import pandas as pd
import numpy as np
import faiss
from openai import OpenAI
import tempfile
from PyPDF2 import PdfReader
import io
from sentence_transformers import SentenceTransformer
import streamlit as st
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from collections import Counter
#from langdetect import detect
#import jieba
#import jieba.analyse
import nltk
@st.cache_data
def download_nltk():
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('stopwords')
def chunkstring(string, length):
return (string[0+i:length+i] for i in range(0, len(string), length))
def pdf_parser(input_pdf):
pdf = PdfReader(input_pdf)
pdf_content = ""
for page in pdf.pages:
pdf_content += page.extract_text()
return pdf_content
def get_keywords(file_paths): #这里的重点是,对每一个file做尽可能简短且覆盖全面的summarization
download_nltk()
keywords_list = []
for file_path in file_paths:
with open(file_path, 'r') as file:
data = file.read()
# tokenize
words = word_tokenize(data)
# remove punctuation
words = [word for word in words if word.isalnum()]
# remove stopwords
stop_words = set(stopwords.words('english'))
words = [word for word in words if word not in stop_words]
# lemmatization
lemmatizer = WordNetLemmatizer()
words = [lemmatizer.lemmatize(word) for word in words]
# count word frequencies
word_freq = Counter(words)
# get top 20 most common words
keywords = word_freq.most_common(20)
new_keywords = []
for word in keywords:
new_keywords.append(word[0])
str_keywords = ''
for word in new_keywords:
str_keywords += word + ", "
keywords_list.append(f"Top20 frequency keywords for {file_path}: {str_keywords}")
return keywords_list
def get_completion_from_messages(client, messages, model="gpt-4-1106-preview", temperature=0):
client = client
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
)
return completion.choices[0].message.content
def genarating_outline(client, keywords, num_lessons,language):
system_message = 'You are a great AI teacher and linguist, skilled at create course outline based on summarized knowledge materials.'
user_message = f"""You are a great AI teacher and linguist,
skilled at generating course outline based on keywords of the course.
Based on keywords provided, you should carefully design a course outline.
Requirements: Through learning this course, learner should understand those key concepts.
Key concepts: {keywords}
you should output course outline in a python list format, Do not include anything else except that python list in your output.
Example output format:
[[name_lesson1, abstract_lesson1],[name_lesson2, abstrct_lesson2]]
In the example, you can see each element in this list consists of two parts: the "name_lesson" part is the name of the lesson, and the "abstract_lesson" part is the one-sentence description of the lesson, intruduces knowledge it contained.
for each lesson in this course, you should provide these two information and organize them as exemplified.
for this course, you should design {num_lessons} lessons in total.
the course outline should be written in {language}.
Start the work now.
"""
messages = [
{'role':'system',
'content': system_message},
{'role':'user',
'content': user_message},
]
response = get_completion_from_messages(client, messages)
list_response = ['nothing in the answers..']
try:
list_response = eval(response)
except SyntaxError:
pass
return list_response
def courseOutlineGenerating(client, file_paths, num_lessons, language):
summarized_materials = get_keywords(file_paths)
course_outline = genarating_outline(client, summarized_materials, num_lessons, language)
return course_outline
def constructVDB(file_paths):
#把KM拆解为chunks
chunks = []
for filename in file_paths:
with open(filename, 'r') as f:
content = f.read()
for chunk in chunkstring(content, 730):
chunks.append(chunk)
chunk_df = pd.DataFrame(chunks, columns=['chunk'])
#从文本chunks到embeddings
model = SentenceTransformer('paraphrase-mpnet-base-v2')
embeddings = model.encode(chunk_df['chunk'].tolist())
# convert embeddings to a dataframe
embedding_df = pd.DataFrame(embeddings.tolist())
# Concatenate the original dataframe with the embeddings
paraphrase_embeddings_df = pd.concat([chunk_df, embedding_df], axis=1)
# Save the results to a new csv file
#从embeddings到向量数据库
# Load the embeddings
embeddings = paraphrase_embeddings_df.iloc[:, 1:].values # All columns except the first (chunk text)
# Ensure that the array is C-contiguous
embeddings = np.ascontiguousarray(embeddings, dtype=np.float32)
# Preparation for Faiss
dimension = embeddings.shape[1] # the dimension of the vector space
index = faiss.IndexFlatL2(dimension)
# Normalize the vectors
faiss.normalize_L2(embeddings)
# Build the index
index.add(embeddings)
# write index to disk
return paraphrase_embeddings_df, index
def searchVDB(search_sentence, paraphrase_embeddings_df, index):
#从向量数据库中检索相应文段
try:
data = paraphrase_embeddings_df
embeddings = data.iloc[:, 1:].values # All columns except the first (chunk text)
embeddings = np.ascontiguousarray(embeddings, dtype=np.float32)
model = SentenceTransformer('paraphrase-mpnet-base-v2')
sentence_embedding = model.encode([search_sentence])
# Ensuring the sentence embedding is in the correct format
sentence_embedding = np.ascontiguousarray(sentence_embedding, dtype=np.float32)
# Searching for the top 3 nearest neighbors in the FAISS index
D, I = index.search(sentence_embedding, k=3)
# Printing the top 3 most similar text chunks
retrieved_chunks_list = []
for idx in I[0]:
retrieved_chunks_list.append(data.iloc[idx].chunk)
except Exception:
retrieved_chunks_list = []
return retrieved_chunks_list
def generateCourse(client, topic, materials, language, style_options):
system_message = 'You are a great AI teacher and linguist, skilled at writing informative and easy-to-understand course script based on given lesson topic and knowledge materials.'
