Spaces:
Running

Running
Update README with images
Browse files- .gitignore +1 -1
- README.md +17 -21
- assets/evaluate.png +0 -0
- assets/gui.png +0 -0
- assets/help.png +0 -0
- assets/predict.png +0 -0
- assets/space.png +0 -0
- assets/train.png +0 -0
.gitignore
CHANGED
|
@@ -196,4 +196,4 @@ pyrightconfig.json
|
|
| 196 |
# Custom
|
| 197 |
data/*
|
| 198 |
!data/slang.json
|
| 199 |
-
|
|
|
|
| 196 |
# Custom
|
| 197 |
data/*
|
| 198 |
!data/slang.json
|
| 199 |
+
!data/test.csv
|
README.md
CHANGED
|
@@ -17,7 +17,7 @@ models:
|
|
| 17 |
---
|
| 18 |
|
| 19 |
|
| 20 |
-
# Sentiment Analysis [](https://
|
| 21 |
|
| 22 |
|
| 23 |
### Table of Contents
|
|
@@ -64,8 +64,7 @@ To see the available commands and options, run:
|
|
| 64 |
```bash
|
| 65 |
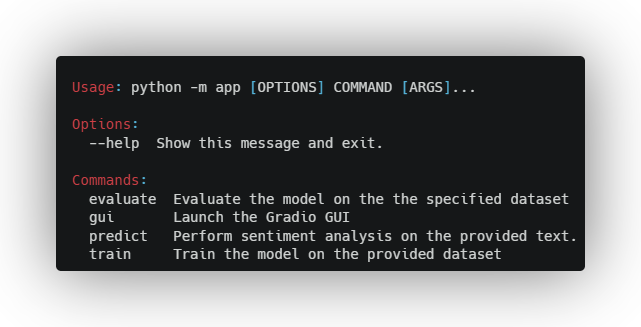
python -m app --help
|
| 66 |
```
|
| 67 |
-
|
| 68 |
-
<!-- Image of the output -->
|
| 69 |
|
| 70 |
|
| 71 |
### Predict
|
|
@@ -79,8 +78,7 @@ Alternatively, you can pipe the text into the command:
|
|
| 79 |
```bash
|
| 80 |
echo "I love this movie" | python -m app predict --model <model>
|
| 81 |
```
|
| 82 |
-
|
| 83 |
-
<!-- Image of the output -->
|
| 84 |
|
| 85 |
|
| 86 |
### GUI
|
|
@@ -89,11 +87,10 @@ To launch the GUI, run the following command:
|
|
| 89 |
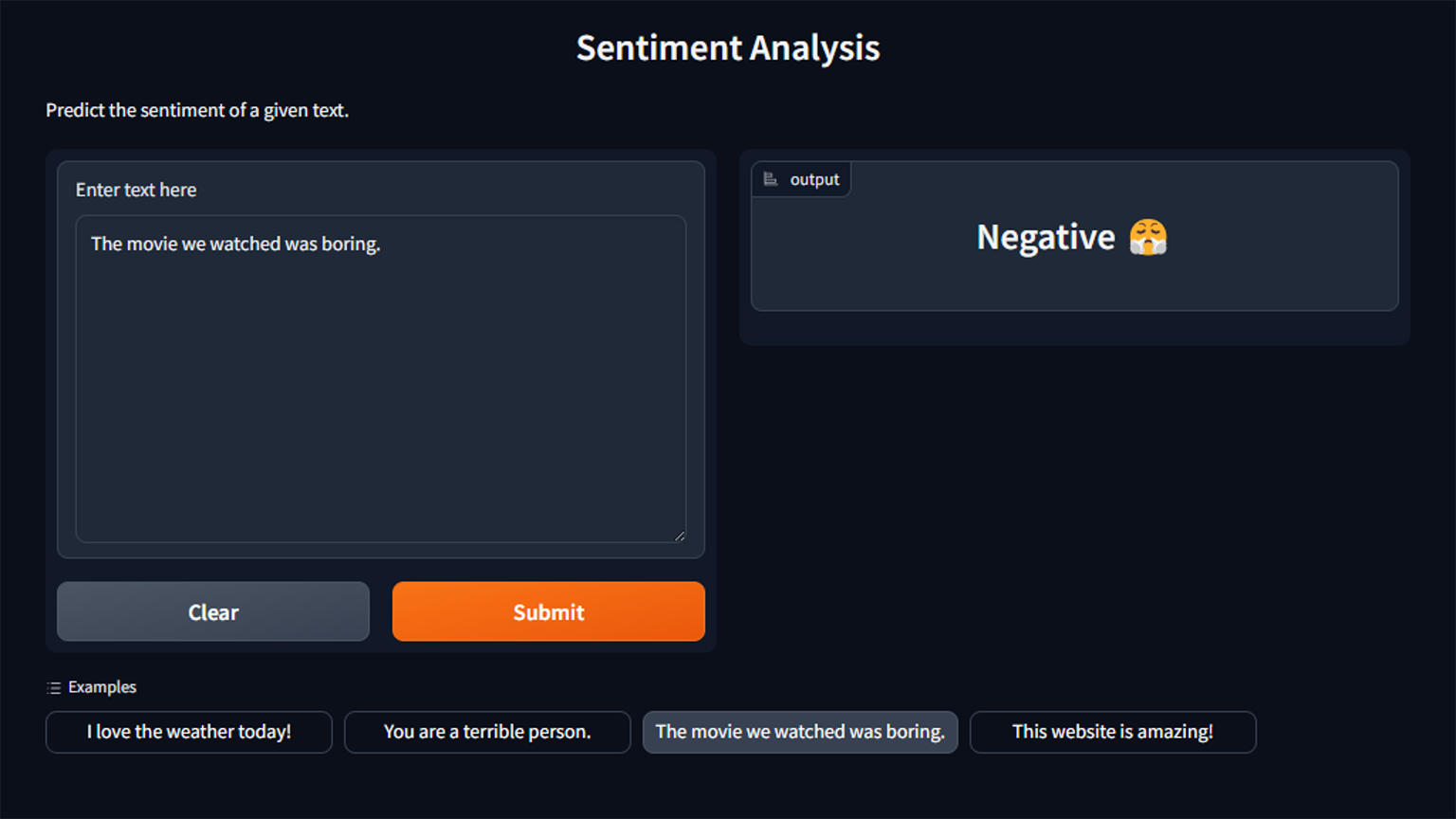
python -m app gui --model <model>
|
| 90 |
```
|
| 91 |
where `<model>` is the path to the trained model. Add the `--share` flag to create a publicly accessible link.
|
|
|
|
| 92 |
|
| 93 |
After running the command, open the link from the terminal in your browser to access the GUI.
|
| 94 |
-
|
| 95 |
-
<!-- Image of the output -->
|
| 96 |
-
<!-- Image of the GUI -->
|
| 97 |
|
| 98 |
|
| 99 |
### Training
|
|
@@ -109,8 +106,7 @@ To see all available options, run:
|
|
| 109 |
```bash
|
| 110 |
python -m app train --help
|
| 111 |
```
|
| 112 |
-
|
| 113 |
-
<!-- Image of the output -->
|
| 114 |
|
| 115 |
|
| 116 |
### Evaluation
|
|
@@ -124,8 +120,7 @@ To see all available options, run:
|
|
| 124 |
```bash
|
| 125 |
python -m app evaluate --help
|
| 126 |
```
|
| 127 |
-
|
| 128 |
-
<!-- Image of the output -->
|
| 129 |
|
| 130 |
|
| 131 |
## Options
|
|
@@ -136,10 +131,10 @@ python -m app evaluate --help
|
|
| 136 |
| sentiment140 | `data/sentiment140.csv` | | [Twitter Sentiment Analysis](https://www.kaggle.com/kazanova/sentiment140) |
