
Christopher Capobianco
commited on
Commit
·
5b37a61
1
Parent(s):
fc8e190
Add Music LSTM Model Visualization
Browse files- assets/music_lstm.png +0 -0
- projects/06_Generative_Music.py +4 -0
assets/music_lstm.png
ADDED
|
projects/06_Generative_Music.py
CHANGED
|
@@ -6,6 +6,9 @@ import numpy as np
|
|
| 6 |
from music21 import instrument, note, stream, chord
|
| 7 |
from keras.saving import load_model
|
| 8 |
from scipy.io import wavfile
|
|
|
|
|
|
|
|
|
|
| 9 |
|
| 10 |
@st.cache_resource
|
| 11 |
def load_notes():
|
|
@@ -119,6 +122,7 @@ st.markdown("The data that our model will be trained on will consist of piano MI
|
|
| 119 |
st.markdown("The sequence of notes and chords from the MIDI files are broken down into increments of 100, which are used to predict the next note or chord.")
|
| 120 |
st.markdown("#### Model")
|
| 121 |
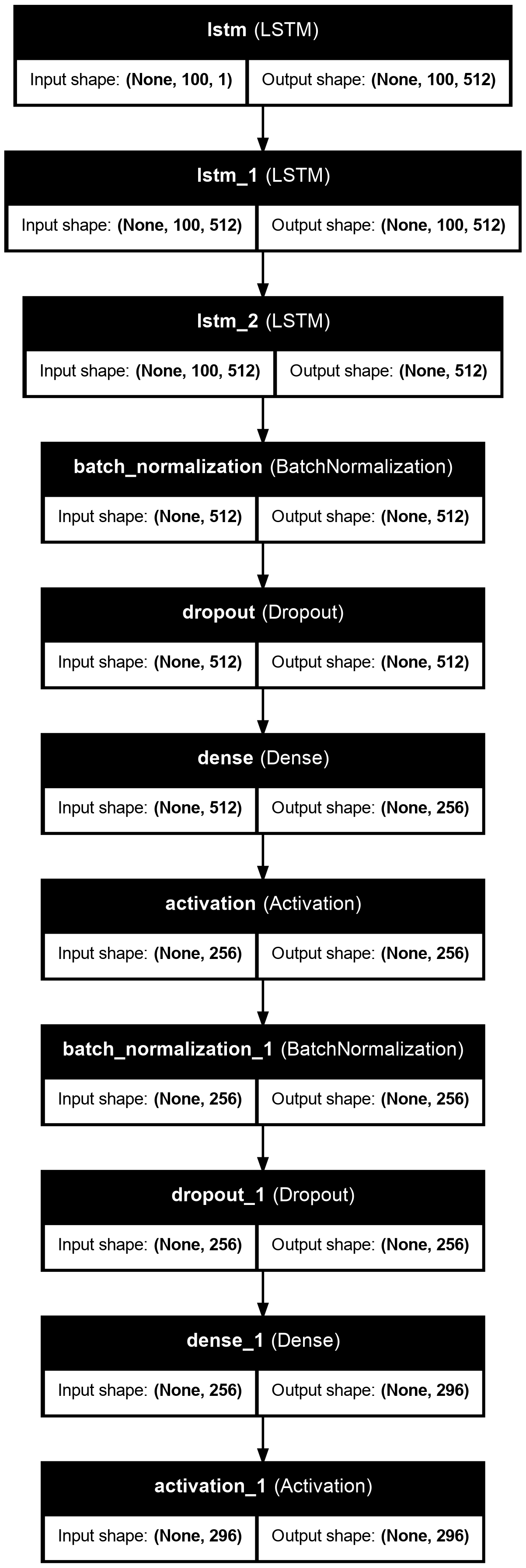
st.markdown("For this project we will use a network consisting of three LSTM layers, three Dropout layers, two Dense layers and one activation layer.")
|
|
|
|
| 122 |
st.markdown("It may be possible to improve this model by playing around with the the structure of the network, or adding new categories (e.g. varying note duration, rest periods between notes, etc). However, to achieve satisfying results with more classes we would also have to increase the depth of the LSTM network.")
|
| 123 |
st.markdown("*This is based off the tutorial by Sigurður Skúli [How to Generate Music using a LSTM Neural Network in Keras](https://towardsdatascience.com/how-to-generate-music-using-a-lstm-neural-network-in-keras-68786834d4c5)*")
|
| 124 |
st.divider()
|
|
|
|
| 6 |
from music21 import instrument, note, stream, chord
|
| 7 |
from keras.saving import load_model
|
| 8 |
from scipy.io import wavfile
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
lstm = Image.open("assets/music_lstm.png")
|
| 12 |
|
| 13 |
@st.cache_resource
|
| 14 |
def load_notes():
|
|
|
|
| 122 |
st.markdown("The sequence of notes and chords from the MIDI files are broken down into increments of 100, which are used to predict the next note or chord.")
|
| 123 |
st.markdown("#### Model")
|
| 124 |
st.markdown("For this project we will use a network consisting of three LSTM layers, three Dropout layers, two Dense layers and one activation layer.")
|
| 125 |
+
st.image(lstm, caption = 'Music Generation Model', height = 250)
|
| 126 |
st.markdown("It may be possible to improve this model by playing around with the the structure of the network, or adding new categories (e.g. varying note duration, rest periods between notes, etc). However, to achieve satisfying results with more classes we would also have to increase the depth of the LSTM network.")
|
| 127 |
st.markdown("*This is based off the tutorial by Sigurður Skúli [How to Generate Music using a LSTM Neural Network in Keras](https://towardsdatascience.com/how-to-generate-music-using-a-lstm-neural-network-in-keras-68786834d4c5)*")
|
| 128 |
st.divider()
|