Spaces:
Runtime error

Runtime error
Merge pull request #1 from TuanaCelik/new-diagram
Browse files- diagram.png +0 -0
- pages/1_⭐️_Info.py +49 -4
diagram.png
CHANGED
|

|
pages/1_⭐️_Info.py
CHANGED
|
@@ -7,9 +7,54 @@ st.markdown("""
|
|
| 7 |
# Better Image Retrieval With Retrieval-Augmented CLIP 🧠
|
| 8 |
|
| 9 |
|
| 10 |
-
CLIP is a neural network
|
| 11 |
-
|
| 12 |
|
| 13 |
-
|
|
|
|
|
|
|
| 14 |
|
| 15 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 7 |
# Better Image Retrieval With Retrieval-Augmented CLIP 🧠
|
| 8 |
|
| 9 |
|
| 10 |
+
[CLIP](https://openai.com/blog/clip/) is a neural network that can predict how semantically close images and text pairs are.
|
| 11 |
+
In simpler terms, it can tell that the string "Cat" is closer to images of cats rather than images of dogs.
|
| 12 |
|
| 13 |
+
What makes CLIP so powerful is that is a zero-shot model: that means that it can generalize concepts,
|
| 14 |
+
understand text and images it has never seen before. For example, it can tell that the string "an animal with yellow eyes"
|
| 15 |
+
is closer to images of cats rather than dogs, even though such pair was not in its training data.
|
| 16 |
|
| 17 |
+
Why does this matter? Because zero shot capabilities allow models to understand descriptions. And in fact
|
| 18 |
+
CLIP understands that "an animal with pink feathers" matches a flamingo better than a pig.
|
| 19 |
+
|
| 20 |
+
However, these descriptions need to be related to what the image shows. CLIP knows nothing about the animal features,
|
| 21 |
+
history and cultural references: It doesn't know which animals live longer than others, that jaguars were often depicted
|
| 22 |
+
in Aztec wall paintings, or that wolves and bears are typical animals that show up in European fairy tales. It doesn't even
|
| 23 |
+
know that cheetas are fast, because it cannot tell it from the image.
|
| 24 |
+
|
| 25 |
+
However, Wikipedia contains all this information, and more. Can we make CLIP "look up" the answer to
|
| 26 |
+
our questions on Wikipedia before looking for matches?
|
| 27 |
+
|
| 28 |
+
In this demo application, we see how can we combine traditional Extractive QA on Wikipedia and CLIP with Haystack.""")
|
| 29 |
+
|
| 30 |
+
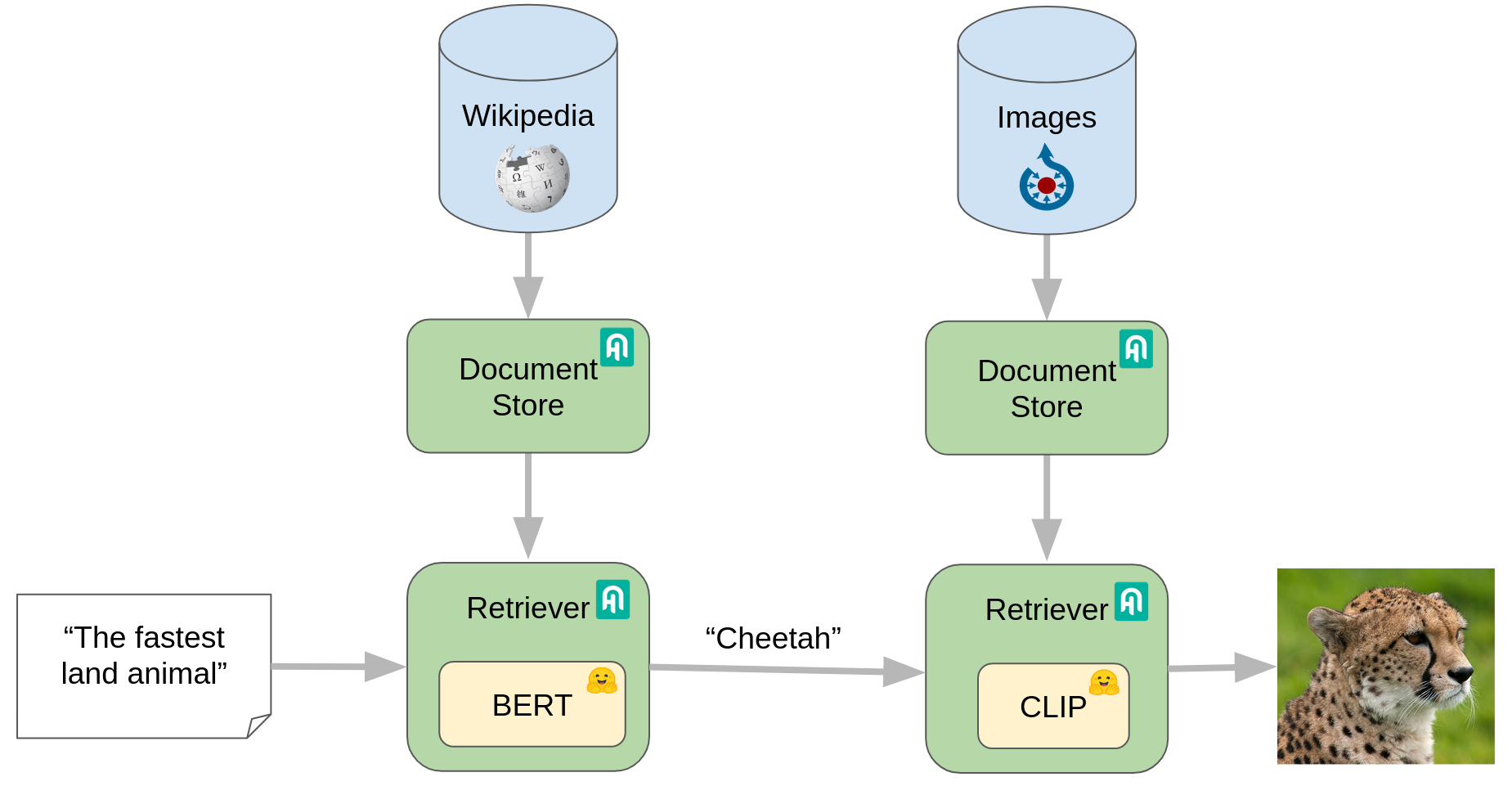
st.image("diagram.png")
|
| 31 |
