Spaces:
Runtime error

Runtime error
Mariusz Kossakowski
commited on
Commit
•
9f7f573
1
Parent(s):
739b527
Add more datasets
Browse files
clarin_datasets/cst_wikinews_dataset.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from datasets import load_dataset
|
| 3 |
+
import streamlit as st
|
| 4 |
+
|
| 5 |
+
from clarin_datasets.dataset_to_show import DatasetToShow
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class CSTWikinewsDataset(DatasetToShow):
|
| 9 |
+
def __init__(self):
|
| 10 |
+
DatasetToShow.__init__(self)
|
| 11 |
+
self.dataset_name = "clarin-pl/cst-wikinews"
|
| 12 |
+
self.description = """
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def load_data(self):
|
| 17 |
+
DatasetToShow.load_data(self)
|
| 18 |
+
|
| 19 |
+
def show_dataset(self):
|
| 20 |
+
pass
|
clarin_datasets/kpwr_ner_datasets.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from datasets import load_dataset
|
| 2 |
+
import streamlit as st
|
| 3 |
+
|
| 4 |
+
from clarin_datasets.dataset_to_show import DatasetToShow
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class KpwrNerDataset(DatasetToShow):
|
| 8 |
+
|
| 9 |
+
def __init__(self):
|
| 10 |
+
DatasetToShow.__init__(self)
|
| 11 |
+
self.dataset_name = "clarin-pl/kpwr-ner"
|
| 12 |
+
self.description = """
|
| 13 |
+
KPWR-NER is a part the Polish Corpus of Wrocław University of Technology (Korpus Języka
|
| 14 |
+
Polskiego Politechniki Wrocławskiej). Its objective is named entity recognition for fine-grained categories
|
| 15 |
+
of entities. It is the ‘n82’ version of the KPWr, which means that number of classes is restricted to 82 (
|
| 16 |
+
originally 120). During corpus creation, texts were annotated by humans from various sources, covering many
|
| 17 |
+
domains and genres.
|
| 18 |
+
|
| 19 |
+
Tasks (input, output and metrics)
|
| 20 |
+
Named entity recognition (NER) - tagging entities in text with their corresponding type.
|
| 21 |
+
|
| 22 |
+
Input ('tokens' column): sequence of tokens
|
| 23 |
+
|
| 24 |
+
Output ('ner' column): sequence of predicted tokens’ classes in BIO notation (82 possible classes, described
|
| 25 |
+
in detail in the annotation guidelines)
|
| 26 |
+
|
| 27 |
+
example:
|
| 28 |
+
|
| 29 |
+
[‘Roboty’, ‘mają’, ‘kilkanaście’, ‘lat’, ‘i’, ‘pochodzą’, ‘z’, ‘USA’, ‘,’, ‘Wysokie’, ‘napięcie’, ‘jest’,
|
| 30 |
+
‘dużo’, ‘młodsze’, ‘,’, ‘powstało’, ‘w’, ‘Niemczech’, ‘.’] → [‘B-nam_pro_title’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’,
|
| 31 |
+
‘O’, ‘B-nam_loc_gpe_country’, ‘O’, ‘B-nam_pro_title’, ‘I-nam_pro_title’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’, ‘O’,
|
| 32 |
+
‘B-nam_loc_gpe_country’, ‘O’]
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def load_data(self):
|
| 36 |
+
raw_dataset = load_dataset(self.dataset_name)
|
| 37 |
+
self.data_dict = {
|
| 38 |
+
subset: raw_dataset[subset].to_pandas()
|
| 39 |
+
for subset in self.subsets
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
def show_dataset(self):
|
| 43 |
+
header = st.container()
|
| 44 |
+
description = st.container()
|
| 45 |
+
dataframe_head = st.container()
|
| 46 |
+
|
| 47 |
+
with header:
|
| 48 |
+
st.title(self.dataset_name)
|
| 49 |
+
|
| 50 |
+
with description:
|
| 51 |
+
st.header("Dataset description")
|
| 52 |
+
st.write(self.description)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
clarin_datasets/nkjp_pos_dataset.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from datasets import load_dataset
|
| 3 |
+
import streamlit as st
|
| 4 |
+
|
| 5 |
+
from clarin_datasets.dataset_to_show import DatasetToShow
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class NkjpPosDataset(DatasetToShow):
