnig(bert_model=bert_for_logreg)
|
| 41 |
+
|
| 42 |
+
model_tunning.load_state_dict(torch.load('best_weights_berttinnug(2).pt'))
|
| 43 |
+
|
| 44 |
+
def predict_2(text):
|
| 45 |
+
|
| 46 |
+
preprocessed_text, attention_mask = preprocess_bert(text, MAX_LEN=MAX_LEN)
|
| 47 |
+
preprocessed_text, attention_mask = torch.tensor(preprocessed_text).unsqueeze(0), torch.tensor([attention_mask])
|
| 48 |
+
|
| 49 |
+
with torch.inference_mode():
|
| 50 |
+
|
| 51 |
+
predict = model_tunning(preprocessed_text, attention_mask=attention_mask).item()
|
| 52 |
+
|
| 53 |
+
return round(predict)
|
models/LSTM.py
ADDED
|
File without changes
|
models/LogReg.py
ADDED
|
File without changes
|
models/datasets/embedding_matrix.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dbcae4631c684cea4bef1df946822bdfc66cadddc240ffd39f917f200bb5894a
|
| 3 |
+
size 6643840
|
models/datasets/vocab_to_int.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
models/preprocess_stage/bert_model.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
from transformers import BertModel, BertTokenizer
|
| 4 |
+
|
| 5 |
+
weights = 'DeepPavlov/rubert-base-cased'
|
| 6 |
+
tokenizer_bert = BertTokenizer.from_pretrained(weights)
|
| 7 |
+
bert_for_logreg = BertModel.from_pretrained(weights)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def preprocess_bert(text, MAX_LEN):
|
| 11 |
+
|
| 12 |
+
tokenized_text = tokenizer_bert.encode(
|
| 13 |
+
text=text,
|
| 14 |
+
add_special_tokens=True,
|
| 15 |
+
truncation=True,
|
| 16 |
+
max_length=MAX_LEN
|
| 17 |
+
)
|
| 18 |
+
|
| 19 |
+
padded_text = np.array(tokenized_text + [0] * (MAX_LEN - len(tokenized_text)))
|
| 20 |
+
attention_mask = np.where(padded_text != 0, 1, 0)
|
| 21 |
+
|
| 22 |
+
return padded_text, attention_mask
|
models/preprocess_stage/preprocess_lstm.py
ADDED
|
File without changes
|
models/weights/BertTunnigWeights.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21a77e82f2fafc9e5cec46b6494f45dc5edb397c13fea55238eaabaf7832cffd
|
| 3 |
+
size 712320552
|
models/weights/LSTMBestWeights.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:317df198794e02b19bbb9f6cc3201950d773f9719df4391228c125ac101cd323
|
| 3 |
+
size 3375698
|
models/weights/LogRegBestWeights.sav
ADDED
|
Binary file (6.94 kB). View file
|
|
|
pages/classification_reviews.py
ADDED
|
File without changes
|
pages/results.py
ADDED
|
File without changes
|
requirements.txt
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
altair==5.2.0
|
| 2 |
+
attrs==23.1.0
|
| 3 |
+
blinker==1.7.0
|
| 4 |
+
cachetools==5.3.2
|
| 5 |
+
certifi==2023.11.17
|
| 6 |
+
charset-normalizer==3.3.2
|
| 7 |
+
click==8.1.7
|
| 8 |
+
filelock==3.13.1
|
| 9 |
+
fsspec==2023.12.2
|
| 10 |
+
gitdb==4.0.11
|
| 11 |
+
GitPython==3.1.40
|
| 12 |
+
huggingface-hub==0.19.4
|
| 13 |
+
idna==3.6
|
| 14 |
+
importlib-metadata==6.11.0
|
| 15 |
+
Jinja2==3.1.2
|
| 16 |
+
joblib==1.3.2
|
| 17 |
+
jsonschema==4.20.0
|
| 18 |
+
jsonschema-specifications==2023.11.2
|
| 19 |
+
markdown-it-py==3.0.0
|
| 20 |
+
MarkupSafe==2.1.3
|
| 21 |
+
mdurl==0.1.2
|
| 22 |
+
mpmath==1.3.0
|
| 23 |
+
networkx==3.2.1
|
| 24 |
+
nltk==3.8.1
|
| 25 |
+
numpy==1.26.2
|
| 26 |
+
nvidia-cublas-cu12==12.1.3.1
|
| 27 |
+
nvidia-cuda-cupti-cu12==12.1.105
|
| 28 |
+
nvidia-cuda-nvrtc-cu12==12.1.105
|
| 29 |
+
nvidia-cuda-runtime-cu12==12.1.105
|
| 30 |
+
nvidia-cudnn-cu12==8.9.2.26
|
| 31 |
+
nvidia-cufft-cu12==11.0.2.54
|
| 32 |
+
nvidia-curand-cu12==10.3.2.106
|
| 33 |
+
nvidia-cusolver-cu12==11.4.5.107
|
| 34 |
+
nvidia-cusparse-cu12==12.1.0.106
|
| 35 |
+
nvidia-nccl-cu12==2.18.1
|
| 36 |
+
nvidia-nvjitlink-cu12==12.3.101
|
| 37 |
+
nvidia-nvtx-cu12==12.1.105
|
| 38 |
+
packaging==23.2
|
| 39 |
+
pandas==2.1.4
|
| 40 |
+
Pillow==10.1.0
|
| 41 |
+
protobuf==4.25.1
|
| 42 |
+
pyarrow==14.0.1
|
| 43 |
+
pydeck==0.8.1b0
|
| 44 |
+
Pygments==2.17.2
|
| 45 |
+
python-dateutil==2.8.2
|
| 46 |
+
pytz==2023.3.post1
|
| 47 |
+
PyYAML==6.0.1
|
| 48 |
+
referencing==0.32.0
|
| 49 |
+
regex==2023.10.3
|
| 50 |
+
requests==2.31.0
|
| 51 |
+
rich==13.7.0
|
| 52 |
+
rpds-py==0.13.2
|
| 53 |
+
safetensors==0.4.1
|
| 54 |
+
scikit-learn==1.3.2
|
| 55 |
+
scipy==1.11.4
|
| 56 |
+
six==1.16.0
|
| 57 |
+
smmap==5.0.1
|
| 58 |
+
st-pages==0.4.5
|
| 59 |
+
streamlit==1.29.0
|
| 60 |
+
sympy==1.12
|
| 61 |
+
tenacity==8.2.3
|
| 62 |
+
threadpoolctl==3.2.0
|
| 63 |
+
tokenizers==0.15.0
|
| 64 |
+
toml==0.10.2
|
| 65 |
+
toolz==0.12.0
|
| 66 |
+
torch==2.1.2
|
| 67 |
+
tornado==6.4
|
| 68 |
+
tqdm==4.66.1
|
| 69 |
+
transformers==4.36.1
|
| 70 |
+
triton==2.1.0
|
| 71 |
+
typing_extensions==4.9.0
|
| 72 |
+
tzdata==2023.3
|
| 73 |
+
tzlocal==5.2
|
| 74 |
+
urllib3==2.1.0
|
| 75 |
+
validators==0.22.0
|
| 76 |
+
watchdog==3.0.0
|
| 77 |
+
zipp==3.17.0
|