user_message = f"""You are a great AI teacher and linguist,
skilled at writing informative and easy-to-understand course script based on given lesson topic and knowledge materials.\n
You should write a course for new hands, they need detailed and vivid explaination to understand the topic. \n
A high-quality course should meet requirements below:\n
(1) Contains enough facts, data and figures to be convincing\n
(2) The internal narrative is layered and logical, not a simple pile of items\n
Make sure all these requirements are considered when writing the lesson script content.\n
Please follow this procedure step-by-step when disgning the course:\n
Step 1. Write down the teaching purpose of the lesson initially in the script. \n
Step 2. Write down the outline of this lesson (outline is aligned to the teaching purpose), then follow the outline to write the content. Make sure every concept in the outline is explined adequately in the course. \n
Your lesson topic and abstract is within the 「」 quotes, and the knowledge materials are within the 【】 brackets. \n
lesson topic and abstract: 「{topic}」, \n
knowledge materials related to this lesson:【{materials} 】 \n
the script should be witten in {language}, and mathematical symbols should be written in markdown form. \n
{style_options} \n
Start writting the script of this lesson now.
"""
messages = [
{'role':'system',
'content': system_message},
{'role':'user',
'content': user_message},
]
response = get_completion_from_messages(client, messages)
return response
def decorate_user_question(user_question, retrieved_chunks_for_user):
decorated_prompt = f'''You're a brilliant teaching assistant, skilled at answer stundent's question based on given materials.
student's question: 「{user_question}」
related materials:【{retrieved_chunks_for_user}】
if the given materials are irrelavant to student's question, please use your own knowledge to answer the question.
You need to break down the student's question first, find out what he really wants to ask, and then try your best to give a comprehensive answer.
The language you're answering in should aligned with what student is using.
Now you're talking to the student. Please answer.
'''
return decorated_prompt
def initialize_file(added_files):
temp_file_paths = []
with st.spinner('Processing file...'):
for added_file in added_files:
if added_file.name.endswith(".pdf"):
string = pdf_parser(added_file)
with tempfile.NamedTemporaryFile(suffix=".md", delete=False) as tmp:
tmp.write(string.encode("utf-8"))
tmp_path = tmp.name
else:
with tempfile.NamedTemporaryFile(delete=False, suffix=".md") as tmp:
tmp.write(added_file.getvalue())
tmp_path = tmp.name
temp_file_paths.append(tmp_path)
st.success('Processing file...Done')
return temp_file_paths
def initialize_vdb(temp_file_paths):
with st.spinner('Constructing vector database from provided materials...'):
embeddings_df, faiss_index = constructVDB(temp_file_paths)
st.success("Constructing vector database from provided materials...Done")
return embeddings_df, faiss_index
def initialize_outline(client, temp_file_paths, num_lessons, language):
with st.spinner('Generating Course Outline...'):
course_outline_list = courseOutlineGenerating(client, temp_file_paths, num_lessons, language)
st.success("Generating Course Outline...Done")
course_outline_string = ''
lessons_count = 0
for outline in course_outline_list:
lessons_count += 1
course_outline_string += f"{lessons_count}." + outline[0]
course_outline_string += '\n\n' + outline[1] + '\n\n'
with st.expander("Check the course outline", expanded=False):
st.write(course_outline_string)
return course_outline_list
def initialize_content(client, course_outline_list, embeddings_df, faiss_index, language, style_options):
count_generating_content = 0
course_content_list = []
for lesson in course_outline_list:
count_generating_content += 1
with st.spinner(f"Writing content for lesson {count_generating_content}..."):
retrievedChunksList = searchVDB(lesson, embeddings_df, faiss_index)
courseContent = generateCourse(client, lesson, retrievedChunksList, language, style_options)
course_content_list.append(courseContent)
st.success(f"Writing content for lesson {count_generating_content}...Done")
with st.expander(f"Learn the lesson {count_generating_content} ", expanded=False):
st.markdown(courseContent)
return course_content_list
