Spaces:
Sleeping



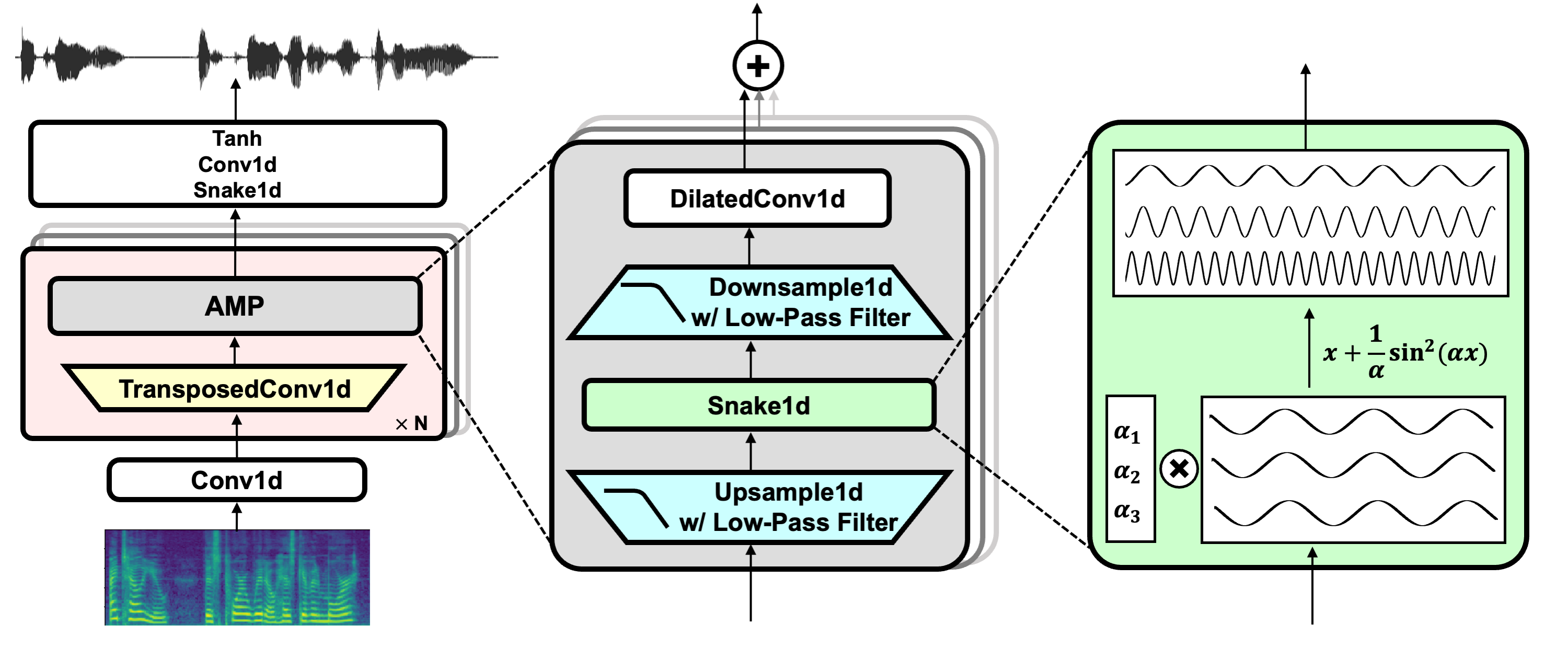
BigVGAN: A Universal Neural Vocoder with Large-Scale Training
Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, Sungroh Yoon
Paper
Audio demo
Installation
Clone the repository and install dependencies.
# the codebase has been tested on Python 3.8 / 3.10 with PyTorch 1.12.1 / 1.13 conda binaries
git clone https://github.com/NVIDIA/BigVGAN
pip install -r requirements.txt
Create symbolic link to the root of the dataset. The codebase uses filelist with the relative path from the dataset. Below are the example commands for LibriTTS dataset.
cd LibriTTS && \
ln -s /path/to/your/LibriTTS/train-clean-100 train-clean-100 && \
ln -s /path/to/your/LibriTTS/train-clean-360 train-clean-360 && \
ln -s /path/to/your/LibriTTS/train-other-500 train-other-500 && \
ln -s /path/to/your/LibriTTS/dev-clean dev-clean && \
ln -s /path/to/your/LibriTTS/dev-other dev-other && \
ln -s /path/to/your/LibriTTS/test-clean test-clean && \
ln -s /path/to/your/LibriTTS/test-other test-other && \
cd ..
Training
Train BigVGAN model. Below is an example command for training BigVGAN using LibriTTS dataset at 24kHz with a full 100-band mel spectrogram as input.
python train.py \
--config configs/bigvgan_24khz_100band.json \
--input_wavs_dir LibriTTS \
--input_training_file LibriTTS/train-full.txt \
--input_validation_file LibriTTS/val-full.txt \
--list_input_unseen_wavs_dir LibriTTS LibriTTS \
--list_input_unseen_validation_file LibriTTS/dev-clean.txt LibriTTS/dev-other.txt \
--checkpoint_path exp/bigvgan
Synthesis
Synthesize from BigVGAN model. Below is an example command for generating audio from the model.
It computes mel spectrograms using wav files from --input_wavs_dir and saves the generated audio to --output_dir.
python inference.py \
--checkpoint_file exp/bigvgan/g_05000000 \
--input_wavs_dir /path/to/your/input_wav \
--output_dir /path/to/your/output_wav
inference_e2e.py supports synthesis directly from the mel spectrogram saved in .npy format, with shapes [1, channel, frame] or [channel, frame].
It loads mel spectrograms from --input_mels_dir and saves the generated audio to --output_dir.
Make sure that the STFT hyperparameters for mel spectrogram are the same as the model, which are defined in config.json of the corresponding model.
python inference_e2e.py \
--checkpoint_file exp/bigvgan/g_05000000 \
--input_mels_dir /path/to/your/input_mel \
--output_dir /path/to/your/output_wav
Pretrained Models
We provide the pretrained models. One can download the checkpoints of generator (e.g., g_05000000) and discriminator (e.g., do_05000000) within the listed folders.
| Folder Name | Sampling Rate | Mel band | fmax | Params. | Dataset | Fine-Tuned |
|---|---|---|---|---|---|---|
| bigvgan_24khz_100band | 24 kHz | 100 | 12000 | 112M | LibriTTS | No |
| bigvgan_base_24khz_100band | 24 kHz | 100 | 12000 | 14M | LibriTTS | No |
| bigvgan_22khz_80band | 22 kHz | 80 | 8000 | 112M | LibriTTS + VCTK + LJSpeech | No |
| bigvgan_base_22khz_80band | 22 kHz | 80 | 8000 | 14M | LibriTTS + VCTK + LJSpeech | No |
The paper results are based on 24kHz BigVGAN models trained on LibriTTS dataset.
We also provide 22kHz BigVGAN models with band-limited setup (i.e., fmax=8000) for TTS applications.
Note that, the latest checkpoints use snakebeta activation with log scale parameterization, which have the best overall quality.
TODO
Current codebase only provides a plain PyTorch implementation for the filtered nonlinearity. We are working on a fast CUDA kernel implementation, which will be released in the future.
References
HiFi-GAN (for generator and multi-period discriminator)
Snake (for periodic activation)
Alias-free-torch (for anti-aliasing)
Julius (for low-pass filter)
UnivNet (for multi-resolution discriminator)