

Merge pull request #3 from argilla-io/feat/avoid-usage-withou-argilla
Browse files
README.md
CHANGED
|
@@ -32,7 +32,7 @@ hf_oauth_scopes:
|
|
| 32 |
<img alt="CI" src="https://img.shields.io/pypi/v/synthetic-dataset-generator.svg?style=flat-round&logo=pypi&logoColor=white">
|
| 33 |
</a>
|
| 34 |
<a href="https://pepy.tech/project/synthetic-dataset-generator">
|
| 35 |
-
<img alt="CI" src="https://static.pepy.tech/personalized-badge/
|
| 36 |
</a>
|
| 37 |
<a href="https://huggingface.co/spaces/argilla/synthetic-data-generator?duplicate=true">
|
| 38 |
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg"/>
|
|
@@ -80,16 +80,25 @@ pip install synthetic-dataset-generator
|
|
| 80 |
|
| 81 |
### Environment Variables
|
| 82 |
|
| 83 |
-
- `HF_TOKEN`: Your Hugging Face token to push your datasets to the Hugging Face Hub and run Inference Endpoints Requests. You can get one [here](https://huggingface.co/settings/tokens/new?ownUserPermissions=repo.content.read&ownUserPermissions=repo.write&globalPermissions=inference.serverless.write&tokenType=fineGrained).
|
|
|
|
|
|
|
|
|
|
| 84 |
- `ARGILLA_API_KEY`: Your Argilla API key to push your datasets to Argilla.
|
| 85 |
- `ARGILLA_API_URL`: Your Argilla API URL to push your datasets to Argilla.
|
| 86 |
|
| 87 |
-
##
|
| 88 |
|
| 89 |
```bash
|
| 90 |
python app.py
|
| 91 |
```
|
| 92 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 93 |
## Custom synthetic data generation?
|
| 94 |
|
| 95 |
Each pipeline is based on distilabel, so you can easily change the LLM or the pipeline steps.
|
|
|
|
| 32 |
<img alt="CI" src="https://img.shields.io/pypi/v/synthetic-dataset-generator.svg?style=flat-round&logo=pypi&logoColor=white">
|
| 33 |
</a>
|
| 34 |
<a href="https://pepy.tech/project/synthetic-dataset-generator">
|
| 35 |
+
<img alt="CI" src="https://static.pepy.tech/personalized-badge/synthetic-dataset-generator?period=month&units=international_system&left_color=grey&right_color=blue&left_text=pypi%20downloads/month">
|
| 36 |
</a>
|
| 37 |
<a href="https://huggingface.co/spaces/argilla/synthetic-data-generator?duplicate=true">
|
| 38 |
<img src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-sm.svg"/>
|
|
|
|
| 80 |
|
| 81 |
### Environment Variables
|
| 82 |
|
| 83 |
+
- `HF_TOKEN`: Your Hugging Face token to push your datasets to the Hugging Face Hub and run *Free* Inference Endpoints Requests. You can get one [here](https://huggingface.co/settings/tokens/new?ownUserPermissions=repo.content.read&ownUserPermissions=repo.write&globalPermissions=inference.serverless.write&tokenType=fineGrained).
|
| 84 |
+
|
| 85 |
+
Optionally, you can also push your datasets to Argilla for further curation by setting the following environment variables:
|
| 86 |
+
|
| 87 |
- `ARGILLA_API_KEY`: Your Argilla API key to push your datasets to Argilla.
|
| 88 |
- `ARGILLA_API_URL`: Your Argilla API URL to push your datasets to Argilla.