+
|
| 32 |
+
st.markdown("""
|
| 33 |
+
In the image above you can see how the process looks like.
|
| 34 |
+
|
| 35 |
+
First, we download a slice of Wikipedia with information about all the animals in the Lisbon zoo and preprocess,
|
| 36 |
+
index, embed and store them in a DocumentStore. For this demo we're using
|
| 37 |
+
[FAISSDocumentStore](https://docs.haystack.deepset.ai/docs/document_store).
|
| 38 |
+
|
| 39 |
+
At this point they are ready to be queried by the text Retriever, in this case an instance of
|
| 40 |
+
[EmbeddingRetriever](https://docs.haystack.deepset.ai/docs/retriever#embedding-retrieval-recommended).
|
| 41 |
+
It compares the user's question ("The fastest animal") to all the documents indexed earlier and returns the
|
| 42 |
+
documents which are more likely to contain an answer to the question.
|
| 43 |
+
In this case, it will probably return snippets from the Cheetah Wikipedia entry.
|
| 44 |
+
|
| 45 |
+
Once the documents are found, they are handed over to the Reader (in this demo, a
|
| 46 |
+
[FARMReader](https://docs.haystack.deepset.ai/docs/reader) node):
|
| 47 |
+
a model that is able to locate precisely the answer to a question into a document.
|
| 48 |
+
These answers are strings that should be now very easy for CLIP to understand, such as the name of an animal.
|
| 49 |
+
In this case, the Reader will return answers such as "Cheetah", "the cheetah", etc.
|
| 50 |
+
|
| 51 |
+
These strings are then ranked and the most likely one is sent over to the
|
| 52 |
+
[MultiModalRetriever](https://docs.haystack.deepset.ai/docs/retriever#multimodal-retrieval)
|
| 53 |
+
that contains CLIP, which will use its own document store of images to find all the pictures that match the string.
|
| 54 |
+
Cheetah are present in the Lisbon zoo, so it will find pictures of them and return them.
|
| 55 |
+
|
| 56 |
+
These nodes are chained together using a [Pipeline](https://docs.haystack.deepset.ai/docs/pipelines) object,
|
| 57 |
+
so that all you need to do to run a system like this is a single call: `pipeline.run(query="What's the fastest animal?")`
|
| 58 |
+
will return the list of images directly.
|
| 59 |
+
Have a look at [how we implemented it](https://github.com/TuanaCelik/find-the-animal/blob/main/utils/haystack.py)!
|
| 60 |
+
""")
|