def regenerate_outline(course_outline_list):
try:
course_outline_string = ''
lessons_count = 0
for outline in course_outline_list:
lessons_count += 1
course_outline_string += f"{lessons_count}." + outline[0]
course_outline_string += '\n\n' + outline[1] + '\n\n'
with st.expander("Check the course outline", expanded=False):
st.write(course_outline_string)
except Exception:
pass
def regenerate_content(course_content_list):
try:
count_generating_content = 0
for content in course_content_list:
count_generating_content += 1
with st.expander(f"Learn the lesson {count_generating_content} ", expanded=False):
st.markdown(content)
except Exception:
pass
def add_prompt_course_style(selected_style_list):
initiate_prompt = 'Please be siginificantly aware that this course is requested to: \n'
customize_prompt = ''
if len(selected_style_list) != 0:
customize_prompt += initiate_prompt
for style in selected_style_list:
if style == "More examples":
customize_prompt += '- **contain more examples**. You should use your own knowledge to vividly exemplify key concepts occured in this course.\n'
elif style == "More excercises":
customize_prompt += '- **contain more excercises**. So last part of this lesson should be excercises.\n'
elif style == "Easier to learn":
customize_prompt += '- **Be easier to learn**. So you should use plain language to write the lesson script, and apply some metaphors & analogys wherever appropriate.\n'
return customize_prompt
def app():
st.title("OmniTutor v0.1.0")
announce = st.caption('''
:blue[⚠️Key Announcement:] The free service has been disrupted due to high costs. In order to use OmniTutor you need to type your own OPENAI API key into the sidebar.
:blue[⚠️关键公告:] 免费服务现在已经因为过高的支出而中断。为了使用OmniTutor,你需要在边栏顶部输入自己的Openai API key。
''')
divider = st.divider()
st.markdown("""
""", unsafe_allow_html=True)
with st.sidebar:
api_key = st.text_input('Your OpenAI API key:', 'sk-...')
st.image("https://siyuan-harry.oss-cn-beijing.aliyuncs.com/oss://siyuan-harry/20231021212525.png")
added_files = st.file_uploader('Upload .md or .pdf files, simultaneous mixed upload these types is supported.', type=['.md','.pdf'], accept_multiple_files=True)
with st.expander('Customize my course'):
num_lessons = st.slider('How many lessons do you want this course to have?', min_value=2, max_value=15, value=5, step=1)
custom_options = st.multiselect(
'Preferred teaching style :grey[(Recommend new users not to select)]',
['More examples', 'More excercises', 'Easier to learn'],
max_selections = 2
)
style_options = add_prompt_course_style(custom_options)
language = 'English'
Chinese = st.checkbox('Output in Chinese')
if Chinese:
language = 'Chinese'
btn = st.button('Generate my course!')
if "description1" not in st.session_state:
st.session_state.description = ''
if "start_col1" not in st.session_state:
st.session_state.start_col1 = st.empty()
if "start_col2" not in st.session_state:
st.session_state.start_col2 = st.empty()
if "case_pay" not in st.session_state:
st.session_state.case_pay = st.empty()
if "embeddings_df" not in st.session_state:
st.session_state.embeddings_df = ''
if "faiss_index" not in st.session_state:
st.session_state.faiss_index = ''
if "course_outline_list" not in st.session_state:
st.session_state.course_outline_list = ''
if "course_content_list" not in st.session_state:
st.session_state.course_content_list = ''
if "OPENAI_API_KEY" not in st.session_state:
st.session_state["OPENAI_API_KEY"] = ''
#if "client" not in st.session_state:
# st.session_state["client"] = ''
if "openai_model" not in st.session_state:
st.session_state["openai_model"] = "gpt-4-1106-preview"
if "messages_ui" not in st.session_state:
st.session_state.messages_ui = []
if "messages" not in st.session_state:
st.session_state.messages = []
st.session_state.start_col1, st.session_state.start_col2 = st.columns(2)
with st.session_state.start_col1:
st.session_state.description = st.markdown('''
An all-round teacher. A teaching assistant who really knows the subject. **Anything. Anywhere. All at once.** :100:
Github Repo (for this prototype version): https://github.com/Siyuan-Harry/OmniTutor
- Github Repo (for **OmniTutor 2.0**): https://github.com/Siyuan-Harry/OmniTutor_2
### ✨ Key features
- 🧑🏫 **Concise and clear course creation**: Generated from your learning notes (**.md**) or any learning materials (**.pdf**)!