|
| 89 |
|
| 90 |
+
## Quickstart
|
| 91 |
|
| 92 |
```bash
|
| 93 |
python app.py
|
| 94 |
```
|
| 95 |
|
| 96 |
+
### Argilla integration
|
| 97 |
+
|
| 98 |
+
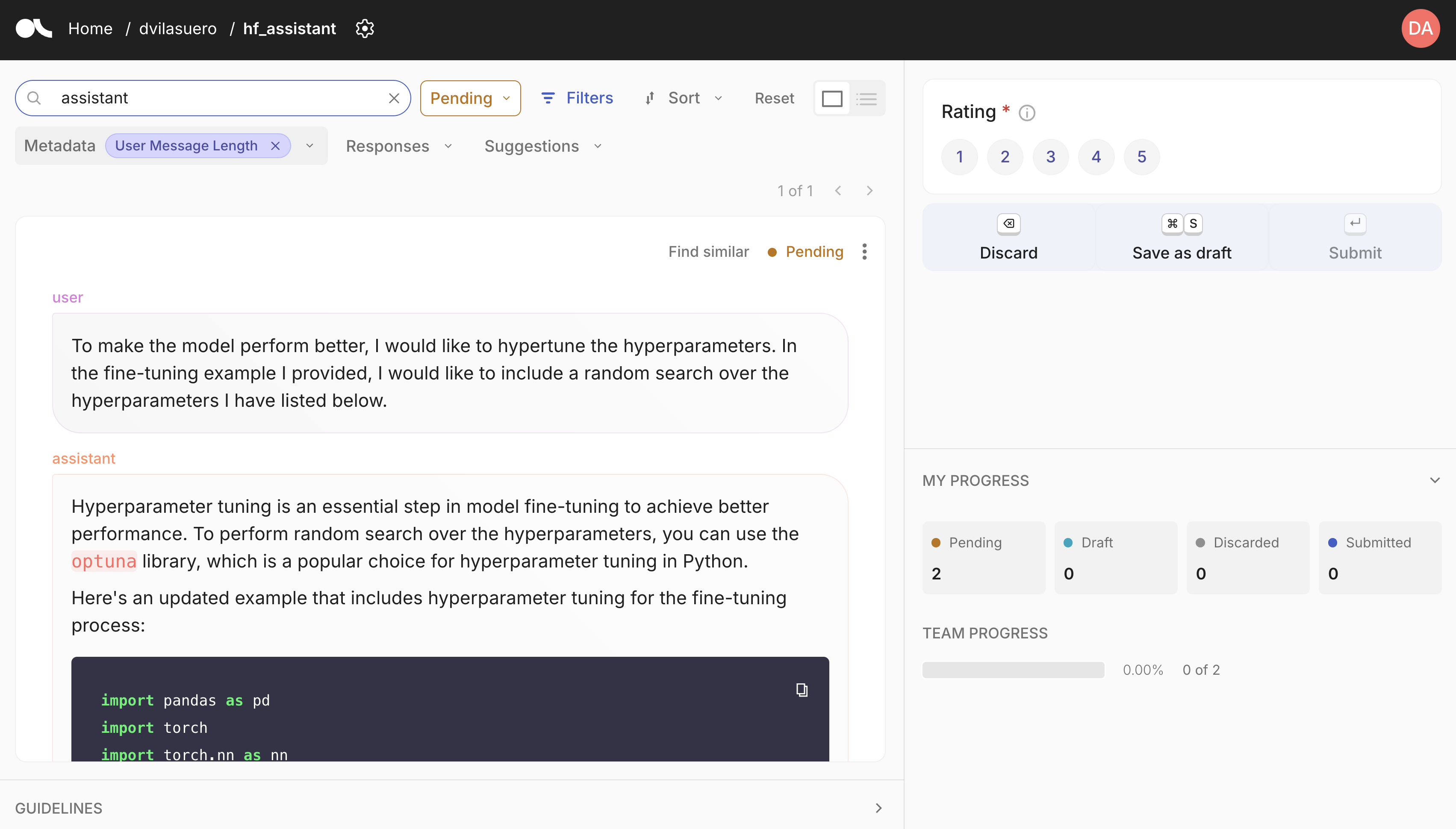
Argilla is a open source tool for data curation. It allows you to annotate and review datasets, and push curated datasets to the Hugging Face Hub. You can easily get started with Argilla by following the [quickstart guide](https://docs.argilla.io/latest/getting_started/quickstart/).
