Deep Neural Networks (DNNs) have achieved excellent performance in various fields. However, DNNs’ vulnerability to
Adversarial Examples (AE) hinders their deployments to safety-critical applications. In this paper, we present BEYOND,
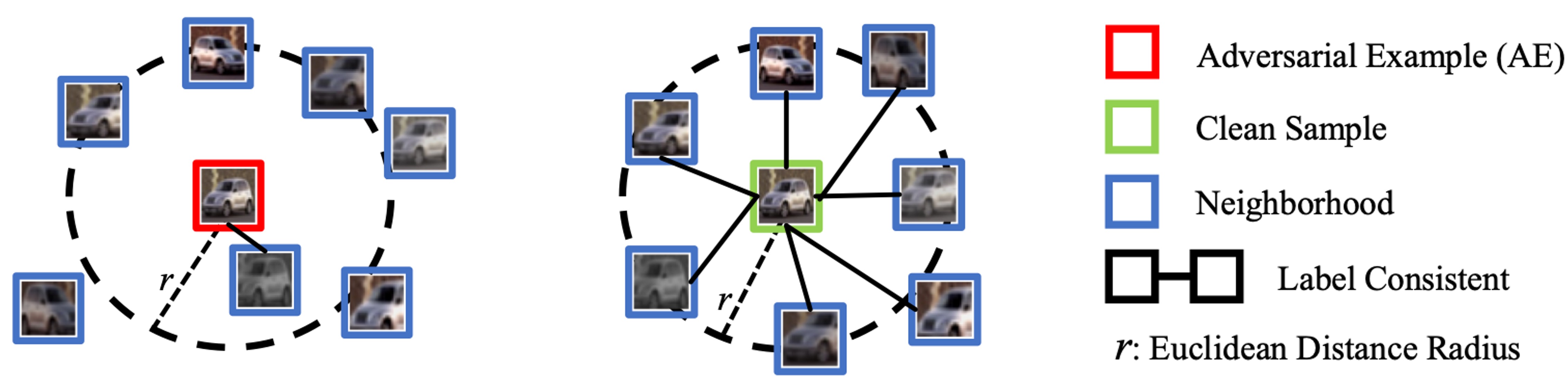
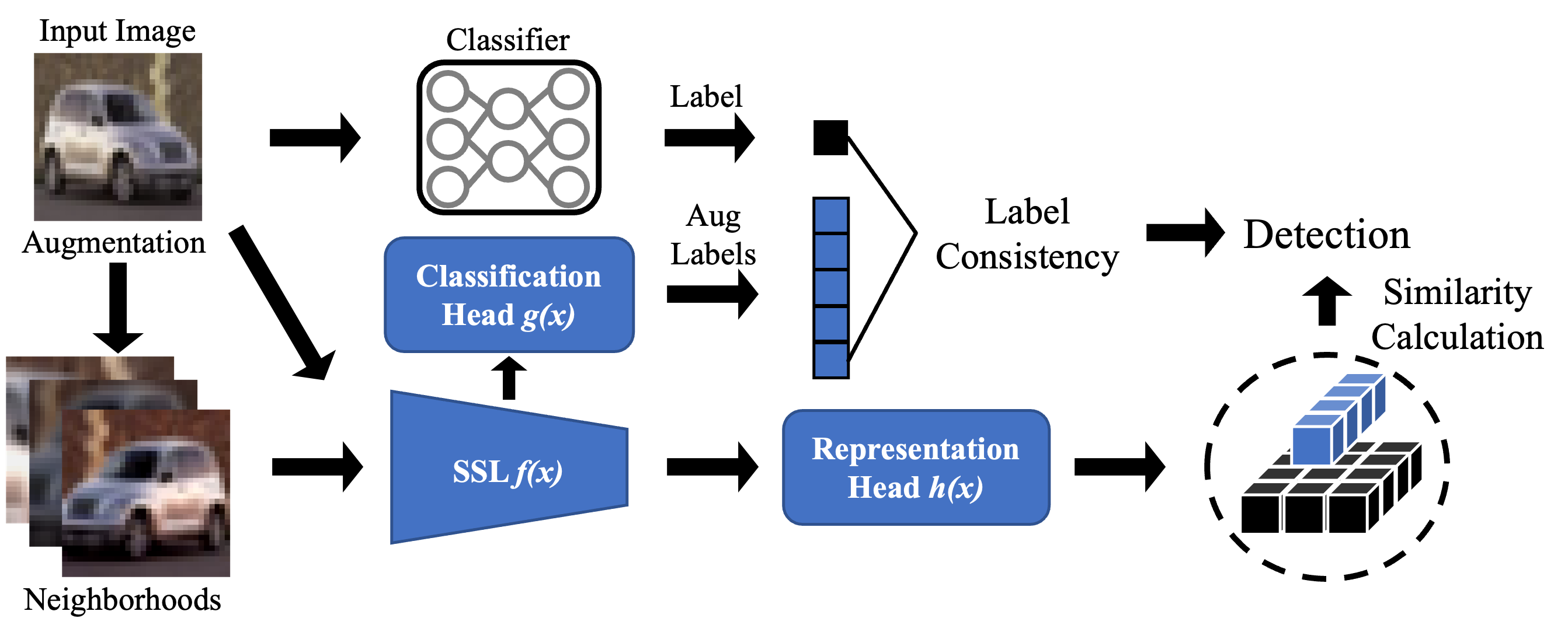
an innovative AE detection frameworkdesigned for reliable predictions. BEYOND identifies AEs by distinguishing the AE’s
abnormal relation with its augmented versions, i.e. neighbors, from two prospects: representation similarity and label
consistency. An off-the-shelf Self-Supervised Learning (SSL) model is used to extract the representation and predict the
label for its highly informative representation capacity compared to supervised learning models. We found clean samples
maintain a high degree of representation similarity and label consistency relative to their neighbors, in contrast to AEs
which exhibit significant discrepancies. We explain this obser vation and show that leveraging this discrepancy BEYOND can
accurately detect AEs. Additionally, we develop a rigorous justification for the effectiveness of BEYOND. Furthermore, as a
plug-and-play model, BEYOND can easily cooperate with the Adversarial Trained Classifier (ATC), achieving state-of-the-art
(SOTA) robustness accuracy. Experimental results show that BEYOND outperforms baselines by a large margin, especially under
adaptive attacks. Empowered by the robust relationship built on SSL, we found that BEYOND outperforms baselines in terms
of both detection ability and speed.