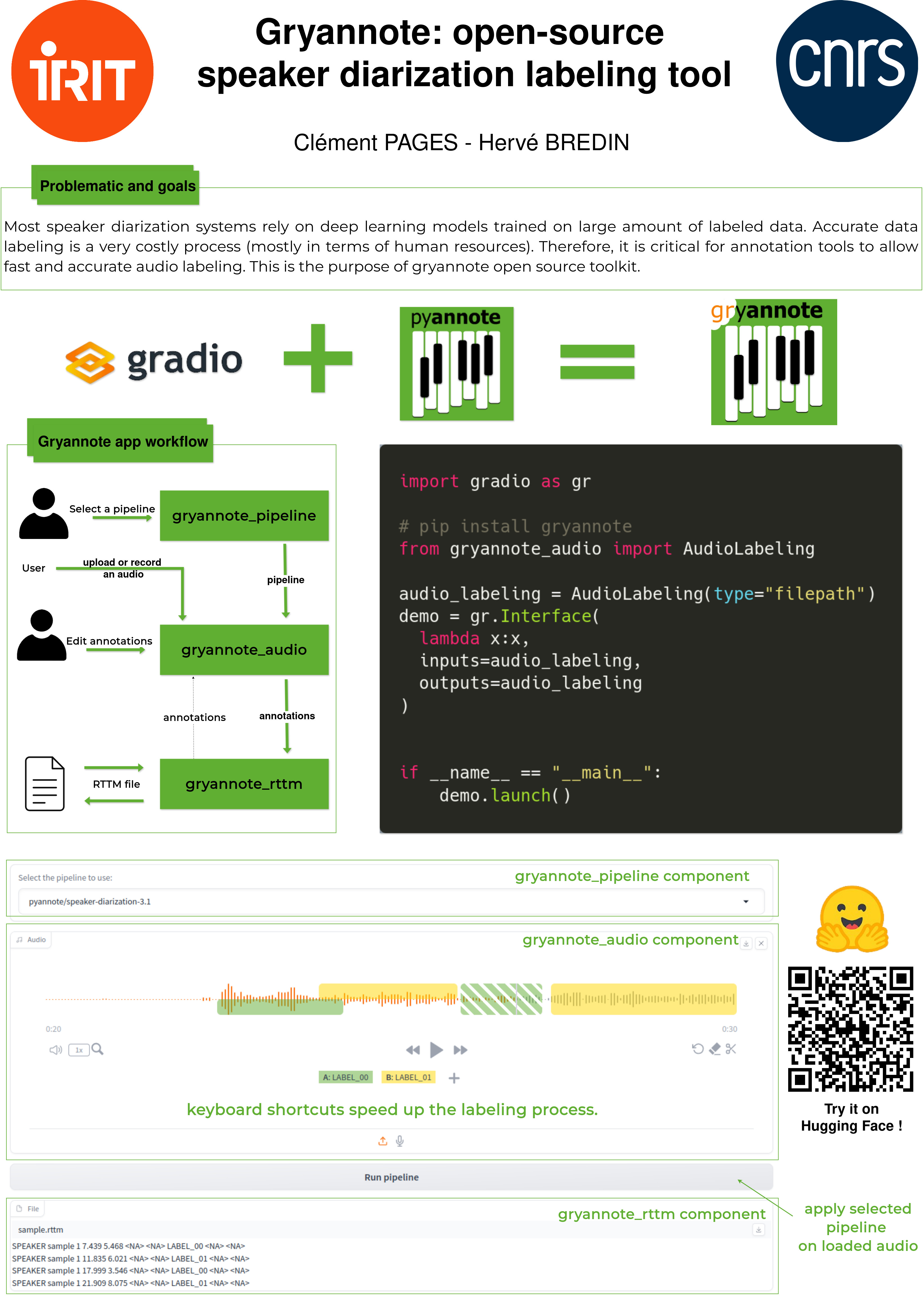
import spaces
import gradio as gr
from gryannote_audio import AudioLabeling
from gryannote_rttm import RTTM
from pyannote.audio import Pipeline
import os
import torch
@spaces.GPU(duration=120)
def apply_pipeline(audio):
"""Apply specified pipeline on the indicated audio file"""
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization-3.1", use_auth_token=os.environ["HF_TOKEN"])
pipeline.to(torch.device("cuda"))
annotations = pipeline(audio)
return ((audio, annotations), annotations)
def update_annotations(data):
return rttm.on_edit(data)
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
with gr.Row():
with gr.Column(scale=1):
gr.Markdown(
' ',
)
with gr.Column(scale=10):
gr.Markdown('
',
)
with gr.Column(scale=10):
gr.Markdown('gryannote
')
gr.Markdown()
gr.Markdown('Make the audio labeling process easier and faster!
')
with gr.Tab("application"):
gr.Markdown(
"To use the component, start by loading or recording audio."
"Then apply the diarization pipeline (here [pyannote/speaker-diarization-3.1](https://huggingface.co/pyannote/speaker-diarization-3.1))"
"or double-click directly on the waveform to add an annotations. The annotations produced can be edited."
" You can also use keyboard shortcuts to speed things up! Click on the help button to see all the available shortcuts."
" Finally, annotations can be saved by cliking on the downloading button in the RTTM component."
)
gr.Markdown()
gr.Markdown()
audio_labeling = AudioLabeling(
type="filepath",
interactive=True,
)
gr.Markdown()
gr.Markdown()
run_btn = gr.Button("Run pipeline")
rttm = RTTM()
with gr.Tab("poster"):
gr.Markdown(
'
'
)
run_btn.click(
fn=apply_pipeline,
inputs=audio_labeling,
outputs=[audio_labeling, rttm],
)
audio_labeling.edit(
fn=update_annotations,
inputs=audio_labeling,
outputs=rttm,
preprocess=False,
postprocess=False,
)
rttm.upload(
fn=audio_labeling.load_annotations,
inputs=[audio_labeling, rttm],
outputs=audio_labeling,
)
if __name__ == "__main__":
demo.launch()