|
| 99 |
+
|
| 100 |
+
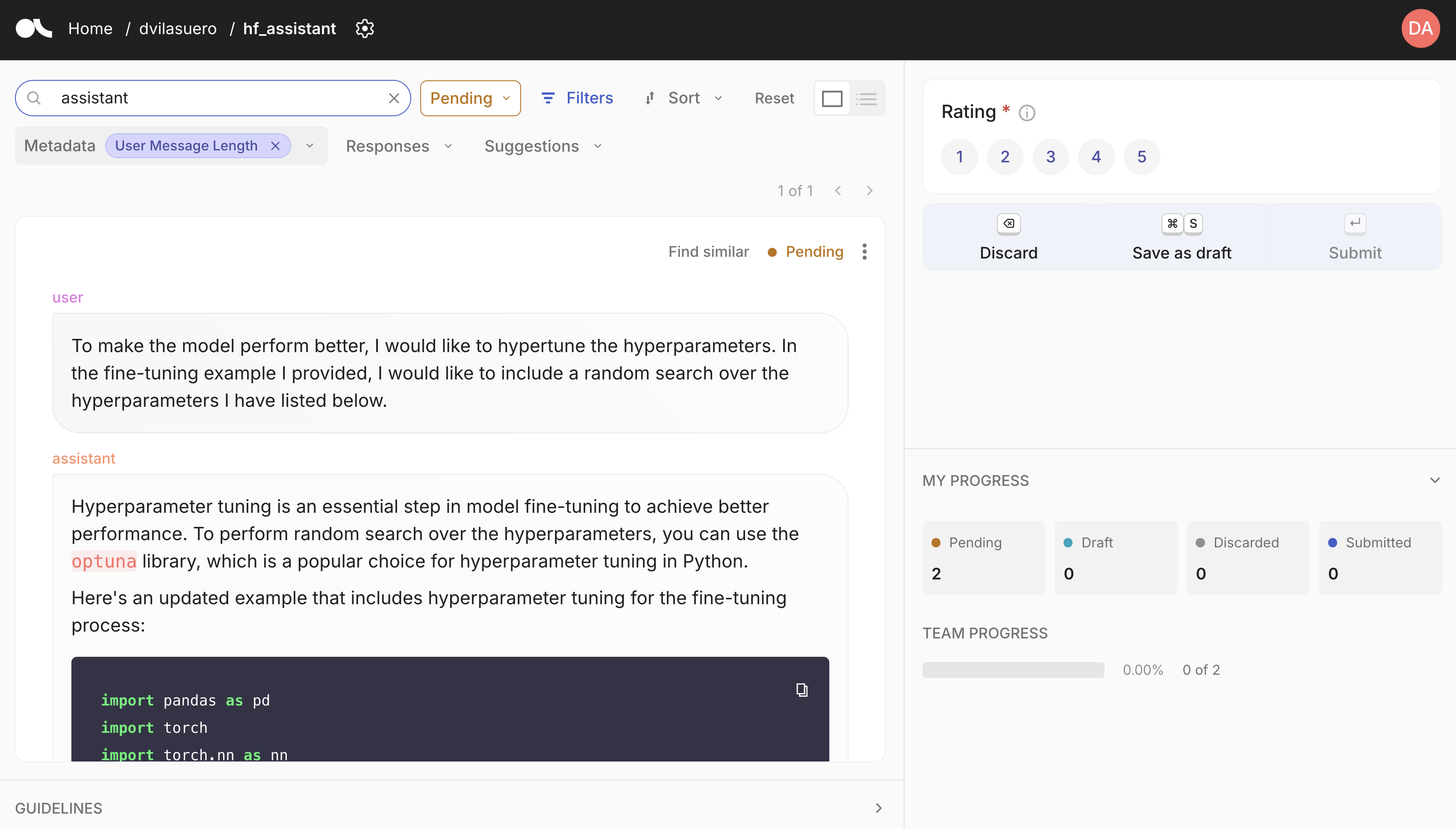
|
| 101 |
+
|
| 102 |
## Custom synthetic data generation?
|
| 103 |
|
| 104 |
Each pipeline is based on distilabel, so you can easily change the LLM or the pipeline steps.