- 📚 **All disciplines**: Whether it's math, physics, literature, history or coding, OmniTutor covers it all.
- ⚙️ **Customize your own course**: Choose your preferred teaching style, lesson count and language.
- ⚡️ **Fast respond with trustable accuracy**: Problem-solving chat with the AI teaching assistant who really understand the materials.
### 🏃♂️ Get started!
1. **Input Your OpenAI API Key**: Give OmniTutor your own OpenAI API key (On top of the **sidebar**) to get started.
2. **Upload learning materials**: The upload widget in the sidebar supports PDF and .md files simutaenously.
3. **Customize your course**: By few clicks and swipes, adjusting teaching style, lesson count and language for your course.
4. **Start course generating**: Touch "Generate my course!" button in the sidebar, then watch how OmniTutor creates personal-customized course for you.
5. **Interactive learning**: Learn the course, and ask OmniTutor any questions related to this course whenever you encountered them.
🎉 Have fun playing with Omnitutor!
''', unsafe_allow_html=True
)
with st.session_state.start_col2:
st.session_state.case_pay = st.markdown('''
### 💡Application Cases 使用案例
> 用OmniTutor阅读专业的论文!
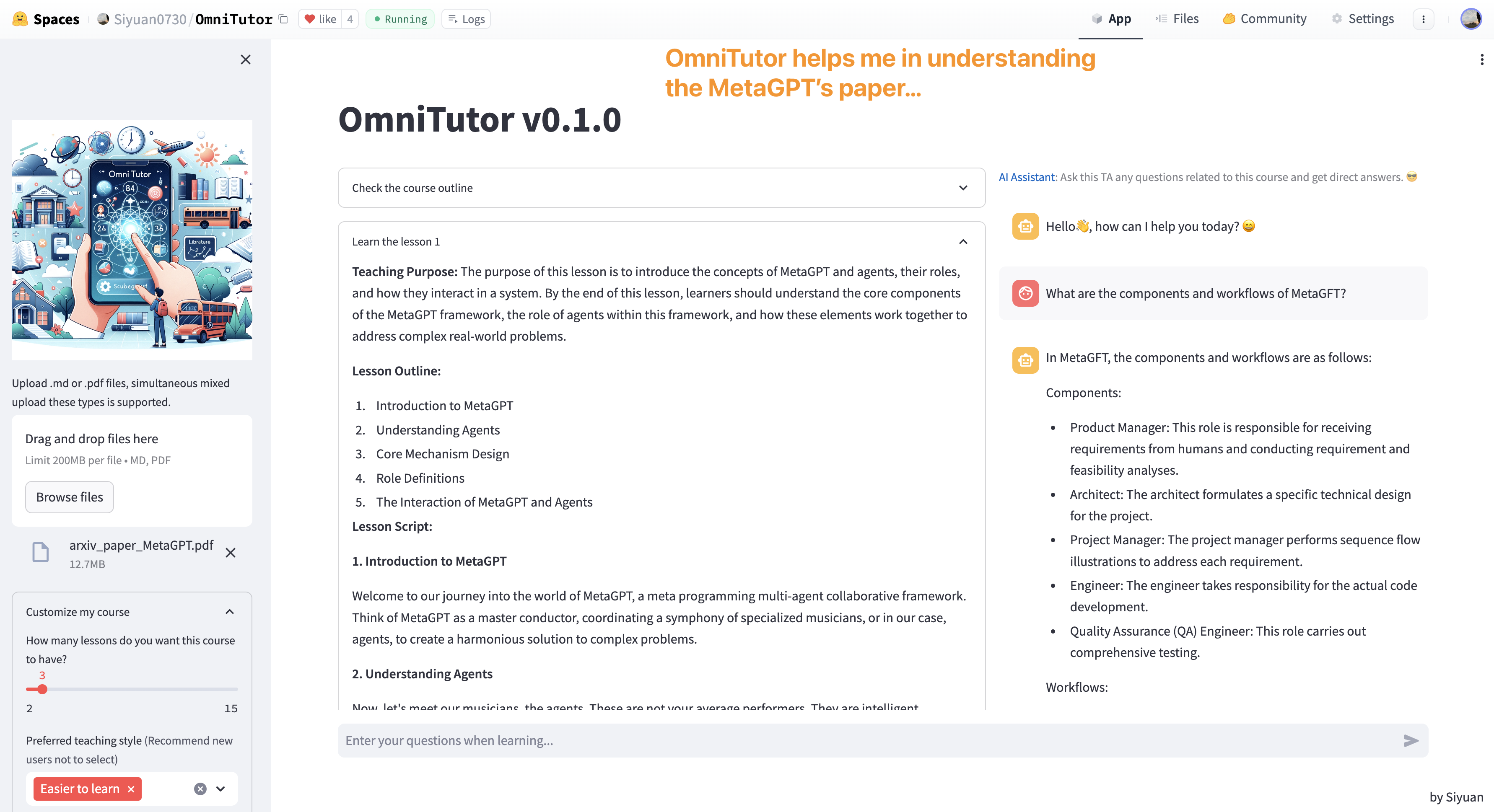
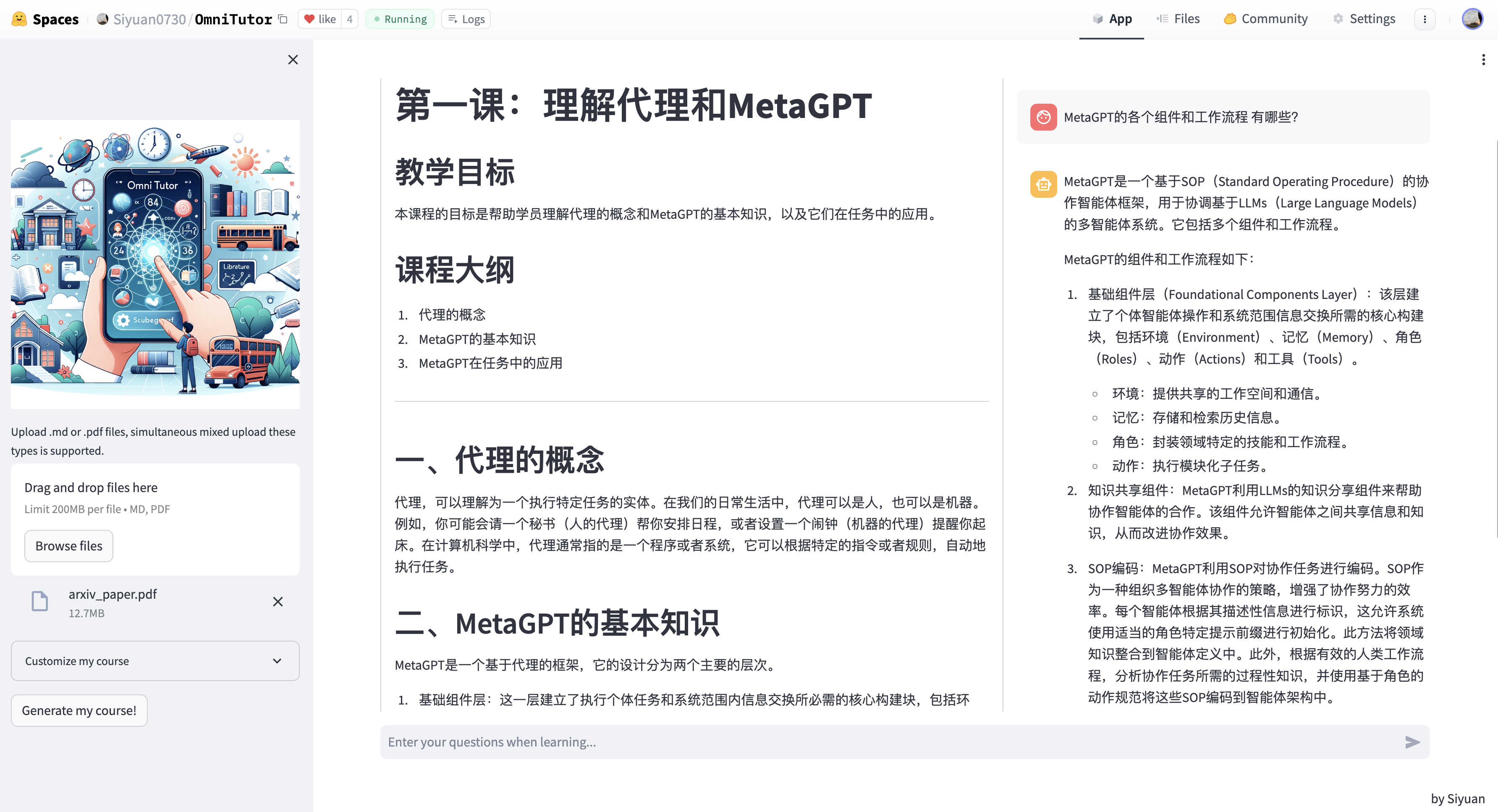 > 用OmniTutor学习Python!
> 用OmniTutor学习Python!