|
| 137 |
| amazonreviews | `data/amazonreviews.bz2` | only train is used | [Amazon Product Reviews](https://www.kaggle.com/bittlingmayer/amazonreviews) |
|
| 138 |
| imdb50k | `data/imdb50k.csv` | | [IMDB Movie Reviews](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews) |
|
| 139 |
-
| test | `data/test.csv` |
|
| 140 |
|
| 141 |
-
####
|
| 142 |
-
|
| 143 |
|
| 144 |
|
| 145 |
### Vectorizers
|
|
@@ -164,8 +159,9 @@ The following environment variables can be set to customize the behavior of the
|
|
| 164 |
|
| 165 |
### Architecture
|
| 166 |
The input text is first preprocessed and tokenized using `re` and `spaCy` where:
|
| 167 |
-
-
|
| 168 |
-
-
|
|
|
|
| 169 |
- URLs, email addresses and numbers are removed
|
| 170 |
- Words are converted to lowercase
|
| 171 |
- Lemmatization is performed (words are converted to their base form based on the surrounding context)
|
|
@@ -198,7 +194,6 @@ graph LR
|
|
| 198 |
subgraph Classification
|
| 199 |
direction LR
|
| 200 |
D1[LogisticRegression]
|
| 201 |
-
D2[LinearSVC]
|
| 202 |
end
|
| 203 |
|
| 204 |
Classification --> |sentiment|END:::hidden
|
|
@@ -211,9 +206,10 @@ graph LR
|
|
| 211 |
The following pre-trained models are available for use:
|
| 212 |
| Dataset | Vectorizer | Classifier | Features | Accuracy on test | Accuracy on self | Model |
|
| 213 |
| --- | --- | --- | --- | --- | --- | --- |
|
| 214 |
-
| `imdb50k` | `tfidf` | `LinearRegression` | 20 000 |
|
| 215 |
-
| `sentiment140` | `tfidf` | `LinearRegression` | 20 000 |
|
| 216 |
-
| `amazonreviews` | `tfidf` | `LinearRegression` | 20 000 |
|
|
|
|
| 217 |
|
| 218 |
## License
|
| 219 |
Distributed under the MIT License. See [LICENSE](LICENSE) for more information.
|
|
|
|
| 17 |
---
|
| 18 |
|
| 19 |
|
| 20 |
+
# Sentiment Analysis [](https://tymec-sentiment-analysis.hf.space)
|
| 21 |
|
| 22 |
|
| 23 |
### Table of Contents
|
|
|
|
| 64 |
```bash
|
| 65 |
python -m app --help
|
| 66 |
```
|
| 67 |
+

|
|
|
|
| 68 |
|
| 69 |
|
| 70 |
### Predict
|
|
|
|
| 78 |
```bash
|
| 79 |
echo "I love this movie" | python -m app predict --model <model>
|
| 80 |
```
|
| 81 |
+

|
|
|
|
| 82 |
|
| 83 |
|
| 84 |
### GUI
|
|
|
|
| 87 |
python -m app gui --model <model>
|
| 88 |
```
|
| 89 |
where `<model>` is the path to the trained model. Add the `--share` flag to create a publicly accessible link.
|
| 90 |
+