|
assets/argilla.png
ADDED
|
src/distilabel_dataset_generator/apps/base.py
CHANGED
|
@@ -475,6 +475,27 @@ def get_success_message_row() -> gr.Markdown:
|
|
| 475 |
|
| 476 |
def show_success_message(org_name, repo_name) -> gr.Markdown:
|
| 477 |
client = get_argilla_client()
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 478 |
argilla_api_url = client.api_url
|
| 479 |
return gr.Markdown(
|
| 480 |
value=f"""
|
|
|
|
| 475 |
|
| 476 |
def show_success_message(org_name, repo_name) -> gr.Markdown:
|
| 477 |
client = get_argilla_client()
|
| 478 |
+
if client is None:
|
| 479 |
+
return gr.Markdown(
|
| 480 |
+
value="""
|
| 481 |
+
<div style="padding: 1em; background-color: #e6f3e6; border-radius: 5px; margin-top: 1em;">
|
| 482 |
+
<h3 style="color: #2e7d32; margin: 0;">Dataset Published Successfully!</h3>
|
| 483 |
+
<p style="margin-top: 0.5em;">
|
| 484 |
+
The generated dataset is in the right format for fine-tuning with TRL, AutoTrain, or other frameworks. Your dataset is now available at:
|
| 485 |
+
<a href="https://huggingface.co/datasets/{org_name}/{repo_name}" target="_blank" style="color: #1565c0; text-decoration: none;">
|
| 486 |
+
https://huggingface.co/datasets/{org_name}/{repo_name}
|
| 487 |
+
</a>
|
| 488 |
+
</p>
|
| 489 |
+
<p style="margin-top: 1em; font-size: 0.9em; color: #333;">
|
| 490 |
+
By configuring an `ARGILLA_API_URL` and `ARGILLA_API_KEY` you can curate the dataset in Argilla.
|
| 491 |
+
Unfamiliar with Argilla? Here are some docs to help you get started:
|
| 492 |
+
<br>• <a href="https://docs.argilla.io/latest/getting_started/quickstart/" target="_blank">How to get started with Argilla</a>
|
| 493 |
+
<br>• <a href="https://docs.argilla.io/latest/how_to_guides/annotate/" target="_blank">How to curate data in Argilla</a>
|
| 494 |
+
<br>• <a href="https://docs.argilla.io/latest/how_to_guides/import_export/" target="_blank">How to export data once you have reviewed the dataset</a>
|
| 495 |
+
</p>
|
| 496 |
+
</div>
|
| 497 |
+
"""
|
| 498 |
+
)
|
| 499 |
argilla_api_url = client.api_url
|
| 500 |
return gr.Markdown(
|
| 501 |
value=f"""
|
src/distilabel_dataset_generator/apps/eval.py
CHANGED
|
@@ -39,9 +39,9 @@ from src.distilabel_dataset_generator.utils import (
|
|
| 39 |
extract_column_names,
|
| 40 |
get_argilla_client,
|
| 41 |
get_org_dropdown,
|
|
|
|
| 42 |
process_columns,
|
| 43 |
swap_visibility,
|
| 44 |
-
pad_or_truncate_list,
|
| 45 |
)
|
| 46 |
|
| 47 |
|
|
@@ -334,8 +334,10 @@ def push_dataset(
|
|
| 334 |
push_dataset_to_hub(dataframe, org_name, repo_name, oauth_token, private)
|
| 335 |
try:
|
| 336 |
progress(0.1, desc="Setting up user and workspace")
|
| 337 |
-
client = get_argilla_client()
|
| 338 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
|
|
|
|
|
|
|
|
|
| 339 |
if eval_type == "ultrafeedback":
|
| 340 |
num_generations = len((dataframe["generations"][0]))