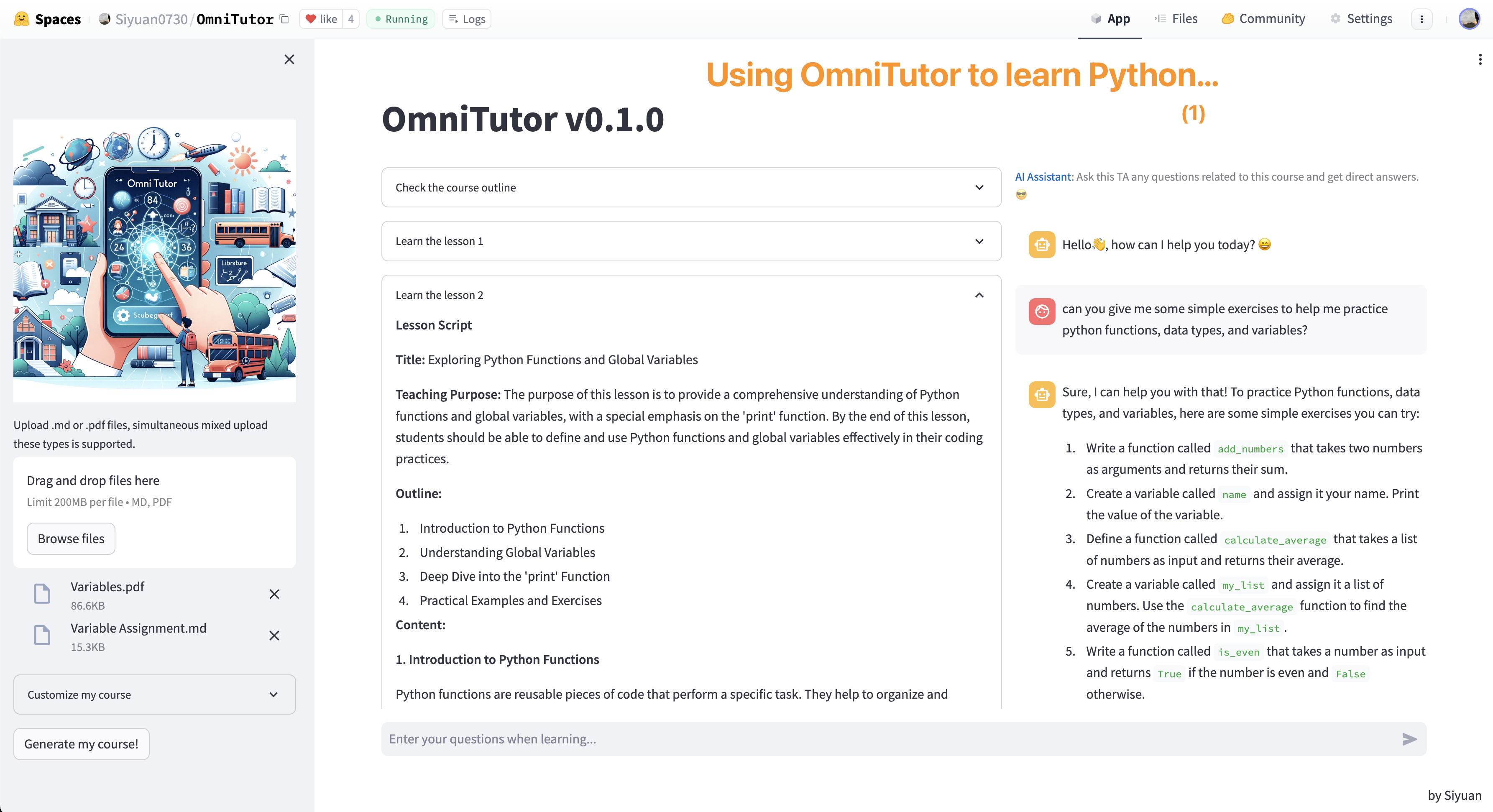
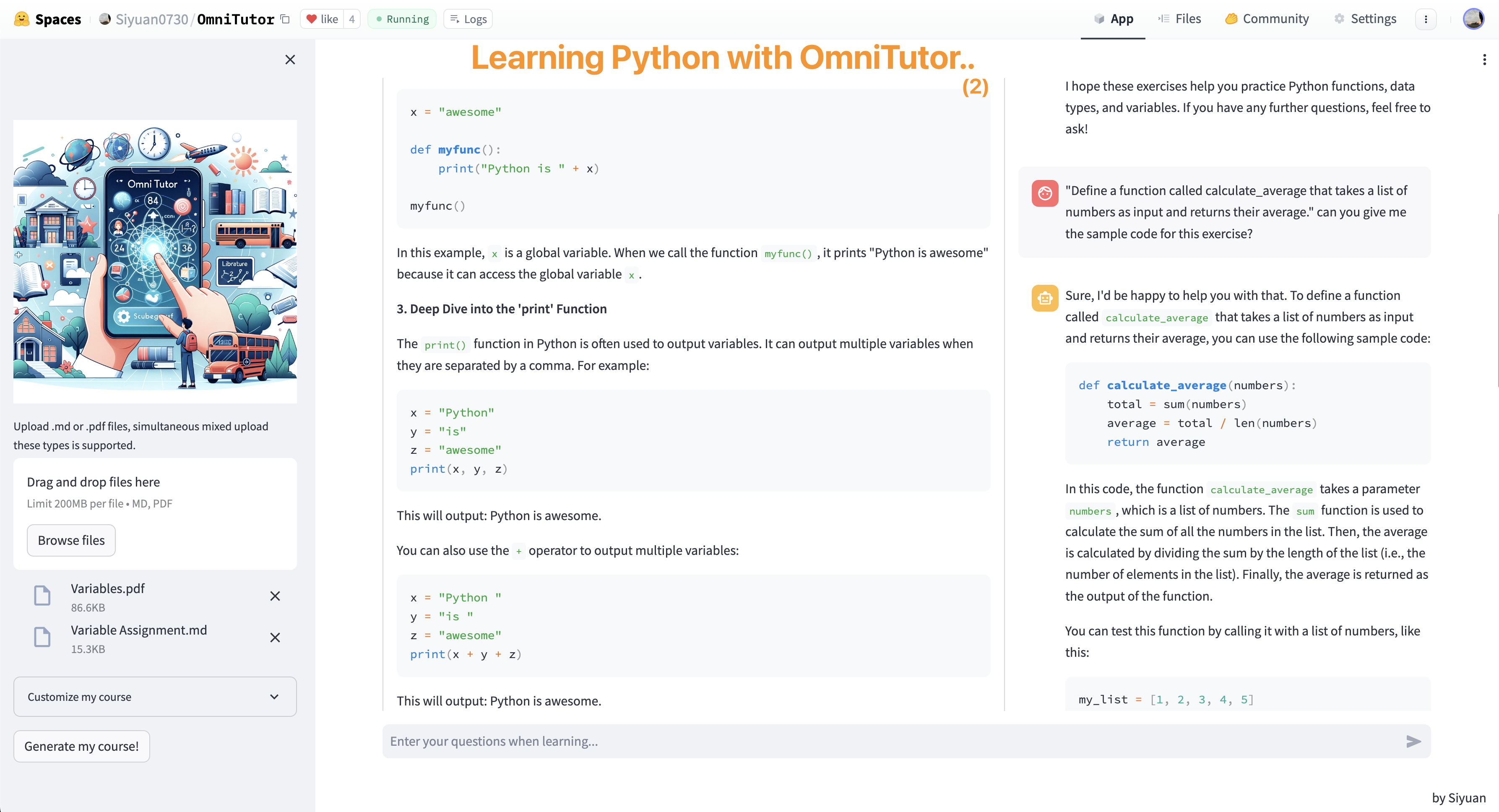 ---
### 🙌 Contact me 联系我
欢迎联系开发者 @何思远方Siyuan. Feel free to get in touch with me!
- 邮箱📮:siyuanfang@foxmail.com
- B站:何思远方Siyuan
''', unsafe_allow_html=True)
if btn:
if api_key != "sk-..." and api_key !="" and api_key.startswith("sk-"):
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
#initialize app
temp_file_paths = initialize_file(added_files)
st.session_state["OPENAI_API_KEY"] = api_key
client = OpenAI(api_key = st.session_state["OPENAI_API_KEY"])
st.session_state.embeddings_df, st.session_state.faiss_index = initialize_vdb(temp_file_paths)
st.session_state.course_outline_list = initialize_outline(client, temp_file_paths, num_lessons, language)
st.session_state.course_content_list = initialize_content(client, st.session_state.course_outline_list, st.session_state.embeddings_df, st.session_state.faiss_index, language, style_options)
st.markdown('''
> 🤔 **Not satisfied with this course?** Simply click "Generate my course!" button to regenerate a new one!
>
> 😁 If the course is good enough for you, learn and enter questions related in the input box below 👇...