|
| 9 |
+
def __init__(self):
|
| 10 |
+
DatasetToShow.__init__(self)
|
| 11 |
+
self.dataset_name = "clarin-pl/nkjp-pos"
|
| 12 |
+
self.description = """
|
| 13 |
+
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
def load_data(self):
|
| 17 |
+
DatasetToShow.load_data(self)
|
| 18 |
+
|
| 19 |
+
def show_dataset(self):
|
| 20 |
+
pass
|
clarin_datasets/punctuation_restoration_dataset.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
from datasets import load_dataset
|
| 3 |
+
import streamlit as st
|
| 4 |
+
|
| 5 |
+
from clarin_datasets.dataset_to_show import DatasetToShow
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class PunctuationRestorationDataset(DatasetToShow):
|
| 9 |
+
def __init__(self):
|
| 10 |
+
DatasetToShow.__init__(self)
|
| 11 |
+
self.dataset_name = "clarin-pl/2021-punctuation-restoration"
|
| 12 |
+
self.description = """
|
| 13 |
+
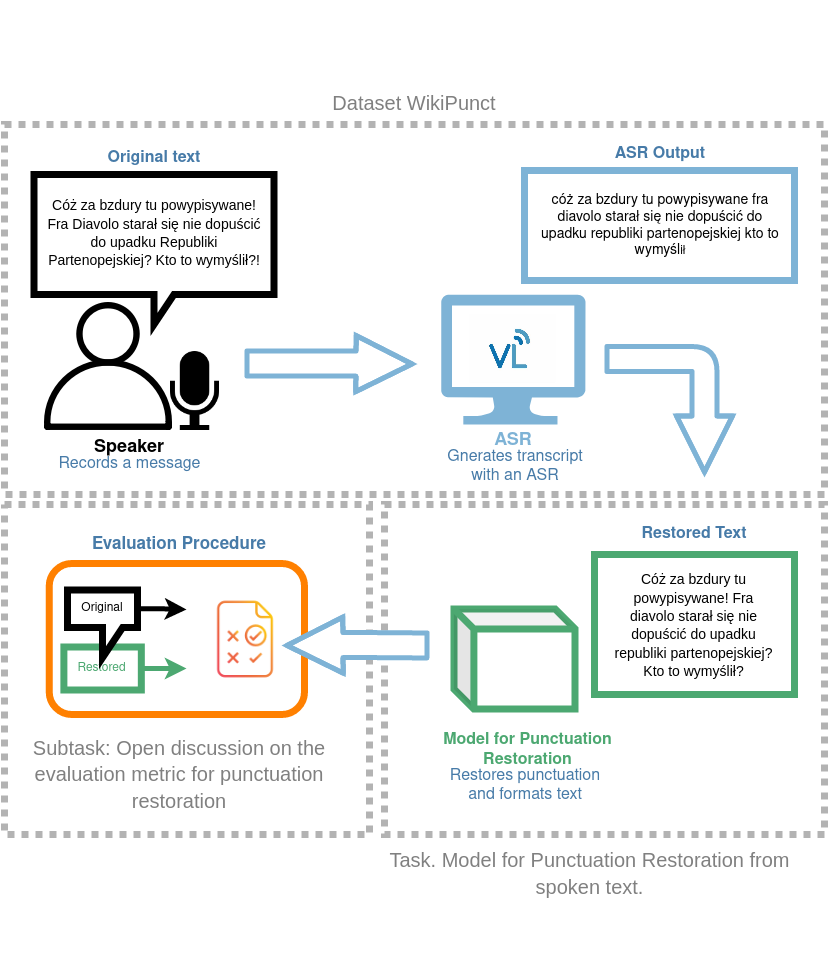
Speech transcripts generated by Automatic Speech Recognition (ASR) systems typically do
|
| 14 |
+
not contain any punctuation or capitalization. In longer stretches of automatically recognized speech,
|
| 15 |
+
the lack of punctuation affects the general clarity of the output text [1]. The primary purpose of
|
| 16 |
+
punctuation (PR) and capitalization restoration (CR) as a distinct natural language processing (NLP) task is
|
| 17 |
+
to improve the legibility of ASR-generated text, and possibly other types of texts without punctuation. Aside
|
| 18 |
+
from their intrinsic value, PR and CR may improve the performance of other NLP aspects such as Named Entity
|
| 19 |
+
Recognition (NER), part-of-speech (POS) and semantic parsing or spoken dialog segmentation [2, 3]. As useful
|
| 20 |
+
as it seems, It is hard to systematically evaluate PR on transcripts of conversational language; mainly
|
| 21 |
+
because punctuation rules can be ambiguous even for originally written texts, and the very nature of
|
| 22 |
+
naturally-occurring spoken language makes it difficult to identify clear phrase and sentence boundaries [4,
|
| 23 |
+
5]. Given these requirements and limitations, a PR task based on a redistributable corpus of read speech was
|
| 24 |
+
suggested. 1200 texts included in this collection (totaling over 240,000 words) were selected from two
|
| 25 |
+
distinct sources: WikiNews and WikiTalks. Punctuation found in these sources should be approached with some
|
| 26 |
+
reservation when used for evaluation: these are original texts and may contain some user-induced errors and
|
| 27 |
+
bias. The texts were read out by over a hundred different speakers. Original texts with punctuation were
|
| 28 |
+
forced-aligned with recordings and used as the ideal ASR output. The goal of the task is to provide a
|
| 29 |
+
solution for restoring punctuation in the test set collated for this task. The test set consists of
|
| 30 |
+
time-aligned ASR transcriptions of read texts from the two sources. Participants are encouraged to use both
|
| 31 |
+
text-based and speech-derived features to identify punctuation symbols (e.g. multimodal framework [6]). In
|
| 32 |
+
addition, the train set is accompanied by reference text corpora of WikiNews and WikiTalks data that can be
|
| 33 |
+
used in training and fine-tuning punctuation models.
|
| 34 |
+
|
| 35 |
+
Task description
|
| 36 |
+
The purpose of this task is to restore punctuation in the ASR recognition of texts read out loud.
|
| 37 |
+
"""
|
| 38 |
+
|
| 39 |
+
def load_data(self):
|
| 40 |
+
DatasetToShow.load_data(self)
|
| 41 |
+
|
| 42 |
+
def show_dataset(self):
|
| 43 |
+
pass
|
clarin_datasets/punctuation_restoration_task.png
ADDED
|