|
| 341 |
fields = [
|
|
@@ -580,6 +582,7 @@ def push_dataset(
|
|
| 580 |
def show_pipeline_code_visibility():
|
| 581 |
return {pipeline_code_ui: gr.Accordion(visible=True)}
|
| 582 |
|
|
|
|
| 583 |
def hide_pipeline_code_visibility():
|
| 584 |
return {pipeline_code_ui: gr.Accordion(visible=False)}
|
| 585 |
|
|
@@ -708,15 +711,15 @@ with gr.Blocks() as app:
|
|
| 708 |
visible=False,
|
| 709 |
) as pipeline_code_ui:
|
| 710 |
code = generate_pipeline_code(
|
| 711 |
-
|
| 712 |
-
|
| 713 |
-
|
| 714 |
-
|
| 715 |
-
|
| 716 |
-
|
| 717 |
-
|
| 718 |
-
|
| 719 |
-
|
| 720 |
pipeline_code = gr.Code(
|
| 721 |
value=code,
|
| 722 |
language="python",
|
|
|
|
| 39 |
extract_column_names,
|
| 40 |
get_argilla_client,
|
| 41 |
get_org_dropdown,
|
| 42 |
+
pad_or_truncate_list,
|
| 43 |
process_columns,
|
| 44 |
swap_visibility,
|
|
|
|
| 45 |
)
|
| 46 |
|
| 47 |
|
|
|
|
| 334 |
push_dataset_to_hub(dataframe, org_name, repo_name, oauth_token, private)
|
| 335 |
try:
|
| 336 |
progress(0.1, desc="Setting up user and workspace")
|
|
|
|
| 337 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
| 338 |
+
client = get_argilla_client()
|
| 339 |
+
if client is None:
|
| 340 |
+
return ""
|
| 341 |
if eval_type == "ultrafeedback":
|
| 342 |
num_generations = len((dataframe["generations"][0]))
|
| 343 |
fields = [
|
|
|
|
| 582 |
def show_pipeline_code_visibility():
|
| 583 |
return {pipeline_code_ui: gr.Accordion(visible=True)}
|
| 584 |
|
| 585 |
+
|
| 586 |
def hide_pipeline_code_visibility():
|
| 587 |
return {pipeline_code_ui: gr.Accordion(visible=False)}
|
| 588 |
|
|
|
|
| 711 |
visible=False,
|
| 712 |
) as pipeline_code_ui:
|
| 713 |
code = generate_pipeline_code(
|
| 714 |
+
repo_id=search_in.value,
|
| 715 |
+
aspects=aspects_instruction_response.value,
|
| 716 |
+
instruction_column=instruction_instruction_response,
|
| 717 |
+
response_columns=response_instruction_response,
|
| 718 |
+
prompt_template=prompt_template.value,
|
| 719 |
+
structured_output=structured_output.value,
|
| 720 |
+
num_rows=num_rows.value,
|
| 721 |
+
eval_type=eval_type.value,
|
| 722 |
+
)
|
| 723 |
pipeline_code = gr.Code(
|
| 724 |
value=code,
|
| 725 |
language="python",
|
src/distilabel_dataset_generator/apps/sft.py
CHANGED
|
@@ -220,8 +220,10 @@ def push_dataset(
|
|
| 220 |
push_dataset_to_hub(dataframe, org_name, repo_name, oauth_token, private)
|
| 221 |
try:
|
| 222 |
progress(0.1, desc="Setting up user and workspace")
|
| 223 |
-
client = get_argilla_client()
|
| 224 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
|
|
|
|
|
|
|
|
|
| 225 |
if "messages" in dataframe.columns:
|
| 226 |
settings = rg.Settings(
|
| 227 |
fields=[
|
|
|
|
| 220 |
push_dataset_to_hub(dataframe, org_name, repo_name, oauth_token, private)
|
| 221 |
try:
|
| 222 |
progress(0.1, desc="Setting up user and workspace")
|
|
|
|
| 223 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