|
| 91 |
|
| 92 |
After running the command, open the link from the terminal in your browser to access the GUI.
|
| 93 |
+

|
|
|
|
|
|
|
| 94 |
|
| 95 |
|
| 96 |
### Training
|
|
|
|
| 106 |
```bash
|
| 107 |
python -m app train --help
|
| 108 |
```
|
| 109 |
+

|
|
|
|
| 110 |
|
| 111 |
|
| 112 |
### Evaluation
|
|
|
|
| 120 |
```bash
|
| 121 |
python -m app evaluate --help
|
| 122 |
```
|
| 123 |
+

|
|
|
|
| 124 |
|
| 125 |
|
| 126 |
## Options
|
|
|
|
| 131 |
| sentiment140 | `data/sentiment140.csv` | | [Twitter Sentiment Analysis](https://www.kaggle.com/kazanova/sentiment140) |
|
| 132 |
| amazonreviews | `data/amazonreviews.bz2` | only train is used | [Amazon Product Reviews](https://www.kaggle.com/bittlingmayer/amazonreviews) |
|
| 133 |
| imdb50k | `data/imdb50k.csv` | | [IMDB Movie Reviews](https://www.kaggle.com/lakshmi25npathi/imdb-dataset-of-50k-movie-reviews) |
|
| 134 |
+
| test | `data/test.csv` | only used in `evaluate` | [Sentiment Analysis Evaluation Dataset](https://www.kaggle.com/datasets/prishasawhney/sentiment-analysis-evaluation-dataset) |
|
| 135 |
|
| 136 |
+
#### Other
|
| 137 |
+
During text preprocessing, this [slang map](Https://www.kaggle.com/code/nmaguette/up-to-date-list-of-slangs-for-text-preprocessing) is used to convert slang words to their formal form.
|
| 138 |
|
| 139 |
|
| 140 |
### Vectorizers
|
|
|
|
| 159 |
|
| 160 |
### Architecture
|
| 161 |
The input text is first preprocessed and tokenized using `re` and `spaCy` where:
|
| 162 |
+
- Any HTML tags are removed
|
| 163 |
+
- Emojis and slang words are converted to their text form
|
| 164 |
+
- Stop words, punctuation and special characters are removed
|
| 165 |
- URLs, email addresses and numbers are removed
|
| 166 |
- Words are converted to lowercase
|
| 167 |
- Lemmatization is performed (words are converted to their base form based on the surrounding context)
|
|
|
|
| 194 |
subgraph Classification
|
| 195 |
direction LR
|
| 196 |
D1[LogisticRegression]
|
|
|
|
| 197 |
end
|
| 198 |
|
| 199 |
Classification --> |sentiment|END:::hidden
|
|
|
|
| 206 |
The following pre-trained models are available for use:
|
| 207 |
| Dataset | Vectorizer | Classifier | Features | Accuracy on test | Accuracy on self | Model |
|
| 208 |
| --- | --- | --- | --- | --- | --- | --- |
|
| 209 |
+
| `imdb50k` | `tfidf` | `LinearRegression` | 20 000 | 75.63% ± 4.73% | 89.24% ± 0.13% (cv=5) | [Here](models/imdb50k_tfidf_ft20000.pkl) |
|
| 210 |
+
| `sentiment140` | `tfidf` | `LinearRegression` | 20 000 | 75.63% ± 4.73% | 77.32% ± 0.28% (cv=5) | [Here](models/sentiment140_tfidf_ft20000.pkl) |
|
| 211 |
+
| `amazonreviews` | `tfidf` | `LinearRegression` | 20 000 | 65.49% ± 7.03% | 90.08% ± 0.00% (cv=1) | [Here](models/amazonreviews_tfidf_ft20000.pkl) |
|
| 212 |
+
|
| 213 |
|
| 214 |
## License
|
| 215 |
Distributed under the MIT License. See [LICENSE](LICENSE) for more information.
|
assets/evaluate.png
ADDED

|
assets/gui.png
ADDED

|
assets/help.png
ADDED
|
assets/predict.png
ADDED

|
assets/space.png
ADDED
|
assets/train.png
ADDED

|