:blue[Wish you all the best in your learning journey :)]
''', unsafe_allow_html=True)
else:
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
warning = st.write("请输入正确的OpenAI API Key令牌")
col1, col2 = st.columns([0.6,0.4])
user_question = st.chat_input("Enter your questions when learning...")
if user_question:
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
with col1:
regenerate_outline(st.session_state.course_outline_list)
regenerate_content(st.session_state.course_content_list)
with col2:
st.caption(''':blue[AI Assistant]: Ask this TA any questions related to this course and get direct answers. :sunglasses:''')
# Set a default model
with st.chat_message("assistant"):
st.write("Hello👋, how can I help you today? 😄")
# Display chat messages from history on app rerun
for message in st.session_state.messages_ui:
with st.chat_message(message["role"]):
st.markdown(message["content"])
#更新ui上显示的聊天记录
st.session_state.messages_ui.append({"role": "user", "content": user_question})
# Display new user question.
with st.chat_message("user"):
st.markdown(user_question)
#这里的session.state就是保存了这个对话会话的一些基本信息和设置
retrieved_chunks_for_user = searchVDB(user_question, st.session_state.embeddings_df, st.session_state.faiss_index)
prompt = decorate_user_question(user_question, retrieved_chunks_for_user)
st.session_state.messages.append({"role": "user", "content": prompt})
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
client = OpenAI(api_key = st.session_state["OPENAI_API_KEY"])
for response in client.chat.completions.create(
model=st.session_state["openai_model"],
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages #用chatbot那边的隐藏消息记录
],
stream=True,
):
try:
full_response += response.choices[0].delta.content
except:
full_response += ""
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
st.session_state.messages_ui.append({"role": "assistant", "content": full_response})
if __name__ == "__main__":
app()
---
### 🙌 Contact me 联系我
欢迎联系开发者 @何思远方Siyuan. Feel free to get in touch with me!
- 邮箱📮:siyuanfang@foxmail.com
- B站:何思远方Siyuan
''', unsafe_allow_html=True)
if btn:
if api_key != "sk-..." and api_key !="" and api_key.startswith("sk-"):
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
#initialize app
temp_file_paths = initialize_file(added_files)
st.session_state["OPENAI_API_KEY"] = api_key
client = OpenAI(api_key = st.session_state["OPENAI_API_KEY"])
st.session_state.embeddings_df, st.session_state.faiss_index = initialize_vdb(temp_file_paths)
st.session_state.course_outline_list = initialize_outline(client, temp_file_paths, num_lessons, language)
st.session_state.course_content_list = initialize_content(client, st.session_state.course_outline_list, st.session_state.embeddings_df, st.session_state.faiss_index, language, style_options)
st.markdown('''
> 🤔 **Not satisfied with this course?** Simply click "Generate my course!" button to regenerate a new one!
>
> 😁 If the course is good enough for you, learn and enter questions related in the input box below 👇...
:blue[Wish you all the best in your learning journey :)]
''', unsafe_allow_html=True)
else:
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
warning = st.write("请输入正确的OpenAI API Key令牌")
col1, col2 = st.columns([0.6,0.4])
user_question = st.chat_input("Enter your questions when learning...")
if user_question:
st.session_state.start_col1.empty()
st.session_state.start_col2.empty()
st.session_state.description.empty()
st.session_state.case_pay.empty()
announce.empty()
divider.empty()
with col1:
regenerate_outline(st.session_state.course_outline_list)
regenerate_content(st.session_state.course_content_list)
with col2:
st.caption(''':blue[AI Assistant]: Ask this TA any questions related to this course and get direct answers. :sunglasses:''')
# Set a default model
with st.chat_message("assistant"):
st.write("Hello👋, how can I help you today? 😄")
# Display chat messages from history on app rerun
for message in st.session_state.messages_ui:
with st.chat_message(message["role"]):
st.markdown(message["content"])
#更新ui上显示的聊天记录
st.session_state.messages_ui.append({"role": "user", "content": user_question})
# Display new user question.
with st.chat_message("user"):
st.markdown(user_question)
#这里的session.state就是保存了这个对话会话的一些基本信息和设置
retrieved_chunks_for_user = searchVDB(user_question, st.session_state.embeddings_df, st.session_state.faiss_index)
prompt = decorate_user_question(user_question, retrieved_chunks_for_user)
st.session_state.messages.append({"role": "user", "content": prompt})
# Display assistant response in chat message container
with st.chat_message("assistant"):
message_placeholder = st.empty()
full_response = ""
client = OpenAI(api_key = st.session_state["OPENAI_API_KEY"])
for response in client.chat.completions.create(
model=st.session_state["openai_model"],
messages=[
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages #用chatbot那边的隐藏消息记录
],
stream=True,
):
try:
full_response += response.choices[0].delta.content
except:
full_response += ""
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
st.session_state.messages_ui.append({"role": "assistant", "content": full_response})
if __name__ == "__main__":
app()