| 224 |
+
client = get_argilla_client()
|
| 225 |
+
if client is None:
|
| 226 |
+
return ""
|
| 227 |
if "messages" in dataframe.columns:
|
| 228 |
settings = rg.Settings(
|
| 229 |
fields=[
|
src/distilabel_dataset_generator/apps/textcat.py
CHANGED
|
@@ -58,7 +58,10 @@ def generate_system_prompt(dataset_description, temperature, progress=gr.Progres
|
|
| 58 |
labels = data["labels"]
|
| 59 |
return system_prompt, labels
|
| 60 |
|
| 61 |
-
|
|
|
|
|
|
|
|
|
|
| 62 |
dataframe = generate_dataset(
|
| 63 |
system_prompt=system_prompt,
|
| 64 |
difficulty=difficulty,
|
|
@@ -138,11 +141,7 @@ def generate_dataset(
|
|
| 138 |
# create final dataset
|
| 139 |
distiset_results = []
|
| 140 |
for result in labeller_results:
|
| 141 |
-
record = {
|
| 142 |
-
key: result[key]
|
| 143 |
-
for key in ["labels", "text"]
|
| 144 |
-
if key in result
|
| 145 |
-
}
|
| 146 |
distiset_results.append(record)
|
| 147 |
|
| 148 |
dataframe = pd.DataFrame(distiset_results)
|
|
@@ -212,13 +211,16 @@ def push_dataset(
|
|
| 212 |
push_dataset_to_hub(
|
| 213 |
dataframe, org_name, repo_name, num_labels, labels, oauth_token, private
|
| 214 |
)
|
|
|
|
| 215 |
dataframe = dataframe[
|
| 216 |
(dataframe["text"].str.strip() != "") & (dataframe["text"].notna())
|
| 217 |
]
|
| 218 |
try:
|
| 219 |
progress(0.1, desc="Setting up user and workspace")
|
| 220 |
-
client = get_argilla_client()
|
| 221 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
|
|
|
|
|
|
|
|
|
| 222 |
labels = get_preprocess_labels(labels)
|
| 223 |
settings = rg.Settings(
|
| 224 |
fields=[
|
|
|
|
| 58 |
labels = data["labels"]
|
| 59 |
return system_prompt, labels
|
| 60 |
|
| 61 |
+
|
| 62 |
+
def generate_sample_dataset(
|
| 63 |
+
system_prompt, difficulty, clarity, labels, num_labels, progress=gr.Progress()
|
| 64 |
+
):
|
| 65 |
dataframe = generate_dataset(
|
| 66 |
system_prompt=system_prompt,
|
| 67 |
difficulty=difficulty,
|
|
|
|
| 141 |
# create final dataset
|
| 142 |
distiset_results = []
|
| 143 |
for result in labeller_results:
|
| 144 |
+
record = {key: result[key] for key in ["labels", "text"] if key in result}
|
|
|
|
|
|
|
|
|
|
|
|
|
| 145 |
distiset_results.append(record)
|
| 146 |
|
| 147 |
dataframe = pd.DataFrame(distiset_results)
|
|
|
|
| 211 |
push_dataset_to_hub(
|
| 212 |
dataframe, org_name, repo_name, num_labels, labels, oauth_token, private
|
| 213 |
)
|
| 214 |
+
|
| 215 |
dataframe = dataframe[
|
| 216 |
(dataframe["text"].str.strip() != "") & (dataframe["text"].notna())
|
| 217 |
]
|
| 218 |
try:
|
| 219 |
progress(0.1, desc="Setting up user and workspace")
|
|
|
|
| 220 |
hf_user = HfApi().whoami(token=oauth_token.token)["name"]
|
| 221 |
+
client = get_argilla_client()
|
| 222 |
+
if client is None:
|
| 223 |
+
return ""
|
| 224 |
labels = get_preprocess_labels(labels)
|
| 225 |
settings = rg.Settings(
|
| 226 |
fields=[
|